Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications

 ,
, 

Abstract
1. Introduction
2. Materials and Methods
2.1. Permutation Entropy
- The embedded dimension m. The recommended range for this parameter is [11], but other greater values have been used successfully [12,24,26,27]. Since this parameter is also part of the inequality under analysis in this work, m will be varied in the experiments, taking values from within the recommended range, and in some cases beyond that.
- The embedded delay . The influence of the embedded delay has been studied in several previous publications [10,29] for specific applications. This parameter is not directly involved in the relationship, and therefore it will not be assessed in this work. Moreover, this parameter contributes to a reduction in the amount of data available when in practical terms [30], and therefore might have a detrimental effect on the analysis. Thus, will be considered as in all the experiments except a few cases for illustrative purposes.
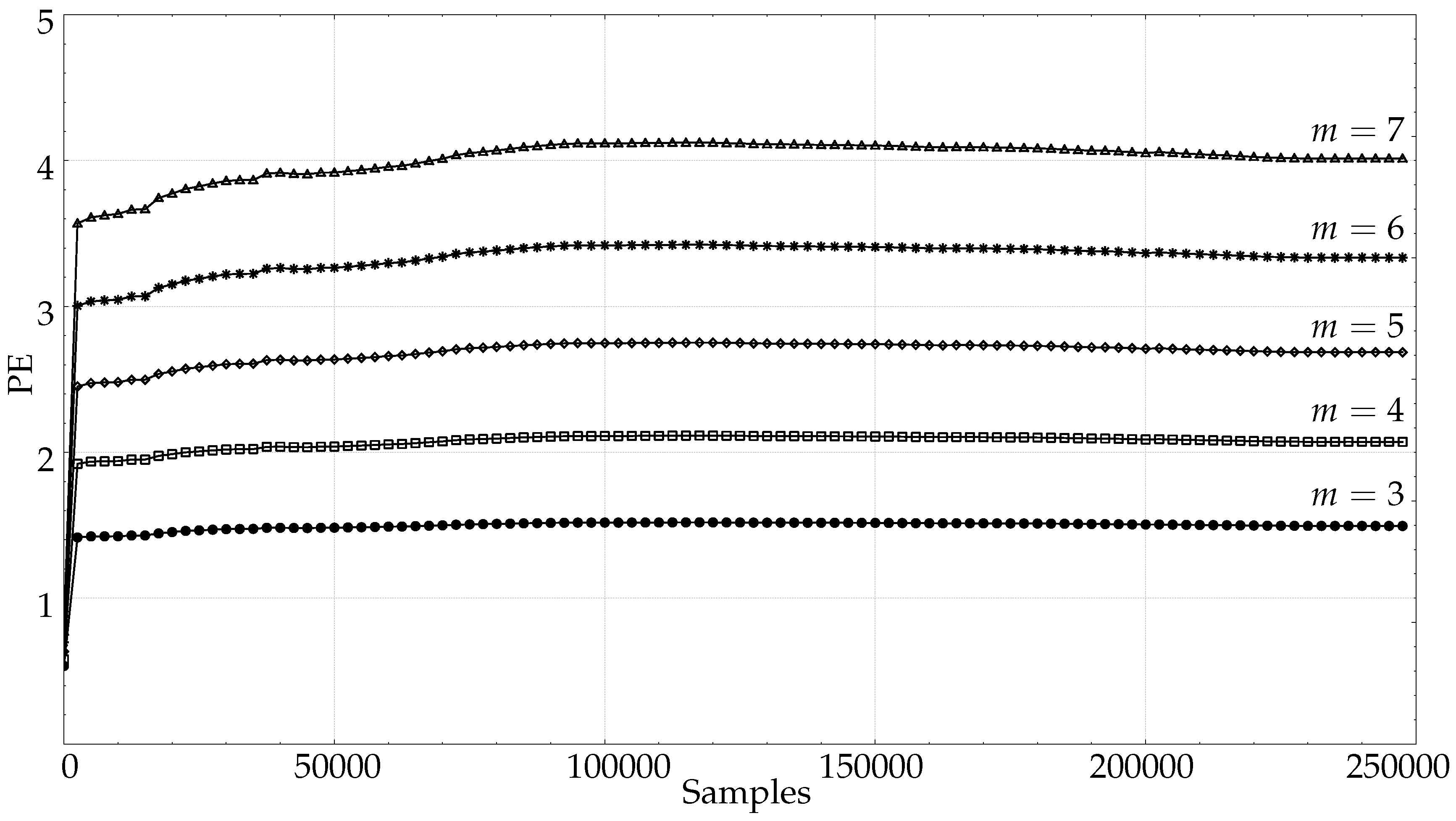
- The length of the time series N. As stated before, the recommended relationship is commonplace in practically all the publications related to PE, but no study so far has quantified this relationship as planned in the present paper. N will be varied in the experiments to obtain a representative set of PE curve points accounting for increasing time series lengths, from 10 samples up to the maximum length available. Each time series was run at different lengths and m values.
2.2. Experimental Dataset
2.2.1. Synthetic Dataset
- RAND. A sequence of random numbers following a normal distribution (Figure 1a).
- LMAP. A sequence of numbers computed from the logistic map equation . This dataset really corresponds to 2 subsets obtained by changing the value of the parameter R: 100 random initialisations of with , and with and to create 3 classes of 100 periodic records each (Figure 1c), and 3x100 randomly initialised records with and to create 3 classes of 100 more chaotic records each (Figure 1d).
- SIN. A sequence of values from a sinusoid with random phase variations. Used specifically to study the number of patterns found in deterministic records.
2.2.2. Real Dataset
- CLIMATOLOGY. Symbolic dynamics have a place in the study of climatology [33], with many time series databases publicly available nowadays [37,38,39]. This group includes time series of temperature anomalies from the Global Historic Climatology Network temperature database available through the National Oceanic and Atmospheric Administration [39]. The data correspond to monthly global surface temperature anomaly readings dating back from 1880 to the present. The temperature anomaly corresponds to the difference between the long–term average temperature, and the actual temperature. In this case, anomalies are based on the climatology from 1971 to 2000, with a total of 1662 samples for each record. These time series exhibit a clear growing trend from year 2000, probably due to the global warming effect, as illustrated in Figure 2a. In [36], average daily temperatures in Mexico City and New York City were used, with more than 2000 samples. Other works have also used climate data, such as in [40], where surface temperature anomaly data in Central Europe were analysed using Multi-scale entropy, with .
- SEISMIC. Seismic data have also been successfully analysed using PE [41], and these time series are a very promising field of research using PE. The data included in this paper was drawn from the Seismic data database, US Geological Survey Earthquake Hazards Program [42]. The time series correspond to worldwide earthquakes whose magnitude is greater than 2.5, detected each month, from January to July 2018. The lengths of these time series are not uniform, since they depend on the number of earthquakes detected each month. It ranges from 2104 up to 9090 samples. An example of these records is show in Figure 2b.
- FINANCIAL. This set of financial time series was included as an additional representative field of application of PE [43]. Specifically, data corresponding to daily simple returns of Apple, American Express, and IBM, from 2001 to 2010 [44] were included, with a total length of 2519 samples. One of these time series are shown in Figure 2c. There is a good review of entropy applications to financial data in [45].
- Biomedical time series. This is probably the most thoroughly studied group of records using PE [14]. Three subsets have been included:
- EMG. Three (healthy, myopathy, neuropathy) very extensive records corresponding to electromyographic data (Examples of electromyograms [46]). The data were acquired at 50 kHz and downsampled to 4 kHz, and band–pass filtered during the recording process between 20 Hz and 5 kHz. All three records contain more than 50,000 samples. These records were later split into consecutive non-overlapping sequences of 5000 samples to create three corresponding groups for classification analysis (10 healthy, 22 myopathy, and 29 neuropathy resulting records).
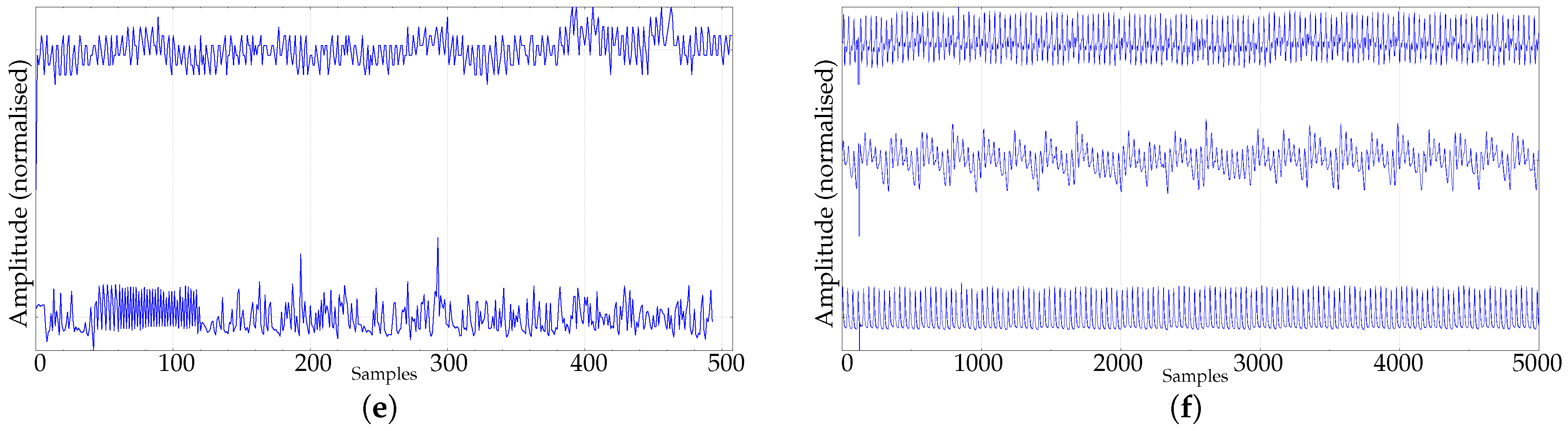
- PAF. The PAF (Paroxysmal Atrial Fibrillation) prediction challenge database is also publicly available at Physionet [46], and is described in [47]. The PAF records used correspond to 50 time series of short duration (5 minute records), coming from subjects with PAF. Even–numbered records contain an episode of PAF, whereas odd–numbered records are PAF–free (Figure 2e). This database was selected because the two classes are easily distinguishable, and the short duration of the records (some 400–500 samples) can be challenging for PE, even at low m values.
- PORTLAND. Very long time series (more than 1,000,000 samples) from Portland State University corresponding to traumatic brain injury data. Arterial blood, central venous, and intracranial pressure, sampled at 125 Hz during 6 h (Figure 2f) from a single paediatric patient, are available in this public database [48]. Time series of this length enable the study of the influence of great m values on PE, and are also very likely to exhibit non-stationarities or drifts [5].
- EEG. Electroencephalograph records with 4097 samples from the Department of Epileptology, University of Bonn [49], publicly available at http://epileptologie-bonn.de. This database is included in the present paper because it has been used in a myriad of classification studies using different feature extraction methods [50,51,52,53,54], including PE [55], and whose results make an interesting comparison here. Records correspond to the 100 EEGs of this database from epilepsy patients, but with no seizures included, and 100 EEGs including seizures. More details of this database can be found in the references included and in many other papers.
3. Experiments and Results
3.1. Length Analysis
3.2. Classification Analysis
3.3. Justification Analysis
- Firstly, the possible differences among classes in terms of PE may become apparent before stability is reached. As occurred with ties [24], artefacts, including lack of samples, exert an equal impact on all the classes under analysis, and therefore, PE results are skewed, but differences remain almost constant. In other words, the curves corresponding to the evolution of PE with N remain parallel even for very small N values. An example of this relationship is shown in Figure 9 for PAF records using and . Analytically, PE reaches stability at 45 samples for , but at 30 samples, both classes become significantly separable, which is confirmed by numerical results in Table 5. For there are not enough samples to reach stability, as defined in Section 3.1, but class separability can be achieved with less than 50 samples. Shorter lengths may have a detrimental effect on classification accuracy, but such accuracy is still very significant. This behaviour is quite common (Table 3 and Table 5).
- Secondly, the recommendation was devised to ensure that all patterns could be found with high probability [16]. However, this is a very restrictive limitation, since this is only achievable for random time series. More deterministic time series, even chaotic time series like the ones included in the experimental dataset, have forbidden patterns that cannot be found whatever the length is [58]. Therefore, all the possible different patterns involved in a chaotic time series can be found with shorter records than the recommendation suggests. This is very well illustrated in Table 10, where random sequences (RANDOM, SEISMIC) exhibit more different patterns than chaotic ones (EMG, PAF) per length unit. Thus, for most real–world signals that recommendation could arguably be softened.
- Third, and finally, not all the patterns, in terms of estimated probability, have the same impact, positive or negative, on PE calculation. Indirectly, this impact will also have an influence on the discriminative power of PE. In other words, a subset of the patterns can be more beneficial than the entire set. To assess this point, we modified the PE algorithm to sort the estimated non-zero probabilities in ascending order, and remove the k–smallest ones from the final computation. The approximated PE value was used in the classification analysis instead. Some experiments were carried out to quantify the possible loss incurred by this removal in cases previously studied. The corresponding results are shown in Table 11, for records with a significant number of patterns as per the data in Table 10.
Relevance Analysis
| Algorithm 1: RELIEF-F for ordinal patterns selection |
 |
4. Discussion
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Lake, D.E.; Richman, J.S.; Griffin, M.P.; Moorman, J.R. Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol.-Regul. Integr. Comp. Physiol. 2002, 283, R789–R797. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.; Chen, X.; Kanters, J.K.; Solomon, I.C.; Chon, K.H. Automatic Selection of the Threshold Value r for Approximate Entropy. IEEE Trans. Biomed. Eng. 2008, 55, 1966–1972. [Google Scholar]
- Alcaraz, R.; Abásolo, D.; Hornero, R.; Rieta, J. Study of Sample Entropy ideal computational parameters in the estimation of atrial fibrillation organization from the ECG. In Proceedings of the 2010 Computing in Cardiology, Belfast, UK, 26–29 September 2010; pp. 1027–1030. [Google Scholar]
- Yentes, J.M.; Hunt, N.; Schmid, K.K.; Kaipust, J.P.; McGrath, D.; Stergiou, N. The Appropriate Use of Approximate Entropy and Sample Entropy with Short Data Sets. Ann. Biomed. Eng. 2013, 41, 349–365. [Google Scholar] [CrossRef]
- Mayer, C.C.; Bachler, M.; Hörtenhuber, M.; Stocker, C.; Holzinger, A.; Wassertheurer, S. Selection of entropy-measure parameters for knowledge discovery in heart rate variability data. BMC Bioinform. 2014, 15, S2. [Google Scholar] [CrossRef]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn, and SampEn. Med. Eng. Phys. 2009, 31, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Li, K.; Zhao, L.; Liu, F.; Zheng, D.; Liu, C.; Liu, S. Analysis of heart rate variability using fuzzy measure entropy. Comput. Biol. Med. 2013, 43, 100–108. [Google Scholar] [CrossRef]
- Bošković, A.; Lončar-Turukalo, T.; Japundžić-Žigon, N.; Bajić, D. The flip-flop effect in entropy estimation. In Proceedings of the 2011 IEEE 9th International Symposium on Intelligent Systems and Informatics, Subotica, Serbia, 8–10 September 2011; pp. 227–230. [Google Scholar]
- Li, D.; Liang, Z.; Wang, Y.; Hagihira, S.; Sleigh, J.W.; Li, X. Parameter selection in permutation entropy for an electroencephalographic measure of isoflurane anesthetic drug effect. J. Clin. Monit. Comput. 2013, 27, 113–123. [Google Scholar] [CrossRef] [PubMed]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Riedl, M.; Müller, A.; Wessel, N. Practical considerations of permutation entropy. Eur. Phys. J. Spec. Top. 2013, 222, 249–262. [Google Scholar] [CrossRef]
- Amigó, J.M.; Zambrano, S.; Sanjuán, M.A.F. True and false forbidden patterns in deterministic and random dynamics. Europhys. Lett. (EPL) 2007, 79, 50001. [Google Scholar] [CrossRef]
- Zanin, M.; Zunino, L.; Rosso, O.A.; Papo, D. Permutation Entropy and Its Main Biomedical and Econophysics Applications: A Review. Entropy 2012, 14, 1553–1577. [Google Scholar] [CrossRef]
- Rosso, O.; Larrondo, H.; Martin, M.; Plastino, A.; Fuentes, M. Distinguishing Noise from Chaos. Phys. Rev. Lett. 2007, 99, 154102. [Google Scholar] [CrossRef]
- Amigó, J.M.; Zambrano, S.; Sanjuán, M.A.F. Combinatorial detection of determinism in noisy time series. EPL 2008, 83, 60005. [Google Scholar] [CrossRef]
- Yang, A.C.; Tsai, S.J.; Lin, C.P.; Peng, C.K. A Strategy to Reduce Bias of Entropy Estimates in Resting-State fMRI Signals. Front. Neurosci. 2018, 12, 398. [Google Scholar] [CrossRef]
- Shi, B.; Zhang, Y.; Yuan, C.; Wang, S.; Li, P. Entropy Analysis of Short-Term Heartbeat Interval Time Series during Regular Walking. Entropy 2017, 19, 568. [Google Scholar] [CrossRef]
- Karmakar, C.; Udhayakumar, R.K.; Li, P.; Venkatesh, S.; Palaniswami, M. Stability, Consistency and Performance of Distribution Entropy in Analysing Short Length Heart Rate Variability (HRV) Signal. Front. Physiol. 2017, 8, 720. [Google Scholar] [CrossRef]
- Cirugeda-Roldán, E.; Cuesta-Frau, D.; Miró-Martínez, P.; Oltra-Crespo, S.; Vigil-Medina, L.; Varela-Entrecanales, M. A new algorithm for quadratic sample entropy optimization for very short biomedical signals: Application to blood pressure records. Comput. Methods Programs Biomed. 2014, 114, 231–239. [Google Scholar] [CrossRef]
- Lake, D.E.; Moorman, J.R. Accurate estimation of entropy in very short physiological time series: The problem of atrial fibrillation detection in implanted ventricular devices. Am. J. Physiol.-Heart Circ. Physiol. 2011, 300, H319–H325. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Novák, D.; Burda, V.; Molina-Picó, A.; Vargas, B.; Mraz, M.; Kavalkova, P.; Benes, M.; Haluzik, M. Characterization of Artifact Influence on the Classification of Glucose Time Series Using Sample Entropy Statistics. Entropy 2018, 20, 871. [Google Scholar] [CrossRef]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of biological signals. Phys. Rev. E 2005, 71, 021906. [Google Scholar] [CrossRef]
- Cuesta–Frau, D.; Varela-Entrecanales, M.; Molina-Picó, A.; Vargas, B. Patterns with Equal Values in Permutation Entropy: Do They Really Matter for Biosignal Classification? Complexity 2018, 2018, 1–15. [Google Scholar] [CrossRef]
- Keller, K.; Unakafov, A.M.; Unakafova, V.A. Ordinal Patterns, Entropy, and EEG. Entropy 2014, 16, 6212–6239. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Miró-Martínez, P.; Oltra-Crespo, S.; Jordán-Núñez, J.; Vargas, B.; Vigil, L. Classification of glucose records from patients at diabetes risk using a combined permutation entropy algorithm. Comput. Methods Programs Biomed. 2018, 165, 197–204. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Miró-Martínez, P.; Oltra-Crespo, S.; Jordán-Núñez, J.; Vargas, B.; González, P.; Varela-Entrecanales, M. Model Selection for Body Temperature Signal Classification Using Both Amplitude and Ordinality-Based Entropy Measures. Entropy 2018, 20, 853. [Google Scholar] [CrossRef]
- Tay, T.-T.; Moore, J.B.; Mareels, I. High Performance Control; Springer: Berlin, Germany, 1997. [Google Scholar]
- Little, D.J.; Kane, D.M. Permutation entropy with vector embedding delays. Phys. Rev. E 2017, 96, 062205. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Amplitude-aware permutation entropy: Illustration in spike detection and signal segmentation. Comput. Methods Programs Biomed. 2016, 128, 40–51. [Google Scholar] [CrossRef]
- Naranjo, C.C.; Sanchez-Rodriguez, L.M.; Martínez, M.B.; Báez, M.E.; García, A.M. Permutation entropy analysis of heart rate variability for the assessment of cardiovascular autonomic neuropathy in type 1 diabetes mellitus. Comput. Biol. Med. 2017, 86, 90–97. [Google Scholar] [CrossRef]
- Zunino, L.; Zanin, M.; Tabak, B.M.; Pérez, D.G.; Rosso, O.A. Forbidden patterns, permutation entropy and stock market inefficiency. Phys. A Stat. Mech. Appl. 2009, 388, 2854–2864. [Google Scholar] [CrossRef]
- Saco, P.M.; Carpi, L.C.; Figliola, A.; Serrano, E.; Rosso, O.A. Entropy analysis of the dynamics of El Niño/Southern Oscillation during the Holocene. Phys. A Stat. Mech. Appl. 2010, 389, 5022–5027. [Google Scholar] [CrossRef]
- Konstantinou, K.; Glynn, C. Temporal variations of randomness in seismic noise during the 2009 Redoubt volcano eruption, Cook Inlet, Alaska. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 23–28 April 2017; Volume 19, p. 4771. [Google Scholar]
- Molina-Picó, A.; Cuesta-Frau, D.; Aboy, M.; Crespo, C.; Miró-Martínez, P.; Oltra-Crespo, S. Comparative Study of Approximate Entropy and Sample Entropy Robustness to Spikes. Artif. Intell. Med. 2011, 53, 97–106. [Google Scholar] [CrossRef]
- DeFord, D.; Moore, K. Random Walk Null Models for Time Series Data. Entropy 2017, 19, 615. [Google Scholar] [CrossRef]
- Chirigati, F. Weather Dataset. 2016. Available online: https://doi.org/10.7910/DVN/DXQ8ZP (accessed on 1 August 2018).
- Thornton, P.; Thornton, M.; Mayer, B.; Wilhelmi, N.; Wei, Y.; Devarakonda, R.; Cook, R. Daymet: Daily Surface Weather Data on a 1-km Grid for North America, Version 2; ORNL DAAC: Oak Ridge, TN, USA, 2014.
- Zhang, H.; Huang, B.; Lawrimore, J.; Menne, M.; Smith, T.M. NOAA Global Surface Temperature Dataset (NOAAGlobalTemp, ftp.ncdc.noaa.gov), Version 4.0, August 2018. Available online: https://doi.org/10.7289/V5FN144H (accessed on 1 August 2018).
- Balzter, H.; Tate, N.J.; Kaduk, J.; Harper, D.; Page, S.; Morrison, R.; Muskulus, M.; Jones, P. Multi-Scale Entropy Analysis as a Method for Time-Series Analysis of Climate Data. Climate 2015, 3, 227–240. [Google Scholar] [CrossRef]
- Glynn, C.C.; Konstantinou, K.I. Reduction of randomness in seismic noise as a short-term precursor to a volcanic eruption. Nat. Sci. Rep. 2016, 6, 37733. [Google Scholar] [CrossRef]
- Search Earthquake Catalog, National Earthquake Hazards Reduction Program (NEHRP). 2018. Available online: https://earthquake.usgs.gov/earthquakes/search/ (accessed on 1 August 2018).
- Zhang, Y.; Shang, P. Permutation entropy analysis of financial time series based on Hill’s diversity number. Commun. Nonlinear Sci. Numer. Simul. 2017, 53, 288–298. [Google Scholar] [CrossRef]
- Wharton Research Data Services (WRDS), 1993–2018. Available online: https://wrds-web.wharton.upenn.edu/wrds/ (accessed on 1 August 2018).
- Zhou, R.; Cai, R.; Tong, G. Applications of Entropy in Finance: A Review. Entropy 2013, 15, 4909–4931. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, 215–220. [Google Scholar] [CrossRef]
- Moody, G.B.; Goldberger, A.L.; McClennen, S.; Swiryn, S. Predicting the Onset of Paroxysmal Atrial Fibrillation: The Computers in Cardiology Challenge 2001. Comput. Cardiol. 2001, 28, 113–116. [Google Scholar]
- Aboy, M.; McNames, J.; Thong, T.; Tsunami, D.; Ellenby, M.S.; Goldstein, B. An automatic beat detection algorithm for pressure signals. IEEE Trans. Biomed. Eng. 2005, 52, 1662–1670. [Google Scholar] [CrossRef]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 061907. [Google Scholar] [CrossRef]
- Polat, K.; Güneş, S. Classification of epileptiform EEG using a hybrid system based on decision tree classifier and fast Fourier transform. Appl. Math. Comput. 2007, 187, 1017–1026. [Google Scholar] [CrossRef]
- Subasi, A. EEG signal classification using wavelet feature extraction and a mixture of expert model. Expert Syst. Appl. 2007, 32, 1084–1093. [Google Scholar] [CrossRef]
- Güler, I.; Übeyli, E.D. Adaptive neuro-fuzzy inference system for classification of EEG signals using wavelet coefficients. J. Neurosci. Methods 2005, 148, 113–121. [Google Scholar]
- Lu, Y.; Ma, Y.; Chen, C.; Wang, Y. Classification of single-channel EEG signals for epileptic seizures detection based on hybrid features. Technol. Health Care 2018, 26, 1–10. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Miró-Martínez, P.; Núñez, J.J.; Oltra-Crespo, S.; Picó, A.M. Noisy EEG signals classification based on entropy metrics. Performance assessment using first and second generation statistics. Comput. Biol. Med. 2017, 87, 141–151. [Google Scholar] [CrossRef]
- Redelico, F.O.; Traversaro, F.; García, M.D.C.; Silva, W.; Rosso, O.A.; Risk, M. Classification of Normal and Pre-Ictal EEG Signals Using Permutation Entropies and a Generalized Linear Model as a Classifier. Entropy 2017, 19, 72. [Google Scholar] [CrossRef]
- Fadlallah, B.; Chen, B.; Keil, A.; Príncipe, J. Weighted-permutation entropy: A complexity measure for time series incorporating amplitude information. Phys. Rev. E 2013, 87, 022911. [Google Scholar] [CrossRef]
- Zunino, L.; Pérez, D.; Martín, M.; Garavaglia, M.; Plastino, A.; Rosso, O. Permutation entropy of fractional Brownian motion and fractional Gaussian noise. Phys. Lett. 2008, 372, 4768–4774. [Google Scholar] [CrossRef]
- Zanin, M. Forbidden patterns in financial time series. Chaos: Interdiscip. J. Nonlinear Sci. 2008, 18, 013119. [Google Scholar] [CrossRef]
- Vallejo, M.; Gallego, C.J.; Duque-Muñoz, L.; Delgado-Trejos, E. Neuromuscular disease detection by neural networks and fuzzy entropy on time-frequency analysis of electromyography signals. Expert Syst. 2018, 35, 1–10. [Google Scholar] [CrossRef]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and Empirical Analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the Myopia of Inductive Learning Algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Rodríguez-Sotelo, J.; Peluffo-Ordoñez, D.; Cuesta-Frau, D.; Castellanos-Domínguez, G. Unsupervised feature relevance analysis applied to improve ECG heartbeat clustering. Comput. Methods Programs Biomed. 2012, 108, 250–261. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m | CLIMATOLOGY | SEISMIC | FINANCIAL | EMG | EEG | PAF | PORTLAND | ||
|---|---|---|---|---|---|---|---|---|---|
| (1662) | (2104–9090) | (2519) | (>50,000) | (4097) | (400–500) | () | |||
| 3 | 6 | 60 | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 |
| 4 | 24 | 240 | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 |
| 5 | 120 | 1200 | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | – | 🗸 |
| 6 | 720 | 7200 | – | 🗸 | – | 🗸 | – | – | 🗸 |
| 7 | 5040 | 50,400 | – | – | – | 🗸 | – | – | 🗸 |
| 8 | 40,320 | 403,200 | – | – | – | – | – | – | 🗸 |
| 9 | 362,880 | 3,628,800 | – | – | – | – | – | – | – |
| m | Sensitivity | Specificity | p | AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 02 | 12 | ||||||||||
| 3 | 0.67(0.06) | 0.66(0.05) | 0.66(0.13) | 0.38(0.04) | 0.35(0.04) | 0.38(0.14) | 0.7837 | 0.8990 | 0.6981 | 0.51(0.01) | 0.50(0.01) | 0.51(0.02) |
| 4 | 0.49 | 0.68 | 0.67 | 0.55 | 0.41 | 0.41 | 0.6891 | 0.4214 | 0.6681 | 0.51 | 0.53 | 0.51 |
| 5 | 1 | 1 | 0.58 | 1 | 1 | 0.5 | <0.0001 | <0.0001 | 0.5807 | 1 | 1 | 0.52 |
| 6 | 1 | 1 | 0.61 | 1 | 1 | 0.65 | <0.0001 | <0.0001 | 0.0006 | 1 | 1 | 0.64 |
| 7 | 1 | 1 | 0.56 | 1 | 1 | 0.66 | <0.0001 | <0.0001 | 0.0193 | 1 | 1 | 0.59 |
| 8 | 1 | 1 | 0.64 | 1 | 1 | 0.66 | <0.0001 | <0.0001 | <0.0001 | 1 | 1 | 0.66 |
| 9 | 1 | 1 | 0.64 | 1 | 1 | 0.76 | <0.0001 | <0.0001 | <0.0001 | 1 | 1 | 0.73 |
| m | N | Sensitivity | Specificity | p | AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 02 | 12 | |||||||||||
| 3 | 100 | 0.59 | 0.53 | 0.59 | 0.49 | 0.49 | 0.47 | 0.0959 | 0.4840 | 0.3219 | 0.56 | 0.52 | 0.54 |
| 3 | 200 | 0.51 | 0.74 | 0.69 | 0.54 | 0.34 | 0.40 | 0.6228 | 0.4599 | 0.1891 | 0.51 | 0.53 | 0.55 |
| 4 | 100 | 0.33 | 0.35 | 0.44 | 0.71 | 0.71 | 0.58 | 0.9359 | 0.5087 | 0.5919 | 0.50 | 0.52 | 0.52 |
| 4 | 200 | 0.46 | 0.50 | 0.48 | 0.69 | 0.56 | 0.60 | 0.0965 | 0.4465 | 0.3909 | 0.56 | 0.53 | 0.53 |
| 5 | 100 | 1 | 1 | 0.52 | 1 | 1 | 0.59 | <0.0001 | <0.0001 | 0.7850 | 1 | 1 | 0.51 |
| 5 | 200 | 1 | 1 | 0.52 | 1 | 1 | 0.53 | <0.0001 | <0.0001 | 0.9414 | 1 | 1 | 0.50 |
| 6 | 100 | 0.86 | 0.83 | 0.46 | 0.98 | 1 | 0.69 | <0.0001 | <0.0001 | 0.0075 | 0.95 | 0.92 | 0.61 |
| 6 | 200 | 1 | 1 | 0.61 | 1 | 1 | 0.54 | <0.0001 | <0.0001 | 0.1867 | 1 | 1 | 0.55 |
| 7 | 100 | 0.44 | 0.44 | 0.67 | 1 | 0.84 | 0.54 | 0.0001 | 0.0424 | 0.0074 | 0.65 | 0.58 | 0.61 |
| 7 | 200 | 0.98 | 0.98 | 0.63 | 1 | 1 | 0.54 | <0.0001 | <0.0001 | 0.1212 | 0.99 | 0.99 | 0.55 |
| 8 | 100 | 0.67 | 0.52 | 0.66 | 0.72 | 0.82 | 0.72 | <0.0001 | 0.0012 | 0.0025 | 0.71 | 0.63 | 0.62 |
| 8 | 200 | 0.98 | 0.94 | 0.66 | 0.95 | 1 | 0.6 | <0.0001 | <0.0001 | 0.0087 | 0.99 | 0.98 | 0.60 |
| 9 | 100 | 0.94 | 0.92 | 0.61 | 0.94 | 0.99 | 0.66 | <0.0001 | <0.0001 | 0.0053 | 0.97 | 0.97 | 0.61 |
| 9 | 200 | 1 | 1 | 0.5 | 1 | 1 | 0.78 | <0.0001 | <0.0001 | 0.0899 | 1 | 1 | 0.57 |
| 9 | 300 | 1 | 1 | 0.5 | 1 | 1 | 0.83 | <0.0001 | <0.0001, | <0.0001 | 1 | 1 | 0.66 |
| m | Sensitivity | Specificity | p | AUC |
|---|---|---|---|---|
| 3 | 0.76 | 0.88 | <0.0001 | 0.8560 |
| ( | 0.92 | 0.72 | <0.0001 | 0.8560 |
| ( | 0.84 | 0.72 | 0.0002 | 0.8016 |
| 4 | 0.80 | 0.84 | <0.0001 | 0.8608 |
| 5 | 0.80 | 0.80 | <0.0001 | 0.8688 |
| 6 | 0.92 | 0.72 | <0.0001 | 0.8672 |
| 7 | 0.96 | 0.68 | <0.0001 | 0.8432 |
| m | N | Sensitivity | Specificity | p | AUC |
|---|---|---|---|---|---|
| 3 | 10 | 0.52 | 0.68 | 1.0000 | 0.5000 |
| 3 | 25 | 0.68 | 0.56 | 0.0857 | 0.6416 |
| 3 | 40 | 0.68 | 0.72 | 0.0045 | 0.7336 |
| 3 | 45 | 0.76 | 0.84 | 0.0002 | 0.8048 |
| 3 | 50 | 0.80 | 0.80 | 0.0002 | 0.7984 |
| 3 | 60 | 0.84 | 0.72 | 0.0003 | 0.7920 |
| 3 | 75 | 0.76 | 0.76 | 0.0004 | 0.7904 |
| 3 | 100 | 0.92 | 0.60 | 0.0003 | 0.7920 |
| 4 | 10 | 0.64 | 0.52 | 0.1278 | 0.6184 |
| 4 | 25 | 0.52 | 0.68 | 0.2169 | 0.6016 |
| 4 | 50 | 0.72 | 0.76 | 0.0004 | 0.7904 |
| 4 | 75 | 0.80 | 0.72 | 0.0003 | 0.7936 |
| 4 | 100 | 0.88 | 0.68 | 0.0001 | 0.8096 |
| 4 | 150 | 0.92 | 0.68 | <0.0001 | 0.8496 |
| 5 | 10 | 0.00 | 1.00 | 0.8083 | 0.5200 |
| 5 | 25 | 0.52 | 0.60 | 0.2192 | 0.5984 |
| 5 | 50 | 0.68 | 0.84 | 0.0012 | 0.7664 |
| 5 | 75 | 0.60 | 0.84 | 0.0007 | 0.7784 |
| 5 | 100 | 0.76 | 0.72 | 0.0017 | 0.7584 |
| 5 | 200 | 0.88 | 0.64 | 0.0001 | 0.8208 |
| m | Sensitivity | Specificity | p | AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 02 | 12 | ||||||||||
| 3 | 1 | 1 | 0.51 | 1 | 0.62 | 0.81 | <0.0001 | 0.2602 | 0.0203 | 1 | 0.6206 | 0.6912 |
| 4 | 1 | 1 | 1 | 1 | 0.62 | 1 | <0.0001 | 0.2602 | <0.0001 | 1 | 0.6209 | 1 |
| 5 | 1 | 1 | 1 | 1 | 0.62 | 1 | <0.0001 | 0.2602 | <0.0001 | 1 | 0.6209 | 1 |
| 6 | 1 | 0.9 | 1 | 1 | 0.62 | 1 | <0.0001 | 0.3033 | <0.0001 | 1 | 0.6103 | 1 |
| 7 | 1 | 0.9 | 1 | 1 | 0.55 | 1 | <0.0001 | 0.3678 | <0.0001 | 1 | 0.5965 | 1 |
| m | N | Sensitivity | Specificity | p | AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 02 | 12 | |||||||||||
| 3 | 100 | 0.40 | 0.55 | 0.51 | 1 | 0.6 | 0.91 | 0.6843 | 0.8469 | 0.2699 | 0.5454 | 0.5206 | 0.5909 |
| 3 | 200 | 0.80 | 0.80 | 0.76 | 0.81 | 0.58 | 0.59 | 0.0009 | 0.2602 | 0.0236 | 0.8681 | 0.6206 | 0.6865 |
| 3 | 300 | 0.80 | 0.70 | 0.72 | 0.91 | 0.58 | 0.63 | 0.0008 | 0.7722 | 0.0034 | 0.8727 | 0.5310 | 0.7413 |
| 3 | 400 | 0.90 | 0.90 | 0.58 | 0.91 | 0.55 | 0.77 | <0.0001 | 0.4994 | 0.0036 | 0.9409 | 0.5724 | 0.7398 |
| 3 | 500 | 0.90 | 0.90 | 0.51 | 1 | 0.62 | 0.68 | <0.0001 | 0.2340 | 0.0347 | 0.9636 | 0.6275 | 0.6739 |
| 4 | 100 | 0.7 | 0.41 | 0.58 | 0.86 | 0.8 | 0.81 | 0.0064 | 0.8976 | 0.0034 | 0.8045 | 0.5137 | 0.7413 |
| 4 | 200 | 1 | 0.80 | 0.86 | 0.95 | 0.51 | 0.86 | <0.0001 | 0.4594 | <0.0001 | 0.9863 | 0.5793 | 0.9090 |
| 4 | 400 | 1 | 0.70 | 0.89 | 1 | 0.62 | 1 | <0.0001 | 0.5200 | <0.0001 | 1 | 0.5689 | 0.9623 |
| 4 | 600 | 1 | 0.90 | 0.93 | 1 | 0.58 | 1 | <0.0001 | 0.3678 | <0.0001 | 1 | 0.5965 | 0.9890 |
| 4 | 800 | 1 | 1 | 1 | 1 | 0.58 | 0.95 | <0.0001 | 0.2216 | <0.0001 | 1 | 0.6310 | 0.9968 |
| 5 | 100 | 0.8 | 0.48 | 0.82 | 0.91 | 0.80 | 0.81 | 0.0008 | 0.6758 | <0.0001 | 0.8727 | 0.5448 | 0.8463 |
| 5 | 200 | 1 | 0.60 | 0.89 | 0.95 | 0.51 | 0.95 | <0.0001 | 1 | <0.0001 | 0.9954 | 0.5 | 0.9502 |
| 5 | 500 | 1 | 0.80 | 1 | 1 | 0.62 | 0.95 | <0.0001 | 0.4594 | <0.0001 | 1 | 0.5793 | 0.9952 |
| 5 | 750 | 1 | 0.80 | 1 | 1 | 0.58 | 1 | <0.0001 | 0.3851 | <0.0001 | 1 | 0.5931 | 1 |
| 5 | 1000 | 1 | 0.80 | 1 | 1 | 0.58 | 1 | <0.0001 | 0.3678 | <0.0001 | 1 | 0.5965 | 1 |
| m | Sensitivity | Specificity | p | AUC |
|---|---|---|---|---|
| 3 | 0.93 | 0.90 | <0.0001 | 0.9619 |
| () | 0.72 | 0.64 | <0.0001 | 0.7186 |
| () | 0.62 | 0.56 | 0.2569 | 0.5464 |
| 4 | 0.93 | 0.89 | <0.0001 | 0.9579 |
| 5 | 0.92 | 0.89 | <0.0001 | 0.9563 |
| 6 | 0.91 | 0.89 | <0.0001 | 0.9526 |
| 7 | 0.93 | 0.85 | <0.0001 | 0.9443 |
| m | N | Sensitivity | Specificity | p | AUC |
|---|---|---|---|---|---|
| 3 | 100 | 0.76 | 0.86 | <0.0001 | 0.8604 |
| 3 | 200 | 0.83 | 0.83 | <0.0001 | 0.8966 |
| 3 | 300 | 0.85 | 0.84 | <0.0001 | 0.9183 |
| 3 | 400 | 0.86 | 0.86 | <0.0001 | 0.9241 |
| 3 | 500 | 0.89 | 0.83 | <0.0001 | 0.9336 |
| 3 | 1000 | 0.87 | 0.87 | <0.0001 | 0.9362 |
| 4 | 100 | 0.75 | 0.85 | <0.0001 | 0.8531 |
| 4 | 200 | 0.86 | 0.81 | <0.0001 | 0.8898 |
| 4 | 300 | 0.86 | 0.80 | <0.0001 | 0.9086 |
| 4 | 400 | 0.87 | 0.83 | <0.0001 | 0.9167 |
| 4 | 500 | 0.83 | 0.88 | <0.0001 | 0.9264 |
| 4 | 1000 | 0.86 | 0.87 | <0.0001 | 0.9307 |
| 5 | 100 | 0.74 | 0.84 | <0.0001 | 0.8441 |
| 5 | 200 | 0.82 | 0.82 | <0.0001 | 0.8746 |
| 5 | 300 | 0.84 | 0.80 | <0.0001 | 0.8963 |
| 5 | 400 | 0.85 | 0.83 | <0.0001 | 0.8999 |
| 5 | 500 | 0.86 | 0.84 | <0.0001 | 0.9132 |
| 5 | 1000 | 0.87 | 0.85 | <0.0001 | 0.9260 |
| 6 | 100 | 0.73 | 0.83 | <0.0001 | 0.8239 |
| 6 | 200 | 0.81 | 0.79 | <0.0001 | 0.8513 |
| 6 | 300 | 0.82 | 0.79 | <0.0001 | 0.8729 |
| 6 | 400 | 0.85 | 0.81 | <0.0001 | 0.8800 |
| 6 | 500 | 0.86 | 0.81 | <0.0001 | 0.8940 |
| 6 | 1000 | 0.89 | 0.81 | <0.0001 | 0.9146 |
| 7 | 100 | 0.71 | 0.79 | <0.0001 | 0.7991 |
| 7 | 200 | 0.78 | 0.79 | <0.0001 | 0.8283 |
| 7 | 300 | 0.75 | 0.81 | <0.0001 | 0.8461 |
| 7 | 400 | 0.87 | 0.82 | <0.0001 | 0.8533 |
| 7 | 500 | 0.85 | 0.78 | <0.0001 | 0.8700 |
| 7 | 1000 | 0.89 | 0.78 | <0.0001 | 0.8942 |
| N | ||||||
|---|---|---|---|---|---|---|
| RANDOM | 5000 | |||||
| EMG | 5000 | |||||
| SINUS | 5000 | |||||
| LMAP (Periodic) | 5000 | |||||
| LMAP (Chaotic) | 5000 | |||||
| PAF | 400 | |||||
| SEISMIC | 2000–9000 |
| m | Remaining Patterns | ||||||
|---|---|---|---|---|---|---|---|
| (Sensitivity)(Specificity) | |||||||
| PAF | 3 | 6 | 5 | 4 | 3 | 2 | 1 |
| (0.76)(0.88) | (0.76)(0.92) | (0.8)(0.8) | (0.8)(0.8) | (0.72)(0.8) | (0.76)(0.68) | ||
| 4 | 24 | 20 | 16 | 12 | 8 | 4 | |
| (0.80)(0.84) | (0.72)(0.88) | (0.8)(0.88) | (0.8)(0.84) | (0.8)(0.84) | (0.84)(0.8) | ||
| 5 | 120 | 100 | 80 | 60 | 40 | 20 | |
| (0.8)(0.8) | (0.8)(0.8) | (0.84)(0.76) | (0.92)(0.76) | (0.88)(0.8) | (0.88)(0.8) | ||
| EMG | 3 | 6 | 5 | 4 | 3 | 2 | 1 |
| (1,1,0.51)(1,0.62,0.81) | (1,1,0.51)(1,0.62,0.81) | (1,1,0.86)(1,0.62,0.44) | (1,1,0.41)(1,0.62,1) | (1,1,0.62)(1,0.62,0.8) | (1,1,0.62)(1,0.62,0.81) | ||
| 4 | 24 | 20 | 16 | 12 | 8 | 4 | |
| (1,1,1)(1,0.62,1) | (1,1,1)(1,0.62,1) | (1,0.7,1)(1,0.65,1) | (1,0.7,1)(1,0.62,1) | (1,0.38,1)(1,0.8,1) | (1,0.51,1)(1,0.8,1) | ||
| 5 | 120 | 100 | 80 | 60 | 40 | 20 | |
| (1,1,1)(1,0.62,1) | (1,0.8,1)(1,0.48,1) | (1,0.9,1)(1,0.44,1) | (1,0.7,1)(1,0.55,1) | (1,0.8,1)(1,0.58,1) | (1,0.9,1)(1,0.62,0.91) | ||
| Ordinal Pattern | ||||||
|---|---|---|---|---|---|---|
| 123 | 132 | 213 | 231 | 321 | 312 | |
| Rank | 1 | 3 | 5 | 6 | 2 | 4 |
| Weight | 0.02 | 0.01 | −0.005 | −0.0077 | 0.013 | 0.0074 |
| p-value | 0.0002 | 0.0170 | 0.0270 | 0.1510 | 0.0123 | 0.0681 |
| Recommendation | Supporting Data | Justification | |
|---|---|---|---|
| PE (absolute value) | Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7 | Pattern probability estimation in other works. | |
| PE (relative value) For classification | Figure 8, Figure 9 and Figure 10 Very similar results in other studies ([24,26,27]). Table 2, Table 3, Table 4, Table 5, Table 6 and Table 7, Table 9, Table 10, Table 11 and Table 12. Very similar results for 10 datasets exhibiting a varied and diverse set of features and properties. | Class differences are present at any length in stationary records. Long records are usually non-stationary. There are forbidden patterns. No need to look for them. Not all the ordinal patterns are representative of the differences. Real signals are mostly chaotic. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cuesta-Frau, D.; Murillo-Escobar, J.P.; Orrego, D.A.; Delgado-Trejos, E. Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications. Entropy 2019, 21, 385. https://doi.org/10.3390/e21040385
Cuesta-Frau D, Murillo-Escobar JP, Orrego DA, Delgado-Trejos E. Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications. Entropy. 2019; 21(4):385. https://doi.org/10.3390/e21040385
Chicago/Turabian StyleCuesta-Frau, David, Juan Pablo Murillo-Escobar, Diana Alexandra Orrego, and Edilson Delgado-Trejos. 2019. "Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications" Entropy 21, no. 4: 385. https://doi.org/10.3390/e21040385
APA StyleCuesta-Frau, D., Murillo-Escobar, J. P., Orrego, D. A., & Delgado-Trejos, E. (2019). Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications. Entropy, 21(4), 385. https://doi.org/10.3390/e21040385