LSSVR Model of G-L Mixed Noise-Characteristic with Its Applications


1
College of Computer and Information Engineering, Henan Normal University, Xinxiang 453007, China
2
School of Computer Science and Technology, Tianjin University, Tianjin 300350, China
3
Engineering Lab of Intelligence Business and Internet of Things, Xinxiang 453007, China
4
The State-Owned Assets Management Office, Henan Normal University, Xinxiang 453007, China
*
Authors to whom correspondence should be addressed.
Entropy 2020, 22(6), 629; https://doi.org/10.3390/e22060629
Submission received: 27 April 2020
/
Revised: 1 June 2020
/
Accepted: 2 June 2020
/
Published: 6 June 2020
(This article belongs to the Special Issue Artificial Intelligence and Computational Methods in the Modeling of Complex Systems)
Abstract
:Due to the complexity of wind speed, it has been reported that mixed-noise models, constituted by multiple noise distributions, perform better than single-noise models. However, most existing regression models suppose that the noise distribution is single. Therefore, we study the Least square of the Gaussian–Laplacian mixed homoscedastic () and heteroscedastic noise () for complicated or unknown noise distributions. The ALM technique is used to solve model . is used to predict short-term wind speed with historical data. The prediction results indicate that the presented model is superior to the single-noise model, and has fine performance.
1. Introduction
In practical applications, if the data are collected in a multi-source environment, the noise distribution is complex and unknown. Therefore, it is almost impossible for a single-noise distribution to clearly describe the real-noise [1]. is a method of that implements a sum-of-squares error function together with regularization, thus controlling the bias–variance trade-off [2,3]. It is intended to find the concealed linear structures in the original data [4,5]. For the sake of transition from linear to nonlinear function, the following generalization can be made [6]: by mapping input vectors into a high-dimensional feature space H (H is Hilbert space) through some nonlinear-mapping, seek the solution of the optimization problem in space H. Using a suitable kernel function , nonlinear-mappings can be estimated by kernel , which is an extended with kernel techniques. In recent years, as a data-rich nonlinear forecasting tool has been increasingly welcomed [7], which is applicable in many different contexts [8,9,10], such as machine learning, optical character recognition, and especially wind speed/power forecasting.
Generally, the existing techniques used for wind-speed forecasting include: (i) physical; (ii) statistical (also called data-driven); and (iii) artificial intelligence (AI)-based methods. The physical models attempt to estimate wind flow around and inside the wind farm using physical laws governing the atmospheric behavior [11,12]. The statistical models seek the relationships between a set of explanatory variables and the on-line measured generation data, and the historical wind speed data recorded at the site are only used to establish the statistical model. We can model it in a variety of ways, including persistence method and auto-regressive model [13,14]. AI methods include artificial neural networks (ANNs) [15], deep learning [16], SVR machines [17,18], and the hybrid methods [19,20].
Suykens et al. [21,22,23] proposed least square support vector regression model with Gaussian noise (, also known as kernel ridge regression ()). Mixed-model based on multi-objective optimization [24,25], mixed-method based on singular spectrum analysis, firefly algorithm, and BP neural network predict wind speed with complicated noise [26], indicating that the mixed prediction method has the ability of powerful prediction. Mixed machine [27] is applied to forecast the wind speed noise, which improves performance of wind-speed prediction. [28] models fitted by Gaussian–Laplacian (G-L) mixed noise are developed, and good performance is obtained compared with the existing regression algorithm.
To solve the above problems, we study model of G-L mixed noise-characteristic for complex or unknown noise distribution. In this case, we construct a technique to search the optimal solution of the corresponding regression task. Although many algorithms have been implemented in past years, we exploit ALM method, as shown in Section 4. If the task is not differentiable or discontinuous, the sub gradient descent method can be employed, or the SMO [29] can also be used if there is a very large sample size.
The structure of this paper is as follows. Section 2 derives the optimal empirical risk loss by Bayesian principle. Section 3 constructs the model of G-L mixed noise. Section 4 gives the solution and algorithm design of . In Section 5, the numerical experiment of short-term wind-speed prediction is presented. Finally, we conclude the work.
2. Bayesian Principle to Mixed Noise Empirical Risk Loss
Given the Dataset
where , is the training data. R represents real number set, is the n-dimensional Euclidean-Space, and N is the sample size. Superscript T is the transpose of matrix. Assuming that the sample of dataset is generated by the additive noise function , the relationship between the measured value and predicted value is:
where is random, i.i.d. (independent, identical probability distribution) with of mean and standard deviation . Generally, the noise (probability density function) is unknown. It is necessary to predict unknown target from training set .
Following the authors of [30,31], the optimal empirical risk loss in the sense of Maximum Likelihood (MLE) is
i.e., the empirical risk loss is the log-likelihood of noise characteristic.
It is assumed that noise in Equation (2) is Laplacian, with . By Equation (3), in MLE the optimal empirical risk loss should be .
Suppose noise in Equation (2) is Gaussian of zero mean and homoscedastic standard deviation . By Equation (3), the empirical risk loss of Gaussian noise with homoscedasticity is . The noise in Equation (2) is Gaussian of zero mean and heteroscedastic standard deviation . By Equation (3), the empirical risk loss for Gaussian-noise with heteroscedasticity is ().
Assume noise in Equation (2) is the mixed noise of two kinds of noise with the s and , respectively. Suppose that . By Equation (3), the corresponding empirical risk loss of mixed-noise is
where are the convex empirical risk losses of the above two kinds of noise characteristic, respectively. The weight factors are and .
3. Model of G-L Mixed Noise-Characteristic
Given the training samples , construct the linear regressor . To deal with nonlinear problems, it can be summarized as follows: mapping input vectors into high-dimension feature space H through the nonlinear mapping (take a prior distribution), induced by nonlinear kernel function , kernel mapping is any positive definite Mercer kernel.
Definition 1
([6,28]). Positive definite Mercer kernel: Assume that X is a subset of . Assume that the kernel function defined on is a positive definite Mercer kernel functionl the kernel mapping Φ is called a positive definite Mercer kernel if there is mapping (H is Hilbert Space), such that
where represents the inner-product in Space H.
Therefore, the optimization problem of Space H is solved. At present, the input vectors are replaced by inner product in feature space H. Through the use of kernel , the linear model be extended to a nonlinear .
In general, the mixed distribution has fine approximation ability to any continuous distribution. When there is no prior knowledge of real-noise, it can well adapt to unknown or complicated noise. Thus, it is presented that a uniform model with mixed noise characteristics (). The primal problem of model is formalized as
where parameter represents weight-vector, b is the bias-term, is the penalty parameter, and the weight factors are , . , is a nonlinear mapping which transfers the input dataset to a higher-dimensional feature space H. is the random noise variable at time . is the convex loss-functions for noise characteristic in sample-point ().
In the application domain, most distributions do not obey Gaussian distribution, and they also do not satisfy Laplacian distribution. the noise distribution is complicated, and it is almost impossible to describe real noise with a single distribution. It has been reported that mixed noise models, constituted by multiple noise distributions, perform better than single-noise model [1]. As the function fitting -machine, the goal is to estimate an unknown function from dataset . In this section, G-L mixed homoscedastic and heteroscedastic noise distributions are used to fit complicated noise characteristic.
3.1. Model of G-L Mixed Homoscedastic Noise-Characteristic
Suppose noise in Equation (2) is Gaussian of zero mean and homoscedastic standard deviation . By Equation (3), we have that the empirical risk loss of homoscedastic-Gaussian-noise characteristic is . The Laplacian-noise is . Adopting G-L mixed homoscedastic noise distribution to fit complicated noise-characteristic, by Equation (4), the empirical risk loss about G-L mixed homoscedastic noise is . Putting forward the model of G-L mixed homoscedastic noise-characteristic (), the primal problem of is depicted as
where parameter vector , is homoscedastic, is a penalty parameter, and the weight factors are and .
Proposition 1.
The solution of the primal problem in Equation (7) of is existent and unique about ϖ.
Theorem 1.
The dual problem of the primal problem in Equation (7) is
where is homoscedastic, is a penalty parameter, and the weight factors are and .
Proof.
We introduce Lagrange functional as
Minimizing and deriving the partial-derivative , respectively, on the basis of KKT-conditions, we get
We obtain
Therefore,
The decision-maker for may be represented as
where the parameter vector , , is the inner-product of H and is the kernel-function.
Suppose the noise in Equation (2) is Gaussian homoscedastic noise, which is Gaussian noise of zero mean and the homoscedastic variance . Thus, the dual problem of can be derived by Theorem 2:
3.2. Model of G-L Mixed Heteroscedastic Noise-Characteristic
It is assumed that the noise in Equation (2) is Gaussian of zero mean and heteroscedastic standard deviation , that is , . From Equation (3), the empirical risk loss of heteroscedastic Gaussian-noise characteristic is and the loss-function of Laplacian-noise is , . Utilizing G-L mixed heteroscedastic noise distribution to predict complicated noise-characteristic, from Equation (4), the loss function corresponding to G-L mixed heteroscedastic noise is . The new model with G-L mixed heteroscedastic noise-characteristic () is proposed. The primal problem of is depicted as
where the parameter vector is , are heteroscedastic, and is the penalty parameter. The weight-factors are and .
Proposition 2.
The solution of the primal problem in Equation (10) of is existent and unique about ϖ.
Theorem 2.
The dual problem of model in Equation (10) is
where are heteroscedastic and is the penalty parameter. The weight factors are and .
Proof.
It is easier to derive the proof of Theorem 2 by analogy with Theorem 1. □
We have
The decision-maker for may be expressed as
where the parameter vector is , , and is the kernel function.
Suppose noise in Equation (2) is G-L mixed-homoscedastic-noise, in which Gaussian-noise of zero mean and homoscedastic-variance , Theorem 1 can be deduced from Theorem 2.
4. Solution from ALM
In this section, we use Augmented Lagrange-multiplier method (ALM) [32] to solve the dual problem in Equation (8) by applying Gradient descent or Newton’s method to a sequence of equality-constrained problems. By eliminating equality constraints, arbitrary equality constraints can be reduced to equivalent unconstrained problems [33,34]. If there are large-scale training samples, some rapid optimization techniques can be combined with the proposed model, for example the sequential minimal optimization (SMO) algorithm [29] and the stochastic gradient decent (SDG) algorithm [35].
Theorems 1 and 2 provide effective recognition techniques for and , respectively. In this section, we derive the solution from ALM and the algorithm for model of G-L mixed homoscedastic noise characteristic (). Analogously, the solution of model can be obtained by ALM method.
(1) Let dataset be , where , , .
(2) The optimal parameters were searched by using the 10-fold cross-validation strategy, and the appropriate kernel function was selected.
(3) Solve model of the problem in Equation (8), and get the optimal solution .
(4) Build the decision-function as follows
The parameter vector is , , , () is the inner product in H, is a kernel function.
5. Case Study
This section tests and verifies the validity of constructed model by comparing it with other techniques in the Heilongjiang, China dataset . This case study consists of the following subsections: G-L mixed-noise characteristic of wind speed, prediction performance evaluation criteria, and short-term wind-speed forecasting based on an actual dataset.
5.1. G-L Mixed-Noise-Characteristic of Wind-Speed
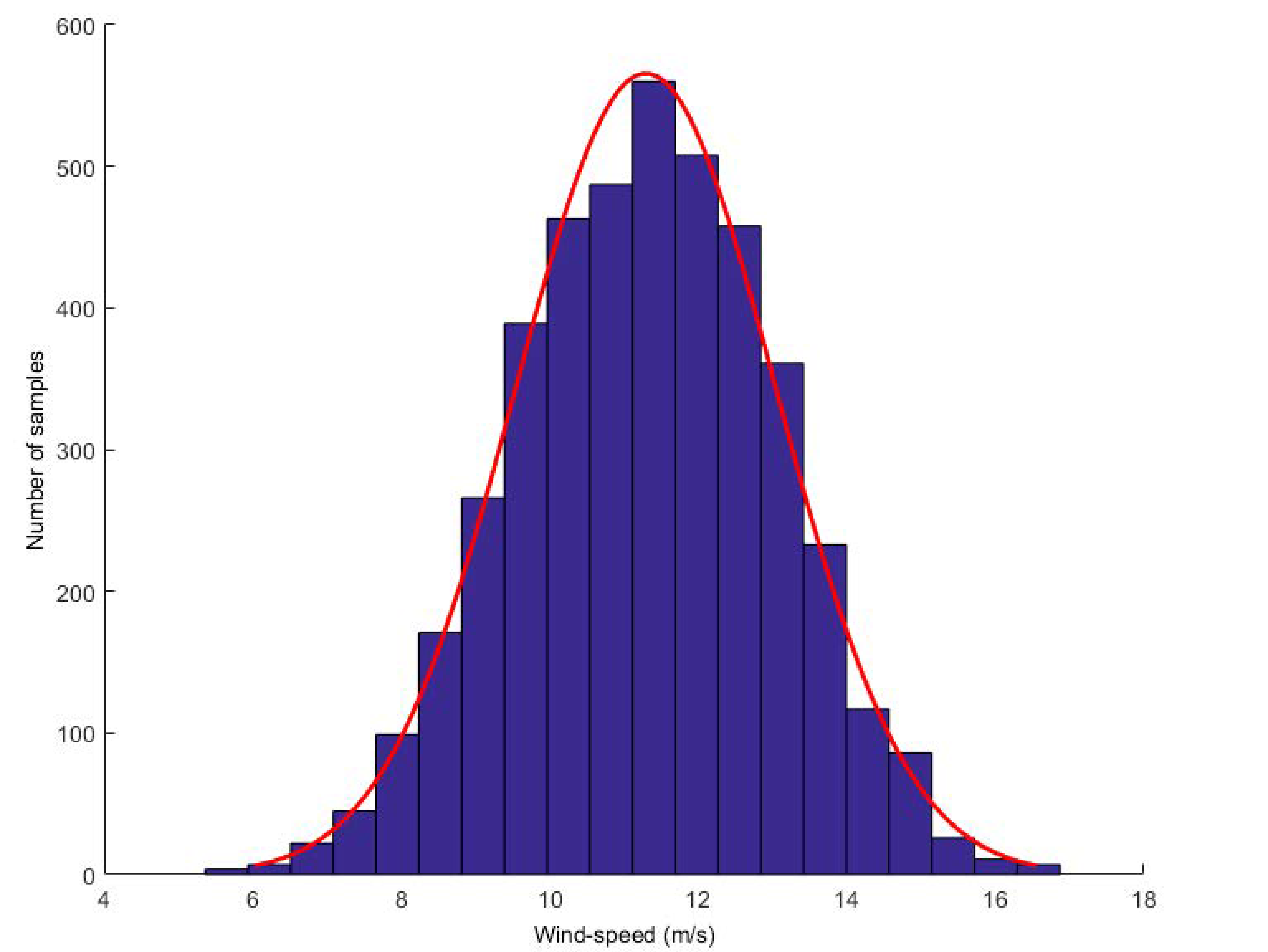
To demonstrate the effectiveness of the proposed model, we collected wind speed data from Heilongjiang. The dataset consists of more than one year of wind speed data, recording wind speed values every 10 min. We first discovered the G-L mixed noise and conducted experiments on it. We found that turbulence is the main reason for the high uncertainty of wind speed random fluctuations. From the perspective of wind energy, the most significant feature of wind energy resources is their variability. Now, it shows the distribution of wind speed. Take a wind speed value every 5 s and calculate the histogram of wind speed within 1–2 h. Two typical distributions are given: one is calculated when the wind speed is high and the other is calculated when the wind speed is low (see Figure 2 and Figure 3, respectively).
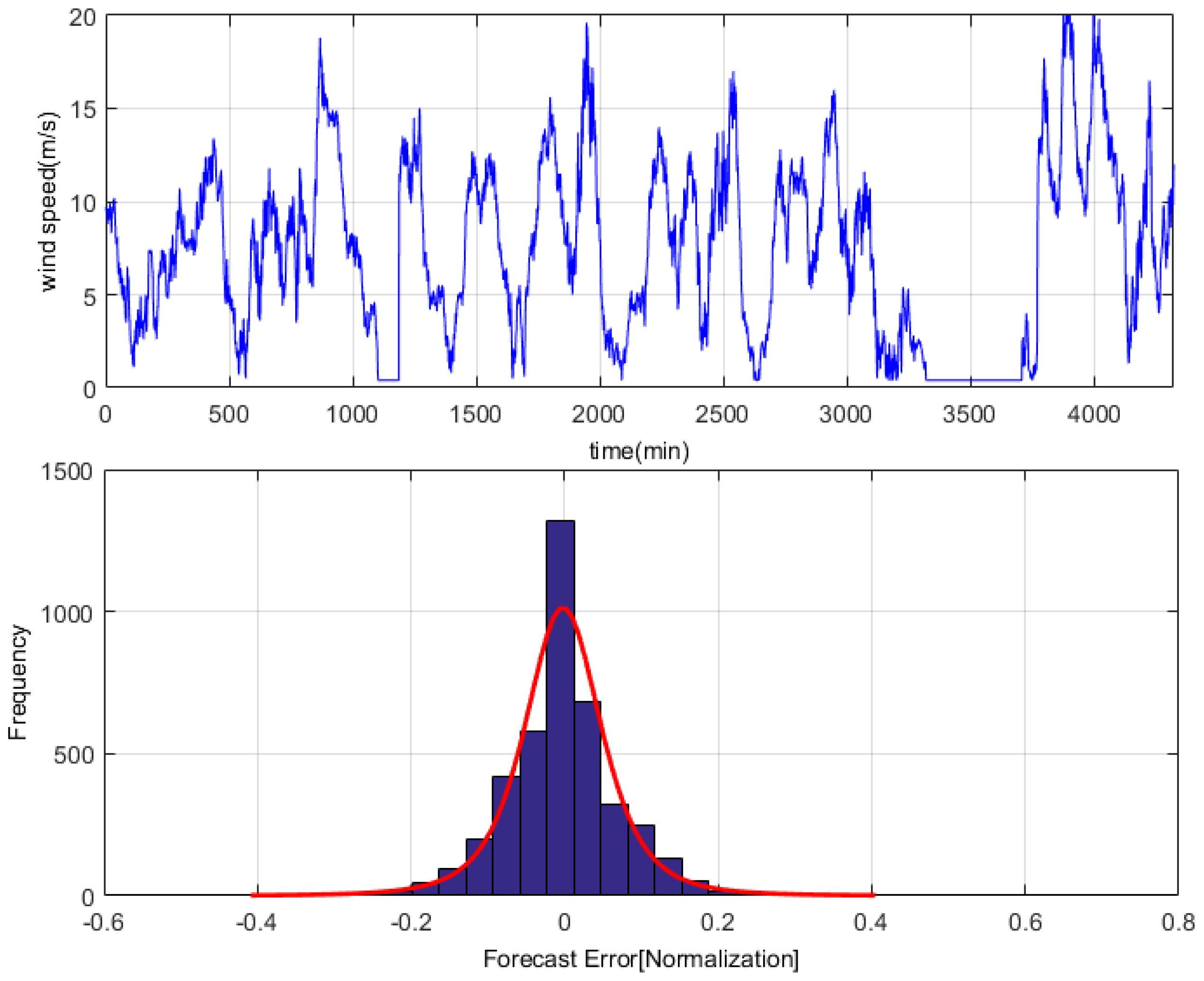
We analyzed the one-month time-series dataset, and used the persistence method to investigate the error distribution [32]. The results show that the wind speed error obtained from the persistence prediction is not subject to single distribution, while approximately to G-L mixed distribution, and of is , as shown in Figure 4.
As can be seen from the above charts and figures, wind speed error approximately satisfies G-L mixed distribution. This is a mixed kind of task.
5.2. Prediction Performance Evaluation Criteria
It is generally known that no prediction model forecasts perfectly. The predictable performance of , , , and also has certain evaluation criteria, for example MAE (mean absolute error), RMSE (root mean square error), MAPE (mean absolute percentage error), and SEP (the standard error of prediction). The four criteria be defined as follows:
where N is the size of the dataset , is the ith actual observed data, and is the ith forecasted-result. is the mean value of observations [36,37,38,39,40]. shows how similar the predicted value is to the observed value, while measures overall deviation between predicted value and observed value. is the ratio between error and observed value. is the ratio of to average observation. They are dimensionless measurements of accuracy of wind speed system, and are sensitive to small changes.
5.3. Short-Term Wind-Speed Forecasting with Real dataset
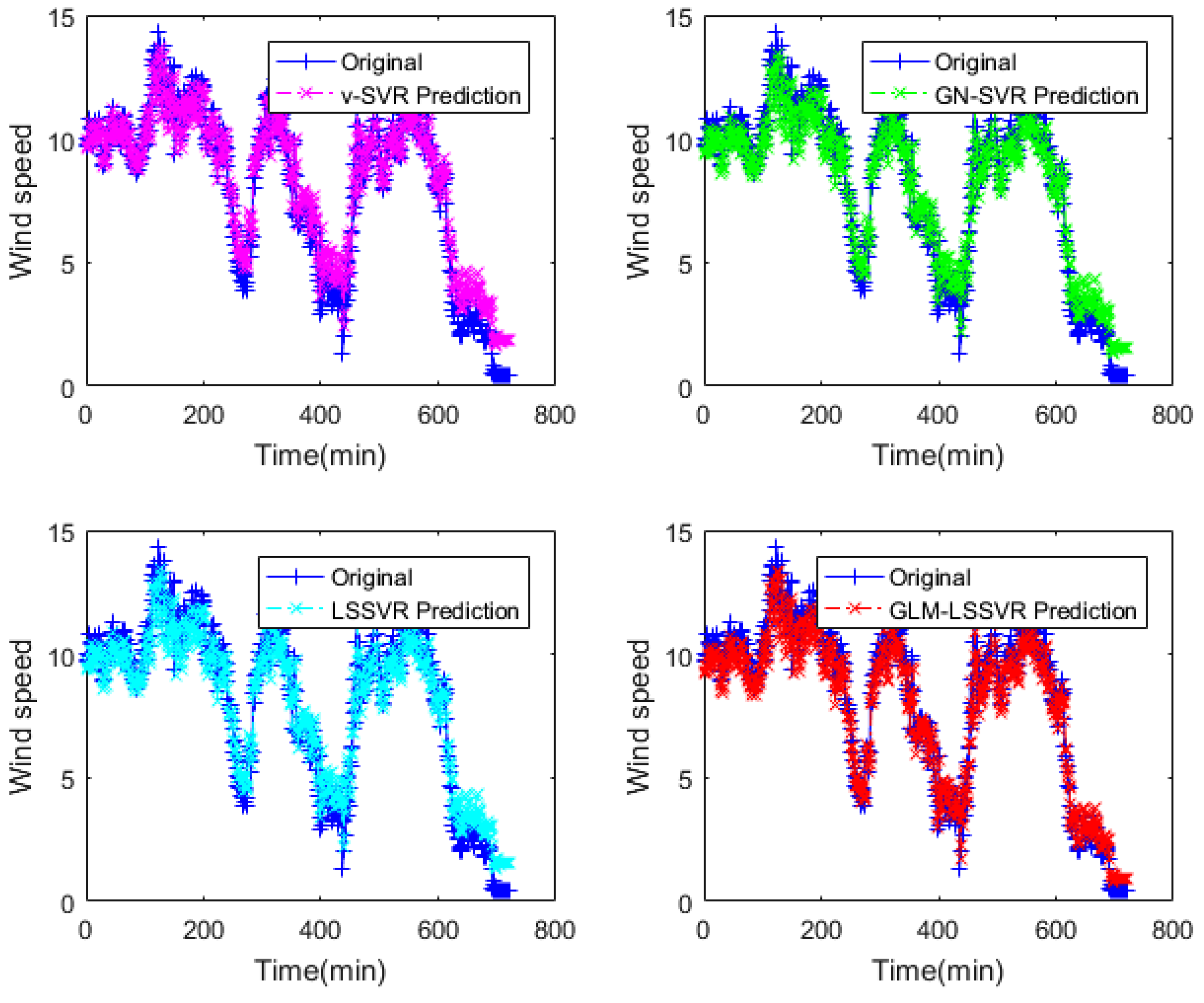
In this section, 2160 consecutive data (1–2160, time span of 15-days) are extracted as the training set and 720 consecutive data (2161–2880, time span of 5-days) are extracted as the testing set. The input vector is , is the actual observed data of wind speed at moment , and the forecasting value is , where . That is, the above models are used to forecast wind speed of each point after 10, 30 and 60 min, respectively. Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12 and Figure 13 describe the forecasting results given by models , , , and .
The models , , , and were implemented in Matlab 7.8. Initial parameters of were , , and . The optimal parameters were searched by using 10-fold cross-validation technique. The technology of parameter selection is studied in detail in [41,42]. In this simulation, parameters were set to . The practical application demonstrates that both polynomial kernel and Gaussian kernel perform well under the assumption of smoothness. Under these circumstances, models , , , and employ polynomial and Gaussian kernel functions [43]:
where d is a positive integer and is a positive number.
The dual problem of and of the Gaussian-noise model () and are as follows.
: The authors of [45,46] studied with equality constraints and inequality constraints. The loss-function of Gaussian-noise is , (). Thus, thus dual problem of is
: [22] studied for Gaussian-noise model. The dual problem of is
where are slack-variables. , are constants. For and , the size of is not gained, but is a variable whose value is compromised by a constant with the model complexity and relaxation variables through [35].
In Figure 5, Figure 8 and Figure 11, wind-speed forecasting-results at -point of , , , and are presented after 10, 30, and 60 min, respectively. Figure 6, Figure 9, and Figure 12 show the error statistic of wind-speed prediction using the above four models. The box plots (Figure 7, Figure 10, and Figure 13) of several noise levels further intuitively demonstrate the comparative effect of error statistics using the above four wind-speed forecasting models. The statistical criteria of , , and are displayed in Table 1, Table 2 and Table 3.
From box-whisker plots in Figure 7, Figure 10, and Figure 13, as well as Table 1, Table 2 and Table 3, it can be concluded that, in most cases, the forecasting-error of calculation is superior to , and . With the increase of prediction horizon to 30 and 60 min, the forecasting error of different models increases and the relative error decreases. Thus, in these cases, it is not that important. However, Table 1, Table 2 and Table 3 show that, under all the criteria of , , , and , the Gaussian–Laplacian mixed-noise model is slightly better than the classical model.
6. Conclusions
Most existing regression-techniques suppose that the noise model is single. Wind-speed forecasting is complicated due to its volatility and uncertainty, thus it is difficult to model with a single-noise distribution. This section summarizes our main work: (1) optimal empirical risk loss of G-L mixed noise is deduced by Bayesian principle; (2) the of G-L mixed homoscedastic noise () and G-L mixed heteroscedastic noise () for complicate noise is developed; (3) the dual problem of and is obtained using Lagrange-functional and according to KKT conditions; (4) the stability and effectiveness of the algorithm are guaranteed by solving with the ALM method; and (5) the proposed technology is used to predict short-term wind speed by historical data, and then forecast the wind speed at some time after 10, 30, and 60 min, respectively. The comparison results display that the proposed model is better than classical technologies in statistical criteria.
In the same way, we can also study Gaussian–Laplacian, or Gaussian–Weibull mixed noise classification models. The new hybrid noise models would effectively solve complicated noise classification problems.
Author Contributions
Conceptualization, S.Z.; Formal analysis, S.Z. and T.Z.; Methodology, S.Z. and L.S.; Writing–original draft, S.Z. and T.Z.; Writing–review & editing, W.W. and B.C. All authors have read and approved the final published version. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National natural science foundation of China (NSFC) (Nos. 11702087 and 61772176) and Natural Science Foundation Project of Henan (No. 182300410130).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LR | Linear regression model |
| -SVR | -Support vector regression |
| GN-SVR | -SVR model of Gaussian homoscedastic-noise |
| LSSVR | Least squares support vector regression model |
| GLM-LSSVR | LSSVR model of Gaussian–Laplacian mixed homoscedastic-noise |
| ALM | Augmented Lagrange multiplier method |
References
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Tikhonov, A.A.; Arsenin, V.Y. Solutions of Ill-Posed Problems; New York Wiley: New York, NY, USA, 1977. [Google Scholar]
- Gonen, A.; Orabona, F.; Shalev-Shwartz, S. Solving Ridge Regression using Sketched Preconditioned SVRG. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Hoerl, A.E. Application of ridge analysis to regression problems. Chem. Eng. Prog. 1962, 58, 54–59. [Google Scholar]
- Zhang, Z.H.; Dai, G.; Xu, C.F. Regularized Discriminant Analysis, Ridge Regression and Beyond. J. Mach. Learn. Res. 2010, 11, 2199–2228. [Google Scholar]
- Sun, L.; Wang, L.; Ding, W.; Qian, Y.; Xu, J. Feature Selection Using Fuzzy Neighborhood Entropy-Based Uncertainty Measures for Fuzzy Neighborhood Multigranulation Rough Sets. IEEE Trans. Fuzzy Syst. 2020. [Google Scholar] [CrossRef]
- Jiao, L.C.; Bo, L.F.; Wang, L. Fast Sparse Approximation for Least Squares Support Vector Machine. IEEE Trans. Neural Netw. 2007, 18, 685–697. [Google Scholar] [CrossRef]
- Völgyesi, L.; Palánc, B.; Fekete, K.; Popper, G. Application of Kernel Ridge Regression to Network Levelling via Mathematica. Geophys. Res. Abstr. 2005, 73, 263–276. [Google Scholar]
- Sun, L.; Zhang, X.; Qian, Y.; Xu, J.; Zhang, S. Feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification. Inf. Sci. 2019, 502, 18–41. [Google Scholar] [CrossRef]
- Douak, F.; Melgani, F.; Benoudjit, N. Kernel ridge regression with active learning for wind-speed prediction. Appl. Energy. 2013, 103, 328–340. [Google Scholar] [CrossRef]
- Alexiadis, M.C.; Dokopoulos, P.S.; Sahsamanoglou, H.S.; Manousaridis, I.M. Short term forecasting of wind speed and related electrical power. J. Sol. Energy 1998, 63, 61–68. [Google Scholar] [CrossRef]
- Negnevitsky, M.; Potter, C.W. Innovative short-term wind generation prediction techniques. In Proceedings of the power systems conference and exposition, Atlanta, GA, USA, 29 October–1 November 2006. [Google Scholar]
- Torres, J.L.; Garcia, A.; De Blas, M.; De Francisco, A. Forecast of hourly average wind speed with ARMA models in Navarre (Spain). J. Sol. Energy 2005, 79, 65–77. [Google Scholar] [CrossRef]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind-speed forecasting using f-ARIMA models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 2010, 87, 2313–2320. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, R.; Zhou, Y. Transfer learning for short-term wind-speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ortiz-Garcı, E.G.; Pérez-Bellido, Á.M.; Portilla-Figueras, A.; Prieto, L. Short term wind-speed prediction based on evolutionary support vector regression algorithms. Expert Syst. Appl. 2011, 38, 4052–4057. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, J.; Li, G. Fine tuning support vector machines for short-term wind speed forecasting. Energy Convers. Manag. 2011, 52, 1990–1998. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.-Q.; Chen, C.; Li, Y.-F. A hybrid statistical method to predict wind speed and wind power. Renew. Energy 2010, 35, 1857–1861. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, Q.; Li, L.; Foley, A.M.; Srinivasan, D. Approaches to wind power curve modeling: A review and discussion. Renew. Sustain. Energy Rev. 2019, 116, 109422. [Google Scholar] [CrossRef]
- Suykens, J.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Suykens, J.; Lukas, L.; Vandewalle, J. Sparse approximation using least square vector machines. In Proceedings of the IEEE International Symposium on Circuits and Systems, Geneva, Switzerland, 28–31 May 2000; pp. 757–760. [Google Scholar]
- Suykens, J.; De Brabanter, J.; Lukas, L.; Vandewalle, J. Weighted least squares support vector machines: robustness and sparse approximation. Neurocomputing 2002, 48, 85–105. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Guo, Z.; Yang, W. Research and application of a novel hybrid forecasting system based on multi-objective optimization for wind speed forecasting. Energy Convers. Manag. 2017, 150, 90–107. [Google Scholar] [CrossRef]
- Sun, L.; Wang, L.; Ding, W.; Qian, Y.; Xu, J. Neighborhood multi-granulation rough sets-based attribute reduction using Lebesgue and entropy measures in incomplete neighborhood decision systems. Knowl. -Based Syst. 2020, 192, 105373. [Google Scholar] [CrossRef]
- Jiang, Y.; Huang, G.Q. A hybrid method based on singular spectrum analysis, firefly algorithm, and BP neural network for short-term wind-speed forecasting. Energies 2016, 9, 757. [Google Scholar]
- Jiang, Y.; Huang, G. Short-term wind speed prediction: Hybrid of ensemble empirical mode decomposition, feature selection and error correction. Energy Convers. Manag. 2017, 144, 340–350. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, T.; Sun, L.; Wang, W.; Wang, C.; Mao, W. ν-Support Vector Regression Model Based on Gauss-Laplace Mixture Noise Characteristic for Wind Speed Prediction. Entropy 2019, 21, 1056. [Google Scholar] [CrossRef] [Green Version]
- Shevade, S.; Keerthi, S.S.; Bhattacharyya, C.; Murthy, K. Improvements to the SMO algorithm for SVM regression. IEEE Trans. Neural Netw. 2000, 11, 1188–1193. [Google Scholar] [CrossRef] [Green Version]
- Klaus-Robert, M.; Sebastian, M. An introduction to kernel-based learning algorithms. IEEE Trans. Neural Netw. 2001, 12, 181–202. [Google Scholar]
- Chu, W.; Keerthi, S.; Ong, C.J. Bayesian Support Vector Regression Using a Unified Loss Function. IEEE Trans. Neural Netw. 2004, 15, 29–44. [Google Scholar] [CrossRef] [Green Version]
- Rockafellar, R.T. Augmented Lagrange Multiplier Functions and Duality in Nonconvex Programming. SIAM J. Control 1974, 12, 268–285. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004; pp. 521–620. [Google Scholar]
- Wang, S.; Zhang, N.; Wu, L.; Wang, Y. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Bordes, A.; Bottou, L.; Gallinari, P. SGD-QN: Careful quasiNewton stochastic gradient descent. J. Mach. Learn. Res. 2009, 10, 1737–1754. [Google Scholar]
- Bludszuweit, H.; Dominguez-Navarro, J.; Llombart, A. Statistical Analysis of Wind Power Forecast Error. IEEE Trans. Power Syst. 2008, 23, 983–991. [Google Scholar] [CrossRef]
- Fabbri, A.; Román, T.G.S.; Abbad, J.R.; Quezada, V.H.M. Assessment of the cost associated with wind generation prediction errors in a liberalized electricity market. IEEE Trans. Power Syst. 2005, 20, 1440–1446. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, J.; Zhang, W.; Wang, J. A corrected hybrid approach for wind speed prediction in Hexi Corridor of China. Energy 2011, 36, 1668–1679. [Google Scholar] [CrossRef]
- Wang, J.Z.; Hu, J.M. A robust combination approach for short-term wind-speed forecasting and analysis-Combination of the ARIMA, ELM, SVM and LSSVM forecasts using a GPR model. Energy 2015, 93, 41–56. [Google Scholar] [CrossRef]
- Abdoos, A.A. A new intelligent method based on combination of VMD and ELM for short term wind power forecasting. Neurocomputing 2016, 203, 111–120. [Google Scholar] [CrossRef]
- Chalimourda, A.; Schölkopf, B.; Smola, A.J. Experimentally optimal ν in support vector regression for different noise models and parameter settings. Neural Netw. 2004, 17, 127–141. [Google Scholar] [CrossRef]
- Cherkassky, V.; Ma, Y. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef] [Green Version]
- Kwok, J.T.; Tsang, I.W. Linear dependency between and the input noise in ϵ-support vector regression. IEEE Trans. Neural Netw. 2003, 14, 544–553. [Google Scholar] [CrossRef] [Green Version]
- Schölkopf, B.; Smola, A.J.; Williamson, R.C.; Bartlett, P. New Support Vector Algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar]
- Wu, Q. A hybrid-forecasting model based on Gaussian support vector machine and chaotic particle swarm optimization. Expert Syst. Appl. 2010, 37, 2388–2394. [Google Scholar] [CrossRef]
- Wu, Q.; Law, R. The forecasting model based on modified SVRM and PSO penalizing Gaussian noise. Expert Syst. Appl. 2011, 38, 1887–1894. [Google Scholar] [CrossRef]
Figure 1.
G-L empirical risk loss of different parameters.

Figure 2.
High wind speed distribution.

Figure 3.
Low wind speed distribution.

Figure 4.
G-L mixed distribution of wind-speed forecasting-error with the persistence method.

Figure 5.
Result of four wind-speed forecasting models after 10 min.

Figure 6.
Error of four wind-speed forecasting models after 10 min.

Figure 7.
Residual box plot of four wind-speed forecasting models after 10 min.

Figure 8.
Result of four wind-speed forecasting models after 30 min.

Figure 9.
Error of four wind-speed forecasting models after 30 min.

Figure 10.
Residual box plot of four wind-speed forecasting models after 30 min.

Figure 11.
Result of four wind-speed forecasting models after 60 min.

Figure 12.
Error of four wind-speed forecasting models after 60 min.

Figure 13.
Residual box plot of four wind-speed forecasting models after 60 min.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Error statistic of four wind-speed forecasting models after 10 min.
| Model | MAE (m/s) | RMSE (m/s) | MAPE (%) | SEP (%) |
|---|---|---|---|---|
| 0.4280 | 0.5833 | 8.02 | 7.12 | |
| 0.4256 | 0.5789 | 7.92 | 7.07 | |
| 0.4219 | 0.5768 | 7.94 | 7.06 | |
| 0.4190 | 0.5711 | 7.91 | 7.05 |
Table 2.
Error statistic of four wind-speed forecasting models after 30 min.
| Model | MAE (m/s) | RMSE (m/s) | MAPE (%) | SEP (%) |
|---|---|---|---|---|
| 0.7979 | 1.0116 | 23.36 | 12.53 | |
| 0.7368 | 0.9886 | 19.93 | 11.89 | |
| 0.7109 | 0.9226 | 17.17 | 11.43 | |
| 0.6185 | 0.8241 | 10.71 | 10.19 |
Table 3.
Error statistic of four wind-speed forecasting models after 60 min.
| Model | MAE (m/s) | RMSE (m/s) | MAPE (%) | SEP (%) |
|---|---|---|---|---|
| 0.9994 | 1.2580 | 33.93 | 15.66 | |
| 0.9728 | 1.2355 | 31.78 | 15.37 | |
| 0.9646 | 1.2177 | 29.01 | 15.16 | |
| 0.8835 | 1.1180 | 25.72 | 13.97 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, S.; Zhou, T.; Sun, L.; Wang, W.; Chang, B. LSSVR Model of G-L Mixed Noise-Characteristic with Its Applications. Entropy 2020, 22, 629. https://doi.org/10.3390/e22060629
AMA Style
Zhang S, Zhou T, Sun L, Wang W, Chang B. LSSVR Model of G-L Mixed Noise-Characteristic with Its Applications. Entropy. 2020; 22(6):629. https://doi.org/10.3390/e22060629
Chicago/Turabian StyleZhang, Shiguang, Ting Zhou, Lin Sun, Wei Wang, and Baofang Chang. 2020. "LSSVR Model of G-L Mixed Noise-Characteristic with Its Applications" Entropy 22, no. 6: 629. https://doi.org/10.3390/e22060629
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.