1. Introduction
The formula for “classical” logical entropy goes back to the early Twentieth Century [
1]. It is the derivation of the formula from basic logic that is new and accounts for the name. The ordinary Boolean logic of subsets has a dual logic of partitions [
2] since partitions (=equivalence relations = quotient sets) are category-theoretically dual to subsets. Just as the quantitative version of subset logic is the notion of logical finite probability, so the quantitative version of partition logic is logical information theory using the notion of logical entropy [
3]. This paper generalizes that “classical” (i.e., non-quantum) logical information theory to the quantum version. The classical logical information theory is briefly developed before turning to the quantum version. Applications of logical entropy have already been developed in several special mathematical settings; see [
4] and the references cited therein.
2. Duality of Subsets and Partitions
The foundations for classical and quantum logical information theory are built on the logic of partitions ([
2,
5]), which is dual (in the category-theoretic sense) to the usual Boolean logic of subsets. This duality can be most simply illustrated using a set function
. The image
is a
subset of the codomain
Y and the inverse-image or coimage
is a
partition on the domain
X, where a
partition on a set
U is a set of subsets or blocks
that are mutually disjoint and jointly exhaustive (
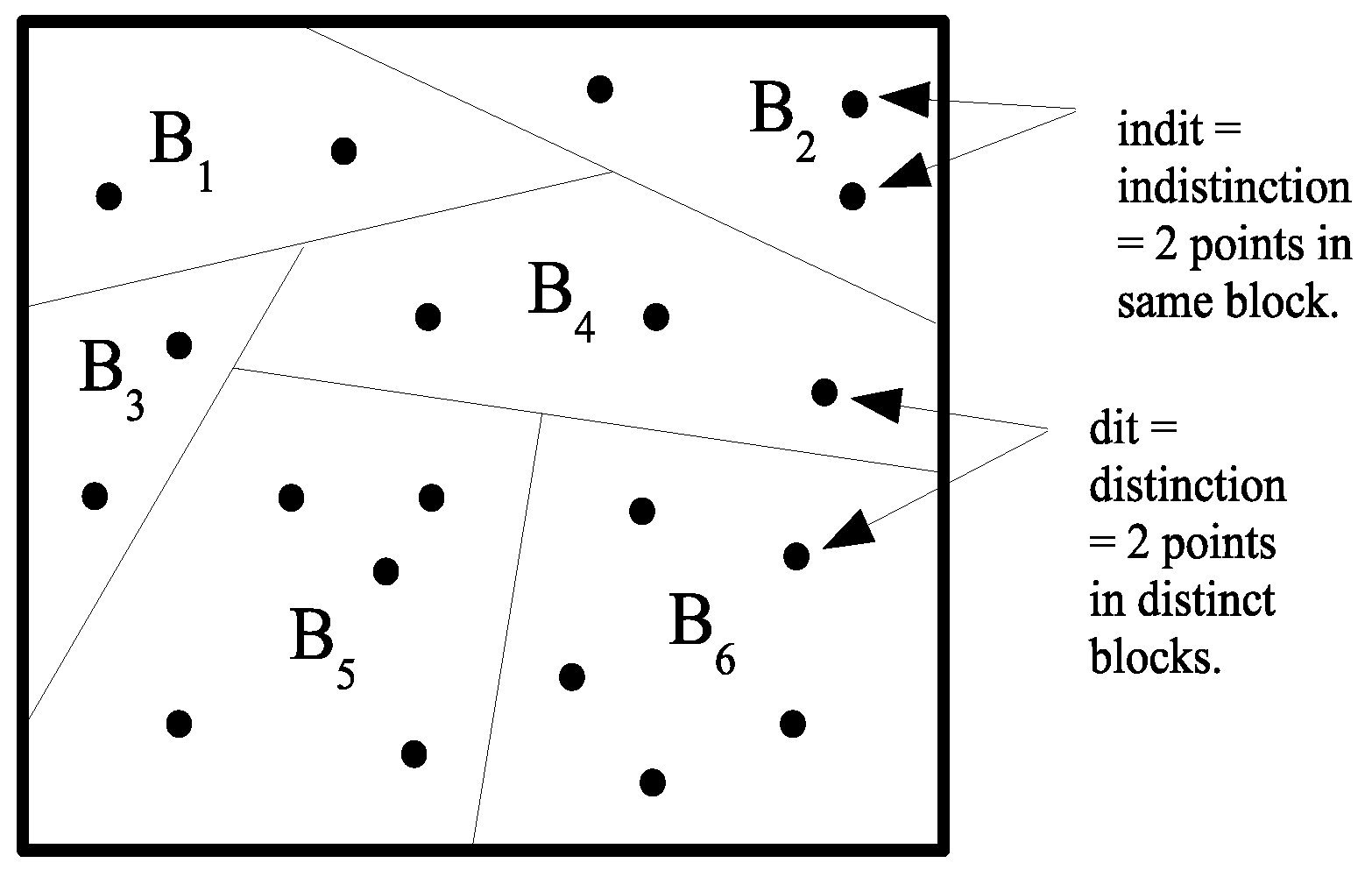
) In category theory, the duality between subobject-type constructions (e.g., limits) and quotient-object-type constructions (e.g., colimits) is often indicated by adding the prefix “co-” to the latter. Hence, the usual Boolean logic of “images” has the dual logic of “coimages”. However, the duality runs deeper than between subsets and partitions. The dual to the notion of an “element” (an “it”) of a subset is the notion of a “distinction” (a “dit”) of a partition, where
is a distinction or dit of
if the two elements are in different blocks. Let
be the set of distinctions or
ditset of
. Similarly an
indistinction or
indit of
is a pair
in the same block of
. Let
be the set of indistinctions or
inditset of
. Then,
is the equivalence relation associated with
, and
is the complementary binary relation that might be called
apartition relation or an
a partness relation. The notions of a distinction and indistinction of a partition are illustrated in
Figure 1.
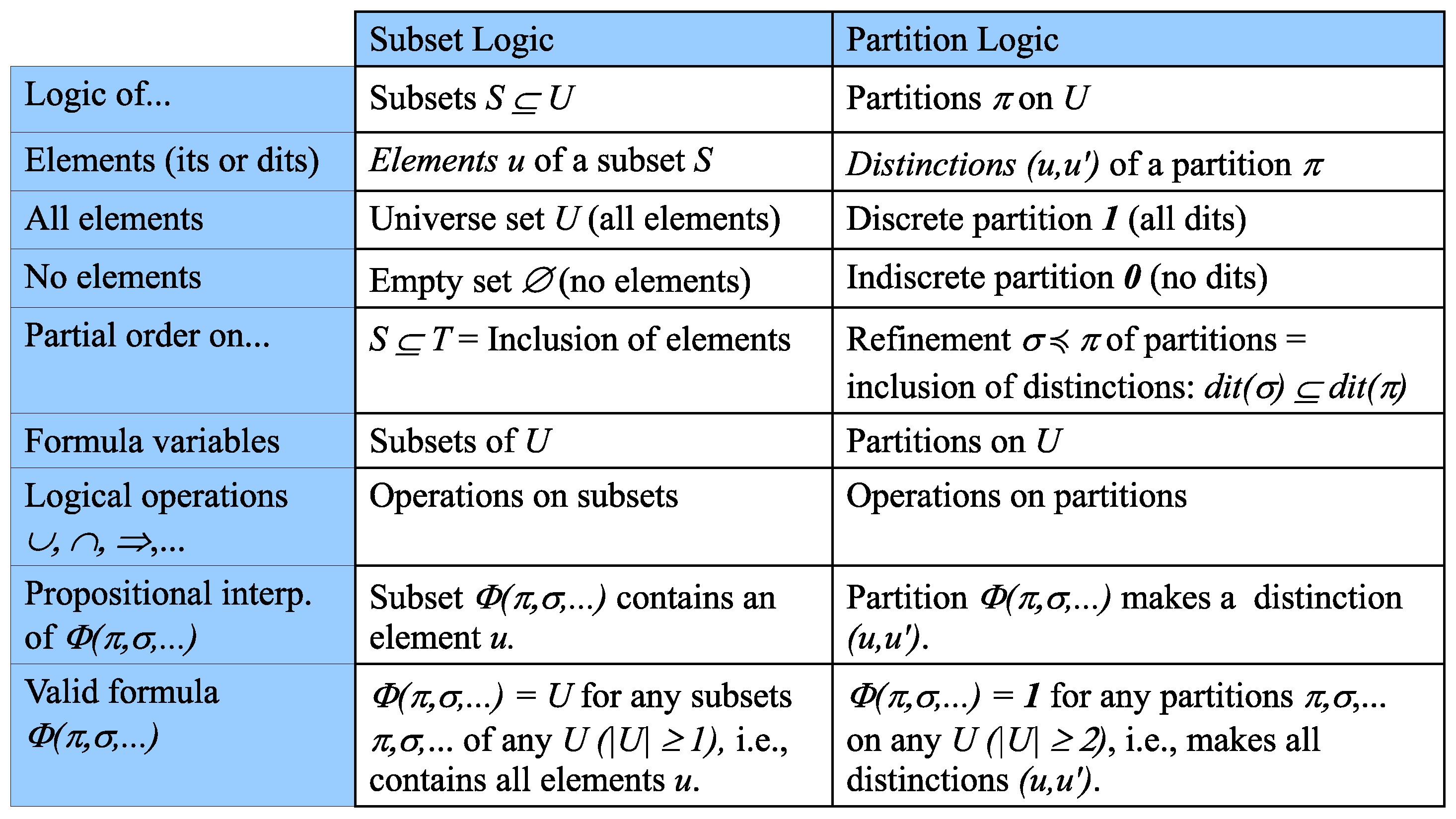
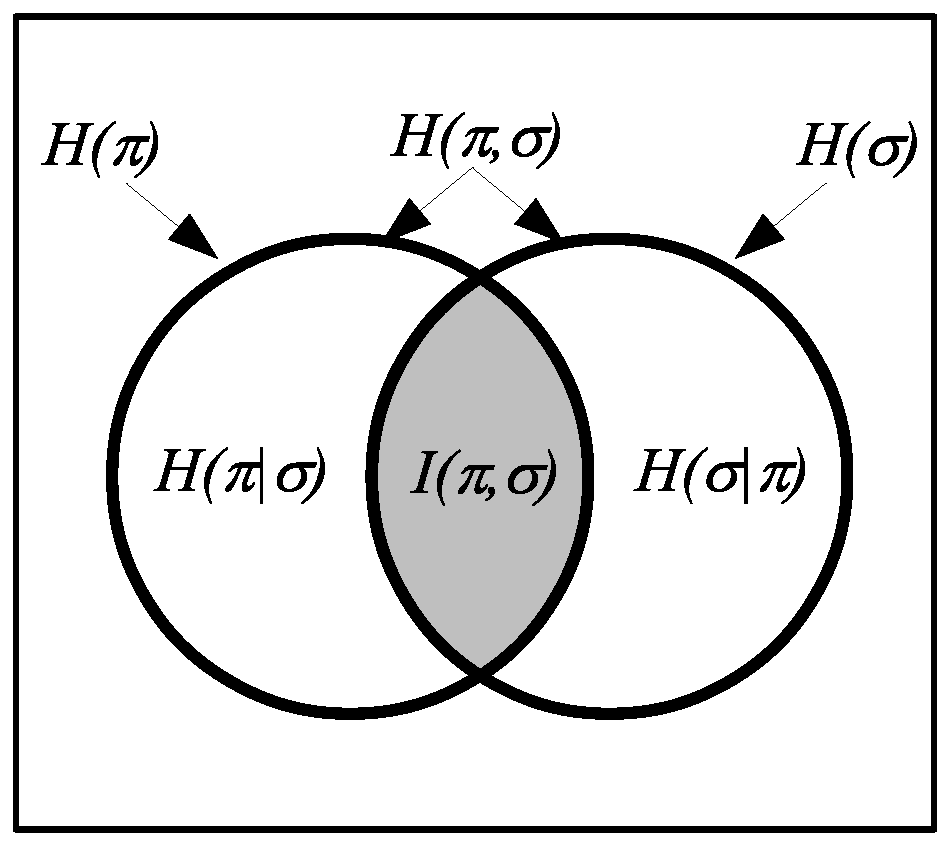
The relationships between Boolean subset logic and partition logic are summarized in
Figure 2, which illustrates the dual relationship between the elements (“its”) of a subset and the distinctions (“dits”) of a partition.
3. From the Logic of Partitions to Logical Information Theory
In Gian-Carlo Rota’s Fubini Lectures [
6] (and in his lectures at MIT), he remarked in view of duality between partitions and subsets that, quantitatively, the “lattice of partitions plays for information the role that the Boolean algebra of subsets plays for size or probability” ([
7] p. 30) or symbolically:
Andrei Kolmogorov has suggested that information theory should start with sets, not probabilities.
Information theory must precede probability theory, and not be based on it. By the very essence of this discipline, the foundations of information theory have a finite combinatorial character.
The notion of information-as-distinctions does start with the
set of distinctions, the
information set, of a partition
on a finite set
U where that set of distinctions (dits) is:
The normalized size of a subset is the logical probability of the event, and the normalized size of the ditset of a partition is, in the sense of measure theory, the measure of the amount of information in a partition. Thus, we define the
logical entropy of a partition
, denoted
, as the size of the ditset
normalized by the size of
:
In two independent draws from U, the probability of getting a distinction of is the probability of not getting an indistinction.
Given any probability measure
on
, which defines
for
, the
product measure has for any binary relation
the value of:
The
logical entropy of
in general is the product-probability measure of its ditset
, where
:
The standard interpretation of is the two-draw probability of getting a distinction of the partition , just as is the one-draw probability of getting an element of the subset-event S.
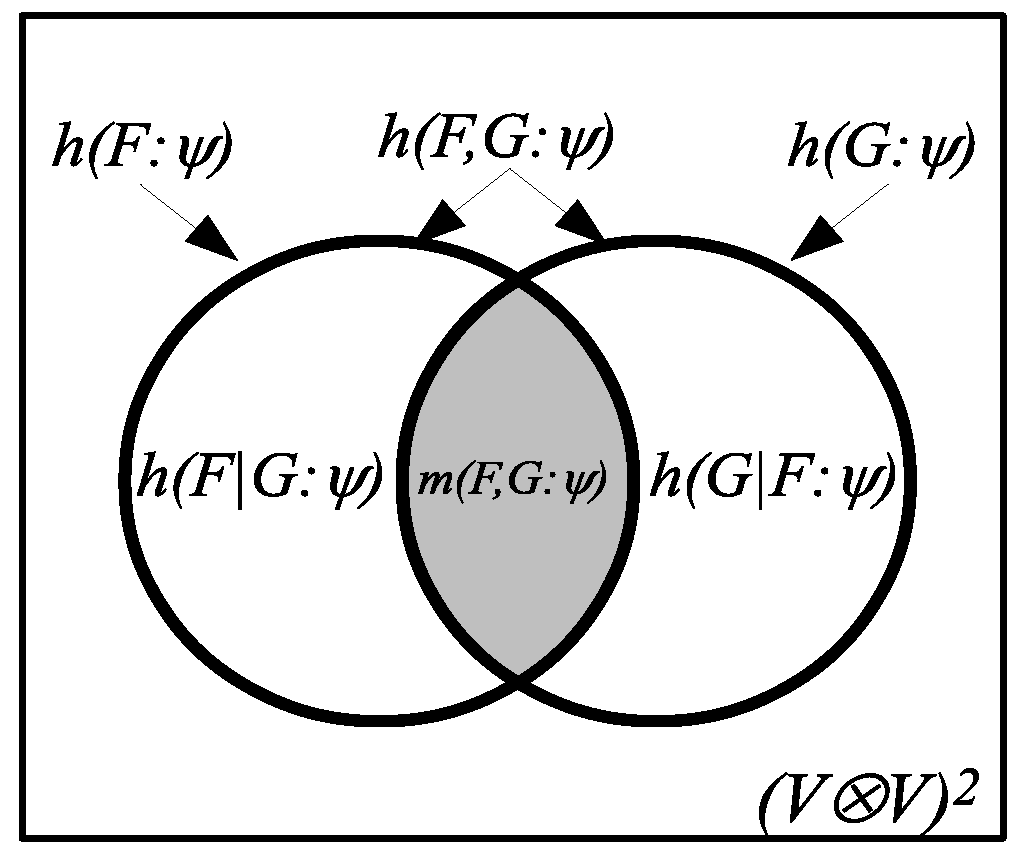
4. Compound Logical Entropies
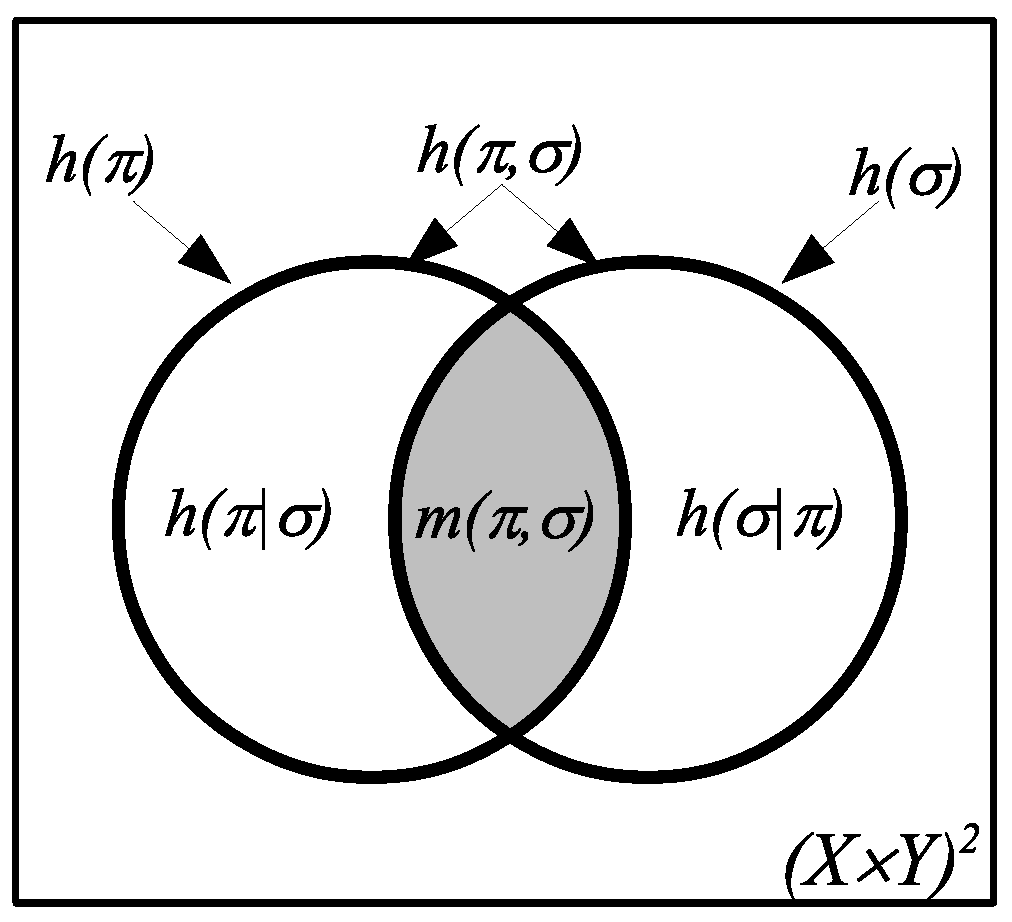
The compound notions of logical entropy are also developed in two stages, first as sets and then, given a probability distribution, as two-draw probabilities. After observing the similarity between the formulas holding for the compound Shannon entropies and the Venn diagram formulas that hold for any measure (in the sense of measure theory), the information theorist, Lorne L. Campbell, remarked in 1965 that the similarity:
suggests the possibility that and are measures of sets, that is the measure of their union, that is the measure of their intersection, and that is the measure of their difference. The possibility that is the entropy of the “intersection” of two partitions is particularly interesting. This “intersection,” if it existed, would presumably contain the information common to the partitions and .
Yet, there is no such interpretation of the Shannon entropies as measures of sets, but the logical entropies precisely fulfill Campbell’s suggestion (with the “intersection” of two partitions being the intersection of their ditsets). Moreover, there is a uniform requantifying transformation (see the next section) that obtains all the Shannon definitions from the logical definitions and explains how the Shannon entropies can satisfy the Venn diagram formulas (e.g., as a mnemonic) while not being defined by a measure on sets.
Given partitions
and
on
U, the
joint information set is the union of the ditsets, which is also the
ditset for their join:
. Given probabilities
on
U, the
joint logical entropy is the product probability measure on the union of ditsets:
The information set for the
conditional logical entropy is the difference of ditsets, and thus, that logical entropy is:
The information set for the
logical mutual information is the intersection of ditsets, so that logical entropy is:
Since all the logical entropies are the values of a measure
on subsets of
, they automatically satisfy the usual Venn diagram relationships as in
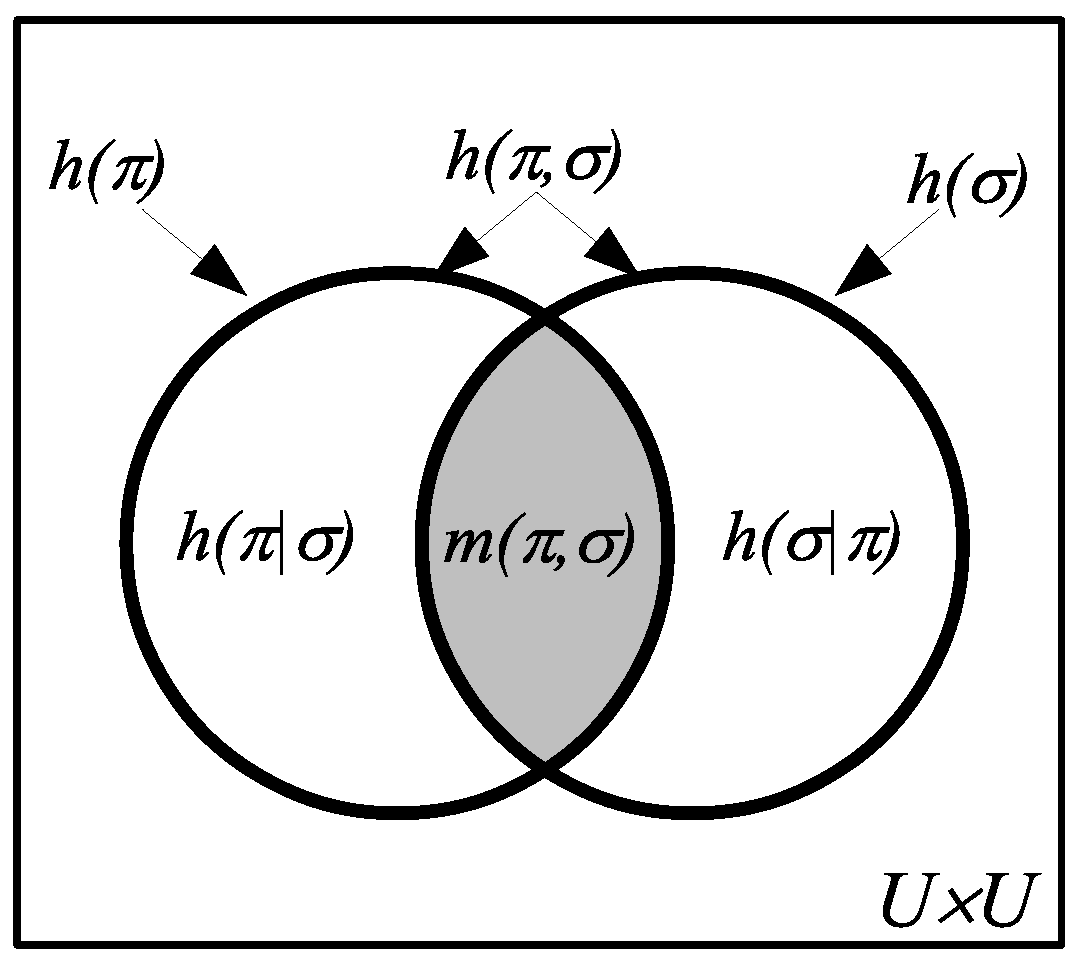
Figure 3.
At the level of information sets (w/o probabilities), we have the information algebra , which is the Boolean subalgebra of generated by ditsets and their complements.
5. Deriving the Shannon Entropies from the Logical Entropies
Instead of being defined as the values of a measure, the usual notions of simple and compound entropy ‘burst forth fully formed from the forehead’ of Claude Shannon [
10] already satisfying the standard Venn diagram relationships (one author surmised that “Shannon carefully contrived for this ‘accident’ to occur” ([
11] p. 153)). Since the Shannon entropies are not the values of a measure, many authors have pointed out that these Venn diagram relations for the Shannon entropies can only be taken as “analogies” or “mnemonics” ([
9,
12]). Logical information theory explains this situation since all the Shannon definitions of simple, joint, conditional and mutual information can be obtained by a uniform requantifying transformation from the corresponding logical definitions, and the transformation preserves the Venn diagram relationships.
This transformation is possible since the logical and Shannon notions of entropy can be seen as two different ways to quantify distinctions; and thus, both theories are based on the foundational idea of information-as-distinctions.
Consider the canonical case of
n equiprobable elements,
. The logical entropy of
=
where
with
is:
The normalized number of distinctions or ‘dit-count’ of the discrete partition
is
. The general case of logical entropy for any
is the average of the dit-counts
for the canonical cases:
In the canonical case of
equiprobable elements, the minimum number of binary partitions (“yes-or-no questions” or “bits”) whose join is the discrete partition
with
, i.e., that it takes to uniquely encode each distinct element, is
n, so the Shannon–Hartley entropy [
13] is the canonical bit-count:
The general case of Shannon entropy is the average of these canonical bit-counts
:
The
dit-bit transform essentially replaces the canonical dit-counts by the canonical bit-counts. First, express any logical entropy concept (simple, joint, conditional or mutual) as an average of canonical dit-counts
, and then, substitute the canonical bit-count
to obtain the corresponding formula as defined by Shannon.
Figure 4 gives examples of the dit-bit transform.
For instance,
is the expression for
as an average over
and
, so applying the dit-bit transform gives:
The dit-bit transform is linear in the sense of preserving plus and minus, so the Venn diagram formulas, e.g.,
, which are automatically satisfied by logical entropy since it is a measure, carry over to Shannon entropy, e.g.,
as in
Figure 5, in spite of it not being a measure (in the sense of measure theory):
6. Logical Entropy via Density Matrices
The transition to quantum logical entropy is facilitated by reformulating the classical logical theory in terms of density matrices. Let be the sample space with the point probabilities . An event has the probability .
For any event
S with
, let:
(the superscript
t indicates transpose) which is a normalized column vector in
where
is the characteristic function for
S, and let
be the corresponding row vector. Since
is normalized,
. Then, the
density matrix representing the event
S is the
symmetric real matrix:
Then, , so borrowing language from quantum mechanics, is said to be a pure state density matrix.
Given any partition
on
U, its density matrix is the average of the block density matrices:
Then,
represents the
mixed state, experiment or lottery where the event
occurs with probability
. A little calculation connects the logical entropy
of a partition with the density matrix treatment:
where
is substituted for
and the trace is substituted for the summation.
For the throw of a fair die, (note the odd faces ordered before the even faces in the matrix rows and columns) where represents the number j coming up, the density matrix is the “pure state” matrix with each entry being .
The nonzero off-diagonal entries represent indistinctions or indits of the partition or, in quantum terms, “coherences” where all 6 “eigenstates” cohere together in a pure “superposition” state. All pure states have a logical entropy of zero, i.e., (i.e., no dits) since for any density matrix, so if , then and .
The logical operation of classifying undistinguished entities (like the six faces of the die before a throw to determine a face up) by a numerical attribute makes distinctions between the entities with different numerical values of the attribute. Classification (also called sorting, fibering or partitioning ([
14] Section 6.1)) is the classical operation corresponding to the quantum operation of “measurement” of a superposition state by an observable to obtain a mixed state.
Now classify or “measure” the die-faces by the parity-of-the-face-up (odd or even) partition (observable)
. Mathematically, this is done by the Lüders mixture operation ([
15] p. 279), i.e., pre- and post-multiplying the density matrix
by
and by
, the projection matrices to the odd or even components, and summing the results:
Theorem 1 (
Fundamental(classical))
. The increase in logical entropy, , due to a Lüders mixture operation is the sum of amplitudes squared of the non-zero off-diagonal entries of the beginning density matrix that are zeroed in the final density matrix.
Proof. Since for any density matrix
,
([
16] p. 77), we have:
, if
, then and only then are the off-diagonal terms corresponding to
and
zeroed by the Lüders operation. ☐
The classical fundamental theorem connects the concept of information-as-distinctions to the process of “measurement” or classification, which uses some attribute (like parity in the example) or “observable” to make distinctions.
In the comparison with the matrix of all entries , the entries that got zeroed in the Lüders operation correspond to the distinctions created in the transition = , i.e., the odd-numbered faces were distinguished from the even-numbered faces by the parity attribute. The increase in logical entropy = sum of the squares of the off-diagonal elements that were zeroed = . The usual calculations of the two logical entropies are: and .
Since, in quantum mechanics, a projective measurement’s effect on a density matrix is the Lüders mixture operation, that means that the effects of the measurement are the above-described “making distinctions” by decohering or zeroing certain coherence terms in the density matrix, and the sum of the absolute squares of the coherences that were decohered is the increase in the logical entropy.
7. Quantum Logical Information Theory: Commuting Observables
The idea of information-as-distinctions carries over to quantum mechanics.
[Information] is the notion of distinguishability abstracted away from what we are distinguishing, or from the carrier of information. …And we ought to develop a theory of information which generalizes the theory of distinguishability to include these quantum properties…
Let be a self-adjoint operator (observable) on a n-dimensional Hilbert space V with the real eigenvalues , and let be an orthonormal (ON) basis of eigenvectors of F. The quantum version of a dit, a qudit, is a pair of states definitely distinguishable by some observable. Any nondegenerate self-adjoint operator such as , where is the projection to the one-dimensional subspace generated by , will distinguish all the vectors in the orthonormal basis U, which is analogous classically to a pair of distinct elements of U that are distinguishable by some partition (i.e., ). In general, a qudit is relativized to an observable, just as classically a distinction is a distinction of a partition. Then, there is a set partition on the ON basis U so that is a basis for the eigenspace of the eigenvalue and is the “multiplicity” (dimension of the eigenspace) of the eigenvalue for . Note that the real-valued function takes each eigenvector in to its eigenvalue so that contains all the information in the self-adjoint operator since F can be reconstructed by defining it on the basis U as .
The generalization of “classical” logical entropy to quantum logical entropy is straightforward using the usual ways that set-concepts generalize to vector-space concepts: subsets → subspaces, set partitions → direct-sum decompositions of subspaces (hence the “classical” logic of partitions on a set will generalize to the quantum logic of direct-sum decompositions [
18] that is the dual to the usual quantum logic of subspaces), Cartesian products of sets → tensor products of vector spaces and ordered pairs
basis elements
. The eigenvalue function
determines a partition
on
U, and the blocks in that partition generate the eigenspaces of
F, which form a direct-sum decomposition of
V.
Classically, a dit of the partition on U is a pair of points in distinct blocks of the partition, i.e., . Hence, a qudit of F is a pair (interpreted as in the context of ) of vectors in the eigenbasis definitely distinguishable by F, i.e., , distinct F-eigenvalues. Let be another self-adjoint operator on V, which commutes with F so that we may then assume that U is an orthonormal basis of simultaneous eigenvectors of F and G. Let be the set of eigenvalues of G, and let be the eigenvalue function so a pair is a qudit ofG if , i.e., if the two eigenvectors have distinct eigenvalues of G.
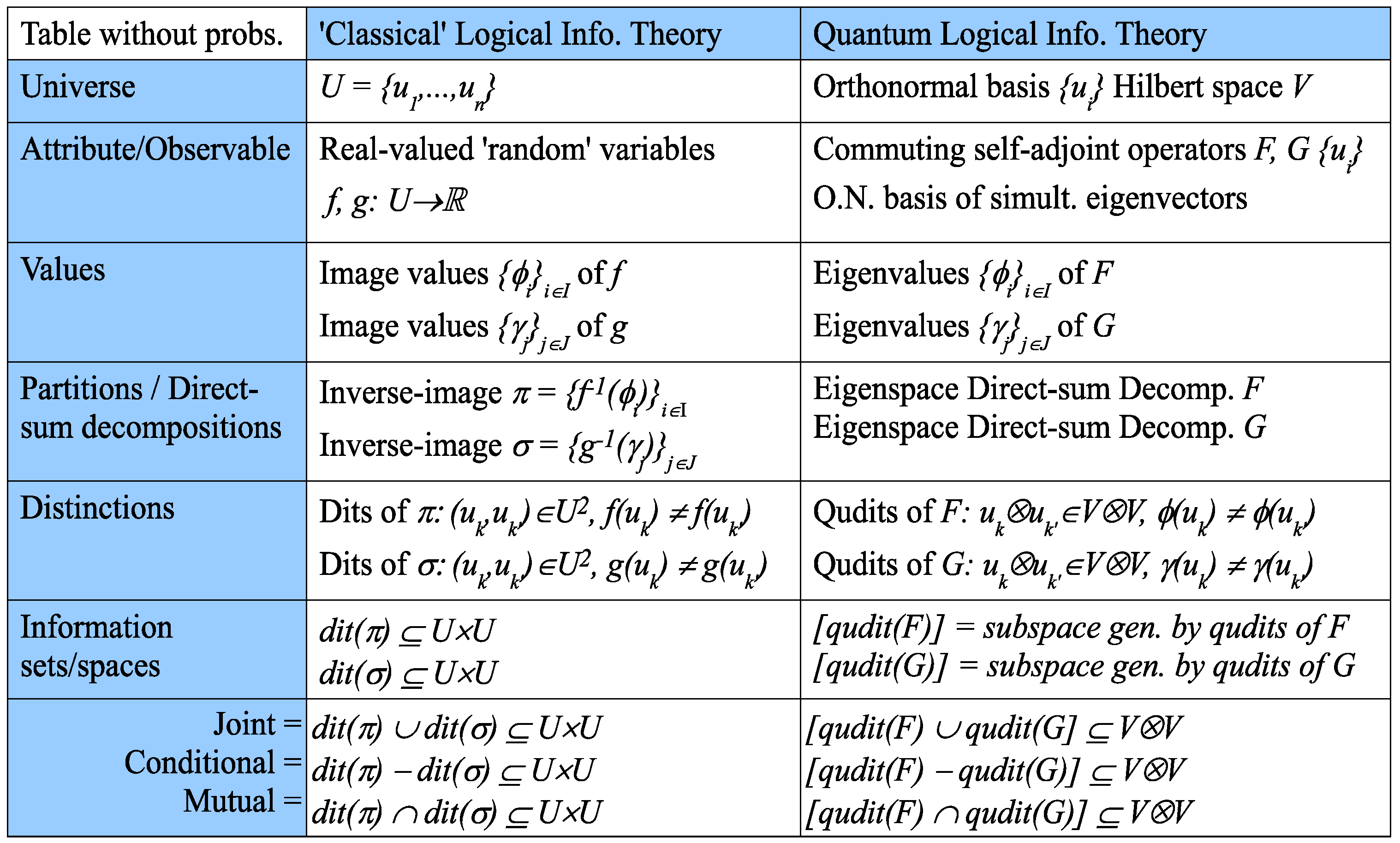
As in classical logical information theory, information is represented by certain subsets (or, in the quantum case, subspaces) prior to the introduction of any probabilities. Since the transition from classical to quantum logical information theory is straightforward, it will be presented in table form in
Figure 6 (which does not involve any probabilities), where the qudits
are interpreted as
.
The
information subspace associated with
F is the subspace
generated by the qudits
of
F. If
is a scalar multiple of the identity
I, then it has no qudits, so its information space
is the zero subspace. It is an easy implication of the common dits theorem of classical logical information theory (([
19] (Proposition 1)) or ([
5] (Theorem 1.4))) that any two nonzero information spaces
and
have a nonzero intersection, i.e., have a nonzero mutual information space. That is, there are always two eigenvectors
and
that have different eigenvalues both by
F and by
G.
In a measurement, the observables do not provide the point probabilities; they come from the pure (normalized) state
being measured. Let
be the resolution of
in terms of the orthonormal basis
of simultaneous eigenvectors for
F and
G. Then,
(
is the complex conjugate of
) for
are the point probabilities on
U, and the pure state density matrix
(where
is the conjugate-transpose) has the entries:
, so the diagonal entries
are the point probabilities.
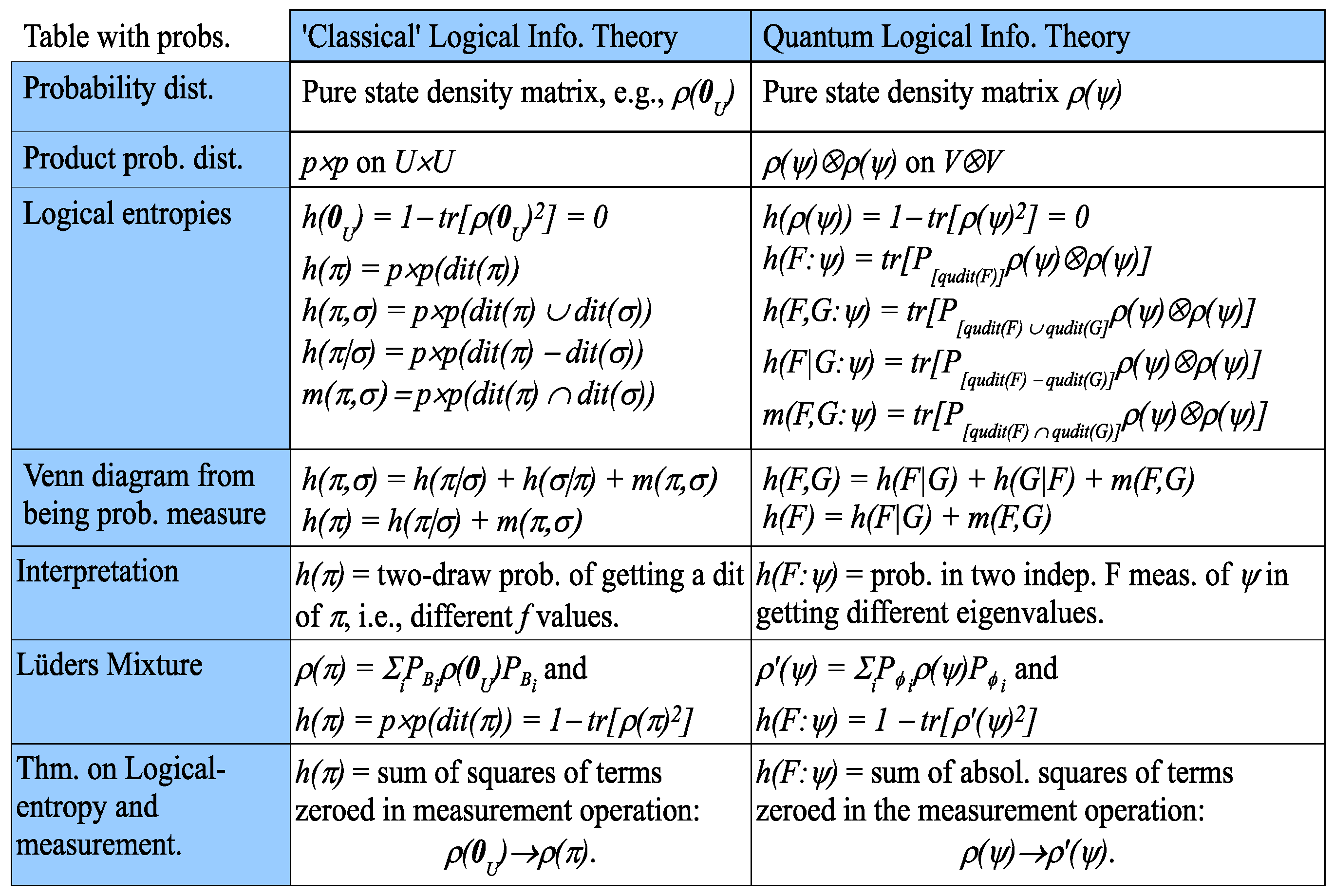
Figure 7 gives the remaining parallel development with the probabilities provided by the pure state
where we write
as
.
The formula
is hardly new. Indeed,
is usually called the
purity of the density matrix since a state
is
pure if and only if
, so
, and otherwise,
, so
; and the state is said to be
mixed. Hence, the complement
has been called the “mixedness” ([
20] p. 5) or “impurity” of the state
. The seminal paper of Manfredi and Feix [
21] approaches the same formula
(which they denote as
) from the viewpoint of Wigner functions, and they present strong arguments for this notion of quantum entropy (thanks to a referee for this important reference to the Manfredi and Feix paper). This notion of quantum entropy is also called by the misnomer “linear entropy” even though it is quadratic in
, so we will not continue that usage. See [
22] or [
23] for references to that literature. The logical entropy is also the quadratic special case of the Tsallis–Havrda–Charvat entropy ([
24,
25]) and the logical distance special case [
19] of C. R. Rao’s quadratic entropy [
26].
What is new here is not the formula, but the whole back story of partition logic outlined above, which gives the logical notion of entropy arising out of partition logic as the normalized counting measure on ditsets of partitions; just as logical probability arises out of Boolean subset logic as the normalized counting measure on subsets. The basic idea of information is differences, distinguishability and distinctions ([
3,
19]), so the logical notion of entropy is the measure of the distinctions or dits of a partition, and the corresponding quantum version is the measure of the qudits of an observable.
8. Two Theorems about Quantum Logical Entropy
Classically, a pair of elements
either “cohere” together in the same block of a partition on
U, i.e., are an indistinction of the partition, or they do not, i.e., they are a distinction of the partition. In the quantum case, the nonzero off-diagonal entries
in the pure state density matrix
are called quantum “coherences” ([
27] p. 303; [
15] p. 177) because they give the amplitude of the eigenstates
and
“cohering” together in the coherent superposition state vector
. The coherences are classically modeled by the nonzero off-diagonal entries
for the indistinctions
, i.e., coherences ≈ indistinctions.
For an observable
F, let
be for
F-eigenvalue function assigning the eigenvalue
for each
in the ON basis
of
F-eigenvectors. The range of
is the set of
F-eigenvalues
. Let
be the projection matrix in the
U-basis to the eigenspace of
. The projective
F-measurement of the state
transforms the pure state density matrix
(represented in the ON basis
U of
F-eigenvectors) to yield the Lüders mixture density matrix
([
15] p. 279). The off-diagonal elements of
that are zeroed in
are the coherences (quantum indistinctions or
quindits) that are turned into “decoherences” (quantum distinctions or qudits of the observable being measured).
For any observable F and a pure state , a quantum logical entropy was defined as . That definition was the quantum generalization of the “classical” logical entropy defined as . When a projective F-measurement is performed on , the pure state density matrix is transformed into the mixed state density matrix by the quantum Lüders mixture operation, which then defines the quantum logical entropy . The first test of how the quantum logical entropy notions fit together is showing that these two entropies are the same: . The proof shows that they are both equal to classical logical entropy of the partition defined on the ON basis of F-eigenvectors by the F-eigenvalues with the point probabilities . That is, the inverse images of the eigenvalue function define the eigenvalue partition on the ON basis with the point probabilities provided by the state for . The classical logical entropy of that partition is: where .
We first show that
. Now,
, and
is the subspace of
generated by it. The
pure state density matrix
has the entries
, and
is an
matrix. The projection matrix
is an
diagonal matrix with the diagonal entries, indexed by
:
if
and zero otherwise. Thus, in the product
, the nonzero diagonal elements are the
where
, and so, the trace is
, which by definition, is
. Since
,
. By grouping the
in the trace according to the blocks of
, we have:
.
To show that
for
, we need to compute
. An off-diagonal element in
of
survives (i.e., is not zeroed and has the same value) the Lüders operation if and only if
. Hence, the
j-th diagonal element of
is:
where
. Then, grouping the
j-th diagonal elements for
gives
. Hence, the whole trace is:
, and thus:
This completes the proof of the following theorem.
Theorem 2. .
Measurement creates distinctions, i.e., turns coherences into “decoherences”, which, classically, is the operation of distinguishing elements by classifying them according to some attribute like classifying the faces of a die by their parity. The fundamental theorem about quantum logical entropy and projective measurement, in the density matrix version, shows how the quantum logical entropy created (starting with for the pure state ) by the measurement can be computed directly from the coherences of that are decohered in .
Theorem 3 (
Fundamental (quantum))
. The increase in quantum logical entropy, , due to the F-measurement of the pure state ψ, is the sum of the absolute squares of the nonzero off-diagonal terms (coherences) in (represented in an ON basis of F-eigenvectors) that are zeroed (‘decohered’) in the post-measurement Lüders mixture density matrix .
Proof. . If and are a qudit of F, then and only then are the corresponding off-diagonal terms zeroed by the Lüders mixture operation to obtain from . ☐
Density matrices have long been a standard part of the machinery of quantum mechanics. The fundamental theorem for logical entropy and measurement shows there is a simple, direct and quantitative connection between density matrices and logical entropy. The theorem directly connects the changes in the density matrix due to a measurement (sum of absolute squares of zeroed off-diagonal terms) with the increase in logical entropy due to the F-measurement (where for the pure state ).
This direct quantitative connection between state discrimination and quantum logical entropy reinforces the judgment of Boaz Tamir and Eliahu Cohen ([
28,
29]) that quantum logical entropy is a natural and informative entropy concept for quantum mechanics.
We find this framework of partitions and distinction most suitable (at least conceptually) for describing the problems of quantum state discrimination, quantum cryptography and in general, for discussing quantum channel capacity. In these problems, we are basically interested in a distance measure between such sets of states, and this is exactly the kind of knowledge provided by logical entropy [Reference to [
19]].
Moreover, the quantum logical entropy has a simple “two-draw probability” interpretation, i.e.,
is the probability that two independent
F-measurements of
will yield distinct
F-eigenvalues, i.e., will yield a qudit of
F. In contrast, the von Neumann entropy has no such simple interpretation, and there seems to be no such intuitive connection between pre- and post-measurement density matrices and von Neumann entropy, although von Neumann entropy also increases in a projective measurement ([
30] Theorem 11.9, p. 515).
The development of the quantum logical concepts for two non-commuting operators (see
Appendix B) is the straightforward vector space version of the classical logical entropy treatment of partitions on two set
X and
Y (see
Appendix A).
9. Quantum Logical Entropies of Density Operators
The extension of the classical logical entropy of a probability distribution to the quantum case is where a density matrix replaces the probability distribution p and the trace replaces the summation.
An arbitrary density operator , representing a pure or mixed state on V, is also a self-adjoint operator on V, so quantum logical entropies can be defined where density operators play the double role of providing the measurement basis (as self-adjoint operators), as well as the state being measured.
Let and be two non-commuting density operators on V. Let be an orthonormal (ON) basis of eigenvectors, and let be the corresponding eigenvalues, which must be non-negative and sum to one, so they can be interpreted as probabilities. Let be an ON basis of eigenvectors for , and let be the corresponding eigenvalues, which are also non-negative and sum to one.
Each density operator plays a double role. For instance, acts as the observable to supply the measurement basis of and the eigenvalues , as well as being the state to be measured supplying the probabilities for the measurement outcomes. In this section, we define quantum logical entropies using the discrete partition on the set of “index” states and similarly for the discrete partition on , the ON basis of eigenvectors for .
The qudit sets of are then defined according to the identity and difference on the index sets and independent of the eigenvalue-probabilities, e.g., . The, n the qudit subspaces are the subspaces of generated by the qudit sets of generators:
;
;
;
;
; and
.
Then, as qudit sets: , and the corresponding qudit subspaces stand in the same relation where the disjoint union is replaced by the disjoint sum.
The density operator is represented by the diagonal density matrix in its own ON basis X with and similarly for the diagonal density matrix with . The density operators on V define a density operator on with the ON basis of eigenvectors and the eigenvalue-probabilities of . The operator is represented in its ON basis by the diagonal density matrix with diagonal entries where . The probability measure on defines the product measure on where it can be applied to the qudit subspaces to define the quantum logical entropies as usual.
In the first instance, we have:
and similarly
. Since all the data are supplied by the two density operators, we can use simplified notation to define the corresponding joint, conditional and mutual entropies:
;
;
; and
.
Then, the usual Venn diagram relationships hold for the probability measure
on
, e.g.,
and probability interpretations are readily available. There are two probability distributions
and
on the sample space
. Two pairs
and
are drawn with replacement; the first entry in each pair is drawn according to
and the second entry according to
. Then,
is the probability that
or
(or both);
is the probability that
and
, and so forth. Note that this interpretation assumes no special significance to a
and
having the same index since we are drawing a pair of pairs.
In the classical case of two probability distributions and on the same index set, the logical cross-entropy is defined as: and interpreted as the probability of getting different indices in drawing a single pair, one from p and the other from q. However, this cross-entropy assumes some special significance to and having the same index. However, in our current quantum setting, there is no correlation between the two sets of “index” states and . However, when the two density operators commute, , then we can take as an ON basis of simultaneous eigenvectors for the two operators with respective eigenvalues and for with . In that special case, we can meaningfully define the quantum logical cross-entropy as , but the general case awaits further analysis below.
10. The Logical Hamming Distance between Two Partitions
The development of logical quantum information theory in terms of some given commuting or non-commuting observables gives an analysis of the distinguishability of quantum states using those observables. Without any given observables, there is still a natural logical analysis of the distance between quantum states that generalizes the “classical” logical distance between partitions on a set. In the classical case, we have the logical entropy of a partition where the partition plays the role of the direct-sum decomposition of eigenspaces of an observable in the quantum case. However, we also have just the logical entropy of a probability distribution and the related compound notions of logical entropy given another probability distribution indexed by the same set.
First, we review that classical treatment to motivate the quantum version of the logical Hamming distance between states. A binary relation
on
can be represented by an
incidence matrix where:
Taking
R as the equivalence relation
associated with a partition
, the
density matrix of the partition (with equiprobable points) is just the incidence matrix
rescaled to be of trace one (i.e., the sum of diagonal entries is one):
From coding theory ([
31] p. 66), we have the notion of the
Hamming distance between two vectors or matrices (of the same dimensions), which is the number of places where they differ. Since logical information theory is about distinctions and differences, it is important to have a classical and quantum logical notion of Hamming distance. The powerset
can be viewed as a vector space over
where the sum of two binary relations
is the symmetric difference, symbolized as
, which is the set of elements (i.e., ordered pairs
) that are in one set or the other, but not both. Thus, the Hamming distance
between the incidence matrices of two binary relations is just the cardinality of their symmetric difference:
. Moreover, the size of the symmetric difference does not change if the binary relations are replaced by their complements:
.
Hence, given two partitions
and
on
U, the unnormalized Hamming distance between the two partitions is naturally defined as (this is investigated in Rossi [
32]):
and the
Hamming distance between and
is defined as the normalized
:
This motivates the general case of point probabilities
where we define the
Hamming distance between the two partitions as the sum of the two logical conditional entropies:
To motivate the bridge to the quantum version of the Hamming distance, we need to calculate it using the density matrices and of the two partitions. To compute the trace , we compute the diagonal elements in the product and add them up: where the only nonzero terms are where for some and . Thus, if , then . Therefore, the diagonal element for is the sum of the for in the same intersection as , so it is . Then, when we sum over the diagonal elements, then for all the for any given , we just sum so that .
Hence, if we define the
logical cross-entropy of
and
as:
then for partitions on
U with the point probabilities
, the logical cross-entropy
of two partitions is the same as the logical joint entropy, which is also the logical entropy of the join:
Thus, we can also express the logical Hamming distance between two partitions entirely in terms of density matrices:
11. The Quantum Logical Hamming Distance
The quantum logical entropy of a density matrix generalizes the classical for a probability distribution . As a self-adjoint operator, a density matrix has a spectral decomposition where is an orthonormal basis for V and where all the eigenvalues are real, non-negative and . Then, so can be interpreted as the probability of getting distinct indices in two independent measurements of the state with as the measurement basis. Classically, it is the two-draw probability of getting distinct indices in two independent samples of the probability distribution , just as is the probability of getting distinct indices in two independent draws on p. For a pure state , there is one with the others zero, and is the probability of getting distinct indices in two independent draws on .
In the classical case of the logical entropies, we worked with the ditsets or sets of distinctions of partitions. However, everything could also be expressed in terms of the complementary sets of indits or indistinctions of partitions (ordered pairs of elements in the same block of the partition) since:
. When we switch to the density matrix treatment of “classical” partitions, then the focus shifts to the indistinctions. For a partition
, the logical entropy is the sum of the distinction probabilities:
, which in terms of indistinctions is:
When expressed in the density matrix formulation, then
is the sum of the indistinction probabilities:
The nonzero entries in have the form for ; their squares are the indistinction probabilities. That provides the interpretive bridge to the quantum case.
The quantum analogue of an indistinction probability is the absolute square of a nonzero entry in a density matrix , and is the sum of those “indistinction” probabilities. The nonzero entries in the density matrix might be called “coherences” so that may be interpreted as the amplitudes for the states and to cohere together in the state , so is the sum of the coherence probabilities, just as is the sum of the indistinction probabilities. The quantum logical entropy may then be interpreted as the sum of the decoherence probabilities, just as is the sum of the distinction probabilities.
This motivates the general quantum definition of the joint entropy
, which is the:
To work out its interpretation, we again take ON eigenvector bases
for
and
for
with
and
as the respective eigenvalues and compute the operation of
. Now,
so
, and then, for
, so
. Thus,
in the
basis would have the diagonal entries
, so the trace is:
which is symmetrical. The other information we have is the
, and they are non-negative. The classical logical cross-entropy of two probability distributions is
, where two indices
i and
j are either identical or totally distinct. However, in the quantum case, the “index” states
and
have an “overlap” measured by the inner product
. The trace
is real since
and
is the probability of getting
when measuring
in the
basis and the probability of getting
when measuring
in the
basis. The twofold nature of density matrices as states and as observables then allows
to be interpreted as the average value of the observable
when measuring the state
or vice versa.
We may call
the
proportion or
extent of overlap for those two index states. Thus,
is the sum of all the probability combinations
weighted by the overlaps
for the index states
and
. The quantum logical cross-entropy can be written in a number of ways:
.
Classically, the “index state”
completely overlaps with
when
and has no overlap with any other
from the indices
, so the “overlaps” are, as it were,
, the Kronecker delta. Hence, the classical analogue formulas are:
The quantum logical cross-entropy
can be interpreted by considering two measurements, one of
with the
measurement basis and the other of
with the
measurement basis. If the outcome of the
measurement was
with probability
, then the outcome of the
measurement is different than
with probability
; however, that distinction probability
is only relevant to the extent that
and
are the “same state” or overlap, and that extent is
. Hence, the quantum logical cross-entropy is the sum of those two-measurement distinction probabilities weighted by the extent that the states overlap. The interpretation of
and
, as well as the later development of the quantum logical conditional entropy
and the quantum Hamming distance
are all based on using the eigenvectors and eigenvalues of density matrices, which Michael Nielsen and Issac Chuang seem to prematurely dismiss as having little or no “special significance” ([
30] p. 103).
When the two density matrices commute, , then (as noted above) we have the essentially classical situation of one set of index states which is an orthonormal basis set of simultaneous eigenvectors for both and with the respective eigenvalues and . Then, , so is the probability of getting two distinct index states and for in two independent measurements, one of and one of in the same measurement basis of . This interpretation includes the special case when and .
We saw that classically, the logical Hamming distance between two partitions could be defined as:
so this motivates the quantum definition. Nielsen and Chuang suggest the idea of a Hamming distance between quantum states, only to then dismiss it. “Unfortunately, the Hamming distance between two objects is simply a matter of labeling, and a priori there are not any labels in the Hilbert space arena of quantum mechanics!” ([
30] p. 399). They are right that there is no correlation, say, between the vectors in the two ON bases
and
for
V, but the cross-entropy
uses all possible combinations in the terms
; thus, the definition of the Hamming distance given below does not use any arbitrary labeling or correlations.
This is the definition of the quantum logical Hamming distance between two quantum states.
There is another distance measure between quantum states, namely the Hilbert–Schmidt norm, which has been recently investigated in [
29] (with an added
factor). It is the square of the Euclidean distance between the quantum states, and ignoring the
factor, it is the square of the “trace distance” ([
30] Chapter 9) between the states.
where we write
for
. Then, the naturalness of this norm as a “distance” is enhanced by the fact that it is the same as the quantum Hamming distance:
Theorem 4. Hilbert–Schmidt norm = quantum logical Hamming distance.
Proof. ☐
Hence, the
information inequality holds trivially for the quantum logical Hamming distance:
The fundamental theorem can be usefully restated in this broader context of density operators instead of in terms of the density matrix represented in the ON basis for F-eigenvectors. Let be any state to be measured by an observable F, and let be the result of applying the Lüders mixture operation (where the are the projection operators to the eigenspaces of F). Then, a natural question to ask is the Hilbert–Schmidt norm or quantum logical Hamming distance between the pre- and post-measurement states. It might be noted that the Hilbert–Schmidt norm and the Lüders mixture operation are defined independently of any considerations of logical entropy.
Theorem 5 (
Fundamental (quantum))
. .
Proof. where , , and . Also using the orthogonality of the distinct projection operators. Then, using the idempotency of the projections and the cyclicity of the trace, so , and hence, . ☐
12. Results
Logical information theory arises as the quantitative version of the logic of partitions just as logical probability theory arises as the quantitative version of the dual Boolean logic of subsets. Philosophically, logical information is based on the idea of information-as-distinctions. The Shannon definitions of entropy arise naturally out of the logical definitions by replacing the counting of distinctions by the counting of the minimum number of binary partitions (bits) that are required, on average, to make all the same distinctions, i.e., to encode the distinguished elements uniquely, which is why the Shannon theory is so well adapted for the theory of coding and communication.
This “classical” logical information theory may be developed with the data of two partitions on a set with point probabilities.
Section 7 gives the generalization to the quantum case where the partitions are provided by two commuting observables (the point set is an ON basis of simultaneous eigenvectors), and the point probabilities are provided by the state to be measured. In
Section 8, the fundamental theorem for quantum logical entropy and measurement established a direct quantitative connection between the increase in quantum logical entropy due to a projective measurement and the eigenstates (cohered together in the pure superposition state being measured) that are distinguished by the measurement (decohered in the post-measurement mixed state). This theorem establishes quantum logical entropy as a natural notion for a quantum information theory focusing on distinguishing states.
The classical theory might also start with partitions on two different sets and a probability distribution on the product of the sets (see
Appendix A).
Appendix B gives the quantum generalization of that case with the two sets being two ON bases for two non-commuting observables, and the probabilities are provided by a state to be measured. The classical theory may also be developed just using two probability distributions indexed by the same set, and this is generalized to the quantum case where we are just given two density matrices representing two states in a Hilbert space.
Section 10 and
Section 11 carry over the Hamming distance measure from the classical to the quantum case where it is equal to the Hilbert–Schmidt distance (square of the trace distance). The general fundamental theorem relating measurement and logical entropy is that the Hilbert–Schmidt distance (=quantum logical Hamming distance) between any pre-measurement state
and the state
resulting from a projective measurement of the state is the difference in their logical entropies,
.
13. Discussion
The overall argument is that quantum logical entropy is the simple and natural notion of information-as-distinctions for quantum information theory focusing on the distinguishing of quantum states. These results add to the arguments already presented by Manfredi and Feix [
21] and many others (see [
23]) for this notion of quantum entropy.
There are two related classical theories of information, classical logical information theory (focusing on information-as-distinctions and analyzing classification) and the Shannon theory (focusing on coding and communications theory). Generalizing to the quantum case, there are also two related quantum theories of information, the logical theory (using quantum logical entropy to focus on distinguishing quantum states and analyzing measurement as the quantum version of classification) and the conventional quantum information theory (using von Neumann entropy to develop a quantum version of the Shannon treatment of coding and communications).


{kind=link}
{kind=link}
{kind=link}
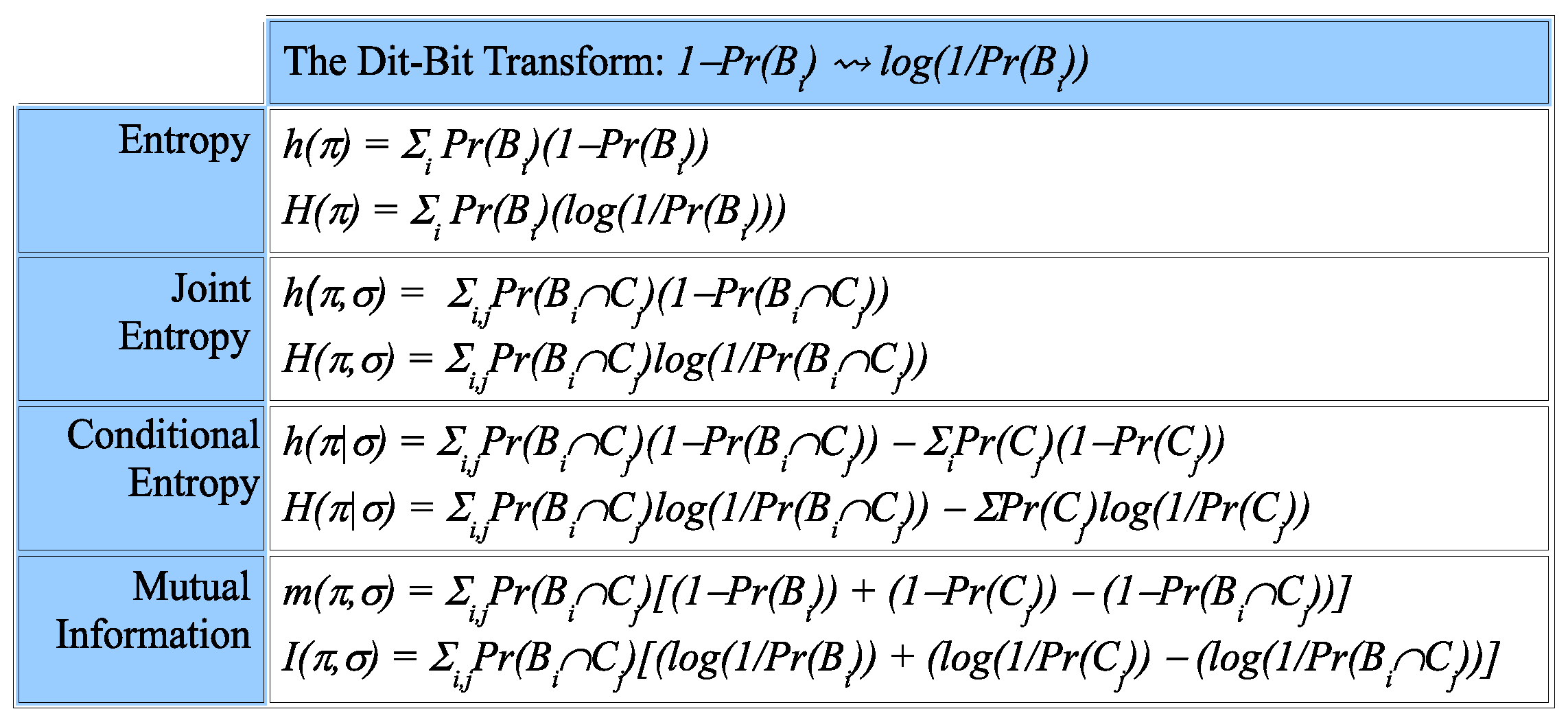{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








