Heartbeats Do Not Make Good Pseudo-Random Number Generators: An Analysis of the Randomness of Inter-Pulse Intervals


Abstract
:1. Introduction
Overview of Our Results
- We have downloaded 19 public databases with information about heart signals from different people. All datasets are taken from the Physionet repository (https://physionet.org/physiobank/database/#ecg) [31], which contains heart signals from both healthy volunteers and people with cardiac conditions. We then extracted the last four bits of the IPI of each person per database, thus creating a bit stream whose quality can be tested. In doing so, we attempt to address the gap detected in [12].
- We analyze all files independently to check if the ECG can be considered to be a good random number generator. To do so, two random number suites (ENT, general purpose, and NIST STS, security) have been run over all previously generated files. To the best of our knowledge, this is the first work that discusses how the ECG signal should be used in cryptographic protocols as a source of random numbers. Our scripts are made public (https://github.com/aylara/Random_ECG) to facilitate the replication of our results by other researchers.
- Contrary to prior proposals, we demonstrate that the ECG signal contains some degree of randomness, but its use in cryptographic applications is questionable. Some databases obtained reasonable results on either ENT or NIST STS. However, none of the tested databases obtained good results on both at the same time except the mitdb database.
2. Background
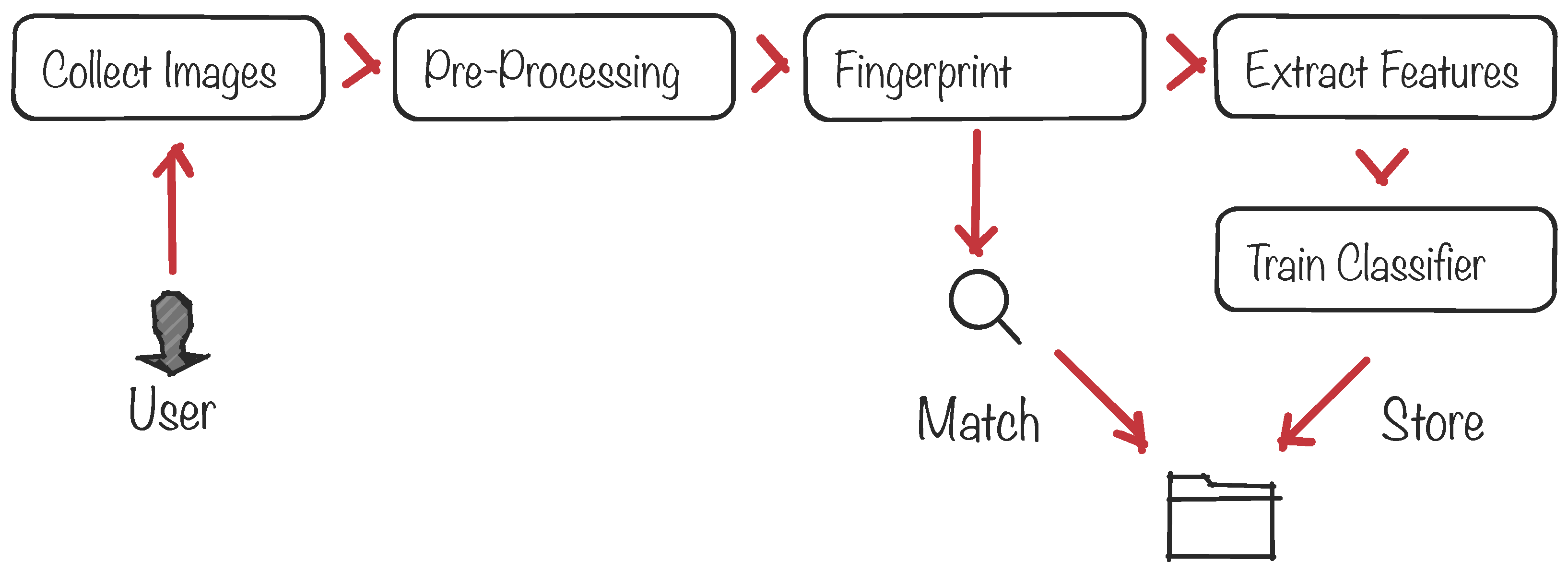
2.1. Biometric Authentication
2.2. IPI-Based Security Protocols
2.3. Randomness Tests
3. The Randomness of IPI Sequences
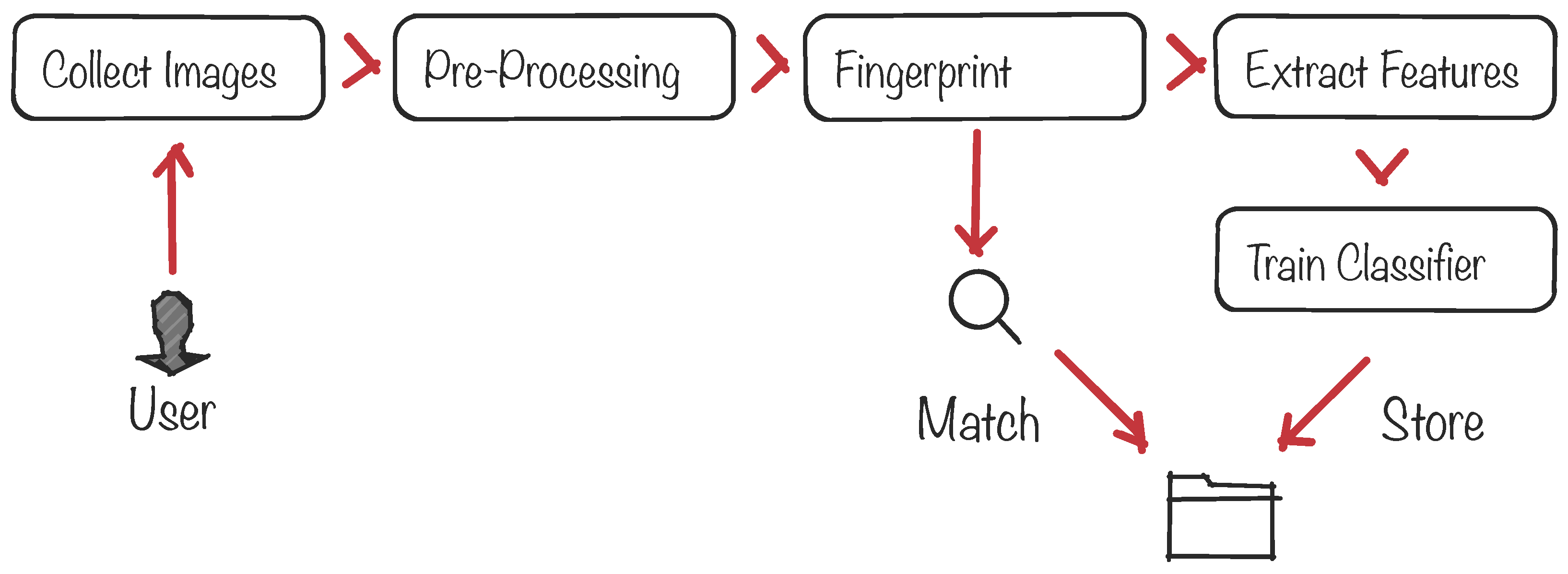
3.1. Dataset
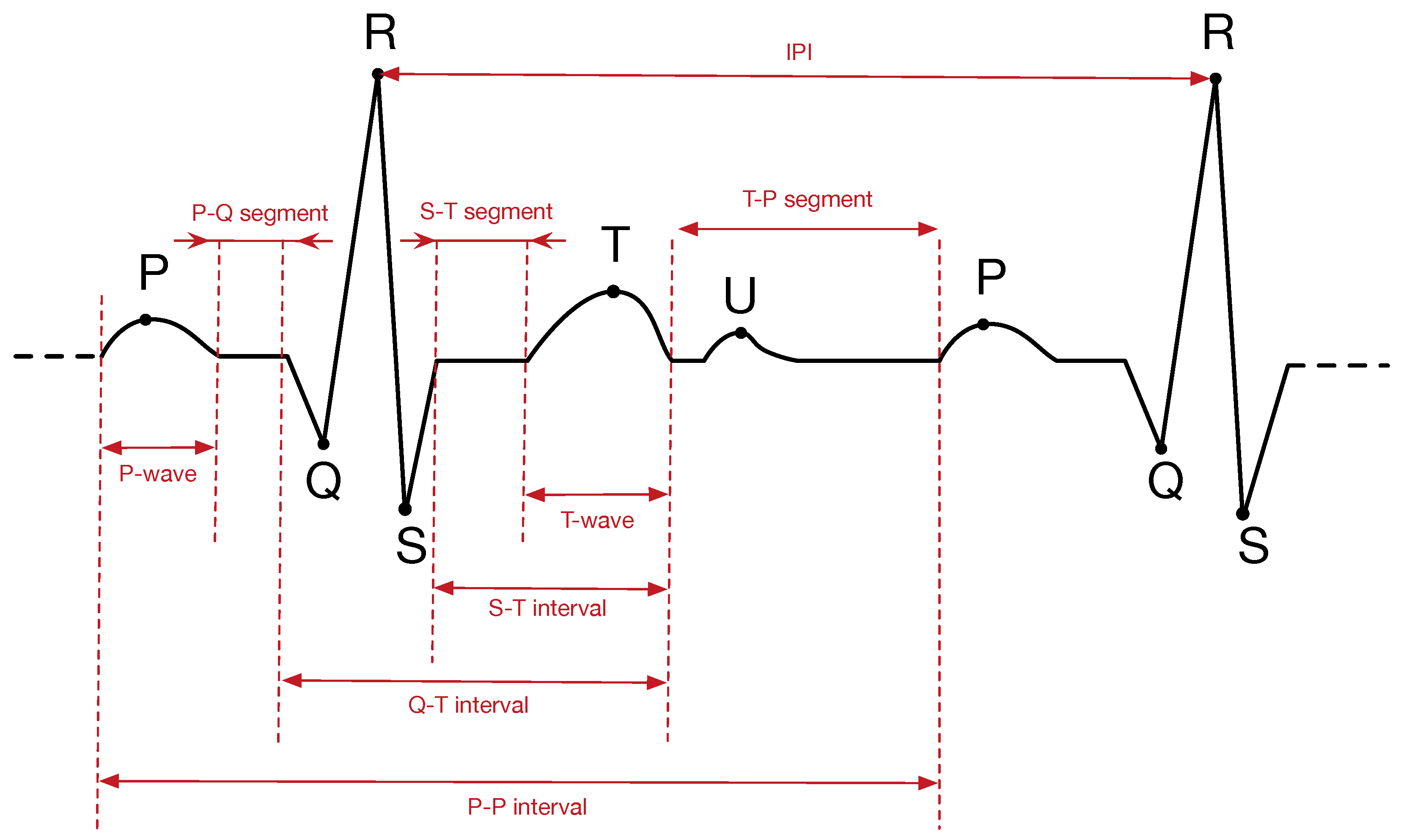
3.2. IPI Extraction
- Get the sampling frequency for each signal, which is available in an associated description record.
- Run Pan–Tomkins’s QRS detection algorithm [74] over the ECG signal to extract the R-peaks.
- Get the timestamp of each R-peak and calculate the difference between each pair of consecutive R-peaks to obtain the sequence of raw IPI values.
- Apply a dynamic quantization algorithm to each IPI to decrease the measurement errors. This process consists of generating discrete values from an ECG (continuous signal).
- Apply a Grey code to the resulting quantized IPI values to increase the error margin of the physiological parameters.
- Extract the four LSB from each coded IPI value.
3.3. Measuring Randomness
3.3.1. ENT
3.3.2. NIST STS
3.4. Discussion
- When the median number of IPIs is higher than 1800, then the databases achieve extremely poor results (two passed tests out of 15 in the worst case) in the NIST STS. Examples of these databases are vfdb, szdb, slpdb, mghdb, edb, apnea-ecg and shareedb.
- When the median number of IPIs is between 1800 and 415, then the databases are on the borderline of passing (at least) half of the NIST STS. Examples of these databases are svdb, cudb, stdb, qtdb, mitdb and nstdb. There is also one exception to this rule: aami-ec13, which has a median of 48.5 IPIs, and it achieves a 33.3% (five passed tests out of 15), which is similar to the results of svdb.
- When the median number of IPIs is between 415 and 37, the databases achieve extremely good results (14 passed tests out of 15 in the best case) in the NIST STS. Examples of these databases are cdb, twadb, pbdb, iafdb, cebsdb. As before, there is an exception to this rule: aami-ec13, which has a median of 48.5 IPIs, and it only passes five out of 15 tests.
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Random Tests
Appendix A.1. ENT
Appendix A.2. NIST STS
References
- Patel, M.; Wang, J. Applications, Challenges, and Prospective in Emerging Body Area Networking Technologies. Wirel. Commun. 2010, 17, 80–88. [Google Scholar] [CrossRef]
- Hanson, M.A.; Powell, H.C. Jr.; Barth, A.T.; Ringgenberg, K.; Calhoun, B.H.; Aylor, J.H.; Lach, J. Body Area Sensor Networks: Challenges and Opportunities. Computer 2009, 42, 58–65. [Google Scholar] [CrossRef]
- Ullah, S.; Higgins, H.; Braem, B.; Latre, B.; Blondia, C.; Moerman, I.; Saleem, S.; Rahman, Z.; Kwak, K.S. A comprehensive survey of wireless body area networks. J. Med. Syst. 2012, 36, 1065–1094. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chien, J.C.; Wang, J.P.; Cho, C.L.; Chong, F.C. Security biosignal transmission based on face recognition for telemedicine. Biomed. Eng. Appl. Basis Commun. 2007, 19, 63–69. [Google Scholar] [CrossRef]
- Löhr, H.; Sadeghi, A.R.; Winandy, M. Securing the e-health cloud. In Proceedings of the 1st ACM International Health Informatics Symposium, Arlington, VA, USA, 11–12 November 2010; pp. 220–229. [Google Scholar]
- Rostami, M.; Juels, A.; Koushanfar, F. Heart-to-heart (H2H): Authentication for implanted medical devices. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 1099–1112. [Google Scholar]
- Zúquete, A.; Quintela, B.; da Silva Cunha, J.P. Biometric Authentication using Brain Responses to Visual Stimuli. In Proceedings of the BIOSIGNALS 2010, Valencia, Spain, 20–23 January 2010; pp. 103–112. [Google Scholar]
- Seepers, R.M.; Strydis, C.; Sourdis, I.; Zeeuw, C.I.D. On Using a Von Neumann Extractor in Heart-Beat-Based Security. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; Volume 1, pp. 491–498. [Google Scholar]
- Rasmussen, K.B.; Roeschlin, M.; Martinovic, I.; Tsudik, G. Authentication Using Pulse-Response Biometrics. In Proceedings of the NDSS, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Eng, A.; Wahsheh, L.A. Look into My Eyes: A Survey of Biometric Security. In Proceedings of the 2013 Tenth International Conference on Information Technology: New Generations (ITNG), Las Vegas, NV, USA, 15–17 April 2013; pp. 422–427. [Google Scholar]
- Yao, L.; Liu, B.; Wu, G.; Yao, K.; Wang, J. A biometric key establishment protocol for body area networks. Int. J. Distrib. Sens. Netw. 2011, 2011, 282986. [Google Scholar] [CrossRef]
- Bassham, L.E., III; Rukhin, A.L.; Soto, J.; Nechvatal, J.R.; Smid, M.E.; Barker, E.B.; Leigh, S.D.; Levenson, M.; Vangel, M.; Banks, D.L.; et al. SP 800-22 Rev. 1a. A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; Technical Report; National Institute of Standards & Technology: Gaithersburg, MD, USA, 2010.
- Guo, Z.; Xin, Y.; Zhao, Y. Cancer classification using entropy analysis in fractional Fourier domain of gene expression profile. Biotechnol. Biotechnol. Equip. 2017, 1–5. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Yang, X.; Sun, P.; Dong, Z.; Liu, A.; Yuan, T.F. Pathological Brain Detection by a Novel Image Feature—Fractional Fourier Entropy. Entropy 2015, 17, 8278–8296. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Y.; Phillips, P.; Liu, G.; Zhou, X.; Wang, S. A Multilayer Perceptron Based Smart Pathological Brain Detection System by Fractional Fourier Entropy. J. Med. Syst. 2016, 40, 173. [Google Scholar] [CrossRef] [PubMed]
- Lucchini, M.; Pini, N.; Fifer, W.P.; Burtchen, N.; Signorini, M.G. Entropy Information of Cardiorespiratory Dynamics in Neonates during Sleep. Entropy 2017, 19, 225. [Google Scholar] [CrossRef] [PubMed]
- Kumar, M.; Pachori, R.B.; Acharya, U.R. Automated Diagnosis of Myocardial Infarction ECG Signals Using Sample Entropy in Flexible Analytic Wavelet Transform Framework. Entropy 2017, 19, 488. [Google Scholar] [CrossRef]
- Shi, B.; Zhang, Y.; Yuan, C.; Wang, S.; Li, P. Entropy Analysis of Short-Term Heartbeat Interval Time Series during Regular Walking. Entropy 2017, 19, 568. [Google Scholar] [CrossRef]
- Altawy, R.; Youssef, A.M. Security Tradeoffs in Cyber Physical Systems: A Case Study Survey on Implantable Medical Devices. IEEE Access 2016, 4, 959–979. [Google Scholar] [CrossRef]
- Li, T.; Zhou, M. ECG Classification Using Wavelet Packet Entropy and Random Forests. Entropy 2016, 18, 285. [Google Scholar] [CrossRef]
- Zheng, G.; Fang, G.; Shankaran, R.; Orgun, M.A. Encryption for Implantable Medical Devices Using Modified One-Time Pads. IEEE Access 2015, 3, 825–836. [Google Scholar]
- Szczepanski, J.; Wajnryb, E.; Amigó, J.; Sanchez-Vives, M.V.; Slater, M. Biometric random number generators. Comput. Secur. 2004, 23, 77–84. [Google Scholar] [CrossRef]
- Chen, G. Are electroencephalogram (EEG) signals pseudo-random number generators? J. Comput. Appl. Math. 2014, 268, 1–4. [Google Scholar] [CrossRef]
- Petchlert, B.; Hasegawa, H. Using a Low-Cost Electroencephalogram (EEG) Directly as Random Number Generator. In Proceedings of the IIAIAAI, Kitakyushu, Japan, 31 August–4 September 2014; pp. 470–474. [Google Scholar]
- Altop, D.K.; Levi, A.; Tuzcu, V. Deriving cryptographic keys from physiological signals. Pervasive Mob. Comput. 2016, 39, 65–79. [Google Scholar] [CrossRef]
- Zhang, G.H.; Poon, C.C.Y.; Zhang, Y.T. Analysis of Using Interpulse Intervals to Generate 128-Bit Biometric Random Binary Sequences for Securing Wireless Body Sensor Networks. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 176–182. [Google Scholar] [CrossRef] [PubMed]
- Zheng, G.; Fang, G.; Shankaran, R.; Orgun, M.; Zhou, J.; Qiao, L.; Saleem, K. Multiple ECG Fiducial Points based Random Binary Sequence Generation for Securing Wireless Body Area Networks. IEEE J. Biomed. Health Inform. 2017, 21, 655–663. [Google Scholar] [CrossRef] [PubMed]
- Seepers, R.M.; Strydis, C.; Peris-Lopez, P.; Sourdis, I.; De Zeeuw, C.I. Peak misdetection in heart-beat-based security: Characterization and tolerance. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Chicago, IL, USA, 26–30 August 2014; pp. 5401–5405. [Google Scholar]
- Vasyltsov, I.; Lee, S. Entropy Extraction from Bio-Signals in Healthcare IoT. In Proceedings of the 1st ACM Workshop on IoT Privacy, Trust, and Security (IoTPTS’15), Singapore, 14–17 April 2015; pp. 11–17. [Google Scholar]
- Seepers, R.M.; Strydis, C.; Sourdis, I.; Zeeuw, C.D. Enhancing Heart-Beat-Based Security for mHealth Applications. IEEE J. Biomed. Health Inform. 2017, 21, 254–262. [Google Scholar] [CrossRef] [PubMed]
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Wildes, R.P. Iris recognition: An emerging biometric technology. Proc. IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef]
- Maltoni, D.; Maio, D.; Jain, A.K.; Prabhakar, S. Handbook of Fingerprint Recognition, 2nd ed.; Springer: London, UK, 2009. [Google Scholar]
- Erkin, Z.; Franz, M.; Guajardo, J.; Katzenbeisser, S.; Lagendijk, I.; Toft, T. Privacy-Preserving Face Recognition. In Privacy Enhancing Technologies, Proceedings of the International Symposium on Privacy Enhancing Technologies Symposium (PETS ’09), Seattle, WA, USA, 5–7 August 2009; Springer-Verlag: Berlin/Heidelberg, Germany, 2009; pp. 235–253. [Google Scholar]
- Jain, A.K.; Ross, A.; Prabhakar, S. An introduction to biometric recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar]
- Sidek, K.A.; Khalil, I.; Jelinek, H.F. ECG Biometric with Abnormal Cardiac Conditions in Remote Monitoring System. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1498–1509. [Google Scholar] [CrossRef]
- Jain, A.K.; Nandakumar, K.; Nagar, A. Biometric Template Security. EURASIP J. Adv. Signal Process 2008, 2008, 113. [Google Scholar] [CrossRef]
- Uludag, U.; Pankanti, S.; Prabhakar, S.; Jain, A.K. Biometric cryptosystems: Issues and challenges. Proc. IEEE 2004, 92, 948–960. [Google Scholar] [CrossRef]
- Chun, H.; Elmehdwi, Y.; Li, F.; Bhattacharya, P.; Jiang, W. Outsourceable Two-party Privacy-preserving Biometric Authentication. In Proceedings of the 9th ACM Symposium on Information, Computer and Communications Security (ASIA CCS’14), Kyoto, Japan, 4–6 June 2014; pp. 401–412. [Google Scholar]
- Upmanyu, M.; Namboodiri, A.M.; Srinathan, K.; Jawahar, C.V. Blind Authentication: A Secure Crypto- biometric Verification Protocol. IEEE Trans. Inf. Forensics Secur. 2010, 5, 255–268. [Google Scholar] [CrossRef]
- Chaudhry, S.A.; Mahmood, K.; Naqvi, H.; Khan, M.K. An Improved and Secure Biometric Authentication Scheme for Telecare Medicine Information Systems Based on Elliptic Curve Cryptography. J. Med. Syst. 2015, 39, 175. [Google Scholar] [CrossRef] [PubMed]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based Encryption for Fine-grained Access Control of Encrypted Data. In Proceedings of the 13th ACM Conference on Computer and Communications Security 2006 (CCS’06), Alexandria, VA, USA, 30 October–3 November 2006; pp. 89–98. [Google Scholar]
- Oberoi, D.; Sou, W.Y.; Lui, Y.Y.; Fisher, R.; Dinca, L.; Hancke, G.P. Wearable security: Key derivation for Body Area sensor Networks based on host movement. In Proceedings of the 2016 IEEE 25th International Symposium on Industrial Electronics (ISIE), Santa Clara, CA, USA, 8–10 June 2016; pp. 1116–1121. [Google Scholar]
- Hu, C.; Cheng, X.; Zhang, F.; Wu, D.; Liao, X.; Chen, D. OPFKA: Secure and efficient Ordered-Physiological- Feature-based key agreement for wireless Body Area Networks. In Proceedings of the 32nd IEEE International Conference on Computer Communications (IEEE INFOCOM), Turin, Italy, 14–19 April 2013; pp. 2274–2282. [Google Scholar]
- Miao, F.; Jiang, L.; Li, Y.; Zhang, Y.T. Biometrics based novel key distribution solution for body sensor networks. In Proceedings of the 2009 31st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Minneapolis, MN, USA, 3–6 September 2009; pp. 2458–2461. [Google Scholar]
- Venkatasubramanian, K.K.; Gupta, S.K.S. Physiological Value-based Efficient Usable Security Solutions for Body Sensor Networks. ACM Trans. Sens. Netw. 2010, 6, 31. [Google Scholar] [CrossRef]
- Xu, F.; Qin, Z.; Tan, C.C.; Wang, B.; Li, Q. IMDGuard: Securing implantable medical devices with the external wearable guardian. In Proceedings of the 2011 IEEE International Conference on Computer Communications (IEEE INFOCOM), Shanghai, China, 10–15 April 2011; pp. 1862–1870. [Google Scholar]
- Li, M.; Yu, S.; Guttman, J.D.; Lou, W.; Ren, K. Secure Ad Hoc Trust Initialization and Key Management in Wireless Body Area Networks. ACM Trans. Sens. Netw. 2013, 9, 18. [Google Scholar] [CrossRef]
- Zhang, G.H.; Poon, C.C.Y.; Zhang, Y.T. A fast key generation method based on dynamic biometrics to secure wireless body sensor networks for p-health. In Proceedings of the 2010 32nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Buenos Aires, Argentina, 31 August–4 September 2010; pp. 2034–2036. [Google Scholar]
- Jurik, A.D.; Weaver, A.C. Securing Mobile Devices with Biotelemetry. In Proceedings of the International Conference on Computer Communications and Networks (ICCCN 2011), Maui, HI, USA, 31 July–4 August 2011; pp. 1–6. [Google Scholar]
- Bao, S.D.; Poon, C.C.; Zhang, Y.T.; Shen, L.F. Using the Timing Information of Heartbeats As an Entity Identifier to Secure Body Sensor Network. Trans. Inf. Technol. Biomed. 2008, 12, 772–779. [Google Scholar]
- Chen, X.; Zhang, Y.; Zhang, G.; Zhang, Y. Evaluation of ECG random number generator for wireless body sensor networks security. In Proceedings of the 2012 5th International Conference on Biomedical Engineering and Informatics (BMEI), Chongqing, China, 16–18 October 2012; pp. 1308–1311. [Google Scholar]
- Hong, T.; Bao, S.D.; Zhang, Y.T.; Li, Y.; Yang, P. An improved scheme of IPI-based entity identifier generation for securing body sensor networks. In Proceedings of the 2011 33rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Boston, MA, USA, 30 August–3 September 2011; pp. 1519–1522. [Google Scholar]
- Walker, J. A Pseudorandom Number Sequence Test Program. Available online: http://www.fourmilab.ch/random/ (accessed on 27 Junuary 2018).
- García-González, M.; Argelagós, A.; Fernández-Chimeno, M.; Ramos-Castro, J. Differences in QRS locations due to ECG lead: Relationship with breathing. In Proceedings of the XIII Mediterranean Conference on Medical and Biological Engineering and Computing 2013, Seville, Spain, 25–28 September 2013; Springer: Cham, Switzerland, 2014; pp. 962–964. [Google Scholar]
- García-González, M.A.; Argelagós-Palau, A.; Fernández-Chimeno, M.; Ramos-Castro, J. A comparison of heartbeat detectors for the seismocardiogram. In Proceedings of the 2013 Computing in Cardiology Conference (CinC), Zaragoza, Spain, 22–25 September 2013; pp. 461–464. [Google Scholar]
- Bousseljot, R.; Kreiseler, D.; Schnabel, A. Nutzung der EKG-Signaldatenbank CARDIODAT der PTB über das Internet. Biomed. Eng. 1995, 40, 317–318. [Google Scholar] [CrossRef]
- Moody, G.B. The PhysioNet/Computers in Cardiology Challenge 2008: T-Wave Alternans. Comput. Cardiol. 2008, 35, 505–508. [Google Scholar]
- Taddei, A.; Distante, G.; Emdin, M.; Pisani, P.; Moody, G.; Zeelenberg, C.; Marchesi, C. The European ST-T database: Standard for evaluating systems for the analysis of ST-T changes in ambulatory electrocardiography. Eur. Heart J. 1992, 13, 1164–1172. [Google Scholar] [CrossRef] [PubMed]
- Moody, G.B.; Mark, R.G.; Goldberger, A.L. Evaluation of theTRIM’ECG data compressor. In Proceedings of the 1998 Computers in Cardiology, Washington, DC, USA, 25–28 September 1988; pp. 167–170. [Google Scholar]
- Moody, G.B.; Muldrow, W.; Mark, R.G. A noise stress test for arrhythmia detectors. Comput. Cardiol. 1984, 11, 381–384. [Google Scholar]
- Moody, G.B.; Mark, R.G. The impact of the MIT-BIH arrhythmia database. Eng. Med. Biol. Mag. IEEE 2001, 20, 45–50. [Google Scholar] [CrossRef]
- Laguna, P.; Mark, R.G.; Goldberg, A.; Moody, G.B. A database for evaluation of algorithms for measurement of QT and other waveform intervals in the ECG. In Proceedings of the 1997 Computers in Cardiology, Lund, Sweden, 7–10 September 1997; pp. 673–676. [Google Scholar]
- Albrecht, P. ST Segment Characterization for Long Term Automated ECG Analysis; Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology: Cambridge, MA, USA, 1983. [Google Scholar]
- Nolle, F.; Badura, F.; Catlett, J.; Bowser, R.; Sketch, M.H. CREI-GARD, a new concept in computerized arrhythmia monitoring systems. In Proceedings of the 1986 Computers in Cardiology, Boston, MA, USA, 7–10 October 1986. [Google Scholar]
- American National Standards Institute; Association for the Advancement of Medical Instrumentation. Cardiac Monitors, Heart Rate Meters and Alarms; Association for the Advancement of Medical Instrumentation: Arlington, VA, USA, 2002. [Google Scholar]
- Greenwald, S.D.; Patil, R.S.; Mark, R.G. Improved detection and classification of arrhythmias in noise-corrupted electrocardiograms using contextual information. In Proceedings of the 1990 Computers in Cardiology, Chicago, IL, USA, 23–26 September 1990; pp. 461–464. [Google Scholar]
- Greenwald, S.D. The Development and Analysis of a Ventricular Fibrillation Detector. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1986. [Google Scholar]
- Al-Aweel, I.; Krishnamurthy, K.; Hausdorff, J.; Mietus, J.; Ives, J.; Blum, A.; Schomer, D.; Goldberger, A. Postictal heart rate oscillations in partial epilepsy. Neurology 1999, 53, 1590. [Google Scholar] [CrossRef] [PubMed]
- Ichimaru, Y.; Moody, G. Development of the polysomnographic database on CD-ROM. Psychiatry Clin. Neurosci. 1999, 53, 175–177. [Google Scholar] [CrossRef] [PubMed]
- Welch, J.; Ford, P.; Teplick, R.; Rubsamen, R. The Massachusetts General Hospital-Marquette Foundation hemodynamic and electrocardiographic database—Comprehensive collection of critical care waveforms. Clin. Monit. 1991, 7, 96–97. [Google Scholar]
- Penzel, T.; Moody, G.; Mark, R.; Goldberger, A.; Peter, J. The apnea-ECG database. In Proceedings of the 2000 Computers in Cardiology, Cambridge, MA, USA, 24–27 September 2000; pp. 255–258. [Google Scholar]
- Melillo, P.; Izzo, R.; Orrico, A.; Scala, P.; Attanasio, M.; Mirra, M.; De Luca, N.; Pecchia, L. Automatic prediction of cardiovascular and cerebrovascular events using heart rate variability analysis. PLoS ONE 2015, 10, e0118504. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Tompkins, W.J. A Real-Time QRS Detection Algorithm. IEEE Trans. Biomed. Eng. 1985, 32, 230–236. [Google Scholar] [CrossRef] [PubMed]
- Gerhardts, I. Ilja Gerhardt—Random Number Tests. Available online: https://gerhardt.ch/random.php (accessed on 27 Junuary 2018).
- Sýs, M.; Říha, Z. Faster Randomness Testing with the NIST Statistical Test Suite. In Proceedings of the 4th International Conference on Security, Privacy, and Applied Cryptography Engineering (SPACE 2014), Pune, India, 18–22 October 2014; Chakraborty, R.S., Matyas, V., Schaumont, P., Eds.; Springer: Cham, Switzerland, 2014; pp. 272–284. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Dataset | Randomness Test |
|---|---|---|
| [25] | 50 subjects from the MIMICII Waveform | Shannon’s Entropy |
| [51] | 99 subjects from a private dataset | NIST STS (5/15) |
| [52] | 50 subjects from a private dataset | NIST STS (15/15) |
| [53] | Not specified | NIST STS (6/15) |
| [6] | 47 subjects from mitdb; 290 from ptdb; 250 from mghdb | NIST STS (8/15) |
| [28] | mitdb (no info is given) | Shannon’s entropy |
| [30] | mitdb (no info is given) | Shannon’s entropy |
| [8] | mitdb (no info is given) | ENT |
| [29] | mitdb (no info is given) | Rényi’s entropy |
| [47] | PhysioNet | NIST STS (9/15) |
| [26] | 84 subjects from a private dataset and European ST-T | NIST STS (5/15) |
| [27] | 18 subjects from MIT-BIHand 79 from the European ST-T | NIST STS (10/15) |
| Dataset | #Records | Frequency (Hz) | Median (IPIs) | Pathology |
|---|---|---|---|---|
| cebsdb [31,55,56] | 54 | 5000 | 175 | Healthy volunteers |
| ptbdb [57] | 545 | 1000 | 68 | Myocardial problems and healthy controls |
| twadb [58] | 5 | 500 | 87 | Myocardial problems |
| iafdb [59] | 5 | 1000 | 37 | Atrial fibrillation or flutter |
| cdb [60] | 53 | 250 | 12 | Holter recordings |
| nstdb [61] | 14 | 360 | 1246 | Physically-active volunteers |
| mitdb [62] | 46 | 360 | 1113 | Arrhythmia |
| qtdb [63] | 104 | 250 | 520.5 | Holter recordings |
| stdb [64] | 28 | 360 | 1243 | Stress tests |
| cudb [65] | 9 | 250 | 415 | Ventricular problems |
| aami-ec13 [66] | 10 | 720 | 48.5 | Tachycardia |
| svdb [67] | 47 | 128 | 1192 | Partial epilepsy |
| vfdb [68] | 17 | 250 | 1800 | Tachycardia |
| szdb [69] | 7 | 200 | 4439 | Partial epilepsy |
| slpdb [70] | 17 | 250 | 11,517 | Sleep apnea syndrome |
| edb [59] | 90 | 250 | 4405 | Myocardial and hypertension |
| mghdb [71] | 202 | 360 | 2426 | Unstable patients in critical care units |
| apnea-ecg [72] | 77 | 100 | 15,786 | Tachycardia |
| shareedb [73] | 23 | 128 | 46,910 | Hypertension |
| Test | Optimal Value | Threshold | Counter |
|---|---|---|---|
| Entropy | 1.0 | >0.85 | 0.99 |
| Optimum compression | <0% | <5% | 0% |
| Chi square | 95% | 95% | 1% |
| Arithmetic mean | 0.5 | 0.4 0.6 | 0.46 |
| Monte Carlo value for | error = 0% | error < 5% | 12.38% |
| Serial correlation coefficient | 0 | or | 0.012 |
| Dataset | Entropy | Optimum Compression | Chi Square | Arithmetic Mean | Monte Carlo Value for | Serial Correlation |
|---|---|---|---|---|---|---|
| cebsdb | 100% | 100% | 0% | 50% | 10% | 60% |
| ptbdb | 99.82% | 100% | 0% | 97.98% | 22.20% | 99.63% |
| twadb | 100% | 100% | 0% | 80% | 0% | 100% |
| iafdb | 100% | 100% | 0% | 100% | 40% | 100% |
| cdb | 100% | 100% | 0% | 81.13% | 1.89% | 96.23% |
| nstdb | 100% | 100% | 0% | 92.86% | 35.71% | 100% |
| mitdb | 100% | 100% | 0% | 97.83% | 47.83% | 97.83% |
| qtdb | 99.04% | 100% | 0% | 96.15% | 38.46% | 100% |
| stdb | 100% | 100% | 0% | 100% | 35.71% | 100% |
| cudb | 100% | 100% | 0% | 44.44% | 11.11% | 100% |
| aami-ec13 | 80% | 100% | 0% | 50% | 10% | 60% |
| svdb | 100% | 100% | 0% | 97.87% | 42.55% | 97.87% |
| vfdb | 83% | 100% | 0% | 17% | 6% | 94% |
| szdb | 85.71% | 100% | 0% | 85.71% | 71.43% | 85.71% |
| slpdb | 100% | 100% | 0% | 100% | 74.47% | 100% |
| edb | 98.89% | 100% | 0% | 98.89% | 60% | 100% |
| mghdb | 72.28% | 100% | 0% | 59.41% | 22.28% | 86.14% |
| apnea-ecg | 75.32% | 100% | 0% | 62.34% | 29.87% | 81.82% |
| shareedb | 95.65% | 100% | 0% | 95.65% | 55.52% | 100% |
| Test Name | n | m or M |
|---|---|---|
| Frequency (Monobit) | - | |
| Frequency Test within a Block | - | |
| Run | - | |
| Longest Run of Ones in a Block | ||
| Binary Matrix Rank | - | |
| Discrete Fourier Transform (Spectral) | - | |
| Non-Overlapping Template Matching | ||
| Overlapping Template Matching | ||
| Maurer’s “Universal Statistical” Test | ||
| Linear Complexity | ||
| Serial | ||
| Approximate Entropy | ||
| Cumulative Sums | ||
| Random Excursions | ||
| Random Excursions Variant |
| Dataset | Monobit Frequency | Block Frequency | Runs | Longest Run Ones | Binary Matrix Rank | Spectral | Non Overlapping Template Matching | Overlapping Template Matching | Universal Statistic | Linear Complexity | Serial | Approximate Entropy | Cumulative Sums | Random Excursions | Random Excursions Variant |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cebsdb | 94% | 81% | 85% | 87% | 98% | 100% | 96% | 72% | 100% | 20% | 85% | 96% | 96% | 98% | 100% |
| ptbdb | 89% | 89% | 89% | 89% | 85% | 92% | 98% | 84% | 1% | 0% | 100% | 85% | 98% | 99% | 65% |
| twadb | 80% | 60% | 80% | 100% | 80% | 80% | 100% | 80% | 20% | 0% | 100% | 60% | 100% | 80% | 80% |
| iafdb | 100% | 100% | 100% | 80% | 100% | 100% | 100% | 100% | 20% | 0% | 100% | 100% | 80% | 100% | 40% |
| cdb | 94% | 25% | 92% | 94% | 100% | 94% | 96% | 81% | 0% | 0% | 100% | 77% | 100% | 100% | 0% |
| nstdb | 14% | 21% | 7% | 64% | 21% | 50% | 71% | 57% | 86% | 57% | 7% | 93% | 93% | 71% | 100% |
| mitdb | 46% | 33% | 33% | 50% | 35% | 59% | 91% | 52% | 89% | 39% | 9% | 87% | 96% | 85% | 100% |
| qtdb | 47% | 41% | 44% | 54% | 25% | 53% | 92% | 56% | 89% | 0% | 0% | 77% | 98% | 81% | 95% |
| stdb | 50% | 7% | 29% | 54% | 21% | 21% | 64% | 32% | 64% | 21% | 4% | 71% | 100% | 32% | 100% |
| cudb | 0% | 11% | 0% | 56% | 11% | 22% | 11% | 67% | 67% | 0% | 11% | 56% | 100% | 22% | 78% |
| aami-ec13 | 10% | 20% | 30% | 40% | 20% | 10% | 90% | 90% | 0% | 0% | 100% | 60% | 100% | 0% | 40% |
| svdb | 23% | 11% | 19% | 28% | 6% | 9% | 77% | 43% | 77% | 21% | 0% | 77% | 100% | 28% | 94% |
| vfdb | 29% | 12% | 12% | 41% | 18% | 12% | 29% | 29% | 88% | 18% | 0% | 71% | 100% | 24% | 100% |
| szdb | 14% | 0% | 0% | 29% | 0% | 0% | 43% | 29% | 71% | 0% | 0% | 86% | 100% | 0% | 86% |
| slpdb | 24% | 0% | 6% | 35% | 6% | 12% | 76% | 12% | 24% | 0% | 0% | 76% | 94% | 6% | 94% |
| edb | 23% | 1% | 14% | 29% | 3% | 7% | 62% | 21% | 43% | 9% | 0% | 86% | 100% | 2% | 94% |
| mghdb | 22% | 14% | 14% | 33% | 11% | 12% | 35% | 34% | 34% | 7% | 19% | 57% | 99% | 15% | 60% |
| apnea-ecg | 5% | 4% | 4% | 17% | 1% | 0% | 27% | 26% | 23% | 0% | 9% | 68% | 96% | 1% | 75% |
| shareedb | 9% | 0% | 0% | 4% | 0% | 0% | 17% | 0% | 0% | 0% | 0% | 48% | 100% | 0% | 96% |
| Average | 36.8% | 21.0% | 26.3% | 52.6% | 26.3% | 42.1% | 68.4% | 52.6% | 47.3% | 5.2% | 31.5% | 94.7% | 100% | 42.1% | 84.2% |
| Dataset | ENT | NIST STS | Avg. No. Samples | Median (IPI) | Pathology |
|---|---|---|---|---|---|
| cebsdb | 66.6% | 93.3% | 4,968,780 | 175 | Healthy volunteers |
| ptbdb | 66.6% | 86.6% | 108,818 | 68 | Myocardial problems and Healthy controls |
| twadb | 66.6% | 86.6% | 59,770 | 87 | Myocardial problems |
| iafdb | 66.6% | 80.0% | 19,707,034 | 37 | Atrial fibrillation or flutter |
| cdb | 66.6% | 73.3% | 5,120 | 12 | Holter recordings |
| nstdb | 66.6% | 66.6% | 650,000 | 1246 | Physically active volunteers |
| mitdb | 66.6% | 60.0% | 650,000 | 1113 | Arrhythmia |
| qtdb | 66.6% | 60.0% | 224,999 | 520.5 | Holter recordings |
| stdb | 66.6% | 46.6% | 624,166 | 1243 | Stress tests |
| cudb | 50.0% | 40.0% | 127,232 | 415 | Ventricular problems |
| aami-ec13 | 66.6% | 33.3% | 55,522 | 48.5 | Tachycardia |
| svdb | 66.6% | 33.3% | 230,400 | 1192 | Partial epilepsy |
| vfdb | 50.0% | 26.6% | 525,000 | 1800 | Tachycardia |
| szdb | 83.3% | 26.6% | 17,245,701 | 4439 | Partial epilepsy |
| slpdb | 83.3% | 26.6% | 4,188,530 | 11,517 | Sleep apnea syndrome |
| edb | 83.3% | 26.6% | 1,800,000 | 4405 | Myocardial and hypertension |
| mghdb | 66.6% | 20.0% | 1,479,358 | 2426 | Unstable patients in critical care units |
| apnea-ecg | 66.6% | 20.0% | 11,930 | 15,786 | Tachycardia |
| shareedb | 83.3% | 13.3% | 10,553,116 | 46,910 | Hypertension |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortiz-Martin, L.; Picazo-Sanchez, P.; Peris-Lopez, P.; Tapiador, J. Heartbeats Do Not Make Good Pseudo-Random Number Generators: An Analysis of the Randomness of Inter-Pulse Intervals. Entropy 2018, 20, 94. https://doi.org/10.3390/e20020094
Ortiz-Martin L, Picazo-Sanchez P, Peris-Lopez P, Tapiador J. Heartbeats Do Not Make Good Pseudo-Random Number Generators: An Analysis of the Randomness of Inter-Pulse Intervals. Entropy. 2018; 20(2):94. https://doi.org/10.3390/e20020094
Chicago/Turabian StyleOrtiz-Martin, Lara, Pablo Picazo-Sanchez, Pedro Peris-Lopez, and Juan Tapiador. 2018. "Heartbeats Do Not Make Good Pseudo-Random Number Generators: An Analysis of the Randomness of Inter-Pulse Intervals" Entropy 20, no. 2: 94. https://doi.org/10.3390/e20020094
APA StyleOrtiz-Martin, L., Picazo-Sanchez, P., Peris-Lopez, P., & Tapiador, J. (2018). Heartbeats Do Not Make Good Pseudo-Random Number Generators: An Analysis of the Randomness of Inter-Pulse Intervals. Entropy, 20(2), 94. https://doi.org/10.3390/e20020094