
FASSVid: Fast and Accurate Semantic Segmentation for Video Sequences

 , , , , , ,
, , , , , ,  , and
, and
Abstract
:1. Introduction
- We propose a methodology for evaluating the performance of semantic video segmentation networks and introduce CityscapesVid, a new dataset based on Cityscapes.
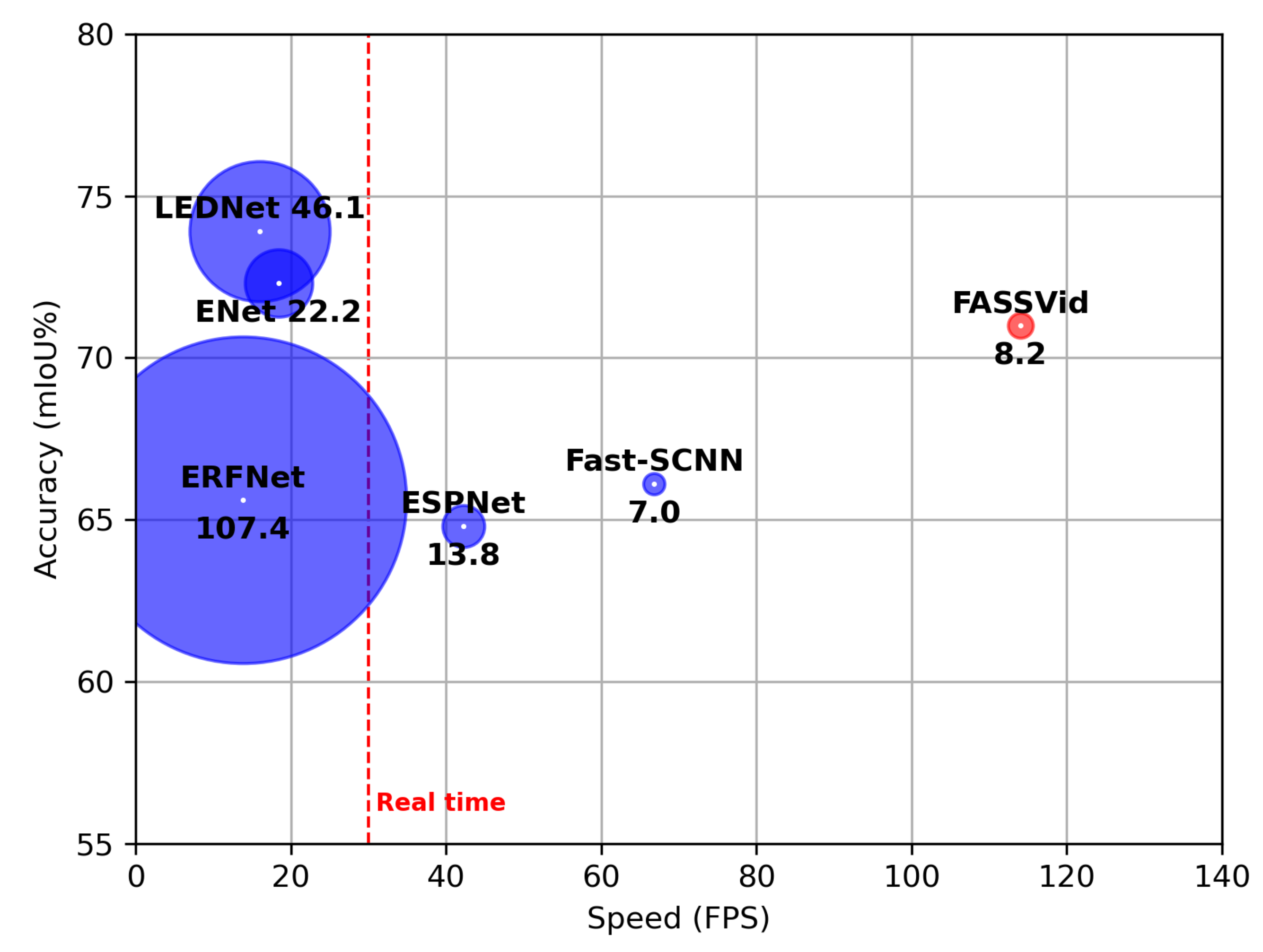
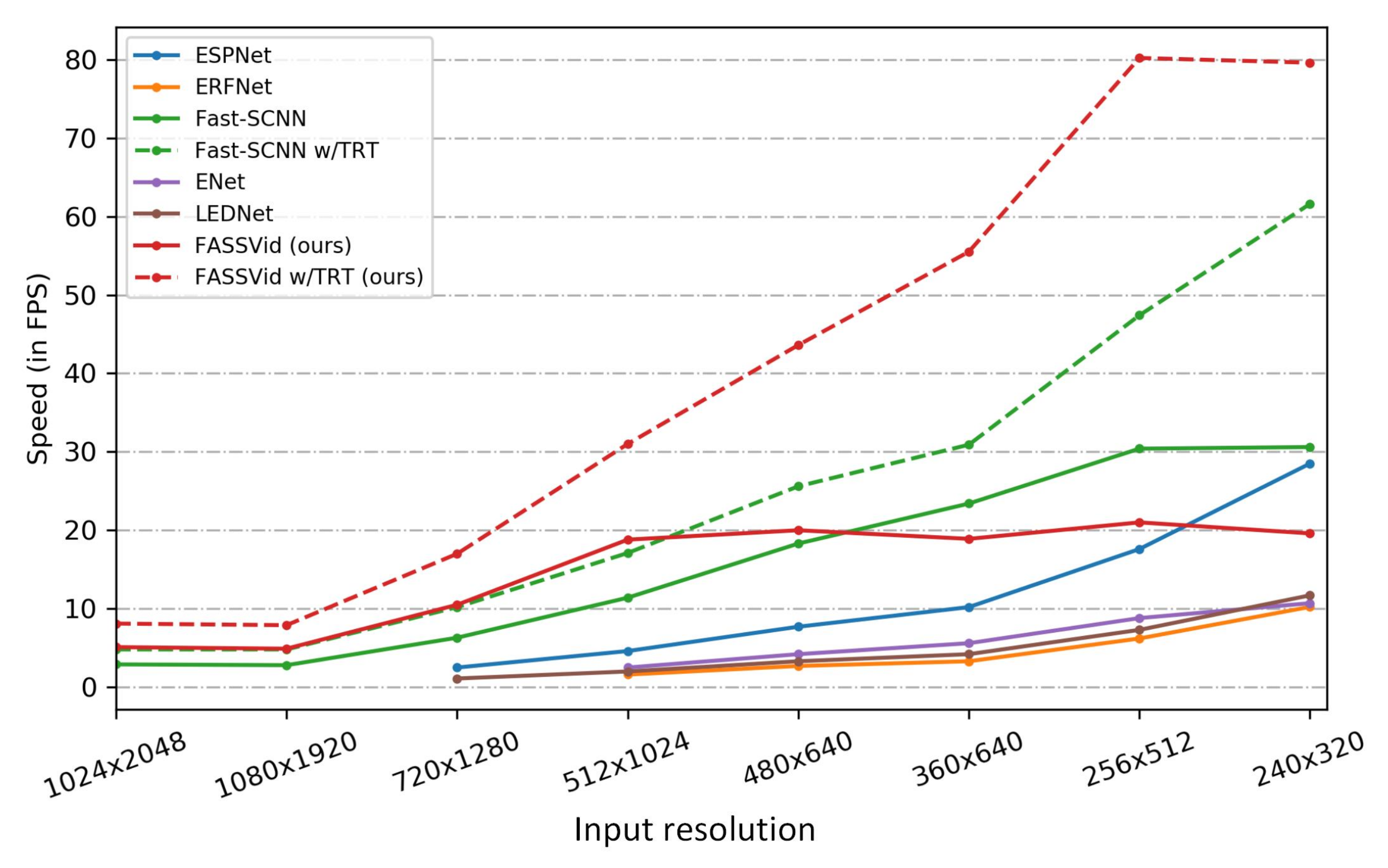
- We introduce FASSVid, a fast and accurate lightweight network designed specifically for semantic video segmentation. As shown in Figure 1, FASSVid surpasses the speed of all other state-of-the-art lightweight networks, maintaining high accuracy and a low number of computations.
- We demonstrate the effectiveness of our methods through multiple experiments and report the implementation results on the NVIDIA GTX 1080Ti GPU and the NVIDIA Jetson Nano embedded board.
- This proposal is an evolution of a previous work of the authors, FASSDNet; both works share a common structure; however, FASSVid, is intended to obtain information from a sequence of frames using temporal information, while FASSDNet aims at segmentation in isolated frames.
2. Related Work
2.1. Semantic Segmentation
2.2. Real-Time Semantic Segmentation
2.3. Video Segmentation
3. Proposed Methodology
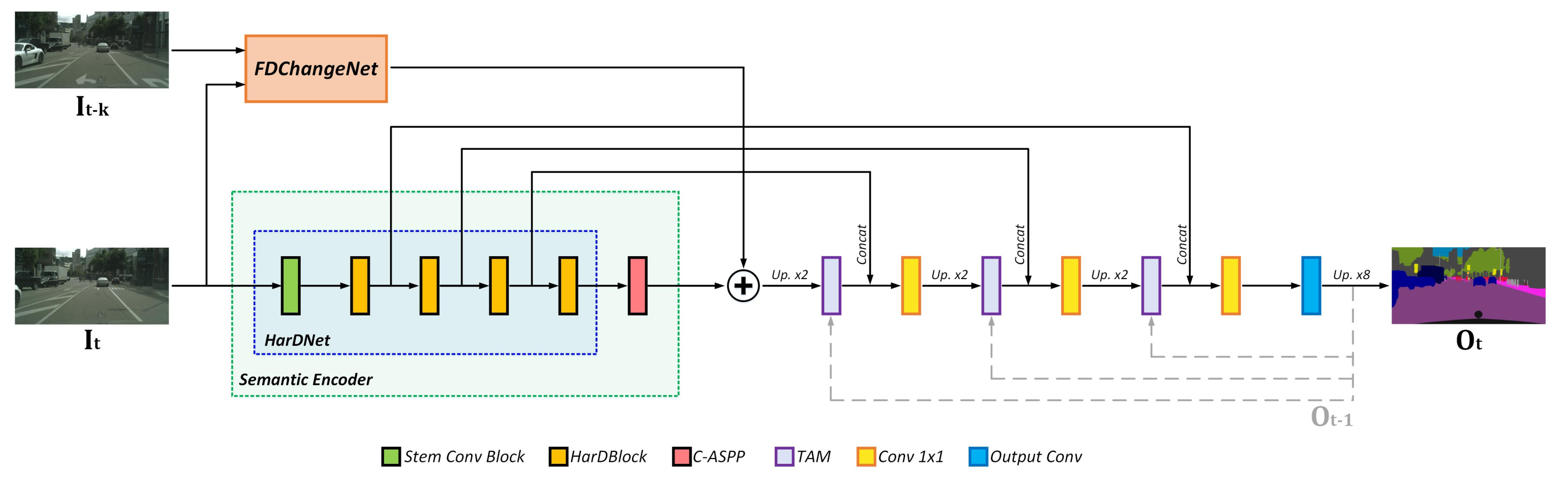
3.1. Network Architecture
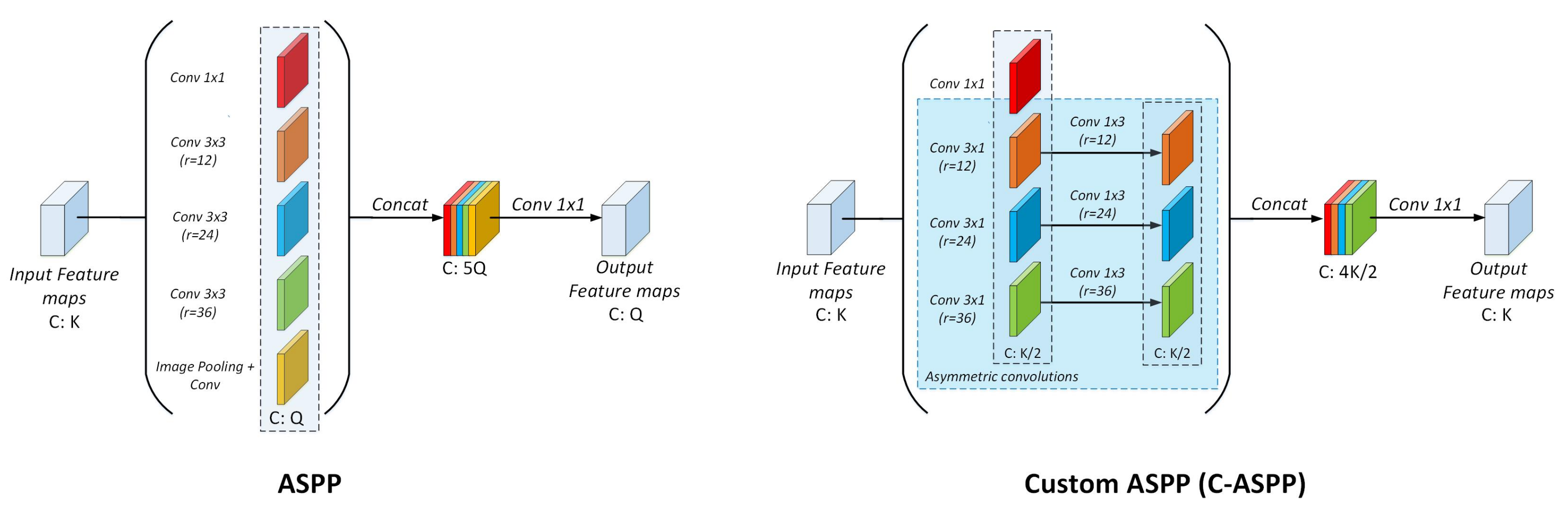
3.1.1. Custom Atrous Spatial Pyramidal Pooling Module (C-ASPP)
- 1 × Conv 1 × 1
- 1 × Pooling + Conv 1 × 1
- 3 × Atrous Conv 3 × 3 (with dilation rates r = 12, 24 and 36, respectively).
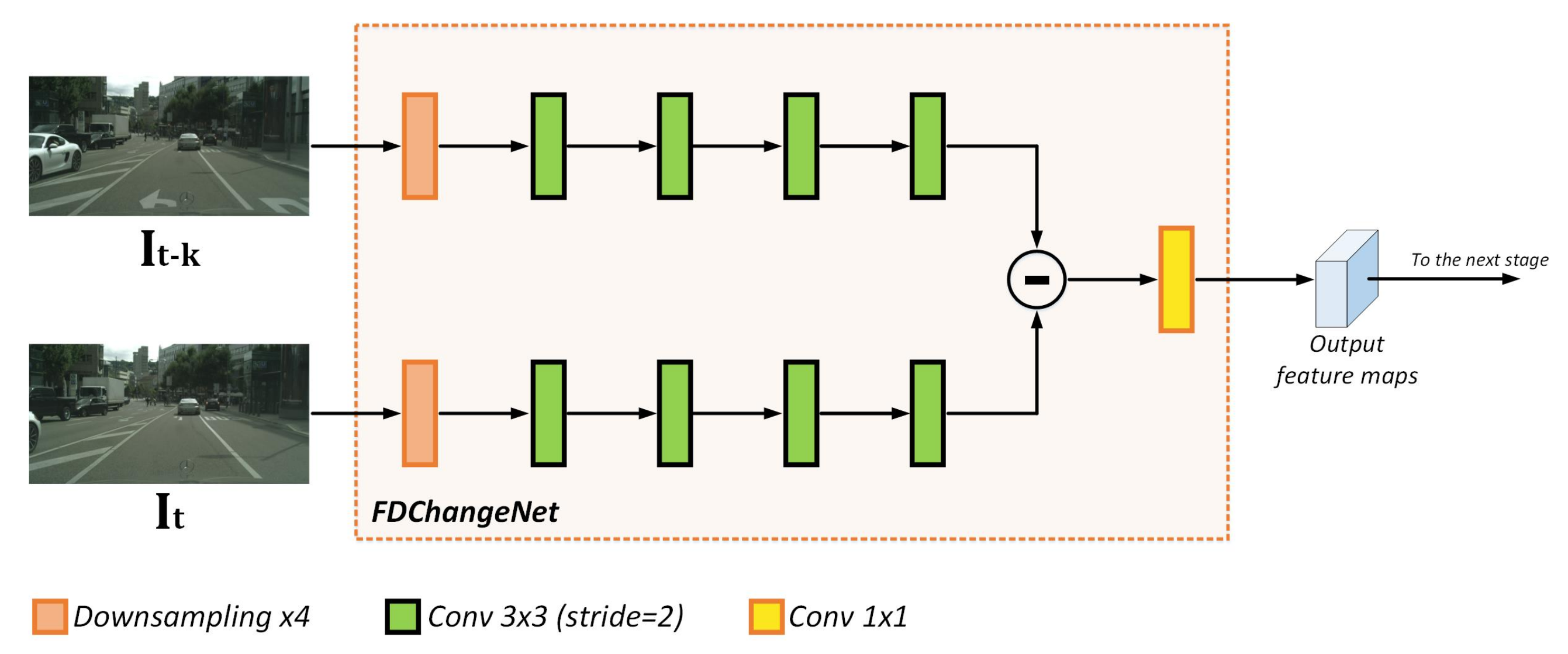
3.1.2. FDChangeNet
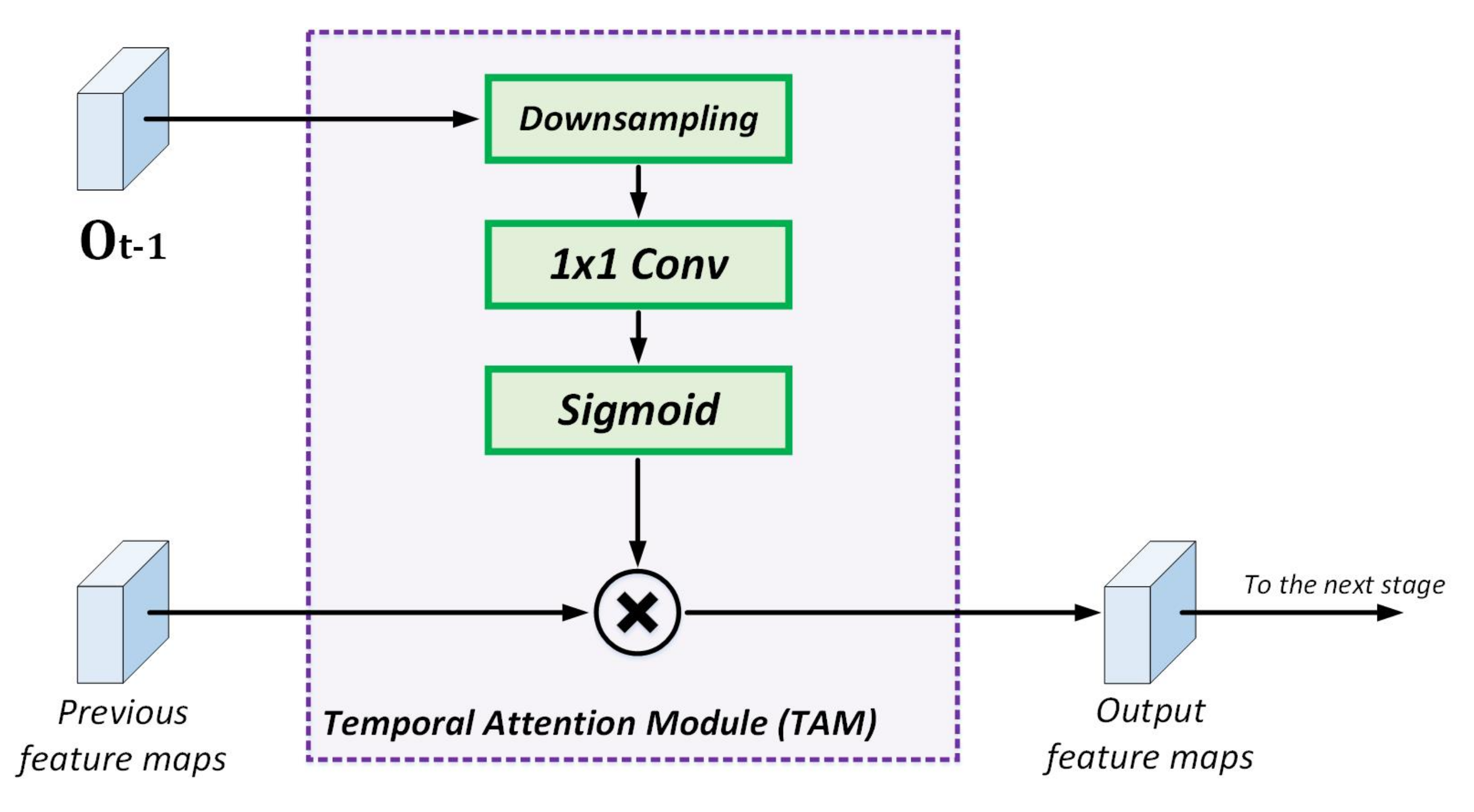
3.1.3. Temporal Attention Module (TAM)
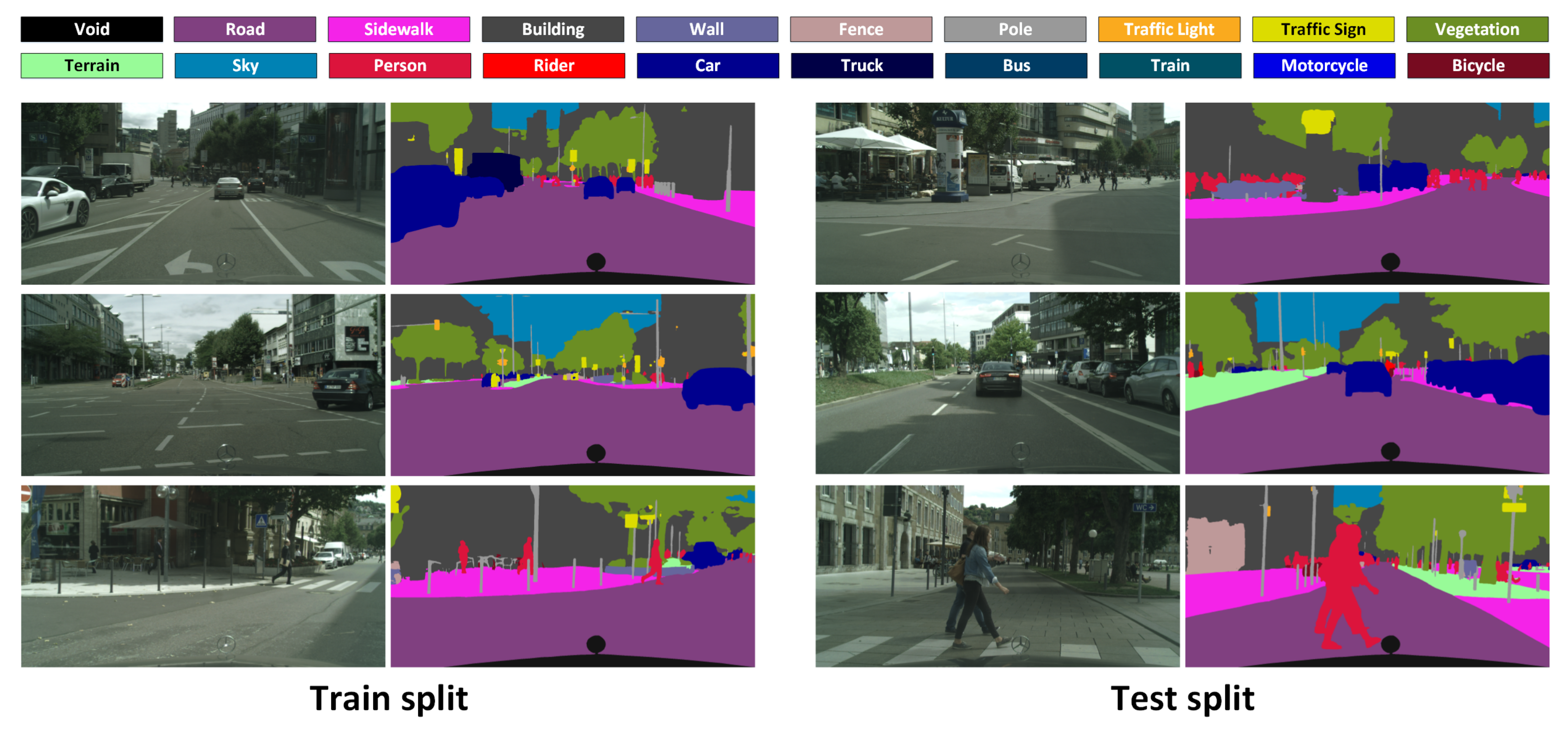
3.2. Sequential Training and Evaluation for Semantic Video Segmentation
- stuttgart_00: Frames from 1 to 420 are for training and frames from 421 to 599 are for testing.
- stuttgart_01: Frames from 1 to 770 are for training and frames from 771 to 1100 are for testing.
- stuttgart_02: Frames from 1 to 840 are for training and frames from 841 to 1200 are for testing.
4. Results
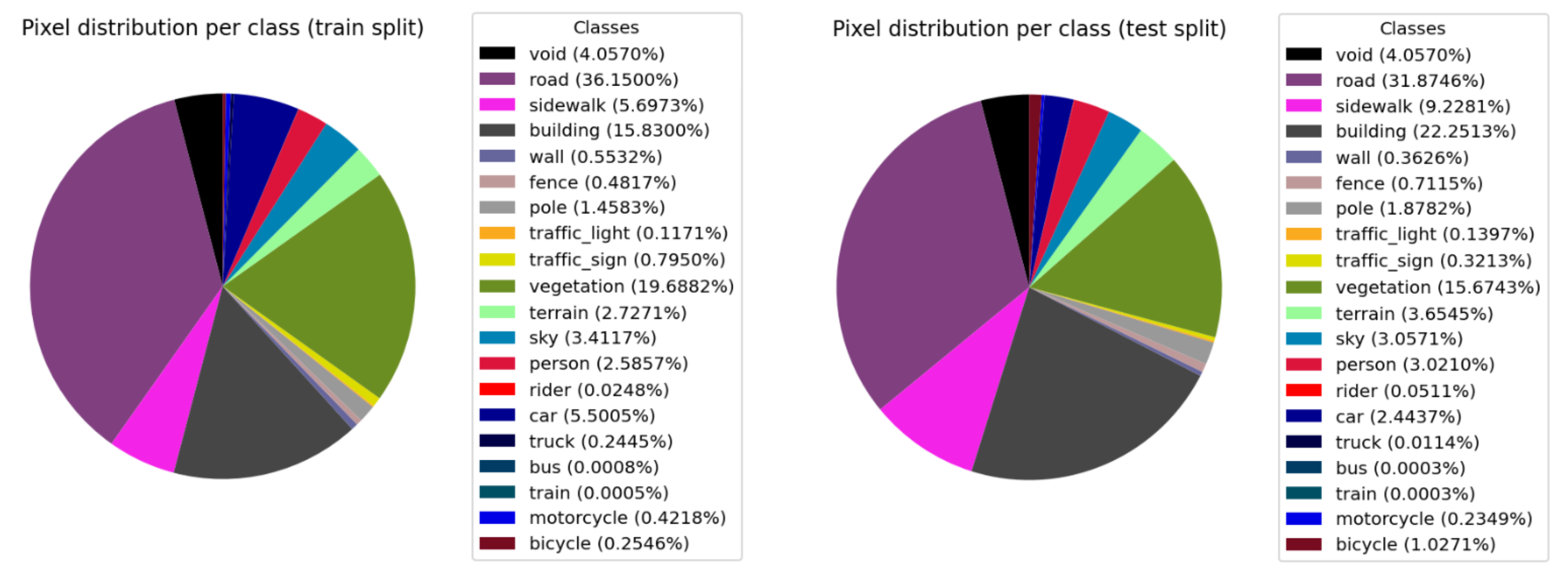
4.1. Experimental Setup
4.2. Ablation Study
- Baseline + Att: Attention directly to the output convolution layer of the network with the raw (no Conv ).
- Baseline + Att_conv: Attention directly to the output convolution layer of the network ( processed by a Conv ).
- Baseline + Att_conv_all: Attention to both every decoder stage as well as the output convolution layer of the network (the latter follows the same strategy as in “Baseline + Att”).
- Baseline + Att_conv_dec: Attention to all the decoder stages only (as illustrated in Figure 2).
4.3. Comparison with Other State-of-the-Art Lightweight Networks
4.4. Implementation on Jetson Nano
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 7 October–2 November 2019; pp. 603–612. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. PolarMask: Single Shot Instance Segmentation with Polar Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Ryselis, K.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R. Computer-Aided Depth Video Stream Masking Framework for Human Body Segmentation in Depth Sensor Images. Sensors 2022, 22, 3531. [Google Scholar] [CrossRef] [PubMed]
- Malūkas, U.; Maskeliūnas, R.; Damaševičius, R.; Woźniak, M. Real time path finding for assisted living using deep learning. J. Univers. Comput. Sci. 2018, 24, 475–487. [Google Scholar]
- Wong, C.C.; Gan, Y.; Vong, C.M. Efficient outdoor video semantic segmentation using feedback-based fully convolution neural network. IEEE Trans. Ind. Inform. 2019, 16, 5128–5136. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Li, G.; Kim, J. DABNet: Depth-wise Asymmetric Bottleneck for Real-time Semantic Segmentation. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Chao, P.; Kao, C.Y.; Ruan, Y.S.; Huang, C.H.; Lin, Y.L. HarDNet: A Low Memory Traffic Network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Orsic, M.; Kreso, I.; Bevandic, P.; Segvic, S. In Defense of Pre-Trained ImageNet Architectures for Real-Time Semantic Segmentation of Road-Driving Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Xu, Y.S.; Fu, T.J.; Yang, H.K.; Lee, C.Y. Dynamic Video Segmentation Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, Y.; Shen, C.; Yu, C.; Wang, J. Efficient Semantic Video Segmentation with Per-frame Inference. In Proceedings of the European Conference on Computer Vision ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Siam, M.; Mahgoub, H.; Zahran, M.; Yogamani, S.; Jagersand, M.; El-Sallab, A. Modnet: Motion and appearance based moving object detection network for autonomous driving. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2859–2864. [Google Scholar]
- Wehrwein, S.; Szeliski, R. Video Segmentation with Background Motion Models. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-Maximization Attention Networks for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Romera, E.; Álvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Chen, W.; Gong, X.; Liu, X.; Zhang, Q.; Li, Y.; Wang, Z. FasterSeg: Searching for Faster Real-time Semantic Segmentation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, Y.; Zhou, Q.; Wu, X. ESNet: An Efficient Symmetric Network for Real-time Semantic Segmentation. arXiv 2019, arXiv:1906.09826. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. ESPNetv2: A Light-Weight, Power Efficient, and General Purpose Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. Lednet: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1860–1864. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Li, P.; Zhen, X.; Cao, X. Model-free tracking with deep appearance and motion features integration. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 101–110. [Google Scholar]
- Mallya, A.; Wang, T.C.; Sapra, K.; Liu, M.Y. World-Consistent Video-to-Video Synthesis. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020. [Google Scholar]
- Rashed, H.; Yogamani, S.; El-Sallab, A.; Krizek, P.; El-Helw, M. Optical flow augmented semantic segmentation networks for automated driving. arXiv 2019, arXiv:1901.07355. [Google Scholar]
- Zhang, Y.; Wan, B. Vehicle Motion Detection using CNN. IEEE Access 2017, 5, 24023–24031. [Google Scholar]
- Shelhamer, E.; Rakelly, K.; Hoffman, J.; Darrell, T. Clockwork convnets for video semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 October 2016; pp. 852–868. [Google Scholar]
- Hu, P.; Caba, F.; Wang, O.; Lin, Z.; Sclaroff, S.; Perazzi, F. Temporally distributed networks for fast video semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 8818–8827. [Google Scholar]
- Pfeuffer, A.; Schulz, K.; Dietmayer, K. Semantic Segmentation of Video Sequences with Convolutional LSTMs. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1441–1447. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 9–22 September 2016; p. 87. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Shen, C.; van den Hengel, A. High-performance Semantic Segmentation Using Very Deep Fully Convolutional Networks. arXiv 2016, arXiv:1604.04339. [Google Scholar]
- TensorRT. Available online: https://developer.nvidia.com/tensorrt (accessed on 16 May 2022).
- Zhu, Y.; Sapra, K.; Reda, F.A.; Shih, K.J.; Newsam, S.; Tao, A.; Catanzaro, B. Improving semantic segmentation via video propagation and label relaxation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8856–8865. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | GFLOPs | No. Parameters | FPS | mIoU (%) |
|---|---|---|---|---|
| Baseline | 7.9 | 1.99 M | 140.8 | 68.6 |
| Baseline + FDChangeNet (before C-ASPP) | 8.2 | 2.22 M | 123.4 | 68.4 |
| Baseline + FDChangeNet (after C-ASPP) | 8.2 | 2.22 M | 127.4 | 69.3 |
| Method | GFLOPs | No. Parameters | FPS | mIoU (%) |
|---|---|---|---|---|
| Baseline | 7.9 | 1.99 M | 140.8 | 68.6 |
| Baseline + FDChangeNet (standard version) | 8.2 | 2.22 M | 127.4 | 69.3 |
| Baseline + FDChangeNet (light version) | 8.0 | 2.06 M | 132.1 | 67.6 |
| Method | GFLOPs | No. Parameters | FPS | mIoU (%) |
|---|---|---|---|---|
| Baseline | 7.9 | 1.99 M | 140.8 | 68.6 |
| Baseline + Att | 7.9 | 1.99 M | 101.3 | 68.0 |
| Baseline + Att_conv | 8.7 | 1.99 M | 77.8 | 68.0 |
| Baseline + Att_conv_all | 8.0 | 2.0 M | 99.7 | 64.7 |
| Baseline + Att_conv_dec | 8.0 | 2.0 M | 130.5 | 69.1 |
| Method | GFLOPs | No. Parameters | FPS | mIoU (%) |
|---|---|---|---|---|
| Baseline | 7.9 | 1.99 M | 140.8 | 68.6 |
| + FDChangeNet | 8.2 | 2.22 M | 127.4 | 69.3 |
| + TAM | 8.0 | 2.0 M | 130.5 | 69.1 |
| + FDChangeNet + TAM | 8.2 | 2.22 M | 114.9 | 71.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Portillo-Portillo, J.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Hernandez-Suarez, A.; Olivares-Mercado, J.; Perez-Meana, H.; Velarde-Alvarado, P.; Orozco, A.L.S.; García Villalba, L.J. FASSVid: Fast and Accurate Semantic Segmentation for Video Sequences. Entropy 2022, 24, 942. https://doi.org/10.3390/e24070942
Portillo-Portillo J, Sanchez-Perez G, Toscano-Medina LK, Hernandez-Suarez A, Olivares-Mercado J, Perez-Meana H, Velarde-Alvarado P, Orozco ALS, García Villalba LJ. FASSVid: Fast and Accurate Semantic Segmentation for Video Sequences. Entropy. 2022; 24(7):942. https://doi.org/10.3390/e24070942
Chicago/Turabian StylePortillo-Portillo, Jose, Gabriel Sanchez-Perez, Linda K. Toscano-Medina, Aldo Hernandez-Suarez, Jesus Olivares-Mercado, Hector Perez-Meana, Pablo Velarde-Alvarado, Ana Lucila Sandoval Orozco, and Luis Javier García Villalba. 2022. "FASSVid: Fast and Accurate Semantic Segmentation for Video Sequences" Entropy 24, no. 7: 942. https://doi.org/10.3390/e24070942