
How Size Matters: Diversity for Fragment Library Design



Abstract
1. Introduction
2. Results
2.1. Library Selection
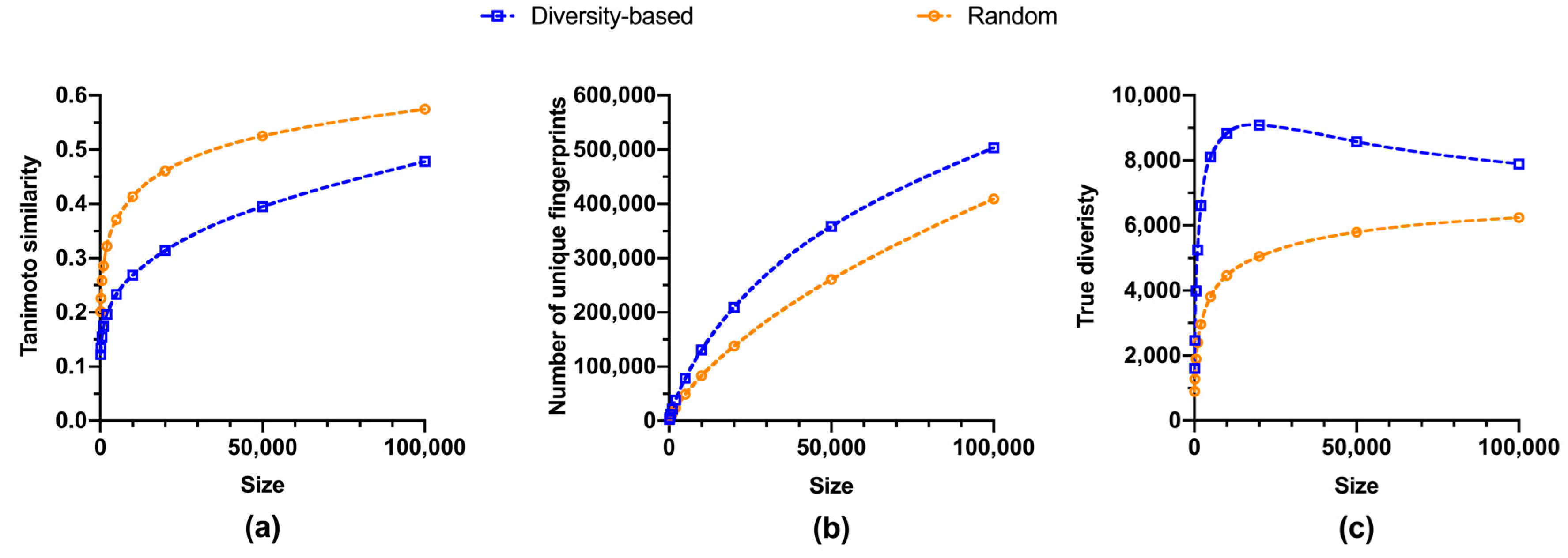
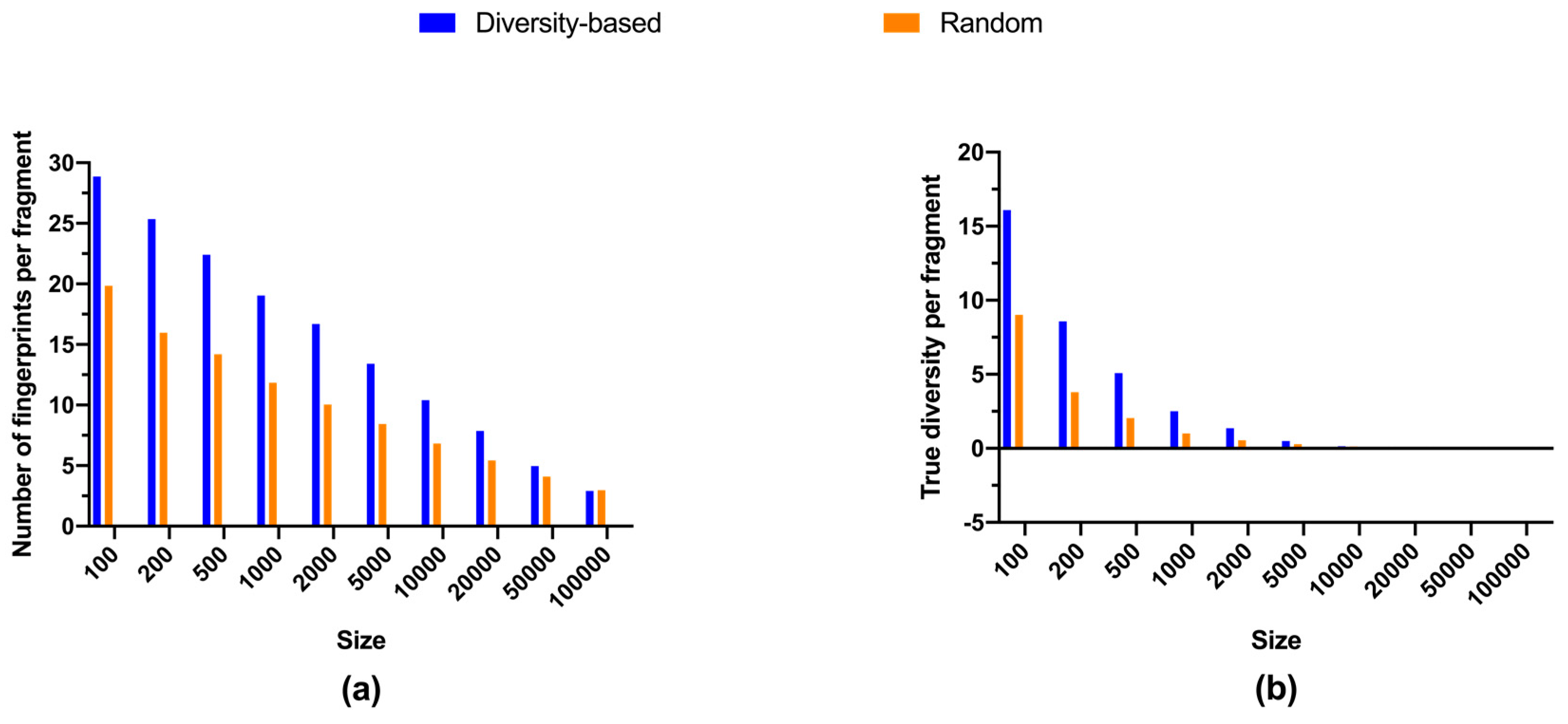
2.2. Size-Diversity Relationship of Regular Fragment Libraries
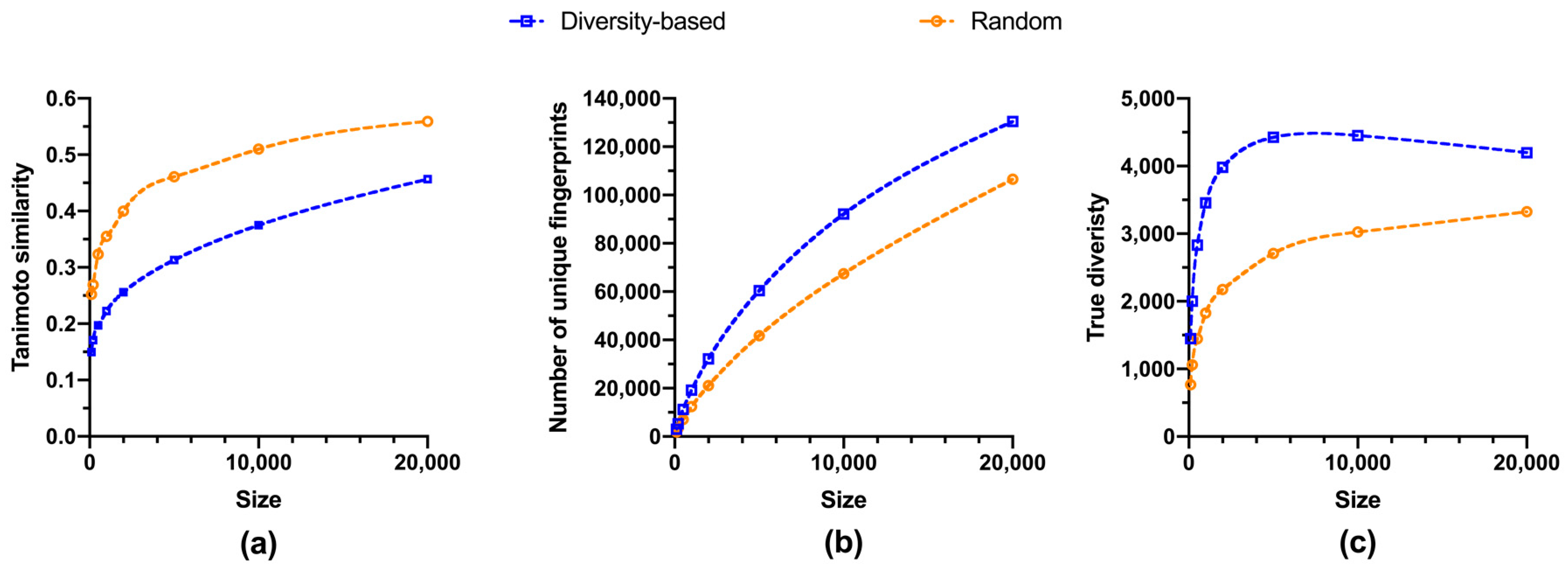
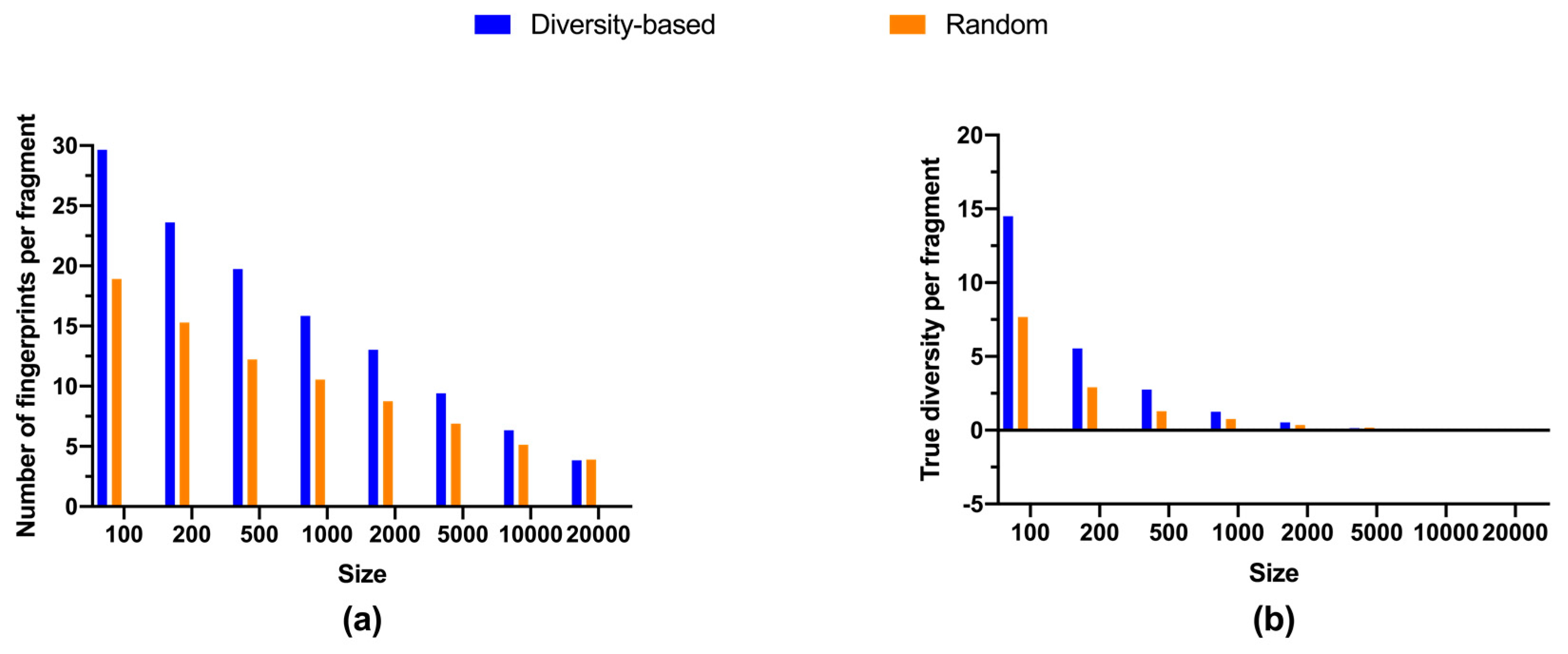
2.3. Size-Diversity Relationship of Fluorinated Fragment Libraries
3. Discussion
4. Materials and Methods
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shuker, S.B.; Hajduk, P.J.; Meadows, R.P.; Fesik, S.W. Discovering High-Affinity Ligands for Proteins: SAR by NMR. Science 1996, 274, 1531–1534. [Google Scholar] [CrossRef] [PubMed]
- Erlanson, D.A.; McDowell, R.S.; O’Brien, T. Fragment-Based Drug Discovery. J. Med. Chem. 2004, 47, 3463–3482. [Google Scholar] [CrossRef] [PubMed]
- Rees, D.C.; Congreve, M.; Murray, C.W.; Carr, R. Fragment-based lead discovery. Nat. Rev. Drug Discov. 2004, 3, 660–672. [Google Scholar] [CrossRef] [PubMed]
- Erlanson, D.A.; Fesik, S.W.; Hubbard, R.E.; Jahnke, W.; Jhoti, H. Twenty years on: the impact of fragments on drug discovery. Nat. Rev. Drug Discov. 2016, 15, 605–619. [Google Scholar] [CrossRef] [PubMed]
- Congreve, M.; Carr, R.; Murray, C.; Jhoti, H. A ‘Rule of Three’ for fragment-based lead discovery? Drug Discov. Today 2003, 8, 876–877. [Google Scholar] [CrossRef]
- Lipinski, C.A.; Lombardo, F.; Dominy, B.W.; Feeney, P.J. Experimental and computational approaches to estimate solubility and permeability in drug discovery and development settings1PII of original article: S0169-409X(96)00423-1. The article was originally published in Advanced Drug Delivery Reviews 23 (1997) 3–25.1. Adv. Drug Deliv. Rev. 2001, 46, 3–26. [Google Scholar] [PubMed]
- Hann, M.M.; Leach, A.R.; Harper, G. Molecular Complexity and Its Impact on the Probability of Finding Leads for Drug Discovery. J. Chem. Inf. Comput. Sci. 2001, 41, 856–864. [Google Scholar] [CrossRef]
- Hopkins, A.L.; Groom, C.R.; Alex, A. Ligand efficiency: A useful metric for lead selection. Drug Discov. Today 2004, 9, 430–431. [Google Scholar] [CrossRef]
- Murray, C.W.; Rees, D.C. The rise of fragment-based drug discovery. Nat. Chem. 2009, 1, 187–192. [Google Scholar] [CrossRef]
- Romasanta, A.K.S.; van der Sijde, P.; Hellsten, I.; Hubbard, R.E.; Keseru, G.M.; van Muijlwijk-Koezen, J.; de Esch, I.J.P. When fragments link: a bibliometric perspective on the development of fragment-based drug discovery. Drug Discov. Today 2018, 23, 1596–1609. [Google Scholar] [CrossRef]
- Tsai, J.; Lee, J.T.; Wang, W.; Zhang, J.; Cho, H.; Mamo, S.; Bremer, R.; Gillette, S.; Kong, J.; Haass, N.K.; et al. Discovery of a selective inhibitor of oncogenic B-Raf kinase with potent antimelanoma activity. Proc. Natl. Acad. Sci. USA 2008, 105, 3041–3046. [Google Scholar] [CrossRef] [PubMed]
- Bollag, G.; Hirth, P.; Tsai, J.; Zhang, J.; Ibrahim, P.N.; Cho, H.; Spevak, W.; Zhang, C.; Zhang, Y.; Habets, G.; et al. Clinical efficacy of a RAF inhibitor needs broad target blockade in BRAF-mutant melanoma. Nature 2010, 467, 596–599. [Google Scholar] [CrossRef]
- Souers, A.J.; Leverson, J.D.; Boghaert, E.R.; Ackler, S.L.; Catron, N.D.; Chen, J.; Dayton, B.D.; Ding, H.; Enschede, S.H.; Fairbrother, W.J.; et al. ABT-199, a potent and selective BCL-2 inhibitor, achieves antitumor activity while sparing platelets. Nat. Med. 2013, 19, 202–208. [Google Scholar] [CrossRef]
- Perera, T.P.S.; Jovcheva, E.; Mevellec, L.; Vialard, J.; Lange, D.D.; Verhulst, T.; Paulussen, C.; Ven, K.V.D.; King, P.; Freyne, E.; et al. Discovery and Pharmacological Characterization of JNJ-42756493 (Erdafitinib), a Functionally Selective Small-Molecule FGFR Family Inhibitor. Mol. Cancer Ther. 2017, 16, 1010–1020. [Google Scholar] [CrossRef]
- Practical Fragments. Health and Environmental Effects of Particulate Matter (PM). 2014. Available online: http://practicalfragments.blogspot.hu/2016/10/poll-results-affiliation-metrics-and.html (accessed on 18 May 2019).
- Practical Fragments. Poll Results: The Modern Fragment Library. Available online: http://practicalfragments.blogspot.com/2018/12/poll-results-library-vendors.html (accessed on 18 May 2019).
- Messick, T.E.; Smith, G.R.; Soldan, S.S.; McDonnell, M.E.; Deakyne, J.S.; Malecka, K.A.; Tolvinski, L.; van den Heuvel, A.P.J.; Gu, B.-W.; Cassel, J.A.; et al. Structure-based design of small-molecule inhibitors of EBNA1 DNA binding blocks Epstein-Barr virus latent infection and tumor growth. Sci. Transl. Med. 2019, 11, eaau5612. [Google Scholar] [CrossRef] [PubMed]
- Böttcher, J.; Dilworth, D.; Reiser, U.; Neumüller, R.A.; Schleicher, M.; Petronczki, M.; Zeeb, M.; Mischerikow, N.; Allali-Hassani, A.; Szewczyk, M.M.; et al. Fragment-based discovery of a chemical probe for the PWWP1 domain of NSD3. Nat. Chem. Biol. 2019, 15, 822–829. [Google Scholar] [CrossRef]
- Keserű, G.M.; Erlanson, D.A.; Ferenczy, G.G.; Hann, M.M.; Murray, C.W.; Pickett, S.D. Design Principles for Fragment Libraries: Maximizing the Value of Learnings from Pharma Fragment-Based Drug Discovery (FBDD) Programs for Use in Academia. J. Med. Chem. 2016, 18, 8189–8206. [Google Scholar] [CrossRef]
- Chen, I.-J.; Hubbard, R.E. Lessons for fragment library design: analysis of output from multiple screening campaigns. J. Comput. Aided Mol. Des. 2009, 23, 603–620. [Google Scholar] [CrossRef]
- Dixon, S.L.; Villar, H.O. Bioactive Diversity and Screening Library Selection via Affinity Fingerprinting. J. Chem. Inf. Comput. Sci. 1998, 38, 1192–1203. [Google Scholar] [CrossRef] [PubMed]
- Roth, H.-J. There is no such thing as ‘diversity’! Curr. Opin. Chem. Biol. 2005, 9, 293–295. [Google Scholar] [CrossRef] [PubMed]
- Koutsoukas, A.; Paricharak, S.; Galloway, W.R.J.D.; Spring, D.R.; IJzerman, A.P.; Glen, R.C.; Marcus, D.; Bender, A. How Diverse Are Diversity Assessment Methods? A Comparative Analysis and Benchmarking of Molecular Descriptor Space. J. Chem. Inf. Model. 2014, 54, 230–242. [Google Scholar] [CrossRef] [PubMed]
- Kauvar, L.M.; Higgins, D.L.; Villar, H.O.; Sportsman, J.R.; Engqvist-Goldstein, Å.; Bukar, R.; Bauer, K.E.; Dilley, H.; Rocke, D.M. Predicting ligand binding to proteins by affinity fingerprinting. Chem. Biol. 1995, 2, 107–118. [Google Scholar] [CrossRef]
- Wawer, M.J.; Li, K.; Gustafsdottir, S.M.; Ljosa, V.; Bodycombe, N.E.; Marton, M.A.; Sokolnicki, K.L.; Bray, M.-A.; Kemp, M.M.; Winchester, E.; et al. Toward performance-diverse small-molecule libraries for cell-based phenotypic screening using multiplexed high-dimensional profiling. Proc. Natl. Acad. Sci. USA 2014, 111, 10911–10916. [Google Scholar] [CrossRef] [PubMed]
- Carbó, R.; Leyda, L.; Arnau, M. How similar is a molecule to another? An electron density measure of similarity between two molecular structures. Int. J. Quantum Chem. 1980, 17, 1185–1189. [Google Scholar] [CrossRef]
- Rogers, D.; Hahn, M. Extended-Connectivity Fingerprints. J. Chem. Inf. Model. 2010, 50, 742–754. [Google Scholar] [CrossRef] [PubMed]
- Duan, J.; Dixon, S.L.; Lowrie, J.F.; Sherman, W. Analysis and comparison of 2D fingerprints: Insights into database screening performance using eight fingerprint methods. J. Mol. Graph. Model. 2010, 29, 157–170. [Google Scholar] [CrossRef]
- Gillet, V.J. Diversity selection algorithms. Wiley Interdiscip. Rev. Comput. Mol. Sci. 2011, 1, 580–589. [Google Scholar] [CrossRef]
- Jaccard, P. Distribution de la Flore Alpine dans le Bassin des Dranses et dans quelques régions voisines. Bulletin de la Societe Vaudoise des Sciences Naturelles 1901, 37, 241–272. [Google Scholar]
- Tanimoto, T.T. An Elementary Mathematical Theory of Classification and Prediction; International Business Machines Corporation: Armonk, NY, USA, 1958. [Google Scholar]
- Martin, E.J.; Blaney, J.M.; Siani, M.A.; Spellmeyer, D.C.; Wong, A.K.; Moos, W.H. Measuring Diversity: Experimental Design of Combinatorial Libraries for Drug Discovery. J. Med. Chem. 1995, 38, 1431–1436. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Simpson, E.H. Measurement of Diversity. Nature 1949, 163, 688. [Google Scholar] [CrossRef]
- Hill, M.O. Diversity and Evenness: A Unifying Notation and Its Consequences. Ecology 1973, 54, 427–432. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Sylvester, J.J. XIX. A demonstration of the theorem that every homogeneous quadratic polynomial is reducible by real orthogonal substitutions to the form of a sum of positive and negative squares. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1852, 4, 138–142. [Google Scholar] [CrossRef]
- Sauer, W.H.B.; Schwarz, M.K. Molecular Shape Diversity of Combinatorial Libraries: A Prerequisite for Broad Bioactivity. J. Chem. Inf. Comput. Sci. 2003, 43, 987–1003. [Google Scholar] [CrossRef]
- Jordan, J.B.; Poppe, L.; Xia, X.; Cheng, A.C.; Sun, Y.; Michelsen, K.; Eastwood, H.; Schnier, P.D.; Nixey, T.; Zhong, W. Fragment Based Drug Discovery: Practical Implementation Based on 19F NMR Spectroscopy. J. Med. Chem. 2012, 55, 678–687. [Google Scholar] [CrossRef]
- Vulpetti, A.; Dalvit, C. Design and Generation of Highly Diverse Fluorinated Fragment Libraries and their Efficient Screening with Improved 19|NMR Methodology. ChemMedChem 2013, 8, 2057–2069. [Google Scholar] [CrossRef]
- Visini, R.; Awale, M.; Reymond, J.-L. Fragment Database FDB-17. J. Chem. Inf. Model. 2017, 57, 700–709. [Google Scholar] [CrossRef]
- Downs, G.M.; Barnard, J.M. Clustering Methods and Their Uses in Computational Chemistry. In Reviews in Computational Chemistry; John Wiley & Sons, Ltd.: Marblehead, MA, USA, 2003; pp. 1–40. ISBN 978-0-471-43351-4. [Google Scholar]
- Gobbi, A.; Lee, M.-L. DISE: Directed Sphere Exclusion. J. Chem. Inf. Comput. Sci. 2003, 43, 317–323. [Google Scholar] [CrossRef] [PubMed]
- Sterling, T.; Irwin, J.J. ZINC 15—Ligand Discovery for Everyone. J. Chem. Inf. Model. 2015, 55, 2324–2337. [Google Scholar] [CrossRef] [PubMed]
- Gillet, V.J.; Willett, P.; Bradshaw, J. Identification of Biological Activity Profiles Using Substructural Analysis and Genetic Algorithms. J. Chem. Inf. Comput. Sci. 1998, 38, 165–179. [Google Scholar] [CrossRef] [PubMed]
- Weininger, D.; Weininger, A.; Weininger, J.L. SMILES. 2. Algorithm for generation of unique SMILES notation. J. Chem. Inf. Comput. Sci. 1989, 29, 97–101. [Google Scholar] [CrossRef]
Sample Availability: Not available. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structural Diversity (Value) | Minimum Size (Ratio of Total 227,787 Fragments) 1 |
|---|---|
| 5% total richness 2 (33,834) | 1,715 (0.75%) |
| 10% total richness 2 (67,669) | 4,103 (1.80%) |
| Overall true diversity (6,662.4) | 2,052 (0.90%) |
| Maximum true diversity 1 (9,097.6) | 17,666 (7.76%) |
| Structural Diversity (Value) | Minimum Size (Ratio of Total 47,708 Fluorinated Fragments) 1 |
|---|---|
| 5% total richness 2 (8,992) | 675 (1.41%) |
| 10% total richness 2 (17,983) | 1,616 (3.39%) |
| Overall true diversity (3,621.9) | 1,203 (2.52%) |
| Maximum true diversity 1 (4,485.5) | 7,483 (15.69%) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; von Itzstein, M. How Size Matters: Diversity for Fragment Library Design. Molecules 2019, 24, 2838. https://doi.org/10.3390/molecules24152838
Shi Y, von Itzstein M. How Size Matters: Diversity for Fragment Library Design. Molecules. 2019; 24(15):2838. https://doi.org/10.3390/molecules24152838
Chicago/Turabian StyleShi, Yun, and Mark von Itzstein. 2019. "How Size Matters: Diversity for Fragment Library Design" Molecules 24, no. 15: 2838. https://doi.org/10.3390/molecules24152838
APA StyleShi, Y., & von Itzstein, M. (2019). How Size Matters: Diversity for Fragment Library Design. Molecules, 24(15), 2838. https://doi.org/10.3390/molecules24152838