1. Introduction
A drug-drug interaction (DDI) is a combined effect produced by taking two or more drugs at the same time or within a certain period of time. Adverse drug reactions (ADRs) may bring huge health risks and dangerous effects to a patient’s body [
1]. Therefore, increasing our understanding of unknown interactions between drugs is of great importance in order to reduce public health safety accidents. With the increasing research efforts of medical practitioners on DDIs, a large amount of valuable information is buried in a body of unstructured biomedical literature which is growing exponentially. Currently, many DDIs can be found in publicly available drug-related databases such as Drugbank [
2], PharmGKB [
3], Drug Interaction database [
4] and Stockley’s Drug Interactions [
5]. However, the most common way to update databases is still to rely on human experts; this is time-consuming and dependent on the availability of suitable experts who are able to find DDIs from many sources and keep up-to-date with the latest discoveries. Therefore, the automatic extraction of structured DDIs from the overwhelming amount of unstructured biomedical literature has become an urgent problem for researchers.
DDI extraction is a typical relation-extraction task in natural language processing (NLP). Early DDI extraction was relatively rare due to the lack of annotated gold standard corpora. In recent years, with the success of the DDIExtraction 2011 [
6] and DDIExtraction 2013 [
7] challenges, a well-recognized benchmarking corpus was provided to evaluate the performance of various DDI extraction methods, which greatly stimulated the research enthusiasm of researchers and played an important role in the development of DDI tasks. The challenge of DDIExtraction 2013—
Extraction of drug-drug interactions from biomedical texts is to classify the interaction types (
Mechanism,
Effect,
Advice,
Int and
Negative) between two drug entities in a sentence from the biomedical literature. For instance, given the example sentence [
8]
“[Pantoprazole] has a much weaker effect on [clopidogrel]’s pharmacokinetics and on platelet reactivity during concomitant use.”
with annotated target drug entity mentions
the goal is to automatically recognize that this sentence expresses a
Mechanism DDI type between
and
.
In recent years, considerable efforts have been devoted to DDI extraction; existing methods can be divided into two categories: rule-based methods and machine-learning-based methods. The rule-based methods [
9,
10] use manually pre-defined rules which match expression patterns in the labelled text which correspond to DDI pairs. The limitation of these methods is that the performance will depend heavily on the ability of professionals and domain experts to devise large bodies of rules.
Compared with rule-based methods, machine-learning-based methods usually show better performance and generalization. These methods regard DDI extraction as a standard supervised learning problem. Various types of features are extracted and fed to a classifier, for example context features [
11], shortest path features, domain knowledge features [
12], heterogeneous features [
13], a combination of word, parse tree and dependency graph features [
14], integrated lexical, syntactic and phrase auxiliary features [
15], and so on. The biggest challenges of feature-based machine learning methods are firstly to choose good features which result in effective learning, and secondly to extract those features accurately from a biomedical text.
With the improvement in computing power, the availability of large data sets and the continuous innovation of algorithms, deep learning technology has developed rapidly, and has achieved great success in many health data analysis tasks. The Convolutional Neural Network (CNN) is well-known deep learning approach. Morabito et al. [
16] employed CNNs to detect early-stage Creutzfeldt-Jakob disease (CJD) from other forms of rapidly progressive dementia (RPD) and achieved outstanding experimental results. Acharya et al. [
17] presented a novel computer model for EEG-based screening of depression using CNNs, which extended the diagnosis of different stages and levels of severity of depression. Yu et al. [
18] proposed a CNN-based method to segment small organs from abdominal CT scans, hence enabling computers to assist human doctors for clinical purposes. Rajpurkar et al. [
19] developed an algorithm which employs a 121-layer convolutional neural network to detect pneumonia from chest X-rays at a level exceeding practicing radiologists. Recently, some researchers have already successfully applied CNNs to DDI extraction and have shown better results than traditional statistical feature-based machine learning methods. CNNs aim to generalize the local and consecutive context of the sentence that mentions a DDI by using filters of different sizes. Liu et al. applied a CNN model to DDI extraction with word and position embedding [
20]. Zhao et al. used a syntax word embedding to capture the syntactic information of a sentence and fed it into a CNN model for detecting DDIs [
21]. Quan et al. used a multichannel CNN model with five types of word embedding to extract DDIs from unstructured biomedical literature [
22]. Asada et al. encoded textual drug pairs with CNNs and encoded their molecular pairs with graph convolutional networks (GCNs) to predict DDIs [
23], and obtained the best result so far for CNN-based DDI extraction methods. Although CNNs have been shown to perform well in the DDI task, due to the characteristics of a typical convolution operation, CNNs cannot capture the dependency between words or phrases which are some distance apart in a text. An example is a referring expression like “Azithromycin...” and an anaphoric reference to it later on in the text such as “it”, as shown in the following: “Azithromycin had no significant impact on the Cmax and AUC of zidovudine, although it significantly decreased the zidovudine tmax by 44% and increased the intracellular exposure to phosphorylated zidovudine by 110%.”
In addition to CNN models, Recurrent Neural Network (RNN) models have also been applied in DDI extraction. RNNs adaptively accumulate the contextual features in the whole sentence sequence via memory units [
24]. Huang et al. presented a two-stage method, in which the first stage identified the positive instances using a feature-based binary classifier, and the second stage classified the positive instances into a specific category using a Long Short Term Memory (LSTM) based classifier [
25]. Sahu and Anand used a joint RNN model with attention pooling to extract DDI information, and obtained a higher result than CNN-based methods [
26]. Zhang et al. proposed a hierarchical RNN-based method to integrate the Shortest Dependency Paths (SDPs) and the sentence sequence for DDI extraction [
27]. Zhou et al. employed the relative position information by means of an attention-based Bidirectional Long Short Term Memory (BiLSTM) to extract DDIs from biomedical texts [
28]. This approach achieved an F-score of 72.99% which is the best performance so far on the DDIExtraction 2013 corpus. Although many methods have been proposed, DDI extraction research is still at an early stage and there is great potential for further improvements in its performance. However, four problems have first to be addressed:
Firstly, the embedding layers of existing models only use word embeddings to express the semantics of the text. However, polysemy is very common: in different contexts, the same word may have different meanings. Simply relying on word embeddings does not accurately express the actual meaning of the words. For example, the word “agent” shows different meanings in the following sentences; In “There is the risk of convulsions occurring in susceptible patients following the use of the new anaesthetic agents which are capable of inducing CNS excitability”, the word “agent” is referring to a drug. By contrast, in “All these years he’s been an agent for the East”, “agent” is referring to a person.
Secondly, most of the existing models that achieve better performance used off-the-shelf NLP toolkits to obtain stems, POS tags, syntactic chunk features [
12], syntactic features [
21], shortest dependency paths [
27] and so on. Such tools may not be as accurate as they could be, because they are not tailored to the application domain; this can result in avoidable errors which propagate through the system and hence reduce its performance.
Thirdly, position embedding is the key information that reflects the core word information inside the sentence and allows the differences between the sentences in a DDI task to be distinguished [
20,
29]. Inappropriate setting of a model’s embedding vector dimension can cause effective information to be overwhelmed. For example, in the methods of Liu et al. [
20] and Zhou et al. [
28], the word embedding is set to 300 dimensions while position embedding is just 20 dimensions, meaning that important position information is almost ignored.
Lastly, the ratios of positive and negative instances in the original training set and test set (the DDIExtraction 2013 corpus) are 1:5.91 and 1:4.84 respectively. Obviously, the data set has a very serious class imbalance problem. Liu et al. [
20] and Quan et al. [
22] used negative instance filtering to alleviate class imbalance issues. The fundamental problem of class imbalance, however, remains. Therefore, other strategies are needed to solve this problem.
To address all four issues which we have described above, we propose a novel Recurrent Hybrid Convolutional Neural Network (RHCNN) for DDI extraction from biomedical literature. As stated in Lai et al. [
30], a recurrent structure can capture contextual information. So we combine word embedding with the left- and right-context information of each word which is obtained by a BiLSTM model. Then we use the fully-connected layer for information fusion to obtain the final semantic embedding of the current word. Meanwhile, this operation will reduce the dimension of the semantic embedding, so that there is no large dimension gap between semantic information and position information; this avoids valuable position information being overwhelmed.
In addition, we propose a hybrid convolutional neural network that consists of typical convolutions and dilated convolutions to construct a sentence-level representation which contains both the local context features and the dependency features. The local and consecutive context features of the sentence that mentions DDI candidates are captured by typical convolution operations. The dependency features between separated words, such as are needed to link phrases or perform anaphora resolution, are extracted by dilated convolution operations. The architecture is based on the idea that dilated convolutions operate on a sliding window of context which need not be consecutive—the dilated window skips over every dilation of width
inputs. Dilated convolutions have exhibited great potential for other NLP tasks such as machine translation [
31], entity recognition [
32] and text modeling [
33]. To the best of our knowledge, it is the first time dilated CNNs have been used for DDI extraction.
The DDIExtraction 2013 corpus is divided into five categories, but the number of samples in each category is extremely imbalanced. Inspired by the work of focal loss in the image recognition field [
34], we use the improved focal loss function for multiclass classification model training to avoid class imbalance and over-fitting. The proposed model (The experimental source-code is available at
https://github.com/DongKeee/DDIExtraction) has been evaluated on the DDIExtraction 2013 corpus and achieves a micro F-score of 75.48%, outperforming the state-of-the-art approach [
28] by 2.49%, thus demonstrating its effectiveness.
In sum, our key contributions are as follows:
Our model does not rely on any NLP tools in the embedding layer, instead the sentences that mention DDI pairs are represented as sequences of semantic embeddings and position embeddings. In particular, we use the fully-connected layer for semantic information fusion between a word embedding and the contextual information that is learnt by recurrent structure; the two combined are employed to obtain a complete semantic representation of each word.
We propose a hybrid convolutional neural network that consists of typical convolutions and dilated convolutions, and we believe it is the first time dilated CNNs have been used for DDI extraction.
We introduce an improved focal loss function into the multiclass classification task in order to avoid class imbalance and the resulting over-fitting problem.
We achieve state-of-the-art results for DDI extraction with a micro F-score of 75.48% on the DDIExtraction 2013 dataset, outperforming the methods relying on significantly richer domain knowledge.
2. Method
In this section, we present our recurrent hybrid convolutional neural network model.
Figure 1 illustrates the overview of our architecture for DDI extraction. Given an input sentence
S with a labeled pair of drug entity mentions
and
, DDI extraction is the task of identifying the semantic relation holding between
and
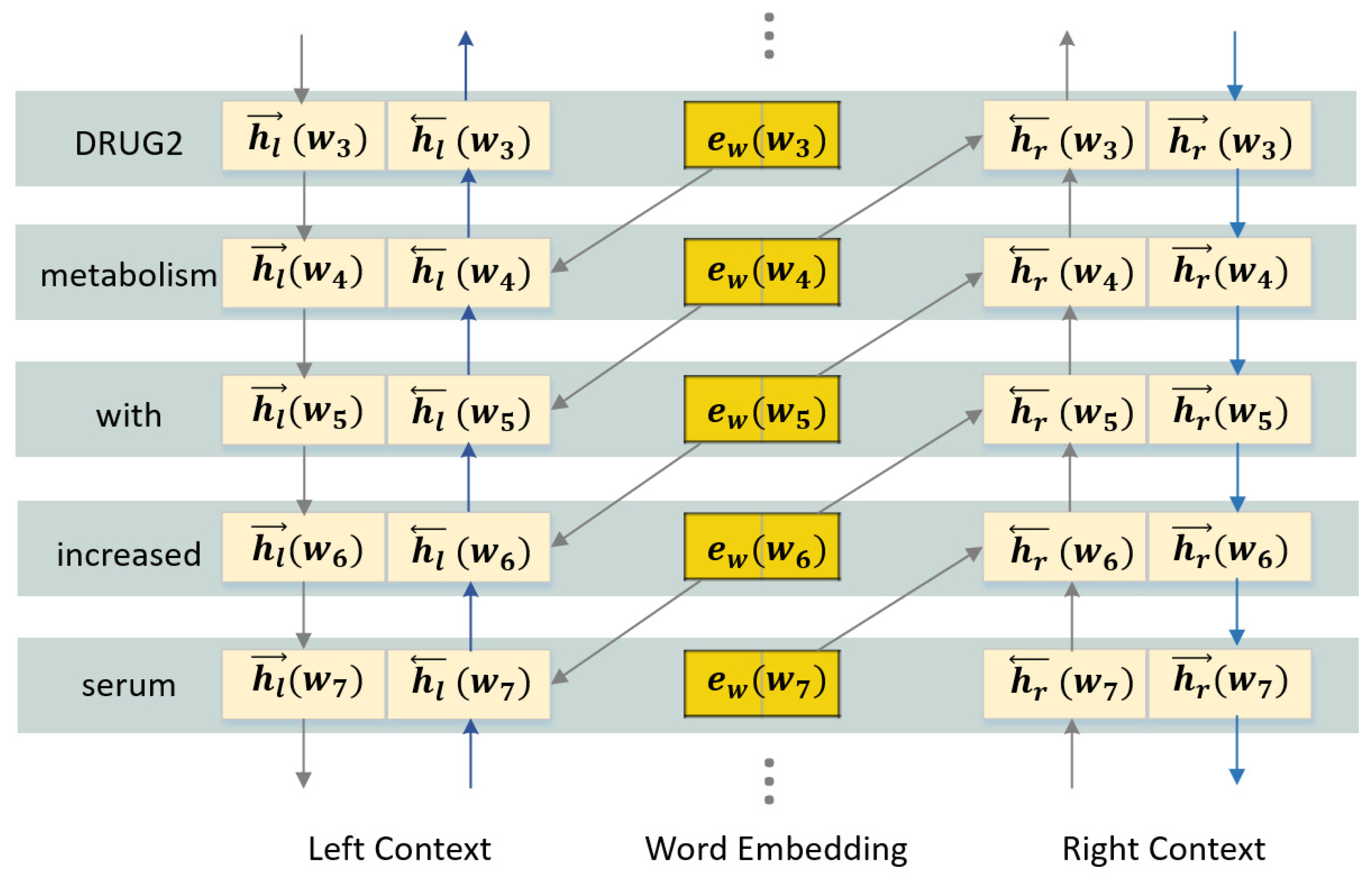
among a set of candidate DDI types. In the word embedding layer, each word is represented by a semantic embedding and a position embedding. The semantic embedding is fused by the fully connected layer, which contains a word embedding for each word as well as the contextual features captured by the BiLSTM model from the word’s left and right context. These are combined to obtain a semantic vector for each word and hence narrow the dimension gap between semantic information and position information.
Next we use the hybrid convolutional neural network that consists of typical convolutions and dilated convolutions to construct the sentence-level representation which contains the local context features from consecutive words together with the dependency features between separated words. In the max pooling layer, the most important features are extracted from the output of the previous layer, and the dimensions of the features are reduced at the same time. Finally, we concatenate these features to form the sentence representation, and feed it to the fully-connected softmax layer for classification. Recall also that the final output is given by a new improved focal loss function. The remainder of this section will provide further details about this architecture.
2.1. Preprocessing
The DDI corpus contains two or more drug entities in each sentence. Given a sentence of
n entities, there are
DDI candidates which need to be classified. To allow generalization during learning and to keep only one drug pair remaining in each instance, we replace the two candidate entities with symbols “DRUG1” and “DRUG2” while all other drug entities are replaced by “DRUG0”, in common with previous methods [
14,
35].
Table 1 shows one example of a drug blinding. However, the result of the preprocessing operation is to generate a dataset with an imbalanced sample. For example, the sentence
“When drugEntity1 or other hepatic enzyme inducers such as drugEntity2 and drugEntity3 have been taken concurrently with drugEntity4, lowered drugEntity5 plasma levels have been reported.”
contains 5 drug entities, and three positive instances of DDI pairs: (
drugEntity1,
drugEntity4), (
drugEntity2,
drugEntity4) and (
drugEntity3,
drugEntity4). Thus the sentence reflects the existence of interactions between the stated drug entity pairs, and the DDI type for each pair is one of
Mechanism,
Effect,
Advice and
Int. On the other hand, the
i.e., 7 DDI pairs such as (
drugEntity1,
drugEntity2), (
drugEntity1,
drugEntity3), (
drugEntity1,
drugEntity5) and so on are all negative instances, meaning that the sentence does not reflect the existence of these interactions. So the number of negative samples (7) is significantly more than that of the positive samples (3). In order to alleviate the problem of class imbalance and prevent the resulting performance degradation, we use a negative instance filtering strategy to filter out as many negative instances as possible, based on manually-formulated rules proposed by other researchers [
14,
20,
22]. These rules can be summarised as follows:
If a drug pair has the same name (like the instance shown in the third row of
Table 1) or one drug is an abbreviation of the other entity, filter out the corresponding instances.
If a drug pair are in a coordinate structure, filter out the corresponding instances.
If one drug is a special case of the other, filter out the corresponding instances.
The statistics of the resulting dataset after negative instance filtering are shown in
Table 2.
2.2. Embedding Layer
The input to our model is a sentence S that mentions two drug entities, where , “DRUG1” and “DRUG2” (). Each word of the sentence sequence is represented by both a semantic embedding and a position embedding.
Recently, word embedding has been successfully applied in various NLP tasks, such as sentiment analysis [
36], relation classification [
29], information retrieval [
37] and so on. Word embedding refers to the mapping of words or phrases to real-value vectors, which must be learnt from significant amounts of unlabeled data. Various models [
38,
39,
40] have been proposed to learn the word embedding. In order to obtain suitable high-quality vector space representations for biomedical NLP tasks, it is necessary to use a large number of articles in the biomedical field as training data. Unfortunately, it always takes too much time to train word embeddings. However, there are many pre-trained word embeddings that are freely available and of high quality [
41,
42]. So our experiments directly utilize the embedding provided by Pyysalo et al. [
41], which is trained using articles from PubMed and the English Wikipedia.
Simply relying on word embeddings alone does not accurately express the actual meaning of a word due to the fact that it may have different meanings in different contexts, so we combine the embedding with contextual information to obtain fuller semantic information for each word. As depicted in
Figure 2, the semantic embedding is generated by the bidirectional long short term memory model. Let
,
and
denote the word embeddings, left-context embeddings and right-context embeddings. The left-side and right-side context embeddings are calculated by Equations (
1)–(
6):
where
f is a non-linear activation function,
and
are weight matrices of the input and recurrent connections respectively. Then the semantic information can be represented as
, and the number of dimensions of it is
where
are the number of dimensions of the left-context embedding, word embedding and right-context embedding. To get the final semantic embedding
of each word, we fuse the word and contextual features by a fully connected layer, using Equation (
7).
In order to capture significant information about the target entities, we combine semantic and position embedding. The position embedding is the key information that reflects the core word information inside the sentence and the differences between the sentences. In DDI extraction, given a sentence of
n entities, there are
DDI candidates which need to be classified, and these samples’ semantic embeddings are very similar. So it is necessary to specifically distinguish the target drug entities and magnify the differences between similar sentences. In our method, the position embedding
is the combination of the vectors
and
, which themselves are the relative distances of the word
from the two marked entity mentions
and
[
29,
43] and which are then mapped to a randomly initialized vector of dimension
. So the final word embedding for
is
and is of size
.
2.3. Hybrid Convolutional Layer
From the embedding layer we can obtain the local basic features for each word. In DDI extraction, the DDI types are judged by the semantic expression of whole sentences, so it is necessary to utilize all kinds of local features and to predict a candidate DDI type globally [
29]. In our method, we use a hybrid convolutional neural network which consists of typical convolutions and dilated convolutions to obtain the sentence level representation.
The typical convolution operation is used to capture the local and consecutive contextual features of the sentence that mention DDI pairs, and the approach is expressed by Equation (
8):
where
k donates the filter size.
is the filter applied to all possible consecutive context windows of
k words.
is a bias term, and rectified linear units (ReLU) is a non-linear activation function. Then, a consecutive contextual feature vector
is obtained.
The dilated convolution operation is used to learn the dependency features between separated words in a text, such as a phrase and an anaphoric reference to it, and the method is expressed by Equation (
9):
where
donates the filter size,
d is the dilation size,
is the filter applied to all possible consecutive context windows of
k words, and
is a bias term. Then, an interval contextual feature vector from separated words
is obtained.
2.4. Max Pooling Layer
After the hybrid convolutional layer, the consecutive contextual features and the dependency features between the separated words are obtained. To determine the important local feature in each feature vector learnt by the prior layer and to reduce the computational complexity by decreasing the feature vector dimension, we use the max pooling operation to take the maximum value of each local feature of
and
, using Equations (
10) and (
11) where
w is the window size of the pooling layer:
Then we will get the higher level features, denoted by and . In our model, we use two layers of typical convolutions and dilated convolutions followed by a max pooling layer. When we get the final feature vectors and obtained by hybrid convolutions and a max pooling layer, the sentence vector will be represented as ,.
2.5. Softmax Layer for Classification
In order to prevent the model from overfitting, we randomly drop out the neuron units from the network during the training process [
44]. To do this, we randomly set some elements of
s to 0 with a probability
p and get a new sentence vector
. Then it will be fed to a fully-connected softmax layer in which the output size is the number of the DDI classes, and the conditional probability value
P of each DDI type is obtained by Equation (
12) where the softmax is a non-linear activation to achieve probability normalization:
2.6. Model Training
The following parameters of the RHCNN model need to be updated during training:
Recently, the cross-entropy function is widely used as a loss function in the training of the existing DDI extraction models as shown in Equation (
13):
where
y is the one-hot vector corresponding to the true category of the instance, and
C is the number of DDI types. Cross-entropy reflects the gap between the predicted probability distribution and the true probability distribution. In model training, we expect the probability that the model predicts the sample to be as similar as possible to the true probability. As can be seen from the equation, if the predicted probability
that the model predicted its true category (when
) as close to its true probability distribution
as we expect, the contribution of this sample to loss function (cross-entropy) will be reduced. Using cross-entropy as a loss function, aiming at minimizing the objective loss function will yield results that are consistent with our expectations. Therefore, cross-entropy is a commonly-used loss function in model training. In our experiments, the DDIExtraction 2013 corpus we used divides the samples into five categories (
Mechanism,
Effect,
Advice,
Int and
Negative) and is imbalanced. The statistics of each category are shown in
Table 2. As can be seen from the table, the
Negative class has the largest number of samples. If we use cross-entropy as the objective function, it will give equal weight to all categories when calculating loss and cause huge interference to the learning process of the model parameters. A vast number of
Negative class samples constitute a large proportion of the losses and hence dominate the direction of the gradient update so that the final trained model is more inclined to classify the sample into this type. However, it does not make much sense for us to divide the sample into
Negative category to achieve a higher performance, because this category means that the text does not reflect the existence of interaction between two target drug entities. The DDI extraction task is more interested in knowing which interaction (
Advice,
Effect,
Mechanism and
Int) between drug entities is expressed in the biomedical literature.
Therefore, in order to solve the problems in the above cross-entropy function and avoid over-fitting, we use the improved focal loss function which consists of the focal loss together with the cross-entropy function for multiclass classification model training inspired by the work of focal loss in the image field [
34] which has been used to solve the binary classification problem when data is imbalanced.
For notational convenience, we define
as the corresponding
when
is 1. So the cross-entropy loss function can be rewritten as Equation (
14):
The improved objective function is shown as Equation (
15):
where the left side of Equation (
15) is the focal loss function proposed by Lin et al. [
34],
is a weighting factor to balance the importance of samples from different classes (
), and is calculated by Equation (
16), where
is the instance number of the
i-th type. Under the action of
, we can flexibly calculate the weights of various samples according to the number of samples from different categories in the dataset, so that the final trained model has stronger ability to divide specific DDI categories than one using the traditional cross-entropy function. The
value of each category in the training set after the instance filtering of our experiment is shown in
Table 3. As seen in table, the class with a small number of samples has larger weight and the type with a larger number of samples has smaller weight.
The is a modulating factor for the improved focal loss function (), and smoothly adjusts the weight of easily-classified samples. For instance, when , a sample with the probability (such that ) has a loss contribution 100 times lower than one using a traditional cross-entropy function. Intuitively, the modulating factor reduces the loss contribution of examples that are easy to classify, so that more attention is paid to more difficult examples.
In addition, to prevent overfitting, we combine the focal loss with a traditional cross-entropy function [
45], where
e is a hyperparameter to adjust the weights of two functions. We optimize the parameters of the objective function
with the Adam Method [
46] used in each training step. After the end of training, our model can classify the interaction types between two drug entities with an excellent performance.

 ,
, 


{kind=link}
{kind=link}