4.1. Formula Derivation
By employing PHD to approximate Equation (
6), we can estimate
which depends on RFS based modeling. According to the relationship between the PHD and the RFS based PDF detailed in [
22], Equation (
6) can be rewritten as the following equation
The advantage of Equation (27) is that the posterior PHD is defined on the standard vector based state space , so the calculation of the RFS based posterior PDF is quite easy.
The observed data likelihood
of the accumulated sequence of observation dataset which features in Equations (
5) and (27) can be calculated by using the following equation:
Now, the problem is how to calculate the measurement likelihood
using the results of PHD filter. The equations and SMC based implementation of the PHD filter for recursively estimating
have been introduced in
Section 3.1 and
Section 3.2. The measurement likelihood
, which is defined as in [
21], can be calculated as follows
From Equations (28) and (29), we can find the tight relationship between the parameter estimation problem and the state estimation problem. The key challenge is how to deal with the unknown system states. The PHD filter implemented by the SMC method is used to solve this problem. Thus,
can be obtained by using PHD filer, and can be calculated as follows:
where
is a proportionality constant.
As described in
Section 3.2, we can use the weighted particle system
to represent the posterior PHD
. To estimate the posterior
, we should firstly obtain the approximation of
given by Equation (30) by running the PHD filter. According to Equation (22), the predicted PHD
is approximated by the following particles
Substituting Equation (31) into Equation (30), we can obtain the following result:
Therefore, according to Equation (28),
can be calculated as follows:
4.2. Simulated Tempering Based Importance Sampling
We have obtained the estimate of
by running the PHD filter, the following step is to compute
according to Equation (
5). Since the analytic solution for
is difficult to compute, we solve Equation (
5) by using the simulated tempering based importance sampling method.
Since we are interested in the values of the unknown parameters, we can compute them as the posterior mean by using the following equation:
To avoid doing integral calculus, we propose to approximate Equation (34) via importance sampling. Here, we assume the sample size is
M, we draw a sample
from the importance density
. Thus, the integral in Equation (34) can be approximated by the following equation:
The sample weights
are defined as:
According to Equation (36), we find that can be omitted, since it cancels out if we normalize the weights. Thus, for convenience, we assume . The determination of sample weight depends on the selection of importance density . A good selection of importance density should be proportional to the posterior PDF and produce sample weights with a small variance.
Since we can only obtain an estimation of
after running the SMC based PHD filter, the selection of the importance density
is quite important. If the sample size
, the approximation Equation (35) will be quite accurate for many importance densities. However, if
M is finite, the approximation accuracy will depend greatly on the specific selection of importance density
. As shown in Equation (36), the accuracy of importance sampling by using the prior information is not satisfactory for any possible sample size, since the posterior PDF
which is proportional to
is unknown. We propose a simulated tempering [
2] based importance sampling method to obtain a better importance density
which is similar to the posterior PDF
.
Here, we use
S to represent the maximum stages number and
,
, represent the proposal density for the
s-th stage. The main idea of tempering is to sequentially generate a serious of importance densities from which we can sequentially draw samples. The first importance density usually resembles the prior density
, and the final importance density is the posterior PDF
. The sequential importance density in the sequence should have very small difference. We obtain
at the final stage
S . A sequence of importance densities that begin with the prior density and increasingly resemble the posterior PDF can be generated by the following equation, for
where
with
and at the final stage we have
. Thus,
increases with the growth of
s and its upper bound is 1.
During the tempering process, we should sequentially draw samples from importance densities . At the first stage (), we draw the sample from the prior density . At the s-th stage, we use the sample drawn from at the th stage to obtain a sample from . Firstly, we need to compute weights from particles in by using the equation for . Then, we normalize the weights.
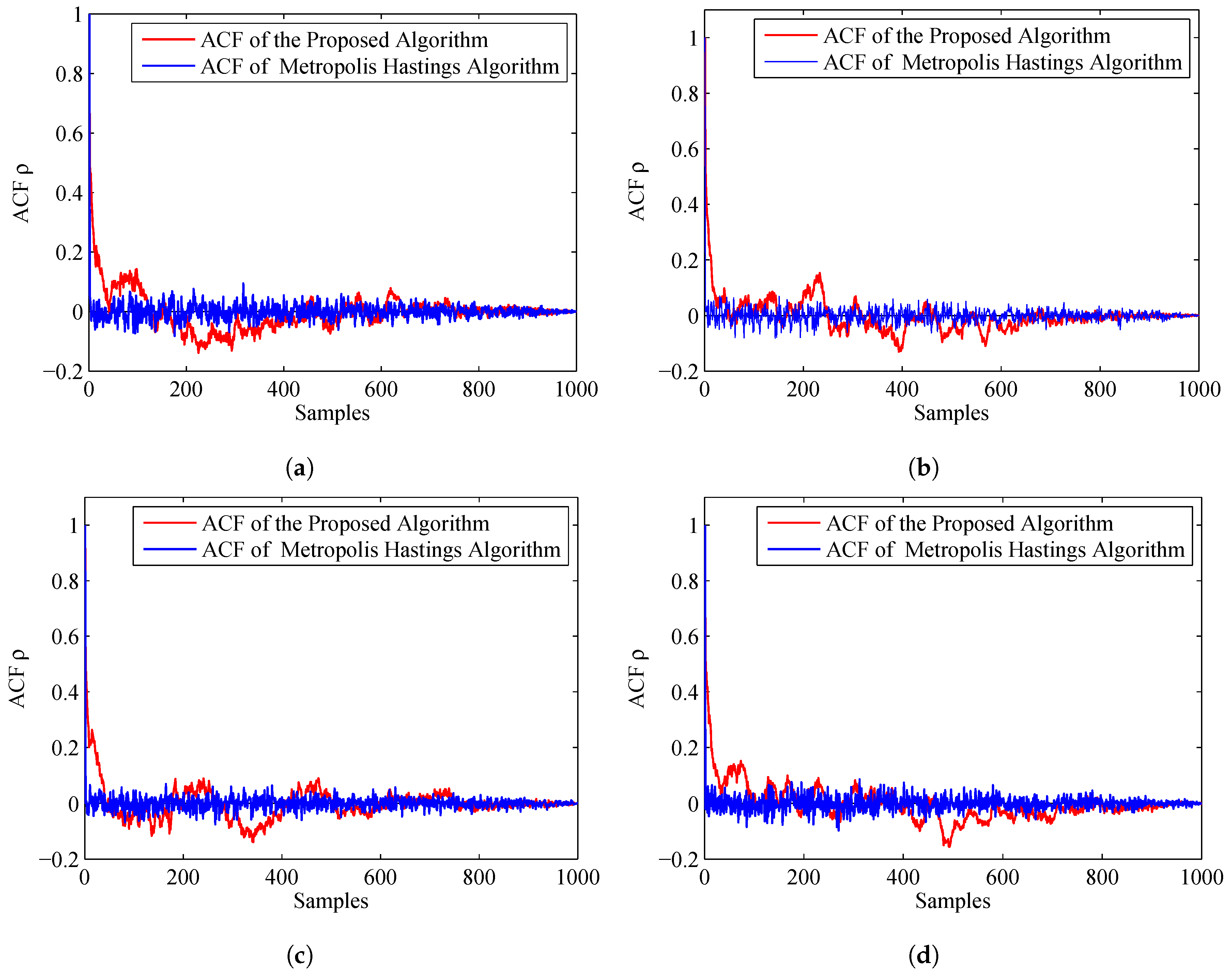
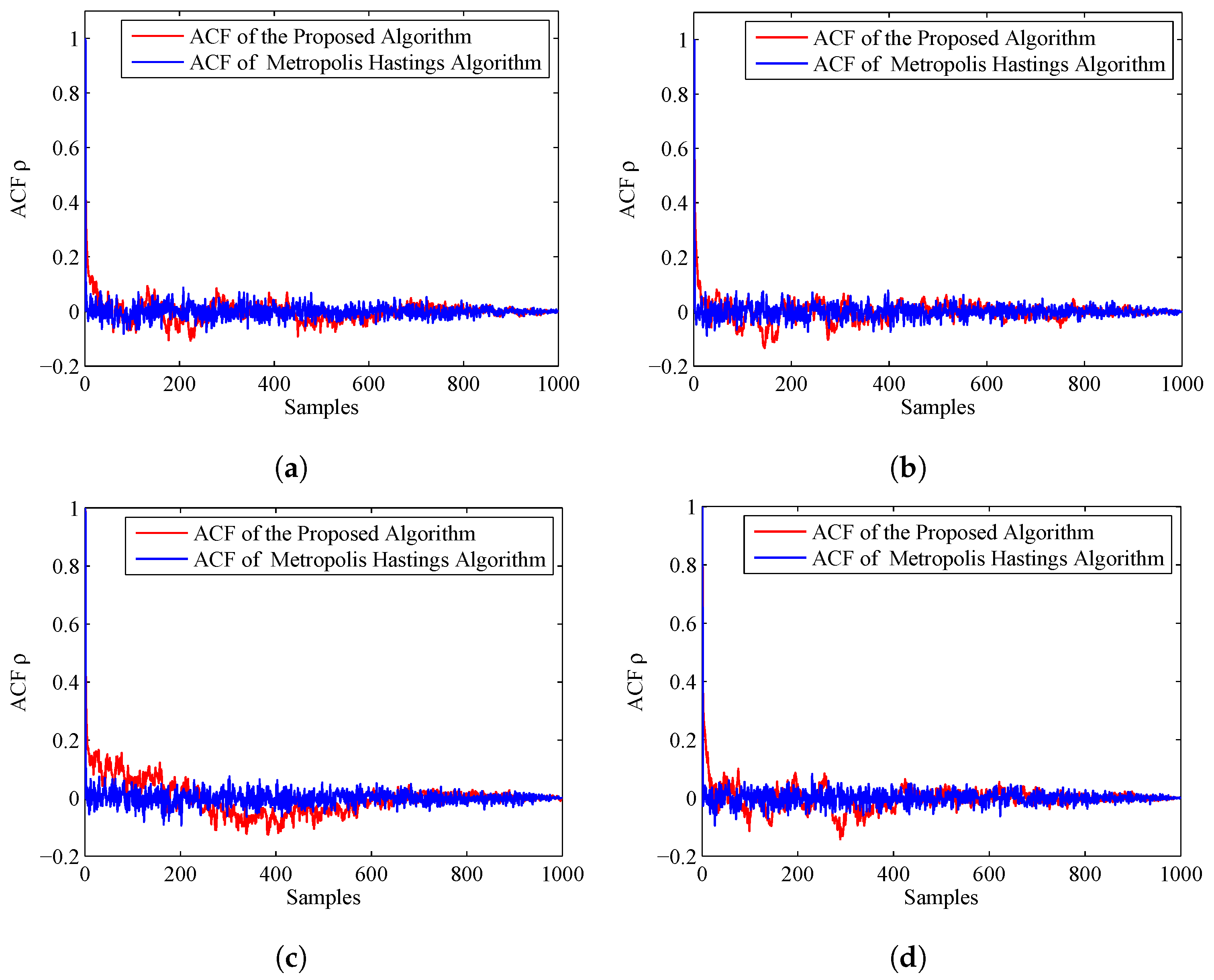
Resampling is quite necessary for tempering, because it can help to remove the particles with lower weights from the sample and improve the diversity of the remaining particles. Thus, the second step is resampling. Resampling means selecting M indices with probability .
After resampling, the particles
will almost surely have repeated elements, because the weights
will be the most possible to be uneven. Here, the MCMC (Markov Chain Monte Carlo) [
34] is employed to the sample
that have been resampled. MCMC can help to remove the duplicate particles, thus the diversity of the sample will be increased. For each particle of
, a new sample particle can be drawn as follows
where
represents the importance density for the
s-th stage. The decision of accepting or rejecting
with certain probability is made by using the Metropolis–Hastings algorithm. If the MCMC move is accepted,
. If the move is rejected,
. Thus, we can obtain a new sample
. The probability of accepting the MCMC move is determined by the following equation
To diversify the sample, the importance density
should generate the candidate particles over a fairly large area of the parameter space. We should ensure that
is still within the area where the likelihood is high. We can select the importance density by the following method as introduced in [
35]:
where
denotes a Gaussian distribution;
and
are respectively the mean and covariance matrix of the weighted particles
.
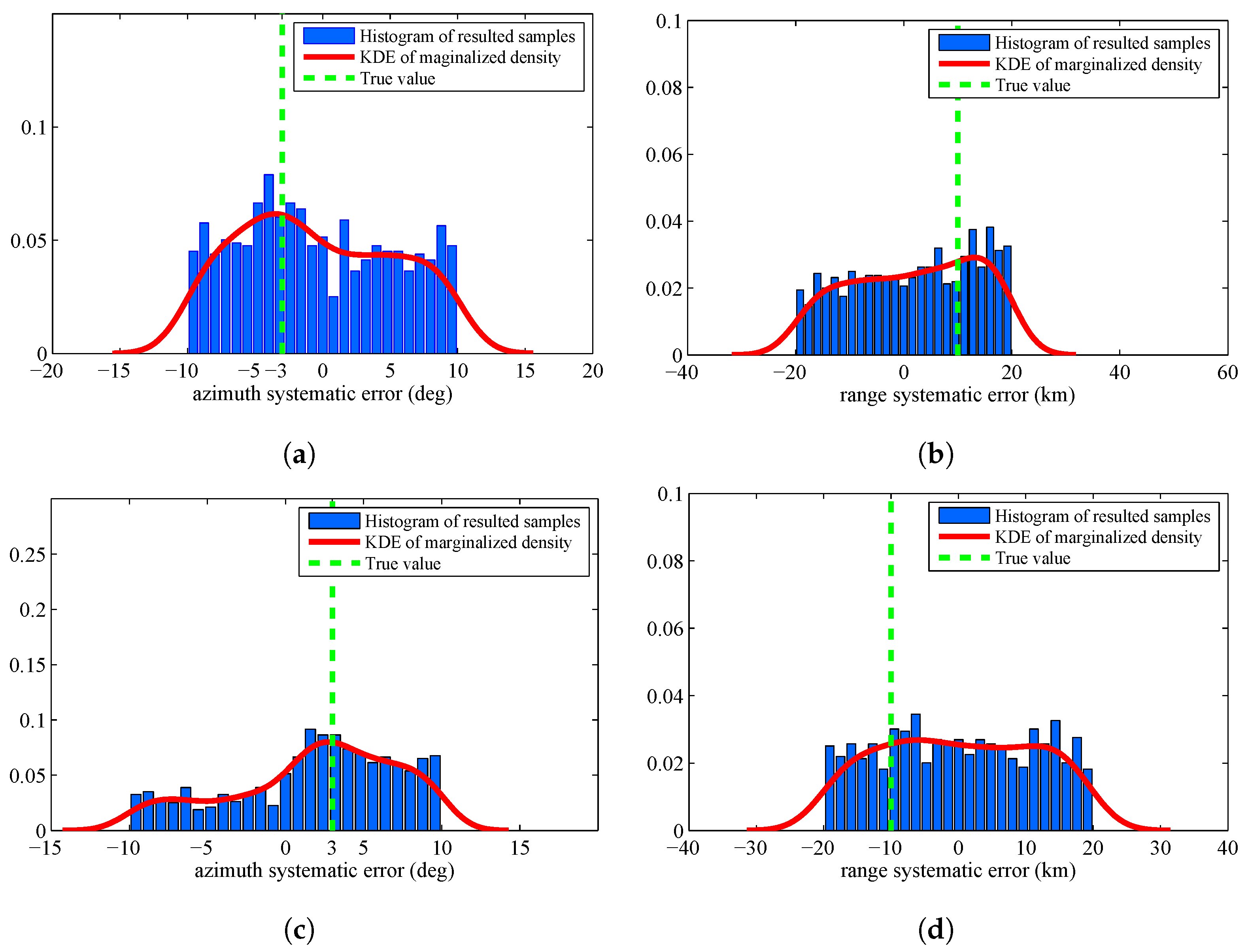
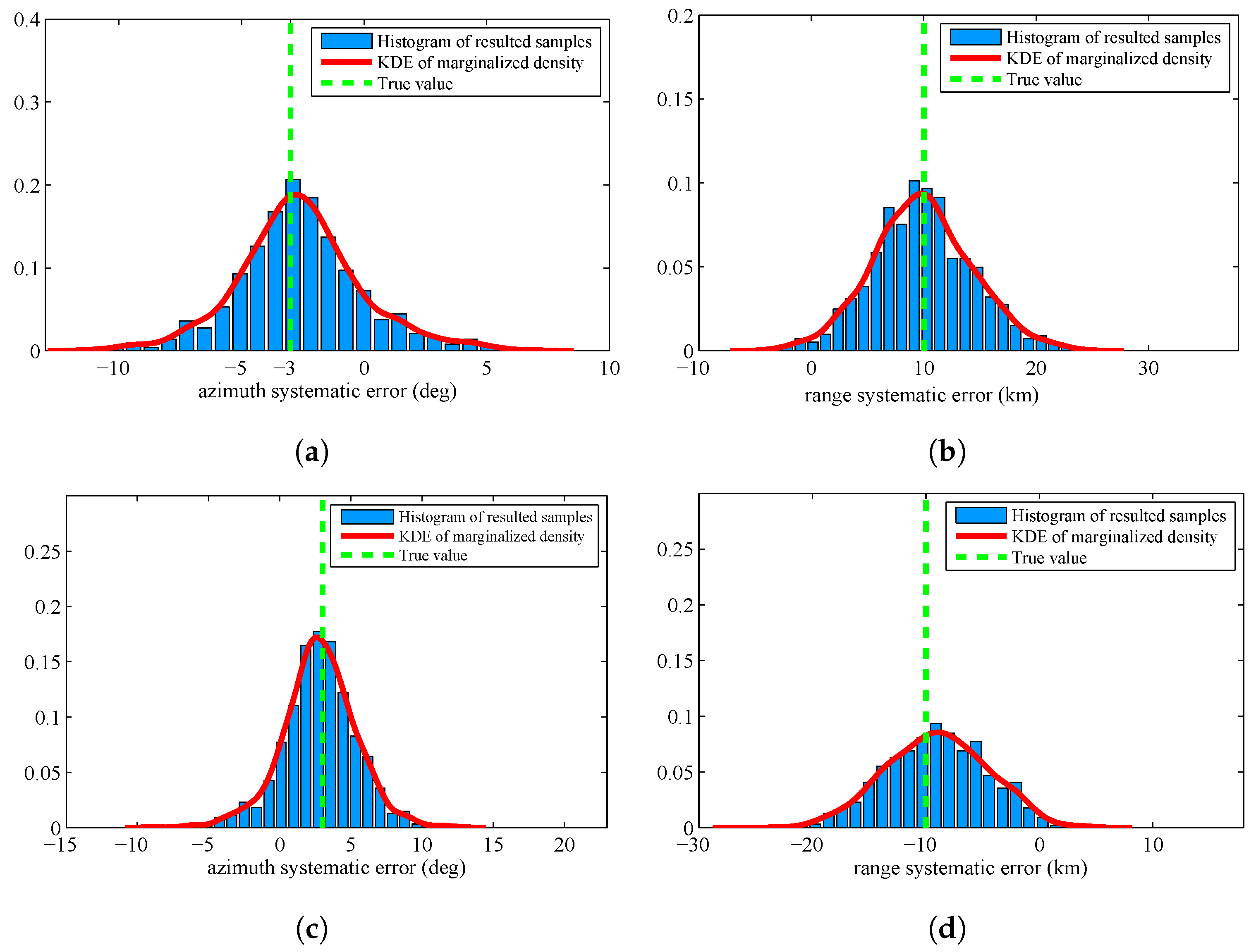
The pseudo-code of the proposed parameter estimation algorithm is shown in Algorithm 1. Here, and are parameters that should be defined by users.
| Algorithm 1: Random Finite Set based Parameter Estimation Algorithm |
![Entropy 20 00569 i001]() |



















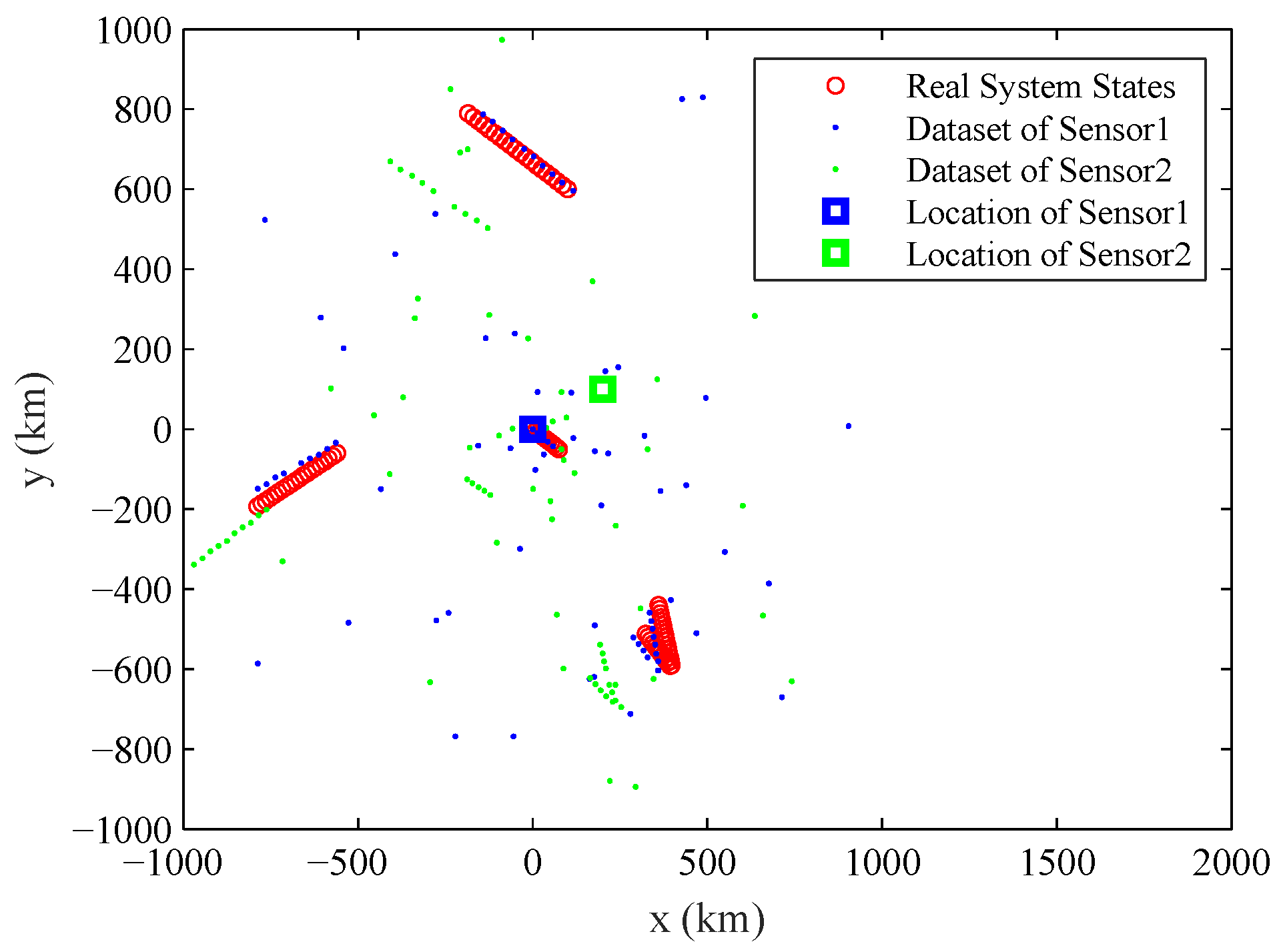{kind=link}
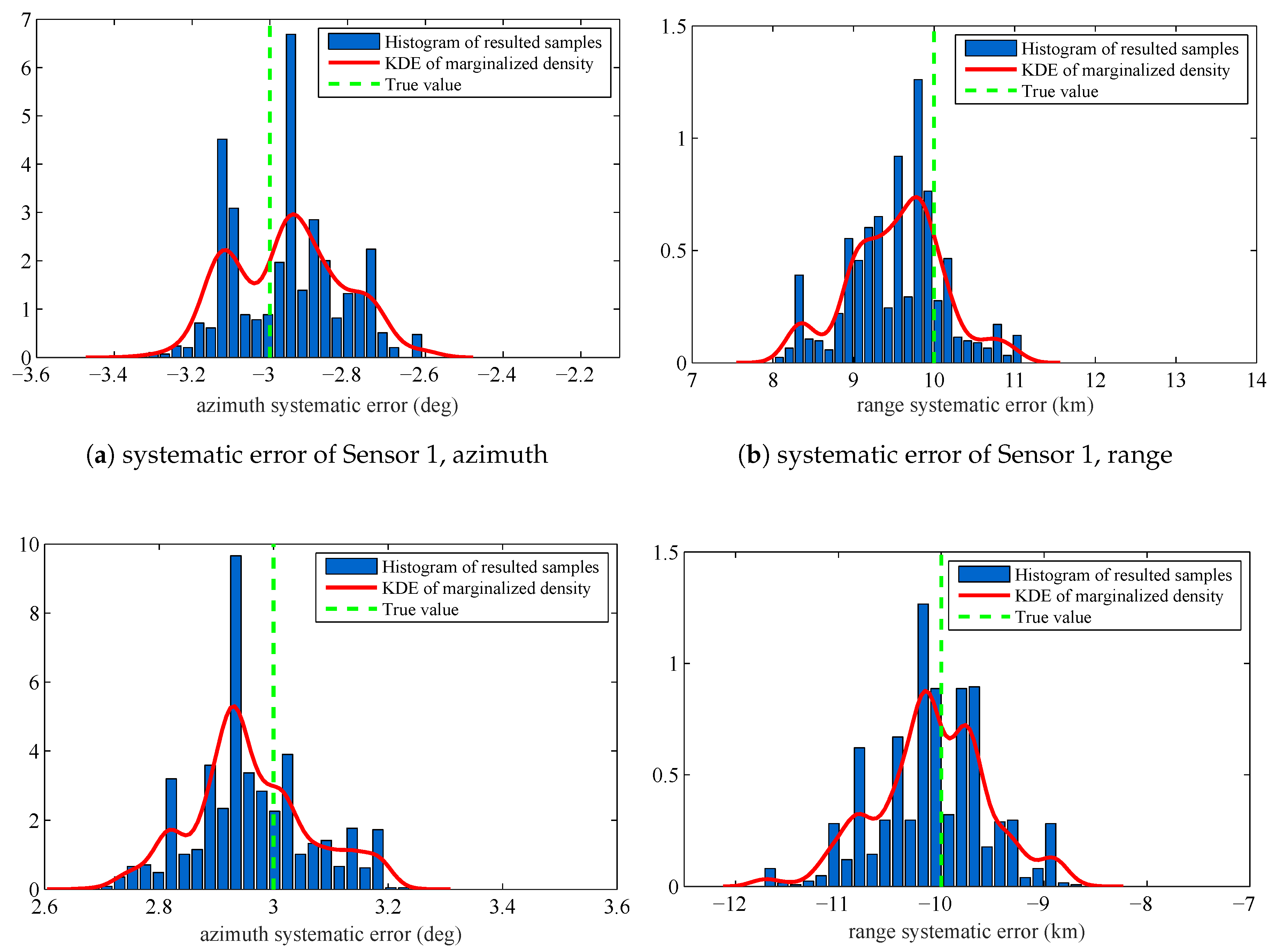{kind=link}
{kind=link}
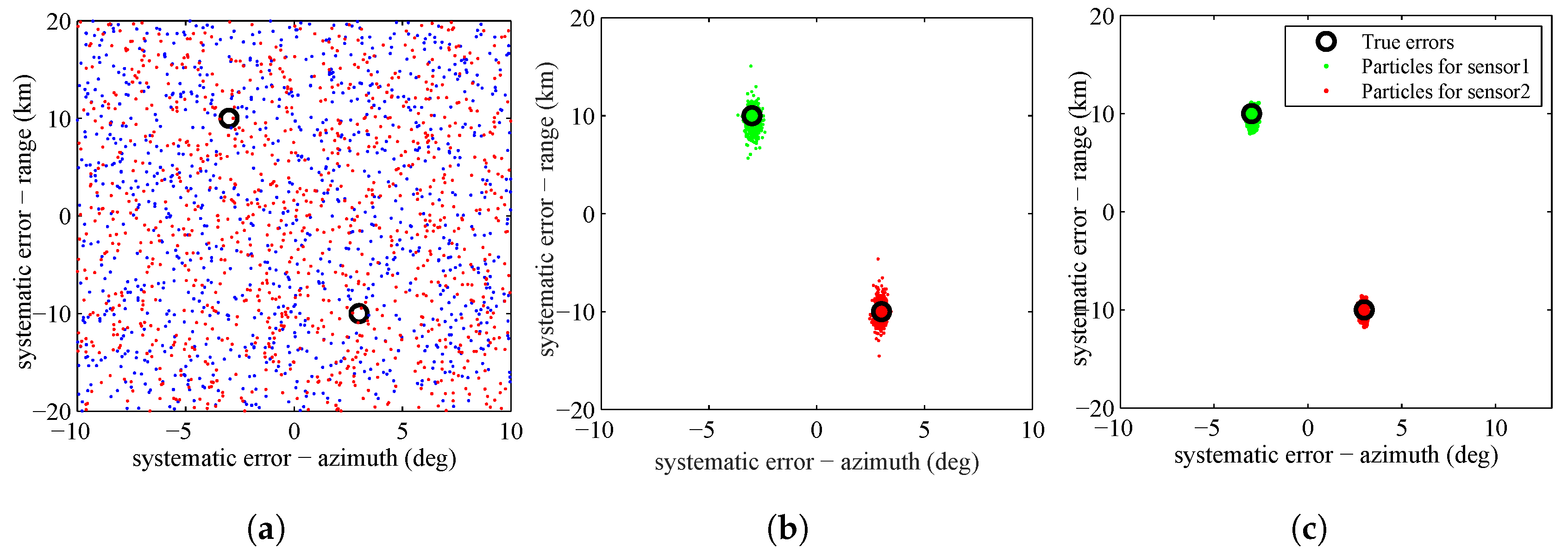{kind=link}
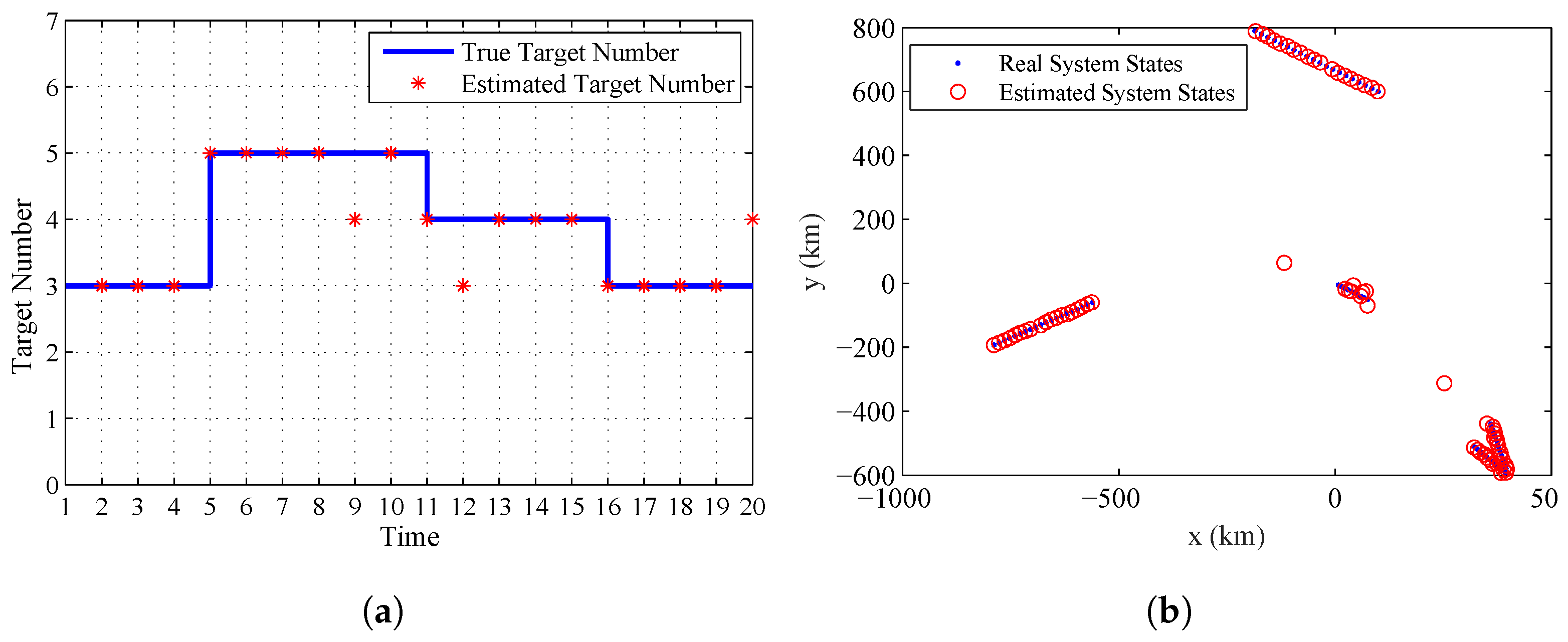{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
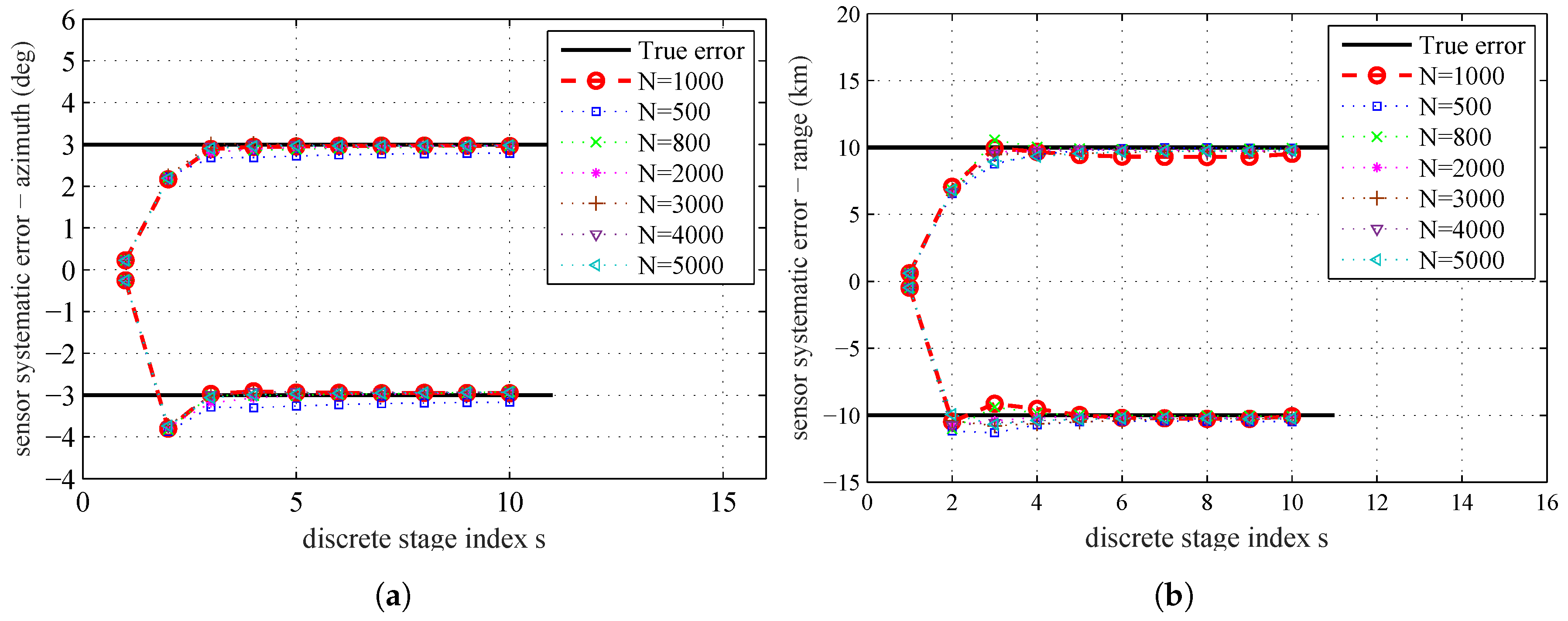{kind=link}
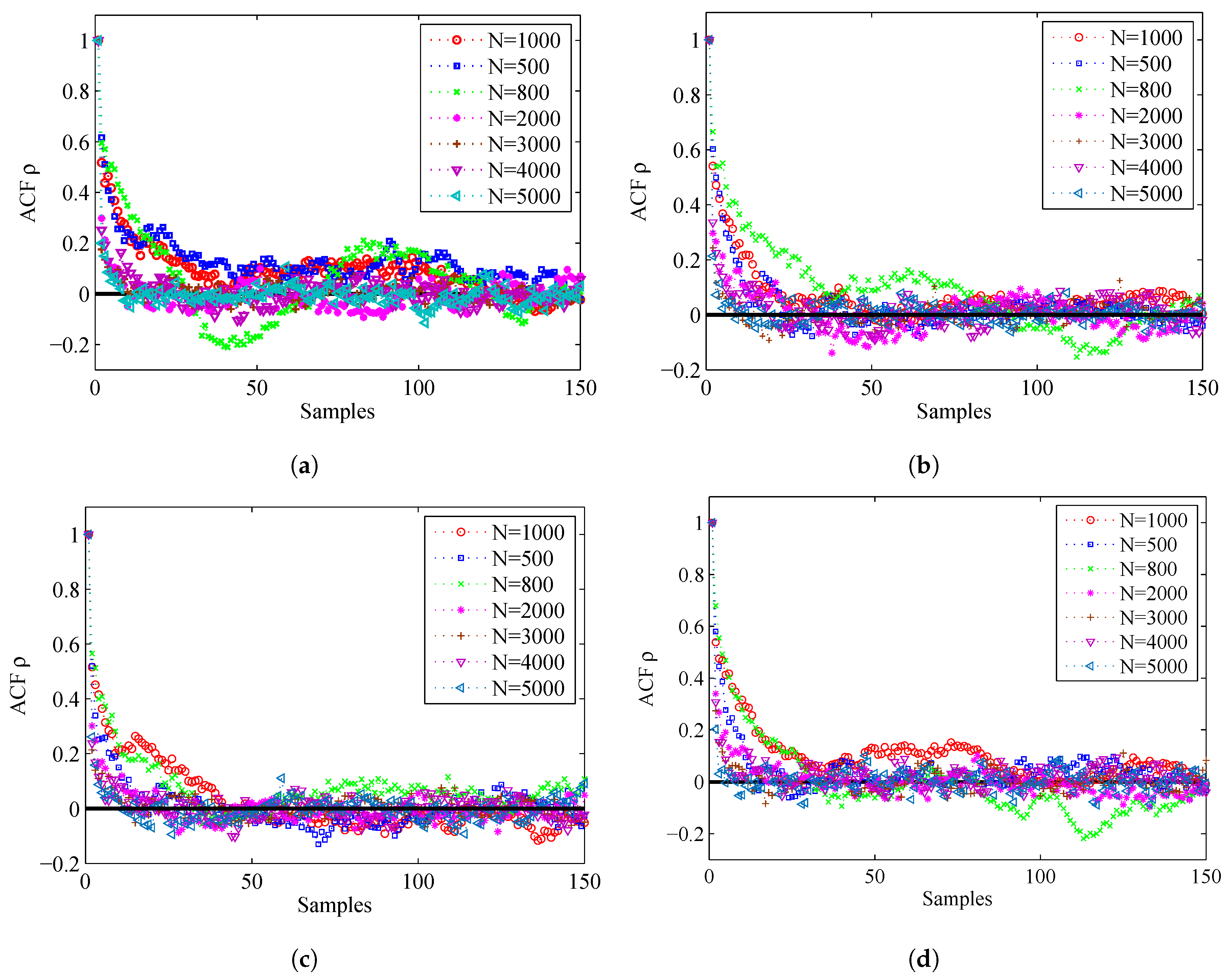{kind=link}
{kind=link}
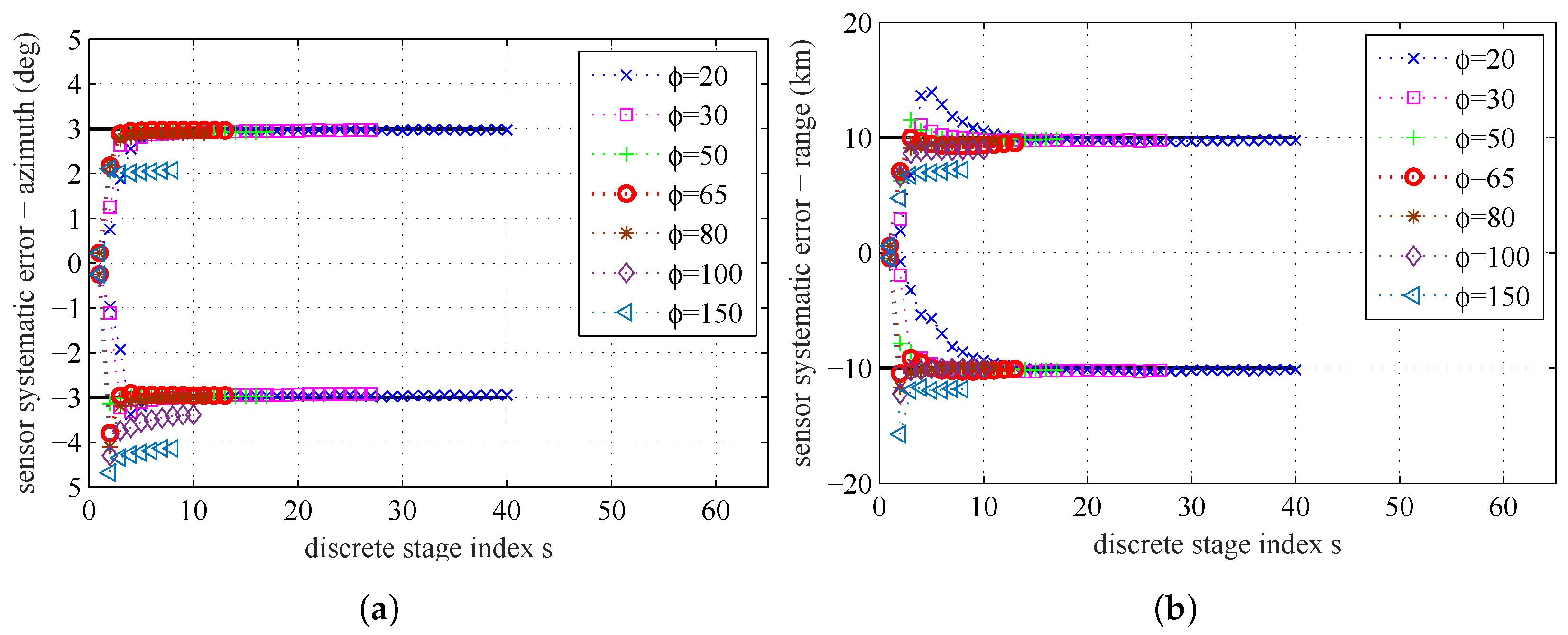{kind=link}
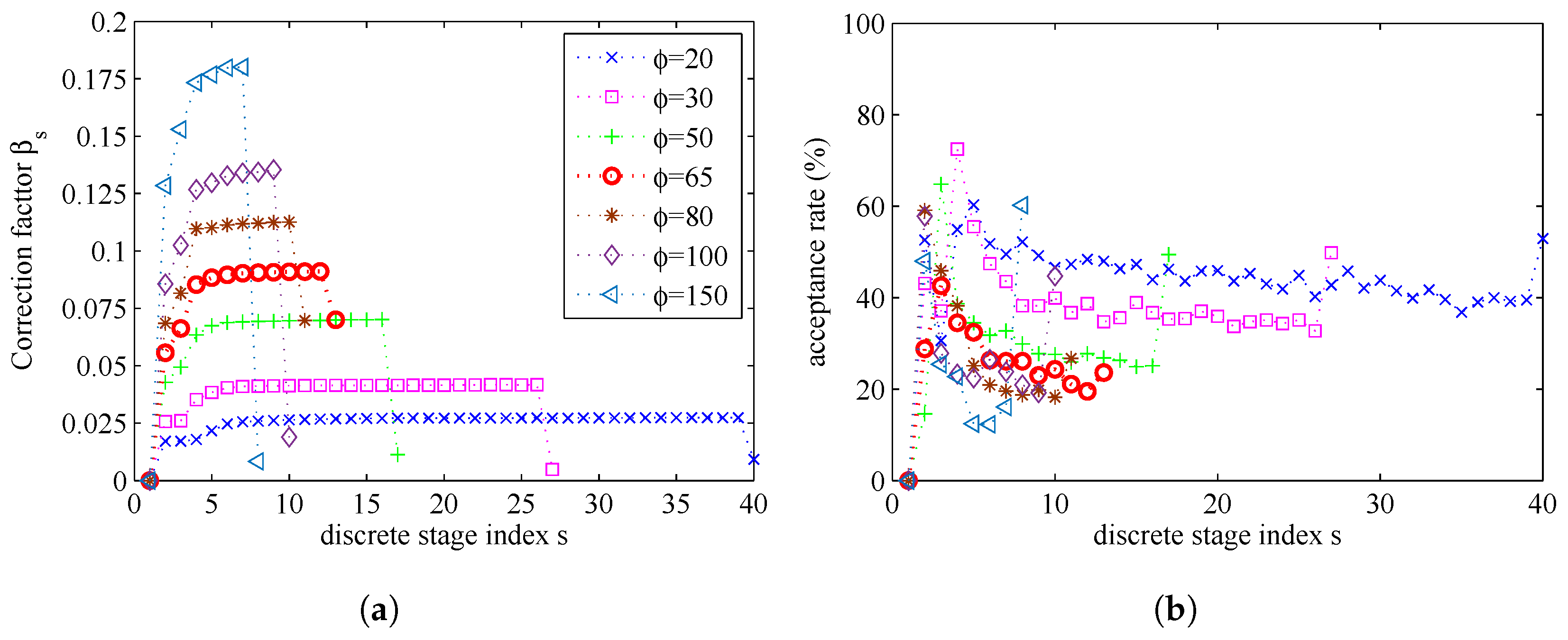{kind=link}