
The Information Bottleneck’s Ordinary Differential Equation: First-Order Root Tracking for the Information Bottleneck

School of Computer Science and Engineering, The Hebrew University of Jerusalem, Jerusalem 9190401, Israel
Entropy 2023, 25(10), 1370; https://doi.org/10.3390/e25101370
Submission received: 16 May 2023
/
Revised: 8 August 2023
/
Accepted: 9 August 2023
/
Published: 22 September 2023
(This article belongs to the Special Issue Theory and Application of the Information Bottleneck Method)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The Information Bottleneck (IB) is a method of lossy compression of relevant information. Its rate-distortion (RD) curve describes the fundamental tradeoff between input compression and the preservation of relevant information embedded in the input. However, it conceals the underlying dynamics of optimal input encodings. We argue that these typically follow a piecewise smooth trajectory when input information is being compressed, as recently shown in RD. These smooth dynamics are interrupted when an optimal encoding changes qualitatively, at a bifurcation. By leveraging the IB’s intimate relations with RD, we provide substantial insights into its solution structure, highlighting caveats in its finite-dimensional treatments. Sub-optimal solutions are seen to collide or exchange optimality at its bifurcations. Despite the acceptance of the IB and its applications, there are surprisingly few techniques to solve it numerically, even for finite problems whose distribution is known. We derive anew the IB’s first-order Ordinary Differential Equation, which describes the dynamics underlying its optimal tradeoff curve. To exploit these dynamics, we not only detect IB bifurcations but also identify their type in order to handle them accordingly. Rather than approaching the IB’s optimal tradeoff curve from sub-optimal directions, the latter allows us to follow a solution’s trajectory along the optimal curve under mild assumptions. We thereby translate an understanding of IB bifurcations into a surprisingly accurate numerical algorithm.
1. Introduction
The Information Bottleneck (IB) describes the fundamental tradeoff between the compression of information on an input X to the preservation of relevant information on a hidden reference variable Y. Formally, let X and Y be random variables defined, respectively, on finite source and label alphabets and , and let be their joint probability distribution, or for short (without loss of generality, for every and so is well-defined). One seeks [1] to maximize the information over all Markov chains , subject to a constraint on the mutual information ,
The latter maximization is over conditional probability distributions or encoders . The graph of is the IB curve. We write , for a codebook or representation alphabet . An encoder which achieves the maximum in (1) is IB optimal or simply optimal.
Written in a Lagrangian formulation with (normalization constraints omitted for clarity), [1] showed that a necessary condition for extrema in (1) is that the IB Equations hold. Namely,
In these, is the partition function, is the Kullback–Leibler divergence, , and in (3) is defined by the Bayes rule . The IB Equations (2)–(4) are a necessary condition for an extremum of also when it is considered as a functional in three independent families of normalized distributions , and , ref. [1] (Section 3.3), rather than in alone. While satisfying them is necessary to achieve the curve (1), it is not sufficient. Indeed, Equations (2)–(4) have solutions that do not achieve curve (1), and so are sub-optimal. This results in sub-optimal IB curves, which intersect or bifurcate as the multiplier varies (see Section 3.4 in [1]).
Iterating over the IB Equations (2)–(4) is essentially Blahut–Arimoto’s algorithm variant for the IB (BA-IB) due to [1], brought below for reference. While the minimization problem (1) can be solved exactly in special cases [2] (Section IV), exact solutions of an arbitrary finite IB problem whose distribution is known are usually obtained nowadays using BA-IB; see [3] (Section 3) for a survey of other computation approaches. Write for a single iteration of BA-IB. Since encodes an iteration over the IB Equations (2)–(4), then an encoder is its fixed point, , if and only if it satisfies the IB Equations. Or equivalently, if is a root of the IB operator,
in a manner similar to [4]. We shall then call it an IB root. Agmon et al. [4] used a similar formulation of rate-distortion (RD) and its relations in [5] to the IB, to show that BA-IB suffers from critical slowing down near critical points, where the marginal of a representor in an optimal encoder vanishes gradually. That is, the number of BA-IB iterations required until convergence increases dramatically as one approaches such points.
Formulating fixed points of an iterative algorithm as operator roots can also be leveraged for computational purposes in a constrained optimization problem, as noted recently by [6] for RD. Indeed, let be a differentiable operator on for some , , where is a (real) constraint parameter. Suppose now that is a root of F,
such that is a differentiable function of . Write for its Jacobian matrix, and for its vector of partial derivatives with respect to . The point of evaluation is omitted whenever understood. As is often discussed along with the Implicit Function Theorem, e.g., [7], applying the multivariate chain rule to in (6) yields an implicit ordinary differential equation (ODE)
for the roots of F. Plugging in explicit expressions for the first-order derivative tensors and , one can specialize (7) to a particular setting, which allows one to compute the implicit derivatives numerically. While [6] discovered the RD ODE this way, they showed that (7) can be generalized to arbitrary order under suitable differentiability assumptions. Namely, they showed that the derivatives implied by (6) can be computed via a recursive formula, for an arbitrary-order . By specializing this with the higher derivatives of Blahut’s algorithm [8], they obtained a family of numerical algorithms for following the path of an optimal RD root (Part I there).
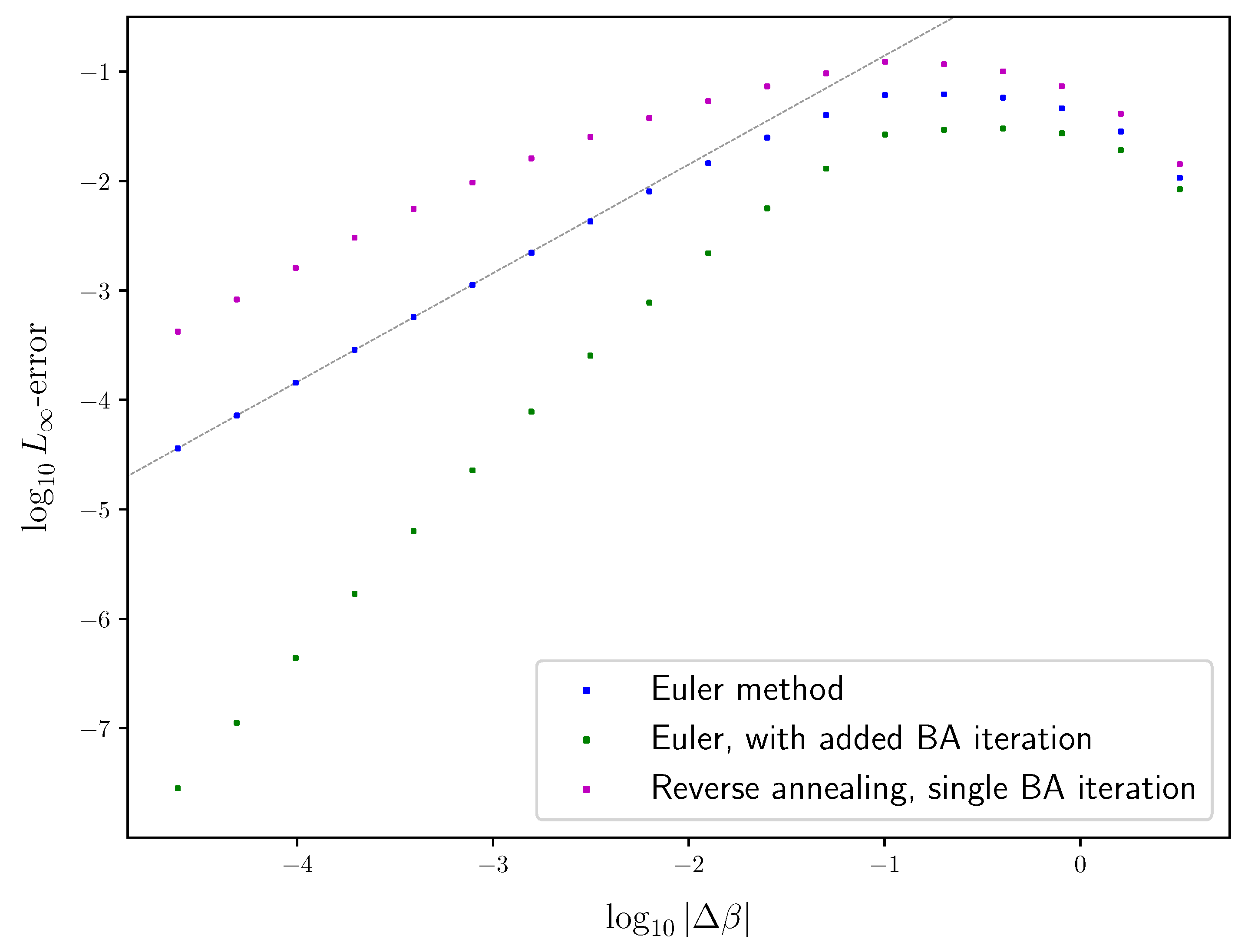
In this work, we specialize the implicit ODE (7) to the IB. Namely, we plug into (7) the first-order derivatives of the IB operator (5) to obtain the IB ODE, and then use it to reconstruct the path of an optimal IB root, in a manner similar to [6]. This is not to be confused with the gradient flow (of arbitrary encoders) towards an optimal root at a fixed value, described in [9] (Equation (6)) by an ODE, which is a different optimization approach. In contrast, the implicit Equation (7) describes how a root evolves with . So, in principle, one may compute an optimal IB root once and then follow its evolution along the IB curve (1). While the discovery of the IB ODE is due to [10], we derive it here anew in a form that is better suited for computational (and other) purposes, especially when there are fewer possible labels than input symbols , as often is the case. To that end, we consider several natural choices of a coordinate system for the IB in Section 2 and compare their properties. This allows us to make an apt choice for the ODE’s variable in (7). In Section 3, we present the IB ODE in these coordinates (Theorem 1). This enables one to numerically compute the first-order implicit derivatives at an IB root, if it can be written as a differentiable function in . So long as an optimal root remains differentiable, a simple way to reconstruct its trajectory is by taking small steps at a direction determined by the IB ODE. This is Euler’s method for the IB. The error accumulated by Euler’s method from the true solution path is roughly proportional to the step size, when small enough. For comparison, reverse deterministic annealing [11] with BA-IB is nowadays common for computing IB roots. The dependence of its error on the step size is roughly the same as in Euler’s method. This is discussed in Section 4, where we combine Euler’s method with BA-IB to obtain a modified numerical method whose error decreases at a faster rate than either of the above.
However, the differentiability of optimal IB roots breaks where the solution changes qualitatively. Such a point is often called a phase transition in the IB literature, or a bifurcation—namely, a point where there is a change in the problem’s number of solutions; e.g., [12] (Section 2.3) for basic definitions. As noted already by Tishby et al. in [1], their existence in the IB stems from restricting the cardinality of the representation alphabet . Since IB roots are the solutions of the fixed-point Equations (2)–(4), then the gap between achieving the IB curve (1) to merely satisfying these Equations lies in understanding the solution structure of the IB operator (5), or equivalently its bifurcations. While IB bifurcations were analyzed in several works, including [9,13,14] and others, little is known about the practical value of understanding them. In [15,16] it was shown that they correspond to the onset of learning new classes, and in [4] that they inflict a hefty computational cost to BA-IB. Following [6], this work demonstrates that understanding bifurcations can be translated to a new numerical algorithm to solve the IB. To that end, merely detecting a bifurcation along a root’s path does not suffice. Rather, it is also necessary to identify its type, as this allows one to handle the bifurcation accordingly. One can then continue following the path dictated by the IB ODE.
Almost all of the literature on IB bifurcations is based on a perturbative approach, in a manner similar to [17] (Section IV.C). That is, suppose that the first variation
of the IB Lagrangian vanishes, for every perturbation . This condition is necessary for extremality and implies [1] the IB Equations (2)–(4). Then, is said to be a phase transition only if there exists a particular direction at which can be perturbed without affecting the Lagrangian’s value to second order,
For finite IB problems, condition (8) boils down to requiring that the gradient of vanishes, while condition (9) is equivalent to requiring that its Hessian matrix has a non-trivial kernel (as both are conditions on the directional derivatives, e.g., [18]). The works [9,14,15,16] take such an approach, while [13] focuses on one type of IB bifurcations.
While a perturbative approach is common in analyzing phase transitions, it has several shortcomings when applied to the IB, as noted by [10]. First, the IB’s Lagrangian is constant on a linear manifold of encoders [9] (Section 3.1), and so condition (9) leads to false detections. While this was considered there and in its sequel [19] by giving subtle conditions on the nullity of the second variation in (9), in practice it is difficult to tell whether a particular direction is in the kernel due to a bifurcation or due to other reasons, as they note. Second, note that a finite IB problem can be written as an infinite RD problem [20]. As discussed in Section 5, representing an IB root by a finite-dimensional vector leads to inherent subtleties in its computation. Among other things, these may well result in a bifurcation not being detectable under certain circumstances (Section 5.3). To our understanding, many of the difficulties that hindered the understanding of IB bifurcations throughout the years are, in fact, artifacts of finite dimensionality. Third, conditions (8) and (9) do not suffice to reveal the type of the bifurcation, information which is necessary for handling it when following a root’s path. While [19] (Section 2.9) give conditions for identifying the type, these partially agree with our findings and do not suggest a straightforward way for handling a bifurcation.
Rather than imposing conditions on the scalar functional , our approach to IB bifurcations follows that of [6] for RD. That is, we rely on the fact that the IB’s local extrema are fixed points of an iterative algorithm, and so they also satisfy a vector equation (6). We shall now consider a toy problem to motivate our approach. “Bifurcation Theory can be briefly described by the investigation of problem (6) in a neighborhood of a root where is singular” [21]. Indeed, recall that if is non-singular at a root , then by the Implicit Function Theorem (IFT), there exists a function through the root, , which satisfies (6) at the vicinity of . The function is then not only unique at some neighborhood of , but further, inherits the differentiability properties of F [21] (I.1.7). In particular, if the operator F is real-analytic in its variables—as with the IB operator (5)—then so is its root . While a bifurcation can occur only if is singular, singularity is not sufficient for a bifurcation to occur. For example, the roots of the operator
on consist of the vertical line , , for every . For a fixed y, each such root is real-analytic in . However, one cannot deduce this directly from the IFT, as the Jacobian of F (10) is always singular. Note, however, that in this particular example, the x coordinate alone suffices to describe the problem’s dynamics, and so its y coordinate is redundant. One can ignore the y coordinate by considering the “reduction” of F to . Further, discarding y also removes or mods-out the direction from , which does not pertain to a bifurcation in this case. This results in the non-singular Jacobian matrix of , and so it is now possible to invoke the IFT on the reduced problem. The root guaranteed by the IFT can always be considered in by putting back a redundant y coordinate at some fixed value. In [6], a similarly defined reduction of finite RD problems was used to show that their dynamics are piecewise real-analytic under mild assumptions.
The intuition behind our approach is similar to [20] (Section III), who observed that “in the IB one can also get rid of irrelevant variables within the model”. Nevertheless, the details differ. Mathematically, we consider the quotient of a vector space V by its subspace W. Elements of V are identified in the quotient if they differ by an element of W: , for . This way, one “mods-out” W, collapsing it to a single point in the quotient vector space . The resulting problem is smaller and so easier to handle, whether for theoretical or practical purposes (although not needed for our purposes, this can be made precise in terms of the tangent space of a differentiable manifold; cf., Section 3 in [22]). This is how the one-dimensional vector space in our toy example (10) was reduced to the trivial . However, one needs to understand the solution structure, for example, to ensure that the directions in W are not due to a bifurcation. We note in passing that has a simple geometric interpretation as the translations of W in V, in a manner reminiscent of its better-known counterparts of quotient groups and rings; e.g., [23] (Section 10.2). To keep things simple, however, we shall not use quotients explicitly. Instead, the reader may simply consider the sequel as a removal of redundant coordinates, for we shall only remove coordinates that the reader does not care about anyway, as in the above toy example.
To achieve this approach, one needs to consider the IB in a coordinate system that permits a simple reduction as in (10), and to understand its solution structure. We achieve these in Section 5 by exploiting two properties of the IB which are often overlooked. First, proceeding with the coordinates’ exchange of Section 2, the intimate relations [5,20] of the IB with RD suggest a “minimally sufficient” coordinate system for the IB, just as the x axis is for problem (10). Reducing an IB root to these coordinates is a natural extension of reduction in RD [6]. Reduction of IB roots facilitates a clean treatment of IB bifurcations. These are roughly divided into continuous and discontinuous bifurcations, in Section 5.2 and Section 5.3, respectively. While understanding continuous bifurcations is straightforward, the IB’s relations with RD allow us to understand the discontinuous bifurcation examples of which we are aware as a support switching bifurcation in RD, by leveraging [6] (Section 6). A second property is the analyticity of the IB operator (5), which stems from the analyticity of the IB Equations (2)–(4). By building on the first property, analyticity leads us to argue that the Jacobian of the IB operator (5) is generally non-singular (Conjecture 1) when considered in reduced coordinates as above. As an immediate consequence, the dynamics underlying the IB curve (1) are piecewise real-analytic in , in a manner similar to RD. Indeed, the fact that there exist dynamics underlying the IB curve (1) in the first place can arguably be attributed to analyticity (see the discussion following Conjecture 1). Combining both properties sheds light on several subtle yet important practical caveats in solving the IB (Section 5.3) due to using finite-dimensional representations of its roots. These subtleties are compatible with our numerical experience. The results here suggest that, unlike RD, the IB is inherently infinite-dimensional, even for finite problems.
Finally, Section 6 combines the modified Euler method of Section 4 with the understanding of IB bifurcations in Section 5, to obtain an algorithm for following the path of an optimal IB root, in Section 6.1. That is, First-order Root Tracking for the IB (IBRT1). For simplicity, we focus mainly on continuous IB bifurcations, as these are the ones most often encountered in practice (see Section 6.3 on the algorithm’s handling of discontinuous bifurcations). The resulting approximations in the information plane are surprisingly close to the true IB curve (1), even on relatively sparse grids (i.e., with large step sizes), as seen in Figure 1. See Section 6.2 for the numerical results underlying the latter. The reasons for this are discussed in Section 6.3, along with the algorithm’s basic properties. Unlike BA-IB, which suffers from an increased computational cost near bifurcations, our IBRT1 algorithm suffers from a reduced accuracy there, in a manner similar to root tracking for RD [6].
With that, we note that there are standard techniques in Bifurcation Theory for handling a non-trivial kernel of at a root. For example, the Lyapunov–Schmidt reduction replaces the high-dimensional problem (6) on by a smaller but equivalent problem , where maps vectors in the (right) kernel of to vectors in its left kernel. To achieve this, it separates the kernel and non-kernel directions of the problem, essentially handling each in turn; e.g., [21] (Theorem I.2.3) or [24] (Section 9.7). This technique is generic, as it does not rely on any particular property of the problem at hand. As such, it is considerably more involved than removing redundant coordinates, which requires an understanding of the solution structure. In contrast, reduction in the IB is straightforward. For the purpose of following a root’s path, carrying on with redundant kernel directions is burdensome, computationally expensive, and sensitive to approximation errors. Applying Lyapunov–Schmidt to our toy problem (10), for instance, reduces (6) to choosing a continuously differentiable function on the y-axis there (which is obtained by first solving for ; see the proof of Theorem I.2.3 in [21] for details). However, since y is redundant in this example, then solving for can provide no useful information on the dynamics of its roots. In [19], a variant of the Lyapunov–Schmidt reduction was used to consider IB bifurcations due to symmetry breaking. While our findings are in partial agreement with theirs for continuous IB bifurcations, they differ for discontinuous bifurcations (see Section 5.2 and Section 5.3).
Notations
Vectors are written in boldface , and scalars in regular font x. A distribution p pertaining to a particular multiplier value of the IB Lagrangian is denoted with a subscript, . Blahut–Arimoto’s algorithm for the IB (BA-IB) is brought below as Algorithm 1, with a single iteration over the IB Equations (2)–(4) (in steps 1.4–1.8) denoted . The probability simplex on a set S is denoted (see Section 5.1). The support of a probability distribution p on S is . The source, label, and representation alphabets of an IB problem are denoted , and , respectively; we write . denotes Dirac’s delta function, if , and zero otherwise.
| Algorithm 1 Blahut–Arimoto for the Information Bottleneck (BA-IB), [1]. | |
| 1: | function BA-IB() |
| Input: | |
| An initial encoder , a problem definition , and . | |
| Output: | |
| A fixed point of the IB Equations (2)–(4). | |
| 2: | Initialize . |
| 3: | repeat |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | until convergence. |
| 11: | end function |
2. Coordinates Exchange for the IB
Just as a point in the plane can be described by different coordinate systems, so can IB roots. As demonstrated recently by [6] for the related rate-distortion theory, picking the right coordinates matters when analyzing its bifurcations. The same holds also for the IB. Our primary motivations for exchanging coordinates are to reduce computational costs and to mod-out irrelevant kernel directions, as explained in Section 1. In this Section, we discuss three natural choices of a coordinate system for parameterizing IB roots and the reasoning behind our choice for the sequel before setting to derive the IB ODE in the following Section 3. This work is complemented by the later Section 5.1, which facilitates a transparent analysis of IB bifurcations.
IB roots have been classically parameterized in the literature by (direct) encoders , following [1]. Considering the BA-IB Algorithm 1 reveals two other natural choices, illustrated by Equation (11) below. First, an encoder determines a cluster marginal and an inverse encoder , via steps 4 and 5 of Algorithm 1 (denoted 1.4 and 1.5, for short), respectively. These can be interpreted geometrically as -weighted points in the simplex of X, so long as they are well-defined, . No more than points in the simplex are required to represent an IB root [2]. The latter is readily seen to analyze the IB in these coordinates, although it pre-dates [1] and has generally escaped broader attention. Second, an inverse encoder determines a decoder , via step 6. Along with the cluster marginal, can be similarly interpreted as -weighted points in the simplex of Y. This choice of coordinates is implied already by Theorem 5 in [1]. Cycling around Equation (11), a decoder determines via steps 7 and 8 a new encoder, which may differ from the one with which we have started. For notational simplicity, we shall usually write rather than for decoder coordinates (similarly for inverse encoder coordinates).
[9:04] Leona Kong
![Entropy 25 01370 i001]() The above allows us to define three BA operators as the composition of three consecutive maps in Equation (11), encoding an iteration of Algorithm 1. When starting at an encoder , its output is a newly defined encoder. Similarly, when starting at one of the other two vertices, it sends an inverse encoder or a decoder pair to a newly defined one. By abuse of notation, we denote all three compositions by , with the choice of coordinate system mentioned accordingly. Indeed, these are representations of a single BA-IB iteration in three different coordinate systems, and so may be considered as distinct representations of the same operator. For completeness, in decoder coordinates is spelled out explicitly in Equation (A1) in Appendix A. A newly defined encoder (or inverse encoder or decoder) at a cycle’s completion need not generally equal the one at which we have started. These are equal precisely at IB roots, when the IB Equations (2)–(4) hold. Therefore, the choice of a coordinate system does not matter then, and so moving around Equation (11) from one vertex to another yields different parameterizations of the same root, at least when . In particular, this shows that the inverse encoders in of an IB root are in bijective correspondence with its decoders in , an observation which shall come in handy in Section 5.
The above allows us to define three BA operators as the composition of three consecutive maps in Equation (11), encoding an iteration of Algorithm 1. When starting at an encoder , its output is a newly defined encoder. Similarly, when starting at one of the other two vertices, it sends an inverse encoder or a decoder pair to a newly defined one. By abuse of notation, we denote all three compositions by , with the choice of coordinate system mentioned accordingly. Indeed, these are representations of a single BA-IB iteration in three different coordinate systems, and so may be considered as distinct representations of the same operator. For completeness, in decoder coordinates is spelled out explicitly in Equation (A1) in Appendix A. A newly defined encoder (or inverse encoder or decoder) at a cycle’s completion need not generally equal the one at which we have started. These are equal precisely at IB roots, when the IB Equations (2)–(4) hold. Therefore, the choice of a coordinate system does not matter then, and so moving around Equation (11) from one vertex to another yields different parameterizations of the same root, at least when . In particular, this shows that the inverse encoders in of an IB root are in bijective correspondence with its decoders in , an observation which shall come in handy in Section 5.

Next, we consider how well each of these coordinate systems can serve for following the path of an IB root. The minimal number of symbols needed to write down an IB root typically varies with the constraints, cf., [1] (Section 3.4) or [2] (Section II.A). Therefore, inverse encoder and decoder coordinates are better suited than encoder coordinates for considering the dynamics of a root with , as they allow us to consider its evolution via a varying number of points in a fixed space, or , respectively. Indeed, a direct encoder can be interpreted geometrically as a point in the -fold product of simplices [9] (Section 2). So, if a particular symbol is not in use anymore, , then one is forced to choose between replacing by a smaller space or carrying on with a redundant symbol . The latter leads to non-trivial kernels in the IB due to duplicate clusters (e.g., Section 3.1 there), making it difficult to tell whether a particular kernel direction pertains to a bifurcation (or to a “perpetual kernel” [9,19]). In contrast, when considered in decoder coordinates, for example, an IB root is nothing but -weighted paths in , with a path for each . And so, once a symbol is not needed anymore, then one can discard the path without replacing the underlying space . This permits the clean treatment of IB bifurcations in Section 5.
The computational cost of solving a first-order ODE as in (7) numerically in depends on . Much of this cost is due to computing a linear pre-image under , which is of order [25] (Section 28.4); cf., Section 6. Representing an IB root on T clusters in encoder coordinates requires dimensions (ignoring normalization constraints), in inverse encoder coordinates dimensions, and in decoder coordinates dimensions. Thus, the computational cost is lowest in decoder coordinates, at least when there are fewer possible labels than input symbols .
A priori, one might expect that derivatives with respect to vanish when the solution barely changes, regardless of the choice of coordinate system. For example, at a very large “” value, an obvious IB root is the diagonal encoder (setting and ), as can be seen by a direct examination of the IB Equations (2)–(4). It consists of one IB cluster of weight (or mass) at for each , and so one might expect that it would barely change so long as is very large. However, the logarithmic derivative in encoder coordinates need not vanish even when the derivatives and in decoder coordinates do (see Section 3 on logarithmic coordinates), as seen to the right of Figure 2. Indeed, given the derivative in decoder coordinates, one can exchange it to encoder coordinates by
where and are the two coordinate exchange Jacobian matrices of orders and , respectively, given by Equations (A68) and (A70) in Appendix B.4.2. And so, would often be non-zero even if both and vanish. This unintuitive behavior of the derivative in encoder coordinates is due to the explicit dependence of the IB’s encoder Equation (2) on . This dependence is the source of the last two terms in Equation (12) (see Equation (A73)). The comparison between encoder and inverse encoder coordinates can be seen to be similar. See Appendix B.4 for further details.
In light of the above, we proceed with decoder coordinates in the sequel.
3. Implicit Derivatives at an IB Root and the IB’s ODE
We now specialize the implicit ODE (7) (of Section 1) to the IB, using the decoder coordinates of the previous Section 2. This allows us to compute first-order implicit derivatives at an IB root (Theorem 1) with remarkable accuracy, under one primary assumption—that the root is a differentiable function of . While differentiability breaks at IB bifurcations (Section 5), this allows us to reconstruct a solution path from its local approximations in the following Section 4, so long as it holds.
To simplify calculations, we take the logarithm of the decoder coordinates of Section 2 as our variables. Exchanging the operator to log-decoder coordinates is immediate, by writing . For short, we denote it when in these coordinates, by abuse of notation. Similarly, exchanging the IB ODE (below) back to non-logarithmic coordinates is immediate, via . In Section 6, we shall assume that never vanishes. To ensure that taking logarithms is well-defined, we require that no decoder coordinate vanishes (while it may have a well-defined derivative even with a vanished coordinate, calculation details would differ). A sufficient condition for that is that for every x and y (Lemma A1 in Appendix A).
Next, define a variable as the concatenation of the vector with . Differentiating with respect to log-probabilities is given by , by the chain rule (setting , , or equivalently ; see Appendix B.1 for a gentler treatment). This gives meaning to the Jacobian matrix with respect to our logarithmic variable . The Jacobian of a single Blahut–Arimoto iteration in these log-decoder coordinates is a square matrix of order . Its upper-left block (below) corresponds to perturbations of BA’s output log-decoder due to varying an input log-decoder . Since we prime input but not output coordinates, this is to say that the columns of this block are indexed by pairs and its rows by (one could also enumerate and explicitly, replacing and throughout by and , respectively, with and ). Its upper-right block corresponds to perturbations in BA’s output log-decoder due to varying an input log-marginal . That is, its columns are indexed by and rows by . Similarly, for the bottom-left and bottom-right blocks, of respective sizes and . See (A25) ff., in Appendix B.2, and the end-result at Equation (A44) there. Explicitly, when evaluated at an IB root , BA’s Jacobian matrix is given by
where if and is 0 otherwise. As mentioned above, primed coordinates and index the columns, and un-primed coordinates y and the rows. Indices and with more than a single prime are summation variables. , and C are a scalar, a vector, and a matrix, each involving two IB clusters. They are defined by
In these, y indexes B and the rows of C, the columns of C, and is a summation variable. These -labeled tensors have only entries along each axis, thanks to our choice of decoder coordinates. A and B can be expressed in terms of C via some obvious relations; see Equation (A32) and below in Appendix B.2. Appendix B.1 elaborates on the mathematical subtleties involved in calculating the Jacobian (13). See also Equation (A45) in Appendix B.2 for an implementation-friendly form of (13).
Together with (Equations (A58) and (A57) in Appendix B.3), we have both of the first-order derivative tensors of in log-decoder coordinates. This allows us to specialize the implicit ODE (7) (of Section 1) to the IB, in terms of our variable . By abuse of notation, we write for its coordinates, and similarly for its derivatives vector (15) below.
Theorem 1
(The IB’s ODE). Let be an IB root, and suppose that it can be written as a differentiable function in β. If none of its coordinates vanish, then the vector
of its implicit logarithmic derivatives is well-defined and satisfies an ordinary differential equation in β,
where I is the identity matrix of order , and the Jacobian matrix at the given IB root is given by Equation (13). The right-hand side of (16) is indexed as in (15), by at its top and at its bottom coordinates.
While the IB ODE was discovered by [10], it is derived here anew in log-decoder coordinates due to the considerations in Section 2. It is analogous to the RD ODE, due to [6]; Corollary 1 and around (in Section 5.1) provides a relation between these two ODEs. We emphasize that the first assumption of Theorem 1, that the IB root is a differentiable function of , is essential. It consists of two parts: (i) that the root can be written as a function of , and (ii) that this function is differentiable. These are precisely the assumptions needed to compute the first-order implicit multivariate derivative (15) at the given root [6] (Section 2.1). Continuous IB bifurcations violate (ii) (Section 5.2), while discontinuous ones violate (i) (Section 5.3). In contrast, the requirement that no coordinate vanishes is a technical one, due to our choice of logarithmic coordinates.
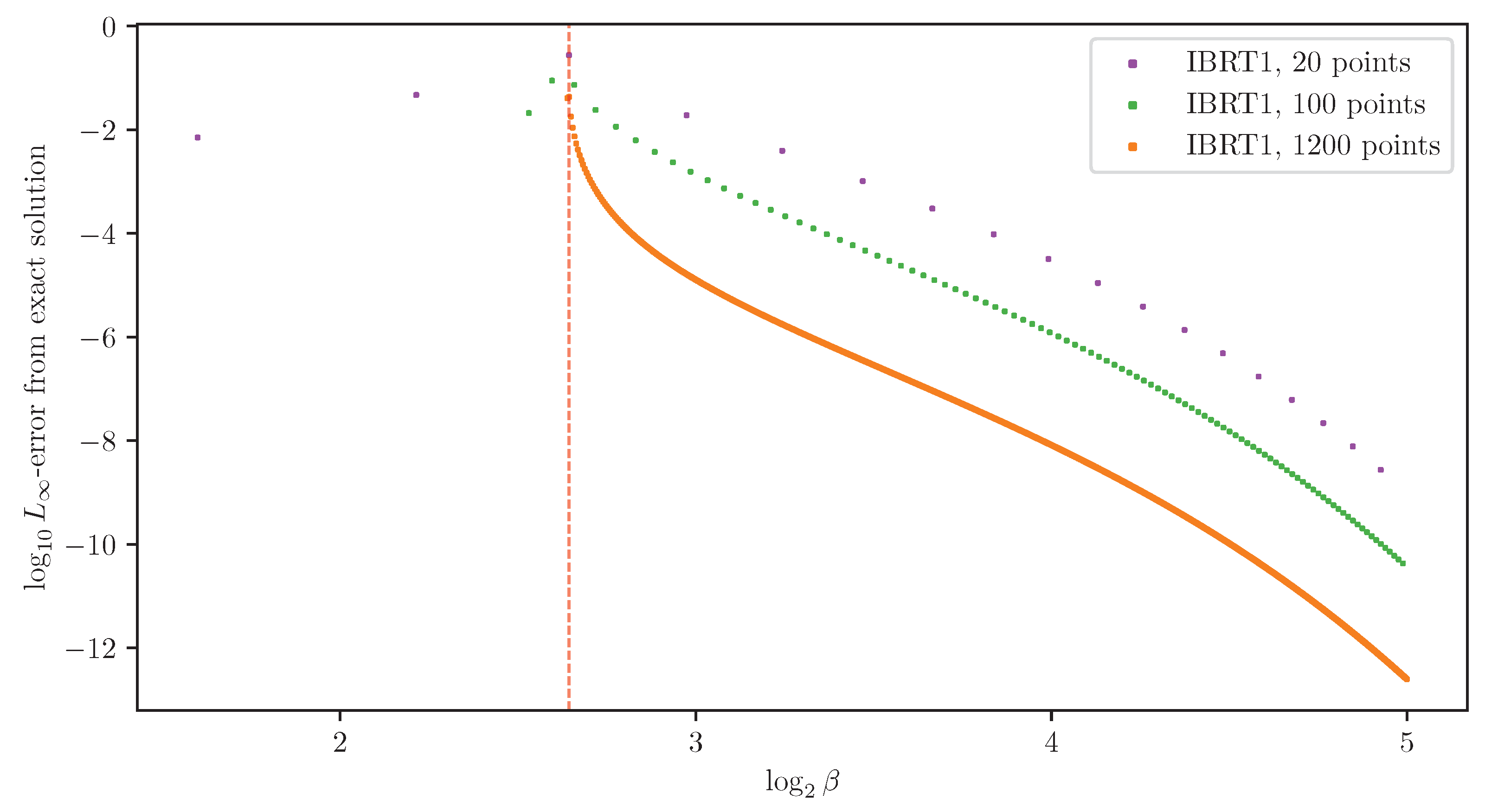
It is not necessary for the Jacobian of the IB operator (5) (to the left of (16)) to be non-singular in order to solve the IB ODE numerically. Nevertheless, non-singularity of the Jacobian will follow from the sequel (see Conjecture 1 in Section 5). With that, the derivatives (15) computed numerically from the IB ODE (16) at an exact root are remarkably accurate, as demonstrated in Figure 3. As in RD [6], calculating implicit derivatives numerically loses its accuracy when approaching a bifurcation because the Jacobian is increasingly ill-conditioned there. For comparison, the BA-IB Algorithm 1 also loses its accuracy near a bifurcation. This is a consequence of BA’s critical slowing down [4], just as with its corresponding RD variant.
Each coordinate of is treated by the IB ODE (16) as an independent variable. However, the normalization of imposes one constraint per cluster (and one for the normalization of ). Thus, one might expect the behavior of BA’s Jacobian (13) to be determined by fewer than coordinates, at least qualitatively. This intuition is justified by the following Lemma 1, which allows us to consider the kernel of the IB operator (5) by a smaller and simpler matrix S; see Appendix C for its proof.
Lemma 1.
Given an IB root as above, define a square matrix of order by
Then, the nullity of the Jacobian of the IB operator (5) equals that of , where I is the identity matrix (of the respective order), and S is defined by (17),
Specifically, write for a left eigenvector which corresponds to . Then, there is a bijective correspondence between the left kernels at both sides of (18), mapping
where is defined by .
In addition to offering a form more transparent than BA’s Jacobian in (13), Lemma 1 also reduces the computational cost of testing (16) for singularity, by using the smaller (17) in its place. This makes it easier to detect upcoming bifurcations (see Conjecture 1 in Section 5). Further, one can verify directly that the IB ODE (16) indeed follows the right path. Indeed, if the ODE is non-singular, then, by the Implicit Function Theorem, there is (locally) a unique IB root, which is a differentiable function of . And so, there is a unique solution path for a numerical approximation to follow. Finally, we note that a relation similar to (18) holds also for eigenvalues of (13) other than 1. This can be seen either empirically or by tracing the proof of Lemma 1.
4. A Modified Euler Method for the IB
We follow the path of a given IB root away from bifurcation by using its implicit derivatives computed from the IB ODE (16), of Section 3. We follow the classic Euler method for simplicity, modifying it slightly to get the most out of the calculated derivatives. Improvements using more sophisticated numerical methods are left to future work. The detection and handling of IB bifurcations are deferred to the following Section 5, and thus are ignored in this section.
Let and define an initial value problem. In numerical approximations of ordinary differential equations (ODEs), the Euler method for this problem is defined by setting
where , and is the step size. The global truncation error is the largest error of the approximations from the true solutions . A numerical method for solving ODEs is said to be of order d if its global truncation error is of order , for step sizes small enough. Euler’s method error analysis is a standard result, provided as Theorem 2 below. See [26] (Theorem 212A) or [27] (Theorem 2.4), for example. It shows that Euler’s method (20) is of order , under mild assumptions, as demonstrated in Figure 4. The immediate generalization of (20) using derivatives until order d is Taylor’s method, which is a method of order d.
Theorem 2
(Euler’s method error analysis). Let an initial value problem be defined on by as above (with allowed to deviate from ), and suppose that f satisfies the Lipschitz condition with some constant . Namely, for every and .
Then, Euler’s method (20) global truncation error satisfies
Specializing Euler’s method to our needs, replace in (20) above by the log-decoder coordinates of an IB root, as in Section 3. So long as an IB root is a differentiable function of in the vicinity of , it can be approximated by
where and are calculated from the IB ODE (16). Thus, applying (22) repeatedly, we obtain an Euler method for the IB. We shall take only negative steps when approximating the IB, due to reasons explained in Section 5.3 (after Proposition 1). In contrast to the BA-IB Algorithm 1, Euler’s method (22) can be used to interpolate intermediate points, yielding a piecewise linear approximation of the root.
The problem of tracking an operator’s root belongs in general to a family of hard-to-solve numerical problems—known as stiff—if the problem has a bifurcation [6] (Section 7.2). See [26] or [27] for example on stiff differential equations. Stopping early in the vicinity of a bifurcation restricts the computational difficulty and permits convergence guarantees. Early stopping in the IB shall be handled later, in Section 5.2. [6] (Theorem 5) proves that Euler’s method convergence guarantees (Theorem 2) hold for the closely related Euler method for RD with early stopping. While Euler’s method may inadvertently switch between solution branches of the IB ODE (16), the latter guarantees ensure that it indeed follows the true solution path between bifurcations, if the step size is small enough and initializing close enough to the true solution (see Section 5 and Section 6.3 on the distinction between IB bifurcations and singularities of the IB ODE (16)). Although we do not dive into these details for brevity, we note that similar convergence guarantees can also be proven here. Alternatively, Euler’s method can be ensured to follow the true solution path by noting that an optimal IB root is (strongly) stable when negative steps are taken; these details are deferred to Section 6.3, as they depend on Section 5.
Following the discussion in Section 2, there is a subtle disadvantage in choosing decoder coordinates as our variables compared to the other two coordinate systems there. Indeed, recall that the IB is defined as a maximization over Markov chains . An (arbitrary) encoder defines a joint probability distribution which is Markov. An inverse encoder pair also similarly defines a Markov chain. In contrast, an arbitrary decoder pair need not necessarily define a Markov chain. Rather, by invoking the error analysis of Euler’s method, one can see that Markovity is approximated at an increasingly improved quality as the step-size in (22) becomes smaller. To enforce Markovity, we shall perform a single BA iteration (in decoder coordinates) after each Euler method step. This ensures that the newly generated decoder pair satisfies the Markov condition, as it is now generated from an encoder.
As a side effect, adding a single BA-IB iteration after each Euler method step improves the approximation’s quality significantly. By linearizing around a fixed point, one can show that deterministic annealing with a fixed number of BA iterations per grid point is a first-order method. Thus, deterministic annealing may arguably be considered a first-order method, as is with Euler’s method. A similar argument shows that adding a single BA iteration after each Euler method step yields a second-order method. However, while a larger number of added BA iterations obviously improves the approximation’s quality, it does not improve the method’s order. See Appendix D for an approximate error analysis. The predicted orders are in good agreement with the ones found empirically, shown in Figure 4. We note that while [6] did not attempt an added BA iteration, they do discuss a variety of other improvements to root tracking (see Section 3.4 in [6]).
5. On IB Bifurcations
For the IB Equations (2)–(4) to exhibit a bifurcation, it is necessary that the Jacobian of the IB operator (5) be singular, as illustrated by Figure 5. However, a priori singularity is not sufficient to detect a bifurcation (cf., Section 3.1 in [9]), nor does this allow one to distinguish between bifurcations of different types. At an IB root, singularities of the IB ODE (16) (Section 3) coincide with those of (5) (in log-decoder coordinates). Thus, in order to be able to exploit the IB ODE (16), we shall now take a closer look into IB bifurcations. These can be broadly classified into two types: where an optimal root is continuous in and where it is not. As noted after Theorem 1, each type violates an assumption necessary to compute implicit derivatives. Section 5.2 and Section 5.3 provide the means to identify bifurcations, distinguish between their types, and handle them accordingly, mainly for continuous bifurcations. To facilitate the discussion, Section 5.1 considers the IB as a rate-distortion problem, following [20] and others. This allows us to leverage recent insights on RD bifurcations [6], while suggesting a “minimally sufficient” choice of coordinates for the IB. The latter permits a clean treatment of continuous IB bifurcations in Section 5.2. Viewing the IB as an infinite-dimensional RD problem facilitates the understanding of its discontinuous bifurcations, which in turn highlight subtleties in its finite-dimensional coordinate systems (of Section 2). These provide insight into the IB and are also of practical implications (Section 5.3), and so are necessary for our algorithms in Section 6.
5.1. The IB as a Rate-Distortion Problem
We now explore the intimate relation between the IB and RD, following [5,20]. This leads to a “minimally sufficient” coordinate system for the IB, thereby completing the work of Section 2. In this coordinate system, results [6] on the dynamics of RD roots are readily considered in the IB context. This leads to Conjecture 1, that the IB operator (5) in these coordinates is typically non-singular. The discussion here facilitates the treatment of IB bifurcations in the following Section 5.2 and Section 5.3.
First, recall a few definitions. A rate distortion problem on a source alphabet and a reproduction alphabet is defined by a distortion measure (a non-negative function on with no further requirements—see Section 2.2 in [28]) and a source distribution . One seeks the minimal rate subject to a constraint D on the expected distortion [29,30],
known as the rate-distortion curve. The minimization is over test channels . A test channel that attains the RD curve (23) is called an achieving distribution. We say that an RD problem is finite if both of the alphabets and are finite. Using Lagrange multipliers for (23) with (normalization omitted for clarity), one obtains a pair of fixed-point equations
in the marginal and test channel , similar to the IB Equations (2) and (4). Iterating over these is Blahut’s algorithm for RD [8], denoted here. As with the IB (1), parameterizes the slope of the optimal curve (23) also for RD. See [28] or [31] for an exposition of rate-distortion theory.
We clarify a definition needed to rewrite the IB as an RD problem. We define the simplex on a (possibly infinite) set S as the collection of finite formal convex combinations of elements of S. That is, as the S-indexed vectors (equivalently, as functions mapping each s in S to a real number ) that satisfy and , with non-zero for only finitely many elements s (the support of ). Addition and multiplication are defined pointwise, as in . is closed under finite convex combinations because the sum of finitely supported vectors is finitely supported. When taking the standard basis vectors of , then one can identify the formal operations with those in , reducing the simplex to its usual definition. We write r for an element of . In particular, an element of is merely a finite convex combination of distinct probability distributions on (note that is a set). When setting to be a finite subset of distributions, , then is a special case of the decoder coordinates of Section 2 (unlike here, the decoder coordinates of Section 2 are not required to have their clusters r distinct).
Now, let a finite IB problem be defined by a joint probability distribution , as in Section 1. To write it down as an RD problem [5,20], define the IB distortion measure by
for , , and the conditional probability distribution at . The distortion measure (25) and define an RD problem on the continuous reproduction alphabet . Minimizing the IB Lagrangian (in Section 1) is equivalent to minimizing the Lagrangian of this RD problem [20] (Theorem 5). That is, the IB is a rate-distortion problem when considered in these coordinates. IB clusters assume the role of RD reproduction symbols, while an IB root (considered now as an RD root) is equivalently described either by the probabilities of each cluster—namely, by a point in —or, by a test channel . The astute reader might notice that the IB Equations (2) and (4) are then equivalent to RD’s fixed-point Equations (24), with the decoder Equation (3) implied by the IB’s Markovity. The IB’s Y-information equals the expected distortion in (23) up to a constant [20] (Section 5), and so is linear in the test channel . Unlike the finite-dimensional coordinate systems of Section 2, this definition of the IB entails no subtleties due to finite dimensionality, such as duplicate clusters (see more below). However, while it allows us to spell out the IB explicitly as an RD problem, handling an infinite reproduction alphabet is difficult for practical purposes. Since no more than reproduction symbols are needed to write down an IB root [2], this motivates one to consider the IB’s local behavior, with clusters fixed.
So instead, one may require the reproduction symbols of (25) to be in a list indexed by some finite set , with each in (the elements need not be distinct a priori). This defines a finite RD problem, for which (25) is merely an -by-T matrix. Yet, placing identical clusters in the list inadvertently introduces degeneracy to the matrix (25), as discussed below. In [5] (Section 6), is taken to be the decoders defined by a given encoder , as in Equation (11) (Section 2). We shall then refer to (25) as the distortion matrix defined by . When is an optimal IB root then the problem defined by it is called the tangent RD problem. Indeed, its RD curve (23) coincides with the IB curve (1) at this point (since an optimal choice of IB clusters is already encoded into (25), then solving the IB boils down to finding the clusters’ optimal weights , which is an RD problem). However, the curves differ outside this point since IB clusters usually vary with , while the distortion of the tangent problem was defined at and so is fixed. By definition (1), it follows that the IB curve is the lower envelope of the curves of its tangent RD problems [5] (Corollary 2). We note that a similar construction can also be carried out in inverse encoder coordinates, cf., [2].
Regardless of the formulation used to rewrite the IB as an RD problem, the associated RD problem has an expected distortion of at an IB root (Section 5 in [20] and Lemma 8 in [5]). That is, the IB is a method of lossy compression that strives to preserve the relevant information . Due to the Markov condition, information on Y is available only through X. Thus, one may intuitively consider the IB as a lossy compression method of the information on Y that is embedded in X. These intimate relations between the IB and RD suggest that studying bifurcations in either context could be leveraged to understand the other. Bifurcations in finite RD problems are discussed at length in [6] (Section 6). To facilitate the study of IB bifurcations in the sequel (Section 5.2 and Section 5.3) using results from RD, we need a “minimally-sufficient” coordinate system for the IB.
Consider an IB root in decoder coordinates as finitely many -weighted points in , as in Section 2. Exchanging to decoder coordinates (Equation (11) there) is well-defined as long as there are no zero-mass clusters, . Yet, even then, the points in yielded by BA’s steps 4 through 6 (Algorithm 1) need not be distinct. Namely, they may yield identical clusters at distinct indices . This leads to a discussion of structural symmetries of the IB (its degeneracies), which is not of use for our purposes; cf., [9]. To avoid such subtleties, we shall say that an IB root is reduced if it has no zero-mass clusters, , and all its clusters are distinct, . A root that is not reduced is called degenerate or degenerately represented. An IB root can be reduced by removing clusters of zero mass and merging identical clusters of distinct indices—see our reduction algorithm in Section 5.2 below. It is straightforward to see from the IB Equations (2)–(4) that reduction preserves the property of being an IB root. Similarly, reducing a root does not change its location in the information plane. So, a root achieves the IB curve (1) if and only if its reduction does. Therefore, reduction decreases the dimension in which the problem is considered while preserving all its essential properties. This allows us to represent an IB root on the smallest number of clusters possible—its effective cardinality—by factoring out the IB’s structural symmetries. See also [13] (2.3 in Chapter 7), upon which this definition is based.
While the purpose of reduction is to mod-out redundant kernel coordinates (Section 1), it highlights the differences between the various IB definitions found in the literature, bringing to light a subtle caveat of finite dimensionality. To see this, note that reduction could have been defined above in terms of the other coordinate systems of the IB. Its definition in inverse encoder coordinates is nearly identical to that above, while defining it in encoder coordinates is a straightforward exercise. Since the coordinate systems of Section 2 are equivalent at an IB root (without zero-mass clusters), the precise definition does not matter then. Each of these parameterizations encodes the coordinates of a root’s clusters r using a finite-dimensional vector (note Equation (11)). This enables one to represent duplicate clusters with , and obliges one to choose the order in which clusters are being encoded into the coordinates of . A finite-dimensional representation of an IB root is invariant to interchanging clusters precisely when they are identical, . The IB’s functionals (e.g., its X- and Y-information) are invariant to any cluster permutation; cf., [9,19]. Both of these structural symmetries result from using a finite-dimensional parameterization, with the former eliminated by reduction. In contrast, the elements of are distinct by definition (since is a set), and so parameterizing the IB by points in does not permit identical clusters. An element of assigns a probability mass to every point r in , with only finitely many points r supported. Thus, it implicitly encodes all the entries of every probability distribution in a “one size fits all” approach, giving no room for the choices above. This leads us to argue that the IB’s structural symmetries are not an inherent property but rather an artifact of using its finite-dimensional representations. This is best understood in the context of discontinuous bifurcations, in Section 5.3 below. For comparison, both of the IB formulations [2,20] do not impose an a priori restriction on the number of clusters. The latter does not enable one to encode duplicate clusters, while the former does. The formulation [1] ignores these subtleties altogether, and [9,19] consider the IB on a pre-determined number of possibly duplicate clusters.
In rate-distortion, the reduction of a finite RD problem is defined similarly [6] (Section 3.1), by removing a symbol from the reproduction alphabet and its column from the distortion matrix once it is not in use anymore (of zero mass). A distortion matrix d is non-degenerate if its columns are distinct, for all . Non-degeneracy arises naturally when considering the RD problem tangent to a given IB root . Indeed, the distortion matrix (25) defined by has duplicate columns if the root has identical clusters, while the other direction holds under mild assumptions (if the vectors span , then for all x implies that ). Under these assumptions, the distortion matrix induced by an IB root is reduced and non-degenerate precisely when is a reduced IB root.
Reduction in RD provides the means to show that the dynamics underlying the RD curve (23) are piecewise analytic in [6], under mild assumptions. Just as in definition (5) of the IB operator, [4] (Equation (5)) similarly define the RD operator in terms of Blahut’s algorithm for RD [8]. By using their Theorem 1, [6] (Section 3.1) observed that reducing a finite RD problem to the support of a given RD root mods-out redundant kernel coordinates if the distortion measure is finite and non-degenerate (the support of is defined by ). That is, the Jacobian of the RD operator on the reduced problem is then non-singular (in the right coordinate system—see therein), just as with our toy problem (10) in Section 1. By the Implicit Function Theorem, there is therefore a unique RD root of the reduced problem through the given one; this root is real-analytic in (details there). Considering this for the RD problem tangent to a reduced IB root immediately yields the following:
Corollary 1.
Let be a reduced IB root of a finite IB problem defined by , such that the matrix is of rank . Then, near , there is a unique function continuous in β, which is a root of the tangent RD problem through ; it is real-analytic in β.
Corollary 1 shows that the local approximation of an IB problem (the roots of its tangent RD problem) is guaranteed to be as well-behaved as one could hope for, provided that the IB is viewed in the right coordinate system. Note, however, that the RD root through of the tangent problem does not in general coincide with the IB root outside of since the IB distortion (25) varies along with the clusters that define it. However, when the IB clusters are fixed, then one might expect that the Jacobian (13) of in log-decoder coordinates would be the same as the Jacobian of its RD variant. Indeed, the Jacobian matrix of is the bottom-right sub-block of the Jacobian (13) of , up to a multiplicative factor. For this, see Equations (5) and (6) in [4], Equations (14) and (13) in Section 3, and (A25) in Appendix B.2.
As in RD, we argue that reduction in the IB also provides the means to show that the dynamics underlying the optimal curve (1) are piecewise analytic in . Corollary 1 concludes that, under mild assumptions, through every reduced IB root passes a unique real-analytic RD root. However, its crux is that the Jacobian of the RD operator is non-singular at a reduced root. Due to the IB’s close relations with RD, and since reduction in the IB is a natural extension of reduction in RD, we argue that the same is also to be expected of the IB operator (5) in decoder coordinates. To see this, note that IB roots are finitely supported [2] (Lemma 2.2(i)), and so one may take finitely supported probability distributions for the IB’s optimization variable. Thus, the IB’s operator in decoder coordinates (of Section 2) may be considered as an operator on . Next, consider the RD problem defined by and (25) on the continuous reproduction alphabet , as in [20]. This defines on also the BA operator for RD. Now that both BA operators are considered on an equal footing, we note the following. First, while iterates over the IB Equations (2) and (4), its IB variant iterates also over the decoder Equation (3) (plug the IB distortion measure (25) into the Equations (24) defining to see this). The latter Equation (3) is a necessary condition for to be Markov, and so can be understood as an enforcement of Markovity (in contrast, an arbitrary triplet of random variables only satisfies ). That is, IB roots are RD roots with an extra constraint. Second, by Theorem 1 in [4], reducing from the continuous reproduction alphabet to a root of finite support renders it non-singular, under mild assumptions. This suggests that reducing (5) from to a root’s effective cardinality should also render it non-singular, due to the similarity between these operators, and since reduction in the IB is a natural extension of reduction in RD. In line with the discussion of Section 1 on reduction, we therefore state the following:
Conjecture 1.
The intuition behind this conjecture stems from analyticity, as follows. The IB operator (5) is real-analytic, since each of the Equations 1.4–1.8 defining it (in the BA-IB Algorithm 1) is real-analytic in its variables. For a root of a real-analytic operator F, one might expect that, in general, (i) no roots other than exist in its vicinity and that (ii) has no kernel. That is, unless the operator is degenerate at in some manner or is a bifurcation. To see this, recall [32] (Section IX.3) that a real-valued function in is real-analytic in some open neighborhood of if it is a power series in , within some radius of convergence (although a strictly positive radius is needed, we omit these details for clarity). For every practical purpose, one may replace by a polynomial in when is close enough to the base-point , by truncating the power series. Viewed this way, a root of an operator is nothing but a solution of n polynomial equations in n variables. However, a square polynomial system typically has only isolated roots, which is (i). This is best understood in terms of Bézout’s Theorem; see [33] (6 in IV.4) for example. For (ii), a vector is in precisely when it is orthogonal to each of the gradients . However, is the vector of the first-order monomial coefficients of in . In a general position, these n coefficient vectors are linearly independent, and so must vanish as claimed. If F is degenerate such that for particular , for example, then both points fail, of course. See also Section I.2 of [34] for (i) and (ii). This intuition accords with the comments of [28] (Section 2.4) on RD: “usually, each point on the rate distortion curve […] is achieved by a unique conditional probability assignment. However, if the distortion matrix exhibits certain form of symmetry and degeneracy, there can be many choices of [a minimizer]”. Indeed, the fact that the dynamics underlying the RD curve (23) are piecewise real-analytic [6] (under mild assumptions) can be similarly understood to stem from the analyticity of the RD operator .
Subject to Conjecture 1, a Jacobian eigenvalue of the IB operator (5) must vanish gradually as one approaches a bifurcation, causing the critical slowing down of BA-IB [4] (observe that BA’s Jacobian (13) is continuous in the root at which it is evaluated). When an IB root traverses a bifurcation in which its effective cardinality decreases, then it is not reduced anymore. One can then handle the bifurcation by reducing the root anew. To ensure proper handling by the bifurcation’s type, we consider the latter closely in Section 5.2 and Section 5.3 below. In a nutshell, following the IB’s ODE (16) along with a proper handling of its bifurcations is the idea behind our root-tracking algorithm (in Section 6), for approximating the IB numerically.
Conjecture 1 is compatible with our numerical experience. However, we leave its proof to future work. To that end, one could examine closely the smaller matrix S (17) (of Lemma 1 in Section 3), for example. However, even if Conjecture 1 were violated, then one could detect that easily by inspecting the Jacobian’s eigenvalues. Conjecture 1 also implies that IB roots are locally unique outside of bifurcations when presented in their reduced form. Non-uniqueness of optimal roots is detectable by inspecting the Jacobian’s eigenvalues—see Corollary 3 in Section 5.3 and the discussion following it. See also Section 6.3 in [6] for the respective discussion in RD. With that, most of the results in Section 5.2 and Section 5.3 below do not depend on the validity of Conjecture 1.
5.2. Continuous IB Bifurcations: Cluster Vanishing and Cluster Merging
Following [10], we consider the evolution of IB roots which are a continuous function of . By representing an IB root in its reduced form (Section 5.1), it is evident that there are two types of continuous IB bifurcations. We provide a practical heuristic (Algorithm 2) for identifying and handling such bifurcations. The discussion here is complemented by Section 5.3 below, which considers the case where continuity does not hold.
The evolution of an IB root in obeys the ODE (16) as long as it can be written as a differentiable function in , as in Theorem 1. Considering the root in decoder coordinates, this amounts to an evolution of a T-tuple of points in and their weights . These typically traverse the simplex smoothly as the constraint is varied, as demonstrated in Figure 6. We now consider two cases where this evolution does not obey the ODE (16), due to violating differentiability.
Consider an optimal IB root in its reduced form (see Section 5.1). Namely, consider the reduced form of a root that achieves the IB curve (1). Suppose that its decoders and weights are continuous in . Then, a qualitative change in the root can occur only if either (i) two (or more) of its clusters collide or (ii) the marginal probability of a cluster vanishes. In either case, the minimal number of points in required to represent the root decreases. That is, its effective cardinality decreases (a qualitative change where the effective cardinality increases is obtained by merely reversing the dynamics in ). We call the first a cluster-merging bifurcation and the second a cluster-vanishing bifurcation, or continuous bifurcations collectively. Both types were observed already in [17] (Section IV.C) in the related setting of RD problems with a continuous source alphabet. Among the two, cluster-vanishing bifurcations are more frequent in practice than cluster merging. This can be understood by considering cluster trajectories in the simplex. In a general position, one might expect clusters to seldom be at the same “time” and place (that is, and ).
We argue that cluster merging and cluster vanishing are indeed bifurcations, where IB roots of distinct effective cardinalities collide and merge into one. We offer two ways to see this. First, using the inverse encoder formulation of the IB in [2] (Section II.A), one can consider an optimization problem in which the number of IB clusters is constrained explicitly (the inverse encoders of an IB root with no zero-mass clusters are in bijective correspondence with its decoders, as noted in Section 2, and so inverse encoder and decoder coordinates are interchangeable). By the arguments therein, the constrained problem has an optimal root (due to compactness), which achieves the optimal curve of the constrained problem. The latter curve must be sub-optimal if fewer clusters are allowed than needed to achieve the IB curve (1). Thus, whenever the effective cardinality of an optimal root (in the un-constrained problem) decreases, it must therefore collide with an optimal root of the constrained IB problem (by Corollary 3 in Section 5.3 below). This accords with [1] (Section 3.4), which describes IB bifurcations as a separation of optimal and sub-optimal IB curves according to their effective cardinalities. Second, consider the reduced form of an IB root at the point of a continuous bifurcation. Since its effective cardinality decreases there strictly, say from to , then the root can be represented on clusters at the bifurcation itself. However, the Jacobian of the IB operator (5) in log-decoder coordinates is non-singular when represented on clusters, as discussed after Proposition 1 (in Section 5.3). Thus, by the Implicit Function’s Theorem, there is a unique IB root on clusters through this point. It exists at both sides of the bifurcation (above and below the critical point). When represented on clusters, however, the latter intersects at the bifurcation with the root of effective cardinality , and so the two roots collide and merge there to one. This argument is identical to [6] (Section 6.2), which proves that distinct RD roots collide and merge at cluster-vanishing bifurcations in RD.
At a continuous bifurcation, IB roots of distinct effective cardinalities collide and merge into one, as discussed above. Specifically, one root achieves the minimal value of the IB Lagrangian and so is stable, while the other root is sub-optimal. As we shall now elaborate, continuous IB bifurcations are thus pitchfork bifurcations (e.g., Section 3.4 in [35]), in accordance with [19]. Even though the optimal root is continuous in (by assumption), its differentiability is violated at the point of bifurcation. This can be inferred from the comments following Theorem 1 and seen in Figure 6. Strictly speaking, several copies of the root of larger effective cardinality collide at a continuous bifurcation. When two clusters collide in a cluster merging bifurcation, then the root itself is invariant to interchanging their coordinates after the collision but not before it, breaking the IB’s first structural symmetry discussed in Section 5.1. Interchanging the coordinates of r and (and their marginals) before the collision yields two distinct copies of essentially the same root. For a cluster vanishing bifurcation, the IB’s functionals (e.g., its X- and Y-information) do not depend on the coordinates of a vanished cluster r, rendering these redundant; cf., [9] (Section 3.1). Before the cluster r vanishes, there is one copy of the root for each index , with r placed at its coordinates. Considered in reduced coordinates, these coincide to a single copy after the cluster vanishes. This breaks the IB’s second structural symmetry.
With that, we note that cluster-vanishing bifurcations cannot be detected directly by standard local techniques (i.e., considering the derivative’s kernel directions at the bifurcation point), whether considering the Hessian of the IB’s loss function as in [9] or the Jacobian of the IB operator (5) as here. The technical reason for this is as follows, while the root cause underlying it is best understood in the context of discontinuous bifurcations (after Proposition 1 in Section 5.3). Observe that the and functionals do not depend on the coordinates of clusters r of zero mass. Thus, the directions corresponding to these coordinates are always in the kernel regardless of whether evaluating at a bifurcation or not, and so cannot be used to detect a bifurcation (the direction corresponding to a cluster’s marginal is useless when one does not know which coordinates to pick for r). Indeed, with its dynamics in reversed, “a new symbol grows continuously from zero mass” in a cluster-vanishing bifurcation, as [17] (Section IV.C) comments in a related setting. It is then not clear a priori which point in should be chosen for the new symbol, rendering the perturbative condition at Equation (9) difficult to test. In accordance with this, Ref. [9] (Section 5) offers a perturbative condition for detecting arbitrary IB bifurcations, while ref. [13] (3.2 in Part III) offers a condition for detecting cluster-merging bifurcations by analyzing cluster stability. However, both conditions are equivalent (Appendix F), and so must detect the same type of bifurcations. In contrast, a cluster-splitting (or merging) bifurcation is straightforward to detect because the stability of a particular cluster is a property of the root itself—see Appendix F and the references therein for details.
One may wonder whether bifurcations exist in the IB for the same reason as they do in RD. As in the IB, RD problems typically have many sub-optimal curves [6] (Section 6.1). While (continuous) bifurcations in the IB stem from restricting the effective cardinality [1] (Section 3.4), in RD they stem from the various restrictions that a reproduction alphabet has. For example, a reproduction alphabet of an RD problem may be restricted to the distinct subsets and , usually yielding distinct sub-optimal RD curves (e.g., Figure 6.1 in [6]). In contrast to RD, the IB’s distortion (25) defined by a root’s clusters is determined a posteriori by the problem’s solution rather than a priori by the problem’s definition. As a result, both reasons for the existence of bifurcations coincide. To see this, consider the IB as an RD problem whose reproduction symbols are a finite subset of which is allowed to vary (i.e., as if defining the tangent RD problem anew at each ). Distinct restrictions of a reproduction alphabet can be forced to agree by altering the symbols themselves, so long as they are of the same size. For example, restricting the set of reproduction symbols to is the same as restricting it to instead, and then replacing with in the restricted problem (this is not to be confused with cluster permutations, which change the order in which clusters are listed but do not alter the symbols themselves).
The dynamical point of view above, considering an IB root as weighted points traversing , offers a straightforward way to identify and handle continuous IB bifurcations. It is spelled out as our root-reduction Algorithm 2. For cluster-vanishing bifurcations, one can set a small threshold value and consider the cluster as vanished if (Step 2.3), as in [6] (Section 3.1). Similarly, for cluster-merging bifurcations, one can set a small threshold and consider the clusters to have merged if (Step 2.9). A vanished cluster is then erased (and merged clusters replaced by one), resulting in an approximate IB root on fewer clusters. This not only identifies continuous IB bifurcations but also handles them, since the output of the root-reduction Algorithm 2 is a numerically reduced root, represented in its effective cardinality. To re-gain accuracy, we shall later invoke the BA-IB Algorithm 1 on the reduced root, as part of our root-tracking algorithm (in Section 6). We note that one should pick the thresholds and small enough to avoid false detections, and yet not too small so as to cause mis-detections. Mis-detections will be handled later, in Section 6.1, using a heuristic algorithm.
| Algorithm 2 Root reduction for the IB | |
| 1: | function Reduce root() |
| Input: | |
| An approximate IB root in decoder coordinates, | |
| a cluster-mass threshold and a cluster-merging threshold . | |
| Output: An approximate IB root at its effective cardinality. | |
| 2: | for do |
| 3: | if then ▹ Delete clusters of near-zero mass. |
| 4: | delete the coordinates of , from and . |
| 5: | end if |
| 6: | end for |
| 7: | normalize ▹ Preserve normalization, in case clusters were removed. |
| 8: | for do |
| 9: | if then ▹ Merge nearly identical points in . |
| 10: | |
| 11: | delete the coordinates of , from and . |
| 12: | end if |
| 13: | end for |
| 14: | return |
| 15: | end function |
Using the root-reduction Algorithm 2 allows one to stop early in the vicinity of a bifurcation when following the path of an IB root. As mentioned in Section 4, early stopping restricts the computational difficulty of root tracking [6]. Further, reducing the root before invoking BA-IB (Algorithm 1) allows us to avoid BA’s critical slowing down [4], since reduction removes the nearly vanished Jacobian eigenvalues that pertain to the nearly vanished (or nearly merged) cluster(s), which are the cause of BA’s critical slowing down. cf., Proposition 1 (Section 5.3) and the discussion around it. See also [6] (Figure 3.1(C) and Section 3.2) for the respective behavior in RD. Finally, we comment that the root-reduction Algorithm 2 can also be implemented in the other two coordinate systems of Section 2.
5.3. Discontinuous IB Bifurcations and Linear Curve Segments
In the previous Section 5.2, we considered continuous IB bifurcations—namely, when the clusters and weights of an IB root are continuous functions of . By exploiting the intimate relations between the IB and RD (Section 5.1), we now consider IB bifurcations where these cannot be written as a continuous function of . In our experience, discontinuous bifurcations are infrequent in practice. However, the theory they evoke has several subtle consequences of practical implications important for computing IB roots (in Section 6). Though, perhaps more importantly, they oblige one to ask what is the IB? We start with several examples before diving into the theory; e.g., Figure 7.
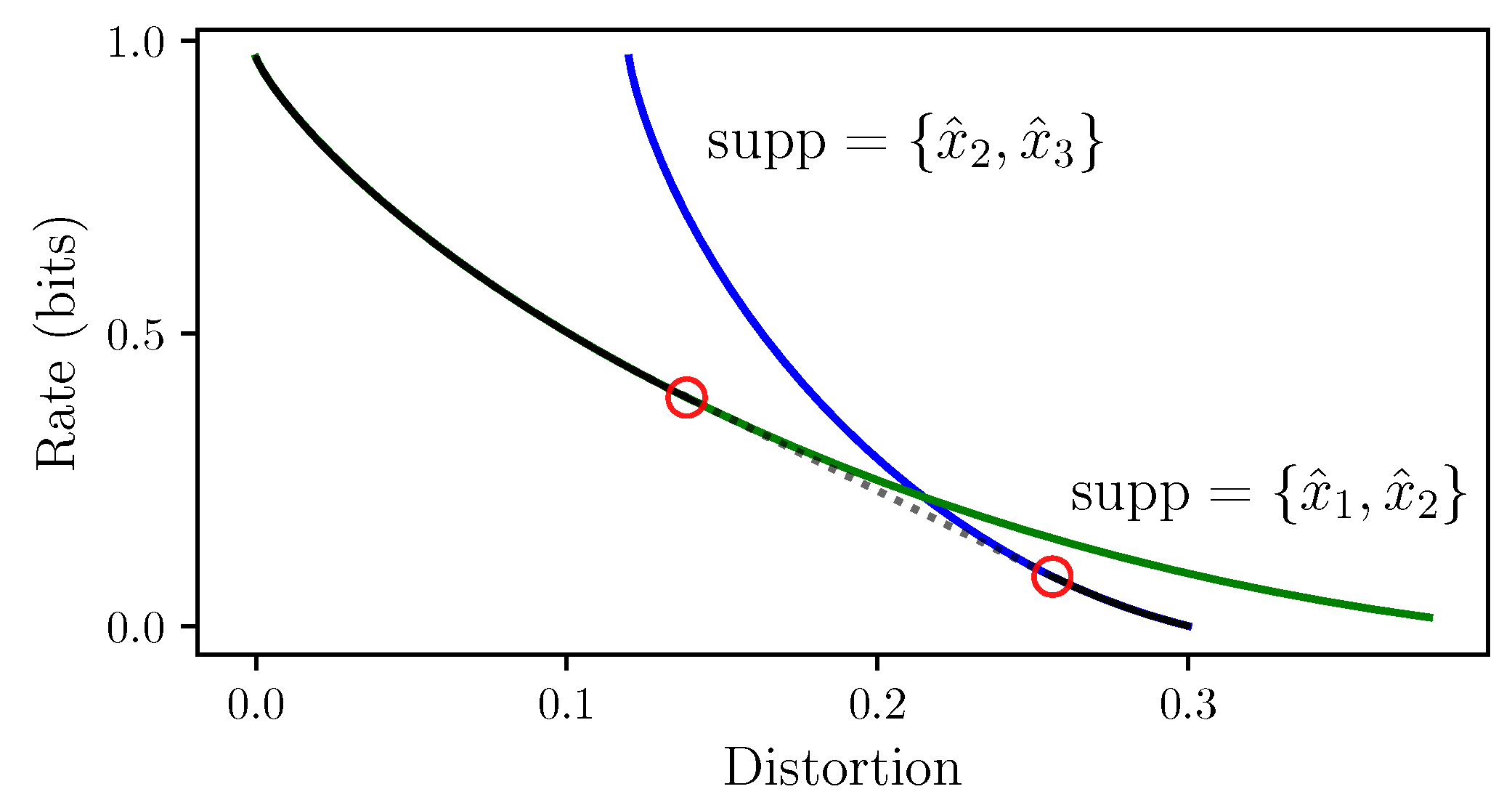
The examples of discontinuous IB bifurcations of which we are aware can be understood in RD context as follows. Consider the IB as an RD problem on the continuous reproduction alphabet , with IB roots parameterized by points in (see Section 5.1). In RD, the existence of linear curve segments is well-known [28]—e.g., Figure 2.7.6 in the latter and its reproduction in [6] (Figure 6.2). Section 6.5 in [6] offers an explanation of linear segments in terms of a support-switching bifurcation. Namely, a bifurcation where two RD roots of distinct supports exchange optimality at a particular multiplier value . Both roots evolve smoothly in while only exchanging optimality at the bifurcation. At itself, every convex combination of these two roots is also an RD root. In particular, the optimal RD root cannot be written as a continuous function of . The sudden emergence of an entire segment of roots at can be understood by RD’s convexity and analyticity properties, as follows. The RD curve (23) is parameterized by the slope of its tangents [28] (Theorems 2.5.1 and 2.5.2). Above and below , specifying the tangent’s slope determines a curve-achieving distribution on the optimal root (the root whose curve is lower at this slope value). Equivalently, the lower convex envelope of these roots in the RD plane coincides with one root above and with the other below it, as seen in Figure 8 (black). At itself, specifying the slope determines a distribution on both roots. Thus, the convexity of the RD curve and of the set of achieving distributions implies a linear segment at (Theorem 2.4.1 in [28] and Theorem 5 below). Finally, this behavior is possible due to analyticity, since the roots of a real-analytic operator are either isolated (typical) or an algebraic curve (atypical) by Bézout’s Theorem—see (i) in the discussion following Conjecture 1.
For one example of linear curve segments in the IB, say that a matrix M decomposes if it can be written (non-trivially) as a block matrix by permuting its rows or columns. In light of the above, we have the following refinement of Theorem 2.6 in [2]:
Theorem 3.
The IB curve (1) has a linear segment at if and only if the problem’s definition decomposes.
Recall that the slope of the IB curve is at a multiplier value [1] (Equation (32)). Thus, Theorem 3 equates decomposable problems with linear curve segments of slope 1 (the slope cannot exceed one due to the data processing inequality). Figure 7 provides a simple decomposable example, exhibiting a support-switching bifurcation between its trivial and non-trivial roots. Non-decomposable examples also exist, exhibiting a support-switching bifurcation at lower slope values (higher critical ’s). For example, a symmetric binary erasure channel exhibits a support-switching bifurcation [2] (Section IV.B), which is manifested by a linear segment of slope , for (switching between the trivial root at and a bi-clustered root supported on and ; the linear segment of slope is Equation (4.8) there). See [2] (Section IV) for further examples. We argue that in the IB, support-switching bifurcations exhibit the same behavior as in RD. That is, two roots that evolve smoothly in and exchange optimality at the bifurcation. While the sequel can justify this in general, there is a simple way to see this in practice. Namely, following the two roots of Figure 7 through the bifurcation by using BA-IB with deterministic annealing [11] (follow the trivial root of Figure 7 from left to right and the non-trivial one from right to left, through the bifurcation at there). As deterministic annealing usually follows a solution branch continuously, this immediately reveals either root at the region where it is sub-optimal (not displayed).
A support-switching bifurcation evidently has similar characteristics to a transcritical bifurcation (e.g., Section 3.2 in [35]), though it should perhaps be classified as an imperfect transcritical since the roots do not intersect per se as in a classical transcritical. This extends the results of [19], who conclude that IB bifurcations “are only of pitchfork type” (Theorem 5 therein says that the bifurcations detected by their Theorem 3 are degenerate rather than transcritical, concluding that “the bifurcation guaranteed by Theorem 3 is [generically] pitchfork-like”). To see the reason for this discrepancy, note that they employ the mathematical machinery in [36] of bifurcations under symmetry. Since pitchfork bifurcations are “common in physical problems that have a symmetry” [35] (Section 3.4), then detecting only pitchforks by using the above machinery might not come as a surprise. Both [9] and its sequel [19] consider the IB’s symmetry to interchanging the coordinates of identical clusters (Definition 1(1) in [19]). However, this is a structural symmetry of the IB which stems from representing IB roots by finite-dimensional vectors (Section 5.1), and is broken in continuous IB bifurcations (Section 5.2). On the other hand, discontinuous IB bifurcations need not break this symmetry, as can be seen by inspecting the roots of Figure 7 closely (the trivial solution to the left of there may be given a degenerate bi-clustered representation, which is fully supported on but has a second cluster of zero mass. Neither of its roots then possesses a symmetry to interchanging cluster coordinates, at either side of ).
A few convexity results from rate-distortion theory are needed to consider discontinuous bifurcations in general. These have subtle practical implications, which are of interest in their own right.
Theorem 4
Viewing the IB as an RD problem as in [20] immediately yields an identical result for the IB:
Corollary 2.
The proof is provided below for completeness. We note that a version of Corollary 2 in inverse encoder coordinates can also be synthesized from the ideas leading to Theorem 2.3 in [2].
Proof of Corollary 2.
Consider a finite IB problem as an RD problem on the continuous reproduction alphabet , as defined by (25) in Section 5.1. As noted above, its encoders (or test channels) are conditional probability distributions , with , supported on finitely many coordinates .
Let and be encoders achieving a point on the IB curve (1). Define their support by , where is defined from via marginalization, as in (4). By Theorem 5 in [20], and may be considered as test channels achieving the curve (23) of the RD problem . The reproduction symbols supporting a convex combination , , are contained in the the supports of and : . Therefore, is finitely supported. Although Berger’s Theorem 4 assumes that the reproduction alphabet is finite, one can readily see that its proof works just as well when the distributions involved are finitely supported. Thus, by Theorem 4, achieves the above point on the RD curve (23). Since this point is on the IB curve (1), then is an optimal IB root. □
The RD curve (23) is the envelope of lines of slope and intercept along the R-axis, e.g., [28]. Thus, Theorem 4 can be generalized by considering the achieving distributions that pertain to a particular slope value rather than to a particular curve point —see [6] (Section 6.3).
Theorem 5
As with Corollary 2, we immediately have an identical result for roots achieving the IB curve (1):
Corollary 3.
For any value, the set of optimal IB encoders that correspond to β is convex.
See also [2] (Section IV) for an argument in inverse encoder coordinates. In particular, note the duality technique leading to (b) and (c) in Theorem 4.1 there. This duality boils down to describing a compact convex set in the plane by its lines of support, as in the observation leading to Theorem 5. Commensurate with the IB being a special case of RD, Corollary 3 can also be proven directly from the IB’s definitions in direct encoder terms [37]. Note that the requirement that the IB root indeed achieves the curve is necessary. Otherwise, one could take convex combinations with the trivial IB root (which satisfies the IB Equations (2)–(4) for every , as one can verify directly). This yields absurd results, since the trivial root contains no information on either X or Y.
As in [6] (Section 6.3), the convexity of optimal IB roots (Corollary 3) has several important consequences. For one, unlike the (local) bifurcations we have considered so far, bifurcation theory also has global bifurcations. These are “bifurcations that cannot be detected by looking at small neighborhoods of fixed points” [12] (Section 2.3). From convexity, it immediately follows that
Corollary 4.
There are no global bifurcations in finite IB problems.
Indeed, if at a given value there exists more than one optimal root, then the Jacobian of the IB operator (5) must have a kernel vector pointing along the line connecting these optimal roots, by Corollary 3.
With that comes an important practical caveat. Corollaries 2 and 3 hold for the IB when parameterized by points in . However, the above kernel vector (which exists due to convexity) may not be detectable if an IB root is improperly represented by a finite-dimensional vector. For example, consider the bifurcation in Figure 7, where a line segment at connects the trivial (single-clustered) root to the 2-clustered root. Obviously, the bifurcation there cannot be detected by the Jacobian of the IB operator (5) when it is computed on clusters (Jacobian of order ). Indeed, the root of effective cardinality two cannot be represented on a single cluster, and so the line segment connecting it to the trivial root does not exist in a 1-clustered representation. This is demonstrated in Figure 9, which compares Jacobian eigenvalues at reduced representations to those at 2-clustered representations. The same reasoning gives the following necessary condition:
Proposition 1
(A necessary condition for detectability of IB bifurcations). A bifurcation at in a finite IB problem which involves roots of effective cardinalities and is detectable by a non-zero vector in only if the latter is evaluated at a representation on at least clusters.
Indeed, suppose that (the conclusion is trivial if ). By definition, a root of effective cardinality does not exist in representations with less than clusters. Thus, there is no bifurcation in a T-clustered representation if , and so there is then nothing to detect. As a special case of this argument, note that Conjecture 1 (Section 5.1) implies that the Jacobian is non-singular in a -clustered representation of the -clustered root (namely, at its reduced representation). With that, we have observed numerically that the eigenvalues of do not depend on the representation’s dimension if computed on strictly more clusters than the effective cardinality (which makes sense considering Theorem 2.6.1 in [28] or Lemma 2.2(i) in [2]). Rather, only the eigenvalues’ multiplicities vary by dimension. We omit practical caveats on exchanging between the coordinate systems of Section 2 for brevity.
The discussion of discontinuous bifurcations naturally leads one to consider the IB as an RD problem on the continuous reproduction alphabet , as in Corollaries 2 and 3, unlike its usual definitions in the literature. When considered this way, IB roots are merely paths in , following a piecewise smooth trajectory dictated by the IB ODE (16) (which may be considered as a non-autonomous ODE on ). Due to Conjecture 1 and the IFT, these paths are isolated outside bifurcations. Two (or more) roots may intersect in a continuous bifurcation. If one of the intersecting roots is optimal, then the other must be of a strictly smaller effective cardinality due to the arguments in Section 5.2. If two distinct roots are optimal simultaneously, then contains an entire segment of optimal IB roots, due to Corollary 3. Viewing the IB this way also highlights several subtleties in its calculation. First, parameterizing IB roots with avoids its structural symmetries (Section 5.1). Second, it shows that, a priori, it is possible to follow the path of an optimal root using local techniques (Corollary 4). Third, it highlights that one must compute on enough clusters to detect a bifurcation (Proposition 1). Though obvious in retrospect, this caveat was not given proper attention in the IB literature. Fourth, as we shall now see, cluster-vanishing bifurcations can only be detected by following an optimal root to its collision with a root of smaller effective cardinality. Fifth, this implies (below) that only negative step sizes should be used to follow an optimal root.
The arguments above imply that cluster-vanishing bifurcations cannot be detected directly by considering kernel directions of the IB operator (5) at the bifurcation, as argued in Section 5.2. Indeed, consider a continuous bifurcation, where roots and of respective effective cardinalities intersect. These are paths in that coincide at the bifurcation itself, , and so in particular are of the same effective cardinality there. This is in contrast to the situation in Corollary 3, where two distinct roots are simultaneously optimal at , leading to an entire segment of optimal roots. Asking whether a bifurcation is detectable amounts to considering the evaluation of at a finite-dimensional representation (or “projection”) of . The Jacobian of the IB operator (5) is non-singular when evaluated on a -clustered representation of in log-decoder coordinates, as noted after Proposition 1. We argue that evaluating it on representations with more clusters does not allow one to detect the bifurcation (even if ). See Appendix H for a formal argument. Intuitively, this is because picking a degenerate representation amounts to duplicating clusters of the reduced representation or adding clusters of zero mass (see reduction in Section 5.1). Introducing degeneracies to a reduced root adds no information about the problem at hand.
Due to the above, cluster-vanishing bifurcations cannot be detected by following a root of effective cardinality through the bifurcation point, but only by following a root with to its collision with . As discussed after Conjecture 1 (Section 5.1), the Jacobian of in reduced log-decoder coordinates can then be used to indicate the upcoming collision of with , in addition to the root-reduction Algorithm 2. The exact same arguments as above apply also to cluster-merging bifurcations. However, as noted in Section 5.2 (and Appendix F), the stability of a particular IB cluster is a property of the root itself. Thus, these are detectable by standard local techniques at the point of bifurcation. Unlike continuous bifurcations, discontinuous bifurcations are inherently detectable due to the line segment in connecting the roots at the bifurcation (Corollary 3), as long as the IB root is represented on sufficiently many clusters (Proposition 1)—see Figure 9. These results make sense, considering that cluster-vanishing bifurcations are more frequent in practice than other types. Intuitively, branching from a suboptimal root to an optimal one is harder than the other way around, just as learning new relevant information is harder than discarding it. Cases where both directions are equally difficult are the exception, as one might expect. This is consistent with the later discussion in Section 6.3 on the stability of optimal IB roots (Appendix G).
When following the path of a reduced IB root (as in Section 4), one would like to ensure that its bifurcations are indeed detectable by BA’s Jacobian. Due to the caveats involved in detecting bifurcations of either type, it is necessary to follow the path as the effective cardinality decreases rather than increases. As a result, we take only negative step sizes , since the effective cardinality of an optimal IB root cannot decrease with . To see this, first note that the IB curve (1) is concave, and so its slope cannot increase with . That is, cannot decrease with . Second, note that allowing more clusters cannot decrease the X-information achieved by the IB’s optimization variables. Indeed, a T-clustered variable (not necessarily a root) can always be considered as -clustered, by adding a cluster of zero mass; cf., the construction of [2] (Section II.A). Thus, the effective cardinality of an optimal root cannot decrease as the constraint on the X-information is relaxed. With both points combined, the effective cardinality cannot decrease with , as argued. In contrast to the IB, we note that the behavior of RD problems is more complicated since the distortion of each reproduction symbol is fixed a priori; e.g., Example 2.7.3 and Problems 2.8–2.10 in [28].
Returning to discontinuous IB bifurcations, we proceed with the argument of Section 5.2 when continuity fails. That is, consider the reduced form of an optimal IB root, and suppose that either its decoders or its weights (or both) cannot be written as a continuous function of at . Write and for its distinct decoders as and , respectively. Similarly, write and for its non-zero weights. Consider the tangent RD problem on the reproduction alphabet , as in Section 5.1. See also [4] (Section V), upon which this argument is based. By construction, the IB coincides with its tangent RD problem at the two points , and . Since both points achieve the optimal curve at the same slope value , then the linear segment of distributions connecting these points is also optimal, by Theorem 5. Alternatively, one could apply Corollary 3 directly to the IB problem. Either way, there exists a line segment of optimal IB roots, which pertain to the given slope value. In summary,
Theorem 6.
Let a finite IB problem have a discontinuous bifurcation at . Then, its IB curve (1) has a linear segment of slope .
Unless the decoder sets and are identical, then this is a support-switching bifurcation [6] (Section 6.5), as in Figure 7. A priori, the IB roots and may achieve the same point in the information plane, in which case the linear curve segment is of length zero. However, we are unaware of such examples. Yet, even if such bifurcations exist, they would be detectable by the Jacobian of BA-IB (when represented on enough clusters), subject to Conjecture 1.
6. First-Order Root Tracking for the Information Bottleneck
Gathering the results of Section 2, Section 3, Section 4 and Section 5, we can now not only follow the evolution of an IB root along the first-order Equation (16), but can also identify and handle IB bifurcations. This is summarized by our First-order Root-Tracking algorithm for the IB (IBRT1) in Section 6.1, with some numerical results in Section 6.2. Section 6.3 discusses the basic properties of IBRT1, and mainly the surprising quality of approximations of the IB curve (1) that it produces, as seen in Figure 1. We focus on continuous bifurcations (Section 5.2), since these are far more frequent in our experience than discontinuous ones and are straightforward to handle (see Section 6.3 on the handling of discontinuous bifurcations).
6.1. The IBRT1 Algorithm 5
To assist the reader, we first present a simplified version of IBRT1 as Algorithm 3, with edge cases handled later by Algorithm 4—clarifications follow. When combined, these two form our IBRT1 Algorithm 5, specified below.
We now elaborate on the main steps of the Simplified First-order Root Tracking for the IB (Algorithm 3), following Root Tracking for RD [6] (Algorithm 3). Its purpose is to follow the path of a given IB root in a finite IB problem. The initial condition is required to be reduced and IB-optimal. Its optimality is needed below to ensure that the path traced by the algorithm is indeed optimal. The step-size is negative, for reasons explained in Section 5.3 (Proposition 1 ff.). The cluster mass and cluster merging thresholds are as in the root-reduction Algorithm 2 (Section 5.2).
Denote (step 3 of Algorithm 3) for the distributions generated from an encoder (see Equation (11) in Section 2). Algorithm 3 iterates over grid points , with each while iteration generating the reduced form of the next grid point, as follows. On step 6, evaluate the IB ODE (16) at the current root , solving the linear equations numerically. By Conjecture 1 (Section 5.1), the IB ODE has a unique numerical solution if is a reduced root and not a bifurcation. Steps 7 and 8 approximate the root at the next grid point at , by exponentiating Euler method’s step (22) (Section 4). Normalization is enforced on step 9, since it is assumed throughout. Off-grid points can be generated by repeating steps 7 through 9 for intermediate values if desired. The approximate root at is reduced on step 11, by invoking the root-reduction Algorithm 2 (Section 5.2). Note that Algorithm 2 returns its input root unmodified unless reducing it numerically. If reduced, then the root is a vector of a lower dimension—either a cluster mass has nearly vanished or distinct clusters have nearly merged. To re-gain accuracy, we invoke (on step 14) the Blahut–Arimoto Algorithm 1 for the IB until convergence, on the encoder defined at step 13 by the reduced root. Although BA-IB is invoked near a bifurcation, this does not incur a hefty computational cost due to its critical slowing down [4]—see comments at the bottom of Section 5.2. Invoking BA (on step 14) before reducing (on step 11) would have inflicted a hefty computational cost to BA-IB due to the nearby bifurcation. Finally, a single BA-IB iteration in decoder coordinates is invoked on the approximate root (step 17), whether reduced earlier or not. This enforces Markovity while improving the order of this method (see Section 4, and Figure 4 in particular). Algorithm 3 continues this way (step 4) until the approximate solution is trivial (single-clustered), or is non-positive. In the IB, the trivial solution is always optimal for tradeoff values . However, here plays the role of the ODE’s independent variable instead. Thus, we allow Algorithm 3 to continue beyond , as long as , which is assumed throughout (the condition on step 4 ensures that the target value of the next grid point is non-negative). This shall be useful for overshooting—see below.
| Algorithm 3 Simplified First-order Root-Tracking for the IB | |
| 1: | function sIBRT1() |
| Input: | |
| An IB problem definition with . | |
| A reduced IB-optimal root at . A step size . | |
| Cluster-mass threshold and cluster-merging threshold , with . | |
| Output: Approximations of the optimal IB roots at . | |
| 2: | Initialize and . |
| 2: | Initialize from , via Steps 1.4–1.6. |
| 4: | while and do ▹ See main text on stopping condition. |
| 5: | Append to . |
| 6: | solve the IB ODE (16) at . |
| 7: | |
| 8: | ▹ Exponentiate the linear approximations (22). |
| 9: | |
| 10: | |
| 11: | . ▹ Algorithm 2. |
| 12: | if then ▹ Root was reduced due to bifurcation. |
| 13: | the encoder defined by , via Steps 1.7–1.8. |
| 14: | . |
| ▹ Ensure accuracy of the reduced root, using BA-IB Algorithm 1 till convergence. | |
| 15: | end if |
| 16: | . |
| 17: | ▹ A single BA-IB iteration in decoder coordinates. |
| 18: | end while |
| 19: | Append to . |
| 20: | return . |
| 21: | end function |
With that, there are caveats in Algorithm 3, which stem from passing too far or close to a bifurcation. For one, suppose that the error accumulated from the true solution is too large for a bifurcation to be detected. The approximations generated by the algorithm will then overshoot the bifurcation. Namely, it will proceed with more clusters than needed until the conditions for reduction are met later on (see Section 6.3 below), as demonstrated by the two sparse grids in Figure 10 (Section 6.2). For another, suppose that the current grid point is too close to a bifurcation. This might happen due to a variety of numerical reasons, e.g., thresholds too small, or due to the particular grid layout. The coefficients matrix of the IB ODE (16) (which is the Jacobian of the IB operator (5)) would then be ill-conditioned, typically resulting in very large implicit numerical derivatives on step 6; cf., Conjecture 1 ff. in Section 5.1. Any inaccuracy in might then send the next grid point astray, derailing the algorithm from there on (e.g., inaccuracies due to the accumulated approximation error or due to the error caused by computing implicit derivatives in the vicinity of a bifurcation—see Figure 3 (top) in Section 3). Indeed, the derivatives defined by the implicit ODE (7) are in general unbounded near a bifurcation of F (in our case, is always non-singular outside bifurcations, due to Conjecture 1 and the use of reduced coordinates). This can be seen in Figure 2 (Section 2) for example, where the derivatives “explode” at the bifurcation’s vicinity. See also [6] (Section 7.2) on the computational difficulty incurred by a bifurcation. While overshooting a bifurcation is not a significant concern for our purposes (see Section 6.3), passing too close to one is. The latter is important, especially when the step size is small. While decreasing generally improves the error of Euler’s method, it also makes it easier for the approximations to come close to a bifurcation, thus potentially worsening the approximation dramatically if it derails. This motivates one to consider how singularities of the IB ODE (16) should be handled.
| Algorithm 4 A heuristic for handling singularities of the IB ODE (16) | |
| 1: | function Handle singularity() |
| Input: | |
| An IB problem definition , with . | |
| An approximate root of the given problem, near a singularity of the IB ODE (16). | |
| Approximate numerical derivatives at the given root. | |
| The value of the next (output) grid point. | |
| Output: An approximate IB root at on one fewer cluster. | |
| 2: | the two indices of largest value (norm of y-indexed vectors). |
| 3: | ▹ Replace fastest-moving clusters by their mean. |
| 4: | Erase from the decoder . |
| 5: | |
| 6: | Erase from the marginal . |
| 7: | the encoder generated from , via Steps 1.7–1.8. |
| ▹ A new encoder on one cluster less than the input. | |
| 8: | . ▹ Re-gain accuracy, by the BA-IB Algorithm 1. |
| 9: | return |
| 10: | end function |
Next, we elaborate on our heuristic for handling singularities of the IB ODE (16), Algorithm 4. The inputs of this heuristic are defined as in Algorithm 3. It starts with the assumption that the coefficients matrix of the IB ODE (16) is nearly singular at the current grid point due to a nearby bifurcation (although a priori the Jacobian may be singular also due to other reasons, by Conjecture 1 it is non-singular at the approximations generated so far since they are assumed to be in their reduced form—see Section 5.1). As a result, the implicit derivatives at are not to be used directly to extrapolate the next grid point, as explained above. Instead, we use them to identify the two fastest moving clusters, on step 2 of Algorithm 4 (while this can be refined to handle more than two fast-moving clusters at once, that is not expected to be necessary for typical bifurcations). These are replaced by a single cluster (steps 3 through 6), resulting in an approximate root on one fewer cluster. To re-gain accuracy, the BA-IB Algorithm 1 is then invoked (on step 8) on the encoder generated (on step 7) from the latter root, thereby generating the next grid point. If the fastest-moving clusters have merged (in the true solution) by the next grid point, then the output of Algorithm 4 will be an IB-optimal root if its input grid point is so. Namely, the branch followed by the algorithm remains an optimal one. Otherwise, if these clusters merge shortly after the next grid point, then Algorithm 4 yields a sub-optimal branch. However, optimality is re-gained shortly afterward since the sub-optimal branch collides and merges with the optimal one in continuous IB bifurcations (Section 5.3). Figure 10 below demonstrates Algorithm 4. cf., [6] (Section 3.2) on the similar heuristic in root tracking for RD, which may also lose optimality near a bifurcation and re-gain it shortly after.
| Algorithm 5 First-order Root Tracking for the IB (IBRT1) | |
| 1: | function IBRT1() |
| Input: | |
| An IB problem definition with . | |
| A reduced IB-optimal root at . A step size . | |
| Thresholds for the root-reduction Algorithm 2 (cluster mass and merging). | |
| A threshold for eigenvalues’ singularity. | |
| Output: Approximations of the optimal IB roots at . | |
| 2: | Initialize and . |
| 3: | Initialize from , via Steps 1.4–1.6. |
| 4: | while and do |
| 5: | Append to . |
| 6: | solve the IB ODE (16) at . |
| 7: | ▹ Test ODE for singularity, using S (17) from Lemma 1. |
| 8: | if then ▹ ODE is nearly singular. |
| 9: | |
| ▹ Handle an otherwise undetected singularity using Algorithm 4. | |
| 10: | else |
| 11: | |
| 12: | |
| 13: | |
| 14: | |
| 15: | . |
| 16: | if then |
| 17: | encoder defined from , via Steps 1.7–1.8. |
| 18: | . |
| 19: | end if |
| 20: | end if |
| 21: | . |
| 22: | |
| 23: | end while |
| 24: | Append to . |
| 25: | return . |
| 26: | end function |
The heuristic Algorithm 4 is motivated by cluster-merging bifurcations. In these, the implicit derivatives are very large only at the coordinates of the points colliding in (note that cluster masses barely change in the vicinity of a cluster merging, until the point of bifurcation itself). While intended for cluster-merging bifurcations, this heuristic works nicely in practice also for cluster-vanishing ones. To see why, note that one can always add a cluster of zero mass to an IB root without affecting the root’s essential properties, regardless of its coordinates in (cf., Section 5.1 on reduction in the IB). Therefore, a numerical algorithm may, in principle, do anything with the coordinates of a nearly vanished cluster , , without affecting the approximation’s quality too much. Thus, for numerical purposes, one may treat a cluster-vanishing bifurcation as a cluster-merging one. Conversely, in a cluster-merging bifurcation, a numerical algorithm may, in principle, zero the mass of one cluster while adding it to the remaining cluster, again without affecting the approximation’s quality too much. To conclude, for numerical purposes, cluster vanishing is very similar to cluster merging. A variety of treatments between these extremities may be possible by a numerical algorithm. Empirically, we have observed that our ODE-based algorithm treats both as cluster-merging bifurcations. To our understanding, this is because our algorithm operates in decoder coordinates, unlike the BA-IB Algorithm 1, for example, which operates in encoder coordinates.
Finally, we combine the simplified root-tracking Algorithm 3 with the heuristic Algorithm 4 for handling singularities, yielding our IBRT1 Algorithm 5. It follows the lines of the simplified Algorithm 3, except that after solving for the implicit derivatives on step 6, we test the IB ODE (16) for singularity. To that end, we propose using the matrix S (17) (from Lemma 1 in Section 3), since its order is smaller than the order of the ODE’s coefficients matrix. This might make it computationally cheaper to test for singularity (on steps 7 and 8 of Algorithm 5). Our heuristic Algorithm 4 is invoked (on step 9) if the ODE (16) is found to be nearly singular, otherwise proceeding as in Algorithm 3.
6.2. Numerical Results for the IBRT1 Algorithm 5
To demonstrate the IBRT1 Algorithm 5, we present the numerical results used to approximate the IB curve in Figure 1 (Section 1)—see Section 6.3 below on the approximation quality and the algorithm’s basic properties. This example was chosen both because it has an analytical solution (Appendix E) and because it allows one to get a good idea of the bifurcation handling added (in Section 6.1) on top of the modified Euler method (from Section 4).
We discuss the numerical examples of this Section in light of the explanations provided in the previous Section 6.1. The error of the IBRT1 Algorithm 5 generally improves as the step-size becomes smaller, as expected. The single BA-IB iteration added to Euler’s method (in Section 4) typically allows one to achieve the same error by using much fewer grid points, thus lowering computational costs. For example, the two denser grids in Figure 10 require about an order of magnitude fewer points to achieve the same error compared to Euler’s method for the IB; this can be seen from Figure 4 (Section 4).
In sparse grids, the approximations often pass too far away from a bifurcation for the root-reduction Algorithm 2 to detect it. When overshooting it, the conditions for numerical reduction are generally met later on, as discussed in Section 6.3 below. Decreasing further often leads the approximations too close to a bifurcation, as can be seen in the densest grid of Figure 10. The implicit derivatives are typically very large at the proximity of a bifurcation, while the least accurate there (see Section 6.1). As these might send subsequent grid points off-track, the heuristic Algorithm 4 is invoked to handle the nearby singularity (see inset of Figure 10). As noted earlier, the computational difficulty in tracking IB roots (or root tracking in general) stems from the presence of a bifurcation, manifested here by large approximation errors in its vicinity. While the algorithm’s error peaks at the bifurcation, it typically decreases afterward when overshooting, as seen in Figure 11. The reasons for this are discussed below in Section 6.3.
6.3. Basic Properties of the IBRT1 Algorithm 5 and Why It Works
Apart from presenting the basic properties of the IBRT1 Algorithm 5, the primary purpose of this section is to understand why it approximates the problem’s true IB curve (1) so well, despite its apparent errors in approximating the IB roots. While shown here only in Figure 1 and Figure 10 (in Section 1 and Section 6.2), this behavior is consistent in the few numerical examples that we have tested. We offer an explanation why this may be true in general.
To understand why the IBRT1 Algorithm 5 approximates the true IB curve (1) so well, we first explain why overshooting is not a significant concern, as noted earlier in Section 6.1. To that end, consider the implicit ODE (7)
from Section 1. As long as and at its right-hand side are well-defined, it defines a vector field on the entire phase space of admissible values, at least when is non-singular. That is, even for ’s which are not roots (6) of F. Ignoring several technicalities, the IB ODE (16) therefore defines a vector field also outside IB roots (although at a reduced root singularities of the IB ODE (16) coincide with IB bifurcations, the IB’s vector field might a priori be singular elsewhere). Indeed, due to Conjecture 1, the Jacobian of the IB operator (5) is non-singular in the vicinity of a reduced root ( (13) is continuous in the distributions defining it, and thus so are its eigenvalues, under mild assumptions—cf., Lemma A1 in Appendix A). Now, suppose that is an optimal IB root, and consider a point in its vicinity. An argument based on a strong notion of Lyapunov stability (in Appendix G) shows that flows along the IB’s vector field towards in regions that do not contain a bifurcation, though only if flowing in decreasing as done by our IBRT Algorithm 5. An approximation would then be “pulled” towards the true root. Stability in decreasing (rather than increasing) values is very reasonable, considering that follows a path of decreasingly informative representations as decreases. Indeed, all the paths to oblivion lead to one place—the trivial solution, whose representation in reduced coordinates is unique. As a result, a numerical approximation would gradually settle in the vicinity of the true root as seen in Figure 10 and Figure 11, so long as does not change much and the step-size is small enough. While this explanation obviously breaks near a bifurcation, it does suggest that the approximation error should decrease when overshooting it (see Section 6.1), once the true reduced root has settled down. In a sense, overshooting is similar to being in the right place but at the wrong time.
The above suggests that the IBRT1 Algorithm 5 should generally approximate the true IB curve (1) well, despite its errors in approximating IB roots. To see this, note that while is the slope of the optimal curve (1) of the IB [1] (Equation (32)), for the IB ODE (16) it is merely an independent “time-like” variable. When solving for the optimal curve (1), one is not interested in an optimal root or in its value, but rather in its image in the information plane. As a result, achieving the optimal roots but with the wrong values does yield the true IB curve (1), as required. This is the reason that the true curve (1) is achieved in Figure 1 (Section 1) even on sparse grids, despite the apparent approximation errors in Figure 10 and Figure 11 (Section 6.2). With that, we expect the approximate IB curve produced by the IBRT1 Algorithm 5 to be of lesser quality when there are more than two possible labels y. To see why, note that the space traversed by approximate clusters is not one-dimensional when , and so it is possible to maneuver around the clusters of an optimal root.
Next, we briefly discuss the basic properties of the IBRT1 Algorithm 5. Its computational complexity is determined by the complexity of a single grid point. The latter is readily seen to be dominated by the complexity of computing the coefficients matrix of the IB ODE (16) and of solving it numerically (on step 6). To that, one should add the complexity of the BA-IB Algorithm 1 each time a root is reduced. However, the critical slowing down of BA-IB [4] is avoided since we reduce the root before invoking BA-IB (see Section 5.2). The complexity is only linear in thanks to the choice of decoder coordinates. Had we chosen one of the other coordinate systems in Section 2, then solving the ODE would have been cubic in rather than linear (see there). The computational difficulty in following IB roots stems from the existence of bifurcations (Section 4), as it generally is with following an operator’s root [6] (Section 7.2).
As noted in Section 4, convergence guarantees can be derived for Euler’s method for the IB when away from bifurcation, in terms of the step-size , in a manner similar to [6] (Theorem 5) for RD. These imply similar guarantees for the IBRT1 Algorithm 5, since adding a single BA-IB iteration in our modified Euler method improves its order (see there). These details are omitted for brevity, however.
For a numerical method of order (see Section 4) with a fixed step-size and a fixed computational cost per grid point, the cost-to-error tradeoff is given by
as in [6] (Equation (3.6)), when is small enough. See [26] for example. Figure 3.4 in [6] demonstrates for RD that methods of higher order achieve a better tradeoff, as expected, as in the fixed-order Taylor methods they employ. Since computing implicit derivatives of higher orders requires the calculation of many more derivative tensors of (5) than done here [6] (Section 2.2), we have used only first-order derivatives for simplicity. However, while the vanilla Euler method for the IB is of order , the discussion in Section 4 (and Figure 4 in particular) suggests that the order d of the modified Euler method used by the IBRT1 Algorithm 5 is nearly twice than that; cf., Section 6.2 and Appendix D.
With that, we comment on the behavior of the IBRT1 Algorithm 5 at discontinuous bifurcations. Consider the problem in Figure 7 (Section 5.3), for example. When Algorithm 5 follows the optimal 2-clustered root there, the Jacobian’s singularity (in Figure 9) is detectable by it because the step size is negative (see the discussion in Section 5.3 there). Indeed, due to Conjecture 1 ff., the algorithm can detect discontinuous bifurcations in general. Whether a particular discontinuous bifurcation is detected by Algorithm 5 in practice depends on the details, of course, as with continuous bifurcations (e.g., on the threshold value for detecting singularity and on the precise grid point layout). Indeed, the details may or may not cause a particular example to be detected by the conditions on steps 7 and 8 (in Algorithm 5). If missed, Algorithm 5 will continue to follow the 2-clustered root in Figure 7 to the left of the bifurcation, where it is sub-optimal, just as BA-IB with reverse deterministic annealing would. Once detected, though, one may wonder whether the heuristic Algorithm 4 works well also for discontinuous bifurcations. The example of Figure 7 has just one single-clustered root to the left of the bifurcation. Thus, the BA-IB Algorithm 1 invoked on step 8 (of Algorithm 4) must converge to it. However, there may generally be more than a single root of smaller effective cardinality to the left of the bifurcation, to which BA-IB may converge. The handling of discontinuous bifurcations is left to future work. Such handling is expected to be easier in the IB than in RD, since, in contrast to RD, the effective cardinality of an optimal IB root cannot decrease with (bottom of Section 5.3). See Problems 2.8–2.10 in [28] for counter-examples in RD. This makes detecting discontinuous bifurcations easier in the IB and is also expected to assist with their handling.
We list the assumptions used along the way for reference. These are needed to guarantee the optimality of the IBRT1 Algorithm 5 at the limit of small step-sizes , except at a bifurcation’s vicinity. In Section 1, it was assumed without loss of generality that the input distribution is of full support, for every x (otherwise, one may remove symbols x with from the source alphabet). The requirement was added in Section 3 as a sufficient technical condition for exchanging to logarithmic coordinates (Lemma A1 in Appendix A), and could perhaps be alleviated in alternative derivations. Together, these are equivalent to having a never-vanishing IB problem definition, for every x and y. The algorithm’s initial condition is assumed to be a reduced and optimal IB root, since reduction is needed by Conjecture 1 in Section 5.1. Finally, the given IB problem is assumed to have only continuous bifurcations, except perhaps for its first (leftmost) one. While these assumptions are sufficient to guarantee optimality, we note that milder conditions might do in a particular problem.
7. Concluding Remarks
The IB is intimately related to several problems in adjacent fields [3], including coding problems, inference, and representation learning. Despite its importance, there are surprisingly few techniques to solve it numerically. This work attempts to fill this gap by exploiting the dynamics of IB roots.
The end result of this work is a new numerical algorithm for the IB, which follows the path of a root along the IB’s optimal tradeoff curve (1). A combination of several novelties was required to achieve this goal. First, the dynamics underlying the IB curve (1) obeys an ODE [10]. Following the discussion around Conjecture 1 (in Section 5.1), the existence of such a dynamics stems from the analyticity of the IB’s fixed-point Equations (2)–(4), thus typically resulting in piece-wise smooth dynamics of IB roots. Several natural choices of a coordinate system for the IB were considered, both for computational purposes and to facilitate a clean treatment of IB bifurcations below. The IB’s ODE (16) was derived anew in appropriate coordinates, allowing an efficient computation of implicit derivatives at an IB root. Combining BA-IB with Euler’s method yields a modified numerical method whose order is higher than either.
Second, one needs to understand where the IB ODE (16) is not obeyed, thereby violating the differentiability of an optimal root with respect to . To that end, one not only needs to detect IB bifurcations but also needs to identify their type in order to handle them properly. Unlike standard techniques, our approach is to remove redundant coordinates, following root tracking for RD [6] (see Section 1). To achieve a reduction, we follow the arguably better definition of the IB in [20]. Namely, a finite IB problem is an RD problem on the continuous reproduction alphabet . Therefore, the IB may be intuitively considered as a method of lossy compression of the information on Y embedded in X. Viewing a finite IB problem as an infinite RD problem suggests a particular choice of a coordinate system for the IB, which enables reduction in the IB; this extends reduction in RD [6]. Furthermore, this point of view highlights subtleties of finite dimensionality in computing representations of IB roots. To our understanding, these subtleties hindered the understanding of IB bifurcations throughout the years.
Combining the above allows us to translate an understanding of IB bifurcations to a new numerical algorithm for the IB (the IBRT1 Algorithm 5). There are several directions that one could consider to improve our algorithm. Near bifurcations, one could improve its handling of discontinuous bifurcations. While we used implicit derivatives only of the first order for simplicity, higher-order derivatives generally offer a better cost-to-error tradeoff when away from bifurcations. See also [6] (Section 3.4) on possible improvements for following an operator’s root.
Funding
This work was partially funded by the Israel Science Foundation grant 1641/21.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The author is grateful to Or Ordentlich for helpful conversations and for his support, and to Noam and Dafna Agmon for their unwavering support throughout this journey. The author thanks the late Naftali Tishby for insightful conversations and Etam Benger for his involvement during the early stages of this work. The author thanks the reviewers for their helpful comments.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IB | Information Bottleneck |
| RD | Rate Distortion |
| IFT | Implicit Function Theorem |
| ODE | Ordinary Differential Equation |
| BA | Blahut–Arimoto |
Appendix A. The BA-IB Operator in Decoder Coordinates
For reference, we give an explicit expression for the BA-IB operator in decoder coordinates, defined in Section 2.
Denote by and the vectors whose coordinates are . We denote the evaluation of at this point by . Its output is again a decoder–marginal pair, whose coordinates are denoted, respectively, and . Explicitly, in decoder coordinates is given by
where is defined in terms of and as in the IB’s encoder Equation (2) (Section 1).
The following lemma is handy when exchanging to logarithmic coordinates in Section 3.
Lemma A1.
Let define a finite IB problem, such that for every x and y. Let be the decoder of an IB root, and such that . Then for every y.
Proof of Lemma A1.
This follows immediately from the IB’s decoder Equation (3), since is a well-defined normalized conditional probability distribution if . □
Appendix B. The First-Order Derivative Tensors of Blahut–Arimoto for the IB
We calculate the first-order derivative tensors of the Blahut–Arimoto operator in log-decoder coordinates (see Section 2 and Section 3). Namely, its Jacobian matrix , and the vector of its partial derivatives with respect to . See also Appendix A for explicit formulae of in decoder coordinates.
While these are “just” differentiations, many subtleties are involved in getting the math right. For example, one needs to correctly identify the inputs and outputs of , when considered as an operator on log-decoder coordinates. For another, one must take special care as to which variable depends on which, and especially on which they do not depend, since multiple variables are involved. Above all, these calculations require a deep understanding of the chain rule. With that, a common caveat in such calculations is that the operator (and the equations defining it) should be differentiated before they are evaluated. While this is obvious for real functions, where stands for the derivative function of evaluated at , for the operator, this might be obfuscated by the myriad of variables and variable dependencies that comprise it. Although calculating the derivative of (at an arbitrary point) first and only then evaluating at a fixed point might appear as a mere technical necessity, it is required by this work, for example, when considering the vector field defined by the IB operator (5) in Section 6.3. cf., [6] (Section 5), for the derivative tensors of Blahut’s algorithm [8] for RD, of arbitrary order.
The subtitles involved in these differentiations are discussed in Appendix B.1, with the bulk of the calculations carried out in Appendix B.1.1. The latter are gathered and simplified in Appendix B.2 to obtain the Jacobian matrix , and in Appendix B.3 to obtain the partial-derivatives vector . The results provided here naturally depend on the choice of coordinate system. To compare results between log-decoder and log-encoder coordinates in Section 2 (e.g., in Figure 2), we derive in Appendix B.4 the coordinate-exchange Jacobians between these coordinate systems.
Appendix B.1. Calculation Setups and Partial Derivatives of Unnamed Functions
We explain the mathematical subtitles relevant to the sequel.
As we are interested in the derivatives of the Blahut–Arimoto Algorithm 1 for the IB (in Section 1), we shall follow its notation. Namely, distributions are subscripted i or by the algorithm’s iteration number. A subscript i is usually considered an input distribution, and a subscript is usually considered an output distribution, e.g., or . These need not be IB roots but rather are arbitrary distributions. On the other hand, a subscript denotes a distribution of an IB root at a tradeoff value , as in for a root’s decoders. To avoid subtleties due to zero-mass clusters, we usually assume in the sequel that for every . cf., Section 2 and Section 5.1 on reduction in the IB.
It is important to distinguish which variables are dependent and which are independent in a particular calculation, e.g., in Appendix B.3. Since this task is easier for a single real variable (as opposed to distributions, for example), we consider simplifications to the real case. Note that each of the Steps 1.4 through 1.8 defining the BA-IB Algorithm 1 yields a new distribution in terms of already-specified ones. These define unnamed functions, whose variables and values are probability distributions. For example, one could have formally defined in 1.5 by the function
where and are the variables of , and its output is a conditional probability distribution, with x conditioned upon . As the input and representation alphabets and are finite, and , the arguments and values of (A2) are merely real vectors. Thus, enumerating the variables and allows us to spell out (A2) by its coordinates,
While (A3) is too cumbersome to work with, it does highlight that is merely a vector of real vector-valued functions, in real variables. This allows us to use partial derivatives rather than their infinite-dimensional counterparts (namely, variational derivatives), as in
This is the derivative of (A3) with respect to a particular -entry of its argument, by definition. However, to maintain a concise notation, we shall carry on with un-named function definitions, writing for the partial derivative of (A2) rather than its explicit form (A4). If disoriented, the reader is encouraged to return to the definitions (A4).
We often exchange variables implicitly to logarithmic coordinates, as in Section 3. For example, is to be understood as exchanging variables to , with now differentiated with respect to its variables and ,
The output of may similarly be exchanged to logarithmic coordinates, as in
.
To proceed, carefully note the dependencies between the various variables in a BA-IB iteration, in Steps 1.4 through 1.8. These are summarized compactly by the following diagram:
![Entropy 25 01370 i002]() by their order of appearance in the BA-IB Algorithm 1. This diagram proceeds to both sides by the iteration number i. Each node in (A6) serves both as a function of the nodes preceding it and as a variable for those succeeding it, and so it is a “function-variable”.
by their order of appearance in the BA-IB Algorithm 1. This diagram proceeds to both sides by the iteration number i. Each node in (A6) serves both as a function of the nodes preceding it and as a variable for those succeeding it, and so it is a “function-variable”.

To differentiate along the dependencies graph (A6), we shall need the multivariate chain rule
for a function . As the dependencies graph (A6) involves multiple function variables, such as , we pause on the definition’s subtleties. The partial derivative of a function g in several variables with respect to its i-th entry is defined by
We emphasize that variables other than are fixed when calculating . And so, it makes no difference in (A8) whether or not they depend on , as in for .
Next, suppose we would like to calculate how changing an input distribution affects some output distribution. This is relevant in Appendix B.2 for example, when considering how a change in a coordinate of an input decoder or marginal affects a particular coordinate of the output decoder or marginal. For exposition’s simplicity, though, suppose that we would like to calculate how a change in the coordinate of an input encoder affects the coordinate of the output encoder. That is, deriving the rightmost node in (A6) with respect to a coordinate of the leftmost one,
where we have exchanged to logarithmic coordinates to simplify calculations. To calculate (A9), one needs to apply the multivariate chain rule (A7) along all the possible dependencies of the output on the input coordinate . This amounts to following all the paths in (A6) connecting these two nodes, summing the contributions of every possible path. For example, traversing from the input rightwards at (A6) to , then downwards to and then to the output yields the term
corresponding to this path, at particular x and coordinates. To collect the contribution from every intermediate function variable coordinate, we need to sum the latter over x and . Writing down all such paths, one has for (A9),
Repeated unbounded variables are understood to be summed over, as in Einstein’s summation convention.
Appendix B.1.1. Differentiating along the Dependencies Graph
Next, we differentiate each edge in (the logarithm of) the dependency graph (A6). These are necessary to evaluate derivatives along dependency paths, which underlie the subsequent sections’ calculations.
Step 1.4 in the BA-IB Algorithm 1 defines the cluster marginal in terms of the direct encoder,
In the first and second equalities we have used the identity for the differentiation of a function’s logarithm, when y is a function of x.
Following the comments around the definition (A8) of a partial derivative, note that Step 1.5 defines the inverse encoder as a function of the variables and (and , which we ignore under differentiation). Thus, differentiating this equation with respect to an entry of the variable implies that the entries of the other variable are held fixed, and vice versa. So, for the Bayes rule Step 1.5 we have
where at the right-hand side is different from the variable of differentiation, and so its partial derivative vanishes. Next, differentiating Step 1.5 with respect to a coordinate of its other variable ,
Using again the logarithmic derivative identity , by the decoder Step 1.6 we have
Next, consider the KL-divergence term in the Definition 1.7 of the partition function ,
Since the partition Function 1.7 depends on the decoder only via the KL-divergence,
Hence,
For the derivative of the partition function with respect to the marginal ,
where the second equality follows from the logarithmic derivative identity. Hence,
Finally, for the encoder Step 1.8,
The first two terms to the right, and , take the role of a variable in Step 1.8. In contrast, we consider the last divergence term as a shorthand for summing over . Thus, the latter is a variable of (A20). With (A15), we thus have
For the other derivatives of the encoder Step 1.8,
and
where the variable of Step 1.8 differs from the variables and , on which the crossed-out terms depend.
We summarize the calculations of this subsection in the following diagram:
![Entropy 25 01370 i003]() A differentiation variable is denoted with commas, at an arrow’s source in this diagram. A coordinate of the function which we differentiate is written without commas, at an arrow’s end, e.g.,
A differentiation variable is denoted with commas, at an arrow’s source in this diagram. A coordinate of the function which we differentiate is written without commas, at an arrow’s end, e.g.,

Appendix B.2. The Jacobian Matrix of BA-IB in Log-Decoder Coordinates
By gathering the results of Appendix B.1.1 and following the lines of Appendix B.1, we calculate the Jacobian matrix (13) (in Section 3) of the Blahut–Arimoto operator in log-decoder coordinates, defined in Section 2.
The derivative of in decoder coordinates boils down to the four quantities: the effect that varying a coordinate of an input cluster has on a coordinate of an output cluster, the effect that varying an input marginal coordinate has on a coordinate of an output cluster, and so forth. And so, the Jacobian it is a block matrix,
Its rows correspond to the output coordinates of . We index its upper rows by and , while its lower rows are indexed by alone. Similarly, its columns correspond to the input coordinates of . We index its leftmost columns by and , and its rightmost columns by alone. Each block in (A25) consists of contributions along all the distinct paths connecting two vertices in the dependencies graph (A6). For example, the lower-left block in (A25) consists of the contributions along all the paths in (A6) connecting to .
We now spell out the paths contributing to each block in (A25), with repeated dummy indices understood to be summed over. Afterward, we shall calculate the contributing paths explicitly, carrying out the summations. The upper-left block of (A25) consists of
This Equation (A26) encodes the four paths connecting the vertex to in (A6). When accumulating the contributions in (A26), one must carefully sum only over repeated dummy indices that appear in the given term. For example, the two paths in (A26) which traverse the edge (pointing from to ) do not involve a summation over . In contrast, the two paths involving there do entail a summation over . This is relevant for the calculations below, as in (A31) for example.
Similarly, for the upper-right block of (A25),
For the lower-left block of (A25),
Last, for the lower-right block of (A25),
Next, by using the intermediate results summarized in (A24) (Appendix B.1.1), we calculate each of the four blocks of (A25) explicitly. For the upper-left block (A26), we have
For clarity, we elaborate on each step needed to complete the calculation of the upper-left block (A26) while providing only the main steps for the other blocks. To carry out the summations over the dummy variables , and in (A30), we carefully sum only over repeated dummy indices, as explained after (A26). We carry out one summation at a time, starting with . This yields
In the first equality above we carried out the summation over , in the second over , in the third over , in the fourth over , and in the fifth over .
To simplify the notation, we replace summations over x with definitions as in Equation (14) (Section 3),
and note that
The quantities , and C involve two IB clusters. They are a scalar, a vector, and a matrix, respectively. The definition of D involves only one IB cluster and coincides with in [13] (3.2 in Part III). The relations to the right of (A32) show that each can be expressed in terms of . Equation (A33) shows that the latter can be rewritten as a right-stochastic matrix, up to trivial manipulations. As seen below, the Jacobian matrix (A25) of a BA-IB step in log-decoder coordinates can be computed in terms of the quantities in (A32).
For the upper-right block (A27),
In a manner similar to (A31), summing over all ten dummy variables other than and yields
In a manner similar to (A31), summing over all ten dummy variables other than and yields
The two terms involving cancel out when summing over and at the first equality. Rewriting with the definitions (A32) of A and B further simplifies (A36) to
For the lower-left block (A28),
Summing over dummy variables and simplifying yields
In terms of definitions (A32), this simplifies to
Finally, for the lower-right block (A29),
This simplifies to
With definitions (A32), this can be written as
Collecting the results from (A34), (A37), (A40), and (A43) back into (A25), BA’s Jacobian in these coordinates is
When evaluated at an IB root, this is Equation (13) of Section 3. Equivalently, it can be written in the following form, which is more convenient for implementation:
Appendix B.3. The Partial β-Derivatives of BA-IB in Log-Decoder Coordinates
We calculate the vector of partial derivatives of the operator in log-decoder coordinates (of Section 2), which appears at the right-hand side of the IB-ODE (16) (in Section 3).
To that end, we differentiate backward along the dependencies graph (A6) (in Appendix B.1) with respect to , starting at the output coordinates and of . After differentiating, we mind our independent variables. Here, these are , and the input coordinates and of . The differentiation of these with respect to vanishes (except for ), as they are independent. Finally, we compose the differentiations to obtain the effect of changing on BA’s output. We note that, in principle, one can differentiate the explicit formulae (A1) of in decoder coordinates (Appendix A) with respect to . However, we find that to be cumbersome and far more error-prone than our approach, and so proceed in the spirit of the previous Appendix B.2.
We start by differentiating each of the equations defining the Blahut–Arimoto Algorithm 1 with respect to , as if all its variables are dependent. For the cluster marginal Step 1.4,
For the inverse encoder Step 1.5,
For the decoder Step 1.6,
For the KL-divergence,
And for its exponent,
where we have written for short. Thus, for the partition function’s Step 1.7, we have
Finally, for the encoder Step 1.8 we have
Next, picking and the inputs and of as our independent variables, we compose the differentiations above to obtain at an output coordinate. That is, we seek and . By the chain rule, we trace the dependencies graph (A6) (Appendix B.1) backwards, from the output nodes and back to the input nodes. The derivatives of the latter with respect to vanish, as these are our independent variables.
Starting with a decoder output coordinate,
Since and are independent input variables, their derivatives with respect to the independent variable vanish, yielding
To complete the calculation at (A53), note that the same argument can be used for two of the three summands in (A51), reducing it to
since and are considered as independent variables. Therefore,
At the second equality to the bottom we started with the third summand, then with the first, and only then with the third and fourth summands. And so,
Next, consider a cluster marginal output coordinate,
Since and are independent variables, their derivatives with respect to vanish, yielding
Thus, for the marginals’ coordinates, we have obtained
When evaluated at an IB root, Equations (A57) and (A60) form, respectively, the decoder and marginal coordinates of , which appears at the right-hand side of the IB ODE (16) (note the extra minus sign in the implicit ODE (7)).
Appendix B.4. The Coordinate Exchange Jacobians between Log-Decoder and Log-Encoder Coordinates
Following the discussion in Section 2 on the pros and cons of each coordinate system, we leverage the observations of Appendix B.1 in order to derive the coordinate exchange Jacobians between the log-decoder and log-encoder coordinate systems. Exchanging between the other coordinate system pairs adds little to the below and thus is omitted.
Given the encoder’s logarithmic derivative , we would like to compute from it the logarithmic derivative in decoder coordinates, and vice versa. To that end, recall that an (arbitrary) encoder determines a decoder–marginal pair and vice versa (e.g., Equation (11) in Section 2). So, one can follow the dependencies graph (A6) (in Appendix B.1) backward between these coordinate systems to exchange the coordinates of an implicit derivative. For example, consider and as functions of the encoder preceding it in the graph (A6). When at an IB root, multiplying by the coordinates’ exchange Jacobian yields
Similarly, considering an encoder as a function of and ,
The last term in (A63) stems from the fact that the encoder Step 1.8 depends explicitly on , unlike the marginal and decoder Steps 1.4 and 1.6. cf., the comments around (A8) in Appendix B.1.
The matrices and for exchanging from encoder to decoder coordinates follow from the chain rule, and are calculated in Appendix B.4.1 below, at Equations (A64) and (A66). Similarly, the matrices and and the partial derivative for exchanging from decoder to encoder coordinates are Equations (A68), (A70), and (A73), in Appendix B.4.2.
Appendix B.4.1. Exchanging from Encoder to Decoder Coordinates
An input encoder determines a decoder and a marginal . As in previous subsections, we follow the dependencies graph (A6) along all the paths between these.
Using diagram (A24) from Appendix B.1.1, for the marginal one has
while for the decoder,
Summing over the three dummy variables as before, the latter simplifies to
Appendix B.4.2. Exchanging from Decoder to Encoder Coordinates
In the other way around, a decoder and a marginal determine the subsequent encoder . Using diagram (A24), one has
Summing over the dummy variable , this is the coordinates’ exchange Jacobian mentioned in Section 2:
Next, for the derivative with respect to the marginal,
Summing over the five dummy variables, this is the coordinates’ exchange Jacobian from Section 2:
Finally, note that the encoder Step 1.8 depends on explicitly, rather than indirectly only via its other variables. So, to calculate the partial derivative term in (A63), write as follows for :
Thus,
And so, from the encoder Step 1.8, we have
where the term vanishes since it is considered as an independent variable here.
Appendix C. Proof of Lemma 1, on the Kernel of the Jacobian of the IB Operator in Log-Decoder Coordinates
We prove Lemma 1 from Section 3, using the results of Appendix B.
In the first direction, suppose that is a vector in the left kernel of the Jacobian of the IB operator (5) in log-decoder coordinates, , as in (16) in Section 3. Using the Jacobian’s implicit form (A25) (Appendix B.2), this is to say that
hold, for every and . We spell out and manipulate these equations to obtain the desired result.
By the Jacobian’s explicit form (A44) from Appendix B.2, Equation (A74) spells out as
while the second Equation (A75) spells out as
Next, we expand and simplify each of the terms in (A76) and (A77), using the definition (A32) of , and C from Appendix B.2.
For the first summand to the right of (A76),
We simplify each of the four addends to the right of (A78) while temporarily ignoring the coefficient. For the term,
For the term,
For the term,
And for the last term,
Collecting (A79)–(A82) back into (A78), we obtain
for the first summand to the right of (A76).
The second summand to the right of (A76) equals
Combining (A83) and (A84), Equation (A76) is equivalent to
for any and . Summing (A85) over and simplifying, we obtain
for any .
Next, we expand and simplify Equation (A77). Using the definition (A32) of B, the first summand to its right can be written as
Similarly, the second summand to the right of (A77) can be written as
Combining (A87) and (A88), Equation (A77) can now be written explicitly,
for every . Next, subtracting (A89) from (A86), we obtain
for any .
Substituting (A90) into (A85) and using the decoder Step 1.6 to expand there,
Next, inserting into the sums on the last line,
Finally, this simplifies to
The latter is to say that is a left-eigenvector of the eigenvalue 1 of the matrix to the right. At an IB root, this is precisely the matrix S (17) from the Lemma’s statement, as desired.
As a side note, we comment that Equations (A74) and (A75) also imply
which can be seen by summing (A85) and (A89), respectively, over , and simplifying.
In the other direction, let be a left-eigenvector of the eigenvalue 1 of S (17). That is, assume that Equation (A93) holds. Define a vector by Equation (A90). Reversing the algebra, (A93) is equivalent to (A91). Substituting (A90) into the latter yields back (A85), which is equivalent to the explicit form (A76) of Equation (A74). Next, summing (A85) over and simplifying yields (A86). Adding the latter to (A90) yields back (A89), which is equivalent to Equation (A77), the explicit form of (A75). To conclude, both of the Equations (A74) and (A75) hold, as claimed.
Appendix D. Approximate Error Analysis for Deterministic Annealing and for Euler’s Method with BA
Complementing the results of Section 4, we provide an approximate error analysis for two computation methods for the IB: deterministic annealing and Euler’s method combined with a fixed number of BA iterations.
First, we recap the linearization argument around Equation (10) in [4]. Denote repeated BA iterations initialized at by
Linearizing around a fixed-point of BA,
where denotes the Jacobian matrix of evaluated at . Rewriting in terms of the error of the k-th iterate,
Thus, to first order, repeated applications of reduce the initial error according to
Next, consider applications of to a root at . This is similar to deterministic annealing, but with a capped number of BA iterations. Plugging the initial error into Equation (A98) shows that this method is of the first order:
Finally, we combine BA with Euler’s method for the IB, Equation (22). Consider applications of to the approximation produced by an Euler method step. Its initial error is
where the last equality follows from the second-order expansion , with . Similar to before, plugging this into Equation (A98) shows that this method is of the second order:
Appendix E. An Exact Solution for a Binary Symmetric Channel
Define an IB problem by and for independent of Y, , where ⊕ denotes addition modulo 2. Explicitly, it is given by and . We synthesize exact solutions for this problem using Mrs. Gerber’s Lemma [38] and by following [2].
Let be the binary entropy, with . It is injective on , with a maximal value of at . So, its inverse function is well-defined on . Given a constraint on , , define a random variable and set , where is defined by or equivalently in terms of by . Explicitly, , with its rows indexed by and columns by x. is also a variable since X is, and so
showing that the constraint on holds. The chain of random variables is readily seen to be Markov. By Corollary 4 in [38], it follows that , where . Finally, equality follows by Theorem 1 there. Thus, the above is IB-optimal.
The above defines an IB solution as a function of . However, our numerical computations are phrased in terms of the IB’s Lagrange multiplier . To that end, note that [2] (Section IV.A) show that
and that the bifurcation of this problem occurs at
To conclude, we have as a function of , as a function of , and the encoder as a function of . These functional dependencies are summarized as follows:
![Entropy 25 01370 i004]() where the variable at the tail of each arrow is a function of that at its head.
where the variable at the tail of each arrow is a function of that at its head.

Writing , its derivative with respect to can be calculated by the chain rule:
where we have applied the derivative of an inverse function to in (A103), to differentiate . From the argument around (A102), . While this yields an analytical expression for the derivative , both of the terms to the right of (A106) are evaluated at , for a given value. Although it is straightforward to compute numerically from (A103), this entails numerical error, especially as approaches near the bifurcation. For the solution with respect to decoder coordinates, an immediate application of the Bayes rule shows that
where the rows of are indexed by y, and columns by . Along with , its derivatives with respect to follow as in (A106).
Appendix F. Equivalent Conditions for Cluster-Merging Bifurcations
We briefly discuss the equivalent conditions for cluster-merging bifurcations in the IB (Section 5.2) found in the literature.
Rose et al. [39] (Section 4) derive a condition for cluster-splitting phase transitions (Equation (17) there) in the context of fuzzy clustering. Following this, [13] (3.2 in Part III) derives an analogous condition for cluster splitting in the IB (Equation (12) there):
where I is the identity. Namely, for a cluster to split, it is necessary that be an eigenvalue of an -by- matrix , whose entries at an IB root are given by
While the coefficients matrix (A109) for the IB differs from the one for fuzzy clustering, inter-cluster interactions are explicitly neglected in both derivations (see therein). Indeed, the definition (A109) of involves the coordinates of cluster alone, as one might expect when considering a root in either decoder or in inverse encoder coordinates (Section 2). Reversing the dynamics in , condition (A108) characterizes cluster-merging bifurcations in the IB (Section 5.2).
In [13] it is noted that (A108) is closely related to the bifurcation analysis of [9]. The latter provides a condition to identify the critical values of IB bifurcations, given in their Theorem 5.3. Indeed, their condition is equivalent to (A108), and therefore it also characterizes cluster-merging bifurcations. To see this, the necessary condition they give for a phase transition at is that must be an eigenvalue of a matrix V (Equation (21) there). When written in our notation, this matrix is given by
However, V (A110) is readily seen to be the transpose of (A109), and so they have the same eigenvalues.
Appendix G. Lyapunov Stability of an Optimal IB Root
We provide the essential parts of a proof that an optimal IB root is Lyapunov uniformly asymptotically stable on closed intervals which do not contain a bifurcation when following the flow dictated by the IB’s ODE (16) in decreasing . Definitions for the below are as in [40] (see especially Section 4.2 there). See Section 6.3 for a discussion of the results below.
Let be an optimal IB root. We start by rewriting it as an equilibrium of a non-autonomous ODE, as in [40] (Equation (4.1)). Consider the implicit ODE (7) , specialized to the IB by setting (5). Denote , for an arbitrary . Subtracting the ODE at from that at yields a non-autonomous ODE in the error from the optimal root:
This rewrites the given root as an equilibrium of this ODE (A111), simplifying the below.
Next, we define a Lyapunov function for the flow of the equilibrium along the ODE (A111), when its dynamics in is reversed. Consider the IB’s Lagrangian as a functional in , and let be its optimal value at . Then,
is the desired Lyapunov function. Specifically, (i) is positive definite and (ii) is negative definite, when the dynamics in are reversed. Theorem 4.1 in [40] then implies that is uniformly asymptotically stable [40] (Definition 4.6).
For (i), (A112) is immediately seen to be positive semi-definite from the definition of , up to technicalities ignored here (cf., Definition 4.7 in [40]). The results of Section 5.3 (after Proposition 1) imply that representing in reduced log-decoder coordinates renders (A112) strictly positive definite. Indeed, is non-singular in a reduced representation in these coordinates, as mentioned there, and so an optimal root is locally unique. As for condition (ii), from the definition of we have
where in the last equality follows by direct calculations similar to those in the Appendix of [13] (Part III). Thus, for the -derivative of (A112), we have
The latter is always positive semi-definite around , since by definition (1) yields the maximal Y-information subject to a constraint on the X-information. The same argument as above shows that it is strictly positive definite. Finally, reversing the dynamics in leaves the ODE (A111) unaffected but flips the sign of (A114), rendering it negative definite as required.
Appendix H. Introducing Degeneracies to the IB Operator in Decoder Coordinates Is Uninformative at an Isolated Optimal Root
Suppose that the Jacobian of the IB operator (5) in log-decoder coordinates is non-singular at a reduced representation of an IB root, as in the argument following Proposition 1 (Section 5.3). We show that evaluating it on a non-reduced (degenerate) representation only permits one to detect kernel directions which are due to the selected degeneracy. Thus, it is inadequate for detecting bifurcations, as explained in Section 5.3.
Let be an IB root of effective cardinality . A T-clustered representation of a root (e.g., in decoder coordinates) is a function , defined on some neighborhood of . In the other way around, one can consider the inclusion , defined in the obvious way on normalized decoder coordinates at some neighborhood of . Let be a representation of in its effective cardinality , and a degenerate one on clusters. These satisfy
where is the reduction map (defined similar to the root-reduction Algorithm 2, by setting its thresholds to zero, , and replacing its strict inequalities with non-strict ones. Note that Algorithm 2 has a well-defined output for every input). In the other way around, one can pick a particular degenerating map (e.g., “split the third cluster to two copies of probability ratio 1:2”). Applying a particular degeneracy and then reducing is the identity,
though not the other way around. Let i and be the inclusions corresponding to and , respectively. Similar to (A115), degenerating a root has no effect before it is included into ,
Recall from Section 5.1 (before Conjecture 1) that in decoder coordinates may be considered as an operator on . To summarize, we have the following diagram:
![Entropy 25 01370 i005]() Next, consider the representations of the IB operator (5) on and clusters. These amount to pre-composing with the inclusions and post-composing with the representation maps. Denote by the identity operator on . By identities (A115), (A116), and (A117), the -clustered representation of (5) satisfies
Differentiating, by the chain rule we have
Multiplying a matrix B from the left can only enlarge the kernel, , and so
Since the left-hand side is evaluated at a reduced representation, it vanishes by assumption. Thus, is of full rank, yielding
where denotes the vectors tangent to the column space of . Stated differently, the Jacobian of a -clustered representation of (5) can only detect directions in , which are determined by the choice of the degenerating map , as argued.
Next, consider the representations of the IB operator (5) on and clusters. These amount to pre-composing with the inclusions and post-composing with the representation maps. Denote by the identity operator on . By identities (A115), (A116), and (A117), the -clustered representation of (5) satisfies
Differentiating, by the chain rule we have
Multiplying a matrix B from the left can only enlarge the kernel, , and so
Since the left-hand side is evaluated at a reduced representation, it vanishes by assumption. Thus, is of full rank, yielding
where denotes the vectors tangent to the column space of . Stated differently, the Jacobian of a -clustered representation of (5) can only detect directions in , which are determined by the choice of the degenerating map , as argued.

For completeness, splitting a cluster into two at some fixed ratio is of the form . Adding a pre-defined cluster of zero mass is constant on the newly added coordinates. A general degeneracy map is a composition of these, and is otherwise the identity map on unaffected coordinates.
References
- Tishby, N.; Pereira, F.C.; Bialek, W. The Information Bottleneck Method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Witsenhausen, H.; Wyner, A. A Conditional Entropy Bound for a Pair of Discrete Random Variables. IEEE Trans. Inf. Theory 1975, 21, 493–501. [Google Scholar] [CrossRef]
- Zaidi, A.; Estella-Aguerri, I.; Shamai, S. On the Information Bottleneck Problems: Models, connections, Applications and Information Theoretic Views. Entropy 2020, 22, 151. [Google Scholar] [CrossRef] [PubMed]
- Agmon, S.; Benger, E.; Ordentlich, O.; Tishby, N. Critical Slowing Down Near Topological Transitions in Rate-Distortion Problems. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 2625–2630. [Google Scholar]
- Gilad-Bachrach, R.; Navot, A.; Tishby, N. An Information Theoretic Tradeoff between Complexity and Accuracy. In Learning Theory and Kernel Machines; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Agmon, S. Root Tracking for Rate-Distortion: Approximating a Solution Curve with Higher Implicit Multivariate Derivatives. IEEE Trans. Inf. Theory 2023, in press. [Google Scholar]
- De Oliveira, O. The Implicit and the Inverse Function Theorems: Easy Proofs. Real Anal. Exch. 2014, 39, 207–218. [Google Scholar] [CrossRef]
- Blahut, R. Computation of Channel Capacity and Rate-Distortion Functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef]
- Gedeon, T.; Parker, A.E.; Dimitrov, A.G. The Mathematical Structure of Information Bottleneck Methods. Entropy 2012, 14, 456–479. [Google Scholar] [CrossRef]
- Agmon, S. On Bifurcations in Rate-Distortion Theory and the Information Bottleneck Method. Ph.D. Thesis, The Hebrew University of Jerusalem, Jerusalem, Israel, 2022. [Google Scholar]
- Rose, K.; Gurewitz, E.; Fox, G. A deterministic annealing approach to clustering. Pattern Recognit. Lett. 1990, 11, 589–594. [Google Scholar] [CrossRef]
- Kuznetsov, Y.A. Elements of Applied Bifurcation Theory, 3rd ed.; Springer Science & Business Media: New York, NY USA, 2004; Volume 112. [Google Scholar]
- Zaslavsky, N. Information-Theoretic Principles in the Evolution of Semantic Systems. Ph.D. Thesis, The Hebrew University of Jerusalem, Jerusalem, Israel, 2019. [Google Scholar]
- Ngampruetikorn, V.; Schwab, D.J. Perturbation Theory for the Information Bottleneck. Adv. Neural Inf. Process. Syst. 2021, 34, 21008–21018. [Google Scholar] [PubMed]
- Wu, T.; Fischer, I.; Chuang, I.L.; Tegmark, M. Learnability for the Information Bottleneck. PMLR 2020, 115, 1050–1060. [Google Scholar] [CrossRef]
- Wu, T.; Fischer, I. Phase Transitions for the Information Bottleneck in Representation Learning. In Proceedings of the Eighth International Conference on Learning Representations (ICLR 2020), Virtual Conference, 26 April–1 May 2020. [Google Scholar]
- Rose, K. A Mapping Approach to Rate-Distortion Computation and Analysis. IEEE Trans. Inf. Theory 1994, 40, 1939–1952. [Google Scholar] [CrossRef]
- Giaquinta, M.; Hildebrandt, S. Calculus of Variations I; Springer: Berlin/Heidelberg, Germany, 2004; Volume 310. [Google Scholar]
- Parker, A.E.; Dimitrov, A.G. Symmetry-Breaking Bifurcations of the Information Bottleneck and Related Problems. Entropy 2022, 24, 1231. [Google Scholar] [CrossRef] [PubMed]
- Harremoës, P.; Tishby, N. The Information Bottleneck Revisited or How to Choose a Good Distortion Measure. In Proceedings of the 2007 IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 566–570. [Google Scholar]
- Kielhöfer, H. Bifurcation Theory: An Introduction with Applications to Partial Differential Equations, 2nd ed.; Springer: New York, NY, USA, 2012. [Google Scholar]
- Lee, J.M. Introduction to Smooth Manifolds, 2nd ed.; Spinger: New York, NY, USA, 2012. [Google Scholar]
- Dummit, D.S.; Foote, R.M. Abstract Algebra, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2004. [Google Scholar]
- Teschl, G. Topics in Linear and Nonlinear Functional Analysis; University of Vienna: Vienna, Austria, 2022; Available online: https://www.mat.univie.ac.at/~gerald/ftp/book-fa/fa.pdf (accessed on 20 December 2022).
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 2nd ed.; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Butcher, J.C. Numerical Methods for Ordinary Differential Equations, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Atkinson, K.E.; Han, W.; Stewart, D. Numerical Solution of Ordinary Differential Equations; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 108. [Google Scholar]
- Berger, T. Rate Distortion Theory: A Mathematical Basis for Data Compression; Prentice-Hall: Englewood Cliffs, NJ, USA, 1971. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Shannon, C.E. Coding Theorems for a Discrete Source with a Fidelity Criterion. IRE Nat. Conv. Rec. 1959, 4, 325–350. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2006; p. 748. [Google Scholar]
- Dieudonné, J. Foundations of Modern Analysis; Academic Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Gowers, T.; Barrow-Green, J.; Leader, I. The Princeton Companion to Mathematics; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Coolidge, J.L. A Treatise on Algebraic Plane Curves; Dover: Dover, NY, USA, 1959. [Google Scholar]
- Strogatz, S.H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Golubitsky, M.; Stewart, I.; Schaeffer, D.G. Singularities and Groups in Bifurcation Theory II; Springer: New York, NY, USA, 1988. [Google Scholar]
- Benger, E.; (The Hebrew University of Jerusalem, Jerusalem, Israel). Private communications, 2019.
- Wyner, A.; Ziv, J. A Theorem on the Entropy of Certain Binary Sequences and Applications: Part I. IEEE Trans. Inf. Theory 1973, 19, 769–772. [Google Scholar] [CrossRef]
- Rose, K.; Gurewitz, E.; Fox, G.C. Statistical Mechanics and Phase Transitions in Clustering. Phys. Rev. Lett. 1990, 65, 945. [Google Scholar] [CrossRef] [PubMed]
- Slotine, J.J.E.; Li, W. Applied Nonlinear Control; Prentice Hall: Englewood Cliffs, NJ, USA, 1991; Volume 199. [Google Scholar]
Figure 1.
The approximate IB curves yielded by our algorithm, based on the IB ODE (16). Our First-order Root Tracking algorithm for the IB (IBRT1) of Section 6.1 was used to approximate the optimal IB roots of a binary symmetric channel with crossover probability 0.3 and a uniform source, BSC(0.3), for several grid densities. The points in the information plane yielded from these approximations are plotted on top of the problem’s exact solution (see Appendix E). Despite the algorithm’s approximation errors (Section 6.2), the approximate curves it yields are visually indistinguishable from the true IB curve (1), even on relatively few grid points. The reasons for this are discussed below (Section 6.3).
Figure 1.
The approximate IB curves yielded by our algorithm, based on the IB ODE (16). Our First-order Root Tracking algorithm for the IB (IBRT1) of Section 6.1 was used to approximate the optimal IB roots of a binary symmetric channel with crossover probability 0.3 and a uniform source, BSC(0.3), for several grid densities. The points in the information plane yielded from these approximations are plotted on top of the problem’s exact solution (see Appendix E). Despite the algorithm’s approximation errors (Section 6.2), the approximate curves it yields are visually indistinguishable from the true IB curve (1), even on relatively few grid points. The reasons for this are discussed below (Section 6.3).

Figure 2.
Derivatives’ norm by coordinate system, for the exact solution of BSC(0.3) with a uniform source, as in Figure 1; see Appendix E. The derivative’s -norm is plotted in green for encoder coordinates and blue for decoder coordinates. The solution barely changes at high values, and so the derivative in decoder coordinates is smaller (see main text). Nevertheless, the derivative in encoder coordinates does not vanish then, due to Equation (12). At low values, however, the derivative in either coordinate system may generally be large. Both vanish to the left of the bifurcation in this problem (dashed red vertical), as the solution there is trivial (single-clustered). The derivatives diverge near the bifurcation (to its right) regardless of the coordinate system, as might be expected by the implicit ODE (7)—see also Section 6.1.
Figure 2.
Derivatives’ norm by coordinate system, for the exact solution of BSC(0.3) with a uniform source, as in Figure 1; see Appendix E. The derivative’s -norm is plotted in green for encoder coordinates and blue for decoder coordinates. The solution barely changes at high values, and so the derivative in decoder coordinates is smaller (see main text). Nevertheless, the derivative in encoder coordinates does not vanish then, due to Equation (12). At low values, however, the derivative in either coordinate system may generally be large. Both vanish to the left of the bifurcation in this problem (dashed red vertical), as the solution there is trivial (single-clustered). The derivatives diverge near the bifurcation (to its right) regardless of the coordinate system, as might be expected by the implicit ODE (7)—see also Section 6.1.

Figure 3.
The implicit derivatives computed from the IB ODE (16) are very accurate, as is the BA-IB Algorithm 1. However, both lose their accuracy near a bifurcation. To verify their accuracy, we compared both to the exact solutions of BSC(0.3) with a uniform source (see Appendix E). (Top): Derivatives were computed at the problem’s exact solution using the IB ODE (16) and compared to the problem’s exact derivatives. These are accurate beyond the machine’s precision, except when approaching the bifurcation (red vertical), since the Jacobian of the IB operator (5) is ill-conditioned there. (Bottom): The -errors of the solutions produced by the BA-IB Algorithm 1, with a stopping condition, and uniform initial conditions. Error is measured from the true direct encoder to avoid biases due to clusters of low mass. Both plots are as in Figure 2.3 of [6].
Figure 3.
The implicit derivatives computed from the IB ODE (16) are very accurate, as is the BA-IB Algorithm 1. However, both lose their accuracy near a bifurcation. To verify their accuracy, we compared both to the exact solutions of BSC(0.3) with a uniform source (see Appendix E). (Top): Derivatives were computed at the problem’s exact solution using the IB ODE (16) and compared to the problem’s exact derivatives. These are accurate beyond the machine’s precision, except when approaching the bifurcation (red vertical), since the Jacobian of the IB operator (5) is ill-conditioned there. (Bottom): The -errors of the solutions produced by the BA-IB Algorithm 1, with a stopping condition, and uniform initial conditions. Error is measured from the true direct encoder to avoid biases due to clusters of low mass. Both plots are as in Figure 2.3 of [6].

Figure 4.
Error by step-size for a vanilla Euler method using the IB ODE (16), and with an added BA-IB iteration at each step, for BSC(0.3) with a uniform source (Appendix E). The linear regression (dashed black) of the third leftmost markers for the vanilla Euler method is of slope (), matching the theory’s prediction almost perfectly. A similar regression (not shown) for Euler’s method with a single added BA iteration is of nearly double slope . For comparison, reverse deterministic annealing with a single BA iteration at each grid point yields a slope of in this example. Taking a larger (pre-determined) number of iterations at each grid point pushes the error downwards, as expected. Yet, the resulting slopes approach 1 as the number of iterations is increased (not shown). See main text and Appendix D for details. The error was calculated as the supremum of the pointwise errors as in Figure 3, over the interval which contains no bifurcation. Each method was initialized with the exact solution at , with halved between consecutive markers.
Figure 4.
Error by step-size for a vanilla Euler method using the IB ODE (16), and with an added BA-IB iteration at each step, for BSC(0.3) with a uniform source (Appendix E). The linear regression (dashed black) of the third leftmost markers for the vanilla Euler method is of slope (), matching the theory’s prediction almost perfectly. A similar regression (not shown) for Euler’s method with a single added BA iteration is of nearly double slope . For comparison, reverse deterministic annealing with a single BA iteration at each grid point yields a slope of in this example. Taking a larger (pre-determined) number of iterations at each grid point pushes the error downwards, as expected. Yet, the resulting slopes approach 1 as the number of iterations is increased (not shown). See main text and Appendix D for details. The error was calculated as the supremum of the pointwise errors as in Figure 3, over the interval which contains no bifurcation. Each method was initialized with the exact solution at , with halved between consecutive markers.

Figure 5.
While the Jacobian must be singular at a bifurcation, this does not suffice to identify its type. The Jacobian eigenvalues of (13) with respect to log-decoder coordinates are plotted for BSC(0.3) with a uniform source, as in Figure 1; see Appendix E for its exact solution. An eigenvalue reaches one (dashed green) precisely at the bifurcation (dashed red vertical), as expected by Conjecture 1 in Section 5.1. In particular, the Jacobian is increasingly ill-conditioned when approaching the bifurcation, as noted in Figure 3 (top). While this allows one to detect the bifurcation, identifying its type is necessary for handling it.
Figure 5.
While the Jacobian must be singular at a bifurcation, this does not suffice to identify its type. The Jacobian eigenvalues of (13) with respect to log-decoder coordinates are plotted for BSC(0.3) with a uniform source, as in Figure 1; see Appendix E for its exact solution. An eigenvalue reaches one (dashed green) precisely at the bifurcation (dashed red vertical), as expected by Conjecture 1 in Section 5.1. In particular, the Jacobian is increasingly ill-conditioned when approaching the bifurcation, as noted in Figure 3 (top). While this allows one to detect the bifurcation, identifying its type is necessary for handling it.

Figure 6.
A cluster-merging bifurcation. The reduced form of the optimal IB root in decoder coordinates as a function of , for the exact solution of BSC(0.3) with a uniform source, as in Figure 1 (see Appendix E). At high enough , the root consists of two clusters (in green and blue), each of a marginal probability . The clusters collide at (dashed red vertical) and merge to one, yielding the trivial solution—a single cluster of probability 1 at . Carefully note that only a single IB root is plotted here, in its reduced form, with one cluster to the left of and two to the right. The violation of clusters’ differentiability at can be observed visually (top), and the root is otherwise real-analytic in , as can be deduced from Figure 5. Since the trivial solution is an IB root for every (not shown), then is indeed a bifurcation, where the trivial and non-trivial roots intersect. To see this, consider the degenerate form of the trivial solution on two copies of , each of probability . The marginals (bottom) appear to be discontinuous at because the root was reduced before plotted (the latter degenerate form of the trivial root is not plotted to the left of ).
Figure 6.
A cluster-merging bifurcation. The reduced form of the optimal IB root in decoder coordinates as a function of , for the exact solution of BSC(0.3) with a uniform source, as in Figure 1 (see Appendix E). At high enough , the root consists of two clusters (in green and blue), each of a marginal probability . The clusters collide at (dashed red vertical) and merge to one, yielding the trivial solution—a single cluster of probability 1 at . Carefully note that only a single IB root is plotted here, in its reduced form, with one cluster to the left of and two to the right. The violation of clusters’ differentiability at can be observed visually (top), and the root is otherwise real-analytic in , as can be deduced from Figure 5. Since the trivial solution is an IB root for every (not shown), then is indeed a bifurcation, where the trivial and non-trivial roots intersect. To see this, consider the degenerate form of the trivial solution on two copies of , each of probability . The marginals (bottom) appear to be discontinuous at because the root was reduced before plotted (the latter degenerate form of the trivial root is not plotted to the left of ).

Figure 7.
A discontinuous IB bifurcation at , of the problem defined by . (Left): to the left of , the optimal solution is the trivial one, supported on the IB cluster . To the right it is supported on the boundary points (1, 0) and (0, 1) of . (Middle): the marginals are constant, except at the point of bifurcation. Any convex combination of the trivial and non-trivial roots is optimal there (dotted). That is, this is a support-switching bifurcation as in RD [6] (Figure 6.2). (Right): the IB curve exhibits a linear segment of slope , connecting the image of the trivial solution in the information plane (bottom-left) to that of the non-trivial one (top-right). See comments in the main text.
Figure 7.
A discontinuous IB bifurcation at , of the problem defined by . (Left): to the left of , the optimal solution is the trivial one, supported on the IB cluster . To the right it is supported on the boundary points (1, 0) and (0, 1) of . (Middle): the marginals are constant, except at the point of bifurcation. Any convex combination of the trivial and non-trivial roots is optimal there (dotted). That is, this is a support-switching bifurcation as in RD [6] (Figure 6.2). (Right): the IB curve exhibits a linear segment of slope , connecting the image of the trivial solution in the information plane (bottom-left) to that of the non-trivial one (top-right). See comments in the main text.

Figure 8.
A support-switching bifurcation in RD, reproducing Figure 6.2(F) in [6] (details therein). The RD curve (23) (black) is the envelope of its tangents, parameterized by their slope , [28]. At high slopes, the envelope coincides with that of the problem restricted to the reproduction alphabet (green), and at low slopes with that restricted to (blue). At a critical slope , the tangent touches both curves (red circles). Convexity then implies a linear segment (dashed)—see main text.
Figure 8.
A support-switching bifurcation in RD, reproducing Figure 6.2(F) in [6] (details therein). The RD curve (23) (black) is the envelope of its tangents, parameterized by their slope , [28]. At high slopes, the envelope coincides with that of the problem restricted to the reproduction alphabet (green), and at low slopes with that restricted to (blue). At a critical slope , the tangent touches both curves (red circles). Convexity then implies a linear segment (dashed)—see main text.

Figure 9.
Bifurcations can be detected by ’s Jacobian only if computed on enough clusters. The approximate eigenvalues of are plotted by the representation’s dimension for the problem in Figure 7. The eigenvalues are evaluated at solutions obtained by the BA-IB Algorithm 1 (stopping condition = ), initialized anew at random for each . While the random initializations account for much of the eigenvalues’ spread, they reveal the solution’s behavior through its various approximations. Other factors which contribute to this spread are the degeneracy of the solutions (when , right panel), BA’s loss of accuracy near the bifurcation (Figure 3 bottom), and the decoders’ proximity to the simplex boundaries (see Equation (13)). (Left): when computed at reduced representations (on clusters to the left, to the right), then the eigenvalues at the trivial solution give no indication of the upcoming bifurcation (at ), unlike the eigenvalues at the 2-clustered root (). (Right): the bifurcation’s presence is clearly noticed also at the trivial solution () when evaluated at its degenerate 2-clustered representations. Indeed, the trivial solution is then represented on the same number of clusters () as the root to the right ()—see Proposition 1. However, due to the bifurcation, the eigenvalues’ trajectories are not smooth at . Both: a similar dependency on the representation’s dimension also exists in the other bifurcation examples in this paper (though without the eigenvalues’ spread).
Figure 9.
Bifurcations can be detected by ’s Jacobian only if computed on enough clusters. The approximate eigenvalues of are plotted by the representation’s dimension for the problem in Figure 7. The eigenvalues are evaluated at solutions obtained by the BA-IB Algorithm 1 (stopping condition = ), initialized anew at random for each . While the random initializations account for much of the eigenvalues’ spread, they reveal the solution’s behavior through its various approximations. Other factors which contribute to this spread are the degeneracy of the solutions (when , right panel), BA’s loss of accuracy near the bifurcation (Figure 3 bottom), and the decoders’ proximity to the simplex boundaries (see Equation (13)). (Left): when computed at reduced representations (on clusters to the left, to the right), then the eigenvalues at the trivial solution give no indication of the upcoming bifurcation (at ), unlike the eigenvalues at the 2-clustered root (). (Right): the bifurcation’s presence is clearly noticed also at the trivial solution () when evaluated at its degenerate 2-clustered representations. Indeed, the trivial solution is then represented on the same number of clusters () as the root to the right ()—see Proposition 1. However, due to the bifurcation, the eigenvalues’ trajectories are not smooth at . Both: a similar dependency on the representation’s dimension also exists in the other bifurcation examples in this paper (though without the eigenvalues’ spread).

Figure 10.
Clusters of the approximate IB roots generated by the IBRT1 Algorithm 5 for several step-sizes, on top of the exact solutions of BSC(0.3) with a uniform source (Appendix E). Carefully note that only a single IB root is plotted here; its two clusters merge at (dashed red vertical), as seen in Figure 6 (Section 5.2). At 20 and 100 grid points, the approximations overshoot the bifurcation, terminating due to (approximate) cluster collision, while on 1200 grid points, the approximations pass too close to the bifurcation, terminating due to the nearby singularity. This can be seen in the inset to the right: The leftmost green marker has passed the cluster-merging threshold (dashed green lines), and so was numerically reduced to the trivial (single-clustered) solution by the root-reduction Algorithm 2. On the other hand, the orange markers to the right are still far from the cluster-merging threshold; the leftmost one was reduced by the singularity-handling heuristic Algorithm 4 since the IB ODE (16) is nearly singular there. Indeed, the numerical derivative is about five orders of magnitude larger there than at the algorithm’s initial condition (see Figure 2) due to the bifurcation’s proximity. The leftmost green and orange markers were drawn after the reductions took place. See main text and Section 6.1 for details, Figure 11 for errors, and Figure 1 (in Section 1) for the approximate IB curves. The marginals are not shown, as these barely deviate from their true value in this problem. For each step-size , the algorithm was initialized at the problem’s exact solution at , with thresholds set to , for i = 1, 2, 3. The lines connecting consecutive markers are for visualization only.
Figure 10.
Clusters of the approximate IB roots generated by the IBRT1 Algorithm 5 for several step-sizes, on top of the exact solutions of BSC(0.3) with a uniform source (Appendix E). Carefully note that only a single IB root is plotted here; its two clusters merge at (dashed red vertical), as seen in Figure 6 (Section 5.2). At 20 and 100 grid points, the approximations overshoot the bifurcation, terminating due to (approximate) cluster collision, while on 1200 grid points, the approximations pass too close to the bifurcation, terminating due to the nearby singularity. This can be seen in the inset to the right: The leftmost green marker has passed the cluster-merging threshold (dashed green lines), and so was numerically reduced to the trivial (single-clustered) solution by the root-reduction Algorithm 2. On the other hand, the orange markers to the right are still far from the cluster-merging threshold; the leftmost one was reduced by the singularity-handling heuristic Algorithm 4 since the IB ODE (16) is nearly singular there. Indeed, the numerical derivative is about five orders of magnitude larger there than at the algorithm’s initial condition (see Figure 2) due to the bifurcation’s proximity. The leftmost green and orange markers were drawn after the reductions took place. See main text and Section 6.1 for details, Figure 11 for errors, and Figure 1 (in Section 1) for the approximate IB curves. The marginals are not shown, as these barely deviate from their true value in this problem. For each step-size , the algorithm was initialized at the problem’s exact solution at , with thresholds set to , for i = 1, 2, 3. The lines connecting consecutive markers are for visualization only.

Figure 11.
The error of the IBRT1 Algorithm 5 from the exact solution for several step-sizes. The figure shows the (log-) -error of the numerical approximations in Figure 10 from the exact solutions; the error is measured as in Figure 3 (bottom). Increasing the grid density decreases the error, as one might expect. While the error peaks at the bifurcation (dashed red vertical), it decreases afterward—see main text and Section 6.3 below. The rightmost marker for each grid density is missing since the initial error is zero.
Figure 11.
The error of the IBRT1 Algorithm 5 from the exact solution for several step-sizes. The figure shows the (log-) -error of the numerical approximations in Figure 10 from the exact solutions; the error is measured as in Figure 3 (bottom). Increasing the grid density decreases the error, as one might expect. While the error peaks at the bifurcation (dashed red vertical), it decreases afterward—see main text and Section 6.3 below. The rightmost marker for each grid density is missing since the initial error is zero.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Agmon, S. The Information Bottleneck’s Ordinary Differential Equation: First-Order Root Tracking for the Information Bottleneck. Entropy 2023, 25, 1370. https://doi.org/10.3390/e25101370
AMA Style
Agmon S. The Information Bottleneck’s Ordinary Differential Equation: First-Order Root Tracking for the Information Bottleneck. Entropy. 2023; 25(10):1370. https://doi.org/10.3390/e25101370
Chicago/Turabian StyleAgmon, Shlomi. 2023. "The Information Bottleneck’s Ordinary Differential Equation: First-Order Root Tracking for the Information Bottleneck" Entropy 25, no. 10: 1370. https://doi.org/10.3390/e25101370
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.