Real-Time Robust Voice Activity Detection Using the Upper Envelope Weighted Entropy Measure and the Dual-Rate Adaptive Nonlinear Filter

Abstract
:1. Introduction
1.1. Voice Activity Detection
1.2. Discriminative Features and Classification
1.3. VAD Systems and Performance Measurement
1.4. The Contributions of This Article
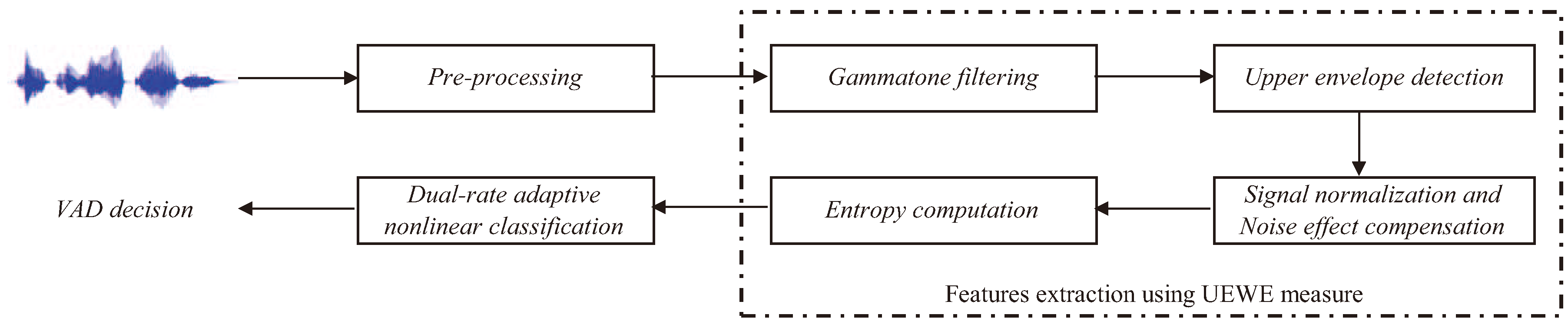
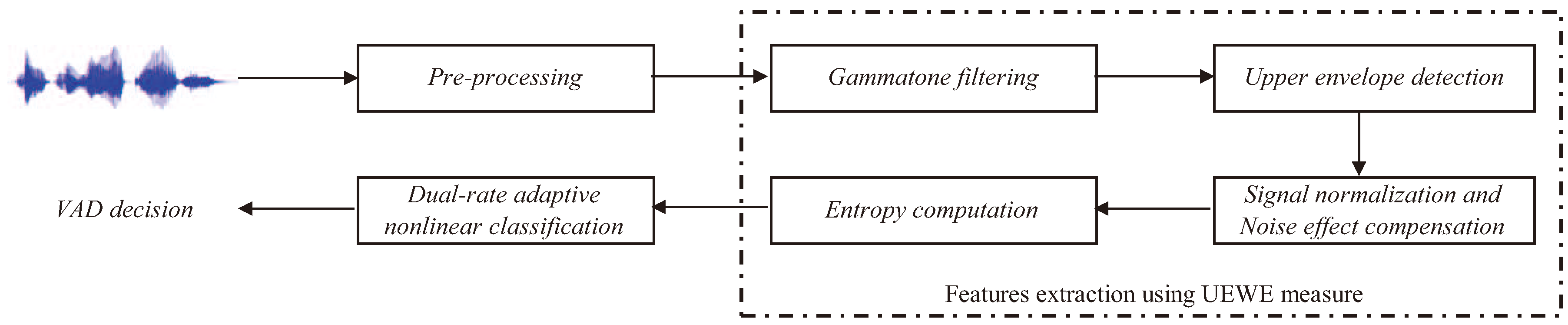
2. Proposed Voice Activity Detection Algorithm
2.1. Background and Motivation
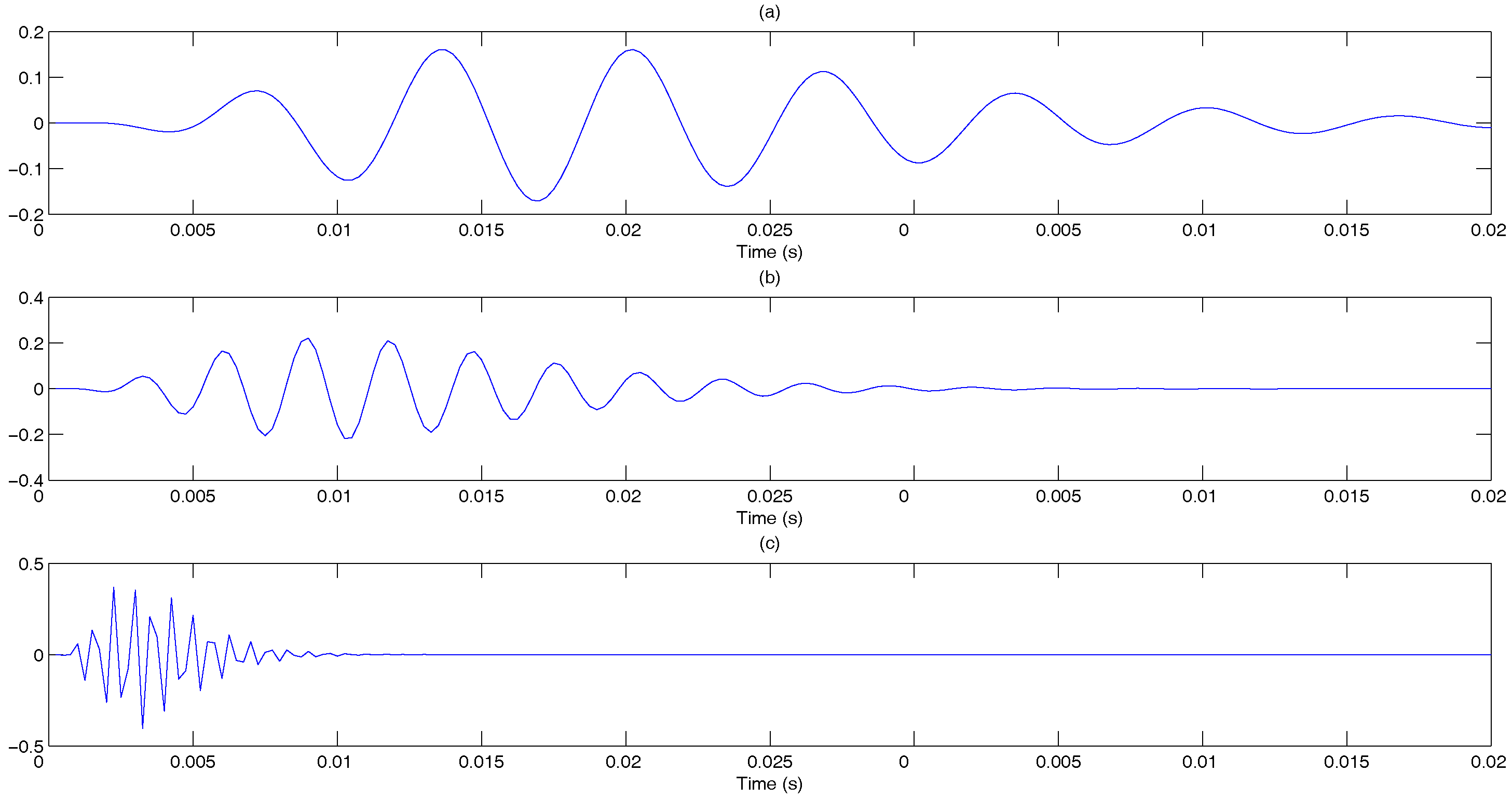
2.1.1. Gammatone Filter
2.1.2. Asymmetric Nonlinear Filter
2.1.3. Entropy as a Information-Theoretic Measures
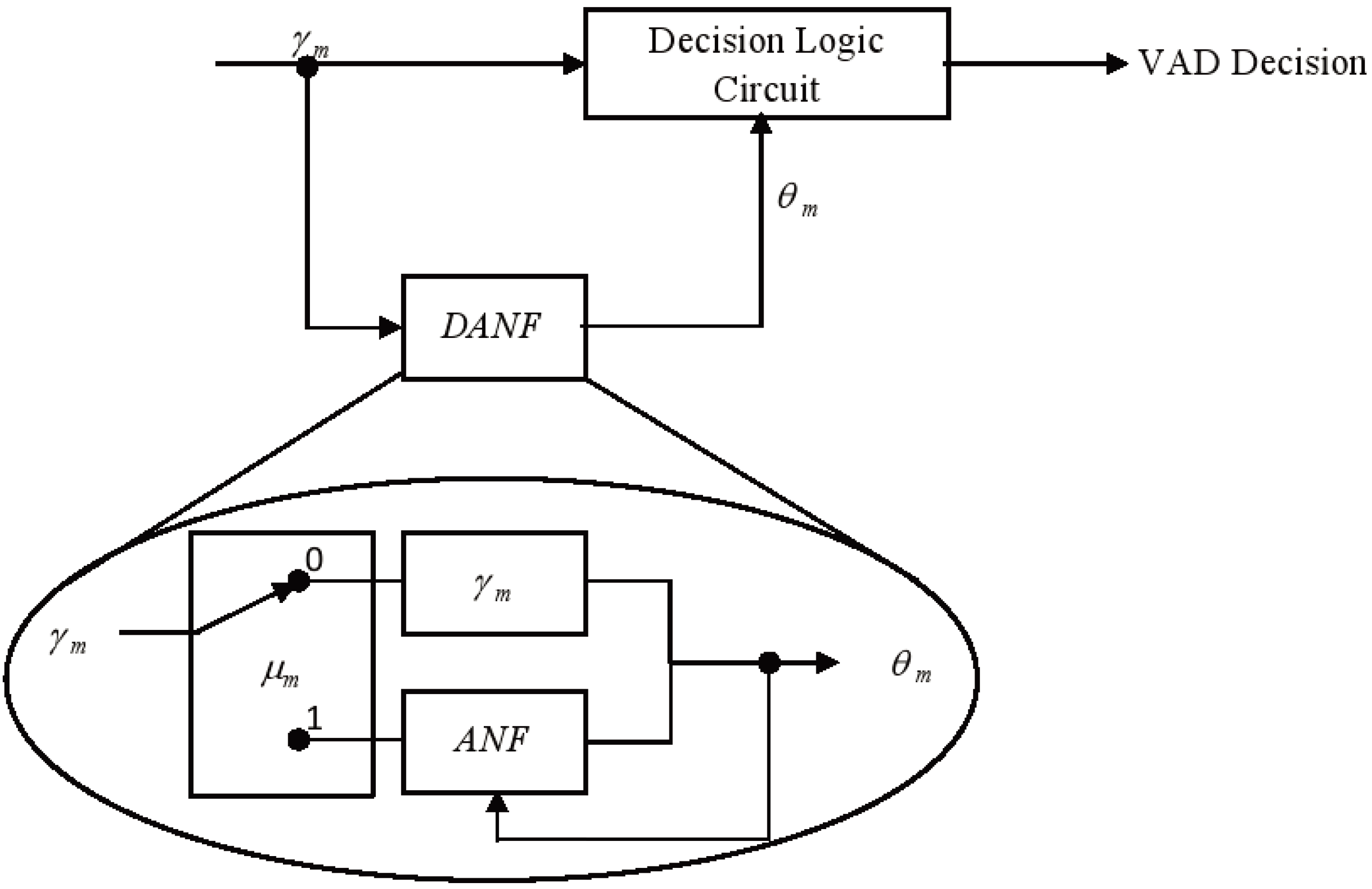
2.1.4. Dual-Rate Adaptive Nonlinear Filter
2.2. The Proposed Voice Activity Detection Algorithm
- Step 1
- Pre-emphasis: Signal is pre-emphasized, and the resultant signal is denoted as , where is the pre-emphasis factor.
- Step 2
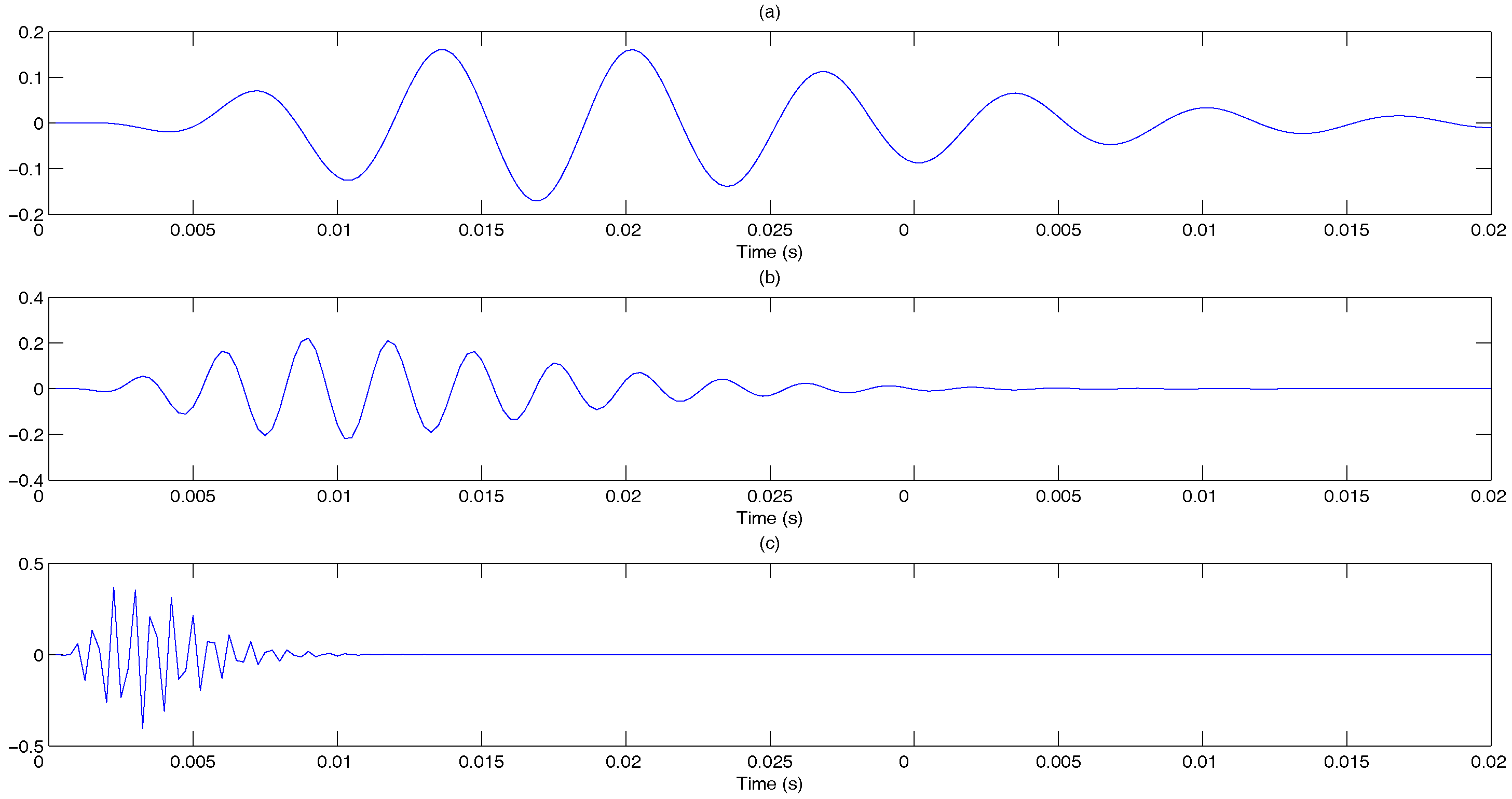
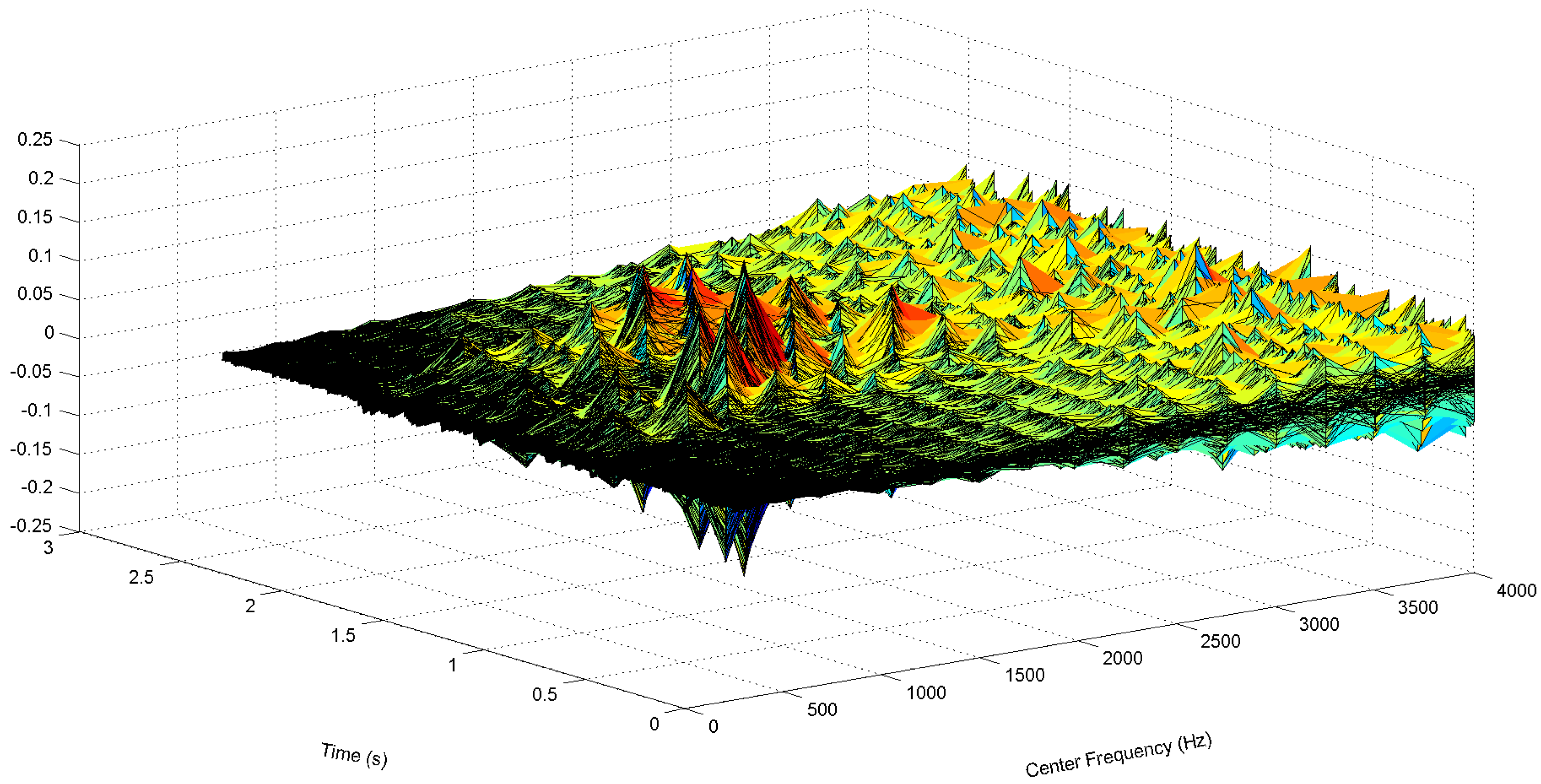
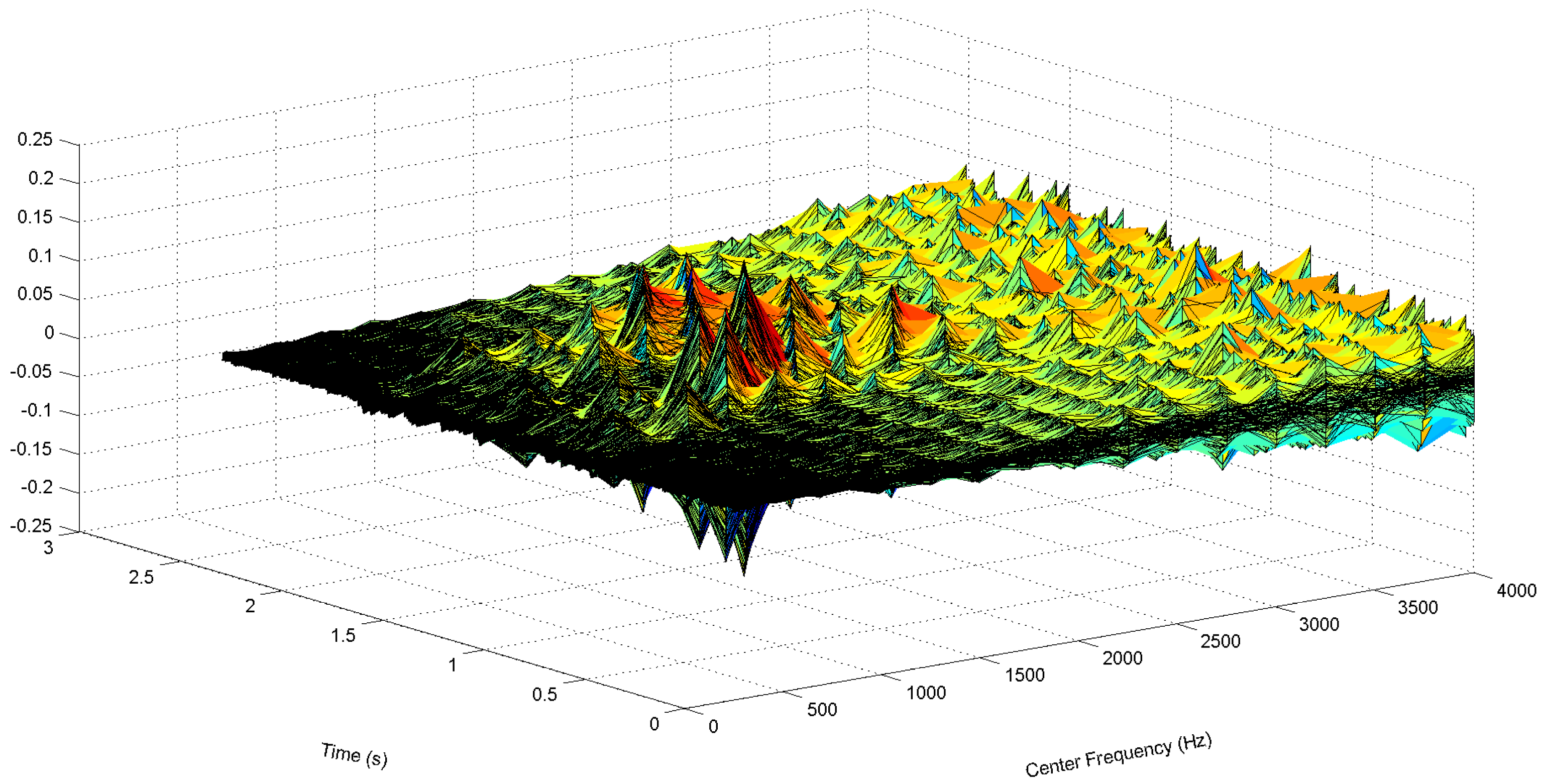
- Gammatone filtering: A K channel gammatone filter bank, where each filter has length L, is constructed based on Equations (1)–(3). The impulse response of the k-th gammatone filter is denoted as , where , with center frequency , where the frequencies , …, , …, are equally distributed on the ERB-rate scale to cover the useful speech spectral bands. Figure 6 shows the plots of the gammatone impulse response at three different center frequencies. The pre-emphasized signal is then passed through each gammatone filter, and the output is denoted as:and illustrated in Figure 7.
- Step 3
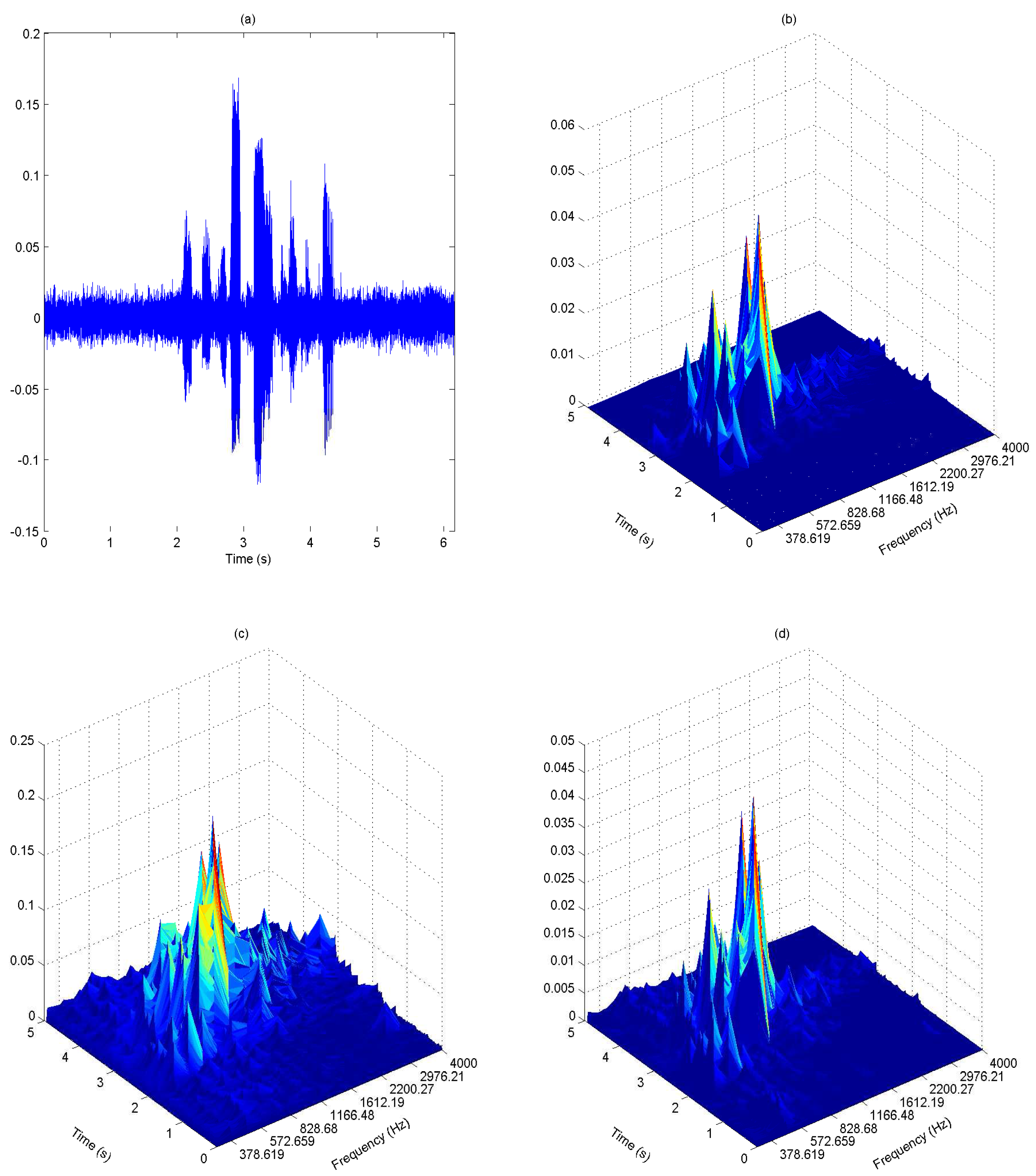
- Signal envelope: The envelope of signal is obtained by taking the magnitude of the gammatone filtered signal.
- Step 4
- Weight function: The average value of in a frame is calculated according to Equation (8).Then, the weight factor is computed using the asymmetric nonlinear filter to track the upper envelope of , i.e.,where .
- Step 5
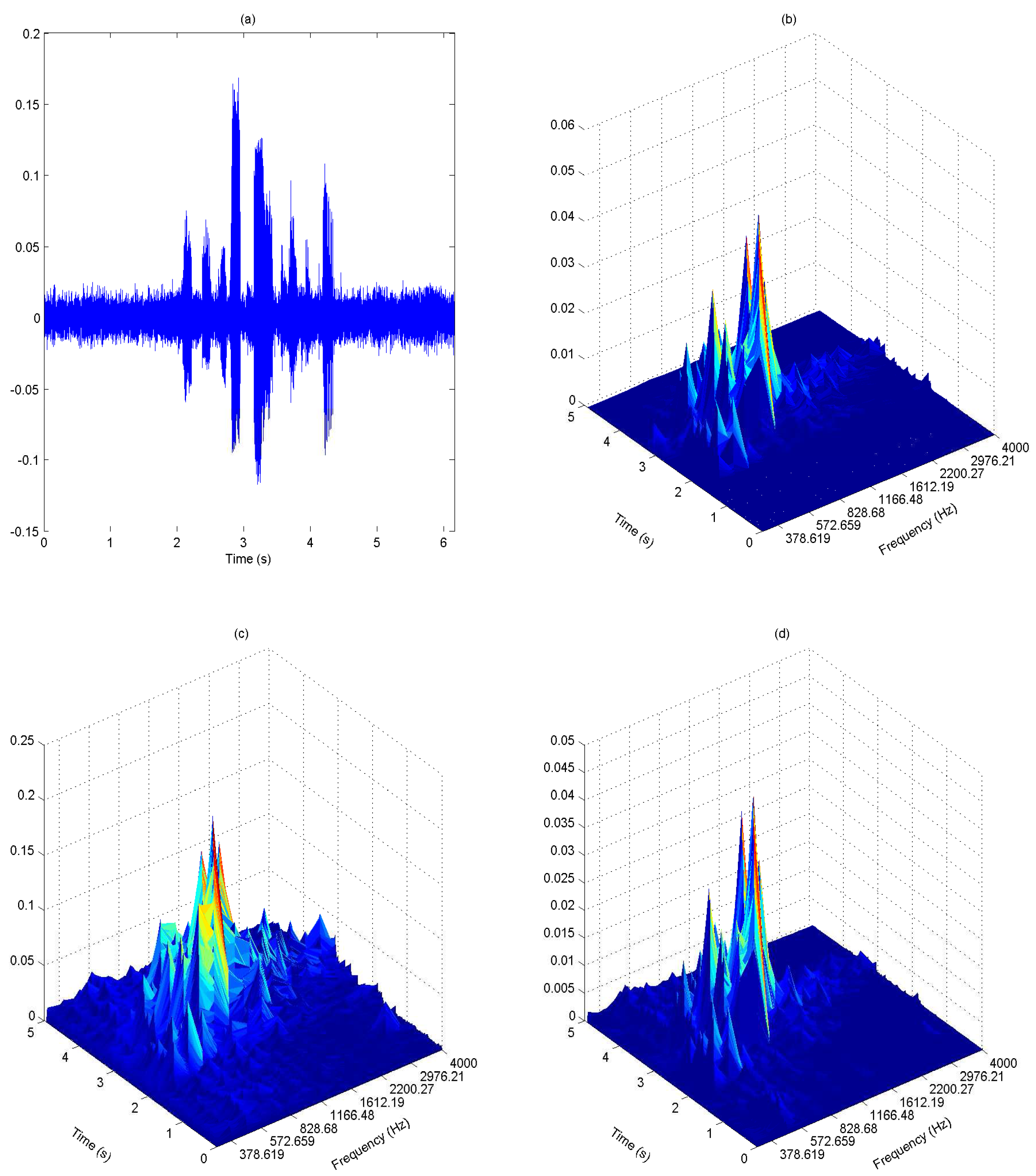
- Signal normalization and noise effect compensation: The envelope is normalized across the K frequency bands to obtain:This is then multiplied with the weight factor to compensate noise effect at each frequency band, i.e.,We observe from Figure 8 that the speech signal has better representation in the weighted envelopes as compared to the gammatone filter output envelope. The speech region has a relatively higher magnitude than the noise region in the weighted envelopes. They are represented with higher magnitude at certain frequencies, while the magnitude of the noise region is evenly spread across the frequency.
- Step 6
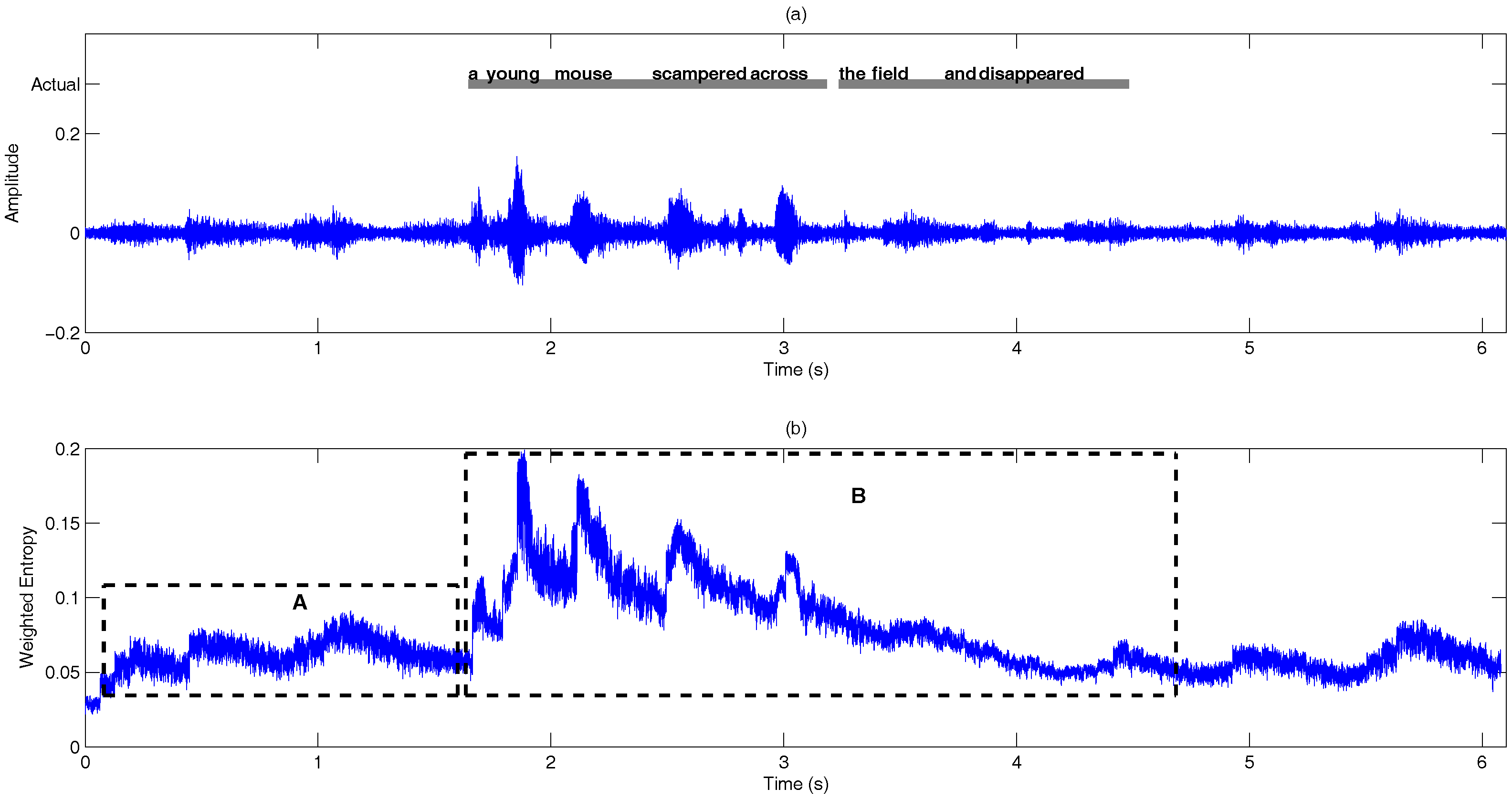
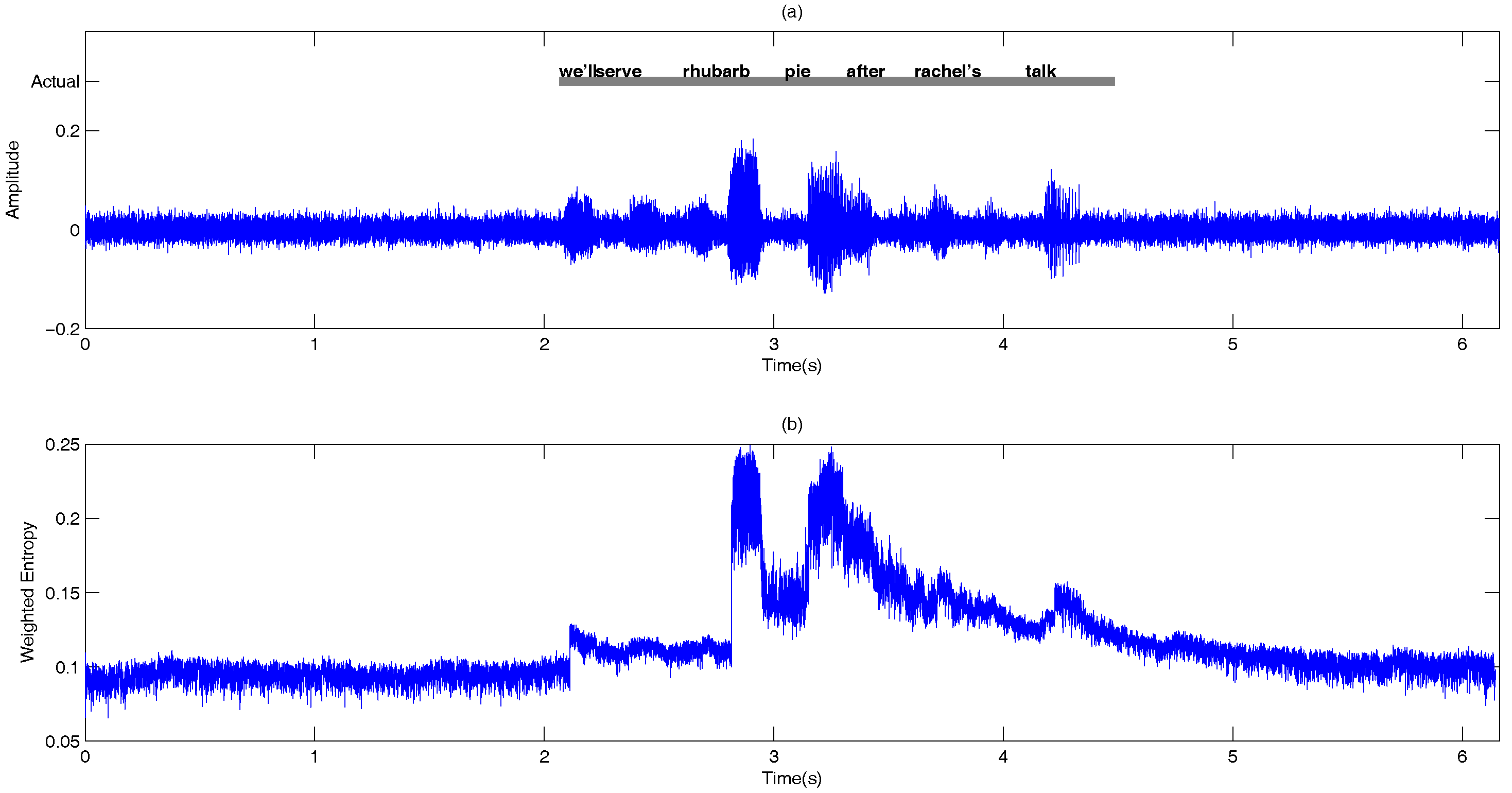
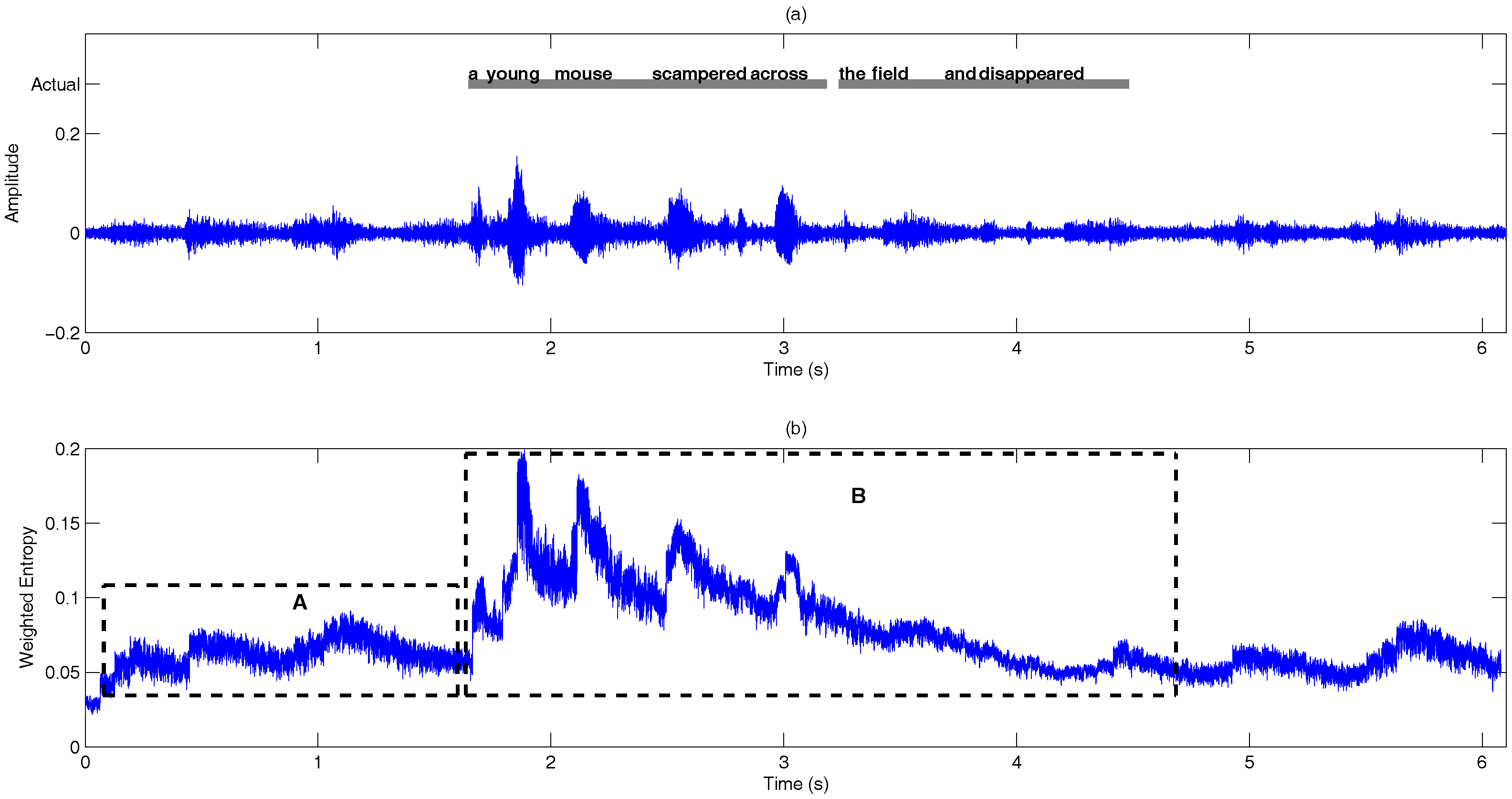
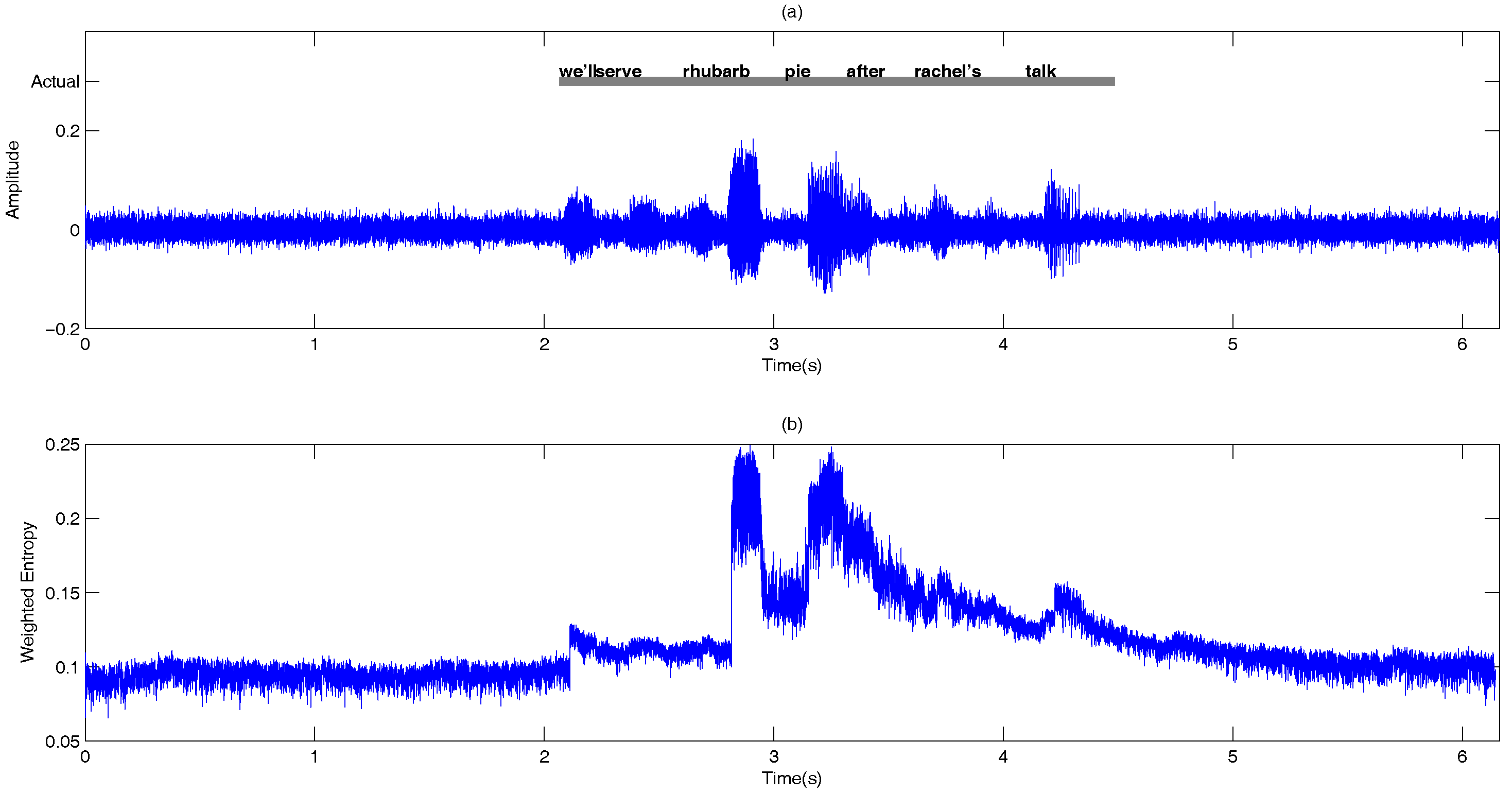
- Information-theoretic measures: The entropy of is measured across frequency according to:Figure 9 shows the entropy of the noise-compensated signal envelope for speech signal degraded by crowd noise at 0 dB SNR. We can observe from the figure that speech and noise regions have significant differences in terms of their entropy values, and this can be exploited as an appropriate discriminative feature to decide the presence or absence of speech.
- Step 7
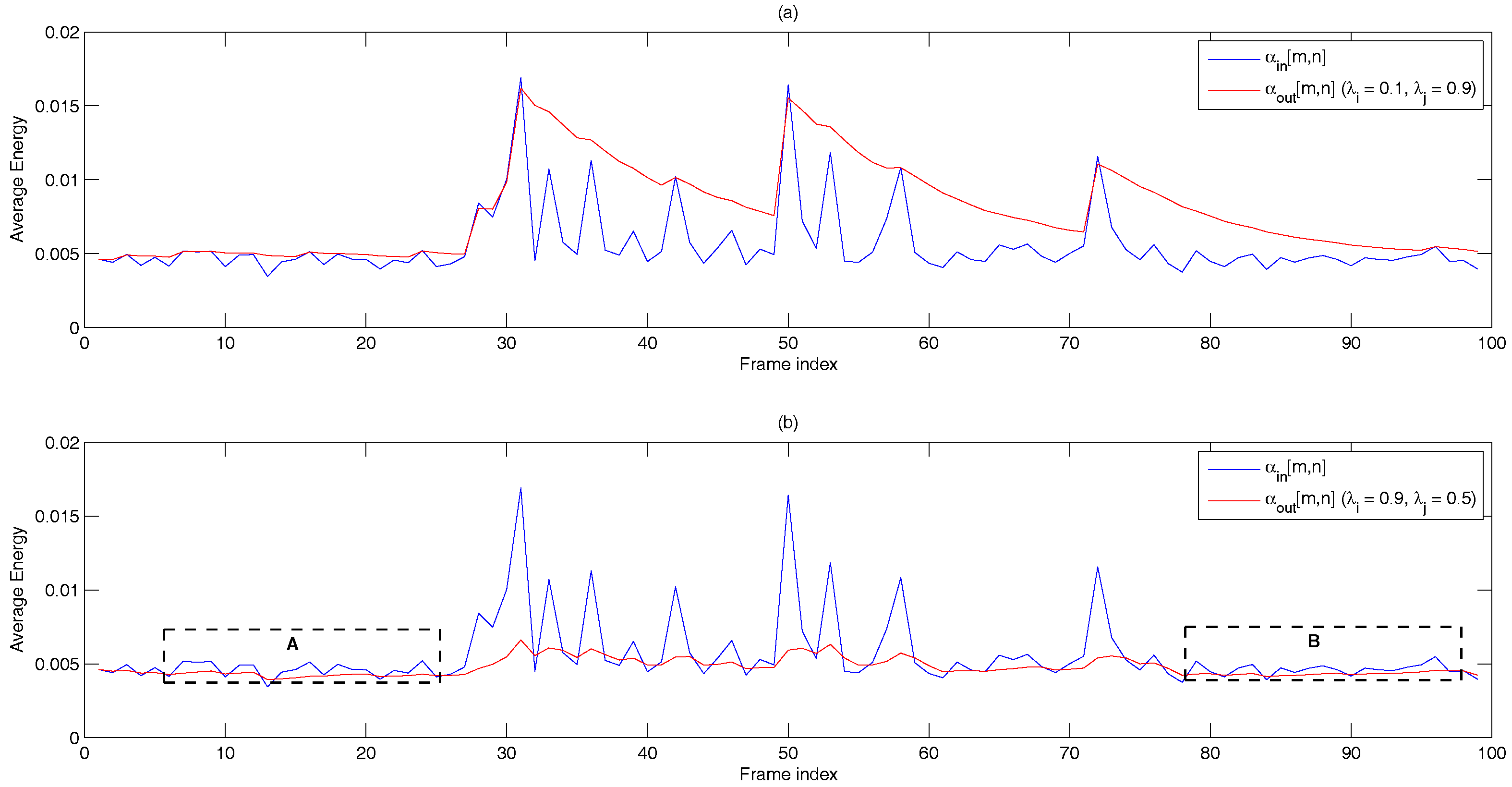
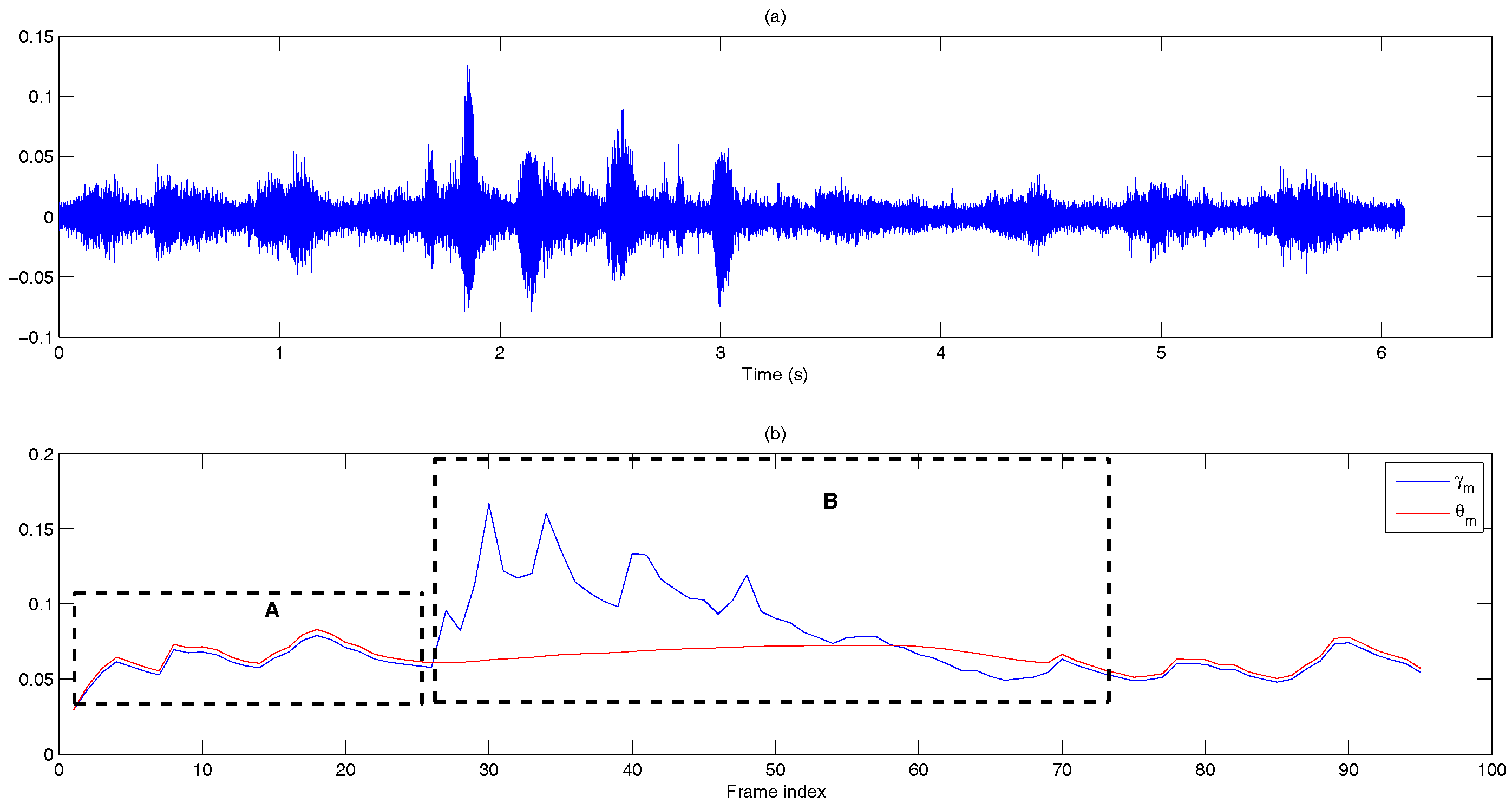
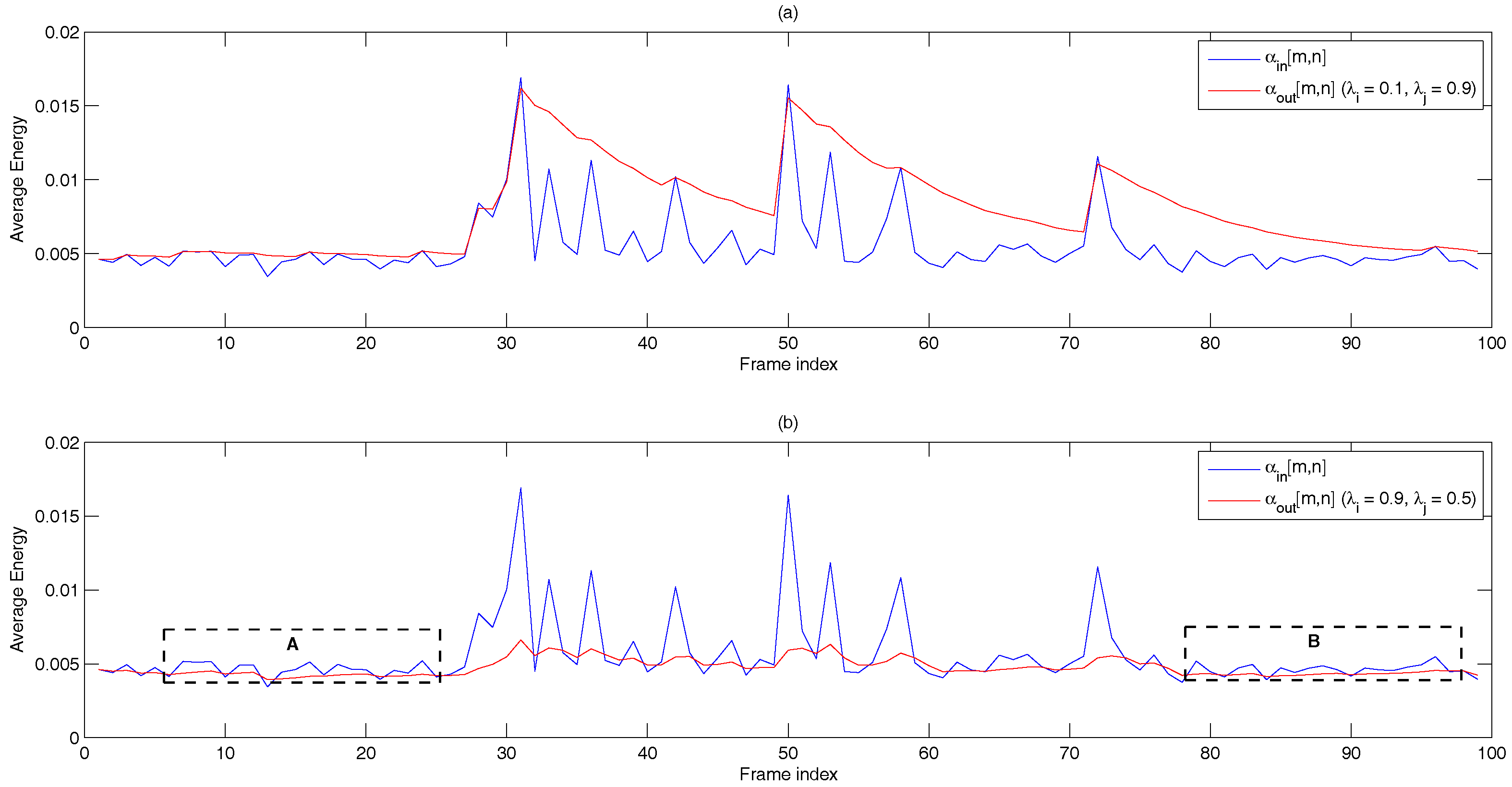
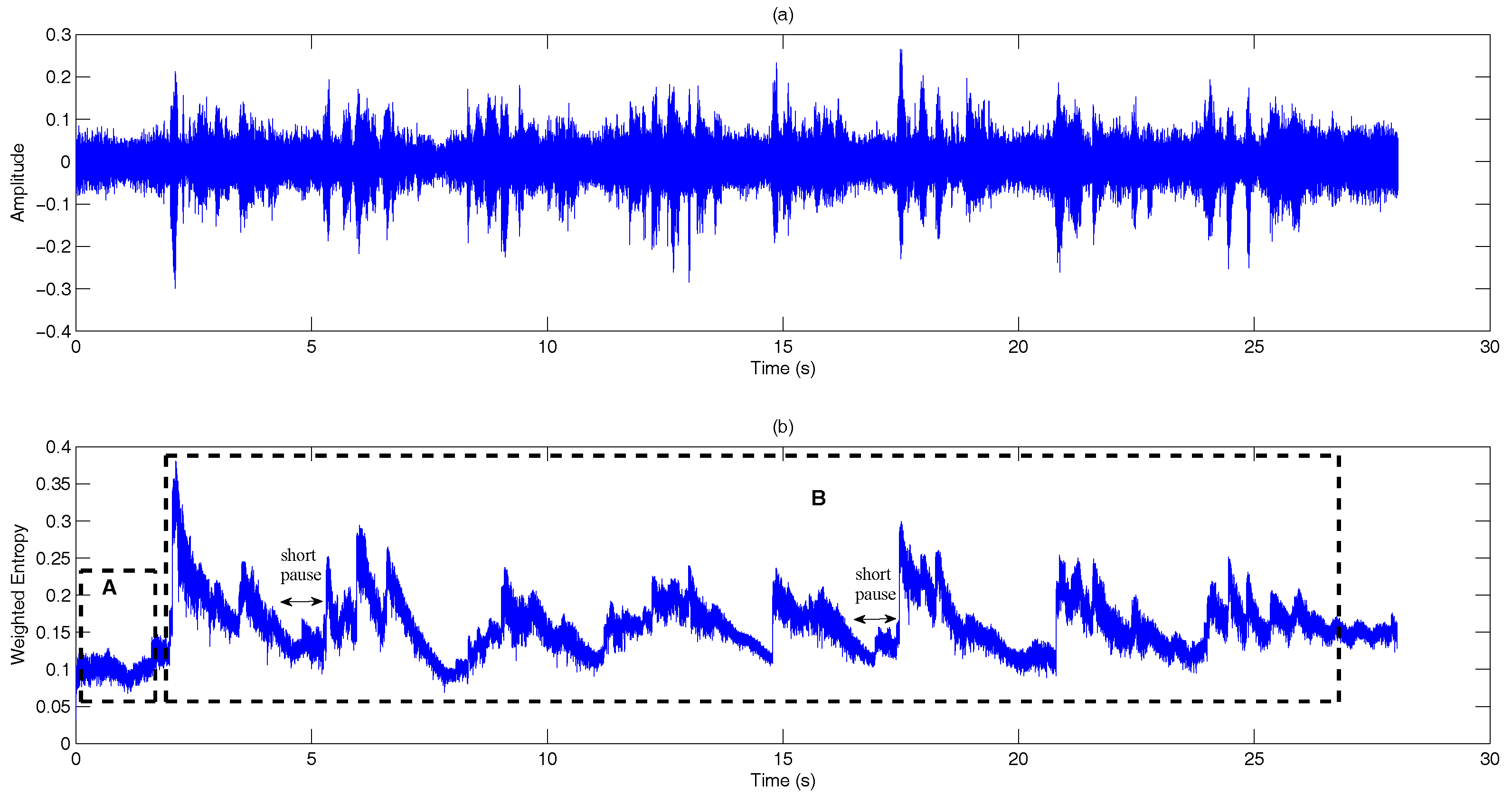
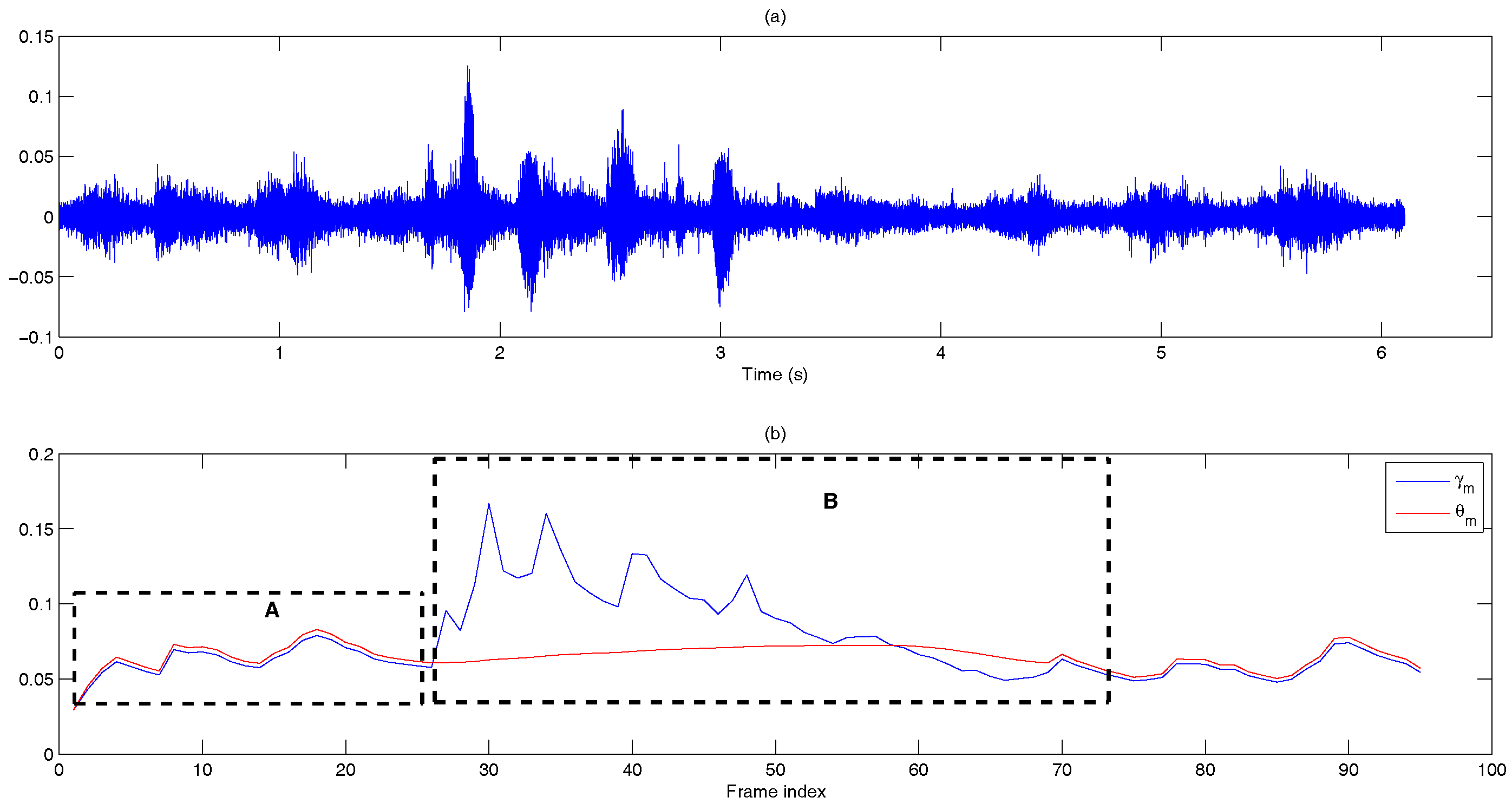
- Dual-rate adaptive nonlinear filter: The input of the filter is the frame averaged entropy, i.e.,A controller, , is used to differentiate the long noise interval (Region A) and potential speech segments (Region B). We set = 0 and in the starting frame. In subsequent frames, and are given by:where is the transition threshold to set from zero (Region A) to one (Region B), where and are the mean and standard deviation of the eight most recent values of of only the noise frame. Figure 10 demonstrates the adaptivity of the decision threshold of a noisy signal. In Region B, when , the decision threshold, computed using ANF, varies slowly with respect to the DANF input, whereas in Region A, the decision threshold adapts itself to the fluctuating noise floor.
- Step 8
- Decision logic: The VAD decision is made based on:where 1 represents speech, while 0 represents noise.
- Step 9
- Noise frame counter: The number of identified noise frames is counted, and this is used to reset accordingly, i.e.,where 0 represents a long interval of noise and 1 represents otherwise.
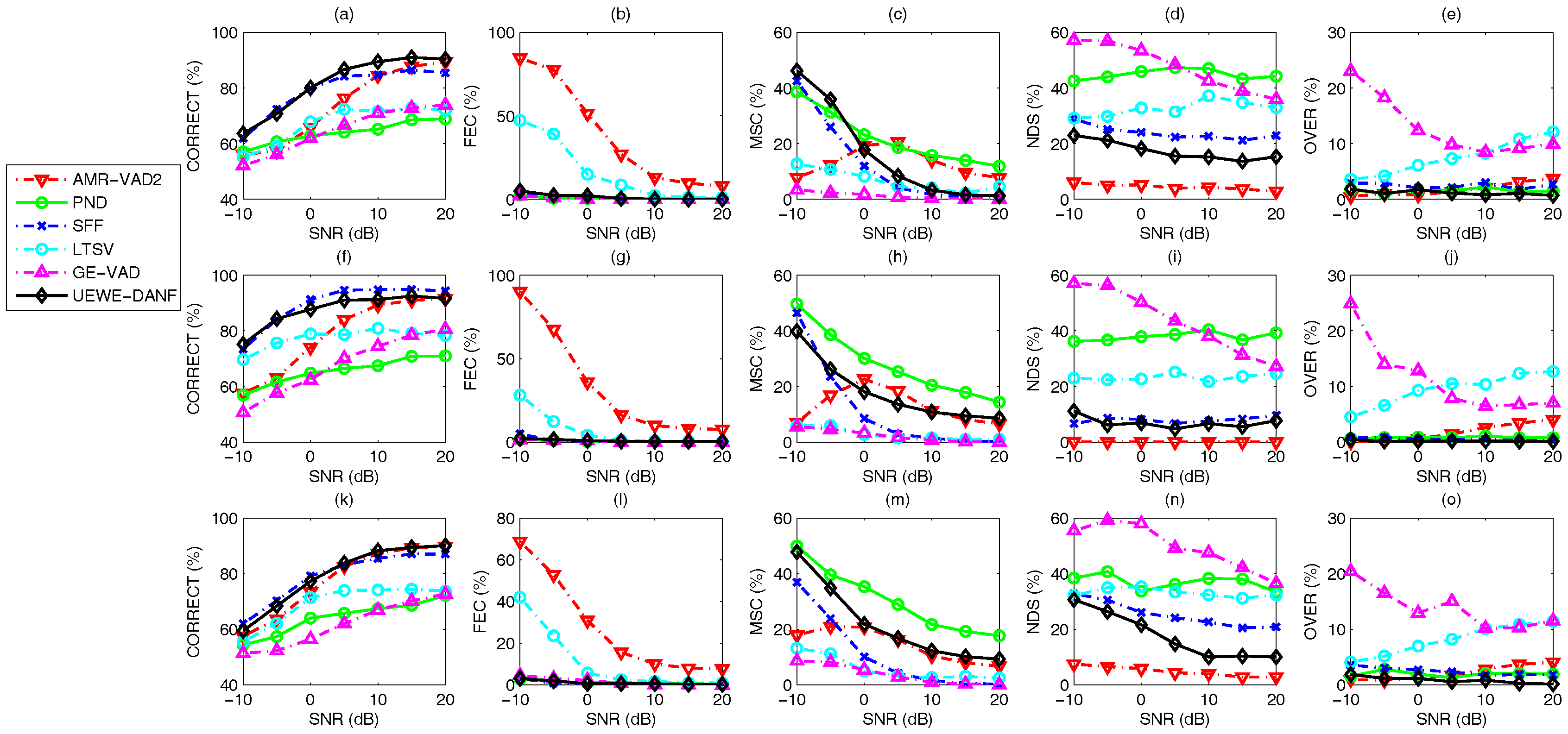
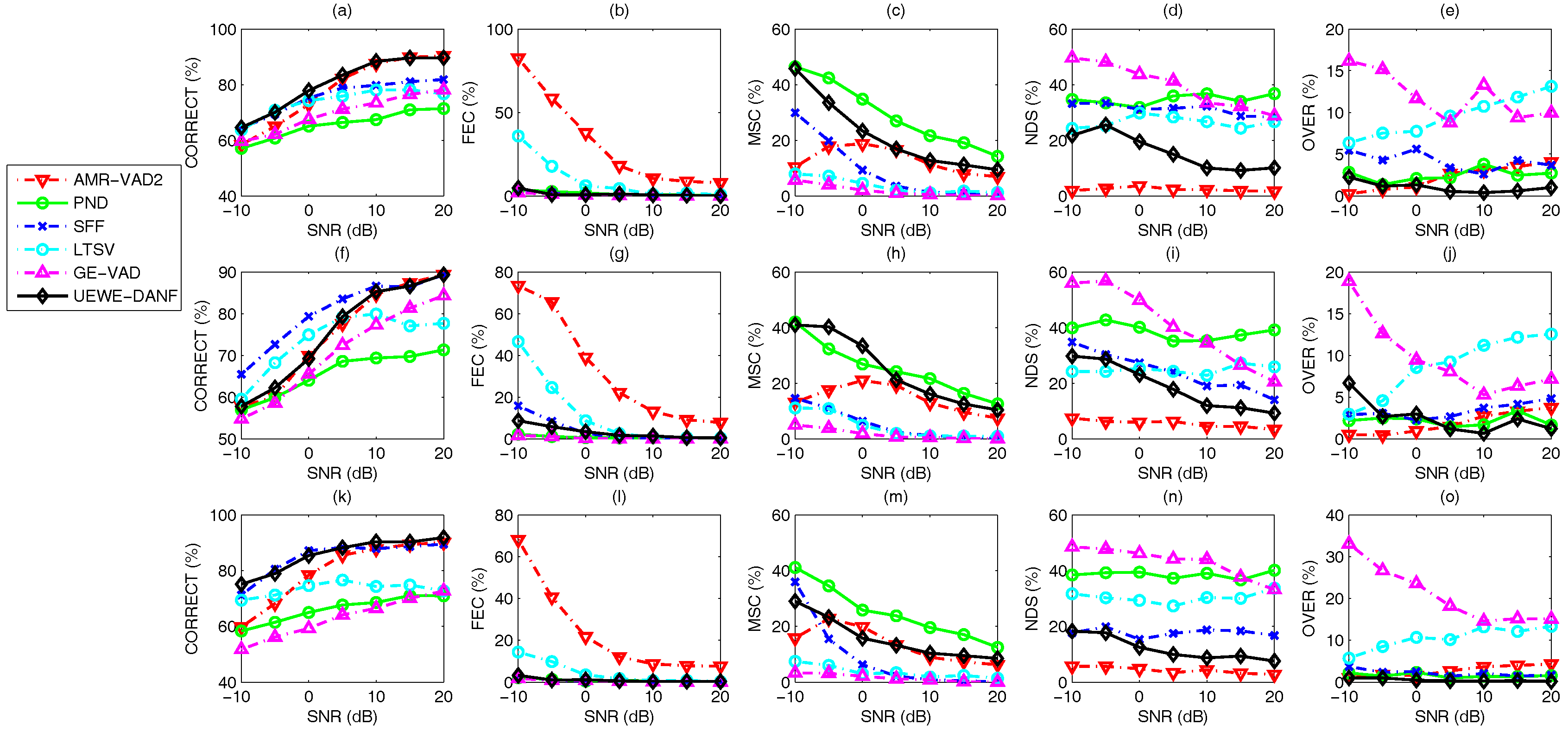
3. Results
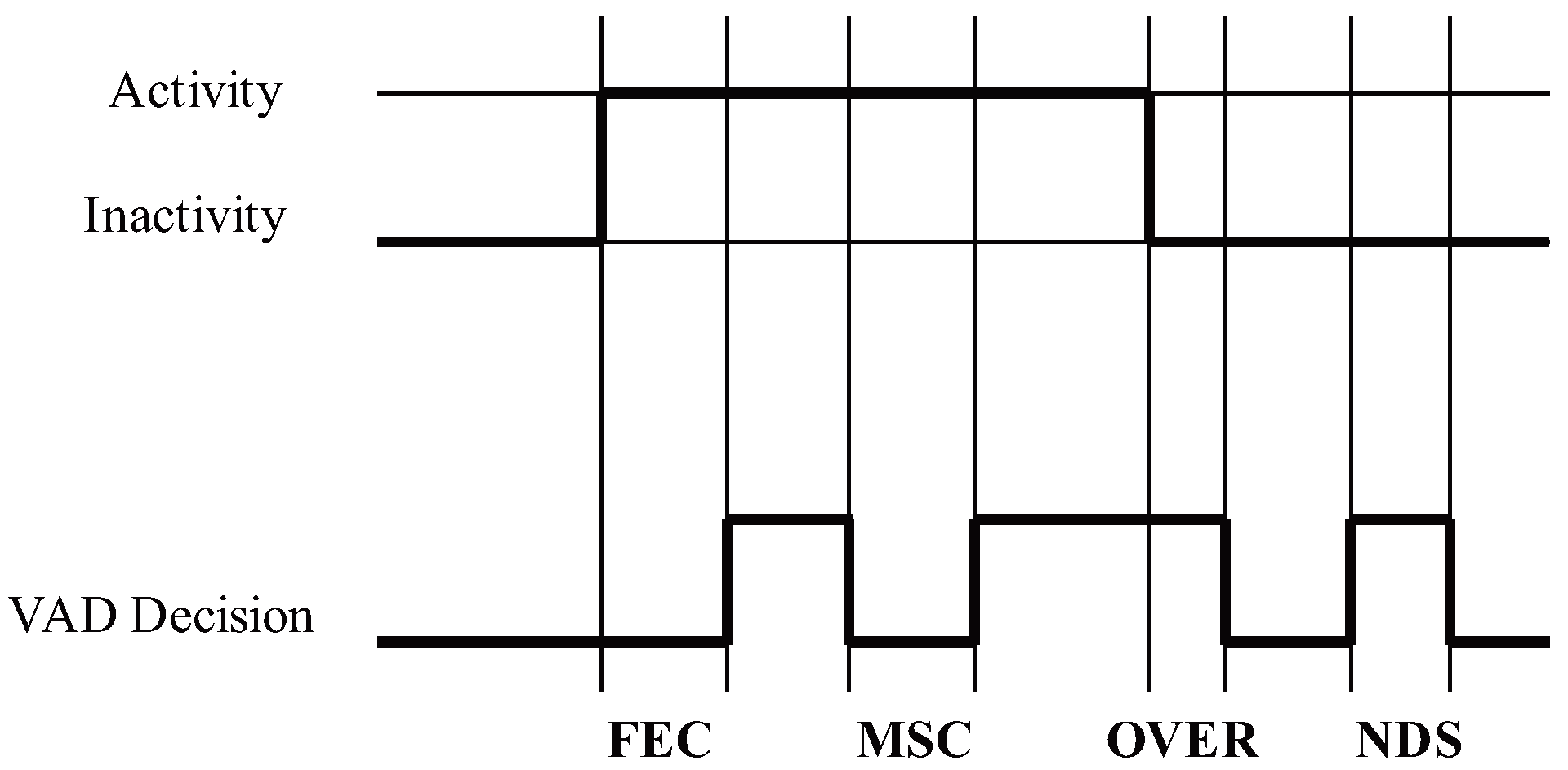
3.1. Performance Evaluation Metrics
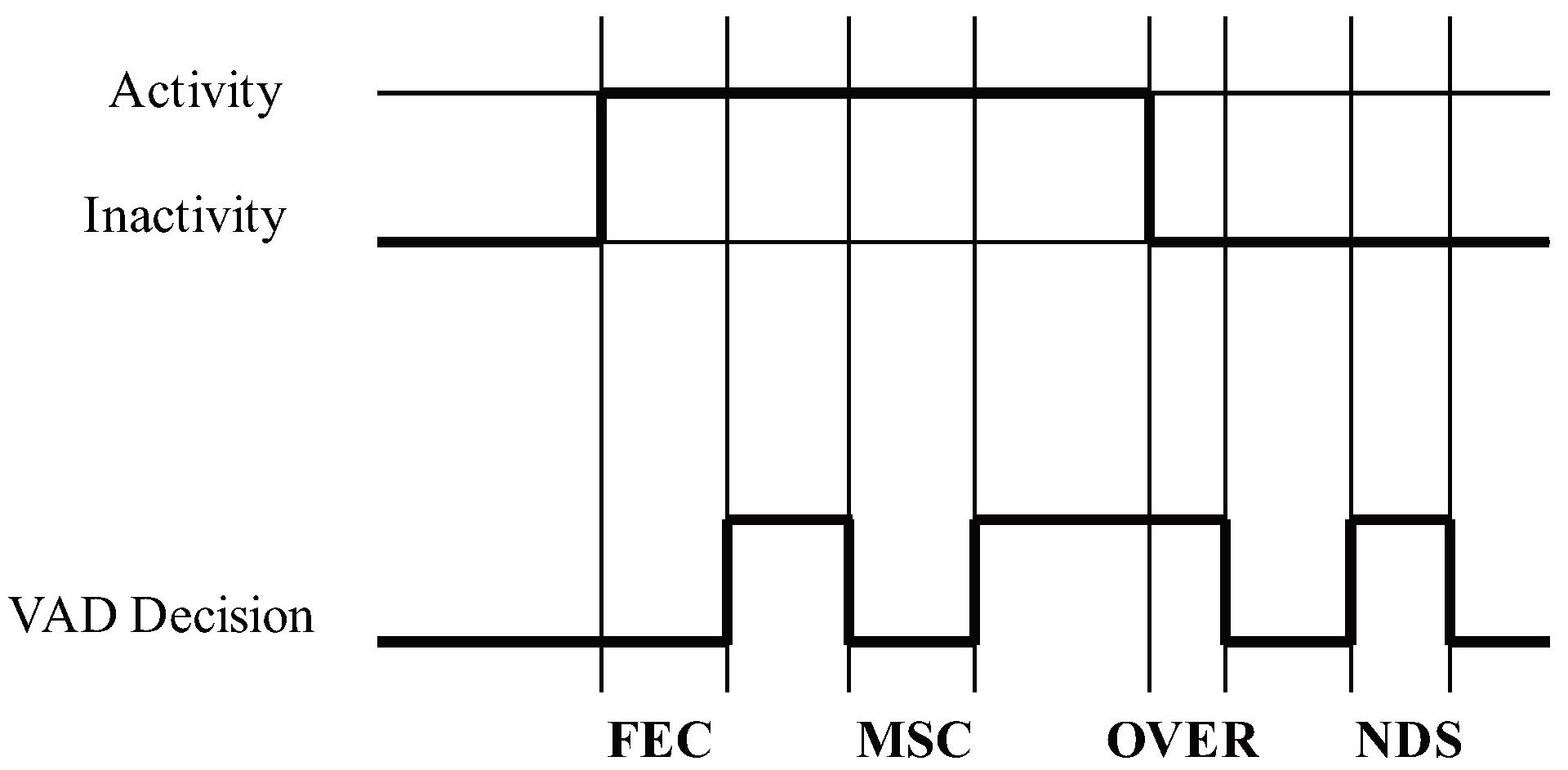
- CORRECT: The correct speech or non-speech detection done by the VAD algorithm.
- Front-end clipping (FEC): Clipping caused by misclassification of speech as noise at the shift of the noise segment to the speech segment.
- Mid-speech clipping (MSC): Clipping caused by misclassification of speech as noise within a speech segment.
- Carry over (OVER): Noise misclassified as speech at the shift of the speech segment to the noise segment.
- Noise detected as speech (NDS): Noise misclassified as speech within the noise segment.
3.2. Experimental Setup
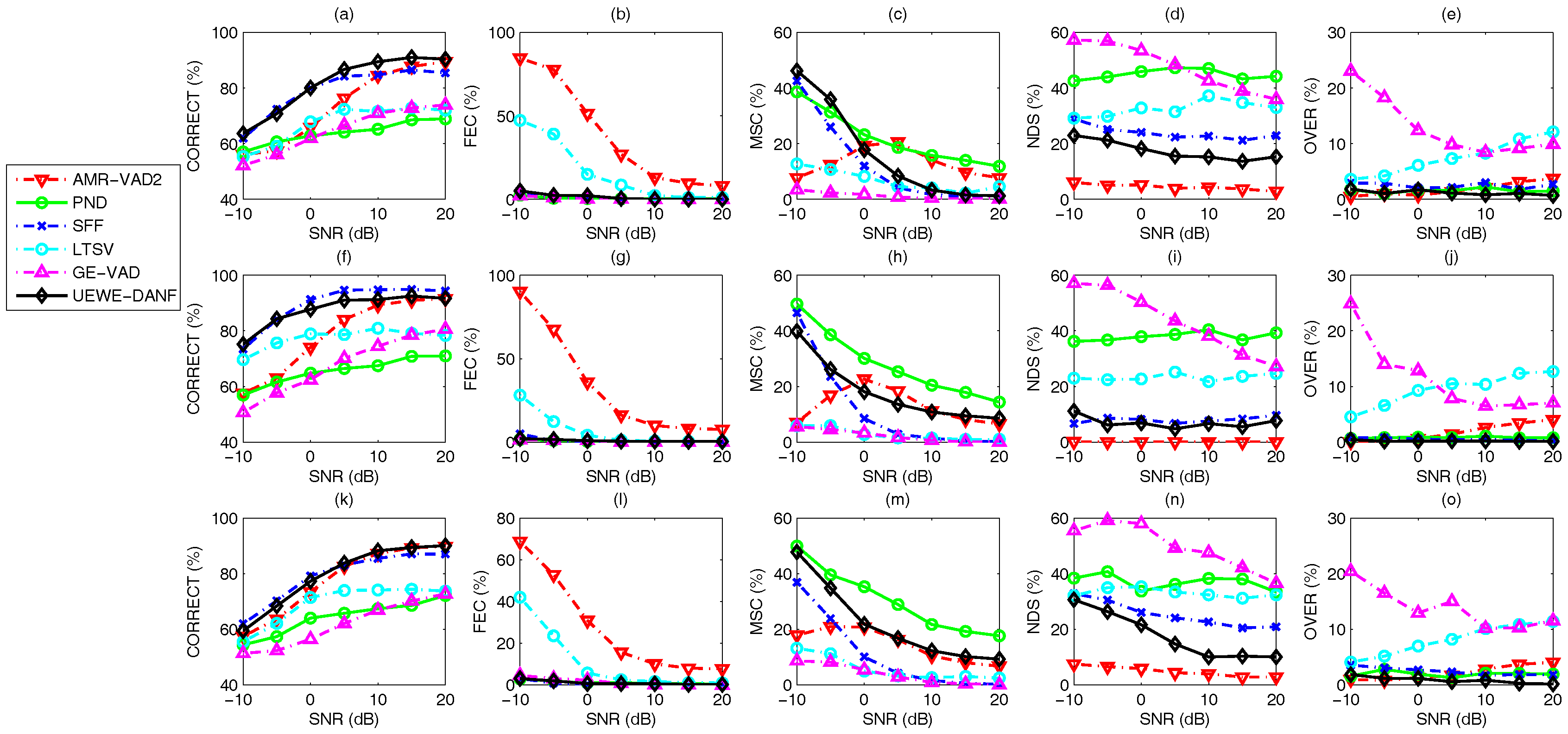
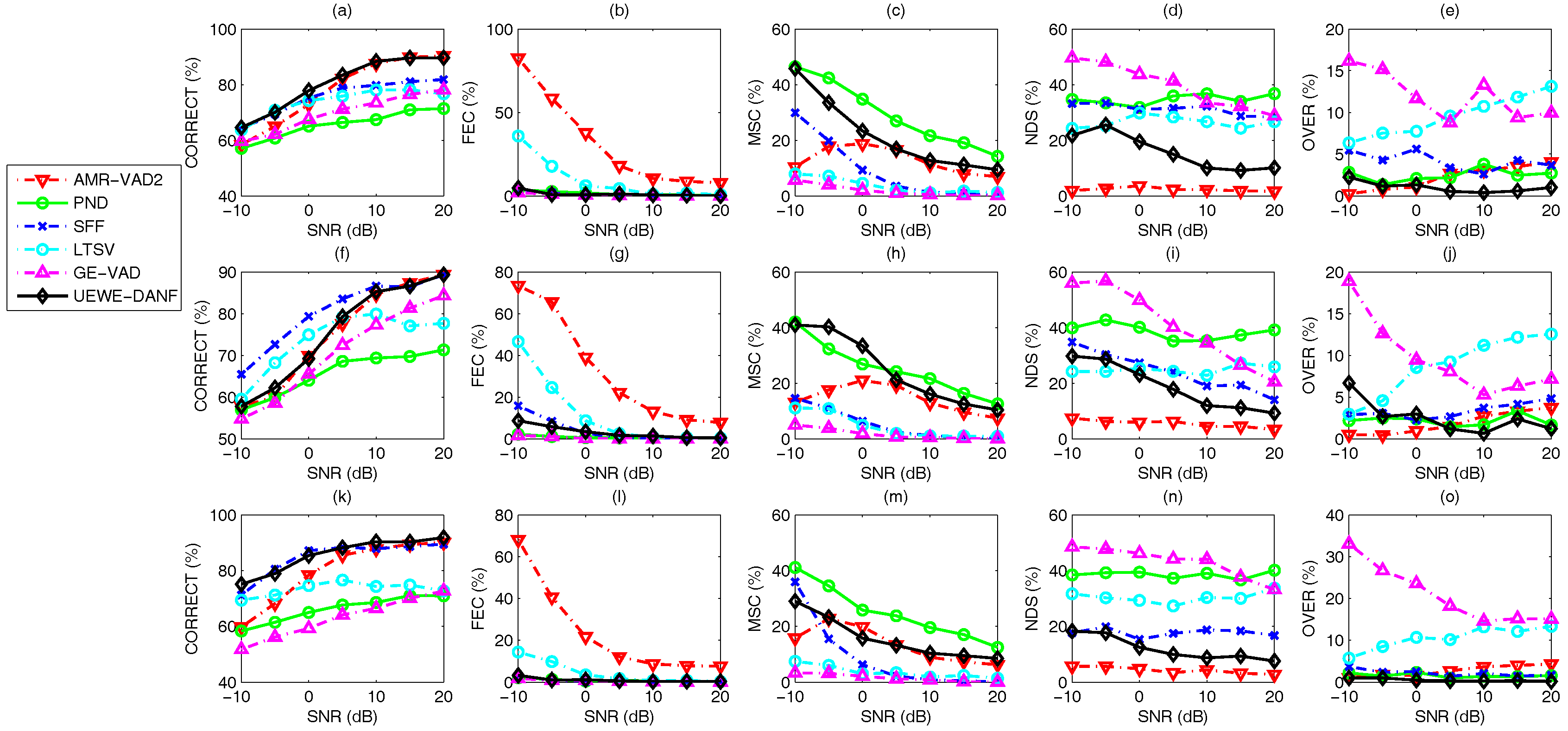
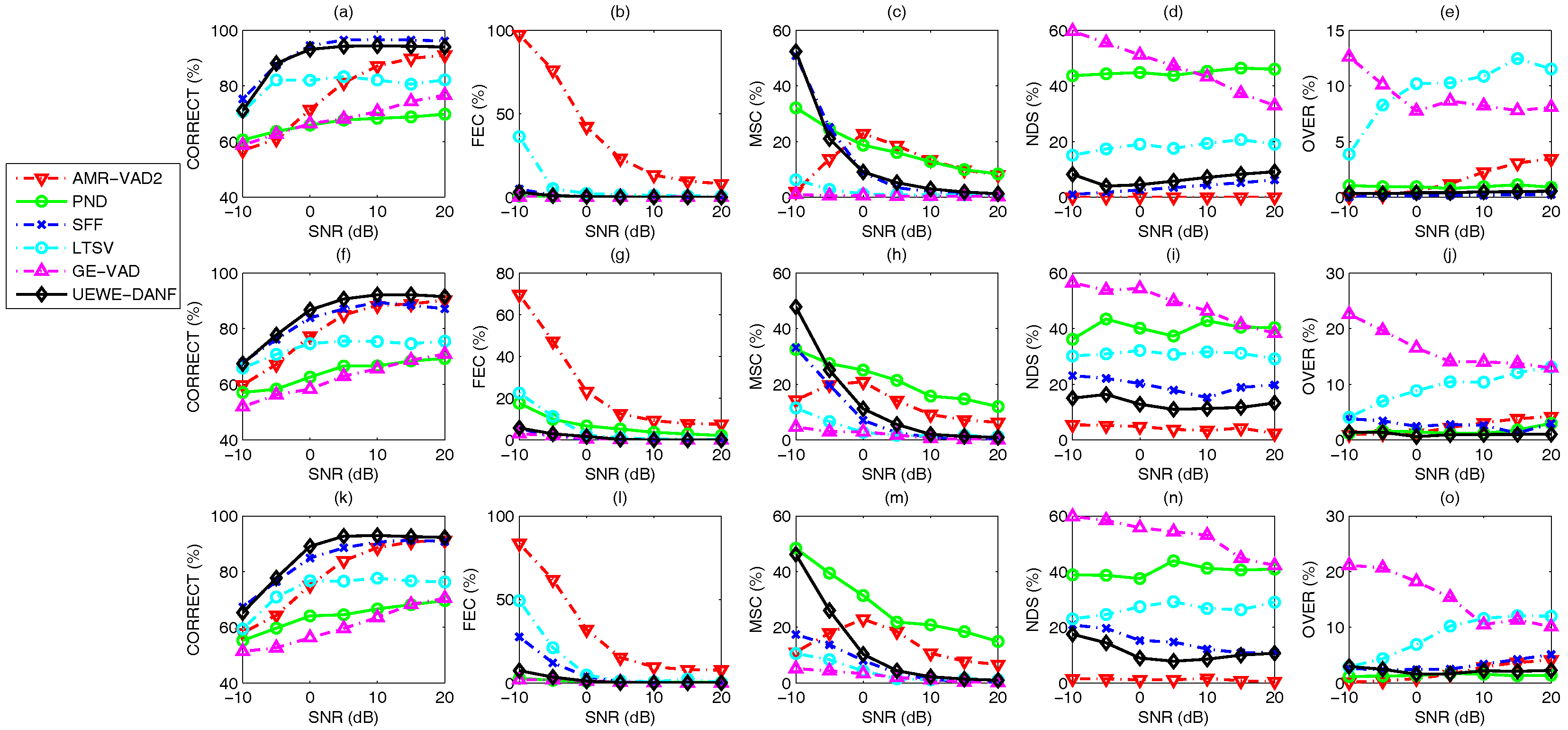
3.3. Voice Activity Detection Results and Benchmarking
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| VAD | Voice activity detection |
| SNR | Signal-to-noise ratio |
| UEWE | Upper envelope weighted entropy |
| ANF | Asymmetric nonlinear filter |
| DANF | Dual-rate adaptive nonlinear filter |
| VoIP | Voice over Internet Protocol |
| SVM | Support vector machine |
| LRT | Likelihood ratio test |
| GMMs | Gaussian mixture models |
| HMMs | Hidden Markov models |
| MFCCs | Mel frequency cepstral coefficients |
| AMR-VAD2 | Voice activity detection for adaptive multi-rate Option 2 |
| PND | Peak neighbor difference |
| SFF | Single frequency filtering |
| GE-VAD | Gammatone and entropy-based voice activity detector |
| ERB | Equivalent rectangular bandwidth |
| LTSV | Long-term signal variability |
| FEC | Front-end clipping |
| MSC | Mid-speech clipping |
| OVER | Carry over |
| NDS | Noise detected as speech |
| ETSI | European Telecommunications Standards Institute |
| AWGN | Additive white Gaussian noise |
| MIPS | Million instructions per second |
| DSP | Digital signal processor |
References
- Ghosh, P.K.; Tsiartas, A.; Narayanan, S. Robust Voice Activity Detection Using Long-Term Signal Variability. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 600–613. [Google Scholar] [CrossRef]
- Beritelli, F.; Casale, S.; Ruggeri, G. New Speech Processing Issues in IP Telephony. In Proceedings of the International Conference on Communication Technology Proceedings (WCC-ICCT), Beijing, China, 21–25 August 2000; pp. 652–656. [Google Scholar]
- Adeli, M.; Rouat, J.; Wood, S.; Molotchnikoff, S.; Plourde, E. A Flexible Bio-Inspired Hierarchical Model for Analyzing Musical Timbre. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 875–889. [Google Scholar] [CrossRef]
- Kathirvel, P.; Manikandan, M.S.; Senthilkumar, S.; Soman, K.P. Noise Robust Zerocrossing Rate Computation for Audio Signal Classification. In Proceedings of the 3rd International Conference on Trendz in Information Sciences & Computing (TISC2011), Chennai, India, 8–9 December 2011; pp. 65–69. [Google Scholar]
- Lokhande, N.N.; Nehe, N.S.; Vikhe, P.S. Voice Activity Detection Algorithm for Speech Recognition Applications. In Proceedings of the International Conference in Computational Intelligence (ICCIA), Maharastra, India, 11–12 February 2012; pp. 5–7. [Google Scholar]
- Ma, Y.; Nishihara, A. Efficient voice activity detection algorithm using long-term spectral flatness measure. EURASIP J. Audio Speech Music Process. 2013. [Google Scholar] [CrossRef]
- Haghani, S.K.; Ahadi, S.M. Robust Voice Activity Detection Using Feature Combination. In Proceedings of the 21st Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 14–16 May 2013; pp. 1–5. [Google Scholar]
- Saeedi, J.; Ahadi, S.M.; Faez, K. Robust Voice Activity Detection directed by noise classification. Signal Image Video Process. 2015, 9, 561–572. [Google Scholar] [CrossRef]
- Yoo, I.C.; Lim, H.; Yook, D. Formant-Based Robust Voic Activity Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2238–2245. [Google Scholar]
- Kola, J.; Espy-Wilson, C.; Pruthi, T. Voice Activity Detection; Merit Bien: College Park, MD, USA, 2011; pp. 1–6. [Google Scholar]
- Benyassine, A.; Shlomot, E.; Su, H.Y. ITU-T Recommendation G.729 Annex B: A Slience Compression Scheme for Use with G.729 Optimized for V.70 Digital Simultaneous Voice and Data Applications. IEEE Commun. Mag. 1997, 35, 64–73. [Google Scholar] [CrossRef]
- European Telecommunications Standards Institute (ETSI). Voice Activity Detection (VAD) for Adaptive Multi-Rate (AMR) Speech Traffic Channels; ETSI EN 301 708 v.7.1.1; ETSI: Valbonne, France, 1999. [Google Scholar]
- Germain, F.G.; Sun, D.L.; Mysore, G.J. Speaker and Noise Independent Voice Activity Detection. In Proceedings of the 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 732–736. [Google Scholar]
- Pham, C.K. Noise Robust Voice Activity Detection. Master’s Thesis, Nanyang Technology University, Singapore, 2012. [Google Scholar]
- Tan, L.N.; Borgstrom, B.J.; Alwan, A. Voice Activity Detection Using Harmonic Frequency Components in Likelihood Ratio Test. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4466–4469. [Google Scholar]
- Minotto, V.P.; Jung, C.R.; Lee, B. Simultaneous-Speaker Voice Activity Detection and Localization Using Mid-Fusion of SVM and HMMs. IEEE Trans. Multimed. 2014, 16, 1032–1044. [Google Scholar] [CrossRef]
- Popović, B.; Pakoci, E.; Pekar, D. Advanced Voice Activity Detection on Mobile Phones by Using Microphone Array and Phoneme-Specific Gaussian Mixture Models. In Proceedings of the IEEE 14th International Symposium on Intelligent Systems and Informatics, Subotica, Serbia, 29–31 August 2016; pp. 45–50. [Google Scholar]
- Ferroni, G.; Bonfigli, R.; Principi, E.; Squartini, S.; Piazza, P. A Deep Neural Network Approach for Voice Activity Detection in Multi-Room Domestic Scenarios. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Luo, D.; Yang, R.; Huang, J. Detecting Double Compressed AMR Audio Using Deep Learning. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Proccesing, Florence, Italy, 4–9 May 2014; pp. 2669–2673. [Google Scholar]
- Touazi, A.; Debyeche, M. A Case Study on Back-End Voice Activity Detection for Distributed Speech Recognition System using Support Vector Machines. In Proceedings of the 2014 Tenth International Conference on Signal-Image Technology and Internet-Based Systems, Marrackech, Morocco, 23–27 November 2014; pp. 21–26. [Google Scholar]
- Souissi, N.; Cherif, A. Dimensionality Reduction for Voice Disorders Identification System Based on Mel Frequency Cepstral Coefficients and Support Vector Machine. In Proceedings of the 7th International Conference on Modelling, Identification and Control, Sousse, Tunisia, 18–20 December 2015; pp. 1–6. [Google Scholar]
- Ying, D.; Yan, Y.; Dang, J.; Soong, F.K. Voice Activity Detection Based on an Unsupervised Learning Framework. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2624–2633. [Google Scholar] [CrossRef]
- Cornu, E.; Sheikhzadeh, H.; Brennan, R.L.; Abutalebi, H.R.; Tam, E.C.Y.; Iles, P.; Wong, K.W. ETSI-AMR2 VAD: Evaluation and Ultra Low-Resource Implementation. In Proceedings of the International Conference on Multimedia and Expo, Baltimore, MD, USA, 6–9 July 2003; Volume 2, p. II-841-4. [Google Scholar]
- Ong, W.Q.; Tan, A.W.C. Robust Voice Activity Detection Using Gammatone Filtering and Entropy. In Proceedings of the International Conference on Robotics, Automation and Sciences, Melaka, Malaysia, 5–6 November 2016; pp. 1–5. [Google Scholar]
- Aneeja, G.; Yegnanarayana, B. Single Frequency Filtering Apporach for Discriminating Speech and Nonspeech. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 705–717. [Google Scholar] [CrossRef]
- Moore, B.C.J. Coding of sounds in the Auditory System and Its Relevance to Signal Processing and Coding in Cochlear Implants. Otol. Neurotol. 2003, 24, 243–254. [Google Scholar] [CrossRef] [PubMed]
- Johannesma, P.I.M. The pre-response stimulus ensemble of neuron in the cochlear nucleus. In Proceedings of the Symposium of Hearing Theory, Eindhoven, The Netherlands, 22–23 June 1972; pp. 58–69. [Google Scholar]
- Schlider, R.; Bezrukov, I.; Wagner, H.; Ney, H. Gammatone Features and Feature Combination for Large Vocabulary Speech Recognition. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; pp. IV-649–IV-652. [Google Scholar]
- Qi, J.; Wang, D.; Jiang, Y.; Liu, R. Auditory Features Based on Gammatone Filters for Robust Speech Recognition. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013; pp. 305–308. [Google Scholar]
- Kim, C.; Stern, R.M. Power-Normalized Cepstral Coefficient (PNCC) for Robust Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1315–1329. [Google Scholar] [CrossRef]
- Papadopoulos, P.; Tsiartas, A.; Narayanan, S. Long-term SNR Estimation of Speech Signals in Known and Unknown Channel Conditions. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2495–2506. [Google Scholar] [CrossRef]
- Renevey, P.; Drygajlo, A. Entropy Based Voice Activity Detection in Very Noisy Condition. In Proceedings of the EUROSPEECH 2001 Scandinavia, 7th European Conference on Speech Communication and Technology, 2nd INTERSPEECH Event, Aalborg, Denmark, 3–7 September 2001; pp. 1887–1890. [Google Scholar]
- Asgari, M.; Sayadian, A.; Farhadloo, M.; Mehrizi, E.A. Voice Activity Detection Using Entropy in Spectrum Domain. In Proceedings of the Australasian Telecommunication Networks and Applications Conference, Adelaide, Australia, 7–10 December 2008; pp. 407–410. [Google Scholar]
- Metzger, R.A.; Doherty, J.E.; Jenkins, D.M. Using Approximate Entropy as a Speech Quality Measure for a Speaker Recognition System. In Proceedings of the Annual Conference on Information Science and Systems, Princeton, NJ, USA, 16–18 March 2016; pp. 292–297. [Google Scholar]
- Humeau-Heurtier, A.; Wu, C.W.; Wu, S.D.; Mahe, G.; Abraham, P. Refined Multiscale Hilbert-Huang Spectral Entropy and Its Application to Central and Peripheral Cardiovascular Data. IEEE Trans. Biomed. Eng. 2016, 63, 2405–2415. [Google Scholar] [CrossRef] [PubMed]
- Freeman, D.K.; Cosier, G.; Southcott, C.B.; Boyd, I. The Voice Activity Detector for The Pan-European Digital Cellular Mobile Telephone Service. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Glasgow, UK, 23–26 May 1989; pp. 369–372. [Google Scholar]
- Beritelli, F.; Casale, S.; Cavallaero, A. A robust voice activity detector for wireless communications using soft computing. IEEE J. Sel. Areas Commun. 1998, 16, 1818–1829. [Google Scholar] [CrossRef]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallet, D.S.; Dahlgren, N.L.; Zue, V. TIMIT Acoustic-Phonetic Continuous Speech Corpus LDC93S1; Linguistic Data Consortium: Philadelphia, PA, USA, 1993; Available online: https://catalog.ldc.upenn.edu/docs/LDC93S1/ (accessed on 9 September 2017).
- ELDA S.A.S. ELRA Catalogue. AURORA Project Database 2.0, ISLRN: 977-457-139-304-2, ELRA ID: AURORA/CD0002. Available online: http://catalog.elra.info (accessed on 9 September 2017).
- Rajamani, K.; Lai, Y.; Farrow, C.W. An Efficient Algorithm for Sample Rate Conversion from CD to DAT. IEEE Signal Process. Lett. 2000, 7, 288–290. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Sampling frequency | 8000 Hz |
| Frame size, N | 512 (64 ms) |
| Pre-emphasis factor, | −0.9375 |
| Number of gammatone filter channel, K | 16 |
| Number of gammatone filter tap, L | 200 |
| Gammatone filter bank frequency range, ; | 300 Hz; 4000 Hz |
| ANF coefficient, ; | 0.1; 0.9 |
| Transition threshold coefficient, | 3 |
| Threshold value, | 20 |
| ANF coefficient, ; | 0.99; 0.9 |
| SNR (dB) | Voice Activity Detection Algorithms | |||||
|---|---|---|---|---|---|---|
| AMR-VAD2 | PND | SFF | LTSV | GE-VAD | UEWE-DANF | |
| −10 | 57.96 | 57.07 | 67.67 | 63.23 | 53.58 | 66.62 |
| −5 | 63.3 | 60.36 | 76.59 | 70.06 | 57.16 | 75.36 |
| 0 | 73.17 | 64.25 | 83.93 | 74.97 | 61.58 | 82.95 |
| 5 | 82.03 | 66.43 | 87.2 | 76.81 | 66.37 | 87.8 |
| 10 | 87.21 | 67.44 | 88.44 | 77.01 | 69.93 | 90.27 |
| 15 | 89.35 | 69.46 | 88.98 | 76.38 | 73.38 | 90.94 |
| 20 | 90.34 | 70.49 | 89.06 | 76.04 | 75.61 | 91.2 |
| SNR (dB) | Voice Activity Detection Algorithms | ||||||
|---|---|---|---|---|---|---|---|
| AMR-VAD2 | PND | SFF | LTSV | GE-VAD | UEWE | UEWE-DANF | |
| −10 | 60.11 | 58.63 | 62.59 | 55.58 | 53.91 | 62.4 | 64.16 |
| −5 | 69.23 | 63.39 | 67.63 | 64.41 | 57.82 | 70.51 | 72.84 |
| 0 | 80.16 | 68.84 | 71.67 | 68.52 | 64.38 | 72.82 | 84.4 |
| 5 | 79.12 | 72.71 | 75.28 | 63.44 | 67.43 | 70.51 | 88.44 |
| 10 | 81.36 | 76.42 | 77.82 | 62.96 | 70.79 | 70.49 | 92.06 |
| 15 | 81.54 | 78.9 | 80.88 | 65.76 | 72.78 | 69.5 | 91.67 |
| 20 | 87.91 | 80.17 | 81.12 | 64.07 | 74.89 | 66.54 | 91.56 |
| Number of Channels, K | Number of Taps, L | MIPS |
|---|---|---|
| 16 | 50 | 232.3–250.3 |
| 16 | 30 | 148.8–159.4 |
| 14 | 50 | 47.4–49.86 |
| 12 | 100 | 8.53–8.84 |
| 12 | 50 | 8.0–9.3 |
| 12 | 30 | 8.9–9.4 |
| 8 | 100 | 16–16.5 |
| 8 | 50 | 16.3–17.5 |
| 8 | 30 | 16.5–17.0 |
| SNR (dB) | Highest Value among the Existing VADs | UEWE-DANF (K = 16, L = 200) | UEWE-DANF (K = 12, L = 50) |
|---|---|---|---|
| −10 | 62.59 | 64.16 | 62.91 |
| −5 | 69.23 | 72.84 | 69.39 |
| 0 | 80.16 | 84.4 | 81.6 |
| 5 | 79.12 | 88.44 | 87.71 |
| 10 | 81.36 | 92.06 | 91.81 |
| 15 | 81.54 | 91.67 | 91.47 |
| 20 | 87.91 | 91.56 | 91.43 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ong, W.Q.; Tan, A.W.C.; Vengadasalam, V.V.; Tan, C.H.; Ooi, T.H. Real-Time Robust Voice Activity Detection Using the Upper Envelope Weighted Entropy Measure and the Dual-Rate Adaptive Nonlinear Filter. Entropy 2017, 19, 487. https://doi.org/10.3390/e19110487
Ong WQ, Tan AWC, Vengadasalam VV, Tan CH, Ooi TH. Real-Time Robust Voice Activity Detection Using the Upper Envelope Weighted Entropy Measure and the Dual-Rate Adaptive Nonlinear Filter. Entropy. 2017; 19(11):487. https://doi.org/10.3390/e19110487
Chicago/Turabian StyleOng, Wei Qing, Alan Wee Chiat Tan, V. Vijayakumar Vengadasalam, Cheah Heng Tan, and Thean Hai Ooi. 2017. "Real-Time Robust Voice Activity Detection Using the Upper Envelope Weighted Entropy Measure and the Dual-Rate Adaptive Nonlinear Filter" Entropy 19, no. 11: 487. https://doi.org/10.3390/e19110487