1. Introduction
In survival studies, it is common to observe two or more lifetimes for the same client, patient or equipment. For instance, in a bivariate scenario, the lifetimes of a pair of organs can be observed, such as a pair of kidneys, liver, or eyes in patients; or the lifetimes of engines in a twin-engine airplane.
These variables are usually correlated and we are interested in the bivariate model that considers the dependence between them. The copula model is useful for modeling this kind of bivariate data. It has been used in several articles, including the following: [
1] describes a comparison between bivariate frailty models, and models based on bivariate exponential and Weibull distributions; [
2] proposes a copula model to study the association between survival time of individuals infected with HIV and persistence time of infection; [
3] models the association of bivariate failure times by copula functions, and investigates two-stage parametric and semi-parametric procedures; and [
4] considers a Gaussian copula model and estimates the copula association parameter using a two-stage estimation procedure.
According to [
5,
6], a copula is a joint distribution function of random variables for which the marginal probability distribution of each variable is uniformly distributed on the interval
.
There are many parametric copula families in the literature, each one representing a different dependence structure between the random variables. One advantage of a copula model is its simplicity when applied to model bivariate data. This is explored by many authors in survival analysis. Among them are: Romeo et al. [
7] and da Cruz et al. [
8], who considered the Archimedean copula family; Louzada et al. [
9] and Suzuki et al. [
10], who considered the Farlie–Gumbel–Morgenstern (FGM) copula; and Romeo et al. [
11], who considered the two-parameter Archimedean family of power variance function (PVF) copulas.
In this paper, we apply the Ali–Mikhail–Haq (AMH) copula to model bivariate survival data with random right-censored observations. From a practical point of view, the main reason for using the AMH copula is that it is an Archimedean copula that allows both positive and negative values for the dependence parameter, and whose mathematical formula is simpler than other Archimedean copulas. Another advantage is that assuming the AMH copula, the Kendall rank-order correlation
between the bivariate lifetimes is a monotonic function of the dependence parameter
. According to [
12], the Kendall’s
can range from (approximately)
to
, with
when
; and the Spearman’s
associated to
can range (approximately) from
to
, indicating that the AMH copula is adequate for modeling bivariate data with a weak correlation.
In order to proceed with the copula model it is necessary to specify the marginal distributions. At this point, several probability distributions could be considered. Generally, the choice for marginal distributions depends on the application. We restrict our analysis to the case where the marginal distributions are Weibull distributions. This is because it is a very flexible distribution for the modeling of various types of lifetime data. In addition, the parametrization of the Weibull distribution—as well as the mathematical expression of the AMH copula—is very attractive from the mathematical point of view, allowing the development of a Bayesian approach to estimate the parameters of interest in a clear and concise way.
As the conditional posterior distributions for parameters of interest does not follow any familiar distribution, the estimation procedure was carried out using versions of the Metropolis–Hastings algorithm, referred to here as Independent Metropolis–Hastings (IMH), Random Walk Metropolis (RWM) and Metropolis–Hastings (MH). MH refers to the Metropolis–Hastings algorithm with a natural candidate generating density whose parameters depend on the hyperparameter values and the observed data. Since the creation of a good candidate generating density in IMH and RWM can be difficult, we also used the slice sampling algorithm [
13].
Combining IMH, RWM, MH and SS in different ways, we developed three MCMC algorithms to estimate the model parameters. A simulation study was carried out with the objective of investigating the behavior of each algorithm. The data sets were generated by considering different sample sizes and percentages of right-censored observations. Based on the root mean square error (RMSE), we identified the algorithms with the best performances when estimating the model parameters. We also compared the performances of the three algorithms using the effective sample size and the integrated autocorrelation time [
14]. Results obtained from these simulations show that the algorithm that applied the SS algorithm is an effective alternative for standard MCMC methods (IMH and RWM) when simulating values from the posterior distribution of the model parameters, especially when the sample size is small.
We applied the three proposed algorithms to a real data set. This data set is related to diabetic retinopathy, described in The Diabetic Retinopathy Study Research Group [
15], and is available in the `survival’ package [
16] of the R software [
17]. For this case, we compared the performance of the algorithms. Comparison was based on the RMSE relative to the empirical distribution function obtained from Kaplan–Meier estimates.
The remainder of the paper is organized as follows. In
Section 2, we introduce the bivariate survival model based on the AMH copula with Weibull marginal distributions. The Bayesian approach and the three MCMC algorithms are described in
Section 3. In
Section 4, the simulation study is reported. In
Section 5 we apply the three algorithms to the real data set.
Section 6 summarizes our findings.
2. Bivariate Survival Model and Observed Data
Let be the vector of bivariate lifetimes of an item (or an individual) with marginal density functions and the survival functions be , where and are unknown parameters (scalars or vectors).
Consider that
comes from the copula
, where
is a parameter showing dependence between
and
. Then the joint survival function for
is given by
where
and
is a dependence parameter.
We also assume that copula
is given by the Ali–Mikhail–Haq copula [
18]. Thus, we have
for
. Note that under this assumption the survival functions and the dependence structure can be visualized separately with the dependence structure represented by the copula.
Let
and
be a sample of size
n of bivariate lifetimes and censured bivariate lifetimes, respectively. Suppose
and
are independent, for
. Consider
—the
i-th observed value and
—a censorship indicator given by
for
and
. We denote the observed values using
and
, where
,
,
and
.
The likelihood function for
, given
, is (see Lawless, [
19])
where
is the joint probability density function for
,
,
, and
is the copula given by (
1), for
.
From Equation (
1), we have
where
is the cumulative distribution function for
and
.
Weibull Marginal Distribution
Assume that the marginal distributions for
and
are given by Weibull distributions [
20], i.e.,
with shape parameter
and scale parameter
[
21], each one having a probability density function
for
and
.
The survival function
and hazard function
are
respectively, where
for
and
.
Thus, the joint survival function in (
1) is
where
. The likelihood function for
is
where
is the number of uncensored observations for
,
, and
for
.
3. Bayesian Approach
In order to develop the Bayesian approach, we need to specify the prior distributions for
,
and
, for
. We assume that priors are independent, i.e.,
. Therefore, we consider the following prior distributions
where
is the Gamma distribution and
,
,
and
are known hyperparameters, all of them with support on
, for
. The parametrization of the Gamma distribution is such that the mean is
and the variance is
, for
. The choice of values for the hyperparameters depends on the application. In the remainder of the article, we set up the hyperparameters values that give prior distributions with large variances. In particular, we set
, for
. For
we chose the uniform prior distribution on the interval
,
.
Using Bayes theorem, the joint posterior distribution for
is
where
is given in Equation (
3).
The conditional posterior distributions are
where
, for
, is the vector of parameters
without the parameter
,
.
The conditional posterior distributions in Equations (
4)–(6) are not familiar distributions. Thus, in order to simulate from conditional posterior distributions, we used the Metropolis–Hastings algorithm. At each iteration, the Metropolis–Hastings algorithm considers a value generated from a proposal distribution. This value is accepted according to a properly specified acceptance probability. This procedure guarantees the convergence of the Markov chain for the target density. More details on the Metropolis–Hastings algorithm can be found in [
22,
23,
24,
25] and their references.
3.1. MCMC for
Without loss of generality, we describe here how to update parameter conditional on all other parameters, and . The update procedure for is similar.
Let
be the current state of the Markov chain. Consider
a value generated from a candidate generating density
. The value
is accepted with probability
, where
and
is the likelihood function, given in Equation (
3).
The Metropolis–Hastings algorithm is implemented as follows.
Metropolis–Hastings Algorithm: Let the current state of the Markov chain be , where l is the l-th iteration of the algorithm, , and are the values of , and in -th iteration, respectively, for , in which, , and are the initial values. At the l-th iteration of the algorithm, we updated as follows:
- (1)
Generate ;
- (2)
Calculate
, where
is given by (
7);
- (3)
Generate . If accept and do . Otherwise, reject and set .
3.1.1. Two Common Choices for
To implement the Metropolis–Hastings algorithm, the candidate-generating density needs to be specified. Generally, one may explore the form of the conditional posterior distribution to set the candidate-generating density. For example, if we can write as , where is a density that can be easily generated and is uniformly bounded, then we may set up . However, this is not the case for .
Another option is to generate
from a candidate generating density that does not depend on the current
value. That is, we may set up
. Thus, we have a special case of the original MH algorithm, called Independent Metropolis–Hastings (IMH), where
is given in (
7) and simplifies to
In order to implement this case, one may set
as the prior distribution, i.e.,
. Then,
is given by the likelihood ratios,
This algorithm is implemented as follows.
Although the choice of the prior distribution as the candidate generating density may be mathematically attractive, it usually leads to a slow convergence of the algorithm. This happens when vague prior information is available and prior distribution has large variance. As a consequence, many of the proposed values are rejected.
An alternative is to explore the neighborhood of the current value of the Markov chain to propose a new value. This method is termed the random walk Metropolis (RWM). In the RWM, the candidate value
is generated from a symmetric density
. That is, we set up
and the probability of generating a move from
to
depends only on the distance between them. For this case,
given in (
7) simplifies to
since the proposal kernels from numerator and denominator cancel.
In order to implement the RWM it is necessary to simulate setting , where is a random perturbation generated from a Normal distribution with mean 0 and variance , , meaning that . This algorithm is implemented as follows.
Random Walk Metropolis Algorithm: Let the current state of the Markov chain be . For the l-th iteration of the algorithm, , do the following:
- (1)
Generate and set ;
- (2)
Calculate
, where
is given by (
9);
- (3)
Generate . If accept and set . Otherwise, reject and set .
An issue in RWM is how to choose the value of
. It has a strong influence on the efficiency of the algorithm. If
is too small, the random perturbations will be small in magnitude and almost all will be accepted. The consequence is that it will take a large number of iterations to explore the entire state-space. On the other hand, if
is large there will be many rejections of the proposed values, slowing down the convergence. More details on this issue can be found in [
23,
26,
27,
28].
Typically, one may fix the value of
by testing some values on a few pilot runs and then choosing a value whose acceptance ratio lies between
and
(see, for example, [
24,
25]). Thus, after a pilot run we set up
.
3.1.2. Slice Sampling Algorithm
An alternative to the IMH and RWM sampling from some generic distribution is the slice sampling algorithm. This algorithm is a type of Gibbs sampling based on the simulation of specific uniform random variables. Here we explain the algorithm slice sampling in the context of the simulation of
. The sampling procedure for
is similar. More details about SS can be found in [
13].
In SS, an auxiliary variable
U is introduced and the joint distribution
is given by a uniform distribution over the region
below the curve defined by
. From (
4), we have
Marginalizing
over
U yields
, so sampling from
and discarding
U is equivalent to sampling from
.
As sampling from is not straightforward, we implemented a Gibbs sampling algorithm where at every iteration l, we first generate and then sample , where . However, as the inverse of cannot be obtained analytically, we adopted the following procedure to update :
- (i)
Let and be an empty set.
- (a)
For :
Set
If do else break
- (b)
For :
Set
If do else break
- (ii)
Generate .
This algorithm is implemented as follows.
Slice sampling algorithm: Let the current state of the Markov chain be and . For the l-th iteration of the algorithm, :
- (1)
Generate
, where
is given by (
10).
- (2)
obtain , conditional on .
- (3)
Generate .
3.2. MCMC for and
Note from (5) that the conditional posterior distribution for the scale parameter
,
, is given by the kernel of a Gamma distribution with parameters
and
multiplied by
. In other words,
may be written as
, where
is the density of the Gamma distribution
with
being uniformly bounded. Thus, we set up the candidate generating density for
as
. The acceptance probability for the generated value
is given by
, where
This algorithm is implemented as follows.
Metropolis–Hastings Algorithm: Let the current state of the Markov chain be , where . For the l-th iteration of the algorithm, :
- (1)
Generate .
- (2)
Calculate
, where
is given by (
11).
- (3)
Generate . If accept and set . Otherwise, reject and set .
The Metropolis–Hastings algorithm for updating is similar. To update the dependence parameter conditional on the remaining parameters , we used the following IMH algorithm. Let be a grid from to 1 with increments of . Consider , an interval defined by two adjacent grid values of where a is the index of the a-th value of the grid for . For example, for we have the interval ; for , we have the interval ; and for we have the interval . Then generate the a candidate value as follows:
- (i)
If the current value of
is in the interval
, then generate
from one of the two following Uniform distributions
For this case, we generate an auxiliary variable ; if , then we generate from , , otherwise we generate from , .
- (ii)
If the current value of
is in
, then generate
from one of the two following uniform distributions
Similarly to item (i), we generate an auxiliary variable ; if , then , otherwise .
- (iii)
If the current value of
is in the interval
, for
and
, then generate
from one of three following uniform distributions
For this case, we generate an auxiliary variable ; if , then we generate from , ; if , then we generate from , ; and if , we generate from , .
The acceptance probability is given by , where for or according to items (i)–(iii) described above. This algorithm is implemented as follows.
IMH algorithm for : Let the current state of the Markov chain be . For the l-th iteration of the algorithm, :
- (1)
Generate according to one of the items (i), (ii) or (iii) described above.
- (2)
Calculate .
- (3)
Generate . If accept and set . Otherwise, reject and set .
3.3. MCMC Algorithms
Using the algorithms IMH, RWM, SS and MH described above, we implemented three MCMC algorithms:
Algorithm : Parameters ’s are updated via IMH,
Algorithm : Parameters ’s are updated via RWM,
Algorithm : Parameters ’s are updated via SS.
For these three algorithms, the parameters
and
are updated via MH and IMH, as described in
Section 3.2, for
.
After defining the algorithms, we ran them for L iterations and a burn-in B. We also consider jumps of size J, i.e., only 1 drawn from every J was extracted from the original sequence obtaining a sub sequence of size to make inferences.
The estimates for parameters are given by
where
is the value generated for
in the
-th iteration of the algorithm, for
and
.
4. Simulation Study
In this section, we present the comparison between the performances of the three algorithms applied to simulated data sets. Simulated random samples of sizes
and 250 with
,
,
,
and
random right-censored were generated to represent small, medium and large data sets. Using these, we generated four simulated data sets with fixed parameters, as specified in
Table 1.
Data set has two increasing hazard functions with a positive dependence parameter, while data set has a constant and increasing hazard function with a negative dependence parameter. Data set has parameters to produce a decreasing and a constant hazard function with weak dependence, while data set has strong dependence and two increasing hazard functions.
The simulation procedure to generate n observations , for , is given by the following steps:
- (i)
Set up the sample size n and set ;
- (ii)
Generate the censoring times , where controls the percentage of censored observations, for ;
- (iii)
Generate uniform values , and calculate , the solution of the nonlinear equation . Here we used the rootsolve package and the uniroot.all command from R software to solve the nonlinear equation and obtain ;
- (iv)
Calculate and ;
- (v)
Calculate the times and the censorship indicators , which are equal to 1 if and 0 otherwise, for ;
- (vi)
Set . If stop. Otherwise, return to step (ii).
We generated different simulated data sets according to steps (i)–(vi) described above and the parameters were estimated according to algorithms , and .
We used hyperparameters to obtain prior distributions with large variance, for . For the m-th generated data set, we applied algorithms , and fixing L = 55,000 iterations, burn-in B = 5000 and .
Comparison of the algorithms was made using the sample Root Mean Square Error (RMSE), given by
A smaller RMSE indicates better overall quality of the estimates.
Table 2 presents the RMSE value for each simulated data set by algorithm, sample size and percentage of censorship. The smaller RMSE value for each sample size and percentage of censorship is highlighted in bold. For the three algorithms, by fixing the sample size and increasing the censuring percentage (% cens.), the RMSE values increased. When the sample size increases at a fixed percentage of censures, the RMSE values decrease, consequently improving the precision of the estimators.
Based on the results presented in
Table 2, for the smaller sample size
, the algorithm
(with SS) outperformed algorithm
(with IMH) and algorithm
(with RWM), i.e., it gave a smaller RMSE value for all percentages of censures. This better performance also happened for data sets
and
for
. For all other simulated cases, the algorithm
outperformed algorithms
and
. An exception is the case with
and
of censuring in data set
, in which algorithm
had a better performance. These results suggest a possible complementarity between algorithms
and
, where algorithm
performs better for higher sample sizes and algorithm
performs better for smaller sample sizes.
We verified the convergence of algorithms
,
and
using the effective sample size [
14] and the integrated autocorrelation time (IAT). The effective sample size (ESS) is the number of effectively independent draws from the posterior distribution. Method with larger ESS are the most efficient. The IAT is a MCMC diagnostic that estimates the average number of autocorrelated samples required to produce one independent sample draw. Lower IAT is means more efficiency. The EES and IAT values were obtained using the
coda and
LaplacesDemon. Both packages are available in the
R software.
Table A1 and
Table A2 in
Appendix A show the average of ESS and IAT values for each algorithm by parameter for data set
. Algorithm
showed a better performance than algorithms
and
, i.e., it had the highest ESS values and smallest IAT values by parameter for all simulated cases. Note that algorithm
had the worst results, especially for simulated values for
,
. Results for data sets
,
and
were similar.
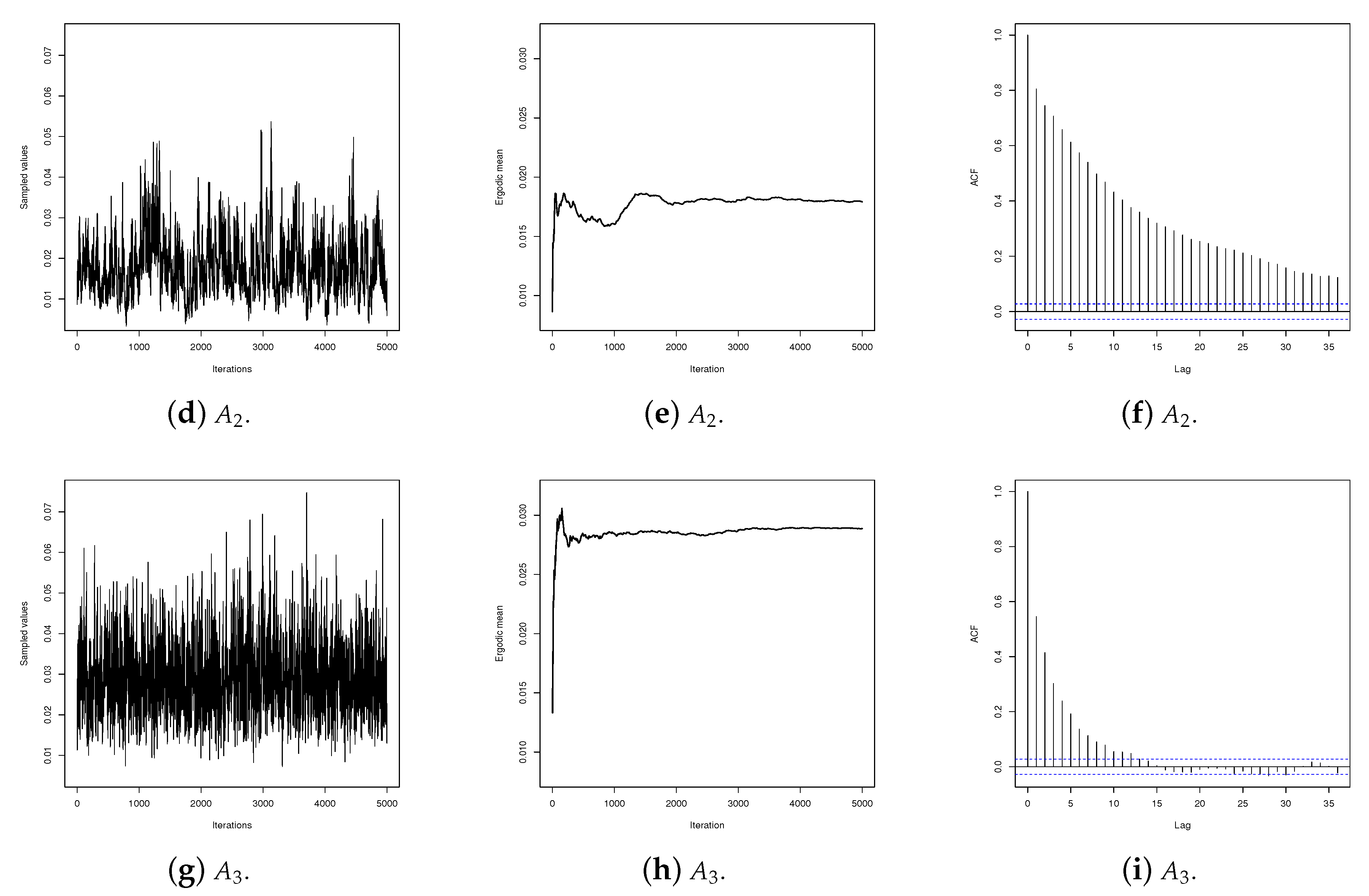
Appendix B presents an empirical convergence check for the sampled values for
for each algorithm. As shown in
Figure A1, the generated values for
by algorithm
did not mix well and the stability for the ergodic mean and estimated autocorrelation were not satisfactory. On the other hand, the values generated by algorithms
and
were well mixed and present satisfactory stability for the ergodic mean and autocorrelation. As an illustration of convergence diagnostic,
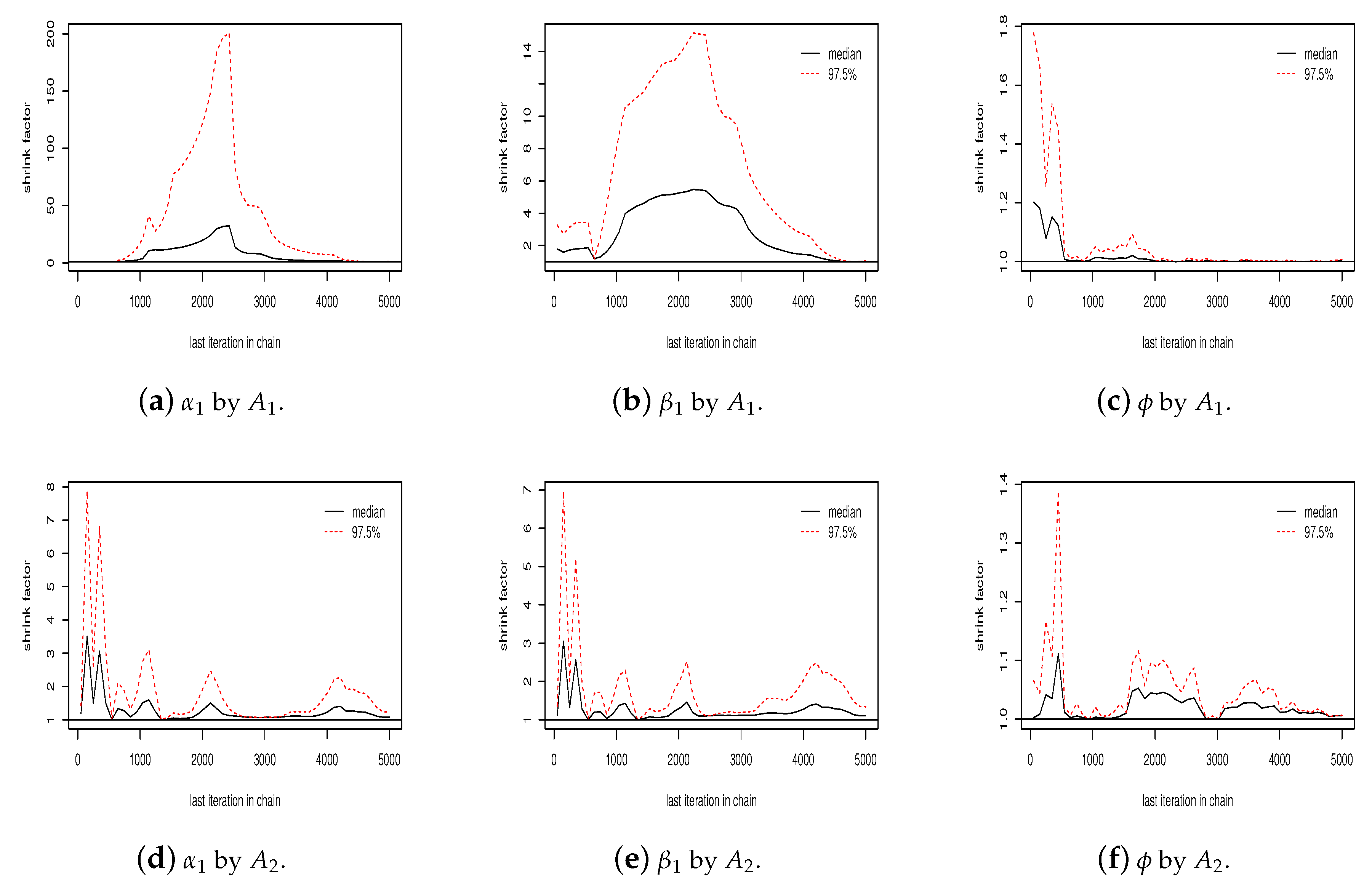
Figure A1 (j–l) shows the Gelman plot for the sequence of
values in two chains by each algorithm. As can be seen in the figure, the number of iterations was sufficient for algorithms
and
to reach convergence, but not for algorithm
. In addition, the scale reduction factor of the Gelman–Rubin diagnostic [
29] for each parameter in algorithms
and
were smaller than
, meaning that there is no indication of non-convergence. This implies a faster convergence of algorithms
and
in relation to algorithm
. For
sampled values, the three algorithms present satisfactory properties, i.e., good mixing, and satisfactory stability for ergodic mean and autocorrelation (see
Figure A2 in
Appendix B).
The results indicate that algorithm (SS for ) is an effective alternative to algorithms (with IMH for ) and (with RWM for ) to simulate samples from the posterior distribution of bivariate survival models based on the Ali–Mikhail–Haq copula with marginal Weibull distributions.
5. Application to a Real Data Set
Next, we examine the performance of algorithms
,
and
on the diabetic retinopathy data set described in [
15], which is available in the R software `survival’ package [
16]. This data set consists of the follow-up times of 197 diabetic patients under 60 years of age. The main objective of the study was to evaluate the effectiveness of the photocoagulation treatment for proliferative retinopathy. The treatment was randomly assigned to one eye of each patient and the other eye was taken as a control.
Let be the bivariate times, where is the time to visual loss for the treatment eye and is the time to visual loss for the control eye. The percentage of censure times for each variable is (143 observations) for and (96 observations) for .
We used (
1) to model this data with Weibull marginal distributions with parameters
and
and dependence parameter
.
We compared the performances of the algorithms using the RMSE in relation to the empirical distribution function,
where
is obtained by substituting the estimates of
,
and
(obtained by each algorithm); and
is the empirical distribution function obtained from the Kaplan–Meier estimates, for
and
.
We ran the three algorithms using the same number of iterations, burn-in, thinning and hyperparameters values used with the simulation data.
Table 3 shows the parameters estimates, the credibility intervals (
) and RMSE values by algorithm. For this data set, the algorithm
(with SS for
) gave the smaller RMSE value.
Figure 1 shows the estimated survival functions by algorithms
(red line) and
(blue line). The step functions (black lines) are the Kaplan–Meier estimates. The estimated curves by algorithms
and
are very close and so we show only the curve estimated by
, in order to provide a good visualization. The Kaplan–Meier estimates were obtained using the survival package and the survfit command in the
R software.
Table 4 shows the ESS and IAT values for the sequences generated by algorithms
,
, and
. Algorithm
had a better performance than algorithms
and
, i.e., the highest ESS value and the lowest IAT value per parameter.
We also compared the performances of the algorithms in relation to the sequences generated for each parameter.
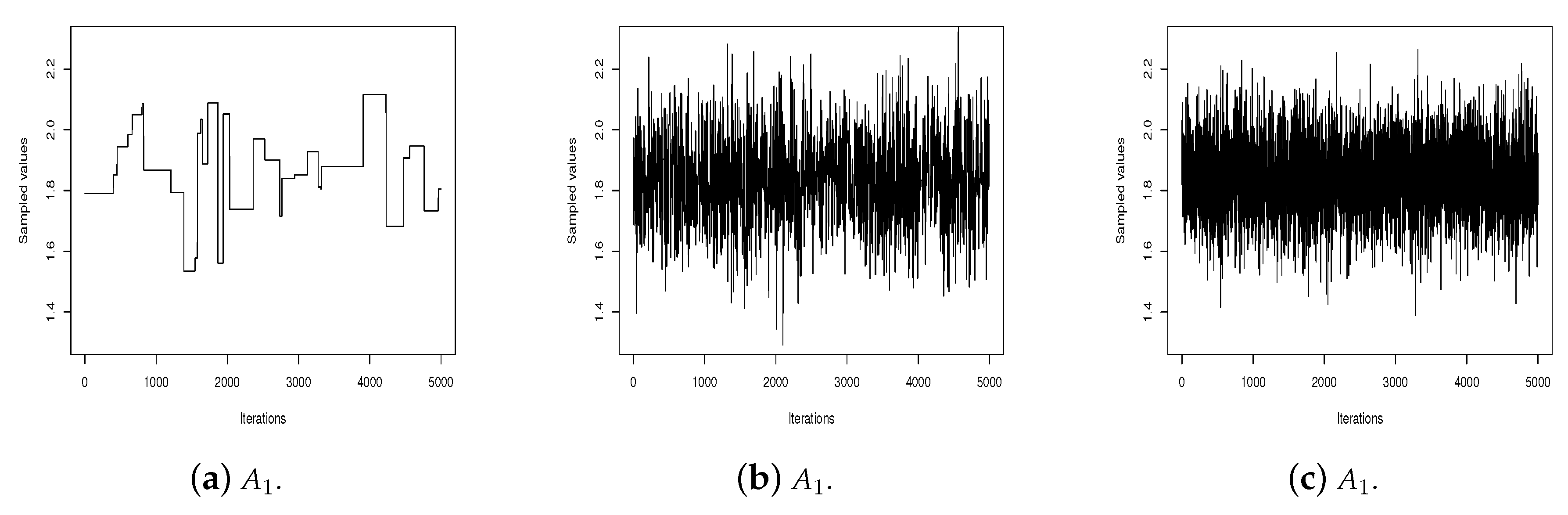
Figure 2 shows the traceplots, the ergodic means, and the autocorrelations for sequences of
values simulated by algorithms
,
and
.
It can be observed in these graphs that the
values generated by the IMH (algorithm
) has poor mixing, does not show satisfactory stability for the ergodic mean, and the autocorrelation is high for long lags. On the other hand, the values generated by the RWM (algorithm
) and SS (algorithm
) are better mixed and present satisfactory stability for the ergodic mean. However, the sequence produced by the SS presents the steepest decreasing autocorrelation.
Figure 3 shows the same graphs for parameter
. As can be seen, for
the performances of the three algorithms are satisfactory. These results, together with those presented by the RMSE, show that for the data set analyzed here SS provides a better performance than IMH or RWM.
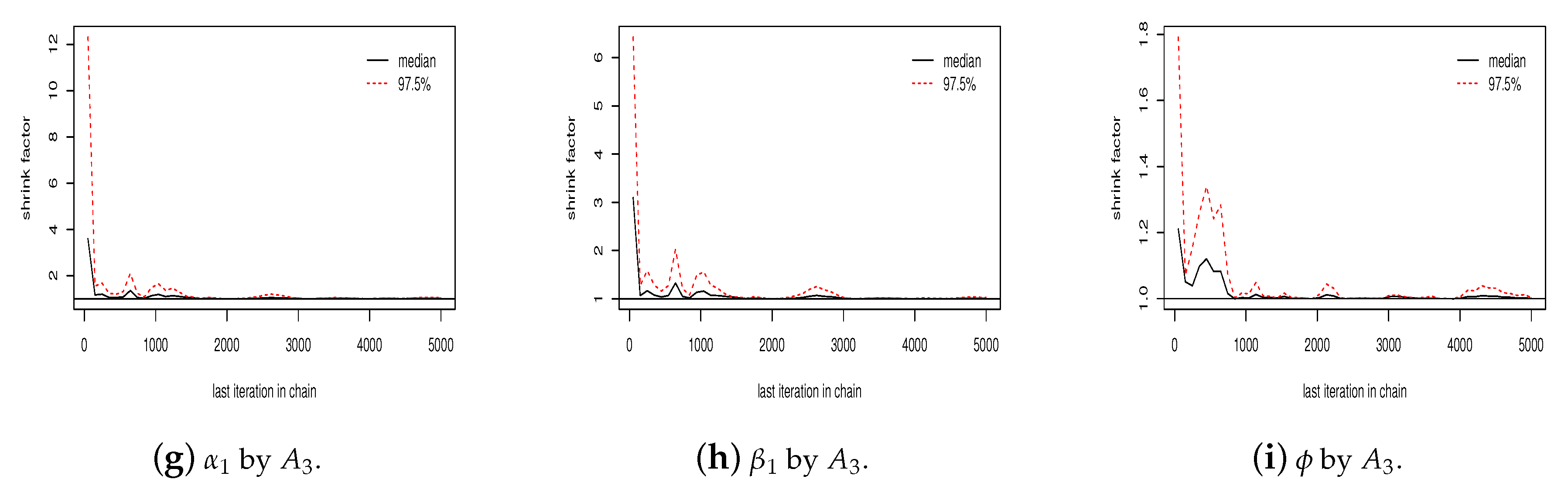
Figure 4 shows the Gelman plot for the simulated values for
,
and
in two chains by each algorithm. As can be seen, the number of iterations was sufficient for algorithms
and
to reach the convergence, but not sufficient for algorithm
(
Figure 4a,b). The scale reduction factor for each parameter in algorithms
and
are all less than
, while for algorithm
only
presents a scale reduction factor less than
.
6. Final Remarks
We investigated the performances of three Bayesian computational methods to estimate parameters of a bivariate survival model based on the Ali–Mikhail–Haq copula with marginal Weibull distributions. The performances of the MCMC algorithms were compared using the RMSE criterion. The RMSE values were calculated for different sample sizes and different percentages of censures.
The results obtained from the simulated data sets showed that the RWM and SS algorithms outperformed the IMH algorithm, and that the SS algorithm performed better for lower sample sizes. The results show evidence that MCMC sequences obtained with SS with the same number of iterations L, burn in B and thinning value, have better properties (i.e., higher ESS and lower IAT values) than for IMH and RWM, which are standard methods to sample from the joint posterior distribution.
We also illustrate the application of the algorithms using a real data set, available in the literature. The algorithm (with SS generating the ’s) presented a better performance when applied to this data set. The criteria used to reach this conclusion were the stability for the ergodic mean, the autocorrelation, the minimum RMSE value, the maximum value, and the minimum value. In addition, the algorithm using SS presented a satisfactory performance in relation to scale factor reduction, and the Gelman plot of the Gelman–Rubin convergence diagnostic.
Our results show that algorithm , which is composed by a mixing of SS for generating , MH for and IMH for , is an effective algorithm to simulate values from the joint posterior distribution of an AMH copula with Weibull marginal distributions. Moreover, two advantages of SS are that it is easy to implement and it does not need to specify a candidate generating density. A disadvantage in our specific case is that it took longer to perform the simulation when compared with IMH and RWM. The reason for this longer time is that we needed an iterative method to obtain the inverse of the function . This was because an analytical solution is not available. All calculations were implemented using the software R and can be obtained from the authors.
An extension of the results obtained here for other Arquimedian copulas as well other marginal distributions and a possible generalization would be a fruitful area for future work.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










