
Understanding Gating Operations in Recurrent Neural Networks through Opinion Expression Extraction


Abstract
:
1. Introduction
- Zuma also [pledged]DSE continued support for Zimbabwe and its people.
- She [congratulated]DSE him on his re-election.
- The South African government [was happy]DSE with the SAOM report.
- Now [all eyes are on]ESE this issue.
- I [can never forget]DSE what I saw that day [as long as I live]ESE
- The detainees [should]ESE be treated [as] prisoners of war according to international law.
- To our knowledge, this is the first work that introduces long short-term memory into the task of sentiment expression extraction.
- We explore various structures (deep form, bidirectional form) of the network and achieve new state-of-the-art performance on the task.
- Unlike previous works treating the networks as black boxes, we explore a new perspective to analyze the micro activations at run-time to understand the internal mechanisms.
- Not restricted to existing researches emphasizing LSTM getting rid of the vanishing gradient problem, we firstly discuss the cooperation mechanisms of Constant Error Carousel (CEC), connection weights and multiplicative gates during information source selection through statistical experiments.
2. Related Works
2.1. Opinion Expression Extraction
2.2. Interpretability of Long Short-Term Memory
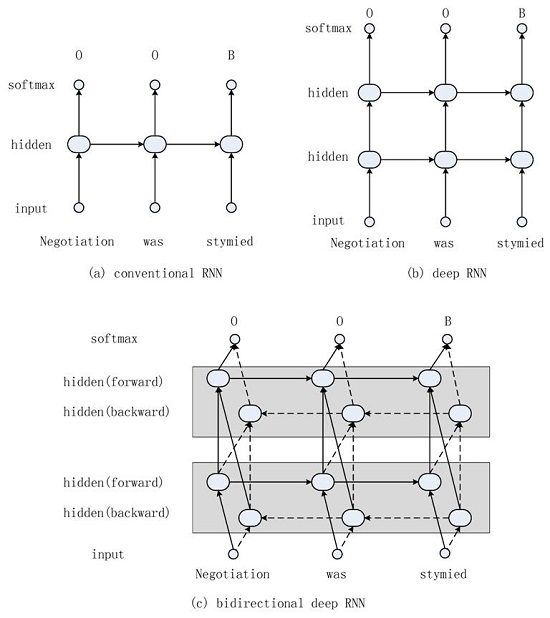
3. Extraction Methodology
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Baseline Methods
- Wiebe lexicon and Wilson lexicon: Breck et al. report the performances of lexicon-based unsupervised methods on this task [8]. They leverage two dictionaries of subjectivity clues (words and phrases that may be used to express private states). One is collected by Wiebe and Riloff [27], and the other one is compiled by Wilson et al. [28]. An expression is considered as a subjective one if it matches some item in the dictionary.
- CRF: Breck et al. addressed the task with conditional random fields. Bag-of-words features, syntactic features, such as Part-of-Speech (POS) tags, and semantic features, such as the WordNet lexicon, are exploited in their work [8].
- Semi-CRF: Yang and Cardie introduce parser results to get reliable segments for semi-Markov CRF. Segment-level features, such as syntactic categories or the polarities of words in the verb phrases, are involved to capture the context information [10].
- +vec: İrsoy and Cardie report the performance of CRF and semi-CRF using word vectors as additional features [2]. CRF takes the word-level embeddings as features, while semi-CRF uses the mean value of word embeddings in the segment.
- Bi-RNN: We take bidirectional deep Elman-type RNN as one of our baselines, which is the state-of-the-art performer on the opinion expression extraction [2].
- Self-training: We implement a self-training system based on bi-RNN, which is a strong semi-supervised baseline. The softmax layer outputs the probabilities of the three tags, and we take the highest one as the confidence level of the token. The confidence of a sentence is the mean confidences of all tokens in it. The top 200 sentences with the highest confidence are selected as additional training samples in the next iteration.
- Joint-Loss: The joint inference approach with a probability-based objective function achieves remarkable performance [14]. To compare to their work, we test the LSTM approach in their settings.
4.5. Comparison with Feature-Engineering Methods
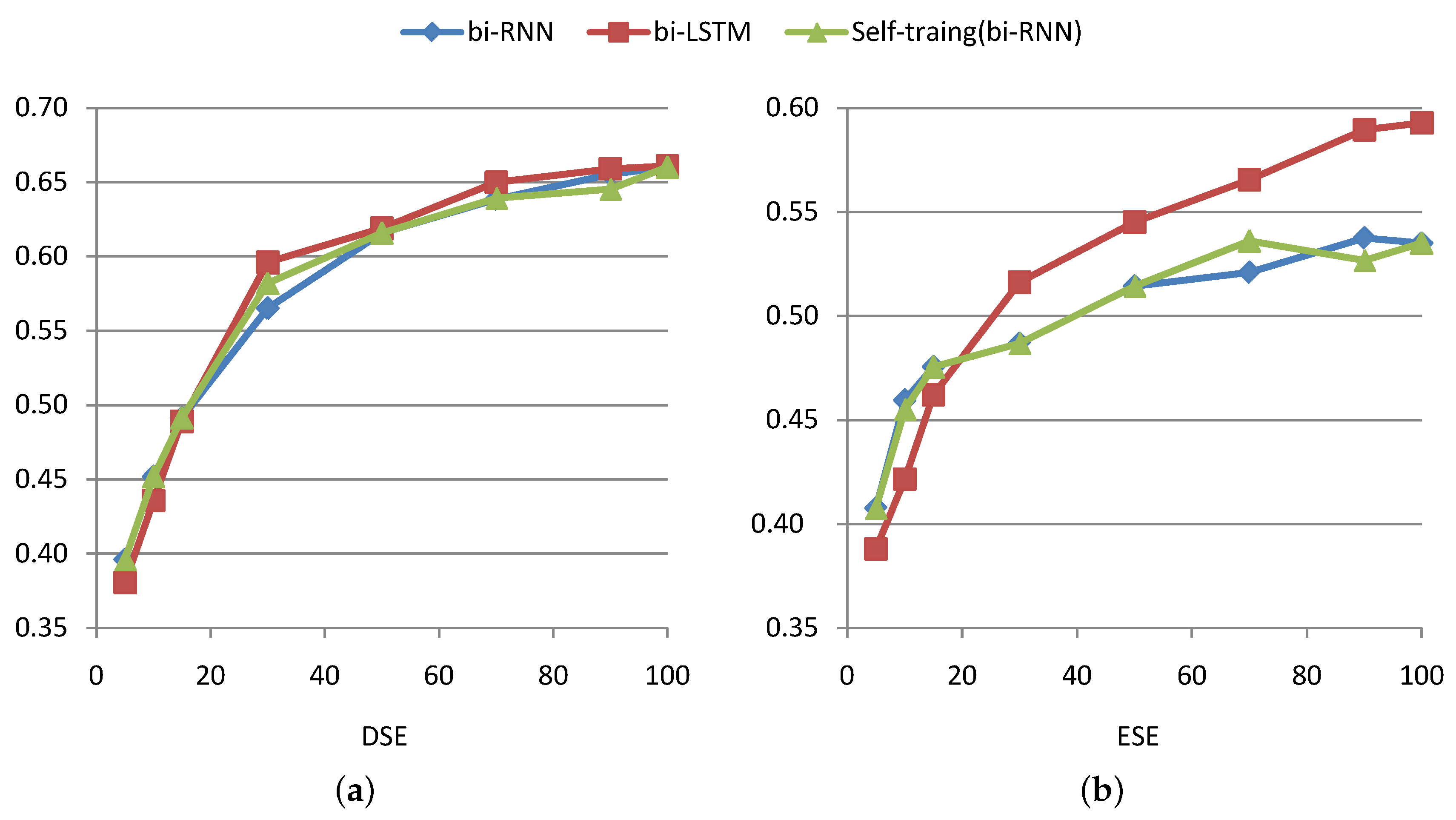
4.6. Comparison with Unsupervised and Semi-Supervised Approaches
4.7. Comparison with the Elman Network
4.8. Network Parameters
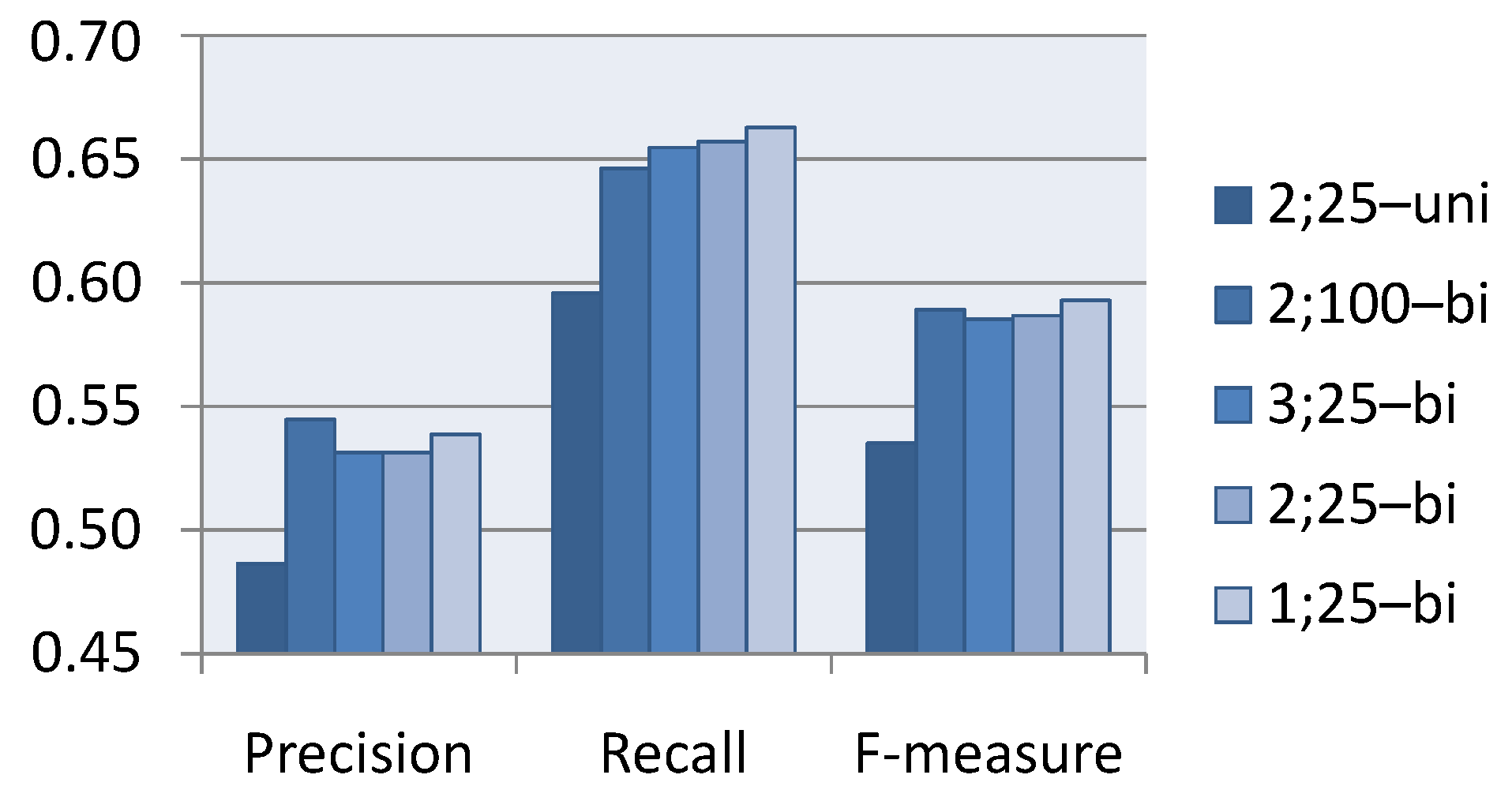
- Hidden size : Experimentally, LSTM networks with 25 blocks in the hidden layer, producing better results (about by 1%) compared to those with 100 hidden blocks; while the situation is opposite in the Elman network. This suggests that LSTM blocks with multiplicative gates provide more flexible compositional functions, even with a smaller hidden size.
- Depth of networks: Networks with 1–3 hidden layers produce a similar precision, recall and F-value. Different depths lead to variation by less than 0.7%, and the one hidden layer shallow form performs best. This indicates that the LSTM units have the capacity to simulate a complex composition that SRNN could only accommodate with deep cascaded nonlinearities.
- Directionality: Bidirectional networks outperform unidirectional networks by 6.2% on DSE and by 5.2% on ESE. We see that bidirectional LSTMs get access to the future words and provide more context information.
5. Interpretable Analysis
5.1. Finding Improved Patterns
5.1.1. Motivation for Finding Improved Cases
5.1.2. Significance Test on the Difference of Single-Word Pattern Predicting
5.2. Comparison of the Context Adaptability of Recurrent Models
5.2.1. Context Dependence of Tags of the Word “as”
5.2.2. Experiment about Context Adaptability
- Contiguous interaction: the tag of FA is influenced by the later word. For instance, FA followed by an adjective or adverb (e.g., as quickly) tends to be part of opinion expression, while FA followed by a noun (e.g., as China) is not. We would like to explore whether LSTM and SRNN are sensitive to this difference.
- Divorced interaction: the tag of FA is influenced by words that are not directly adjoined. For instance, in the phrases “as ... as” and “as ... said”, the labels of FAs should be predicted differently. We will show how LSTM and SRNN could accommodate the different situations.
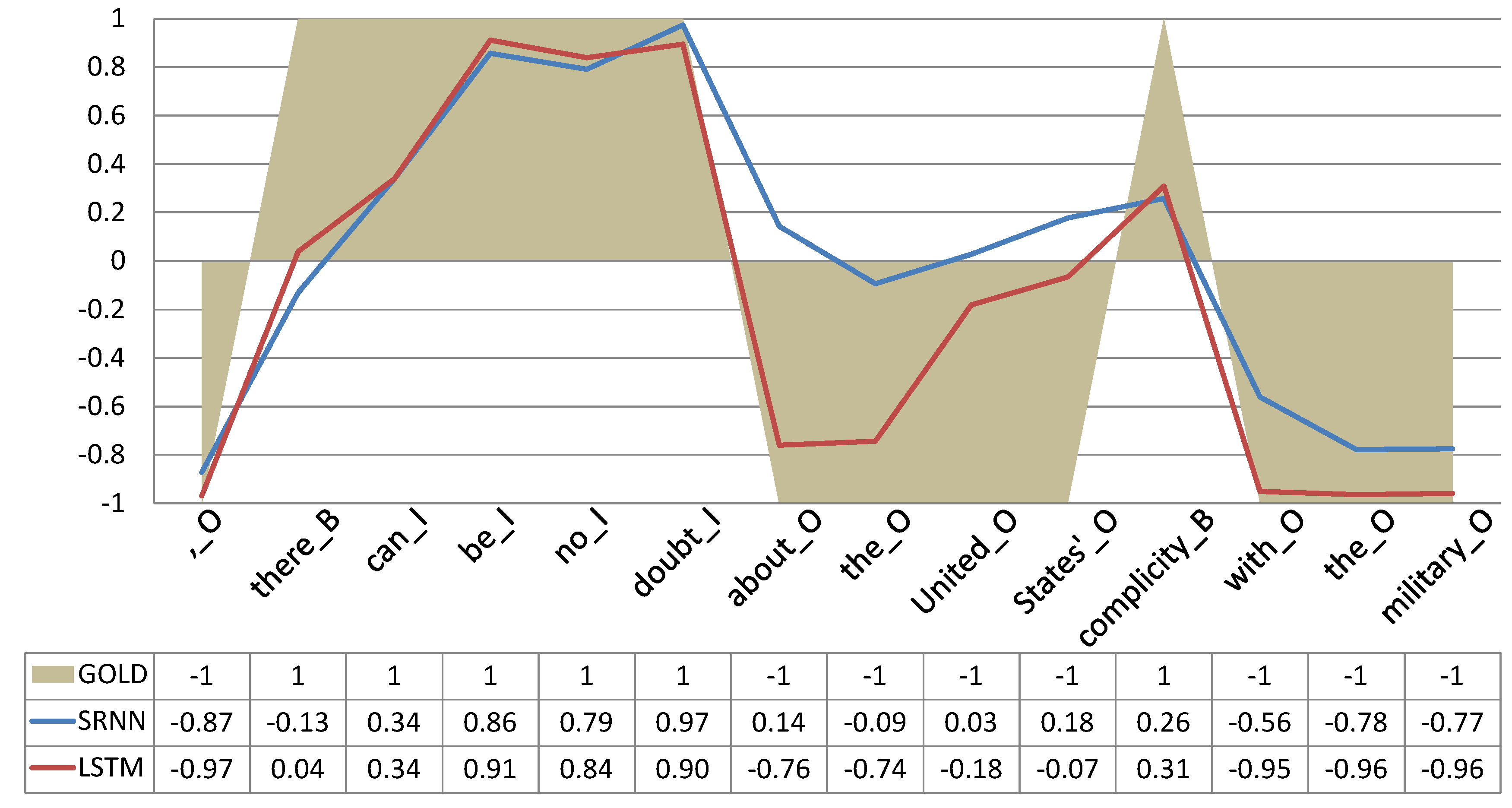
5.2.3. Visualization of the Internal Activations of LSTM
5.3. Internal Analysis: Gating Selection of Information
5.3.1. Motivation of the Analyzing Internal Mechanism of LSTM
5.3.2. Finding Determinant of Context Sensitivity
5.3.3. Independence of Current and Previous Signals in LSTM
5.3.4. Information Selection in “as” Phrases
5.4. Forget at the Boundary
5.5. Source of the Advantages of LSTM
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wiebe, J.; Wilson, T.; Cardie, C. Annotating expressions of opinions and emotions in language. Lang. Resour. Eval. 2005, 39, 165–210. [Google Scholar] [CrossRef]
- İrsoy, O.; Cardie, C. Opinion mining with deep recurrent neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 720–728.
- Socher, R.; Perelygin, A.; Wu, J.Y.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642.
- İrsoy, O.; Cardie, C. Modeling compositionality with multiplicative recurrent neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015.
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F. Long Short-Term Memory in Recurrent Neural Networks. Ph.D. Thesis, Universität Hannover, Hannover, Germany, 2001. [Google Scholar]
- Choi, Y.; Breck, E.; Cardie, C. Joint extraction of entities and relations for opinion recognition. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydeny, Australia, 22–23 July 2006; pp. 431–439.
- Breck, E.; Choi, Y.; Cardie, C. Identifying expressions of opinion in context. IJCAI 2007, 7, 2683–2688. [Google Scholar]
- Johansson, R.; Moschitti, A. Syntactic and semantic structure for opinion expression detection. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning, Uppsala, Sweden, 15–16 July 2010; pp. 67–76.
- Yang, B.; Cardie, C. Extracting opinion expressions with semi-markov conditional random fields. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 1335–1345.
- Choi, Y.; Cardie, C. Hierarchical sequential learning for extracting opinions and their attributes. In Proceedings of Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 269–274.
- Johansson, R.; Moschitti, A. Extracting opinion expressions and their polarities—Exploration of pipelines and joint models. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 2, pp. 101–106.
- Johansson, R.; Moschitti, A. Relational features in fine-grained opinion analysis. Comput. Linguist. 2013, 39, 473–509. [Google Scholar] [CrossRef]
- Yang, B.; Cardie, C. Joint modeling of opinion expression extraction and attribute classification. Trans. Assoc. Comput. Linguist. 2014, 2, 505–516. [Google Scholar]
- Yang, B.; Cardie, C. Joint Inference for Fine-grained Opinion Extraction. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 1640–1649.
- Liu, P.; Joty, S.; Meng, H. Fine-grained opinion mining with recurrent neural networks and word embeddings. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015.
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2342–2350.
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. 2015; arXiv:1503.04069. [Google Scholar]
- Elman, J.L. Finding structure in time. Cognit. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649.
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 1556–1566.
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Baldi, P.; Brunak, S.; Frasconi, P.; Soda, G.; Pollastri, G. Exploiting the past and the future in protein secondary structure prediction. Bioinformatics 1999, 15, 937–946. [Google Scholar] [CrossRef] [PubMed]
- Graves, A. RNNLIB: A Recurrent Neural Network Library for Sequence Learning Problems. Available online: http://sourceforge.net/projects/rnnl (accessed on 10 August 2016).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119.
- Wiebe, J.; Riloff, E. Creating subjective and objective sentence classifiers from unannotated texts. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Mexico City, Mexico, 13–19 February 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 486–497. [Google Scholar]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Vancouver, BC, Canada, 6–8 October 2005; pp. 347–354.
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | F-measure | ||||
|---|---|---|---|---|---|---|---|
| Prop. | Bin. | Prop. | Bin. | Prop. | Bin. | ||
| Wiebe lexicon | - | - | 31.10 | - | 45.69 | - | 36.97 |
| Wilson lexicon | - | - | 30.73 | - | 55.15 | - | 39.44 |
| CRF | - | 74.96 | 82.28 | 46.98 | 52.99 | 57.74 | 64.45 |
| semi-CRF | - | 61.67 | 69.41 | 67.22 | 73.08 | 64.27 | 71.15 |
| CRF | +vec | 74.97 | 82.43 | 49.47 | 55.67 | 59.59 | 66.44 |
| semi-CRF | +vec | 66.00 | 71.98 | 60.96 | 68.13 | 63.30 | 69.91 |
| bi-RNN | 3 hidden layers, 100 units | 65.56 | 69.12 | 66.73 | 74.69 | 66.01 | 71.72 |
| uni-LSTM | 2 hidden layers, 25 units | 57.53 | 64.29 | 62.46 | 70.10 | 59.89 | 67.07 |
| bi-LSTM | 1 hidden layer, 25 units | 64.28 | 68.30 | 68.28 | 75.74 | 66.09 | 71.72 |
| Model | Precision | Recall | F-measure | ||||
|---|---|---|---|---|---|---|---|
| Prop. | Bin. | Prop. | Bin. | Prop. | Bin. | ||
| Wiebe lexicon | - | - | 43.03 | - | 56.36 | - | 48.66 |
| Wilson lexicon | - | - | 40.94 | - | 66.10 | - | 50.38 |
| CRF | - | 56.09 | 68.36 | 42.26 | 51.84 | 48.10 | 58.85 |
| semi-CRF | - | 45.64 | 69.06 | 58.05 | 64.15 | 50.95 | 66.37 |
| CRF | +vec | 57.15 | 69.84 | 44.67 | 54.38 | 50.01 | 61.01 |
| semi-CRF | +vec | 53.76 | 70.82 | 52.72 | 61.59 | 53.10 | 65.73 |
| bi-RNN | 3 hidden layers, 100 units | 52.04 | 60.50 | 61.71 | 76.02 | 56.26 | 67.18 |
| uni-LSTM | 2 hidden layers, 25 units | 48.64 | 58.73 | 59.57 | 74.46 | 53.50 | 65.67 |
| bi-LSTM | 1 hidden layer, 25 units | 53.87 | 65.92 | 66.27 | 79.55 | 59.28 | 71.96 |
| Types of Patterns | Example | Number |
|---|---|---|
| Part-of-Speech | noun, adjective, adverb, etc. | 25 |
| Position | beginning of the sentence, end of the sentence | 2 |
| Frequent words | the, of, to, etc. | 35 |
| Patterns | The p-Value in t-Test |
|---|---|
| Adverbs | 0.046 |
| The first word of the sentences | 0.032 |
| The word “as” | 0.008 |
| Group | Phrase Form | “B” in SRNN | “B” in LSTM | Accuracy of SRNN | Accuracy of LSTM |
|---|---|---|---|---|---|
| +A | as AD as | 6.16 | 58.46 | 6.16 | 58.46 |
| +N | as NN as | 2.63 | 5.48 | - | - |
| #A | as AD | 7.28 | 55.54 | - | - |
| #N | as NN | 3.5 | 4.2 | - | - |
| −A | as AD said | 1.28 | 31.16 | - | - |
| −N | as NN said | 0 | 0.47 | 100 | 99.53 |
| Factors | -Value | A/N Group Distinguished |
|---|---|---|
| Random | 0.488 | False |
| 0.135 | True | |
| 0.462 | False | |
| 0.153 | True | |
| 0.455 | False | |
| 0.147 | True |
| Tag at Time | Tag at Time t | Model | |
|---|---|---|---|
| O | B | SRNN | 0.44 |
| O | B | LSTM | 0.49 |
| I or B | O | SRNN | −0.56 |
| I or B | O | LSTM | −0.62 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Liu, Y.; Liu, M.; Sun, C.; Wang, X. Understanding Gating Operations in Recurrent Neural Networks through Opinion Expression Extraction. Entropy 2016, 18, 294. https://doi.org/10.3390/e18080294
Wang X, Liu Y, Liu M, Sun C, Wang X. Understanding Gating Operations in Recurrent Neural Networks through Opinion Expression Extraction. Entropy. 2016; 18(8):294. https://doi.org/10.3390/e18080294
Chicago/Turabian StyleWang, Xin, Yuanchao Liu, Ming Liu, Chengjie Sun, and Xiaolong Wang. 2016. "Understanding Gating Operations in Recurrent Neural Networks through Opinion Expression Extraction" Entropy 18, no. 8: 294. https://doi.org/10.3390/e18080294