Examining the Schelling Model Simulation through an Estimation of Its Entropy


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methodology
2.1. Schelling Model Outline
2.2. Estimating the Entropy of the Schelling Model from the Microstate and Macrostate Assignments
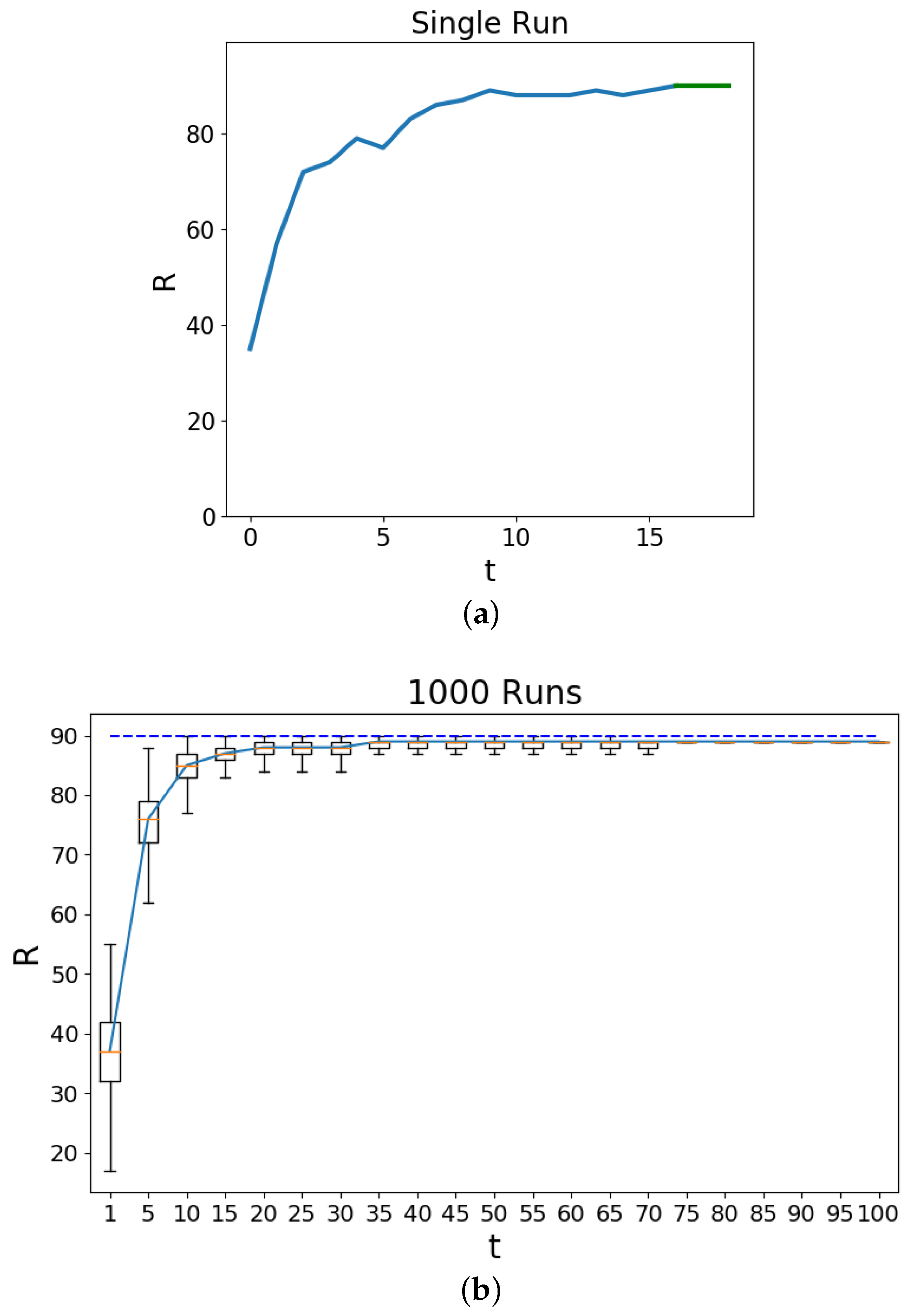
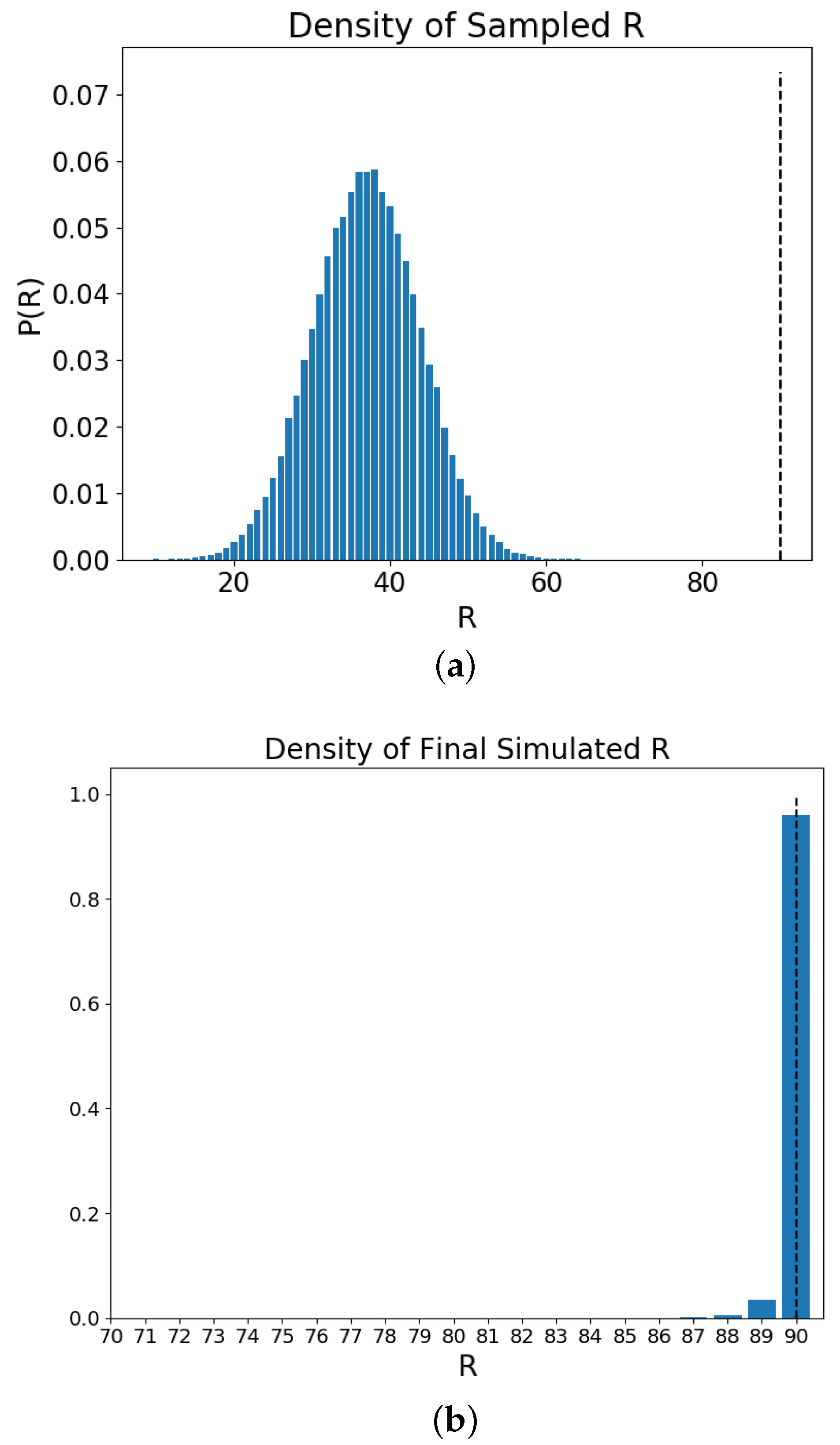
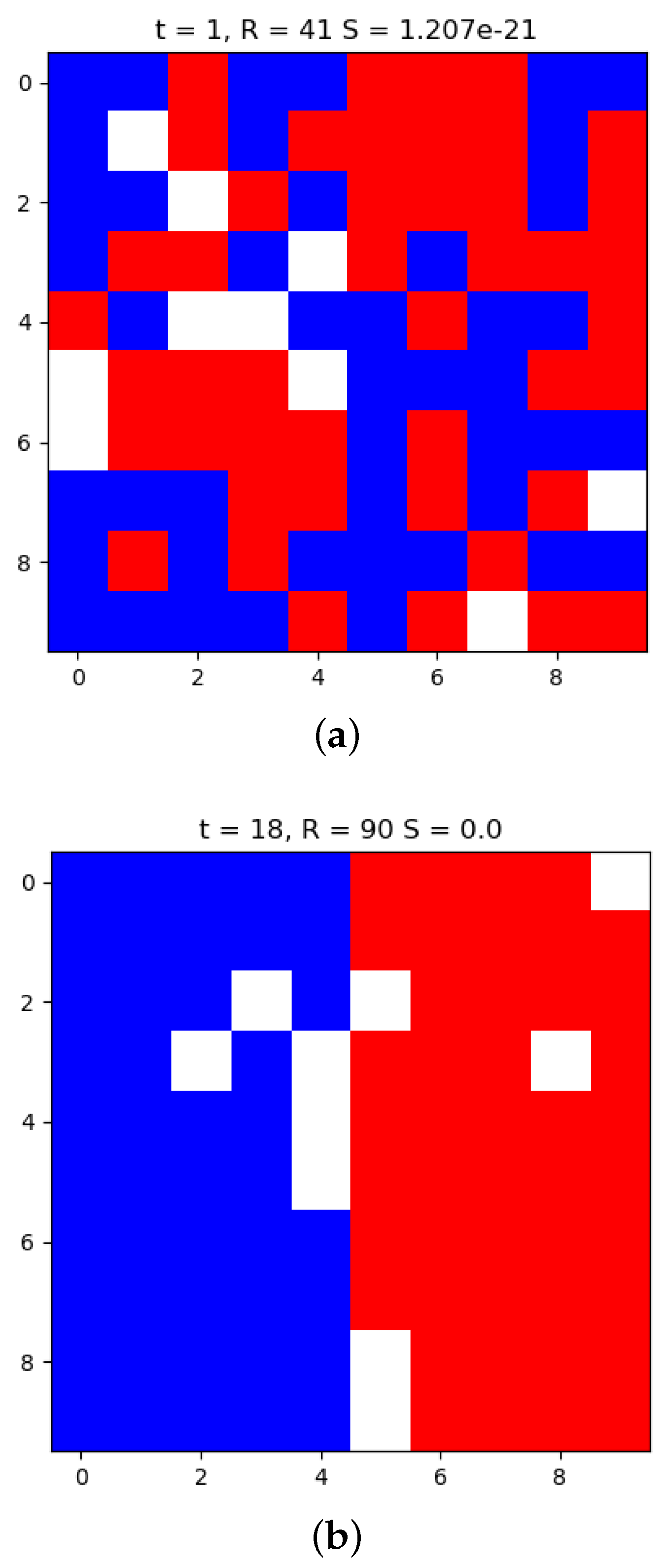
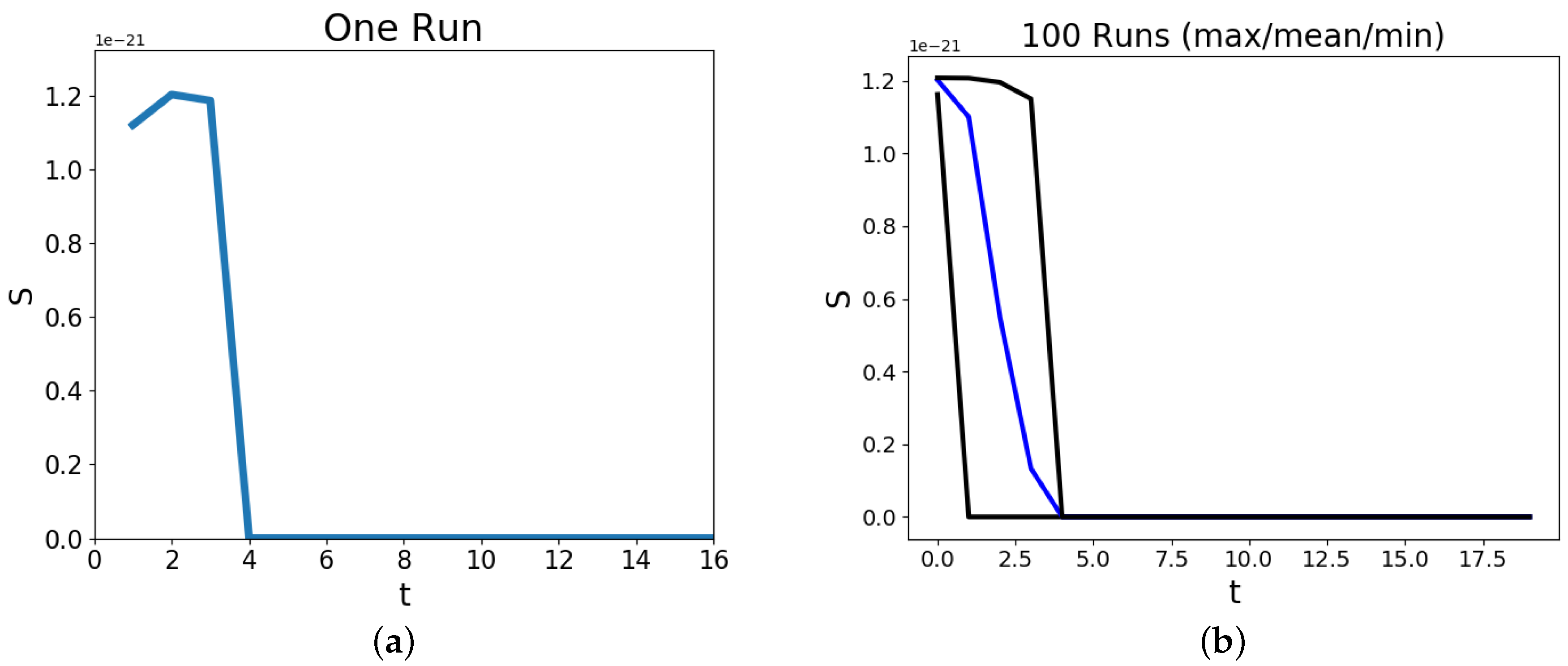
3. Results and Discussion
4. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A. Note on the use of the Terminology for the Agent Satisfaction
References
- Schelling, T.C. Dynamic models of segregation. J. Math. Sociol. 1971, 1, 143–186. [Google Scholar] [CrossRef]
- Rogers, T.; McKane, A.J. A unified framework for Schelling’s model of segregation. J. Stat. Mech. 2011, 2011, 1742–5468. [Google Scholar] [CrossRef]
- Styer, D.F. Insight into entropy. Am. J. Phys. 2000, 68, 1090–1096. [Google Scholar] [CrossRef]
- Hatna, E.; Benenson, I. Combining segregation and integration: Schelling model dynamics for heterogeneous population. J. Artif. Soc. Soc. Simul. 2015, 18. [Google Scholar] [CrossRef]
- Nielsen, A.V.; Gade, A.L.; Juul, J.; Strandkvist, C. Schelling model of cell segregation based only on local information. Phys. Rev. E 2015, 92. [Google Scholar] [CrossRef] [PubMed]
- Gauvin, L.; Vannimenus, J.; Nadal, J.P. Phase diagram of a Schelling segregation model. Eur. Phys. J. B 2009, 70, 293–304. [Google Scholar] [CrossRef]
- Vinković, D.; Kirman, A. A physical analogue of the Schelling model. Proc. Natl. Acad. Sci. USA 2006, 103, 19261–19265. [Google Scholar] [CrossRef] [PubMed]
- Dall’Asta, L.; Castellano, C.; Marsili, M. Statistical physics of the Schelling model of segregation. J. Stat. Mech. 2008, 2008. [Google Scholar] [CrossRef]
- Bhakta, P.; Miracle, S.; Randall, D. Clustering and mixing times for segregation models on Z2. In Proceedings of the Twenty-Fifth Annual ACM-SIAM Symposium on Discrete Algorithms, Urbana-Champaign, IL, USA; 2014; pp. 327–340. [Google Scholar]
- Cortez, V.; Medina, P.; Goles, E.; Zarama, R.; Rica, S. Attractors, statistics and fluctuations of the dynamics of the Schelling’s model for social segregation. Eur. Phys. J. B 2015, 88, 25. [Google Scholar] [CrossRef]
- Mora, F.; Urbina, F.; Cortez, V.; Rica, S. In Nonlinear Dynamics: Materials, Theory and Experiments. Proceeding of the 3rd Dynamics Days South America, Valparaiso, Chile, 3–7 November 2014. [Google Scholar]
- Avetisov, V.; Gorsky, A.; Maslov, S.; Nechaev, S.; Valba, O. Phase transitions in social networks inspired by the Schelling model. arXiv, 2018; arXiv:1801.03912. [Google Scholar]
- Granovetter, M.S. The strength of weak ties. Am. J. Soc. 1973, 78, 1360–1380. [Google Scholar] [CrossRef]
- Gibbs, J.W. Elementary Principles in Statistical Mechanics; Courier Corporation: North Chelmsford, MA, USA, 2014; ISBN 978-0-486-78995-8. [Google Scholar]
- Ising, E. Beitrag zur theorie des ferromagnetismus. Zeitschrift für Physik 1925, 31, 253–258. [Google Scholar] [CrossRef]
- McCoy, B.M.; Wu, T.T. The Two-Ddimensional Ising Model; Courier Corporation: North Chelmsford, MA, USA, 2014; ISBN 978-0-486-49335-0. [Google Scholar]
- Baxter, R.J. Exactly Solved Models in Statistical Mechanics; Academic Press: San Diego, California, USA, 2016; ISBN 0-12-083180-5. [Google Scholar]
- Ódor, G. Universality classes in nonequilibrium lattice systems. Rev. Mod. Phys. 2004, 76, 663–724. [Google Scholar] [CrossRef]
- Stauffer, D.; Solomon, S. Ising, Schelling and Self-Organising Segregation. Eur. Phys. J. B 2007, 57, 473–479. [Google Scholar] [CrossRef]
- Stauffer, D. Social applications of two-dimensional Ising models. Am. J. Phys. 2008, 76, 470–473. [Google Scholar] [CrossRef]
- Lieberson, S. Measuring population diversity. Am. Sociol. Rev. 1969, 34, 850–862. [Google Scholar] [CrossRef]
- Gracia-Lázaro, C.; Lafuerza, L.F.; Floría, L.M.; Moreno, Y. Residential segregation and cultural dissemination: An Axelrod-Schelling model. Phys. Rev. E 2009, 80, 0461231–0461235. [Google Scholar] [CrossRef] [PubMed]
- Ódor, G. Self-organizing, two-temperature Ising model describing human segregation. Int. J. Mod. Phys. C 2008, 19, 393–398. [Google Scholar] [CrossRef]
- Tolman, R.C. The Principles of Statistical Mechanics; Dover: New York, NY, USA, 1979; ISBN GB3N-CL4-5HL4. [Google Scholar]
- Singh, A.; Vainchtein, D.; Weiss, H. Schelling’s segregation model: Parameters, scaling, and aggregation. Demogr. Res. 2009, 21, 341–366. [Google Scholar] [CrossRef]
- Pickhardt, M.; Seibold, G. Income tax evasion dynamics: Evidence from an agent-based econophysics model. J. Econ. Psychol. 2014, 40, 147–160. [Google Scholar] [CrossRef]
- Sokal, A. Monte Carlo methods in statistical mechanics: foundations and new algorithms. In Functional Integration; Springer: Boston, MA, USA, 1997; Volume 361, pp. 131–192. ISBN 978-1-4899-0321-1. [Google Scholar]
- Landau, D.P.; Binder, K. A Guide to Monte Carlo Simulations in Statistical Physics; Cambridge University Press: New York, NY, USA, 2014; ISBN 978-0-511-65176-2. [Google Scholar]
- Bezanson, J.; Karpinski, S.; Shah, V.B.; Edelman, A. Julia: A fast dynamic language for technical computing. arXiv, 2012; arXiv:1209.5145. [Google Scholar]
- Bezanson, J.; Edelman, A.; Karpinski, S.; Shah, V.B. Julia: A fresh approach to numerical computing. SIAM Rev. 2017, 59, 65–98. [Google Scholar] [CrossRef]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mantzaris, A.V.; Marich, J.A.; Halfman, T.W. Examining the Schelling Model Simulation through an Estimation of Its Entropy. Entropy 2018, 20, 623. https://doi.org/10.3390/e20090623
Mantzaris AV, Marich JA, Halfman TW. Examining the Schelling Model Simulation through an Estimation of Its Entropy. Entropy. 2018; 20(9):623. https://doi.org/10.3390/e20090623
Chicago/Turabian StyleMantzaris, Alexander V., John A. Marich, and Tristin W. Halfman. 2018. "Examining the Schelling Model Simulation through an Estimation of Its Entropy" Entropy 20, no. 9: 623. https://doi.org/10.3390/e20090623
APA StyleMantzaris, A. V., Marich, J. A., & Halfman, T. W. (2018). Examining the Schelling Model Simulation through an Estimation of Its Entropy. Entropy, 20(9), 623. https://doi.org/10.3390/e20090623