1. Introduction
Shannon’s information theory [
1] has contributed to the development of communication and storage systems in which sequences can be compressed up to the entropy of the source assuming that the sender and receiver know the probability of each sequence. In the 30 years since its birth, information theory has developed such that sequences can be compressed without sharing the associated probability (universal coding): the probability of each future sequence can be learned from the past sequence such that the compression ratio of the total sequence converges to its entropy.
Mutual information is a quantity that can be used to analyze the performances of encoding and decoding in information theory, and its value expresses the dependency of two random variables and is nonnegative (that is, zero) if and only if they are independent. Mutual information can be estimated from actual sequences. In this paper, we construct an estimator of the mutual information based on the minimum description length (MDL) principle [
2] such that the estimator is zero if and only if the two variables are independent for long sequences.
In any science, a law is determined based on experiments: the law should be simple and explain the experiments. Suppose that we generate pairs of a rule and its exceptions for the experiments and describe the pairs using universal coding. Then, the MDL principle chooses the rule of the pair that has the shortest description length (the number of bits) as the scientific law: the simpler the rule is, the more exceptions there are. In our situation, two variables may be either independent or dependent, and we compute the values of the corresponding description lengths to choose one of them based on which length is shorter. We estimate mutual information based on the difference between the description length values assuming that the two variables are independent and dependent, divided by the original sequence length n.
Let X and Y be discrete random variables. Suppose that we have examples and that we wish to know whether X and Y are independent, denoted as , not knowing the distributions , and of X, Y and , respectively.
One way of approaching this problem would be to estimate the correlation coefficient
of
to determine whether it is close to zero. Although the notions of independence and correlation are close, simply because
does not mean that
X and
Y are independent. For example, let
X and
U be mutually independent variables with a standard Gaussian distribution and
with probability 0.5, respectively, and let
. Apparently,
X and
Y are not independent, but note that
,
,
, and
which means that
For this problem, we know that the mutual information defined by
satisfies
Thus, it is sufficient to estimate to determine whether it is positive.
Given
and
, one might estimate
by plugging in the frequencies
,
, and
of
,
, and
divided by
n into
,
, and
, respectively, to obtain the quantity
However, we observe that
even when
for large values of
n. In fact, since Equation (
1) is the Kullback-Leibler divergence between
and
, we have
, and
if and only if
for all
, which does not hold infinitely many times with a positive probability, even when
. Thus, we need to guess
when
is small, say when
for some appropriate function of
n:
Nobody was certain that such a function of sample size n exists.
In 1993, Suzuki [
3] identified such a function
δ and proposed a new mutual information estimator
such that
for large
n based on the minimum description length (MDL) principle. The exact form of function
δ is presented in
Section 2. In this paper, we consider an extension of the estimation
of mutual information
for a case where
X and
Y may be continuous.
There are many ways of estimating mutual information for continuous variables. If we assume that
X and
Y are Gaussian, then the mutual information is expressed by
and we can show that
for large
n, where
is the maximum likelihood estimator of
. However, the equivalence only holds for Gaussian variables.
For general settings, several mutual information estimators are available, such as kernel density-based estimators [
4], k-nearest neighbors [
5,
6], and other estimators based on quantizers [
7]. In general, the kernel-based method requires an extraordinarily large computational effort to test for independence. To overcome this problem, efficient estimators have been proposed, such as one that completes the test in
time [
5]. However, correctness, such as consistency, is required and has a higher priority than efficiency. Although some of these methods converge to the correct value
for large
n in
time [
7], the estimation values are positive with nonzero probability for large
n when
X and
Y are independent (
).
Currently, the construction of nonlinear alternatives of
to test for independence between
X and
Y by using positive definite kernels is becoming popular. In particular, a quantity known as the
Hilbelt-Schmidt independence criterion (HSIC) [
8], which is defined in
Section 2, is extensively used for independence testing. It is known that the HSIC value
depends on the kernels
k and
l w.r.t. the ranges of
X and
Y, and
if the kernel pair
is chosen properly. In this paper, we assume that we always use such a kernel pair and denote
simply by
. For the estimation of
given
and
, the most popular estimator
of
, which is defined in
Section 2, always takes positive values, and given a significance level of
(typically,
), we need to obtain
such that the decision
is as accurate as possible.
In this paper, we propose a new estimator
of mutual information. This new estimator quantizes the two-dimensional Euclidean space
of
X and
Y into
bins for
. For each value of
u that indicates a histogram, we obtain the estimation
of mutual information for discrete variables. The maximum value of
over
is the final estimation. We prove that the optimal value of
u is at most
. In particular, the proposed method divides
without distinguishing between discrete and continuous data, and it satisfies Equation (
3).
Then, we experimentally compare the proposed estimator of with the estimator of HSIC in terms of independence testing. Although we obtained several insights, we could not obtain confirmation that one of the estimators outperforms the other. However, we found that the HSIC only considers the magnitude of the data and would fail to detect relations among the data that cannot be identified by simply observing the changes in magnitude. We present two examples for which the HSIC fails to detect the dependencies among and due to the aforementioned limitation. The proposed estimation procedure completes the computation in time, whereas the HSIC requires time. In this sense, the proposed method based on mutual information would be useful in many situations.
The remainder of this paper is organized as follows.
Section 2 provides the background for the work presented in this paper, and
Section 2.1 and
Section 2.2 explain the mutual information and HSIC estimations, respectively.
Section 3 presents the contributions of this paper, and
Section 3.1 proposes the new algorithm for estimating mutual information.
Section 3.2 mathematically proves the merits of the proposed method, and
Section 3.3 presents the results of the preliminary experiments.
Section 4 presents the results of the experiments using the R language to compare the performance in terms of independence testing for the proposed estimator of mutual information and its HSIC counterpart.
Section 5 summarizes the contributions and discusses opportunities for future work.
Throughout the paper, the base two logarithm is assumed unless specified otherwise.
4. Application to Independence Tests
We conducted experiments using the R language, and we obtained evidence that supports the “No Free Lunch” theorem [
15] for independence tests: no single independence test is capable of outperforming all the other tests. The proposed and HSIC methods require
and
time, respectively, to perform the computation; thus, the former is considerably faster than the latter, particularly for large values of
n.
For the HSIC method, we used the Gaussian kernel [
8]
with
for both
and
. We set the significance level
α to be 0.05. To compute the threshold
such that we decide
if and only if
, because only
and
are available, this requires us to repeatedly and randomly reorder
to generate mutually independent
and
such that we can simulate the null hypothesis. However, this process is time-consuming for our experiments, and we generate mutually independent pairs
and
to compute
200 times to estimate the distribution of
under the null hypothesis and the 95 percentile point
.
For the proposed method, we set the prior probability of to be 0.5.
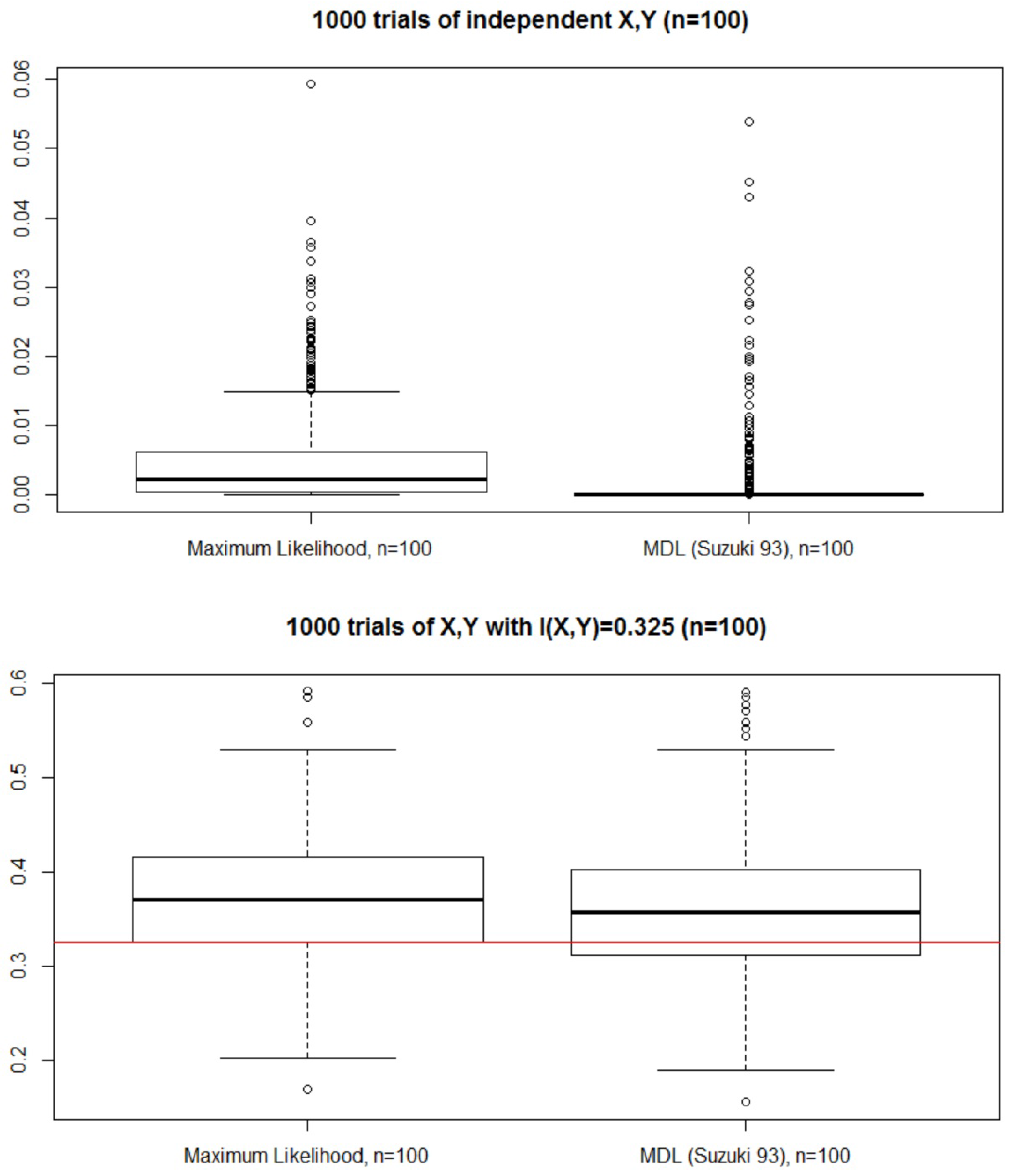
4.1. Binary and Gaussian Sequences
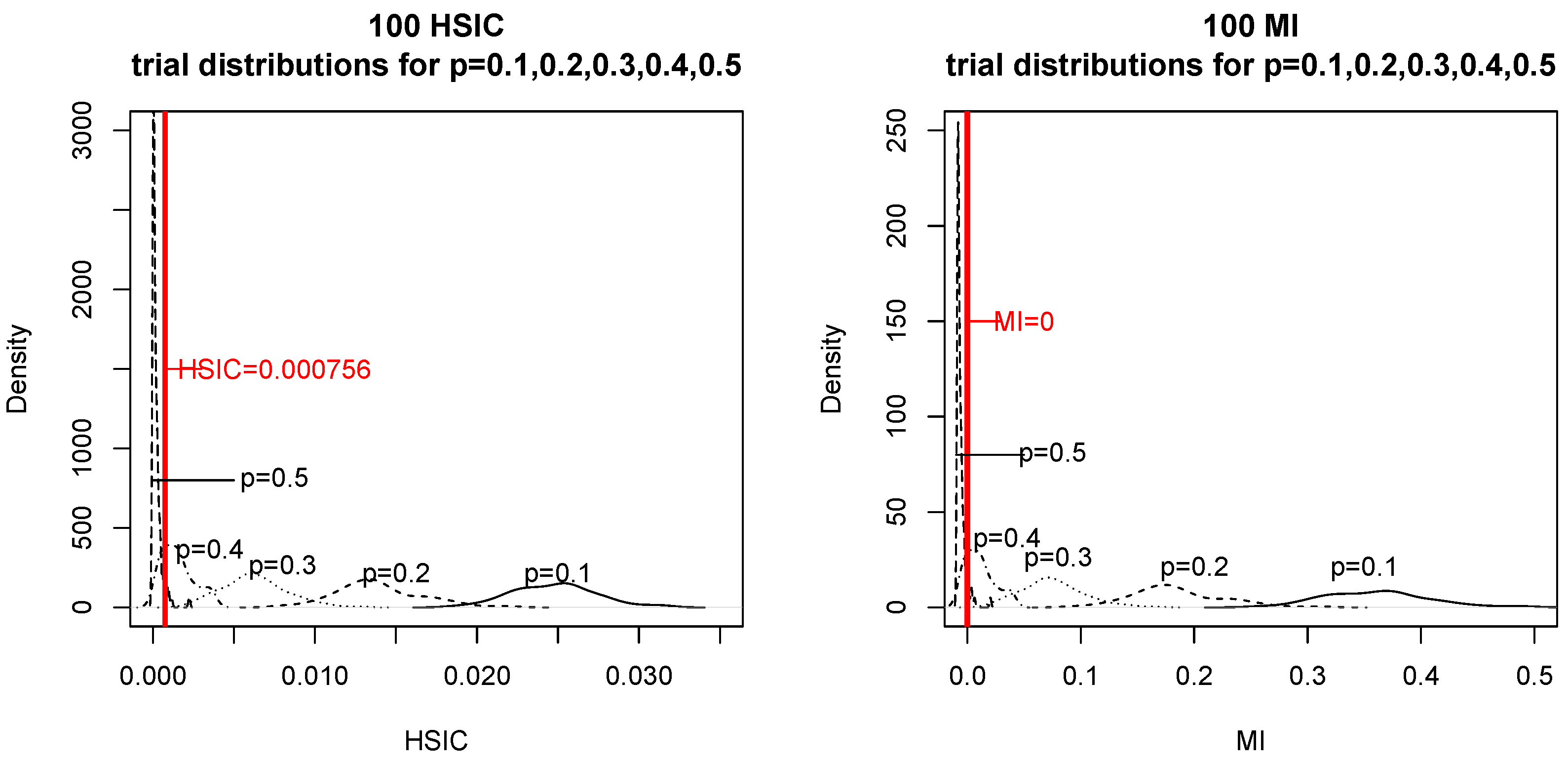
First, we generated mutually independent binary X and U, with the probabilities of and being 0.5 and , respectively, to obtain mod 2. When we simulated the null hypothesis, we generated in the same way as that used for generating . We computed and 100 times for and .
The obtained results are presented in
Figure 5. For each
p and
, we depict the distributions of
and
in the plots on the left and right, respectively. If the data occur to the left of the red vertical line, then the tests consider
and
to be independent. In particular, for
(
) and
(
X ![Entropy 18 00109 i001]() Y
Y), we counted how many times the two tests chose
and
X ![Entropy 18 00109 i001]() Y
Y (see
Table 1).
We could not find any significant difference in the correctness of testing for the two tests.
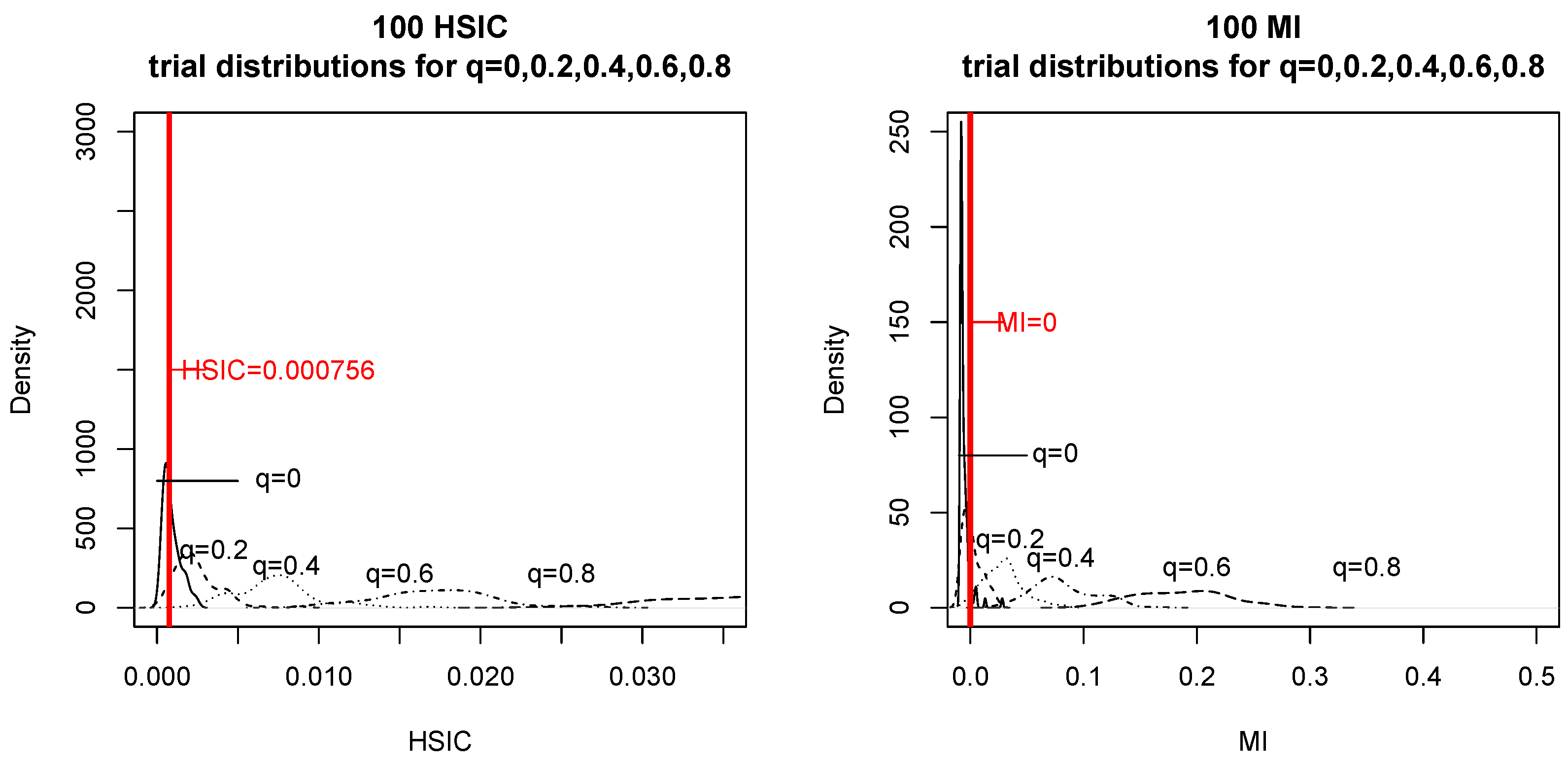
Next, we generated mutually independent Gaussian X and U with mean zero and variance one, and for . When we simulated the null hypothesis, we generated in the same way as that used for generating . We computed and 100 times for and .
The obtained results are presented in
Figure 6. For each
q and
, we depict the distributions of
and
on the left and right, respectively. If the data occur to the left of the red vertical line, then the tests consider
and
to be independent. In particular, for
(
) and
(
X ![Entropy 18 00109 i001]() Y
Y), we counted how many times the two tests chose
and
X ![Entropy 18 00109 i001]() Y
Y (see
Table 2).
We could not find any significant difference in the correctness of testing between the two tests.
4.2. When is the Proposed Method Superior?
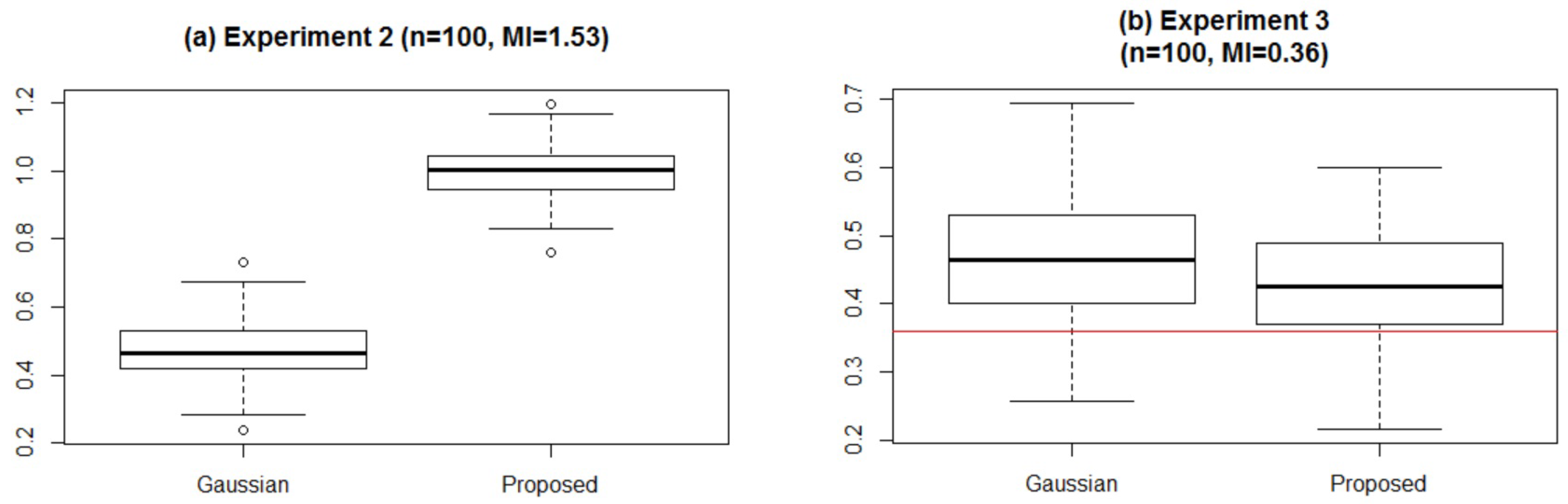
We found two cases in which the proposed method outperforms the HSIC:
X and U are mutually independent and follow the Gaussian distribution with mean 0 and variance 0.25, and , where is the rounded integer of x ( = 1) (ROUNDING).
X takes a value in uniformly and Y takes a value in either or uniformly depending on the value of X such that is an even number (INTEGER).
We refer to the two problems as ROUNDING and INTEGER, respectively. Apparently, the answers to both of these are that are not independent, although the correlation coefficient is zero.
Table 3 shows the number of times the tests chose
and
X ![Entropy 18 00109 i001]() Y
Y for the experiments. We observed that the HSIC failed to detect dependencies for both of the problems, whereas the proposed method successfully found
X and
Y to not be independent.
The obvious reason appears to be that the HSIC simply considers the magnitudes of . For the ROUNDING problem, are independent for the integer parts, but the fractional parts are related. However, when using HSIC, because the integer part contributes to the score considerably more than the fractional part, the HSIC cannot detect the relation between the whole parts.
The same reasoning can be applied to the INTEGER problem. In fact, the values of and are independent, where denotes the largest integer not exceeding x. However, the relation mod 2 always holds, and this cannot be detected by the HSIC.
Note that we do not claim that the proposed method is always superior to the HSIC. Admittedly, for many problems, the HSIC performs better. For example, for typical problems such as
- 3
X and U follow the standard Gaussian and binary (probability 0.5) distributions, and (ZERO-COV),
we find that the HSIC offers more advantages (see
Table 4).
We rather claim that no single independence test outperforms all the others.
4.3. Execution Time
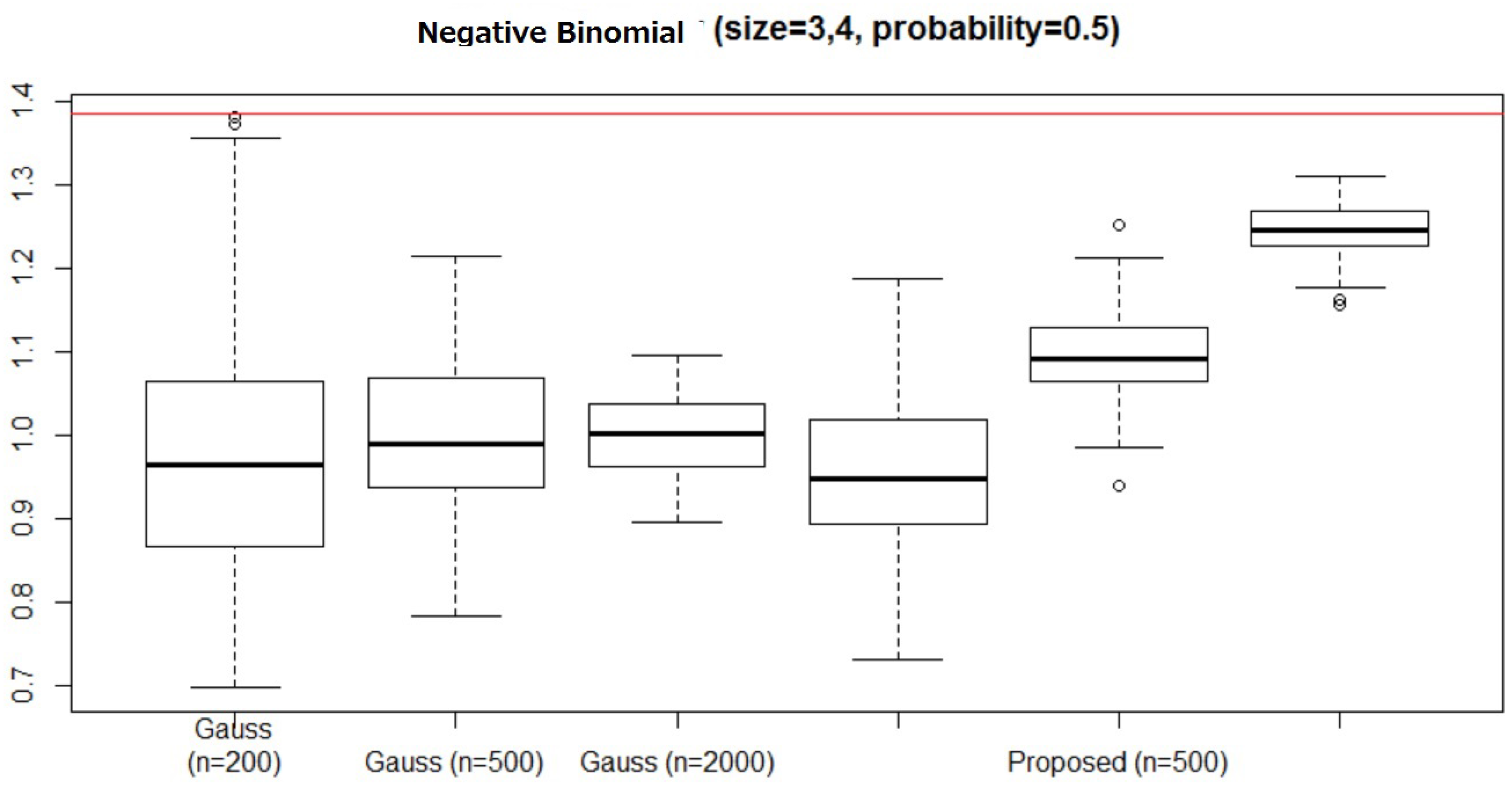
We compare the execution times for the Gaussian sequences.
Table 5 lists the average execution times for
, and 2000 and
(the results were almost identical for the other values of
q).
We find that the proposed method is considerably faster than the HSIC, particularly for large n. This result occurs because the proposed method requires time for the computation, whereas the HSIC requires time. Although the HSIC estimator might detect some independence for large n because of its (weak) consistency, it appears that the HSIC is not efficient for large n. Because the HSIC requires the null hypothesis to be simulated, a considerable amount of additional computation would be required.
5. Concluding Remarks
We proposed an estimator of mutual information and demonstrated the effectiveness of the algorithm in solving the independence testing problem.
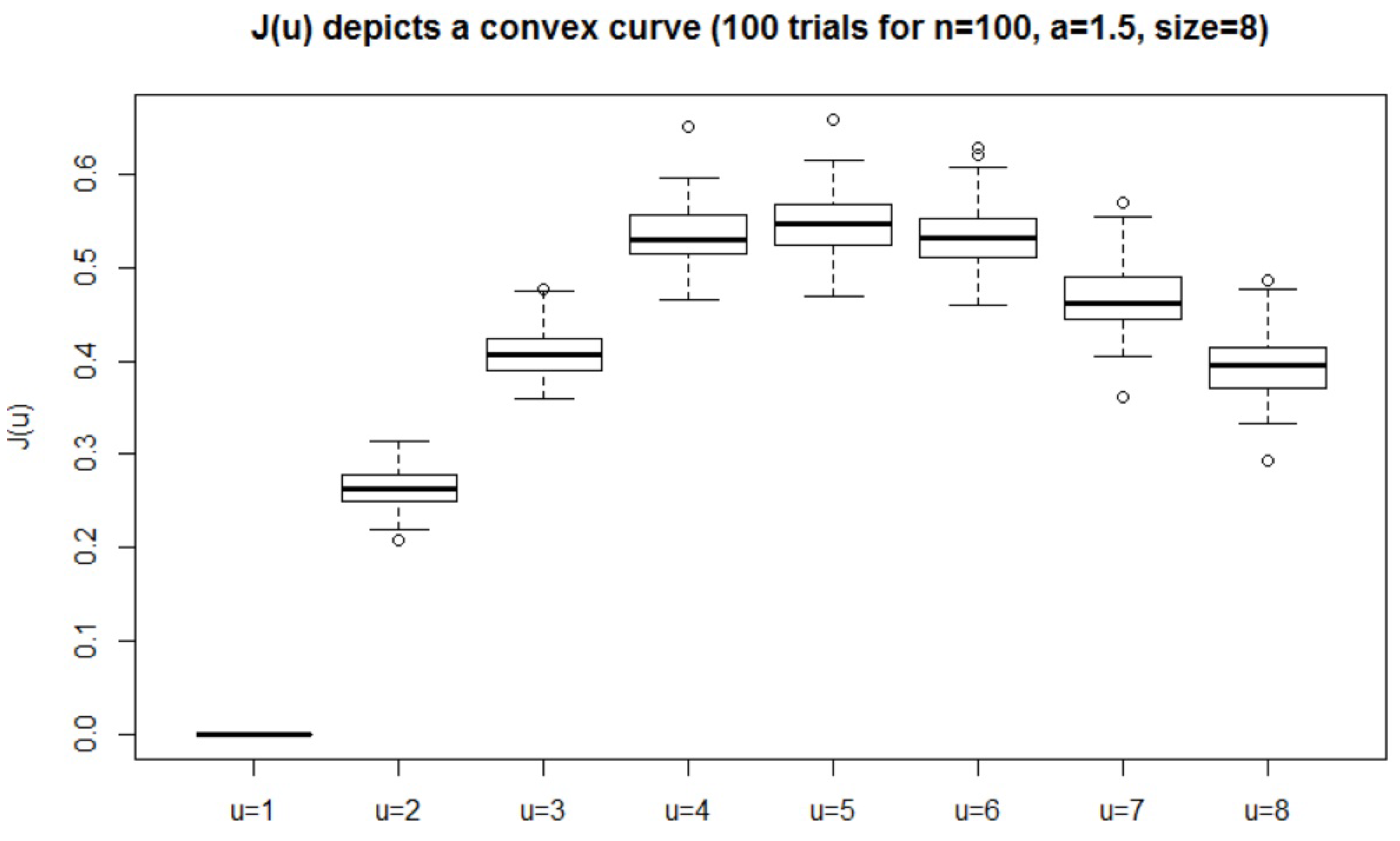
Although estimating mutual information of continuous variables was considered to be difficult, the proposed estimator was shown to detect independence for a large sample size if and only if the two variables are independent. The estimator constructs many histograms of size , estimates their mutual information , and chooses the one with the maximum value over . We find that the optimal u has an upper bound of . The proposed algorithm requires time to perform the computation.
Then, we compared the performance of our proposed estimator with that of the HSIC estimator, de facto for the independence testing principle. The two methods differ in that the proposed method is based on the MDL principle given data , although the HSIC detects abnormalities assuming the null hypothesis given the data. We could not obtain a definite answer to enable us to determine which method is superior for general settings; rather, we obtained evidence that no single statistical test outperforms all the others for all problems. In fact, although HSIC will clearly be superior when certain specific dependency structures form the alternative hypothesis, the proposed estimator is more universal.
One meaningful insight obtained is that the HSIC only considers the magnitude of the data and neglects to find relations that cannot be detected by simply considering the changes in magnitude.
The most notable merit of the proposed algorithm compared to the HSIC is its efficiency. The HSIC requires computational time for one test. However, prior to the test, it is necessary to simulate the null hypothesis and set the threshold such that the algorithm determines that the data are independent if and only if the HSIC values do not exceed the threshold. In this sense, executing the HSIC would be time-consuming, and it would be safe to say that the proposed algorithm is useful for designing intelligent machines, whereas the HSIC is appropriate for scientific discovery.
In future work, we will consider exactly when the proposed method exhibits a particularly good performance.
Moreover, we should address the question of how generalizations to three dimensions might work. In this paper, it is not clear whether one would want to estimate some form of total independence such as
or conditional mutual information such as
. In fact, for Bayesian network structure learning (BNSL), we need to compute Bayesian scores of conditional mutual information from the data to apply a standard scheme of BNSL based on dynamic programming [
16]. Currently, a constraint-based approach for estimating conditional mutual information values using positive definite kernels is available [
17], but no theoretical guarantee, such as consistency, is obtained by the method.



 Y), we counted how many times the two tests chose and X
Y), we counted how many times the two tests chose and X 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}