
Entropy Approximation in Lossy Source Coding Problem

Department of Mathematics and Computer Science, Jagiellonian University, Lojasiewicza 6, 30-348 Kraków, Poland
*
Author to whom correspondence should be addressed.
Entropy 2015, 17(5), 3400-3418; https://doi.org/10.3390/e17053400
Submission received: 26 March 2015
/
Revised: 11 May 2015
/
Accepted: 12 May 2015
/
Published: 18 May 2015
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:In this paper, we investigate a lossy source coding problem, where an upper limit on the permitted distortion is defined for every dataset element. It can be seen as an alternative approach to rate distortion theory where a bound on the allowed average error is specified. In order to find the entropy, which gives a statistical length of source code compatible with a fixed distortion bound, a corresponding optimization problem has to be solved. First, we show how to simplify this general optimization by reducing the number of coding partitions, which are irrelevant for the entropy calculation. In our main result, we present a fast and feasible for implementation greedy algorithm, which allows one to approximate the entropy within an additive error term of log2 e. The proof is based on the minimum entropy set cover problem, for which a similar bound was obtained.
1. Introduction
Lossy source coding transforms possibly continuously-distributed information into a finite number of codewords [1,2]. Although this allows one to encode data efficiently, such an operation is irreversible, and once modified, information cannot be restored accurately. One of the fundamental questions in lossy coding is the following: What is the lowest achievable statistical code length given a maximal coding error? To answer this question, the precise formulation of the coding error and related definition of the entropy need to be given. In this paper, we present how to approximate the value of the entropy in the case when every entry element has a fixed upper limit on the permitted error.
1.1. Motivation
In order to explain our results, we give a more precise problem formulation. Suppose that a random source represented by a probability measure µ produces the information from space X. We fix a partition
of X and encode an arbitrary element x ∈ X by a unique
, such that x ∈ P. The statistical code length is described by the Shannon entropy of µ with respect to
[3]:
Example 1. Suppose that we want to encode numbers picked randomly from [0,n). One can use a coding partition with equally-sized sets, e.g.,
. When the source elements are encoded by the centers of these sets, then the (de)coding error does not exceed δ/2. Clearly, one may construct partitions that contain different types of sets. Roughly speaking, highly probable elements should be coded with high accuracy (smaller sets), while the rare numbers can be coded with low precision (larger sets). DjVuis an example of a file format that uses different precision for various image elements: it compresses the text layer and the background separately [4]. The proposed approach allows one to define a maximal coding error for every dataset element separately.
To control the maximal coding error in the above formulation, we propose to use an additional family
of subsets of X, which we call an error-control family. The error-control family is a kind of a fidelity criterion [5]. We accept only these coding partitions
where every element is a subset of some element of
(we say that
is
-acceptable). The optimal
-acceptable coding partition is the one with the minimal entropy. Thus, we define the entropy of an error-control family
by [6-8]:
The above problem differs from the rate distortion theory [9,10], which is the most common approach to lossy source coding. Instead of specifying an upper limit on the allowed average distortion rate, an upper limit on the permitted distortion for any symbol is considered. The above formulation can be seen as a kind of vector quantization [11,12] and was partially motivated by the notion of epsilon-entropy proposed by Posner [13,14]. The entropy of specific error-control families in the case of metric spaces appears also in the definition of Rényi entropy dimension [15]. It is worth mentioning that our idea is partially connected with perceptual source coding considered by Jayant et al. [16].
Answering the question raised at the beginning of the paper concerning the lowest code length given a maximal coding error is equivalent to the calculation of the entropy of an error-control family (1). In this paper, we focus on methods that allow us to approximate this quantity.
1.2. Main Results
In our main result, Theorem 4, we present a method that allows us to approximate the entropy of an error-control family within an additive term. More precisely, we propose a fast and easy to implement algorithm, the greedy entropy algorithm, which for a given finite error-control family
produces a
-acceptable partition
satisfying:
The obtained bound is sharp and cannot be improved. Moreover, it is independent of a coding problem instance characterized by a probability measure µ and an error-control family
.
Our method is reminiscent of the procedure used to approximate the solution of the minimum entropy set cover problem (MESC) [17,18], where a similar bound was derived. Roughly speaking, MESC focuses on an optimization problem, where one seeks for partition compatible with a fixed cover of a finite dataset X with minimal entropy. In fact, it looks for an assignment
, which can be seen as a special case of a partition. A similar greedy algorithm was used for producing a partition with the entropy approximating the minimal entropy value. To be able to apply the results obtained for MESC, the precise relationships between these two problems were established. In particular, in Theorem 3, we show that the entropy of an error-control family equals the minimal entropy for a set cover. Let us observe that our main minimization problem (1) is very complex, since for most examples of error-control families, there exists an uncountable number of acceptable partitions (see Section 2.2). As a consequence, an exhaustive search through all acceptable partitions cannot be done in practice. The second key part for establishing the inequality (2) was to show that the number of partitions relevant for the entropy calculation may be drastically reduced. In Theorem 1, we derive that finding the entropy of an error-control family, it is sufficient to consider only partitions constructed from the elements of σ-algebra generated by an error-control family.
1.3. Discussion
Before presenting the details of the proposed algorithm, let us first demonstrate its sample effects. The reader interested in its full description may skip this part during the first reading.
In order to show the capabilities of the greedy entropy algorithm, we apply this procedure for image segmentation. For simplicity, we assume that every pixel is represented by a three-dimensional feature vector, i.e., the intensity of each color coordinate ranges between zero and 255.
Let the error-control family
consist of all cubes with a side length δ, i.e.,
. The greedy entropy algorithm selects sequentially the most probable cubes from the image histogram. The final partition
, for two color components—green and blue—is shown in Figure 1b. Table 1a presents the comparison between the entropies calculated for partition
and another
-acceptable partition
, including all pairwise disjoint cubes with the side length δ > 0. Surprisingly, both partitions gave similar entropies. This might be explained by the fact that
contains only the elements of the error-control family
.
Clearly, this is not always the case. To observe this, let the error-control family
consist of all balls with radius δ. Figure 1c shows the partition
returned by the greedy entropy algorithm for two color components: green and blue. As in the previous case, we consider also a
-acceptable partition
of maximally-sized pairwise disjoint cubes with a fixed side length. We can see from the results placed in Table 1b that a greedy selection provided significantly lower entropy values.
The convergence behavior of the partitions produced by the greedy entropy algorithm was shown in Figure 2. One can observe that the entropy, as well as the cardinality of resultant partitions decrease in a hyperbolic way when the diameters of sets included in the error-control family increase.
1.4. Paper Organization
The paper is organized as follows. In Section 2, we formulate our lossy source coding problem and show that the entropy optimization problem can be simplified by reducing the number of partitions, which are irrelevant for entropy calculation. Section 3 contains our main result. First, the minimum entropy set cover problem is recalled, and its relationship with our notion of entropy is established. Next, we define the greedy entropy algorithm and derive that it constructs a partition with the entropy close to the optimal one.
2. Entropy Calculation
We start this section with establishing basic notations and definitions. Then, we present the main problem of this paper concerning the entropy calculation and show how to reduce its complexity by eliminating irrelevant coding partitions.
2.1. Lossy Source Coding and Error-Control Families
Let us assume that (X, Σ, µ) is a probability space. In our formulation of lossy source coding, we are interested in encoding elements of X produced by a probability measure µ by a countable number of symbols. The source code is determined by a partition of X, which is a countable family of measurable, pairwise disjoint subsets of X, such that:
More precisely, every element x ∈ X is transformed into a code related to a unique
, such that x ∈ P. The statistical code length of an arbitrary element of X in the optimal coding scheme can be calculated by the entropy of
[3]:
Definition 1. The entropy of a partition is defined by:
where sh : [0,1] → [0, ∞) is the Shannon function, i.e.,
where by −0 • log2(0), we understand zero.
Although the entropy and the partition depend strictly on the probability measure, we consequently omit the symbol µ in their definitions to simplify notations.
The use of a partition causes a coding error (distortion). To be able to control the maximal coding error (the upper limit of permitted distortion), an additional family
of subsets of X is introduced, which we call an error-control family [7]. The error-control family restricts the number of permissible partitions that can be used for encoding. More precisely, a partition
is said to be
-acceptable iff for every
, there exists
, such that P ⊂ Q (which we write
).
The partitions that are allowed to be used for encoding are limited by a fixed error-control family. The optimal lossy coding scheme (determined by a partition) is the one that minimizes the entropy and does not violate the upper limit of permitted distortion, i.e.,
. This leads to the following definition of the entropy of an error-control family [7].
Definition 2. Let be an error-control family. The entropy of is defined by:
In this paper, we focus on the computational methods for finding the value of
and possibly a partition
, which satisfies
. One should look for a partition
satisfying
. However, Example II.1 in [7] shows that the value of entropy does not have to be attained on any partition in general.
2.2. Partition Reduction
In order to find the entropy of an error-control family, a minimization problem (3) has to be solved. Let us first observe that for very simple error-control families, the number of acceptable partitions can be uncountable. Given a family
, any partition of the form
, where a ∈ (0,1), is
-acceptable. Clearly, some of them do not lead to the optimal solution. As a consequence, it is extremely important to eliminate partitions that are irrelevant for entropy calculation (3).
The main result of this section shows that to find the entropy, it is sufficient to consider only partitions constructed from the sets of
: the σ-algebra generated by the error-control family
. In the aforementioned example, there are only three such partitions:
,
and
.
Theorem 1. Let (X, Σ, µ) be a probability space, and let be an error-control family. Then, we have:
To derive this fact, for any
-acceptable partition
, we will construct a partition
with the entropy not greater than
. To describe the process of construction of such a partition, let us first establish the notation: for a given partition (or, more generally, family of sets)
of X and a set A ⊂ X, we denote:
This notation will be used through this section.
Then, for a
-acceptable partition
, a family
is built by the following Algorithm 1.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
Our goal is to show that the partition reduction algorithm produces a partition
, such that:
We need to observe that the following property of the Shannon function holds.
Proposition 1. Given numbers p ≥ q ≥ 0 and r > 0, such that p, q,p + r,q − r ∈ [0,1], we have:
Let us focus on a single iteration of the partition reduction algorithm.
Lemma 1. Let (X,Σ,µ) be a subprobability space, i.e., (X, Σ) is measurable space, and µ is a non-negative measure on (X, Σ), such that µ(X) ≤ 1. We consider an error-control family and a-acceptable partition of X. Let be such that:
If is chosen so that Pmax ⊂ Q, then:
Proof. Clearly, if
, then the inequality (5) holds trivially Thus, we assume that
.
Let us observe that it is enough to consider only elements of
with non-zero measures: the number of such sets that can be at most countable. Thus, let us assume that
(the case when
is finite can be treated in a similar manner).
For simplicity, we put P1 := Pmax. For every
, we consider the sequence of sets, defined by:
Clearly, for
, we have:
To complete the proof, it is sufficient to derive that for every
, we have:
and:
Making use of Observation 1, we obtain:
which proves (9).
By (8),
To calculate
, we will use Lebesgue’s dominated convergence theorem [19]. We consider a sequence of functions:
Let us observe that the Shannon function sh is increasing on
and decreasing on
Thus, for a certain
,
and:
for every
. Since
, then:
Moreover,
for every
.
As the sequence of functions
satisfies the assumptions of Lebesgue’s dominated convergence theorem [19], then we get:
Consequently, we have:
which completes the proof. □
Making use of the above lemma, we summarize the analysis of the partition reduction algorithm in the following theorem.
Theorem 2. We assume that (X, Σ, µ) is a subprobability space. Let be an error-control family on X, and let be a-acceptable partition of X. A family constructed by the partition reduction algorithm is a partition of X and satisfies:
Proof. Directly from the partition reduction algorithm, we get that
is a countable family of pairwise disjoint sets. The fact that:
follows from Lebesgue’s dominated convergence theorem [19] applied to a sequence of functions
defined by:
We prove the inequality (11). If
, then the inequality (11) is straightforward. Thus, let us discuss the case when
We denote
, since at most, a countable number of elements of the partition can have a positive measure (the case when
Directly from Lemma 1, we obtain:
Consequently, for every
, we get:
Our goal is to show that:
for every
.
Making use of (12), we have:
for every
.
We will calculate
using Lebesgue’s dominated convergence theorem [19] for a sequence of functions
, defined by:
Similar reasoning was used in the proof of Lemma 1.
Similarly to the proof of Lemma 1, we may assume that there exists
, such that:
and:
for every
. Moreover,
for every
, since
is a partition of X.
Making use of Lebesgue’s dominated convergence theorem [19], we get:
Consequently, for every
, we have:
which completes the proof. □
As a consequence of Theorem 2, we directly get that Theorem 1 holds. In the case of finite error-control families, we get that there exists an acceptable partition with minimal entropy.
Corollary 1. Let (X, Σ, µ) be a probability space, and let be a finite error-control family. Then, there exists a-acceptable partition, such that:
3. Entropy Approximation
In the previous section, we simplified the problem of entropy calculation by reducing the number of partitions that are necessary to consider to find the entropy of an error-control family Since the number of acceptable partitions grows exponentially with the cardinality of the error-control family, it might be impossible to test all of them for entropy calculation. In this section, we show an algorithm that allows us to approximate the entropy within an additive term.
The presented formulation of lossy source coding is closely related to the minimum entropy set cover problem (MESC) [17,18], where one focuses on a similar optimization problem. There exists an algorithm for approximation of the solution of MESC within an additive term of log2 e. First, we present a description of MESC and its relationship with the introduced coding problem. Next, we use these facts to apply a similar technique for approximating the entropy of an error-control family.
3.1. Relationship with the Minimum Entropy Set Cover Problem
In order to define MESC, let X = {x1,…, xn} be a finite dataset, where every observation x ∈ X appears with a probability px. A random source produces a signal from a probability distribution
and passes it through the noisy channel. Each observation has a type, but due to the noise, we only know that it is one of a given set of types defined by a finite cover
of data space X. We map an observation to a type by defining an assignment
, which is compatible with
,i.e.,
for all x ∈ X.
Let us denote by qi the probability that the random point is assigned to Qi:
The goal is to find such an assignment that minimizes the entropy of the distribution of the types, i.e.,
Such an optimal assignment is denoted by
.
MESC is an NP-hard problem (Theorem 1 in [18]). To find an assignment that efficiently approximates the minimal entropy value, a simple greedy algorithm can be used (which we call the greedy MESC algorithm). It relies on the iterative execution of the following steps:
- choose the most probable type
- if , then assign x to , i.e., put ,
- remove from X (and from all ) the elements of ,
Cardinal et al. proved a sharp bound for the entropy of assignment constructed with the use of the greedy MESC algorithm:
Greedy MESC approximation (see [17] Theorem 1): If
is an assignment produced by the greedy algorithm, then:
To be able to obtain a similar approximation of the entropy of an error-control family, the relationship between MESC and our formulation of entropy has to be established. For this purpose, our lossy source coding problem will be considered on a discrete probability space (X, Σ,µ), where X is a finite set, Σ is a σ-algebra generated by all singletons of X and
is an atomic measure on (X, Σ). A cover
plays the role of an error-control family
We start our analysis with showing that given an assignment
compatible with
, one can construct a
-acceptable partition with equal entropy:
Lemma 2. Let be an assignment compatible with. Then, the family, where, is a-acceptable partition, and:
Proof. Directly from the definition of compatible assignment, we get that
is a
-acceptable partition of X.
Moreover, let us observe that:
The following example illustrates that the natural inverse construction is not possible, i.e., for some
-acceptable partitions, there does not exist any compatible assignment with identical entropy
Example 2. Let (X, Σ, µ) be a probability space with an error-control family, where:
Then:
is a-acceptable partition with the entropy equal to one. However, there is no compatible assignments with the entropy of one: the only assignment compatible with is defined by:
which entropy equal to zero.
The following result demonstrates that given a partition, one can find an assignment without greater entropy:
Lemma 3. Let be a partition. Then, there exists an assignment compatible with, such that:
Proof. Since
is a partition, the function:
is well defined. Moreover, as
is
-acceptable, we find a mapping
, such that:
Finally, we put an assignment
, by:
Clearly,
is an assignment compatible with
. Let us calculate the entropy of
. We have:
Making use of the subadditivity of the Shannon function, we get:
As a consequence, we get that the entropy of the optimal assignment equals the entropy of an error-control family.
Theorem 3. We have:
Proof. If
is an optimal assignment, then making use of Lemma 2, we construct a
-acceptable partition
that satisfies:
On the other hand, since
is a finite error-control family, then from Theorem 1, we get:
for a specific
-acceptable partition
. Using Lemma 3, we find an assignment
compatible with
, such that:
which completes the proof.
3.2. Greedy Approximation
In this section, we show that the analogue of the greedy MESC algorithm can be applied for the case of our formulation of lossy source coding. Furthermore, similar bounds can be established.
Let us start with an extended version of the approximation algorithm, which we call the greedy entropy algorithm (Algorithm 2). Contrary to the greedy MESC algorithm, our procedure works directly with partitions; hence, it is more general. We assume that
is a finite error-control family.
 |
To see that the greedy entropy algorithm is not well defined for infinite error-control families, let us consider the example:
Example 3. Let us consider an open segment (0,1) with σ-algebra generated by all Borel subsets of (0,1), Lebesgue measure λ and an error control family, defined by:
There does not exist a set of maximal measure from family; hence, the greedy entropy algorithm cannot be applied directly in such a case.
Let us observe that both greedy algorithms create partitions with the same entropies. For this purpose, we denote by
a set of all assignments produced by the greedy MESC algorithm, while by
, we denote a set of all partitions returned by the greedy entropy algorithm:
Proposition 2. We have:
- For every, there exists, such that:
- For every, there exists, such that:
The main result of this section shows that the greedy entropy algorithm produces a partition with the entropy not greater that the entropy of an error-control family
Theorem 4. Let (X, Σ, µ) be a probability space, and let be a finite error-control family. Then:
The proof of Theorem 4 involves two facts:
- To calculate the entropy, it is sufficient to consider only partitions constructed from the elements of σ-algebra generated by (see Corollary 1).
- The calculation of the entropy of an error-control family is closely related to MESC optimization problem (see Theorem 3 and Proposition 2).
To be able to apply these facts, we need an additional lemma:
Lemma 4. Let (X, Σ,µ) be an arbitrary (not necessarily discrete) probability space, and let be a finite error-control family. Then, there exists a probability space with an error-control family, such that,
and are finite,
is an atomic measure,
and for every, there exists satisfying:
Proof. We restrict our consideration to partitions
, since, by Corollary 1, the entropy
is attained on some partition generated by
. Let us denote the set of generators of
:
Next, for every set
, we fix exactly one point xG ∈ G.
Then, we obtain a probability space
and an error-control family
by:
It is easy to see that every
-acceptable
-partition
corresponds naturally to a specific
-acceptable partition
and conversely The measures of corresponding sets are equal.
Thus:
Moreover, for every
, there exists
, which satisfies:
Finally, the proof of our main result is as follows:
Proof. (of Theorem 4) Making use of Lemma 4, we find a probability space
with the error-control family
, such that
,
,
are finite,
is an atomic measure and:
By Theorem 3, we get that if
is an optimal assignment compatible with
, then:
Moreover, making use of Proposition 2, for every
, we find
, such that:
Thus, by the greedy MESC approximation, we have:
Consequently, using Lemma 4, we get:
4. Conclusion and Future Work
The paper focused on a non-standard type of lossy source coding. In contrast to rate distortion theory, a cover of the source alphabet, which defines a maximal distortion permitted on every element, was introduced. The calculation of the entropy in such a formulation of lossy coding is equivalent to solving the minimum entropy optimization problem, where one would like to find a coding partition compatible with a fixed distortion with minimal entropy. Our results show how to simplify this optimization problem and to find the approximated entropy value. The proposed algorithm is fast, feasible for implementation and produces a partition that has a proven upper bound on accuracy, i.e., the entropy of the returned partition is not higher than log2 e the true entropy value.
In the future, we plan to consider a more general family of entropy functions, including Rényi and Tsallis entropies, which are of great importance in the theory of coding and related problems [6,20,21]. Moreover, there also arises a natural question concerning the compression of n-tuple random variables. More precisely, it is worth investigating how the coding efficiency increases when the larger blocks of source elements are compressed jointly.
Acknowledgments
This research was partially funded by the National Centre of Science (Poland) Grant Nos. 2014/13/N/ST6/01832 and 2014/13/B/ST6/01792. The authors are very grateful to the reviewers for many useful remarks and corrections, as well as for inspiring suggestions concerning further work.
Author Contributions
Marek Śmieja established the connections with Minimum Entropy Set Cover Problem, proved most of the theorems, performed experiments and wrote most of the manuscript. Jacek Tabor proposed the research problem, designed Partition Reduction Algorithm, corrected proofs and the manuscript. Both authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Berger, T. Lossy source coding. IEEE Trans. Inf. Theory 1998, 44, 2693–2723. [Google Scholar]
- Gray, R.M.; Neuhoff, D.L. Quantization. IEEE Trans. Inf. Theory 1998, 44, 2325–2383. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar]
- Bottou, L.; Haffner, P.; Howard, P.G.; Simard, P.; Bengio, Y.; LeCun, Y. High quality document image compression with “DjVu”. J. Electron. Imaging 1998, 7, 410–425. [Google Scholar]
- Kieffer, J.C. A survey of the theory of source coding with a fidelity criterion. IEEE Trans. Inf. Theory 1993, 39, 1473–1490. [Google Scholar]
- Śmieja, M. Weighted approach to general entropy function. IMA J. Math. Control Inf. 2014, 32. [Google Scholar] [CrossRef]
- Śmieja, M.; Tabor, J. Entropy of the mixture of sources and entropy dimension. IEEE Trans. Inf. Theory 2012, 58, 2719–2728. [Google Scholar]
- Śmieja, M.; Tabor, J. Rényi entropy dimension of the mixture of measures. Proceedings of 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 685–689.
- Berger, T. Rate-Distortion Theory; Wiley: Hoboken, NJ, USA, 1971. [Google Scholar]
- Ortega, A.; Ramchandran, K. Rate-distortion methods for image and video compression. IEEE Signal Process. Mag. 1998, 15, 23–50. [Google Scholar]
- Gray, R.M. Vector quantization. IEEE ASSP Mag. 1984, 1, 4–29. [Google Scholar]
- Nasrabadi, N.M.; King, R.A. Image coding using vector quantization: A review. IEEE Trans. Commun. 1998, 36, 957–971. [Google Scholar]
- Posner, E.C.; Rodemich, E.R. Epsilon entropy and data compression. Ann. Math. Stat. 1971, 42, 2079–2125. [Google Scholar]
- Posner, E.C.; Rodemich, E.R.; Rumsey, J.H. Epsilon entropy of stochastic processes. Ann. Math. Stat. 1967, 38, 1000–1020. [Google Scholar]
- Rényi, A. On the dimension and entropy of probability distributions. Acta Math. Hungar. 1959, 10, 193–215. [Google Scholar]
- Jayant, N.; Johnston, J.; Safranek, R. Signal compression based on models of human perception. Proc. IEEE 1993, 81, 1385–1422. [Google Scholar]
- Cardinal, J.; Fiorini, S.; Joret, G. Tight results on minimum entropy set cover. Algorithmica 2008, 51, 49–60. [Google Scholar]
- Halperin, E.; Karp, R.M. The minimum-entropy set cover problem. Theor. Comput. Sci. 2005, 348, 240–250. [Google Scholar]
- Kingman, J.F.C.; Taylor, S.J. Introduction to measures and probability; Cambridge University Press: Cambridge, UK, 1966. [Google Scholar]
- Bercher, J.F. Source coding with escort distributions and Rényi entropy bounds. Phys. Lett. A 2009, 373, 3235–3238. [Google Scholar] [Green Version]
- Czarnecki, W.M.; Tabor, J. Multithreshold entropy linear classifier: Theory and applications. Expert Syst. Appl. 2015, 42, 5591–5606. [Google Scholar]
Figure 1.
Input image for compression (a) and partitions produced by the greedy entropy algorithm for two cases of error-control families: the first one (b) consists of cubes with a given side length, while the second (c) contains balls with a given radius. For the visualization, only two color components were used: green and blue in (b) and (c).
Figure 1.
Input image for compression (a) and partitions produced by the greedy entropy algorithm for two cases of error-control families: the first one (b) consists of cubes with a given side length, while the second (c) contains balls with a given radius. For the visualization, only two color components were used: green and blue in (b) and (c).

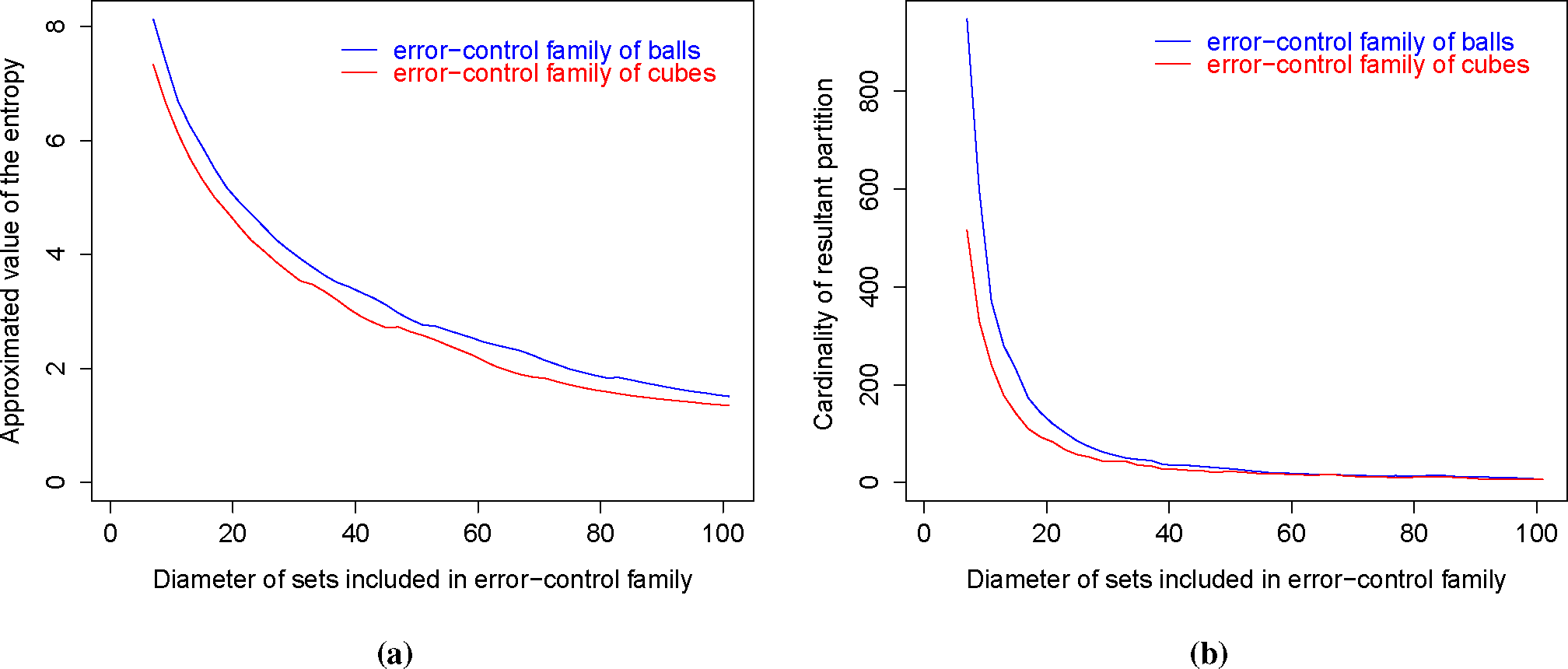
Figure 2.
Convergence behavior (entropy (a) and cardinality (b)) of the partitions produced by the greedy entropy algorithm for two cases of error control families: the first one consists of cubes with a given side length, while the second contains balls with a given radius. In every case, the diameters of elements included in the error-control family were increased, which caused the decrease of the entropy and the cardinality of resultant partitions.
Figure 2.
Convergence behavior (entropy (a) and cardinality (b)) of the partitions produced by the greedy entropy algorithm for two cases of error control families: the first one consists of cubes with a given side length, while the second contains balls with a given radius. In every case, the diameters of elements included in the error-control family were increased, which caused the decrease of the entropy and the cardinality of resultant partitions.

Table 1.
Entropies calculated for partitions
(a),
(b) returned by the greedy entropy algorithm for two cases of error control families. The first one consists of cubes with a given side length, while the second contains balls with a given radius. In each case, the results are compared with the entropy of the acceptable partition consisting of maximally-sized pairwise disjoint cubes
,
, respectively.
| (a)
| ||
|---|---|---|
| δ | ||
| 3 | 12.73 | 12.59 |
| 5 | 10.81 | 10.83 |
| 9 | 8.62 | 8.62 |
| 15 | 6.95 | 6.72 |
| (b)
| ||
|---|---|---|
| δ | ||
| 5 | 14.11 | 12.25 |
| 9 | 10.81 | 9.87 |
| 17 | 8.62 | 7.23 |
| 25 | 7.15 | 5.82 |
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Śmieja, M.; Tabor, J. Entropy Approximation in Lossy Source Coding Problem. Entropy 2015, 17, 3400-3418. https://doi.org/10.3390/e17053400
AMA Style
Śmieja M, Tabor J. Entropy Approximation in Lossy Source Coding Problem. Entropy. 2015; 17(5):3400-3418. https://doi.org/10.3390/e17053400
Chicago/Turabian StyleŚmieja, Marek, and Jacek Tabor. 2015. "Entropy Approximation in Lossy Source Coding Problem" Entropy 17, no. 5: 3400-3418. https://doi.org/10.3390/e17053400