Function Analysis of the Euclidean Distance between Probability Distributions

Division of Electronic & Information Communication, Kangwon National University, Samcheok 25913, Korea
Entropy 2018, 20(1), 48; https://doi.org/10.3390/e20010048
Submission received: 20 November 2017
/
Revised: 31 December 2017
/
Accepted: 8 January 2018
/
Published: 11 January 2018
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:Minimization of the Euclidean distance between output distribution and Dirac delta functions as a performance criterion is known to match the distribution of system output with delta functions. In the analysis of the algorithm developed based on that criterion and recursive gradient estimation, it is revealed in this paper that the minimization process of the cost function has two gradients with different functions; one that forces spreading of output samples and the other one that compels output samples to move close to symbol points. For investigation the two functions, each gradient is controlled separately through individual normalization of each gradient with their related input. From the analysis and experimental results, it is verified that one gradient is associated with the role of accelerating initial convergence speed by spreading output samples and the other gradient is related with lowering the minimum mean squared error (MSE) by pulling error samples close together.
1. Introduction
Adaptive signal processing is carried out by minimizing or maximizing an appropriate performance criterion for adjusting weights of algorithms designed based on that criterion [1]. The mean squared error (MSE) criterion that measures the average of the squares of the error signal is widely employed in the Gaussian noise environment. However in non-Gaussian noise like impulsive noise, the averaging process of squared error samples that may mitigate the effects of the Gaussian noise is defeated because a single large, impulse can dominate these sums. As recent signal processing methods, the information-theoretic learning (ITL) is based on the information potential concept that data samples can be treated as physical particles in an information potential field where they interact with each other by information forces [2]. The ITL method usually exploits probability distribution functions constructed by the kernel density estimation method with the Gaussian kernel.
Among the ITL criteria, Euclidian distance (ED) between two distributions has been known to be effective in signal processing fields demanding similarity measure functions [3,4,5]. For training of adaptive systems for medical diagnosis, the ED criterion has been successfully applied to distinguish biomedical datasets [6]. For finite impulse response (FIR) adaptive filter structures in impulsive noise environments, ED between the output distribution and a set of Dirac delta functions has been used as an efficient performance criterion taking advantage of the outlier-cutting effect of Gaussian kernel for output pairs and symbol-output pairs [7]. In this approach with output distribution and delta functions, minimization of the ED (MED) leads to adaptive algorithms that adjust weights so as for the output distribution to be formed into the shape of delta functions located at each symbol point, that is, output samples concentrate on symbol points. Though the blind MED algorithm shows superior performance of robustness against impulsive noise and channel distortions, a drawback of heavy computational burden lies in it. The computational complexity is due in large part to the double summation operations at each iteration time for its gradient estimation. A follow-up study [8], however, shows that the drawback can be reduced significantly by employing a recursive gradient estimation method.
The gradient in ED minimization process of the MED algorithm has two components; one for kernel function of output pairs and the other for kernel function of symbol-output pairs. The roles of these two components have not been investigated or analyzed in scientific literature. In this paper, we analyze the roles of the two components and prove the analysis through controlling each component individually by normalizing each component with component-related input power. Through simulation in multipath channel equalization under impulsive noise, their roles of managing sample pairs are verified, and it is shown that the proposed method of controlling each component through power normalization increases convergence speed and lowers steady state MSE significantly in multipath and impulsive noise environment.
2. MSE Criterion and Related Algorithms
Employing the tapped delay line (TDL) structure, the output yk becomes at time k with the input vector and weight . Given the desired signal dk chosen randomly among the M symbol points (A1, A2, …, AM), the system error is calculated as ek = dk − yk. In blind equalization, the constant modulus error where is mostly used [9].
The MSE criterion, one of the most widely used criteria, is the statistical average E[·] of error power in supervised equalization and of CME power in a blind one. For practical implementation we can use the instant squared error as a cost function in supervised equalization. With the gradient and a step size μLMS, minimization of leads to the least mean square (LMS) algorithm [1]:
As an extension of the LMS algorithm, the normalized LMS (NLMS) algorithm has been introduced where the gradient is normalized as proportional to the inverse of the dot product of the input vector with itself as a result of minimizing weight perturbation of the LMS algorithm [1]. Then the NLMS algorithm becomes:
The NLMS algorithm is known to be more stable with unknown signals and effective in real time adaptive systems [10,11]. We can see under impulsive noise environments that a single large error sample induced by impulsive noise can generate large weight perturbations. The perturbation becomes zero only when the error ek is zero. So we can predict that the weight update process (1) may be unstable so that it requires a very small step size in impulsive noise environment. Also the LMS and NLMS algorithms utilizing instant error power may cause instability in an impulsive noise environment.
3. ED Criterion and Entropy
Unlike the MSE based on error power, probability distribution functions can be used in constructing performance criterion. As one of the criteria utilizing distributions, the ED between the distribution of transmitted symbol fD(d) and the equalizer output distribution fY(y) is defined as (3) [3,6].
Assuming that modulation schemes are known to receivers beforehand and all the M symbol points (A1, A2, …, AM) are equally likely, the distribution of the transmitted symbols can be expressed as:
The output distribution can be estimated based on kernel density estimation method with a set of available N output samples {y1, y2, …, yN} [6].
Then the ED can be expressed as:
The first term 1/M in (5) is a constant which is not adjustable, so the ED can be reduced to the following performance criterion CED [7]:
In ITL methods, data samples are treated as physical particles interacting with each other. If we place physical particles in the locations of yi and yj, the Gaussian kernel produces an exponentially decaying positive value as the distance between the two particles increases. This leads us consider the Gaussian kernel as a potential field-inducing interaction among particles. Then corresponds to the sum of interactions on the i-th particle and is the averaged sum of all pairs of interactions. This summed potential energy is referred to as information potential in ITL methods [2]. Therefore, the term in (6) is the information potential between symbol points and output samples, and in (6) indicates the information potential among output samples themselves.
On the other hand, the information potential can be interpreted in the concept of entropy that can be described in terms of “energy dispersal” or the “spreading of energy” [11]. As one of the convenient entropy definitions, Reny’s entropy of order 2, HReny(y) is defined in (7) as logarithm of the sum of the power of probability which is much easier to estimate [2]:
When the Reny’s entropy is used along with the kernel density estimation method , we obtain a much simpler form of Reny’s quadratic entropy as:
This leads to:
Likewise:
Therefore the cost function CED becomes:
Equations (9) and (11) indicate that the entropy of output samples increases as the distance (yj − yi) between the two information particles yj and yi increases. Therefore, (yj − yi) can be referred to as entropy-governing output and we can notice that (9) controls the spreading of output samples. Likewise, the term in (6), that is, in (11) governs dispreading or recombining the sample pairs of symbol points and output samples.
4. Entropy-Governing Variables and Recursive Algorithms
When defining yj,i = (yj − yi) and em,i = (Am – yi) and Xj.i = (Xj – Xi) for convenience’s sake, yj,i, em,i and Xj,i can be referred to as entropy-governing output, entropy-governing error and entropy-governing input, respectively. Using these entropy-governing variables and the on-line density estimation method instead of fY(y), the cost function at time k, CED,k can be written as:
where:
Minimization of CED,k indicates that Uk forces spreading of output samples and −Vk compels output samples to move close to symbol points. Considering that initial-stage output samples which may have clustered about wrong places due to channel distortion, Uk is associated with the role of getting the output samples to move out in search of each destination, that is, accelerating initial convergence speed. On the other hand, Vk is related with compelling output samples near a symbol point to come close lowering the minimum MSE.
On the other hand, the double summation operations for Uk and Vk impose a heavy computational burden. In the work [8] it has been revealed that each component Uk+1 and Vk+1 of CED,k+1 = Uk+1 − Vk+1 can be recursively calculated so that the computational complexity of (12) is significantly reduced as in the following equations (15) and (16):
Similarly, Vk+1 can be divided into the terms with yk+1 and the terms with yk−N+1:
The gradients and are calculated recursively by using Equations (15) and (16) as:
Similarly, is calculated recursively as described below:
Since the argument in (17) is a function of the entropy-governing output yk,i, we can define as the modified entropy-output , which becomes a significantly mitigated value through the Gaussian kernel when the entropy-governing output yk,i is a large value.
Then (17) becomes
Similarly, we see that the argument in (18) is a function of entropy-governing error em,k, so that we have the modified entropy-error as:
The modified entropy-error also becomes a significantly reduced value through the Gaussian kernel when the entropy-governing error em,k is large. Then (18) becomes:
Through minimization of CED,k = Uk − Vk with the gradients and obtained by (20) and (22), the following recursive MED (RMED) algorithm can be derived [7]:
Comparing the gradients of RMED to the gradient of the LMS algorithm in (1) which is composed of error and input, we may find that the gradients and in (20) and (22) have similar terms (modified entropy-output multiplied by entropy-input) and (modified entropy-error multiplied by input), respectively. Considering that impulsive noise may induce large entropy-governing output yk,i or entropy-governing error em,k, modified entropy-output and modified entropy-error which are significantly mitigated by the Gaussian kernel can be viewed as playing a crucial role in obtaining stable gradients under strong impulsive noise. Therefore we can anticipate that the RMED algorithm (23) can have a low weight perturbation in impulsive noise environments.
5. Input Power Estimation for Normalized Gradient
For the purpose of minimizing the weight perturbation of the LMS algorithm in (1), the NLMS algorithm has been introduced where the gradient is normalized by the averaged power of the current input samples [1].
Applying this approach to RMED we propose in this section to normalize the gradients in some ways. Since the role of Uk (spreading output samples) is different from that of Vk (moving output samples close to symbol points), the gradients of (23) can be normalized separately as:
where PU(k) is the average power of Xi,k and PV(k) is the average power of Xk as:
Since defeating the impulsive noise contained in the input by way of the average operation is considered to be ineffective, the denominators of (26) and (27) are likely to be fluctuating under impulsive noise. This may cause the algorithm to be sensitive to impulsive noise. Also the summation operators make the algorithm demand computationally burdensome. To avoid these drawbacks, we can track the average power PU(k) and PV(k) recursively with the balance parameter β (0 < β <1) as:
With the recursive power estimation (28) and (29), we may summarize the proposed algorithm in a more formal one as in the Table 1. In the following section, we will investigate the new RMED algorithm (25) with separate normalization by PU(k) in (28) and PV(k) in (29) in the aspect of convergence speed and steady state MSE.
6. Results and Discussion
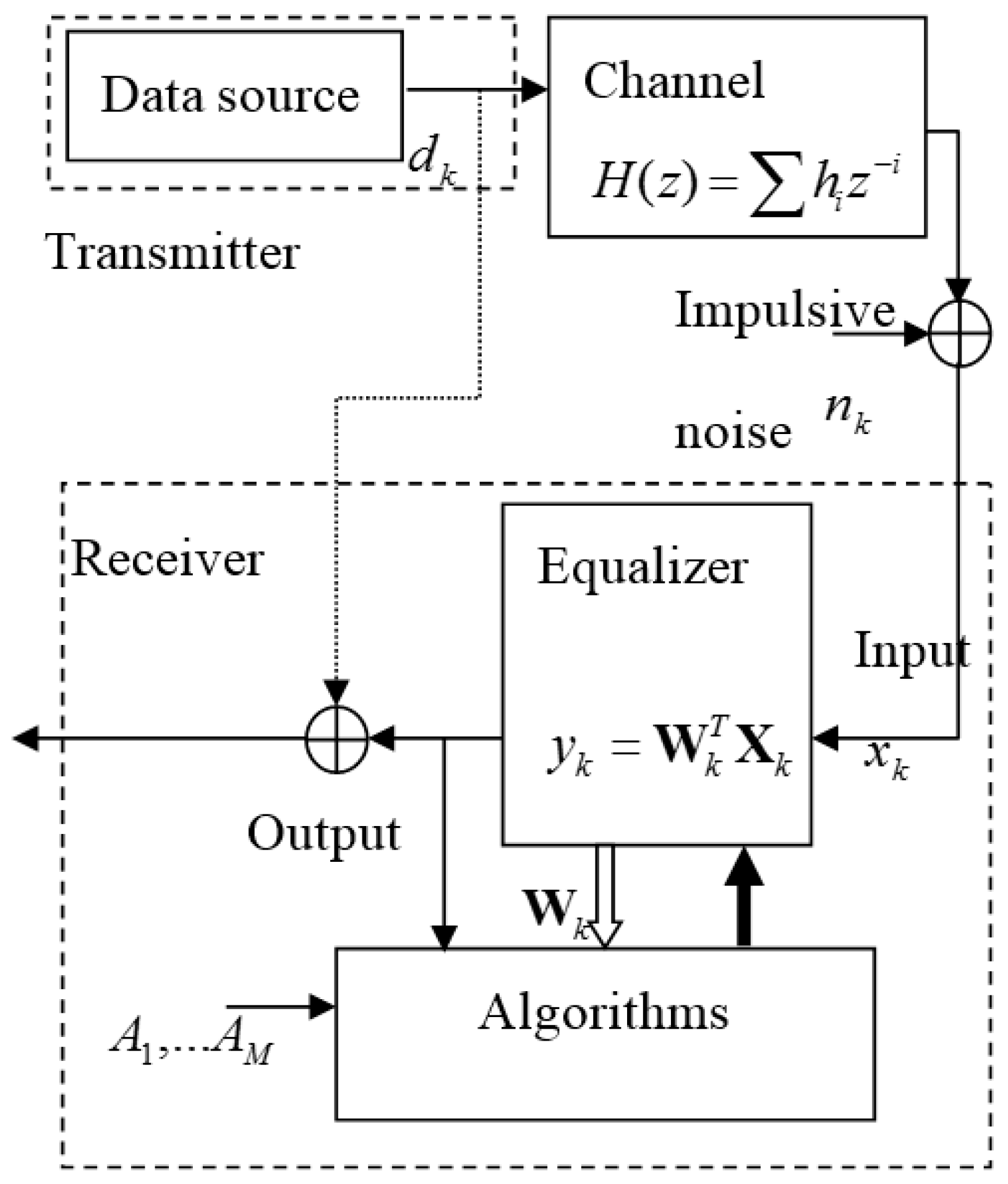
A base-band communication system with multipath fading channel and impulsive noise used in the experiment is depicted in Figure 1. The symbol set in the transmitter is composed of equally probable four symbols (−3, −1, 1, 3). The transmitted symbol is to be distorted by the multipath channel H(z) = 0.26 + 0.93z−1 + 0.26z−2 [12]. The channel output is added by impulsive noise nk. The distribution function of nk, f(nk) is expressed in Table 2 where is the variance of impulses which are generated according to Poisson process (occurrence rate ε) and is that of the background Gaussian noise [13]. The simulation setup and parameter values are described in the Figure 1 and the Table 2.
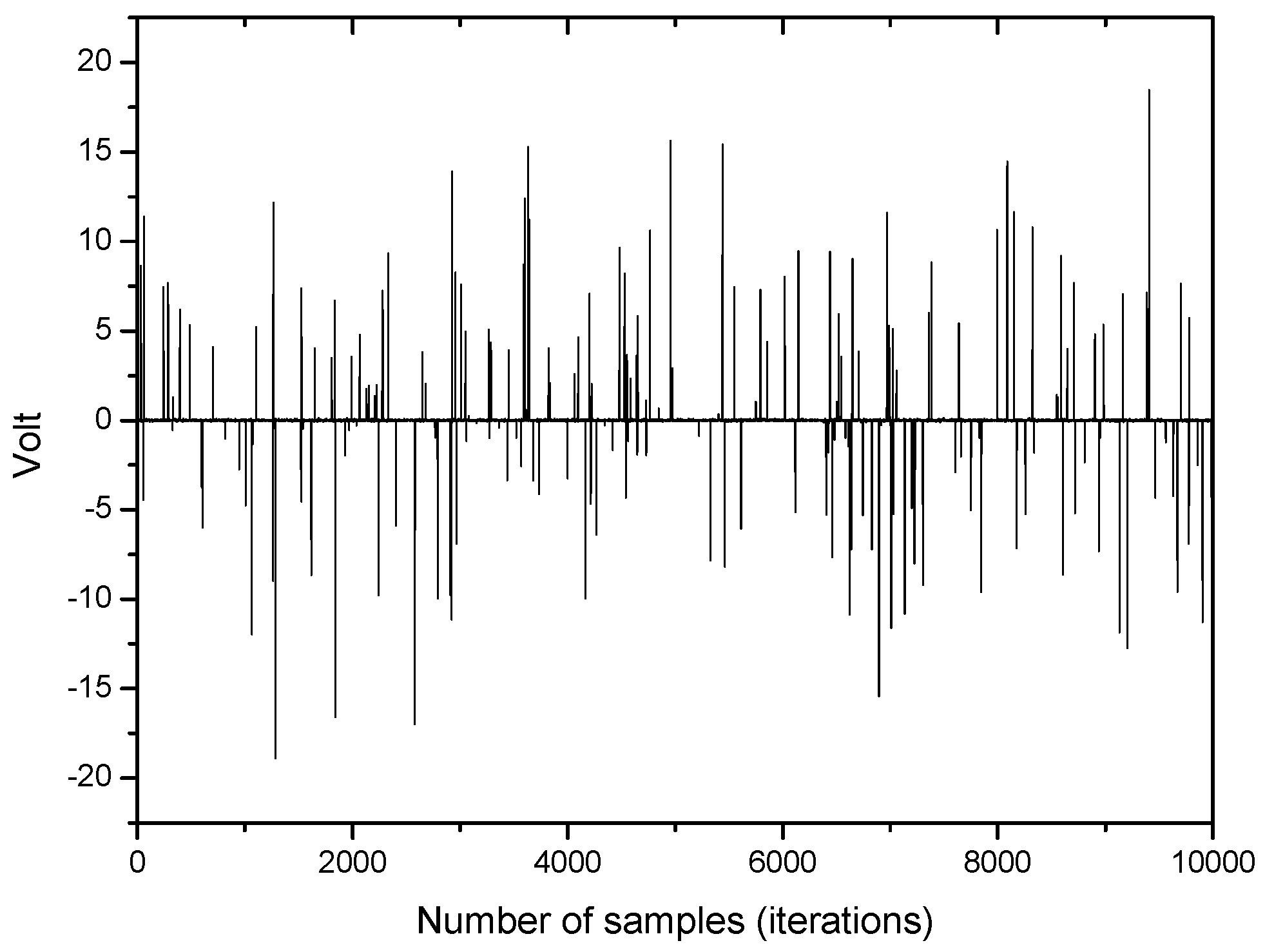
An example of impulsive noise being used in this simulation is depicted in Figure 2.
It has in Section 4 been analyzed that Uk is associated with the role of spreading output samples which are clustered to wrong positions due to distorted channel characteristics and Vk is related with moving output samples close to symbol points. This process can be explained through initial-stage investigation of what happens in the error distribution and observing how the distribution of output samples changes in the experimental environment.
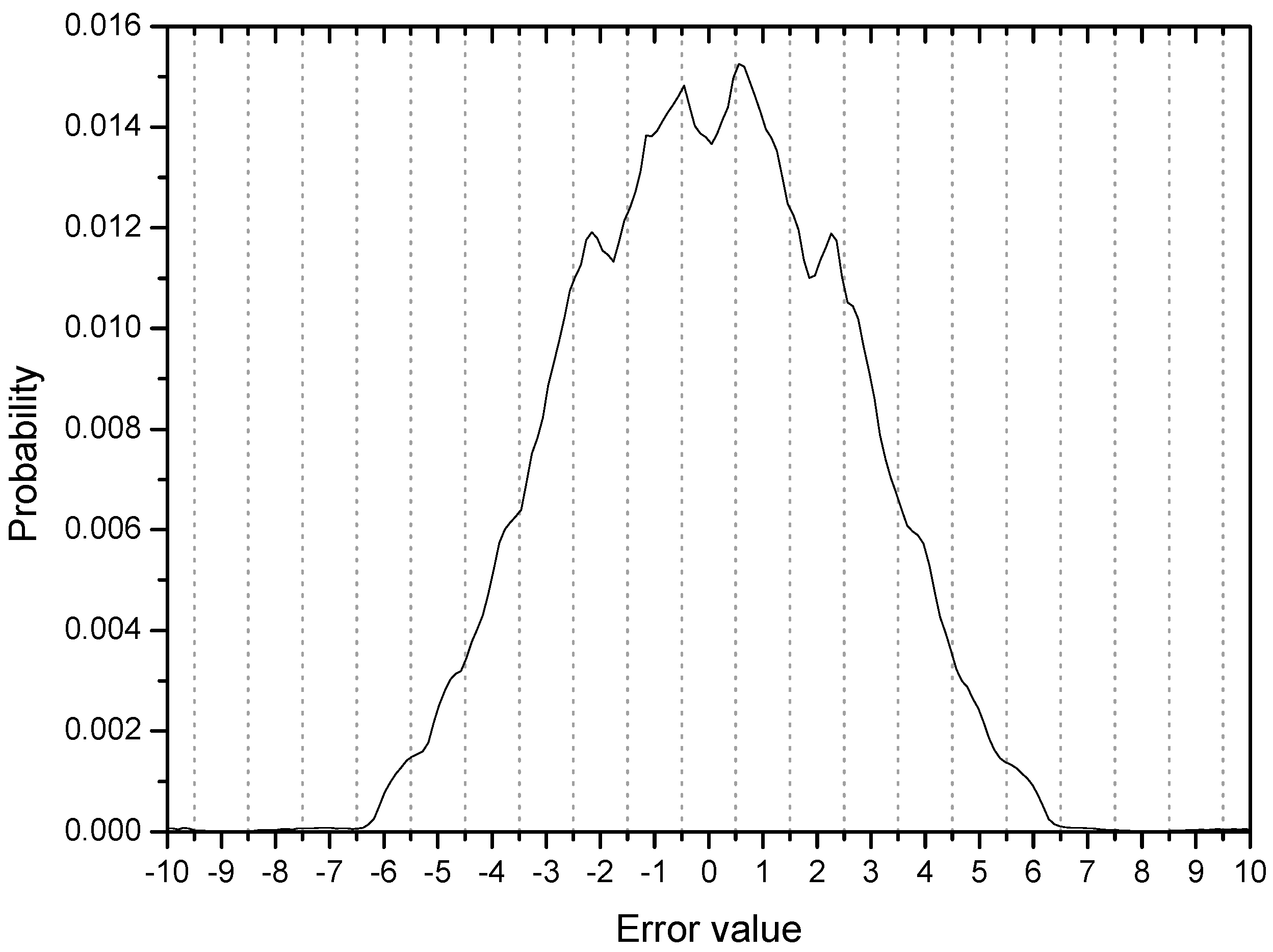
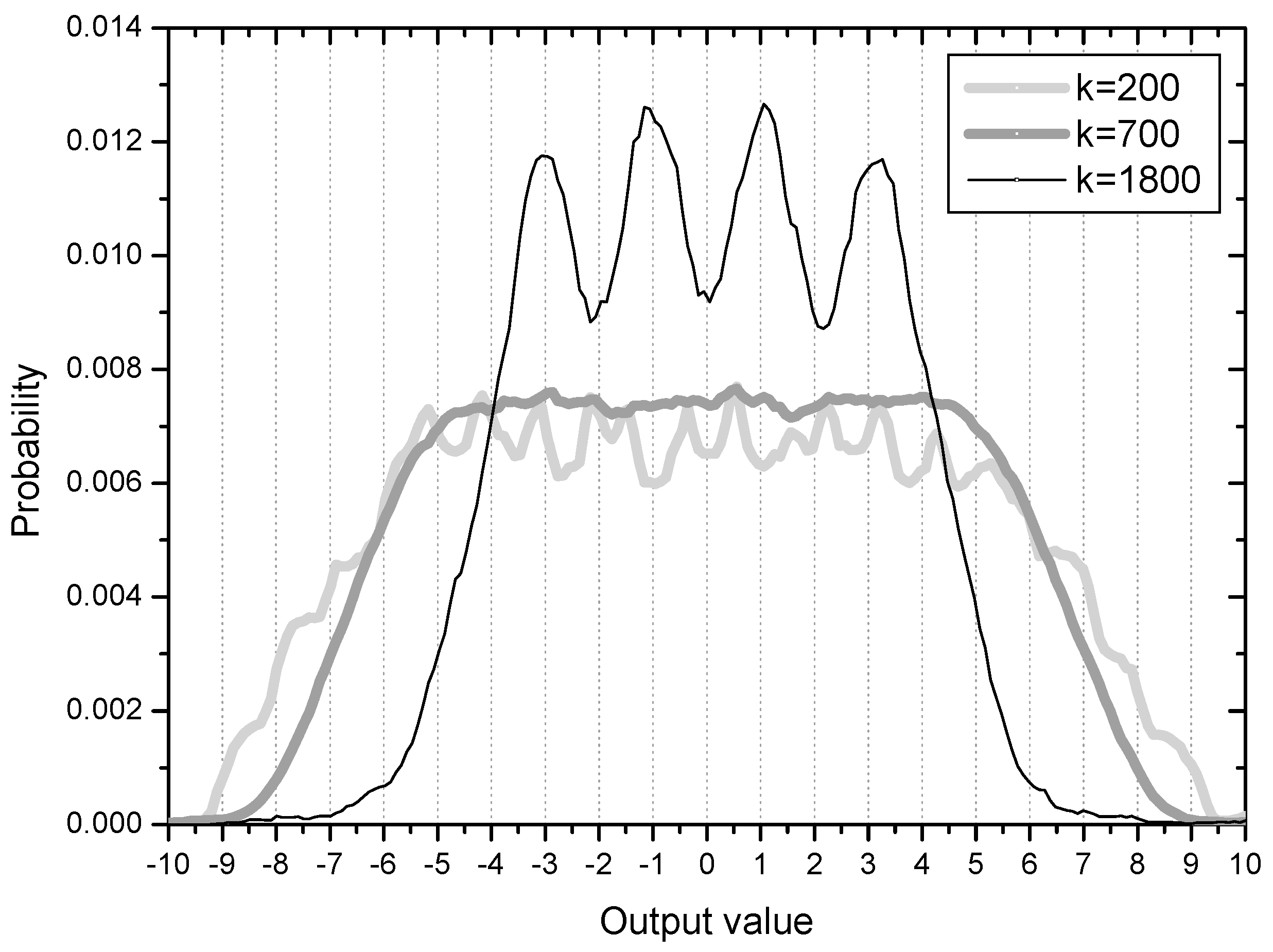
Figure 3 shows the error distribution in the initial stage with 200 error samples and ensemble average of 500 runs. Considering the four symbol points are (−3, −1, 1, 3), error values greater than 1.0 are associated with output samples which can be decided as wrong symbols. The cumulative probability of initial output samples placed in the wrong regions in this respect is calculated to be 0.35 from the Figure 3 (35% output samples are not in place). The peaks or ridges in the error distribution are about 6 on each side. This observation may indicate that output samples are clustered or grouped in some regions (two groups are within the correct range but 4 groups are in the incorrect positions on each side of the distribution). This result coincides clearly with the initial output distribution in Figure 4. The output distribution showing about 12 peaks indicates that the initial output samples are clustered into 12 groups mostly located out of place, that is, not around −3, −1, 1, 3.
On the 35% output samples clustered in the wrong symbol regions, the spreading force has a positive effect in order for them in blind search to move out for finding their correct symbol positions. This process is observed in the graph of k = 700 in Figure 4. The output distribution at time k = 700 has an evenly spread shape, indicating that the clustered output samples have moved out and mingled with one another. At the sample time k = 1800 the output samples start to position at their correct symbol areas. From this phase, the force moving output samples close to the symbol points is in effect on lowering steady state MSE.
These results imply that Uk is related with convergence speed and Vk with steady state MSE. To verify this analysis we experiment the proposed algorithm in the following three modes with respect to convergence speed and steady state MSE (we assume that steady state MSE is close to minimum MSE):
Mode 1 of RMED-SN algorithm in (30) is for observing changes in initial convergence speed by normalizing only by the average power PU(k) of entropy-input Xi,k compared to the not-normalized RMED. Mode 2 is to observe whether the normalization of by PV(k) of input Xk without managing Uk lowers the steady state MSE of RMED. Finally we see if Mode 3 employing normalization of and simultaneously yields both of the two performance enhancements; faster convergence and lowered steady state MSE.
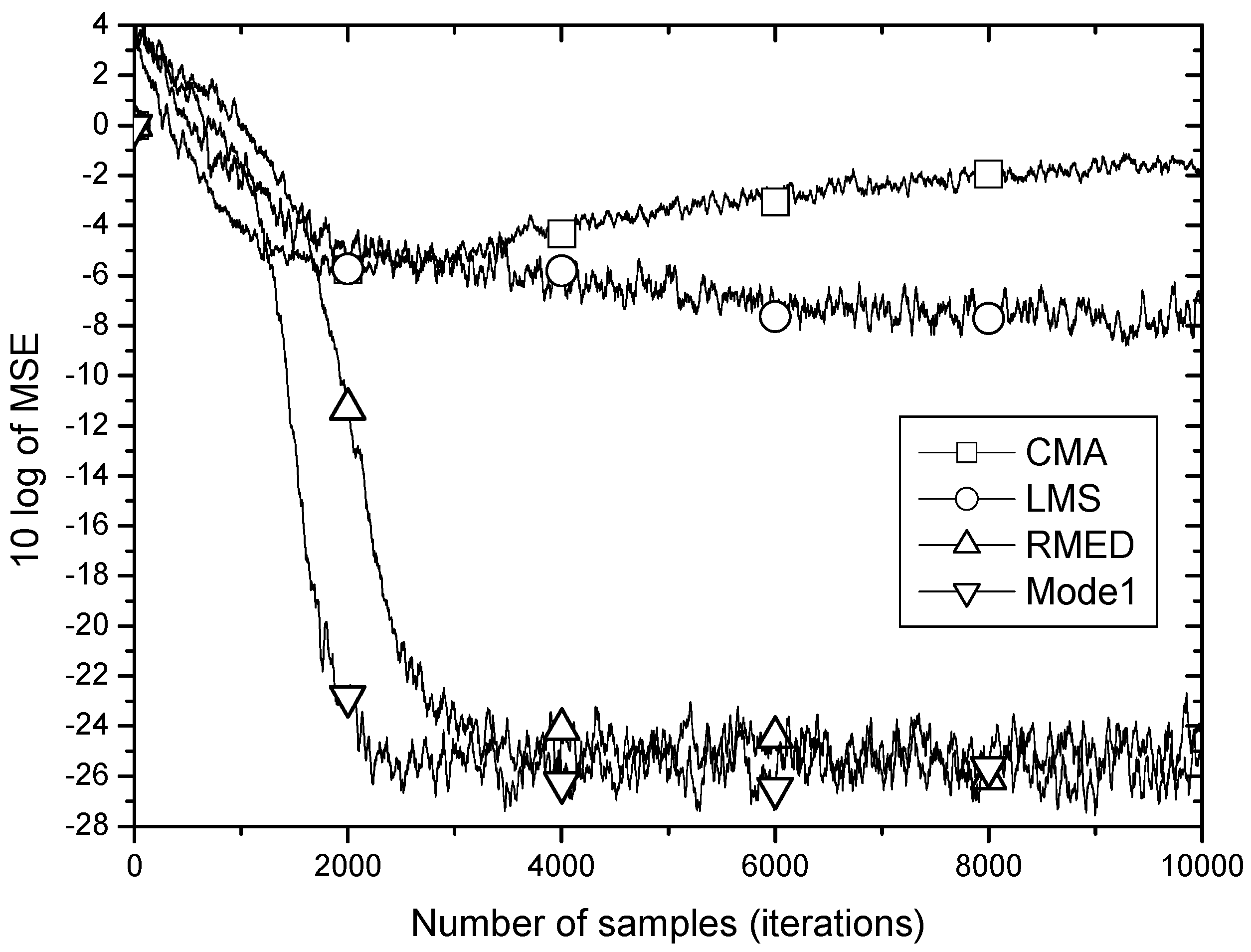
Figure 5 shows the MSE learning performance for CMA, LMS, RMED and Mode 1 of the proposed algorithm. As discussed in Section 2, the learning curves of the MSE-based algorithms, CMA and LMS do not fall down below −6 dB being defeated by the impulsive noise. On the other hand, the RMED and proposed algorithm show a rapid and stable convergence. The difference of convergence speed between RMED and Mode 1 is clearly observed. While the RMED converges in about 4000 samples, the Mode 1 does in about 2000 samples. Therefore, Mode 1 shows faster convergence than the RMED algorithm by 2 times verifying the analysis of the role of since only is normalized but is not, and we see little difference (about 1 dB) in the steady state MSE.
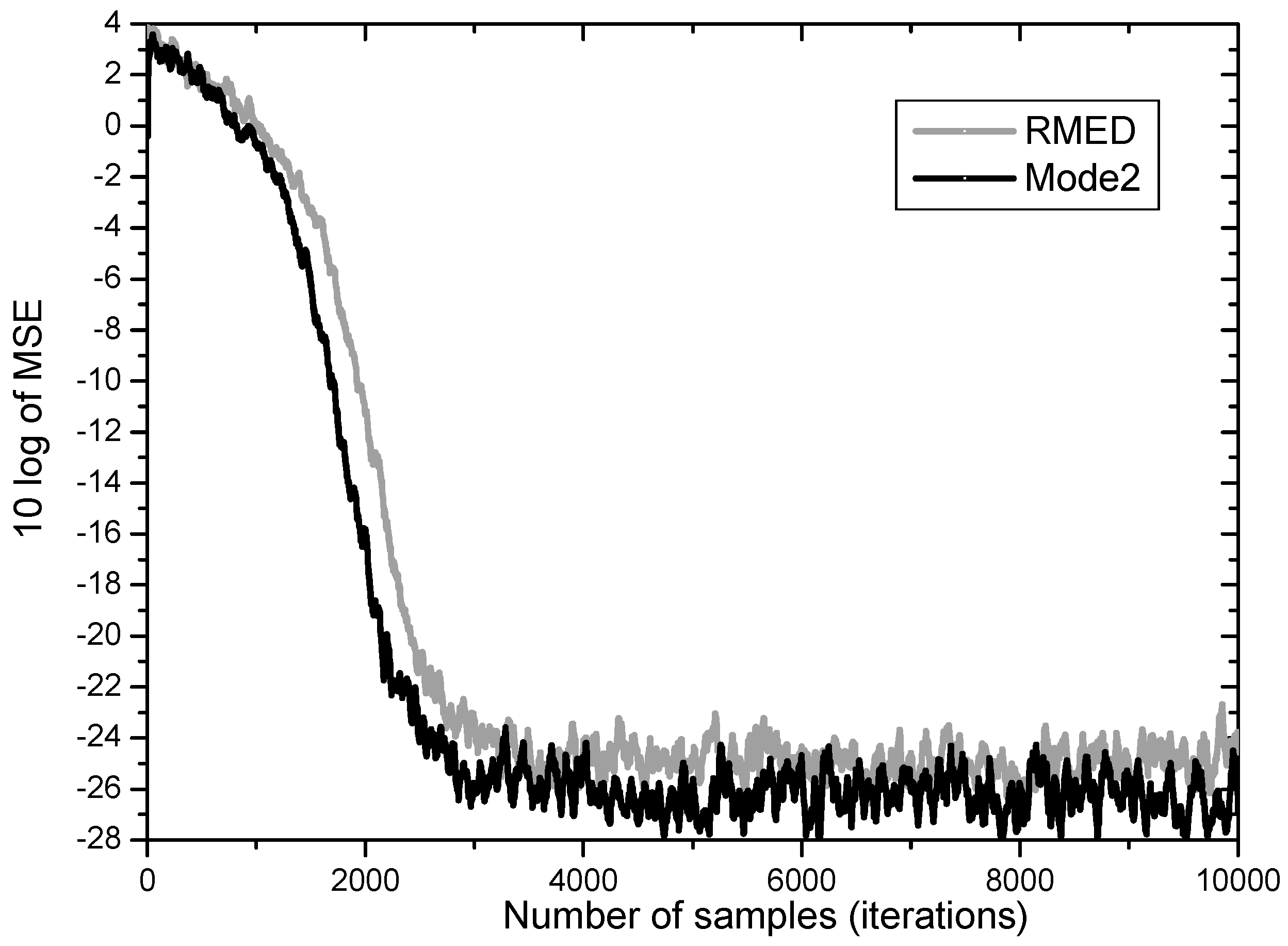
In Figure 6 RMED and Mode 2 are compared. Both algorithms have similar convergence speed with difference of only 500 samples. But after convergence the Mode 2 yields much lower steady state MSE than the original RMED by over 2 dB. These findings indicate that the role of Vk is definitely related with lowering minimum MSE. This is in accordance with the analysis that Uk plays the role of pulling error samples close together.
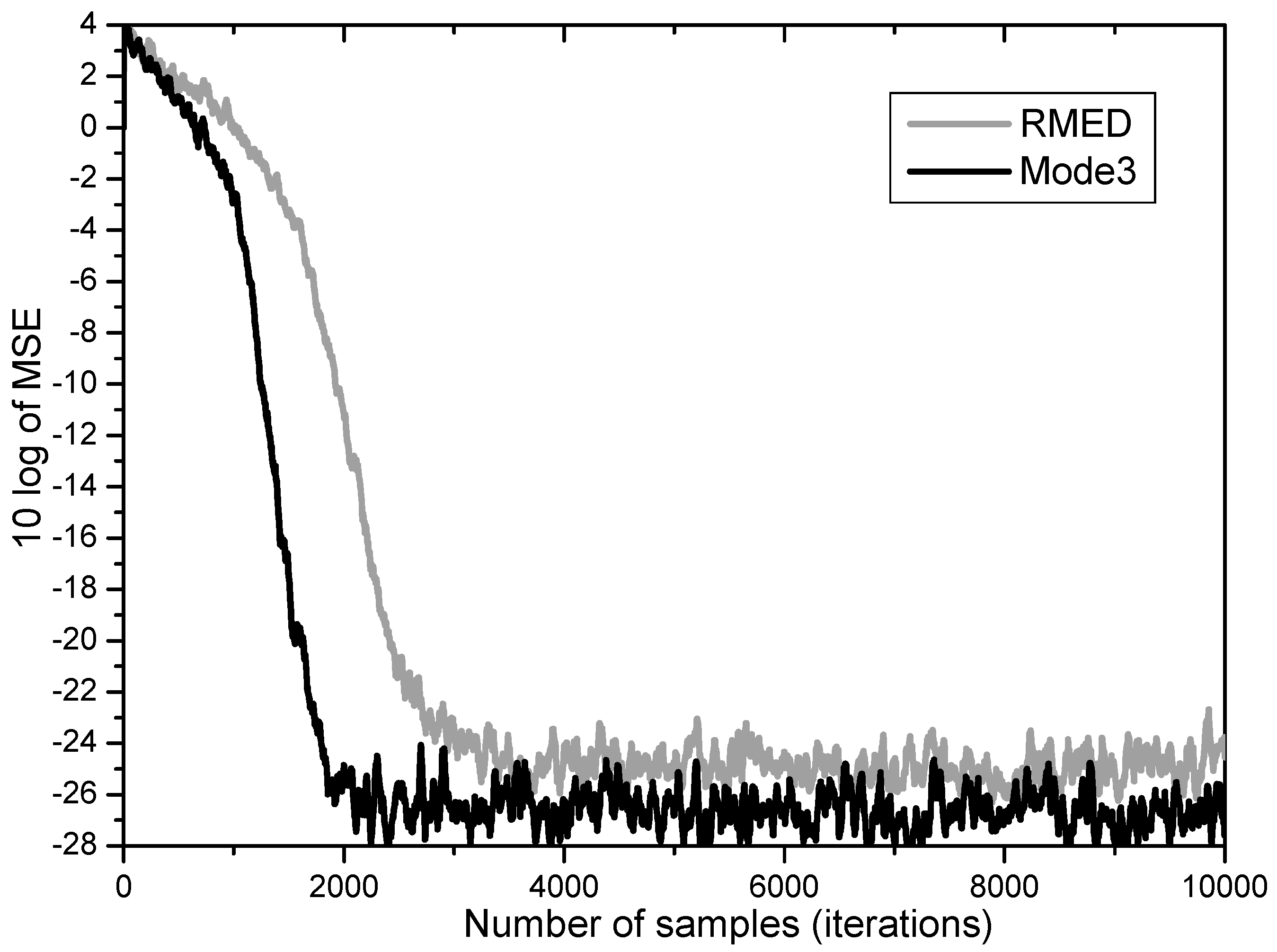
Furthermore, Mode 3 employing normalization of and simultaneously proves to yield the two merits of performance enhancement revealing increased speed and lowered steady state MSE as depicted in Figure 7. While the RMED converges in about 4000 samples and leaves its steady state MSE at about 25 dB, the Mode 3 converges in about 2000 samples and has about 27 dB of steady state MSE. By employing Mode 3, we obtained faster convergence by about 2 times and lower steady state MSE by over 2 dB.
In Mode 3, it is still not clear whether the normalization to Uk for speeding up the initial convergence may have a negative influence in later iterations, so we try to reduce the Uk normalization gradually after convergence (k ≥ 3000) by using in place of PU(k) as:
where k ≥ 3000 and a constant c is 0 ≤ c ≤ 1.
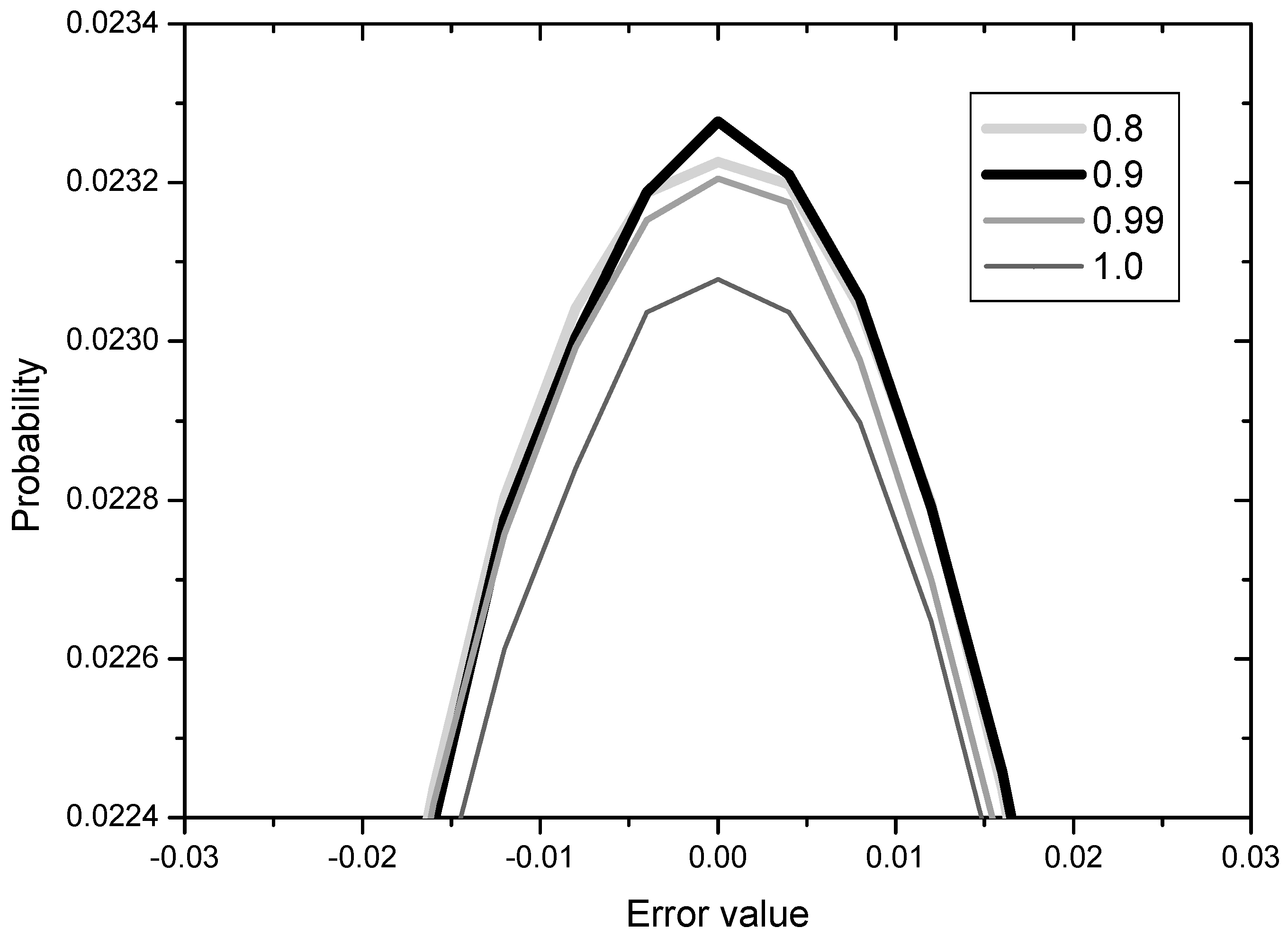
The results for c = 0.8, 0.9, 0.99, 1.0 are shown in Figure 8 in terms of error distribution since the learning curves for the various constant values are not clearly distinguishable.
The value of c in (33) may be related with the degree of gradual reduction in the normalization to Uk, that is, c = 1 indicates no reduction (Mode 3 as it is) and c = 0.8 means comparatively rapid reduction. From the Figure 8, we observe that the error performance becomes better and then worse as the degree of reduction decreases from 0.8 to 1.0. This implies that the gradual reduction of the normalization to Uk is effective but not much. We may conclude that the normalization to Uk for speeding up the initial convergence has a slight negative influence in later iterations and this can be overcome by employing the gradual reduction of the Uk normalization.
7. Conclusions
Minimization of the Euclidean distance between output distribution and Dirac delta function as a performance criterion is known to force the distribution of system output to come to a set of delta functions located at each symbol point. In the analysis of the algorithm RMED developed based on that criterion and recursive gradient estimation, it has been revealed in this paper that the minimization process of the cost function uses its two gradients with different functions; one for Uk that forces spreading of output samples and the other one for Vk that compels output samples to move close to symbol points. In order to verify the roles of Uk and Vk explained in the analysis by controlling Uk and Vk separately, we proposed to normalize with the averaged power of entropy-governing input and to normalize with that of input. From the results through simulation for the separate normalization of the gradients of RMED in multipath channel equalization under impulsive noise, faster convergence by about two times through normalization of and lower steady state MSE by over 2 dB by normalization of have been observed. From the analysis and experimental results, we can conclude that Uk is associated with the role of accelerating initial convergence speed by spreading output samples which may have clustered around wrong places in the initial-stage due to channel distortions, and Vk is related with lowering the minimum MSE by pulling error samples close together through the minimization of CED,k. Also it can be concluded that through applying normalization to the two factors and separately with each related input power, significant performance enhancement can be achieved.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Haykin, S. Adaptive Filter Theory, 4th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2001. [Google Scholar]
- Principe, J.; Xu, D.; Fisher, J. Information theoretic learning. In Unsupervised Adaptive Filtering; Haykin, S., Ed.; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Erdogmus, D.; Rao, Y.; Principe, J. Supervised training of adaptive systems with partially labeled data. In Proceedings of the International Conference on ASSP, Marrakech, Morocco, 9–15 April 2005; pp. 321–324. [Google Scholar]
- Soleimani, H.; Tomasin, S.; Alizadeh, T.; Shojafar, M. Cluster-head based feedback for simplified time reversal prefiltering in ultra-wideband systems. Phys. Commun. 2017, 25, 100–109. [Google Scholar] [CrossRef]
- Ahmadi, A.; Shojafar, M.; Hajeforosh, S.F.; Dehghan, M.; Singhal, M. An efficient routing algorithm to preserve k-coverage in wireless sensor networks. J. Supercomput. 2014, 68, 599–623. [Google Scholar] [CrossRef]
- Jeong, K.; Xu, J.W.; Erdogmus, D.; Principe, J.C. A new classifier based on information theoretic learning with unlabeled data. Neural Netw. 2005, 18, 719–726. [Google Scholar] [CrossRef] [PubMed]
- Kim, N.; Kang, M. Blind signal processing algorithms based on recursive gradient estimation. Int. J. Electr. Comput. Eng. 2015, 5, 548–561. [Google Scholar]
- Treichler, R.; Agee, B. A new approach to multipath correction of constant modulus signals. IEEE Trans. 1983, 31, 349–372. [Google Scholar] [CrossRef]
- Bharani, L.; Radhika, P. FPGA implementation of optimal step size NLMS algorithm and its performance analysis. Int. J. Res. Eng. Technol. 2013, 2, 885–890. [Google Scholar]
- Chinaboina, R.; Ramkiran, D.; Khan, H.; Usha, M.; Madhav, B.; Srinivas, K.; Ganesh, G. Adaptive algorithms for acoustic echo cancellation in speech processing. Int. J. Res. Rev. Appl. Sci. 2011, 7, 38–42. [Google Scholar]
- Leff, H.S. Thermodynamic entropy: The spreading and sharing of energy. Am. J. Phys. 1996, 64, 1261–1271. [Google Scholar] [CrossRef]
- Proakis, J. Digital Communications, 2nd ed.; McGraw-Hill: New York, NY, USA, 1989. [Google Scholar]
- Santamaria, I.; Pokharel, P.; Principe, J. Generalized correlation function: Definition, properties, and application to blind equalization. IEEE Trans. Signal Process. 2006, 54, 2187–2197. [Google Scholar] [CrossRef]
Figure 1.
Base-band communication system for simulation.

Figure 2.
An example of impulsive noise.
Figure 3.
The error distribution at time k = 200 with 200 error samples.
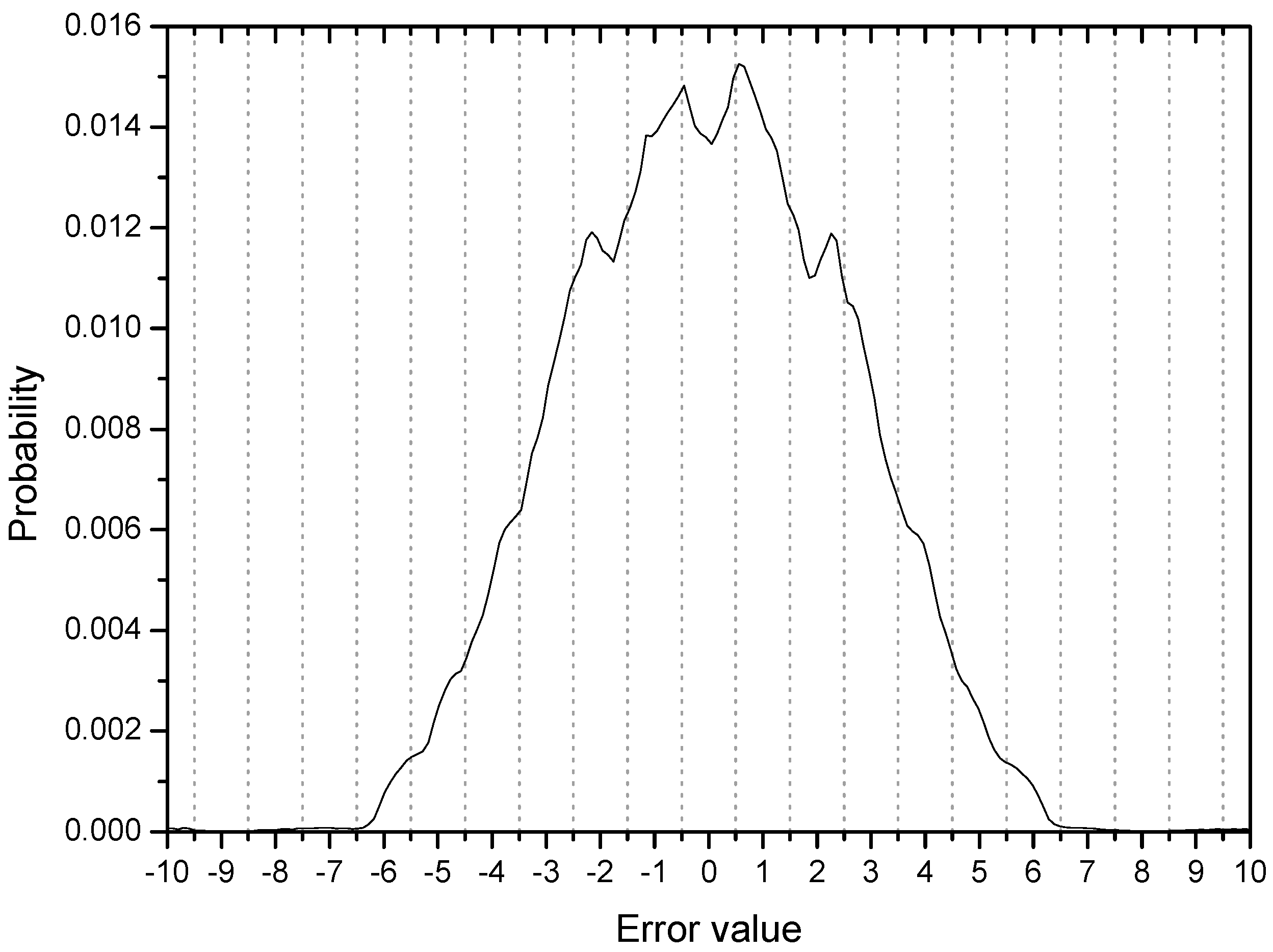
Figure 4.
Output distributions in an initial stage.
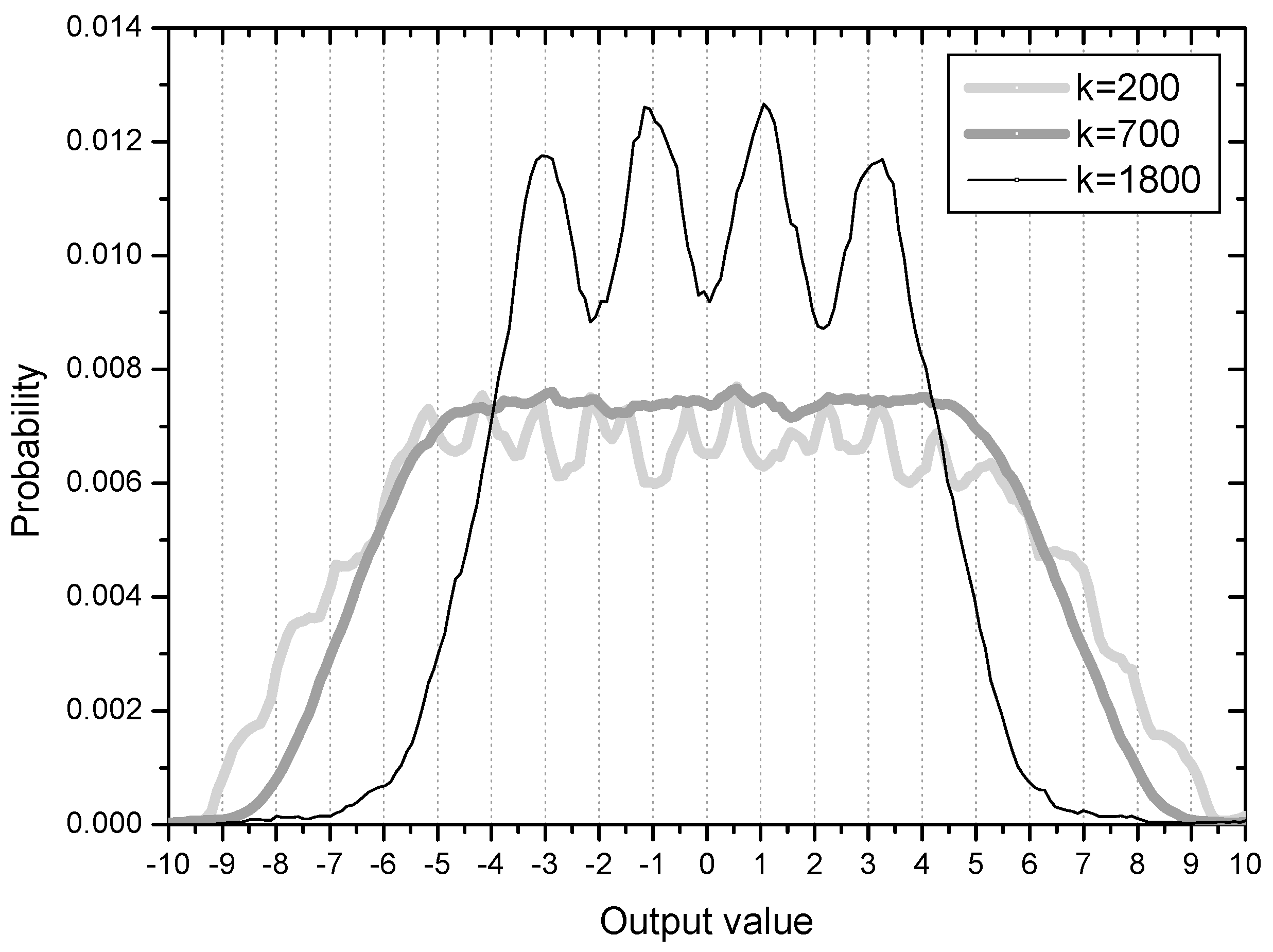
Figure 5.
MSE convergence performance for Uk normalization.
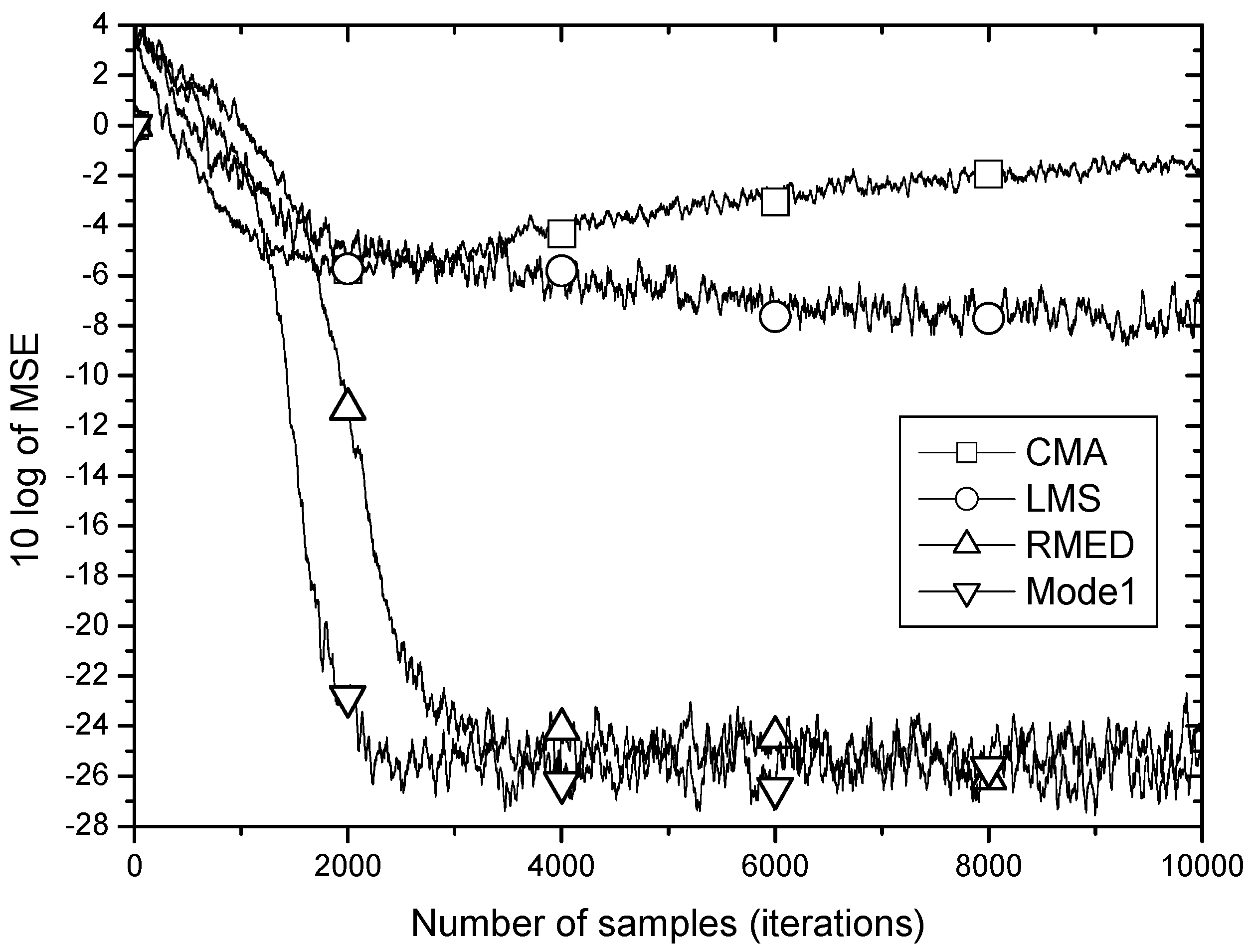
Figure 6.
MSE convergence performance for normalization of Vk.
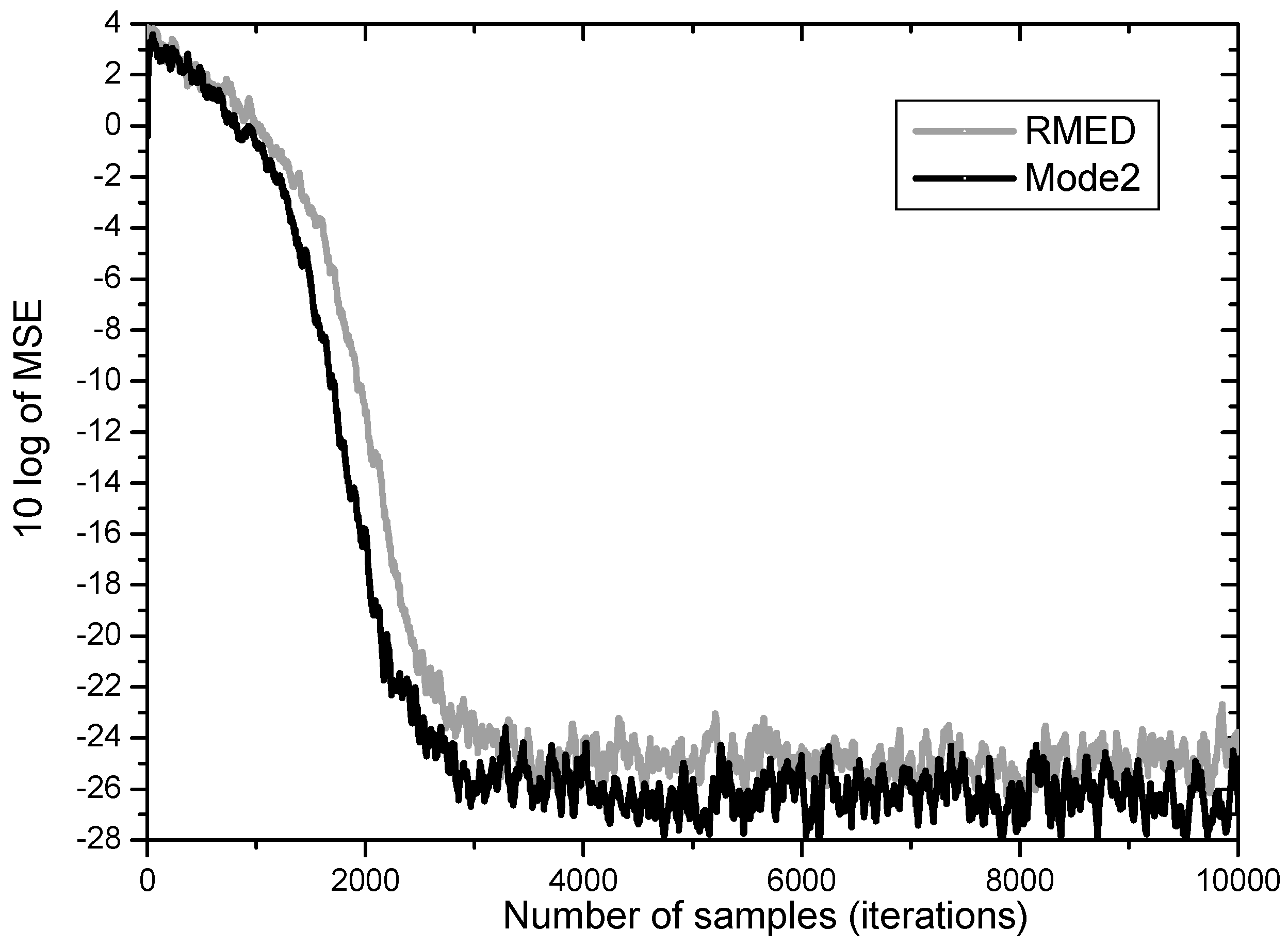
Figure 7.
MSE convergence performance for normalization of both Uk and Vk.

Figure 8.
Error distribution with respect to the values of c for normalization of Uk.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
A summary of the proposed algorithm.
| Process | Equations |
|---|---|
| Initialization | , , , , |
| Update of gradient function | |
| Update of gradient function | |
| Update of | |
| Update of | |
| Update of |
Table 2.
Simulation setup and parameter values.
| Features | Parameters |
|---|---|
| The symbol points in the transmitter | |
| The channel transfer function | |
| The noise distribution function | , , , |
| NNumber of weights | 11 |
| 4 Step size | , , |
| Sample size | |
| Kernel size |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kim, N. Function Analysis of the Euclidean Distance between Probability Distributions. Entropy 2018, 20, 48. https://doi.org/10.3390/e20010048
AMA Style
Kim N. Function Analysis of the Euclidean Distance between Probability Distributions. Entropy. 2018; 20(1):48. https://doi.org/10.3390/e20010048
Chicago/Turabian StyleKim, Namyong. 2018. "Function Analysis of the Euclidean Distance between Probability Distributions" Entropy 20, no. 1: 48. https://doi.org/10.3390/e20010048
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.