1. Introduction
Complex systems (CS) are frequent in many natural (e.g., geophysics, cosmology, ecology, biology, genetics) and man-made (e.g., economy, computer science, chemical and physical apparatus) systems [
1–
10]. They are often constituted by multiple interacting entities that contribute to a collective behavior revealing surprising dynamical phenomena. CS modeling can adopt sophisticated mathematical tools, but often, we verify that those methods are still far from capturing the overall richness of the system evolution. Therefore, a fruitful interplay is possible by experimenting in a given case with mathematical tools that are usual in distinct areas [
11].
Multidimensional scaling (MDS) is a computer method for visualizing and comparing data that have been applied in many distinct areas [
12–
15]. Polzella and Reid [
16] used MDS in the study of pilot performance data obtained during simulated combat. Costa
et al. [
17] considered MDS to analyze DNA code in the perspective of identifying structural patterns in the nuclear and mitochondrial genomes. Machado
et al. [
18] adopted MDS to study fifteen stock markets and to unveil time-varying correlations between them. Oñate and Pou [
19] analyzed the temperature time-series from eleven meteorological stations over the Iberian Peninsula. Trends were identified by means of Mann–Kendall tests, while MDS was employed to build automatic grouping. More recently, Stephenson and Doblas-Reyes [
20] used MDS as an exploratory tool for describing ensembles of forecasts. Lopes and Machado [
11] studied global temperature time-series, showing that MDS is able to provide an intuitive and useful visual representation of the complex relationships present in the data.
In this paper, we combine MDS tools and parametric similarity indices (PSI) in the analysis of CS. Each phenomenon is viewed as a dynamical system whose output is a time-series. The time-series are interpreted as manifestations of the system behavior. The novel methodology is structured as follows. First, we adopt a sliding time-window to convert the original data into smaller parts that reflect evolution in time. Second, for a given PSI, we compare the time-windows for different values of the parameter, and we generate the corresponding MDS maps of “points”. Third, we transform the individual MDS charts for obtaining the maximum object superposition. The construction of the global MDS map unveils the characteristics of the CS.
Our approach represents a generalization of MDS classical schemes. In fact, standard MDS representations capture the system dynamics by means of a single similarity index. Such an index depends of the researcher’s choice, and therefore, we can define distinct criteria. The MDS interpretation is based on the emerging clusters and distances between “objects” (“points”) in the map, rather than on their absolute coordinates or the geometrical form of the locus. We propose subdividing each time-series into several smaller slices, to capture time dynamics, and to adopt PSI in each MDS map, providing distinct comparisons for the same windows. The interpretation of the MDS map is now based on “objects” consisting of “shapes” (a collection of points) instead of “points”, capturing the time evolution of the phenomena and being sensitive to the parametric index adopted.
Loosely speaking, with the standard MDS methods, we are viewing “objects” under a monochrome beam of light, while with the PSI approach, we vary the light wavelength, leading to a more colorful and detailed characterization of the “objects”.
The generalized correlation, Minkowski distance and entropy are tested as candidates for the parameter-dependent comparison indices. The proposed approach is applied to the Dow Jones Industrial Average stock market index (DJ) and Europe Brent Spot Prices FOB (BR) time-series.
Bearing these ideas in mind, this paper is organized as follows. Section 2 introduces the main mathematical tools used for processing the data. Section 3 analyses real data by means of several PSI and MDS. Finally, Section 4 outlines the main conclusions.
3. MDS Analysis and Visualization of Complex Systems
In this section, we apply PSI and MDS tools in the analysis of real-world time-series. In Section 3.1, we use a simple example to introduce the approach. In Sections 3.2, 3.3 and 3.4, we process data from two CS by means of the generalized correlation index, the Minkowski distance and entropy, respectively. We use DJ and BR time-series at a daily time horizon [
38,
39] to characterize the CS dynamics. The data are available at the Yahoo Finance (
https://finance.yahoo.com/) and the U.S. Energy Information Administration (
http://www.eia.gov/) websites. The time period of analysis is from 20 May 1987, up to 5 January 2015. Some missing values are estimated by means of a linear interpolation algorithm, applied between neighbor values, so that all weeks have five values.
3.1. Illustrative Example
Given a time-series representative of a CS over the period T,
, 0 ≤ t < T, we divided the data into h intervals, denoted by xk(t), kT/h ≤ t < (k + 1)T/h, k = {0, 1, 2, …, h − 1}. For a PSI, we calculate p similarity matrices, Mq, h × h dimensional, where q ∈ {q1, q2,…, qp}. Matrices Mq feed the MDS algorithm, which generates p intermediate maps of “points” (i.e., one map per value q). The charts are then processed by means of Procrustes analysis in order to obtain a single global plot of “shapes” where the “points” of the original maps are optimally “superimposed”.
Procrustes analysis performs linear transformations, namely translation, reflection, orthogonal rotation and scaling, with the objective of minimizing a measure of the difference between the “points” in the original maps. The algorithm: (i) chooses a reference MDS map (by selecting one of the available instances); (ii) superimposes all other MDS instances into the current reference; (iii) computes the mean form of the current set of superimposed maps; (iv) compares the distance between the mean and the reference instances to a given threshold value and, if above, sets the reference to the mean form and continues to Step (ii).
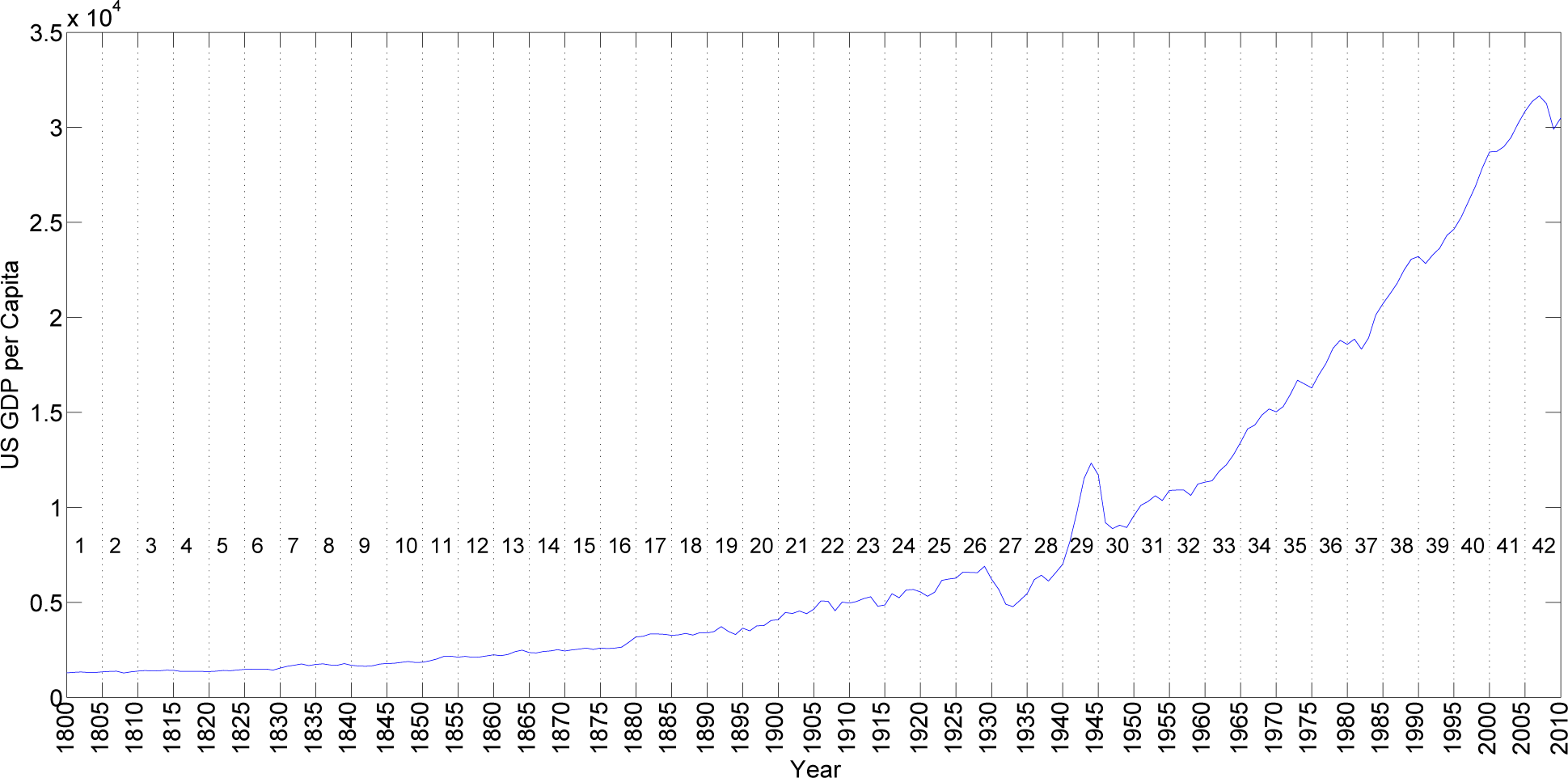
For illustrating our approach, we start by using a time-series consisting of the U.S. GDP per capita, for the period from year 1800 up to 2010, with units of 1990 GK dollars per capita. This time-series has the advantage of being simple and smooth over time, but rich enough to be used as an illustrative example. The data are from the Maddison Project [
40].
Figure 1 shows the GDP time-series divided into
h = 42 non-overlapping intervals of five years each. We adopt the Minkowski distance
(9) with
p = 22 parameter values and
q varying uniformly in the interval
q ∈ [0.12, 1.20]. We then calculate the matrices
, (
i,
j) = 0, …, 41, that constitute the input for the MDS algorithm.
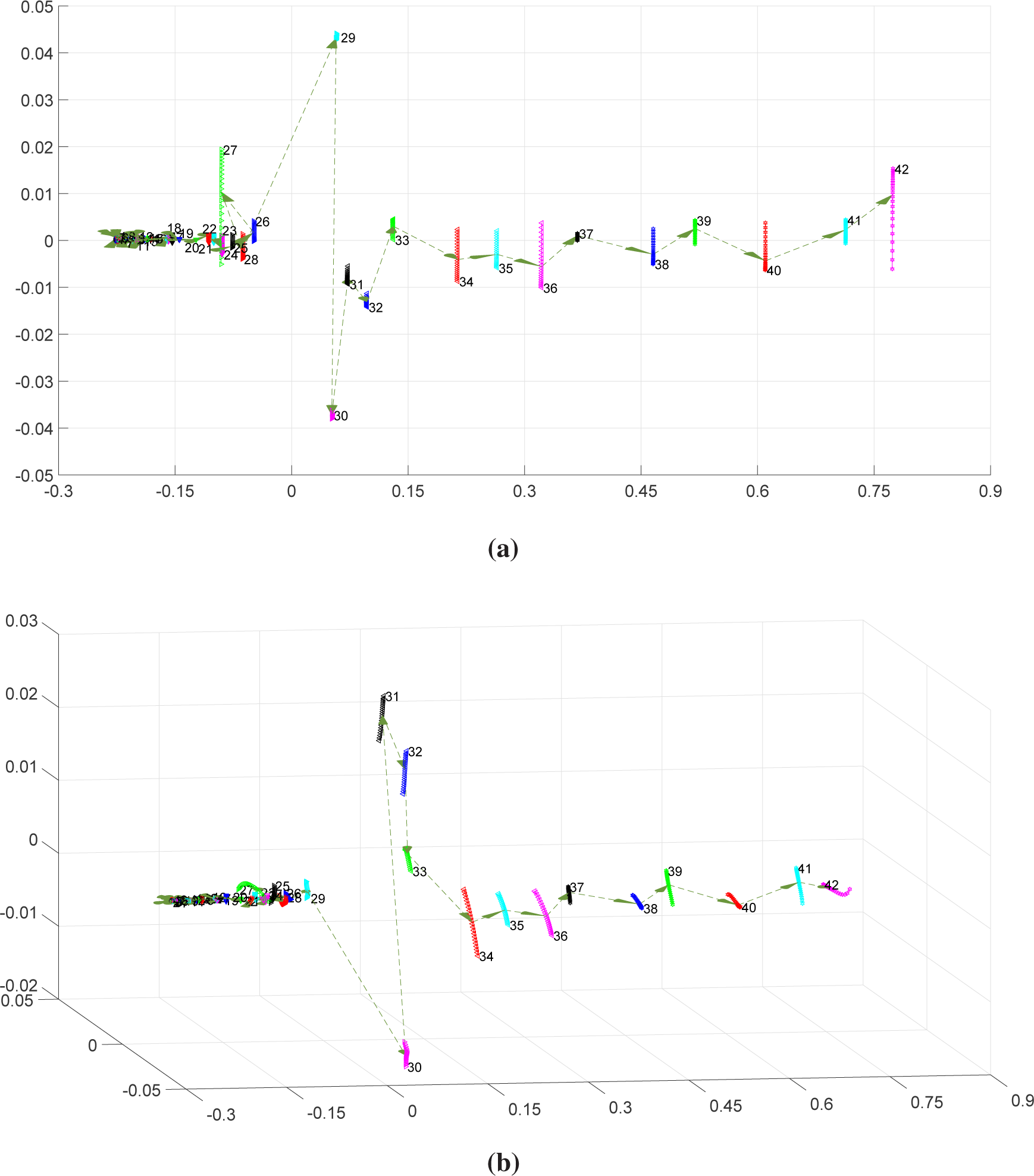
Figure 2 depicts the two- and three-dimensional global MDS maps that result from the Procrustes analysis. In these charts, we get a continuous set of
p points for each time-window, meaning that we have maps of “shapes”, instead of merely “points”. We verify that the “shapes” have a one-dimensional nature and that their length varies along time. For example, “shapes” of windows {27, 31, 32, 34, 36, 42} exhibit a larger length, meaning that they are more sensitive to the variation of
q.
Superimposed to the global maps, we represent the time behavior of the CS by means of a set of oriented arrows that connect the window “shapes” and indicate the flow of time. We verify longer “jumps” between certain time-windows, namely {29–30, 30–31, 31–32, 32–33, 33–34}, which means that they have different characteristics from the rest.
The following list emphasizes the relationships between the GDP time-series and the MDS global maps:
During the time period 1800–1930, the GDP had a moderate growth with small oscillations over time. In the MDS maps, we observe small “shapes”, representing Windows 1 up to 26, appearing in sequence and close to each other;
In the time period 1930–1935, corresponding to the worst years of the Great Depression, the GDP had a strong oscillation, increasing (with small fluctuation) during the subsequent five-year period, 1935–1940. Such behavior is observed in the MDS maps as two moderate length “jumps” from Window 26 towards Window 27 and then towards Window 28;
Periods 1940–1945, 1945–1950 and 1950–1955 had contrasting behavior, characterized by growth and recession, mostly determined by World War II. In the MDS maps, we observe large “jumps” across Windows 29 up to 31;
For the time period 1955–1960, GDP growth became slower and then recovered during the period 1960–1965. This corresponds to large “jumps” across Windows 31, 32 and 33 in the MDS;
From year 1960 onward, we observe a GDP moderate growth trend, with oscillations over time. This behavior translates into moderate, and similar, length “jumps” between shapes in the MDS maps.
3.2. MDS Based on the Generalized Correlation Index
We start by dividing the total DJ series into h = 27 non-overlapping intervals of approximately a one-year time-length each. This value of h mitigates the problems related to the non-stationarity of the data and establishes a good compromise between time discrimination and solid histogram representation. We then adopt p = 22 distinct parameter values, uniformly distributed in the interval q ∈ [0, 1], and we calculate the corresponding matrices
, (i, j) = 0, …, 26, where
represents the generalized correlation between xi(t) and xj(t).
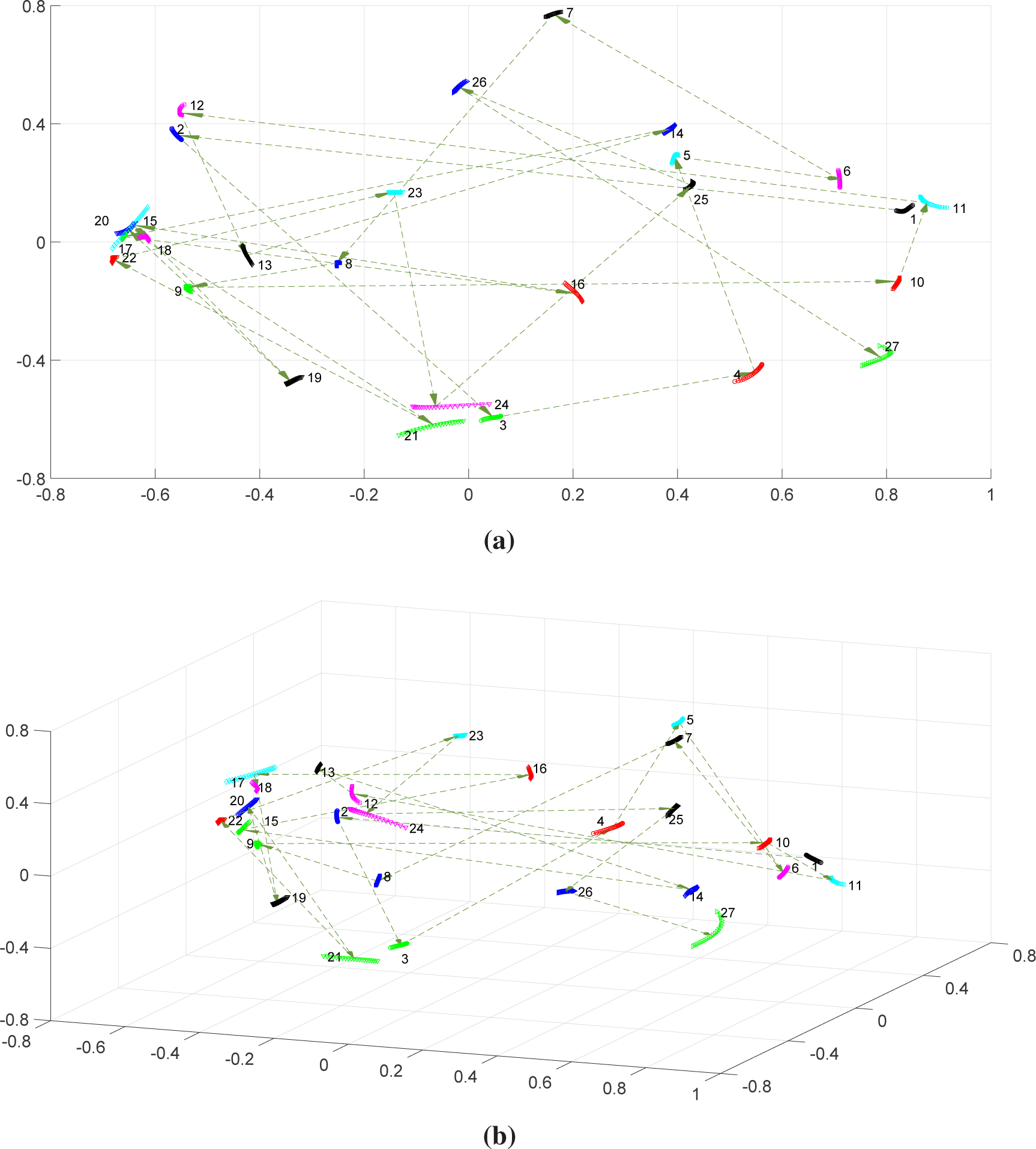
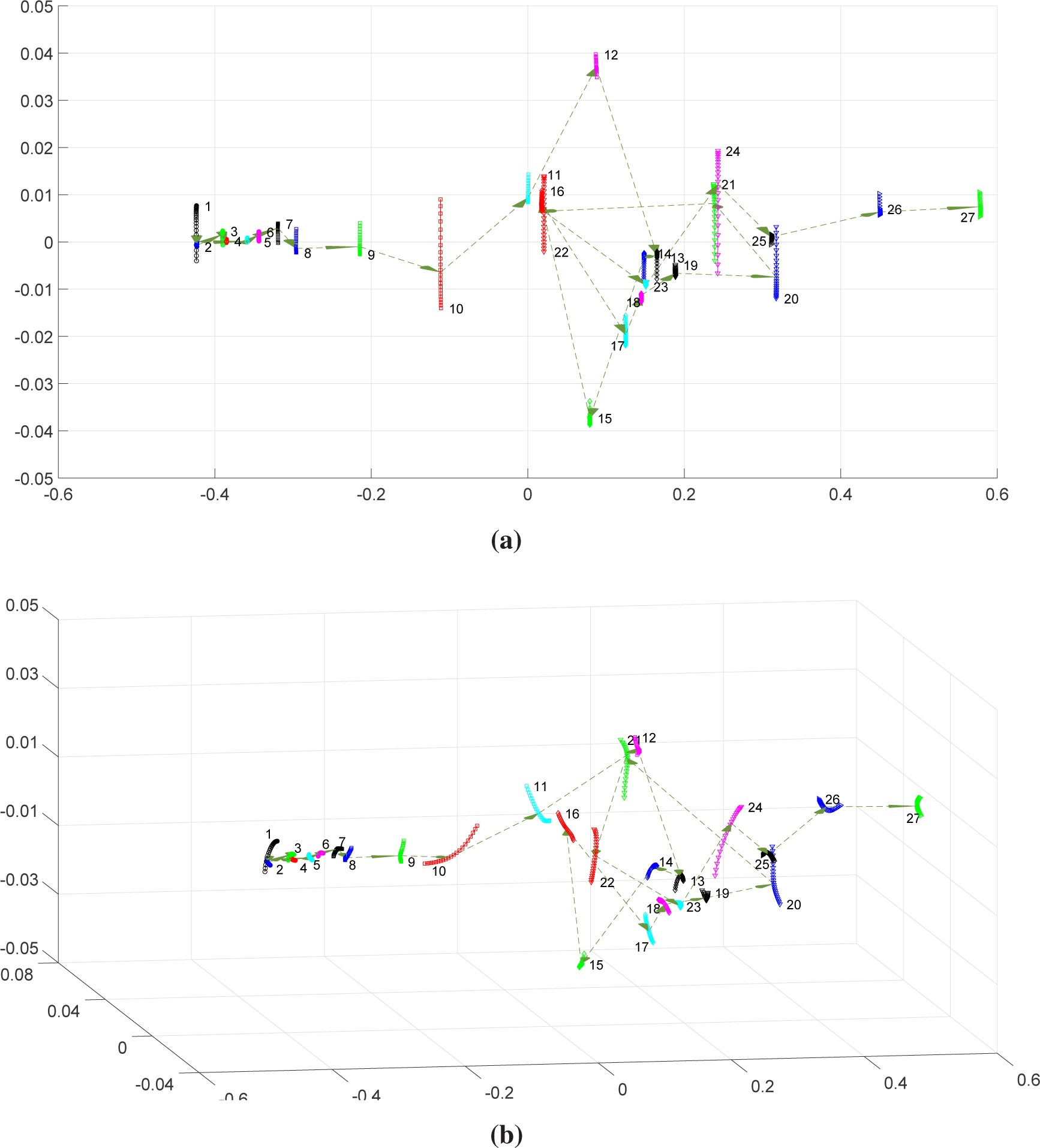
Figure 3 shows the two- and three-dimensional MDS maps obtained after Procrustes analysis. We can see that the generalized correlation index leads successfully to maps of one-dimensional “shapes”. Windows {1, 5, 14, 18, 19, 21, 22, 23, 25} are more sensitive to the variation of
q, since they are larger than the others. Furthermore, we observe the emergence of two main clusters of “shapes”:
and
.
We verify longer “jumps” between certain time-windows, namely {1–2, 3–4, 15–16, 20–21, 21–22}, which means that they have distinctive characteristics. Nevertheless, we can see that ρq reveals difficulties with time flow discretization, since we obtain a large number of chaotic “jumps” between “shapes”.
The length of the “shapes” seems to be closely related to the annual volatility of the DJ stock market. In fact, windows exhibiting a larger length correspond to higher volatility time periods of the DJ. On the other hand, longer “jumps” seem to be related to periods of stock market crashes and bear markets, namely the “Black Monday of 1987” (Windows 1–2), the “Friday the 13th 1989 mini-crash” (3–4) the “Stock market downturn of 2002” (Windows 15–16) and the “United States bear market of 2007–2009” (Windows 20–21 and 21–22).
Identically to the DJ data, we process the BR time-series.
Figure 4 shows the two- and three-dimensional MDS maps of “shapes” and the time behavior of the CS obtained after Procrustes analysis. In this case, two main clusters of “shapes” emerge:
and
. Larger length “shapes” correspond to Windows {1, 2, 9, 11, 13, 14. 27}, while longer “jumps” correspond to Periods {4–5, 12–13, 17–18, 20–21, 21–22, 24–25, 26–27}. As for the DJ,
ρq leads to a poor time discrimination between the data.
To assess the quality of the
p intermediate MDS maps that are used to construct the global map of “shapes”, we plot the Shepard and the stress diagrams. We illustrate the results obtained for the DJ time-series and
ρq. For the BR data, and for all PSI, the results are similar.
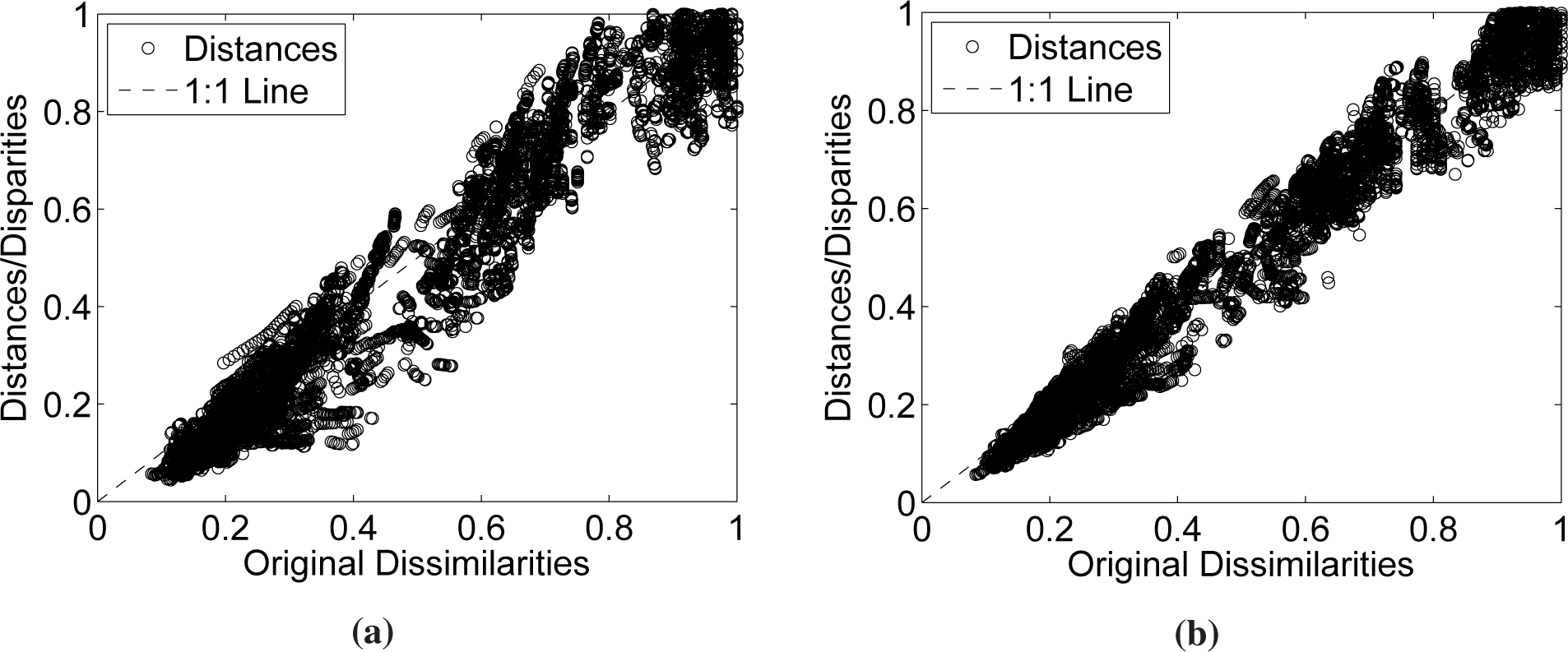
Figure 5 represents the
p Shepard diagrams superimposed in a single chart. We can observe a scatter of points distributed around the 45-degree line, which means a good fit of the observed distances to the dissimilarities. As expected, for
m = 3, we get slightly better results than for
m = 2.
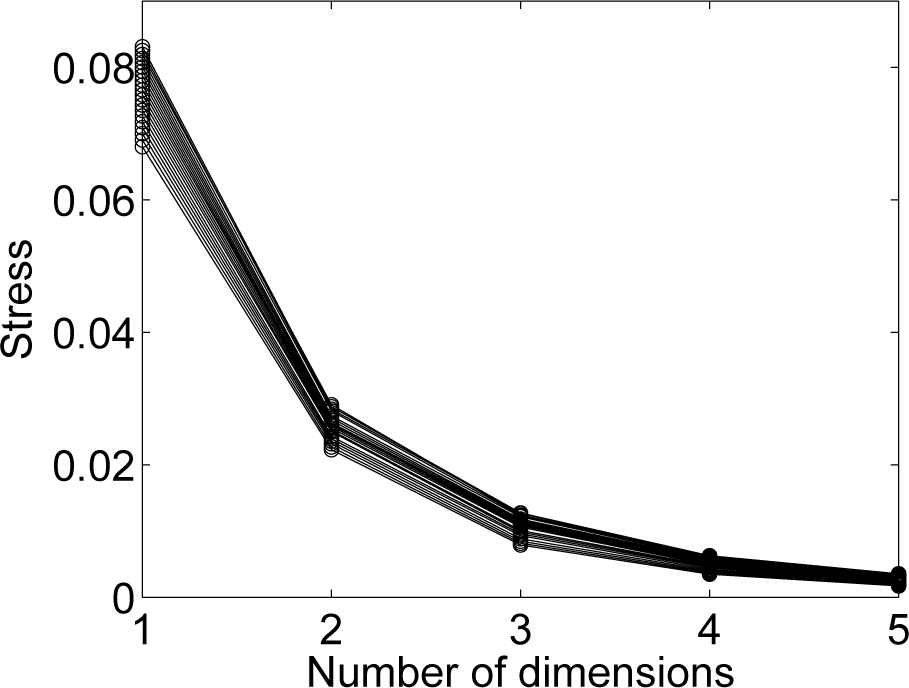
Figure 6 depicts the superposition of the stress diagrams, revealing that, for the
p intermediate MDS maps, a three-dimensional space describes the data well.
3.3. MDS Based on Minkowski Distance
In this subsection, we embed the Minkowski distance
(9) into the MDS. The parameter
q varies uniformly in the interval
q ∈ [0.12, 1.20]. The remaining parameters stay unchanged with respect to Section 3.2. We calculate the matrices
, and we use them as the input for the MDS algorithm.
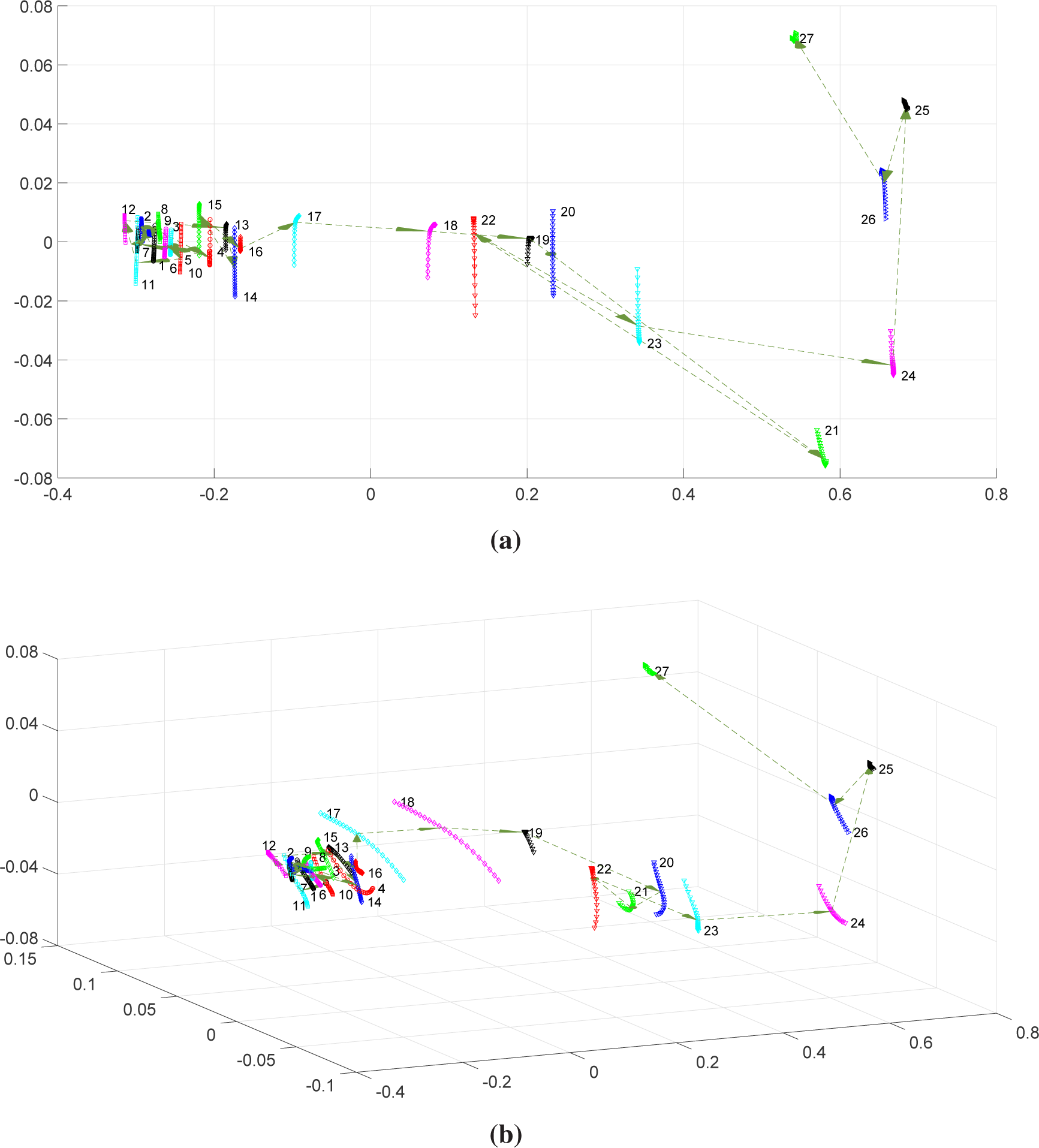
Figures 7 and
8 depict the two- and three-dimensional MDS maps for the DJ and BR time-series, respectively. As before, the global charts show continuous sets of points,
i.e., “shapes” for each time-window. Furthermore, both for DJ and BR,
dq is able to discriminate time. Here, we consider ‘good time discrimination’ as the ability to depict charts with a small content of discontinuities over time evolution. For the DJ, we observe three distinct clusters of “shapes”:
,
and
. For
and
, the time-windows that are closer to each other in time appear closer to each other in the MDS map. For cluster
, the time behavior is more “random”.
For the BR, we have identical results, but now with two distinct clusters:
,
.
3.4. MDS Based on Entropy Measures
In this subsection, we embed entropy-based PSI into the MDS. For data comparison, we compute the
p matrices,
, where
represents the Canberra distance between the entropy values of the time-windows
xi(
t) and
xj(
t):
The entropy,
, is estimated by means of the histograms of relative frequencies. For constructing the histograms, we use N = 10 bins.
The results obtained with Expressions
(11),
(12),
(13) and
(15) are similar for both the DJ and the BR time-series. We opt for presenting the MDS maps generated with the generalized entropy
(15), since it is more sensitive to the data.
The parameter q varies uniformly in the interval q ∈ [0, 0.3], and h and p take the values adopted in the previous subsections.
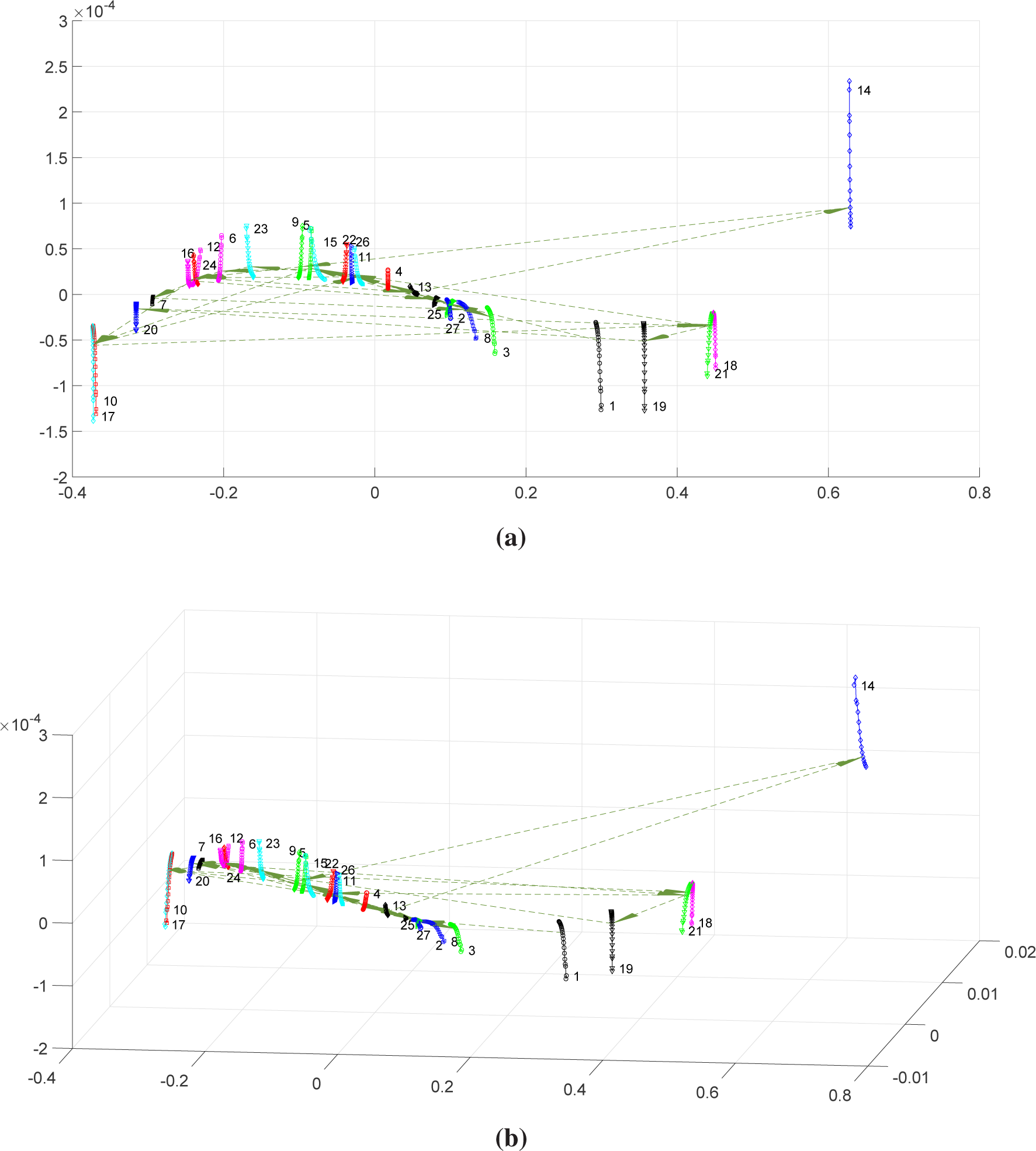
Figures 9 and
10 depict the two- and three-dimensional MDS maps for the DJ and BR time-series, respectively. As before, we observe that the global charts exhibit continuous sets of points (“shapes”) for all time windows. On the other hand, as for
ρq, the entropy-based indices reveal difficulties with time discrimination, giving rise to a large number of “jumps” between “shapes”. For the DJ time-series, windows
and
have different behavior, being located far apart from the remaining. Regarding the BR data, windows
and
unveil different characteristics of those exhibited by the other time periods.
The proposed methodology yields two orthogonal descriptions, namely the set of “shapes” and the set of time discrete steps, referred previously as “jumps”. Therefore, it is of interest to check how the two concepts evolve along the series, for distinct indices.
Figure 11 depicts the locus of “jump”
versus “shape” lengths (
and Σ, respectively), where the labels represent the windows numbers. For avoiding having distinct ranges and scales that could mislead, both variables are normalized to the interval [0, 1]. We show the results obtained for the DJ data; however identical conclusions can be drawn for the BR data series.
We observe a pattern where time is an irregular flux, but where it visits often the same trail. The pattern varies with the comparison index, so it is not an intrinsic property, but rather the results of the observation perspective provided by each individual index. The patterns reveal trains, somehow in a tree structure.
Another aspect to investigate is the effect of the window length over the time MDS map. Therefore, we consider shorter time windows, namely
h = 2 × 27 and
h = 3 × 27, corresponding to periods of approximately six and four months, respectively.
Figure 12 shows the locus of
versus Σ for the DJ time-series, where the labels represent the windows. We observe the emergence of more complex, fractal-like, trees. Moreover, we verify that the CS revisits the same areas of the locus over time. The study of their properties needs to be pursuit, but it seems to reveal that for the CS under analysis time flow has a non-smooth texture.
In conclusion, we have demonstrated that the choice of the comparison index leads to distinct sensitivities to the variation of the parameter and the evolution of time. While the graphical layout of the MDS “points” is usually of smaller importance, their clustering is fundamental in tracing conclusions. Therefore, the construction of MDS “shapes” can be explored to get an extra insight into the phenomena under analysis. This study constitutes a step towards building a more general formulation of the standard MDS method, and several questions emerge. Since we can explore indices with several parameters, do they lead to useful multidimensional “shapes” in the MDS maps? How can we analyze more assertively the sensitivity of different time windows? While the standard visualization of the flux of time as a constant velocity process, is MDS pointing to a variable speed time arrow? We plan to apply the new methodology to several data series in the future, aiming to clarify some of these issues.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











