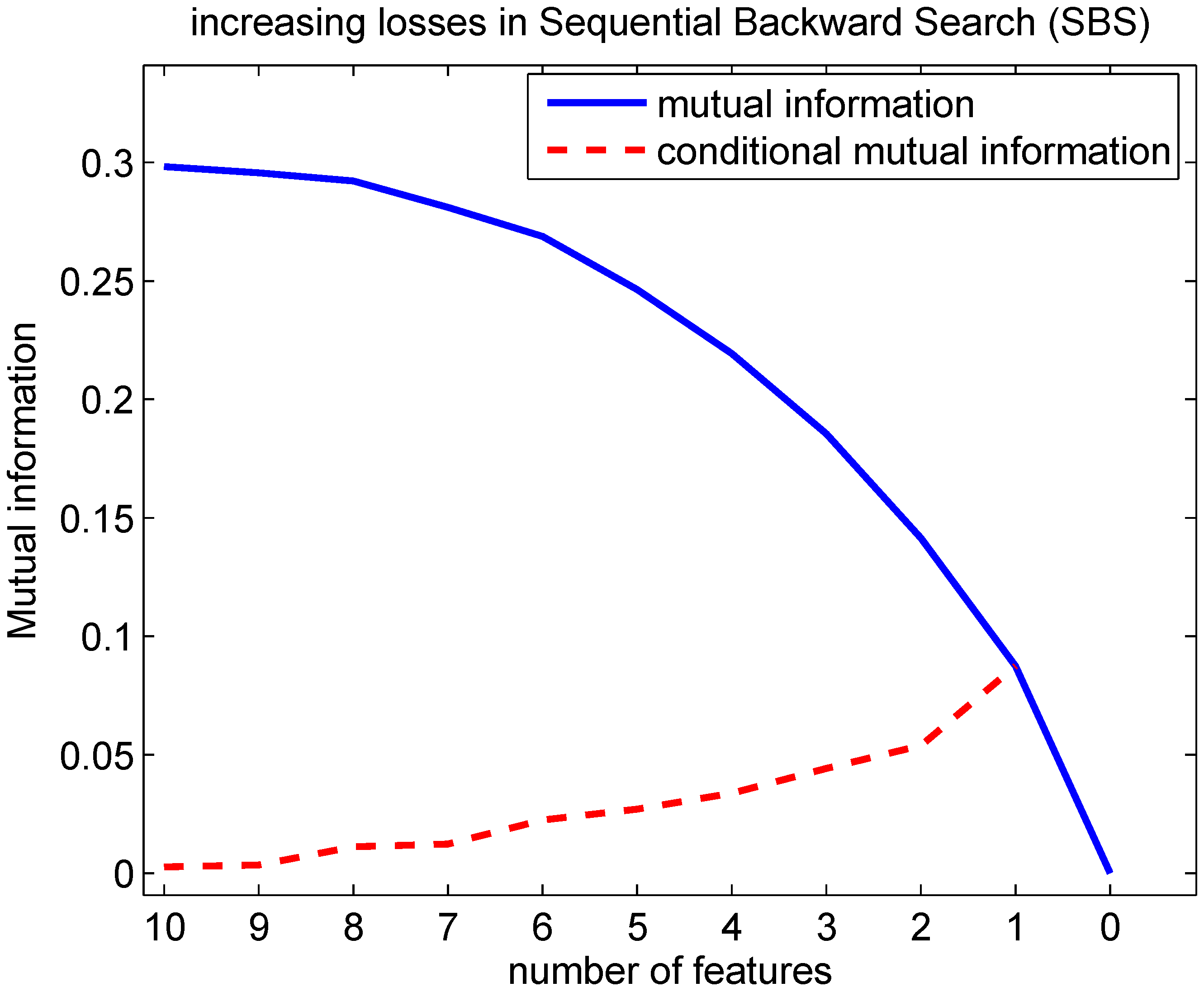
4.1. Increasing Returns
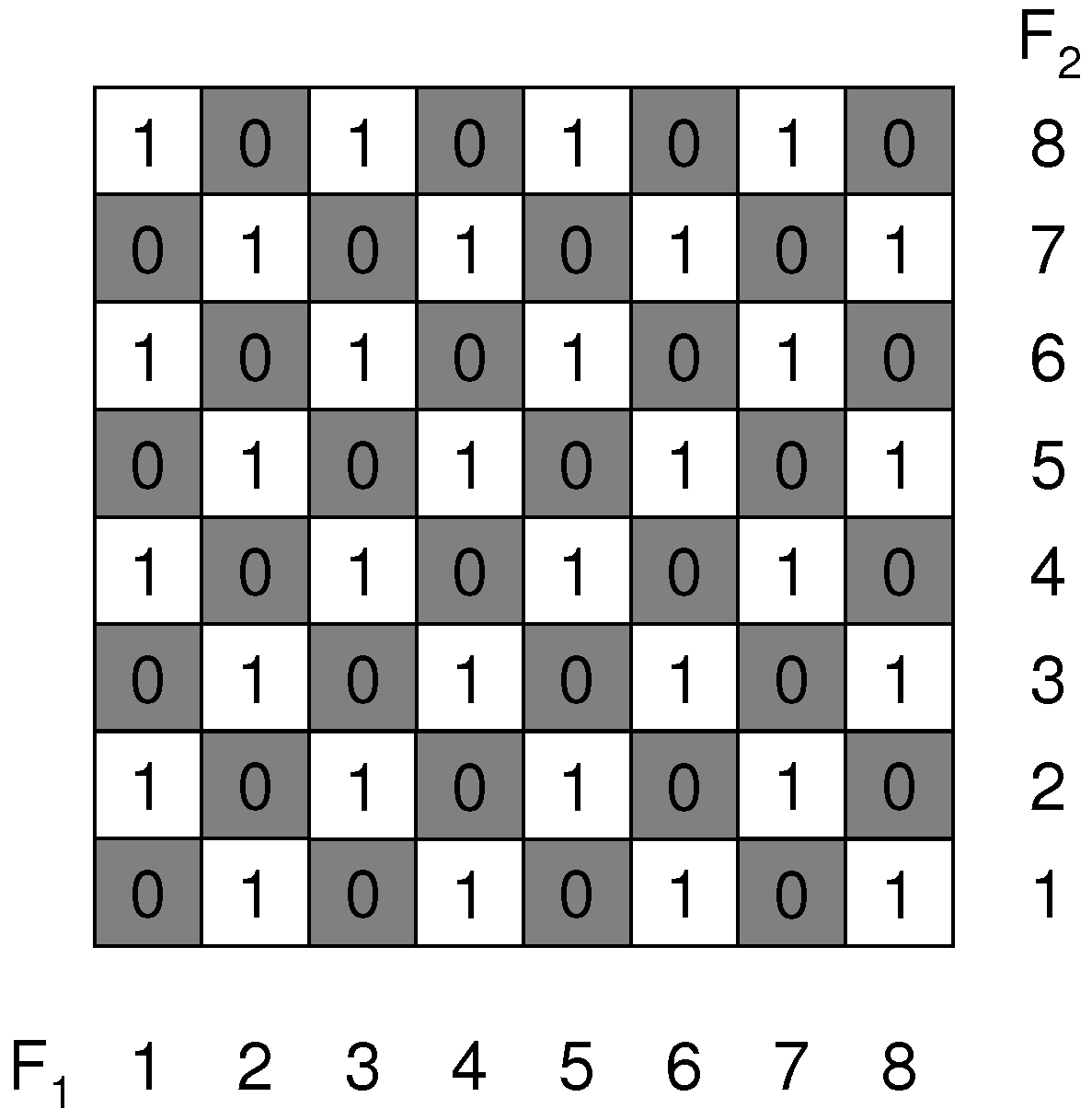
Previously, it was found in [
8] that in the sequential forward search (SFS), when features are selected later in the forward search, they contribute less in the increase of information of the target variable compared to previously selected ones. Let us illustrate this with an example. Suppose that we dispose of 3 features F
, F
and F
and that F
is the first feature for which MI(F
;C) > MI(F
;C) > MI(F
;C). In the first iteration of the SFS, the feature, for which the objective MI(F
;C) is the highest, is selected. In this case, the selected feature will be F
. Suppose that in the second iteration of the SFS, we have: MI(F
;C∣F
) > MI(F
;C∣F
). The second selected feature will be F
. In the third iteration, the only feature left is F
and the incremental increase in information is: MI(F
;C∣F
,F
). The ‘decreasing returns’ (
i.e. every additional investment in a feature results in a smaller return) is then observed as: MI(F
;C) > MI(F
;C∣F
) > MI(F
;C∣F
,F
). However, this is not always true. We show with a counterexample that the opposite behavior can occur: although the order of selected features is F
, F
and finally F
, it can hold that MI(F
;C) < MI(F
;C∣F
) < MI(F
;C∣F
,F
),
i.e. we observe ‘increasing returns’ (every additional investment in a feature results in an increased return) instead of decreasing returns. Consider a possible extension of the checkerboard to 3 dimensions in
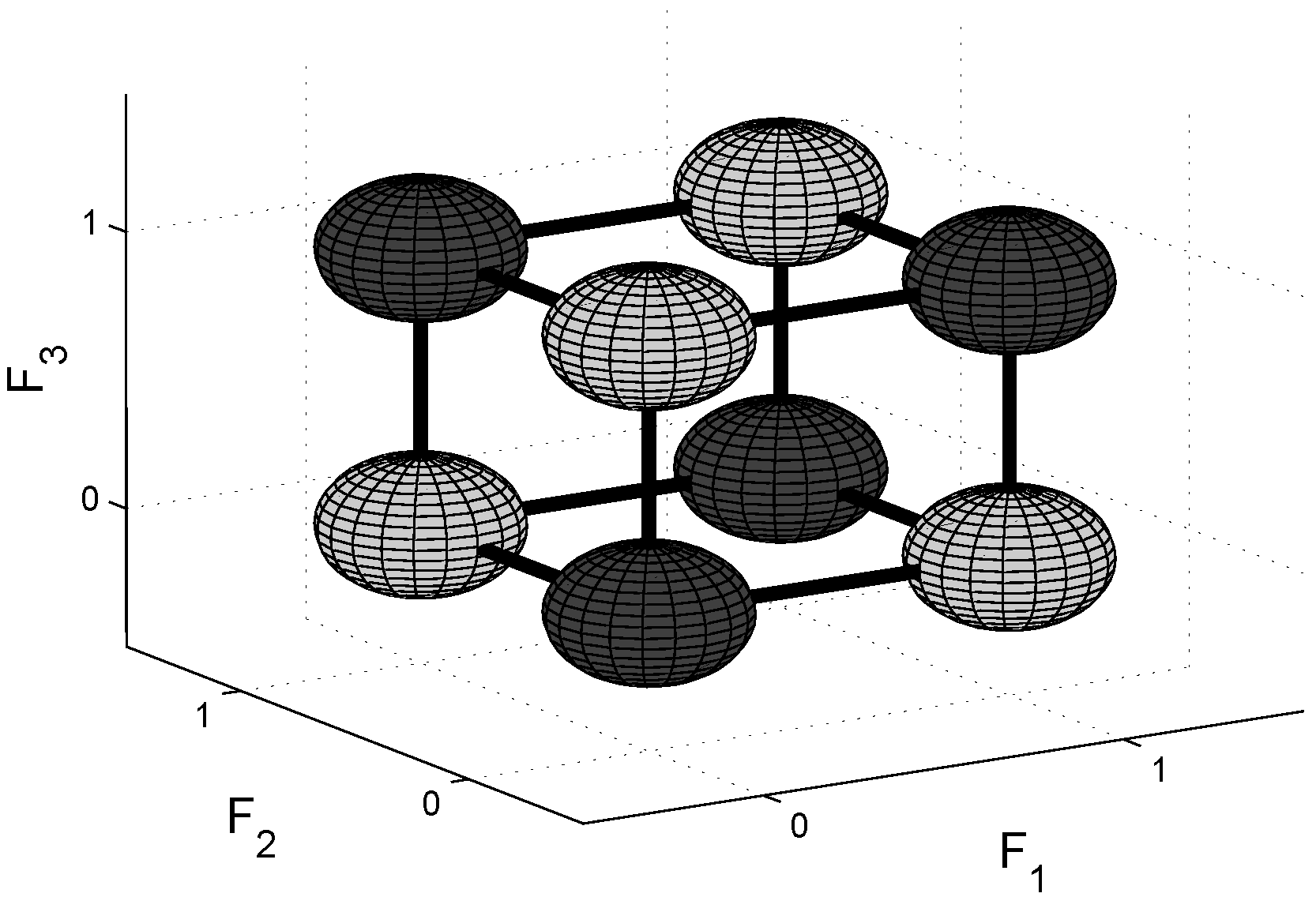
Figure 3.
Figure 3.
7-5-3 XOR Cube. Extension of checkerboard to 3 dimensions, the number of values that each feature can take is odd and different for each feature.
Figure 3.
7-5-3 XOR Cube. Extension of checkerboard to 3 dimensions, the number of values that each feature can take is odd and different for each feature.
Here, the three features F
, F
and F
take an odd number of values: 7, 5 and 3 respectively. We will refer to this example as ‘7-5-3 XOR’. As opposed to ‘m’ even, now each feature individually, as well as each subset of features, contains information about the target variable. We computed the conditional entropies for this example in
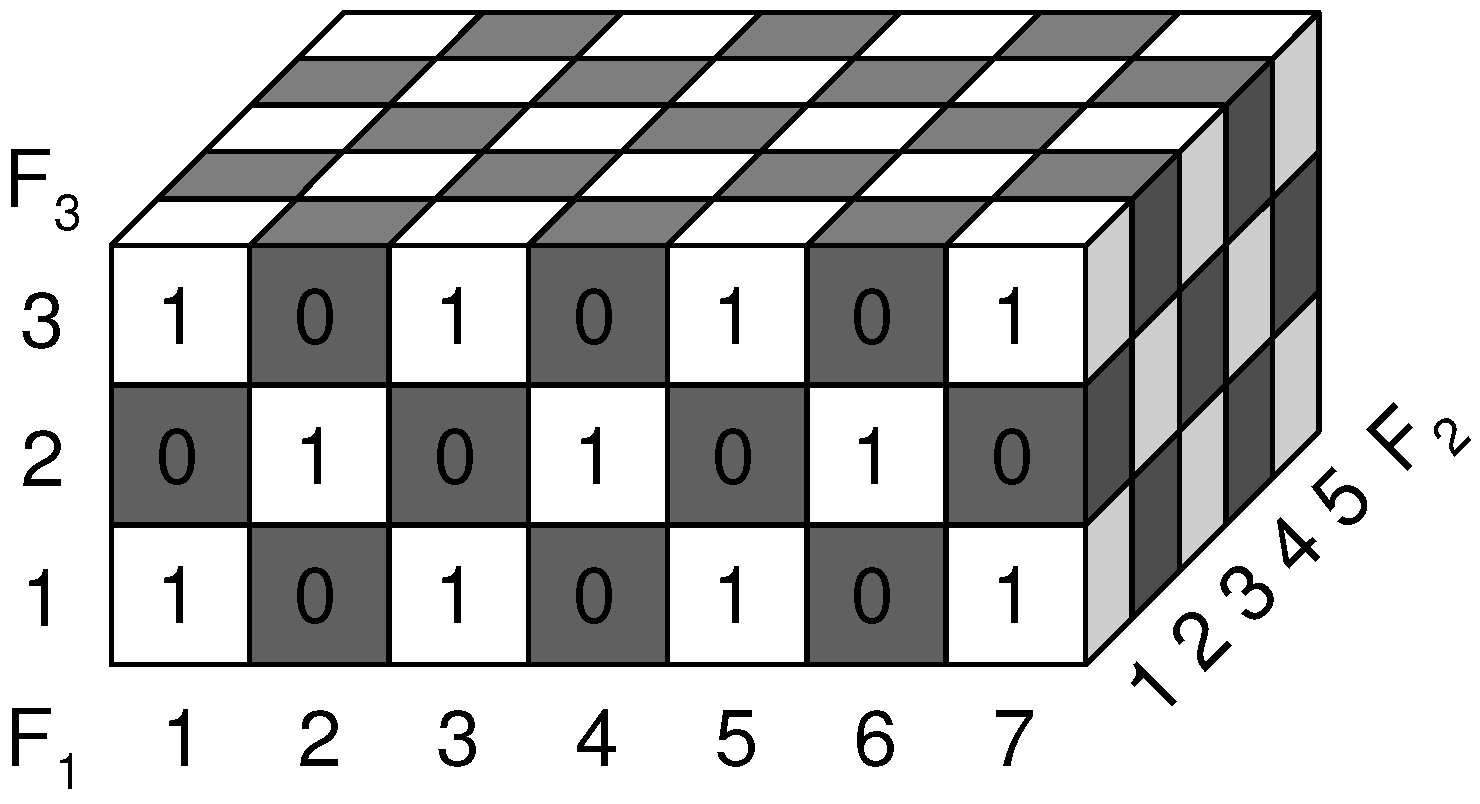
Table 1.
The mutual information and the conditional mutual information can be derived from the conditional entropies and are shown on the right side of the table. Clearly, the first feature that will be selected is F
, as this feature contains individually the most information about the target variable. The next feature selected is F
, because conditioned on F
, F
contains the most information. Finally, F
will be selected with a large increase in information: MI(F
;C∣F
,F
) ≈ 0,9183 bits. This increasing returns behavior can be shown to hold more generally for a
XOR hypercube, with ‘n’ the number of features. The total number of cells (feature value combinations) in such a hypercube is equal to
. This can be written as a double factorial:
This is an odd number of cells.
of the cells have been assigned a 0 or a 1 value. The entropy H(C) can therefore be written as:
Table 1.
7-5-3 XOR Cube. Entropies and Mutual Information for the SFS, NA = not available.
Table 1.
7-5-3 XOR Cube. Entropies and Mutual Information for the SFS, NA = not available.
| Entropy | value(bit) | Mutual Inf. | value(bit) |
| H(C) | -log
-log
≈ 0,9999 | NA | NA |
| H(C∣F) | -log
-log
≈ 0,9968 | MI(F;C) | ≈ 3,143.10 |
| H(C∣F) | -log
-log
≈ 0,9984 | MI(F;C) | ≈ 1,571.10 |
| H(C∣F) | -log
-log
≈ 0,9994 | MI(F;C) | ≈ 5,235.10 |
| H(C∣F,F) | -log
-log
≈ 0,9183 | MI(F;C∣F) | ≈ 7,850.10 |
| H(C∣F,F) | -log
-log
≈ 0,9710 | MI(F;C∣F) | ≈ 2,584.10 |
| H(C∣F,F) | -log
-log
≈ 0,9852 | MI(F;C∣F) | ≈ 1,314.10 |
| H(C∣F,F,F) | 0 | MI(F;C∣F,F) | ≈ 0,9183 |
In every step of the sequential forward search, the feature that takes the largest number of feature values will be selected first, because this will decrease the conditional entropy (and hence increase the mutual information) the most. This can be observed from
Table 1: first F
(which can take 7 values) is selected, subsequently conditioned on F
, F
(which can take 5 values) is selected. Finally, conditioned on F
and F
, F
(which can take 3 values) is selected. The conditional entropy conditioned on k variables needs to be computed over hypercubes with dimension (n-k), each containing
cells. Again
cells have been assigned a 0 or a 1 value. Therefore the conditional entropy after k steps,
, of the SFS can be computed as:
4.2. Decreasing Returns
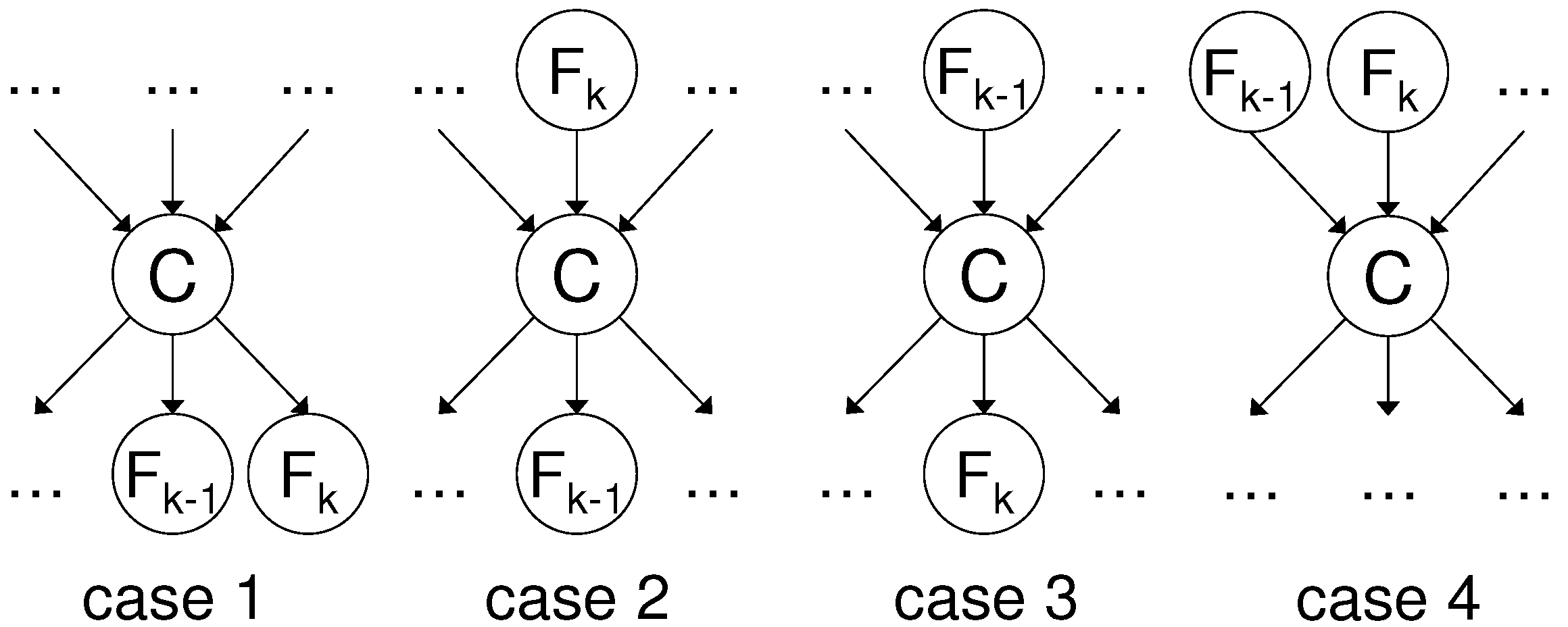
Next, we ask ourselves under what condition the decreasing returns holds. Suppose that the selected subset found so far is
S, and that the feature selected in the current iteration is F
. In order for the decreasing returns to hold, one requires for the next selected feature F
: MI(F
;C∣
S) > MI(F
;C∣
S,F
). First, we expand MI(F
,F
;C∣
S) in two ways by means of the chain rule of information:
In the sequential forward search, F
was selected before F
, thus, it must be that: MI(F
;C∣
S) > MI(F
;C∣
S). In the case of ties, it may be possible that MI(F
;C∣
S) ≥ MI(F
;C∣
S), we focus here on the case where we have a strict ordering >. Then, in Equation (
22) we have that:
Hence, a sufficient condition in order for the decreasing returns to hold is that: MI(F
;C∣
S,F
) ≤ MI(F
;C∣
S). This means that additional conditioning on F
decreases (or equals) information of F
about C.
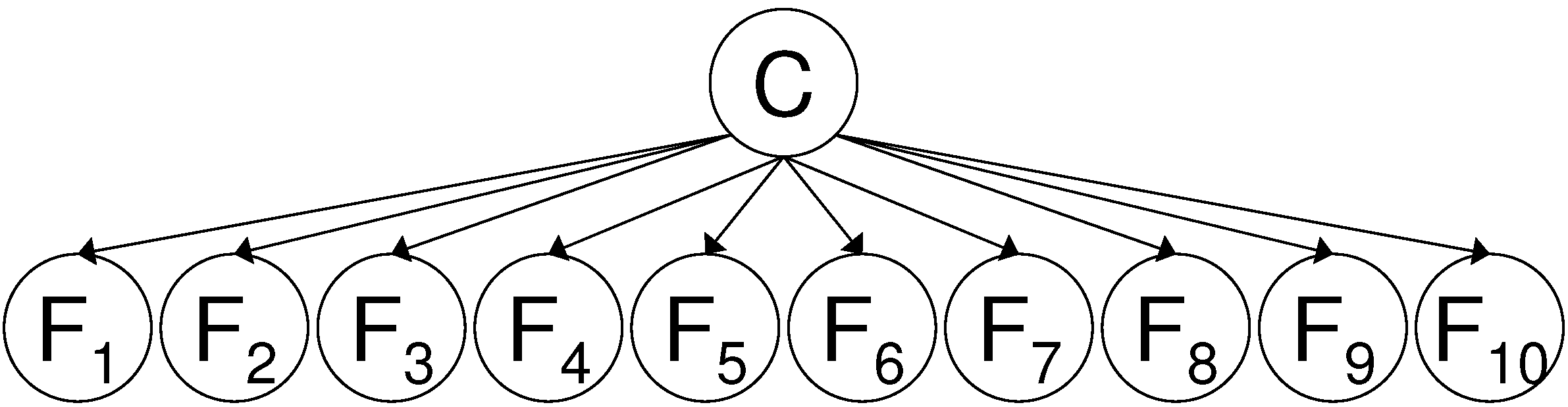
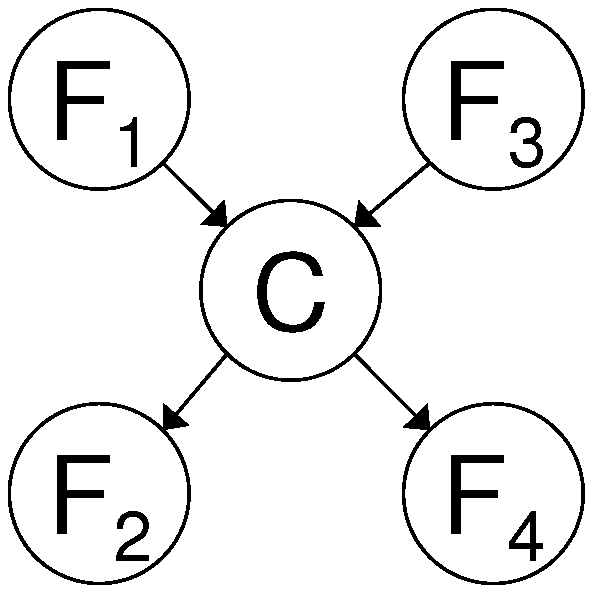
A first dependency structure between variables for which the decreasing returns can be proven to hold in the SFS is when all features are child nodes of the class variable C. This means that all features are conditionally independent given the class variable. This dependency structure is shown in
Figure 4.
Lemma 4.1. Suppose that the order in which features are selected by the SFS is: firstly F subsequently F next F until F. If all features are conditionally independent given the class variable, i.e. p(F,F, …F∣C) = p(F∣C), then the decreasing returns behavior holds: MI(F;C) > MI(F;C∣F) > MI(F;C∣F,F) > … > MI(F;C∣F,F…F).
Proof. First, we show that MI(F
;C) > MI(F
;C∣F
).
In Equation (
24) it holds that, due to the conditional independence of the features given the class variable, MI(F
;F
∣C) = 0. In Equation (25), we have that MI(F
;F
) ≥ 0. Comparing Equations (24) and (25), we obtain that: MI(F
;C) ≥ MI(F
;C∣F
). Because, F
was selected before F
, we have that MI(F
;C) > MI(F
;C) (again we assume a strict ordering among variables, in case of ties we have MI(F
;C) ≥ MI(F
;C)). Hence, we obtain MI(F
;C) > MI(F
;C) ≥ MI(F
;C∣F
).
Using a similar reasoning as above, we can show that it holds in general: MI(F
;C∣F
,F
,…F
) > MI(F
;C∣F
,F
,…F
). We start with the generalization of Equation (
24):
In
appendix (B), we prove that the conditional independence of the variables given C implies that MI(F
;F
∣C,F
,…F
) = 0. Further expansion of the left and the right hand sides in Equation (
26) results in:
Because MI(F
;F
,…F
) ≥ MI(F
;F
,…F
) in Equation (28), we see that MI(F
;C∣F
,…F
) ≤ MI(F
;C∣F
,…F
). But, F
was selected before F
,
i.e. MI(F
;C∣F
,…F
) < MI(F
;C∣F
,…F
), from which we obtain what needed to be proven: MI(F
;C∣F
,…F
) < MI(F
;C∣F
,…F
). ☐
In
Figure 4 we show a Bayesian network [
19,
20] where the class variable C has 10 child nodes. This network has 21 degrees of freedom: we can randomly choose p(c=0) ∈ [0,1] and for the features we can choose p(f
=0∣c=0) ∈ [0,1] and p(f
=0∣c=1) ∈ [0,1]. We generated a Bayesian network where the probability p(c=0) and the conditional probabilities p(f
=0∣c=0) and p(f
=0∣c=1) are generated randomly following a uniform distribution within [0,1]. According to Lemma 4.1, we should find the decreasing returns behavior if we apply the SFS to this network.
Figure 4.
Example of class conditional independence of the features given the class variable C. The joint probability distribution can be factorized as: p(F,F,…F,C) = ( p(F∣C)).p(C).
Figure 4.
Example of class conditional independence of the features given the class variable C. The joint probability distribution can be factorized as: p(F,F,…F,C) = ( p(F∣C)).p(C).
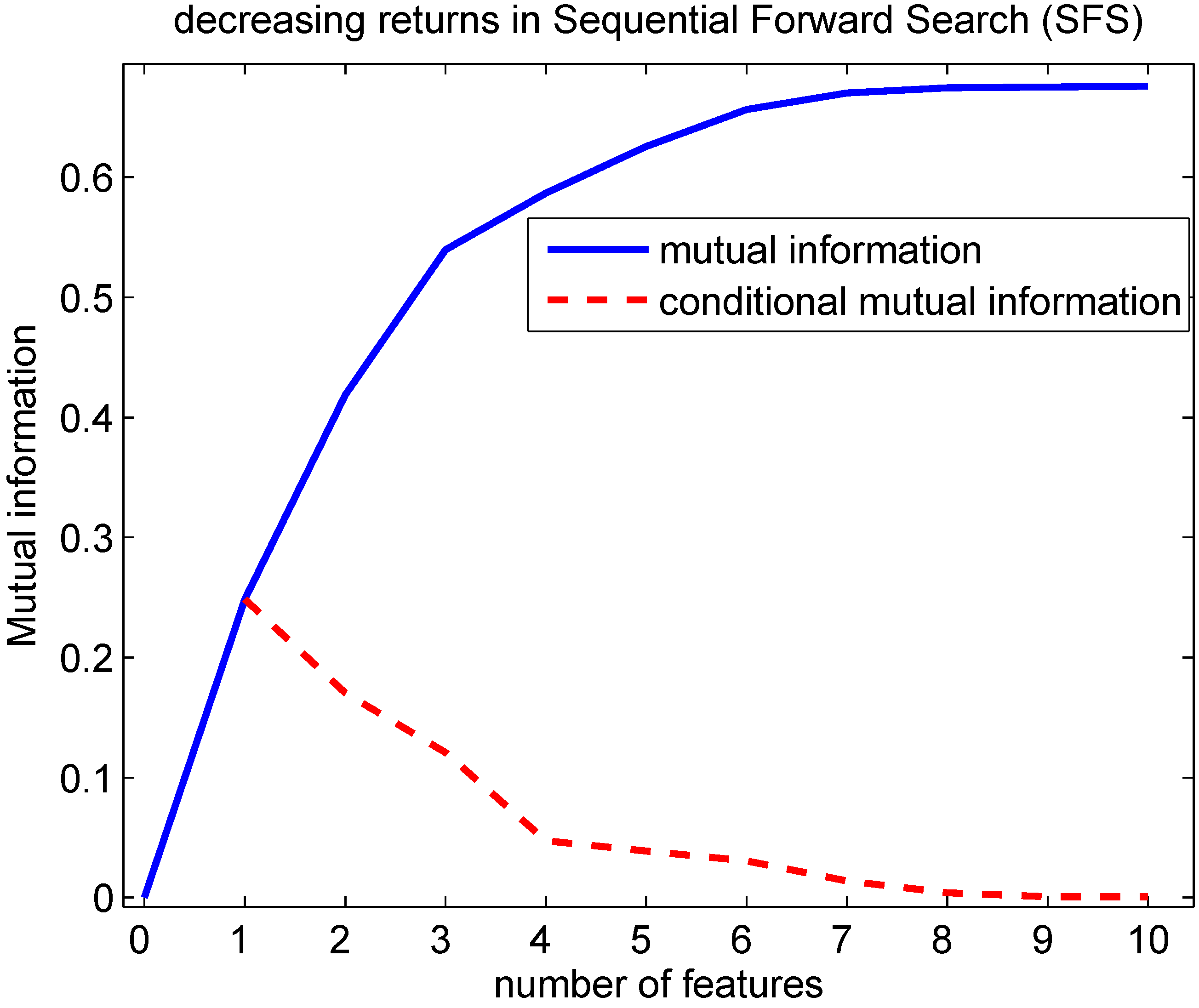
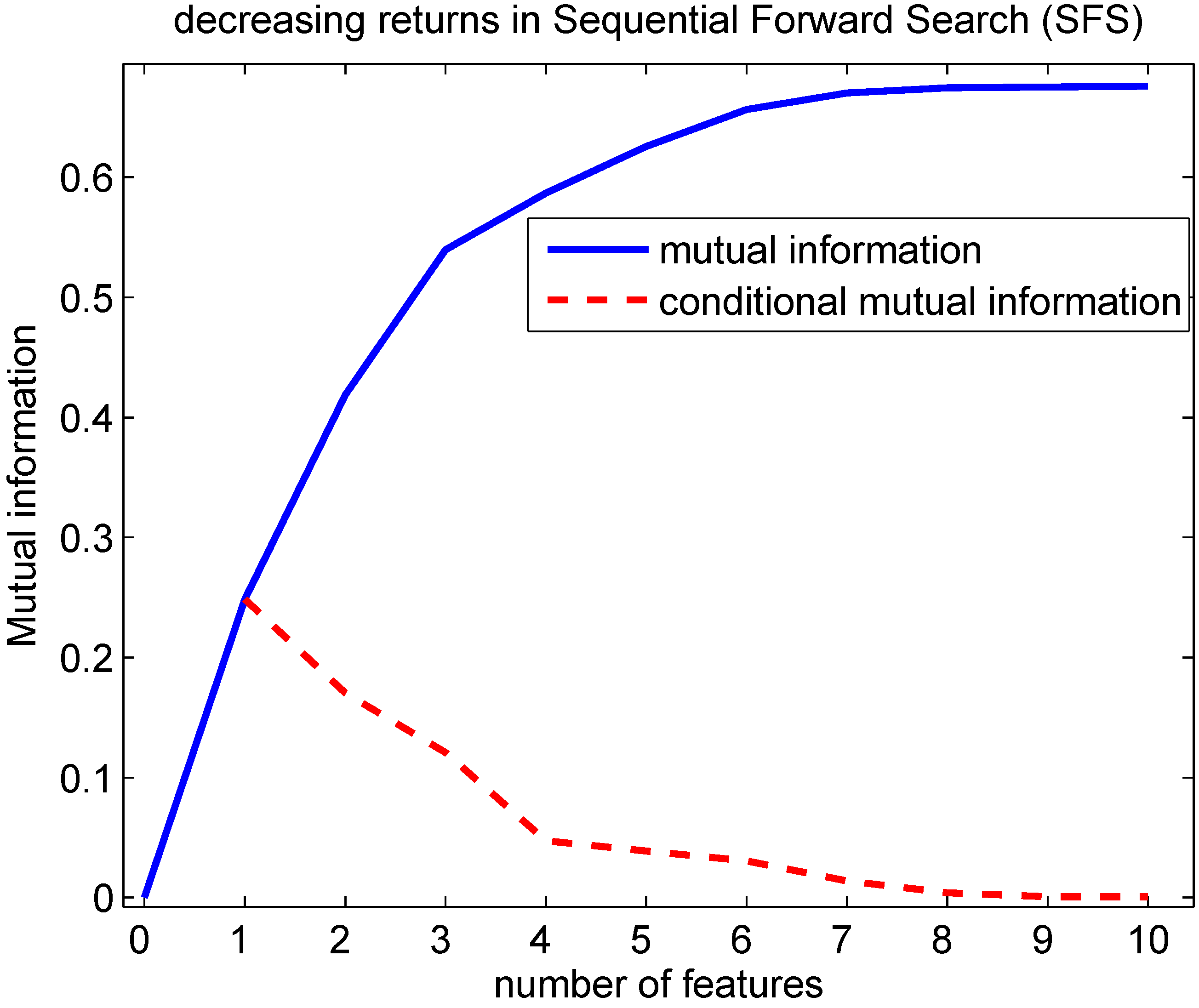
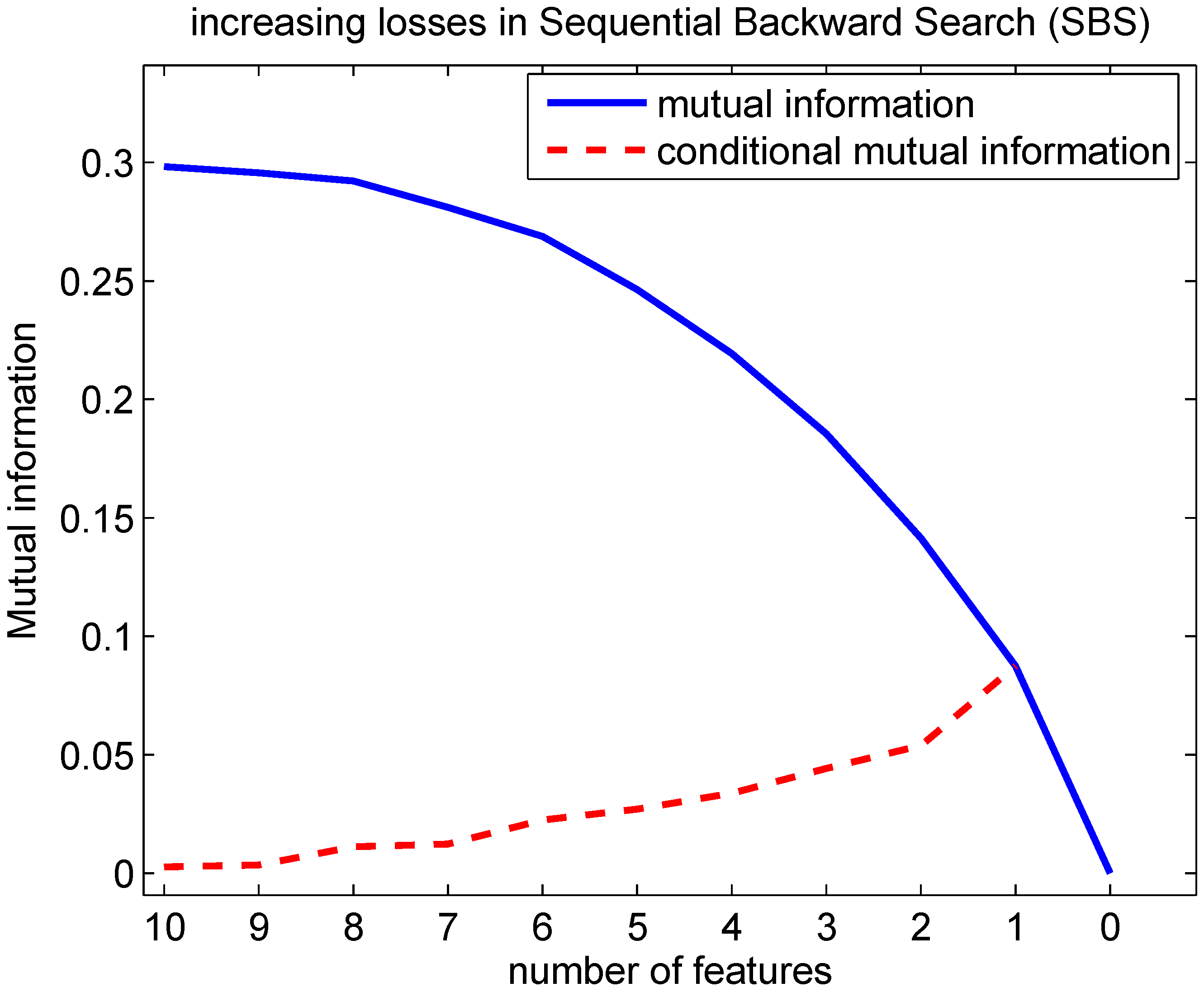
Indeed, this decreasing returns behavior can be observed in
Figure 5 using the generated Bayesian network: Lemma 4.1 predicts that the conditional mutual information decreases with an increasing number of features being selected. This implies that the mutual information is a concave function in function of the number of features selected. This can be seen from the fact that the mutual information can be written as a sum of conditional mutual information terms:
with every next term smaller than the previous one. A particular case of
Figure 4 is obtained if besides class conditional independence among features also independence is assumed. In that case, it can be shown [
21] that the high-dimensional mutual information, can be written as a sum of marginal information contributions:
The SFS, which is in general not optimal, can then be shown to be optimal in mutual information sense. Indeed, at the k’th step of the SFS,
i.e. after ‘k’ features have been selected, there is no subset of ‘k’ or less than ‘k’ features out of the set of ‘n’ features that leads to a higher mutual information than the set that has been found with the SFS at step ‘k’, if MI(F
;C) > 0. Independence and class conditional independence will often not be satisfied for data sets. Nevertheless, for gene expression data sets that typically contain up to 10,000 features, overfitting in a wrapper search can be alleviated if the features with the lowest mutual information are removed before applying the wrapper search [
22].
Figure 5.
Evolution of the mutual information in function of the number of features selected with the SFS. A Bayesian network according to
Figure 4 was created with probability p(c=0), conditional probabilities p(f
=0∣c=0) and p(f
=0∣c=1) drawn randomly following a uniform distribution within [0,1]. The conditional mutual information at 1 feature is MI(F
;C) at 2 features MI(F
;C∣F
),… and finally at 10 features MI(F
;C∣F
,F
,…F
). Lemma 4.1 predicts that the conditional mutual information decreases with an increasing number of features selected. This implies that the mutual information is concave in function of the number of features selected.
Figure 5.
Evolution of the mutual information in function of the number of features selected with the SFS. A Bayesian network according to
Figure 4 was created with probability p(c=0), conditional probabilities p(f
=0∣c=0) and p(f
=0∣c=1) drawn randomly following a uniform distribution within [0,1]. The conditional mutual information at 1 feature is MI(F
;C) at 2 features MI(F
;C∣F
),… and finally at 10 features MI(F
;C∣F
,F
,…F
). Lemma 4.1 predicts that the conditional mutual information decreases with an increasing number of features selected. This implies that the mutual information is concave in function of the number of features selected.
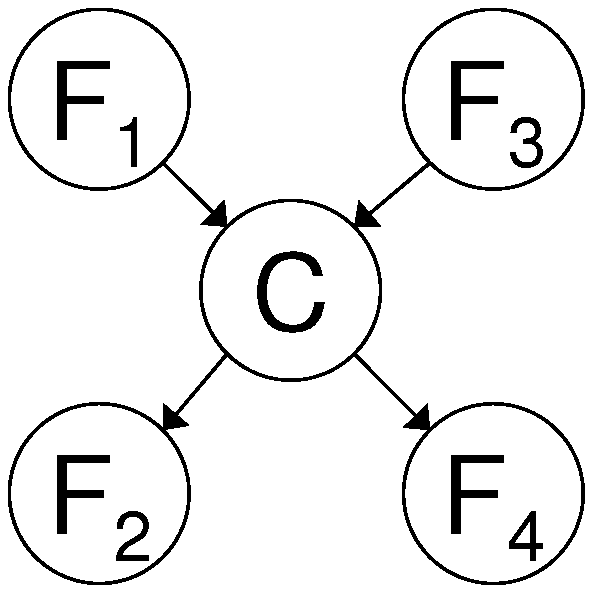
It can be shown that also in more complex settings when there are both child and parent nodes the decreasing returns behavior can still hold. In
Figure 6 an example of dependencies between 4 features is provided for which the decreasing returns holds, if the parent and child nodes are selected alternately. This leads to the following lemma.
Figure 6.
Example of dependencies between features for decreasing returns. The joint probability distribution can be factorized as: p(F,F,F,F,C) = p(F∣C).p(F∣C).p(C∣F,F) .p(F).p(F). This factorization implies that: MI(F,F;F,F∣C) = 0.
Figure 6.
Example of dependencies between features for decreasing returns. The joint probability distribution can be factorized as: p(F,F,F,F,C) = p(F∣C).p(F∣C).p(C∣F,F) .p(F).p(F). This factorization implies that: MI(F,F;F,F∣C) = 0.
Lemma 4.2. Suppose that the order in which features are selected by the SFS is: firstly F subsequently F next F until F. Assume that the odd selected features,i.e.F, F, F …, are parents of C and the even selected features,i.e.F, F, F …, are children of C, then the decreasing returns behavior holds: MI(F;C) > MI(F;C∣F) > MI(F;C∣F,F) > … > MI(F;C∣F,F,…F).
Let us first prove the result for the case with 4 features, as shown in
Figure 6. The order of selected features in the SFS is F
, F
, F
and F
, respectively. We show that MI(F
;C∣F
,F
) < MI(F
;C∣F
).
In Equation (32) MI(F
;F
∣C,F
) = 0, this follows from the fact that MI(F
,F
;F
,F
∣C) = 0, see
appendix (A). We have in Equation (31) and Equation (32) that MI(F
;F
,F
) ≥ MI(F
;F
). Hence, combining previous 2 results yields: MI(F
;C∣F
,F
) ≤ MI(F
;C∣F
). Because feature F
is selected before F
we have: MI(F
;C∣F
) > MI(F
;C∣F
). Finally, we obtain that MI(F
;C∣F
,F
) < MI(F
;C∣F
). Similar expansions for MI(F
;C,F
) and MI(F
;C,F
,F
,F
) as in Equations (31) and (32), enable us to prove that MI(F
;C∣F
) < MI(F
;C) and MI(F
;C∣F
,F
,F
) < MI(F
;C∣F
,F
) respectively. Hence, we can conclude that the decreasing returns holds.
Now let us prove the result for any ‘k’ in general and regardless whether F
is a parent node or a child node. Apply a similar expansion as in Equation (31).
Comparing Equations (33) and (34), we have that: MI(F
;F
,F
,…F
) ≥ MI(F
;F
,F
,…F
). Moreover, in Equation (34): MI(F
;F
∣C,F
,…F
) = 0, due to the fact that parent and child nodes are independent when conditioned on C. Hence, we conclude that MI(F
;C∣F
,F
,…F
) ≤ MI(F
;C∣F
,F
,…F
). Because F
was selected before F
, we have that MI(F
;C∣F
,F
,…F
) < MI(F
;C∣F
,F
,…F
). Hence, finally this yields what is to be proven: MI(F
;C∣F
,F
,…F
) < MI(F
;C∣F
,F
,…F
). Note that we did not need to specify whether F
is a parent or a child node, we only needed that one node F
or F
was a parent node and the other a child node.
Because, the proof is independent regardless F is a child or a parent node, we obtain following corollary of Lemma 4.2.
Corollary 4.3. Suppose that the order in which features are selected by the SFS is: firstly F subsequently F next F until F. Assume that the odd selected features,i.e.F, F, F …, are children of C and the even selected features,i.e.F, F, F …, are parents of C, then the decreasing returns behavior holds: MI(F;C) > MI(F;C∣F) > MI(F;C∣F,F) > … > MI(F;C∣F,F,…F).
We performed an experiment to verify whether it is plausible that parent and child nodes may become selected alternately in the SFS, as Lemma 4.2 and Corollary 4.3 require. We generated 10,000 Bayesian networks with 2 parent and 2 child nodes as shown in
Figure 6. This network contains 10 degrees of freedom. The following probabilities can be chosen freely: the prior probabilities p(f
=0) and p(f
=0), the conditional probability p(c=0∣f
,f
) for all 4 combinations of F
and F
, p(f
=0∣c) for the 2 values of C and p(f
=0∣c) for the 2 values of C. In each of the 10,000 networks, probabilities were drawn following a uniform distribution within [0,1]. It can be shown that randomly assigning conditional distributions in this way, this will result almost always in joint distributions that are faithful to the directed acyclic graph (DAG). This means that no conditional independencies are present in the joint distribution that are not entailed by the DAG based on the Markov condition, see e.g., [
20] on page 99. Next, the SFS was applied to each of the 10,000 networks. In 943 out of 10,000 cases, a parent node was selected first and parent and child nodes were selected alternately. In 1,125 out of 10,000 cases, a child node was selected first and parent and child nodes were selected alternately. In
Table 2 we show the probabilities of a Bayesian network in which first a parent node was selected and the parent and child nodes were selected alternately. The evolution of the mutual information, when the SFS is applied to the Bayesian network with probabilities shown in
Table 2, is shown in
Figure 7.
4.4. Relevance-redundancy Criteria
To avoid the estimation of mutual information in high-dimensional spaces, Battiti [
11] proposed a SFS criterion that selects in each iteration the feature with the largest marginal relevance penalized with a redundancy term. Suppose that the set of features selected thus far is
S and that F
is a candidate feature to be selected, then the feature F
is selected for which following criterion is maximal.
In Battiti’s work
is a user defined parameter and
(F
,F
,C) = 1. Similar criteria were proposed in [
23] (for which
(F
,F
,C) =
), in [
24] (for which
(F
,F
,C) = 1 and
is adaptively chosen as 1/∣S∣) and in [
25] (for which
(F
,F
,C) = 1/min{H(F
),H(F
)} and
is adaptively chosen as 1/∣S∣). All these criteria will not be informative for the examples shown in
Section 3.1,
Section 3.2 and
Section 3.3. These criteria will return for each feature in Equation (35) Crit = 0, because MI(F
;C) = 0 and MI(F
;F
) = 0. Therefore, these criteria may be tempted to include no features at all, despite the fact that all features are strongly relevant. For the 7-5-3 XOR cube all criteria will select the features in the same order: first F
, then F
and then F
. This is due to the fact that F
individually contains more information than F
about the target variable, see
Table 1. Also F
contains more information than F
about the target variable, see
Table 1. Moreover for the 7-5-3 XOR cube all variables are independent, hence MI(F
;F
) = 0. However, from the criterion values Crit = MI(F
;C), then Crit = MI(F
;C) and finally Crit = MI(F
;C) the increasing returns cannot be observed. Another criterion that uses lower-dimensional conditional mutual information to select features was proposed in [
26]. This selection algorithm proceeds in 2 stages:
In the first step in Equation (36) the feature which bears individually most information about the target variable is selected,
i.e., F
. Next, in the k’th step of the second stage,
i.e., Equation (37), the feature is selected which contributes most, conditioned on the set of already selected features F
, F
, …F
. The contribution for feature F
is estimated conservatively as
. This algorithm will be able to detect the increasing returns in the XOR problem in case there are only 2 features. However, it would fail to detect the strongly relevant features in case there are at least 3 features in the XOR problem. To overcome the limitations of the lower-dimensional mutual information estimators, higher-dimensional mutual information estimators for classification purposes were proposed [
21,
22,
27,
28]. In [
27] the authors proposed a density-based method: the probability density is estimated by means of Parzen windows and the mutual information is estimated from this probability density estimate. In [
21,
22] the mutual information was estimated based on pair-wise distances between data points. A similar estimator can be used for regression purposes [
29]. In [
28] the mutual information is estimated also based on distances between data points, but this time from a minimal spanning tree that is constructed from the data points.
4.5. Importance of Increasing and Decreasing Returns
The importance of the decreasing and increasing returns lies in that we can compute an upper bound and a lower bound on the probability of error, without having to compute the mutual information for higher dimensions. Suppose that the mutual information has been computed up to a subset of
features
F, with mutual information MI(
F;C). Suppose that the last increment in going from a subset of
features
F to
F equals ΔMI = MI(
F;C)-MI(
F;C). For the mutual information of a subset of n2 features
F, with
F ⊃
F, it holds, under the decreasing returns, that:
and under the increasing returns that:
For the example shown in
Figure 5, it can be seen that ΔMI (the conditional mutual information) at 4 features is representative for the conditional mutual information at 5, 6 and 7 features. The conditional mutual information at 8 features is representative for the ones at 9 and 10 features. From the inequalities in (38) and (39) one can constrain the probability of error that can be achieved by observing the (
-
) additional features. This can be obtained by exploiting upper and lower bounds that were established for the equivocation H(C∣F). These upper and lower bounds can be restated in terms of the mutual information. In
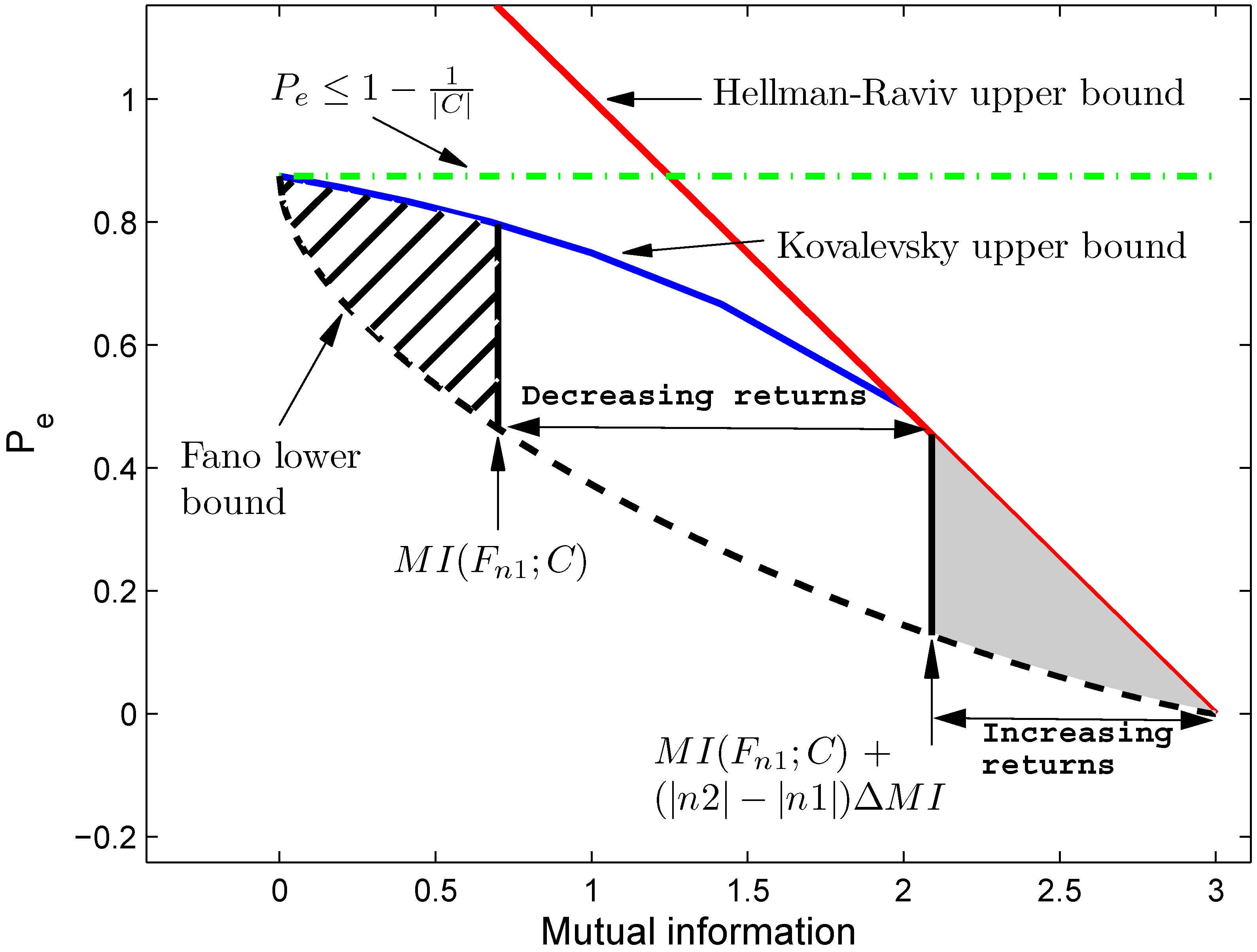
Figure 9 the upper bounds are restated in terms of the mutual information as follows for the Hellman-Raviv upper bound [
30]:
and for the Kovalevsky upper bound [
31]:
with ‘
i’ an integer such that (
)/
i≤ P
≤
i/(
) and ‘
i’ smaller than the number of classes ∣C∣. Let us remark that some of the bounds on the probability of error have been established independently by different researchers. The Hellman-Raviv upper bound has also been found in [
32]. The Kovalevsky upper bound on the probability of error has been proposed at least 3 times: first in [
31,
32] and later in [
33]; see also the discussion in [
34]. The lower bound in
Figure 9 is solved using the Fano lower bound [
12,
35]:
Due to (38) it must be that the probability of error corresponding with
F falls within the white area under the decreasing returns, and, due to (39), within the dark grey area under the increasing returns.
Figure 9.
Bounds on the probability of error. For subset F the mutual information equals MI(F;C), for which the probability of error falls between the Fano lower bound and the Kovalevsky upper bound. The white area represents the possible combinations of probability of error and mutual information for the decreasing returns in the selection of (∣n2∣-∣n1∣) additional features, because MI(F;C) ≤ MI(F;C) + (∣n2∣-∣n1∣)ΔMI. The grey area is the possible area for the increasing returns. The hatched area is not possible, because adding features can only increase the information. This figure illustrates the case when the number of classes ∣C∣ is equal to 8 and when all prior probabilities of the classes are equal.
Figure 9.
Bounds on the probability of error. For subset F the mutual information equals MI(F;C), for which the probability of error falls between the Fano lower bound and the Kovalevsky upper bound. The white area represents the possible combinations of probability of error and mutual information for the decreasing returns in the selection of (∣n2∣-∣n1∣) additional features, because MI(F;C) ≤ MI(F;C) + (∣n2∣-∣n1∣)ΔMI. The grey area is the possible area for the increasing returns. The hatched area is not possible, because adding features can only increase the information. This figure illustrates the case when the number of classes ∣C∣ is equal to 8 and when all prior probabilities of the classes are equal.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}