An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension

1
SAFRAN TECH, Groupe Safran, 78772 Magny-les-Hameaux, France
2
Laboratoire Informatique Gaspard Monge (LIGM)-UMR 8049 CNRS, University Paris-East, 93162 Noisy-le-Grand, France
3
Center for Visual Computing, University Paris-Saclay, 91190 Gif-sur-Yvette, France
4
COSIM Research Laboratory, Higher School of Communication of Tunis (SUP’COM), University of Carthage, 2083 Ariana, Tunisia
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(2), 110; https://doi.org/10.3390/e20020110
Submission received: 4 December 2017
/
Revised: 16 January 2018
/
Accepted: 30 January 2018
/
Published: 7 February 2018
(This article belongs to the Special Issue Probabilistic Methods for Inverse Problems)
Abstract
:In this paper, we are interested in Bayesian inverse problems where either the data fidelity term or the prior distribution is Gaussian or driven from a hierarchical Gaussian model. Generally, Markov chain Monte Carlo (MCMC) algorithms allow us to generate sets of samples that are employed to infer some relevant parameters of the underlying distributions. However, when the parameter space is high-dimensional, the performance of stochastic sampling algorithms is very sensitive to existing dependencies between parameters. In particular, this problem arises when one aims to sample from a high-dimensional Gaussian distribution whose covariance matrix does not present a simple structure. Another challenge is the design of Metropolis–Hastings proposals that make use of information about the local geometry of the target density in order to speed up the convergence and improve mixing properties in the parameter space, while not being too computationally expensive. These two contexts are mainly related to the presence of two heterogeneous sources of dependencies stemming either from the prior or the likelihood in the sense that the related covariance matrices cannot be diagonalized in the same basis. In this work, we address these two issues. Our contribution consists of adding auxiliary variables to the model in order to dissociate the two sources of dependencies. In the new augmented space, only one source of correlation remains directly related to the target parameters, the other sources of correlations being captured by the auxiliary variables. Experiments are conducted on two practical image restoration problems—namely the recovery of multichannel blurred images embedded in Gaussian noise and the recovery of signal corrupted by a mixed Gaussian noise. Experimental results indicate that adding the proposed auxiliary variables makes the sampling problem simpler since the new conditional distribution no longer contains highly heterogeneous correlations. Thus, the computational cost of each iteration of the Gibbs sampler is significantly reduced while ensuring good mixing properties.
1. Introduction
In a wide range of applicative areas, we do not have access to the signal of interest , but only to some observations related to through the following model:
where is the observation matrix that may express a blur or a projection and is the noise model representing measurement errors. In this paper, we are interested in finding an estimator of from the observations . This inverse problem arises in several signal processing applications, such as denoising, deblurring, and tomography reconstruction [1,2].
The common Bayesian procedure for signal estimation consists of deriving estimators from the posterior distribution that captures all information inferred about the target signal from the collected data. Given the observation model (1), the minus logarithm of the density posterior distribution reads:
Hereabove, is the neg-log likelihood that may take various forms depending on the noise statistical model . In particular, if models an additive Gaussian noise with covariance , it reduces (up to an additive constant) to the least squares function . Other common choices can be found for instance in [3,4]. Moreover, is related to some prior knowledge one can have about , and is a linear transform that can describe, for example, a frame analysis [5] or a discrete gradient operator [6]. Within a Bayesian framework, it is related to a prior distribution of density whose logarithm is given by .
Monte Carlo inference approaches allow us to have a good description of the target space from a set of samples drawn from a distribution [7,8,9,10,11,12]. In particular, these samples can be used to infer useful statistics such as the mean and the variance. In the context of Bayesian estimation, these techniques appear useful to compute, for example, the minimum mean square error (MMSE) estimator, which is equivalent to the posterior mean. In this case, the MMSE estimator is approximated using the empirical average over the generated samples from the posterior distribution. When the exact expression of the posterior density is intractable, Markov chain Monte Carlo (MCMC) algorithms have been widely used to approximate it [13]. These techniques are random variable generators that allow us to draw samples from complicated distributions. Perhaps the most commonly used MCMC algorithm is the Metropolis–Hastings (MH), which operates as follows [14]: from a given proposal distribution, we construct an irreducible Markov chain whose stationary distribution is the sought posterior law (i.e., samples generated by the algorithm after a suitable burn-in period are distributed according to desired posterior law). At each iteration t, a decision rule is applied to accept or reject the proposed sample given by the following acceptance probability:
where is the proposed sample at iteration t, generated from a proposal distribution with density that may depend on the current state . Note that when more than one unknown variable needs to be estimated (e.g., acquisition parameters or prior hyperparameters), one can iteratively draw samples from the conditional posterior distribution for each variable given the remaining ones using an MH iteration. This is known as the hybrid Gibbs sampler [15]. High-dimensional models—often encountered in inverse problems (e.g., in multispectral remote sensing applications [16])—constitute a challenging task for Bayesian inference problems. While many popular sampling algorithms have been widely used to fit complex multivariable models in small-dimensional spaces [17,18,19,20,21,22], they generally fail to explore the target distribution efficiently when applied to large-scale problems, especially when the variables are highly correlated. This may be due to the poor mixing properties of the Markov chain or to the high computational cost of each iteration [17].
In this work, we propose a novel approach based on a data augmentation strategy [23] which aims at overcoming the limitations of standard Bayesian sampling algorithms when facing large-scale problems. The remainder of this paper is organized as follows. In Section 2, we discuss the main difficulties encountered in standard sampling methods for large-scale problems. We show how the addition of auxiliary variables to the model can improve their robustness with respect to these issues. The core of our contribution is detailed in Section 3. We first give a complete description of the proposed approach in the case of Gaussian noise, and we study its extension to scale mixtures of Gaussian models. Furthermore, we demonstrate how the proposed approach can facilitate sampling from Gaussian distributions in Gibbs algorithms. Then, some computational issues arising in the proposed Bayesian approach are discussed. Section 4 and Section 5 are devoted to the experimental validation of our method. In Section 4, we show the advantages of the proposed approach in dealing with high-dimensional models involving highly correlated variables over a dataset of multispectral images affected by blur and additive Gaussian noise. In Section 5, we test the performance of our method in sampling from large-scale Gaussian distributions through an application to image recovery under two-term mixed Gaussian noise. Finally, we give some conclusions and perspectives in Section 6.
2. Motivation
2.1. Sampling Issues in High-Dimensional Space
MCMC sampling methods may face two main difficulties when applied to large-scale inverse problems. First, except for particular cases (e.g., circulant observation matrix), the structure of the observation model that links the unknown signal to the observations usually makes the estimation of the parameters of the posterior distribution quite involved. Second, even with simple models, the posterior distribution may still be difficult to sample from directly or to explore efficiently using standard sampling algorithms. As a specific case, this problem arises for Gaussian distributions if the problem dimension is too high [24]. It can also arise in MH algorithms when sophisticated proposal rules are employed with the aim of coping with both the high dimensionality and the strong correlation existing between the target parameters [22]. In what follows, we will give more details about these two contexts.
2.1.1. Sampling from High-Dimensional Gaussian Distribution
Let us focus on the problem of sampling from a multivariate Gaussian distribution with a given precision matrix . This problem emerges in many applications, such as linear inverse problems involving Gaussian or hierarchical Gaussian models. More precisely, let us consider the following linear model:
where is -valued, and let us assume that conditionally to some latent variables, and are drawn from Gaussian distributions , and , respectively, where , , and are positive semi-definite matrices. In the following, when not mentioned, the Gaussian law can be degenerated; that is, the precision matrix is semi-definite positive but not with full rank. In this case, denotes the generalized inverse. The parameters of these Gaussian distributions may be either fixed or unknown (i.e., involving some unknown hyperparameters such as regularization or acquisition parameters). It follows that the posterior distribution of is Gaussian, with mean and precision matrix defined as follows:
A common solution to sample from is to use the Cholesky factorization of the covariance or the precision matrix [25]. However, when implemented through a Gibbs sampler, this method is of limited interest. First, the precision matrix may depend on the unknown parameters of the model and may thus take different values along the algorithm. Thereby, spending such high computational time at each iteration of the Gibbs sampler to compute the Cholesky decomposition of the updated matrix may be detrimental to the convergence speed of the Gibbs sampler. Another concern is that when dealing with high dimensional problems, we generally have to face not only computational complexity issues but also memory limitations. Such problems can be alleviated when the matrix presents some specific structures (e.g., circulant [26,27] or sparse [28]). However, for more complicated structures, the problem remains critical, especially when and cannot be diagonalized in the same basis. Other recently proposed algorithms for sampling Gaussian distributions in high dimension follow a two-step perturbation-optimization approach [24,29,30,31,32,33], which can be summarized as follows:
- Perturbation: Draw a Gaussian random vector .
- Optimization: Solve the linear system .
The solution to the above linear system can be approximated using iterative methods such as conjugate gradient algorithms, leading to an approximate sample of the sought distribution [30,31]. This issue has been considered in [32] by adding a Metropolis step in the sampling algorithm. In [24,33], the authors propose to reduce the computational cost by sampling along mutually conjugate directions instead of the initial high-dimensional space.
2.1.2. Designing Efficient Proposals in MH Algorithms
Non-Gaussian models arise in numerous applications in inverse problems [34,35,36,37]. In this context, the posterior distribution is non-Gaussian and does not generally follow a standard probability model. In this respect, MH algorithms are good tools for exploring such posteriors, and hence for drawing inferences about models and parameters. However, the challenge for MH algorithms is constructing a proposal density that provides a good approximation of the target density while being inexpensive to manipulate. Typically, in large-scale problems, the proposal distribution takes the form of a random walk (RW); that is, in each iteration, the proposal density in (3) is a Gaussian law centered at the current state and with covariance matrix . Moreover, is a positive constant whose value is adjusted so that the acceptance probability in (3) is bounded away from zero at convergence [17]. Other sampling algorithms incorporate information about the derivative of the logarithm of the target distribution to guide the Markov chain toward the target space where samples should be mostly concentrated. For instance, when the target density is differentiable, one can use Langevin-based algorithms where the mean of the Gaussian proposal density is replaced with one iteration of a preconditioned gradient descent algorithm as follows [20,22,38,39,40,41]:
In (7), is the gradient of , is a positive constant, and is a symmetric definite positive matrix that captures possible correlations between the coefficients of the signal. Note that some advanced versions of Langevin-based algorithms have been proposed to address problems with non-smooth laws [42,43]. It is worth noting that the choice of the scale matrices may deeply affect the efficiency of the aforementioned algorithms [22]. In fact, an inappropriate choice of may alter the quality of the Markov chain, leading to very correlated samples and thereby biased estimates. Moreover, computationally cheap matrices are also preferable, especially in high-dimensional spaces. In the case of low-dimensional problems and when the coefficients of the signal are not highly correlated, the standard RW and Metropolis-adapted Langevin algorithm (MALA) obtained for achieve overall good results. For instance, in the context of denoising problems with uncorrelated Gaussian noise, when the coefficients of the signal are assumed to be statistically independent in the prior, they can either be sampled independently using RW or jointly by resorting to MALA. However, these algorithms may be inaccurate for large-scale problems, especially when the coefficients of the signal exhibit high correlations [22]. In this case, the design of a good proposal often requires consideration of the curvature of the target distribution. More sophisticated (and thus more computationally expensive) scale matrices should be chosen to drive the chain in the directions that reflect the dependence structure. Optimally, the curvature matrix should be chosen such that it adequately captures two kinds of dependencies: correlation over the observations specified by the observation model, and correlation between different coefficients of the target signal specified by the prior law. For instance, can be set to the Hessian matrix of the minus logarithm of the posterior density in the current state [20,21], or to the Fisher matrix (especially when the Hessian matrix is not definite positive [22,41]) or to the empirical covariance matrix computed according to the previous states of the Markov chain [44]. When the minus-log of the target density can be expressed as in (2), good candidates of the curvature matrix take the following form:
where and are semi-definite positive matrices. Feasible numerical factorization of can be ensured if and are diagonalizable in the same basis. Otherwise, the use of the full matrix (8) in the scheme (7) remains generally of limited interest, especially for large-scale problems where the manipulation of the resulting proposal generally induces a high computational complexity altering the convergence speed. Alternatively, under mild conditions on the posterior density, the Majorize–Minimize strategy offers a high flexibility for building curvature matrices with a lower computational cost (e.g., diagonal matrices, bloc-diagonal matrices, circulant, etc.) [40]. However, it should be pointed out that MH algorithms with too-simple preconditioning matrices resulting from rough approximations of the posterior density may fail to explore the target space efficiently. Therefore, the scale matrix should be adjusted to achieve a good tradeoff between the computational complexity induced in the algorithm and the accuracy/closeness of the proposal to the true distribution.
2.2. Auxiliary Variables and Data Augmentation Strategies
It is clear that the main difficulty arising in the aforementioned sampling problems is due to the intricate form of the target covariance matrix making difficult the direct sampling or the construction of a good MH proposal that mimics the local geometry of the target law. More specifically, there are generally heterogeneous types of dependencies between the coefficients of the signal, coming either from the likelihood or from the prior information. For instance, the observation matrix in the likelihood may bring high dependencies between distant coefficients, even if the latter are assumed to be statistically dependent in the prior law. One solution is to address the problem in another domain where can be easily diagonalized (i.e., the coefficients of the signal become uncorrelated in the likelihood). However, if one also considers the prior dependencies, this strategy may become inefficient, especially when the prior covariance matrix cannot be diagonalized in the same basis as , which is the case in most real problems. One should therefore process these two sources of correlations separately.
To improve the mixing of sampling algorithms, many works have proposed the elimination of one of these sources of correlation directly related to by adding some auxiliary variables to the initial model, associated with a given conditional distribution such that simulation can be performed in a simpler way in the new larger space. Instead of simulating directly from the initial distribution, a Markov chain is constructed by alternately drawing samples from the conditional distribution of each variable, which reduces to a Gibbs sampler in the new space. This technique has been used in two different statistical literatures: data augmentation [45] and auxiliary variables strategies [46]. It is worth noting that the two methods are equivalent in their general formulation, and the main difference is often related to the statistical interpretation of the auxiliary variable (unobserved data or latent variable) [23]. In the following, we will use the term data augmentation (DA) to refer to any method that constructs sampling algorithms by introducing auxiliary variables. Some DA algorithms have been proposed in [47,48,49,50,51,52,53]. Particular attention has been focused on the Hamiltonian MCMC (HMC) approach [22,54], which defines auxiliary variables based on physically-inspired dynamics.
In the following, we propose to alleviate the problem of heterogeneous dependencies by resorting to a DA strategy. More specifically, we propose to add some auxiliary variables with predefined conditional distribution of density so that the minus logarithm of the joint distribution density can be written as follows:
where up to an additive constant. Two conditions should be satisfied by for the DA strategy to be valid:
where should define a valid probability density function (i.e., nonnegative and with integral with respect to equal to 1). In fact, the importance of Condition is obvious, because the latent variable is only introduced for computational purposes and should not alter the considered initial model. The need for the second requirement stems from the fact that should define the density of a proper distribution. Note that
- the first condition is satisfied thanks to the definition of the joint distribution in (9), provided that is a density of a proper distribution;
- for the second condition, it can be noticed that if the first condition is met, Fubini–Tonelli’s theorem allows us to claim thatThis shows that as defined in is a valid probability density function.
Instead of simulating directly from , we now alternatively draw (in an arbitrary order) samples from the conditional distributions of the two variables and of respective densities and . This simply reduces to a special case of a hybrid Gibbs sampler algorithm with two variables, where each iteration t is composed of two sampling steps which can be expressed as follows:
- Sample from ;
- Sample from .
Under mild technical assumptions [9,55], the constructed chain can be proved to have a stationary distribution . The usefulness of the DA strategy is mainly related to the fact that with an appropriate choice of , drawing samples from the new conditional distributions and is much easier than sampling directly from the initial distribution . Let us emphasize that, for the sake of efficiency, the manipulation of must not induce a high computation cost in the algorithm. In this work, we propose the addition of auxiliary variables to the model such that the dependencies resulting from the likelihood and the prior are separated; that is, is chosen in such a way that only one source of correlations remains related directly to in , the other sources of correlations only intervening through the auxiliary variables and . Note that the advantage of introducing auxiliary variables in optimization or sampling algorithms has also been illustrated in several works in the image processing literature, related to half quadratic approaches [26,56,57,58,59,60]. This technique has also been considered in [61] in order to simplify the sampling task by using a basic MH algorithm in a maximum likelihood estimation problem. Finally, in [62], a half-quadratic formulation was used to replace the prior distribution, leading to a new posterior distribution from which inference results are deduced.
The contribution of our work is the proposal of an extended formulation of the data augmentation method that was introduced in [60] in the context of variational image restoration under uncorrelated Gaussian noise. Our proposal leads to a novel acceleration strategy for sampling algorithms in large-scale problems.
3. Proposed Approach
In this section, we discuss various scenarios typically arising in inverse problems and we explain how our approach applies in these contexts.
3.1. Correlated Gaussian Noise
Let us consider the linear observation model (4) when the noise term is assumed to be Gaussian, additive, and independent from the signal that is , with a symmetric semi-definite positive precision matrix that is assumed to be known. In this context, the minus logarithm of the posterior density takes the following form:
Simulating directly from this distribution is generally not possible, and standard MCMC methods may fail to explore it efficiently due to the dependencies between signal coefficients [22]. In particular, the coupling induced by the matrix may hinder the construction of suitable proposals when using MH algorithms. For example, when and , RW and standard MALA algorithms may behave poorly, as they do not account for data fidelity dependencies, while a preconditioned MALA approach with full curvature matrices may exhibit high computational load due to the presence of heterogeneous dependencies [39].
In the following, we propose the elimination of the coupling induced by the linear operators by adding auxiliary variables. Since the data fidelity term is Gaussian, a natural choice is to define as a Gaussian distribution with mean and covariance matrix :
where is a symmetric positive definite covariance matrix and . Then, the joint distribution satisfies the two conditions and defined in Section 2, and its minus logarithm has the following expression:
with
The expression in (12) yields the sampling scheme:
with . The efficiency of the DA strategy is thus highly related to the choice of the matrices and . Under the requirement that is positive definite, the choice of is subjective and is related to specifying the source of heterogeneous dependencies that one wants to eliminate in the target distribution based on the properties of , , , and . More specifically, one should identify if the main difficulty stems from the structure of matrix or only from the non-trivial form of the precision matrix . In what follows, we will elaborate different solutions according to the type of encountered difficulty.
Alternative I: Eliminate the Coupling Induced by
Let us first consider the problem of eliminating the coupling induced by matrix . This problem is encountered for example for Model (5) with circulant matrices and and with , which induces further correlation when passing to the Fourier domain. In this context, we propose the elimination of the correlations induced by by setting
where is such that , where denotes the spectral norm. This is equivalent to choosing and such that
Note that the condition over allows toguarantees that is positive definite. Under (16), the minus logarithm of the conditional distribution of given and reads, up to an additive constant:
Let us discuss the application of the hybrid Gibbs sampling algorithm from Section 2 to this particular decomposition. The sampling scheme (15) yields:
where . Since and satisfy (17), this leads to:
We can remark that for every , follows the centered Gaussian distribution with covariance matrix . It follows that
where
and is definite positive by construction. Then, the resulting algorithm can be viewed as a hybrid Gibbs sampler, associated to the minus logarithm of the conditional distribution of given and a new auxiliary variable :
The main steps of the proposed Gibbs sampling algorithm are given in Algorithm 1. The appealing advantage of this algorithm with respect to a Gibbs sampler which would be applied directly to Model (5) when and are diagonalizable in the same domain is that it allows easy handling of the case when is not equal to a diagonal matrix having identical diagonal elements.
| Algorithm 1 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by . |
Initialize: , , such that
|
Note that minimizing (23) can be seen as a restoration problem with an uncorrelated noise of variance . It can be expected that Step 3 in Algorithm 1 can be more easily implemented in the transform domain where and are diagonalized, when this is possible (see Section 5 for an example)
Alternative II: Eliminate the Coupling Induced by
In a large class of regularized models, and have different properties. While almost reflects a blur, a projection, or a decimation matrix, may model a wavelet transform or a discrete gradient operator. Such difference in their properties induces a complicated structure of the posterior covariance matrix. To address such cases, we propose the elimination of the source of correlations related to through , by setting , so that and satisfy
where is such that , so that is positive definite. It follows that the minus logarithm of the conditional distribution of given and is defined up to an additive constant as
Let us make the following change of variables within the Gibbs sampling method:
According to (15) and (24), we obtain
where . Let us define , which is positive definite. Since follows a zero-mean Gaussian distribution with covariance matrix , then
and the new target conditional distribution reads
The proposed Gibbs sampling algorithm is then summarized by Algorithm 2.
| Algorithm 2 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by . |
Initialize: , , such that
|
It can be seen that heterogeneous dependencies initially existing in (11), carried by the likelihood and the prior operators, are now dissociated in the new target distribution (28). Likelihood-related correlations are no longer attached directly to the target signal. They intervene in the conditional law only through the auxiliary variable and the observation . In other words, the original problem reduces to solving a denoising problem where the variance of the Gaussian noise is . Thereby, the new target distribution (28) is generally easier to sample from compared with the initial one. In particular, one can sample the components independently when the coefficients of the signal are independent in the prior. Otherwise, if is a smooth function, one can use a Langevin-based MCMC algorithm. For instance, it may be possible to construct an efficient curvature matrix that accounts for the prior correlation and that can be easily manipulated.
Table 1 summarizes the two different cases we have presented here. We would like to emphasize that the approach we propose for adding auxiliary variables according to the structure of the matrix and is sufficiently generic so that it covers a wide diversity of applications.
It is worth noting that the auxiliary variable could be introduced in the data fidelity term as well as in the prior information. The derivation of the proposed method in (13) allows us to identify classes of models for which our approach can be extended. Obviously, the key requirement is that the term which should be simplified can be written as a quadratic function with respect to some variables. Hence, without completely relaxing the Gaussian requirement, we can extend the proposed method to Gaussian models in which some hidden variables control the mean and/or the variance. This includes, for example, scale mixture of Gaussian models [63,64] such as the alpha-stable family (including the Cauchy distribution), the Bernoulli Gaussian model and the generalized Gaussian distributions, and also Gaussian Markov random fields [55]. In Section 3.2, we will investigate the case of the scale mixture of Gaussian models. When both the likelihood and the prior distribution are Gaussian conditionally to some parameters, the proposed method can be applied to each term as explained in Section 3.3.
Another point to pay attention to is the sampling of the auxiliary variable . In particular, in Algorithm 2, we should be able to sample from the Gaussian distribution whose covariance matrix is of the form , which is possible for a large class of observation models as discussed in Section 3.4.
3.2. Scale Mixture of Gaussian Noise
3.2.1. Problem Formulation
Let us consider the following observation model:
such that for every ,
where are independent random variables distributed on according to . Different forms of the mixing distribution lead to different noise statistics. In particular, the Cauchy noise is obtained when are random variables following an inverse Gamma distribution. Let . By assuming that and are independent, the joint posterior distribution of and is given by:
In such a Bayesian estimation context, a Gibbs sampling algorithm is generally adopted to sample alternatively from the distributions and .
In the following, we assume that the set has a zero probability given the vector of observations . Note that by imposing such rule, we ensure that at each iteration t of the Gibbs algorithm, almost surely.
Since sampling from is supposed to be intractable, we propose the addition of auxiliary variables that may depend on the variables of interest and according to a given conditional distribution density which satisfies the following conditions:
- 1.
- ,
- 2.
- ,
where should be a valid probability density function.
Using the same arguments as in Section 2.2, these two properties are satisfied provided that defines a proper probability density function. It follows that the initial two-step Gibbs iteration is replaced by the following three sampling steps. First, sample from then sample from , and finally sample from .
3.2.2. Proposed Algorithms
Let be the diagonal matrix whose diagonal elements are given by
Note that, since has zero probability, we almost surely have
- Suppose first that there exists a constant such thatThen, results in Section 3.1 with a Gaussian noise can be extended to scale mixture of Gaussian noise by substituting—at each iteration t— for , and by choosing in Algorithm 1 and in Algorithm 2. The only difference is that an additional step must be added to the Gibbs algorithm to draw samples of the mixing variables from their conditional distributions given , , and .
- Otherwise, when satisfying (34) does not exist, results in Section 3.1 remain also valid when, at each iteration t, for a given value of , we replace by . However, there is a main difference with respect to the case when , which is that depends on the value of the mixing variable and hence can take different values along the iterations. Subsequently, will denote the chosen value of for a given value of . Here again, two strategies can be distinguished for setting , depending on the dependencies one wants to eliminate through the DA strategy.
Alternative I: Eliminate the Coupling Induced by
A first option is to choose, at each iteration t, positive such that
with and
The auxiliary variable is then drawn as follows:
where is positive definite by construction. The minus logarithm of the posterior density is given by
Alternative II: Eliminate the Coupling Induced by
Similarly, in order to eliminate the coupling induced by the full matrix , can be chosen at each iteration so as to satisfy
with and is given by (36). Then, the auxiliary variable is drawn as
where is positive definite. The minus logarithm of the posterior density then reads
It is worth noting that and are two dependent random variables conditionally to both and . The resulting Gibbs samplers, corresponding to Alternatives I and II, respectively, are summarized in Algorithms 3 and 4.
| Algorithm 3 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by in the case of a scale mixture of Gaussian noise. |
Initialize: , , , ,
|
| Algorithm 4 Gibbs sampler with auxiliary variables in order to eliminate the coupling induced by in the case of a scale mixture of Gaussian noise. |
Initialize: , , , ,
|
3.2.3. Partially Collapsed Gibbs Sampling
It can be noted that it is generally complicated to sample from due to the presence of and in the conditional distribution of . One can replace this step by sampling from ; that is, directly sampling from its marginal posterior distribution with respect to and conditionally to and . In this case, we say that we are partially collapsing in the Gibbs sampler. One of the main benefits of doing so is that, conditionally to and , has independent components. However, as is sampled independently from , the constructed Markov chain may have a transition kernel with an unknown stationary distribution [65]. This problem can also be encountered when the auxiliary variable depends on other unknown hyperparameters changing along the algorithm, such as prior covariance matrix or regularization parameter when the auxiliary variable is added to the prior instead of the likelihood. However, there are some rules based on marginalization, permutation, and trimming that allow the conditional distributions in the standard Gibbs sampler to be replaced with conditional distributions marginalized according to some variables while ensuring that the target stationary distribution of the Markov chain is maintained. The resulting algorithm is known as the Partially Collapsed Gibbs Sampler (PCGS) [65]. Although this strategy can significantly decrease the complexity of the sampling process, it must be implemented with care to guarantee that the desired stationary distribution is preserved. Applications of PCGS algorithms can be found in [66,67,68].
Assume that, in addition to , , , we have a vector of unknown parameters to be sampled. Note that should be integrable with respect to all the variables. Following [65], we propose the use of a PCGS algorithm that allows us to replace the full conditional distribution with its conditional distribution without affecting the convergence of the algorithm to the target stationary law. Algorithm 5 shows the main steps of the proposed sampler. It should be noted that, unlike the standard Gibbs algorithm, permuting the steps of this sampler may result in a Markov chain with an unknown stationary distribution.
| Algorithm 5 PCGS in the case of a scale mixture of Gaussian noise. |
Initialize: , , ,
|
3.3. High-Dimensional Gaussian Distribution
The proposed DA approach can also be applied to the problem of drawing random variables from a high-dimensional Gaussian distribution with parameters and as defined in (5) and (6). The introduction of auxiliary variables can be especially useful in facilitating the sampling process in a number of problems that we discuss below. In order to make our presentation clearer, an additional index will be added to the variables and , introduced in Section 2.
- If the prior precision matrix and the observation matrix can be diagonalized in the same basis, it can be of interest to add the auxiliary variable in the data fidelity term. Following Algorithm 1, let such that andThe resulting conditional distribution of the target signal given the auxiliary variable and the vector of observation is a Gaussian distribution with the following parameters:Then, sampling from the target signal can be performed by passing to the transform domain where and are diagonalizable (e.g., Fourier domain when and are circulant).Similarly, if it is possible to write , such that and can be diagonalized in the same basis, we suggest the introduction of an extra auxiliary variable independent of in the prior term to eliminate the coupling introduced by when passing to the transform domain. Let be such that and let the distribution of conditionally to be given byThe joint distribution of the unknown parameters is given byIt follows that the minus logarithm of the conditional distribution of given , , and is Gaussian with parameters:and
- If and are not diagonalizable in the same basis, the introduction of an auxiliary variable either in the data fidelity term or the prior allows us to eliminate the coupling between these two heterogeneous operators. Let such that andThen, the parameters of the Gaussian posterior distribution of given read:Note that if has some simple structure (e.g,. diagonal, block diagonal, sparse, circulant, etc.), the precision matrix (50) will inherit this simple structure.Otherwise, if does not present any specific structure, one could apply the proposed DA method to both data fidelity and prior terms. It suffices to introduce an extra auxiliary variable in the prior law, additionally to the auxiliary variable in (49). Let be such that andThen, the posterior distribution of given and is Gaussian with the following parameters:andwhere
3.4. Sampling the Auxiliary Variable
It is clear that the main issue in the implementation of all the proposed Gibbs algorithms arises in the sampling of the auxiliary variable . The aim of this section is to propose efficient strategies for implementing this step at a limited computational cost, in the context of large-scale problems.
For the sake of generality, we will consider that follows a multivariate Gaussian distribution with a covariance matrix of the form , where satisfies . Our first suggestion is to set such that
with . For example, one can set and , where . This allows us to verify the requirement . Moreover, it leads to
Thus, the sampling step of the auxiliary variable at iteration can be replaced by the three following steps:
- (1)
- Generate ,
- (2)
- Generate with ,
- (3)
- Compute ,
Hereabove, and are independent random variables. One can notice that the sampling problem of the auxiliary variables is now separated into two independent subproblems of sampling from large-scale Gaussian distributions. The first sampling step can usually be performed efficiently. For instance, if is diagonal (e.g., when the model is a scale mixture of Gaussian variables), coefficients , , can be drawn separately. Let us now discuss the implementation of the second sampling step, requiring sampling from the zero mean Gaussian distribution with covariance matrix .
- In the particular case when is circulant, sampling can be performed in the Fourier domain. More generally, since is symmetric, there exists an orthogonal matrix such that is diagonal with positive diagonal entries. It follows that sampling from the Gaussian distribution with covariance matrix can be fulfilled easily within the basis defined by the matrix .
- Suppose that satisfies with , which is the case, for example, of tight frame synthesis operators or decimation matrices. Note that . We then have:It follows that a sample from the Gaussian distribution with covariance matrix can be obtained as follows:where and are independent Gaussian random vectors with covariance matrices equal to and , respectively.
- Suppose that with and . Hence, one can set and such thatFor example, for , we have . Then, we can set . It follows thatIt appears that if it is possible to draw merely random vectors and from the Gaussian distributions with covariance matrices and , respectively (for example, when is a tight frame analysis operator and is a convolution matrix with periodic boundary condition), a sample from the Gaussian distribution with a covariance matrix can be obtained as follows:
4. Application to Multichannel Image Recovery in the Presence of Gaussian Noise
We now discuss the performance of the proposed DA strategies in the context of restoration of multichannel images (MCIs). Such images are widely used in many application areas, such as medical imaging and remote sensing [69,70,71]. Several medical modalities provide color images, including cervicography, dermoscopy, and gastrointestinal endoscopy [72]. Moreover, in the field of brain exploration with neuro-imaging tools, multichannel magnetic resonance images are widely used for multiple sclerosis lesion segmentation [73]. Indeed, the multicomponent images correspond to different magnetic resonance intensities (e.g., T1, T2, FLAIR). They contain different information on the underlying tissue classes that enable discrimination of the lesions from the background. Multiple channel components typically result from imaging a single scene by sensors operating in different spectral ranges. For instance, about a dozen radiometers may be on-board remote sensing satellites. Most of the time, MCIs are corrupted with noise and blur arising from the acquisition process and transmission steps. Therefore, restoring MCIs is of primary importance as a preliminary step before addressing analysis tasks such as classification, segmentation, or object recognition [74]. Several works dedicated to MCI processing rely on wavelet-based approaches [70,75]. In this section, we propose the adoption of a Bayesian framework for recovering the wavelet coefficients of deteriorated MCI, with the aim of analyzing the performance of the aforementioned hybrid Gibbs samplers.
4.1. Problem Formulation
Let us consider the problem of recovering a multicomponent image with B components in (the images being columnwise reshaped) from some observations which have been degraded by spatially-invariant blurring operators and corrupted by independent zero-mean additive white Gaussian noises having the same known variance . As already stated, here we propose addressing the restoration problem in a transform domain where the target images are assumed to have a sparse representation. Let us introduce a set of tight frame synthesis operators [76] such that
where for every , is a linear operator from to with and is the vector of frame coefficients of the image . Each frame transform operator decomposes the image into M oriented subbands at multiple scales with sizes , , such that :
We propose exploitation of the cross-component similarities by jointly estimating the frame coefficients at a specific orientation and scale through all the B components. In this respect, for every , for every , let be the vector of frame coefficients for a given wavelet subband m at a spatial position k through all the B components. Note that this vector can be easily obtained through , where is a sparse matrix containing B lines of a suitable permutation matrix. To promote the sparsity of the wavelet coefficients and the inter-component dependency, following [70], we assume that for every , the vectors , …, are realizations of a random vector following a generalized multivariate exponential power () distribution with scale matrix , shape parameter , and smoothing parameter . Thus, the minus-log of the prior likelihood is given up to an additive constant by
where for every , , and for all , .
Our goal is to compute the posterior mean estimate of the target image as well as the unknown regularization parameters using MCMC sampling algorithms accelerated thanks to our proposed DA strategies. In the following, we will denote by the vector of unknown regularization parameters to be estimated jointly with in the Gibbs sampling algorithm.
4.2. Sampling from the Posterior Distribution of the Wavelet Coefficients
One can expect that the standard sampling algorithms fail to efficiently explore the target posterior not only because of the high dimensionality of the problem, but also because of the anisotropic nature of the wavelet coefficients. In fact, the coefficients belonging to different scales are assumed to follow priors with different shapes , . For instance, coefficients belonging to the low-resolution subband are generally assumed to be driven from a Gaussian distribution (i.e., ), while priors with very small shape parameter (i.e., ) are generally assigned to high-resolution subbands at the first level of decomposition in order to promote sparsity. Therein, one can better explore the directions of interest separately by using different amplitudes than sampling them jointly. However, the observation matrix causes high spatial dependencies between the coefficients, and thus hinders processing the different wavelet subbands independently.
The DA approaches we introduced in Section 3 allow this preconditioning problem to be tackled by adding auxiliary variables to the data fidelity term. More specifically, following Algorithm 2, we propose the introduction of an auxiliary variable such that:
where .
Since the set of hyperparameters is independent of the auxiliary variable when conditioned to , each iteration of the proposed Gibbs sampling algorithm contains the following steps:
|
If is circulant (by assuming periodic boundary conditions of the blur kernel), the first sampling step can be easily done by passing to the Fourier domain. In particular, if is orthonormal (that is, ), samples of the auxiliary variables can be obtained by first drawing Gaussian random variables in the Fourier domain and then passing to the wavelet domain. Otherwise, if is a non-orthonormal transform, sampling can be performed using our results stated in (59) and (62).
Note that in the new augmented space, the restoration problem reduces to a denoising problem with zero-mean Gaussian noise of variance , and the posterior density reads:
where
It follows that we can draw samples of vectors , , in an independent manner. Thus, the resolution of the initial high-dimensional problem of size reduces to the resolution of K parallel subproblems of size B. This is particularly interesting in the case of MCIs where we generally have .
Instead of processing all the different wavelet coefficients at the same time, the proposed method allows each subproblem to be dealt with independently. This avoids sampling problems related to the heterogeneous prior distribution. Different sampling algorithms may be chosen according to the properties of the target distribution in each subproblem. Specifically, for each sampling subproblem, we propose to use either RW or MALA algorithms [17,77].
In the following, we will discuss the practical implementation of the third step of the Gibbs algorithm; namely, sampling from the posterior distribution of .
4.3. Hyperparameters Estimation
4.3.1. Separation Strategy
For every , controls the shape of the distribution, allowing for heavier tails than the Laplace distribution () and approaching the normal distribution when tends to 1. In this work, we assume that for every , and are fixed. Actually, the shape parameter is set to different values with respect to the resolution level, spanning from very small values () in order to enforce sparsity in the detail subbands at the first levels of decomposition to relatively higher values () for detail subband at higher resolution levels, whereas a Gaussian distribution is generally assigned to the low-frequency subband. Furthermore, we set to a positive small value, ensuring that (78) is differentiable [70]. As already mentioned, the scale matrices will be estimated. Let us define the prior distribution of the scale matrix for each subband and its related density. The associated posterior density reads
When , the prior reduces to a Gaussian distribution. In this case, a common choice of is an inverse Wishart distribution and (72) is also an inverse Wishart distribution [78]. However, when , (72) does not belong to classical families of matrix distributions. In that respect, rather than estimating the scale matrices directly, we resort to a separation strategy. More specifically, we propose the independent estimation of the standard deviations and the correlation terms. Let us decompose the scale matrix for each subband as follows [79]:
where is the correlation matrix (whose diagonal elements are equal to 1 and the remaining ones define the correlation between the coefficients and have absolute value smaller than 1), is a vector formed by the square root of the precision parameters (the inverse of standard deviations), and is a multiplicative constant that depends on and [70]. The advantage of this factorization can be explained by the fact that the estimation of the correlation matrix will not alter the estimation of the variances. For every , we decompose the precision vector as follows:
where is positive and is a vector of positive coefficients whose sum is equal to 1. Then, can be seen as the vector containing positive normalized weights of all the B components in the subband m.
For simplicity, let us assume that the different components of the image have the same correlation and weights in all subbands; i.e., and for every . Furthermore, let us suppose that is known. We then have
4.3.2. Prior and Posterior Distribution for the Hyperparameters
One can construct the correlation matrix by sampling from an inverse Wishart distribution. Specifically, let where is an appropriate positive definite matrix of and . Then, we can write , where is the diagonal matrix whose elements are given by , for every . Following [79], we can show that the prior density of reads:
In the following, we will use the notation to denote this prior. In particular, when , individual correlations have the marginal density for every such that , which can be seen as a rectangular Beta distribution on the interval with both parameters equal to . For , we obtain marginally uniformly distributed correlations, whereas by setting (or ), we get marginal priors with heavier (or lighter) tails than the uniform distribution—that is, distributions that promote high correlation values around the extremity of the intervals (or near-zero values), respectively [79]. Thus, the posterior distribution of is given by
where
Here we propose to sample from (77) at each iteration using an MH algorithm with proposal , where is set to the current value of at iteration t and is chosen to achieve reasonable acceptance probabilities.
For every , we assume a Gamma prior for ; that is, , where and [80]. Then, the posterior distribution of is given by:
4.3.3. Initialization
We propose to set the prior distributions of , using empirical estimators from the degraded image. In particular, a rough estimator of can be computed from the subband containing the low-resolution wavelet coefficients at the highest level of decomposition. In the case when is orthonormal, the variance of wavelet coefficients of the original image are approximately related to those of the degraded image through:
where designates the wavelet coefficients belonging to the subband m and is a positive constant which depends on the subband index m and on the blur matrix. Expression (82) is derived from the considered observation model (65) by assuming a constant approximation of the impulse response of the blur filter in each wavelet subband. Note that can be calculated beforehand as follows. Given noise-free data, we compute the original empirical variance for each wavelet subband. Then, we calculate again the new variances of the subbands when the data is blurred using matrix . The coefficients are finally estimated for each wavelet subband by computing the ratio of the two variances by a linear regression. When is not too small with respect to 1, estimators of can be reliably computed from and using (82). We propose the use of this method to compute estimators of the variances in subbands at the highest levels of decomposition and then deduce the variances of the remaining subbands by using some properties of multiresolution wavelet decompositions. Note that each detail subband m corresponds to a given orientation l (horizontal, vertical, diagonal) and a given scale j (related resolution level). Actually, the variances of the detail subbands can be assumed to follow a power law with respect to the scale of the subband, which can be expressed as follows [81]:
where and are constants depending on the orientation l of the subband m. Once the variances of subbands in the two highest levels of decomposition have been computed using (82), we can calculate and for each orientation l using the slope and the intercept of these variances from a log plot with respect to the scale j. The remaining variances are then estimated by using (83). We then deduce from these variances an empirical estimator of , and set the parameters of the prior distributions of .
4.4. Experimental Results
In these experiments, we consider the Hydice hyperspectral (https://engineering.purdue.edu/~biehl/MultiSpec/hyperspectral.html) data composed of 191 components in the to m region of the visible and infrared spectrum. The test image was constructed by taking only a portion of size and components of Hydice using the channels 52, 67, 82, 97, 112, and 127. Hence, the problem dimension was . The original image was artificially degraded by a uniform blur of size and an additive zero-mean white Gaussian noise with variance so that the initial signal-to-noise ratio (SNR) was dB. We performed an orthonormal wavelet decomposition using the Symlet wavelet of order 3, carried out over three resolution levels, hence and . For the subband corresponding to the approximation coefficients (), we chose a Gaussian prior (i.e., , ). For the remaining subbands (), we set . Moreover, we set for the detail subbands corresponding to the lowest level of decomposition, for the second level of decomposition, and for the third level of decomposition.
We ran the Gibbs sampling Algorithm 2 with a sufficient number of iterations to reach stability. The obtained samples of the wavelet coefficients after the burn-in period were then used to compute the empirical MMSE estimator for the original image. Table 2 reports the results obtained for the different components in terms of SNR, PSNR (peak signal-to-noise ratio), BSNR (blurred signal to noise ratio), and SSIM (structural similarity). It can be noticed that the values of both the objective metrics and the perceptual ones were significantly improved by our method for all the spectral components. For instance, the PSNR values were increased on average by around 4.15 dB, and the SSIM by around 0.23. The achieved gains indicate that the MMSE estimator yielded good numerical results. This can also be corroborated by Figure 1, showing the visual improvements for the different components of the multichannel image. One can observe that all the recovered images were correctly deblurred. Furthermore, small objects were enhanced in all the displayed components.
We propose to compare the performance of the Gibbs sampler with auxiliary variables when the posterior law of the wavelet coefficients is explored using either RW or MALA [17,77] algorithms. We also compared the speed of our proposed approaches with standard RW and MALA without the use of auxiliary variables. Figure 2 shows the evolution—with respect to the computational time—of the scale parameter in the horizontal subband for the first level of decomposition using the various algorithms. The results associated with the proposed algorithms appear in solid lines, while those associated with standard algorithms without use of auxiliary variables are in dashed lines. It can be observed that the proposed algorithms reached stability much faster than the standard methods. Indeed, since the problem dimension is large, the stepsize in the standard algorithms was constrained to take very small values to allow appropriate acceptance probabilities, whereas in the new augmented space the subproblems dimension was smaller allowing large moves to be accepted with high probability values. Note that the MALA algorithm with auxiliary variables exhibited the best performance in terms of convergence speed. We summarize the obtained samples using the proposed algorithms by showing the marginal means and standard deviations of the hyperparameters in Table 3. It can be noted that the two proposed algorithms provided similar estimation results.
It is worth noting that for larger-dimensional problems (i.e., larger values of B), one could further improve the efficiency of the proposed algorithm by exploiting the parallel structure of the sampling tasks.
5. Application to Image Recovery in the Presence of Two Mixed Gaussian Noise Terms
5.1. Problem Formulation
In this second experiment, we consider the observation problem defined in (29), where corresponds to a spatially invariant blur with periodic boundary conditions and the noise is a two-term mixed Gaussian variable; i.e., for every , such that
where are positive, is the probability that the variance of the noise equals , and and denote the discrete measures concentrated at the values and , respectively. Model (84) can approximate, for example, mixed impulse Gaussian noise arising in radar, acoustic, and mobile radio applications [82,83]. In this case, the impulse noise is approximated with a Gaussian one with a large variance , and represents the probability of occurrence of the impulse noise. In the following, we assume without loss of generality that . We address the problem of estimating , , , , and from the observations .
5.2. Prior Distributions
We propose to use conjugate priors for the unknown variances, namely inverse Gamma distributions; i.e., , , where and are positive constants. Here, , , , and are set in practice to small values to ensure weakly informative priors. For the occurrence probability , we chose a uniform prior distribution (i.e., ). Furthermore, the target image was assumed to follow a zero-mean Gaussian prior with a covariance matrix known up to a precision parameter ; i.e.,
Different covariance matrices may be chosen depending on which properties one wants to impose on the estimated image. In this example, we propose to enforce smoothness by setting , where is the circulant convolution matrix associated with a Laplacian filter and is a small constant that aims to ensure the positive definiteness of the prior covariance matrix. We further assume that the regularization parameter follows an inverse Gamma prior with parameters and . The resulting hierarchical model is displayed in Figure 3.
Posterior Distributions
Given the observation model and the prior distribution, we can deduce that the posterior distribution of the target signal given , , , , , and is also Gaussian with mean and precision matrix given by:
where is the diagonal matrix with diagonal elements , .
The posterior distributions of the remaining unknown parameters are given by:
- where such that
- , where is the Beta distribution and and are the cardinals of the sets and , respectively, so that ,
- ,
- ,
- .
5.3. Sampling from the Posterior Distribution of
In the Gibbs algorithm, we need to draw samples from the multivariate Gaussian distribution of parameters (86) and (87) changing along the sampling iterations. In particular, even if and are circulant matrices, sampling cannot be done in the Fourier domain because of the presence of . In the sequel, we will use the method proposed in Section 3.3 to sample from this multivariate Gaussian distribution. More specifically, we exploit the flexibility of the proposed approach by resorting to two variants. In the first variant, we take advantage of the fact that and are diagonalizable in the Fourier domain, and we propose to add the auxiliary variable to the data fidelity term in order to get rid of the coupling caused by when passing to the Fourier domain. In the second variant, we introduce auxiliary variables for both the data fidelity and the prior terms in order to eliminate the coupling effects induced by all linear operators in the posterior distribution of the target image.
5.3.1. First Variant
We introduce the variable whose conditional distribution—given the set of main parameters of the problem—is the Gaussian distribution of mean and covariance matrix , where with . In practice, we set . It follows that the new conditional distribution of the target signal is
where and are defined as follows:
It is worth noting that the auxiliary variable depends on , and also on through and , but does not depend on , , , when conditioned to , , and . Thus, we propose to use the partially collapsed Gibbs sampling algorithm in order to collapse the auxiliary variables in the sampling step of . At each iteration , the proposed algorithm goes through the following steps in an ordered manner:
| AuxV1 |
|
5.3.2. Second Variant
Another strategy is to introduce two independent auxiliary variables and in following Gaussian distributions of means and and covariance matrices and , respectively, where
and
In practice, we set and , where . Then, the posterior distribution of conditioned to , , , , , , , and is Gaussian with mean and precision matrix defined as
and
The auxiliary variable depends implicitly on through and , but does not depend on the remaining parameters when conditioned to , , and . Similarly, does not depend on , , , , , when conditioned to and . We propose a PCGS algorithm that allows to collapse in the sampling step of . Each iteration of the proposed PCGS algorithm is composed of the following arranged sampling steps.
| AuxV2 |
|
Note that since and are circulant matrices and is diagonal, sampling the auxiliary variables in the proposed methods can be easily performed following Section 3.4.
5.4. Experimental Results
We consider a set of three test images denoted by , , and , of size . These images were artificially degraded by a spatially-invariant blur with point spread function h and further corrupted with mixed Gaussian noise. The Gibbs algorithms were run for 6000 iterations and a burn-in period of 4000 iterations was considered. Estimators of the unknown parameters were then computed using the empirical mean over the 2000 obtained samples. Visual results are displayed in Figure 4 as well as estimates of hyper-parameters using AuxV1.
We focus now on image in order to compare the two variants of our proposed method with the Reversible Jump Perturbation Optimization (RJPO) algorithm [32]. For this method, we used the conjugate gradient algorithm as a linear solver at each iteration whose maximal number of iterations and tolerance were adjusted to correspond to an acceptance probability close to 0.9. We used the same initialization for all compared algorithms. Figure 5, Figure 6, Figure 7 and Figure 8 display samples of hyperparameters as a function of iteration or time. By visually examining the trace plots, we can notice that all algorithms were stabilized after an appropriate burn-in period. In particular, RJPO and AuxV1 showed approximately the same iterative behavior, while AuxV2 required about 3000 iterations to reach iconvergence. This corresponds to twice the burn-in length of RJPO and AuxV1. However, each iteration of the RJPO is time consuming since an iterative algorithm is run until convergence at each iteration. Adding auxiliary variables to the model allows the signal to be sampled in a computationally efficient way in the enlarged state space, so that the computational cost of each iteration was highly reduced for both proposed algorithms, and the total time needed to converge was noticeably shortened compared with RJPO. Regarding the stabilization phase, we consider samples generated after the burn-in period (namely, the last 2000 samples for each algorithm). First, we aimed to study the accuracy of estimators of the unknown variables from these samples. More specifically, we computed empirical estimators of the marginal posterior mean and standard deviation of the target parameters as well as those of a randomly chosen pixel . Table 4 reports the obtained results. It can be noted that parameters , , and were correctly estimated by all the algorithms, while the remaining parameters had similar estimated values. Second, in order to evaluate the mixing properties of the chains at convergence, we computed an empirical estimation of the mean square jump in stationary state from the obtained samples. This indicator can be seen as an estimation of the average distance between two successive samples in the parameter space. It was computed after the burn-in period using last samples as follows:
Note that maximizing the mean square jump is equivalent to minimizing a weighted sum of the 1-lag autocorrelations. In Table 5, we show estimates of the mean square jump per second in stationary state, which is defined as the ratio of the mean square jump and the computational time per iteration. This can be seen as an estimation of the average speed of the algorithm for exploring the parameter space at convergence. We also compared the statistical efficiency of the different samplers with respect to RJPO, defined as the mean square jump per second of each sampler over the mean square jump per second of RJPO. We can notice that the speed improvement of the proposed algorithms came at the expense of a deterioration of the quality of the generated samples. In fact, both proposed algorithms yielded lower values of mean square jump than the RJPO algorithm, which indicates that correlation between successive samples was increased. Furthermore, AuxV1 appeared to have better mixing properties compared with AuxV2. However, the generation of every sample in RJPO is very costly, so its efficiency remained globally poorer compared with AuxV1 and AuxV2. The best trade-off between convergence speed and mixing properties of the chain was achieved by the proposed AuxV1 algorithm.
6. Conclusions
In this paper, we have proposed an approach for sampling from probability distributions in large-scale problems. By adding some auxiliary variables to the model, we succeeded in separately addressing the different sources of correlations in the target posterior density. We have illustrated the usefulness of the proposed Gibbs sampling algorithms in two application examples. In the first application, we proposed a wavelet-based Bayesian method to restore multichannel images degraded by blur and Gaussian noise. We adopted a multivariate prior model that takes advantage of the cross-component correlation. Moreover, a separation strategy has been applied to construct prior models of the related prior hyperparameters. We then employed the proposed Gibbs algorithm with auxiliary variables to derive optimal estimators for both the image and the unknown hyperparameters. In the new augmented space, the resulting model makes sampling much easier since the coefficients of the target image are no longer updated jointly, but in a parallel manner. Experiments carried out on a set of multispectral satellite images showed the good performance of the proposed approach with respect to standard algorithms. Several issues could be investigated as future work, such as the ability of the proposed algorithm to deal with inter-scale dependencies in addition to the cross-channel ones. In the second application, we have applied the proposed method to the recovery of signals corrupted with mixed Gaussian noise. When compared to a state-of-the-art method for sampling from high dimensional scale Gaussian distributions, the proposed algorithms achieve a good tradeoff between the convergence speed and the mixing properties of the Markov chain, even if the generated samples are not independent. Note that the proposed method can be applied to a wide class of applications in inverse problems—in particular, those including conditional Gaussian models either for the noise or the target signal.
Author Contributions
Yosra Marnissi wrote the paper and designed the experiments; Emilie Chouzenoux, Amel Benazza-Benyahia and Jean-Christophe Pesquet contributed to the development of analysis tools.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bertero, M.; Boccacci, P. Introduction to Inverse Problems in Imaging; CRC Press: Boca Raton, FL, USA, 1998. [Google Scholar]
- Demoment, G. Image reconstruction and restoration: Overview of common estimation structure and problems. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 2024–2036. [Google Scholar] [CrossRef]
- Marnissi, Y.; Zheng, Y.; Chouzenoux, E.; Pesquet, J.C. A Variational Bayesian Approach for Image Restoration. Application to Image Deblurring with Poisson-Gaussian Noise. IEEE Trans. Comput. Imaging 2017, 3, 722–737. [Google Scholar] [CrossRef]
- Chouzenoux, E.; Jezierska, A.; Pesquet, J.C.; Talbot, H. A Convex Approach for Image Restoration with Exact Poisson-Gaussian Likelihood. SIAM J. Imaging Sci. 2015, 8, 2662–2682. [Google Scholar] [CrossRef]
- Chaari, L.; Pesquet, J.C.; Tourneret, J.Y.; Ciuciu, P.; Benazza-Benyahia, A. A Hierarchical Bayesian Model for Frame Representation. IEEE Trans. Signal Process. 2010, 58, 5560–5571. [Google Scholar] [CrossRef] [Green Version]
- Pustelnik, N.; Benazza-Benhayia, A.; Zheng, Y.; Pesquet, J.C. Wavelet-Based Image Deconvolution and Reconstruction. In Wiley Encyclopedia of Electrical and Electronics Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1999; pp. 1–34. [Google Scholar]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Liu, J.S. Monte Carlo Strategies in Scientific Computing; Springer Series in Statistics; Springer-Verlag: New York, NY, USA, 2001. [Google Scholar]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Interdisciplinary Statistics; Chapman and Hall/CRC: Boca Raton, FL, USA, 1999. [Google Scholar]
- Gamerman, D.; Lopes, H.F. Markov Chain Monte Carlo: Stochastic Simulation for Bayesian Inference; Texts in Statistical Science; Chapman and Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Glynn, P.W.; Iglehart, D.L. Importance sampling for stochastic simulations. Manag. Sci. 1989, 35, 1367–1392. [Google Scholar] [CrossRef]
- Gilks, W.R.; Wild, P. Adaptive rejection sampling for Gibbs sampling. Appl. Stat. 1992, 41, 337–348. [Google Scholar] [CrossRef]
- Neal, R.M. MCMC using Hamiltonian dynamics. In Handbook of Markov Chain Monte Carlo; Brooks, S., Gelman, A., Jones, G.L., Meng, X.L., Eds.; CRC Press: Boca Raton, FL, USA, 2011; pp. 113–162. [Google Scholar]
- Jarner, S.F.; Hansen, E. Geometric ergodicity of Metropolis algorithms. Stoch. Process. Appl. 2000, 85, 341–361. [Google Scholar] [CrossRef]
- Gilks, W.R.; Best, N.; Tan, K. Adaptive rejection Metropolis sampling within Gibbs sampling. Appl. Stat. 1995, 44, 455–472. [Google Scholar] [CrossRef]
- Dobigeon, N.; Moussaoui, S.; Coulon, M.; Tourneret, J.Y.; Hero, A.O. Joint Bayesian Endmember Extraction and Linear Unmixing for Hyperspectral Imagery. IEEE Trans. Signal Process. 2009, 57, 4355–4368. [Google Scholar] [CrossRef] [Green Version]
- Roberts, G.O.; Gelman, A.; Gilks, W.R. Weak convergence and optimal scaling or random walk Metropolis algorithms. Ann. Appl. Probab. 1997, 7, 110–120. [Google Scholar] [CrossRef]
- Sherlock, C.; Fearnhead, P.; Roberts, G.O. The random walk Metropolis: Linking theory and practice through a case study. Stat. Sci. 2010, 25, 172–190. [Google Scholar] [CrossRef]
- Roberts, G.O.; Stramer, O. Langevin diffusions and Metropolis-Hastings algorithms. Methodol. Comput. Appl. Probab. 2002, 4, 337–357. [Google Scholar] [CrossRef]
- Martin, J.; Wilcox, C.L.; Burstedde, C.; Ghattas, O. A Stochastic Newton MCMC Method for Large-Scale Statistical Inverse Problems with Application to Seismic Inversion. SIAM J. Sci. Comput. 2012, 34, 1460–1487. [Google Scholar] [CrossRef]
- Zhang, Y.; Sutton, C.A. Quasi-Newton Methods for Markov Chain Monte Carlo. In Proceedings of the Neural Information Processing Systems (NIPS 2011), Granada, Spain, 12–17 December 2011; pp. 2393–2401. [Google Scholar]
- Girolami, M.; Calderhead, B. Riemann manifold Langevin and Hamiltonian Monte Carlo methods. J. R. Stat. Soc. Ser. B Stat. Methodol. 2011, 73, 123–214. [Google Scholar] [CrossRef]
- Van Dyk, D.A.; Meng, X.L. The art of data augmentation. J. Comput. Graph. Stat. 2012, 10, 1–50. [Google Scholar] [CrossRef]
- Féron, O.; Orieux, F.; Giovannelli, J.F. Gradient Scan Gibbs Sampler: An efficient algorithm for high-dimensional Gaussian distributions. IEEE J. Sel. Top. Signal Process. 2016, 10, 343–352. [Google Scholar] [CrossRef]
- Rue, H. Fast sampling of Gaussian Markov random fields. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 325–338. [Google Scholar] [CrossRef]
- Geman, D.; Yang, C. Nonlinear image recovery with half-quadratic regularization. IEEE Trans. Image Process. 1995, 4, 932–946. [Google Scholar] [CrossRef] [PubMed]
- Chellappa, R.; Chatterjee, S. Classification of textures using Gaussian Markov random fields. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 959–963. [Google Scholar] [CrossRef]
- Rue, H.; Held, L. Gaussian Markov Random Fields: Theory and Applications; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Bardsley, J.M. MCMC-based image reconstruction with uncertainty quantification. SIAM J. Sci. Comput. 2012, 34, A1316–A1332. [Google Scholar] [CrossRef]
- Papandreou, G.; Yuille, A.L. Gaussian sampling by local perturbations. In Proceedings of the Neural Information Processing Systems 23 (NIPS 2010), Vancouver, BC, Canada, 6–11 December 2010; pp. 1858–1866. [Google Scholar]
- Orieux, F.; Féron, O.; Giovannelli, J.F. Sampling high-dimensional Gaussian distributions for general linear inverse problems. IEEE Signal Process. Lett. 2012, 19, 251–254. [Google Scholar] [CrossRef] [Green Version]
- Gilavert, C.; Moussaoui, S.; Idier, J. Efficient Gaussian sampling for solving large-scale inverse problems using MCMC. IEEE Trans. Signal Process. 2015, 63, 70–80. [Google Scholar] [CrossRef]
- Parker, A.; Fox, C. Sampling Gaussian distributions in Krylov spaces with conjugate gradients. SIAM J. Sci. Comput. 2012, 34, B312–B334. [Google Scholar] [CrossRef]
- Lasanen, S. Non-Gaussian statistical inverse problems. Inverse Prob. Imaging 2012, 6, 267–287. [Google Scholar] [CrossRef]
- Bach, F.; Jenatton, R.; Mairal, J.; Obozinski, G. Optimization with sparsity-inducing penalties. Found. Trends Mach. Learn. 2012, 4, 1–106. [Google Scholar] [CrossRef]
- Kamilov, U.; Bostan, E.; Unser, M. Generalized total variation denoising via augmented Lagrangian cycle spinning with Haar wavelets. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2012), Kyoto, Japan, 25–30 March 2012; pp. 909–912. [Google Scholar]
- Kolehmainen, V.; Lassas, M.; Niinimäki, K.; Siltanen, S. Sparsity-promoting Bayesian inversion. Inverse Prob. 2012, 28, 025005. [Google Scholar] [CrossRef]
- Stuart, M.A.; Voss, J.; Wiberg, P. Conditional Path Sampling of SDEs and the Langevin MCMC Method. Commun. Math. Sci. 2004, 2, 685–697. [Google Scholar] [CrossRef]
- Marnissi, Y.; Chouzenoux, E.; Benazza-Benyahia, A.; Pesquet, J.C.; Duval, L. Reconstruction de signaux parcimonieux à l’aide d’un algorithme rapide d’échantillonnage stochastique. In Proceedings of the GRETSI, Lyon, France, 8–11 September 2015. (In French). [Google Scholar]
- Marnissi, Y.; Benazza-Benyahia, A.; Chouzenoux, E.; Pesquet, J.C. Majorize-Minimize adapted Metropolis-Hastings algorithm. Application to multichannel image recovery. In Proceedings of the European Signal Processing Conference (EUSIPCO 2014), Lisbon, Portugal, 1–5 September 2014; pp. 1332–1336. [Google Scholar]
- Vacar, C.; Giovannelli, J.F.; Berthoumieu, Y. Langevin and Hessian with Fisher approximation stochastic sampling for parameter estimation of structured covariance. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2011), Prague, Czech Republic, 22–27 May 2011; pp. 3964–3967. [Google Scholar]
- Schreck, A.; Fort, G.; Le Corff, S.; Moulines, E. A shrinkage-thresholding Metropolis adjusted Langevin algorithm for Bayesian variable selection. IEEE J. Sel. Top. Signal Process. 2016, 10, 366–375. [Google Scholar] [CrossRef]
- Pereyra, M. Proximal Markov chain Monte Carlo algorithms. Stat. Comput. 2016, 26, 745–760. [Google Scholar] [CrossRef]
- Atchadé, Y.F. An adaptive version for the Metropolis adjusted Langevin algorithm with a truncated drift. Methodol. Comput. Appl. Probab. 2006, 8, 235–254. [Google Scholar] [CrossRef]
- Tanner, M.A.; Wong, W.H. The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 1987, 82, 528–540. [Google Scholar] [CrossRef]
- Mira, A.; Tierney, L. On the use of auxiliary variables in Markov chain Monte Carlo sampling. Technical Report, 1997. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.35.7814 (accessed on 1 February 2018).
- Robert, C.; Casella, G. Monte Carlo Statistical Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Doucet, A.; Sénécal, S.; Matsui, T. Space alternating data augmentation: Application to finite mixture of gaussians and speaker recognition. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2005), Philadelphia, PA, USA, 23 March 2005; pp. 708–713. [Google Scholar]
- Févotte, C.; Cappé, O.; Cemgil, A.T. Efficient Markov chain Monte Carlo inference in composite models with space alternating data augmentation. In Proceedings of the IEEE Statistical Signal Processing Workshop (SSP 2011), Nice, France, 28–30 June 2011; pp. 221–224. [Google Scholar]
- Giovannelli, J.F. Unsupervised Bayesian convex deconvolution based on a field with an explicit partition function. IEEE Trans. Image Process. 2008, 17, 16–26. [Google Scholar] [CrossRef] [PubMed]
- David, H.M. Auxiliary Variable Methods for Markov Chain Monte Carlo with Applications. J. Am. Stat. Assoc. 1997, 93, 585–595. [Google Scholar]
- Hurn, M. Difficulties in the use of auxiliary variables in Markov chain Monte Carlo methods. Stat. Comput. 1997, 7, 35–44. [Google Scholar] [CrossRef]
- Damlen, P.; Wakefield, J.; Walker, S. Gibbs sampling for Bayesian non-conjugate and hierarchical models by using auxiliary variables. J. R. Stat. Soc. Ser. B Stat. Methodol. 1999, 61, 331–344. [Google Scholar] [CrossRef]
- Duane, S.; Kennedy, A.; Pendleton, B.J.; Roweth, D. Hybrid Monte Carlo. Phys. Lett. B 1987, 195, 216–222. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. J. Appl. Stat. 1993, 20, 25–62. [Google Scholar] [CrossRef]
- Idier, J. Convex Half-Quadratic Criteria and Interacting Auxiliary Variables for Image Restoration. IEEE Trans. Image Process. 2001, 10, 1001–1009. [Google Scholar] [CrossRef] [PubMed]
- Geman, D.; Reynolds, G. Constrained restoration and the recovery of discontinuities. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 367–383. [Google Scholar] [CrossRef]
- Champagnat, F.; Idier, J. A connection between half-quadratic criteria and EM algorithms. IEEE Signal Process. Lett. 2004, 11, 709–712. [Google Scholar] [CrossRef]
- Nikolova, M.; Ng, M.K. Analysis of half-quadratic minimization methods for signal and image recovery. SIAM J. Sci. Comput. 2005, 27, 937–966. [Google Scholar] [CrossRef]
- Bect, J.; Blanc-Féraud, L.; Aubert, G.; Chambolle, A. A l1-Unified Variational Framework for Image Restoration. In Proceedings of the European Conference on Computer Vision (ECCV 2004), Prague, Czech Republic, 11–14 May 2004; pp. 1–13. [Google Scholar]
- Cavicchioli, R.; Chaux, C.; Blanc-Féraud, L.; Zanni, L. ML estimation of wavelet regularization hyperparameters in inverse problems. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 1553–1557. [Google Scholar]
- Ciuciu, P. Méthodes Markoviennes en Estimation Spectrale Non Paramétriques. Application en Imagerie Radar Doppler. Ph.D. Thesis, Université Paris Sud-Paris XI, Orsay, France, October 2000. [Google Scholar]
- Andrews, D.F.; Mallows, C.L. Scale mixtures of normal distributions. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 99–102. [Google Scholar]
- West, M. On scale mixtures of normal distributions. Biometrika 1987, 74, 646–648. [Google Scholar] [CrossRef]
- Van Dyk, D.A.; Park, T. Partially collapsed Gibbs samplers: Theory and methods. J. Am. Stat. Assoc. 2008, 103, 790–796. [Google Scholar] [CrossRef]
- Park, T.; van Dyk, D.A. Partially collapsed Gibbs samplers: Illustrations and applications. J. Comput. Graph. Stat. 2009, 18, 283–305. [Google Scholar] [CrossRef]
- Costa, F.; Batatia, H.; Oberlin, T.; Tourneret, J.Y. A partially collapsed Gibbs sampler with accelerated convergence for EEG source localization. In Proceedings of the IEEE Statistical Signal Processing Workshop (SSP 2016), Palma de Mallorca, Spain, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Kail, G.; Tourneret, J.Y.; Hlawatsch, F.; Dobigeon, N. Blind deconvolution of sparse pulse sequences under a minimum distance constraint: A partially collapsed Gibbs sampler method. IEEE Trans. Signal Process. 2012, 60, 2727–2743. [Google Scholar] [CrossRef] [Green Version]
- Chouzenoux, E.; Legendre, M.; Moussaoui, S.; Idier, J. Fast constrained least squares spectral unmixing using primal-dual interior-point optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 7, 59–69. [Google Scholar] [CrossRef]
- Marnissi, Y.; Benazza-Benyahia, A.; Chouzenoux, E.; Pesquet, J.C. Generalized multivariate exponential power prior for wavelet-based multichannel image restoration. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2013), Melbourne, Australia, 15–18 September 2013; pp. 2402–2406. [Google Scholar]
- Laruelo, A.; Chaari, L.; Tourneret, J.Y.; Batatia, H.; Ken, S.; Rowland, B.; Ferrand, R.; Laprie, A. Spatio-spectral regularization to improve magnetic resonance spectroscopic imaging quantification. NMR Biomed. 2016, 29, 918–931. [Google Scholar] [CrossRef] [PubMed]
- Celebi, M.E.; Schaefer, G. Color medical image analysis. In Lecture Notes on Computational Vision and Biomechanics; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Criminisi, E. Spatial decision forests for MS lesion segmentation in multi-channel magnetic resonance images. NeuroImage 2011, 57, 378–390. [Google Scholar]
- Delp, E.; Mitchell, O. Image compression using block truncation coding. IEEE Trans. Commun. 1979, 27, 1335–1342. [Google Scholar] [CrossRef]
- Khelil-Cherif, N.; Benazza-Benyahia, A. Wavelet-based multivariate approach for multispectral image indexing. In Proceedings of the SPIE Conference on Wavelet Applications in Industrial Processing, Rabat, Morocco, 10 September–2 October 2004. [Google Scholar]
- Chaux, C.; Pesquet, J.C.; Duval, L. Noise Covariance Properties in Dual-Tree Wavelet Decompositions. IEEE Trans. Inf. Theory 2007, 53, 4680–4700. [Google Scholar] [CrossRef] [Green Version]
- Roberts, G.O.; Tweedie, L.R. Exponential Convergence of Langevin Distributions and Their Discrete Approximations. Bernoulli 1996, 2, 341–363. [Google Scholar] [CrossRef]
- Murphy, K.P. Conjugate Bayesian Analysis of the Gaussian Distribution. Technical Report, 2007. Available online: https://www.cs.ubc.ca/~murphyk/Papers/bayesGauss.pdf (accessed on 1 February 2018).
- Barnard, J.; McCulloch, R.; Meng, X.L. Modeling covariance matrices in terms of standard deviations and correlations, with application to shrinkage. Stat. Sin. 2000, 10, 1281–1311. [Google Scholar]
- Fink, D. A Compendium of Conjugate Priors. 1997. Available online: https://www.johndcook.com/CompendiumOfConjugatePriors.pdf (accessed on 7 February 2018).
- Flandrin, P. Wavelet analysis and synthesis of fractional Brownian motion. IEEE Trans. Inf. Theory 1992, 38, 910–917. [Google Scholar] [CrossRef]
- Velayudhan, D.; Paul, S. Two-phase approach for recovering images corrupted by Gaussian-plus-impulse noise. In Proceedings of the IEEE International Conference on Inventive Computation Technologies (ICICT 2016), Coimbatore, India, 26–27 August 2016; pp. 1–7. [Google Scholar]
- Chang, E.S.; Hung, C.C.; Liu, W.; Yina, J. A Denoising algorithm for remote sensing images with impulse noise. In Proceedings of the IEEE International Symposium on Geoscience and Remote Sensing (IGARSS 2016), Beijing, China, 10–15 July 2016; pp. 2905–2908. [Google Scholar]
Figure 1.
From top to bottom: Original images–Degraded images–Restored images. (a) b = 2; (b) b = 4; (c) b = 6; (d) b = 2; (e) b = 4; (f) b = 6; (g) b = 2; (h) b = 4; (i) b = 6.
Figure 1.
From top to bottom: Original images–Degraded images–Restored images. (a) b = 2; (b) b = 4; (c) b = 6; (d) b = 2; (e) b = 4; (f) b = 6; (g) b = 2; (h) b = 4; (i) b = 6.

Figure 2.
Trace plot of the scale parameter in subband as time (horizontal subband in the first level of decomposition) with (dashed lines) and without (continuous line) auxiliary variables MALA: Metropolis-adapted Langevin algorithm; RW: random walk.
Figure 2.
Trace plot of the scale parameter in subband as time (horizontal subband in the first level of decomposition) with (dashed lines) and without (continuous line) auxiliary variables MALA: Metropolis-adapted Langevin algorithm; RW: random walk.

Figure 3.
Hierarchical model for image deblurring under two-term mixed Gaussian noise.
Figure 4.
Visual results. From top to bottom: Original images–Degraded images—Restored images. (a) ; (b) ; (c) ; (d) : SNR dB, , , h: Gaussian std. 4; (e) : SNR = dB, , , , h: Uniform ; (f) : SNR dB, , , h: Gaussian std. 1.8; (g) : SNR dB, , , × ; (h) : SNR dB, , , × ; (i) : SNR dB, , , × .
Figure 4.
Visual results. From top to bottom: Original images–Degraded images—Restored images. (a) ; (b) ; (c) ; (d) : SNR dB, , , h: Gaussian std. 4; (e) : SNR = dB, , , , h: Uniform ; (f) : SNR dB, , , h: Gaussian std. 1.8; (g) : SNR dB, , , × ; (h) : SNR dB, , , × ; (i) : SNR dB, , , × .

Figure 5.
Chains of versus iteration/time.
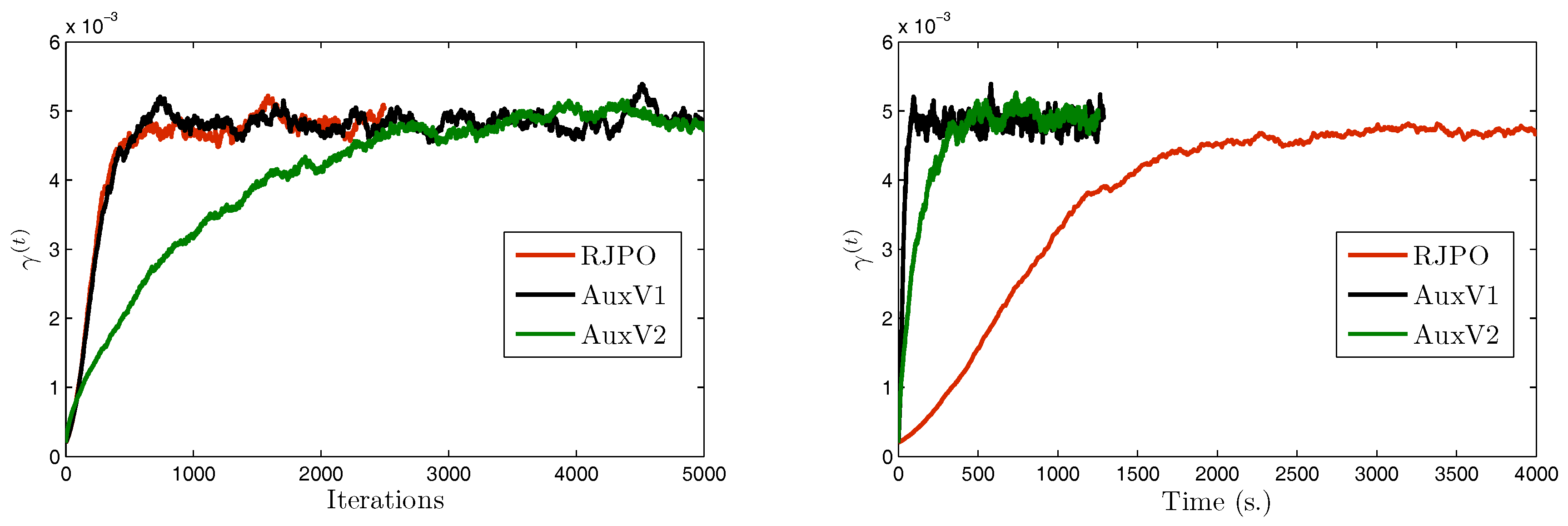
Figure 6.
Chains of versus iteration/time.

Figure 7.
Chains of versus iteration/time.
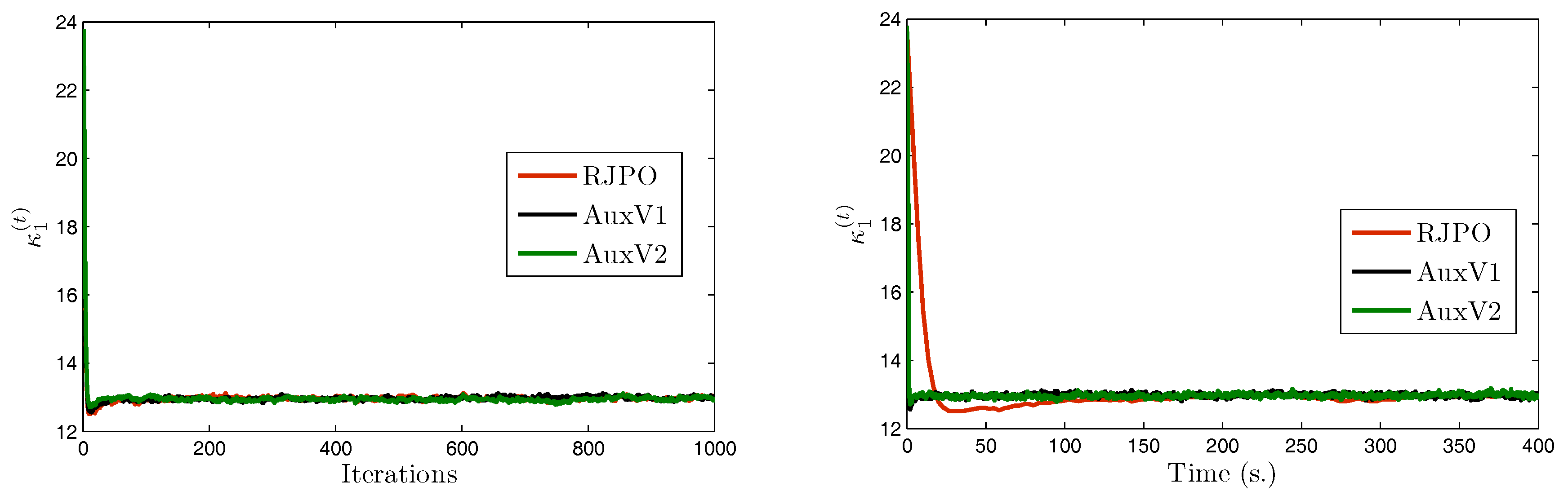
Figure 8.
Chains of versus iteration/time.
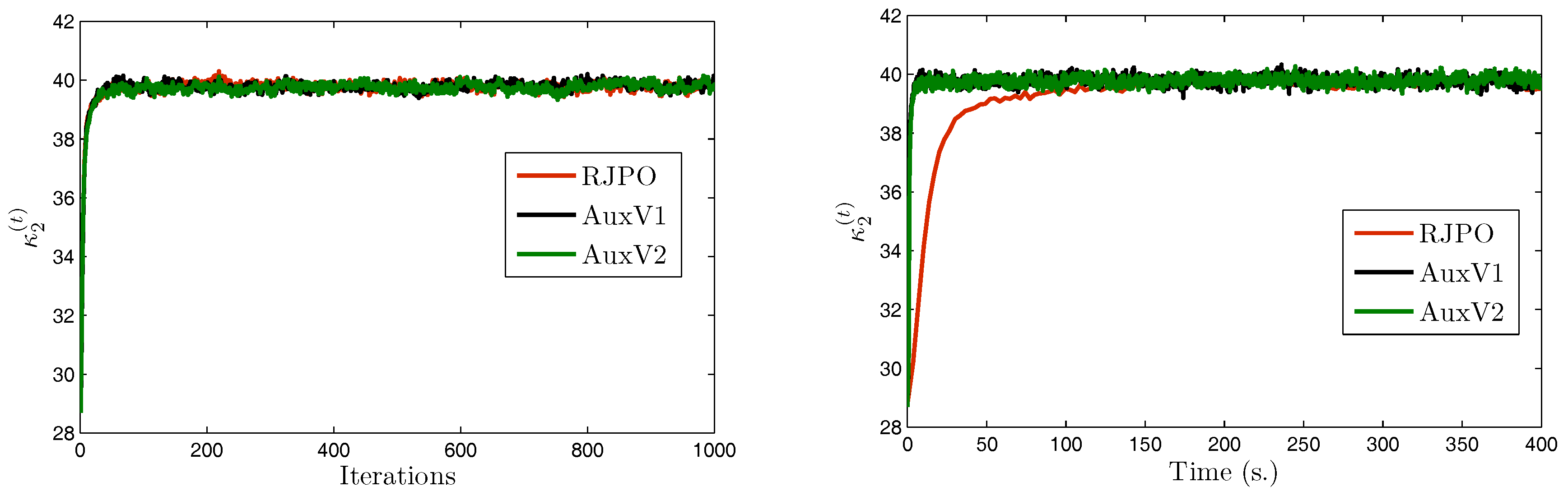

{kind=link}
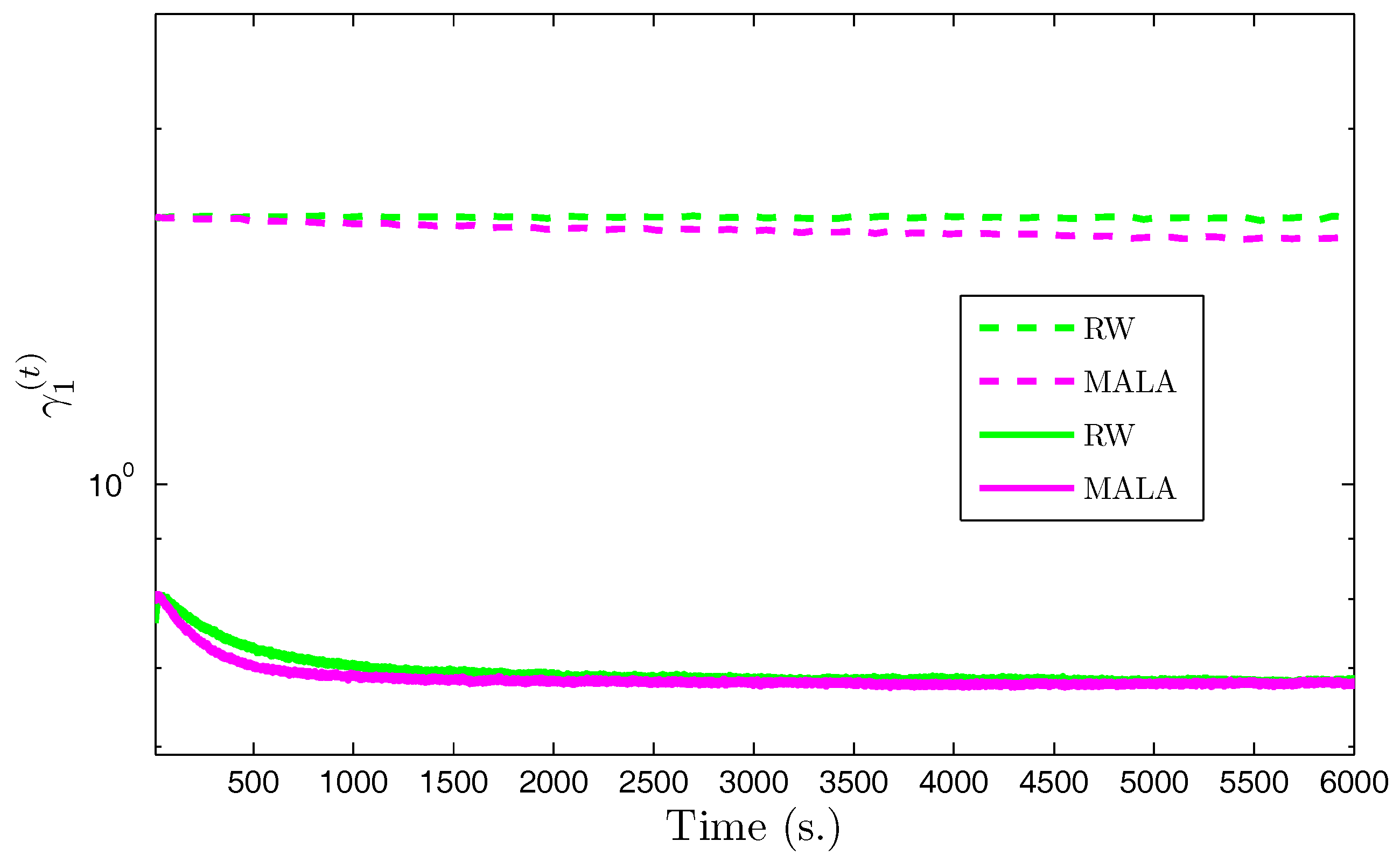{kind=link}
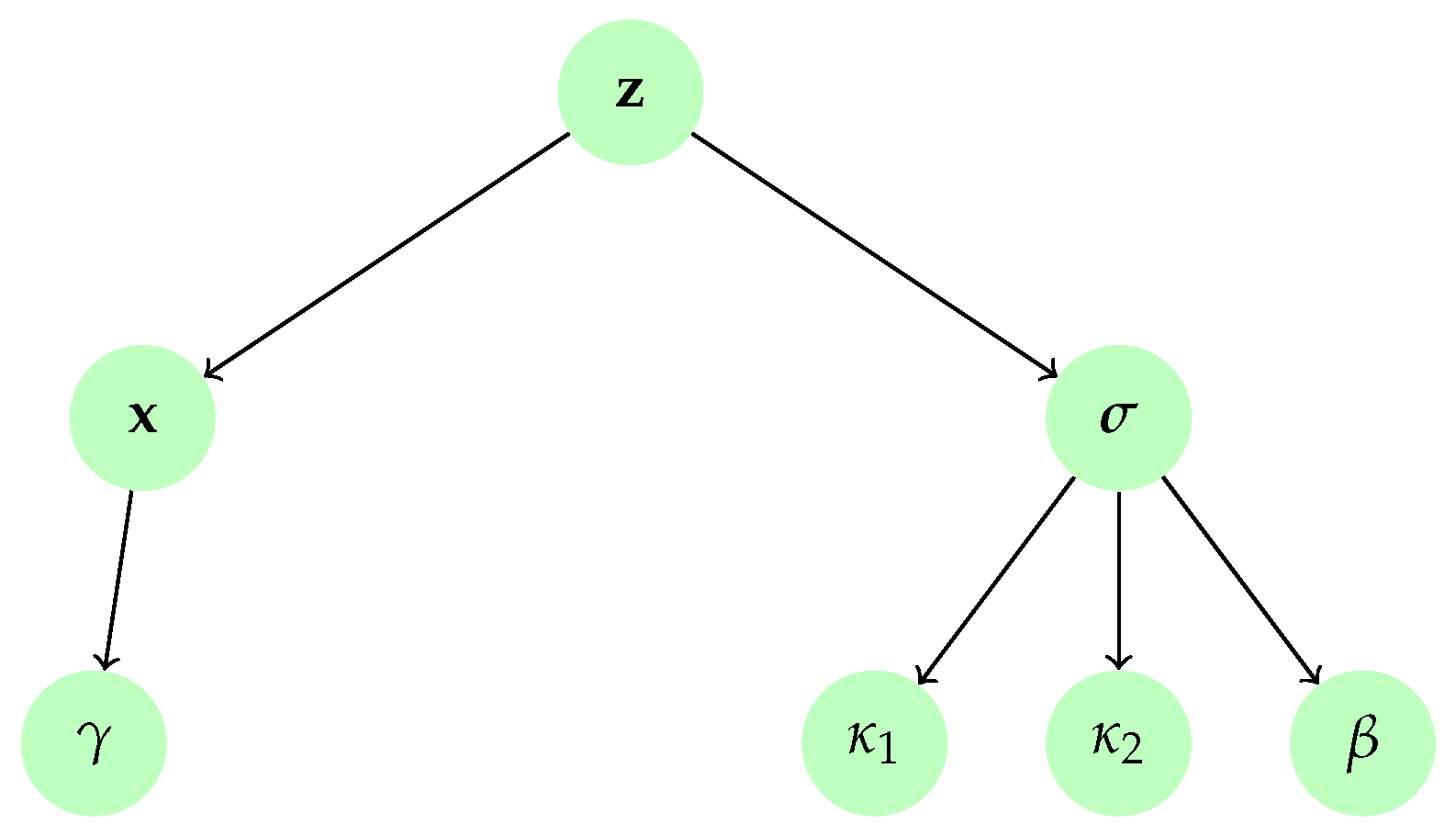{kind=link}
{kind=link}
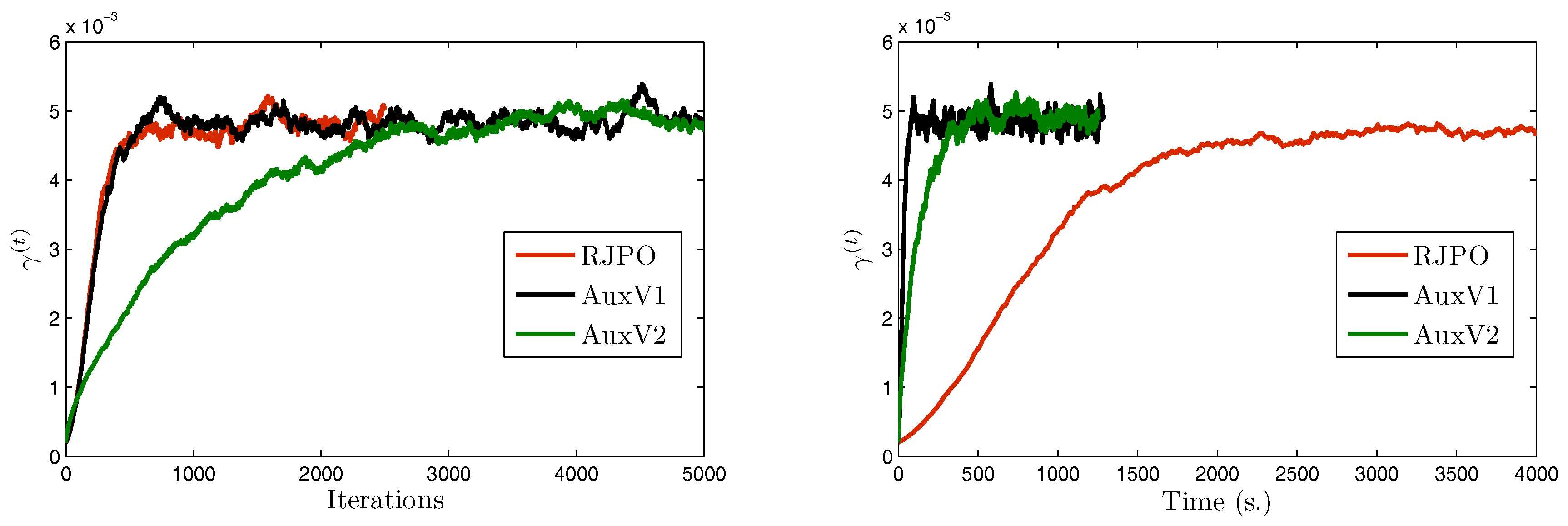{kind=link}
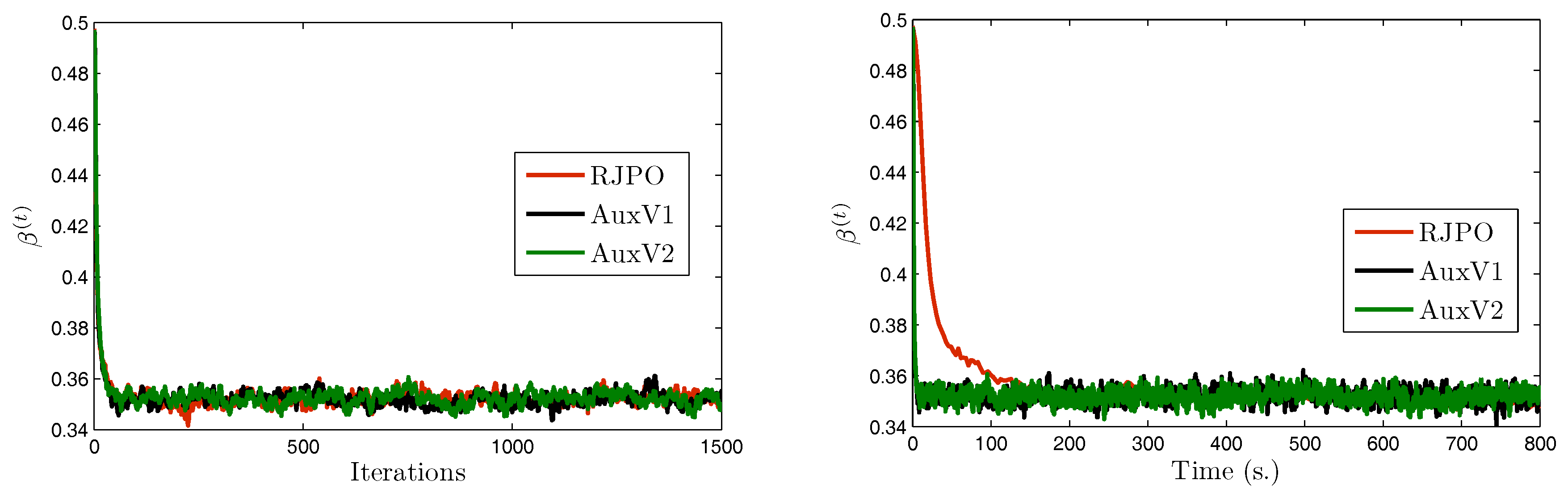{kind=link}
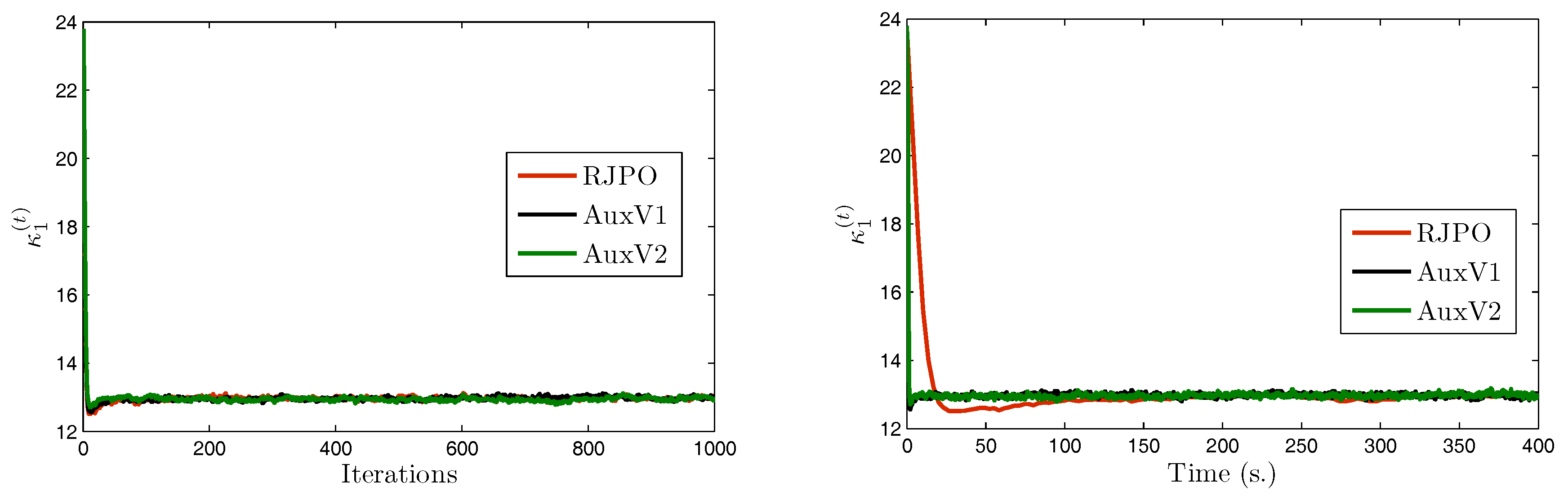{kind=link}
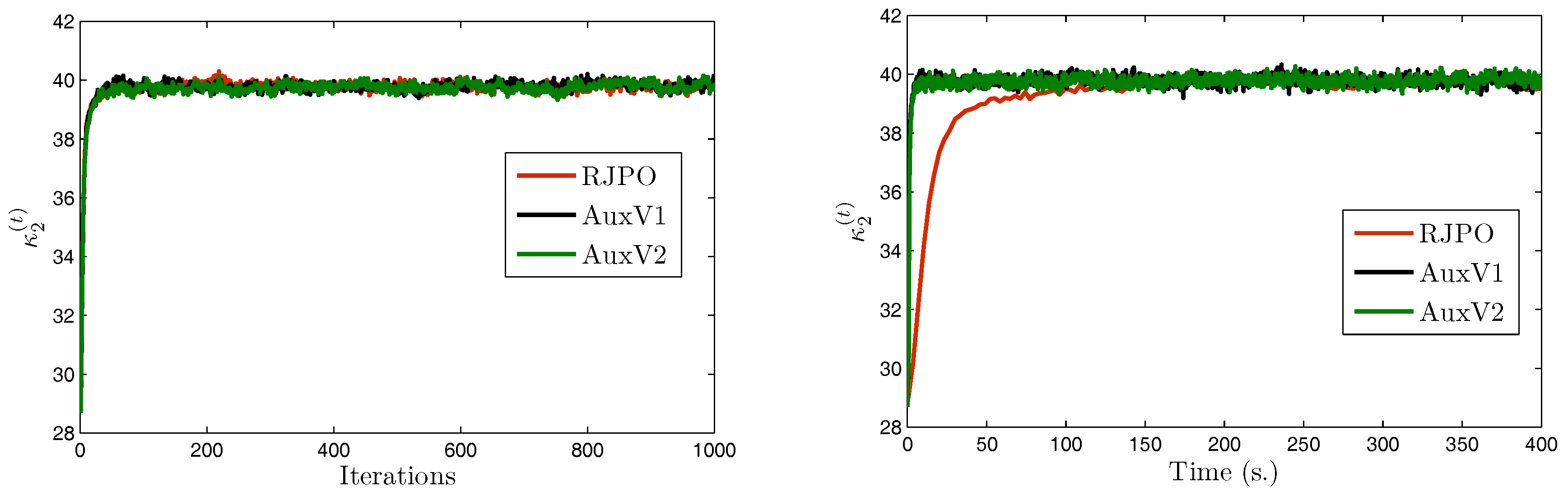{kind=link}
Table 1.
Different alternatives for adding auxiliary variables.
| Problem Source | Proposed Auxiliary Variable | Resulting Conditional Density |
|---|---|---|
Table 2.
Restoration results. SNR: signal-to-noise ratio; BSNR: blurred SNR; PSNR: peak SNR; MMSE: minimum mean square error; SSIM: structural similarity.
Table 2.
Restoration results. SNR: signal-to-noise ratio; BSNR: blurred SNR; PSNR: peak SNR; MMSE: minimum mean square error; SSIM: structural similarity.
| Average | ||||||||
|---|---|---|---|---|---|---|---|---|
| Initial | BSNR | 24.27 | 30.28 | 31.73 | 28.92 | 26.93 | 22.97 | 27.52 |
| PSNR | 25.47 | 21.18 | 19.79 | 22.36 | 23.01 | 26.93 | 23.12 | |
| SNR | 11.65 | 13.23 | 13.32 | 13.06 | 11.81 | 11.77 | 12.47 | |
| SSIM | 0.6203 | 0.5697 | 0.5692 | 0.5844 | 0.5558 | 0.6256 | 0.5875 | |
| MMSE | BSNR | 32.04 | 38.33 | 39.21 | 38.33 | 35.15 | 34.28 | 36.22 |
| PSNR | 28.63 | 25.39 | 23.98 | 26.90 | 27.25 | 31.47 | 27.27 | |
| SNR | 14.82 | 17.50 | 17.60 | 17.66 | 16.12 | 16.38 | 16.68 | |
| SSIM | 0.7756 | 0.8226 | 0.8156 | 0.8367 | 0.8210 | 0.8632 | 0.8225 | |
Table 3.
Mean and variance estimates of hyperparameters.
| RW | MALA | ||
|---|---|---|---|
( = 0.71) | Mean | 0.67 | 0.67 |
| Std. | (1.63 × ) | (1.29 × ) | |
( = 0.99) | Mean | 0.83 | 0.83 |
| Std. | (1.92 × ) | (2.39 × ) | |
( = 0.72) | Mean | 0.62 | 0.61 |
| Std. | (1.33 × ) | (1.23 × ) | |
( = 0.0.24) | Mean | 0.24 | 0.24 |
| Std. | (1.30 × ) | (1.39 × ) | |
( = 0.40) | Mean | 0.37 | 0.37 |
| Std. | (2.10 × ) | (2.42 × ) | |
( = 0.22) | Mean | 0.21 | 0.21 |
| Std. | (1.19 × ) | (1.25 × ) | |
( = 0.0.07) | Mean | 0.08 | 0.08 |
| Std. | (0.91 × ) | (1.08 × ) | |
( = 0.13) | Mean | 0.13 | 0.13 |
| Std. | (1.60 × ) | (1.64 × ) | |
( = 0.07) | Mean | 0.07 | 0.07 |
| Std. | (0.83 × ) | (1 × ) | |
( = 7.44 × ) | Mean | 7.80 × | 7.87 × |
| Std. | (1.34 × ) | (2.12 × ) | |
= 5.79 × | Mean | 1.89 × | 2.10 × |
| Std. | (9.96 × ) | (2.24 × ) | |
Table 4.
Mean and variance estimates. RJPO: Reversible Jump Perturbation Optimization.
| RJPO | AuxV1 | AuxV2 | ||
|---|---|---|---|---|
( = 5.30 × ) | Mean | 4.78 × | 4.84 × | 4.90 × |
| Std. | (1.39 × ) | (1.25 × ) | (9.01 × ) | |
( = 13) | Mean | 12.97 | 12.98 | 12.98 |
| Std. | (4.49 × ) | (4.82 × ) | (4.91 × ) | |
( = 40) | Mean | 39.78 | 39.77 | 39.80 |
| Std. | (0.13) | (0.14) | (0.13) | |
( = 0.35) | Mean | 0.35 | 0.35 | 0.35 |
| Std. | (2.40 × ) | (2.71 × ) | (2.72 × ) | |
( = 140) | Mean | 143.44 | 143.19 | 145.91 |
| Std. | (10.72) | (11.29) | (9.92) | |
Table 5.
Mixing results for the different proposed algorithms. First row: Time per iteration. Second row: Estimates of the mean square jump in stationarity. Third row: Estimates of the mean square jump per second in stationarity. Fourth row: Relative efficiency to RJPO.
Table 5.
Mixing results for the different proposed algorithms. First row: Time per iteration. Second row: Estimates of the mean square jump in stationarity. Third row: Estimates of the mean square jump per second in stationarity. Fourth row: Relative efficiency to RJPO.
| RJPO | AuxV1 | AuxV2 | |
|---|---|---|---|
| T(s.) | 5.27 | 0.13 | 0.12 |
| 15.41 | 14.83 | 4.84 | |
| /T | 2.92 | 114.07 | 40.33 |
| Efficiency | 1 | 39 | 13.79 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Marnissi, Y.; Chouzenoux, E.; Benazza-Benyahia, A.; Pesquet, J.-C. An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension. Entropy 2018, 20, 110. https://doi.org/10.3390/e20020110
AMA Style
Marnissi Y, Chouzenoux E, Benazza-Benyahia A, Pesquet J-C. An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension. Entropy. 2018; 20(2):110. https://doi.org/10.3390/e20020110
Chicago/Turabian StyleMarnissi, Yosra, Emilie Chouzenoux, Amel Benazza-Benyahia, and Jean-Christophe Pesquet. 2018. "An Auxiliary Variable Method for Markov Chain Monte Carlo Algorithms in High Dimension" Entropy 20, no. 2: 110. https://doi.org/10.3390/e20020110
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.