
Information–Theoretic Aspects of Location Parameter Estimation under Skew–Normal Settings


Instituto de Estadística, Facultad de Ciencias, Universidad de Valparaíso, Valparaíso 2360102, Chile
Entropy 2022, 24(3), 399; https://doi.org/10.3390/e24030399
Submission received: 14 February 2022
/
Revised: 9 March 2022
/
Accepted: 11 March 2022
/
Published: 13 March 2022
(This article belongs to the Special Issue Distance in Information and Statistical Physics III)
{kind=link}
{kind=link}
{kind=link}
Abstract
:In several applications, the assumption of normality is often violated in data with some level of skewness, so skewness affects the mean’s estimation. The class of skew–normal distributions is considered, given their flexibility for modeling data with asymmetry parameter. In this paper, we considered two location parameter () estimation methods in the skew–normal setting, where the coefficient of variation and the skewness parameter are known. Specifically, the least square estimator (LSE) and the best unbiased estimator (BUE) for are considered. The properties for BUE (which dominates LSE) using classic theorems of information theory are explored, which provides a way to measure the uncertainty of location parameter estimations. Specifically, inequalities based on convexity property enable obtaining lower and upper bounds for differential entropy and Fisher information. Some simulations illustrate the behavior of differential entropy and Fisher information bounds.
1. Introduction
A typical problem in statistical inference is estimating the parameters from a data sample [1], especially if the data have some level of skewness. Therefore, the estimation of these parameters is affected by asymmetry. Recent research addressed data asymmetry with the class of skew–normal distributions, given their flexibility for modeling data with the skewness (asymmetry/symmetry) parameter [2]. In particular, Ref. [3] focused on estimating location parameter (), assuming that the coefficient of variation and skewness parameter are known. Specifically, they presented the least square estimator (LSE) and the best unbiased estimator (BUE) for . The precision of the location parameter estimation is directly influenced by skewness [4] and, hence, affects the confidence intervals and sample size [5,6].
Given that complex parametric distributions with several parameters are often considered [2], the information measures (entropies and/or divergences) play an important role in quantifying uncertainty provided by a random process about itself, and it is sufficient to study the reproduction of a marginal process through a noiseless system. One main application is related to the selection of models and detection of the number of clusters [7], or the interpretation of physical phenomena [8,9]. However, the use of entropies and/or divergences is widely considered to compare estimations [1]. For example, Ref. [10] considered the Kullback–Leibler (KL) divergence as a method to compare sample correlation matrices to an application in financial markets, assuming two multivariate normal densities. Using the estimated parameters based on maximum likelihood estimation, Ref. [11,12,13] considered the KL divergence for an asymptotic test to evaluate the data skewness and/or bimodality.
Given that precision was evaluated with confidence intervals in [5], the quantification of uncertainty for location parameter estimation under skew–normal settings motivated this study. The properties for MSE and (emphasizing) BUE, using classic theorems and properties of information theory are explored, which enable measuring the uncertainty of location parameter estimations based on differential entropy and Fisher information [1]. The Cramér–Rao inequality [14] linked Fisher information with the variance of an unbiased estimator, which is considered to find a lower bound for Fisher information. In addition, considering a stochastic representation [15] of a skew–normal random variable, the convexity property of Fisher information is also used to find an upper bound for Fisher information.
This paper is organized as follows: some properties and inferential aspects based on information theory are presented in Section 2. In Section 3, the computation and description of information–theoretic theorems related to location parameter estimation of skew–normal distribution are presented. In Section 4, some simulations illustrate the usefulness of the results. Final remarks conclude the paper in Section 5.
2. Information-Theoretic Aspects
In this section, some main theorems and properties of information theory are described. Specifically, these properties are based on differential entropy and Fisher information.
Definition 1.
Let X be a random variable with support in and continuous probability density function (pdf), , which depends on parameter θ. The differential entropy of X [1] is defined by
where notation was used.
Differential entropy depends only on the pdf of the random variable. In the following theorem, the scaling property of differential entropy is presented.
Theorem 1.
For any real constant a, the differential entropy of Theorem 8.6.4 of [1] is given by
In particular, for two random variables, the following differential entropy bounds hold.
Theorem 2.
Let X and Y be two independent random variables. Suppose , where “” denotes equality in distribution, then
- (i)
- (ii)
- For any constant ρ such that ,
Proof.
For part (i), consider first the general case for independent and identically distributed (i.i.d.) random variables see Equations (5) and (6) of [16], then
Considering the latter inequality for two variables, X and Y, and the scaling property of Theorem 1, we obtain , yielding the left side of the inequality. For the right side, see [17]. The inequality of part (ii) is proved in Theorem 7 of [14]. □
The inequality of Theorem 2 (ii) is based on the convexity property, and allows obtaining a lower bound for differential entropy Theorem 8.6.5 of [1].
Theorem 3.
Let X be a random variable with zero mean and finite , then
and equality is achieved if, and only if, .
Theorem 3, also known as the maximum entropy principle, implies that Gaussian distribution maximizes the differential entropy over all distributions with the same variance. This theorem has several implications for information theory, mainly when the differential entropy of an unknown distribution is hard to obtain. Thus, this upper bound is a good alternative. Another consequence is the relationship between estimation error and differential entropy, which includes the Cramér–Rao bound as described next. First, the Fisher information for continuous densities needs to be defined as follows.
Definition 2.
Let X be a random variable with support in and continuous density function , which depends on parameter θ, so . The Fisher information of X [1] is defined by
The Fisher information is a measure of the minimum error in estimating a parameter of a distribution. Classical definitions of Fisher information considered differentiation with respect to to define ; however, by considering a parametric form as , differentiation with respect to x is equivalent to differentiation with respect to as in Equation (1) [1]. The following inequality links Fisher information and variance.
Theorem 4.
Theorem 4, also known as the Cramér–Rao inequality, allows determining the best estimator of to obtain a lower bound for Fisher information. The Cramér–Rao inequality was first planned for any estimator (not necessarily unbiased) of in terms of mean-squared error, in this case
where ; see Equation (11).290 of [1]. Clearly, if is an unbiased estimator of , Theorem 4 is a particular case of the latter inequality. Inequality (2) was obtained through the Cauchy–Schwarz inequality on the variance of all unbiased estimators. The following inequality, also known as the Fisher information inequality, is based on the convexity property and is useful to obtain an upper bound for Fisher information.
Theorem 5.
For any two independent random variables X and Y, and any constant ρ such that , then
Proof.
See proof of Theorem 13 in [14]. □
3. Location Parameter Estimation
The skew–normal distribution is an extension of the normal one, allowing for the presence of skewness.
Definition 3.
X is called a skew–normal random variable [15] and denoted as if it has pdf
with location , scale , and shape parameters. In addition, is the pdf of the standardized normal distribution with 0 mean and variance 1, denoted as , and is the corresponding cumulative distribution function (cdf) of the standardized normal distribution.
Random variable X is represented by the following stochastic representation:
where , and and are independently distributed; see Equation (2.14) of [15].
Additionally, X has a representation based on a link between differential entropy and Fisher information, due to de Bruijn’s identity. By matching the stochastic representation (3) with Equation (20) of [16], it is possible to assign with fixed . Then,
where an approximation for Fisher information appears in the proof of Proposition 5 below (with observation).
Definition 4.
is called a multivariate skew–normal random vector [18] and denoted as if it has pdf
with location vector , scale matrix , and skewness vector parameters. In addition, is the n-dimensional normal pdf with location parameter μ and scale parameter Σ.
Let , with , , and , where and denotes the -identity matrix. Following [3] and Corollary 2.2 of [5], the following properties hold.
Property 1.
, , with .
Property 1 indicates that is a random sample with identically distributed but random variables not independent from a univariate skew–normal population with location , scale , and shape parameters.
Property 2.
and , with and .
Property 3.
.
Property 4.
with , where denotes the chi-square distribution with degrees of freedom, and sample mean and sample variance are independent.
3.1. Least Square Estimator
Assuming that the coefficient of variation and shape parameter are known, Theorem 4.1 of [3] provides the least square estimator for and its variance, given by
where , and is defined in Property 2. The least square estimator for was obtained by minimizing the MSE of with respect to a constant c. The MSE of is
Proposition 1.
Let , with known τ and λ. Thus,
- (i)
- (ii)
Proof.
Differential entropy of corresponds to the difference of the normal differential entropy and a term called negentropy, , that depends on and parameters. Additionally, note that part (ii) yields the upper bound for of part (i), .
As a particular case of Proposition 1, it is possible to obtain the differential entropy of sample mean by choosing :
its respective upper bound
and, from Equation (6), its respective MSE
3.2. Best Unbiased Estimator
Assuming that the coefficient of variation and shape parameter are known, Theorem 5.1 of [3] provides the best unbiased estimator (BUE) for , given by
where denotes the usual gamma function and S is defined in Property 4.
Remark 1.
Equation (10) can be approximated using an asymptotic expression for the gamma function given by , , as [19]. Then,
as . Since the exact form (10) can be undefined for large samples (), approximation (1) is very useful for these cases. Note that from (11) and (1), as , which implies that estimator is only influenced by for large samples.
Given that , from Equations (9), (14) and (15), we obtain
The following proposition provides two upper bounds of differential entropy for based on Theorem 3.
Proposition 2.
Let , with known τ and λ. Thus,
- (i)
- (ii)
Proof.
From Theorem 3 and Equations (14) and (15), the differential entropies of and are, respectively, upper bounded by
The following proposition provides two lower bounds of differential entropy for .
Proposition 3.
Let , with known τ () and λ. Thus
- (i)
- (ii)
where
and
Proof.
Differential entropy of is straightforward from evaluating (13) on Proposition 2.1 of [19] (for the univariate case). Given that distribution of is unknown, Ref. [3] provided its pdf
Through Equations (19) and (3.381.4) of [20], the moments of are given by
and, using Equation (4.352.1) of [20], the moment of is
where is the digamma function. Therefore, by definition (1), the differential entropy of is computed as
Thus, Equations (20) and (21) are evaluated in the latter expression to obtain . By assuming in Theorem 2(i) (), with and , the inequality of part (i) is obtained.
By assuming in Theorem 2(ii), with , (thus ), and , and since and are two unbiased estimators of [3], the inequality of part (ii) is obtained. □
The following proposition provides a lower bound for Fisher information of parameter based on .
Proposition 4.
Let , with known τ and λ. Thus,
Proof.
Considering that is an unbiased estimator of , from the Crámer–Rao inequality of Theorem 4 and Equations (14)–(16), we obtain
yielding the result. □
The following Proposition provides an upper bound of Fisher information for parameter based on and the convexity property.
Proposition 5.
Let , with known τ () and λ. Thus
where
Proof.
By assuming in Theorem 5, with , (thus ), and , and since and are two unbiased estimators of [3], we obtain . Note that condition ensures that .
For , the steps of Section 3.2 of [9] were considered. By Equations (1) and (13), and the change of variable , with , and , can be computed as
where is the zeta function. From Equation (22), the first and second terms are the second moment of a standardized skew–normal random variable () and the first moment of a standardized normal random variable (, ), respectively. The third term is
The following approximation of normal densities (see p. 83 of [15]),
and some basic algebraic operations of normal densities are useful to approximate the third term of Equation (22) as
Given that and , we obtain
Remark 2.
Considering the same argument as in Remark (1), it can be noted that inequalities of Propositions 4 and 5 are only affected by , i.e., for large samples, we obtain
4. Simulations
All location parameter estimators, variances, Fisher information and differential entropies were calculated with R software [21]. Samples based on skew–normal random variables were drawn based on stochastic representation (3) and with the rsn function of sn package. All R codes used in this paper are available upon request from the corresponding author.
In general, takes a value between 0 and 1. If is close to 0, the sample has low variability, and if it is close to 1, the sample has high variability and mean loss reliability. For example, if , the mean is less representative of the sample. Sometimes, if is close to zero, takes high values (high variability) and could exceed unity. Therefore, for illustrative purposes, in all simulations, a coefficient of variation set of is considered. Additionally considered are positive asymmetry parameters , sample sizes and 250, and theoretical location parameters , 0.5 and 1. For the computation of information measures, is replaced by and location parameters are evaluated by their respective estimators.
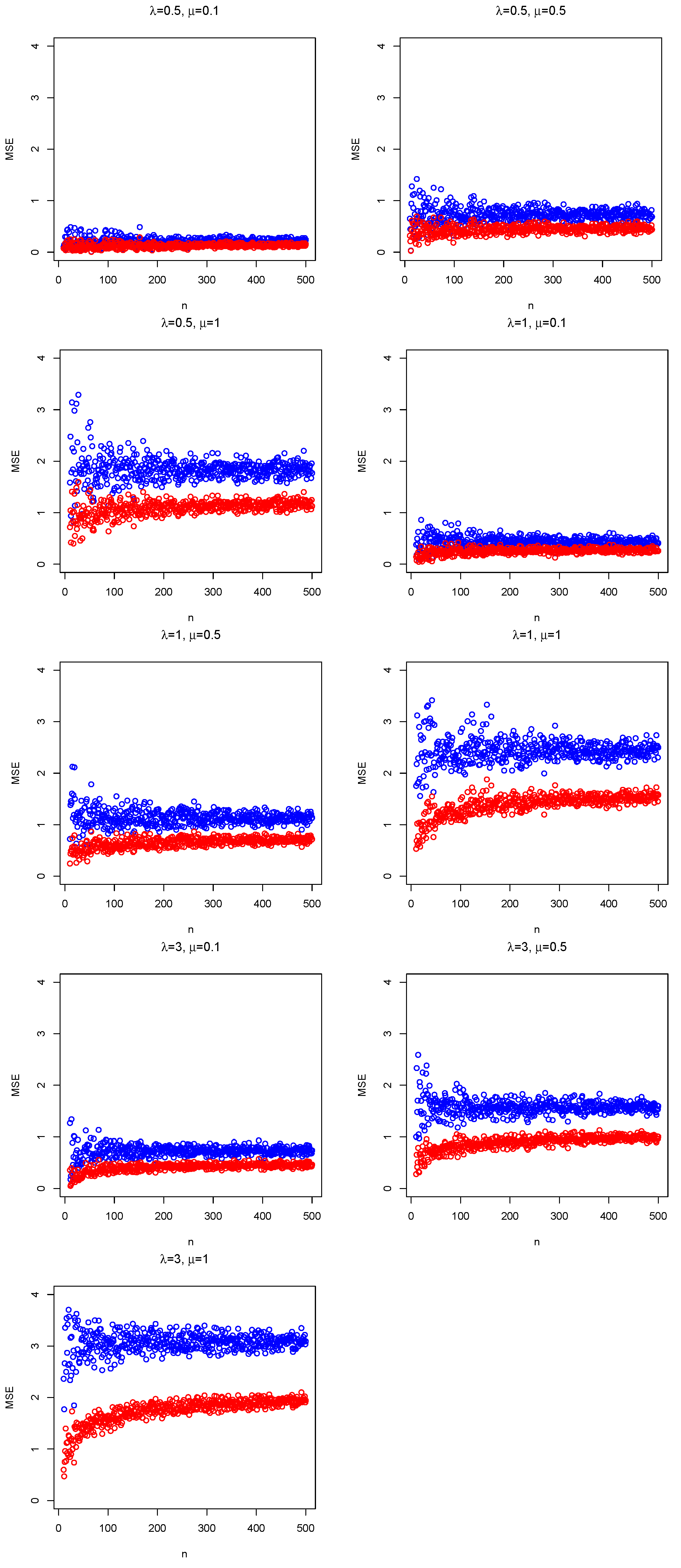
The MSE of is given in Equation (6), and MSE of is the variance of the (unbiased) estimator (see Equation (16)). Without loss of generality, is considered in Figure 1 because the same pattern is repeated for values of between 0 and 1. Comparing the MSE of both estimators, Figure 1 shows for all cases that differences between MSEs tend to increase for large values of , and MSEs turn around a specific value when the sample size increases. Moreover, MSEs of the unbiased estimator are less than those obtained by LSE, i.e., BUE dominates LSE Equation (11.263) of [1]. Therefore, the analysis focuses on BUE in the next section.
Behavior of differential entropy bounds given in Propositions 2 and 3 is illustrated in Figure 2 as 3D plots. Without loss of generality, is considered in Figure 2 because the same pattern is repeated for values of , i.e., entropies keep increasing. The upper bound corresponds to the minimum value between bounds given in Proposition 2(i) and (ii), which is the one given in (ii). Thus, the upper bound of is determined by the variance (or MSE) of the estimator. In contrast, the lower bounds correspond to the maximum value between bounds given in Proposition 3 (i) and (ii) [17].
Sample sizes () imply that and lower bounds only depend on . For small sample sizes (), could be an intermediate value of the interval , thus, lower bounds depend on and . For , the surfaces are rough, given the randomness of bounds produced by the small sample. When (symmetry condition), the bounds decay to negative values. This is analogous to considering the skew–normal density as a non-stationary process [15], when is near zero, so the Hurst exponent decreases abruptly [8]. On the other hand, for , surfaces are soft and bounds increase slightly for large . For all cases, information increases when tends to 1 because it produces more variability in samples.
For practical purposes, the average between bounds can be considered to provide an approximation of differential entropy [7] in similar form to average lengths of the confidence interval [3]. Given that all lower bounds of differential entropy depend on the entropy of , which depends on variance and sample size, they could take negative values and tend to zero when tends to 1. Therefore, the difference between lower and upper bounds could increase and turn out an inadequate approximation if the lower bound is negative. For the latter reason, the Fisher information considers only positive values, as studied next.
The Fisher information bounds given in Propositions 4 and 5 are illustrated in Figure 3 as 3D and 2D plots, respectively. As in the differential entropy case, and without loss of generality, is considered in Figure 3 because the same pattern is repeated for values of , i.e., entropies keep decreasing. Following the Cramér–Rao theorem, the variance of BUE corresponds to the reciprocal of the Fisher information. In contrast, the lower bound corresponds to a combination of the Fisher information of and .
As in the differential entropy case, large sample sizes () imply that and lower bounds only depend on , as mentioned in Remark 2. For small sample sizes (), could be an intermediate value of the interval , thus lower bounds depend on and . When (low variability condition), the lower bounds take the highest values. This reciprocal relationship is determined by the Cramér–Rao theorem: more variability, less Fisher information. In addition, the 2D plot shows that the smallest upper bounds of are produced when [9]. Given that upper bounds do not depend on and because the skew–normal densities are standardized, these measures are illustrated with respect to n and . In addition, when and n increase simultaneously, the upper bounds of Fisher information take the largest values.
5. Concluding Remarks
In this paper, some properties of the best unbiased estimator proposed by [3] were presented, using classic theorems of information theory, which provide a way to measure the uncertainty of location parameter estimations. Given that BUE dominates LSE, this paper focused on this estimator. Inequalities based on differential entropy and Fisher information allowed obtaining lower and upper bounds for these measures. Some simulations illustrated the behavior of differential entropy and Fisher information bounds.
Classical theorems of information theory considered the obtained additional properties of unbiased location parameter estimators. However, these theorems could be applied to other estimators, such as Bayesian [22] (as long as the prior pdf density is known), shrinkage [23], or bootstrap-based [24] ones. The assumption of the sample that came from a multivariate skew–normal distribution is too strong and not always applicable in the real world, so the properties revised here could be extended to more complex densities, for example, those that assess bimodality and heavy tails in data [7,11,13,19]. On the other hand, and given that Fisher information bounds under skew–normal settings were considered in this study, further work could focus on developing time-dependent Fisher information for skew–normal density [25], which could be applied to real data in survival analysis.
Funding
This research was funded by FONDECYT (Chile) grant number 11190116.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The author thanks the editor and three anonymous referees for their helpful comments and suggestions.
Conflicts of Interest
The author declares that there is no conflict of interest in the publication of this paper.
References
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley & Son, Inc.: New York, NY, USA, 2006. [Google Scholar]
- Adcock, C.; Azzalini, A. A selective overview of skew-elliptical and related distributions and of their applications. Symmetry 2020, 12, 118. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.Y.; Wang, C.; Wang, T.H. Estimation of location parameter in the skew normal setting with known coefficient of variation and skewness. Int. J. Intel. Technol. Appl. Stat. 2016, 9, 191–208. [Google Scholar]
- Trafimow, D.; Wang, T.; Wang, C. From a sampling precision perspective, skewness is a friend and not an enemy! Educ. Psychol. Meas. 2019, 79, 129–150. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Wang, T.; Trafimow, D.; Myüz, H.A. Necessary sample sizes for specified closeness and confidence of matched data under the skew normal setting. Comm. Stat. Simul. Comput. 2019, in press. [Google Scholar] [CrossRef]
- Wang, C.; Wang, T.; Trafimow, D.; Talordphop, K. Estimating the location parameter under skew normal settings: Is violating the independence assumption good or bad? Soft Comput. 2021, 25, 7795–7802. [Google Scholar] [CrossRef]
- Abid, S.H.; Quaez, U.J.; Contreras-Reyes, J.E. An information-theoretic approach for multivariate skew-t distributions and applications. Mathematics 2021, 9, 146. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E. Analyzing fish condition factor index through skew-gaussian information theory quantifiers. Fluct. Noise Lett. 2016, 15, 1650013. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E. Fisher information and uncertainty principle for skew-gaussian random variables. Fluct. Noise Lett. 2021, 20, 21500395. [Google Scholar] [CrossRef]
- Tumminello, M.; Lillo, F.; Mantegna, R.N. Correlation, hierarchies, and networks in financial markets. J. Econ. Behav. Organ. 2010, 75, 40–58. [Google Scholar] [CrossRef] [Green Version]
- Contreras-Reyes, J.E. An asymptotic test for bimodality using the Kullback–Leibler divergence. Symmetry 2020, 12, 1013. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E.; Kahrari, F.; Cortés, D.D. On the modified skew-normal-Cauchy distribution: Properties, inference and applications. Comm. Stat. Theor. Meth. 2021, 50, 3615–3631. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E.; Maleki, M.; Cortés, D.D. Skew-Reflected-Gompertz information quantifiers with application to sea surface temperature records. Mathematics 2019, 7, 403. [Google Scholar] [CrossRef] [Green Version]
- Dembo, A.; Cover, T.M.; Thomas, J.A. Information theoretic inequalities. IEEE Trans. Infor. Theor. 1991, 37, 1501–1518. [Google Scholar] [CrossRef] [Green Version]
- Azzalini, A. The Skew-Normal and Related Families; Cambridge University Press: Cambridge, UK, 2013; Volume 3. [Google Scholar]
- Madiman, M.; Barron, A. Generalized entropy power inequalities and monotonicity properties of information. IEEE Trans. Infor. Theor. 2007, 53, 2317–2329. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y. Sum of Two Independent Random Variables. ECE587, Information Theory; 2012; Available online: https://www2.isye.gatech.edu/~yxie77/ece587/SumRV.pdf (accessed on 15 January 2022).
- Azzalini, A.; Dalla-Valle, A. The multivariate skew-normal distribution. Biometrika 1996, 83, 715–726. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E. Asymptotic form of the Kullback–Leibler divergence for multivariate asymmetric heavy-tailed distributions. Phys. A Stat. Mech. Its Appl. 2014, 395, 200–208. [Google Scholar] [CrossRef]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products, 7th ed.; Academic Press: Cambridge, MA, USA; Elsevier: London, UK, 2007. [Google Scholar]
- R Core Team. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: http://www.R-project.org (accessed on 15 January 2022).
- Bayes, C.L.; Branco, M.D. Bayesian inference for the skewness parameter of the scalar skew-normal distribution. Braz. J. Prob. Stat. 2007, 21, 141–163. [Google Scholar]
- Kubokawa, T.; Strawderman, W.E.; Yuasa, R. Shrinkage estimation of location parameters in a multivariate skew-normal distribution. Comm. Stat. Theor. Meth. 2020, 49, 2008–2024. [Google Scholar] [CrossRef]
- Ye, R.; Fang, B.; Wang, Z.; Luo, K.; Ge, W. Bootstrap inference on the Behrens–Fisher-type problem for the skew-normal population under dependent samples. Comm. Stat. Theor. Meth. 2021, in press. [Google Scholar] [CrossRef]
- Kharazmi, O.; Asadi, M. On the time-dependent Fisher information of a density function. Braz. J. Prob. Stat. 2018, 32, 795–814. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Mean square errors (MSE) for [blue dots] and [red dots] considering and several skewness and location parameters in the simulations.
Figure 1.
Mean square errors (MSE) for [blue dots] and [red dots] considering and several skewness and location parameters in the simulations.

Figure 2.
Differential entropy bounds for considering and 250, , 0.5 and 1; and several skewness and coefficient of variation parameters in the simulations.
Figure 2.
Differential entropy bounds for considering and 250, , 0.5 and 1; and several skewness and coefficient of variation parameters in the simulations.

Figure 3.
Fisher information lower bounds for considering , , 2.5 and 5; and several skewness and coefficient of variation parameters in the simulations. The fourth panel shows the upper bounds for considering and several skewness parameters .
Figure 3.
Fisher information lower bounds for considering , , 2.5 and 5; and several skewness and coefficient of variation parameters in the simulations. The fourth panel shows the upper bounds for considering and several skewness parameters .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Contreras-Reyes, J.E. Information–Theoretic Aspects of Location Parameter Estimation under Skew–Normal Settings. Entropy 2022, 24, 399. https://doi.org/10.3390/e24030399
AMA Style
Contreras-Reyes JE. Information–Theoretic Aspects of Location Parameter Estimation under Skew–Normal Settings. Entropy. 2022; 24(3):399. https://doi.org/10.3390/e24030399
Chicago/Turabian StyleContreras-Reyes, Javier E. 2022. "Information–Theoretic Aspects of Location Parameter Estimation under Skew–Normal Settings" Entropy 24, no. 3: 399. https://doi.org/10.3390/e24030399
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.