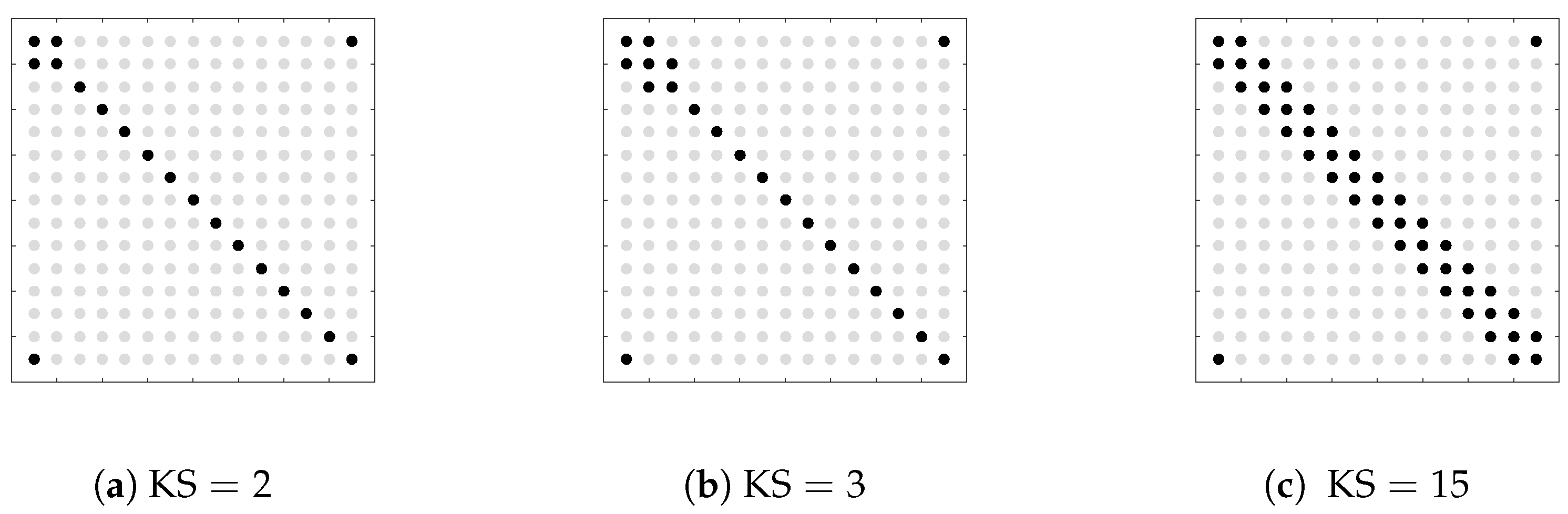
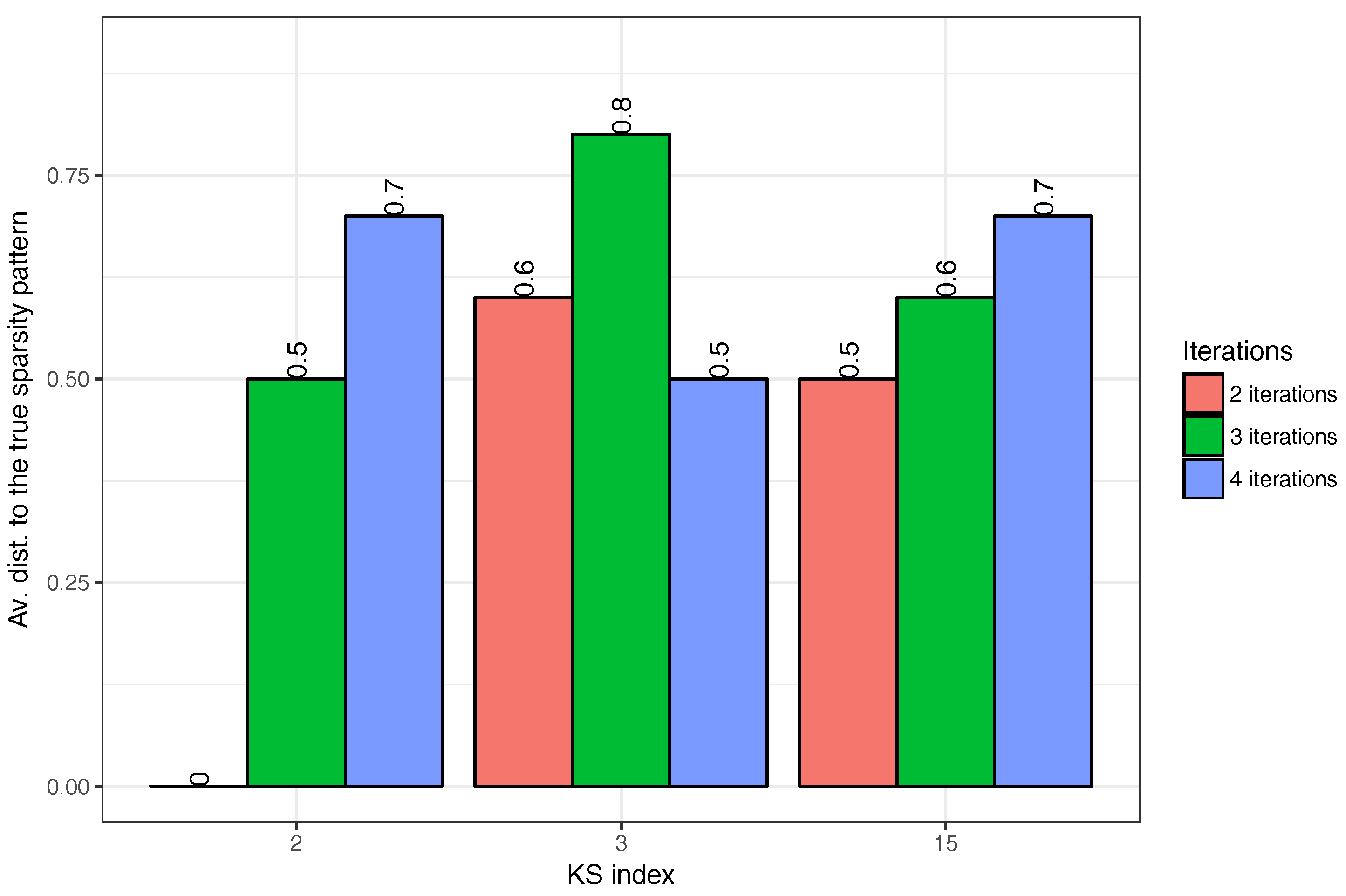
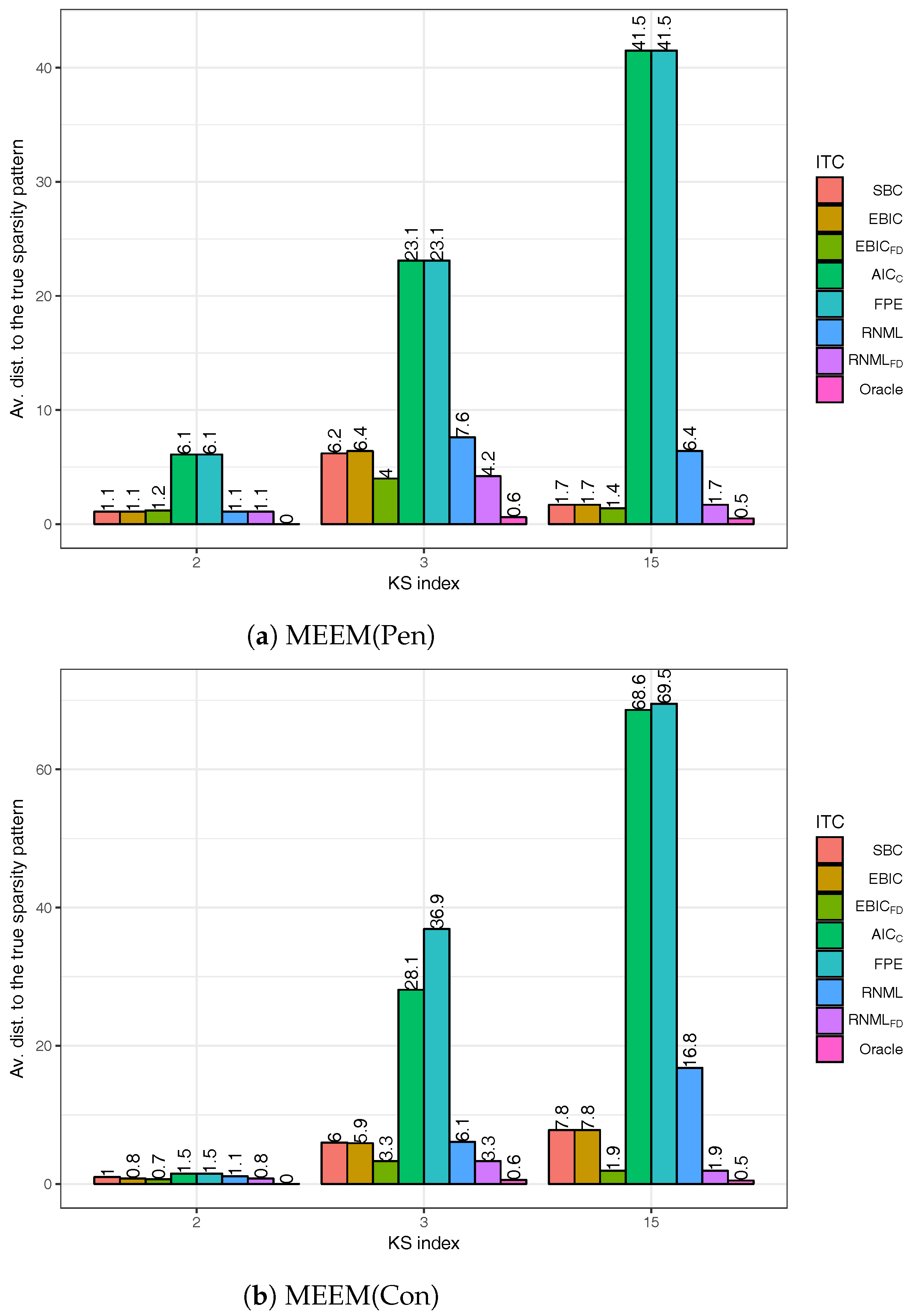
1. Introduction
Graphical models are instrumental in the analysis of multivariate data. Originally, these models have been employed for independently sampled data, but their use has been extended to multivariate, stationary time series [
1,
2], which triggered their popularity in statistics, machine learning, signal processing and neuroinformatics.
For better understanding the significance of graphical models, let
be a random vector having a Gaussian distribution with zero-mean and positive definite covariance matrix
. A graph
can be assigned to
in order to visualize the conditional independence between its components. The symbol
V denotes the vertices of
G, while
E is the set of its edges. There are no loops from a vertex to itself, nor multiple edges between two vertices. Hence,
E is a subset of
. Each vertex of the graph is assigned to an entry of
. We conventionally draw an edge between two vertices
a and
b if the random variables
and
are
not conditionally independent, given all other components of
. The description above follows the main definitions from [
3] and assumes that the graph
G is
undirected. Proposition 1 from the same reference provides a set of equivalent conditions for conditional independence. The most interesting one claims that
and
are conditionally independent if and only if the entry
of
is zero. This shows that the missing edges of
G correspond to zero-entries in the inverse of the covariance matrix, which is called the concentration matrix.
There is an impressive amount of literature on graphical models. In this work, we focus on a generalization of this problem to time series. The main difference between the static case and the dynamic case is that the former relies on the sparsity pattern of the concentration matrix, whereas the latter is looking for zeros in the inverse of the spectral density matrix. One of the main difficulties stems from the fact that the methods developed in the static case cannot be applied straightforwardly to time series.
Parametric as well as non-parametric methods have been already proposed in the previous literature dedicated to graphical models for time series. Some of the recently introduced estimation methods are based on convex optimization. We briefly discuss below the most important algorithms which belong to this class.
Reference [
4] extends the static case by allowing the presence of latent variables. The key point of their approach is to express the manifest concentration matrix as the sum of a sparse matrix and a low-rank matrix. Additionally, they provide conditions for the decomposition to be unique, in order to guarantee the identifiability. The two matrices are estimated by minimizing a penalized likelihood function, where the penalty involves both the
-norm and the nuclear norm. Interestingly enough, the authors of the discussion paper [
5] pointed out that an alternative solution, which relies on the Expectation-Maximization algorithm, can be easily obtained.
In the dynamic case, reference [
6] has an important contribution which consists in showing that the graphical models for multivariate autoregressive processes can be estimated by solving a convex optimization problem which follows from the application of the Maximum Entropy principle. This paved the way for the development of efficient algorithms dedicated to topology selection in graphical models of autoregressive processes [
7,
8] and autoregressive moving average processes [
9].
A happy marriage between the approach from [
4] and the use of Maximum Entropy led to the solution proposed in [
10] for the identification of graphical models of autoregressive processes with latent variables. Similar to [
4], the estimation is done by minimizing a cost function whose penalty term is given by a linear combination of the
-norm and the nuclear norm. The two coefficients of this linear combination are chosen by the user and they have a strong influence on the estimated model. The method introduced in [
10] performs the estimation for various pairs of coefficients which yield a set of candidate models; the winner is decided by using a
score function.
According to the best of our knowledge, there is no other work that extends the estimation method from [
5] to the case of latent-variable autoregressive models. The main contribution of this paper is to propose an algorithm of this type, which combines the strengths of Expectation-Maximization and convex optimization. The key point for achieving this goal is to apply the Maximum Entropy principle.
The rest of the paper is organized as follows. In the next section, we introduce the notation and present the method from [
10].
Section 3 outlines the newly proposed algorithm. The outcome of the algorithm is a set of models from which we choose the best one by employing information theoretic (IT) criteria.
Section 4 is focused on the description of these criteria: We discuss the selection rules from the previous literature and propose a novel criterion. The experimental results are reported in
Section 5.
Section 6 concludes the paper.
2. Preliminaries and Previous Work
Let
be a
-dimensional (
) time series generated by a stationary and stable
process of order
p. We assume that the spacing of observation times is constant and
. The symbol
denotes transposition. The difference equation of the process is
where
are matrix coefficients of size
and
is a sequence of independently and identically distributed random
-vectors. We assume that the vectors
are drawn from a
-variate Gaussian distribution with zero mean vector and covariance matrix
. Additionally, the vectors
are assumed to be constant.
The conditional independence relations between the variables in
are provided by the inverse of the spectral density matrix (ISDM) of the
-process
. The ISDM has the expression
where
and
is the operator for conjugate transpose. We define
, where
stands for the identity matrix of appropriate size, and
. For
, we have that
and
. The sparse structure of the ISDM contains conditional dependence relations between the variables of
, i.e., two variables
and
are independent, conditional on the other variables, if and only if [
1,
11]
In the graph corresponding to the ISDM , the nodes stand for the variables of the model, and the edges stand for conditional dependence, i.e., there is no edge between conditionally independent variables.
In a latent-variable graphical model it is assumed that
, where
variables are accessible to observation (they are called manifest variables) and
variables are latent, i.e., not accessible to observation, but playing a significant role in the conditional independence pattern of the overall model. The existence of latent variables in a model can be described in terms of the ISDM by the block decomposition
where
and
are the manifest and latent components of the spectral density matrix, respectively. Using the Schur complement, the ISDM of the manifest component has the form [
10] (Equation (21)):
When building latent variable graphical models, we assume that
, i.e., few latent variables are sufficient to characterize the conditional dependence structure of the model. The previous formula can therefore be written
where
is sparse, and
has (constant) low-rank almost everywhere in
. Furthermore, we can write [
12] (Equation (4)):
where
is a shift matrix, and
and
are
positive semidefinite matrices. We split all such matrices in
blocks, e.g.,
The block trace operator for such a matrix is
, defined by
For negative indices, the relation
holds. Note that (
8) can be rewritten as
The first
sample covariances of the
process are [
13]:
However, only the upper left
blocks corresponding to the manifest variables can be computed from data; they are denoted
. With
, we build the block Toeplitz matrix
It was proposed in [
10] to estimate the matrices
and
by solving the optimization problem
where
is the trace operator,
denotes the natural logarithm and
stands for the determinant. Minimizing
induces low rank in
and
are trade-off constants. The function
is a group sparsity promoter whose expression is given by
Note that is the i-th degree coefficient of the polynomial that occupies the position in the matrix polynomial . Sparsity is encouraged by minimizing the -norm of the vector formed by the coefficients that are maximum for each position .
3. New Algorithm
The obvious advantage of the optimization problem (
13) is its convexity, which allows the safe computation of the solution. However, a possible drawback is the presence of two parameters,
and
, whose values should be chosen. A way to eliminate one of the parameters is to assume that the number
of latent variables is known. At least for parsimony reasons, it is natural to suppose that
is very small. Since a latent variable influences all manifest variables in the ISDM (
5), there cannot be too many independent latent variables. Therefore, giving
a fixed small value is likely to be not restrictive.
In this section, we describe an estimation method which is clearly different from the one in [
10]. More precisely, we generalize the Expectation-Maximization algorithm from [
5], developed there for independent and identically distributed random variables, to a
process. For this purpose, we work with the full model (
4) that includes the ISDM part pertaining to the
latent variables. Without loss of generality, we assume that
equals the identity matrix
; the effect of the latent variables on the manifest ones in (
5) can be modeled by
alone. Combining with (
2), the model is
where the matrices
have to be found.
The main difficulty of this approach is the unavailability of the latent part of the matrices (
11). Were such matrices available, we could work with SDM
estimators (confined to order
p) of the form
where
denotes the
i-th covariance lag for the VAR process
(see also (
1) and (
11)). We split the matrix coefficients from (
15) and (
16) according to the size of manifest and latent variables, e.g.,
To overcome the difficulty, the Expectation-Maximization algorithm alternatively keeps fixed either the model parameters
or the matrices
, estimating or optimizing the remaining unknowns. The expectation step of Expectation-Maximization assumes that the ISDM
from (
15) is completely known. Standard matrix identities [
5] can be easily extended to matrix trigonometric polynomials for writing down the formula
Identifying (
16) with (
18) gives expressions for estimating the matrices
, depending on the matrices
from (
15). The upper left corner of (
18) needs no special computation, since the natural estimator is
where the sample covariances
are directly computable from the time series. It results that
The other blocks from (
17) result from convolution expressions associated with the polynomial multiplications from (
18). The lower left block of the coefficients is
Note that the trigonometric polynomial
has degree
, since its factors have degree
p. With (
20) available, we can compute
where
if
and
otherwise. Although the degree of the polynomial from the lower right block of (
18) is
, we need to truncate it to degree
p, since this is the degree of the ISDM
from (
15). This is the reason for computing only the coefficients
in (
21). The same truncation is applied on (
20); note that there we cannot compute only the coefficients that are finally needed, since all of them are required in (
21).
In the maximization step of Expectation-Maximization, the covariance matrices are assumed to be known and are fixed; the ISDM can be estimated by solving an optimization problem that will be detailed below. The overall solution we propose is outlined in Algorithm 1, explained in what follows.
| Algorithm 1 Algorithm for Identifying of ISDM (AlgoEM) |
Input: , -order p, number of latent variables , an information theoretic criterion (ITC). Initialization: Evaluate for ; (see ( 11) and the discussion below it) ; ; (see ( 22)); Compute from EIG of ; for all do Maximum Entropy Expectation-Maximization (penalized setting): for do Use and to compute (see ( 16)–( 18)); (see ( 23)); Get from (see ( 15)); end for Use to compute ; Determine (see ( 24)); if ADAPTIVE then end if ; Maximum Entropy Expectation-Maximization (constrained setting): for do Use and to compute (see ( 16)–( 18)); (see ( 25)); Get from (see ( 15)); end for Use to compute ; Find the matrix coefficients of the -model by spectral factorization of and compute . end for ;
|
The initialization stage provides a first estimate for the ISDM, from which the Expectation-Maximization alternations can begin. An estimate for the left upper corner of
is obtained by solving the
classical Maximum Entropy problem for a
-model, using the sample covariances of the manifest variables. We present below the matrix formulation of this problem, which allows an easy implementation in CVX (Matlab-based modeling system for convex optimization) [
14]. The mathematical derivation of the matrix formulation from the information theoretic formulation can be found in [
6,
9].
First Maximum Entropy Problem [
]:
The block Toeplitz operator
is defined in (
12). The size of the positive semidefinite matrix variable
is
. For all
, the estimate
of the ISDM (
15) is given by
.
In order to compute an initial value for , we resort to the eigenvalue decomposition (EIG) of . More precisely, after arranging the eigenvalues of in the decreasing order of their magnitudes, we have . Then, we set and for .
When the covariances
are fixed in the maximization step of the Expectation-Maximization algorithm, the coefficients of the matrix polynomial that is the ISDM (
15) are estimated from the solution of the following optimization problem:
Second Maximum Entropy Problem [
]:
Since now we work with the full model, the size of
is
. The function
is the sparsity promoter defined in (
14) and depends only on the entries of the block corresponding to the manifest variables. The equality constraints in (
23) guarantee that the latent variables have variance one and they are independent, given the manifest variables, corresponding to the lower right block of (
15).
The estimates
obtained after these iterations are further employed to compute
by using (
15). If
is large enough, then
is expected to have a certain sparsity pattern,
. Since the objective of (
23) does not ensure exact sparsification and also because of the numerical calculations, the entries of
that belong to
are small, but not exactly zero. In order to turn them to zero, we apply a method similar to the one from [
6] (Section 4.1.3). We firstly compute the maximum of partial spectral coherence (PSC),
for all
with
. Then
comprises all the pairs
for which the maximum PSC is not larger than a threshold
. The discussion on the selection of parameters
and
is deferred to
Section 5.
The regularized estimate of ISDM is further improved by solving a problem similar to (
23), but with the additional constraint that the sparsity pattern of ISDM is
, more precisely:
Third Maximum Entropy Problem [
]:
This step of the algorithm has a strong theoretical justification which stems from the fact that
is the Maximum Entropy solution for a covariance extension problem (see [
10] (Remark 2.1)). The number of iterations,
, is the same as in the case of the first loop.
The spectral factorization of the positive matrix trigonometric polynomial
is computed by solving a semidefinite programming problem. The implementation is the same as in [
8], except that in our case the model contains latent variables. Therefore, the matrix coefficients produced by spectral factorization are altered to keep only those entries that correspond to manifest variables. The resulting
model is fitted to the data and then various IT criteria are evaluated. The accuracy of the selected model depends on the criterion that is employed as well as on the strategy used for generating the
-values that yield the competing models. In the next section, we list the model selection rules that we apply; the problem of generating the
-values is treated in
Section 5.
As already mentioned, the estimation problem is solved for several values of
:
. From the description above we know that, for each value of the parameter
,
gets the same initialization, which is based on (
22). It is likely that this initialization is poor. A better approach is an
ADAPTIVE algorithm which takes into consideration the fact that the difference
is small for all
. This algorithm initializes
as explained above only when
. When
for
, the initial value of
is taken to be the estimate of this quantity that was previously obtained by solving the optimization problem in (
23) for
. The effect of the
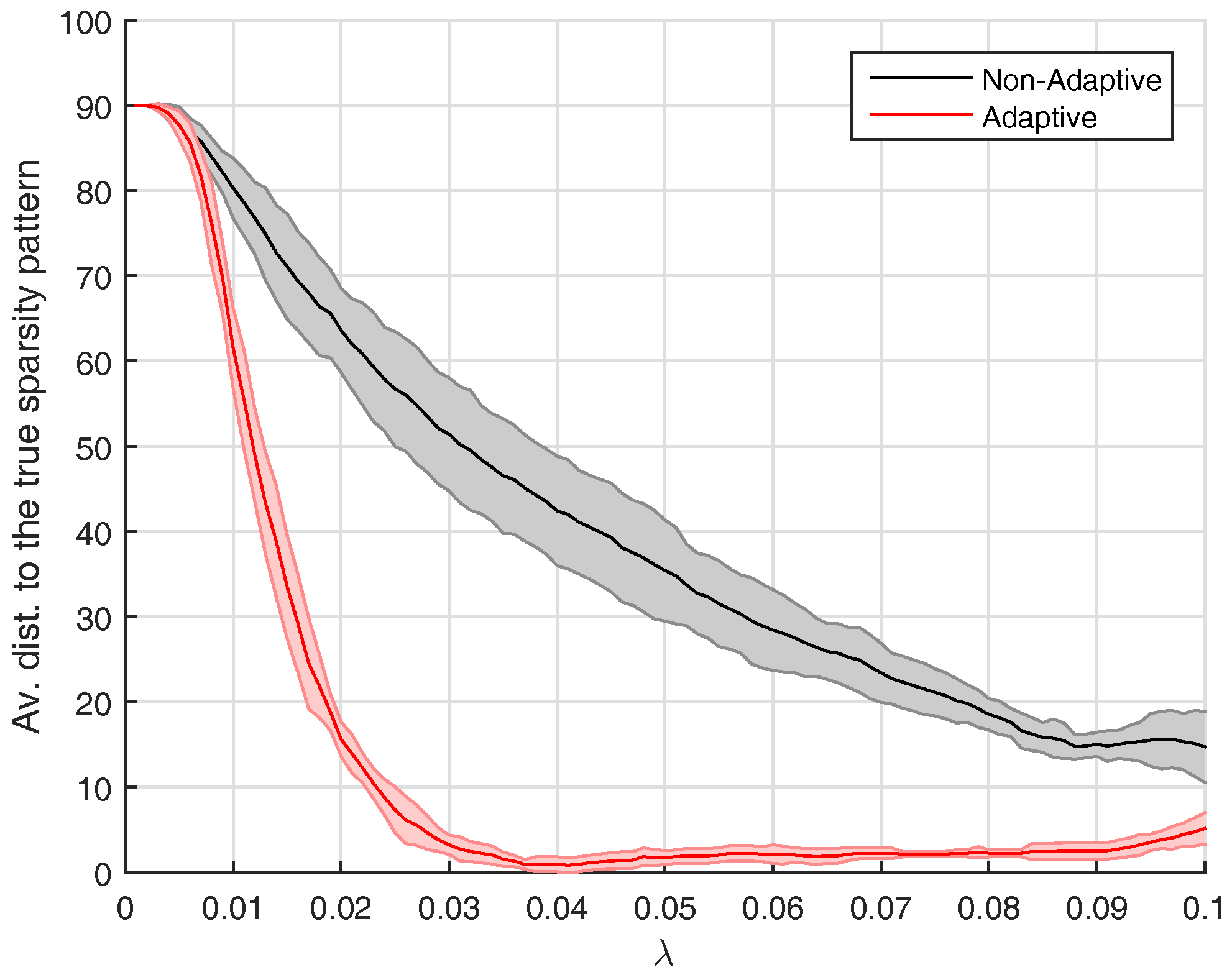
ADAPTIVE procedure will be investigated empirically in
Section 5.




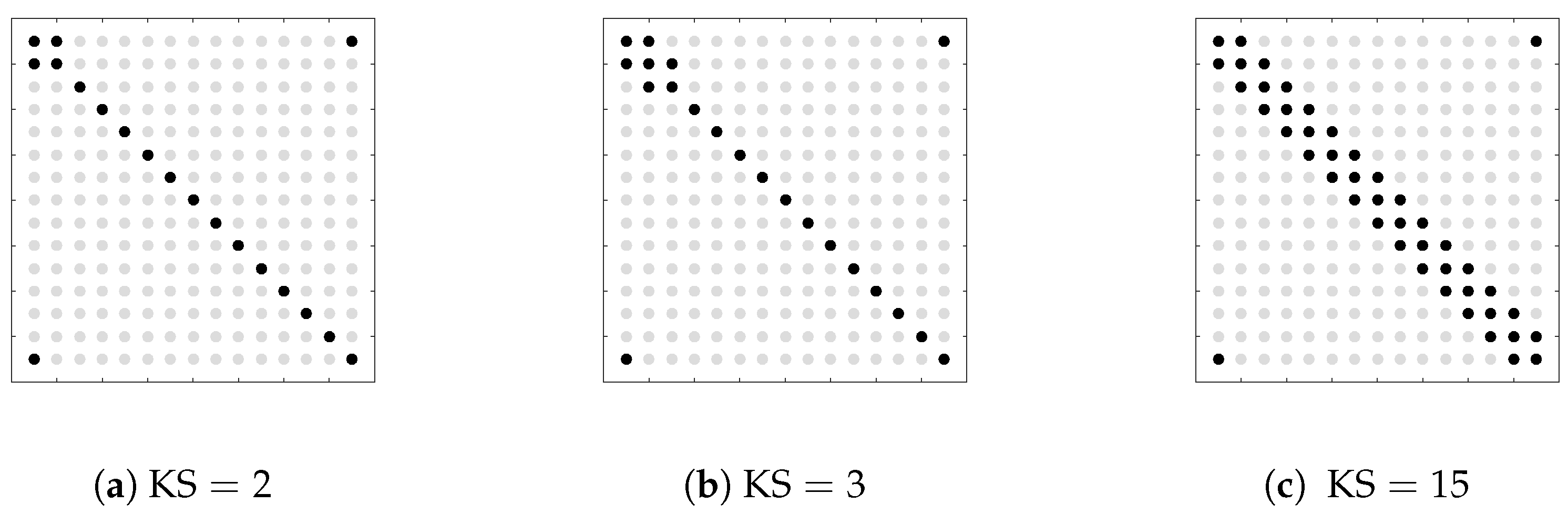{kind=link}
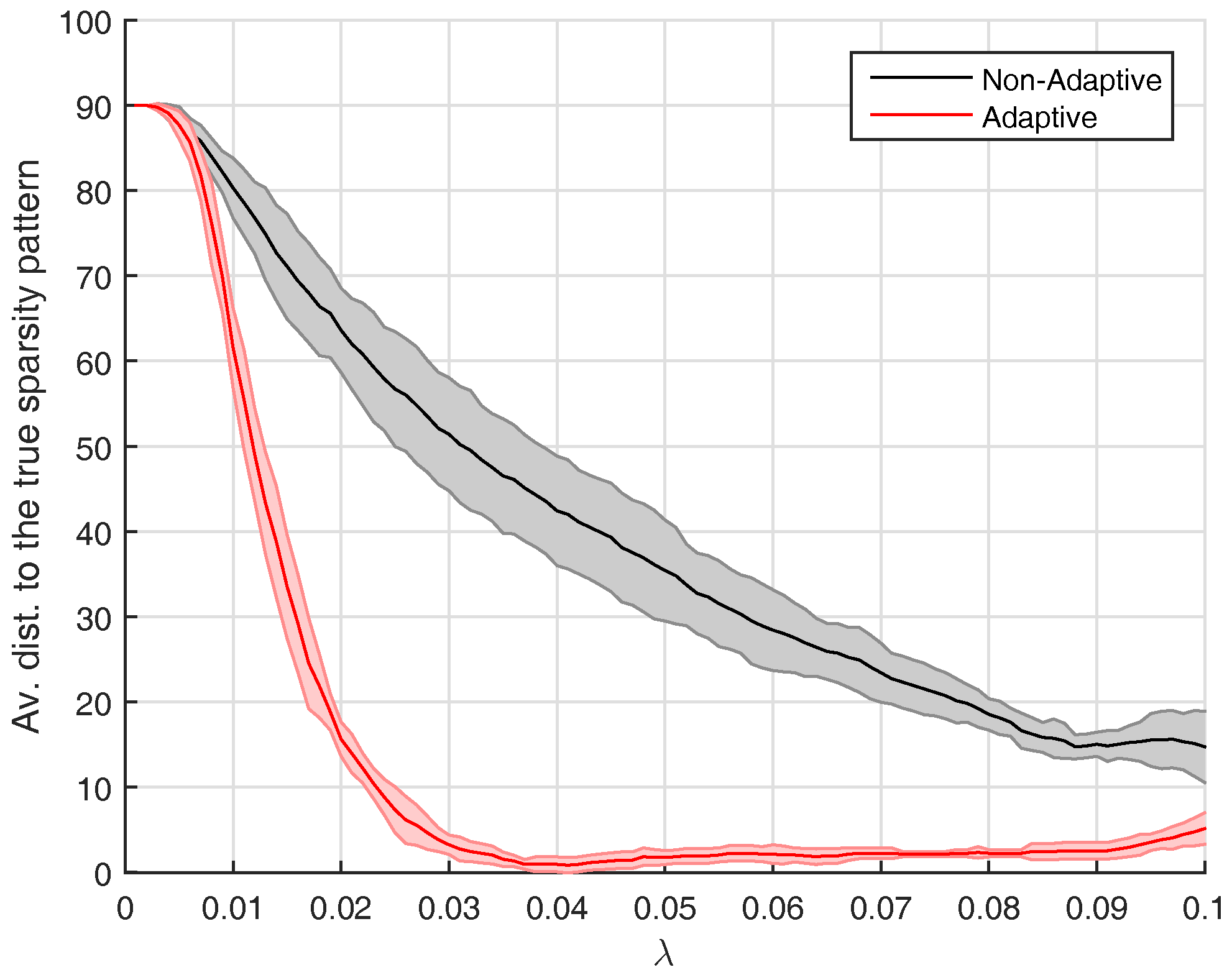{kind=link}
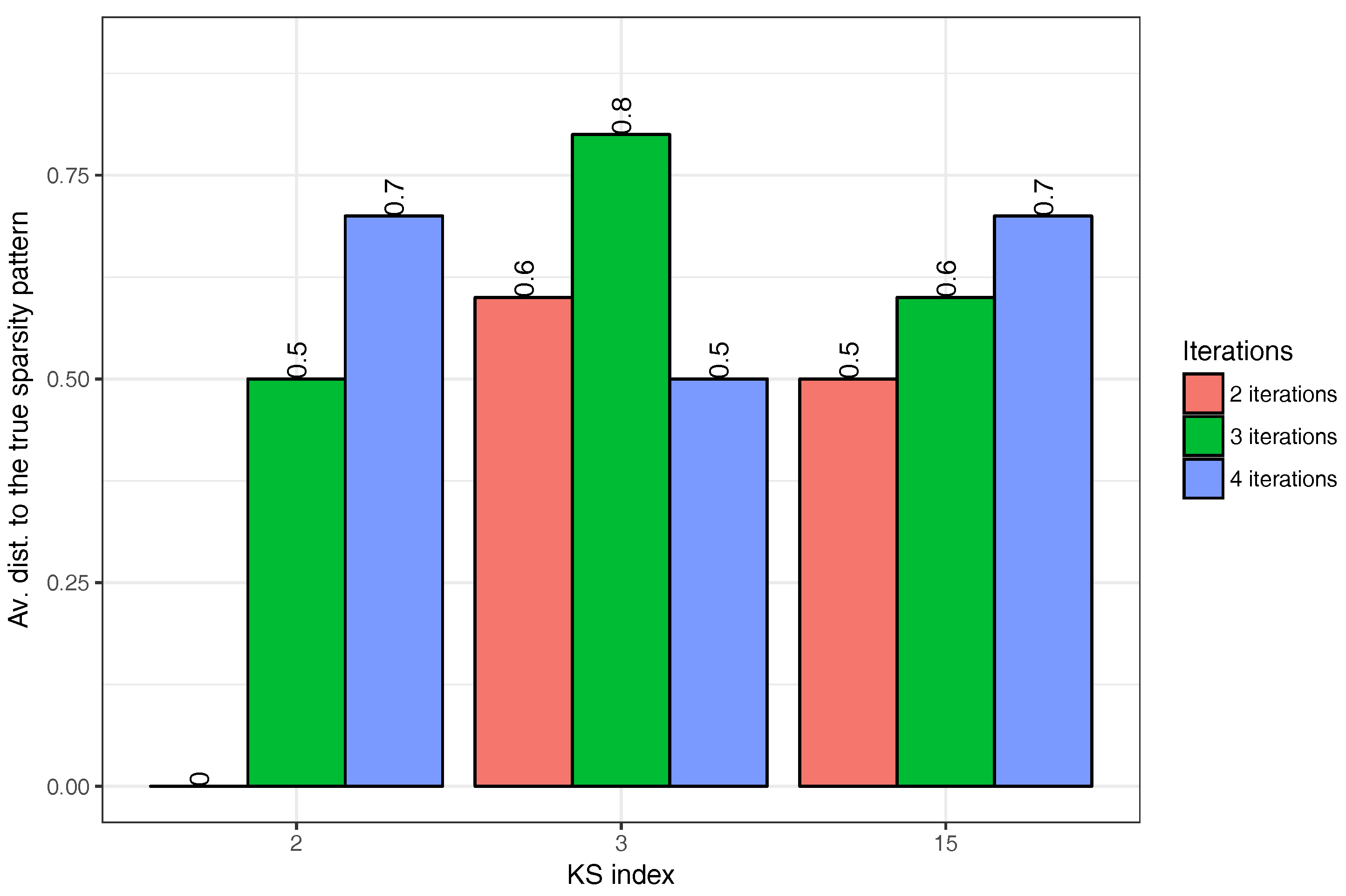{kind=link}
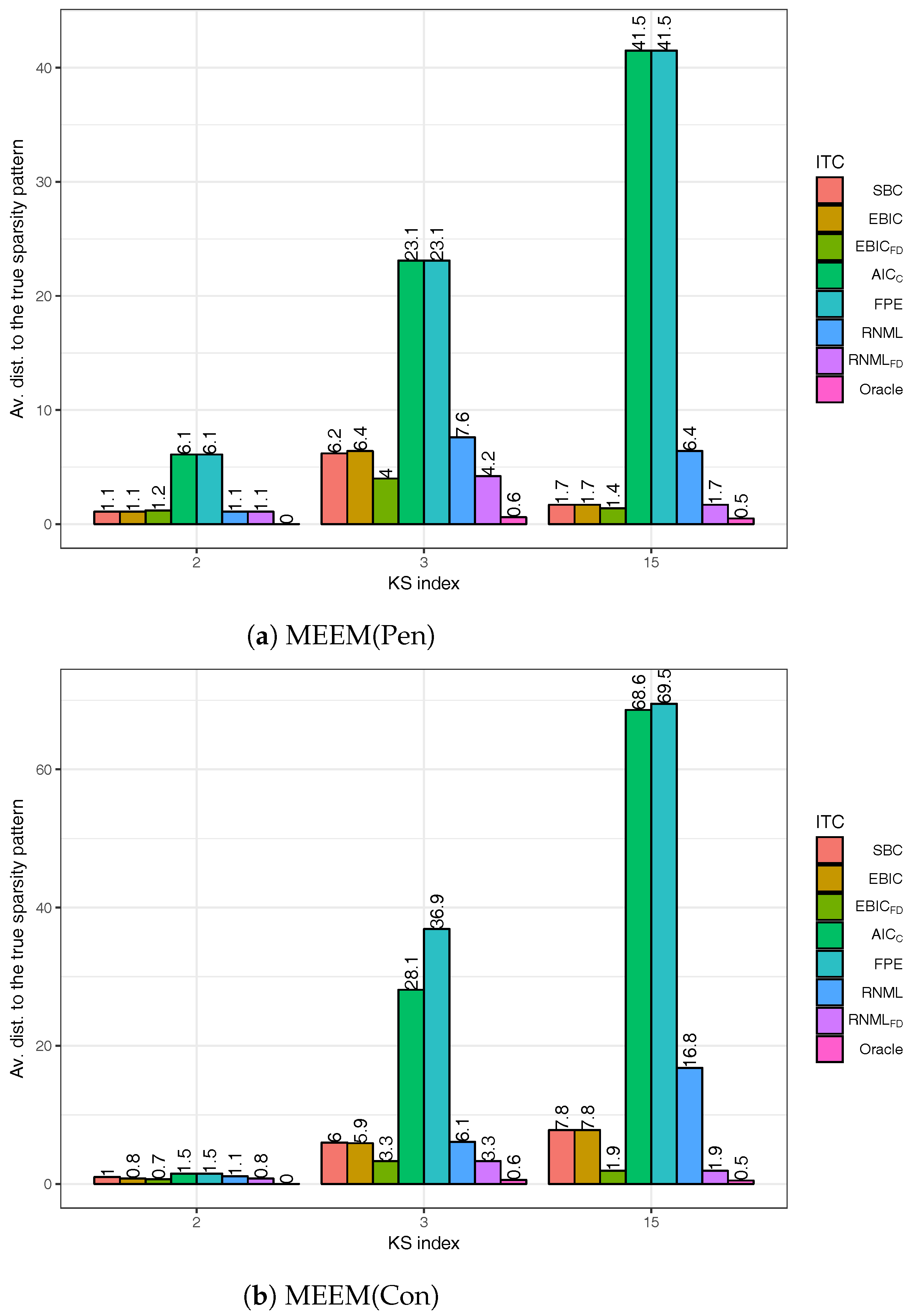{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}