Video Summarization for Sign Languages Using the Median of Entropy of Mean Frames Method


Abstract
:1. Introduction
1.1. Static Video Summarization
1.2. Methods Based on Clustering Techniques
1.3. Dynamic Video Summarization
2. Related Work
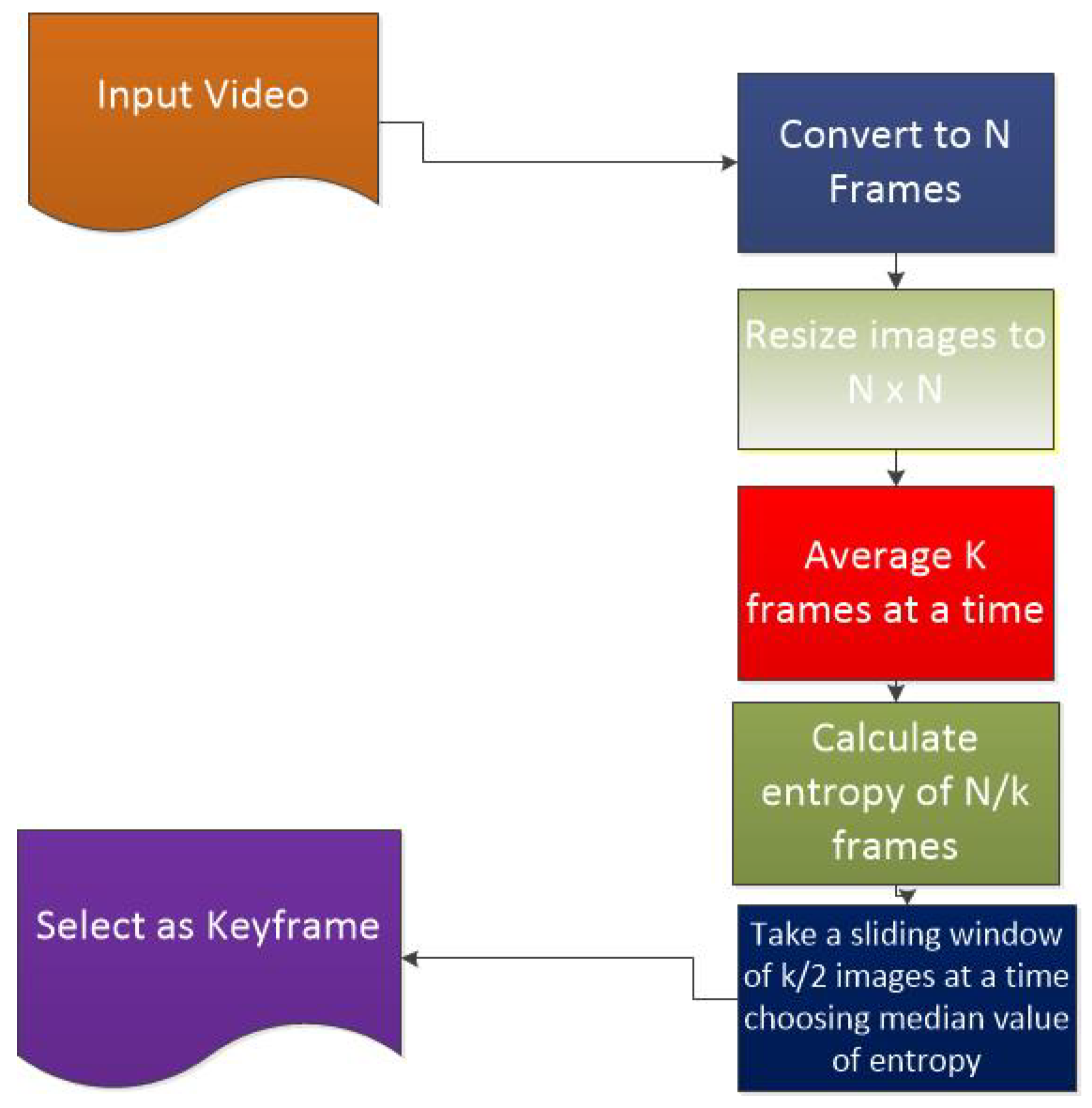
3. The Proposed Median of Entropy of Mean Frames (MME) Technique for Keyframe Selection
3.1. Mean
3.2. Entropy
- Input Video. This is the video that is to be converted into keyframes. It can be in any standard format.
- Frame Extraction. Every video is basically a sequence of a finite number of still images called frames. These frames occupy a large amount of memory. The frame rate is about 20–30 frames per second (FPS). Movies are shown at a rate of almost 24 fps. In some countries, it is 25 fps. In North America and Japan, the movies are shown at 29.97 fps. In other image processing applications, it is usually at 30 frames per second. Other common frame rates are usually multiples of these [19]. It has been found that, usually, 1–2 frames per second creates the illusion of movement. The rest of the frames show almost the same scene repeatedly [30].
- Feature Extraction. This process can be based on features such as colors, edges, or motion features. Some algorithms use other low-level features such as color histograms, frame correlations, and edge histograms [19].
3.3. Algorithm to Find Keyframes
- Input: The video.
- Output: ,, …, where tkfr represents total keyframes
- procedure:
- convert the video to frames ;
- resize each frame to an image size of (in this proposed technique, we chose );
- initialize l to 1;
- ;
- ;
- increment l by 1;
- reduce the frame count to ;
- consider 1st sliding window of size ;
- calculate entropy of frame l, , …;
- compare the frames in the sliding windows;
- choose a frame with the median value of entropy;
- slide window to the next consecutive frames.
| Algorithm 1: Keyframe Extraction through the proposed MME method. |
 |
4. Results and Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shazia, S.; Syed, A.R.K. Repository of Static and Dynamic Signs. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef] [Green Version]
- Saqib, S.; Kazmi, S.A.R. Recognition of static gestures using correlation and cross-correlation. Int. J. Adv. Appl. Sci. 2018, 5, 11–18. [Google Scholar] [CrossRef] [Green Version]
- Sheena, C.V.; Narayanan, N.K. Key-frame extraction by analysis of histograms of video frames using statistical methods. Proc. Comput. Sci. 2015, 70, 36–40. [Google Scholar]
- Elkhattabi, Z.; Youness, T.; Abdelhamid, B. Video summarization: Techniques and applications. World Acad. Sci. Eng. Technol. 2015, 9, 928–933. [Google Scholar]
- Tsai, D.Y.; Yongbum, L.; Eri, M. Information entropy measure for evaluation of image quality. J. Digit. Imaging 2008, 21, 338–347. [Google Scholar] [CrossRef] [PubMed]
- Brigitte, F.; Patrick, B.; Patrick, G.; Fabien, S. A geometrical key-frame selection method exploiting dominant motion estimation in video. In CIVR 2004: Image and Video Retrieval; Springer: Berlin/Heidelberg, Germany, 2004; pp. 419–427. [Google Scholar]
- Vasconcelos, N.; Andrew, L. Bayesian modeling of video editing and structure: Semantic features for video summarization and browsing. In Proceedings of the International Conference on Image Processing, Chicago, IL, USA, 7 October 1998. [Google Scholar]
- Mikolajczyk, K.; Cordelia, S. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sebastian, T.; Jiby, J.P. A survey on video summarization techniques. Int. J. Comput. Appl. 2015, 132, 30–32. [Google Scholar] [CrossRef]
- Supriya, K.; Rohan, M.; Aditya, M.; Abhishek, N. Key frame extraction for video summarization using motion activity descriptors. IJRET 2014, 62, 291–294. [Google Scholar]
- Mentzelopoulos, M.; Alexandra, P. Key-frame extraction algorithm using entropy difference. In Proceedings of the 6th ACM SIGMM International Workshop on Multimedia information Retrieval, New York, NY, USA, 15–16 October 2004; pp. 39–45. [Google Scholar]
- Cahuina, E.J.Y.C.; Guillermo, C.C. A new method for static video summarization using local descriptors and video temporal segmentation. In Proceeding of 2013 XXVI Conference on Graphics, Patterns and Images, Arequipa, Peru, 5–8 August 2013. [Google Scholar]
- Yunyu, S.; Haisheng, Y.; Ming, G.; Xiang, L.; Xia, Y.X. A fast and robust key frame extraction method for video copyright protection. J. Electric. Comput. Eng. 2017, 2017. [Google Scholar] [CrossRef]
- Zhao, Z.; Ahmed, M.E. Information Theoretic Key Frame Selection for Action Recognition. Proc. BMVC. 2008, 2008, 1–10. [Google Scholar]
- Satoshi, H.; Makoto, N.; Shogo, M.; Hisakazu, K. Video key frame selection by clustering wavelet coefficients. In Proceedings of 12th European Signal Processing Conference, Vienna, Austria, 6–10 September 2004; pp. 2303–2306. [Google Scholar]
- Mahmoud, K.; Nagia, G.; Mohamed, I. VGRAPH: An effective approach for generating static video summaries. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 811–817. [Google Scholar]
- Ciocca, G.; Raimondo, S. Dynamic key-frame extraction for video summarization. Int. Imaging VI 2005, 5670, 137–143. [Google Scholar]
- Ejaz, N.; Tayyab, B.T.; Sung, W.B. Adaptive key frame extraction for video summarization using an aggregation mechanism. J. Visual Commun. Image Represent. 2012, 23, 1031–1040. [Google Scholar] [CrossRef]
- Rajendra, S.P.; Keshaveni, N. A survey of automatic video summarization techniques. Int. J. Electron. Elect. Comput. Syst. 2014, 3, 1–6. [Google Scholar]
- Girgensohn, A.; John, B. Time-constrained keyframe selection technique. Multime. Tools Appl. 2000, 11, 347–358. [Google Scholar] [CrossRef]
- Genliang, G.; Zhiyong, W.; Shiyang, L.; Jeremiah, D.D.; David, D.F. Keypoint-based keyframe selection. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 729–734. [Google Scholar]
- Asadi, E.; Nasrolla, M.C. Video summarization using fuzzy c–means clustering. In Proceedings of the 20th Iranian Conference on Electrical Engineering (ICEE2012), Tehran, Iran, 15–17 May 2012; pp. 690–694. [Google Scholar]
- Zhang, Q.; Yu, S.P.; Zhou, D.S.; Wei, X.P. An efficient method of key-frame extraction based on a cluster algorithm. J. Human Kinet. 2013, 39, 5–14. [Google Scholar] [CrossRef] [PubMed]
- Dong, Z.; Zhang, G.F.; Jia, J.Y.; Bao, H.J. Keyframe-based real-time camera tracking. In Proceeding of 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1538–1545. [Google Scholar]
- Kim, S.H.; Lu, Y.; Shi, J.Y.; Alfarrarjeh, A.; Shahabi, S.; Wang, G.F.; Zimmermann, R. Key frame selection algorithms for automatic generation of panoramic images from crowdsourced geo-tagged videos. In Web and Wireless Geographical Information Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 67–84. [Google Scholar]
- Mei, T.; Tang, L.X.; Tang, J.H.; Hua, X.S. Near-lossless semantic video summarization and its applications to video analysis. ACM Trans. Multime. Compu. Commun. Appl. (TOMM) 2013, 9. [Google Scholar] [CrossRef]
- Shu, R.L. Key Frame Detection Algorithm based on Dynamic Sign Language Video for the Non Specific Population. Int. J. Signal Proc. Image Proc. Pattern Recognit. 2015, 8, 135–148. [Google Scholar]
- Ricardo, V.M.; Antonio, B. Spatio-temporal feature-based keyframe detection from video shots using spectral clustering. Pattern Recogni. Lett. 2013, 34, 770–779. [Google Scholar]
- Khurana, K.; Chandak, M.B. Key frame extraction methodology for video annotation. Int. J. Comput. Eng. Technol. 2013, 4, 221–228. [Google Scholar]
- Thakre, K.S.; Rajurkar, A.M.; Manthalkar, R.R. Video Partitioning and Secured Keyframe Extraction of MPEG Video. Proc. Comput. Sci. 2016, 78, 790–798. [Google Scholar] [CrossRef]
- Wang, C.; Shen, H.W. Information theory in scientific visualization. Entropy 2011, 13, 254–273. [Google Scholar] [CrossRef]
- Prasad, M.S.; Krishna, V.R.; Reddy, L.S. Investigations on Entropy Based Threshold Methods. Asian J. Comput. Sci. Inf. Technol. 2013, 1. [Google Scholar]
- Chamoli, N.; Kukreja, S.; Semwal, M. Survey and comparative analysis on entropy usage for several applications in computer vision. Int. J. Comput. Appl. 2014, 97, 1–5. [Google Scholar]
- Qi, C. Maximum entropy for image segmentation based on an adaptive particle swarm optimization. Appl. Math. Inf. Sci. 2014, 8, 3129. [Google Scholar] [CrossRef]
- Naidu, M.S.; Kumar, P.R.; Chiranjeevi, K. Shannon and fuzzy entropy based evolutionary image thresholding for image segmentation. Alexandria Eng. J. 2017. [Google Scholar] [CrossRef]
- Sabuncu, M.R. Entropy-Based Image Registration. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, November 2006. [Google Scholar]
- Ratsamee, P.; Mae, Y.; Jinda, A.A.; Machajdik, J.; Ohara, K.; Kojima, M.; Sablatnig, R.; Arai, T. Lifelogging keyframe selection using image quality measurements and physiological excitement features. In Proceedings of the International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 Novenber 2013; pp. 5215–5220. [Google Scholar]
- Angadi, S.; Naik, V. Entropy based fuzzy C means clustering and key frame extraction for sports video summarization. In Proceedings of the 5th International Conference on Signal and Image Processing, Chennai, India, 14–15 July 2018. [Google Scholar]
- Yuan, Y.; Mei, T.; Cui, P.; Zhu, W. Video Summarization by Learning Deep Side Semantic Embedding. IEEE Trans. Circuits Syst. Video Technol. 2017, 1. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Y.; Ai, Q.; Xu, H.; Yan, J.; Qin, Z. Personalized key frame recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Panda, R.; Das, A.; Wu, Z.; Ernst, J.; Roy, C.A.K. Weakly supervised summarization of web videos. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Mahasseni, B.; Lam, M.; Todorovic, S. Unsupervised video summarization with adversarial lstm networks. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jeong, D.J.; Yoo, H.J.; Cho, N.I. A static video summarization method based on the sparse coding of features and representativeness of frames. EURASIP J. Image Video Proc. 2017, 1. [Google Scholar] [CrossRef]
- Yoon, S.; Khan, F.; Bremond, F. Efficient Video Summarization Using Principal Person Appearance for Video-Based Person Re-Identification. In Proceedings of the The British Machine Vision Conference, London, UK, 4 September 2017. [Google Scholar]
- De Avila, S.E.; Lopes, A.P.; da Luz, J.A.; de Albuquerque, A.A. VSUMM: A mechanism designed to produce static video summaries and a novel evaluation method. Pattern Recognit. Lett. 2011, 32, 56–68. [Google Scholar] [CrossRef]
- Kanehira, A.; Van Gool, L.; Ushiku, Y.; Harada, T. Viewpoint-aware Video Summarization. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7435–7444. [Google Scholar]
- Manis, G.; Aktaruzzaman, M.D.; Sassi, R. Bubble entropy: an entropy almost free of parameters. IEEE Trans. Biomed. Eng. 2017, 64, 2711–2718. [Google Scholar] [PubMed]
- Athitsos, V.; Neidle, C.; Sclaroff, S.; Nash, J.; Stefan, A.; Yuan, Q.; Thangali, A. The american sign language lexicon video dataset. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Pun, T. A new method for grey-level picture thresholding using the entropy of the histogram. Signal process. 1980, 2, 223–237. [Google Scholar] [CrossRef]
- Sluder, G.; Wolf, D.E. Digital Microscopy; Academic Press: London, UK, 2013. [Google Scholar]
- Panagiotakis, C.; Doulamis, A.; Tziritas, G. Equivalent key frames selection based on iso-content principles. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 447–451. [Google Scholar] [CrossRef]
- Song, Y.; Vallmitjana, J.; Stent, A.; Jaimes, A. Tvsum: Summarizing web videos using titles. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–25 June 2015. [Google Scholar]
- Mei, S.; Guan, G.; Wang, Z.; Wan, S.; He, M.; Feng, D.D. Video summarization via minimum sparse reconstruction. Pattern Recognit. 2015, 48, 522–533. [Google Scholar] [CrossRef]
- Ajmal, M.; Naseer, M.; Ahmad, F.; Saleem, A. Human Motion Trajectory Analysis Based Video Summarization. In Proceedings of the International Conference on Machine Learning and Applications, Cancun, Mexico, 18–21 December 2017. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
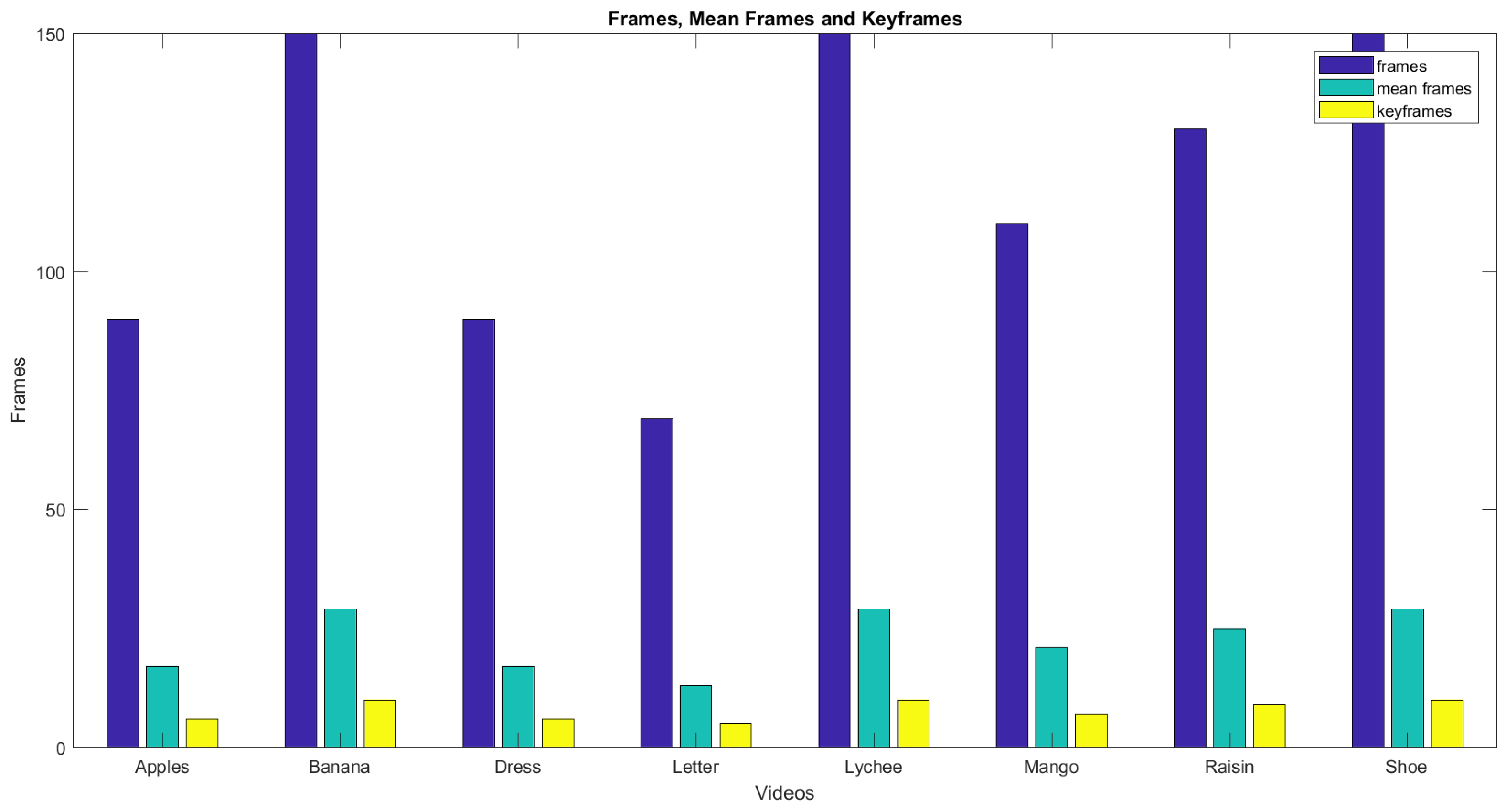
| Query Video | Frames | Video Duration | Frames after Taking Mean | Keyframes Extracted | Compression Ratio (%) |
|---|---|---|---|---|---|
| dress | 90 | 3 | 17 | 6 | 6.67 |
| letter | 69 | 2 | 13 | 5 | 7.24 |
| Apple | 90 | 3 | 17 | 6 | 6.67 |
| Banana | 150 | 5 | 29 | 10 | 6.66 |
| Raisin | 130 | 4.5 | 25 | 9 | 6.6 |
| Lychee | 150 | 5 | 29 | 10 | 6.66 |
| Shoe | 150 | 5 | 29 | 10 | 6.66 |
| mango | 110 | 3.5 | 21 | 7 | 6.36 |
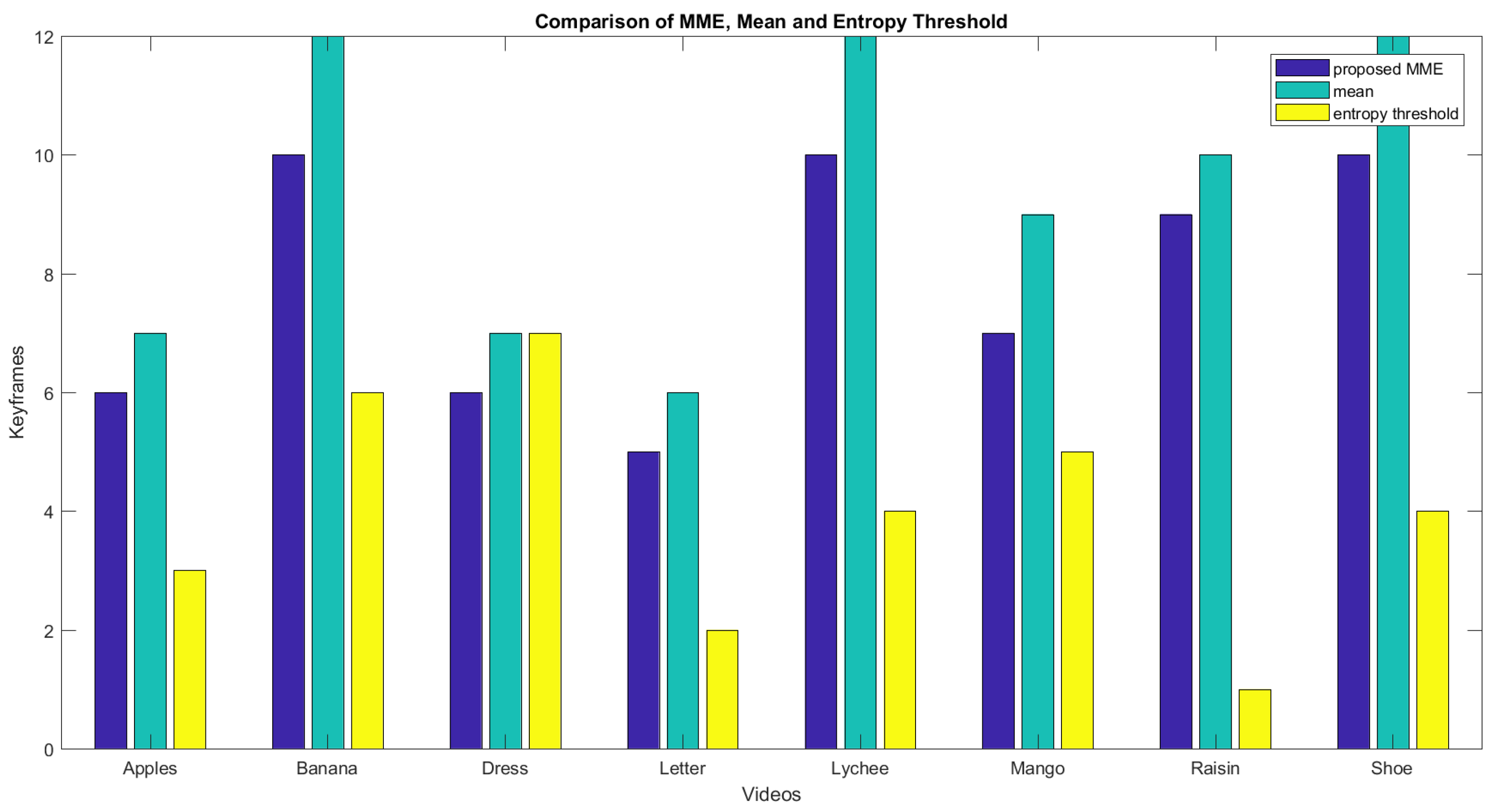
| Query Video | Frames | Keyframes Extracted by the Proposed MME | Keyframes Using Mean | Keyframes Using Threshold of Entropy |
|---|---|---|---|---|
| dress | 90 | 6 | 7 | 7 |
| Khatt (letter) | 69 | 5 | 6 | 2 |
| Apple | 90 | 6 | 7 | 3 |
| Banana | 150 | 10 | 12 | 6 |
| Raisin | 130 | 9 | 10 | 1 |
| Lychee | 150 | 10 | 12 | 4 |
| Shoe | 150 | 10 | 12 | 4 |
| mango | 110 | 7 | 9 | 5 |
| Technique Name | Compression Ratio (%) |
|---|---|
| Analysis of Histograms of Video Frames using Statistical Methods [3] | 7.08 |
| Video Summarization Using Motion Activity Descriptors [10] | 4.25 |
| Keyframe Extraction of Compressed Video Shots using Adaptive Threshold Method [30] | 4.5 |
| Entropy-Based Fuzzy C-Means Clustering and KeyFrame Extraction [38] | 8.4 |
| Video Summarization for Sign Languages using MME | 6.7 |
| Human Motion Trajectory Analysis Based Video Summarization [54] | 6.74 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saqib, S.; Kazmi, S.A.R. Video Summarization for Sign Languages Using the Median of Entropy of Mean Frames Method. Entropy 2018, 20, 748. https://doi.org/10.3390/e20100748
Saqib S, Kazmi SAR. Video Summarization for Sign Languages Using the Median of Entropy of Mean Frames Method. Entropy. 2018; 20(10):748. https://doi.org/10.3390/e20100748
Chicago/Turabian StyleSaqib, Shazia, and Syed Asad Raza Kazmi. 2018. "Video Summarization for Sign Languages Using the Median of Entropy of Mean Frames Method" Entropy 20, no. 10: 748. https://doi.org/10.3390/e20100748
APA StyleSaqib, S., & Kazmi, S. A. R. (2018). Video Summarization for Sign Languages Using the Median of Entropy of Mean Frames Method. Entropy, 20(10), 748. https://doi.org/10.3390/e20100748