1. Introduction
Common strategies in drug discovery include forward pharmacology [
1] and rational drug design [
2]. In the former, a library of compounds is screened, typically in a high throughout manner, for certain phenotypic effects in vitro. In the latter, compounds are virtually screened against a predetermined biological target, and high confidence hits are then assayed for a desired modulation. In both cases, the hits obtained are then assessed for effectiveness in vivo and proceed to clinical trials for eventual FDA approval if successful at each stage. This iterative process can cost billions of dollars and up to 15 years per drug [
3]. These approaches do not consider the promiscuity of approved drugs [
4,
5,
6] in the context of indications/diseases within living systems (evidenced by side effects present for all small molecule therapies [
7,
8]), dooming many novel therapeutics to fail. With the second-leading cause of putative drug attrition being adverse reactions [
9], there is great utility in finding new uses for already approved drugs, which is formally known as drug repurposing or repositioning [
10,
11,
12,
13].
We have developed the Computational Analysis of Novel Drug Opportunities (CANDO) platform [
14,
15,
16] to address these drug discovery challenges. One fundamental tenet of CANDO is that drugs interact with many different proteins and pathways to rectify disease states, and this promiscuous nature is exploited to relate drugs based on their proteomic signatures [
14,
17,
18,
19,
20]. These signatures are typically determined via virtual molecular docking simulations that are applied to predict compound–protein interactions on a proteomic scale. Using a knowledge base of known drug-indication approvals/associations, we can identify putative drug repurposing candidates for a particular indication based on the similarity of their proteomic interaction signatures to all other drugs approved for (or associated with) that indication. When a particular indication does not have any approved drug, the library of human use compounds present in CANDO is screened against the tertiary structures of all relevant and tractable proteins obtained by X-ray diffraction or homology modeling from a particular organismal proteome to suggest new treatments that maximize binding to the disease-causing proteins and minimize off-target effects. High-confidence putative drug candidates generated by CANDO using both approaches have been prospectively validated preclinically for a variety of indications, including dengue, dental caries, diabetes, hepatitis B, herpes, lupus, malaria, and tuberculosis, with 58/163 candidates yielding comparable or better therapeutic activity than standard treatments [
17,
18,
21,
22].
To date, putative drug candidates generated by CANDO have been based on simple comparison metrics, primarily the root mean square deviation (RMSD) of the binding scores present in a pair of drug-proteome interaction signatures. Our platform is evaluated using a benchmarking method that assesses per indication accuracies based on whether or not other drugs associated with the same indication can be captured within a certain cutoff in terms of similarity to a particular drug approved for that indication. Incorporating machine learning, which is continuing to prove its utility in many aspects of biomedicine [
23,
24,
25] including drug discovery and repurposing [
26,
27], into the CANDO platform to increase benchmarking accuracies and therefore its predictive power is of importance. Various algorithms can be incorporated (for example, neural networks, support vector machines, and decision trees), but the well-documented issues described by the curse of dimensionality [
28,
29] will plague any choice in the current (v1.5) implementation of CANDO, especially considering the extremely large number of features (≈50,000 proteins) within each compound–proteome interaction signature vector. Given the relatively few training samples (an average of ≈9 drugs per indication), a machine learning approach to train how drugs interact with proteomes is a much easier task with a vastly reduced set of proteins.
Therefore, in this study, we set out to find a reduced set of proteins that can therapeutically characterize compounds, as well as using the full protein library, with the eventual goal of utilizing them in future machine learning experiments. Our strategy involves using a brute force or greedy feature selection, where the full protein library was split into smaller subsets that were subsequently benchmarked and ranked according to their performance by different metrics. The best performing subsets were recombined into supersets and benchmarked again, which produced substantial improvement with all the benchmarking metrics. Further analysis of the best performing protein subsets and supersets revealed that those that contained proteins predicted to bind to a more equitably diverse ligand structure distribution were strongly associated with increased benchmarking performance, indicating that drugs approved for human use have a specific range and distribution of protein binding site interactions. In addition, protein supersets optimized for independent compound libraries were cross-tested and were able to reproduce the performance of using the full protein library. This indicates that overtraining on a specific compound library during this iterative procedure was limited in scope, making these protein supersets broadly applicable for characterizing drug behavior. We applied one of these protein libraries to generate putative drug candidates against malaria, tuberculosis, and large cell carcinoma, and more of the resulting predictions could be validated in the biomedical literature compared to those suggested by using the full protein library, indicating the utility of our approach.
2. Results
2.1. Benchmarking of Generated Supersets
Figure 1 provides a general overview of our study design (see the Methods). Fifty iterations of splitting the 46,784 proteins into 5848 subsets of 8 were performed, resulting in 292,400 benchmarks. The maximum, minimum, mean, and standard deviation were respectively 11.7%, 6.2%, 9.1%, and 0.5% for average indication accuracy, 20.2%, 12.7%, 16.7%, and 0.8% for pairwise accuracy, and 548, 398, 477.5, and 15.6 for coverage, with each metric following a normal distribution (
Figure S1). The mean benchmarking performance for each superset within a given iteration tends to gradually increase as the number of iterations increases (
Figure 2). Ranking subsets using coverage is overall the best criterion, as it yielded the maximum benchmarking performance for all three metrics. Coverage was the dominant ranking criterion beginning at Iteration 16, as it yielded the maximum average indication accuracy and coverage. Average indication accuracy is overall the second best ranking criterion as evidenced by its very close performance to coverage in the average indication accuracy and pairwise accuracy metrics and being the best metric through Iteration 15. The maximum values obtained by supersets for average indication accuracy, pairwise accuracy, and coverage were 14.0%, 23.2%, and 602, which represents a 14%, 7%, and 10% improvement over the control (using all 46,784 proteins) values of 12.3%, 21.6%, and 546, respectively.
Sorting the supersets by size reveals that at least 80–120 proteins, or 10–15 subsets, are required to reach optimal benchmarking performance (
Figure 3). Nonredundantly combining the worst performing subsets of eight into subpar sets demonstrates worse performance than the control value for the average indication accuracy based on using the full library, with the mean values of these subpar set distributions being below the acceptable 5% threshold of 11.6% for all sizes benchmarked. The random set and subpar set distributions begin to converge toward the average indication accuracy control value as size increases (
Figure 3). The principal component analysis (PCA) matrices score very similarly to the random sets, indicating that the supersets are a superior dimensionality reduction method. The mean average indication accuracies begin to plateau or slightly decrease after sizes of 256–264 for the supersets, while continuing to rise as the subpar set size increases. This suggests that the distribution of features within each protein library is important for describing drug/compound behavior.
2.2. Cross-Testing with Independent Compound Libraries
For the independent compound library experiment, average indication accuracy was chosen as the ranking criterion because it performed the best in all three metrics through ten iterations in the superset experiment (
Figure 2). Box and whisker plots for each compound library show the spread of the benchmarking performance for each metric generated from the protein supersets obtained through the splitting and ranking protocol of their complementary compound library (
Figure 4). Based on the results of
Figure 3, supersets less than a size of 80 (<10 subsets) were excluded because there is a minimum number of protein features required to reach optimal benchmarking performance. The control value for the given metric fell within the inter-quartile range or below in 26 cases (87%), while it was within the upper quartile in the remaining four cases (13%), indicating that these values always fell within the range of the accuracy/coverage distributions. The control value was an extreme outlier below the distribution in five cases (17%), indicating the potential of these supersets to describe compound behavior more effectively than the full protein library.
2.3. Ligand Clustering and Feature-Based Creation of Protein Libraries
The protein subsets and supersets were analyzed based on four criteria to elucidate the feature(s) responsible for benchmarking performance: organismal source, structure source (X-ray diffraction or modeling), fold space, and interacting ligand structure distributions (see the Methods). There were no significant correlations found for the first three criteria; no organism(s) or fold(s) was consistently represented in the best performing sets, while the structure sources were evenly distributed among the best and worst performing subsets and supersets. All ligands in the COFACTOR [
30] database were clustered to investigate the fourth criterion (see the Methods). A total of 7252 ligands were unable to be clustered due to molecular file conversion errors, resulting in 64,592 clustered ligands. Clustering at a distance of 0.3 created 9929 clusters with varying sizes. The number of clusters including at least 10, 100, and 1000 compounds were 568, 52, and 7, respectively, including 5280 singleton clusters. Compound–protein interactions for all 46,784 proteins were mapped to ligand clusters based on the co-crystallized ligand of the binding site that was chosen for each compound–protein pair, and ligand cluster signatures were generated for each protein (see the Methods). The ligand cluster signatures of the best and worst 50 subsets from the first iteration of the splitting and ranking protocol were averaged together, with the resulting distribution of cluster counts at each rank compared using Welch’s
T-test (
Figure 5). The subsets with the best performance were composed of a much more equitable distribution of interactions among clusters than those with the worst performance on average (see Figure 8 for visual examples of proteins that compose the best and worst subsets). The first two ranks showed the greatest contrast between the subsets with
p-values of 1.04 × 10
−8 and 2.38 × 10
−4, respectively, with all but two of the 22 rank distributions tested being significantly different (
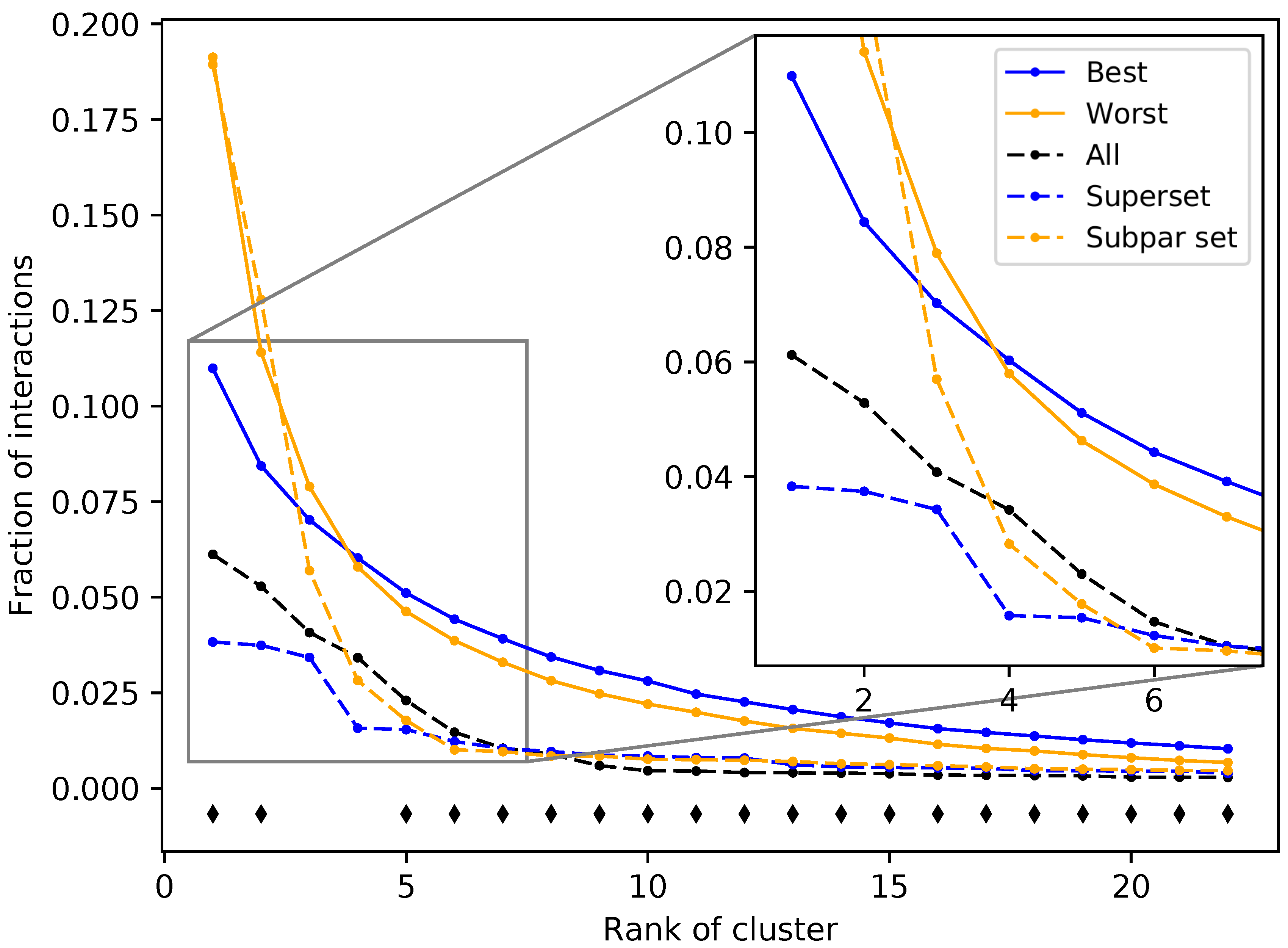
p-value < 0.05). The ligand cluster analysis was repeated for a superset and a subpar set, and both followed a similar pattern to the one previously observed, with the superset having a more equitable distribution of interactions among clusters and the subpar set being far more imbalanced.
Based on the subset analysis, it was hypothesized that proteins having a more diverse and equitable distribution of interactions will benchmark better. Protein libraries were created by ranking the 46,784 proteins in CANDO on the variance of the number of interactions attributed to each ligand cluster (see the Methods). Creating libraries using proteins with the lowest variance of ligand cluster interactions (excluding the trivial case of proteins mapped to only one cluster) results in benchmarking performance much higher than libraries composed of proteins with high variance (
Figure 6 and
Figure 7). To elucidate the impact of the number of ligand clusters mapped to a given protein, we applied an upper cutoff filter for the number of ligand clusters allowed (
Figure 6); all libraries were limited to a size of 80, which is the minimum required to reach optimal performance based on the data in
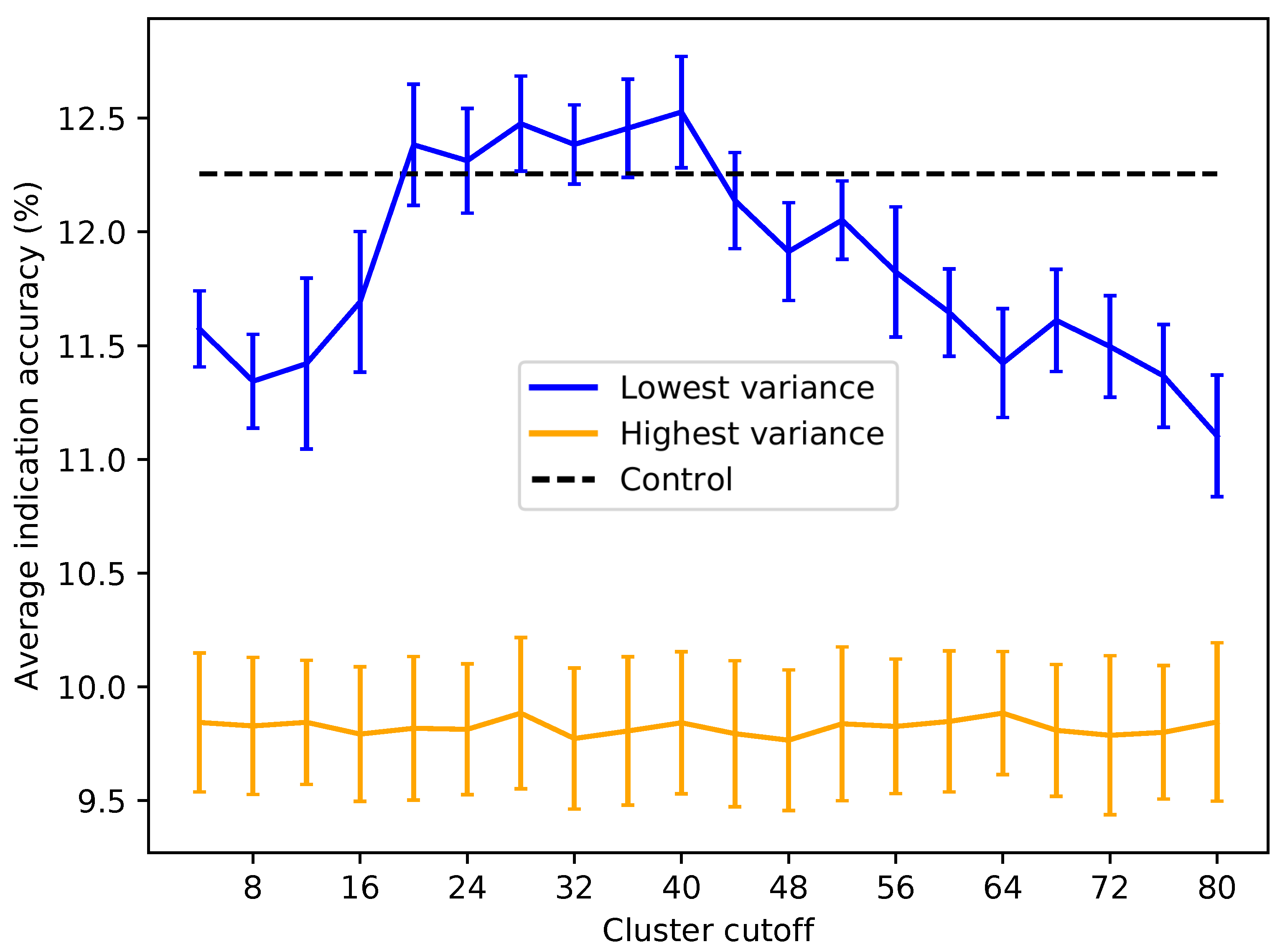
Figure 3. There is an optimal upper limit of ≈20–40 ligand clusters with regard to the benchmarking, indicating that using too many ligand clusters to describe a protein is undesirable for characterizing drug/compound behavior. Based on the data in
Figure 6, we created protein libraries of various sizes using an upper cutoff of 40 (
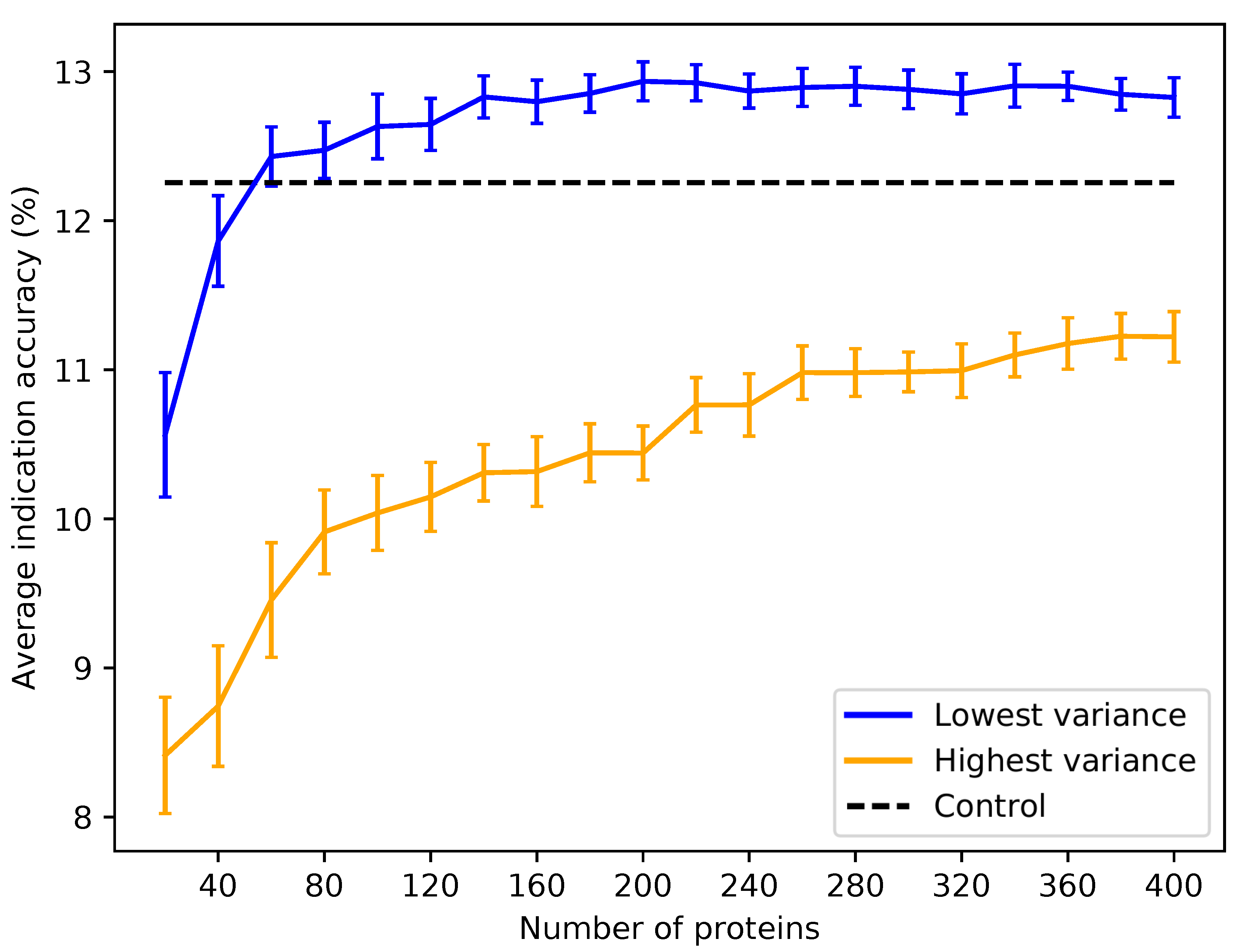
Figure 7). We began to consistently recapture the benchmarking performance of the full library (within 5% error) with as few as 60 proteins. Libraries composed of high variance proteins, which are proteins with greatly imbalanced ligand cluster signatures (i.e., >95% interactions mapped to one cluster), produced benchmarking performance outside of the acceptable 5% error range for all the created libraries (
Figure 6 and
Figure 7). All other distance cutoffs (0.1–0.9) for the ligand clustering step were tested, and the same result was reproduced.
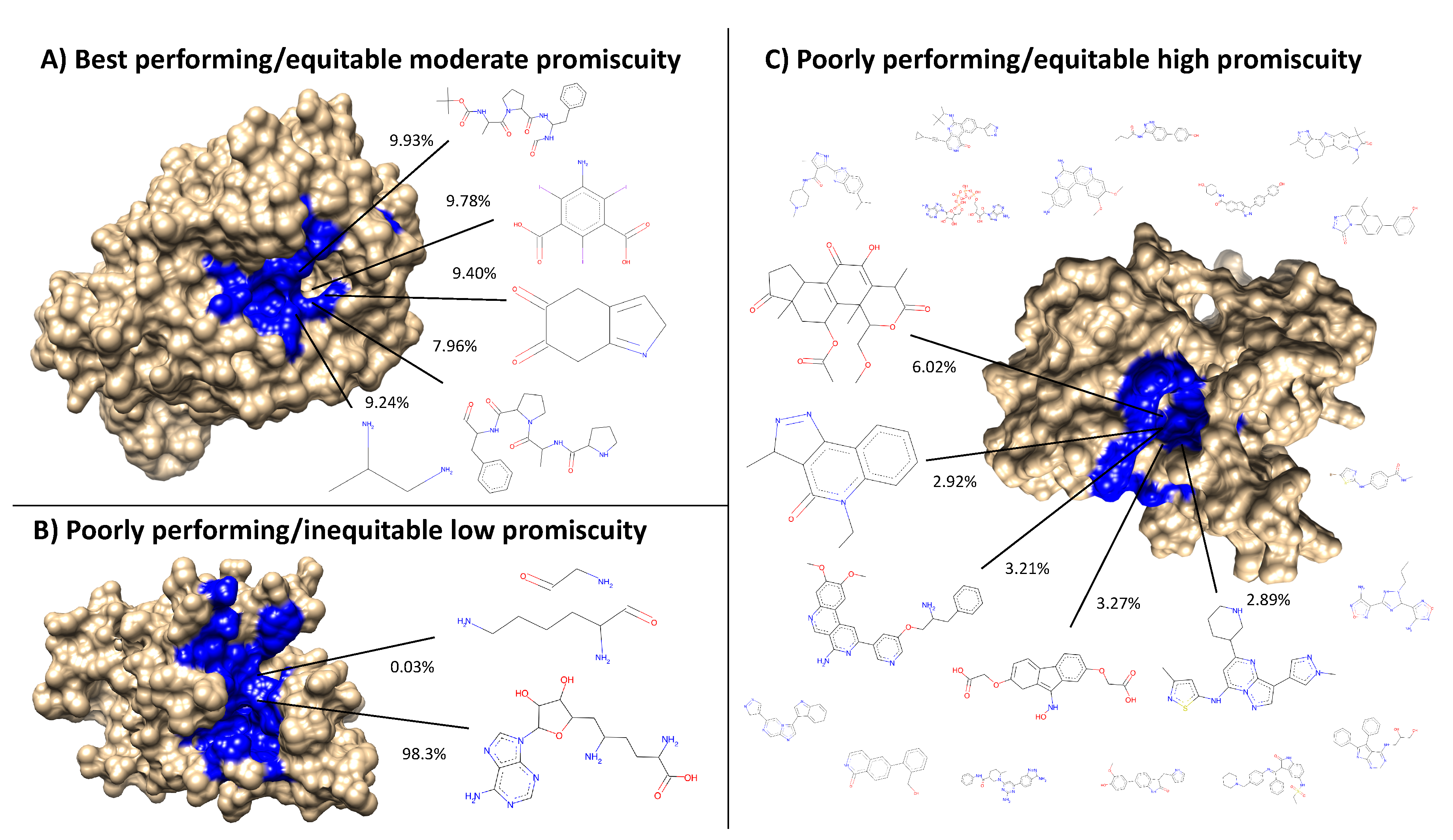
Figure 8 provides a visual depiction of the best and worst types of proteins for benchmarking performance, highlighting the idea that a moderately diverse and equitable distribution of interacting ligand clusters is ideal for describing drug behavior.
2.4. Validation Case Studies
The lists of the putative drug candidates against malaria, tuberculosis, and large cell carcinoma generated using both the created protein library and the full protein library are available in the
Supplementary Information. Many candidates are shared between the two libraries for malaria, including closely-related compounds quinine ethyl carbonate and cinchonine monohydrochloride, as well as tigecycline, with the former two having known anti-malarial activity and the latter having success in vitro and in vivo [
32,
33]. A trivial candidate predicted using the full library is quinacrine, a malaria treatment closely related to and since supplanted by the more efficacious chloroquine. The top two candidates exclusively generated using the created protein library are the antifungal drug posaconazole and experimental compound zosuquidar, both of which have shown anti-malarial activity as lactate dehydrogenase enzyme and P-glycoprotein-specific inhibitors, respectively [
34,
35]. The candidates generated against large cell carcinoma are largely shared between the two libraries, though the drugs suggested from the reduced library include sobuzoxane and cycloserine, both of which have shown anti-cancer activity [
36,
37,
38]. For tuberculosis, the reduced library exclusively generated chlortetracycline and diflunisal with the former significantly enhancing pyrazinamide activity and the latter being a bacterial beta clamp inhibitor [
39,
40]. Another interesting candidate is dacarbazine, a Hodgkin’s disease treatment, which in a few case studies of patients with concomitant Hodgkin’s lymphoma and tuberculosis showed significant recovery of both indications after treatment with dacarbazine and other anti-tubercular drugs [
41,
42]. Both libraries trivially generated methaniazide and rifampicin, known anti-tuberculosis drugs, and pyrazinoic acid, which is a metabolite of pyrazinamide, another known anti-tuberculosis drug; this previously-known information was not present in the drug-indication mappings used to make the predictions. None of the top candidates generated using the full protein library that were not also suggested using the created protein library could be found to have activity against malaria or tuberculosis in our search of the biomedical literature, though the full library also predicted antimony tartrate and clofarabine against large cell carcinoma, the former of which has shown anti-angiogenic activity in non-small cell lung cancer and the latter of which is a known anti-cancer drug [
43].
3. Discussion
The splitting and ranking protocol was originally intended to find a protein subset that benchmarked as least as well as the full set. The improvement of the benchmarking performance is an encouraging sign for incorporating machine learning in the CANDO platform in the future, and discovering how more complex weighting and relating of proteins contribute to drug repurposing accuracy, which is difficult to do with simple RMSD calculations. The smaller-sized protein libraries generated as part of this study, representing a 100–1000-fold reduction in size, will be more conducive to machine learning. Feature reduction through approaches other than PCA, such as neural network-based auto-encoders, will provide an important contrast to our proposed method.
The independent compound library experiment demonstrated that optimized protein sets based on a particular library were capable of therapeutically characterizing a completely different one, indicating that these supersets are generalizable. In other words, if a new drug/compound is added to the CANDO putative drug library, these reduced size supersets are likely able to describe its behavior at least as well as using every protein available. In addition to facilitating machine learning, our findings suggest a greatly reduced time required to generate new proteomic interaction vectors, which is particularly important if the program/protocol of choice for generating interactions is computationally expensive. Any repurposing candidates suggested from using the supersets are on average more clinically relevant, as they were able to recapture drug behavior more accurately than using the full protein library in a statistically-significant manner.
The knowledge that ligand cluster interaction diversity is the key requisite feature in describing drug behavior may also lead to optimization strategies other than the computationally-intensive splitting and ranking protocol used in this study. The importance of ligand cluster interaction diversity may play a role in a variety of applications in systems and synthetic biology, for example in the design of protein systems that are specifically tailored to handle drug absorption, distribution, metabolism, and excretion processes. These optimizations incorporated into our repurposing platform should result in the rapid generation of more accurate putative drug repurposing candidates, thereby alleviating the problems associated with current drug discovery. We used a specific reduced size library of 100 proteins optimized for ligand cluster interaction diversity to generate putative drug candidates against malaria, tuberculosis, and large cell carcinoma to demonstrate its effectiveness. The reduced library suggested twelve drug candidates with some evidence of activity against the respective indications, whereas the full library suggested eight (one of which, quinacrine, is no longer in use); this result cumulatively corresponds to a 50% increase in predictive power and provides evidence of the effectiveness of our protein feature analysis pipeline. Performing a systematic and continuous literature analysis of the putative drug candidates generated using our pipelines for every possible indication would continue to lend further rigor in assessing its effectiveness and is one of our future goals.
The ligand cluster analysis revealed that compound–protein interactions are more therapeutically relevant if the proteins used to describe the behavior of a compound are diverse in terms of the structures of the ligands that interact with their binding sites. Protein libraries with fewer predicted ligand cluster binding partners yield much worse performance than those consisting of proteins interacting with a more structurally-diverse range of ligands. Coupling this with the finding that there is a minimum number of proteins required to reach optimal benchmarking accuracies (
Figure 3), which was also observed by us previously [
15,
16], drugs should realistically be described in the context of their multitarget nature, treating both small molecule compounds and proteins promiscuously, as in biological systems [
4,
44,
45]. However, using libraries of proteins with too many diverse interactions in the CANDO platform also leads to suboptimal performance. We hypothesize this can be attributed to two factors: (1) spreading a compound interaction signature across too many (50 or more) ligand clusters can potentially dilute the therapeutic signal relative to the promiscuity of the corresponding proteins; or (2) these proteins are not therapeutically relevant and are therefore not useful for specifically describing drug behavior.
In the context of drug design, comprehending the promiscuous nature of small molecule drugs to develop strategies that optimize their interactions with macromolecular targets of interest, while minimizing interactions leading to adverse events, will address the two leading causes of drug attrition in clinical trials [
9]. To this end, further studies to enhance the CANDO platform using a variety of molecular fingerprint descriptors for compounds, docking methods, compound–protein interaction parameters, machine learning methods, side effect data, and indication-specific supersets are currently underway.
4. Materials and Methods
Figure 1 provides a general overview of the Computational Analysis of Novel Drug Opportunities (CANDO) platform and the protein subset analysis study design. A more detailed description follows below.
4.1. Compound and Indication Mappings
The putative drug library in the CANDO platform comprises 3733 human use compounds, including all clinically-approved drugs from the U.S. FDA, Europe, Canada, and Japan, as well as some experimental compounds collected from DrugBank [
46], the NCGCPharmaceutical Collection (NPC) [
47], Wikipedia, and PubChem [
48]. Each drug/compound was converted to a three-dimensional (3D) or tertiary structure to standardize input conformation and avoid biasing the results using ChemAxon’s MarvinBeans molconverter v.5.11.3 (
https://chemaxon.com/). InChiKeyswere generated from all preprocessed compounds using Xemistry’s Cactvs Chemoinformatics Toolkit [
49] (
https://www.xemistry.com/) to remove redundancies. Drug–disease associations were obtained from the Comparative Toxicogenomics Database (CTD) [
50] and mapped to our drug/compound library, resulting in associations with 2030 indications, including 1439 indications with at least two drugs that were used to perform our leave-one-out benchmarking protocol described below [
14,
15,
16,
18,
20].
4.2. Compound–Proteome Interaction Matrix Generation
The protein structure library in the CANDO platform is made up of 48,278 tertiary conformations solved using X-ray diffraction taken from the Protein Data Bank (PDB) [
51] (≈80% of the structures), as well as homology models (≈20%). The organism sources for the proteins include
Homo sapiens and several higher order eukaryotes, bacteria, and viruses. Protein structure models were generated using HHBLITS [
52], I-TASSER [
53,
54], and KoBaMIN [
55]. KoBaMIN uses knowledge-based force fields for fast protein model structure refinement, while ModRefiner [
54] also uses physics-based force fields for the same purpose. HHBLITS uses hidden Markov models to increase the speed and accuracy of protein sequence alignments, and LOMETS [
56] uses multiple threading programs to align and score protein targets and templates. SPICKER [
57] identifies native protein folds by clustering the computer-generated models. The I-TASSER modeling pipeline consists of the following steps: (1) HHBLITS and LOMETS for template model selection; (2) threading of protein sequences from templates as structural fragments; (3) replica-exchange Monte Carlo simulations for fragment assembly; (4) SPICKER for the clustering of simulation decoys; (5) ModRefiner for the generation of atomically-refined model SPICKER centroids; (6) KoBaMIN for final refinement of models. Some pathogen proteins failed during the modeling and were removed, ultimately resulting in 46,784 proteins in the final matrix. To generate scores for each compound–protein interaction, COFACTOR [
30] was first used to determine potential ligand binding sites for each protein by scanning a library of experimentally-determined template binding sites with the bound ligand from the PDB. COFACTOR outputs multiple binding site predictions, each with an associated binding site score. For each predicted binding site, the associated co-crystallized ligand is compared to each compound in our set using the OpenBabel FP4 fingerprinting method [
58], which assesses compound similarity based on functional groups from a set of SMARTS [
59] patterns, resulting in a structural similarity score. The score that populates each cell in the compound–protein interaction matrix is the maximum value of all of the possible binding site scores times the structural similarity scores of the associated ligand and the compound.
4.3. Benchmarking Protocol and Evaluation Metrics
The compound–compound similarity matrix is generated using the root mean square deviation (RMSD) calculated between every pair of compound interaction signatures (the vector of 46,784 real value interaction scores between a given compound and every protein in the library). Two compounds with a low RMSD value are hypothesized to have similar behavior [
14,
15,
16,
18,
20]. For each of the 1439 indications with two or more associated drugs, the leave-one-out benchmark assesses accuracies based on whether another drug associated with the same indication can be captured within a certain cutoff of the ranked compound similarity list of the left-out drug. This study primarily focused on a cutoff of the ten most similar compounds (“top10”), the most stringent cutoff used in previous publications [
14,
15,
16,
18,
20]. The benchmarking protocol calculates three metrics to evaluate performance: average indication accuracy, compound-indication pairwise accuracy, and coverage. Average indication accuracy is calculated by averaging the accuracies for all 1439 indications using the formula c/d × 100, where c is the number of times at least one drug was captured within the cutoff (top10 in this study) and d is the number of drugs approved for that given indication. Pairwise accuracy is the weighted average of the per indication accuracies based on how many drugs are approved for a given indication. Coverage is the count of the number of indications with non-zero accuracies within the top10 cutoff.
4.4. Superset Creation and Benchmarking
The 46,784 proteins in the CANDO platform were randomly split into 5848 subsets of 8 and subsequently benchmarked using the method described above. The size of 8 was selected because it offered the widest range of benchmarking values (relative to larger sizes), reduced the computational cost of the experiments (relative to smaller sizes, which increase the number of individual benchmarks that need to be evaluated), divided into 46,784 evenly, and also provided an adequate signal for the multitargeting approach to work according to our prior studies [
17]. A total of 50 iterations were performed, which resulted in 292,400 benchmarking experiments. Each subset was then ranked according to top10 average indication accuracy, pairwise accuracy, and coverage. The fifty best performing subsets from each ranking criterion (average indication accuracy, pairwise accuracy, and coverage) were progressively combined into supersets and benchmarked after each of the 50 iterations of the splitting and ranking protocol. The subsets were nonredundantly combined such that if a given protein was represented in the best performing subsets more than once (from two or more different iterations), then it would only occur once in the superset. The number of proteins in each superset ranged from 8–400. The complete protein–compound interaction matrix was reduced to 8, 80, 160, 240, 320, and 400 dimensions using principal component analysis (PCA) to serve as a control.
4.5. Independent Compound Library Creation and Evaluation
The CANDO putative drug library was split into two disjoint libraries comprising ≈50% of the compounds (1866 and 1867 compounds) five times. For each such library, the indication mapping was reconstructed to include only the disease associations of the drugs present. Each corresponding pipeline comprised of a disjoint compound library was subjected to ten iterations of the splitting and ranking protocol. Protein supersets, composed of the fifty best performing subsets for each metric that were progressively combined (see the previous section), were generated and benchmarked. Supersets less than a size of 80 were excluded due to the results of
Figure 2, which shows that benchmarking performance begins to plateau starting with around that number of proteins. The remaining supersets were then cross-tested on their complementary sets to assess the generalizability of our selection and optimization protocol by comparing it to the corresponding control value based on using the full protein structure library (but with the same disjoint compound library). The benchmarkings for each of these 50% disjoint compound libraries was not directly comparable to each other, nor to the full compound library, because the indication mappings are different.
4.6. Evaluating the Features Responsible for Protein Subset and Superset Accuracy
The best performing protein subsets and supersets were further analyzed to elucidate the protein feature(s) responsible for increased benchmarking performance. The protein subsets and supersets were analyzed based on four criteria: organismal source, structure source (X-ray diffraction or modeling), fold space (based on the CATHclassification of proteins [
60]), and interacting ligand structure distributions. The subsets and supersets were analyzed by counting the specific organisms to which the proteins belonged to see if any were over- or under-represented in the best and worst performing sets. Similarly, the subsets and supersets were analyzed to see if structures obtained via a specific source, X-ray diffraction or modeling, were differentially represented in the best and worst performing sets. Structures obtained via X-ray diffraction are more accurate and may provide a better protein–compound interaction score. Fold assignments were made to each protein in the subsets and supersets, which were again analyzed for differential representation of specific protein folds. The fold of the protein may disclose important features of the binding site, such as overall shape and volume. Finally, since our compound–protein interaction scoring method utilized the structural similarity of each drug/compound to the ligand co-crystallized with the protein (see the previous section), we analyzed these ligands for differential representation. Each co-crystallized ligand in the COFACTOR database of template binding sites was clustered at various distances (0.1–0.9 with increments of 0.1) using the Butina clustering algorithm [
61] in the RDKit [
62] (
http://www.rdkit.org/) library based on the Tanimoto distance [
63] of their Daylight fingerprints (
http://www.daylight.com/). A total of 64,592 ligands were clustered with 7252 ligands failing due to molecular file conversion errors. Each protein in the subsets and supersets was assigned a ligand cluster signature where each value in the vector is the number of times a ligand from a given cluster was chosen while calculating the compound–protein interaction score protocol for that protein. The fraction of interactions belonging to each cluster for each protein set was calculated by first adding the ligand cluster signatures for each protein belonging to the set, then ranking the clusters from greatest to smallest, and finally dividing by the number of total interactions (size of the protein set times 3733). These signatures may provide insight into the structural diversity of ligands with which proteins are interacting, which is a measure of promiscuity. The ligand cluster signatures of the best and worst 50 subsets from the first iteration of the splitting and ranking protocol were averaged together, with the resulting distribution of cluster counts at each rank compared using Welch’s
T-test for equal means. Protein subsets were chosen from only one iteration to ensure independence.
4.7. Creating Protein Libraries Using the Most Important Feature
Of the features evaluated (see above), only the ligand cluster distribution could be correlated with benchmarking performance (see the Results). We then generated new protein structure libraries that captured this feature ideally and assessed benchmarking performance. Each protein was ranked based on the variance of the values in their ligand cluster signatures. A minimum cutoff of two clusters was used to prevent the trivial case of proteins with only one cluster mapped (with a variance of zero). Another cutoff of at least 1867 total mapped interactions was used to account for proteins with interactions mapped to unclustered ligands. Proteins were randomly selected from the top of the ranked list of variances at size increments of 20 and then benchmarked. The cutoff of proteins considered for random selection was two-times the size of the library (for instance, 100 proteins were randomly selected from the top 200 proteins ranked by ligand cluster signature variance). A total of 50 libraries were made for each size to generate a distribution of benchmarking values. This procedure was repeated for the bottom of the ranked list of variances for comparison.
4.8. Validation Case Studies
We analyzed the ability of the created protein libraries to generate putative drug candidates for the treatment of malaria and tuberculosis, indications targeted in previous publications [
16,
17], as well as large cell carcinoma. We used all the indications belonging to the Medical Subject Headings (MeSH) categories related to malaria, tuberculosis, and large cell carcinoma in our drug-indication mapping, namely “malaria” (MeSH:D008288) “falciparum malaria” (MeSH:D016778), “vivax malaria” (MeSH:D016780), “cerebral malaria” (MeSH:D016779), “tuberculosis” (MeSH:D014376), “multidrug-resistant tuberculosis” (MeSH:D018088), “pulmonary tuberculosis” (MeSH:D014397), “spinal tuberculosis” (MeSH:D014399), “central nervous system tuberculosis” (MeSH:D020306), “lymph node tuberculosis” (MeSH:D014388), “meningeal tuberculosis” (MeSH:D014390), “extensively drug-resistant tuberculosis” (MeSH:D054908), and “large cell carcinoma” (MeSH:D018287), as well as a library of 100 proteins from the previous step that achieved a top10 benchmarking accuracy of 13.3%, to generate drug/compound similarities using our platform. We then used a concurrence-ratio scoring method to generate candidates by first counting the number of times each compound appeared in the top10 most similar compounds of each drug approved for each indication and then ranking the compounds by dividing by the number of drugs approved for that indication. We compared this to the putative drug candidate list generated by the full library of 46,784 proteins and searched the biomedical literature for validation using Google Scholar.
5. Conclusions
We have developed an integrated pipeline that allows for the elucidation of proteins and their features, which are important for benchmarking in the CANDO platform and therefore important for drug repurposing and design. We were able to reproduce the performance of the complete CANDO protein structure library with orders of magnitude fewer proteins, allowing for more rapid candidate generation when evaluating new putative drug libraries or any other changes to the platform. We discovered that moderately promiscuous proteins, in terms of the structures of ligands with which they are predicted to interact, are important for describing how drugs behave in biological systems, a claim validated by literature evidence supporting putative drug candidates generated by a library composed of a subset of these proteins for the treatment of malaria, tuberculosis, and large cell carcinoma. The implications for drug design are that appreciating the multitarget nature of small molecule therapies and optimizing their interactions with the range of macromolecular targets that they are exposed to in their environments during their absorption, dispersion, metabolism, and excretion may be more fruitful than traditional rational drug design using single targets.
Supplementary Materials
The following are available online: Figure S1: Distributions of protein subset benchmarking accuracies and coverages, File S1: Putative drug candidates against malaria, tuberculosis, and large cell carcinoma generated using the full protein library, File S2: Putative drug candidates against malaria, tuberculosis, and large cell carcinoma generated using a created library of 100 proteins, and File S3: Drugs approved for the treatment of malaria, tuberculosis, and large cell carcinoma used in this study.
Author Contributions
W.M. conceptualized the experiments, designed the methodology, performed all formal analysis, and drafted the manuscript. R.S. provided general oversight and mentorship, helped with data interpretation, and helped with manuscript development and editing.
Funding
This work was supported in part by a National Institute of Health Director’s Pioneer Award (DP1OD006779), a National Institute of Health Clinical and Translational Sciences Award (UL1TR001412), a National Library of Medicine T15 Award (T15LM012495), a National Cancer Institute/Veterans Affairs Big Data-Scientist Training Enhancement Program Fellowship in Big Data Sciences, and startup funds from the Department of Biomedical Informatics at the University at Buffalo.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; nor in the decision to publish the results.
References
- Broach, J.R.; Thorner, J. High-throughput screening for drug discovery. Nature 1996, 384, 14–16. [Google Scholar] [PubMed]
- Macalino, S.J.Y.; Gosu, V.; Hong, S.; Choi, S. Role of computer-aided drug design in modern drug discovery. Arch. Pharm. Res. 2015, 38, 1686–1701. [Google Scholar] [CrossRef] [PubMed]
- Mullard, A. New drugs cost US [dollar] 2.6 billion to develop. Nat. Rev. Drug Discov. 2014, 13, 877. [Google Scholar]
- Bolognesi, M.L. Polypharmacology in a single drug: Multitarget drugs. Curr. Med. Chem. 2013, 20, 1639–1645. [Google Scholar] [CrossRef] [PubMed]
- Anighoro, A.; Bajorath, J.; Rastelli, G. Polypharmacology: Challenges and opportunities in drug discovery: miniperspective. J. Med. Chem. 2014, 57, 7874–7887. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Bajorath, J. Monitoring drug promiscuity over time. F1000Research 2014, 3, 218. [Google Scholar] [CrossRef] [PubMed]
- Iwata, H.; Mizutani, S.; Tabei, Y.; Kotera, M.; Goto, S.; Yamanishi, Y. Inferring protein domains associated with drug side effects based on drug-target interaction network. BMC Syst. Biol. 2013, 7, S18. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Altman, R.B. Relating essential proteins to drug side-effects using canonical component analysis: A structure-based approach. J. Chem. Inf. Model. 2015, 55, 1483–1494. [Google Scholar] [CrossRef]
- Arrowsmith, J.; Miller, P. Trial watch: Phase II and phase III attrition rates 2011–2012. Nat. Rev. Drug Discov. 2013, 12, 569. [Google Scholar] [CrossRef]
- Liu, X.; Zhu, F.; H Ma, X.; Shi, Z.; Y Yang, S.; Q Wei, Y.; Z Chen, Y. Predicting targeted polypharmacology for drug repositioning and multi-target drug discovery. Curr. Med. Chem. 2013, 20, 1646–1661. [Google Scholar] [CrossRef]
- Achenbach, J.; Tiikkainen, P.; Franke, L.; Proschak, E. Computational tools for polypharmacology and repurposing. Future Med. Chem. 2011, 3, 961–968. [Google Scholar] [CrossRef] [PubMed]
- Yella, J.; Yaddanapudi, S.; Wang, Y.; Jegga, A. Changing trends in computational drug repositioning. Pharmaceuticals 2018, 11, 57. [Google Scholar] [CrossRef] [PubMed]
- Hurle, M.; Yang, L.; Xie, Q.; Rajpal, D.; Sanseau, P.; Agarwal, P. Computational drug repositioning: From data to therapeutics. Clin. Pharmacol. Ther. 2013, 93, 335–341. [Google Scholar] [CrossRef] [PubMed]
- Chopra, G.; Samudrala, R. Exploring polypharmacology in drug discovery and repurposing using the CANDO platform. Curr. Pharm. Des. 2016, 22, 3109–3123. [Google Scholar] [CrossRef] [PubMed]
- Sethi, G.; Chopra, G.; Samudrala, R. Multiscale modelling of relationships between protein classes and drug behavior across all diseases using the CANDO platform. Mini Rev. Med. Chem. 2015, 15, 705–717. [Google Scholar] [CrossRef] [PubMed]
- Minie, M.; Chopra, G.; Sethi, G.; Horst, J.; White, G.; Roy, A.; Hatti, K.; Samudrala, R. CANDO and the infinite drug discovery frontier. Drug Discov. Today 2014, 19, 1353–1363. [Google Scholar] [CrossRef] [PubMed]
- Jenwitheesuk, E.; Samudrala, R. Identification of potential multitarget antimalarial drugs. JAMA 2005, 294, 1487–1491. [Google Scholar]
- Chopra, G.; Kaushik, S.; Elkin, P.L.; Samudrala, R. Combating ebola with repurposed therapeutics using the CANDO platform. Molecules 2016, 21, 1537. [Google Scholar] [CrossRef]
- Jenwitheesuk, E.; Horst, J.A.; Rivas, K.L.; Van Voorhis, W.C.; Samudrala, R. Novel paradigms for drug discovery: Computational multitarget screening. Trends Pharmacol. Sci. 2008, 29, 62–71. [Google Scholar] [CrossRef]
- Horst, J.A.; Laurenzi, A.; Bernard, B.; Samudrala, R. Computational multitarget drug discovery. In Polypharmacology in Drug Discovery; Wiley: New York, NY, USA, 2012; pp. 236–302. [Google Scholar]
- Horst, J.; Pieper, U.; Sali, A.; Zhan, L.; Chopra, G.; Samudrala, R.; Featherstone, J. Strategic protein target analysis for developing drugs to stop dental caries. Adv. Dent. Res. 2012, 24, 86–93. [Google Scholar] [CrossRef]
- Costin, J.M.; Jenwitheesuk, E.; Lok, S.M.; Hunsperger, E.; Conrads, K.A.; Fontaine, K.A.; Rees, C.R.; Rossmann, M.G.; Isern, S.; Samudrala, R. Structural optimization and de novo design of dengue virus entry inhibitory peptides. PLoS Negl. Trop. Dis. 2010, 4, e721. [Google Scholar] [CrossRef] [PubMed]
- Obermeyer, Z.; Emanuel, E.J. Predicting the future—Big data, machine learning, and clinical medicine. N. Engl. J. Med. 2016, 375, 1216. [Google Scholar] [CrossRef] [PubMed]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Ann. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Menden, M.P.; Iorio, F.; Garnett, M.; McDermott, U.; Benes, C.H.; Ballester, P.J.; Saez-Rodriguez, J. Machine learning prediction of cancer cell sensitivity to drugs based on genomic and chemical properties. PLoS ONE 2013, 8, e61318. [Google Scholar] [CrossRef] [PubMed]
- Bakheet, T.M.; Doig, A.J. Properties and identification of human protein drug targets. Bioinformatics 2009, 25, 451–457. [Google Scholar] [CrossRef] [PubMed]
- Keogh, E.; Mueen, A. Curse of dimensionality. In Encyclopedia of Machine Learning and Data Mining; Springer: New York, NY, USA, 2017; pp. 314–315. [Google Scholar]
- Friedman, J.H. On bias, variance, 0/1—Loss, and the curse-of-dimensionality. Data Min. Knowl. Discov. 1997, 1, 55–77. [Google Scholar] [CrossRef]
- Roy, A.; Yang, J.; Zhang, Y. COFACTOR: An accurate comparative algorithm for structure-based protein function annotation. Nucleic Acids Res. 2012, 40, W471–W477. [Google Scholar] [CrossRef]
- Pettersen, E.F.; Goddard, T.D.; Huang, C.C.; Couch, G.S.; Greenblatt, D.M.; Meng, E.C.; Ferrin, T.E. UCSF Chimera—A visualization system for exploratory research and analysis. J. Comput. Chem. 2004, 25, 1605–1612. [Google Scholar] [CrossRef]
- Sahu, R.; Walker, L.A.; Tekwani, B.L. In vitro and in vivo anti-malarial activity of tigecycline, a glycylcycline antibiotic, in combination with chloroquine. Malar. J. 2014, 13, 414. [Google Scholar] [CrossRef]
- Starzengruber, P.; Thriemer, K.; Haque, R.; Khan, W.; Fuehrer, H.; Siedl, A.; Hofecker, V.; Ley, B.; Wernsdorfer, W.; Noedl, H. Antimalarial activity of tigecycline, a novel glycylcycline antibiotic. Antimicrob. Agents Chemother. 2009, 53, 4040–4042. [Google Scholar] [CrossRef] [PubMed]
- Alcantara, L.M.; Kim, J.; Moraes, C.B.; Franco, C.H.; Franzoi, K.D.; Lee, S.; Freitas-Junior, L.H.; Ayong, L.S. Chemosensitization potential of P-glycoprotein inhibitors in malaria parasites. Exp. Parasitol. 2013, 134, 235–243. [Google Scholar] [CrossRef]
- Penna-Coutinho, J.; Cortopassi, W.A.; Oliveira, A.A.; França, T.C.C.; Krettli, A.U. Antimalarial activity of potential inhibitors of Plasmodium falciparum lactate dehydrogenase enzyme selected by docking studies. PloS ONE 2011, 6, e21237. [Google Scholar] [CrossRef] [PubMed]
- Swift, L.P.; Cutts, S.M.; Nudelman, A.; Levovich, I.; Rephaeli, A.; Phillips, D.R. The cardio-protecting agent and topoisomerase II catalytic inhibitor sobuzoxane enhances doxorubicin-DNA adduct mediated cytotoxicity. Cancer Chemother. Pharmacol. 2008, 61, 739–749. [Google Scholar] [CrossRef] [PubMed]
- Inoue, Y.; Tsukasaki, K.; Nagai, K.; Soda, H.; Tomonaga, M. Durable remission by sobuzoxane in an HIV-seronegative patient with human herpesvirus 8-negative primary effusion lymphoma. Int. J. Hematol. 2004, 79, 271. [Google Scholar] [CrossRef] [PubMed]
- Itkonen, H.M.; Gorad, S.S.; Duveau, D.Y.; Martin, S.E.; Barkovskaya, A.; Bathen, T.F.; Moestue, S.A.; Mills, I.G. Inhibition of O-GlcNAc transferase activity reprograms prostate cancer cell metabolism. Oncotarget 2016, 7, 12464. [Google Scholar] [CrossRef] [PubMed]
- Niu, H.; Ma, C.; Cui, P.; Shi, W.; Zhang, S.; Feng, J.; Sullivan, D.; Zhu, B.; Zhang, W.; Zhang, Y. Identification of drug candidates that enhance pyrazinamide activity from a clinical compound library. Emerg. Microbes Infect. 2017, 6, e27. [Google Scholar] [CrossRef] [PubMed]
- Pandey, P.; Verma, V.; Gautam, G.; Kumari, N.; Dhar, S.K.; Gourinath, S. Targeting the β-clamp in Helicobacter pylori with FDA-approved drugs reveals micromolar inhibition by diflunisal. FEBS Lett. 2017, 591, 2311–2322. [Google Scholar] [CrossRef] [PubMed]
- Reddy, R.C.; Mathew, M.; Parameswaran, A.; Narasimhan, R. A case of concomitant Hodgkin’s lymphoma with tuberculosis. Lung India Off. Org. Indian Chest Soc. 2014, 31, 59. [Google Scholar]
- Mahajan, K.; Gupta, G.; Singh, D.P.; Mahajan, A. Case Report: Simultaneous occurrence of Hodgkin’s disease and tubercular lymphadenitis in the same cervical lymph node: A rare presentation. BMJ Case Rep. 2016, 2016. [Google Scholar] [CrossRef]
- Wang, B.; Yu, W.; Guo, J.; Jiang, X.; Lu, W.; Liu, M.; Pang, X. The antiparasitic drug, potassium antimony tartrate, inhibits tumor angiogenesis and tumor growth in nonsmall-cell lung cancer. J. Pharmacol. Exp. Ther. 2015, 352, 129–138. [Google Scholar] [CrossRef] [PubMed]
- Hopkins, A.L. Network pharmacology: The next paradigm in drug discovery. Nat. Chem. Biol. 2008, 4, 682. [Google Scholar] [CrossRef] [PubMed]
- Hart, T.; Dider, S.; Han, W.; Xu, H.; Zhao, Z.; Xie, L. Toward repurposing metformin as a precision anti-cancer therapy using structural systems pharmacology. Sci. Rep. 2016, 6, 20441. [Google Scholar] [CrossRef] [PubMed]
- Knox, C.; Law, V.; Jewison, T.; Liu, P.; Ly, S.; Frolkis, A.; Pon, A.; Banco, K.; Mak, C.; Neveu, V.; et al. DrugBank 3.0: A comprehensive resource for ’omics’ research on drugs. Nucleic Acids Res. 2011, 39, D1035–D1041. [Google Scholar] [CrossRef] [PubMed]
- Huang, R.; Southall, N.; Wang, Y.; Yasgar, A.; Shinn, P.; Jadhav, A.; Nguyen, D.T.; Austin, C.P. The NCGC pharmaceutical collection: A comprehensive resource of clinically approved drugs enabling repurposing and chemical genomics. Sci. Transl. Med. 2011, 3, 80ps16. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Cheng, T.; Wang, Y.; Bryant, S.H. PubChem as a public resource for drug discovery. Drug Discov. Today 2010, 15, 1052–1057. [Google Scholar] [CrossRef] [PubMed]
- Ihlenfeldt, W.D.; Takahashi, Y.; Abe, H.; Sasaki, S.I. Computation and management of chemical properties in CACTVS: An extensible networked approach toward modularity and compatibility. J. Chem. Inf. Comput. Sci. 1994, 34, 109–116. [Google Scholar] [CrossRef]
- Davis, A.P.; Murphy, C.G.; Johnson, R.; Lay, J.M.; Lennon-Hopkins, K.; Saraceni-Richards, C.; Sciaky, D.; King, B.L.; Rosenstein, M.C.; Wiegers, T.C. The comparative toxicogenomics database: Update 2013. Nucleic Acids Res. 2012, 41, D1104–D1114. [Google Scholar] [CrossRef]
- Berman, H.M.; Westbrook, J.; Feng, Z.; Gilliland, G.; Bhat, T.N.; Weissig, H.; Shindyalov, I.N.; Bourne, P.E. The protein data bank, 1999. In International Tables for Crystallography Volume F: Crystallography of Biological Macromolecules; Springer: New York, NY, USA, 2006; pp. 675–684. [Google Scholar]
- Remmert, M.; Biegert, A.; Hauser, A.; Söding, J. HHblits: Lightning-fast iterative protein sequence searching by HMM-HMM alignment. Nat. Methods 2012, 9, 173. [Google Scholar] [CrossRef]
- Zhang, Y. I-TASSER server for protein 3D structure prediction. BMC Bioinform. 2008, 9, 40. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, J.; Roy, A.; Zhang, Y. Automated protein structure modeling in CASP9 by I-TASSER pipeline combined with QUARK-based ab initio folding and FG-MD-based structure refinement. Proteins Struct. Funct. Bioinform. 2011, 79, 147–160. [Google Scholar] [CrossRef]
- Rodrigues, J.P.; Levitt, M.; Chopra, G. KoBaMIN: A knowledge-based minimization web server for protein structure refinement. Nucleic Acids Res. 2012, 40, W323–W328. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Zhang, Y. LOMETS: A local meta-threading-server for protein structure prediction. Nucleic Acids Res. 2007, 35, 3375–3382. [Google Scholar] [CrossRef]
- Zhang, Y.; Skolnick, J. Scoring function for automated assessment of protein structure template quality. Proteins Struct. Funct. Bioinform. 2004, 57, 702–710. [Google Scholar] [CrossRef] [PubMed]
- O’Boyle, N.M.; Banck, M.; James, C.A.; Morley, C.; Vandermeersch, T.; Hutchison, G.R. Open Babel: An open chemical toolbox. J. Cheminform. 2011, 3, 33. [Google Scholar] [CrossRef] [PubMed]
- Laggner, C. SMARTS Patterns for Functional Group Classification; Inte:Ligand Software-Entwicklungs und Consulting GmbH: Maria Enzersdorf, Austria, 2005. [Google Scholar]
- Orengo, C.A.; Michie, A.; Jones, S.; Jones, D.T.; Swindells, M.; Thornton, J.M. CATH—A hierarchic classification of protein domain structures. Structure 1997, 5, 1093–1109. [Google Scholar] [CrossRef]
- Butina, D. Unsupervised data base clustering based on daylight’s fingerprint and Tanimoto similarity: A Fast and automated way to cluster small and large data sets. J. Chem. Inf. Comput. Sci. 1999, 39, 747–750. [Google Scholar] [CrossRef]
- Landrum, G. RDKit: Open-Source Cheminformatics. 2006. Available online: https://www.rdkit.org/ (accessed on 3 January 2019).
- Willett, P. Similarity-based virtual screening using 2D fingerprints. Drug Discov. Today 2006, 11, 1046–1053. [Google Scholar] [CrossRef]
| Sample Availability: Not available. |
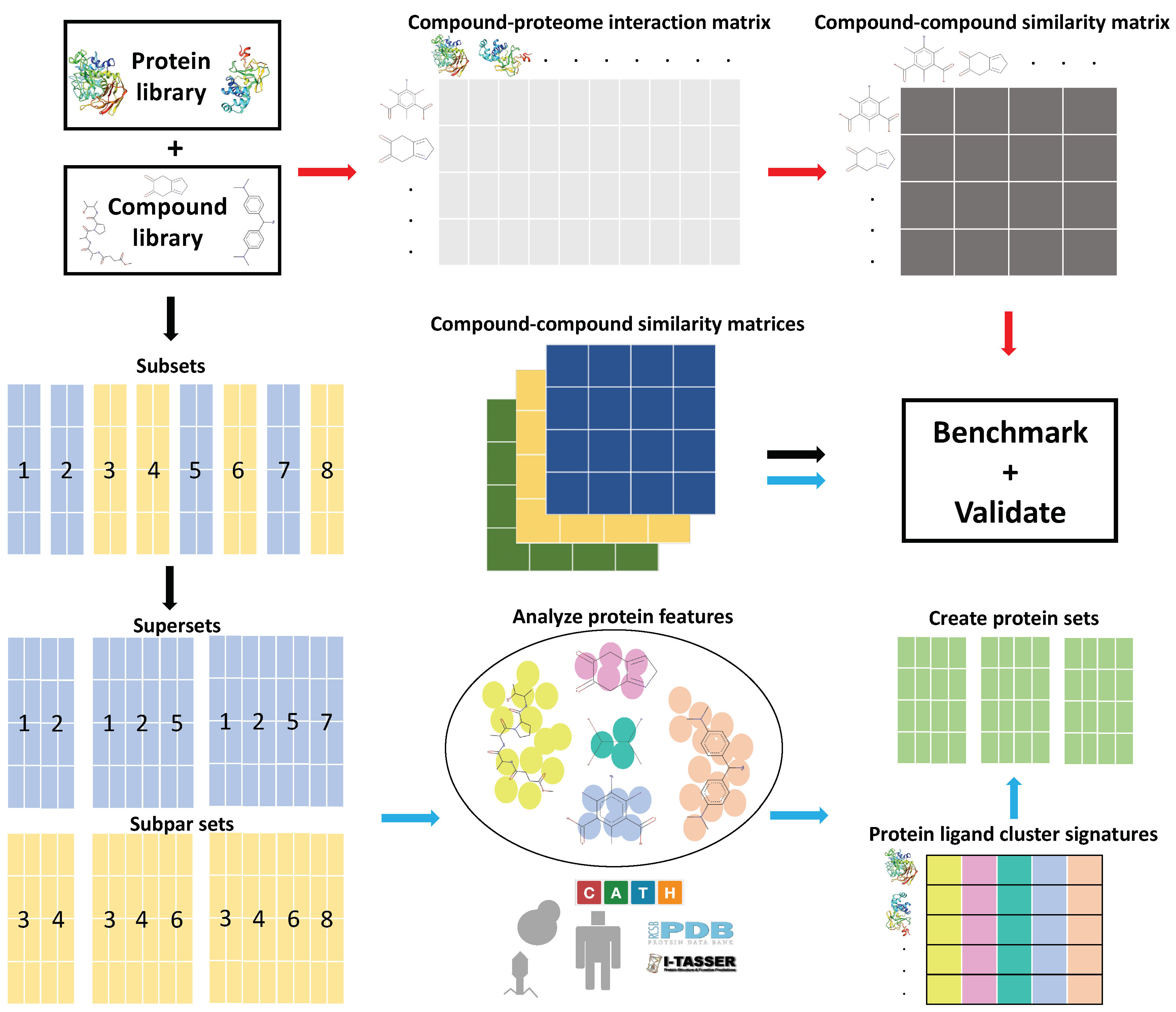
Figure 1.
General overview of the Computational Analysis of Novel Drug Opportunities (CANDO) platform and the protein subset analysis study design (see the Methods for details). Briefly, interactions between every protein and every drug/compound in each library are modeled using a bioinformatic docking protocol. The red arrows signify the typical CANDO platform pipeline: compound–protein interaction scores are used to populate the compound–proteome interaction matrix, which is then used to generate the compound–compound similarity matrix by comparing the rows represented by every pair of compounds using the root mean square deviation (RMSD) metric. The performance of each pipeline within the platform is benchmarked by evaluating the recovery rate of known drugs and/or prospectively validated through pre-clinical, clinical, or literature studies. The black arrows signify the subset analysis pipeline(s), where the full protein library and corresponding interaction matrix are split into smaller subsets and then recombined into supersets or subpar sets, depending on benchmarking performance. The blue arrows signify the feature analysis pipeline, where features that contribute to benchmarking performance were identified from the best and worst performing protein subsets and supersets. Protein sets were created using the ligand cluster interaction diversity feature, which we determined to be most important (see the Methods). Compound–proteome interaction matrices were generated for all subsets, supersets, and created sets, which were then used to generate compound–compound similarity matrices, followed by benchmarking and validation. The ability of the created protein sets to predict novel drugs for treatment of multiple diseases was evaluated relative to using the full library in three validation case studies. This study elucidates the role of particular protein subsets and corresponding ligand interactions that play a role in drug repurposing, with implications for drug design and machine learning approaches to enhance the CANDO platform.
Figure 1.
General overview of the Computational Analysis of Novel Drug Opportunities (CANDO) platform and the protein subset analysis study design (see the Methods for details). Briefly, interactions between every protein and every drug/compound in each library are modeled using a bioinformatic docking protocol. The red arrows signify the typical CANDO platform pipeline: compound–protein interaction scores are used to populate the compound–proteome interaction matrix, which is then used to generate the compound–compound similarity matrix by comparing the rows represented by every pair of compounds using the root mean square deviation (RMSD) metric. The performance of each pipeline within the platform is benchmarked by evaluating the recovery rate of known drugs and/or prospectively validated through pre-clinical, clinical, or literature studies. The black arrows signify the subset analysis pipeline(s), where the full protein library and corresponding interaction matrix are split into smaller subsets and then recombined into supersets or subpar sets, depending on benchmarking performance. The blue arrows signify the feature analysis pipeline, where features that contribute to benchmarking performance were identified from the best and worst performing protein subsets and supersets. Protein sets were created using the ligand cluster interaction diversity feature, which we determined to be most important (see the Methods). Compound–proteome interaction matrices were generated for all subsets, supersets, and created sets, which were then used to generate compound–compound similarity matrices, followed by benchmarking and validation. The ability of the created protein sets to predict novel drugs for treatment of multiple diseases was evaluated relative to using the full library in three validation case studies. This study elucidates the role of particular protein subsets and corresponding ligand interactions that play a role in drug repurposing, with implications for drug design and machine learning approaches to enhance the CANDO platform.

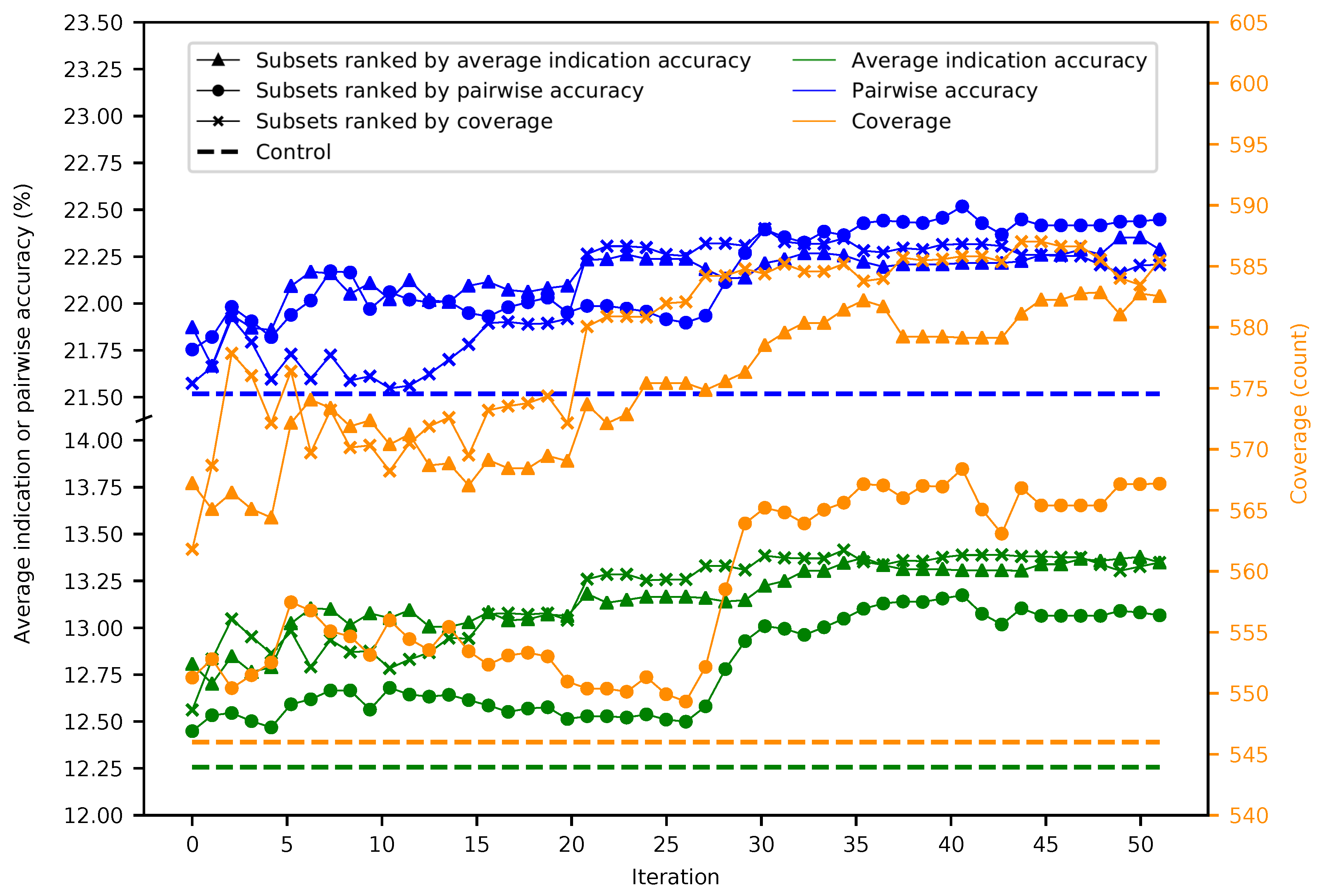
Figure 2.
Mean superset benchmarking performance across 50 iterations. Each point represents the mean average indication accuracy (green), pairwise accuracy (blue), or coverage (orange) of 50 supersets created by consecutively combining the top 50 subsets ranked by average indication accuracy (triangles), pairwise accuracy (circles), or coverage (crosses). Average indication accuracy and pairwise accuracy are plotted on the left axis; coverage on the right. The dashed lines represent the control values for their respective metrics. The supersets improve on the control values and gradually increase in performance with the number of iterations with average indication accuracy being the best ranking criterion through ten iterations, after which coverage is superior, especially when measuring the coverage metric. This result demonstrates that the splitting and ranking protocol can produce supersets with benchmarking performance superior to using the full protein library by combining the best performing subsets with a vastly reduced number of proteins (100–1000-fold reduction in size), further suggesting that specific groups of proteins are relatively more useful for drug repurposing accuracy.
Figure 2.
Mean superset benchmarking performance across 50 iterations. Each point represents the mean average indication accuracy (green), pairwise accuracy (blue), or coverage (orange) of 50 supersets created by consecutively combining the top 50 subsets ranked by average indication accuracy (triangles), pairwise accuracy (circles), or coverage (crosses). Average indication accuracy and pairwise accuracy are plotted on the left axis; coverage on the right. The dashed lines represent the control values for their respective metrics. The supersets improve on the control values and gradually increase in performance with the number of iterations with average indication accuracy being the best ranking criterion through ten iterations, after which coverage is superior, especially when measuring the coverage metric. This result demonstrates that the splitting and ranking protocol can produce supersets with benchmarking performance superior to using the full protein library by combining the best performing subsets with a vastly reduced number of proteins (100–1000-fold reduction in size), further suggesting that specific groups of proteins are relatively more useful for drug repurposing accuracy.

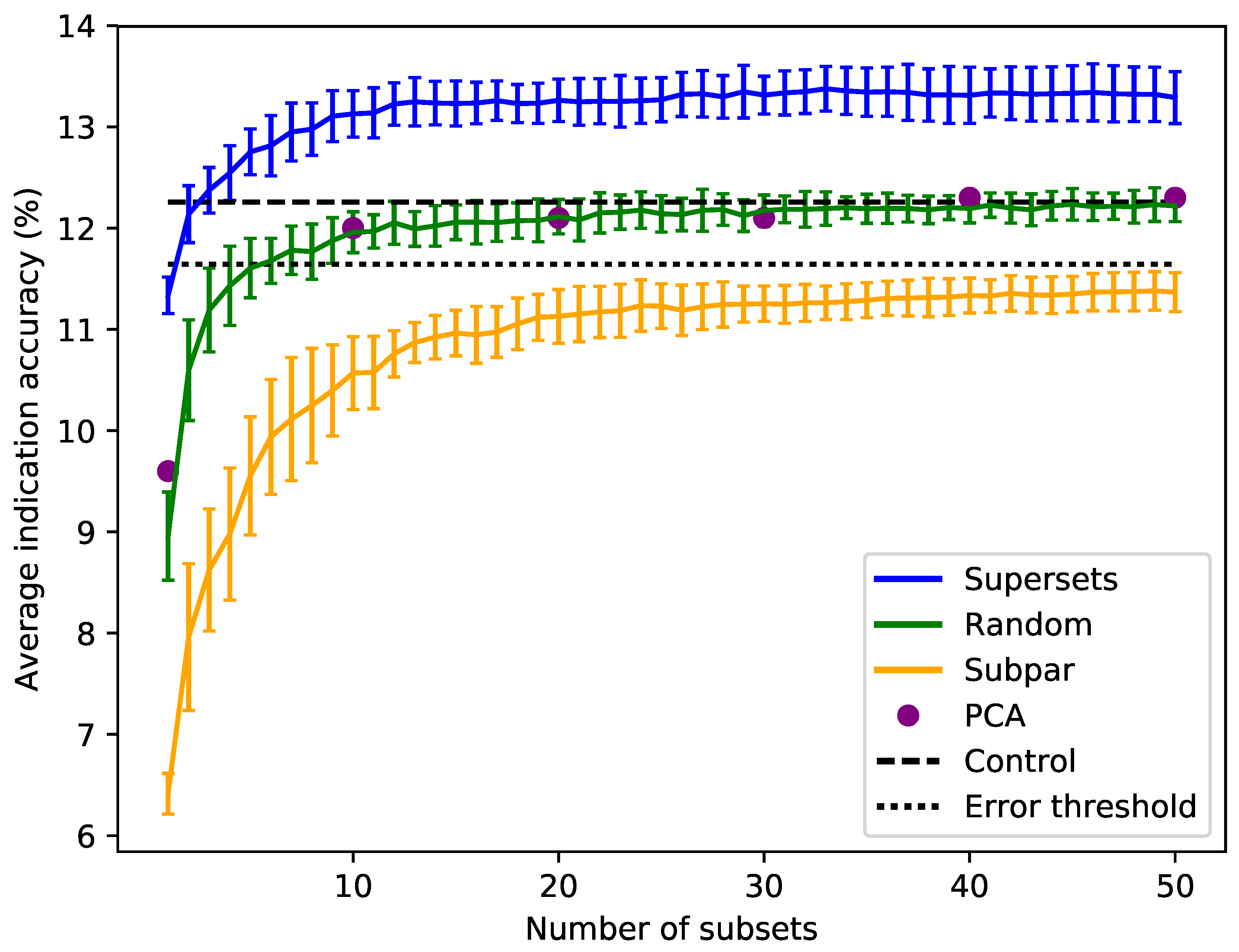
Figure 3.
Superset, subpar set, random set, and PCA matrices average indication accuracies sorted by size. Average indication accuracies are shown for the supersets (blue) generated using the best subsets ranked by the same metric. The line traces the mean score for each size with the bars indicating one standard deviation for the distribution. Subpar sets (orange) are the combinations of the worst performing subsets ranked by average indication accuracy. Randomly-selected protein sets (green) of each size were also generated and benchmarked. Principal component analysis (PCA, purple circles) was used to reduce the complete compound–protein interaction matrix to 8, 80, 160, 240, 320, and 400 dimensions. The control value based on using the full protein library (dashed black at 12.3%) and an acceptable 5% threshold (dotted black at 11.6%) are plotted for reference (i.e., any protein set that benchmarks within 95% of the control value is considered acceptable). For the random sets and supersets, the performance in terms of average indication accuracy begins to plateau around 80–120 proteins, or 10–15 subsets. The supersets begin to slightly decline in performance after 32–33 subsets (256–264 proteins). The mean subpar set accuracies at each size all fall outside the 5% acceptable threshold, while the superset distributions are well above the control value with as few as five subsets. The PCA matrices perform similarly to the control and the random sets. The difference between the superset and subpar set performance suggests that there is a particular distribution of features within their proteins that is correlated with benchmarking performance.
Figure 3.
Superset, subpar set, random set, and PCA matrices average indication accuracies sorted by size. Average indication accuracies are shown for the supersets (blue) generated using the best subsets ranked by the same metric. The line traces the mean score for each size with the bars indicating one standard deviation for the distribution. Subpar sets (orange) are the combinations of the worst performing subsets ranked by average indication accuracy. Randomly-selected protein sets (green) of each size were also generated and benchmarked. Principal component analysis (PCA, purple circles) was used to reduce the complete compound–protein interaction matrix to 8, 80, 160, 240, 320, and 400 dimensions. The control value based on using the full protein library (dashed black at 12.3%) and an acceptable 5% threshold (dotted black at 11.6%) are plotted for reference (i.e., any protein set that benchmarks within 95% of the control value is considered acceptable). For the random sets and supersets, the performance in terms of average indication accuracy begins to plateau around 80–120 proteins, or 10–15 subsets. The supersets begin to slightly decline in performance after 32–33 subsets (256–264 proteins). The mean subpar set accuracies at each size all fall outside the 5% acceptable threshold, while the superset distributions are well above the control value with as few as five subsets. The PCA matrices perform similarly to the control and the random sets. The difference between the superset and subpar set performance suggests that there is a particular distribution of features within their proteins that is correlated with benchmarking performance.

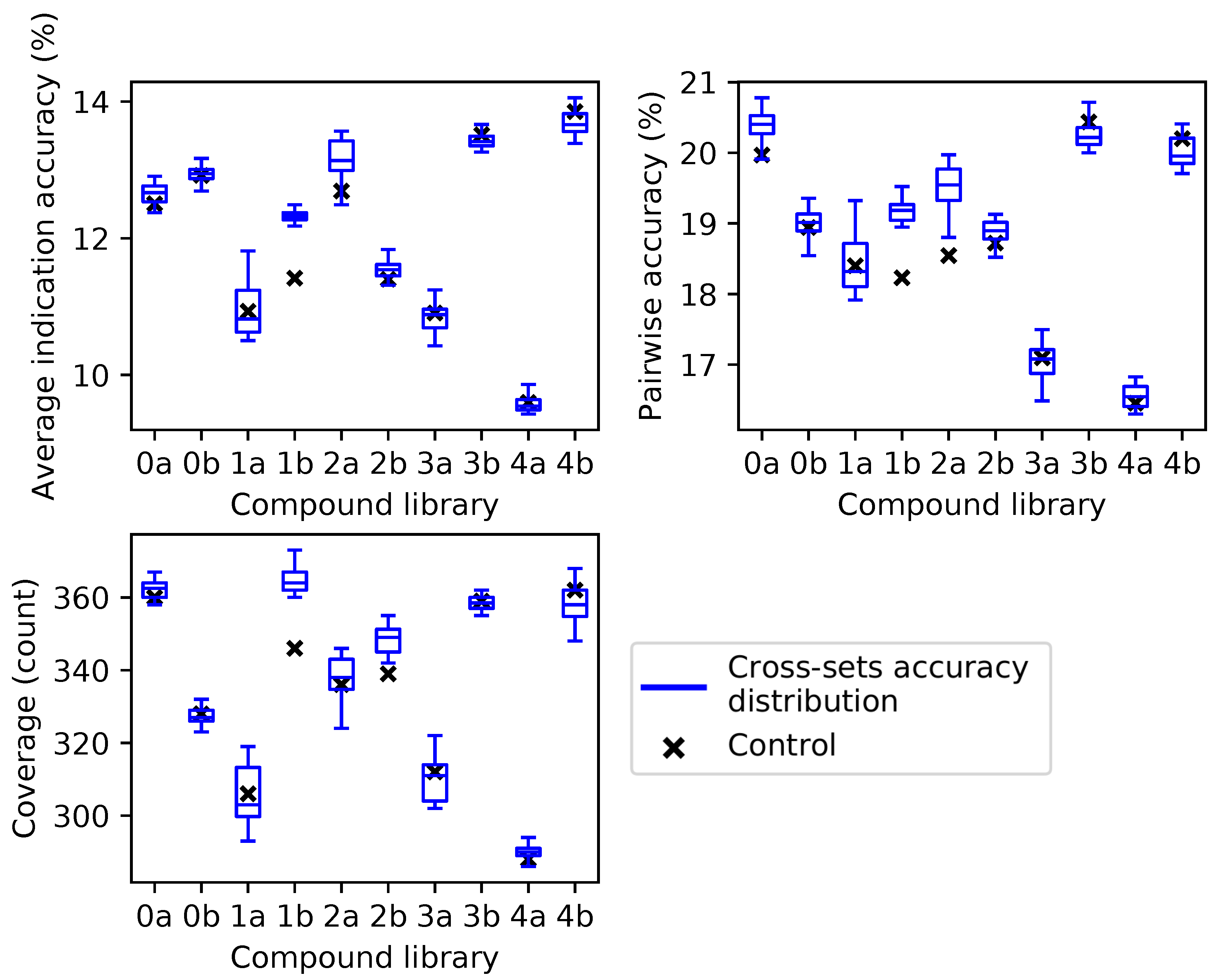
Figure 4.
Benchmarking performance of protein supersets cross-tested with independent compound libraries. Protein supersets were generated using the splitting and ranking protocol with the average indication accuracy metric. Supersets were tested on their complementary library only (for instance, supersets generated from Compound Library 0a were tested on Compound Library 0b and vice versa). The blue box and whisker plots describe the benchmarking performance distributions of the 41 complementary supersets with the middle line being the median value, the box encompassing the first and third quartiles, and the whiskers extending to the maximum and minimum, excluding outliers. The nine supersets less than a size of 80 (<10 subsets) were excluded due to the results in
Figure 3. In all cases, the control value for each compound library (black cross) never lies above the distribution of cross superset accuracies/coverages, indicating that these supersets can be generalized to any library of compounds.
Figure 4.
Benchmarking performance of protein supersets cross-tested with independent compound libraries. Protein supersets were generated using the splitting and ranking protocol with the average indication accuracy metric. Supersets were tested on their complementary library only (for instance, supersets generated from Compound Library 0a were tested on Compound Library 0b and vice versa). The blue box and whisker plots describe the benchmarking performance distributions of the 41 complementary supersets with the middle line being the median value, the box encompassing the first and third quartiles, and the whiskers extending to the maximum and minimum, excluding outliers. The nine supersets less than a size of 80 (<10 subsets) were excluded due to the results in
Figure 3. In all cases, the control value for each compound library (black cross) never lies above the distribution of cross superset accuracies/coverages, indicating that these supersets can be generalized to any library of compounds.

Figure 5.
Fraction of interactions attributed to top ranked ligand clusters from different protein sets. The solid blue and solid orange points are averages of the 50 best and worst subsets, respectively. Dashed lines represent an example of a superset (blue) and a subpar set (orange), which are nonredundant combinations of the best and worst performing subsets, respectively. The control set (dashed black), representing the full protein structure library, falls in between the superset and subpar set. The black diamonds indicate that the distribution of counts at that cluster rank between the best and worst performing subsets, assessed using Welch’s T-test, is significant (p-value < 0.05). The subsets and supersets with the best performance demonstrate a more equitable distribution of interactions among ligand clusters as opposed to the worst performing subsets and subpar sets, indicating that using multitargeting proteins to compose our structure libraries yields superior benchmarking performance.
Figure 5.
Fraction of interactions attributed to top ranked ligand clusters from different protein sets. The solid blue and solid orange points are averages of the 50 best and worst subsets, respectively. Dashed lines represent an example of a superset (blue) and a subpar set (orange), which are nonredundant combinations of the best and worst performing subsets, respectively. The control set (dashed black), representing the full protein structure library, falls in between the superset and subpar set. The black diamonds indicate that the distribution of counts at that cluster rank between the best and worst performing subsets, assessed using Welch’s T-test, is significant (p-value < 0.05). The subsets and supersets with the best performance demonstrate a more equitable distribution of interactions among ligand clusters as opposed to the worst performing subsets and subpar sets, indicating that using multitargeting proteins to compose our structure libraries yields superior benchmarking performance.

Figure 6.
Average indication accuracy performance of created protein libraries of a size of 80 with various upper ligand cluster cutoffs. Protein libraries were created by randomly selecting 80 of the top 160 proteins from the list of proteins ranked by ligand cluster interaction variance (see the Methods). A minimum of two ligand clusters was required to avoid the trivial case of only one cluster mapped (with a variance of zero). An upper ligand cluster count cutoff was applied to these protein libraries to determine the effect on benchmarking performance. The blue line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each cutoff using the top ranked proteins. Similarly, the orange line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each cutoff using the highest variance proteins. The bars indicate one standard deviation for the distribution. Using too small (<20) or too large (>40) of a cutoff results in suboptimal benchmarking performance. The high variance libraries result in average performance far below the acceptable 5% error range, with the cluster cutoff seemingly having no effect on average indication accuracy, as all cutoffs produced comparable distributions. All average indication accuracies produced using an upper cutoff of 20–40 ligand clusters were within the acceptable 5% error range, with the upper cutoff of 40 ligand clusters producing the greatest mean accuracy. This result indicates that there is an optimal range of ligand cluster interactions to best describe therapeutic behavior.
Figure 6.
Average indication accuracy performance of created protein libraries of a size of 80 with various upper ligand cluster cutoffs. Protein libraries were created by randomly selecting 80 of the top 160 proteins from the list of proteins ranked by ligand cluster interaction variance (see the Methods). A minimum of two ligand clusters was required to avoid the trivial case of only one cluster mapped (with a variance of zero). An upper ligand cluster count cutoff was applied to these protein libraries to determine the effect on benchmarking performance. The blue line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each cutoff using the top ranked proteins. Similarly, the orange line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each cutoff using the highest variance proteins. The bars indicate one standard deviation for the distribution. Using too small (<20) or too large (>40) of a cutoff results in suboptimal benchmarking performance. The high variance libraries result in average performance far below the acceptable 5% error range, with the cluster cutoff seemingly having no effect on average indication accuracy, as all cutoffs produced comparable distributions. All average indication accuracies produced using an upper cutoff of 20–40 ligand clusters were within the acceptable 5% error range, with the upper cutoff of 40 ligand clusters producing the greatest mean accuracy. This result indicates that there is an optimal range of ligand cluster interactions to best describe therapeutic behavior.

Figure 7.
Average indication accuracy performance of created protein libraries at various sizes with ligand cluster cutoff of 40. Protein libraries were created by randomly selecting half the number of proteins in the library ranked by ligand cluster interaction variance with 2–40 ligand clusters mapped. The upper cutoff of 40 was chosen due to the results of
Figure 6. The blue line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each size using the top ranked proteins. Similarly, the orange line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each size using the highest variance proteins. The bars indicate one standard deviation for the distribution. Using too small of a size (<60) results in suboptimal benchmarking performance. Creating libraries from proteins with the highest variance results in performance on average far below the acceptable 5% error range, although size does have a positive correlation with performance with these high variance sets. This result reiterates that there is a minimum number of proteins required to reach optimal benchmarking performance and that proteins with high variance in their ligand cluster signatures are far superior for describing drug/compound behavior.
Figure 7.
Average indication accuracy performance of created protein libraries at various sizes with ligand cluster cutoff of 40. Protein libraries were created by randomly selecting half the number of proteins in the library ranked by ligand cluster interaction variance with 2–40 ligand clusters mapped. The upper cutoff of 40 was chosen due to the results of
Figure 6. The blue line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each size using the top ranked proteins. Similarly, the orange line traces the average indication accuracy distribution mean from benchmarking 50 libraries at each size using the highest variance proteins. The bars indicate one standard deviation for the distribution. Using too small of a size (<60) results in suboptimal benchmarking performance. Creating libraries from proteins with the highest variance results in performance on average far below the acceptable 5% error range, although size does have a positive correlation with performance with these high variance sets. This result reiterates that there is a minimum number of proteins required to reach optimal benchmarking performance and that proteins with high variance in their ligand cluster signatures are far superior for describing drug/compound behavior.

Figure 8.
Visualization of the best and worst protein types for benchmarking performance based on ligand cluster signatures. Centroids of the top five ligand clusters from the signatures of each protein are depicted. The percent of interactions belonging to each ligand cluster are next to their respective centroid. Surface representations of the proteins were made using Chimera [
31] with the predicted binding site residues from COFACTOR for each ligand shown (excluding the smaller ligands in (
C) colored in blue). (
A) Alkaline serine protease KP-43 from
Bacillus subtilis: the top five ligand clusters account for 46.3% of the total interactions with the distribution between them being relatively equitable. (
B) SET domain of human histone-lysine
N-methyltransferase: only two ligand clusters are predicted to interact, with one having over 98% of the total interactions. (
C) Human STE20-related kinase adapter protein beta: the ligand cluster signature is too promiscuous with the top five ligand clusters accounting for only 18.3% of the total interactions; the remaining sixteen ligands surrounding the protein account for 28.7%, which combined with the top five clusters is as much as 46.3% of the total interactions shown in (
A) from only five clusters. Subsets and supersets composed of proteins similar to (
A) outperform those composed of proteins similar to (
B) and (
C) in benchmarking, indicating that moderately promiscuous proteins with equitable ligand cluster signatures are the best therapeutic descriptors.
Figure 8.
Visualization of the best and worst protein types for benchmarking performance based on ligand cluster signatures. Centroids of the top five ligand clusters from the signatures of each protein are depicted. The percent of interactions belonging to each ligand cluster are next to their respective centroid. Surface representations of the proteins were made using Chimera [
31] with the predicted binding site residues from COFACTOR for each ligand shown (excluding the smaller ligands in (
C) colored in blue). (
A) Alkaline serine protease KP-43 from
Bacillus subtilis: the top five ligand clusters account for 46.3% of the total interactions with the distribution between them being relatively equitable. (
B) SET domain of human histone-lysine
N-methyltransferase: only two ligand clusters are predicted to interact, with one having over 98% of the total interactions. (
C) Human STE20-related kinase adapter protein beta: the ligand cluster signature is too promiscuous with the top five ligand clusters accounting for only 18.3% of the total interactions; the remaining sixteen ligands surrounding the protein account for 28.7%, which combined with the top five clusters is as much as 46.3% of the total interactions shown in (
A) from only five clusters. Subsets and supersets composed of proteins similar to (
A) outperform those composed of proteins similar to (
B) and (
C) in benchmarking, indicating that moderately promiscuous proteins with equitable ligand cluster signatures are the best therapeutic descriptors.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







