Digital Image Stabilization Method Based on Variational Mode Decomposition and Relative Entropy

1
School of Electrical Engineering and Automation, Harbin Institute of Technology, Harbin 150001, China
2
School of Astronautics, Harbin Institute of Technology, Harbin 150001, China
*
Author to whom correspondence should be addressed.
Entropy 2017, 19(11), 623; https://doi.org/10.3390/e19110623
Submission received: 11 September 2017
/
Revised: 15 November 2017
/
Accepted: 16 November 2017
/
Published: 18 November 2017
Abstract
:Cameras mounted on vehicles frequently suffer from image shake due to the vehicles’ motions. To remove jitter motions and preserve intentional motions, a hybrid digital image stabilization method is proposed that uses variational mode decomposition (VMD) and relative entropy (RE). In this paper, the global motion vector (GMV) is initially decomposed into several narrow-banded modes by VMD. REs, which exhibit the difference of probability distribution between two modes, are then calculated to identify the intentional and jitter motion modes. Finally, the summation of the jitter motion modes constitutes jitter motions, whereas the subtraction of the resulting sum from the GMV represents the intentional motions. The proposed stabilization method is compared with several known methods, namely, medium filter (MF), Kalman filter (KF), wavelet decomposition (MD) method, empirical mode decomposition (EMD)-based method, and enhanced EMD-based method, to evaluate stabilization performance. Experimental results show that the proposed method outperforms the other stabilization methods.
1. Introduction
Digital cameras are frequently used to record video information. However, cameras mounted on vehicles frequently suffer from image shaking caused by the vehicles’ motion [1,2]. In particular, serious image shake occurs in complex terrains or under strenuous motions, thereby blurring the video sequences captured by cameras. Image shake does not only reduce the accuracy of observation, but also increases eye strain of users. To solve this problem, image stabilization has been widely studied in recent years [3,4,5].
Recent image stabilization systems can be generally classified into four categories: (1) optical image stabilization systems, which feature a kind of mechanism that stabilizes video sequences by optical computing with high accuracy and speed [6,7]; (2) electronic image stabilization systems, that use accelerometers or motion gyroscopes to detect camera motion and then compensate the jitter motion [8]; (3) orthogonal transfer charge-coupled device (CCD) stabilization systems, which use CCDs to measure image displacement and shifts the deviation according to the motion of bright stars [9]; (4) digital image stabilization (DIS), which estimates the global motion vector (GMV) and removes unintentional motion components from the GMV to generate stable video sequences using image processing algorithms [10,11,12]. DIS methods outperform other image stabilization methods because they are more flexible and are hardware-independent.
Motion separation is the most critical step in DIS. In signal processing, jitter motion separation from GMV can be considered a noise removal issue. Intentional motions can be considered useful signals, whereas jitter motions can be considered noisy signals. Therefore, various traditional filter methods can be used to remove jitter motions. MF includes a simple mathematical model and is a widely used scheme [13,14]. In this method, intentional motion vector is smoothed by averaging GMVs within a window. However, MF performance highly depends on window size. Another traditional method is KF, which estimates intentional motions using a dynamic motion model [15,16,17]. KF uses the current observation and previously estimated state to generate intentional motion. KF can be easily designed; however, it is unsuitable for nonlinear conditions [18]. WD method is proposed to satisfy nonlinear conditions [19]. However, the WD method must determine a proper wavelet basis function in advance, and this task becomes very difficult in complex conditions. Recently, many empirical mode decomposition (EMD)-based DIS algorithms have been proposed [20,21]. These techniques can adaptively separate jitter and intentional motions from GMV. However, EMD-based methods present many defects, such as having no precise mathematical model, sensitivity to noise, and sampling and mode mixing, which may result in inaccurate separation [22,23].
In the current study, a hybrid DIS method is proposed that uses variational mode decomposition (VMD) and relative entropy (RE). First, the GMV of video sequence is estimated using the scale-invariant feature transform (SIFT) feature matching algorithm. Then, the GMV is decomposed into several band-limit modes via VMD. Intentional motions possess low frequency and high amplitude because they are much slower than the frame rate, whereas jitter motion exhibit the opposite nature [13,20]; thus, jitter and intentional motions usually exhibit different statistical properties. Therefore, the RE value between two jitter motion modes is low, whereas the RE value between the intentional and jitter motion modes is high. Based on this fact, jitter motion modes can be determined. The summation of jitter motion modes constitutes the jitter motion vector, while the substraction of the resulting sum from the GMV represents the intentional motion vector. Several algorithms are then compared, and the experimental results show that the proposed method has better performance than the other algorithms.
The main contributions of this work are listed as follows: (1) A VMD-based motion separation method is proposed in this work. The VMD divides GMV into several narrow-banded modes, which has different center frequencies. The modes with different frequency characteristics decomposed by VMD can reproduce the original GMV. (2) A RE method is proposed to identify relevant modes. The proposed method utilizes statistical information to represent the internal relationship between different modes. Thus, compared with other existing methods (Hausdorff distance [24], power of amplitude [20], correlation coefficients [25]), the proposed method can better differentiate the intentional and jitter motions.
The rest of this paper is organized as follows: Section 2 introduces the related work, including the mathematical model of jitter motions, the VMD theory, and the RE theory. Section 3 illustrates the proposed DIS framework. Section 4 provides the experimental results of the proposed method compared with other methods. Finally, conclusions are drawn in Section 5.
2. Related Work
2.1. Mathematic Model of Jitter Motion
In a vehicle-mounted camera system, irregular pavement, engine, transmission system, and tire vibration all cause random jitters in the camera holder, which makes the video sequences unstable. Among them, the irregular pavement is the most serious factor. The jitter level of the camera pan has strong relationship with road roughness (RR) [26]. The statistical characteristics of RR can be illustrated by the power spectral density of pavement displacement:
where denotes spatial frequency; is the reference spatial frequency, which can be set as ; is the coefficient of RR; and is the frequency index, which is set as 2.
Aside from RR, vehicle speed can affect the frequency of jitter motions [27], as expressed as follows:
where is the time spectral of RR, which reflects the frequency of jitter motions; and represents the vehicle speed. Equation (3) indicates that the frequency of jitter motions is only relative to vehicle speed and RR. In general, the sampling frequency of the video frequency is considerably higher than the frequency of motion vector. Thus, RR and vehicle speed can be assumed invariable within a short time. Then the frequency of jitter motions will be band-limited with large probability within a short time.
2.2. VMD Theory
VMD is different from traditional recursive model. This method concurrently searches modes and their center frequencies. By performing VMD, the signal can be decomposed into several band-limit modes , where is the number of modes. Each mode converges around the center frequency . Therefore, variational problem can be constructed, as shown by Equation (4) [28]:
where is the input signal, is Dirac distribution, is time script, and denotes convolution.
To solve Equation (4), a quadratic penalty term and Lagrangian multiplier are used to transform the constrained variational problem into the following unconstrained variational problem:
Then, using the alternate direction method of multipliers (by updating the , , and alternately), the solution of the optimal problem can be obtained by searching the saddle point of Equation (5) [29]. VMD is implemented as follows:
- (1)
- Initialize the modes , center pulsation , Lagrangian multiplier and the maximum iterations N (5000 in this paper). The cycle index is set to .
- (2)
- The cycle is started, .
- (3)
- The first inner loop is executed, and is updated according to following function:
- (4)
- The second inner loop is executed, and is updated according to the following function:
- (5)
- is updated according to the following:
- (6)
- Steps (2)–(5) are repeated until convergence, as follows:
where is an update parameter, is a small number (0.00001 in this paper). The solution to update and can be solved in the spectral domain, as follows:
Then, the obtained modes in frequency domain are transformed into the time domain via inverse Fourier transform. According to Dragomeretskiy’s theory, there are two important parameters that has influence on the result: the penalty parameter and the mode number [28]. First, Dragomeretskiy suggested that if the principle frequencies of the sub-components are estimated a priori, then a low is preferred to use because gains freedom of mobility to the appropriate modes [28]. In the proposed method, a low (100) is preferred because no prior frequencies of the sub-components are given. Second, when is small, either one of the modes is shared by the neighboring modes (underbinning) or several additional modes will generally consist of texture with a low structure (overbinning). In the first case, the intentional motion and jitter motion may be in the same mode, thereby impeding the good results. If the excess modes are decomposed, then the performance will not be significantly improved, but the computation will be increased. In our simulation, the number 5 can meet the requirement of most tests.
2.3. RE Theroy
In mathematical statistics, RE measures the difference between two probability distributions [30]. For discrete probability distributions and , RE from to is defined as follows:
The RE between two modes reflects the difference of probability distribution. In most cases, jitter and intentional motions exhibit different statistical properties. The jitter motion vector is wide-sense stationary or approximate to the Gaussian distribution, whereas the intentional motion vector is arbitrary. Thus, the RE value between two jitter motion modes is low, whereas that between the intentional and jitter motion modes is high.
3. Proposed Digital Image Stabilization Framework
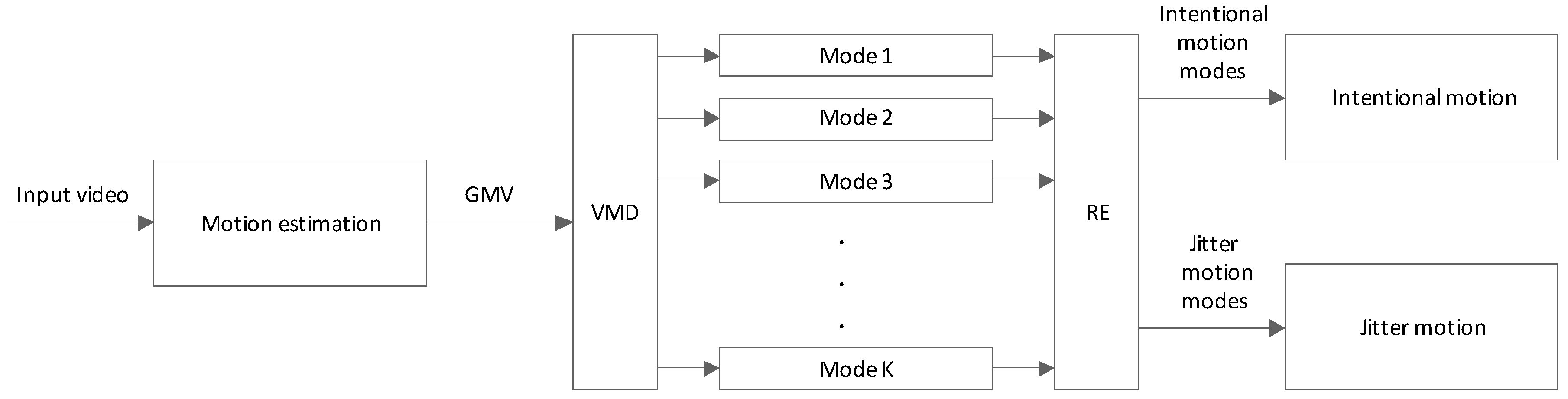
There are three key procedures in the proposed DIS framework, namely, motion estimation, motion separation, and intentional motion vector reconstruction. During the first step, GMV is estimated using the SIFT feature point matching algorithm. Subsequently, VMD is applied to decompose GMV into different modes. RE is used in determining the intentional and jitter motion modes to separate them. Finally, the summation of the jitter motion modes constitutes the jitter motion vector, whereas the subtraction of the resulting sum from the GMV represents the intentional motion vector. The framework of the proposed DIS method is shown in Figure 1.
3.1. Motion Estimation
Lowe proposed SIFT in 1999 [31]. SIFT feature is robust against rotation, scaling, and illumination changes and considered one of the best feature extraction methods. SIFT searches extreme values in the scale space and generates 128 dimensions descriptors. Figure 2 and Figure 3 show the SIFT feature points and feature points of matching results of two test images, respectively. SIFT feature significantly reduces the probability of mismatch. Nevertheless, false matching can still occur among candidate points, as presented in Figure 3. Matching results may also represent the local motion vector instead of GMV when SIFT feature points are on the foreground objects. In general, random sample consensus (RANSAC) is used to solve the mismatching problem [32]. Finally, GMV between two consecutive frames are calculated by averaging the displacements of different feature points. The motion vector between arbitrary two frames can be obtained by following method: Designate a frame as the reference frame, and calculate the motion vectors between the reference frame and current frames.
3.2. Motion Separation
Although the GMV contains translation, rotation, and scaling motions, the motion can be analyzed independently [20]. We take 1D translation displacement as an example in this study.
After conducting motion estimation, the obtained GMV sequence can be considered as a time-varying variable . The amplitude of can be regard as the motion displacement of the camera. Consider the following typical GMV:
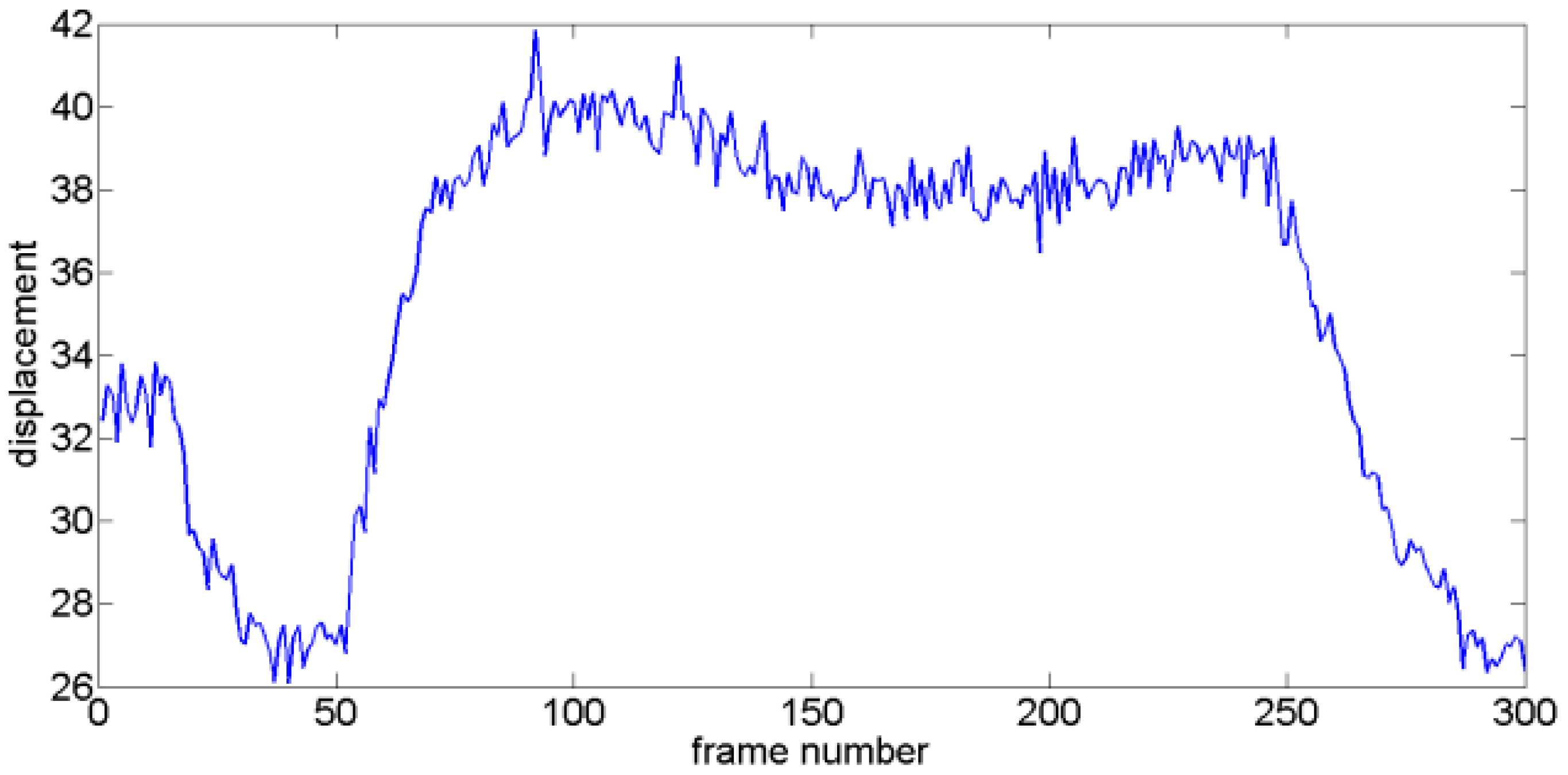
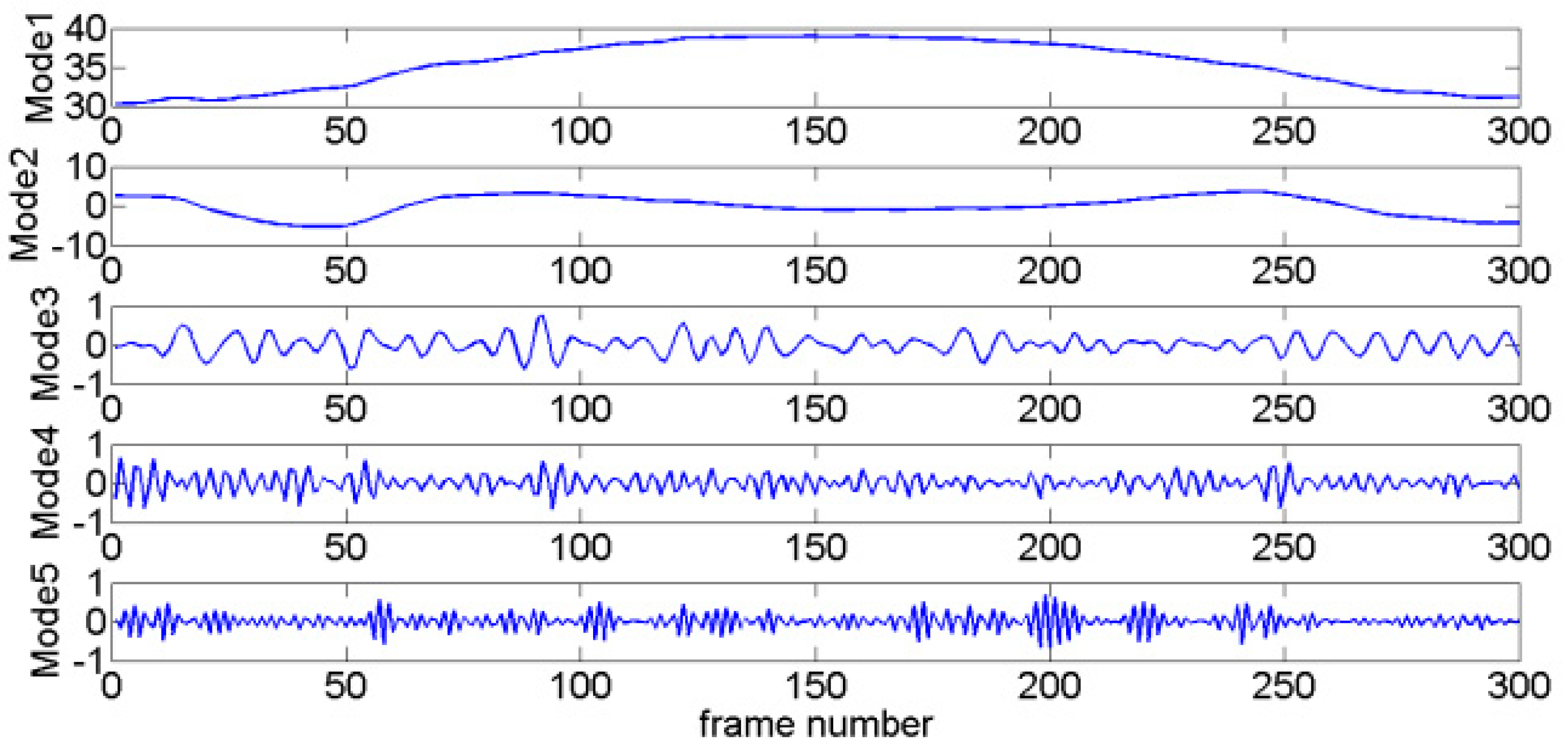
where represents GMV, is the intentional motion vector, and is the jitter motion vector. To separate the jitter and intentional motion components, GMV is decomposed via VMD. For a testing GMV (as Figure 4 shows), the generated modes are shown in Figure 5, which are arranged from low to high frequencies.
On the basis of VMD theory, the relationship between the obtained GMV and its modes is exhibited as follows:
where represents the modes; and are the indexes of intentional and jitter motion modes, respectively.
3.3. Intentional Motion Vector Reconstruction
In the current study, RE is used to identify relevance among modes. The first mode is an intentional motion mode because it features the lowest frequency and largest amplitude [21]. Then, REs between the first mode and the other modes are calculated in sequence (denoted as ). As the intentional motion is much slower than the frame rate, intentional motion shows smooth transition with high amplitude and low frequency between frames. On the other hand, jitter motion is characterized by low amplitude and high frequency. In general, jitter motions can be considered to approximately obey Gaussian distribution [10,15]. Therefore, RE value will remain at low levels when the two modes are both intentional motion components; otherwise, RE value will remain at high levels. The modes exhibit low RE values with the first mode being dominated by intentional motion, whereas the remaining modes are dominated by jitter motion.
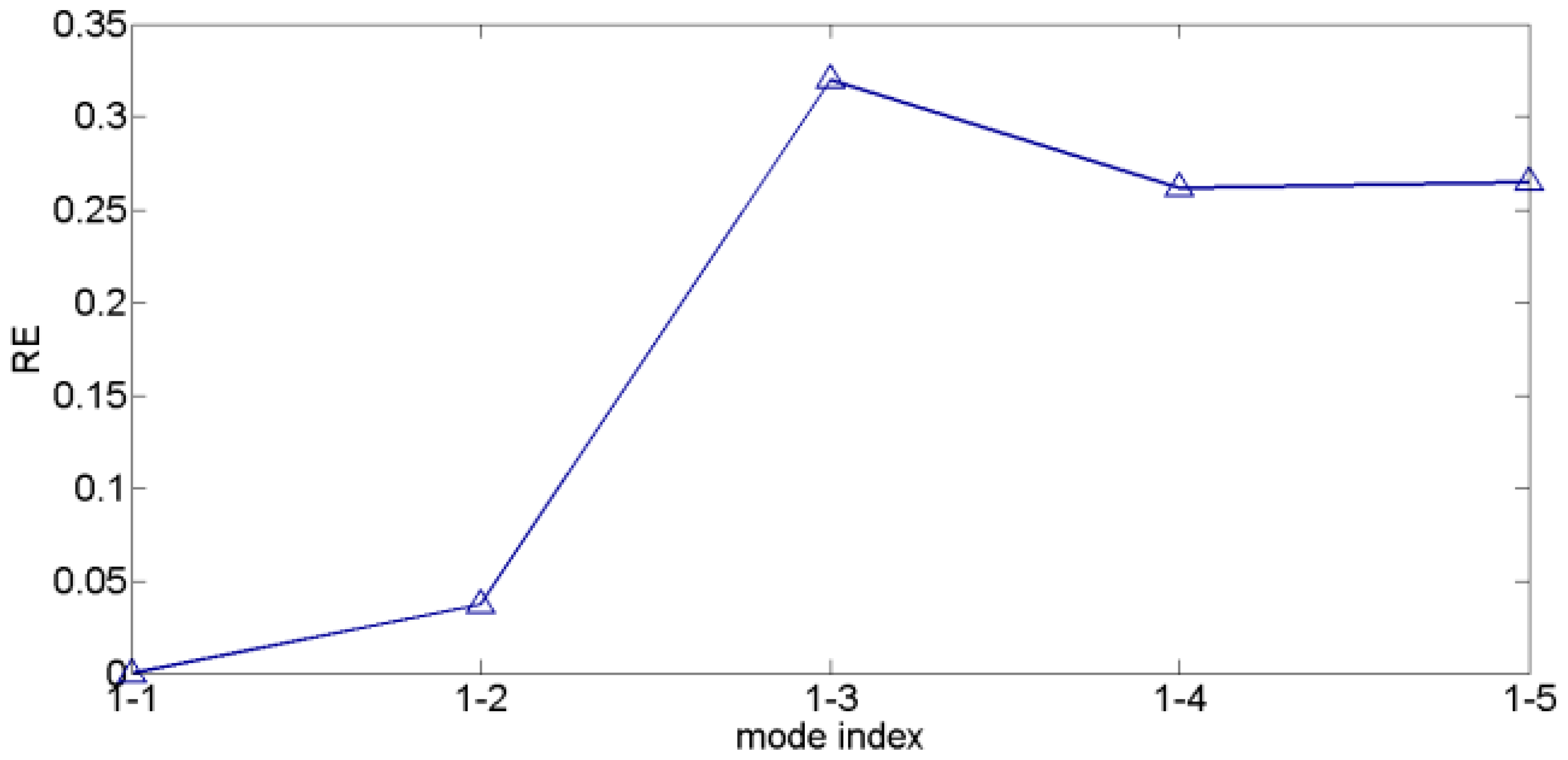
The corresponding REs for the modes presented in Figure 5 are shown in Figure 6. is the smallest, and stays at a low level. However, a sudden increase is observed at , and the subsequent REs all stay at a high level. From the preceding analysis, the modes behind the third mode correspond to jitter motions (including the third mode), whereas the first and second modes comprise intentional motions.
The following procedures describe the DIS steps:
- (1)
- Calculate the GMV by SIFT point matching algorithm.
- (2)
- Decompose the GMV into modes via VMD.
- (3)
- Calculate the REs between the first mode and other modes.
- (4)
- If is smaller than a threshold (usually, can meet the demands of most situations), then the mode is considered an intentional motion mode.
- (5)
- Obtain the reconstructed intentional motion by summing the intentional motion modes as follows:
4. Experimental Results and Discussions
4.1. Performance of the RE
To illustrate the effectiveness of RE, three different tests are performed to evaluate mode separation performance. Given a known clean signal , contaminate the signal with different kind of noises (including the Gaussian noise, office noise, and factory noise) as follows:
where is the noise signal with different input SNRs.
The probability density function of Gaussian noise obeys the Gaussian distribution, which includes a fixed mean and variance. Office noise consists of many signals with different frequencies and high amplitude. Factory noise is caused by mechanical shock, rub impact, and air disturbance and includes numerous intermittent and impulse noises. For signals with different noises, we compare several selection criteria, including the Hausdorff distance [24], power amplitude [20], and correlation coefficient [25]. The evaluation steps are as follows. Noises are downloaded from NoiseX-92 database. Signal length is set as 200.
- (1)
- Noises are added to the original clean signal , and input SNR ranges from −8 dB to 8 dB with interval of 2 dB.
- (2)
- Noisy signals are decomposed into several modes via VMD.
- (3)
- According to different selection criteria, the modes are classified.
- (4)
- The reconstructed clean signals are calculated by summing the relevant modes.
- (5)
- Output SNRs are calculated for different reconstructed signals:
where and correspond to the powers of the original and reconstructed signals, respectively.
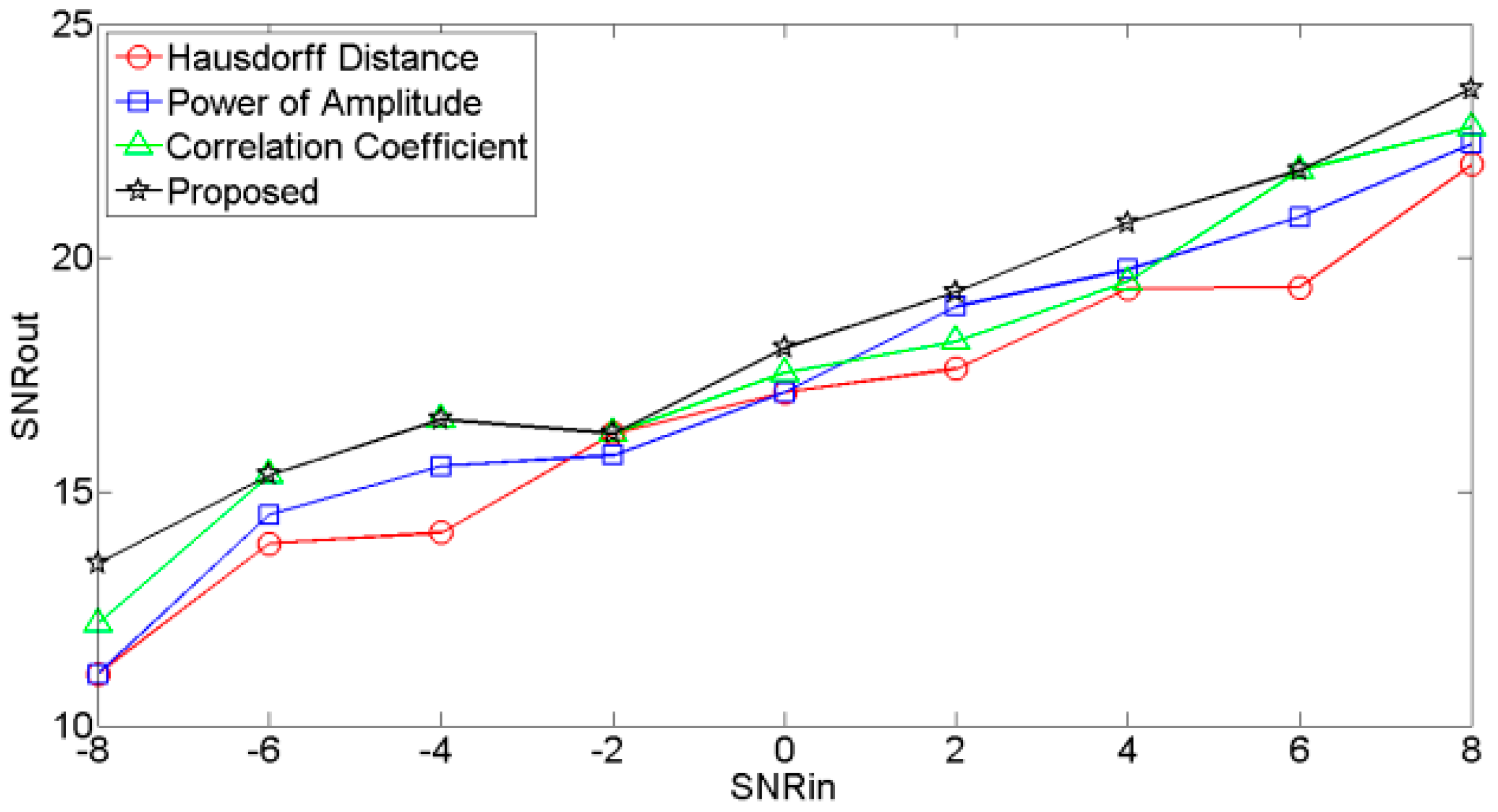
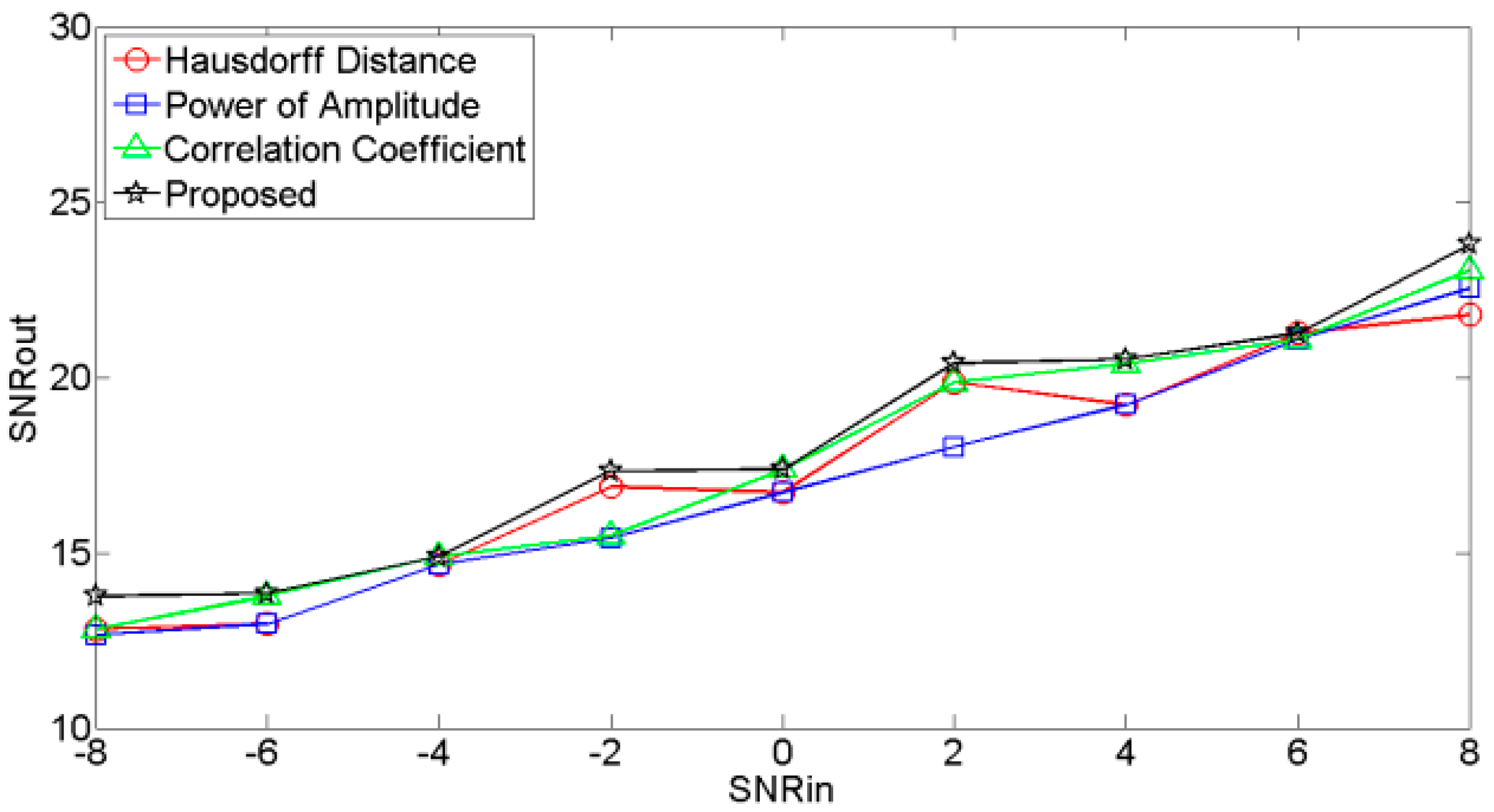
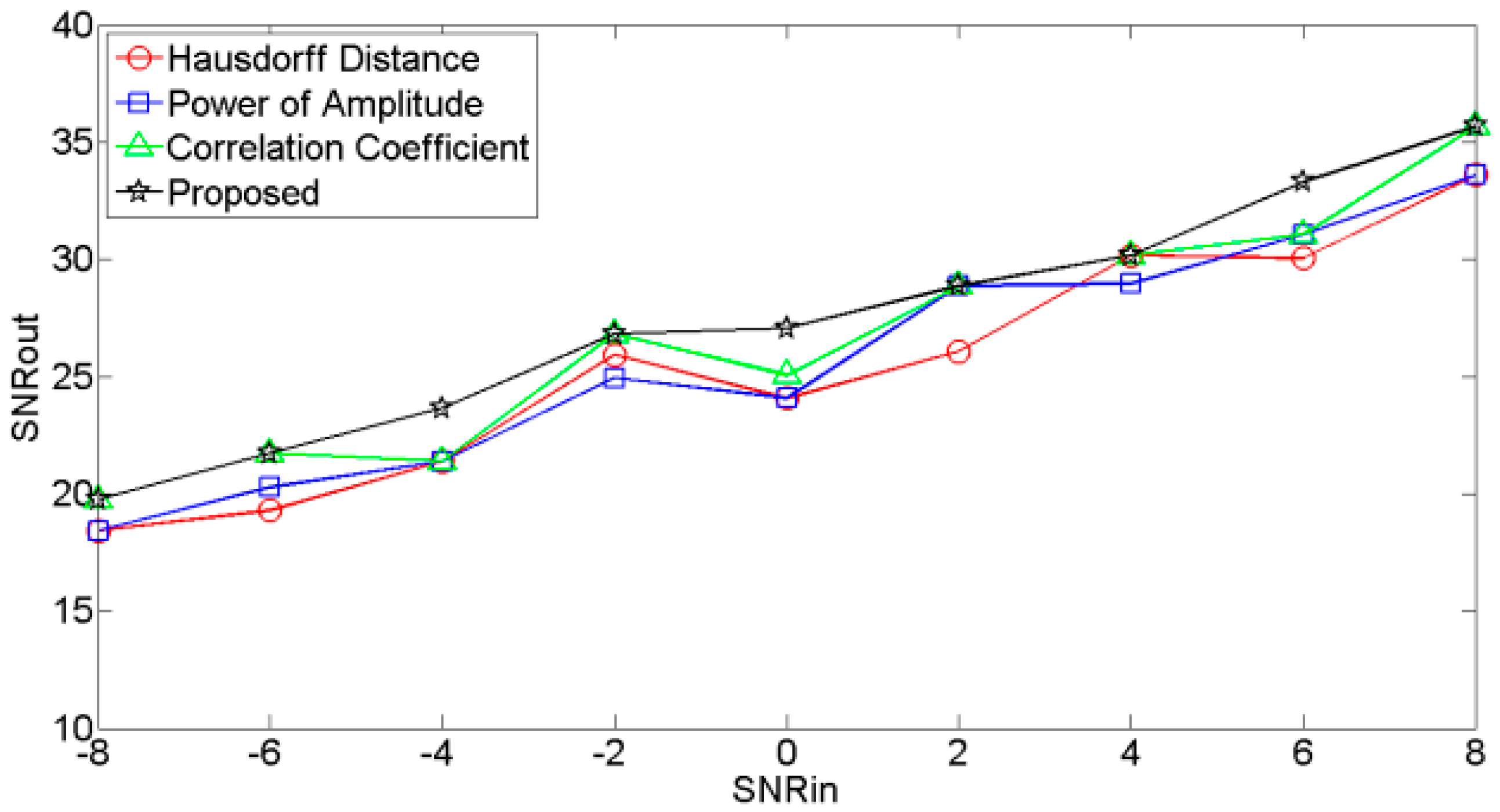
The plots of input SNR (SNRin) versus output SNR (SNRout) for different noisy signals are shown in Figure 7, Figure 8 and Figure 9, respectively. These figures showed that the SNRouts of the RE selection criteria are higher than other selection criteria, which indicates that the RE selection criteria outperforms the other selection criteria.
4.2. Performance of the VMD-RE Method in DIS
Several simulation tests are performed to verify the effectiveness of the proposed VMD-RE method. A camera that mounted on holder mechanism is used to capture the video sequences, as shown in Figure 10. In this paper, we use the SNR and root mean square error (RMSE) [21]:
where and are the powers of the ground truth and the resulted intentional motion, respectively. is the number of sample points; and and are the amplitude of each point in the ground truth and reconstructed motion vectors, respectively.
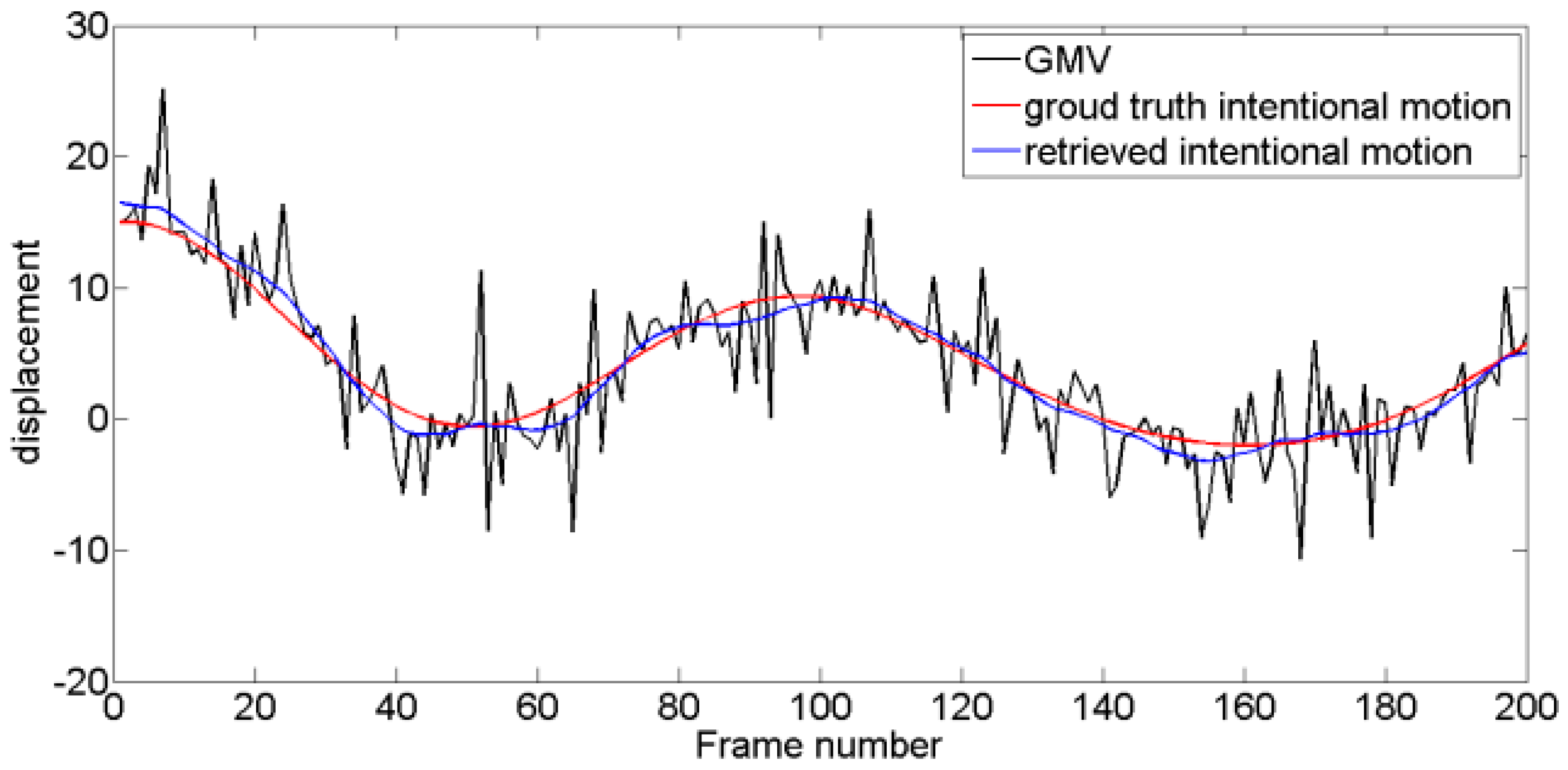
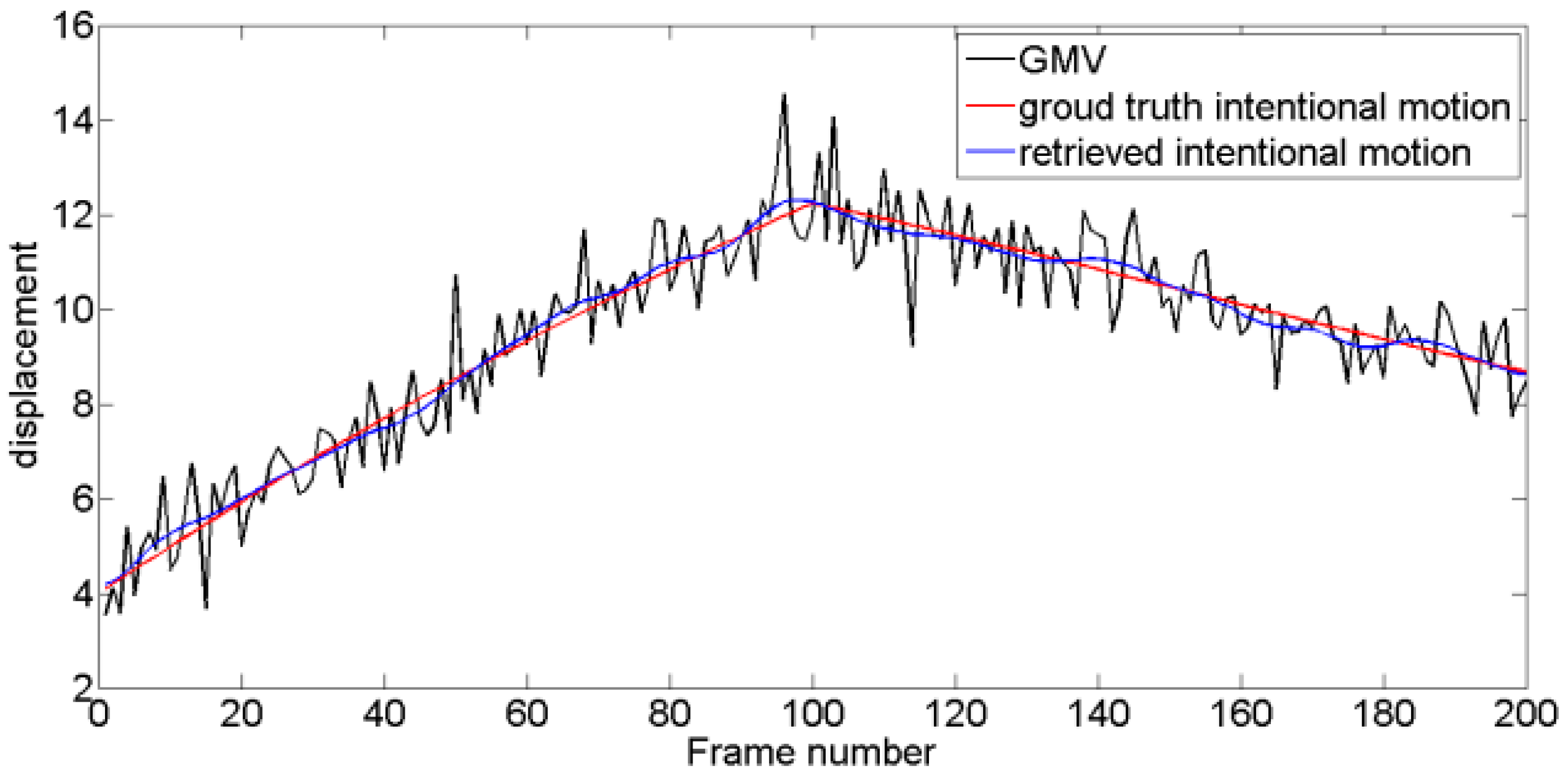
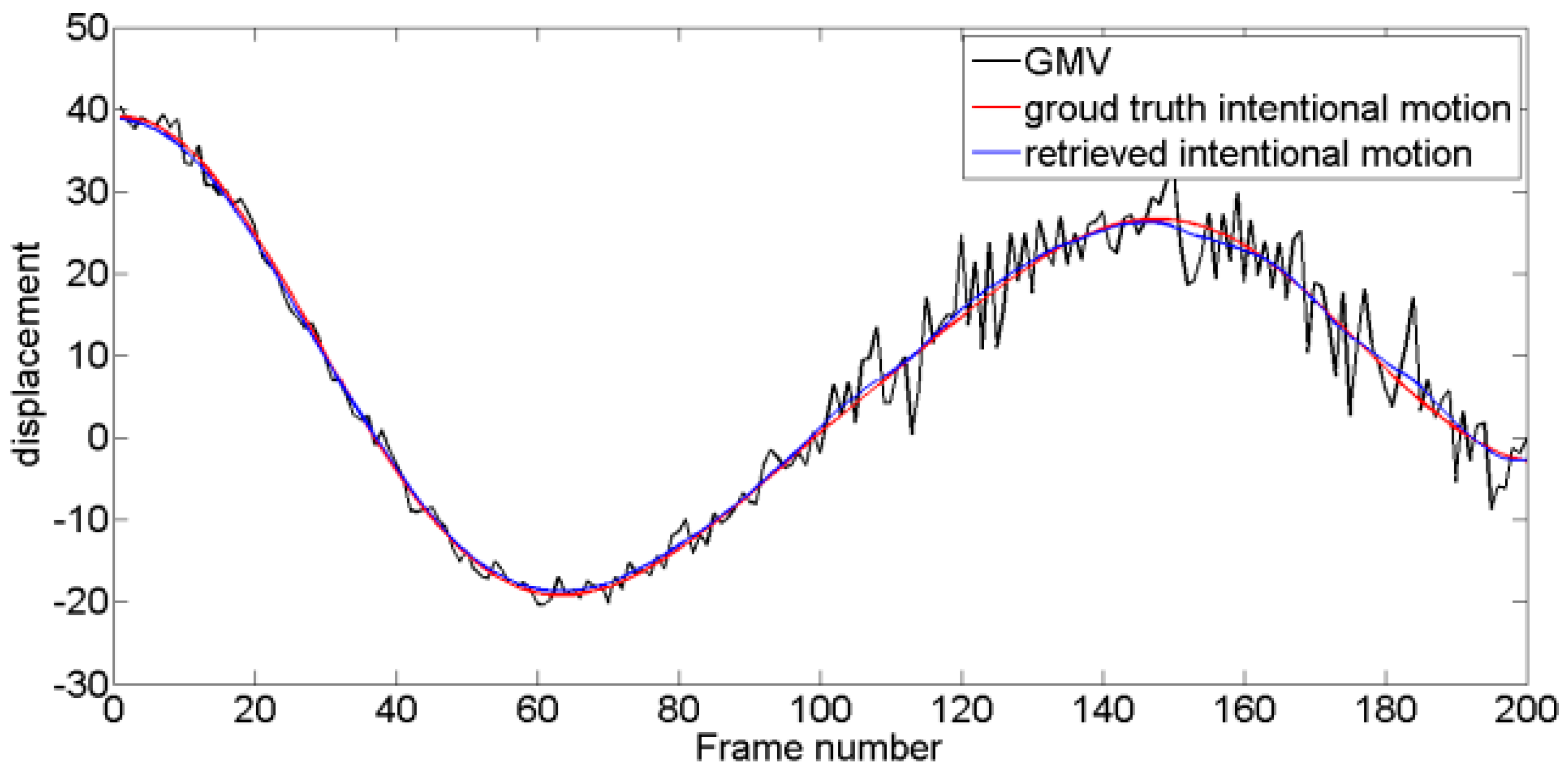
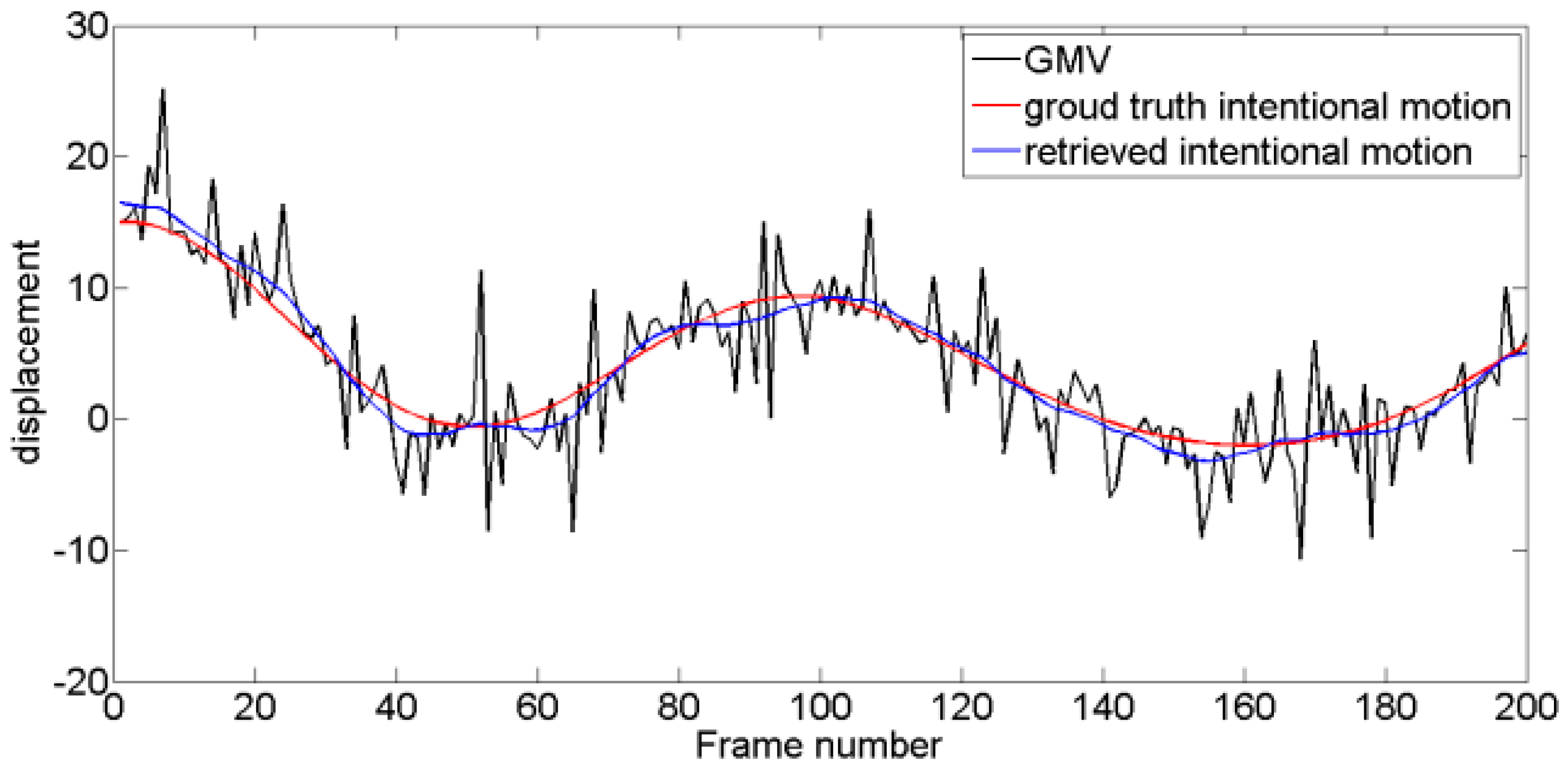
Four typical unstable scouting video sequences are tested. For Test 1, intentional motion is approximately linear, and jitter motion obeys a Gaussian distribution with fixed mean and variance. For Test 2, intentional motion contains multi-frequency components, and jitter motion obeys a Gaussian distribution. For Test 3, the level of jitter motion varies, and variance is low at former frames and increases along with time. For Test 4, the amplitude of jitter motion is maintained at high levels compared with that of intentional motions, and the level of jitter motion is time-varying. Experimental tests are performed using MATLAB® R2013a running on a PC equipped with a 2.60 GHz Intel Core i7-6700HQ CPU with 8 GB RAM. As shown in Figure 11, Figure 12, Figure 13 and Figure 14, four pairs of images are extracted from different video sequences. The displacement between two frames can be obtained using the SIFT feature point matching algorithm. The first picture in each group is the reference frame, whereas the second picture is the current frame. The blue lines show the image matching results. The actual GMV, ground truth intentional motions, and retrieved intentional motions are shown in Figure 15, Figure 16, Figure 17 and Figure 18. Table 1 and Table 2 show the RMSE and SNR values obtained using six different DIS algorithms, including the MF [11], KF [15], wavelet decomposition (WD) method [19], EMD-based method [20], enhanced EMD-based (E-EMD) method [21], and the proposed method.
First, from Table 1 and Table 2, we can conclude that the MF generates the poorest results in Tests 1 and 2, KF in Test 4, and WD in Test 3. These three kinds of methods show unstable performances. MF performance highly depends on window size [11]. Larger window size generates a smoother intentional motion vector and vice versa. In this paper, window size is set as 5. Window size is accurate in some conditions but not in others. KF is not adaptive to changing jitter levels in Tests 3 and 4, and stabilization results are insufficiently accurate. KF requires that observation and transition noises obey the Gaussian distribution, and variances must be constant. However, in many cases, transition variance is time-varying, causing KF to generate poor results in Test 4. The WD method can hardly select an appropriate wavelet basis function applicable in all conditions [19]. The performance may improve if basis function is well-selected and vice versa. These three traditional methods cannot be adapted to changing conditions and cannot be used in complex vehicle-mounted DIS systems. Second, comparing mode decomposition methods with traditional methods, we can conclude that mode decomposition methods generally perform better than traditional ones. Nevertheless, we also note that EMD method performs well in Tests 3 and 4 but poorly in Tests 1 and 2. This result can be attributed to the difficulty of determining the relevant model in complex condition because frequency information of intentional and jitter motions may overlap (mode mixing). E-EMD method generates better results than the traditional EMD method (mode mixing problem can be alleviated by adding white noise series to the targeted data and averaged corresponding intrinsic mode functions). However, compared with the proposed method, such performance remains at a disadvantage. By contrast, the proposed method calculates jitter motion variance and generates considerably better results than the other methods. The proposed method produces the lowest RMSE values and the highest SNR values in all tests.
5. Conclusions
This study proposed a DIS method based on VMD and RE. GMV is estimated using a SIFT feature point matching algorithm. Then, GMV is decomposed via VMD. According to the RE value between modes, relevant modes of intentional and jitter motions are determined. Performance of the proposed method is compared with several state-of-the-art methods. Simulation results show better performance of the proposed method than other related methods based on quantitative comparisons of RMSE and SNR values.
Author Contributions
Hao Duo conceived the algorithm and wrote the manuscript. Chengwei Li, Qiuming Li and Hao Duo designed and performed the experiment. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sato, K.; Ishizuka, S.; Nikami, A.; Sato, M. Control techniques for optical image stabilizing system. IEEE Trans. Consum. Electron. 1993, 39, 461–466. [Google Scholar] [CrossRef]
- Egusa, Y.; Akahori, H.; Morimura, A.; Wakami, N. An application of fuzzy set theory for an electronic video camera image stabilizer. IEEE Trans. Fuzzy Syst. 1995, 3, 351–356. [Google Scholar] [CrossRef]
- Tsytsulin, A.K.; Fakhmi, S.S. Stabilization of images on the basis of a measurement of their displacement, using a photodetector array and two linear photodetectors in combination. J. Opt. Technol. 2012, 79, 727–732. [Google Scholar] [CrossRef]
- Xu, L.; Lin, X. Digital Image Stabilization Based on Circular Block Matching. IEEE Trans. Consum. Electron. 2006, 52, 566–574. [Google Scholar]
- Jin, J.S.; Zhu, Z.; Xu, G. A stable vision system for moving vehicles. IEEE Trans. Intell. Transp. Syst. 2000, 1, 32–39. [Google Scholar] [CrossRef]
- Chiu, C.W.; Chao, P.C.P.; Wu, D.Y. Optimal design of magnetically actuated optical image stabilizer mechanism for cameras in mobile phones via genetic algorithm. IEEE Trans. Magn. 2007, 6, 2582–2584. [Google Scholar] [CrossRef]
- Qian, Y.; Li, Y.; Shao, J.; Miao, H. Real-time Image Stabilization for Arbitray Motion Blurred Image Based on Opto-Electronic Hybrid Joint Transform Correlator. Opt. Express 2011, 19, 10762–10768. [Google Scholar] [CrossRef] [PubMed]
- Kinugasa, T.; Yamamoto, N.; Komatsu, H.; Takase, S.; Imaide, T. Electronic image stabilizer for video camera use. IEEE Trans. Consum. Electron. 1900, 36, 520–525. [Google Scholar] [CrossRef]
- Burke, B.E.; Reich, R.K.; Savoye, E.D.; Tonry, J.L. An orthogonaltransfer CCD imager. IEEE Trans. Electron. Devices 1994, 41, 2482–2484. [Google Scholar] [CrossRef]
- Wang, C.T.; Kim, J.H.; Byun, K.Y.; Ko, S.J. Robust digital image stabilization using Kalman filter. IEEE Trans. Consum. Electron. 2009, 55, 6–14. [Google Scholar] [CrossRef]
- Zvantsev, S.P.; Merzlyutin, E.Y. Digital stabilization of images under conditions of planned movement. J. Opt. Technol. 2012, 79, 721–726. [Google Scholar] [CrossRef]
- Kumar, S.; Azartash, H.; Biswas, M.; Nguyen, T. Real-Time Affine Global Motion Estimation Using Phase Correlation and Its Application for Digital Image Stabilization. IEEE Trans. Image Process. 2011, 20, 3406–3418. [Google Scholar] [CrossRef] [PubMed]
- Ko, S.J.; Lee, S.H.; Lee, K.H. Digital image stabilizing algorithms based on bit-plane matching. IEEE Trans. Consum. Electron. 1998, 44, 617–622. [Google Scholar]
- Ko, S.J.; Lee, S.H.; Jeon, S.W.; Kang, E.S. Fast Digital Stabilizer Based on Gray-Coded Bit-Plane Matching. IEEE Trans. Consum. Electron. 1999, 45, 598–630. [Google Scholar]
- Kir, B.; Kurt, M.; Urhan, O. Local Binary Pattern Based Fast Digital Image Stabilization. IEEE Signal Process. Lett. 2015, 22, 341–345. [Google Scholar] [CrossRef]
- Yang, J.; Schonfeld, D.; Mohamed, M. Robust Video Stabilization Based on Particle Filter Tracking of Projected Camera Motion. IEEE Trans. Circuit Syst. Video Technol. 2009, 19, 945–954. [Google Scholar] [CrossRef]
- Ryu, Y.G.; Chung, M.J. Robust Online Digital Image Stabilization Based on Point-Feature Trajectory without Accumulative Global Motion Estimation. IEEE Signal Process. Lett. 2012, 19, 223–226. [Google Scholar] [CrossRef]
- Li, C.; Zhan, L.; Shen, L. Friction Signal Denoising Using Complete Ensemble EMD with Adaptive Noise and Mutual Information. Entropy 2015, 17, 5965–5979. [Google Scholar] [CrossRef]
- Xia, R.; Ke, M.; Feng, Q.; Wang, Z. Online wavelet denoising via a moving window. Acta Autom. Sin. 2007, 33, 897–901. [Google Scholar] [CrossRef]
- Ioannidis, K.; Andreadis, I. A Digital Image Stabilization Method Based on the Hilbert-Huang Transform. IEEE Trans. Instrum. Meas. 2012, 61, 2446–2457. [Google Scholar] [CrossRef]
- Hao, D.; Li, Q.; Li, C. Digital image stabilization in mountain areas using complete ensemble empirical mode decomposition with adaptive noise and structural similarity. J. Electron. Imaging 2016, 25, 33007. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The Empirical Mode Decomposition and the Hilbert Spectrum for Nonlinear and Non-Stationary Time Series Analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009. [Google Scholar] [CrossRef]
- Komaty, A.; Boudraa, A.; Dare, D. Emd-based filtering using the Hausdorff distance. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology, Ho Chi Minh City, Vietnam, 12–15 December 2013; pp. 292–297. [Google Scholar]
- Zhang, S.Y.; Liu, Y.Y.; Yang, G.L. EMD interval thresholding denoising based on correlation coefficient to select relevant modes. In Proceedings of the 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 4801–4806. [Google Scholar]
- Zhao, Q.; Li, J.; Cui, N. Time field simulation of vibration performance for military automobile under road random input. China Sciencepap. 2012, 7, 862–875. [Google Scholar]
- Yang, Y.; Shen, Y.L.; Cao, Y.; Li, T.S. The exploiture of road simulation shaker table and control system. J. Syst. Simul. 2004, 16, 1044–1046. [Google Scholar]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Rockafellar, T. A Dual Approach to Sloving Nonlinear Programming Problems by Uncontrained Optimization. Math. Program. 1973, 5, 354–373. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Lowe, D.G.; Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. In Readings in Computer Vision: Issues, Problems, Principles, and Paradigms; Fischler, M.A., Ed.; Morgan Kaufmann: San Francisco, CA, USA, 1987; pp. 726–740. [Google Scholar]
Figure 1.
Proposed DIS framework based on VMD and RE.
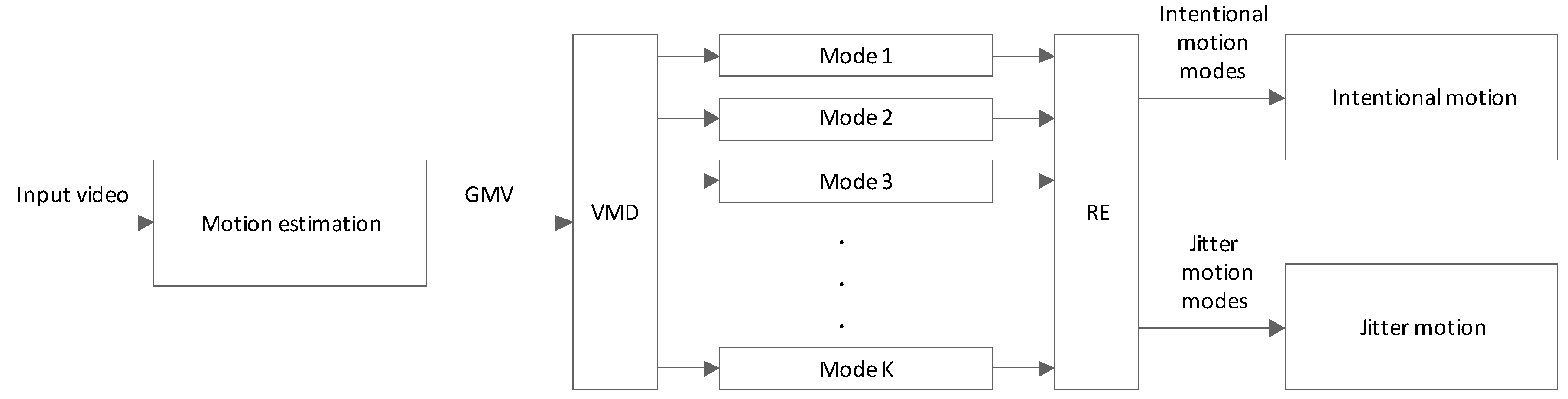
Figure 2.
SIFT feature points of testing images.

Figure 3.
Matching results of SIFT feature points.

Figure 4.
Testing GMV.
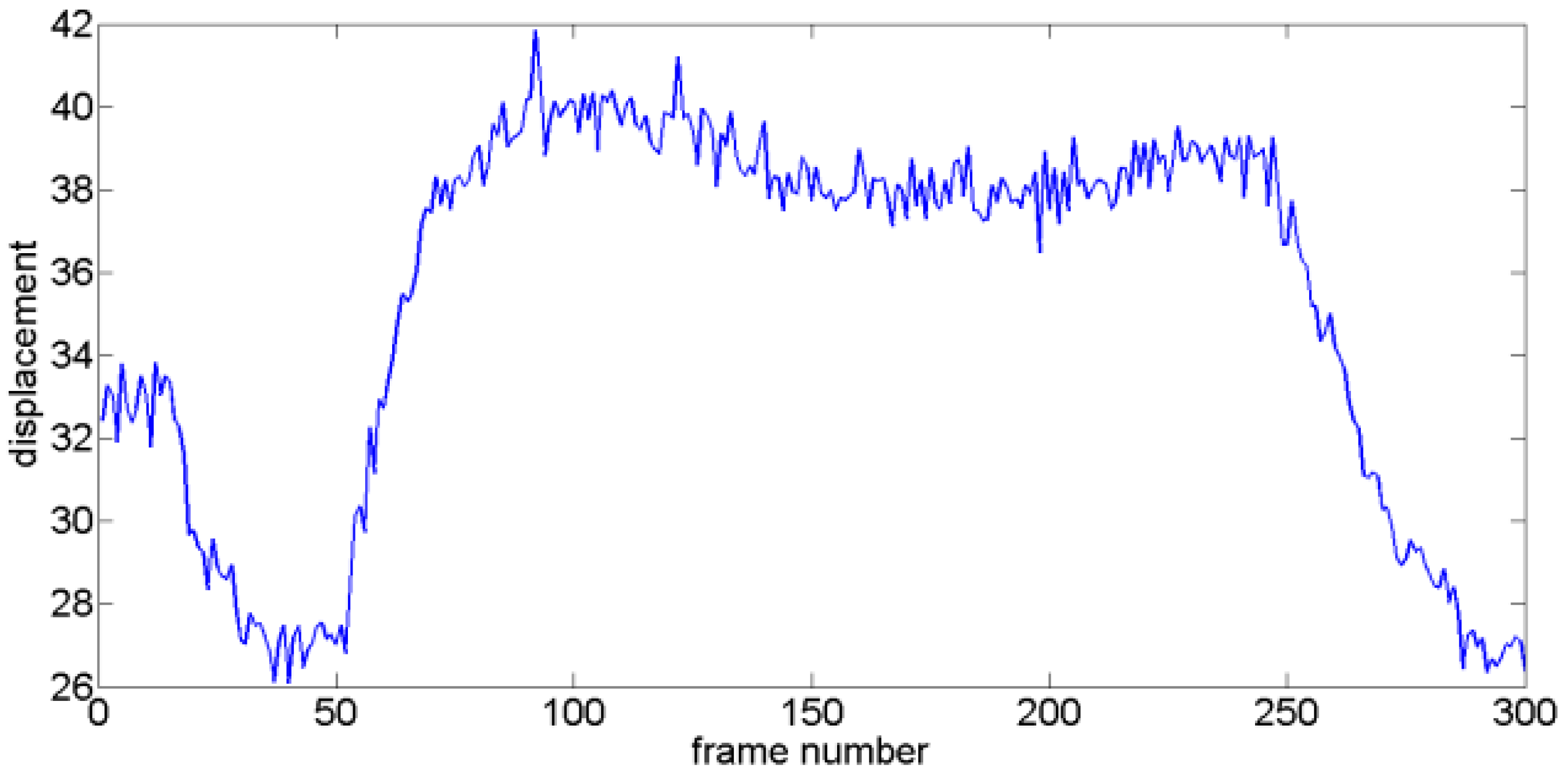
Figure 5.
Modes decomposed via VMD.
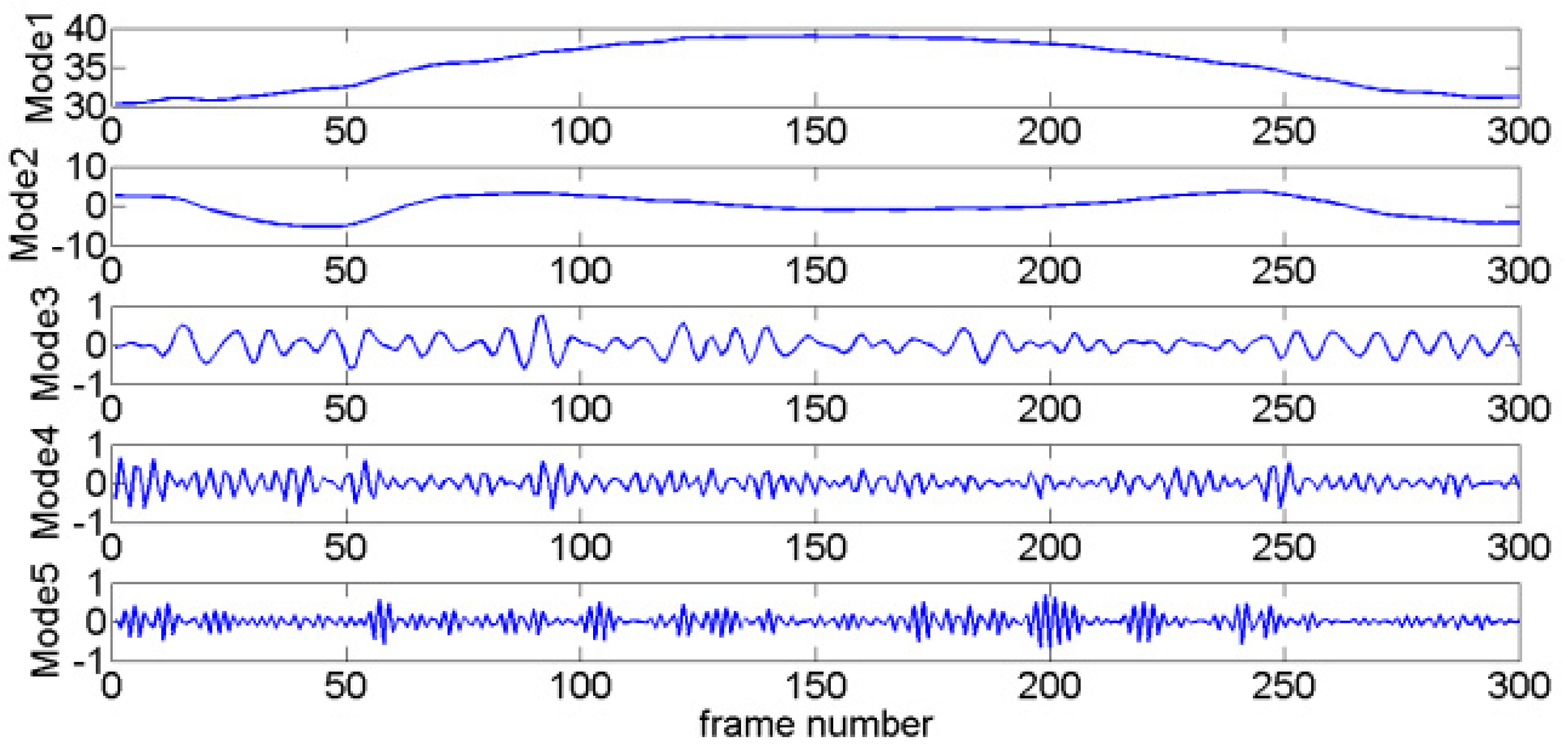
Figure 6.
REs between the first mode and other modes.
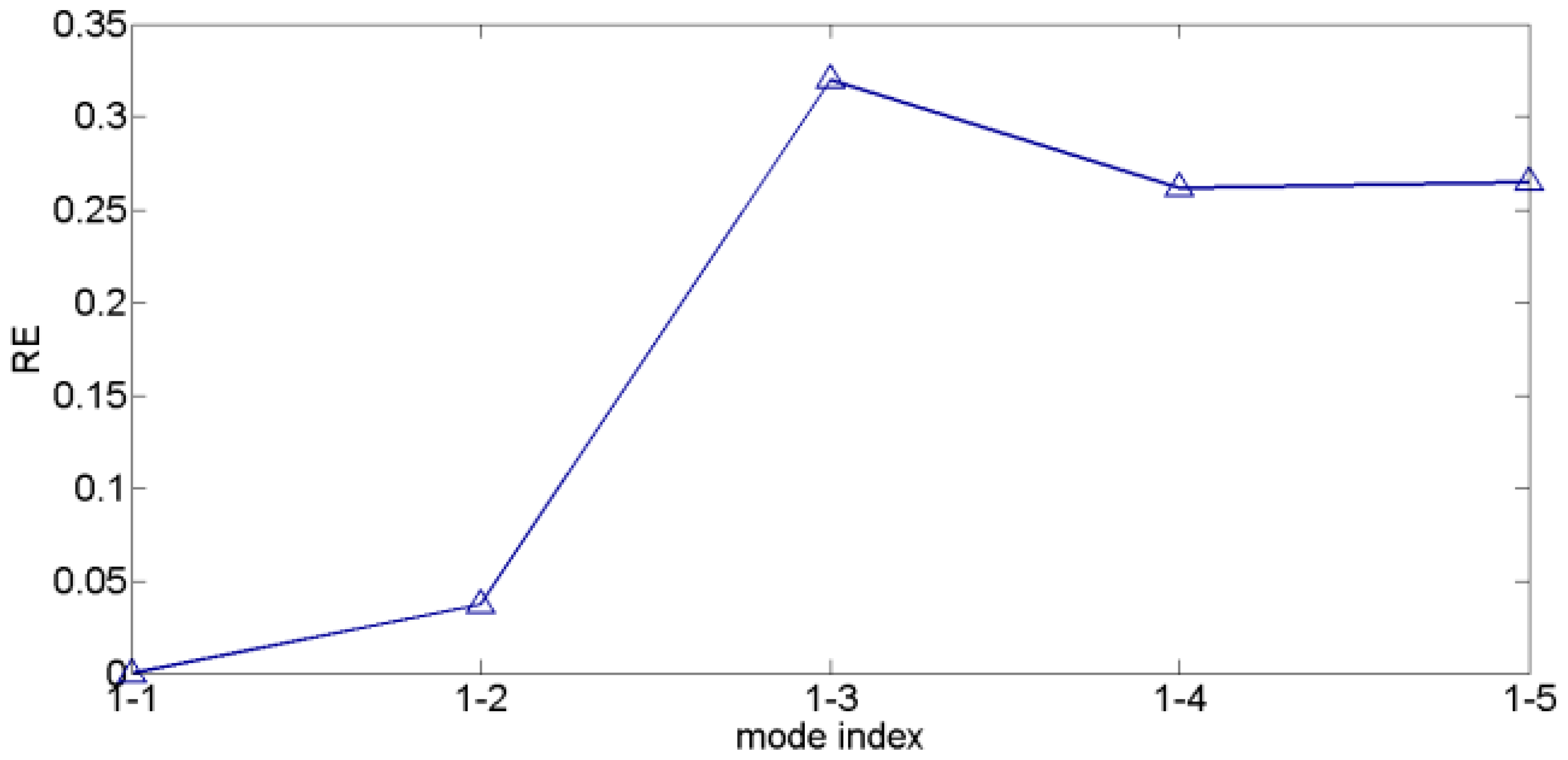
Figure 7.
SNRin vs. SNRout of signal contaminated by Gaussian noise.
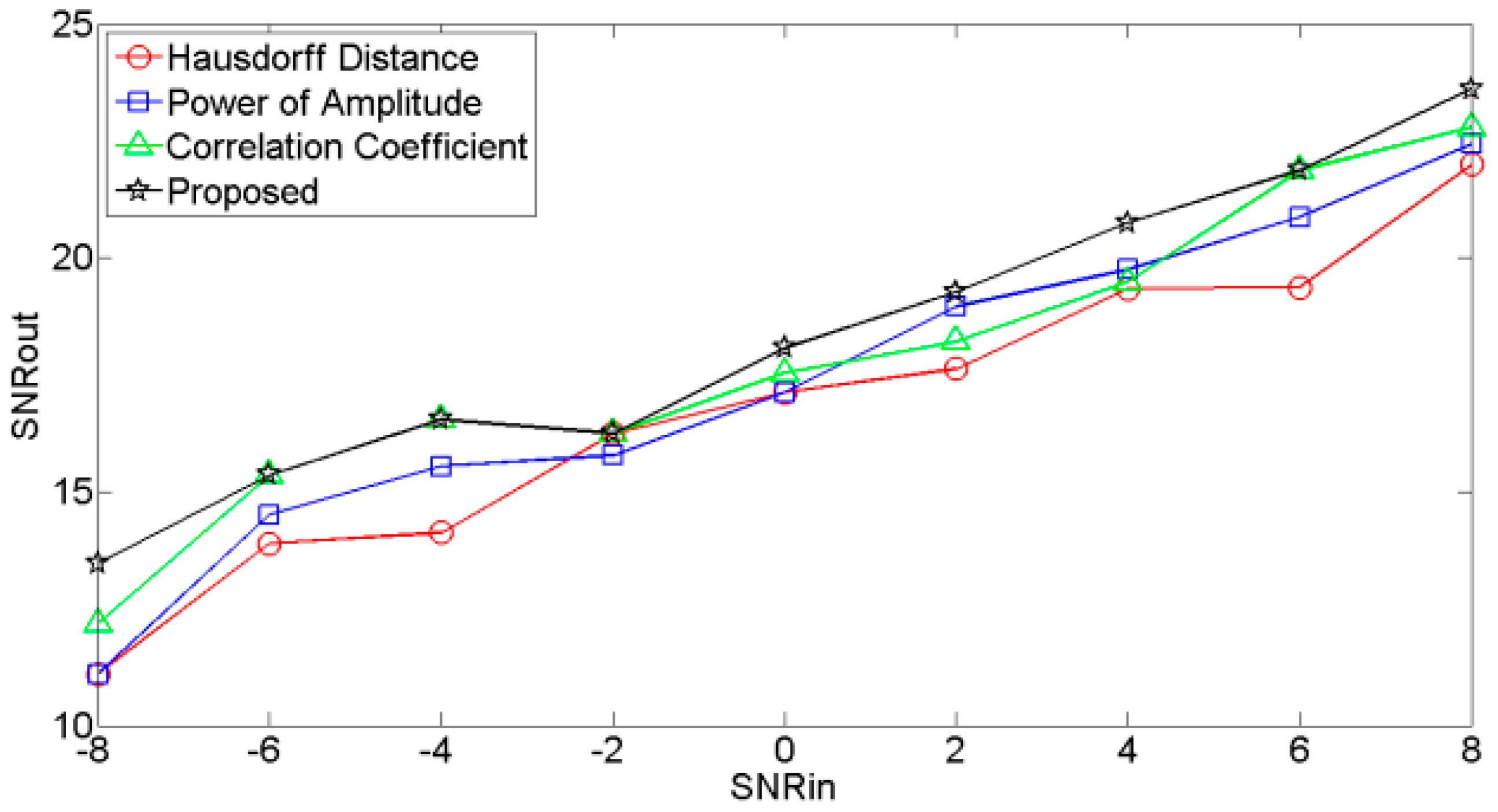
Figure 8.
SNRin vs. SNRout of signal contaminated by office noise.
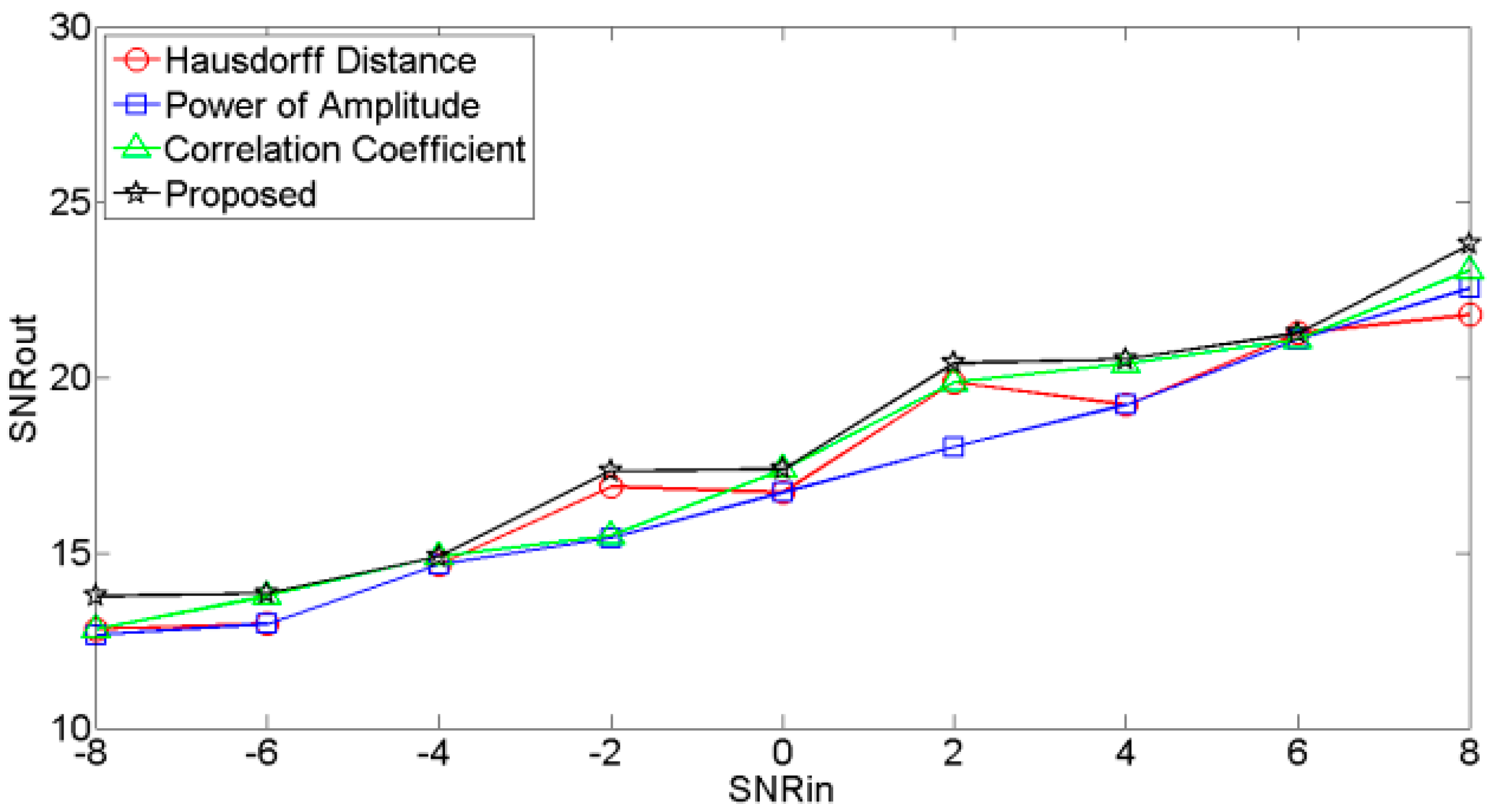
Figure 9.
SNRin vs. SNRout of signal contaminated by factory noise.
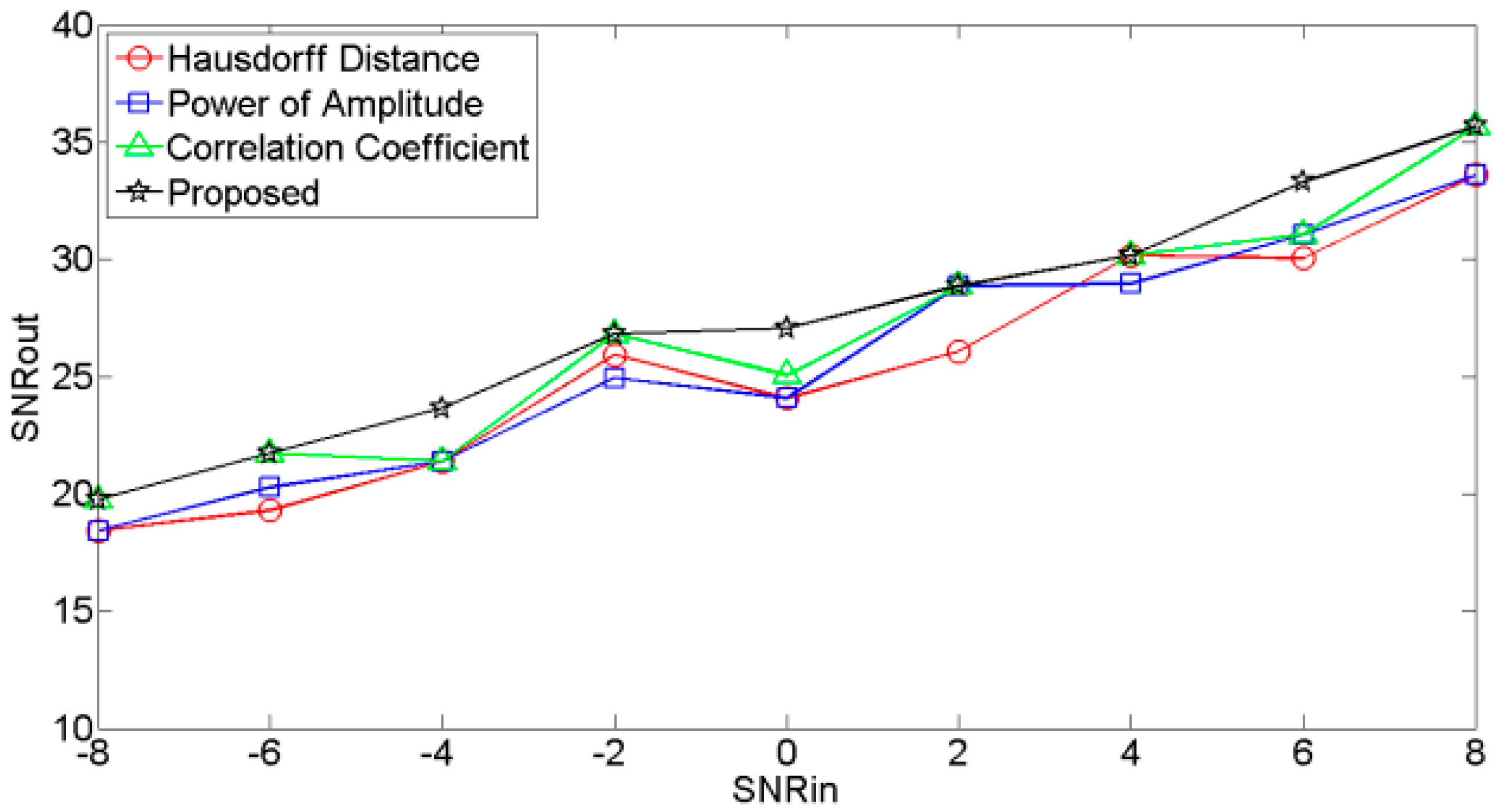
Figure 10.
Holder system.

Figure 11.
SIFT feature point matching result for Test 1.

Figure 12.
SIFT feature point matching result for Test 2.

Figure 13.
SIFT feature point matching result for Test 3.

Figure 14.
SIFT feature point matching result for Test 4.

Figure 15.
Resulting intentional motion compared with the ground truth in Test 1 video sequence.
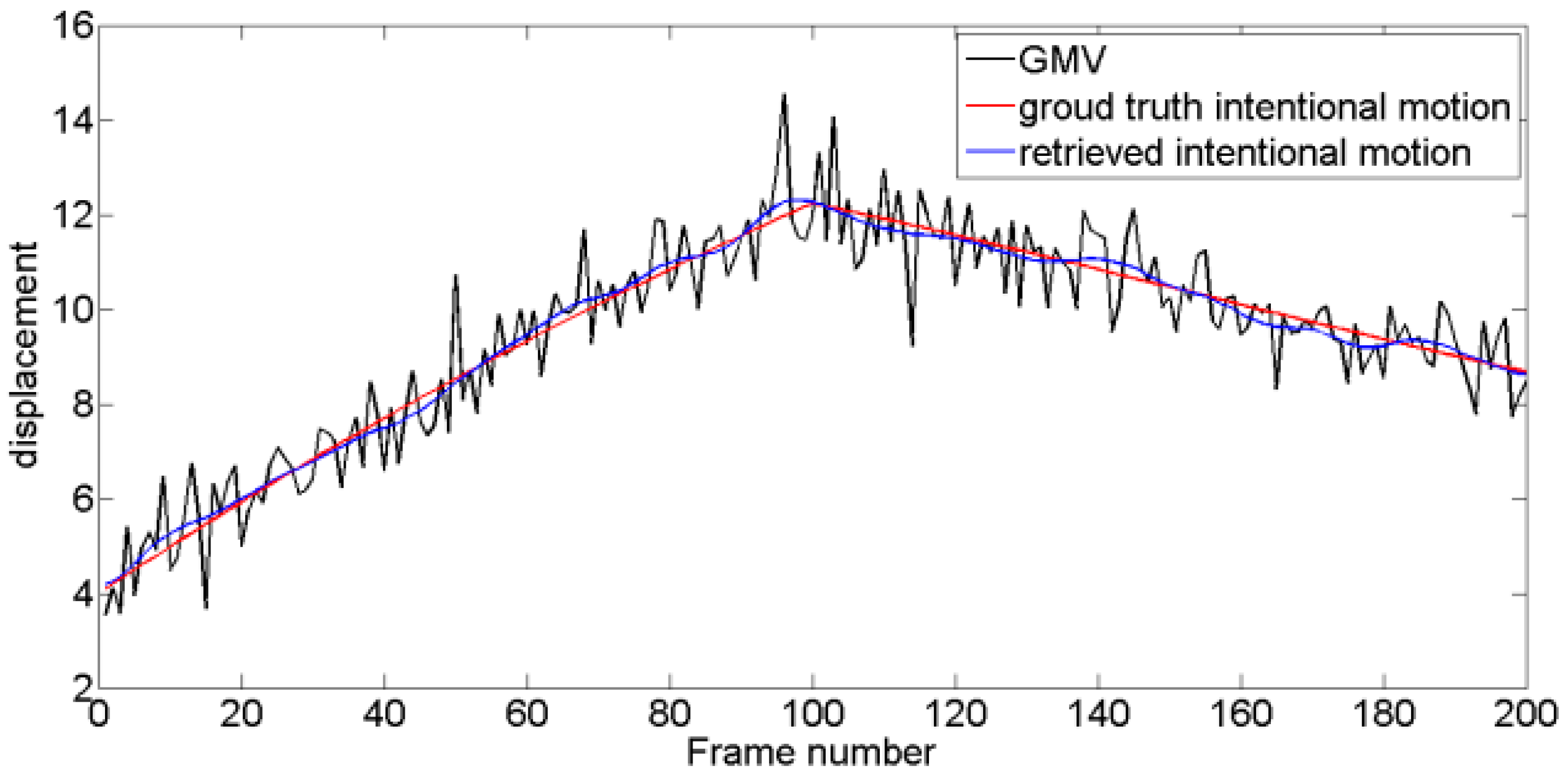
Figure 16.
Resulting intentional motion compared with the ground truth in Test 2 video sequence.
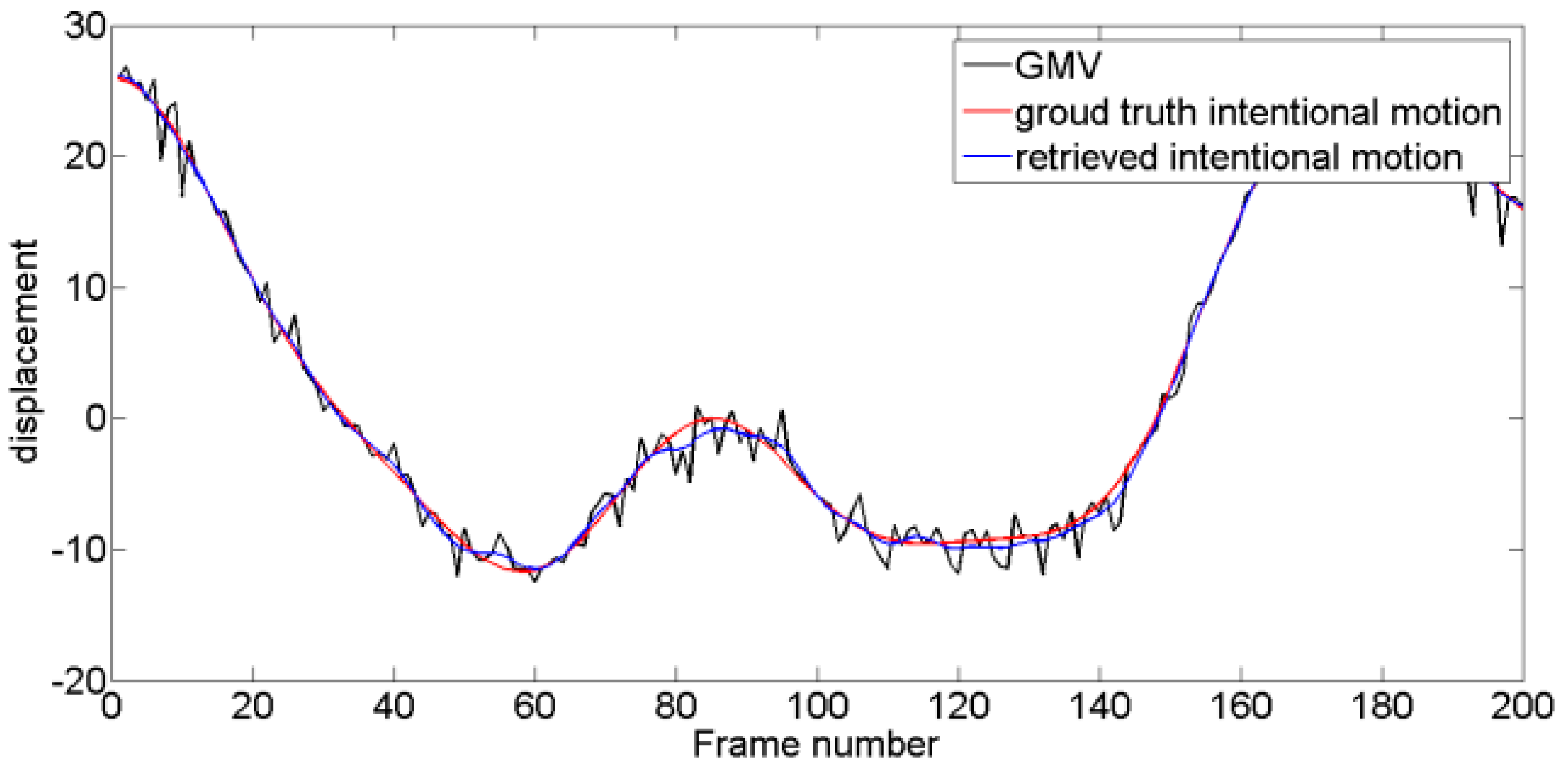
Figure 17.
Resulting intentional motion compared with the ground truth in Test 3 video sequence.

Figure 18.
Resulting intentional motion compared with the ground truth in Test 4 video sequence.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
RMSE values of the DIS algorithms.
| Method | MF | KF | WD | EMD | E-EMD | VMD |
|---|---|---|---|---|---|---|
| Test 1 | 0.0188 | 0.0161 | 0.0110 | 0.0151 | 0.0120 | 0.0071 |
| Test 2 | 0.0384 | 0.0371 | 0.2125 | 0.0794 | 0.0337 | 0.0319 |
| Test 3 | 0.0927 | 0.1131 | 0.1646 | 0.0838 | 0.0547 | 0.0426 |
| Test 4 | 0.1038 | 0.1351 | 0.0815 | 0.0692 | 0.0670 | 0.0610 |
Table 2.
SNR (DB) of the DIS algorithms.
| Method | MF | KF | WD | EMD | E-EMD | VMD |
|---|---|---|---|---|---|---|
| Test 1 | 17.9043 | 19.5021 | 22.5678 | 19.8240 | 21.8030 | 26.3579 |
| Test 2 | 27.4209 | 27.9321 | 12.5721 | 21.1245 | 28.5721 | 29.0528 |
| Test 3 | 22.0902 | 20.3511 | 17.1060 | 22.9722 | 26.6741 | 28.8509 |
| Test 4 | 10.0575 | 8.0307 | 12.1508 | 13.5821 | 13.8527 | 14.6741 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hao, D.; Li, Q.; Li, C. Digital Image Stabilization Method Based on Variational Mode Decomposition and Relative Entropy. Entropy 2017, 19, 623. https://doi.org/10.3390/e19110623
AMA Style
Hao D, Li Q, Li C. Digital Image Stabilization Method Based on Variational Mode Decomposition and Relative Entropy. Entropy. 2017; 19(11):623. https://doi.org/10.3390/e19110623
Chicago/Turabian StyleHao, Duo, Qiuming Li, and Chengwei Li. 2017. "Digital Image Stabilization Method Based on Variational Mode Decomposition and Relative Entropy" Entropy 19, no. 11: 623. https://doi.org/10.3390/e19110623
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.