As it is usually defined, the Shannon entropy of a discrete law
pk =
P {
xk} associated with the values
xk of some random variable is:
and apparently is a non-negative, dimensionless quantity. As a matter of fact, however, it does not depend on all of the details of the distribution: for instance, only the
pk are relevant, while the
xk play no role at all. This means that if we modify our distribution just by moving the
xk, the entropy is left the same: this entails, among others, that
H does not always change along with the variance (or other typical parameters) of the distribution, which instead is contingent on the
xk values. In particular,
H is invariant under every linear transformation
axk +
b (centering and rescaling) of the random quantities: in this sense, every type of law [
1] is isentropic. Surprisingly enough, despite the unsophistication of Definition
(1) and beyond a few elementary examples, explicit formulas displaying the dependence of the entropy
H from the parameters of the most common discrete distributions are not known. If, for instance, we take the entropy
H of the binomial distributions 𝔅
n,p with:
although it would always be possible to calculate the entropy
H for every particular example, no general formula giving its explicit dependence from
n and
p is available, and only its asymptotic behavior for large
n is known in the literature [
2,
3]:
It is remarked moreover that, while this formula explicitly contains
np(1 −
p), namely the variance of 𝔅
n,p, it is easy to recognize that, as long as we leave untouched the
n probabilities
pk, the entropy
H [𝔅
n,p] remains the same when we change the variance by moving the points
xk away from their usual locations
xk =
k. In particular, this is true for the standardized (centered, unit variance) binomial
with:
and the same
pk of
(2), which entails
H [𝔅
n,p] =
H[
]. All this hints to the fact that what seems to be relevant to the entropy is not the variance itself, but some other feature, possibly related to the shape of the distribution. In a similar vein, for the Poisson distributions 𝔓
λ with:
the entropy is:
with an asymptotic expression for large
λ:
which explicitly contains the parameter
λ (also playing the role of the variance), but which is also completely independent from the values of the
xk’s. As a consequence, a standardized Poisson distribution
, with:
and the same probabilities
pk, has the same entropy of 𝔓
λ, namely
H [𝔓
λ] =
H [
].
When, on the other hand, we consider continuous laws (for short, we will call continuous the laws possessing a pdf
f (
x), without insisting on the difference between continuous and absolutely continuous distributions, which is not relevant here) with a pdf
f (
x), Definition
(1) no longer applies, and we are led to introduce another quantity commonly known as differential entropy (we acknowledge that this name for an integral could be misleading, but we will retain it in the following to abide by a long established habit):
which, in several respects, differs from the entropy
(1) of the discrete distributions. First of all, explicit formulas of the entropy
(9) are known for most of the usual laws: for example (see also
Appendix A), the distributions 𝔘(
a) uniform on [0,
a] with
a > 0 have entropy:
while for the centered, Gaussian laws 𝔑(
a) with variance
a2,we have:
An exhaustive list of similar formulas for other families of laws is widely available in the literature, but even from these two examples only, it is apparent that:
- (1)
at variance with the discrete case, the differential entropies explicitly depend on a scaling parameter a, showing now a dependence either on the variance, or on some other dispersion index, such as the interquantile ranges (IQnR); this means, in particular, that the types of continuous laws are no longer isentropic;
- (2)
the differential entropies can take negative values when the parameters of the laws are chosen in such a way that the value of the logarithm argument falls below 1;
- (3)
the logarithm arguments are not in general dimensionless quantities, in an apparent violation of the homogeneity rule that the scalar arguments of transcendental functions (as logarithms are) must be dimensionless quantities; this entails, in particular, that the entropy depends on the units of measurement.
Finally, the two definitions seem not to be reciprocally consistent in the sense that, when, for instance, a continuous law is weakly approximated by a sequence of discrete laws, we would like to see the entropies of the discrete distributions converging toward the entropy of the continuous one. That this is not the case is apparent from a few counterexamples. It is well known, for instance, that, for every 0 <
p < 1, the sequence of the standardized binomial laws
weakly converges to the Gaussian 𝔑(1) when
n → ∞; however, since the binomial probabilities
pk are unaffected by a standardization, the entropies
H [
] still obey Formula
(3), and hence, their sequence diverges as ln
instead of being convergent to the differential entropy of 𝔑(1), which, from
(11), is ln
. In the same vein, the cdf
F (
x) of a uniform law 𝔘(
a) can be approximated by the sequence
Fn(
x) of the discrete uniform laws 𝔘
n(
a) concentrated with equal probabilities
p1 = ... =
pn =
on the
n equidistant points
x1,...,
xn, where
xk =
kΔ for
k = 1, 2,...,
n, and
xk −
xk−1 = Δ =
with
x0 = 0. However, it is easy to see that:
so that their sequence again diverge as ln
n, while the differential entropy
h[𝔘] of the uniform law has the finite value
(10).
As a consequence of these remarks, in the following sections, we will propose a few elementary ways to change the two definitions,
(1) and
(9), in order to possibly rid them of said inconsistencies and to make them reciprocally coherent without losing too much of the essential properties of the usual quantities. These new definitions, moreover, operate an effective renormalization of the said divergences, so that now, when a continuous law is weakly approximated by a sequence of discrete laws, also the entropies of the discrete distributions converge toward the entropy of the continuous one. A few additional points with examples and explicit calculations are finally collected in the appendices. It must be clearly stated at this point, however, that we do not claim here that the Shannon entropy is somehow ill-defined in itself: we rather point out a few reciprocal inconsistencies of the different manifestations of this time-honored concept, and we try to attune them in such a way that every probability distribution (either discrete, or continuous) would now be treated on the same foot.

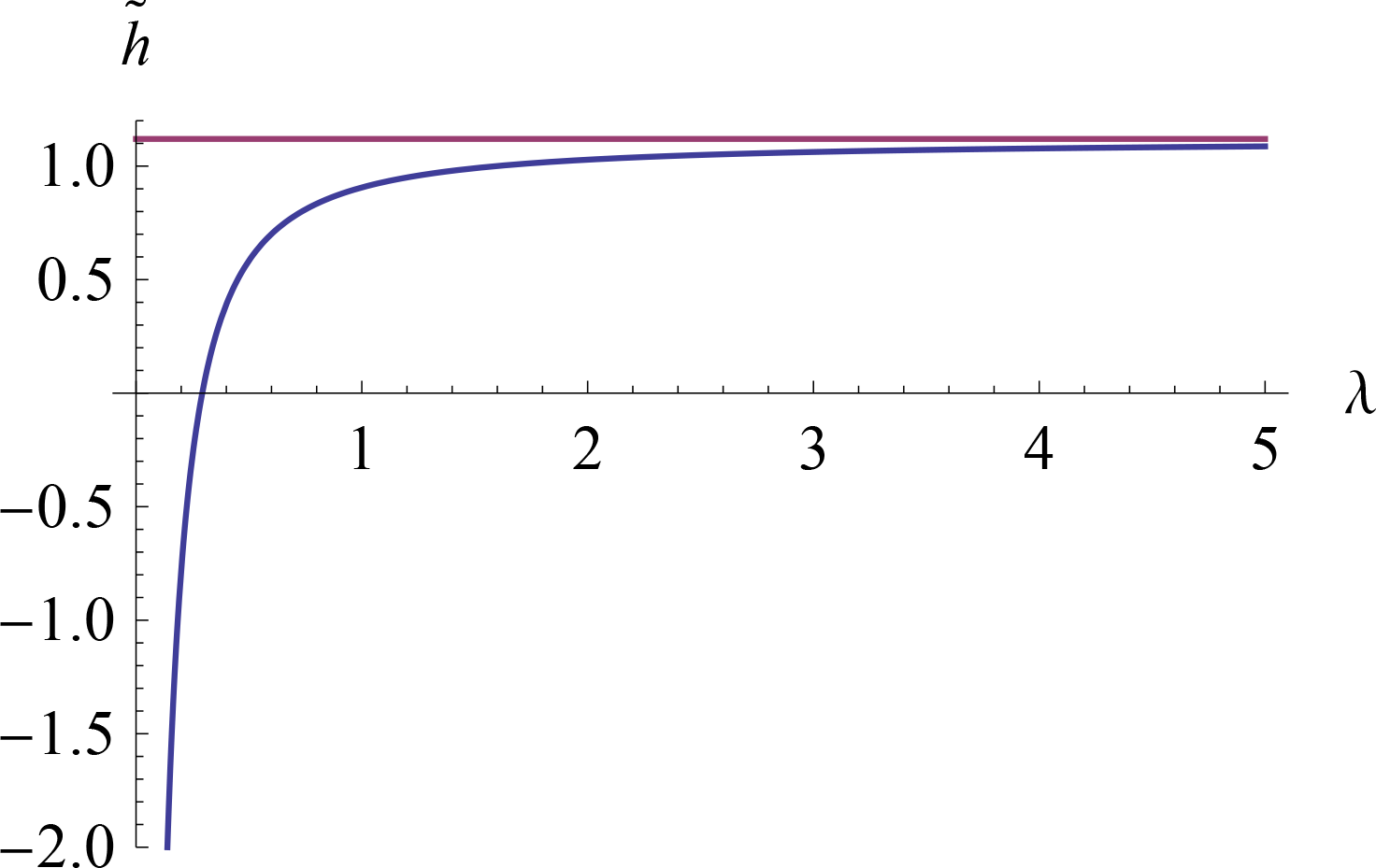{kind=link}
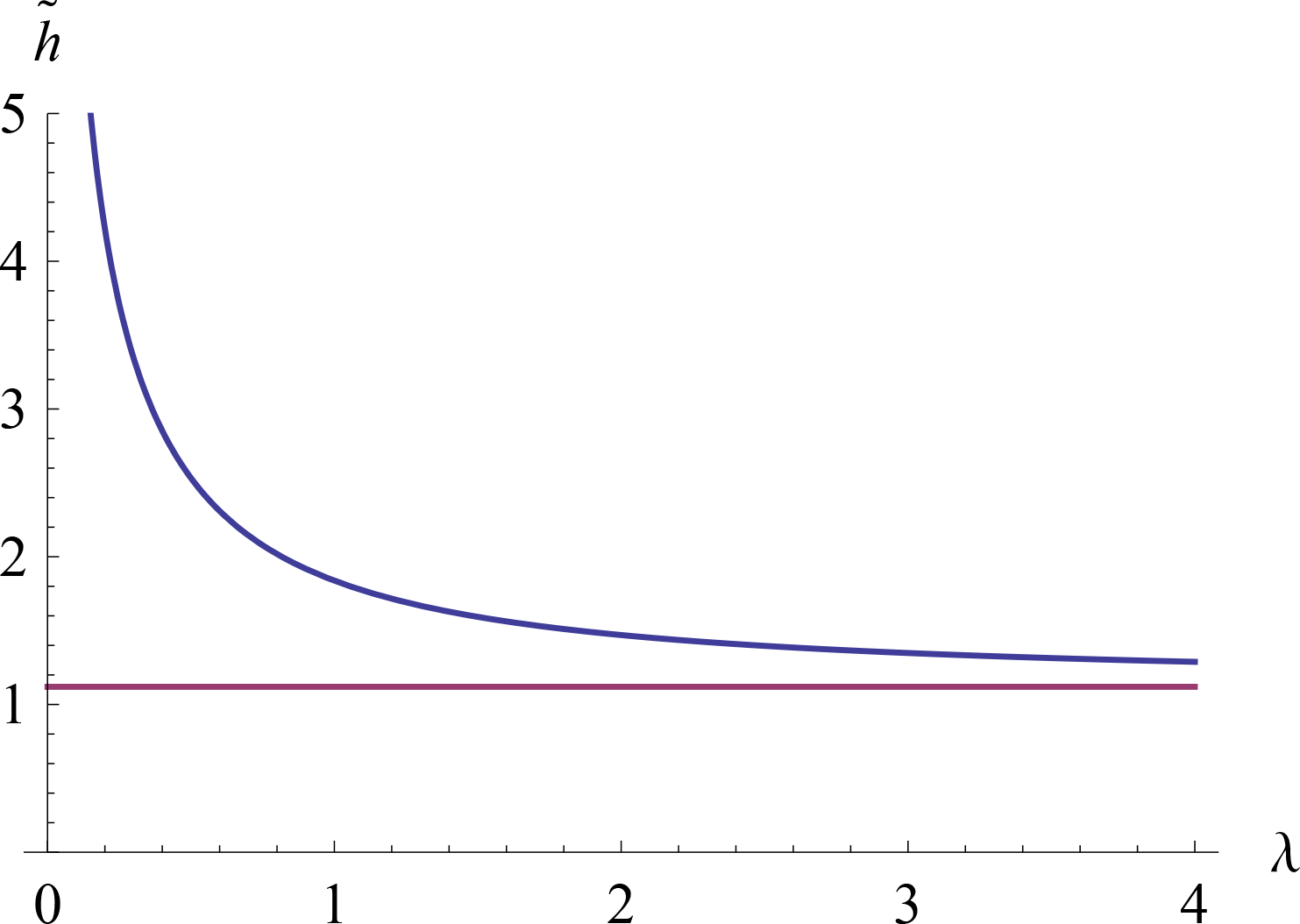{kind=link}
{kind=link}
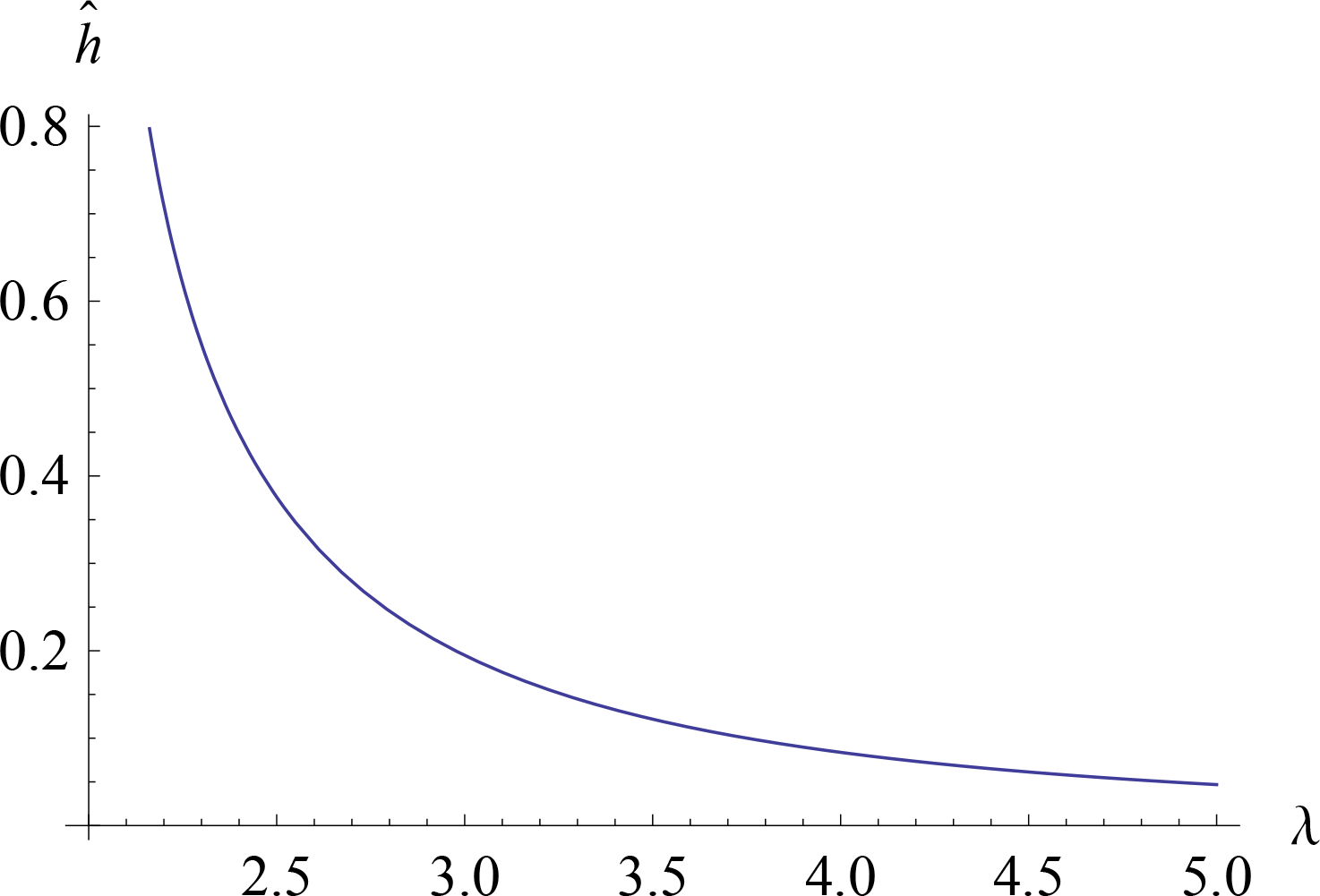{kind=link}
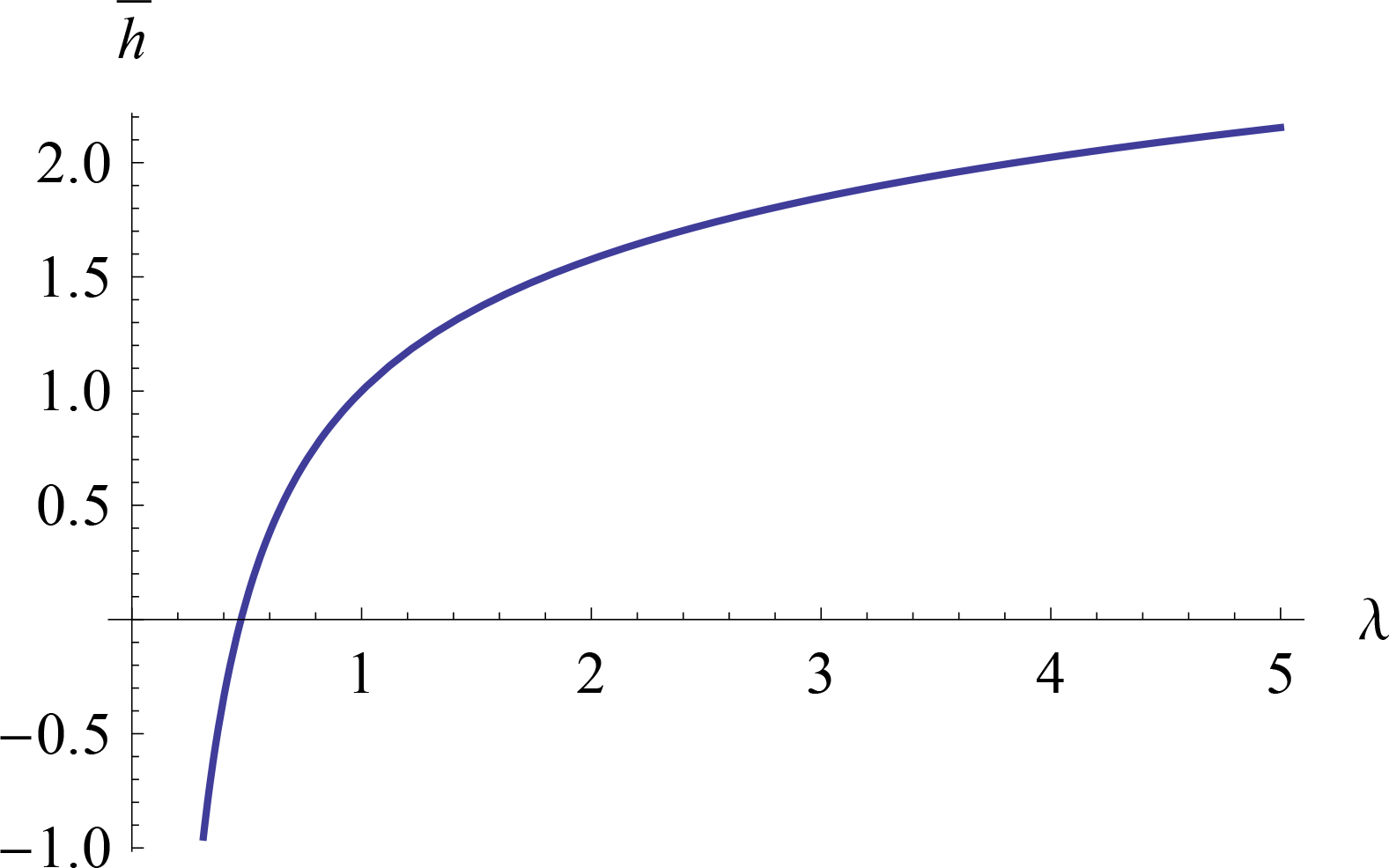{kind=link}
{kind=link}
{kind=link}






