Detecting Metachanges in Data Streams from the Viewpoint of the MDL Principle

Department of Mathematical Informatics, Graduate School of Information Science and Technology, The University of Tokyo, 7-3-1 Hongo, Bunkyo-ku 113-8656, Japan
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(12), 1134; https://doi.org/10.3390/e21121134
Submission received: 11 October 2019
/
Revised: 11 November 2019
/
Accepted: 16 November 2019
/
Published: 20 November 2019
(This article belongs to the Special Issue Information-Theoretical Methods in Data Mining)
Abstract
:This paper addresses the issue of how we can detect changes of changes, which we call metachanges, in data streams. A metachange refers to a change in patterns of when and how changes occur, referred to as “metachanges along time” and “metachanges along state”, respectively. Metachanges along time mean that the intervals between change points significantly vary, whereas metachanges along state mean that the magnitude of changes varies. It is practically important to detect metachanges because they may be early warning signals of important events. This paper introduces a novel notion of metachange statistics as a measure of the degree of a metachange. The key idea is to integrate metachanges along both time and state in terms of “code length” according to the minimum description length (MDL) principle. We develop an online metachange detection algorithm (MCD) based on the statistics to apply it to a data stream. With synthetic datasets, we demonstrated that MCD detects metachanges earlier and more accurately than existing methods. With real datasets, we demonstrated that MCD can lead to the discovery of important events that might be overlooked by conventional change detection methods.
1. Introduction
1.1. Purpose of This Paper
In this study, we are concerned with detecting changes in data streams. The goal of change detection is to detect the time points at which the nature of the data-generating mechanism significantly changes.
Thus far, many algorithms have been proposed to detect change points in data streams (e.g., [1,2,3,4,5,6,7,8,9,10,11]), and several studies addressed or have been related to the issue of changes of changes [12,13,14,15,16,17,18]. In this paper, we refer to the changes of changes as metachanges. A metachange refers to a change in the pattern of when or how changes occur. It is practically important to detect metachanges because they may be early warning signals of important events [12,13]. Metachanges have been treated from a viewpoint of metachanges along time. Metachanges along time indicate that the interval significantly varies between the change points. Such metachanges were called burstiness [12] and volatility [13] in previous studies. The detection of metachanges along time provides users with useful information from data streams. For example, in a machine in a manufacturing factory, a decrease in the interval between change points might be a sign of a serious failure.
There is also another type of metachange: metachanges along state. Here, “state” refers to the parameter value of the probability density function of a distribution. We consider a situation where change points are detected for a data stream , and is drawn from . Here, is a probability density function of distributions, and is the associated parameter. Note that is called state in this paper, and it varies before and after a change point. A metachange along state means a change of how significantly varies before and after a change point. Metachanges along state might provide information such as changes of magnitude and velocity, which indicate an important change in the underlying data-generating mechanism. For example, in a machine in a manufacturing factory, a shift to an abrupt (sudden) change from a gradual (incremental) change [19], or its inverse shift, might be a sign of serious events.
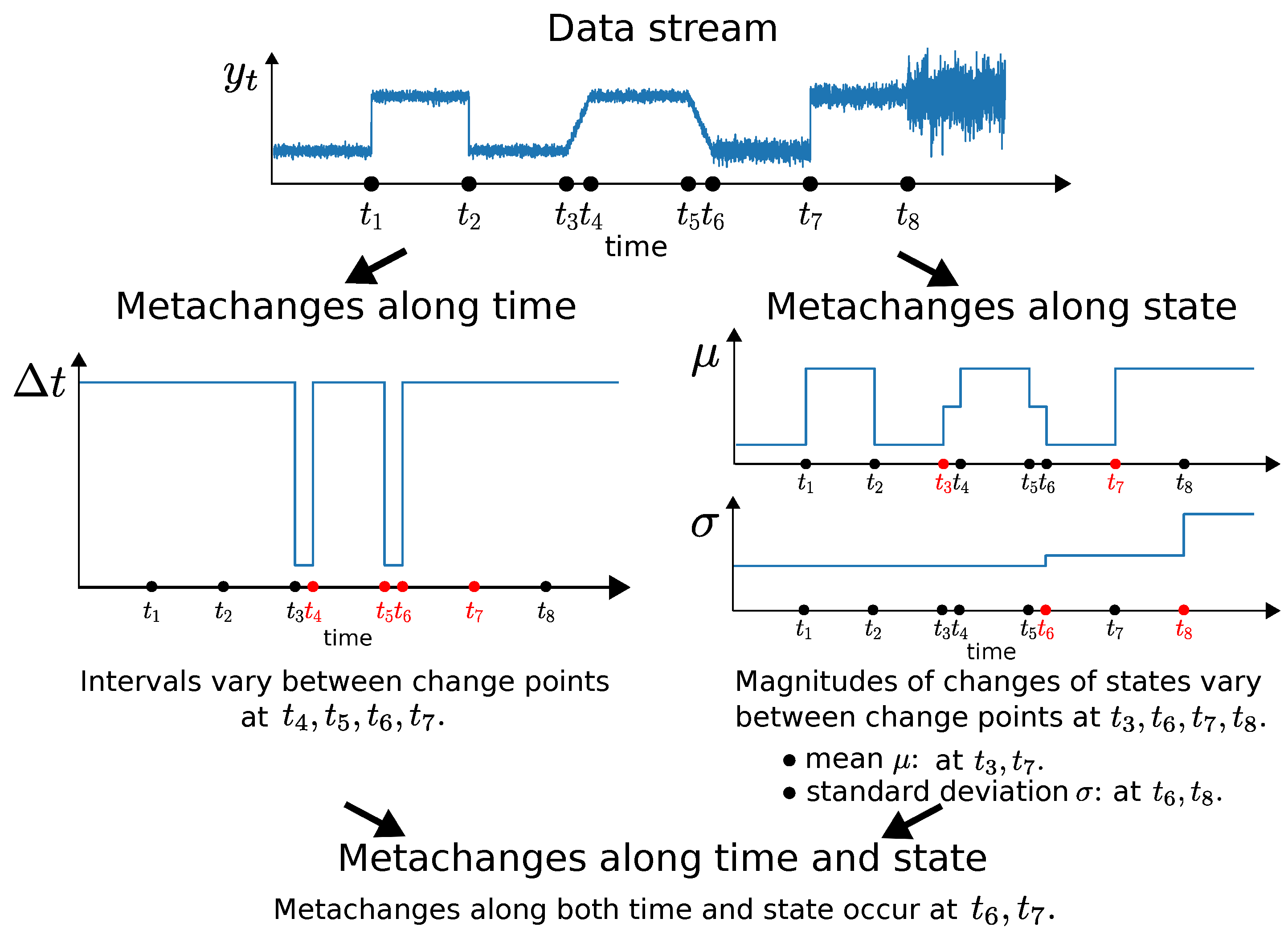
A conceptual illustration of metachanges is shown in Figure 1, where the upper graph shows a data stream and change points on the horizontal axis. The lower left graph shows intervals between change points on the vertical axis. Metachanges along time occur at : for example, is different from and . The lower right graph shows the states estimated piecewisely between the change points. Here, we assume is drawn from the univariate normal distribution , where is the mean and is the standard deviation. In this case, is a state. In Figure 1, because there is no significant change in the magnitude of state change between and , a metachange along state does not occur at . However, there is a significant change in the magnitude of change of between and : thus, a metachange along state occurs at . Because the magnitudes of the changes of and are almost the same between and , a metachange along state does not occur at . Using the same procedure, we conclude that metachanges along state occur at and with respect to . Moreover, metachanges along state occur at and with respect to : the magnitude of the change of standard deviations around () is greater than those around (). As a result, metachanges along state occur at and . We can infer that metachanges along both time and state occur at and , by combining the metachanges along time and state.
Metachanges along time have been investigated in previous studies [12,13], and, although there have been several studies related to metachanges along state [14,15,16,17,18], the focus of these studies was not on metachanges along state in particular. The purpose of this paper is to propose a framework and an approach to detect metachanges along time and state from a unified view with the minimum description length (MDL) [20]. Therefore, our framework and approach not only include previous notions such as burstiness [12] and volatility [13] but also extend these notions to metachanges along state. MDL asserts that the best statistical decision strategy is the one that compresses the data best. Description and coding with MDL are suitable for quantifying changes, and they enable us to easily integrate the code lengths of time and state.
1.2. Related Work
Change detection has been extensively explored in the area of data mining. Thus far, several methods have been proposed to detect metachanges in data streams [12,13], and there have been several studies related to metachanges along state [14,15,16,17,18].
Kleinberg [12] and Huang et al. [13] proposed algorithms for detecting metachanges along time. Kleinberg [12] proposed an algorithm to detect bursts in a time series. This algorithm assumes that intervals between successive events are drawn from an exponential distribution. The discretized values of the parameters of the exponential distribution are regarded as states. For intervals between successive events, states are estimated with dynamic programming. Changes of state indicate changes of intervals between the successive events. Huang et al. [13] proposed an algorithm, called the volatility detector, which detects changes of rates of change. The volatility detector prepares two buckets, called the buffer and the reservoir, to store intervals between change points. The intervals are put into the buffer sequentially. When the buffer is full, an interval is dropped from the buffer and moved to the reservoir in a first-in-first-out fashion. The reservoir stores the dropped interval by randomly replacing one of its stored intervals. If the ratio of variances of the buffer and the reservoir is over or under the specified threshold, the algorithm judges that the intervals change between change points. The authors called this event volatility shift. Both the burst detector and volatility detector are assumed to be used in two steps. That is, change points are detected with other change detection algorithms, and then changes of intervals between the change points are detected. While the burst detector works in an offline fashion, the volatility detector works in an online fashion.
Moreover, there have been several studies related to metachanges along state [14,15,16,17,18]. Aggarwal [15] introduced velocity density estimation to understand, visualize, and determine trends in the evolution of fast data streams. Spiliopoulou et al. [16,17] proposed an algorithm, called MONIC, to model and track cluster transitions. Ntoutsi et al. [18] proposed an algorithm, called FINGERPRINT, to summarize cluster evolution. Huang et al. [14] proposed a change type detector, intended to categorize change types into three relative types, some of which correspond to concept drifts proposed in [19]. Although their algorithms [14,15,16,17,18] are related to metachanges along state, they are not intended to characterize and detect metachanges directly. In addition, many change detection algorithms have been proposed based on detecting changes of state (e.g., [6,7,8,9,21,22]). The dynamic model selection [6,7] is the seminal work to apply MDL to the task of dynamic model selection and change detection. The MDL change statistics [8], SCAW [9], and STREAMKRIMP [22] are change detection algorithms with MDL. However, these algorithms are not intended to characterize and detect metachanges along state directly.
1.3. Significance of This Paper
In the context of Section 1.1 and Section 1.2, the contributions of this paper are summarized in the following subsections.
1.3.1. Proposal of Concept of Metachange
To detect changes of changes in data streams, we define a concept of metachanges along both time and state. Previous studies [12,13] considered metachanges along time only. In this paper, we deal with metachanges along both time and state. Metachanges along time include the notions proposed in previous studies such as burstiness [12] and volatility [13]. Metachange along state could capture changes of changes of the parameters of distribution between change points.
Our concept of metachange can detect the potential change of changes in data streams, which was overlooked by previous studies.
1.3.2. Novel Algorithm for Detection of Metachanges
We define metachange statistics along both time and state. There is a challenge to combining the metachange statistics along time and those along state. In this paper, these statistics are defined based on the MDL principle. Metachange statistics along time (MCAT) is defined as the code length of an interval between the change points, whereas metachange statistics along state (MCAS) is defined as the difference between the predictive code length and the normalized maximum likelihood (NML) code length [23] after a change. It is possible to simply add these statistics because they are defined as code lengths, which enables us to detect metachanges along both time and state in a unified manner.
2. Theoretical Background of Metachange Statistics
In this section, we consider how to encode both intervals between change points and states around the change points. We assume that for a data stream change points are detected and that the intervals between change points and are drawn, respectively, from
where and are probability density functions of distributions and and are the associated parameters. Finally, is the state whose metachanges are addressed in this paper.
2.1. Definitions of Metachanges
In this subsection, we give definitions of metachanges.
Definition 1.
(Metachange along time) For intervals between change points , we say that a metachange along time occurs at a change point for a threshold parameter if and only if
where and are distributions of intervals. means that at and at . d is a distance function between the probability density functions.
Definition 2.
(Metachange along state) For a data stream , we say that a metachange along state occurs at a change point for a threshold parameter if and only if
where , , and are distributions of values of the data stream. Equation (2) means that at , at , and at . Here, d is the same as that in Definition 1.
2.2. Problem Setting
In this subsection, we consider a situation where change points are given. We consider how to encode and as shortly as possible. The ideal code length required for encoding is given by what we call the predictive code length, which is the sum of the negative logarithm of its predictive density at each time point, defined as follows:
where are estimated at each change point. Similarly, the ideal code length required for encoding around change points is given by the predictive code length as follows:
where indicates the neighborhood of a change point . In practice, as explained in Section 3.3, . and are estimated using and , respectively. A change of indicates a change of state. Detection of a metachange along time is asserted as a problem of detection of a change of in Equation (3). On the other hand, detection of a metachange along state is asserted as a problem of detection of a change of how in Equation (4) changes around a change point between change points.
3. Metachange Detection Algorithm
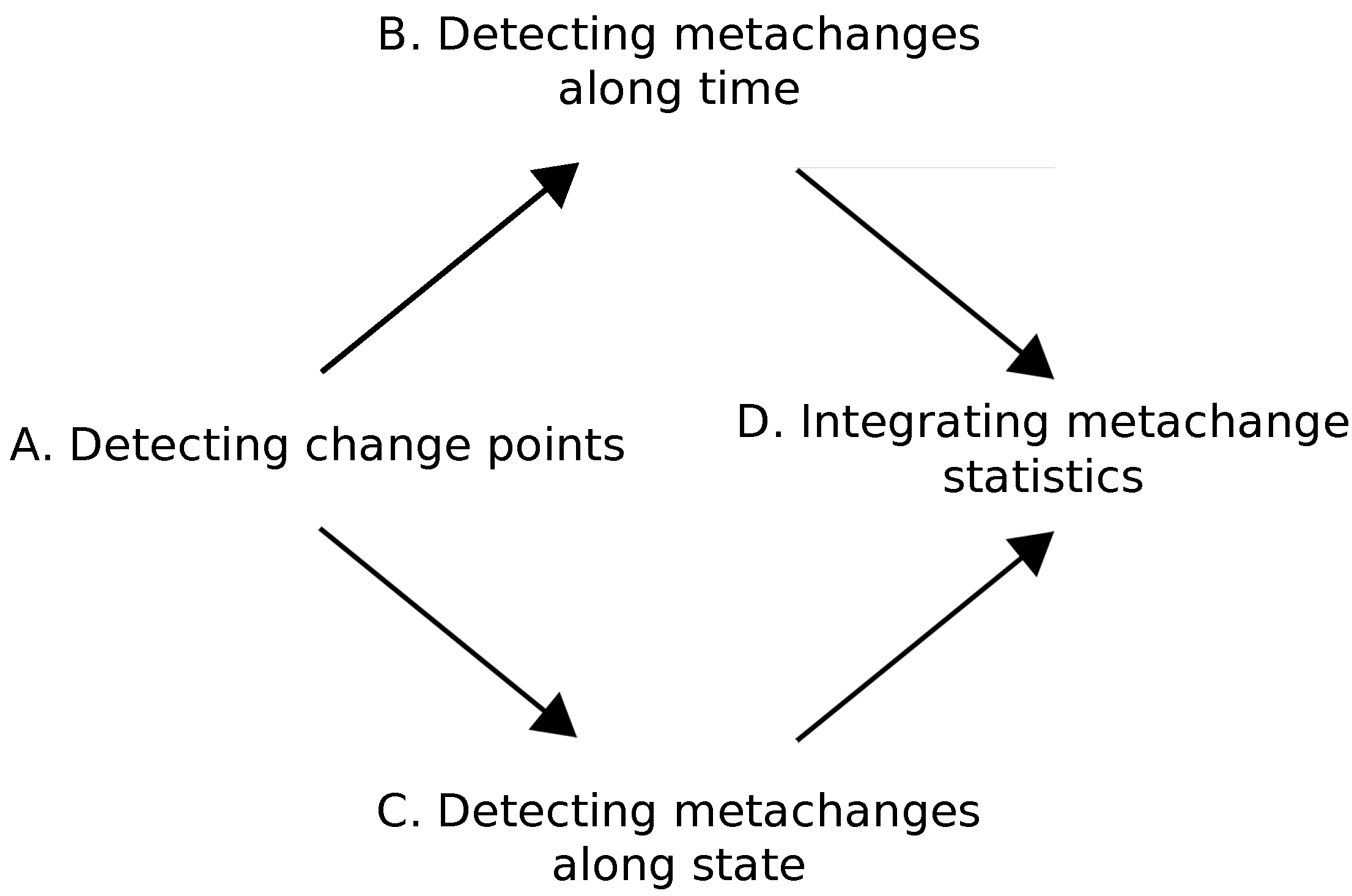
In this section, we present our online algorithm called metachange detection algorithm (MCD) for detecting metachanges along both time and state. We consider how to achieve Equations (3) and (4) in an online fashion. A schematic description of MCD is shown in Figure 2.
First, we detect change points from data stream (A). Next, we concurrently detect metachanges along time (B) and along state (C). We introduce metachange statistics to quantify these metachanges. Finally, we integrate the metachange statistics along time and state into a statistics (D).
The key challenge of detecting metachanges along time and state is how to describe and integrate them. Our approach describes both metachanges as code lengths with MDL; therefore, it is easy to combine them.
3.1. Detecting Change Points
First, we detect change points . As our proposed algorithm MCD works in an online fashion, it is necessary for the change detection algorithm to work in an online fashion (e.g., [1,2,3,4,8,9]). In general, MCD is prone to errors by the change detection algorithm and its threshold parameter. We empirically investigate and discuss this point in detail in Section 4.
3.2. Detecting Metachanges along Time
For the detected change points , let us consider intervals between the successive change points , with length . For an interval sequence , we consider how to achieve Equation (3) in an online fashion. We define metachange along time (MCAT) as the predictive code length
where , is a parametric class of probability distribution, and is estimated using . For example, we can estimate as the maximum likelihood estimator. To deal with nonstationary data streams, we use the online discounting maximum likelihood estimator [24]
where is a discounting parameter. An increase in r has a greater effect on forgetting past data.
In this paper, we introduce a parametric class of the exponential distribution
The inside of argmax in the right-hand side of Equation (8) is expanded as
The right-hand side of Equation (9) is maximized by deriving it with respect to . As a result, we obtain the following optimal solution:
In practice, we judge that a metachange occurs along time when MCAT changes greatly between the change points. Technically, we use the change rate of MCAT: a metachange occurs along time when holds, where is a threshold parameter. We call the algorithm described above as the metachange detection along time algorithm (MCD-T).
and satisfy the following relation:
Therefore, the computational cost of MCAT is .
Example:
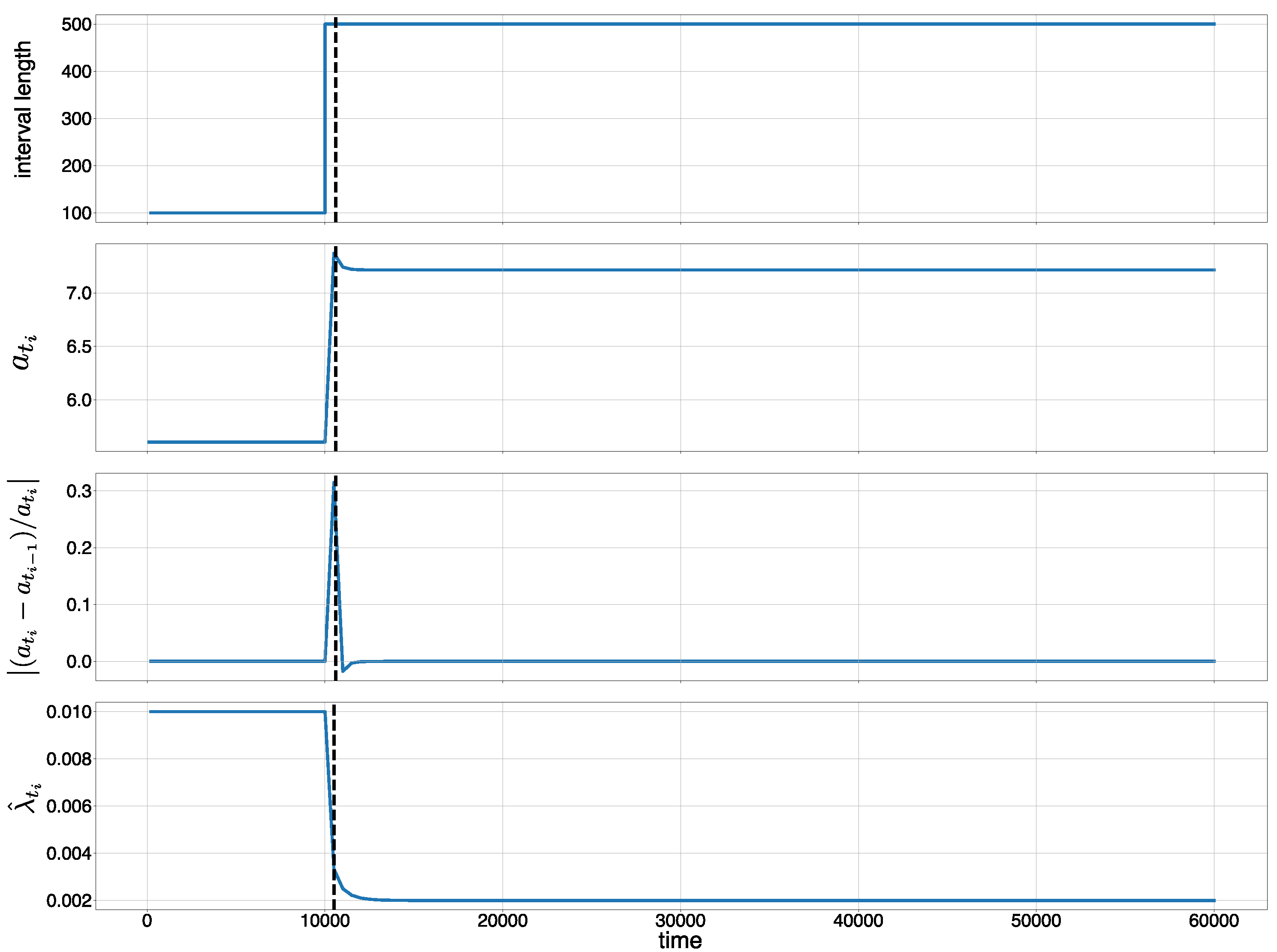
We consider a data stream with a length of 200 time intervals between change points: and . This means that there are 201 change points . If we assume , then 10,100, 10,600, 11,100, 60,100. Then, is calculated as . Figure 3 shows the time intervals at the change points (Figure 3, top), MCATs (Figure 3, second graph), the change rate of MCATs (Figure 3, third graph), and (Figure 3, bottom). We observe in Figure 3 that we can detect the metachange along time when we choose a suitable threshold . Here, the discounting parameter is set to .
3.3. Detecting Metachanges Along State
For a change point detected in Section 3.1, we consider how to achieve Equation (4) in an online fashion. We consider a subset of time around for in Equation (4). The subset is denoted by , where is a window size. Thus, we consider a sequence , with length . We introduce a parametric class of probability distributions . Here, Y is a random variable and is a real-valued parameter. H is the associated parameter space.
Next, we define metachange statistics along state (MCAS) at change point . First, two statistics, and , are introduced. These are defined as the difference between two code lengths for : one is the “expected” code length, estimated using the parameter change at and the estimated parameter with . The other is the code length with the parameter estimated in terms of . Formally, is defined as the difference between the predictive code length and the NML code length [20] after the change point. The former is calculated as the predictive code length, which is the total code length for encoding in a predictive way, using the estimated parameter as follows:
where is defined as
which indicates the parameter change to the same side and the opposite side in the same way as the previous change point . Here, means the maximum likelihood estimator of using .
The latter is calculated as the NML code length, which is defined as the negative logarithm of the NML distribution [20]:
The difference between Equation (12) and Equation (14) is given by
where in Equation (15) is computed using Rissanen’s approximation formula under some regularity conditions [23]:
where k is the dimension of H and is the Fisher information matrix at the parameter value . Intuitively, Equation (15) quantifies the redundant code length for coding with the parameters estimated in terms of the parameter change at and the parameter values in the former part of .
Finally, we define MCAS as
which means that metachanges along state are quantified by the relative magnitude of changes in the parameters in this paper. The computational cost of MCAS is . We judge that a metachange along state occurs at when holds, where is a threshold parameter. We call the algorithm described above as the metachange detection along state algorithm (MCD-S).
Example:
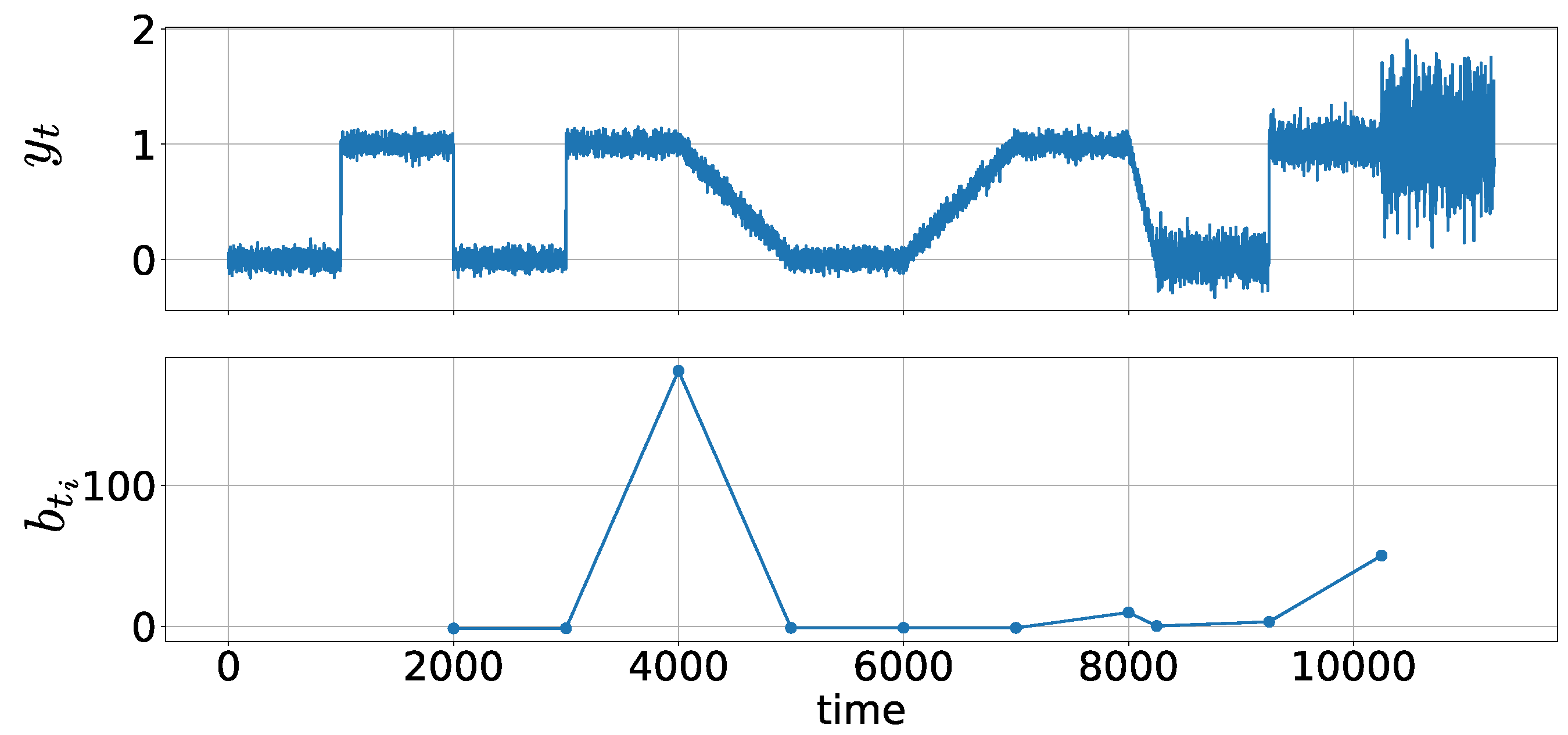
We generate a data stream with length 11,250:
where denotes the probability density function of the univariate normal distribution with mean and standard deviation .
Figure 4 shows data stream (Figure 4, top) and statistics (Figure 4, bottom). The parameter is set to . True change points occur at 1001, 2001, 3001, 4001, 5101, 6001, 7001, 8001, 8251, 9251, and 10,251. Figure 4 shows that the statistics increase when there is a change in how parameters behave around a change point between successive change points. At and , are relatively small, which shows that parameter changes (i.e., their magnitudes) do not differ much between and and between and . However, increases at because the change shifts to a gradual change from an abrupt one. These results indicate that MCAS provides information regarding changes in the behavior around the change points.
3.4. Integrating Metachange Statistics
Finally, we consider how to integrate MCAT and MCAS at a change point . Because and are code lengths, they can be summed. Therefore, we propose adding and with weighting. Integrated metachange (MCI) at is defined as
where is a hyperparameter. We should carefully choose with data. In Section 4.3, is determined using a grid search.
In practice, we judge that a metachange along both time and state occur at when MCI greatly changes between the change points. As in the case of metachanges along time in Section 3.2, we use the change rate of MCI: a metachange along both time and state occurs at if , where is a threshold parameter.
We call the overall algorithm described above MCD; it is summarized in Algorithm 1.
| Algorithm 1 MCD. |
| Input:r: discounting parameter (), h: window size, : threshold parameter Output:: metachange statistics along time, : metachange statistics along state, : integrated metachange statistics.
|
4. Experiment
We conducted five experiments to confirm the effectiveness of the proposed algorithm MCD (https://github.com/s-fuku/metachange).
4.1. Synthetic Dataset 1 (Metachanges along Time)
We defined six levels of time intervals between change points referring to the work in [13,25]. The interval lengths were 100,000, 50,000, 10,000, 5000, 1000, and 500. The change points were set using a Bernoulli distribution oscillating between and . For each combination of two intervals, we generated the streams based on the scheme above. Each stream contained 100 change points. In what follows, and indicate the first and second interval lengths, respectively.
We confirmed the effectiveness of MCD by comparing it with a volatility detector (VD) [13]. We used the SEED algorithm [13] and the sequential MDL-change statistics algorithm (SMDL) [8] for change detection. SEED was based on ADWIN2 [21] and its parameters were set to , and , which are the same as those in [13]. The window size w of SMDL was set to , and the threshold parameter was set to . For the Bernoulli distribution, the change score of SMDL at time t was calculated as
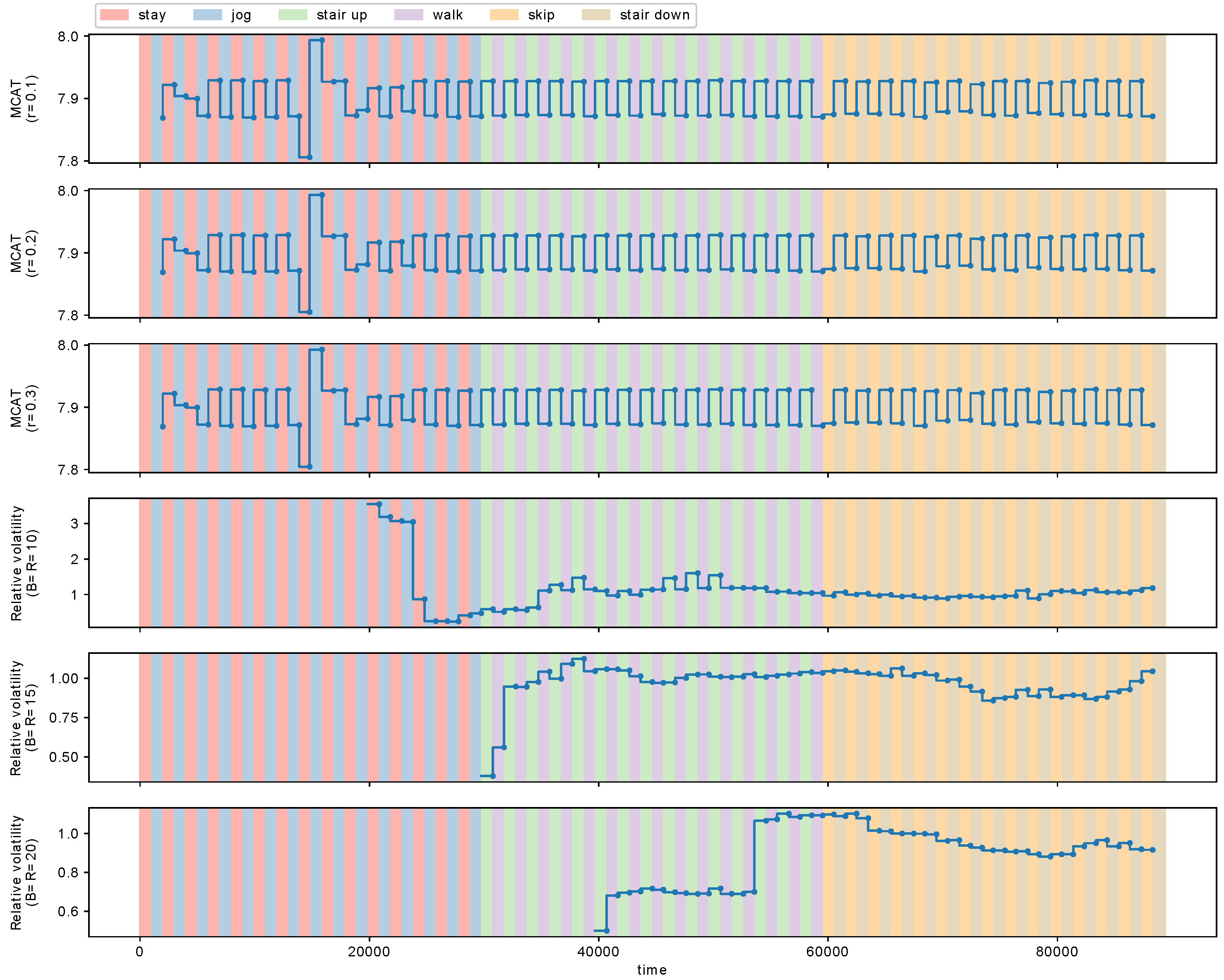
where , , and . If , t is regarded as a change point. We determined that t was a change point if the change score was the maximum. The parameter of MCD-T was set to . Below, we discuss the dependency of MCD-T on r in Figure 5. For VD, buffer size and reservoir size , which were the same as in [13]. We also discuss the dependency of VD on B and R below in Figure 6. In running SEED [13], we used the Java source code provided by the authors (https://www.cs.auckland.ac.nz/research/groups/kmg/DavidHuang.html). We started to use change points when its number reached for MCD-T and VD because the buffer and the reservoir of VD are not full until intervals arrive.
We investigated the trade-off between detection delay and accuracy in terms of benefit and false alarm rate, defined as in [8,26]. For MCD-T, we first fixed the threshold parameter and converted MCAT in Equation (11) to binary alarms . That is, , where denotes the binary function that takes 1 if and only if t is true. We evaluated MCD-T by varying . We let be a maximum tolerant delay of metachange detection. When the metachange really started from , we defined the benefit of an alarm at time t as
The number of false alarms was calculated as
We visualized the performance by plotting the recall rate of the total benefit, b, against the false alarm rate, , with varying. Likewise, for VD, was calculated using the relative volatility between the variances of the buffer and the reservoir by varying the threshold parameter . We evaluated all four combinations of change detectors SEED and SMDL and metachange detectors MCD-T and VD by calculating the average and standard deviation of the area under the curve (AUC) of the benefit vs. FAR curves. The AUC scores were calculated over 50 sequences. The delay parameter was set to . Table 1 shows the average AUC scores. Table 1 shows that MCD-T with SEED or MCD-T with SMDL outperforms VD with SEED or VD with SMDL. This indicates the effectiveness of MCD-T.
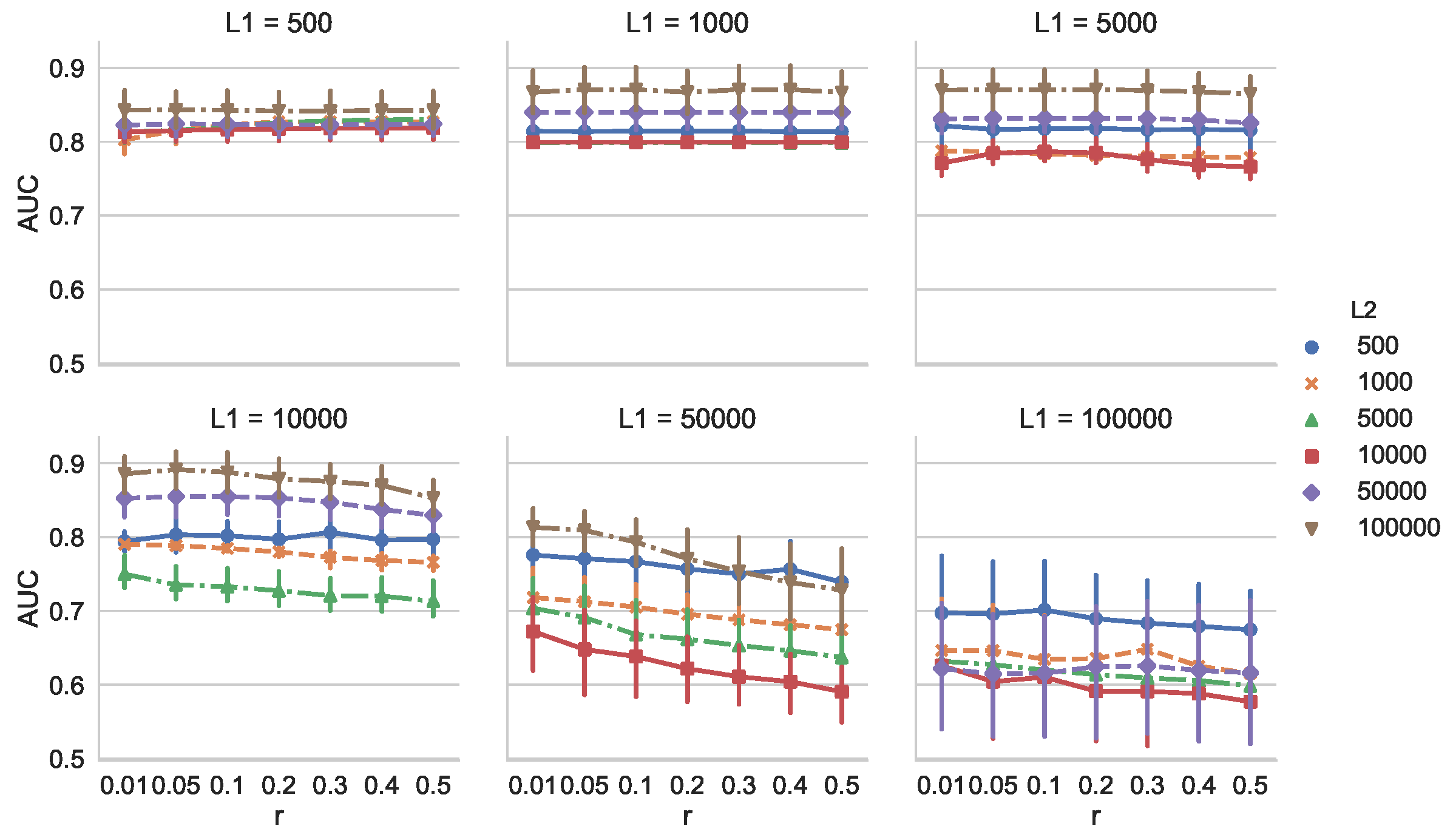
Because MCD-T depends on discounting parameter r and the change detection algorithm used, we investigated these effects. First, we examined the dependency of AUC on r for all combinations of and . We calculated AUC for 30 times with and . We used SEED [13] as the change detection algorithm, and its parameters were set to the same values as above. The dataset used was also the same as in the previous experiment. Figure 5 shows that, when is relatively small (e.g., ), AUC is not heavily dependent on r. When is larger, however, we observe that the larger r is, the smaller AUC is. This is because, with an increase of , the number of false alarms of SEED also increases. In such situations, MCD-T is more prone to the false alarms when r is larger.
Figure 6 shows the dependency of AUC of VD on the buffer size B and the reservoir size R () for comparison. We calculated AUC for 50 times. We observe from Figure 6 that AUC decreases as B increases. In addition, we also see that MCD-T outperforms VD for various combinations of r and by comparing Figure 5 with Figure 6.
Next, we investigated the effect of the change detection algorithm used. We used SEED by changing the parameter , and . Other conditions and the dataset were the same as in the previous experiment. Here, is a hyperparameter that controls the threshold parameter [13]. Figure 7 shows that AUC does not heavily depend on for all combinations of and . In general, the threshold parameter of the change detection algorithm controls the performance of MCD-T. Hence, it should be carefully set.
4.2. Synthetic Dataset 2 (Metachanges along State)
We generated a data stream with length , where . The generated data stream contained a metachange along state. In the former part, each datum was drawn from
After we repeated the procedure 10 times, we obtained a subsequence with length . In the latter part, each datum was drawn from
A metachange along state occurred at . For change detection, we employed four algorithms for comparison: (1) SMDL [8], a semi-instant method with the MDL change statistics; (2) ChangeFinder (CF) [1,2,4], a state-of-the-art method of abrupt change detection; (3) Bayesian online change point detection (BOCPD) [3], a retrospective online change point detection with a Bayesian scheme; and (4) ADWIN2 [21], adaptive windowing methods. As we assumed a situation where change and metachange mechanisms do not vary significantly, we decided to choose the best combinations of parameters of each change detection algorithm by grid search, as in [8,27]. We generated 10 sequences with the scheme above and calculated the F-scores for each combination of the following parameters:
- SMDL: Window size (), (), (). Threshold parameter .
- CF: Discounting rate . Threshold parameter (regression orders , smoothing parameters ).
- BOCPD: Parameter related to change intervals . Threshold parameter .
- ADWIN2: Confidence parameter .
F-score is defined as the harmonic mean of precision and recall, which are calculated using the number of true positives (TP), false positives (FP), and false negatives (FN) as follows [9]: TP is the number of true change points that are -neighbors of estimated change points. Thus, FP and FN are calculated as and , where ℓ and m are calculated as and , where ℓ and m denotes the total number of estimated and true change points, respectively. Finally, we calculated and for each method. In this experiment, we set to 100.
After optimizing the parameters of each change detection algorithm, we generated 30 data streams with the scheme above and detected change points and the metachange. In the metachange detection, we compared MCD-S with SMDL. We chose SMDL for comparison because it calculates a change score at each time based on changes of parameters with MDL. Hence, a change rate of scores between change points is regarded as the degree of metachange along state. Hereafter, we refer to SMDL for metachange detection as SMDL metachange (SMDL-MC) and the window parameter as . We calculated MCAS in Equation (16) for MCD-S and the change rate for SMDL-MC. is the change score at time t for a univariate normal distribution [8]:
where , , and are the maximum likelihood estimators of standard deviations calculated for , and , respectively. is the normalizer of the normalized maximum likelihood code length [20]
where is the gamma function. In this paper, and . The window parameters h of MCD-S and of SMDL-MC were set to (), (), and (). In calculating the F-scores, the maximum tolerant delay was set to .
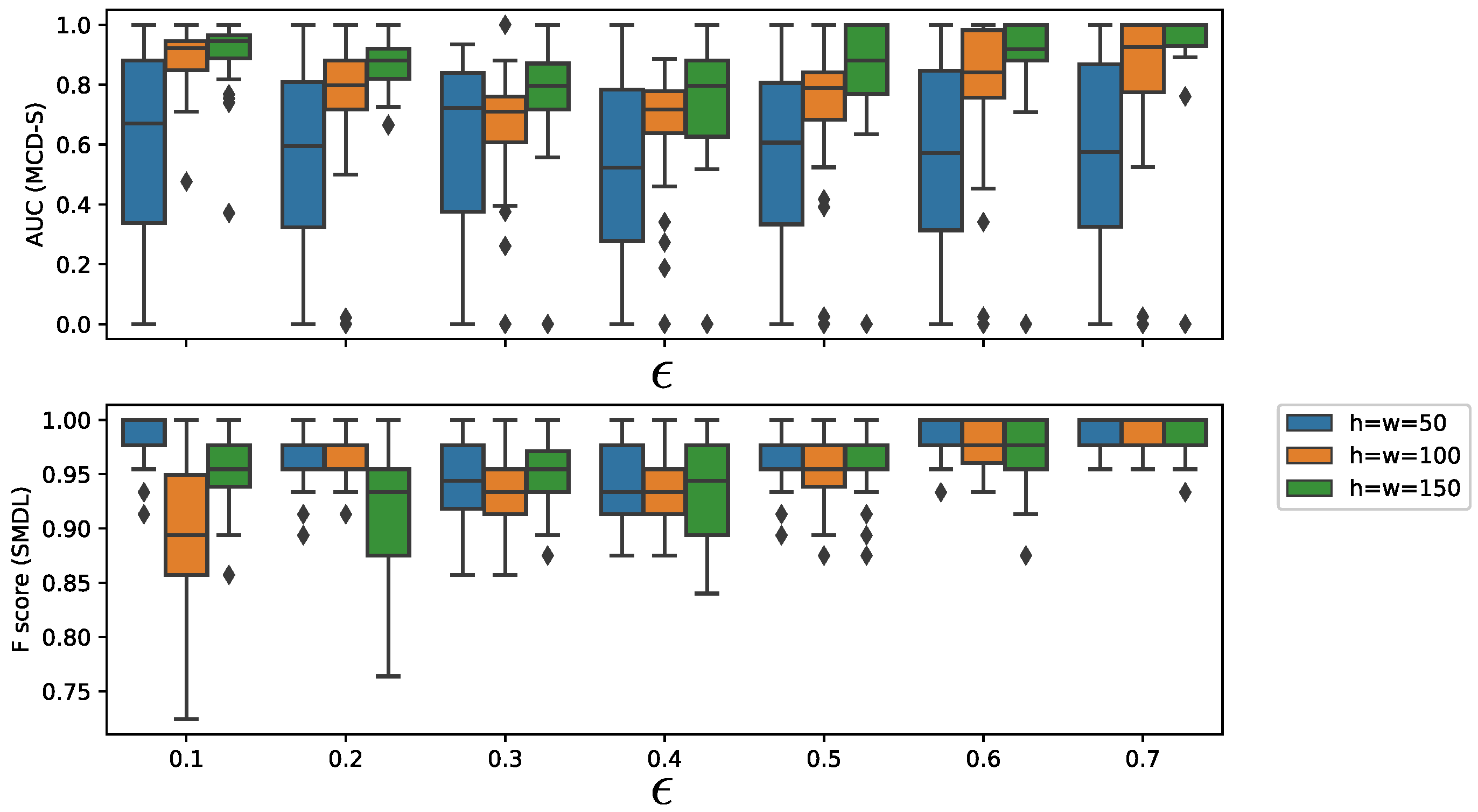
Table 2 shows the average AUC values of MCD-S and SMDL-MC for the detection of metachanges along state at . The first and second rows in the header represent change detection and metachange detection algorithms, respectively. The best parameters for each combination of change detection and metachange detection algorithms are (), (), and (). Table 2 shows that MCD-S outperforms SMDL-MC overall because MCD-S deals with metachanges along state directly in terms of MCAS, whereas SMDL-MC only quantifies the difference in code lengths between situations where there is a change and where there is no change.
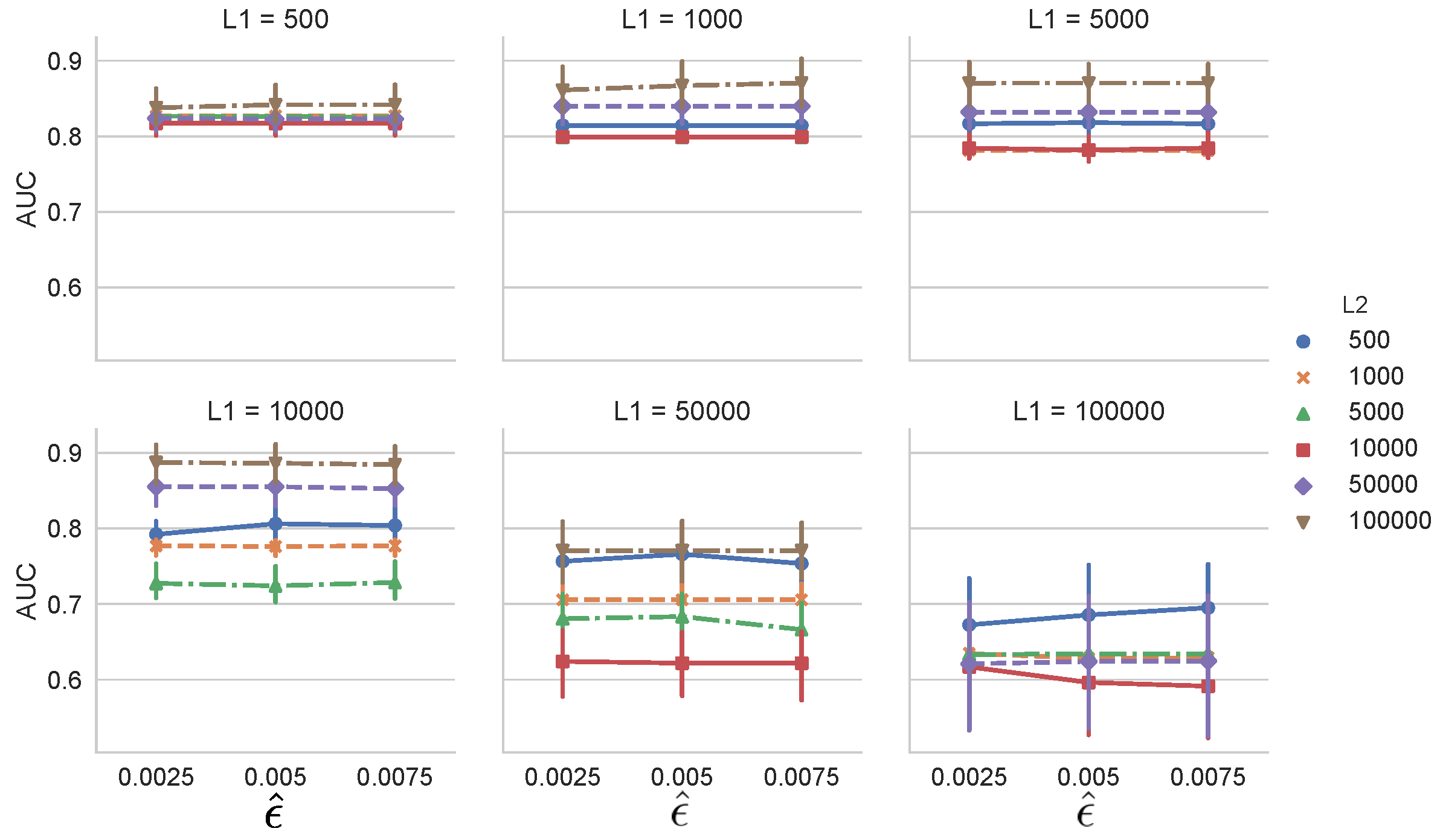
We further investigated the effects of window size h and threshold parameters of the change detection algorithms. We chose SMDL [8] for change detection. Figure 8 shows the dependency of AUC on h and threshold parameter of SMDL. The interval length was set to , threshold parameter was set to , and , where w is the window parameter of SMDL. Figure 8 (top and bottom) shows the dependency of AUC of MCD-S on the threshold parameter of SMDL and the dependency of F-score of SMDL on , respectively. We observe in Figure 8 (top) that AUC of MCD-S decreases between and , but, when exceeds , AUC begins to increase for . This reflects the fact that there are many local maximum points of the change scores of SMDL, leading to false alarms of change points around –. It is noticeable that F-scores of SMDL decrease for , and for , but AUCs of MCD-S do not do so much. This is because SMDL detects many false positive change points, but it detects the metachange point accurately.
As for the dependency of AUC on window size h, we observe that AUC generally increases as h increases for the same .
4.3. Synthetic Dataset 3 (Metachanges Along Time and State)
We generated a data stream that contained metachanges along both time and state. The stream consisted of two subsequences. The former part repeated changes of mean. Each instance was drawn from Equation (20) with . We repeated the procedure for 50 times and obtained a subsequence with length . The latter part comprised the following four parts, each with length :
In total, we obtained a data stream with length . A metachange along both time and state occurred at . We chose lengths and among 400, 450, and 500.
We detected the metachange in the following three ways: we first detected change points with the same algorithms as in Section 4.2, and then detected the metachanges with MCD-T, MCD-S, and MCD. The parameters of the change detection algorithms were tuned as in Section 4.2. The ranges of parameters were the same as those in Section 4.2. except that, for SMDL, the threshold parameter for all combinations of and . The parameter of MCD-T was selected among and MCD-S was among . The window size of SMDL were selected among , and the maximum tolerant delay was . We chose the weight parameter in Equation (17) among . For VD, the buffer and reservoir sizes (B and R) were selected among . All the parameters were selected with grid search for the AUCs of metachange detection to be maximum.
Table 3 shows the average AUC values. Table 3a–c show average AUC values with MCD-T, MCD-S, and MCD. Table 3a shows that MCD combined with SMDL as the change detection algorithm outperforms MCD-S and MCD-T.
Table 4 shows the best parameters for each combination of intervals. We observe that the more intensive a metachange along time is, the bigger r is and the less becomes. These results reflect the fact that it is necessary to adapt to recent data, and MCAT increases in such a situation, leading to the decrease of .
4.4. Real Dataset: Human Action Recognition Data
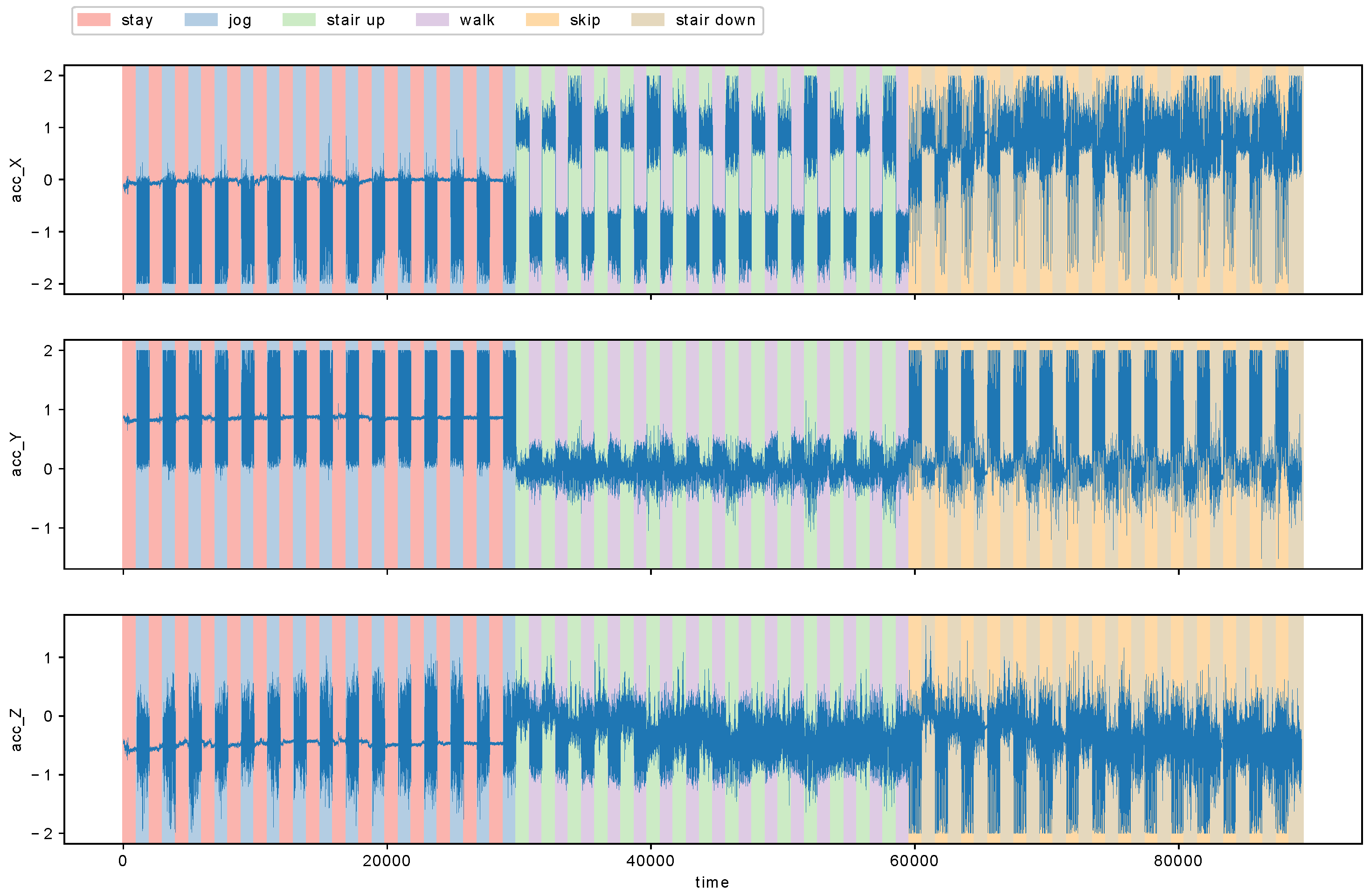
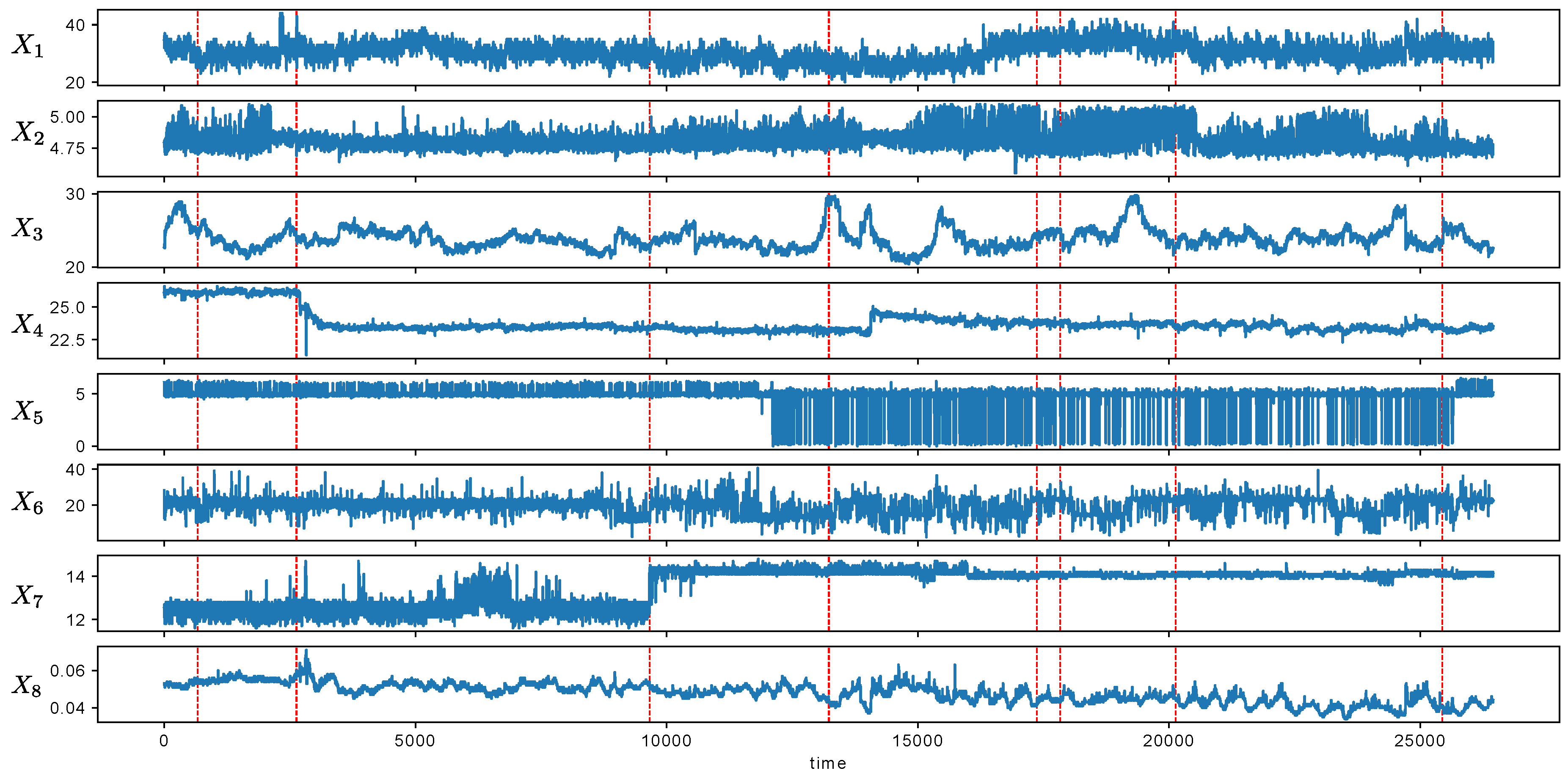
We applied MCD to the detection of metachanges in human action recognition data called HASC-PAC2016 dataset [28] (HASC-PAC2016 dataset is publicly available at http://hub.hasc.jp/). The data were collected from the Human Activity Sensing Consortium (HASC, http://hasc.jp/). HASC-PAC2016 dataset contains sequences of acceleration data for three axes, and each sequence is segmented into one of six action labels: “stay”, “walk”, “jog”, “skip”, “stair up”, (go upstairs) and “stair down” (go downstairs). For this experiment, we aimed to evaluate the effectiveness of our proposed algorithm MCD by using a data stream with ground truth of “changes of action changes” and “changes of intervals of actions”. The former corresponds to metachanges along state, and the latter to metachanges along time. We combined each action into a data stream as follows: first, we repeated “stay” and “walk” alternately for 15 times; then “jog” and “skip” for 15 times; and, finally, “stair up” and “stair down” for 15 times. We repeated each pair of actions for 15 times because “stair up” and “stair down” have only 15 files, which are the fewest in all the six actions. We obtained a data stream of length 89,324. Table 5 shows the files used for a participant named Person06023. We read the files sequentially in alphabetical order for each action. Figure 9 shows the data stream we obtained. Here, acc_X, acc_Y, and acc_Z represent accelerations for x-, y-, and z-axes, respectively.
First, we detected change points with SMDL [8]. It was a challenge to determine the hyperparameters of SMDL—window size w and threshold parameter —in an online change detection. We tuned w and with the remaining dataset for Person06023, which alternated “stay” and “walk” four times, and “jog” and “skip” likewise. Although this dataset lacked “stair up” and “stair down”, we thought that it was enough to estimate the best configuration of w and . We calculated F-score as described in Section 4.2 for the change points between different action labels. We selected and among and . Figure 10 shows histograms of intervals for each action label. We observe in Figure 10 that most of the intervals are around 960–970 for “jog”, “walk”, and “skip”, whereas, for “stay”, “stair up”, and “stair down”, the intervals are around 1020. We can see that was enough to detect changes.
We applied SMDL to the stream and obtained the estimated change scores at each time point. We calculated with the multivariate normal distribution. Specifically, is calculated as
where , , and . , , and .
Note that in Equation (21) is the normalizer of the NML code length [29,30]:
where m is the dimension of the data stream, is the gamma function, and is calculated as
We set and .
Next, we defined the ground truths for metachanges along state at two time points where the changes of action label changes occurred: 29,752 from “jog” to “stair up”, and 59,588 from “walk” to “skip”. Moreover, we also defined the ground truths for metachanges along time at time points where the changes of intervals occurred. We see in Figure 10 that the distributions are significantly different between four types of “changes of action changes”: from “stay” to “jog”, from “jog” to “stair up”, from “stair up” to “walk”, and from “skip” to “stair down”.
We detected metachanges along time with MCD-T and volatility detector (VD) [13], and compared them. Figure 11 shows the estimated MCAT with MCD-T and the relative volatility with VD. The parameter of MCD-T was set to , whereas one of VD was . Figure 11 shows the results.
We observe in Figure 11 that MCAT detects the metachanges along time between the four action pairs, respectively, for and . However, the relative volatility fails to detect some of these metachanges along time.
We detected metachanges along state with MCD-S and the change rate of the MDL change statistics [8]. Figure 12 shows the estimated MCAS with MCD-S and the MDL change statistics. We observe in Figure 12 that both MCD-S and the MDL change statistics detect a time point around 29,752 from “jog” to “stair up”. However, the MDL change statistics do not change significantly at a time point around 59,588, where a metachange along state happened from “walk” to “skip”. It indicates that the change rate of the MDL change statistics failed to detect the metachange along state around 59,588, whereas MCD-S detected it successfully.
In summary, the proposed algorithm MCD detected metachanges along both time and state more accurately than other methods.
4.5. Real Dataset: Production Condition Data
We applied MCD to the detection of metachanges in the production condition data. The data were collected from a factory of a manufacturing company. Each datum comprised eight attributes, and the length of the stream was 26,450. The factory reported that important events occurred 10 times during the study period, at 668, 2634, 2635, 9663, 13,230, 13,231, 17,372, 17,832, 20,131, and 25,441. Figure 13 shows the attributes from the stream. The dashed line indicates the time points where important events occurred. We investigated whether the detected metachanges were signs of important events, and we finally concluded that it might be true. The details are as follows.
Figure 13 shows that the scales of attributes were different. Hence, we normalized each attribute X to , where and are the sample mean and standard deviation, respectively, which were calculated with the first 250 time points. First, we applied SMDL [8] to the stream and obtained the estimated change scores at each time. We calculated with the multivariate normal distribution in Equation (21). The window sizes w of SMDL and h of MCD were set to by field knowledge that it roughly represents a unit of production. Moreover, and in Equation (22) were set to 60 and , respectively. Next, we detected change points as time points where the change scores were locally maximum within an interval where . We set when the total change points detected was less than 0.5% of the total length. It is a business demand by a factory, and so there were not many alarms. The number of detected change points was 97 (0.37%). Finally, we determined the discounting parameter r and the weight parameter of MCD in Equation (17) with the first 5000 time points. We selected and so that the AUC score at and would be the maximum. The AUC score was calculated using Equations (18) and (19).
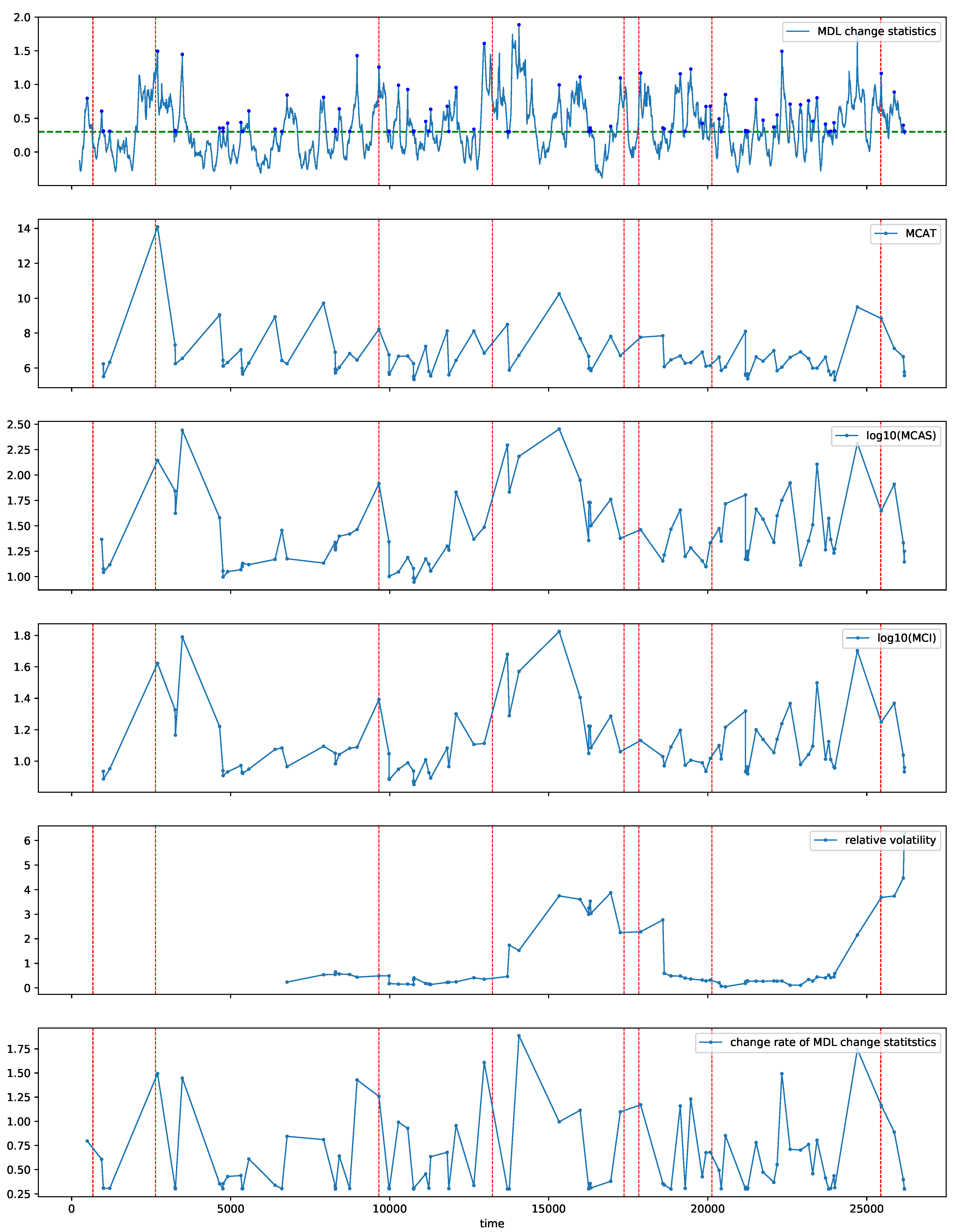
Figure 14 shows the MDL change statistics calculated with SMDL [8] (Figure 14, top), the estimated MCAT (Figure 14, second), logarithm of the estimated MCAS (Figure 14, third), and logarithm of the estimated MCI (Figure 14, fourth). We also estimated the relative volatility with VD [13,25] (Figure 14, fifth) and the change rate of the MDL change statistics (Figure 14, bottom) for comparison in detecting metachanges along both time and state. For VD, the buffer size B and the reservoir size R were both set to 10. In Figure 14 (top), the red points indicate the detected change points.
We summarize what can be seen for metachange statistics in Figure 14 as follows:
- : The trend of MCI increases roughly after , which can be interpreted as a combination of MCAT and MCAS in Figure 14. The relative volatility and the change rate of the MDL change statistics do not show such a significant sign.
- 13,230, 13,231, 17,372, 17,832: For time points between 10,000 and 15,000, the trend of MCI increases. It is also due to the combination of MCAT and MCAS, but is more influenced by MCAS. It might also be a sign of important events at 17,372 and 17,832 as well as 13,230 and 13,231. The relative volatility increases after 13,231, which might be a sign of the important event at 17,372. However, the change rate of the MDL change statistics does not show such a significant sign.
- 25,440: For time points between 20,000 and 25,000, the trend of MCI increases with large fluctuations. It is also more influenced by MCAS. It might also be a sign of important events at 25,440. The relative volatility increases for the time points, but the change rate of the MDL change statistics does not show such a significant sign.
In summary, we can observe a sign of metachange for each important event. We therefore infer that there might have been some symptoms that should be analyzed using field knowledge.
5. Conclusions
We propose the concept of metachanges along time and state in data streams, and we introduce metachange statistics to quantify metachanges from a unified view with MDL. The key idea of our proposed method is to encode the time intervals and change of states with code lengths in the same fashion. Next, we introduce the novel methodology of MCD. Using synthetic datasets, we empirically demonstrated that the proposed algorithm was highly effective in detecting metachanges along time and state. Using a real dataset, we demonstrated that the proposed algorithm could detect metachanges in both time and state, some of which were overlooked by VD [13] and the MDL change statistics [8]. The estimated metachange statistics might have been a sign of important events.
Future work will be directed toward the theoretical guarantee of metachange statistics, especially integrated metachange statistics. We will also consider how to adapt to a non-stationary data stream by updating the weight parameter in Equation (17). Other research directions might lie in the extension of metachange statistics to transient periods between change points. Furthermore, metachange detection of model structure change and its change sign is another interesting line of research.
Author Contributions
Conceptualization, S.F. and K.Y.; methodology, S.F. and K.Y.; software, S.F.; validation, S.F.; formal analysis, S.F.; investigation, S.F.; resources, K.Y.; data curation, S.F.; writing–original draft preparation, S.F.; writing–review and editing, S.F. and K.Y.; visualization, S.F.; supervision, K.Y.; project administration, K.Y.; funding acquisition, K.Y.
Funding
This work was partially supported by JST KAKENHI 19H01114 and JST-AIP JPMJCR19U4.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Yamanishi, K.; Takeuchi, J. A unifying framework for detecting outliers and change points from non-stationary time series data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Edmonton, AB, Canada, 23–25 July 2002; pp. 676–681. [Google Scholar]
- Takeuchi, J.; Yamanishi, K. A unifying framework for detecting outliers and change-points from time series. IEEE Trans. Knowl. Data Eng. 2006, 18, 482–492. [Google Scholar] [CrossRef]
- Adams, R.; MacKay, D. Bayesian online changepoint detection. arXiv 2007, arXiv:0710.3742. [Google Scholar]
- Takahashi, T.; Tomioka, R.; Yamanishi, K. Discovering emerging topics in social streams via link anomaly detection. IEEE Trans. Knowl. Data Eng. 2014, 26, 120–130. [Google Scholar] [CrossRef]
- Miyaguchi, K.; Yamanishi, K. On-line detection of continuous changes in stochastic processes. In Proceedings of the 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Paris, France, 19–21 October 2015; pp. 1–9. [Google Scholar]
- Yamanishi, K.; Maruyama, Y. Dynamic syslog mining for network failure monitoring. In Proceedings of the eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining (KDD), Chicago, IL, USA, 21–24 August 2005; pp. 499–508. [Google Scholar]
- Yamanishi, K.; Maruyama, Y. Dynamic model selection with its applications to novelty detection. IEEE Trans. Inform. Theory 2007, 53, 2180–2189. [Google Scholar] [CrossRef]
- Yamanishi, K.; Miyaguchi, K. Detecting gradual changes from data stream using MDL-change statistics. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 156–163. [Google Scholar]
- Kaneko, R.; Miyaguchi, K.; Yamanishi, K. Detecting changes in streaming data with information-theoretic windowing. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 646–655. [Google Scholar]
- Yamanishi, K.; Fukushima, S. Model change detection with the MDL Principle. IEEE Trans. Inform. Theory 2018, 64, 6115–6126. [Google Scholar] [CrossRef]
- Aminikhanghahi, S.; Cook, D.J. A survey of methods for time series change point detection. Knowl. Inf. Syst. 2017, 51, 339–367. [Google Scholar] [CrossRef] [PubMed]
- Kleinberg, J. Bursty and hierarchical structure in streams. Data Min. Knowl. Discov. 2003, 7, 373–397. [Google Scholar] [CrossRef]
- Huang, D.; Koh, Y.S.; Dobbie, G.; Pears, R. Detecting volatility shift in data streams. In Proceedings of the 2014 IEEE International Conference on Data Mining (ICDM), Shenzhen, China, 14–17 December 2014; pp. 863–868. [Google Scholar]
- Huang, D.; Koh, Y.S.; Dobbie, G.; Pears, R. Tracking drift types in changing data streams. In Proceedings of the International Conference on Advanced Data Mining and Applications, Hangzhou, China, 14–16 December 2013; pp. 72–83. [Google Scholar]
- Aggarwal, C. A framework for diagnosing changes in evolving data streams. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data (SIGMOD), San Diego, CA, USA, 9–13 June 2003; pp. 575–586. [Google Scholar]
- Spiliopoulou, M.; Ntoutsi, I.; Theodoridis, Y.; Schult, R. MONIC: Modeling and monitoring cluster transitions. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Philadelphia, PA, USA, 20–23 August 2006; pp. 706–711. [Google Scholar]
- Spiliopoulou, M.; Ntoutsi, E.; Theodoridis, Y.; Schult, R. MONIC and followups on modeling and monitoring cluster transitions. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD), Prague, Czech Republic, 23–27 September 2013; pp. 622–626. [Google Scholar]
- Ntoutsi, I.; Spiliopoulou, M.; Theodoridis, Y. Summarizing cluster evolution in dynamic environments. In Proceedings of the International Conference on Computational Science and Its Applications, Santander, Spain, 20–23 June 2011; pp. 562–577. [Google Scholar]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Mykola, P.; Abdelhamid, B. A survey on concept drift adaptation. ACM Comput. Surv. 2014, 46, 44:1–44:37. [Google Scholar] [CrossRef]
- Rissanen, J. Optimal Estimation of Parameters; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Bifet, A.; Gavaldá, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- van Leeuwen, M.; Siebes, A. StreamKrimp: Detecting change in data streams. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD), Antwerp, Belgium, 15–19 September 2008; pp. 672–687. [Google Scholar]
- Rissanen, J. Stochastic complexity and modeling. Ann. Stat. 1986, 14, 1080–1100. [Google Scholar] [CrossRef]
- Yamanishi, K.; Takeuchi, J.; Williams, G.; Milne, P. On-line unsupervised outlier detection using finite mixtures with discounting learning algorithms. Data Min. Knowl. J. 2004, 8, 275–300. [Google Scholar] [CrossRef]
- Huang, D. Change Mining and Analysis for Data Streams. Ph.D. Thesis, The University of Auckland, Auckland, New Zealand, 2015. [Google Scholar]
- Fawcett, T.; Provost, F. Activity monitoring: noticing interesting changes in behavior. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Diego, CA, USA, 15–18 August 1999; pp. 53–62. [Google Scholar]
- Liu, S.; Yamada, M.; Collier, N.; Sugiyama, M. Change-point detection in time-series data by relative density-ratio estimation. Neural Netw. 2013, 43, 72–83. [Google Scholar] [CrossRef] [PubMed]
- Ichino, H.; Kaji, K.; Sakurada, K.; Horii, K.; Kawaguchi, N. HASC-PAC2016: Large scale human pedestrian activity corpus and its baseline recognition. In Proceedings of the UBICOMP/ISWC’16 Adjunct, Heidelberg, Germany, 12–16 September 2016; pp. 705–714. [Google Scholar]
- Hirai, S.; Yamanishi, K. Efficient computation of normalized maximum likelihood coding for Gaussian mixtures with its applications to optimal clustering. In Proceedings of the IEEE International Symposium on Information Theory, St. Petersburg, Russia, 31 July–5 August 2011; pp. 1031–1035. [Google Scholar]
- Hirai, S.; Yamanishi, K. Efficient computation of normalized maximum likelihood coding for Gaussian mixtures with its applications to optimal clustering. IEEE Trans. Inform. Theory 2013, 59, 7718–7727. [Google Scholar] [CrossRef]
Figure 1.
Conceptual illustration of metachanges.

Figure 2.
Schematic of the proposed metachange detection algorithm (MCD) algorithm.

Figure 3.
Metachange statistics along time (MCAT): (top) time interval at each change point; (second) MCAT ; (third) change rate of MCAT ; and (bottom) the estimated parameter of the exponential distribution . The discounting parameter .
Figure 3.
Metachange statistics along time (MCAT): (top) time interval at each change point; (second) MCAT ; (third) change rate of MCAT ; and (bottom) the estimated parameter of the exponential distribution . The discounting parameter .

Figure 4.
Metachange statistics along state (MCAS): (top) data stream ; and (bottom) MCAS . Window size .
Figure 4.
Metachange statistics along state (MCAS): (top) data stream ; and (bottom) MCAS . Window size .

Figure 5.
Dependency of AUC on discounting parameter r for MCD-T on Synthetic Dataset 1.

Figure 6.
Dependency of AUC on the buffer size B (= the reservoir size R) for VD on Synthetic Dataset 1.
Figure 6.
Dependency of AUC on the buffer size B (= the reservoir size R) for VD on Synthetic Dataset 1.

Figure 7.
Dependency of AUC on threshold controlling parameter of SEED [13] on Synthetic Dataset 1.
Figure 7.
Dependency of AUC on threshold controlling parameter of SEED [13] on Synthetic Dataset 1.

Figure 8.
Dependency of AUC on threshold parameter for SMDL [8] and window size h of MCD-S on Synthetic Dataset 2.
Figure 8.
Dependency of AUC on threshold parameter for SMDL [8] and window size h of MCD-S on Synthetic Dataset 2.

Figure 9.
Human action recognition data for Person06023. Each row represents accelerations for x-, y-, and z-axes, respectively.
Figure 9.
Human action recognition data for Person06023. Each row represents accelerations for x-, y-, and z-axes, respectively.

Figure 10.
Histograms of intervals for each action label.

Figure 11.
MCAT with MCD-T () and the relative volatility with the volatility detector [13] ().
Figure 11.
MCAT with MCD-T () and the relative volatility with the volatility detector [13] ().

Figure 12.
MCAS of MCD-S () and the MDL change statistics ().

Figure 13.
Data stream of the production condition data. Red dashed line indicates the time points where the important events occurred.
Figure 13.
Data stream of the production condition data. Red dashed line indicates the time points where the important events occurred.

Figure 14.
Metachange statistics of the production condition data: (top) the MDL change statistics . Blue dots show change points , where ; (second) estimated MCAT ; (third) estimated logarithm of MCAS ; (fourth) estimated logarithm of integrated metachange statistics (MCI) ; (fifth) relative volatility [13]; and (bottom) change rate of the MDL change statistics . .
Figure 14.
Metachange statistics of the production condition data: (top) the MDL change statistics . Blue dots show change points , where ; (second) estimated MCAT ; (third) estimated logarithm of MCAS ; (fourth) estimated logarithm of integrated metachange statistics (MCI) ; (fifth) relative volatility [13]; and (bottom) change rate of the MDL change statistics . .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Average area under the curve (AUC) scores on Synthetic Dataset 1 (). Boldfaces describe best performances.
Table 1.
Average area under the curve (AUC) scores on Synthetic Dataset 1 (). Boldfaces describe best performances.
| SEED | SMDL | ||||
|---|---|---|---|---|---|
| MCD-T | VD | MCD-T | VD | ||
| 100,000 | 50,000 | ||||
| 100,000 | 10,000 | ||||
| 100,000 | 5000 | ||||
| 100,000 | 1000 | ||||
| 100,000 | 500 | ||||
| 50,000 | 100,000 | ||||
| 50,000 | 10,000 | ||||
| 50,000 | 5000 | ||||
| 50,000 | 1000 | ||||
| 50,000 | 500 | ||||
| 10,000 | 100,000 | ||||
| 10,000 | 50,000 | ||||
| 10,000 | 5000 | ||||
| 10,000 | 1000 | ||||
| 10,000 | 500 | ||||
| 5000 | 100,000 | ||||
| 5000 | 50,000 | ||||
| 5000 | 10,000 | ||||
| 5000 | 1000 | ||||
| 5000 | 500 | ||||
| 1000 | 100,000 | ||||
| 1000 | 50,000 | ||||
| 1000 | 10,000 | ||||
| 1000 | 5000 | ||||
| 1000 | 500 | ||||
| 500 | 100,000 | ||||
| 500 | 50,000 | ||||
| 500 | 10,000 | ||||
| 500 | 5000 | ||||
| 500 | 1000 | ||||
Table 2.
Average AUC scores on Synthetic Dataset 2. The first and second headers represent change detection and metachange detection algorithms, respectively. Boldfaces describe best performances.
Table 2.
Average AUC scores on Synthetic Dataset 2. The first and second headers represent change detection and metachange detection algorithms, respectively. Boldfaces describe best performances.
| L | SMDL | CF | BOCPD | ADWIN2 | ||||
|---|---|---|---|---|---|---|---|---|
| MCD-S | SMDL-MC | MCD-S | SMDL-MC | MCD-S | SMDL-MC | MCD-S | SMDL-MC | |
| 500 | ||||||||
| 1000 | ||||||||
| 2000 | ||||||||
Table 3.
Average AUC scores of metachange detection on Synthetic Dataset 3. The first and second headers represent change detection and metachange detection algorithms, respectively. Boldfaces describe best performances.
(a) Metachange detection along time.
| SMDL | CF | BOCPD | ADWIN2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MCD-T | VD | MCD-T | VD | MCD-T | VD | MCD-T | VD | ||
| 400 | 450 | ||||||||
| 400 | 500 | ||||||||
| 450 | 400 | ||||||||
| 450 | 500 | ||||||||
| 500 | 400 | ||||||||
| 500 | 450 | ||||||||
(b) Metachange detection along state.
| SMDL | CF | BOCPD | ADWIN2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MCD-S | SMDC-MC | MCD-S | SMDC-MC | MCD-S | SMDC-MC | MCD-S | SMDC-MC | ||
| 400 | 450 | ||||||||
| 400 | 500 | ||||||||
| 450 | 400 | ||||||||
| 450 | 500 | ||||||||
| 500 | 400 | ||||||||
| 500 | 450 | ||||||||
(c) Metachange detection along both time and state.
| SMDL | CF | BOCPD | ADWIN2 | ||
|---|---|---|---|---|---|
| MCD | MCD | MCD | MCD | ||
| 400 | 450 | ||||
| 400 | 500 | ||||
| 450 | 400 | ||||
| 450 | 500 | ||||
| 500 | 400 | ||||
| 500 | 450 |
Table 4.
Best parameters for each combination of intervals.
| r | w | h | |||
|---|---|---|---|---|---|
| 400 | 450 | ||||
| 400 | 500 | ||||
| 450 | 400 | ||||
| 450 | 500 | ||||
| 500 | 400 | ||||
| 500 | 450 |
Table 5.
Files for generating a sequence of Person06023.
| Action Label | Files |
|---|---|
| stay | HASC N-acc.csv (N = 0605581–0605595) |
| walk | HASC N-acc.csv (N = 0608420–0608434) |
| jog | HASC N-acc.csv (N = 0611173–0611187) |
| skip | HASC N-acc.csv (N = 0613411–0613425) |
| stair up | HASC N-acc.csv (N = 0615620–0615634) |
| stair down | HASC N-acc.csv (N = 0614162–0614166) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Fukushima, S.; Yamanishi, K. Detecting Metachanges in Data Streams from the Viewpoint of the MDL Principle. Entropy 2019, 21, 1134. https://doi.org/10.3390/e21121134
AMA Style
Fukushima S, Yamanishi K. Detecting Metachanges in Data Streams from the Viewpoint of the MDL Principle. Entropy. 2019; 21(12):1134. https://doi.org/10.3390/e21121134
Chicago/Turabian StyleFukushima, Shintaro, and Kenji Yamanishi. 2019. "Detecting Metachanges in Data Streams from the Viewpoint of the MDL Principle" Entropy 21, no. 12: 1134. https://doi.org/10.3390/e21121134
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.