1. Introduction
Frequently, the dispersion (variability) of measured data needs to be described. Although standard deviation is used ubiquitously for quantification of variability, such approach has limitations. The dispersion of the probability distribution can be understood in different points of view: as “spread” with respect to the expected value, “evenness” (“randomness”) or “smoothness”. For example highly variable data might not be random at all if it consists only of “extremely small” and “extremely large” measurements. Although the probability density function or its estimate provides a complete view, quantitative methods are needed in order to compare different models or experimental results.
In a series of recent studies [
1,
2] we proposed and justified alternative measures of dispersion. The effort was inspired by various information-based measures of signal regularity or randomness and their interpretations that have gained significant popularity in various branches of science [
3,
4,
5,
6,
7,
8,
9]. For convenience, in what follows we discuss only the
relative dispersion coefficients (
i.e., the data or the probability density function is first normalized to unit mean). Besides the coefficient of variation,
, which is the relative dispersion measure based on standard deviation, we employ the entropy-based dispersion coefficient
, and the Fisher information-based coefficient
. The difference between these coefficients lies in the fact that the Fisher information-based coefficient,
, describes how “smooth” is the distribution and it is sensitive to the modes of the probability density, while the entropy-based coefficient,
, describes how “even” it is, hence being sensitive to the overall spread of the probability density over the entire support. Since multimodal densities can be more evenly spread than unimodal ones, the behavior of
cannot be generally deduced from
(and vice versa).
If a complete description of the data is available,
i.e., the probability density function is known, the values of the above mentioned dispersion coefficients can be calculated analytically or numerically. However, the estimation of these coefficients from data is more problematic, and so far we employed either the parametric approach [
2] or non-parametric estimation of
based on the popular Vasicek’s estimator of differential entropy [
10,
11]. The goal of this paper is to provide a self-contained method of non-parametric estimation. We describe a method that can be used to estimate both
and
as a result of a single procedure.
3. Results
Neurons communicate via the process of synaptic transmission, which is triggered by an electrical discharge called the
action potential or
spike. Since the time intervals between individual spikes are relatively large when compared to the spike duration, and since for any particular neuron the “shape” or character of a spike remains constant, the spikes are usually treated as point events in time. Spike train consists of times of spike occurrences
, equivalently described by a set of
n interspike intervals (ISIs)
,
, and these ISIs are treated as independent realizations of the random variable
. The probabilistic description of the spiking results from the fact that the positions of spikes cannot be predicted deterministically due to presence of intrinsic noise, only the probability that a spike occurs can be given [
27,
28,
29]. In real neuronal data, however, the non-renewal property of the spike trains is often observed [
30,
31]. Taking the serial correlation of the ISIs as well as any other statistical dependence into account would result in the decrease of the entropy and hence of the value of
, see [
12].
We compare exact and estimated values of the dispersion coefficients on three widely used statistical models of ISIs: gamma, inverse Gaussian and lognormal. Since only the relative coefficients are discussed, , we parameterize each distributions by its while keeping .
The gamma distribution is one of the most frequent statistical descriptors of ISIs used in analysis of experimental data [
32]. Probability density function of gamma distribution can be written as
where
is the gamma function, [
22]. The differential entropy is equal to, [
2],
where
denotes the digamma function, [
22]. The Fisher information about the location parameter is
The Fisher information diverges for
, with the exception of
(corresponds to exponential distribution) where
, but the Cramer–Rao based interpretation of
does not hold in this case since
, see [
13] for details.
The inverse Gaussian distribution is often used for description of ISIs and fitted to experimental data. It arises as result of spiking activity of a stochastic variant of the perfect integrate-and-fire neuronal model [
33]. The density of this distribution is
The differential entropy of this distribution is equal to
where
denotes the first derivative of the modified Bessel function of the second kind [
22],
. The Fisher information of the inverse Gaussian distribution results in
The lognormal distribution is rarely presented as model distribution of ISIs. However, it represents a common descriptor in analysis of experimental data [
33], with density
The differential entropy of this distribution is equal to
and the Fisher information is given by
The theoretical values of the coefficients of
and
as functions of
are shown in
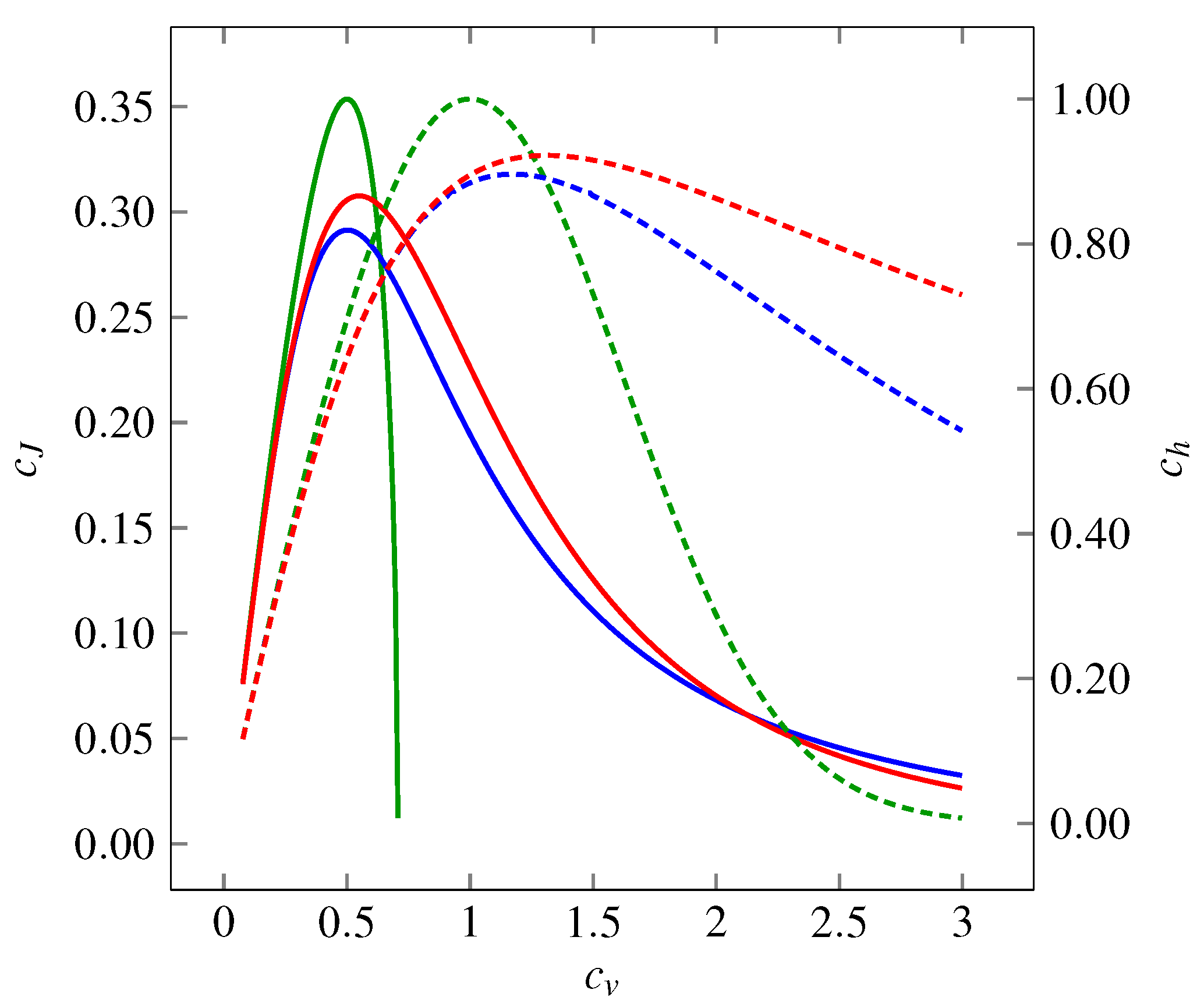
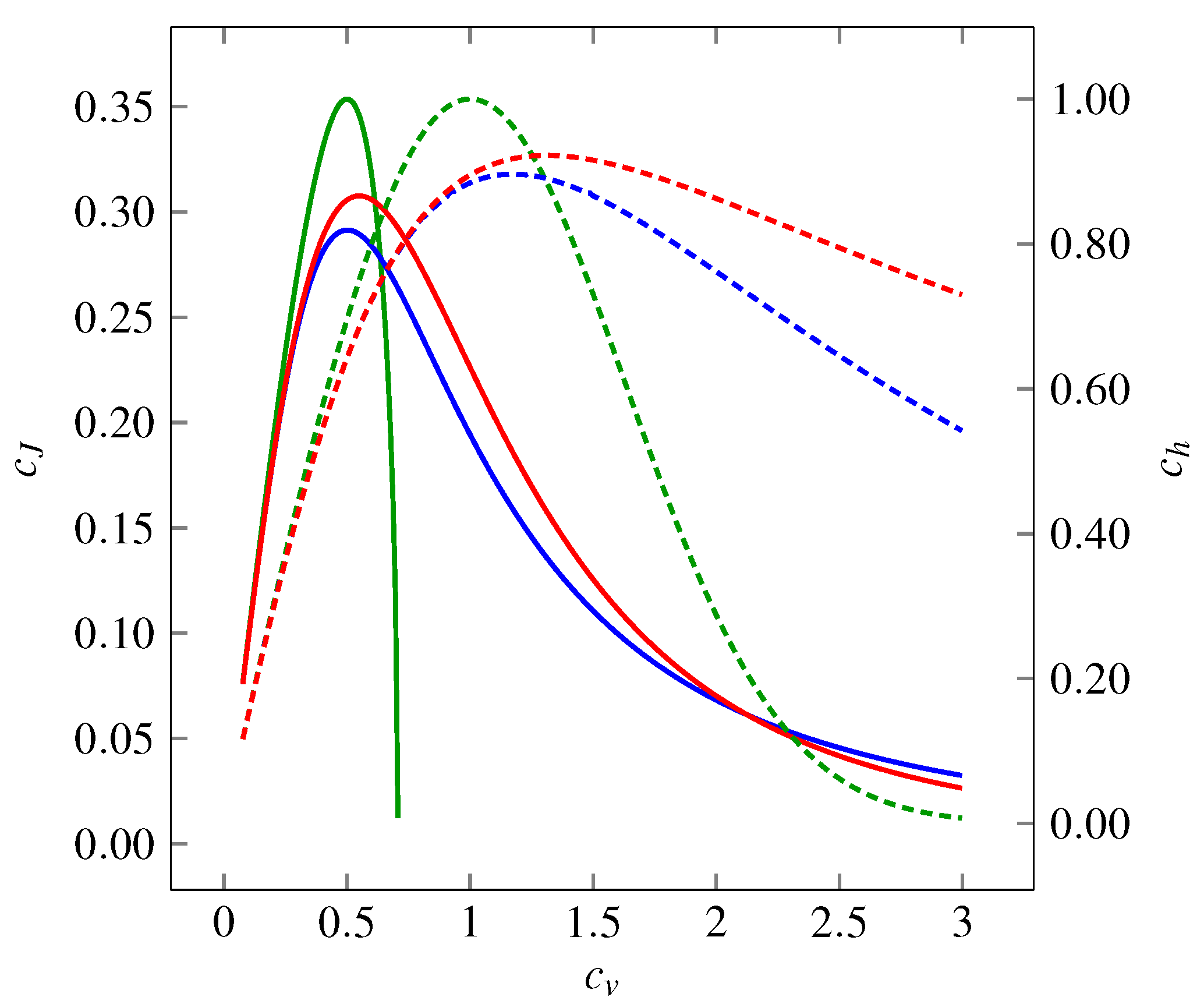
Figure 1 for all the three distributions mentioned above. We see that the functions form hill-shaped curves with local maxima achieved for different values of
. Asymptotically,
as well as
tend to zero for
or
for the three models.
Figure 1.
Variability represented by the coefficient of variation , the entropy-based coefficient (dashed curves, right-hand-side axis) and the Fisher information-based coefficient (solid curves, left-hand-side axis) of three probability distributions: gamma (green curves), inverse Gaussian (blue curves) and lognormal (red curves). The entropy-based coefficient, , expresses the evenness of the distribution. In dependency on , it shows a maximum at for gamma distribution (corresponds to exponential distribution) and between and for inverse Gaussian and lognormal distributions. For all the distributions holds as or . The Fisher information-based coefficient, , grows as the distributions become “smoother”. The overall dependence on shows a maximum around . Similarly to dependencies, as or (does not hold for gamma distribution, where can be calculated only for ).
Figure 1.
Variability represented by the coefficient of variation , the entropy-based coefficient (dashed curves, right-hand-side axis) and the Fisher information-based coefficient (solid curves, left-hand-side axis) of three probability distributions: gamma (green curves), inverse Gaussian (blue curves) and lognormal (red curves). The entropy-based coefficient, , expresses the evenness of the distribution. In dependency on , it shows a maximum at for gamma distribution (corresponds to exponential distribution) and between and for inverse Gaussian and lognormal distributions. For all the distributions holds as or . The Fisher information-based coefficient, , grows as the distributions become “smoother”. The overall dependence on shows a maximum around . Similarly to dependencies, as or (does not hold for gamma distribution, where can be calculated only for ).
![Entropy 14 01221 g001]()
To explore the accuracy of the estimators of the coefficients
and
when the MPL estimations of the densities are employed, we did three separate simulation studies. All the simulations and calculations were performed in the free software package R [
34]. For each model with the probability distribution (21), (24) and (27), respectively, the coefficient of variation,
, varied from
to
in steps of
. One thousand samples, each consisting of 1000 random numbers (a common number of events in experimental records of neuronal firing), were taken for each value of
from the three distributions.
The MPL method was employed on each generated sample to estimate the density. We chose the number of the base functions equal to
. The larger bases,
or
, were examined too, with negligible differences in the estimation for the selected models. The values of the parameters for (15) were chosen as
and
, in accordance with the suggestion ([
26], Appendix A).
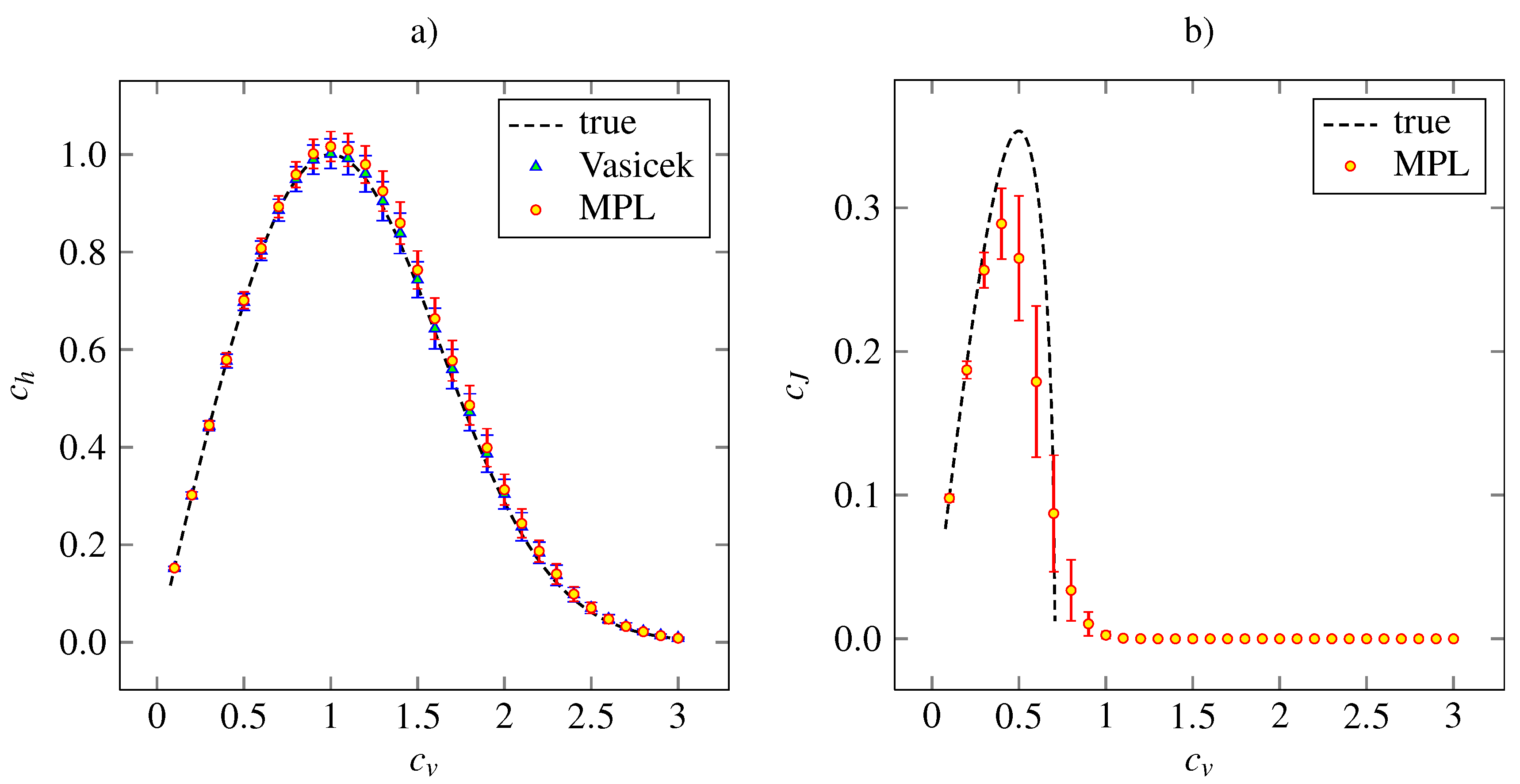
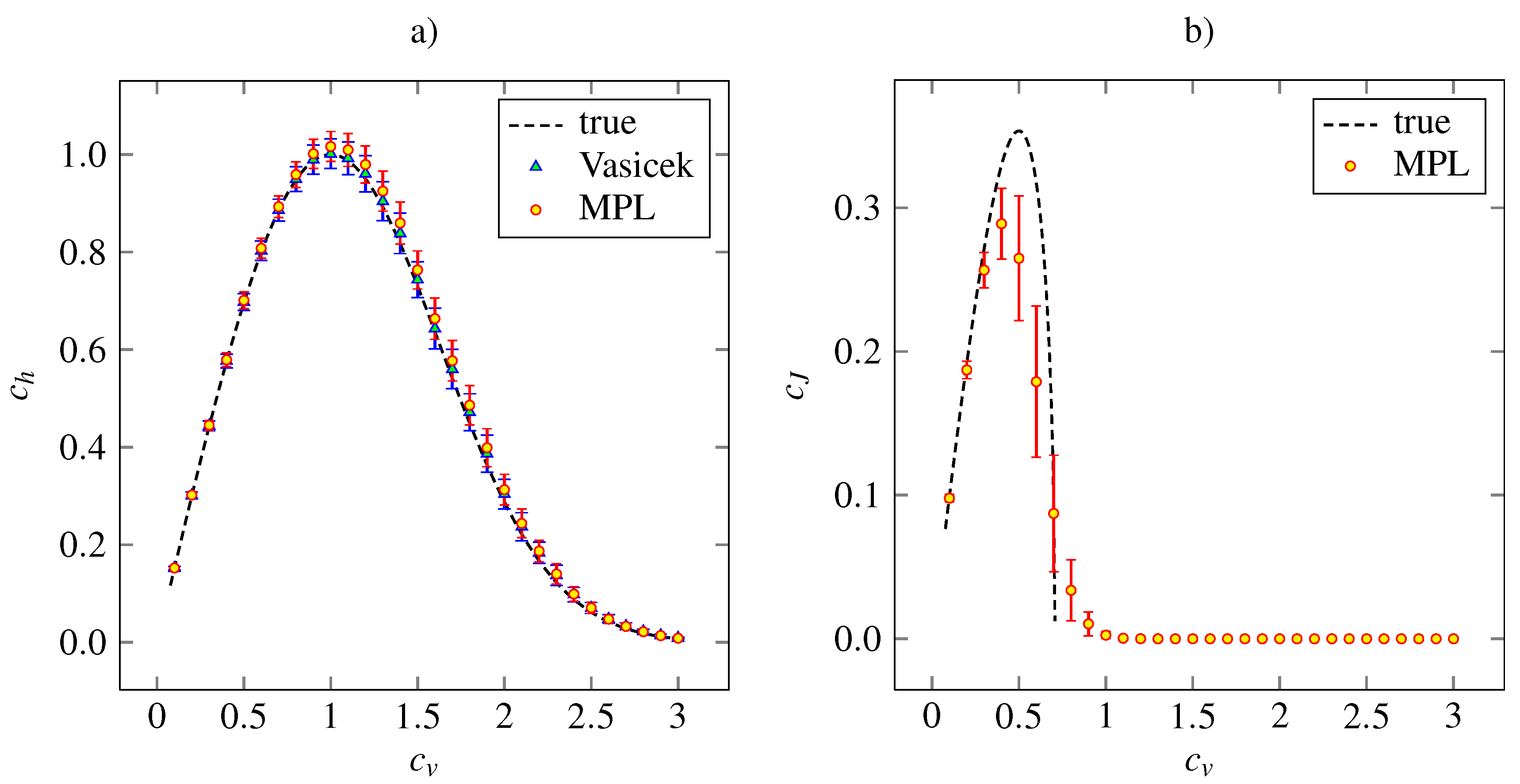
The outcome of the simulation study for the gamma density (21) is presented in
Figure 2, where the theoretical and estimated values of
and
for given
are plotted. In addition, the values of coefficient
calculated by Vasicek’s estimator are shown. We see that the MPL method results in precise estimation of
for low values of
and in slightly overestimated values of
for
. The Vasicek’s estimator gives slightly overestimated values too. Overall, the performances of Vasicek’s and MPL estimators are comparable. The maximum of the MPL estimator of
is achieved at the theoretical value,
. We can see that the standard deviation of the
estimate is higher as
grows from zero. As
, the standard deviation begins to decrease slowly.
We conclude that the MPL estimator of
is accurate for low
. For
it results in underestimated
and it tends to zero as
as well as the theoretical values. The high bias of
for high
is caused by inappropriate choice of the parameters
α and
β, which were kept fixed in accordance with the suggestion of [
26]. Nevertheless, the main shape of the dependency on
remains and the MPL estimates of
achieves local maximum at
, which is slightly lower than the theoretical value.
Figure 2.
The entropy-based variability coefficient (panel a) and the Fisher information-based variability coefficient (panel b), calculated nonparametrically from (18) and (19), respectively, for gamma distribution (24). The mean values (indicated by red discs) accompanied by the standard error (red error bars) are plotted in dependency on the coefficient of variation, . The dashed lines are the theoretical curves. In panel a, the results obtained by estimation (6) are added (blue triangles indicate mean values and blue error bars stand for standard error). The results are based on 1000 trials of samples of size 1000 for each value of .
Figure 2.
The entropy-based variability coefficient (panel a) and the Fisher information-based variability coefficient (panel b), calculated nonparametrically from (18) and (19), respectively, for gamma distribution (24). The mean values (indicated by red discs) accompanied by the standard error (red error bars) are plotted in dependency on the coefficient of variation, . The dashed lines are the theoretical curves. In panel a, the results obtained by estimation (6) are added (blue triangles indicate mean values and blue error bars stand for standard error). The results are based on 1000 trials of samples of size 1000 for each value of .
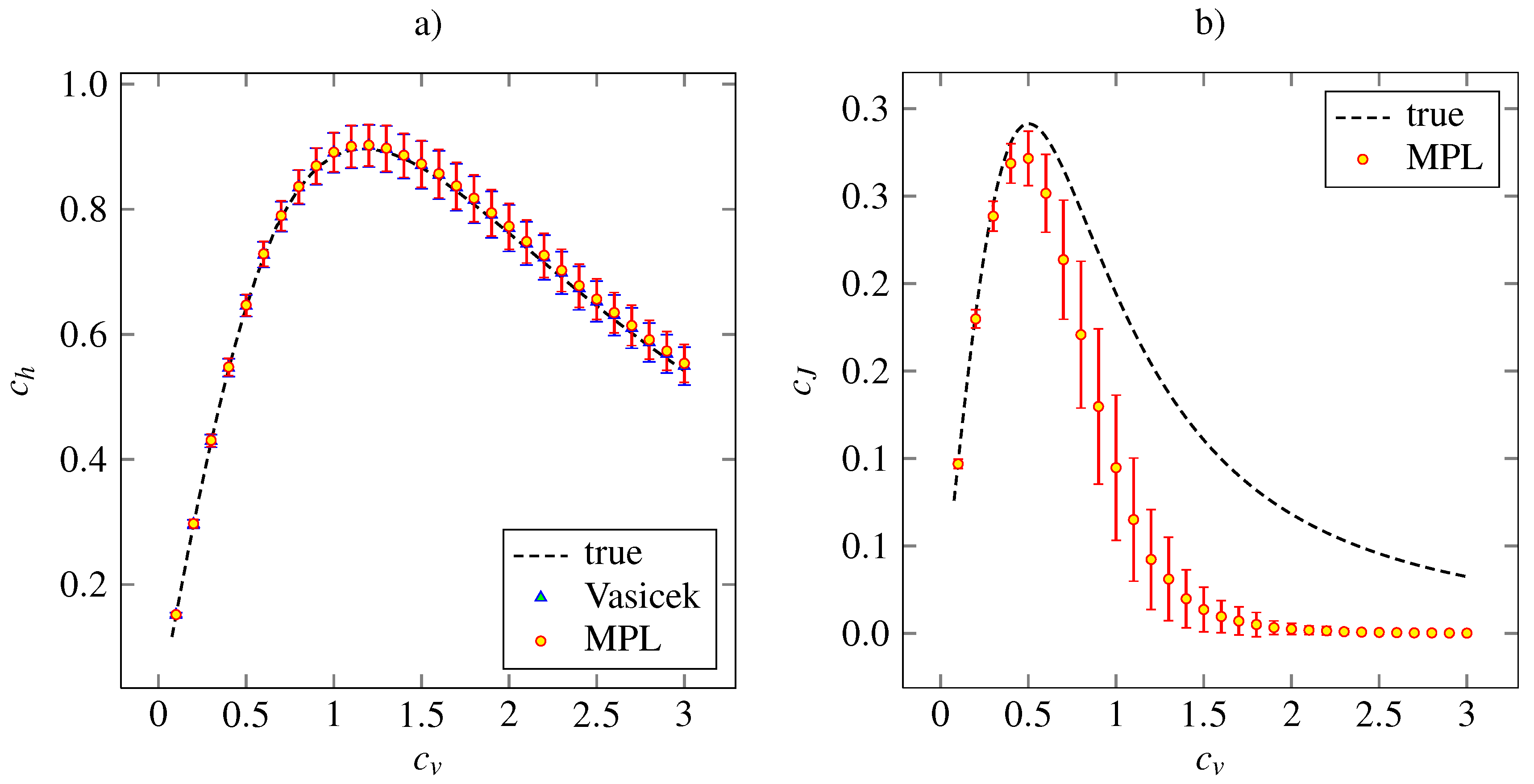
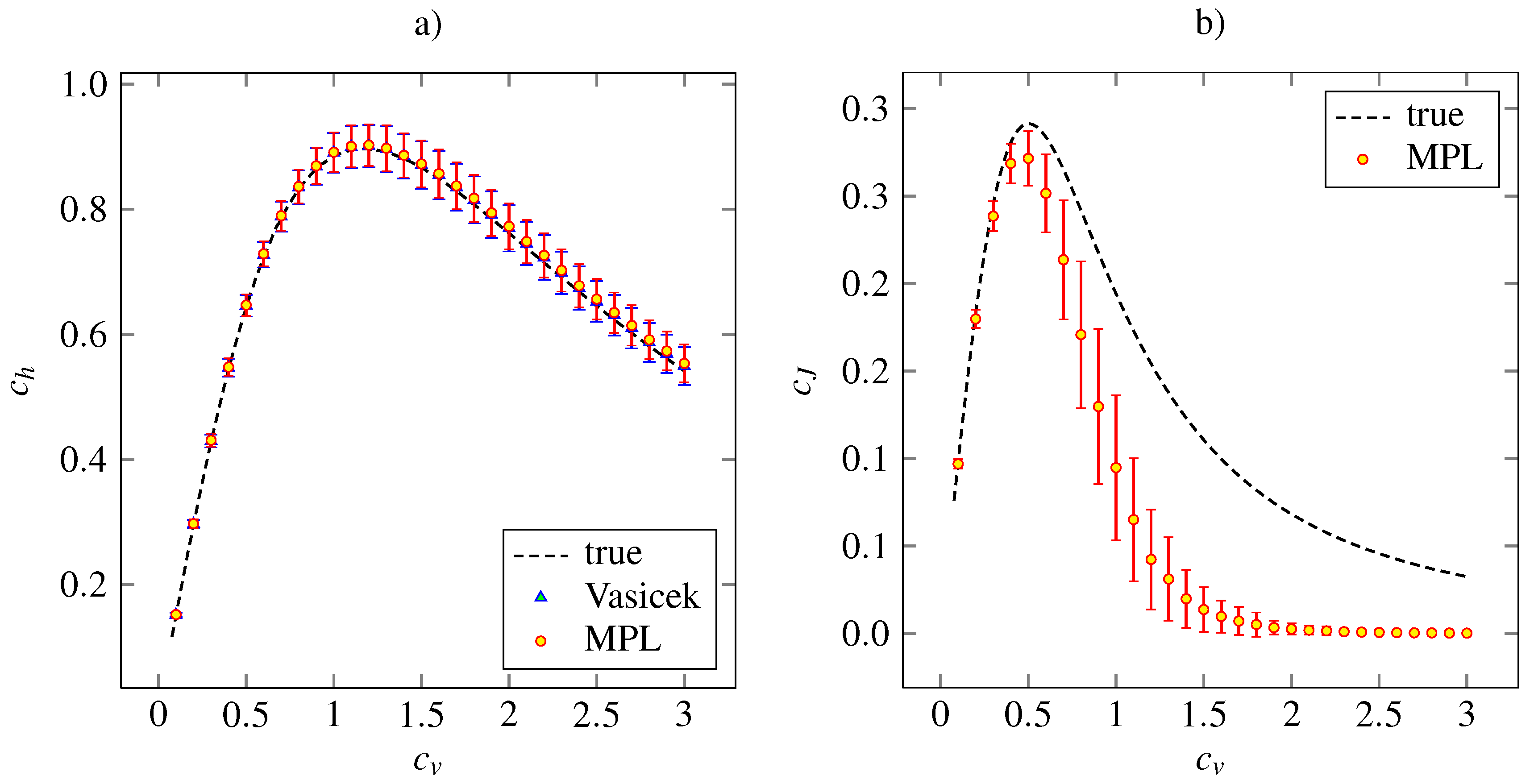
Figure 3 shows the corresponding results for the inverse Gaussian density. The Vasicek’s and MPL estimates of
are almost precise. Both the estimator of
based on MPL method and that based on the Vasicek’s entropy give the same mean values together with the same standard deviations. The MPL estimator of
gives accurate and precise results for
. For higher
, the estimated value is lower than the true one. The maximum of estimated
is achieved at the same point,
. The asymptotical decrease of the estimated
to zero is faster than the true dependency is. By our experience, this can be improved by setting higher
α and
β in order to give higher impact to the roughness penalty (15).
Figure 3.
Estimations of the variability coefficients
(panel
a) and
(panel
b) for inverse Gaussian distribution (24). The notation and the layout is the same as in
Figure 2.
Figure 3.
Estimations of the variability coefficients
(panel
a) and
(panel
b) for inverse Gaussian distribution (24). The notation and the layout is the same as in
Figure 2.
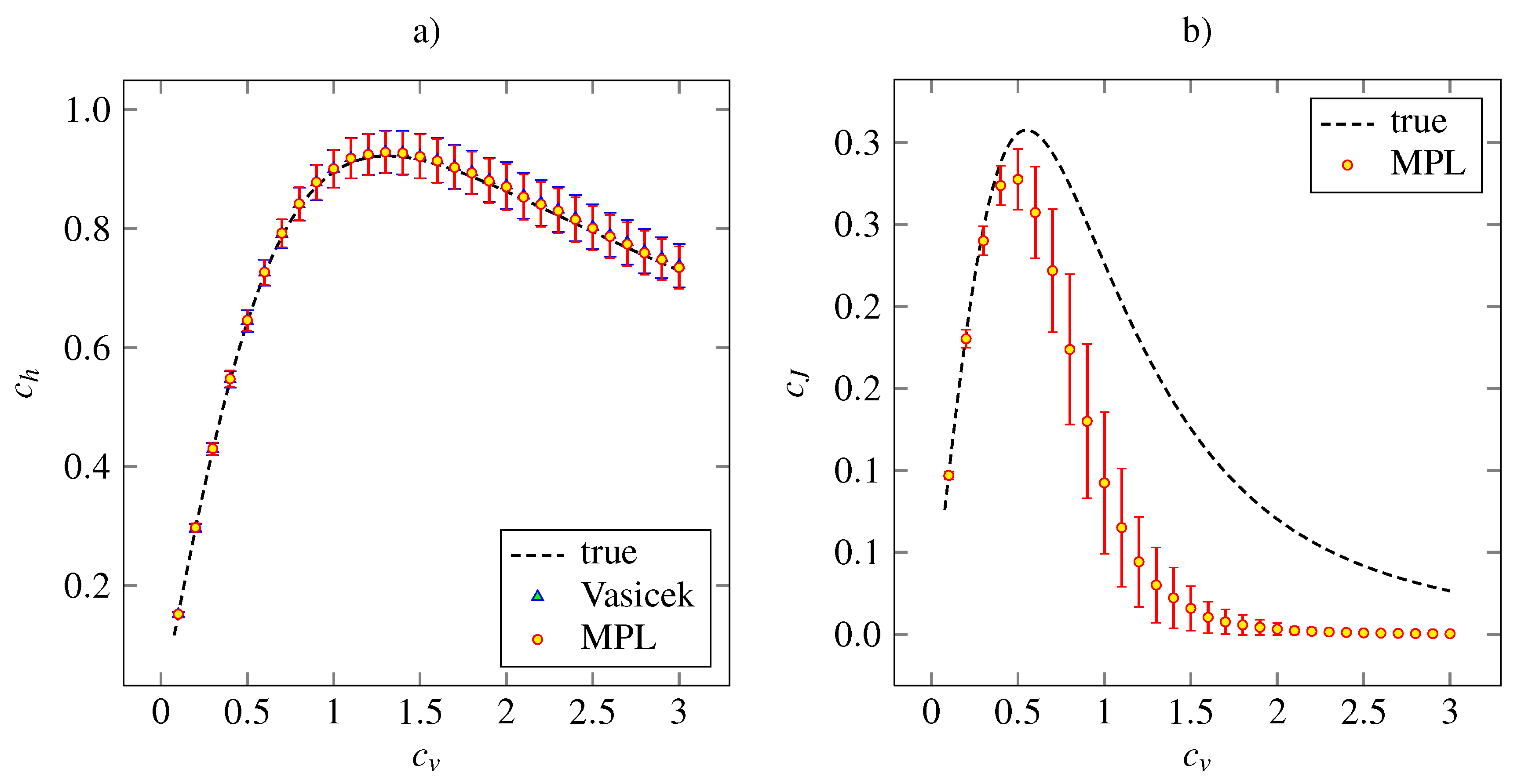
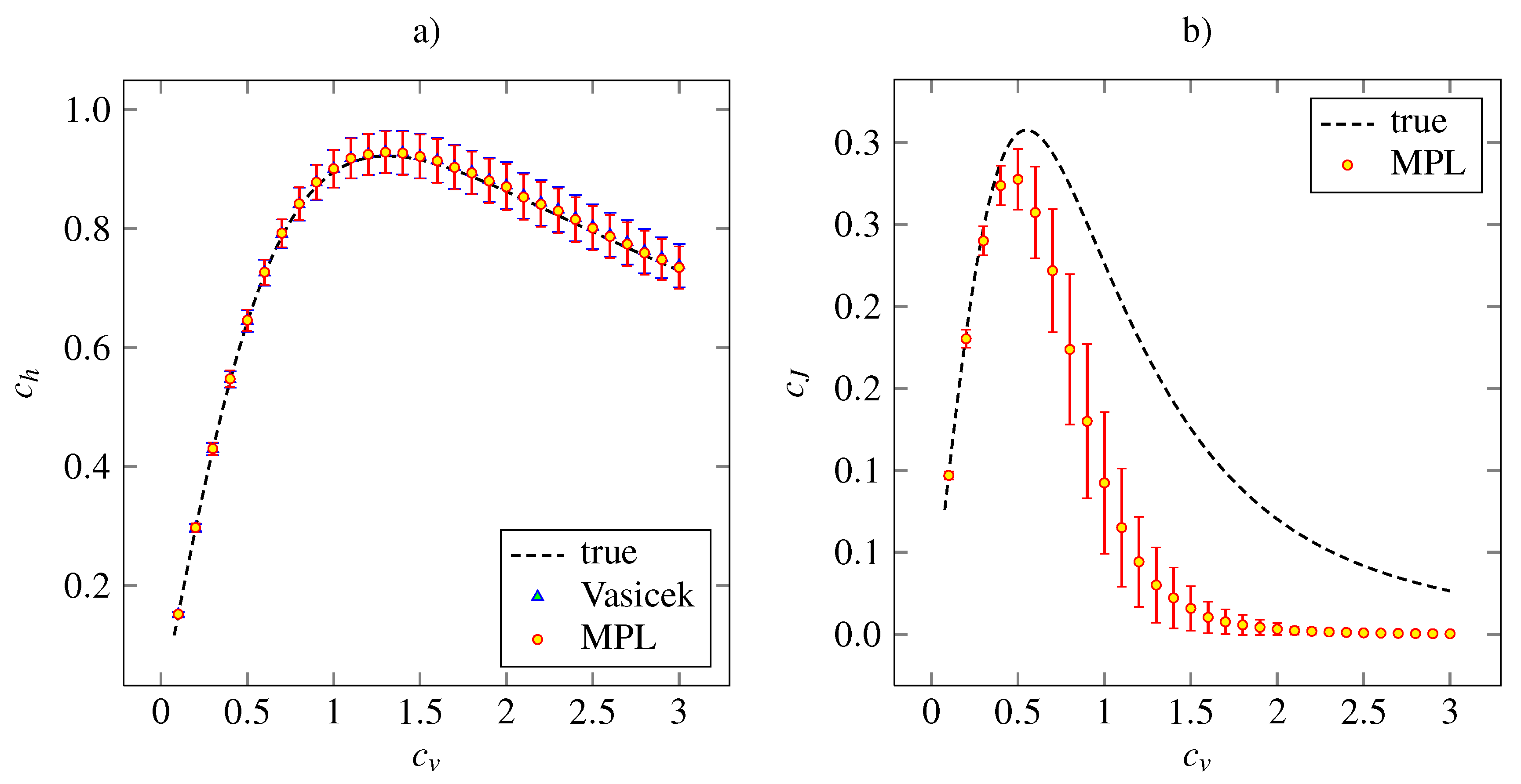
The results of the simulation study on the lognormal distribution with density (27) is plotted in
Figure 4, together with the theoretical dependencies and the results for the Vasicek’s estimator of the entropy. Both the MPL estimators of
and
have qualitatively same accuracy and precision features as the analogous estimators for the inverse Gaussian model.
Figure 4.
Estimations of the variability coefficients
(panel
a) and
(panel
b) for lognormal distribution (27). The notation and the layout is the same as in
Figure 2.
Figure 4.
Estimations of the variability coefficients
(panel
a) and
(panel
b) for lognormal distribution (27). The notation and the layout is the same as in
Figure 2.
4. Discussion and Conclusions
In proposing the dispersion measures based on entropy and Fisher information we were motivated by the difference between frequently mixed up notions of ISI variability and randomness, which, however, represent two different concepts [
1]. The proposed measures have been so far successfully applied mainly to examine differences between various neuronal activity regimes, obtained either by simulation of neuronal models or from experimental measurements [
32]. There, the comparison of neuronal spiking activity under different conditions plays a key role in resolving the question of neuronal coding. However, the methodology is not specific to the research of neuronal coding; it is generally applicable whenever one needs to quantify some additional properties of positive continuous random data.
In this paper, we used the MPL method of Good and Gaskins [
26] to estimate the dispersion coefficients nonparametrically from data. We found that the method performs comparably with the classical Vasicek’s estimator [
10] in the case of entropy-based dispersion.
The estimation of Fisher information-based dispersion is more complicated, but we found that the MPL method gives reasonable results. In fact, so far the MPL method is the best option for
estimation among the possibilities we tested (modified kernel methods, spline interpolation and approximation methods). The key parameters of the MPL method which affect the estimated value of
(and consequently of
) are the values of
α and
β in (15). In this paper we employed the suggestion of [
26], however, we found that different setting may sometimes lead to dramatic improvement in the estimation of
. We tested the performance of the estimation for sample sizes less than 1,000 and we found out that significant and systematic improvement resulting in low bias can be reached if
α and
β are allowed to depend somehow on the sample size. In this sense, the parameters play a similar role to the parameter
m in the Vasicek’s estimator (6). We are currently working on a systematic approach to determine
optimally, but the fine tuning of
α and
β is a difficult numerical task. Nevertheless, even without the fine-tuning, the performance of the entropy estimation is essentially the same as in the case of Vasicek’s estimator.
The length of the neuronal record and hence the sample size is another issue related to the choice of these parameters. As emphasized, e.g., by [
35,
36], particularly short record can considerably modify the empirical distribution. This can be adjusted by the parameter values, choosing whether the distribution should fit the data or it should be rather robust.

{kind=link}
{kind=link}
{kind=link}
{kind=link}