
Increment Entropy as a Measure of Complexity for Time Series

Abstract
:1. Introduction
2. Increment Entropy


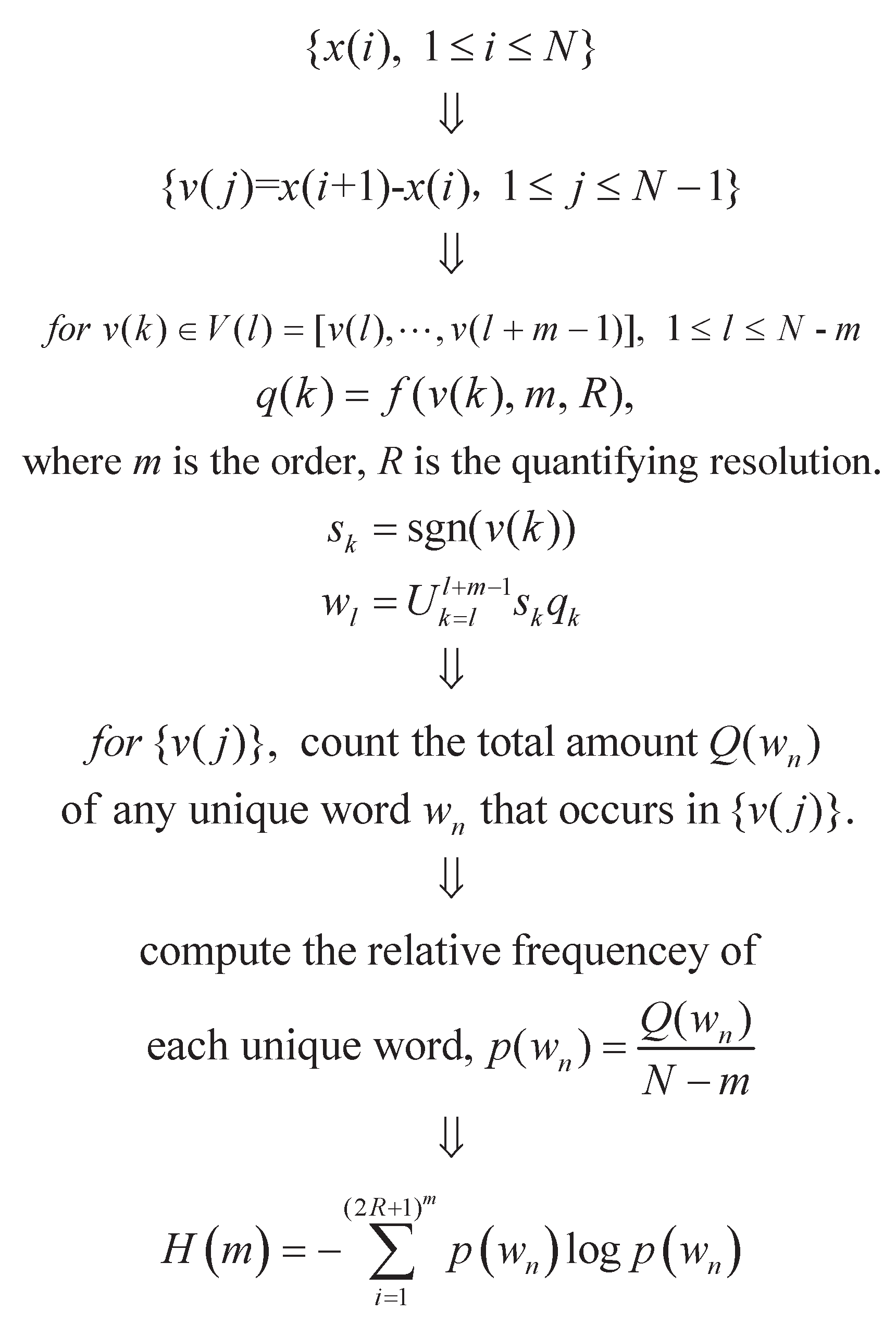{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vectors | ||||||
|---|---|---|---|---|---|---|
| 3 | 3 | 2 | 0 | 0 | 4 | |
| 3 | 2 | 0 | 4 | |||
| 2 | 4 | 1 | 1 | |||
| 4 | 1 | 2 | 1 | 4 | ||
| 4 | 20 | 1 | 4 | 1 | 4 | |
| 4 | 20 | 10 | 1 | 3 | 2 | |
| 20 | 10 | 11 | 4 | 1 | 0 | |
| 10 | 11 | 8 | 1 | 1 | 4 | |
3. Simulation and Results
3.1. Results on Logistic Time Series


3.2. Relationship to Other Approaches
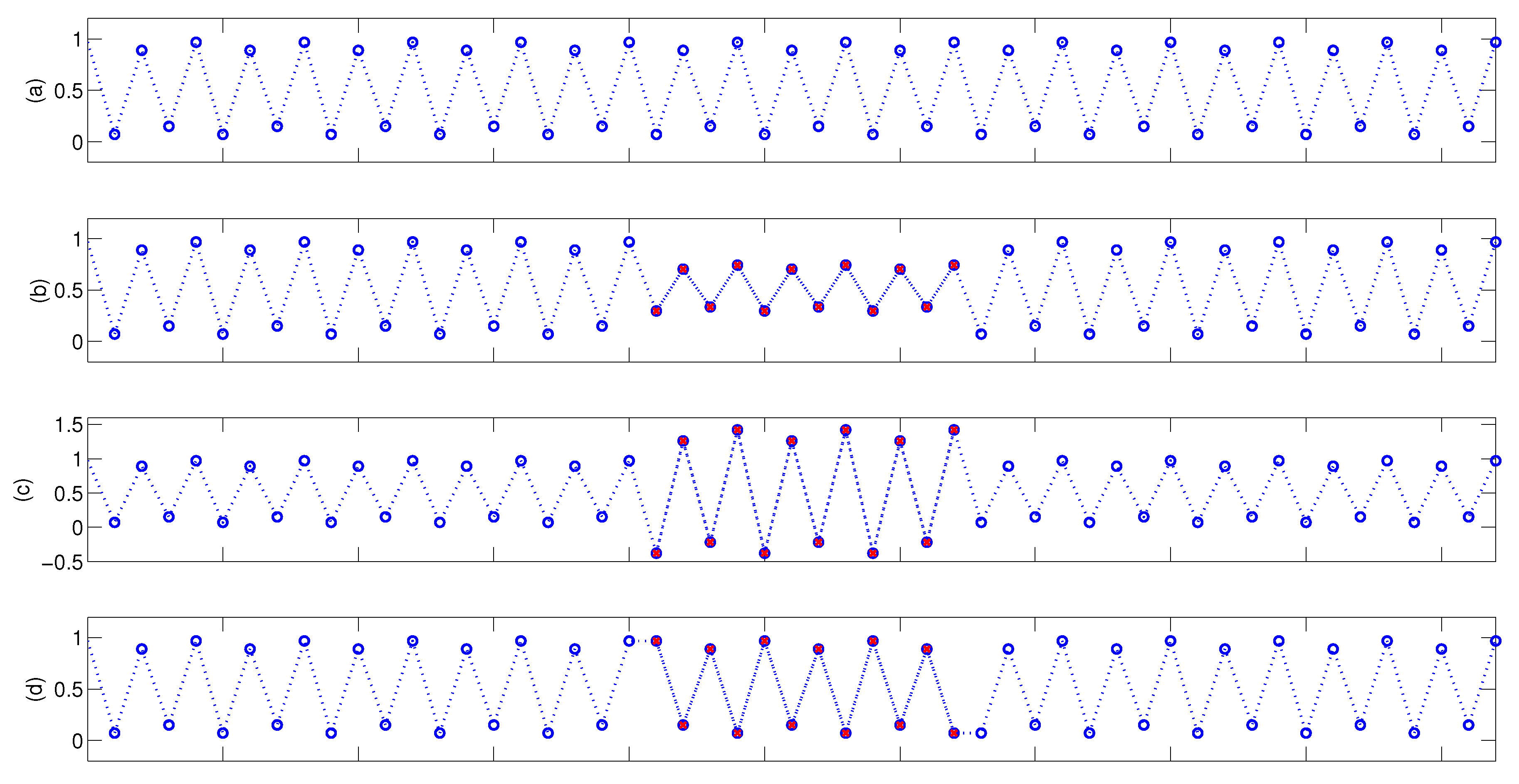
3.2.1. Distinguishing Analogous Patterns

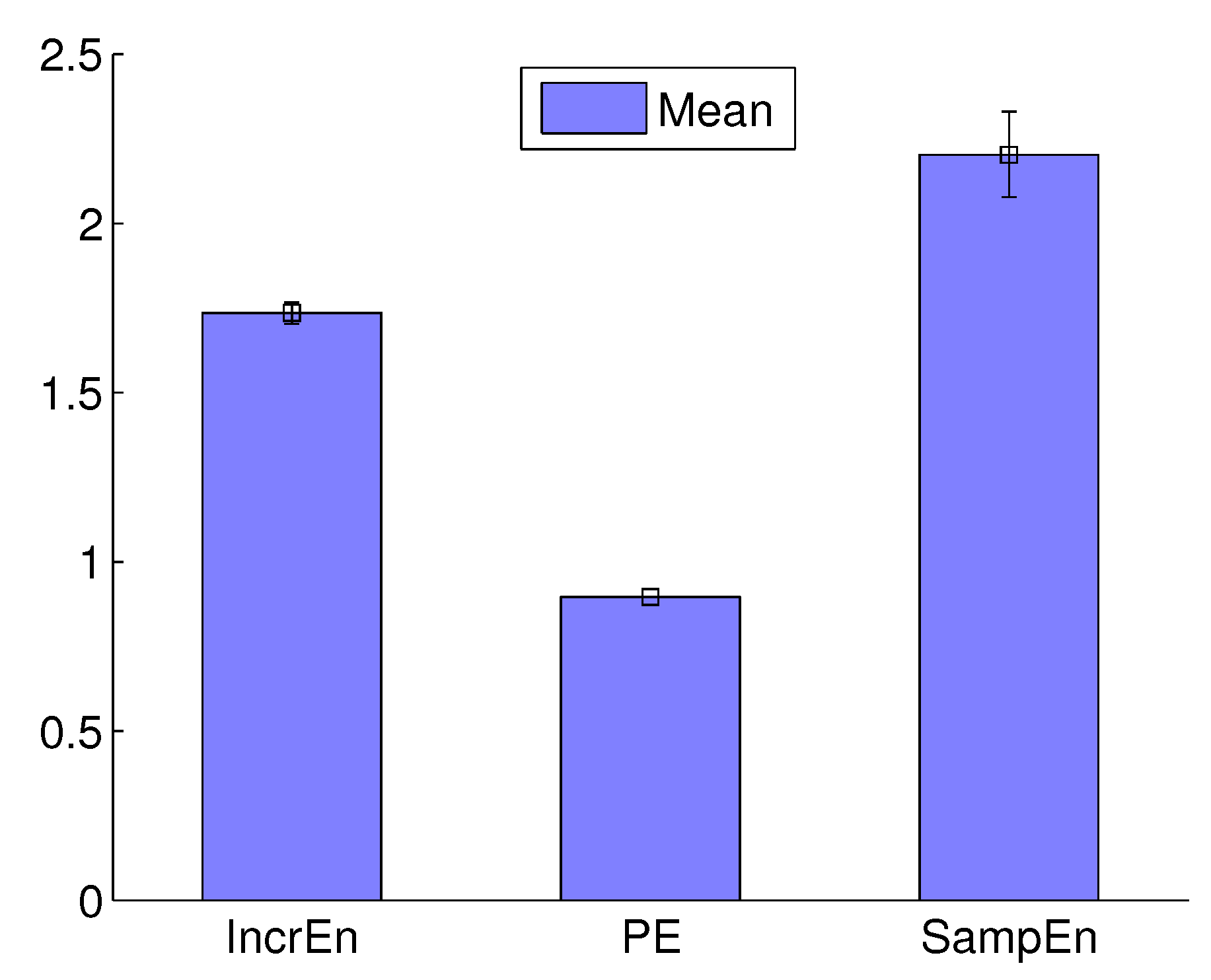
3.2.2. Detecting Energetic Change and Structural Change

| Entropy | Regular | Energetic Mutation | Structural Mutation | |
|---|---|---|---|---|
| IncrEn | 1.3235 ± 0.1380 | 1.3264 ± 0.1372 | 1.3529 ± 0.1378 | |
| 0.6849 ± 0.0379 | 0.6937 ± 0.0387 | 0.7044 ± 0.0388 | ||
| 0.4600 ± 0.0000 | 0.4698 ± 0.0014 | 0.4788 ± 0.0033 | ||
| PE | 0.6367 ± 0.0643 | 0.6367 ± 0.0643 | 0.6386 ± 0.0621 | |
| 0.6271 ± 0.0825 | 0.6275 ± 0.0828 | 0.6397 ± 0.0791 | ||
| 0.4600 ± 0.0000 | 0.4611 ± 0.0031 | 0.4788 ± 0.0033 | ||
| SampEn | 0.0082 ± 0.0577 | 0.0083 ± 0.0577 | 0.0082 ± 0.0577 | |
| 0.0000 ± 0.0000 | 0.0000 ± 0.0000 | 0.0000 ± 0.0000 | ||
| 0.0000 ± 0.0000 | 0.0000 ± 0.0000 | 0.0000 ± 0.0000 | ||
3.2.3. Invariance of IncrEn

3.3. Application to Seizure Detection from EEG Signals


3.4. Application to Bearing Fault Detection by Vibration

4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hornero, R.; Abasolo, D.; Jimeno, N.; Sanchez, C.I.; Poza, J.; Aboy, M. Variability, regularity, and complexity of time series generated by schizophrenic patients and control subjects. IEEE Trans. Biomed. Eng. 2006, 53, 210–218. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez Andino, S.L.; Grave de Peralta Menendez, R.; Thut, G.; Spinelli, L.; Blanke, O.; Michel, C.M.; Landis, T. Measuring the complexity of time series: An application to neurophysiological signals. Hum. Brain Mapp. 2000, 11, 46–57. [Google Scholar] [CrossRef]
- Friston, K.J.; Tononi, G.; Sporns, O.; Edelman, G.M. Characterising the complexity of neuronal interactions. Hum. Brain Mapp. 1995, 3, 302–314. [Google Scholar] [CrossRef]
- Zamora-López, G.; Russo, E.; Gleiser, P.M.; Zhou, C.; Kurths, J. Characterizing the complexity of brain and mind networks. Philos. Trans. R. Soc. Lond. A 2011, 369, 3730–3747. [Google Scholar] [CrossRef] [PubMed]
- Olbrich, E.; Achermann, P.; Wennekers, T. The sleeping brain as a complex system. Philos. Trans. R. Soc. Lond. A 2011, 369, 3697–3707. [Google Scholar] [CrossRef] [PubMed]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale Entropy Analysis of Complex Physiologic Time Series. Phys. Rev. Lett. 2002, 89, 068102. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S.M.; Goldberger, A.L. Physiological time-series analysis: What does regularity quantify? Am. J. Physiol. 1994, 266, H1643–H1656. [Google Scholar] [PubMed]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. 2000, 278, H2039–H2049. [Google Scholar]
- Tononi, G.; Sporns, O.; Edelman, G.M. A measure for brain complexity: Relating functional segregation and integration in the nervous system. Proc. Natl. Acad. Sci. USA 1994, 91, 5033–5037. [Google Scholar] [CrossRef] [PubMed]
- Barnett, W.A.; Medio, A.; Serletis, A. Nonlinear and Complex Dynamics in Economics. Available online: http://econwpa.repec.org/eps/em/papers/9709/9709001.pdf (accessed on 8 January 2016).
- Arthur, W.B. Complexity and the Economy. Science 1999, 284, 107–109. [Google Scholar] [CrossRef] [PubMed]
- Turchin, P.; Taylor, A.D. Complex Dynamics in Ecological Time Series. Ecology 1992, 73, 289–305. [Google Scholar] [CrossRef]
- Boffetta, G.; Cencini, M.; Falcioni, M.; Vulpiani, A. Predictability: A way to characterize complexity. Phys. Rep. 2002, 356, 367–474. [Google Scholar] [CrossRef]
- Lempel, A.; Ziv, J. On the Complexity of Finite Sequences. IEEE Trans. Inf. Theory 1976, 22, 75–81. [Google Scholar] [CrossRef]
- Kolmogorov, A. Logical basis for information theory and probability theory. IEEE Trans. Inf. Theory 1968, 14, 662–664. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Crutchfield, J.P.; Young, K. Inferring statistical complexity. Phys. Rev. Lett. 1989, 63, 105–108. [Google Scholar] [CrossRef] [PubMed]
- Shiner, J.S.; Davison, M.; Landsberg, P.T. Simple measure for complexity. Phys. Rev. E 1999, 59, 1459–1464. [Google Scholar] [CrossRef]
- Pincus, S.M.; Goldberger, A.L. Physiological time-series analysis: What does regularity quantify? Am. J. Physiol. 1994, 266, H1643–H1656. [Google Scholar] [PubMed]
- Porta, A.; Guzzetti, S.; Furlan, R.; Gnecchi-Ruscone, T.; Montano, N.; Malliani, A. Complexity and nonlinearity in short-term heart period variability: Comparison of methods based on local nonlinear prediction. IEEE Trans. Biomed. Eng. 2007, 54, 94–106. [Google Scholar] [CrossRef] [PubMed]
- Lake, D.E.; Richman, J.S.; Griffin, M.P.; Moorman, J.R. Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol. 2002, 283, R789–R797. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, T.; Cho, R.Y.; Mizuno, T.; Kikuchi, M.; Murata, T.; Takahashi, K.; Wada, Y. Antipsychotics reverse abnormal EEG complexity in drug-naive schizophrenia: A multiscale entropy analysis. NeuroImage 2010, 51, 173–182. [Google Scholar] [CrossRef] [PubMed]
- Buzzi, U.H.; Ulrich, B.D. Dynamic stability of gait cycles as a function of speed and system constraints. Mot. Control 2004, 8, 241–254. [Google Scholar]
- Yentes, J.; Hunt, N.; Schmid, K.; Kaipust, J.; McGrath, D.; Stergiou, N. The Appropriate Use of Approximate Entropy and Sample Entropy with Short Data Sets. Ann. Biomed. Eng. 2013, 41, 349–365. [Google Scholar] [CrossRef] [PubMed]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Bandt, C.; Keller, G.; Pompe, B. Entropy of interval maps via permutations. Nonlinearity 2002, 15, 1595–1602. [Google Scholar] [CrossRef]
- Cao, Y.; Tung, W.W.; Gao, J.; Protopopescu, V.; Hively, L. Detecting dynamical changes in time series using the permutation entropy. Phys. Rev. E 2004, 70, 046217. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Zhang, J.; Small, M. Superfamily phenomena and motifs of networks induced from time series. Proc. Natl. Acad. Sci. USA 2008, 105, 19601–19605. [Google Scholar] [CrossRef] [PubMed]
- Staniek, M.; Lehnertz, K. Symbolic transfer entropy. Phys. Rev. Lett. 2008, 100, 158101. [Google Scholar] [CrossRef] [PubMed]
- Olofsen, E.; Sleigh, J.; Dahan, A. Permutation entropy of the electroencephalogram: A measure of anaesthetic drug effect. Br. J. Anaesth. 2008, 101, 810–821. [Google Scholar] [CrossRef] [PubMed]
- Zunino, L.; Zanin, M.; Tabak, B.M.; Pérez, D.G.; Rosso, O.A. Forbidden patterns, permutation entropy and stock market inefficiency. Physica A 2009, 388, 2854–2864. [Google Scholar] [CrossRef]
- Hornero, R.; Abásolo, D.; Escudero, J.; Gómez, C. Nonlinear analysis of electroencephalogram and magnetoencephalogram recordings in patients with Alzheimer’s disease. Philos. Trans. R. Soc. A 2009, 367, 317–336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, X.F.; Wang, Y. Fine-grained permutation entropy as a measure of natural complexity for time series. Chin. Phys. B 2009, 18, 2690–2695. [Google Scholar]
- Ruiz, M.D.C.; Guillamón, A.; Gabaldón, A. A new approach to measure volatility in energy markets. Entropy 2012, 14, 74–91. [Google Scholar] [CrossRef]
- Zanin, M.; Zunino, L.; Rosso, O.A.; Papo, D. Permutation entropy and its main biomedical and econophysics applications: A review. Entropy 2012, 14, 1553–1577. [Google Scholar] [CrossRef]
- Fadlallah, B.; Chen, B.; Keil, A.; Principe, J. Weighted-permutation entropy: A complexity measure for time series incorporating amplitude information. Phys. Rev. E 2013, 87, 022911. [Google Scholar] [CrossRef] [PubMed]
- Bian, C.; Qin, C.; Ma, Q.D.; Shen, Q. Modified permutation-entropy analysis of heartbeat dynamics. Phys. Rev. E 2012, 85, 021906. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.F.; Yu, W.L. A symbolic dynamics approach to the complexity analysis of event-related potentials. Acta Phys. Sin. 2008, 57, 2587–2594. [Google Scholar]
- Daw, C.S.; Finney, C.E.A.; Tracy, E.R. A review of symbolic analysis of experimental data. Rev. Sci. Instrum. 2003, 74, 915–930. [Google Scholar] [CrossRef]
- Marston, M.; Hedlund, G.A. Symbolic Dynamics. Am. J. Math. 1938, 60, 815–866. [Google Scholar]
- Marston, M.; Hedlund, G.A. Symbolic Dynamics II. Sturmian Trajectories. Am. J. Math. 1940, 62, 1–42. [Google Scholar] [CrossRef]
- Graben, P.B.; Saddy, J.D.; Schlesewsky, M.; Kurths, J. Symbolic dynamics of event-related brain potentials. Phys. Rev. E 2000, 62, 5518–5541. [Google Scholar] [CrossRef]
- Ashkenazy, Y.; Ivanov, P.; Havlin, S.; Peng, C.; Goldberger, A.; Stanley, E. Magnitude and sign correlations in heartbeat fluctuations. Phys. Rev. Lett. 2001, 86, 1900–1903. [Google Scholar] [CrossRef] [PubMed]
- CHB-MIT Scalp EEG Database. Available online: http://www.physionet.org/pn6/chbmit/ (accessed on 8 January 2016).
- Shoeb, A.; Edwards, H.; Connolly, J.; Bourgeois, B.; Ted Treves, S.; Guttag, J. Patient-specific seizure onset detection. Epilepsy Behav. 2004, 5, 483–498. [Google Scholar] [CrossRef] [PubMed]
- Shoeb, A.H.; Guttag, J.V. Application of machine learning to epileptic seizure detection. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 975–982.
- Diambra, L.; de Figueiredo, J.C.B.; Malta, C.P. Epileptic activity recognition in EEG recording. Phys. A Stat. Mech. Appl. 1999, 273, 495–505. [Google Scholar] [CrossRef]
- Bearing Data Center. Available online: http://csegroups.case.edu/bearingdatacenter/home (accessed on 8 January 2016).
- Ke, D.-G. Unifying Complexity and Information. Sci. Rep. 2013, 3. [Google Scholar] [CrossRef] [PubMed]
- Grassberger, P. Toward a quantitative theory of self-generated complexity. Int. J. Theor. Phys. 1986, 25, 907–938. [Google Scholar] [CrossRef]
- Crutchfield, J.P. Between order and chaos. Nat. Phys. 2012, 8, 17–24. [Google Scholar] [CrossRef]
- Srinivasan, V.; Eswaran, C.; Sriraam, N. Approximate Entropy-Based Epileptic EEG Detection Using Artificial Neural Networks. IEEE Trans. Inf. Technol. Biomed. 2007, 11, 288–295. [Google Scholar] [CrossRef] [PubMed]
- Kannathal, N.; Choo, M.L.; Acharya, U.R.; Sadasivan, P. Entropies for detection of epilepsy in EEG. Comput. Methods Programs Biomed. 2005, 80, 187–194. [Google Scholar] [CrossRef] [PubMed]
- Lesne, A.; Blanc, J.L.; Pezard, L. Entropy estimation of very short symbolic sequences. Phys. Rev. E 2009, 79, 046208. [Google Scholar] [CrossRef] [PubMed]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Jiang, A.; Xu, N.; Xue, J. Increment Entropy as a Measure of Complexity for Time Series. Entropy 2016, 18, 22. https://doi.org/10.3390/e18010022
Liu X, Jiang A, Xu N, Xue J. Increment Entropy as a Measure of Complexity for Time Series. Entropy. 2016; 18(1):22. https://doi.org/10.3390/e18010022
Chicago/Turabian StyleLiu, Xiaofeng, Aimin Jiang, Ning Xu, and Jianru Xue. 2016. "Increment Entropy as a Measure of Complexity for Time Series" Entropy 18, no. 1: 22. https://doi.org/10.3390/e18010022
APA StyleLiu, X., Jiang, A., Xu, N., & Xue, J. (2016). Increment Entropy as a Measure of Complexity for Time Series. Entropy, 18(1), 22. https://doi.org/10.3390/e18010022