A Measure of Information Available for Inference


Laboratory for Neural Computation and Adaptation, RIKEN Center for Brain Science, 2-1 Hirosawa, Wako, Saitama 351-0198, Japan
Entropy 2018, 20(7), 512; https://doi.org/10.3390/e20070512
Submission received: 11 May 2018
/
Revised: 5 July 2018
/
Accepted: 6 July 2018
/
Published: 7 July 2018
(This article belongs to the Special Issue Information Theory in Neuroscience)
Abstract
:The mutual information between the state of a neural network and the state of the external world represents the amount of information stored in the neural network that is associated with the external world. In contrast, the surprise of the sensory input indicates the unpredictability of the current input. In other words, this is a measure of inference ability, and an upper bound of the surprise is known as the variational free energy. According to the free-energy principle (FEP), a neural network continuously minimizes the free energy to perceive the external world. For the survival of animals, inference ability is considered to be more important than simply memorized information. In this study, the free energy is shown to represent the gap between the amount of information stored in the neural network and that available for inference. This concept involves both the FEP and the infomax principle, and will be a useful measure for quantifying the amount of information available for inference.
1. Introduction
Sensory perception comprises complex responses of the brain to sensory inputs. For example, the visual cortex can distinguish objects from their background [1], while the auditory cortex can recognize a certain sound in a noisy place with high sensitivity, a phenomenon known as the cocktail party effect [2,3,4,5,6,7]. The brain (i.e., a neural network) has acquired these perceptual abilities without supervision, which is referred to as unsupervised learning [8,9,10]. Unsupervised learning, or implicit learning, is defined as the learning that happens in the absence of a teacher or supervisor; it is achieved through adaptation to past environments, which is necessary for higher brain functions. An understanding of the physiological mechanisms that mediate unsupervised learning is fundamental to augmenting our knowledge of information processing in the brain.
One of the consequent benefits of unsupervised learning is inference, which is the action of guessing unknown matters based on known facts or certain observations, i.e., the process of drawing conclusions through reasoning and estimation. While inference is thought to be an act of the conscious mind in the ordinary sense of the word, it can occur even in the unconscious mind. Hermann von Helmholtz, a 19th-century physicist/physiologist, realized that perception often requires inference by the unconscious mind and coined the word unconscious inference [11]. According to Helmholtz, conscious inference and unconscious inference can be distinguished based on whether conscious knowledge is involved in the process. For example, when an astronomer computes the positions or distances of stars in space based on images taken at various times from different parts of the orbit of the Earth, he or she performs conscious inference because the process is “based on a conscious knowledge of the laws of optics”; by contrast, “in the ordinary acts of vision, this knowledge of optics is lacking” [11]. Thus, the latter process is performed by the unconscious mind. Unconscious inference is crucial for estimating the overall picture from partial observations.
In the field of theoretical and computational neuroscience, unconscious inference has been translated as the successive inference of the generative process of the external world (in terms of Bayesian inference) that animals perform in order to achieve perception. One hypothesis, the so-called internal model hypothesis [12,13,14,15,16,17,18,19], states that animals reconstruct a model of the external world in their brain through past experiences. This internal model helps animals infer hidden causes and predict future inputs automatically; in other words, this inference process happens unconsciously. This is also known as the predictive coding hypothesis [20,21]. In the past decade, a mathematical foundation for unconscious inference, called the free-energy principle (FEP), has been proposed [13,14,15,16,17], and is a candidate unified theory of higher brain functions. Briefly, this principle hypothesizes that parameters of the generative model are learned through unsupervised learning, while hidden variables are inferred in the subsequent inference step. The FEP provides a unified framework for higher brain functions including perceptual learning [14], reinforcement learning [22], motor learning [23,24], communication [25,26], emotion, mental disorders [27,28], and evolution. However, the difference between the FEP and a related theory, namely the information maximization (infomax) principle, which states that a neural network maximizes the amount of sensory information preserved in the network [29,30,31,32], is still not fully understood.
In this study, the relationship between the FEP and the infomax principle is investigated. As one of the most simple and important examples, the study focuses on blind source separation (BSS), which is the task of separating sensory inputs into hidden sources (or causes) [33,34,35,36]. BSS is shown to be a subset of the inference problem considered in the FEP, and variational free energy is demonstrated to represent the difference between the information stored in the neural network (which is the measure of the infomax principle [29]) and the information available for inferring current sensory inputs.
2. Methods
2.1. Definition of a System
Let us suppose as hidden sources that follow parameterized by a hyper-parameter set ; as sensory inputs; as neural outputs; as background noises that follow parameterized by ; as reconstruction errors; and , , and as nonlinear functions (see also Table 1). The generative process of the external world (or the environment) is described by a stochastic equation as:
Recognition and generative models of the neural network are defined as follows:
Figure 1 illustrates the structure of the system under consideration. For the generative model, the prior distribution of u is defined as with a hyper-parameter set and the likelihood function as , where indicates a statistical model and is a Gaussian distribution characterized by the mean and covariance . Moreover, suppose , , and as parameter sets for f, g, and h, respectively, as a hyper-parameter set for and , and as a hyper-parameter set for and . Here, hyper-parameters are defined as parameters that determine the shape of distributions (e.g., the covariance matrix). Note that W and V are assumed as synaptic strength matrices for feedforward and backward paths, respectively, while is assumed as a state of neuromodulators similarly to [13,14,15]. In this study, unless specifically mentioned, parameters and hyper-parameters refer to slowly changing variables, so that W, V, and can change their values. Equations (1)–(3) are transformed into probabilistic representations.
Note that is Dirac’s delta function and is a statistical model given a model structure m. For simplification, let be a set of hidden states of the external world and be a set of internal states of the neural network. By multiplying by Equation (4), by Equation (5), and by Equation (6), Equations (4)–(6) become
where is the prior distribution for and is a statistical model given a model structure m, which is determined by the shapes of and . The expression of is used instead of to emphasize the difference between and . While is the actual joint probability of (which corresponds to the posterior distribution), , i.e., the product of the likelihood function and the prior distribution, represents the generative model that the neural network expects to follow. Typically, elements of are supposed to be independent of each other, . For example, sparse priors about parameters are sometimes used to prevent the over-learning [37], while a generative model with sparse priors for outputs is known as a sparse coding model [38,39]. As shown later, the inference and learning are achieved by minimizing the difference between and . At that time, minimizing the difference between and acts as a constraint or a regularizer that prevents over-learning (see Section 2.3 for details).
2.2. Information Stored in the Neural Network
Information is defined as the negative log of probability [40]. When is the probability of given sensory inputs x, its information is given by [nat], where 1 nat = 1.4427 bits. When x takes continuous values, by coarse graining, is replaced with , where is the probability density of x and is the product of the finite spatial resolutions of x’s elements (). The expectation of over gives the Shannon entropy (or average information), which is defined by
where represents the expectation of · over . Note that the use of instead of is useful because this is non-negative ( takes a value between 0 and 1). This is a coarse binning of x and the spatial resolution takes a small but nonzero value so that the addition of constant has no effect except for sliding the offset value. If and only if is Dirac’s delta function (strictly, at one bin and 0 otherwise), is realized. For the system under consideration (Equations (7)–(9)), the information shared between the external world states and the internal states of the neural network is defined by mutual information [41]
Note that is the joint probability of and . Moreover and are their marginal distributions, respectively. This mutual information takes a non-negative value and quantifies how much and are related with each other. High mutual information indicates the internal states are informative for explaining the external world states, while zero mutual information means they are independent of each other.
However, the only information that the neural network can directly access is the sensory input. This is the case because the system under consideration can be described as a Bayesian network (see [42,43] for details on the Markov blanket). Hence, the entropy of the external world states under a fixed sensory input gives information that the neural network cannot infer. Moreover, there is no feedback control from the neural network to the external world in this setup. Thus, under a fixed x, and are conditionally independent of each other. From , we can obtain
Using Shannon entropy, becomes
where
is the conditional entropy of x given . Thus, maximization of is the same as maximization of for this system. As , , and are non-negative, has the range . Zero mutual information occurs if and only if x and are independent, while occurs if and only if x is fully explained by . In this manner, describes the information about the external world stored in the neural network. Note that this can be expressed using the Kullback–Leibler divergence (KLD) [44] as . The KLD takes a non-negative value and indicates the divergence between two distributions.
The infomax principle states that “the network connections develop in such a way as to maximize the amount of information that is preserved when signals are transformed at each processing stage, subject to certain constraints” [29], see also [30,31,32]. According to the infomax principle, the neural network is hypothesized to maximize to perceive the external world. However, does not fully explain the inference capability of a neural network. For example, if neural outputs just express the sensory input itself (), is easily achieved, but this does not mean that the neural network can predict or reconstruct input statistics. This is considered in the next section.
2.3. Free-Energy Principle
If one has a statistical model determined by model structure m, the information calculated based on m is given by the negative log likelihood , which is termed as the surprise (or the marginal likelihood) of the sensory input and expresses the unpredictability of the sensory input for the individual. The neural network is considered to minimize the surprise in the sensory input using the knowledge about the external world, to perceive the external world [13]. To infer if an event is likely to happen based on the past observation, a statistical (i.e., generative) model is necessary; otherwise it is difficult to generalize sensory inputs [45]. Note that the surprise is the marginal over the generative model; hence, the neural network can reduce the surprise by optimizing its internal states, while Shannon entropy of the input is determined by the environment. When the actual probability density and a generative model are given by and , respectively, the cross entropy is always larger than or equal to Shannon entropy because of the non-negativity of KLD. Hence, in this study, the input surprise is defined by
and its expectation over by
This definition of is to ensure is non-negative and if and only if . Since is determined by the environment and constant for the neural network, minimization of this is the same meaning as minimization of .
As the sensory input is generated by the external world generative process, consideration of the structure and dynamics placed in the background of the sensory input can provide accurate inference. According to the internal model hypothesis, animals develop the internal model in their brain to increase the accuracy and efficiency of inference [12,13,14,15,17,18,19]; thus, internal states of the neural network are hypothesized to imitate the hidden states of the external world . A problem is that is intractable for the neural network, because the integral of placed in the logarithm function. The FEP hypothesizes that the neural network calculates an upper bound of instead of the exact value as a proxy, which is more tractable [13] (because is fixed, the free energy is sometimes defined including or excluding this term). This upper bound is termed as variational free energy:
Note that expresses the belief about hidden states of the external world encoded by internal states of the neural network, termed as the recognition density. Due to the non-negativity of KLD, is guaranteed to be an upper bound of and holds if and only if . Furthermore, the expectation of over is defined by
where is the negative log likelihood and called the accuracy [15]. The second and third terms are the cross entropy of and the conditional entropy of given x, , where the difference between them is called the complexity [15]. The last term is a constant. indicates the difference between the actual probability and the generative model . Given the non-negativity of KLD, is always larger than or equal to non-negative value , and holds if and only if . The FEP hypothesized that is minimized by optimizing neural activities (u), synaptic strengths (W and V; i.e., synaptic plasticity), and activities of neuromodulators ().
The accuracy quantifies the amplitude of the reconstruction error. Minimization of the accuracy is the maximum likelihood estimation [10] and provides a solution that (at least locally) minimizes the reconstruction error. Whereas, minimization of the complexity makes closer to . As usually supposes the elements of are mutually independent, this acts as the maximization of the entropy under a constraint. Hence, this leads to the increase of the independence between internal states, which helps neurons to establish an efficient representation, as pointed out by Jaynes’ max entropy principle [46,47]. This is essential for BSS [33,34,35,36] because the optimal parameters that minimize the accuracy are not always uniquely determined. Due to this, the maximum likelihood estimation alone does not always identify the generative process behind the sensory inputs. As is the sum of costs for the maximum likelihood estimation and BSS, free-energy minimization is the rule to simultaneously minimize the reconstruction error and maximize the independence of the internal states. It is recognized that animals perform BSS [2,3,4,5,6,7]. Interestingly, even in vitro neural networks perform BSS, which is accompanied by significant reduction of free energy in accordance with the FEP and Jaynes’ max entropy principle [48].
2.4. Information Available for Inference
We now consider how free energy expectation relates to mutual information . According to unconscious inference and the internal model hypothesis, the aim of a neural network is to predict x, and for this purpose, it infers hidden states of the external world. While the neural network is conventionally hypothesized to express sufficient statistics of the hidden states of the external world [14], here it is hypothesized that internal states of the neural network are random variables and the probability distribution of them imitates the probability distribution of the hidden states of the external world. The neural network hence attempts to match the joint probability of the sensory inputs and the internal states with that of the sensory inputs and the hidden states of the external world. To do so, the neural network shifts the actual probability of internal states closer to those of the generative model that the neural network expects to follow (note that here, and ). This means that the shape or structure of is pre-defined, but the argument can still change. From this viewpoint, the difference between these two distributions is associated with the loss of information.
The amount of information available for inference can be calculated using the following three values related to information loss: (i) because is information of the sensory input and is information stored in the neural network, indicates the information loss in the recognition model (Figure 2); (ii) the difference between actual and desired (prior) distributions of internal states quantifies the information loss for inferring internal states using the prior (i.e., blind state separation). This is a common approach used in BSS methods [33,34,35,36]; and (iii) the difference between distributions of the actual reconstruction error and the reconstruction error under the given model quantifies the information loss for representing inputs using internal states. Therefore, by subtracting these three values from , a mutual-information-like measure representing the inference capability is obtained:
which is called utilizable information in this study. This utilizable information is defined by replacing in with , immediately yielding
Hence, represents the gap between the amount of information stored in the neural network and the amount that is available for inference, which is equivalent to the information loss in the generative model. Note that the sum of losses in the recognition and generative models is an upper bound of because of the non-negativity of (Figure 2). As is generally nonzero, does not usually reach zero, even when .
Furthermore, is transformed into
where
is the so-called reconstruction error, which is similar to the reconstruction error for principal component analysis (PCA) [49], while
is a generalization of Amari’s cost function for independent component analysis (ICA) [50].
PCA is one of the most popular dimensionality reduction methods. It is used to remove background noise and extract important features from sensory inputs [49,51]. In contrast, ICA is a BSS method used to decompose a mixture set of sensory inputs into independent hidden sources [34,36,50,52,53]. Theoreticians hypothesize that the PCA- and ICA-like learning underlies BSS in the brain [3]. This kind of extraction of the hidden representation is also an important problem in machine learning [54,55]. Equation (21) indicates that consists of PCA- and ICA-like parts, i.e., maximization of can perform both dimensionality reduction and BSS (Figure 2). Their relationship is discussed in the next section.
3. Comparison between the Free-Energy Principle and Related Theories
In this section, the FEP is compared with other theories. As described in the Methods, the aim of the infomax principle is to maximize mutual information (Equation (13)), while the aim of the FEP is to minimize free energy expectation (Equation (18)), while maximization of utilizable information (Equation (19)) means to do both of them simultaneously.
3.1. Infomax Principle
The generative process and the recognition and generative models defined in Equations (1)–(3) are assumed. For the sake of simplicity, let us suppose , and follow Dirac’s delta functions; then, the goal of the infomax principle is simplified to maximization of the mutual information between the sensory inputs x and the neural outputs u:
Here W, V, and are still variables, and W is optimized according to the learning while V and do not directly contribute to minimization of . For the sake of simplicity, let us suppose and a linear recognition model , with full-rank matrix W. As is usually assumed and u has an infinite range, monotonically increases as the variance of u increases. Thus, without any constraint is insufficient for deriving learning algorithms for PCA or ICA. To perform PCA and ICA based on the infomax principle, one may consider mutual information between the sensory inputs and the nonlinearly transformed neural outputs with an injective nonlinear function . This mutual information is given by:
3.2. Principal Component Analysis
Both the infomax principle and FEP yield a cost function of PCA. One of the most popular data compression methods, PCA is defined by minimization of the error when the inputs are reconstructed from the compressed representation (i.e., u in this study) [49]. It is known that PCA is derived from the infomax principle under a constraint on the internal states. Although maximization of the mutual information between x and u under the orthonormal constraint on W is usually considered [29], here let us consider another solution. Suppose , , and . From Equation (24), holds. Since the reconstruction error is given by for the linear system under consideration, we obtain . Thus, Equation (26) becomes:
The first term of Equation (27) is maximized if holds (i.e., if W is an orthogonal matrix; here, a coarse graining with a finite resolution of W is supposed). To maximize the second term, outputs u need to be involved in a subspace spanned by the first to the N-th major principal components of x. Therefore, maximization of Equation (27) performs PCA.
Further, PCA is also derived by minimization of (Equation (22)), under the assumption that the reconstruction error follows a Gaussian distribution . Here, is a scalar hyper-parameter that scales the precision of the reconstruction error. Hence, the cost function is given by:
When is fixed, the derivative of Equation (28) with respect to W gives the update rule for the least mean square error PCA [49]. As this cost function quantifies the magnitude of the reconstruction error, the algorithm that minimizes Equation (28) yields the low-dimensional compressed representation that minimizes the loss incurred in reconstructing the sensory inputs. This algorithm is the same as Oja’s subspace rule [51], up to an additional term that does not essentially change its behavior (see, e.g., [56] for a comparison between them). The here is also in the same form as the cost function for an auto-encoder [54].
Moreover, when the priors of , and are flat, and are constants with respect to u, W, V, and , because is supposed to be a delta function. Hence, the free energy expectation (Equation (18)) becomes , where is a constant with respect to u, W, and V. In this case, the optimization of W gives the minimum of because u and V are determined by W while is fixed. Thus, under this condition, is equivalent to the cost function of the least mean square error PCA.
3.3. Independent Component Analysis
It is known that ICA yields independent representation of input data by maximizing the independence between the outputs [52,53]. Thus, ICA reduces the redundancy and yields an efficient representation. When sensory inputs are generated from hidden sources, representing the hidden sources is usually the most efficient representation. Both the infomax principle and FEP yield a cost function of ICA. Let us suppose that sources independently follow an identical distribution . The infomax-based ICA is derived from Equation (26) [52,53]. If is defined to satisfy , negative mutual information becomes the KLD between the actual and prior distributions up to a constant term,
The here is known as Amari’s ICA cost function [50], which is a reduction of (23). While both and provide the same gradient descent rule, formulating requires nonlinearly transformed neural outputs . By contrast, straightforwardly represents that ICA is performed by minimization of the KLD between and . Indeed, if , the background noise is small, and the priors of , and are flat, we obtain . Therefore, ICA is a subset of the inference problem considered in the FEP, and the derivation from the FEP is simpler, although both the infomax principle and FEP yield the same ICA algorithm.
Furthermore, when , minimization of can perform both dimensionality reduction and BSS. When the priors of , and are flat, free energy expectation (Equation (18)) approximately becomes . Here, is fixed so that is a constant with respect to and V. Conditional entropy is ignored in the calculation because it is typically of a smaller order than when is not fine-tuned. As parameterizes the precision of the reconstruction error, it controls the ratio of PCA to ICA. Hence, as decreases to zero, the solution shifts from a PCA-like to an ICA-like solution.
Unlike the case with the scalar described above, if is fine-tuned by high-dimensional to minimize , is obtained. Under this condition, is equal to up to a constant term, and thereby, is obtained. This indicates that consists only of the ICA part. These comparisons suggest that low-dimensional is better for performing noise reduction than high-dimensional .
4. Simulation and Results
The difference between the infomax principle and the FEP is illustrated by a simple simulation using a linear generative process and a linear neural network (Figure 3). For simplification, it is assumed that u quickly converge to compared to the change of s (adiabatic approximation).
For the results shown in Figure 3, s denotes two-dimensional hidden sources following an identical Laplace distribution with zero mean and unit variance; x denotes four-dimensional sensory inputs; u denotes two-dimensional neural outputs; z denotes four-dimensional background Gaussian noises following ; denotes a -dimensional mixing matrix; W is a -dimensional synaptic strength matrix for the bottom-up path; and V is a -dimensional synaptic strength matrix for the top-down path. The priors of , and are supposed to be flat as in Section 3. Sensory inputs are determined by , while neural outputs are determined by . The reconstruction error is given by and used to calculate and . Horizontal and vertical axes in the figure are conditional entropy (Equation (14)) and free energy expectation (Equation (18)), respectively. Simulations were conducted 100 times with randomly selected and for each condition. For each simulation, random sample points were generated and probability distributions were calculated using the histogram method.
First, when W is randomly chosen and V is defined by , both and are scattered (black circles in Figure 3) because neural outputs represent random mixtures of sources and noises. Next, when W is optimized according to either Equation (27) or (28) under the constraint of , the neural outputs express the major principal components of the inputs, i.e., the network performs PCA (blue circles in Figure 3). This is the case when is minimized. In contrast, when , and are optimized according to the FEP (see Equation (18)), the neural outputs represent the independent components that match the prior source distribution; i.e., the network performs BSS or ICA while reducing the reconstruction error (red circles in Figure 3). For linear generative processes, the minimization of can reliably and accurately perform both dimensionality reduction and BSS because the outputs become independent of each other and match the prior belief if and only if the outputs represent true sources up to permutation and sign-flip. As the utilizable information consists of PCA and ICA cost functions (see Equation (21)), the maximization of leads to a solution that is a compromise between the solutions for the infomax principle and the FEP. Interestingly, the infomax optimization (i.e., PCA) provides a W that makes closer to zero than random states, which indicates that the infomax optimization contributes to the free energy minimization. Note that, for nonlinear systems, there are many different transformations that make the outputs independent of each other [57]. Hence, there is no guarantee that minimization of can identify the true sources of nonlinear generative models.
In summary, the aims of the FEP and infomax principle are similar to each other. In particular, when both the sources and noises follow Gaussian distributions, their aims become the same. Conversely, the optimal synaptic weights under the FEP are different from those under the infomax principle when sources follow non-Gaussian distributions. Under this condition, the maximization of the utilizable information leads to a compromise solution between those for the FEP and the infomax principle.
5. Discussion
In this study, the FEP is linked with the infomax principle, PCA, and ICA. It is more likely that the purpose of a neural network in a biological system is to minimize the surprise of sensory inputs to realize better inference rather than maximize the amount of stored information. For example, the visual input captured by a video camera contributes to the stored information, but this amount of information is not equal to the amount of information available for inference. The surprise expectation represents the difference between actual and inferred observations; the free energy expectation provides the difference between recognition and generative models. Utilizable information is introduced to quantify the inference and generalization capability of sensory inputs. Using this approach, the free energy expectation can be explained as the gap between the information stored in the neural network and that available for inference.
To perform ICA based on the infomax principle, one needs to tune the nonlinearity of the neural outputs to ensure the derivative of the nonlinear I/O function matches the prior distribution. Conversely, under the FEP, ICA is straightforwardly derived from the KLD between the actual probability distribution and the prior distribution of u. Especially, in the absence of background noise and prior knowledge of the parameters and hyper-parameters, the free energy expectation is equivalent to the surprise expectation as well as Amari’s ICA cost function, which indicates that ICA is a subproblem of the FEP.
The variational free energy quantifies the gap between the actual probability and the generative model and is a straightforward extension of the cost functions for BSS in the sense that it comprises the cost function for PCA [49] and ICA [50] in some special cases. Apart from that, there are studies that use the gap between the actual probability and the product of the marginal distributions to perform BSS [58] or to evaluate the information loss [59,60]. While the relationship between the product of the marginal distributions and the generative model is non-trivial, the comparison would lead to a deeper understanding about how the information of the external world is encoded by the neural network. In the subsequent work, we would like to see how the FEP and the infomax principle are related to those approaches.
The FEP is a rigorous and promising theory from theoretical and engineering viewpoints because various learning rules are derived from the FEP [14,15]. However, to be a physiologically plausible theory of the brain, the FEP needs to satisfy certain physiological requirements. There are two major requirements: first, physiological evidence that shows the existence of learning or self-organizing processes under the FEP is required. The model structure under the FEP is consistent with the structure of cortical microcircuits [19]. Moreover, in vitro neural networks performing BSS reduce free energy [48]. It is known that the spontaneous prior activity of a visual area enables it to learn the properties of natural pictures [61]. These results suggest the physiological plausibility of the FEP. Nevertheless, further experiments and consideration of information-theoretical optimization under physiological constraints [62] are required to prove the existence of the FEP in the biological brain. Second, the update rule must be a biologically plausible local learning rule, i.e., synaptic strengths must be changed by signals from connected cells or widespread liquid factors. While the synaptic update rule for a discrete system is local [17], the current rule for a continuous system [14] is a non-local rule. Recently developed biologically-plausible three-factor learning models in which Hebbian learning is mediated by a third modulatory factor [56,63,64,65] may help reveal the neuronal mechanism underlying unconscious inference. Therefore, it is necessary to investigate how actual neural networks infer the dynamics placed in the background of the sensory input and whether this is consistent with the FEP (see also [66] for the relationship between the FEP and spike-timing dependent plasticity [67,68]). This may help develop a biologically plausible learning algorithm through which an actual neural network might develop its internal model. Characterization of information from a physical viewpoint may also help understand how the brain physically embodies the information [69,70]. In the subsequent work, we would like to investigate this relationship.
In summary, this study investigated the differences between two types of information: information stored in the neural network and information available for inference. It was demonstrated that free energy represents the gap between these two types of information. This result clarifies the difference between the FEP and related theories and can be utilized for understanding unconscious inference from a theoretical viewpoint.
Acknowledgments
This work was supported by RIKEN Center for Brain Science.
Conflicts of Interest
The author declares no competing financial interests. The founding sponsor had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- DiCarlo, J.J.; Zoccolan, D.; Rust, N.C. How does the brain solve visual object recognition? Neuron 2012, 73, 415–434. [Google Scholar] [CrossRef] [PubMed]
- Bronkhorst, A.W. The cocktail party phenomenon: A review of research on speech intelligibility in multiple-talker conditions. Acta Acust. United Acust. 2000, 86, 117–128. [Google Scholar]
- Brown, G.D.; Yamada, S.; Sejnowski, T.J. Independent component analysis at the neural cocktail party. Trends Neurosci. 2001, 24, 54–63. [Google Scholar] [CrossRef]
- Haykin, S.; Chen, Z. The cocktail party problem. Neural Comput. 2005, 17, 1875–1902. [Google Scholar] [CrossRef] [PubMed]
- Narayan, R.; Best, V.; Ozmeral, E.; McClaine, E.; Dent, M.; Shinn-Cunningham, B.; Sen, K. Cortical interference effects in the cocktail party problem. Nat. Neurosci. 2007, 10, 1601–1607. [Google Scholar] [CrossRef] [PubMed]
- Mesgarani, N.; Chang, E.F. Selective cortical representation of attended speaker in multi-talker speech perception. Nature 2012, 485, 233–236. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Golumbic, E.M.Z.; Ding, N.; Bickel, S.; Lakatos, P.; Schevon, C.A.; McKhann, G.M.; Schroeder, C.E. Mechanisms underlying selective neuronal tracking of attended speech at a “cocktail party”. Neuron 2013, 77, 980–991. [Google Scholar]
- Dayan, P.; Abbott, L.F. Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems; MIT Press: London, UK, 2001. [Google Scholar]
- Gerstner, W.; Kistler, W. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Von Helmholtz, H. Concerning the perceptions in general. In Treatise on Physiological Optics, 3rd ed.; Dover Publications: New York, NY, USA, 1962. [Google Scholar]
- Dayan, P.; Hinton, G.E.; Neal, R.M.; Zemel, R.S. The helmholtz machine. Neural Comput. 1995, 7, 889–904. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.; Kilner, J.; Harrison, L. A free energy principle for the brain. J. Physiol. Paris 2006, 100, 70–87. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J. Hierarchical model in the brain. PLoS Comput. Biol. 2008, 4, e1000211. [Google Scholar] [CrossRef] [PubMed]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef] [PubMed]
- Friston, K. A free energy principle for biological systems. Entropy 2012, 14, 2100–2121. [Google Scholar]
- Friston, K.; FitzGerald, T.; Rigoli, F.; Schwartenbeck, P.; Pezzulo, G. Active inference: A process theory. Neural Comput. 2017, 29, 1–49. [Google Scholar] [CrossRef] [PubMed]
- George, D.; Hawkins, J. Towards a mathematical theory of cortical micro-circuits. PLoS Comput. Biol. 2009, 5, e1000532. [Google Scholar] [CrossRef] [PubMed]
- Bastos, A.M.; Usrey, W.M.; Adams, R.A.; Mangun, G.R.; Fries, P.; Friston, K.J. Canonical microcircuits for predictive coding. Neuron 2012, 76, 695–711. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rao, R.P.; Ballard, D.H. Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 1999, 2, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Friston, K. A theory of cortical responses. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2005, 360, 815–836. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friston, K.J.; Daunizeau, J.; Kiebel, S.J. Reinforcement learning or active inference? PLoS ONE 2009, 4, e6421. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kilner, J.M.; Friston, K.J.; Frith, C.D. Predictive coding: An account of the mirror neuron system. Cognit. Process. 2007, 8, 159–166. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.; Mattout, J.; Kilner, J. Action understanding and active inference. Biol. Cybern. 2011, 104, 137–160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friston, K.J.; Frith, C.D. Active inference, communication and hermeneutics. Cortex 2015, 68, 129–143. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.; Frith, C. A duet for one. Conscious. Cognit. 2015, 36, 390–405. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, P.C.; Frith, C.D. Perceiving is believing: A Bayesian approach to explaining the positive symptoms of schizophrenia. Nat. Rev. Neurosci. 2009, 10, 48–58. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J.; Stephan, K.E.; Montague, R.; Dolan, R.J. Computational psychiatry: The brain as a phantastic organ. Lancet Psychiatry 2014, 1, 148–158. [Google Scholar] [CrossRef]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Linsker, R. Local synaptic learning rules suffice to maximize mutual information in a linear network. Neural Comput. 1992, 4, 691–702. [Google Scholar] [CrossRef]
- Lee, T.W.; Girolami, M.; Bell, A.J.; Sejnowski, T.J. A unifying information-theoretic framework for independent component analysis. Comput. Math. Appl. 2000, 39, 1–21. [Google Scholar] [CrossRef]
- Simoncelli, E.P.; Olshausen, B.A. Natural image statistics and neural representation. Ann. Rev. Neurosci. 2001, 24, 1193–1216. [Google Scholar] [CrossRef] [PubMed]
- Belouchrani, A.; Abed-Meraim, K.; Cardoso, J.F.; Moulines, E. A blind source separation technique using second-order statistics. Signal Process. IEEE Trans. 1997, 45, 434–444. [Google Scholar] [CrossRef] [Green Version]
- Choi, S.; Cichocki, A.; Park, H.M.; Lee, S.Y. Blind source separation and independent component analysis: A review. Neural Inf. Process. Lett. Rev. 2005, 6, 1–57. [Google Scholar]
- Cichocki, A.; Zdunek, R.; Phan, A.H.; Amari, S.I. Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-Way Data Analysis and Blind Source Separation; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Comon, P.; Jutten, C. Handbook of Blind Source Separation: Independent Component Analysis and Applications; Academic Press: Oxford, UK, 2010. [Google Scholar]
- Palmer, J.; Rao, B.D.; Wipf, D.P. Perspectives on sparse Bayesian learning. Adv. Neural Inf. Proc. Syst. 2004, 27, 249–256. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1949. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 1991. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: San Fransisco, CA, USA, 1988. [Google Scholar]
- Friston, K.J. Life as we know it. J. R. Soc. Interface 2013, 10, 20130475. [Google Scholar] [CrossRef] [PubMed]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Arora, S.; Risteski, A. Provable benefits of representation learning. arXiv, 2017; arXiv:1706.04601. [Google Scholar]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. II. Phys. Rev. 1957, 108, 171–190. [Google Scholar] [CrossRef]
- Isomura, T.; Kotani, K.; Jimbo, Y. Cultured Cortical Neurons Can Perform Blind Source Separation According to the Free-Energy Principle. PLoS Comput. Biol. 2015, 11, e1004643. [Google Scholar] [CrossRef] [PubMed]
- Xu, L. Least mean square error reconstruction principle for self-organizing neural-nets. Neural Netw. 1993, 6, 627–648. [Google Scholar] [CrossRef]
- Amari, S.I.; Cichocki, A.; Yang, H.H. A new learning algorithm for blind signal separation. Adv. Neural Inf. Proc. Syst. 1996, 8, 757–763. [Google Scholar]
- Oja, E. Neural networks, principal components, and subspaces. Int. J. Neural Syst. 1989, 1, 61–68. [Google Scholar] [CrossRef]
- Bell, A.J.; Sejnowski, T.J. An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 1995, 7, 1129–1159. [Google Scholar] [CrossRef] [PubMed]
- Bell, A.J.; Sejnowski, T.J. The “independent components” of natural scenes are edge filters. Vis. Res. 1997, 37, 3327–3338. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Isomura, T.; Toyoizumi, T. Error-gated Hebbian rule: A local learning rule for principal and independent component analysis. Sci. Rep. 2018, 8, 1835. [Google Scholar] [CrossRef] [PubMed]
- Hyvärinen, A.; Pajunen, P. Nonlinear independent component analysis: Existence and uniqueness results. Neural Netw. 1999, 12, 429–439. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.H.; Amari, S.I. Adaptive online learning algorithms for blind separation: Maximum entropy and minimum mutual information. Neural Comput. 1997, 9, 1457–1482. [Google Scholar] [CrossRef]
- Latham, P.E.; Nirenberg, S. Synergy, redundancy, and independence in population codes, revisited. J. Neurosci. 2005, 25, 5195–5206. [Google Scholar] [CrossRef] [PubMed]
- Amari, S.I.; Nakahara, H. Correlation and independence in the neural code. Neural Comput. 2006, 18, 1259–1267. [Google Scholar] [CrossRef] [PubMed]
- Berkes, P.; Orbán, G.; Lengyel, M.; Fiser, J. Spontaneous cortical activity reveals hallmarks of an optimal internal model of the environment. Science 2011, 331, 83–87. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, B.; Stemmler, M.B.; Friston, K.J. Information and efficiency in the nervous system—A synthesis. PLoS Comput. Biol. 2013, 9, e1003157. [Google Scholar] [CrossRef] [PubMed]
- Frémaux, N.; Gerstner, W. Neuromodulated Spike-Timing-Dependent Plasticity, and Theory of Three-Factor Learning Rules. Front. Neural Circuits 2016, 9. [Google Scholar] [CrossRef] [PubMed]
- Isomura, T.; Toyoizumi, T. A Local Learning Rule for Independent Component Analysis. Sci. Rep. 2016, 6, 28073. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuśmierz, A.; Isomura, T.; Toyoizumi, T. Learning with three factors: Modulating Hebbian plasticity with errors. Curr. Opin. Neurobiol. 2017, 46, 170–177. [Google Scholar]
- Isomura, T.; Sakai, K.; Kotani, K.; Jimbo, Y. Linking neuromodulated spike-timing dependent plasticity with the free-energy principle. Neural Comput. 2016, 28, 1859–1888. [Google Scholar] [CrossRef] [PubMed]
- Markram, H.; Lübke, J.; Frotscher, M.; Sakmann, B. Regulation of synaptic efficacy by coincidence of postsynaptic APs and EPSPs. Science 1997, 275, 213–215. [Google Scholar] [CrossRef] [PubMed]
- Bi, G.Q.; Poo, M.M. Synaptic modifications in cultured hippocampal neurons: Dependence on spike timing, synaptic strength, and postsynaptic cell type. J. Neurosci. 1998, 18, 10464–10472. [Google Scholar] [CrossRef] [PubMed]
- Karnani, M.; Pääkkönen, K.; Annila, A. The physical character of information. Proc. R. Soc. A Math. Phys. Eng. Sci. 2009, 465, 2155–2175. [Google Scholar] [CrossRef] [Green Version]
- Annila, A. On the character of consciousness. Front. Syst. Neurosci. 2016, 10, 27. [Google Scholar] [CrossRef] [PubMed]
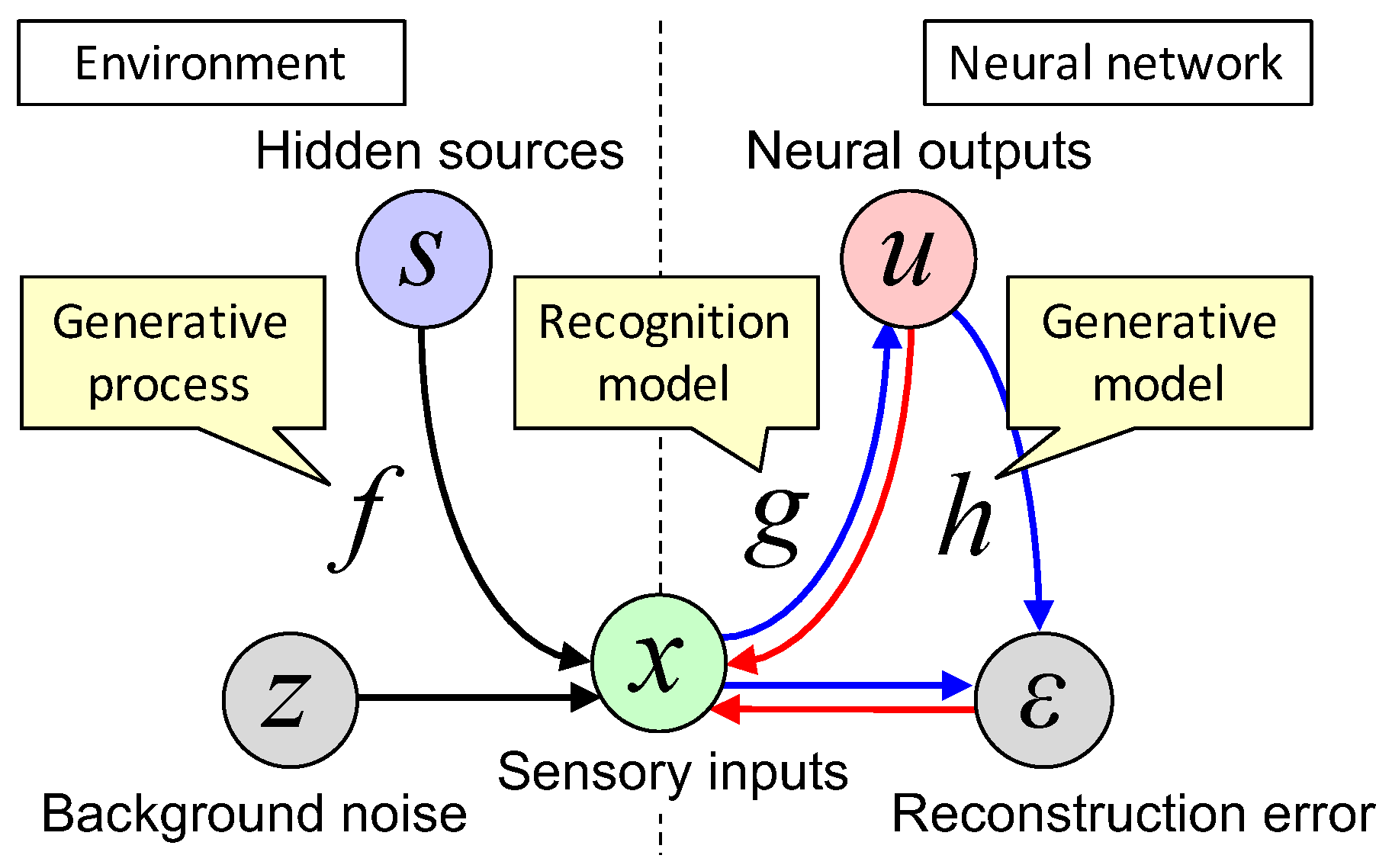
Figure 1.
Schematic images of a generative process of the environment (left) and recognition and generative models of the neural network (right). Note that the neural network can access only the states in the right side of the dashed line, including x (see text in Section 2.2). Black arrows are causal relationships in the external world. Blue arrows are information flows of the neural network (i.e., actual causal relationships in the neural network), while red arrows are hypothesized causal relationships (to imitate the external world) when the generative model is considered. See main text and Table 1 for meanings of variables and functions.
Figure 1.
Schematic images of a generative process of the environment (left) and recognition and generative models of the neural network (right). Note that the neural network can access only the states in the right side of the dashed line, including x (see text in Section 2.2). Black arrows are causal relationships in the external world. Blue arrows are information flows of the neural network (i.e., actual causal relationships in the neural network), while red arrows are hypothesized causal relationships (to imitate the external world) when the generative model is considered. See main text and Table 1 for meanings of variables and functions.

Figure 2.
Relationship between information measures. The mutual information between the inputs and internal states of the neural network () is less than or equal to the Shannon entropy of the inputs () because of the information loss in the recognition model. The utilizable information () is less than or equal to the mutual information, and the gap between them gives the expectation of the variational free energy (), which quantifies the loss in the generative model. The sum of the principal component analysis (PCA) and independent component analysis (ICA) costs () is equal to the gap between the Shannon entropy and the utilizable information, expressing the sum of losses in the recognition and generative models.
Figure 2.
Relationship between information measures. The mutual information between the inputs and internal states of the neural network () is less than or equal to the Shannon entropy of the inputs () because of the information loss in the recognition model. The utilizable information () is less than or equal to the mutual information, and the gap between them gives the expectation of the variational free energy (), which quantifies the loss in the generative model. The sum of the principal component analysis (PCA) and independent component analysis (ICA) costs () is equal to the gap between the Shannon entropy and the utilizable information, expressing the sum of losses in the recognition and generative models.

Figure 3.
Difference between the infomax principle and free-energy principle (FEP) when sources follow a non-Gaussian distribution. Black, blue, and red circles indicate the results when W is a random matrix, optimized for the infomax principle (i.e., PCA), and optimized for the FEP, respectively.
Figure 3.
Difference between the infomax principle and free-energy principle (FEP) when sources follow a non-Gaussian distribution. Black, blue, and red circles indicate the results when W is a random matrix, optimized for the infomax principle (i.e., PCA), and optimized for the FEP, respectively.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Glossary of expressions.
| Expression | Description |
|---|---|
| Generative process | A set of stochastic equations that generate the external world dynamics |
| Recognition model | A model in the neural network that imitates the inverse of the generative process |
| Generative model | A model in the neural network that imitates the generative process |
| Hidden sources | |
| Sensory inputs | |
| A set of parameters | |
| A set of hyper-parameters | |
| A set of hidden states of the external world | |
| Neural outputs | |
| Synaptic strength matrices | |
| State of neuromodulators | |
| A set of the internal states of the neural network | |
| Background noises | |
| Reconstruction errors | |
| The actual probability density of x | |
| Actual probability densities (posterior densities) | |
| Prior densities | |
| Likelihood function | |
| Statistical models | |
| Finite spatial resolution of x, | |
| Expectation of · over | |
| Shannon entropy of | |
| Cross entropy of over | |
| KLD between and | |
| Mutual information between x and | |
| Surprise | |
| Surprise expectation | |
| Free energy | |
| Free energy expectation | |
| Utilizable information between x and |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Isomura, T. A Measure of Information Available for Inference. Entropy 2018, 20, 512. https://doi.org/10.3390/e20070512
AMA Style
Isomura T. A Measure of Information Available for Inference. Entropy. 2018; 20(7):512. https://doi.org/10.3390/e20070512
Chicago/Turabian StyleIsomura, Takuya. 2018. "A Measure of Information Available for Inference" Entropy 20, no. 7: 512. https://doi.org/10.3390/e20070512
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.