The Liang-Kleeman Information Flow: Theory and Applications

1
School of Marine Sciences and School of Mathematics and Statistics, Nanjing University of Information Science and Technology (Nanjing Institute of Meteorology), 219 Ningliu Blvd, Nanjing 210044, China
2
China Institute for Advanced Study, Central University of Finance and Economics, 39 South CollegeAve, Beijing 100081, China
Entropy 2013, 15(1), 327-360; https://doi.org/10.3390/e15010327
Submission received: 17 October 2012
/
Revised: 22 November 2012
/
Accepted: 28 December 2012
/
Published: 18 January 2013
(This article belongs to the Special Issue Transfer Entropy)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Information flow, or information transfer as it may be referred to, is a fundamental notion in general physics which has wide applications in scientific disciplines. Recently, a rigorous formalism has been established with respect to both deterministic and stochastic systems, with flow measures explicitly obtained. These measures possess some important properties, among which is flow or transfer asymmetry. The formalism has been validated and put to application with a variety of benchmark systems, such as the baker transformation, Hnon map, truncated Burgers-Hopf system, Langevin equation, etc. In the chaotic Burgers-Hopf system, all the transfers, save for one, are essentially zero, indicating that the processes underlying a dynamical phenomenon, albeit complex, could be simple. (Truth is simple.) In the Langevin equation case, it is found that there could be no information flowing from one certain time series to another series, though the two are highly correlated. Information flow/transfer provides a potential measure of the cause–effect relation between dynamical events, a relation usually hidden behind the correlation in a traditional sense.
1. Introduction
Information flow, or information transfer as it sometimes appears in the literature, refers to the transference of information between two entities in a dynamical system through some processes, with one entity being the source, and another the receiver. Its importance lies beyond its literal meaning in that it actually carries an implication of causation, uncertainty propagation, predictability transfer, etc., and, therefore, has applications in a wide variety of disciplines. In the following, we first give a brief demonstration of how it may be applied in different disciplines; the reader may skip this part and go directly to the last two paragraphs of this section.
According to how the source and receiver are chosen, information flow may appear in two types of form. The first is what one would envision in the usual sense, i.e., the transference between two parallel parties (for example, two chaotic circuits [1]), which are linked through some mechanism within a system. This is found in neuroscience (e.g., [2,3,4]), network dynamics (e.g., [5,6,7]), atmosphere–ocean science (e.g., [8,9,10,11]), financial economics (e.g., [12,13]), to name but a few. For instance, neuroscientists focus their studies on the brain and its impact on behavior and cognitive functions, which are associated with flows of information within the nervous system (e.g., [3]). This includes how information flows from one neuron to another neuron across the synapse, how dendrites bring information to the cell body, how axons take information away from the cell body, and so forth. Similar issues arise in computer and social networks, where the node–node interconnection, causal dependencies, and directedness of information flow, among others, are of concern [6,14,15]. In atmosphere–ocean science, the application is vast, albeit newly begun. An example is provided by the extensively studied El Niño phenomenon in the Pacific Ocean, which is well known through its linkage to global natural disasters, such as the floods in Ecuador and the droughts in Southeast Asia, southern Africa and northern Australia, to the death of birds and dolphins in Peru, to the increased number of storms over the Pacific, and to the famine and epidemic diseases in far-flung parts of the world [16,17,18]. A major focus in El Niño research is the predictability of the onset of the irregularly occurring event, in order to issue in-advance warning of potential hazardous impacts [19,20,21]. It has now become known that the variabilities in the Indian Ocean could affect the El Niño predictability (e.g., [22]). That is to say, at least a part of the uncertainty source for El Niño predictions is from the Indian Ocean. Therefore, to some extent, the El Niño predictability may also be posed as an information flow problem, i.e., a problem on how information flows from the Indian Ocean to the Pacific Ocean to make the El Niño more predictable or more uncertain.
Financial economics provides another field of application of information flow of the first type; this field has received enormous public attention since the recent global financial crisis triggered by the subprime mortgage meltdown. A conspicuous example is the cause–effect relation between the equity and options markets, which reflects the preference of traders in deciding where to place their trades. Usually, information is believed to flow unidirectionally from equity to options markets because informed traders prefer to trade in the options markets (e.g., [23]), but recent studies show that the flow may also exist in the opposite way: informed traders actually trade both stocks and “out-of-the-money" options, and hence the causal relation from stocks to options may reverse [12]. More (and perhaps the most important) applications are seen through predictability studies. For instance, the predictability of asset return characteristics is a continuing problem in financial economics, which is largely due to the information flow in markets. Understanding the information flow helps to assess the relative impact from the markets and the diffusive innovation on financial management. Particularly, it helps the prediction of jump timing, a fundamental question in financial decision making, through determining information covariates that affect jump occurrence up to the intraday levels, hence providing empirical evidence in the equity markets, and pointing us to an efficient financial management [13].
The second type of information flow appears in a more abstract way. In this case, we have one dynamical event; the transference occurs between different levels, or sometimes scales, within the same event. Examples for this type are found in disciplines such as evolutionary biology [24,25,26], statistical physics [27,28], turbulence, etc., and are also seen in network dynamics. Consider the transitions in biological complexity. A reductionist, for example, views that the emergence of new, higher level entities can be traced back to lower level entities, and hence there is a “bottom-up” causation, i.e., an information flow from the lower levels to higher levels. Bottom-up causation lays the theoretical foundation for statistical mechanics, which explains macroscopic thermodynamic states from a point of view of molecular motions. On the other hand, “top-down” causation is also important [29,30]. In evolution (e.g., [31]), it has been shown that higher level processes may constrain and influence what happens at lower levels; particularly, in transiting complexity, there is a transition of information flow, from the bottom-up to top-down, leading to a radical change in the structure of causation (see, for example [32]). Similar to evolutionary biology, in network dynamics, some simple computer networks may experience a transition from a low traffic state to a high congestion state, beneath which is a flow of information from a bunch of almost independent entities to a collective pattern representing a higher level of organization (e.g., [33]). In the study of turbulence, the notoriously challenging problem in classical physics, it is of much interest to know how information flows over the spectrum to form patterns on different scales. This may help to better explain the cause of the observed higher moments of the statistics, such as excess kurtosis and skewness, of velocity components and velocity derivatives [34]. Generally, the flows/transfers are two-way, i.e., both from small scales to large scales, and from large scales to small scales, but the flow or transfer rates may be quite different.
Apart from the diverse real-world applications, information flow/transfer is important in that it offers a methodology for scientific research. In particular, it offers a new way of time series analysis [35,36,37]. Traditionally, correlation analysis is widely used for identifying the relation between two events represented by time series of measurements; an alternative approach is through mutual information analysis, which may be viewed as a type of nonlinear correlation analysis. But both correlation analysis and mutual information analysis put the two events on an equal stance. As a result, there is no way to pick out the cause and the effect. In econometrics, Granger causality [38] is usually employed to characterize the causal relation between time series, but the characterization is just in a qualitative sense; when two events are mutually causal, it is difficult to differentiate their relative strengths. The concept of information flow/transfer is expected to remedy this deficiency, with the mutual causal relation quantitatively expressed.
Causality implies directionality. Perhaps the most conspicuous observation on information flow/transfer is its asymmetry between the involved parties. A typical example is seen in our daily life when a baker is kneading a dough. As the baker stretches, cuts, and folds, he guides a unilateral flow of information from the horizontal to the vertical. That is to say, information goes only from the stretching direction to the folding direction, not vice versa. The one-way information flow (in a conventional point of view) between the equity and options markets offers another good example. In other cases, such as in the aforementioned El Niño event, though the Indian and Pacific Oceans may interact with each other, i.e., the flow route could be a two-way street, the flow rate generally differs from one direction to another direction. For all that account, transfer asymmetry makes a basic property of information flow; it is this property that distinguishes information flow from the traditional concepts such as mutual information.
As an aside, one should not confuse dynamics with causality, the important property reflected in the asymmetry of information flow. It is temptating to think that, for a system, when the dynamics are known, the causal relations are determined. While this might be the case for linear deterministic systems, in general, however, this need not be true. Nonlinearity may lead a deterministic system to chaos; the future may not be predictable after a certain period of time, even though the dynamics is explicitly given. The concept of emergence in complex systems offers another example. It has long been found that irregular motions according to some simple rules may result in the emergence of regular patterns (such as the inverse cascade in the planar turbulence in natural world [39,40]). Obviously, how this instantaneous flow of information from the low-level entities to high-level entities, i.e., the patterns, cannot be simply explained by the rudimentary rules set a priori. In the language of complexity, emergence does not result from rules only (e.g., [41,42,43]); rather, as said by Corning (2002) [44], “Rules, or laws, have no causal efficacy; they do not in fact `generate’ anything... the underlying causal agencies must be separately specified.”
Historically, quantification of information flow has been an enduring problem. The challenge lies in that this is a real physical notion, while the physical foundation is not as clear as those well-known physical laws. During the past decades, formalisms have been established empirically or half-empirically based on observations in the aforementioned diverse disciplines, among which are Vastano and Swinney’s time-delayed mutual information [45], and Schreiber’s transfer entropy [46,47]. Particularly, transfer entropy is established with an emphasis of the above transfer asymmetry between the source and receiver, so as to have the causal relation represented; it has been successfully applied in many real problem studies. These formalisms, when carefully analyzed, can be approximately understood as dealing with the change of marginal entropy in the Shannon sense, and how this change may be altered in the presence of information flow (see [48], section 4 for a detailed analysis). This motivates us to think about the possibility of a rigorous formalism when the dynamics of the system is known. As such, the underlying evolution of the joint probability density function (pdf) will also be given, for deterministic systems, by the Liouville equation or, for stochastic systems, by the Fokker-Planck equation (cf. §4 and §5 below). From the joint pdf, it is easy to obtain the marginal density, and hence the marginal entropy. One thus expects that the concept of information flow/transfer may be built on a rigorous footing when the dynamics are known, as is the case with many real world problems like those in atmosphere–ocean science. And, indeed, Liang and Kleeman (2005) [49] find that, for two-dimensional (2D) systems, there is a concise law on entropy evolution that makes the hypothesis come true. Since then, the formalism has been extended to systems in different forms and of arbitrary dimensionality, and has been applied with success in benchmark dynamical systems and more realistic problems. In the following sections, we will give a systematic introduction of the theories and a brief review of some of the important applications.
In the rest of this review, we first set up a theoretical framework, then illustrate through a simple case how a rigorous formalism can be achieved. Specifically, our goal is to compute within the framework, for a continuous-time system, the transference rate of information, and, for a discrete-time system or mapping, the amount of the transference upon each application of the mapping. To unify the terminology, we may simply use “information flow/transfer” to indicate either the “rate of information flow/transfer” or the “amount of information flow/transfer” wherever no ambiguity exists in the context. The next three sections are devoted to the derivations of the transference formulas for three different systems. Section 3 and Section 4 are for deterministic systems, with randomness limited within initial conditions, where the former deals with discrete mappings and the latter with continuous flows. Section 5 discusses the case when stochasticity is taken in account. In the section that follows, four major applications are briefly reviewed. While these applications are important per se, some of them also provide validations for the formalism. Besides, they are also typical in terms of computation; different approaches (both analytical and computational) have been employed in computing the flow or transfer rates for these systems. We summarize in Section 7 the major results regarding the formulas and their corresponding properties, and give a brief discussion on the future research along this line. As a convention in the history of development, the terms “information flow” and “information transfer” will be used synonymously. Throughout this review, by entropy we always mean Shannon or absolute entropy, unless otherwise specified. Whenever a theorem is stated, generally only the result is given and interpreted; for detailed proofs, the reader is referred to the original papers.
2. Mathematical Formalism
2.1. Theoretical Framework
Consider a system with n state variables, , , ..., , which we put together as a column vector . Throughout this paper, may be either deterministic or random, depending on the context where it appears. This is a notational convention adopted in the physics literature, where random and deterministic states for the same variable are not distinguished. (In probability theory, they are usually distinguished with lower and upper cases like and .) Consider a sample space of , . Defined on Ω is a joint probability density function (pdf) For convenience, assume that ρ and its derivatives (up to an order as high as enough) are compactly supported. This makes sense, as in the real physical world, the probability of extreme events vanishes. Thus, without loss of generality, we may extend Ω to and consider the problem on , giving a joint density in and n marginal densities :
Correspondingly, we have an entropy functional of ρ (joint entropy) in the Shannon sense
and n marginal entropies
Consider an n-dimensional dynamical system, autonomous or nonautonomous,
where is the vector field. With random inputs at the initial stage, the system generates a continuous stochastic process , which is what we are concerned with. In many cases, the process may not be continuous in time (such as that generated by the baker transformation, as mentioned in the introduction). We thence also need to consider a system in the discrete mapping form:
with τ being positiver integers. Here Φ is an n-dimensional transformation
the counterpart of the vector field . Again, the system is assumed to be perfect, with randomness limited within the initial conditions. Cases with stochasticity due to model inaccuracies are deferred to Section 5. The stochastic process thus formed is in a discrete time form , with signifying the time steps. Our formalism will be established henceforth within these frameworks.
2.2. Toward a Rigorous Formalism—A Heuristic Argument
First, let us look at the two-dimensional (2D) case originally studied by Liang and Kleeman [49]
This is a system of minimal dimensionality that admits information flow. Without loss of generality, examine only the flow/transfer from to .
Under the vector field evolves with time; correspondingly its joint pdf evolves, observing a Liouville equation [50]:
As argued in the introduction, what matters here is the evolution of namely the marginal entropy of . For this purpose, integrate (8) with respect to over to get:
Other terms vanish, thanks to the compact support assumption for ρ. Multiplication of (9) by followed by an integration over gives the tendency of :
where E stands for mathematical expectation with respect to ρ. In the derivation, integration by parts has been used, as well as the compact support assumption.
Now what is the rate of information flow from to ? In [49], Liang and Kleeman argue that, as the system steers a state forward, the marginal entropy of is replenished from two different sources: one is from itself, another from . The latter is through the very mechanism namely information flow/transfer. If we write the former as , and denote by the rate of information flow/transfer from to (T stands for “transfer”), this gives a decomposition of the marginal entropy increase according to the underlying mechanisms:
Here is known from Equation (10). To find , one may look for instead. In [49], Liang and Kleeman find that this is indeed possible, based on a heuristic argument. To see this, multiply the Liouville Equation (8) by , then integrate over . This yields an equation governing the evolution of the joint entropy H which, after a series of manipulation, is reduced to
where ∇ is the divergence operator. With the assumption of compact support, the first term on the right hand side goes to zero. Using E to indicate the operator of mathematical expectation, this becomes
That is to say, the time rate of change of H is precisely equal to the mathematical expectation of the divergence of the vector field. This remarkably concise result tells that, as a system moves on, the change of its joint entropy is totally controlled by the contraction or expansion of the phase space of the system. Later on, Liang and Kleeman show that this is actually a property holding for deterministic systems of arbitrary dimensionality, even without invoking the compact assumption [51]. Moreover, it has also been shown that, the local marginal entropy production observes a law in the similar form, if no remote effect is taken in account [52].
With Equation (12), Liang and Kleeman argue that, apart from the complicated relations, the rate of change of the marginal entropy due to only (i.e., as symbolized above), should be
This heuristic reasoning makes the separation (11) possible. Hence the information flows from to at a rate of
where is the conditional pdf of , given . The rate of information flow from to , written , can be derived in the same way. This tight formalism (called “LK2005 formalism” henceforth), albeit based on heuristic reasoning, turns out to be very successful. The same strategy has been applied again in a similar study by Majda and Harlim [53]. We will have a chance to see these in Section 4 and Section 6.
2.3. Mathematical Formalism
The success of the LK2005 formalism is remarkable. However, its utility is limited to systems of dimensionality 2. For an n-dimensional system with , the so-obtained Equation (14) is not the transfer from to , but the cumulant transfer to from all other components , ,..., . Unless one can screen out from Equation (14) the part contributed from , it seems that the formalism does not yield the desiderata for high-dimensional systems.
To overcome the difficulty, Liang and Kleeman [48,51] observe that, the key part in Equation (14) namely actually can be alternatively interpreted, for a 2D system, as the evolution of with the effect of excluded. In other words, it is the tendency of with frozen instantaneously at time t. To avoid confusing with , denote it as , with the subscript signifying that the effect of is removed. In this way is decomposed into two disjoint parts: namely the rate of information flow and . The flow is then the difference between and :
For 2D systems, this is just a restatement of Equation (14) in another set of symbols; but for systems with dimensionality higher than 2, they are quite different. Since the above partitioning does not have any restraints on n, Equation (15) is applicable to systems of arbitrary dimensionality.
In the same spirit, we can formulate the information transfer for discrete systems in the form of Equation (4). As is mapped forth under the transformation Φ from time step τ to , correspondingly its density ρ is steered forward by an operator termed after Georg Frobenius and Oskar Perron, which we will introduce later. Accordingly the entropies H, , and also change with time. On the interval , let be incremented by from τ to . By the foregoing argument, the evolution of can be decomposed into two exclusive parts according to their driving mechanisms, i.e., the information flow from , , and the evolution with the effect of excluded, written as . We therefore obtain the discrete counterpart of Equation (15):
Equations (15) and (16) give the rates of information flow/transfer from component to component for systems (3) and (4), respectively. One may switch the corresponding indices to obtain the flow between any component pair and , . In the following two sections we will be exploring how these equations are evaluated.
3. Discrete Systems
3.1. Frobenius-Perron Operator
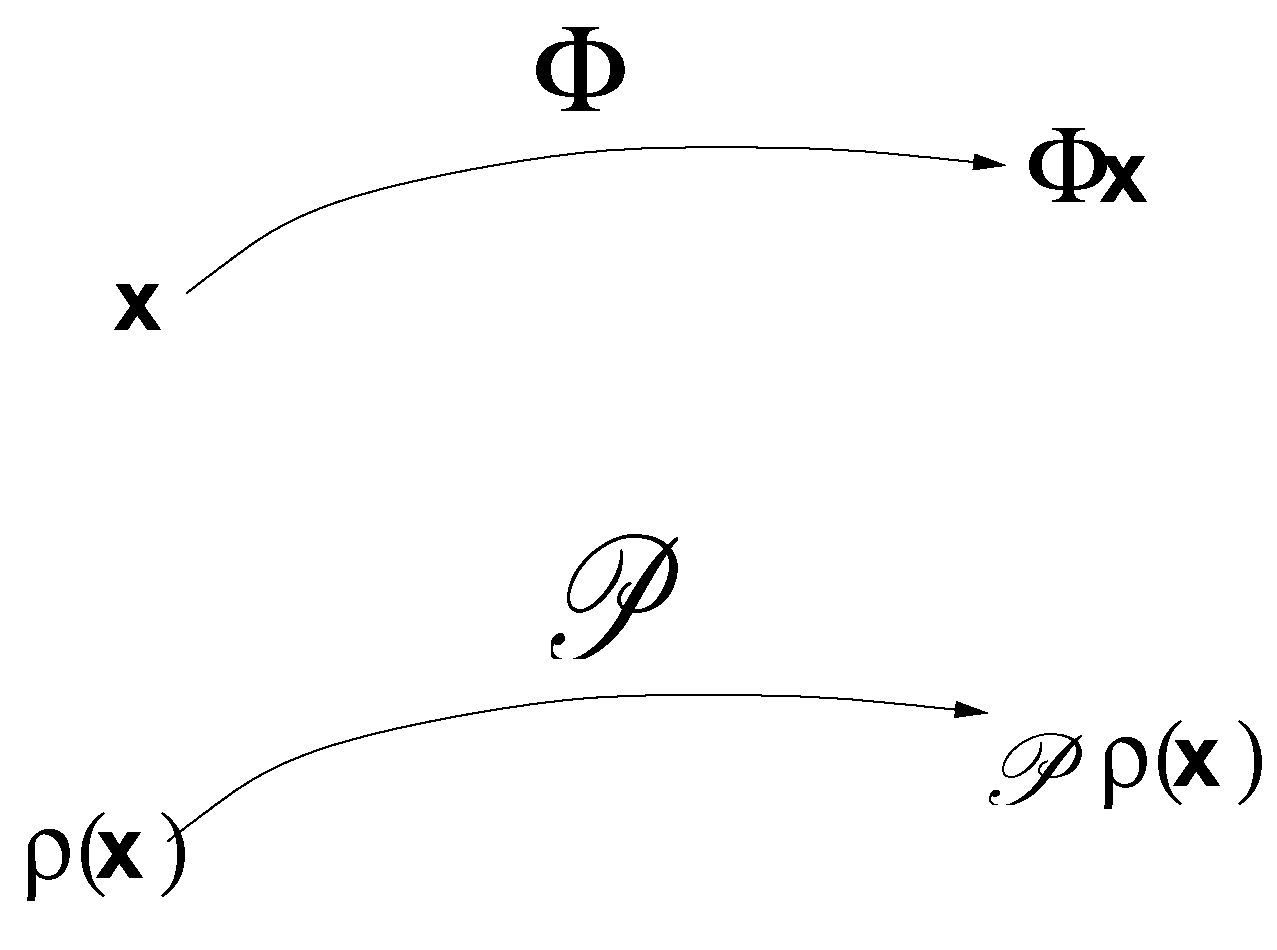
For discrete systems in the form of Equation (4), as is carried forth under the transformation Φ, there is another transformation, called Frobenius–Perron operator (F-P operator hereafter), steering , i.e., the pdf of , to (see a schematic in Figure 1). The F-P operator governs the evolution of the density of .
A rigorous definition requires some ingredients of measure theory which is beyond the scope this review, and the reader may consult with the reference [50]. Loosely speaking, given a transformation (in this review, ), , it is a mapping , , such that
for any . If Φ is nonsingular and invertible, it actually can be explicitly evaluated. Making transformation , the right hand side is, in this case,
where J is the Jacobian of Φ:
and its inverse. Since ω is arbitrarily chosen, we have
If no nonsingularity is assumed for the transformation Φ, but the sample space Ω is in a Cartesian product form, as is for this review, the F-P operator can also be evaluated, though not in an explicit form. Consider a domain
where is some constant point (usually can be set to be the origin). Let the counterimage of ω be , then it has been proved (c.f. [50]) that
In this review, we consider a sample space , so essentially all the F-P operators can be calculated this way.
Figure 1.
Illustration of the Frobenius-Perron operator , which takes to as Φ takes to .

3.2. Information Flow
The F-P operator allows for an evaluation of the change of entropy as the system evolves forth. By the formalism (16) , we need to examine how the marginal entropy changes on a time interval . Without loss of generality, consider only the flow from to . First look at increase of . Let ρ be the joint density at step τ, then the joint density at step is , and hence
Here means the marginal density of at ; it is equal to with all components of but being integrated out. The independent variables with respect to which the integrations are taken are dummy; but for the sake of clarity, we use different notations, i.e., x and y, for them at time step τ and , respectively.
The key to the formalism (16) is the finding of
namely the increment of the marginal entropy of on with the contribution from excluded. Here the system in question is no longer Equation (4), but a system with a mapping modified from Φ:
with frozen instantaneously at τ as a parameter. Again, we use , , , to indicate the state variables at steps τ and , respectively, to avoid any possible confusion. In the mean time, the dependence on τ and are suppressed for notational economy. Corresponding to the modified transformation is a modified F-P operator, written . To find , examine the quantity , where the subscript 1 indicates that this is a marginal density of the first component, and the dependence on tells that this is evaluated at step . Recall how Shannon entropy is defined: is essentially the mathematical expectation, or “average” in loose language, of h. More specifically, it is h multiplied with some pdf followed by an integration over , i.e., the corresponding sample space. The pdf is composed of several different factors. The first is, of course, . But h, as well as , also has dependence on , which is embedded within the subscript . Recall how is treated during : It is frozen at step τ and kept on as a parameter, given all other components at τ. Therefore, the second part of the density is , i.e., the conditional density of on . (Note again that means variables at time step τ.) This factor introduces extra dependencies: , , ..., (that of is embedded in ), which must also be averaged out, so the third factor of the density is namely the joint density of . Put all these together,
Subtraction of from Equation (19) gives, eventually, the rate of information flow/transfer from to :
Notice that the conditional density of is on , not on . ( and are the same state variable evaluated at different time steps, and are connected via .
Likewise, it is easy to obtain the information flow between any pair of components. If, for example, we are concerned with the flow from to (, ), replacement of the indices 1 and 2 in Equation (23) respectively with i and j gives
Here the subscript of means the F-P operator with the effect of the component excluded through freezing it instantaneously as a parameter. We have also abused the notation a little bit for the density function to indicate the marginalization of that component. That is to say,
and is the density after being marginalized twice, with respect to and . To avoid this potential notation complexity, alternatively, one may reorganize the order of the components of the vector such that the pair appears in the first two slots, and modify the mapping Φ accordingly. In this case, the flow/transfer is precisely the same in form as Equation (23). Equations (23) and (24) can be evaluated explicitly for systems that are definitely specified. In the following sections we will see several concrete examples.
3.3. Properties
The information flow obtained in Equations (23) or (24) has some nice properties. The first is a concretization of the transfer asymmetry emphasized by Schreiber [47] (as mentioned in the introduction), and the second a special property for 2D systems.
Theorem 3.1
For the system Equation (4), if is independent of , then (in the mean time, need not be zero).
The proof is rather technically involved; the reader is referred to [48] for details. This theorem states that, if the evolution of has nothing to do with , then there will be no information flowing from to . This is in agreement with observations, and with what one would argue on physical grounds. On the other hand, the vanishing yields no clue on , i.e., the flow from to need not be zero in the mean time, unless does not rely on . This is indicative of a very important physical fact: information flow between a component pair is not symmetric, in contrast to the notion of mutual information ever existing in information theory. As emphasized by Schreiber [47], a faithful formalism must be able to recover this asymmetry. The theorem shows that our formalism yields precisely what is expected. Since transfer asymmetry is a reflection of causality, the above theorem is also referred to as property of causality by Liang and Kleeman [48].
Theorem 3.2
For the system Equation (4), if and is invertible, then , where .
A brief proof will help to gain better understanding of the theorem. If , the modified system has a mapping which is simply with as a parameter. Equation (22) is thus reduced to
where , and the marginal density of evolving from upon one transformation of . By assumption is invertible, that is to say, . The F-P operator hence can be explicitly written out:
So
The conclusion follows subsequently from Equation (16).
The above theorem actually states another interesting fact that parallels what we introduced previously in §2.2 via heuristic reasoning. To see this, reconsider the mapping , . Let Φ be nonsingular and invertible. By Equation (18), the F-P operator of the joint pdf ρ can be explicitly evaluated. Accordingly, the entropy increases, as time moves from step τ to step , by
After some manipulation (see [48] for details), this is reduced to
This is the discrete counterpart of Equation (12), yet another remarkably concise formula. Now, if the system in question is 2-dimensional, then, as argued in §2.2, the information flow from to should be , with being the marginal entropy increase due to itself. Furthermore, if is nonsingular and invertible, then Equation (28) tells us it must be that
and this is precisely what Theorem 3.2 reads.
4. Continuous Systems
For continuous systems in the form of Equation (3), we may take advantage of what we already have from the previous section to obtain the information flow. Without loss of generality, consider only the flow/transfer from to , . We adopt the following strategy to fulfill the task:
- Discretize the continuous system in time on , and construct a mapping Φ to take to ;
- Freeze in Φ throughout to obtain a modified mapping ;
- Compute the marginal entropy change as Φ steers the system from t to ;
- Derive the marginal entropy change as steers the modified system from t to ;
- Take the limitto arrive at the desiderata.
4.1. Discretization of the Continuous System
As the first step, construct out of Equation (3) an n-dimensional discrete system, which steers to . To avoid any confusion that may arise, will be denoted as hereafter. Discretization of Equation (3) results in a mapping, to the first order of , : , :
Clearly, this mapping is always invertible so long as is small enough. In fact, we have
to the first order of . Furthermore, its Jacobian J is
Likewise, it is easy to get
This makes it possible to evaluate the F-P operator associated with Φ. By Equation (18),
Here ; we have suppressed its dependence on to simplify the notation.
As an aside, the explicit evaluation (31), and subsequently (32) and (33), actually can be utilized to arrive at the important entropy evolution law (12) without invoking any assumptions. To see this, recall by Equation (28). Let go to zero to get
which is the very result , just as one may expect.
4.2. Information Flow
To compute the information flow , we need to know and . The former is easy to find from the Liouville equation associated with Equation (3), i.e.,
following the same derivation as that in §2.2:
The challenge lies in the evaluation of . We summarize the result in the following proposition:
Proposition 4.1
For the dynamical system (3), the rate of change of the marginal entropy of with the effect of instantaneously excluded is:
where
and , are the densities after marginalized with and , respectively.
The proof is rather technically involved; for details, see [51], section 5.
With the above result, subtract from and one obtains the flow rate from to . Likewise, the information flow between any component pair , ; , can be obtained henceforth.
Theorem 4.1
For the dynamical system Equation (3), the rate of information flow from to is
where
In this formula, reminds one of the conditional density on , and, if , it is indeed so. We may therefore call it the “generalized conditional density” of on .
4.3. Properties
Recall that, as we argue in §2.2 based on the entropy evolution law (12), the time rate of change of the marginal entropy of a component, say , due to its own reason, is . Since for a 2D system, is precisely , we expect that the above formalism (36) or (39) verifies this result.
Theorem 4.2
If the system Equation (3) has a dimensionality 2, then
and hence the rate of information flow from to is
What makes a 2D system so special is that, when , , and is just the conditional distribution of given , . Equation (36) can thereby be greatly simplified:
Subtract this from what has been obtained above for , and we get an information flow just as that in Equation (14) via heuristic argument.
As in the discrete case, one important property that must possess is transfer asymmetry, which has been emphasized previously, particularly by Schreiber [47]. The following is a concretization of the argument.
Theorem 4.3 (Causality)
For system (3), if is independent of , then ; in the mean time, need not vanish, unless has no dependence on .
Look at the right-hand side of the formula (39). Given that and , as well as (by assumption), are independent of , the integration with respect to can be taken within the multiple integrals. Consider the second integral first. All the variables except have dependence on . But , so the whole term is equal to which vanishes by the assumption of compact support. For the first integral, move the integration with respect to into the parentheses, as the factor outside has nothing to do with . This integration yields
because and . For all that account, both the two integrals on the right-hand side of Equation (39) vanish, leaving a zero flow of information from to . Notice that this vanishing gives no hint on the flow in the opposite direction. In other words, this kind of flow or transfer is not symmetric, reflecting the causal relation between the component pair. As Theorem 3.1 is for discrete systems, Theorem 4.3 is the property of causality for continuous systems.
5. Stochastic Systems
So far, all the systems considered are deterministic. In this section we turn to systems with stochasticity included. Consider the stochastic counterpart of Equation (3)
where is a vector of standard Wiener processes, and the matrix of perturbation amplitudes. In this section, we limit our discussion to 2D systems, and hence have only two flows/transfers to discuss. Without loss of generality, consider only , i.e., the rate of flow/transfer from to .
As before, we first need to find the time rate of change of , the marginal entropy of . This can be easily derived from the density evolution equation corresponding to Equation (47), i.e., the Fokker-Planck equation:
where . This integrated over with respect to gives the evolution of :
Multiply (49) by , and integrate with respect to over . After some manipulation, one obtains, using the compact support assumption,
where E is the mathematical expectation with respect to ρ.
Again, the key to the formalism is the finding of . For stochastic systems, this could be a challenging task. The major challenge is that we cannot obtain an F-P operator as nice as that in the previous section for the map resulting from discretization. In early days, Majda and Harlim [53] have tried our heuristic argument in §2.2 to consider a special system modeling the atmosphere–ocean interaction, which is in the form
Their purpose is to find namely the information transfer from to . In this case, since the governing equation for is deterministic, the result is precisely the same as that of LK05, which is shown in in §2.2. The problem here is that the approach cannot be extended even to finding , since the nice law on which the argument is based, i.e., Equation (12), does not hold for stochastic processes.
Liang (2008) [54] adopted a different approach to give this problem a solution. As in the previous section, the general strategy is also to discretize the system in time, modify the discretized system with frozen as a parameter on an interval , and then let go to zero and take the limit. But this time no operator analogous to the F-P operator is sought; instead, we discretize the Fokker–Planck equation and expand , namely the first component at with frozen at t, using the Euler–Bernstein approximation. The complete derivation is beyond the scope of this review; the reader is referred to [54] for details. In the following, the final result is supplied in the form of a proposition.
Proposition 5.1
For the 2D stochastic system (47), the time change of the marginal entropy of with the contribution from excluded is
In the equation, the second and the third terms on the right hand side are from the stochastic perturbation. The first term, as one may recall, is precisely the result of Theorem 4.2. The heuristic argument for 2D systems in Equation (13) is successfully recovered here. With this the rate of information flow can be easily obtained by subtracting from .
Theorem 5.1
For the 2D stochastic system (47), the rate of information flow from to is
where E is the expectation with respect to .
It has been a routine to check for the obtained flow the property of causality or asymmetry. Here in Equation (52), the first term on the right hand side is from the deterministic part of the system, which has been checked before. For the second term, if , , and hence have no dependence on , then the integration with respect to can be taken inside with or , and results in 1. The remaining part is in a divergence form, which, by the assumption of compact support, gives a zero contribution from the stochastic perturbation. We therefore have the following theorem:
Theorem 5.2
If, in the stochastic system (47), the evolution of is independent of , then .
The above argument actually has more implications. Suppose are independent of , i.e., the noises are uncorrelated with the state variables. This model is indeed of interest, as in the real world, a large portion of noises are additive; in other words, , and hence , are constant more often than not. In this case, no matter what the vector field is, by the above argument the resulting information flows within the system will involve no contribution from the stochastic perturbation. That is to say,
Theorem 5.3
Within a stochastic system, if the noise is additive, then the information flows are the same in form as that of the corresponding deterministic system.
This theorem shows that, if only information flows are considered, a stochastic system with additive noise functions just like deterministic. Of course, the resemblance is limited to the form of formula; the marginal density in Equation (52) already takes into account the effect of stochasticity, as can be seen from the integrated Fokker–Planck Equation (49). A more appropriate statement might be that, for this case, stochasticity is disguised within the formula of information flow.
6. Applications
Since its establishment, the formalism of information flow has been applied with a variety of dynamical system problems. In the following we give a brief description of these applications.
6.1. Baker Transformation
The baker transformation as a prototype of an area-conserving chaotic map is one of the most studied discrete dynamical systems. Topologically it is conjugate to another well-studied system, the horseshoe map, and has been be used to model the diffusion process in real physical world.
The baker transformation mimicks the kneading of dough: first the dough is compressed, then cut in half; the two halves are stacked on one another, compressed, and so forth. Formally, it is defined as a mapping on the unit square , ,
with a Jacobian . This is the area-conserving property, which, by Equation (28) yields ; that is to say, the entropy is also conserved. The nonvanishing Jacobian implies that it is invertible; in fact, it has an inverse
Thus the F-P operator can be easily found
First compute , the information flow from to . Let be the marginal density of at time step τ. Taking integration of Equation (55) with respect to , one obtains the marginal density of at
One may also compute the marginal entropy , which is an entropy functional of . However, here it is not necessary, as will soon become clear.
If, on the other hand, is frozen as a parameter, the transformation (53) then reduces to a dyadic mapping in the stretching direction, , . For any , The counterimage of is
so
Two observations: (1) This result is exactly the same as Equation (56), i.e., is equal to . (2) The resulting has no dependence on the parameter . The latter helps to simplify the computation of in Equation (22): Now the integration with respect to can be taken inside, giving . So is precisely the entropy functional of . But by observation (1). Thus , leading to a flow/transfer
The information flow in the opposite direction is different. As above, first compute the marginal density
The marginal entropy increase of is then
which is reduced to, after some algebraic manipulation,
where
To compute , freeze . The transformation is invertible and the Jacobian is equal to a constant . By Theorem 3.2,
So,
In the expressions for I and , since both ρ and the terms within the brackets are nonnegative, . Furthermore, the two brackets cannot vanish simultaneously, hence . By Equation (64) is strictly positive; in other words, there is always information flowing from to .
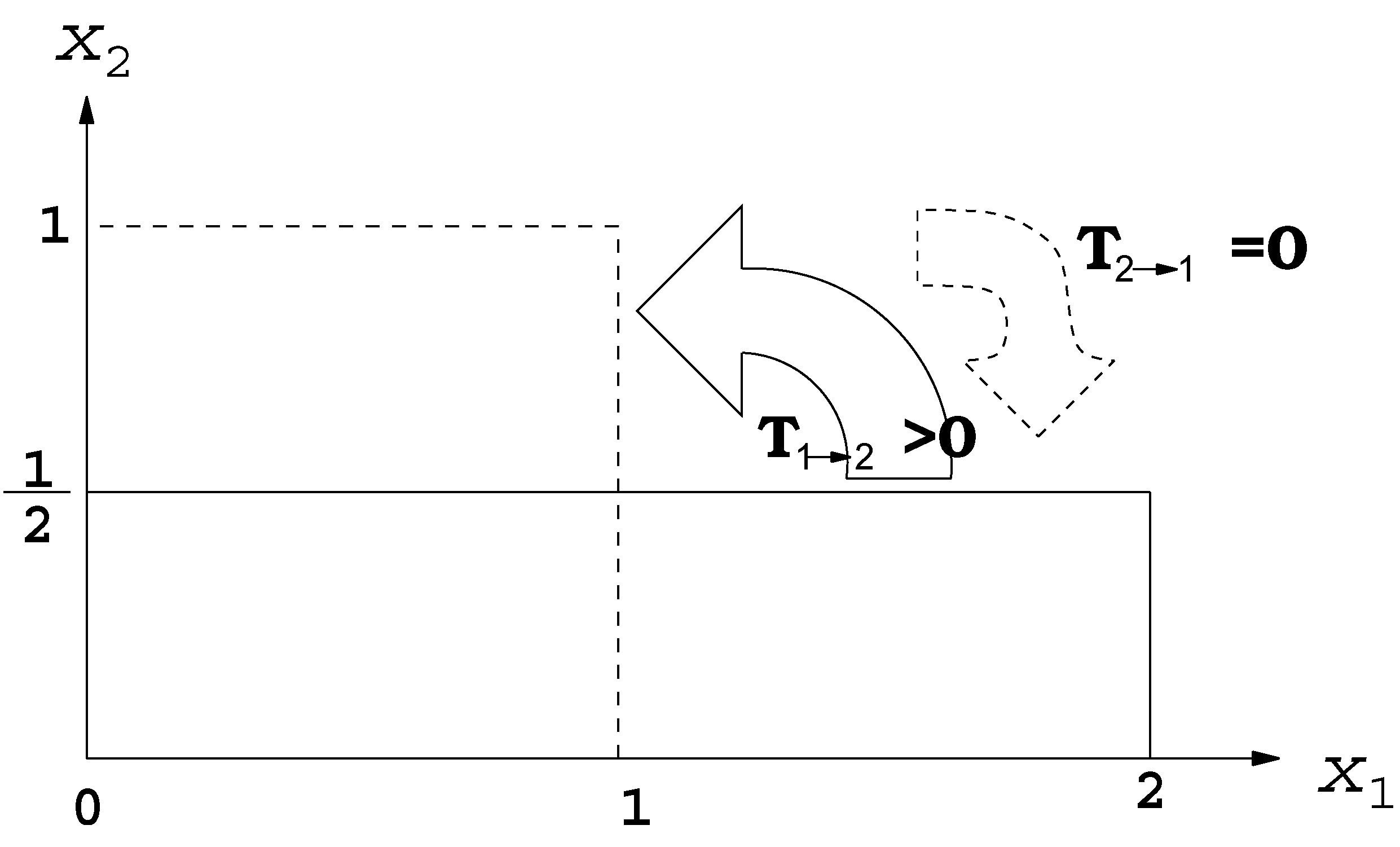
To summarize, the baker transformation transfers information asymmetrically between the two directions and . As the baker stretches the dough, and folds back on top the other, information flows continuously from the stretching direction to the folding direction (), while no transfer occurs in the opposite direction (). These results are schematically illustrated in Figure 2; they are in agreement with what one would observe in daily life, as described in the beginning of this review.
Figure 2.
Illustration of the unidirectional information flow within the baker transformation.

6.2. Hnon Map
The Hnon map is another most studied discrete dynamical systems that exhibit chaotic behavior. Introduced by Michel Hnon as a simplified Poincaré section of the Lorenz system, it is a mapping defined such that
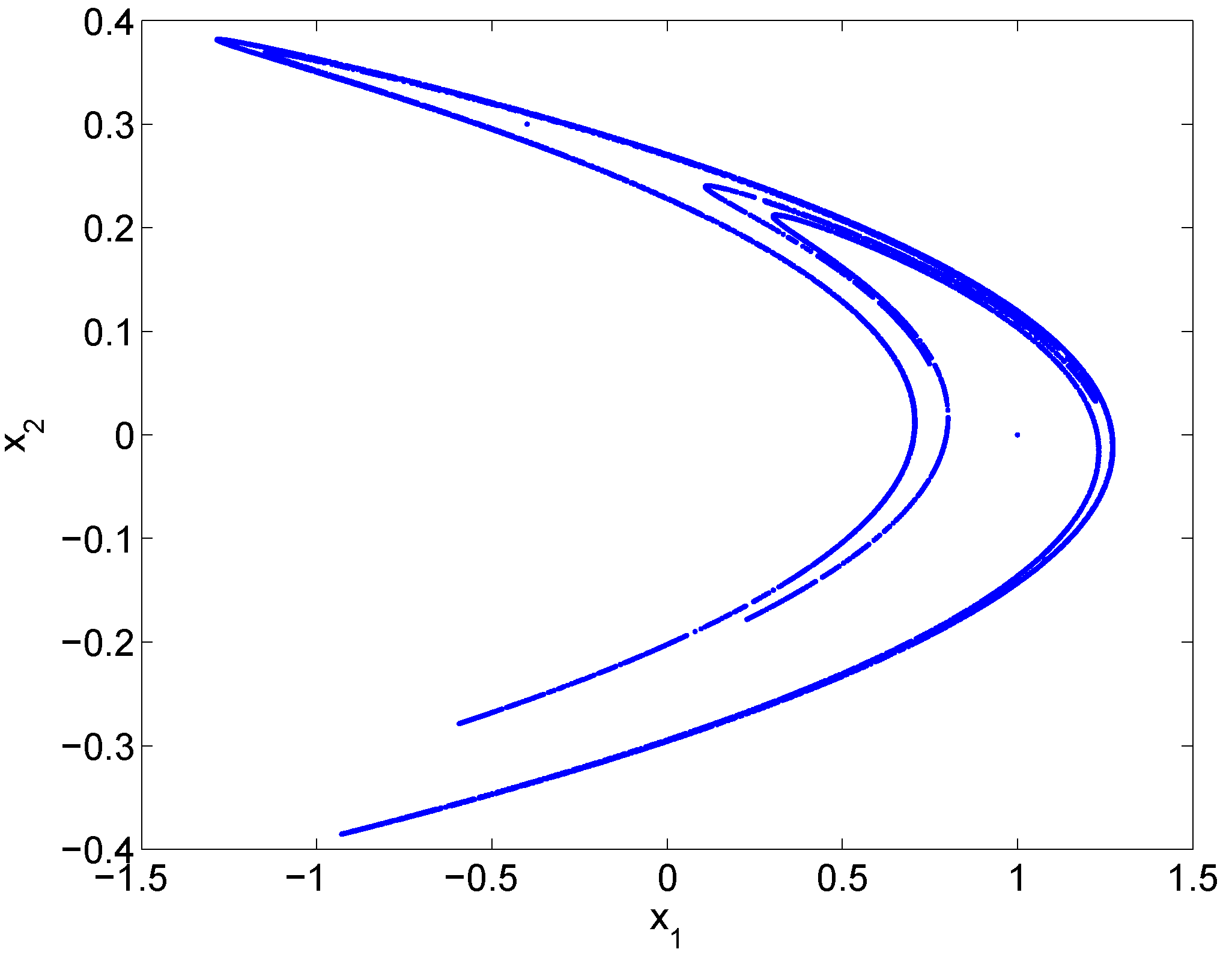
with , . When , , the map is termed “canonical,” for which initially a point will either diverge to infinity, or approach an invariant set known as the Hnon strange attractor. Shown in Figure 3 is the attractor.
Like the baker transformation, the Hnon map is invertible, with an inverse
The F-P operator thus can be easily found from Equation (18):
In the following, we compute the flows/transfers between and .
Figure 3.
A trajectory of the canonical Hnon map (, ) starting at .

First, consider , i.e., the flow from the linear component to the quadratic component . By Equation (23), we need to find the marginal density of at step with and without the effect of , i.e., and . With the F-P operator obtained above, is
If , this integral would be equal to . Note it is the marginal density of , but the argument is . But here , the integration is taken along a parabolic curve rather than a straight line. Still the final result will be related to the marginal density of ; we may as well write it , that is
Again, notice that the argument is .
To compute , let
following our convention to distinguish variables at different steps. Modify the system so that is now a parameter. As before, we need to find the counterimage of under the transformation with frozen:
Therefore,
Denote the average of and as to make an even function of . Then is simply
Note that the parameter does not appear in the arguments. Furthermore, . Substitute all the above into Equation (23) to get
The taking of the integration with respect to inside the integral is legal since all the terms except the conditional density are independent of . With the fact , and the introduction of notations and for the entropy functionals of and , respectively, we have
Next, consider , the flow from the quadratic component to the linear component. As a common practice, one may start off by computing and . However, in this case, things can be much simplified. Observe that, for the modified system with frozen as a parameter, the Jacobian of the transformation So, by Equation (24),
with Equation (67), the marginal density
allowing us to arrive at an information flow from to in the amount of:
That is to say, the flow from to has nothing to do with ; it is equal to the marginal entropy of , plus a correction term due to the factor b.
The simple result of Equation (71) is remarkable; particularly, if , the information flow from to is just the entropy of . This is precisely what what one would expect of the mapping component in Equation (65). While the information flow is interesting per se, it also serves as an excellent example for the verification of our formalism.
6.3. Truncated Burgers–Hopf System
In this section, we examine a more complicated system, the Truncated Burgers–Hopf system (TBS hereafter). Originally introduced by Majda and Timofeyev [55] as a prototype of climate modeling, the TBS results from a Galerkin truncation of the Fourier expansion of the inviscid Burgers’ equation, i.e.,
to the order. Liang and Kleeman [51] examined such a system with two Fourier modes retained, which is governed by 4 ordinary differential equations:
Despite its simplicity, the system is intrinsically chaotic, with a strange attractor lying within
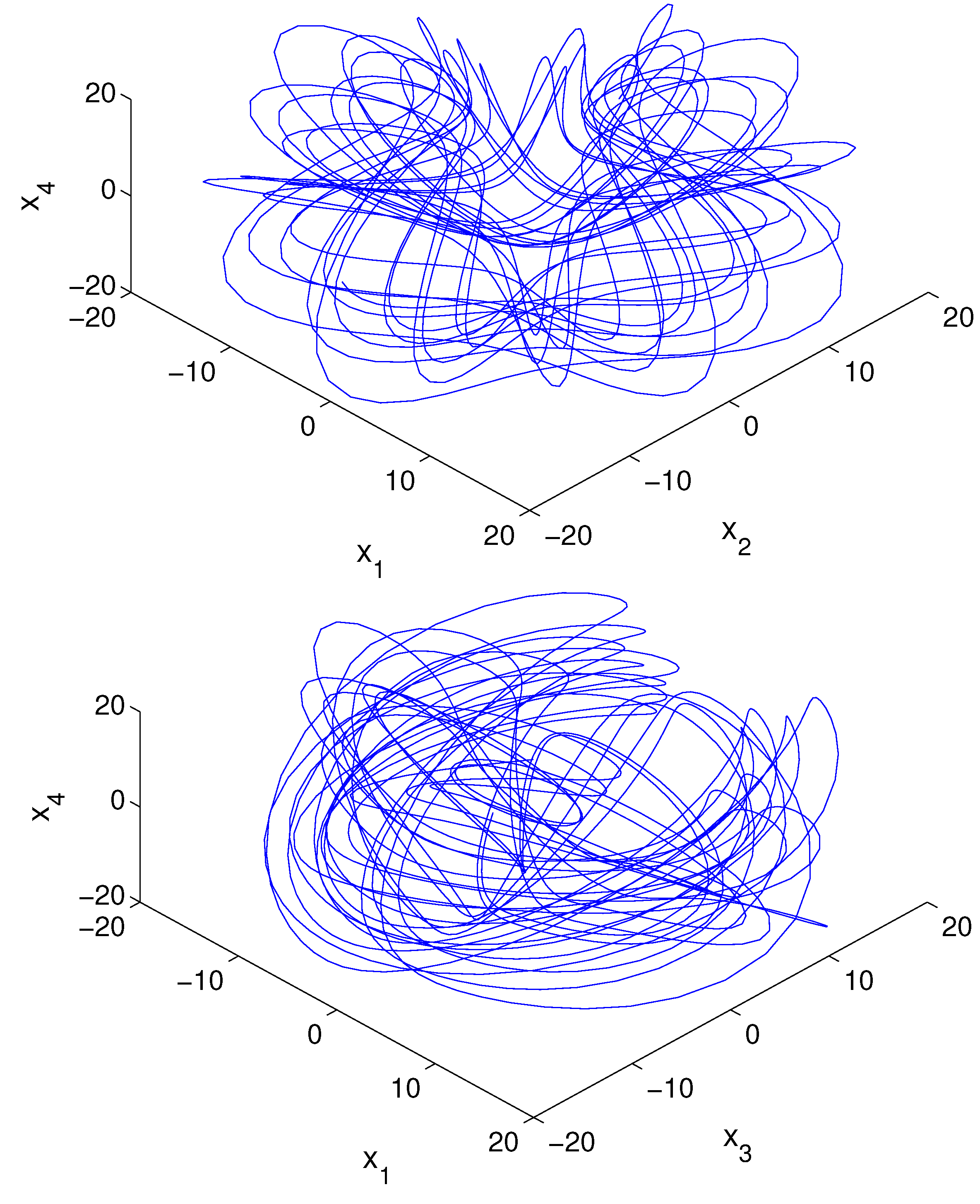
Shown in Figure 4 are its projections onto the -- and -- subspaces, respectively.
Finding the information flows within the TBS system turns out to be a challenge in computation, since the Liouville equation corresponding to Equations (73)–(76) is a four-dimensional partial differential equation. In [51], Liang and Kleeman adopt a strategy of ensemble prediction to reduce the computation to an acceptable level. This is summarized in the following steps:
- Initialize the joint density of with some distribution ; make random draws according to to form an ensemble. The ensemble should be large enough to resolve adequately the sample space.
- Discretize the sample space into “bins.”
- Do ensemble prediction for the system (73)–(74).
- At each step, estimate the probability density function ρ by counting the bins.
- Plug the estimated ρ back to Equation (39) to compute the rates of information flow at that step.
Figure 4.
The invariant attractor of the truncated Burgers–Hopf system (73)–(76). Shown here is the trajectory segment for starting at . (a) and (b) are the 3-dimensional projections onto the subspaces -- and --, respectively.
Figure 4.
The invariant attractor of the truncated Burgers–Hopf system (73)–(76). Shown here is the trajectory segment for starting at . (a) and (b) are the 3-dimensional projections onto the subspaces -- and --, respectively.

Notice that the invariant attractor in Figure 4 allows us to perform the computation on a compact subspace of . Denote by the Cartesian product . Obviously, is large enough to cover the whole attractor, and hence can be taken as the sample space. Liang and Kleeman [51] discretize this space into bins. With a Gaussian initial distribution , where
they generate an ensemble of 2,560,000 members, each steered independently under the system (73)–(76). The details about the sample space discretization, probability estimation, etc., are referred to [51]. Shown in the following are only the major results.
Between the four components of the TBS system, pairwise there are 12 information flows, namely,
To compute these flows, Liang and Kleeman [51] have tried different parameters and , but found the final results are the same after when the trajectories are attracted into the invariant set. It therefore suffices to show the result of just one experiment: and , .
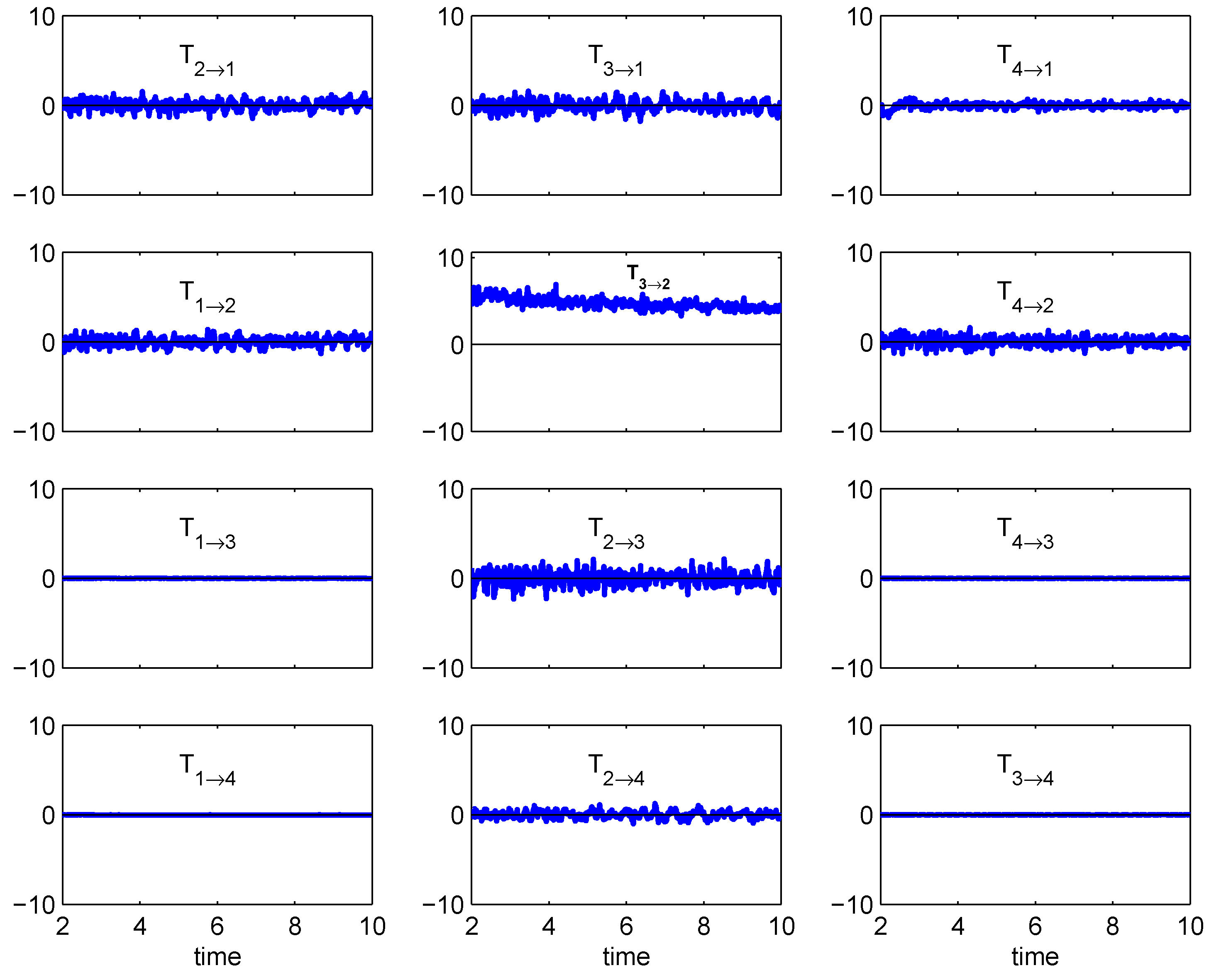
Figure 5.
Information flows within the 4D truncated Burgers-Hopf system. The series prior to are not shown because some trajectories have not entered the attractor by that time.
Figure 5.
Information flows within the 4D truncated Burgers-Hopf system. The series prior to are not shown because some trajectories have not entered the attractor by that time.

Plotted in Figure 5 are the 12 flow rates. First observe that . This is easy to understand, as both and in Equations (75) and (76) have no dependence on nor on , implying a zero flow in either direction between the pair (, ) by the property of causality. What makes the result remarkable is, besides and , essentially all the flows, except , are negligible, although obvious oscillations are found for , , , , , and . The only significant flow, i.e., , means that, within the TBS system, it is the fine component that causes an increase in uncertainty in a coarse component but not conversely. Originally the TBS was introduced by Majda and Timofeyev [55] to test their stochastic closure scheme that models the unresolved high Fourier modes. Since additive noises are independent of the state variables, information can only be transferred from the former to the latter. The transfer asymmetry observed here is thus reflected in the scheme.
6.4. Langevin Equation
Most of the applications of information flow/transfer are expected with stochastic systems. Here we illustrate this with a simple 2D system, which has been studied in reference [54] for the validation of Equation (52):
where and are constant matrices. This is the linear version of Equation (47). Linear systems are particular in that, if initialized with a normally distributed ensemble, then the distribution of the variables will be a Gaussian subsequently (e.g., [56]). This greatly simplifies the computation which, as we have seen in the previous subsection, is often a formidable task. Let . Here is the mean vector, and the covariance matrix; they evolve as
( is the matrix we have seen in Section 5), which determine the joint density of :
By Theorem 5.1, the rates of information flow thus can be accurately computed.
Several sets of parameters have been chosen in [54] to study the model behavior. Here we just look at one such choice:
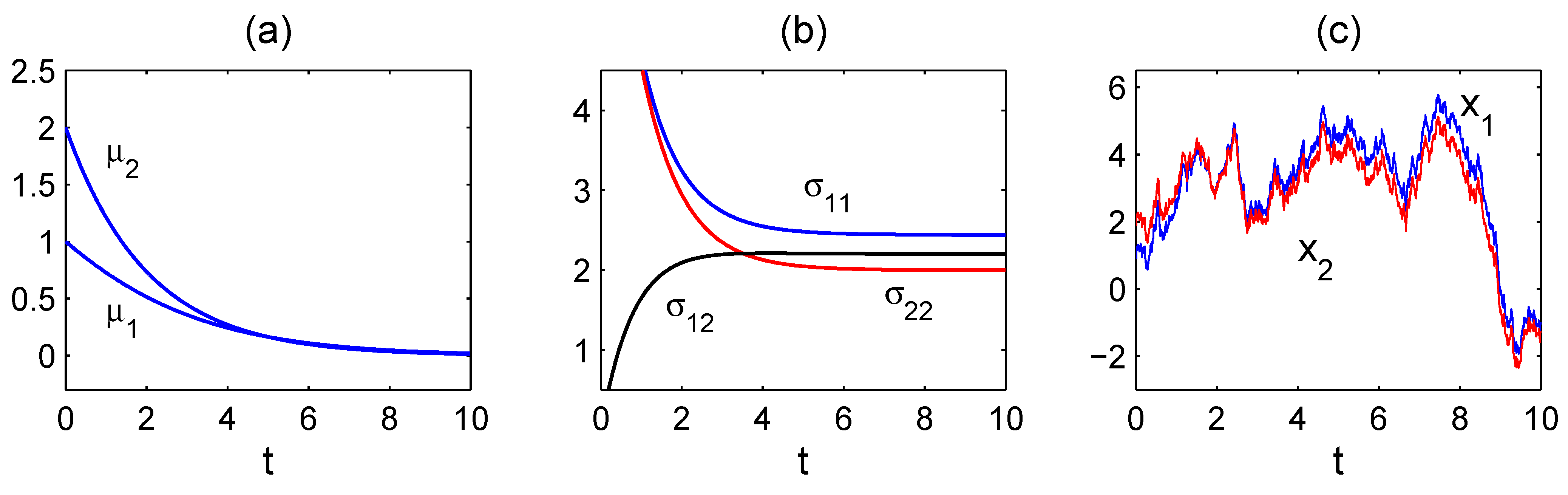
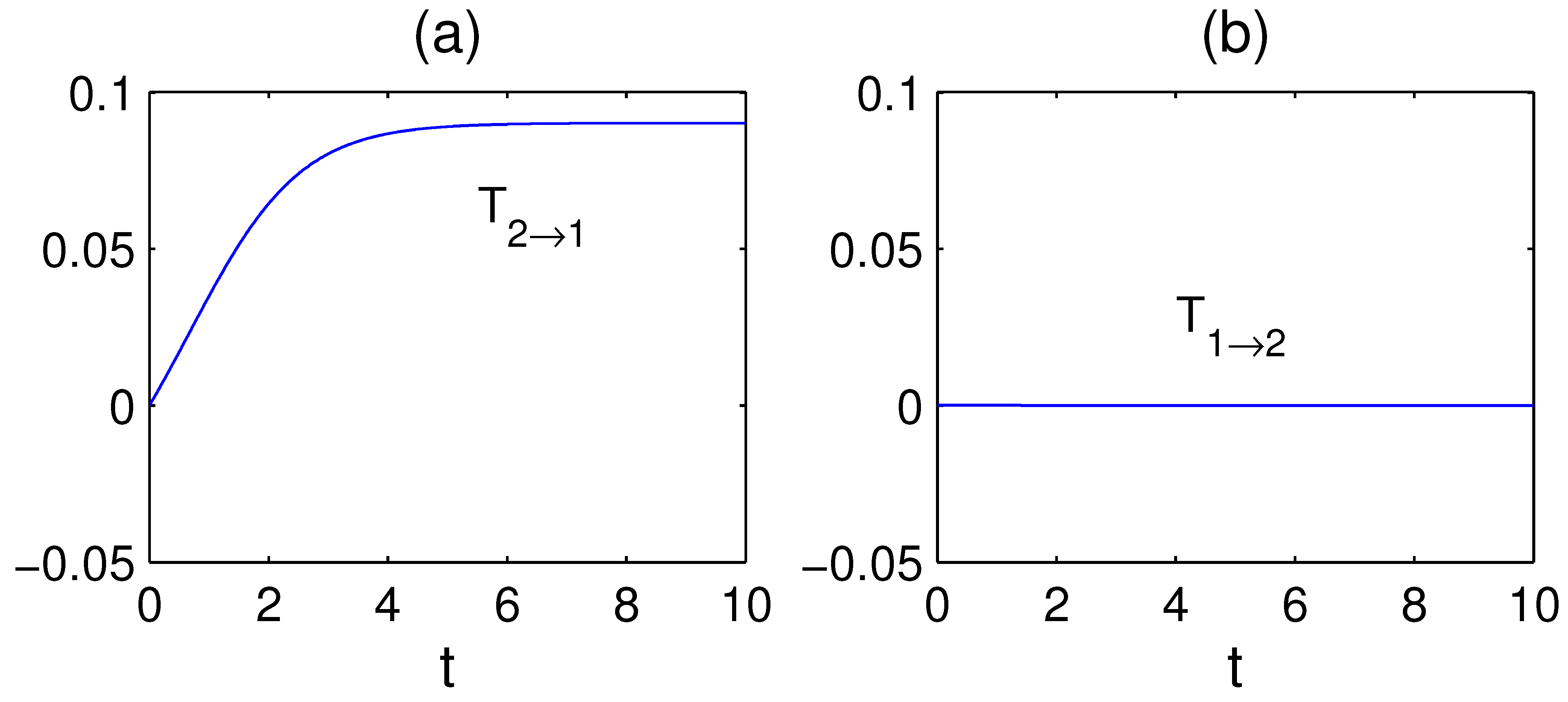
, . Its corresponding mean and covariance approach to an equilibrium: , . Shown in Figure 6 are the time evolutions of and Σ initialized with and , and a sample path of starting from . The computed rates of information flow, and , are plotted in Figure 7a and b. As time moves on, increases monotonically and eventually approaches a constant; on the other hand, vanishes throughout. While this is within one’s expectations, since has no dependence on and hence there should be no transfer of information from to , it is interesting to observe that, in contrast, the typical paths of and could be highly correlated, as shown in Figure 6c. In other words, for two highly correlated time series, say and , one series may have nothing to do with the other. This is a good example illustrating how information flow extends the classical notion of correlation analysis, and how it may be potentially utilized to identify the causal relation between complex dynamical events.
Figure 6.
A solution of Equation (78), the model examined in [54], with and initial conditions as shown in the text: (a) ; (b) Σ; and (c) a sample path starting from (1,2).
Figure 6.
A solution of Equation (78), the model examined in [54], with and initial conditions as shown in the text: (a) ; (b) Σ; and (c) a sample path starting from (1,2).

Figure 7.
The computed rates of information flow for the system (77): (a) , (b) .

7. Summary
The past decades have seen a surge of interest in information flow (or information transfer, as it is sometimes called) in different fields of scientific research, mostly in the appearance of some empirical/half-empirical form. We have shown that, given a dynamical system, deterministic or stochastic, this important notion can actually be formulated on a rigorous footing, with flow measures explicitly derived. The general results are summarized in the theorems in Section 3, Section 4 and Section 5. For two-dimensional systems, the result is fairly tight. In fact, if writing such a system as
where are standard Wiener processes, we have a rate of information flowing from to ,
This is an alternative expression of that in Theorem 5.1; can be obtained by switching the subscripts 1 and 2. In the formula, , is the marginal density of , and E stands for mathematical expectation with respect to ρ, i.e., the joint probability density. On the right-hand side, the third term is contributed by the Brownian notion; if the system is deterministic, this term vanishes. In the remaining two terms, the first is the tendency of , namely the marginal entropy of ; the second can be interpreted as the rate of increase on its own, thanks to the law of entropy production (12) [49], which we restate here:
This interpretation lies at the core of all the theories along this line. It illustrates that the marginal entropy increase of a component, say, , is due to two different mechanisms: the information transferred from some component, say, , and the marginal entropy increase associated with a system without taking into account. On this ground, the formalism is henceforth established, with respect to discrete mappings, continuous flows, and stochastic systems, respectively. Correspondingly, the resulting measures are summarized in Equations (24), (39) and (52).
For an n-dimensional system , its joint entropy H evolves as
The above-obtained measures possess several interesting properties, some of which one may expect based on daily life experiences. The first one is a property of flow/transfer asymmetry, which has been set as the basic requirement for the identification of causal relations between dynamical events. The information flowing from one event to another event, denoted respectively as and , may yield no clue about its counterpart in the opposite direction, i.e., the flow/transfer from to . The second says that, if the evolution of is independent of , then the flow from to is zero. The third one is about the role of stochasticity, which asserts that, if the stochastic perturbation to the receiving component does not rely on the given component, the flow measure then has a form same as that for the corresponding deterministic system. As a direct corollary, when the noise is additive, then in terms of information flow, the stochastic system functions in a deterministic manner.
The formalism has been put to application with benchmark dynamical systems. In the context of the baker transformation, it is found that there is always information flowing from the stretching direction to the folding direction, while no flow exists conversely. This is in agreement with what one would observe in kneading dough. Application to the Hnon map also yields a result just as expected on physical grounds. In a more complex case, the formalism has been applied to the study of the scale–scale interaction and information flow between the first two modes of the chaotic truncated Burgers equation. Surprisingly, all the twelve flows are essentially zero, save for one strong flow from the high-frequency mode to the low-frequency mode. This demonstrates that the route of information flow within a dynamical system, albeit seemingly complex, could be simple. In another application, we test how one may control the information flow by tuning the coefficients in a two-dimensional Langevin system. A remarkable observation is that, for two highly correlated time series, there could be no transfer from one certain series, say , to the other (). That is to say, the evolution of may have nothing to do with , even though and are highly correlated. Information flow/transfer analysis thus extends the traditional notion of correlation analysis and/or mutual information analysis by providing a quantitative measure of causality between dynamical events, and this quantification is based firmly on a rigorous mathematical and physical footing.
The above applications are mostly with idealized systems; this is, to a large extent, intended for the validation of the obtained flow measures. Next, we would extend the results to more complex systems, and develop important applications to realistic problems in different disciplines, as envisioned in the beginning of this paper. The scale–scale information flow within the Burgers–Hopf system in § 6.3, for example, may be extended to the flow between scale windows. By a scale window we mean, loosely, a subspace with a range of scales included (cf. [57]). In atmosphere–ocean science, important phenomena are usually defined on scale windows, rather than on individual scales (e.g., [58]). As discussed in [53], the dynamical core of the atmosphere and ocean general circulation models is essentially a quadratically nonlinear system, with the linear and nonlinear operators possessing certain symmetry resulting from some conservation properties (such as energy conservation). Majda and Harlim [53] argue that the state space may be decomposed into a direct sum of scale windows which inherit evolution properties from the quadratic system, and then information flow/transfer may be investigated between these windows. Intriguing as this conceptual model might be, there still exist some theoretical difficulties. For example, the governing equation for a window may be problem-specific; there may not be such governing equations as simply written as those like Equation (3) for individual components. Hence one may need to seek new ways to the derivation of the information flow formula. Nonetheless, central at the problem is still the aforementioned classification of mechanisms that govern the marginal entropy evolution; we are expecting new breakthroughs along this line of development.
The formalism we have presented thus far is with respect to Shannon entropy, or absolute entropy as one may choose to refer to it. In many cases, such as in the El Niño case where predictability is concerned, this may need to be modified, since the predictability of a dynamical system is measured by relative entropy. Relative entropy is also called Kullback–Leibler divergence; it is defined as
i.e., the expectation of the logarithmic difference between a probability ρ and another reference probability q, where the expectation is with respect to ρ. Roughly it may be interpreted as the “distance” between ρ and q, though it does not satisfy all the axioms for a distance functional. Therefore, for a system, if letting the reference density be the initial distribution, its relative entropy at a time t informs how much additional information is added (rather than how much information it has). This provides a natural choice for the measure of the utility of a prediction, as pointed out by Kleeman (2002) [59]. Kleeman also argues in favor of relative entropy because of its appealing properties, such as nonnegativity and invariance under nonlinear transformations [60]. Besides, in the context of a Markov chain, it has been proved that it always decreases monotonically with time, a property usually referred to as the generalized second law of thermodynamics (e.g., [60,61]). The concept of relative entropy is now a well-accepted measure of predictability (e.g., [59,62]). When predictability problems (such as those problems in atmosphere-ocean science and financial economics as mentioned in the introduction) are dealt with, it is necessary to extend the current formalism to one with respect to the relative entropy functional. For all the dynamical system settings in this review, the extension should be straightforward.
Acknowledgments
This study was supported by the National Science Foundation of China (NSFC) under Grant No. 41276032 to NUIST, by Jiangsu Provincial Government through the “Jiangsu Specially-Appointed Professor Program” (Jiangsu Chair Professorship), and by the Ministry of Finance of China through the Basic Research Funding to China Institute for Advanced Study.
References
- Baptista, M.S.; Garcia, S.P.; Dana, S.K.; Kurths, J. Transmission of information and synchronization in a pair of coupled chaotic circuits: An experimental overview. Eur. Phys. J.-Spec. Top. 2008, 165, 119–128. [Google Scholar] [CrossRef]
- Baptista, M.D.S.; Kakmeni, F.M.; Grebogi, C. Combined effect of chemical and electrical synapses in Hindmarsh-Rose neural networks on synchronization and the rate of information. Phys. Rev. E 2010, 82, 036203. [Google Scholar] [CrossRef] [PubMed]
- Bear, M.F.; Connors, B.W.; Paradiso, M.A. Neuroscience: Exploring the Brain, 3rd ed.; Lippincott Williams & Wilkins: Baltimore, MD, USA, 2007; p. 857. [Google Scholar]
- Vakorin, V.A.; MiAiA, B.; Krakovska, O.; McIntosh, A.R. Empirical and theoretical aspects of generation and transfer of information in a neuromagnetic source network. Front. Syst. Neurosci. 2011, 5, 96. [Google Scholar] [CrossRef] [PubMed]
- Ay, N.; Polani, D. Information flows in causal networks. Advs. Complex Syst. 2008, 11. [Google Scholar] [CrossRef]
- Peruani, F.; Tabourier, L. Directedness of information flow in mobile phone communication networks. PLoS One 2011, 6, e28860. [Google Scholar] [CrossRef] [PubMed]
- Sommerlade, L.; Amtage, F.; Lapp, O.; Hellwig, B.; Licking, C.H.; Timmer, J.; Schelter, B. On the estimation of the direction of information flow in networks of dynamical systems. J. Neurosci. Methods 2011, 196, 182–189. [Google Scholar] [CrossRef] [PubMed]
- Donner, R.; Barbosa, S.; Kurths, J.; Marwan, N. Understanding the earth as a complex system-recent advances in data analysis and modelling in earth sciences. Eur. Phys. J. 2009, 174, 1–9. [Google Scholar] [CrossRef]
- Kleeman, R. Information flow in ensemble weather prediction. J. Atmos. Sci. 2007, 64, 1005–1016. [Google Scholar] [CrossRef]
- Materassi, M.; Ciraolo, L.; Consolini, G.; Smith, N. Predictive space weather: An information theory approach. Adv. Space Res. 2011, 47, 877–885. [Google Scholar] [CrossRef]
- Tribbia, J.J. Waves, Information and Local Predictability. In Proceedings of the Workshop on Mathematical Issues and Challenges in Data Assimilation for Geophysical Systems: Interdisciplinary Perspectives, IPAM, UCLA, 22–25 February 2005.
- Chen, C.R.; Lung, P.P.; Tay, N.S.P. Information flow between the stock and option markets: Where do informed traders trade? Rev. Financ. Econ. 2005, 14, 1–23. [Google Scholar] [CrossRef]
- Lee, S.S. Jumps and information flow in financial markets. Rev. Financ. Stud. 2012, 25, 439–479. [Google Scholar] [CrossRef]
- Sommerlade, L.; Eichler, M.; Jachan, M.; Henschel, K.; Timmer, J.; Schelter, B. Estimating causal dependencies in networks of nonlinear stochastic dynamical systems. Phys. Rev. E 2009, 80, 051128. [Google Scholar] [CrossRef] [PubMed]
- Zhao, K.; Karsai, M.; Bianconi, G. Entropy of dynamical social networks. PLoS One 2011. [Google Scholar] [CrossRef] [PubMed]
- Cane, M.A. The evolution of El Niño, past and future. Earth Planet. Sci. Lett. 2004, 164, 1–10. [Google Scholar] [CrossRef]
- Jin, F.-F. An equatorial ocean recharge paradigm for ENSO. Part I: conceptual model. J. Atmos. Sci. 1997, 54, 811–829. [Google Scholar] [CrossRef]
- Philander, S.G. El Niño, La Niña, and the Southern Oscillation; Academic Press: San Diego, CA, USA, 1990. [Google Scholar]
- Ghil, M.; Chekroun, M.D.; Simonnet, E. Climate dynamics and fluid mechanics: Natural variability and related uncertainties. Physica D 2008, 237, 2111–2126. [Google Scholar] [CrossRef]
- Mu, M.; Xu, H.; Duan, W. A kind of initial errors related to “spring predictability barrier” for El Niño events in Zebiak-Cane model. Geophys. Res. Lett. 2007, 34, L03709. [Google Scholar] [CrossRef]
- Zebiak, S.E.; Cane, M.A. A model El Niño-Southern Oscillation. Mon. Wea. Rev. 1987, 115, 2262–2278. [Google Scholar] [CrossRef]
- Chen, D.; Cane, M.A. El Niño prediction and predictability. J. Comput. Phys. 2008, 227, 3625–3640. [Google Scholar] [CrossRef]
- Mayhew, S.; Sarin, A.; Shastri, K. The allocation of informed trading across related markets: An analysis of the impact of changes in equity-option margin requirements. J. Financ. 1995, 50, 1635–1654. [Google Scholar] [CrossRef]
- Goldenfield, N.; Woese, C. Life is physics: Evolution as a collective phenomenon far from equilibrium. Ann. Rev. Condens. Matt. Phys. 2011, 2, 375–399. [Google Scholar] [CrossRef]
- K¨ppers, B. Information and the Origin of Life; MIT Press: Cambridge, UK, 1990. [Google Scholar]
- Murray, J.D. Mathematical Biology; Springer-Verlag: Berlin, Germany, 2000. [Google Scholar]
- Allahverdyan, A.E.; Janzing, D.; Mahler, G. Thermodynamic efficiency of information and heat flow. J. Stat. Mech. 2009, PO9011. [Google Scholar] [CrossRef]
- Crutchfield, J.P.; Shalizi, C.R. Thermodynamic depth of causal states: Objective complexity via minimal representation. Phys. Rev. E 1999, 59, 275–283. [Google Scholar] [CrossRef]
- Davies, P.C.W. The Physics of Downward Causation. In The Re-emergence of Emergence; Clayton, P., Davies, P.C.W., Eds.; Oxford University Press: Oxford, UK, 2006; pp. 35–52. [Google Scholar]
- Ellis, G.F.R. Top-down causation and emergence: Some comments on mechanisms. J. R. Soc. Interface 2012, 2, 126–140. [Google Scholar] [CrossRef] [PubMed]
- Okasha, S. Emergence, hierarchy and top-down causation in evolutionary biology. J. R. Soc. Interface 2012, 2, 49–54. [Google Scholar] [CrossRef] [PubMed]
- Walker, S.I.; Cisneros, L.; Davies, P.C.W. Evolutionary transitions and top-down causation. arXiv:1207.4808v1 [nlin.AO], 2012. [Google Scholar]
- Wu, B.; Zhou, D.; Fu, F.; Luo, Q.; Wang, L.; Traulsen, A. Evolution of cooperation on stochastic dynamical networks. PLoS One 2010, 5, e11187. [Google Scholar] [CrossRef] [PubMed]
- Pope, S. Turbulent Flows, 8th ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Faes, L.; Nollo, G.; Erla, S.; Papadelis, C.; Braun, C.; Porta, A. Detecting Nonlinear Causal Interactions between Dynamical Systems by Non-uniform Embedding of Multiple Time Series. In Proceedings of the Engineering in Medicine and Biology Society, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 102–105.
- Kantz, H.; Shreiber, T. Nonlinear Time Series Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Schindler-Hlavackova, K.; Palus, M.; Vejmelka, M.; Bhattacharya, J. Causality detection based on information-theoretic approach in time series analysis. Phys. Rep. 2007, 441, 1–46. [Google Scholar] [CrossRef]
- Granger, C. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- McWilliams, J.C. The emergence of isolated, coherent vortices in turbulence flows. J. Fluid Mech. 1984, 146, 21–43. [Google Scholar] [CrossRef]
- Salmon, R. Lectures on Geophysical Fluid Dynamics; Oxford University Press: Oxford, UK, 1998; p. 378. [Google Scholar]
- Bar-Yam, Y. Dynamics of Complex Systems; Addison-Welsley Press: Reading, MA, USA, 1997; p. 864. [Google Scholar]
- Crutchfield, J.P. The calculi of emergence: computation, dynamics, and induction induction. “Special issue on the Proceedings of the Oji International Seminar: Complex Systems-From Complex Dynamics to Artifical Reality”. Physica D 1994, 75, 11–54. [Google Scholar] [CrossRef]
- Goldstein, J. Emergence as a construct: History and issues. Emerg. Complex. Org. 1999, 1, 49–72. [Google Scholar] [CrossRef]
- Corning, P.A. The re-emergence of emergence: A venerable concept in search of a theory. Complexity 2002, 7, 18–30. [Google Scholar] [CrossRef]
- Vastano, J.A.; Swinney, H.L. Information transport in sptiotemporal systems. Phys. Rev. Lett. 1988, 60, 1773–1776. [Google Scholar] [CrossRef] [PubMed]
- Kaiser, A.; Schreiber, T. Information transfer in continuous processes. Physica D 2002, 166, 43–62. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.S.; Kleeman, R. A rigorous formalism of information transfer between dynamical system components. I. Discrete mapping. Physica D 2007, 231, 1–9. [Google Scholar] [CrossRef]
- Liang, X.S.; Kleeman, R. Information transfer between dynamical system components. Phys. Rev. Lett. 2005, 95, 244101. [Google Scholar] [CrossRef] [PubMed]
- Lasota, A.; Mackey, M.C. Chaos, Fractals, and Noise: Stochastic Aspects of Dynamics; Springer: New York, NY, USA, 1994. [Google Scholar]
- Liang, X.S.; Kleeman, R. A rigorous formalism of information transfer between dynamical system components. II. Continuous flow. Physica D 2007, 227, 173–182. [Google Scholar] [CrossRef]
- Liang, X.S. Uncertainty generation in deterministic fluid flows: Theory and applications with an atmospheric stability model. Dyn. Atmos. Oceans 2011, 52, 51–79. [Google Scholar] [CrossRef]
- Majda, A.J.; Harlim, J. Information flow between subspaces of complex dynamical systems. Proc. Natl. Acad. Sci. USA 2007, 104, 9558–9563. [Google Scholar] [CrossRef]
- Liang, X.S. Information flow within stochastic dynamical systems. Phys. Rev. E 2008, 78, 031113. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.J.; Timofeyev, I. Remarkable statistical behavior for truncated Burgers-Hopf dynamics. Proc. Natl. Acad. Sci. USA 2000, 97, 12413–12417. [Google Scholar] [CrossRef] [PubMed]
- Gardiner, C.W. Handbook of Stochastic Methods for Physics, Chemistry, and the Natural Sciences; Springer-Verlag: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Liang, X.S.; Anderson, D.G.M.A. Multiscale window transform. SIAM J. Multiscale Model. Simul. 2007, 6, 437–467. [Google Scholar] [CrossRef]
- Liang, X.S.; Robinson, A.R. Multiscale processes and nonlinear dynamics of the circulation and upwelling events off Monterey Bay. J. Phys. Oceanogr. 2009, 39, 290–313. [Google Scholar] [CrossRef]
- Kleeman, R. Measuring dynamical prediction utility using relative entropy. J. Atmos. Sci. 2002, 59, 2057–2072. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Ao, P. Emerging of stochastic dynamical equalities and steady state thermodynamics from Darwinian dynamics. Commun. Theor. Phys. 2008, 49, 1073–1090. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Deng, Z.; Zhou, X.; Cheng, Y.; Chen, D. Interdecadal variation of ENSO predictability in multiple models. J. Clim. 2008, 21, 4811–4832. [Google Scholar] [CrossRef]
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Liang, X.S. The Liang-Kleeman Information Flow: Theory and Applications. Entropy 2013, 15, 327-360. https://doi.org/10.3390/e15010327
AMA Style
Liang XS. The Liang-Kleeman Information Flow: Theory and Applications. Entropy. 2013; 15(1):327-360. https://doi.org/10.3390/e15010327
Chicago/Turabian StyleLiang, X. San. 2013. "The Liang-Kleeman Information Flow: Theory and Applications" Entropy 15, no. 1: 327-360. https://doi.org/10.3390/e15010327