Construction and Characterization of Three Wheat Bacterial Artificial Chromosome Libraries

Abstract
:1. Introduction
2. Results and Discussion
2.1. Construction of Three Bacterial Artificial Chromosome Libraries

{kind=link}
{kind=link}
{kind=link}
| Repeat | Transformation Efficiency (×104/μg DNA) | Average Insert Size (Kb) | Empty Clones (%) | |||
|---|---|---|---|---|---|---|
| 1-Day | 3-Day | 1-Day | 3-Day | 1-Day | 3-Day | |
| Repeat 1 | 2.25 | 15.4 | 88 | 131 | 7.07 | 2.70 |
| Repeat 2 | 6.45 | 45.1 | 114 | 138 | 3.21 | 0.14 |
| Repeat 3 | 5.57 | 51.5 | 108 | 149 | 3.34 | 0.04 |
2.2. BAC Library Characterization
2.2.1. Average Insert Size

| BAC Library | Enzyme | Organelle DNA (%) | Empty Clones (%) | NO. of Clones | Average Insert size a/min-max (Kb) | Genome Coverage (×) b |
|---|---|---|---|---|---|---|
| TA2026 | BamHI | 0.78 | 3.03 | 170,880 | 88.64/0-310 | 2.60 |
| TA2033-B | BamHI | 0.78 | 1.53 | 183,936 | 59.57/15-285 | 1.91 |
| TA2033-H | HindIII | 0 | 0 | 79,104 | 127.54/80-224 | 1.80 |
| Total | - | 0.55 | 1.07 | 263,040 | 80.01 | 3.71 |
| Wangshuibai-B | BamHI | 0 | 3.2 | 596,736 | 124.49/30-320 | 4.42 |
| Wangshuibai-H | HindIII | 0.78 | 0 | 637,056 | 123.21/20-265 | 4.63 |
| Total | - | 0.40 | 1.54 | 1,233,792 | 122.83 | 9.05 |
2.2.2. Contamination with Organelle DNA
2.2.3. Genome Coverage
| Marker | Positive Pool | Theoretical Probability | Actual Probability | |
|---|---|---|---|---|
| GWM135 | 8 | - | - | |
| GWM95 | 6 | - | - | |
| WMC153 | 5 | - | - | |
| BARC78 | 2 | - | - | |
| GWM293 | 3 | - | - | |
| BARC3 | 4 | - | - | |
| BARC108 | 3 | - | - | |
| BARC61 | 0 a | - | - | |
| BARC7 | 7 | - | - | |
| GWM234 | 10 | - | - | |
| GWM626 | 3 | - | - | |
| BARC65 | 5 | - | - | |
| BARC169 | 18 | - | - | |
| BARC71 | 2 | - | - | |
| BARC225 | 16 | - | - | |
| BARC143 | 8 | - | - | |
| BARC173 | 2 | - | ||
| BARC111 | 6 | - | - | |
| Average | - | 6 | 99.52% | 94.44% |
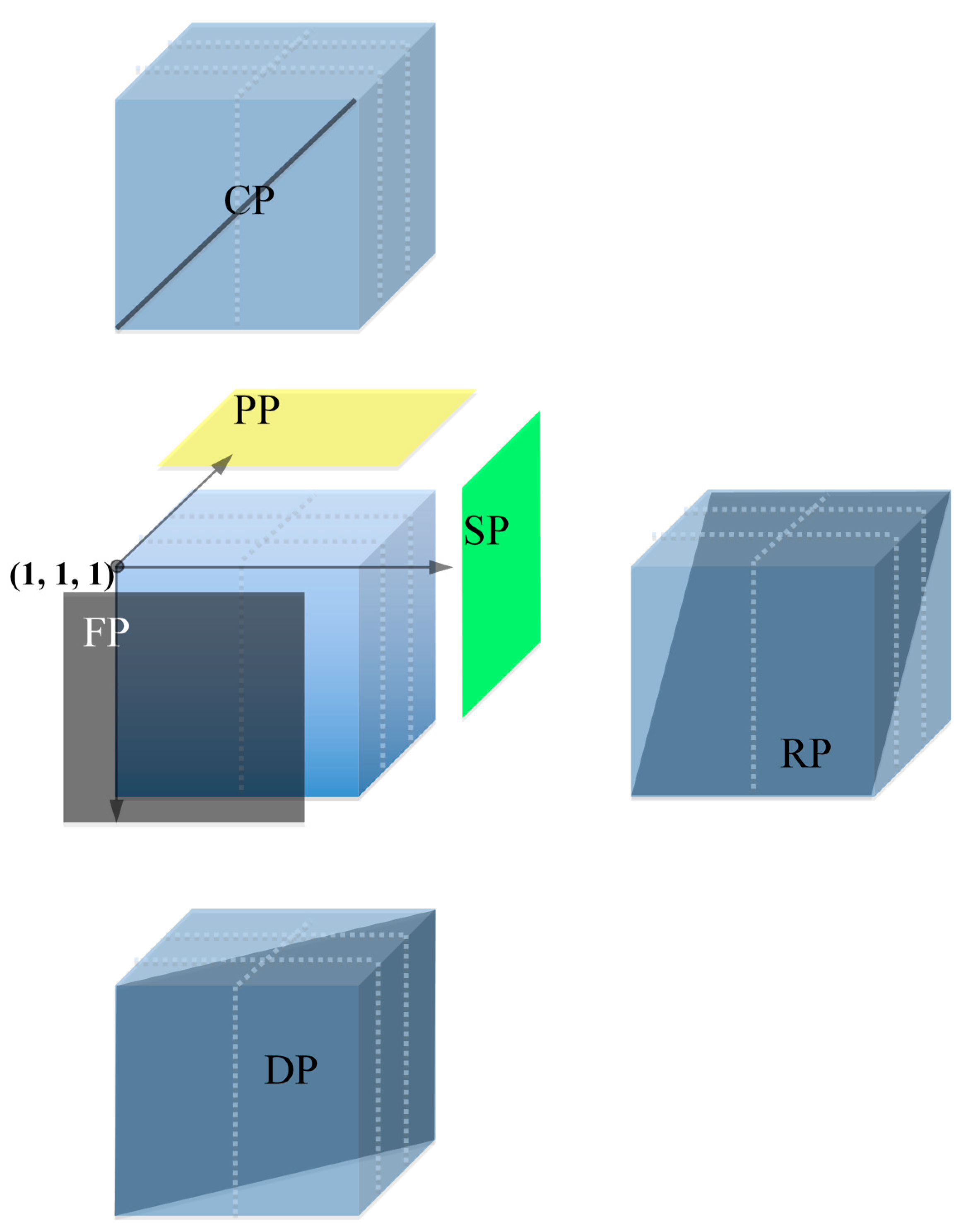
2.3. Descending Pooling
2.4. High Efficiency of Descending Pooling System
| Marker | 6-D Pool | Descending Pool | ||||||
|---|---|---|---|---|---|---|---|---|
| PP | FP | SP | RP | CP | DP | TP | ||
| 18 a | 7 | 9 | 24 | 26 | 16 | 17 | ||
| WMC413-4B | 47 | 45 | 5 | 43 | 3 | 1 | 47 | |
3. Experimental Section
3.1. Plant Material
3.2. HMW DNA Isolation and Partial Digest
3.3. Optimizing Ligation Condition
3.4. Checking Insert Size
3.5. DNA Probes and Southern Blot
3.6. Descending Pooling

3.7. Library Screening
3.8. Comparison between 6D and Descending Pooling Strategy

4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Food and Agriculture Organization of the United Nations. Food and Agricultural commodities production. Available online: http://faostat.fao.org/site/339/default.aspx (accessed on 23 October 2014).
- Yu, Y.; Tomkins, J.P.; Waugh, R.; Frisch, D.A.; Kudrna, D.; Kleinhofs, A.; Brueggeman, R.S.; Muehlbauer, G.J.; Wise, R.P.; Wing, R.A. A bacterial artificial chromosome library for barley (Hordeum vulgare L.) and the identification of clones containing putative resistance genes. Theor. Appl. Genet. 2000, 101, 1093–1099. [Google Scholar]
- Paux, E.; Sourdille, P.; Salse, J.; Saintenac, C.; Choulet, F.; Leroy, P.; Korol, A.; Michalak, M.; Kianian, S.; Spielmeyer, W.; et al. A physical map of the 1–gigabase bread wheat chromosome 3B. Science 2008, 322, 101–104. [Google Scholar]
- Berkman, P.J.; Skarshewski, A.; Lorenc, M.T.; Lai, K.; Duran, C.; Ling, E.Y.; Stiller, J.; Smits, L.; Imelfort, M.; Manoli, S.; et al. Sequencing and assembly of low copy and genic regions of isolated Triticum aestivum chromosome arm 7DS. Plant Biotechnol. J. 2011, 9, 768–775. [Google Scholar]
- Imelfort, M.; Edwards, D. De novo sequencing of plant genomes using second-generation technologies. Brief. Bioinform. 2009, 10, 609–618. [Google Scholar]
- Yan, L.; Fu, D.; Li, C.; Blechl, A.; Tranquilli, G.; Bonafede, M.; Sanchez, A.; Valarik, M.; Yasuda, S.; Dubcovsky, J. The wheat and barley vernalization gene VRN3 is an orthologue of FT. Proc. Natl. Acad. Sci. USA 2006, 103, 19581–19586. [Google Scholar]
- Yan, L.; Loukoianov, A.; Blechl, A.; Tranquilli, G.; Ramakrishna, W.; SanMiguel, P.; Bennetzen, J.; Echenique, V.; Dubcovsky, J. The wheat VRN2 gene is a flowering repressor down-regulated by vernalization. Science 2004, 303, 1640–1644. [Google Scholar]
- Yan, L.; Loukoianov, A.; Tranquilli, G.; Helguera, M.; Fahima, T.; Dubcovsky, J. Positional cloning of the wheat vernalization gene VRN1. Proc. Natl. Acad. Sci. USA 2003, 100, 6263–6268. [Google Scholar]
- Yao, G.Q.; Zhang, J.L.; Yang, L.L.; Xu, H.X.; Jiang, Y.M.; Xiong, L.; Zhang, C.Q.; Zhang, Z.Z.; Ma, Z.Q.; Sorrells, M.E. Genetic mapping of two powdery mildew resistance genes in einkorn (Triticum monococcum L.) accessions. Theor. Appl. Genet. 2007, 114, 351–358. [Google Scholar]
- Akhunov, E.D.; Akhunova, A.R.; Dvořák, J. BAC libraries of Triticum urartu, Aegilops speltoides and Ae. tauschii, the diploid ancestors of polyploid wheat. Theor. Appl. Genet. 2005, 111, 1617–1622. [Google Scholar]
- Moullet, O.; Zhang, H.B.; Lagudah, E.S. Construction and characterization of a large DNA insert library from the D genome of wheat. Theor. Appl. Genet. 1999, 99, 305–313. [Google Scholar]
- Lijavetzky, D.; Muzzi, G.; Wicker, T.; Keller, B.; Wing, R.; Dubcovsky, J. Construction and characterization of a bacterial artificial chromosome (BAC) library for the A genome of wheat. Genome 1999, 42, 1176–1182. [Google Scholar]
- Cenci, A.; Chantret, N.; Kong, X.; Gu, Y.; Anderson, O.D.; Fahima, T.; Distelfeld, A.; Dubcovsky, J. Construction and characterization of a half million clone BAC library of durum wheat (Triticum turgidum ssp. durum). Theor. Appl. Genet. 2003, 107, 931–999. [Google Scholar]
- Allouis, S.; Moore, G.; Bellec, A.; Sharp, R.; Faivre Rampant, P.; Mortimer, K.; Pateyron, S.; Foote, T.N.; Griffiths, S.; Caboche, M.; et al. Construction and characterisation of a hexaploid wheat (Triticum aestivum L.) BAC library from the reference germplasm “Chinese Spring”. Cereal Res. Commun. 2003, 31, 331–338. [Google Scholar]
- Zeng, Q.D.; Yuan, F.P.; Xu, X.; Shi, X.; Nie, X.J.; Zhuang, H.; Chen, X.M.; Wang, Z.H.; Wang, X.J.; Huang, L.L.; et al. Construction and Characterization of a Bacterial Artificial Chromosome Library for the Hexaploid Wheat Line 92R137. BioMed Res. Int. 2014, 2014, 845–806. [Google Scholar]
- Devos, K.M.; Ma, J.; Pontaroli, A.C.; Pratt, L.H.; Bennetzen, J.L. Analysis and mapping of randomly chosen bacterial artificial chromosome clones from hexaploid bread wheat. Proc. Natl. Acad. Sci. USA 2005, 102, 19243–19248. [Google Scholar]
- Paux, E.; Roger, D.; Badaeva, E.; Gay, G.; Bernard, M.; Sourdille, P.; Feuillet, C. Characterizing the composition and evolution of homoeologous genomes in hexaploid wheat through BAC-end sequencing on chromosome 3B. Plant J. 2006, 48, 463–474. [Google Scholar]
- Mozo, T.; Fischer, S.; Shizuya, H.; Altmann, T. Construction and characterization of the IGF Arabidopsis BAC library. Mol. Gen. Genet. 1998, 258, 562–570. [Google Scholar]
- Wang, G.L.; Holsten, T.E.; Song, W.Y.; Wang, H.P.; Ronald, P.C. Construction of a rice bacterial artificial chromosome library and identification of clones linked to the Xa-21 disease resistance locus. Plant J. 1995, 7, 525–533. [Google Scholar]
- Brenchley, R.; Spannagl, M.; Pfeifer, M.; Barker, G.L.; D’Amore, R.; Allen, A.M.; McKenzie, N.; Kramer, M.; Kerhornou, A.; Bolser, D.; et al. Analysis of the bread wheat genome using whole–genome shotgun sequencing. Nature 2012, 491, 705–710. [Google Scholar]
- Ratnayaka, I.; Baga, M.; Fowler, D.B.; Chibbar, R.N. Construction and characterization of a BAC library of a cold–tolerant hexaploid wheat cultivar. Crop Sci. 2005, 45, 1571–1577. [Google Scholar]
- Šafář, J.; Bartoš, J.; Janda, J.; Bellec, A.; Kubaláková, M.; Valárik, M.; Pateyron, S.; Weiserová, J.; Tušková, R.; Číhalíková, J.; et al. Dissecting large and complex genomes: Flow sorting and BAC cloning of individual chromosomes from bread wheat. Plant J. 2004, 39, 960–968. [Google Scholar]
- Klein, P.E.; Klein, R.R.; Cartinhour, S.W.; Ulanch, P.E.; Dong, J.; Obert, J.A.; Morishige, D.T.; Schlueter, S.D.; Childs, K.L.; Ale, M.; et al. A high-throughput AFLP-based method for constructing integrated genetic and physical maps: Progress toward a sorghum genome map. Genome Res. 2000, 10, 789–807. [Google Scholar]
- Wu, X.L.; Zhong, G.H.; Findley, S.D.; Cregan, P.; Stacey, G.; Nguyen, H.T. Genetic marker anchoring by six-dimensional pools for development of a soybean physical map. BMC Genomics 2008, 9. [Google Scholar] [CrossRef]
- Yim, Y.S.; Moak, P.; Sanchez-Villeda, H.; Musket, T.A.; Close, P.; Klein, P.E.; Mullet, J.E.; McMullen, M.D.; Fang, Z.W.; Schaeffer, M.L.; et al. A BAC pooling strategy combined with PCR–based screenings in a large; highly repetitive genome enables integration of the maize genetic and physical maps. BMC Genomics 2007, 8, 47–59. [Google Scholar]
- Luo, M.C.; Xu, K.N.; Ma, Y.Q.; Deal, K.R.; Nicolet, C.M.; Dvorak, J. A high-throughput strategy for screening of bacterial artificial chromosome libraries and anchoring of clones on a genetic map constructed with single nucleotide polymorphisms. BMC Genomics 2009, 10. [Google Scholar] [CrossRef]
- You, F.M.; Luo, M.C.; Xu, K.N.; Deal, K.R.; Anderson, O.D.; Dvorak, J. A new implementation of high-throughput five-dimensional clone pooling strategy for BAC library screening. BMC Genomics 2010, 11, 689–699. [Google Scholar]
- Šimková, H.; Šafář, J.; Suchánková, P.; Kovářová, P.; Bartoš, J.; Kubaláková, M.; Janda, J.; Číhalíková, J.; Mago, R.; Lelley, T.; et al. A novel resource for genomics of Triticeae: BAC library specific for the short arm of rye (Secale cereale L.) chromosome 1R (1RS). BMC Genomics 2008, 9. [Google Scholar] [CrossRef]
- Osoegawa, K.; Woon, P.Y.; Zhao, B.H.; Frengen, E.; Tateno, M.; Catanese, J.J.; de Jong, P.J. An improved approach for construction of bacterial artificial chromosome libraries. Genomics 1998, 52, 1–8. [Google Scholar]
- Frijters, A.C.J.; Zhang, Z.; van Damme, M.; Wang, G.L.; Ronald, P.C.; Michelmore, R.W. Construction of a bacterial artificial chromosome library containing large EcoRI and HindIII genomic fragments of lettuce. Theor. Appl. Genet. 1997, 94, 390–399. [Google Scholar]
- Tao, Q.Z.; Chang, Y.L.; Wang, J.Z.; Chen, H.M.; Islam-Faridi, M.N.; Scheuring, C.; Wang, B.; Stelly, D.M.; Zhang, H.B. Bacterial artificial chromosome-based physical map of the rice genome constructed by restriction fingerprint analysis. Genetics 2001, 158, 1711–1724. [Google Scholar]
- Nilmalgoda, S.D.; Cloutier, S.; Walichnowski, A.Z. Construction and characterization of a bacterial artificial chromosome (BAC) library of hexaploid wheat (Triticum aestivum L.) and validation of genome coverage using locus-specific primers. Genome 2003, 46, 870–878. [Google Scholar]
- Shen, B.; Wang, D.M.; McIntyre, C.L.; Liu, C.J. A “Chinese Spring” wheat (Triticum aestivum L.) bacterial artificial chromosome library and its use in the isolation of SSR markers for targeted genome regions. Theor. Appl. Genet. 2005, 111, 1489–1494. [Google Scholar]
- Zhang, H.B.; Zhao, X.P.; Ding, X.L.; Paterson, A.H.; Wing, R.A. Preparation of megabase-size DNA from plant nuclei. Plant J. 1995, 7, 175–184. [Google Scholar]
- International Human Genome Sequencing Consortium.Initial sequencing and analysis of the human genome. Nature, 2001; 409, 860–921.
- Faris, J.D.; Zhang, Z.; Lu, H.; Lu, S.; Reddy, L.; Cloutier, S.; Fellers, J.P.; Meinhardt, S.W.; Rasmussen, J.B.; Xu, S.S.; et al. A unique wheat disease resistance-like gene governs effector-triggered susceptibility to necrotrophic pathogens. Proc. Natl. Acad. Sci. USA 2010, 107, 13544–13549. [Google Scholar]
- Clarke, L.; Carbon, J. A colony bank containing synthetic Col El hybrid plasmids representative of the entire E. coli genome. Cell 1976, 9, 91–99. [Google Scholar]
- Farrar, K.; Donnison, I.S. Construction and screening of BAC libraries made from Brachypodium genomic DNA. Nat. Protoc. 2007, 2, 1661–1674. [Google Scholar]
- Ma, Z.Y.; Weining, S.; Sharp, P.J.; Liu, C.J. Non-gridded library: A new approach for BAC (bacterial artificial chromosome) exploitation in hexaploid wheat (Triticum aestivum). Nucleic Acids Res. 2000, 28, e106. [Google Scholar] [CrossRef]
- Ling, P.; Chen, X.M. Construction of a hexaploid wheat (Triticum aestivum L.) bacterial artificial chromosome library for cloning genes for stripe rust resistance. Genome 2005, 48, 1028–1036. [Google Scholar]
- Xu, H.X.; Yao, G.Q.; Xiong, L.; Yang, L.L.; Jiang, Y.M.; Fu, B.S.; Zhao, W.F.; Zhang, Z.Z.; Zhang, C.Q.; Ma, Z.Q. Identification and mapping of pm2026: A recessive powdery mildew resistance gene in an einkorn (Triticum monococcum L.) accession. Theor. Appl. Genet. 2008, 117, 471–477. [Google Scholar]
- Peterson, D.G.; Tomkins, J.P.; Frisch, D.A.; Wing, R.A.; Paterson, A.H. Construction of plant bacterial artificial chromosome (BAC) libraries: An illustrated guide. J. Agric. Genomics 2000, 1, 34–40. [Google Scholar]
- Sambrook, J.; Fritsch, E.F.; Maniatis, T. Molecular Cloning: A Laboratory Manual, 3rd ed.; Cold Spring Harbor Laboratory Press: Cold Spring Harbor, NY, USA, 2001; pp. 1123–1125. [Google Scholar]
- Ogihara, Y.; Isono, K.; Kojima, T.; Endo, A.; Hanaoka, M.; Shiina, T.; Terachi, T.; Utsugi, S.; Murata, M.; Mori, N.; et al. Chinese spring wheat (Triticum aestivum L.) chloroplast genome: Complete sequence and contig clones. Plant Mol. Biol. Rep. 2000, 18, 243–253. [Google Scholar]
- Ogihara, Y.; Yamazaki, Y.; Murai, K.; Kanno, A.; Terachi, T.; Shiina, T.; Miyashita, N.; Nasuda, S.; Nakamura, C.; Mori, N.; et al. Structural dynamics of cereal mitochondrial genomes as revealed by complete nucleotide sequencing of the wheat mitochondrial genome. Nucleic Acids Res. 2005, 33, 6235–6250. [Google Scholar]
- Lin, F.; Kong, Z.X.; Zhu, H.L.; Xue, S.L.; Wu, J.Z.; Tian, D.G.; Wei, J.B.; Zhang, C.Q.; Ma, Z.Q. Mapping QTL associated with resistance to Fusarium head blight in the Nanda2419 × Wangshuibai population. I. Type II resistance. Theor. Appl. Genet. 2004, 109, 1504–1511. [Google Scholar]
- Lin, F.; Xue, S.L.; Zhang, Z.Z.; Zhang, C.Q.; Kong, Z.X.; Yao, G.Q.; Tian, D.G.; Zhu, H.L.; Li, C.J.; Cao, Y.; et al. Mapping QTL associated with resistance to Fusarium head blight in the Nanda 2419 × Wangshuibai population. II. Type I resistance. Theor. Appl. Genet. 2006, 112, 528–535. [Google Scholar]
- Xue, S.L.; Zhang, Z.Z.; Lin, F.; Kong, Z.X.; Cao, Y.; Li, C.J.; Yi, H.Y.; Mei, M.F.; Zhu, H.L.; Wu, J.Z.; et al. A high-density intervarietal map of the wheat genome enriched with markers derived from expressed sequence tags. Theor. Appl. Genet. 2008, 117, 181–189. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, W.; Fu, B.; Wu, K.; Li, N.; Zhou, Y.; Gao, Z.; Lin, M.; Li, G.; Wu, X.; Ma, Z.; et al. Construction and Characterization of Three Wheat Bacterial Artificial Chromosome Libraries. Int. J. Mol. Sci. 2014, 15, 21896-21912. https://doi.org/10.3390/ijms151221896
Cao W, Fu B, Wu K, Li N, Zhou Y, Gao Z, Lin M, Li G, Wu X, Ma Z, et al. Construction and Characterization of Three Wheat Bacterial Artificial Chromosome Libraries. International Journal of Molecular Sciences. 2014; 15(12):21896-21912. https://doi.org/10.3390/ijms151221896
Chicago/Turabian StyleCao, Wenjin, Bisheng Fu, Kun Wu, Na Li, Yan Zhou, Zhongxia Gao, Musen Lin, Guoqiang Li, Xinyi Wu, Zhengqiang Ma, and et al. 2014. "Construction and Characterization of Three Wheat Bacterial Artificial Chromosome Libraries" International Journal of Molecular Sciences 15, no. 12: 21896-21912. https://doi.org/10.3390/ijms151221896
APA StyleCao, W., Fu, B., Wu, K., Li, N., Zhou, Y., Gao, Z., Lin, M., Li, G., Wu, X., Ma, Z., & Jia, H. (2014). Construction and Characterization of Three Wheat Bacterial Artificial Chromosome Libraries. International Journal of Molecular Sciences, 15(12), 21896-21912. https://doi.org/10.3390/ijms151221896