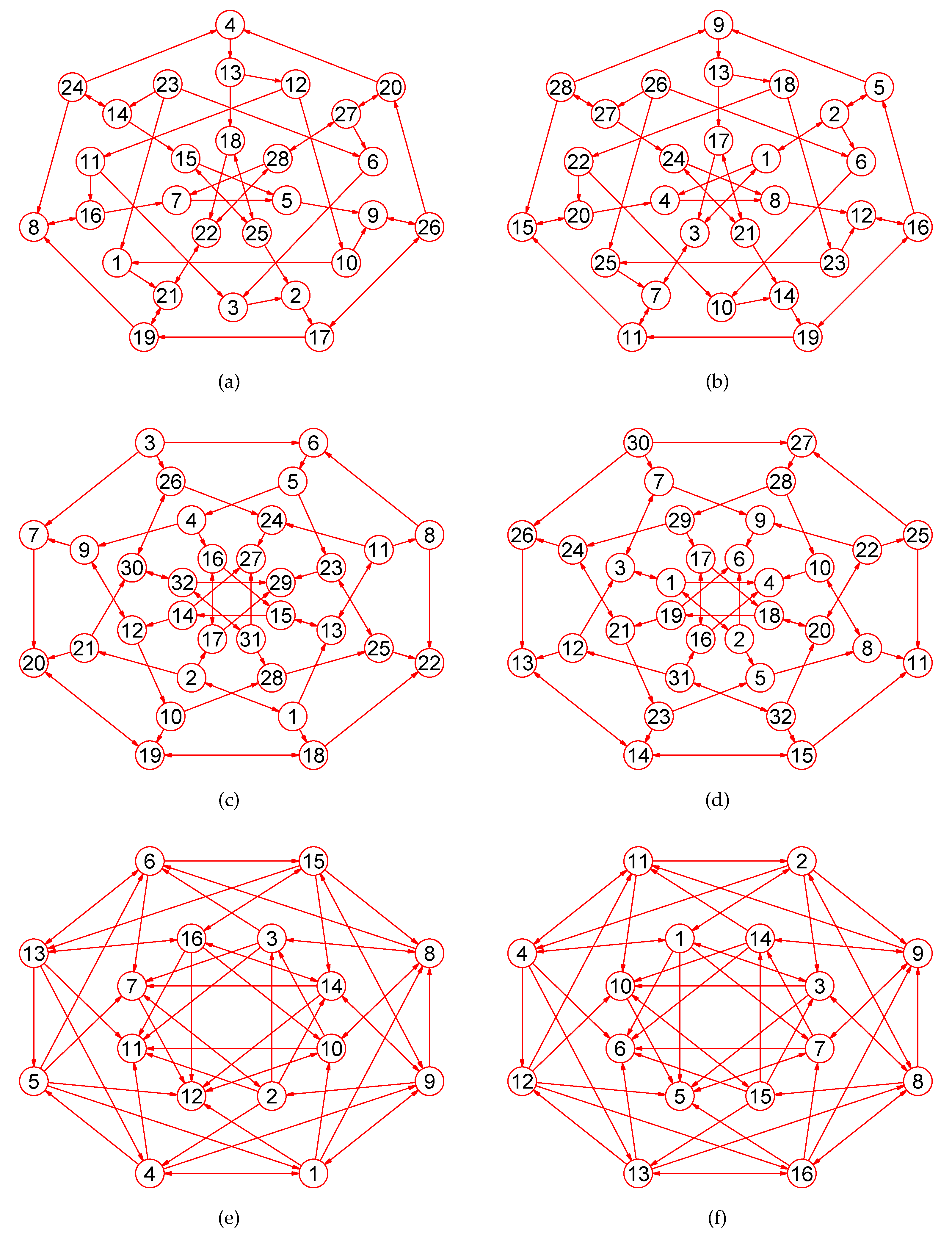
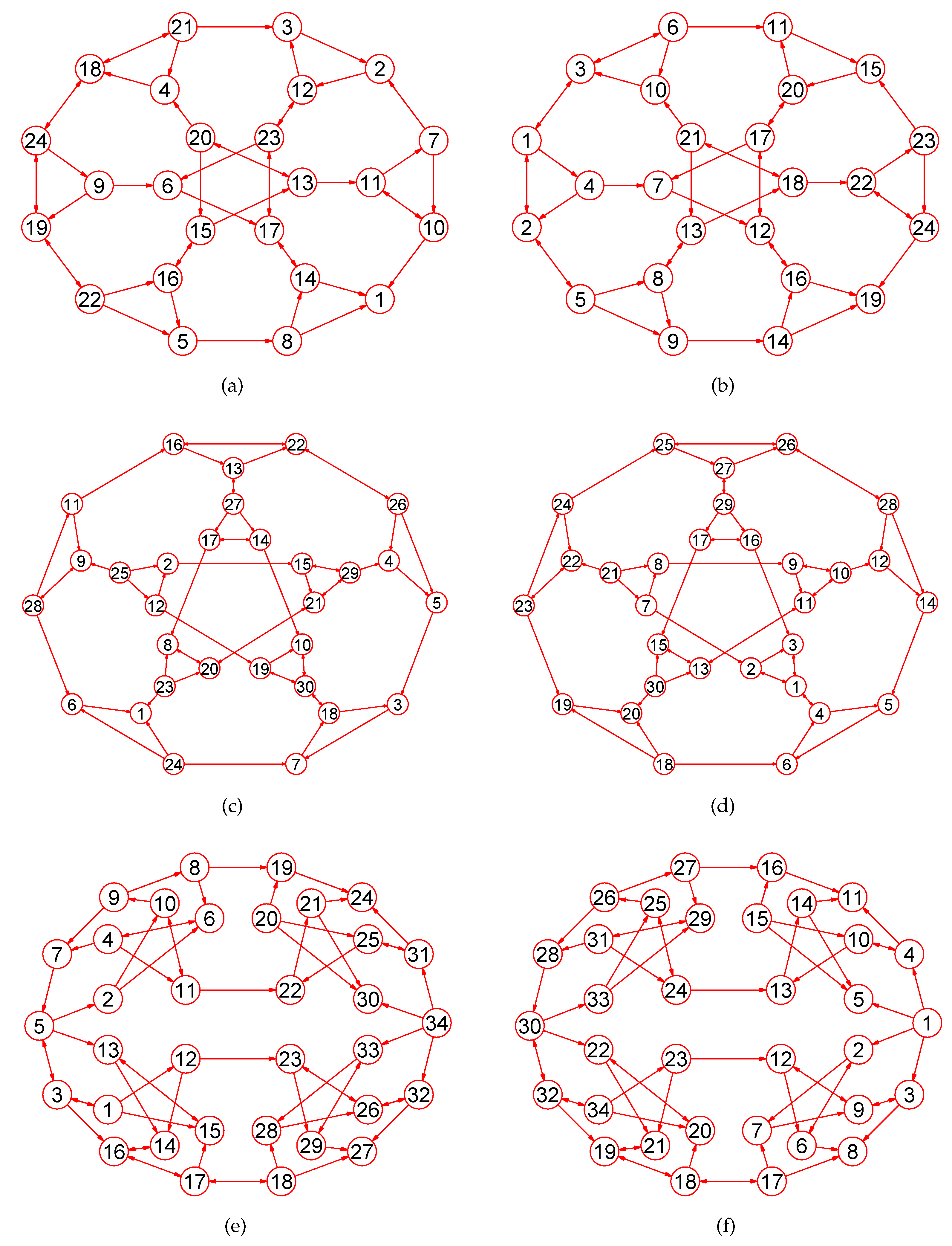
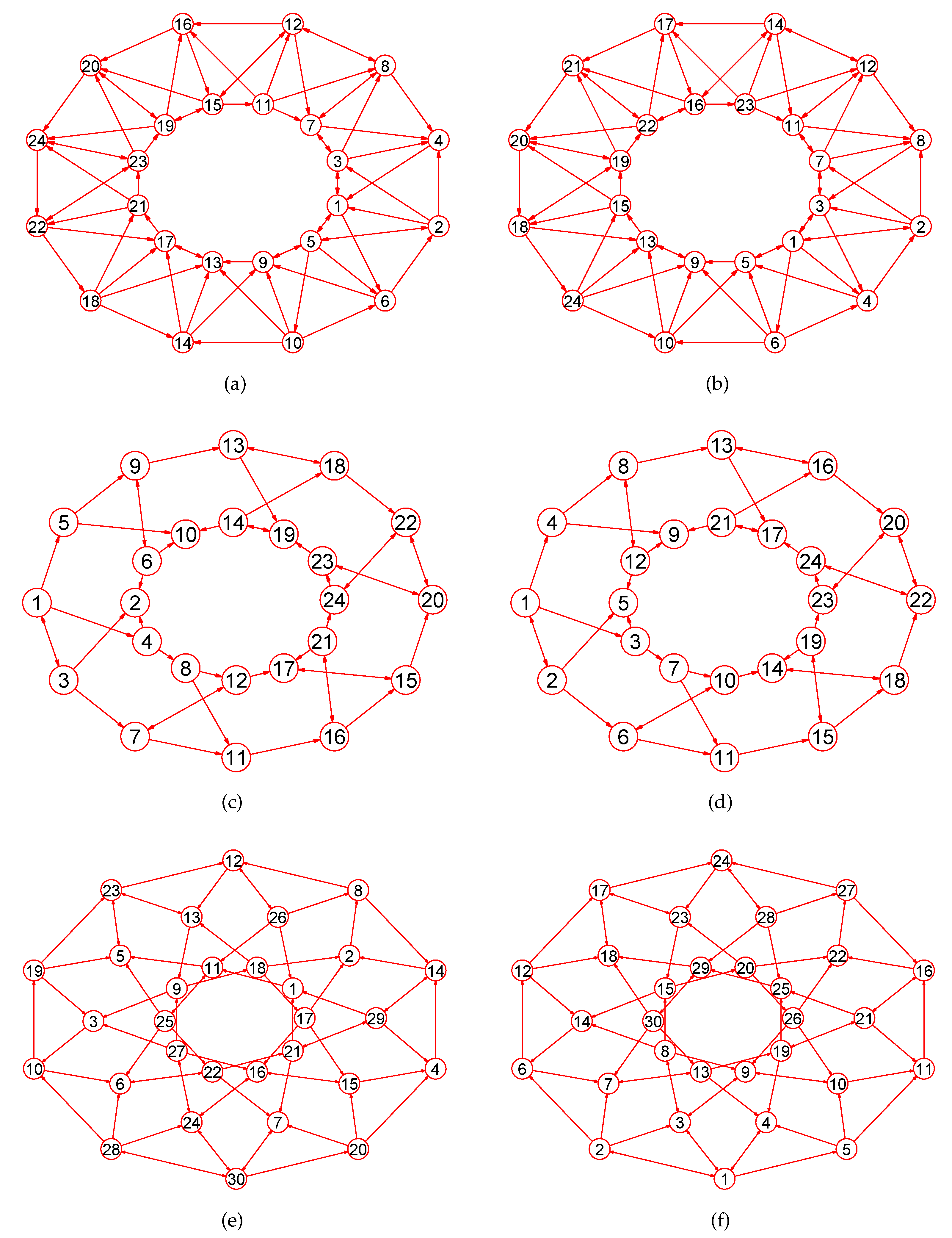
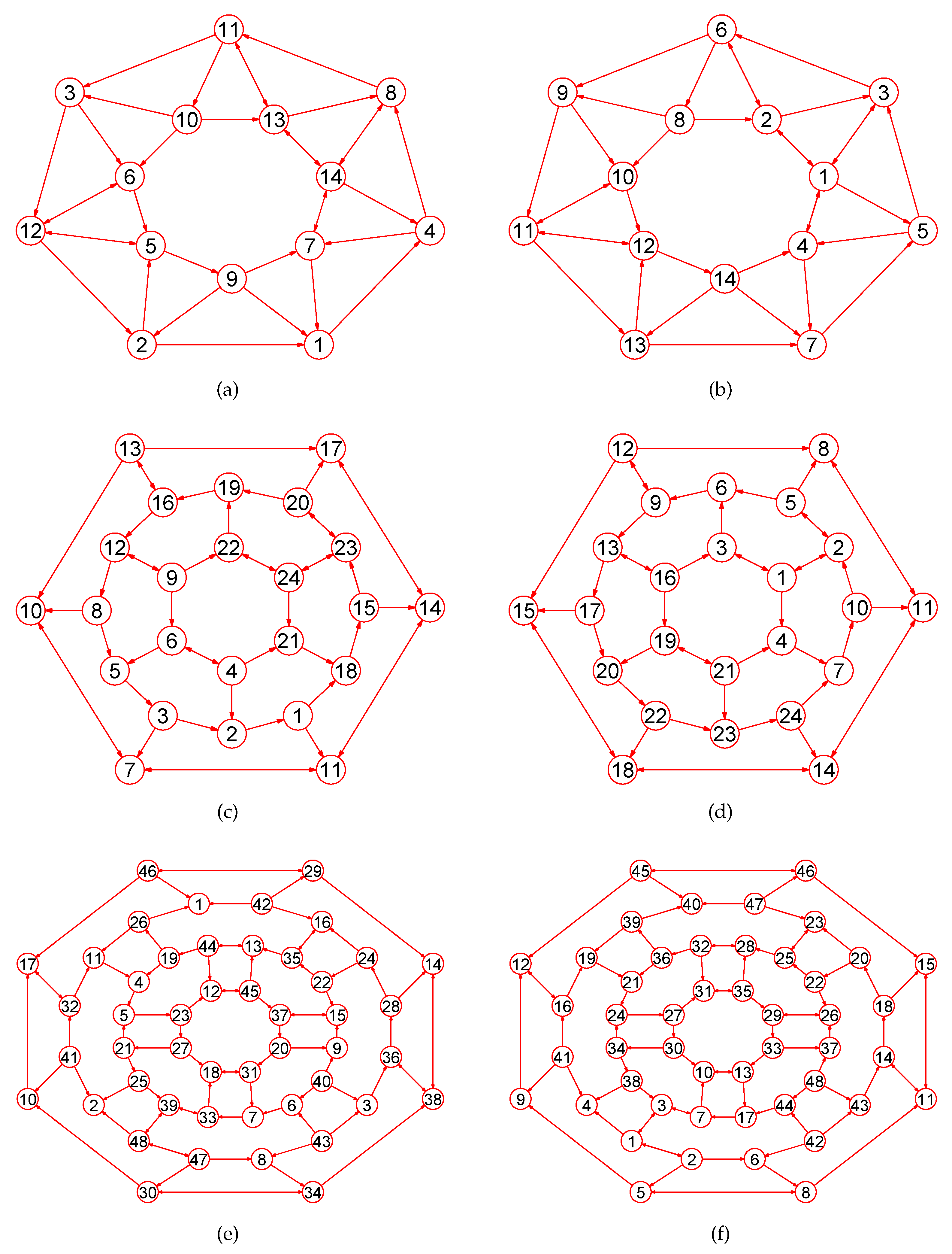
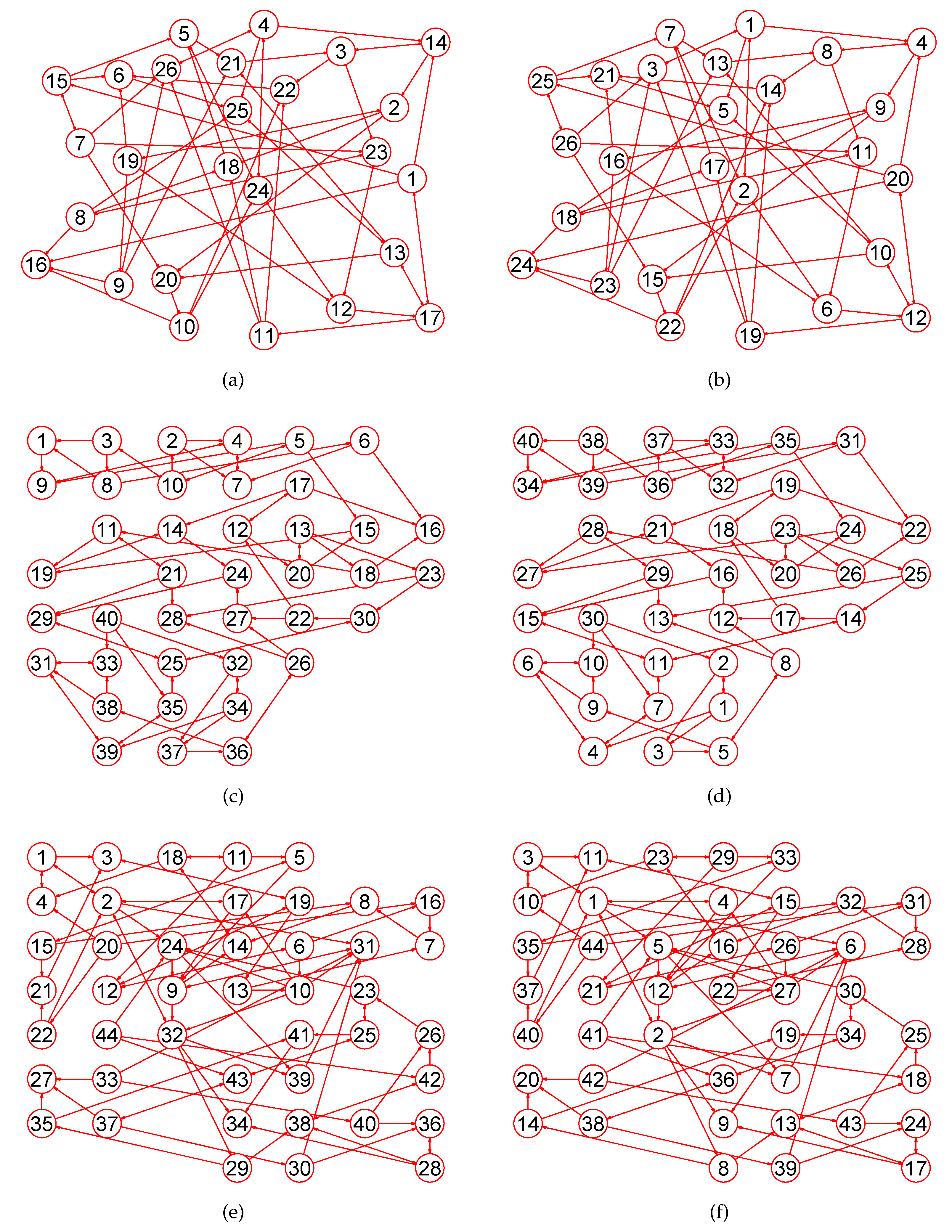
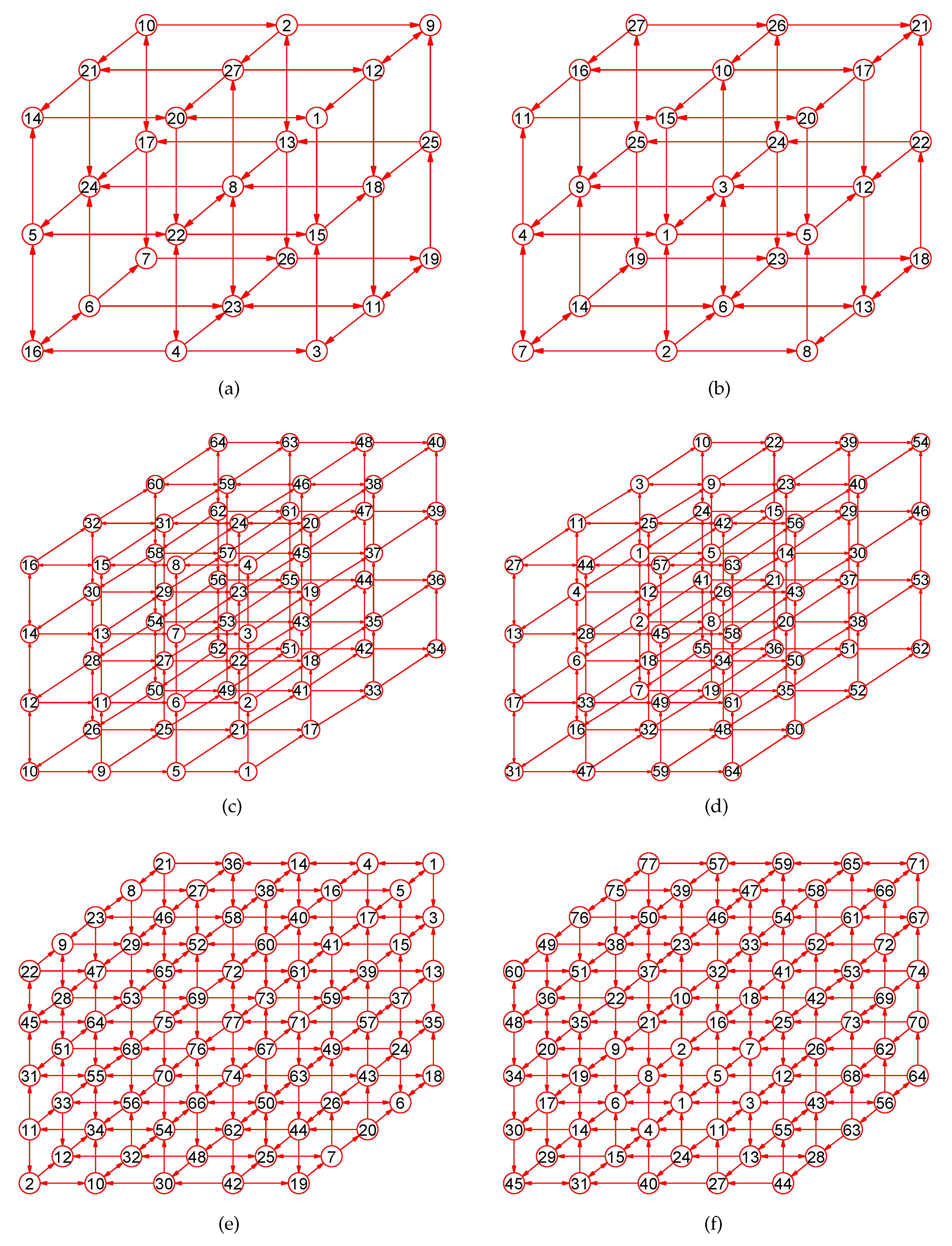
2. Preliminaries
In this section, we provide a brief review of the fundamental information used throughout the paper. A more comprehensive presentation can be found in most standard textbooks [
26,
27]. A directed graph (or digraph)
,
consists of a nonempty set
of vertices (or nodes) and a set
of directed edges (or arcs). A directed edge associated with the ordered pair
is said to start at
u and end at
v. We also say that the vertex
u is its tail and the vertex
v is its head. Throughout the paper, we denote
by
. For the edge
, the vertex
v is said to be adjacent from the vertex
u, the vertex
u is said to be adjacent to the vertex
v, and the edge
is said to be incident from the vertex
u and incident to the vertex
v. The directed distance
from vertex
u to vertex
v in
G is the length of the shortest directed path from
u to
v [
28], if any; otherwise
.
This paper deals with only finite simple digraphs, which have no loops and no multiple edges. For each , let , , , and denote the outindegree, outdegree, indegree, and degree of u respectively, and omit the subscript G when no ambiguity can arise. Denote by , , , and the maximum degree, the maximum outindegree, the maximum outdegree, and the maximum indegree of all vertices of a graph G, respectively.
Denote by , , ⋯, the degree sequence of G, by , , ⋯, the degree sequence of a subset with , , and by , , ⋯, the degree sequence of a subdigraph with , , and omit the subscript G when no ambiguity can arise.
In addition, denote by , , ⋯, the outdegree sequence of G, by , , ⋯, the outdegree sequence of a subset with , , and by , , ⋯, the outdegree sequence of a subdigraph with , , and omit the subscript G when no ambiguity can arise.
Similarly, denote by , , ⋯, the indegree sequence of G, by , , ⋯, the indegree sequence of a subset with , , and by , , ⋯, the indegree sequence of a subdigraph with , , and omit the subscript G when no ambiguity can arise.
Throughout this paper, unless otherwise specified, any given degree sequence is non-increasing. Throughout this paper, let , , , and where .
Definition 1. Let , be a simple digraph with n nodes. The vertex-induced subdigraph on of G is the subdigraph with the nodes set together with any directed edge whose endpoints are both in , denoted by .
Definition 2. Let , and , be two digraphs with n nodes. If there exists a bijection such that if and only if . We say f is an isomorphic map of . Furthermore, we say that the graph G and H are isomorphic, denoted by . An isomorphic map f of G onto itself is said to be an automorphism of G.
Definition 3. Let , be a simple digraph with n nodes , , ⋯, . The adjacency matrix of G is a -square matrix such that if there is an edge and otherwise.
The adjacency matrix for a digraph G does not have to be symmetric, because there may not be an edge , when there is an edge from . In addition, for every since G has no loops.
Given two vectors , in and , , ⋯, in , the question arises as to how to decide which one is greater. The following conventions apply when comparing two vectors.
Definition 4. Let , and be two vectors in N (the collection of natural numbers) with and , respectively. Then, defined the lexicographic order for the two vectors as follows:- 1.
, if and for all .
- 2.
if and only if either of the following is true.- (a)
for , .
- (b)
for and .
Definition 5. Let , and be two vectors with and respectively, with each , being a vector in N (the collection of natural numbers). Then, defined the lexicographic order for the two vectors as follows:- 1.
, if and for all .
- 2.
if and only if either of the following is true.- (a)
for , .
- (b)
for and .
Definition 6. Let and be two matrices with , for .
Then, defined the lexicographic order for the two matrix as follows:- 1.
, if for all .
- 2.
, if satisfying conditions for all , , and with or with .
Given a matrix X, if there is at least one positive element and the remaining elements are 0, we call . Otherwise, if all elements of X are 0, we call .
Definition 7. Let , be a simple digraph with n nodes whose adjacency matrix is (
see (1)).
To concatenate the rows of according to the following order , , ⋯, , , , ⋯, , ⋯,, , ⋯, , ⋯, , , ⋯, forms a corresponding binary number ⋯
⋯
, which is called a labeling of G, denoted by .
The first row of is the labeling piece 1 of , denoted by . Similarly, the second row is the labeling piece 2 of , denoted by . ⋯. The nth row is the labeling piece n of , denoted by . It is clear that .
A permutation π of the vertices of G is an arrangement of the n vertices without repetition. The number of permutations of the vertices of G is . Clearly each distinct permutation π of the n vertices of defines a different adjacency matrix. Given a permutation π, one can obtain a labeling corresponding to π by Definition 7. Denote by the collection of all labelings of G.
For every , , assume that , with , or 1. Let and . By Definition 4, if , then we call . Otherwise, if , then we call . Otherwise, if , then we call .
It is clear that , is a well-ordered set, where ⩽ denotes the less-than-or-equal-to binary relation on the set expressed as above. By the well-ordering theorem, it follows that has a minimum and maximum element, denoted by and respectively.
The two permutations of the n vertices of G corresponding to and are the minimum and maximum node sequence, denoted by and , respectively. Likewise, the two adjacency matrices of G corresponding to and are the minimum and maximum canonical label matrix, denoted by and , individually.
corresponding to are minimum canonical label piece , ⋯, n of canonical labeling , denoted by , , ⋯, , respectively. Likewise, , , ⋯, corresponding to are maximum canonical label piece of canonical labeling , denoted by , , ⋯, , respectively.
Based on the above definitions, the following equations hold.
Theorem 1. Let , and , be two digraphs with n nodes. Their adjacency matrices are and respectively. if and only if =.
Definition 8. Let , be a simple digraph with n nodes. The complement of G is a digraph satisfying the following condition: for all , if and only if .
Lemma 1. Let , be a simple digraph with n nodes. , is the complement digraph of G. We have and .
Proof. The adjacency matrices of
G and
satisfy the condition
J is a matrix of zeros and ones whose main diagonal elements are 0, and all other elements are 1. By and the complement graph , we have . Similarly, by , we have for the complement graph of a graph G. ☐
Theorem 2. Let , be a simple digraph with n nodes. , is the complement graph of G. We have Proof. By Lemma 1, it follows that . Clearly if the k-bit of is 0, the k-bit of is 1, and vice versa. Therefore, one can easily get the by performing a complement operation on . Similarly, by Lemma 1, the equality holds. Clearly if the k-bit of is 0, the k-bit of is 1, and vice versa. Accordingly, one can obtain the of by performing a complement operation on .
Because
is a constant binary number, to minimize
one must maximize
. On the contrary, to maximize
, one must maximize
. Similarly, to minimize
one must maximize
. Contrarily to maximize
, one must minimize
. From the above analysis, the following equations hold.
☐
By Theorem 2, it can be observed that if one has calculated the , one can easily get . Moreover, the calculation methods of and are same.
The paper focuses on the development of efficient methods to calculate . A MaxEm digraph is a digraph with the greatest that corresponds to a permutation of the vertices.
For every , the number of nodes with outdegree is the outdegree multiplicity of u, denoted by . In addition, unless otherwise specified, throughout this paper, the outdegree sequence is non-increasing.
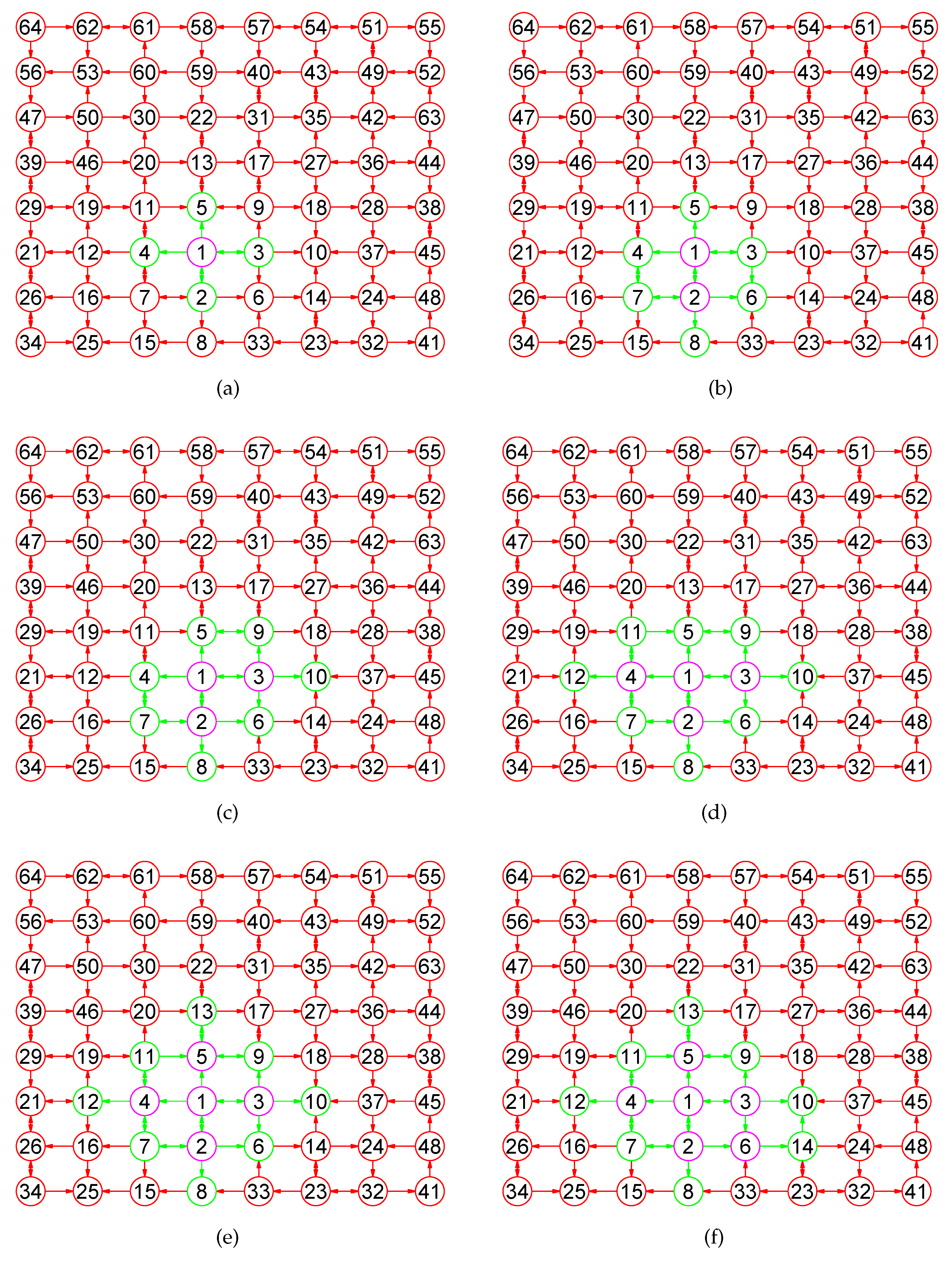
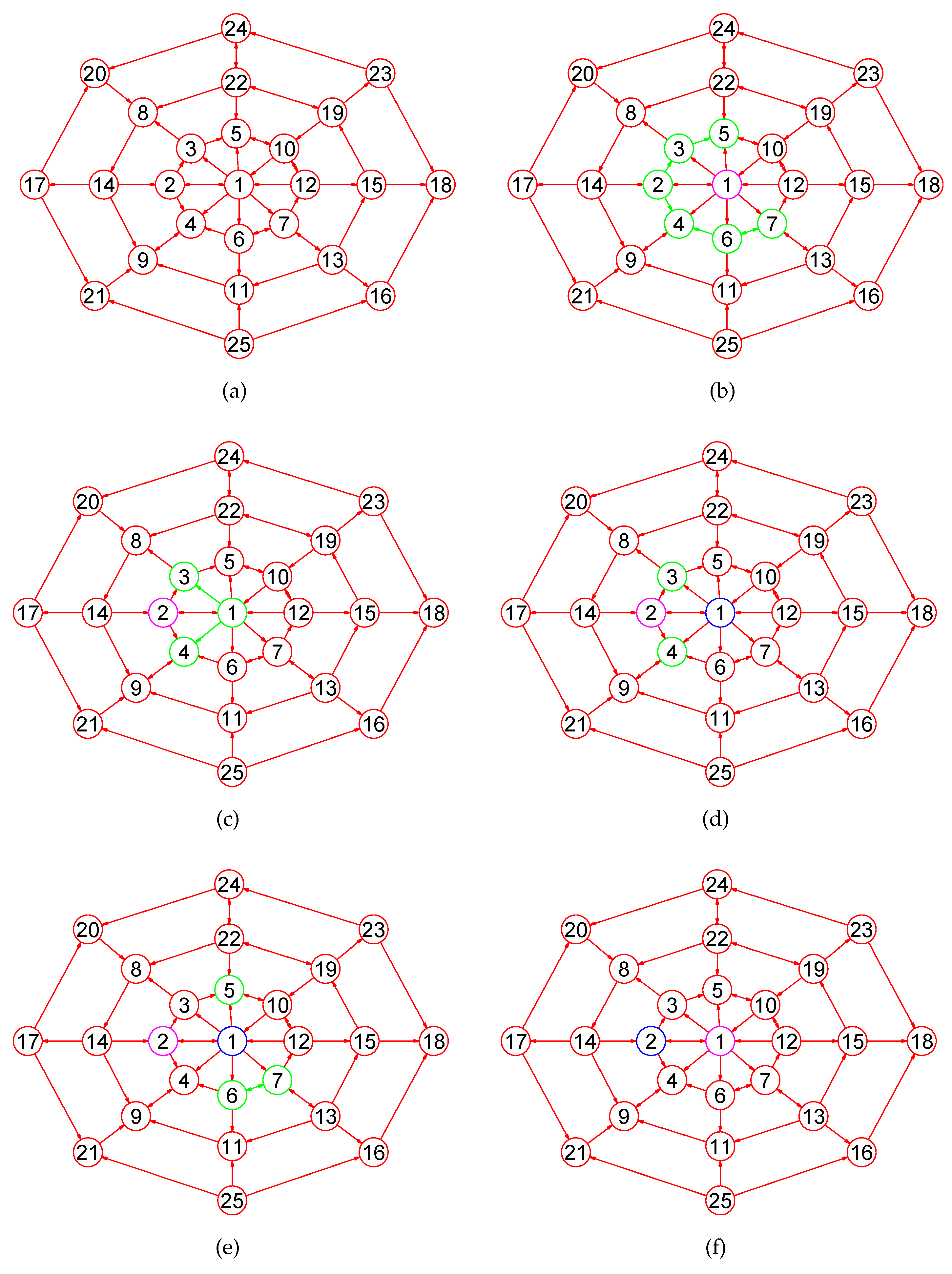
Definition 9. Let , be a simple digraph with n nodes. The open neighborhood, in-neighborhood, out-neighborhood, outin-neighborhood, and mix-neighborhood subdigraphs of a vertex u in G are subdigraphs of G defined aswhere The open k-neighborhood, k-in-neighborhood, k-out-neighborhood, k-outin-neighborhood, and k-mix-neighborhood subdigraphs of u with k ⩾ 2
are subdigraphs of G defined aswhere Definition 10. Let , be a simple digraph with n nodes. The close neighborhood, in-neighborhood, out-neighborhood, outin-neighborhood, and mix-neighborhood subdigraphs of a vertex u in G are subdigraphs of G defined aswhere The close k-neighborhood, k-in-neighborhood, k-out-neighborhood, k-outin-neighborhood, and k-mix-neighborhood subdigraphs of u with k ⩾ 2
are subdigraphs of G defined aswhere Definition 11. Let , be a simple digraph with n nodes. The open neighborhood, in-neighborhood, out-neighborhood, outin-neighborhood, and mix-neighborhood subdigraphs of a nodes set are subdigraphs of G defined aswhere The open k-neighborhood, k-in-neighborhood, k-out-neighborhood, k-outin-neighborhood, and k-mix-neighborhood subdigraphs of Q with k ⩾ 2
are subdigraphs of G defined aswhere Definition 12. Let , be a simple digraph with n nodes. The close neighborhood, in-neighborhood, out-neighborhood, outin-neighborhood, and mix-neighborhood subdigraphs of a nodes set are subdigraphs of G defined aswhere The close k-neighborhood, k-in-neighborhood, k-out-neighborhood, k-outin-neighborhood, and k-mix-neighborhood subdigraphs of Q with k ⩾ 2
are subdigraphs of G defined aswhere In the following section, unless otherwise specified, each k-neighborhood, k-in-neighborhood, k-out-neighborhood, k-outin-neighborhood, and k-mix-neighborhood subdigraphs are closed.
A digraph is connected if its underlying graph is connected. For , we omit the subscript 1 and let , , , and .
Definition 13. Let , be a simple digraph with n nodes. Suppose that and . We denote by the open k-neighborhood subdigraph of u in H, by the close k − neighborhood subdigraph of u in H, by the open k-mix-neighborhood subdigraph of u in H, and by the close k-mix-neighborhood subdigraph of u in H.
For , we omit the superscript 1 and let , , , and .
Definition 14. Let , be a simple connected digraph with n nodes. For every , there exists a positive integer k satisfying conditions and . The value of k is called the diffusion radius of u denoted by of u denoted by , and the subscript G can be omitted when no ambiguity can arise.
By Definition 14, it is clear that for every u in G.
Definition 15. Let , be a simple connected digraph with n nodes. For every , there exists a positive integer k satisfying conditions and . The value of k is called the mix diffusion radius of u denoted by of u denoted by , and the subscript G can be omitted when no ambiguity can arise.
Definition 16. Let , be a simple digraph and u be a node in G whose close k neighborhood subdigraph is with . A node in is a one diffusion node of u. For , a node v in satisfying condition is a k diffusion node of u.
Definition 17. Let , be a simple digraph and u be a node in G whose close k-mix-neighborhood subdigraph is with . A node in is a one mix diffusion node of u. For , a node v in satisfying condition is a k mix diffusion node of u.
Every node
v in
G is assigned an attribute
m_NearestNode whose function, described in
Section 3.1.2.
Definition 18. Let , be a simple digraph and u be a node in G whose close k neighborhood subdigraph is with . Assume that H is a connected component of with . Assume that with , where is in ascending order of attribute with for every , and , contain the diffusion nodes of u respectively, satisfying conditions and for .
We define , ⋯, , ⋯, to be the diffusion outdegree sequence of H where with are the outdegree sequences in descending order induced by all vertices in respectively.
Definition 19. Let , be a simple digraph and u be a node in G whose close k-mix-neighborhood subdigraph is with . Assume that H is a connected component of with . Assume that with , where is in ascending order of attribute with for every , and , contain the mix diffusion nodes of u respectively, satisfying conditions and for .
We define , ⋯, , ⋯, to be the mix diffusion outdegree sequence of H where with are the outdegree sequences in descending order induced by all vertices in respectively.
Definition 20. Let , be a simple digraph and u be a node in G whose close k neighborhood subdigraph is with . Assume that has p connected components , , ⋯, with diffusion outdegree sequences , , ⋯, respectively, satisfying conditions .
Define , , ⋯, to be the entire mix diffusion outdegree sequence of pertaining to u in G, and omit the subscript G when no ambiguity can arise.
Definition 21. Let , be a simple digraph and u be a node in G whose close k-mix neighborhood subdigraph is with . Assume that has p connected components , , ⋯, with mix diffusion outdegree sequences , , ⋯, respectively, satisfying conditions .
Define , , ⋯, to be the entire mix diffusion outdegree sequence of pertaining to u in G, and omit the subscript G when no ambiguity can arise.
Definition 22. Let , be a simple digraph with n nodes. For every with and , let , , ⋯, be the close 1, 2, ⋯, mix-neighborhood subdigraph of u with entire mix diffusion outdegree sequences , , ⋯, , respectively. Let , , ⋯, be the 1, 2, ⋯, mix-neighborhood subdigraph of v with entire mix diffusion outdegree sequences , , ⋯, , respectively. Let , , ⋯, and , , ⋯, . If , we write with respect to G. Otherwise, if , we write with respect to G. Otherwise, if , we write with respect to G, and omit the symbol G when no ambiguity can arise. Denote or by and or by .
It is clear that ≻, ≺, ≍, ≽ define a binary relation on the set of nodes . By Definition 22, for every with , one of the following statements is true: (1) . (2) . (3) .
It can be shown that , is a well-ordered set, where ≽ denotes the binary relation on the set . By the well-ordering theorem, it follows that there exists a maximum and minimum element in , denoted by and respectively with and . The symbol ≽ can be omitted if no confusion arises. The following Lemmas 2–4 immediately follow from Definition 22.
Lemma 2. Let , be a simple digraph with n nodes. For every with , if the symbol ≽ denotes the binary relation on the set , then, all of the nodes in G form a single chain L on G: with , , .
Lemma 3. Let , be a simple digraph with n nodes. Let . For every with , if the symbol ≽ denotes the binary relation on the set , then, all of the nodes in form a single chain L on G: with .
Lemma 4. Let , be a simple digraph with n nodes. For every , suppose that is the close k mix-neighborhood subdigraph of u in G. Let .
For every with , if the symbol ≽ denotes the binary relation on the set , then, all of the nodes in form a single chain L on : with .
The conclusions in the following Propositions 1 and 2 are obvious by Definitions 4, 5, and 22.
Proposition 1. Let , be a simple digraph with n nodes. For every with and , let , , ⋯, be the close 1, 2, ⋯, mix-neighborhood subdigraph of u with entire mix diffusion outdegree sequences , , ⋯, , respectively. Let , , ⋯, be the close 1, 2, ⋯, mix-neighborhood subdigraph of v with entire mix diffusion outdegree sequences , , ⋯, , respectively. Let , , ⋯, with , , ⋯, and , , ⋯, . Let , , ⋯, with , , ⋯, and , , ⋯, . If , then leads to . Otherwise, leads to . Otherwise, leads to . Accordingly, it follows that if , then leads to . Otherwise, leads to . Otherwise, leads to .
Proposition 2. Let , be a simple digraph with n nodes. For every with and , let , , ⋯, be the close 1, 2, ⋯, mix-neighborhood subdigraph of u with entire mix diffusion outdegree sequences , , ⋯, , respectively. Let , , ⋯, be the close 1, 2, ⋯, mix-neighborhood subdigraph of v with entire mix diff usion outdegree sequences , , ⋯, , respectively. If , , ⋯, , , then with respect to G (see Definition 22).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}