Dual Convolutional Neural Network Based Method for Predicting Disease-Related miRNAs

1
School of Computer Science and Technology, Heilongjiang University, Harbin 150080, China
2
School of Information Science and Technology, Heilongjiang University, Harbin 150080, China
3
School of Mathematical Science, Heilongjiang University, Harbin 150080, China
*
Author to whom correspondence should be addressed.
Int. J. Mol. Sci. 2018, 19(12), 3732; https://doi.org/10.3390/ijms19123732
Submission received: 29 October 2018
/
Revised: 15 November 2018
/
Accepted: 19 November 2018
/
Published: 23 November 2018
(This article belongs to the Special Issue Special Protein or RNA Molecules Computational Identification 2018)
Abstract
:Identification of disease-related microRNAs (disease miRNAs) is helpful for understanding and exploring the etiology and pathogenesis of diseases. Most of recent methods predict disease miRNAs by integrating the similarities and associations of miRNAs and diseases. However, these methods fail to learn the deep features of the miRNA similarities, the disease similarities, and the miRNA–disease associations. We propose a dual convolutional neural network-based method for predicting candidate disease miRNAs and refer to it as CNNDMP. CNNDMP not only exploits the similarities and associations of miRNAs and diseases, but also captures the topology structures of the miRNA and disease networks. An embedding layer is constructed by combining the biological premises about the miRNA–disease associations. A new framework based on the dual convolutional neural network is presented for extracting the deep feature representation of associations. The left part of the framework focuses on integrating the original similarities and associations of miRNAs and diseases. The novel miRNA and disease similarities which contain the topology structures are obtained by random walks on the miRNA and disease networks, and their deep features are learned by the right part of the framework. CNNDMP achieves the superior prediction performance than several state-of-the-art methods during the cross-validation process. Case studies on breast cancer, colorectal cancer and lung cancer further demonstrate CNNDMP’s powerful ability of discovering potential disease miRNAs.
1. Introduction
miRNAs are non-coding single-stranded RNA molecules encoded by endogenous genes with a length of about 22 nucleotides. miRNAs exert their biological functions primarily via regulating the expression of target genes (mRNAs). miRNAs usually target to a specific sequence in the 3′ untranslated terminal of mRNAs, inhibiting the translation of the target genes [1,2,3,4,5]. With the development of molecular biology and biotechnology, scientists find that the abnormal expression of miRNAs is closely related to various human diseases [6,7,8]. Therefore, predicting the potential disease-associated miRNAs is of great significance for understanding disease etiology and pathogenesis.
In recent years, several computational methods have been proposed for predicting disease-associated miRNAs, which can be classified into two main categories in general. miRNAs implement their biological functions by regulating the expression of their target mRNAs [9]. Therefore, the first category of methods is based on target genes to predict the potential associations between diseases and miRNAs. Jiang et al. [10] estimated the functional similarities of miRNAs through the number of target genes co-associated with miRNAs. The similarities among diseases is measured according to the phenotype of the disease, and the known miRNA–disease associations are combined to predict the potential miRNA–disease associations. However, the number of experimentally validated target genes is not sufficient, which cannot provide sufficient and effective data to support the prediction. Li et al. [11] used target gene prediction software TargetScan [12], MiRanda [13], and PITA [14] to predict target genes that a certain miRNA might regulate. The disease-related miRNAs are then predicted by measuring the functional consistency between the predicted target genes and existing disease-related genes. As the false-positive rate of target genes predicted by the software are very high, it is difficult for this method to achieve high prediction accuracy. The methods in the second category are based on the biological observation that miRNAs with similar functions are usually associated with similar diseases and vice versa [15,16,17,18]. Xuan et al. [19] and Xiao et al. [20] proposed the method based on non-negative matrix factorization from the similarity and association perspective of miRNAs and diseases. Liu et al. [21] and Liao et al. [22] proposed the method of predicting miRNA–disease associations via random walking in networks composed of multiple data sources. Zeng et al. [23] proposed a disease miRNA prediction algorithm based on the structural perturbation method. Chen et al. [24] and Zhang et al. [25] proposed a path-based method for predicting miRNAs that are associated with diseases. Ding et al. [26] integrated known miRNA–disease associations and experimentally validated miRNA–target associations and proposed a prediction method based on a disease–miRNA–target heterogeneous network. As these methods are based on the traditional computing model [27,28,29], it is difficult to extract the deep feature representation from the multiple kinds of data.
There are limited associations between miRNAs and diseases, so their associations are sparse. The similarities between diseases are also sparse. Since convolutional neural networks (CNNs) are suitable for dealing with this kind of sparse data [30], we propose a CNN-based prediction method. The topological structures of miRNAs and diseases are also very important for miRNA–disease association prediction. Therefore, we construct a dual CNN-based prediction model to learn the depth feature representation in sparse data and capture the topological information in miRNA and disease networks.
2. Results and Discussion
2.1. Performance Evaluation Metrics
Considering that most of the diseases in the HMDD database are only associated with a few miRNAs, they are not sufficient to evaluate the prediction performance of our method. Therefore, we performed five-fold cross-validation on the 15 diseases associated with more than 90 miRNAs to compare the prediction performance between CNNDMP and several state-of-the-art methods. First, we regard the known miRNA–disease associations as positive samples, and randomly divide them into five equal parts, and the unknown associations are regarded as negative samples. The negative samples (whose quantity is equal to that of the positive samples) are selected randomly from all the negative ones. These negative samples are also divided into five equal parts. Four parts of positive samples and four parts of negative samples are used as the training data in each-fold cross-validation. The remaining positive and the remaining negative samples are used as the testing data to verify the prediction performance.
We can obtain the association prediction scores in the testing data via the CNN prediction model and sort them by their values in descending order. If a known association exists between a pair of miRNA–disease sample, and the prediction score of the association is higher than the given threshold , it is a successfully identified positive sample. If the prediction score of a negative sample is lower than , it is a successfully identified negative sample. By changing the threshold, we can calculate the corresponding true positive rate (TPR), false positive rate (FPR), precision (Precision) and recall rate (Recall). They are defined as follows,
where TP and TN represent the number of positive and negative samples correctly identified, FP represents the number of negative samples misidentified as positive samples, and FN represents the number of positive samples misidentified as negative samples. Each time the threshold is changed, the corresponding TPR and FPR values, as well as the Precision and Recall values, are obtained. The receiver operating feature curve (ROC) and the precision–recall curve (PR) are then drawn using these values. The areas under the ROC curve (ROC-AUC) and the PR curve (PR-AUC) are used to evaluate the whole prediction performance.
Biologists usually select the top-ranked miRNA candidates from the prediction result to further validate their associations with the disease. Therefore, we calculate the average recall values of the top 30, 60, 90–210 and 240 candidates for 15 diseases. Through the recall, we compare how many positive samples appear in the top k candidates in different methods. The larger the recall value, the more positive samples are identified successfully.
2.2. Comparison with Other Methods
CNNDMP is compared with GSTRW [22], DMPred [19], PBMDA [24] and Liu’s Method [21], which are state-of-the-art prediction methods for miRNA–disease associations. The parameters involved in each method need to be adjusted to achieve the best prediction performance. In our method, , and are set to 3, 2 and 11, respectively. Each convolutional layer contains 20 convolution filters, so is set to 20. The restart probability of random walk is 0.8, and the harmonic parameter is set to 0.9. varies from 0.1 to 0.9, and the corresponding performances of CNNDMP are listed in Table 1. For the other methods, we use the parameters mentioned in the corresponding papers ( for GSTRW, for PBMDA, for DMPred, for Liu’s Method).
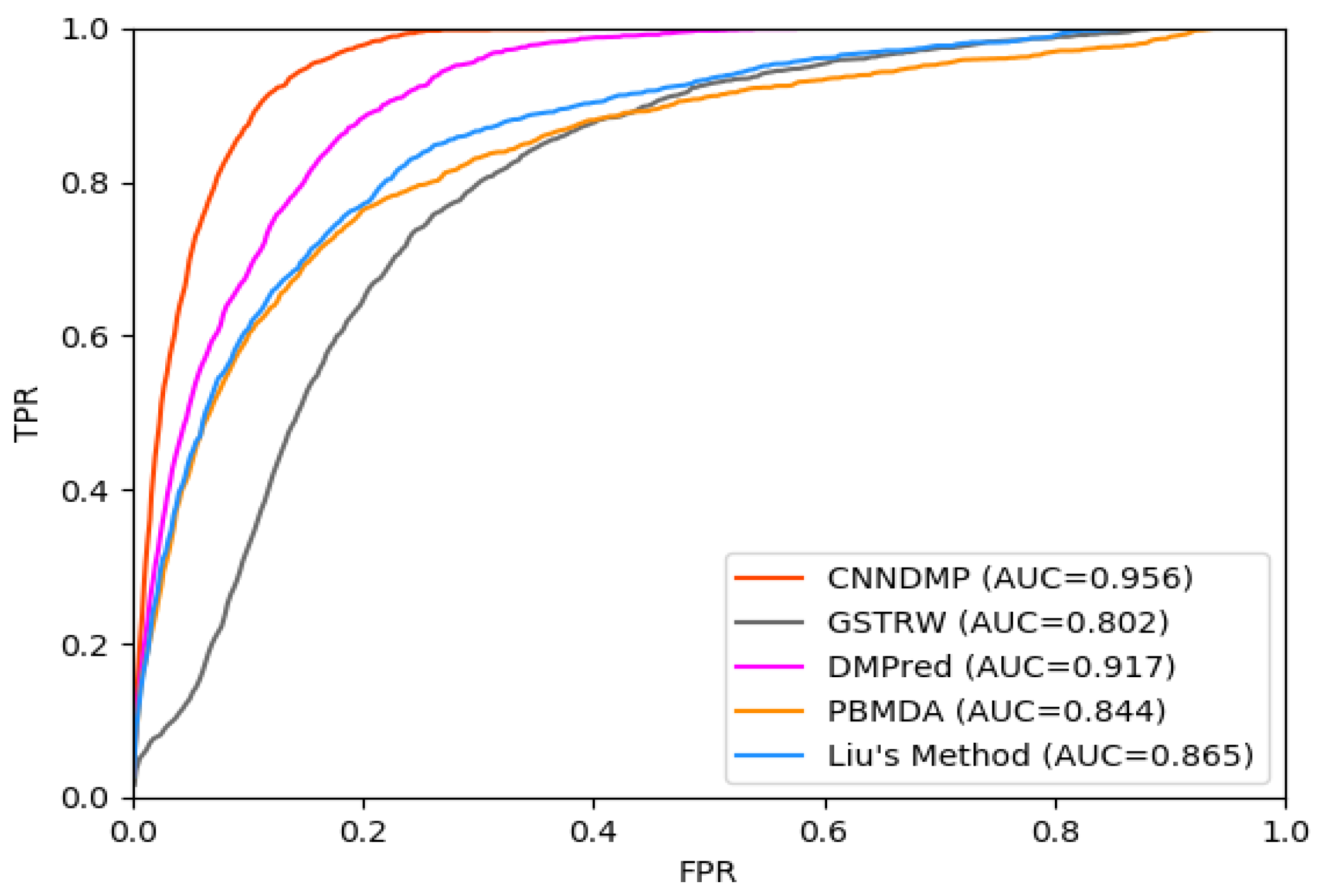
The AUC-ROC values of the five methods (CNNDMP, GSTRW, DMPred, PBMDA, and Liu’s Method) for 15 diseases are 0.956, 0.802, 0.917, 0.844, and 0.865, respectively (Table 2, Figure 1). CNNDMP achieved the best prediction performance, and its average AUC-ROC is 0.956, which is higher by 15.4%, 3.9%, 11.2%, and 9.1% compared to the other four methods, respectively. The miRNA–disease association scores of GSTRW are dependent on the calculation of miRNA similarities and disease similarities. Therefore, GSTRW performs the worst in all methods. The performance of PBMDA is similar to that of Liu’s Method as they all exploit the network topology information. DMPred utilizes miRNA- and disease-related information and achieves a competitive predictive performance. Our method, CNNDMP, completely integrates the original feature of miRNAs, diseases and network topology, combines them with the powerful representation learning capability of CNN and achieves the best prediction performance.
There are far more unobserved miRNA–disease associations than known ones, so there is a serious class imbalance between them. For the imbalanced associations, the PR curves are better than ROC curves in reflecting the prediction performance of different methods. Figure 2 shows the PR curves of CNNDMP, GSTRW, DMPred, PBMDA and Liu’s Method for 15 diseases. Their PR-AUCs are 0.538, 0.177, 0.392, 0.324, and 0.334, respectively. The PR-AUC of CNNDMP is 36.1%, 14.6%, 21.4%, and 20.4% higher than the other methods. As shown in Table 3, CNNDMP yields the best average performance in terms of PR-AUCs and achieves the best performance for 14 of 15 common diseases.
For the top k miRNA candidates, the higher recall rate means that there are more positive samples successfully identified. Figure 3 shows the average recall rates for 15 diseases in the top k miRNA candidates. CNNDMP’s recall rates for the top 30 to 240 candidate results are 0.629, 0.878, 0.966, 0.990, 0.998, 0.999, 1.0, and 1.0, respectively. The results in Figure 1, Figure 2 and Figure 3 and Table 2 and Table 3 show that our method is indeed effective in discovering potential disease miRNAs.
In addition, to further verify that the ROC-AUC and PR-AUC of CNNDMP are significantly higher than the other methods, we performed a paired t-test. All paired t-test results are less than 0.05, which indicates that CNNDMP’s performance is significantly better than the other methods (Table 4).
2.3. Comparison between the Individual Networks and the Integrated Network
To verify that the performance of the integrated network is better than the individual networks, we evaluate the prediction performances of the left and right networks within CNNDMP, respectively. The values of ROC-AUC and PR-AUC of the left network are 0.916 and 0.509, respectively. For the right network, the values of ROC-AUC and PR-AUC are 0.905 and 0.494, respectively. Compared with the left and right networks, the ROC-AUC of the integrated network increased by 4% and 5.1%, and the PR-AUC increased by 2.9% and 4.4%.
2.4. Case Studies on Breast Cancer, Colorectal Cancer and Lung Cancer
To further demonstrate CNNDMP’s ability to discover potential disease-associated miRNAs, we used three independent databases, dbDEMC [31], miRCancer [32], and PhenomiR [33], as well as the relevant literature to verify the candidates of breast cancer, colorectal cancer and lung cancer. We take the prediction results of breast cancer as an example, and list the results of this case analysis in detail.
We list the case study of the top 50 miRNA candidates related to breast cancer in Table 5. dbDEMC is a database of differentially expressed miRNAs in human cancers, and it contains 2224 differentially expressed miRNAs in 36 cancer types. Forty-three of the 50 miRNA candidates are included in this database, which confirmed the differential expression of these candidates in breast cancer. PhenomiR is also a database of differentially expressed miRNAs in human cancers. miRCancer is a miRNA–cancer associations database that collects 6323 miRNA–cancer associations from 4875 academic papers covering 184 cancers. PhenomiR includes two miRNA candidates, and miRCancer contains two candidates. Five miRNA candidates are confirmed in the relevant literature.
The top 50 colorectal cancer-related candidates are given in Supplementary Table S1. The databases of dbDEMC and miRCancer respectively include 48 candidates and one candidate whose abnormal expressions have been identified in colorectal cancer. A candidate marked ‘Unconfirmed’ means that it is not currently supported by the databases and the relevant literature.
In terms of lung cancer, the top 50 candidates are listed in Supplementary Table S2. Forty candidates are included in dbDEMC and three candidates are contained by miRCancer which have abnormal expression in lung cancer. A candidate is supported by PhenomiR to have abnormal regulation in lung cancer. Four candidates are supported by the relevant literature to be differentially expressed in lung cancer. Three candidates marked ‘Unconfirmed’ are not currently supported by the databases and the relevant literature. The case studies on the three diseases confirm that the CNNDMP has a powerful ability to discover potential disease miRNAs.
2.5. Predicting Novel Disease-Related miRNAs
By comparing the ROC curve, PR curve and the recall rate of the top k candidates for the five methods by cross-validation, CNNDMP has achieved the best prediction performance. Subsequent case analysis results further confirm that CNNDMP has good prediction performance in discovering the associations between miRNAs and diseases. Therefore, we further apply this method to all 326 diseases. We take all the positive samples and the corresponding negative samples as training data. Finally, the top 100 miRNA candidates for each disease are given in Supplementary Table S3.
3. Materials and Methods
3.1. Dataset
The miRNA–disease associations used in this study derive from the human miRNA–disease database (HMDD) [39]. HMDD has collected thousands of reliable association pairs between miRNAs and diseases. After integrating different miRNA records and unifying the miRNA and disease names, we finally retained 5088 miRNA–disease associations, involving 490 miRNAs and 326 diseases. Disease terms are available from the National Library of Medicine (http://www.ncbi.nlm.nih.gov/mesh). The phenotypic similarities and the semantic similarities are obtained from a published study [18].
3.2. Construction of a miRNA–Disease Heterogeneous Network
miRNA similarity measurement. Based on the biological observation that miRNAs with similar functions usually tend to be associated with similar diseases, the similarity of two miRNAs is estimated by measuring the similarities of their associated diseases. For example, miRNA is associated with diseases , , , , and , whereas miRNA is associated with diseases , , , and . Wang et al. [40] calculated the similarity between and as the similarity of and , denoted as . The similarity between and includes the following three steps: first, the similarities between and each of the diseases in are calculated, and the maximum similarity is taken as the similarity between and . Similarly, the similarities between and are obtained, respectively. Second, the similarities between each of diseases in and are calculated. Finally, these similarities are accumulated and divided by the total number of diseases in and . We use the matrix to represent the similarities of miRNAs, where is the number of miRNAs. The values of miRNA similarities are distributed between 0 and 1.
Disease similarity measurement. The disease similarity measures how similar they are from the perspectives of disease semantics and phenotype. The terms related to a disease are represented by a directed acyclic graph (DAG). If there are more common terms between the DAGs of two diseases, it means that the two diseases are more similar. At the same time, two diseases that share more common phenotypes are often more similar. Therefore, we quantify the similarity of two diseases based on their semantics and phenotype. Xuan et al. have successfully integrated this information and calculated the similarities between diseases. Therefore, disease similarities can be obtained from published studies [19,41]. We use the matrix to represent the similarities between diseases and values of the similarities vary from 0 and 1, where represents the number of diseases.
miRNA–disease associations. If miRNA is associated with disease then , or when their association has not been observed. We use to represent the associations between miRNAs and diseases.
By exploiting the similarities of miRNAs and diseases, as well as the known associations between miRNAs and diseases, we construct a heterogeneous network including two kinds of nodes (miRNAs and diseases), and the matrix representation of the network (Figure 4).
3.3. Prediction Model Based on Dual CNN
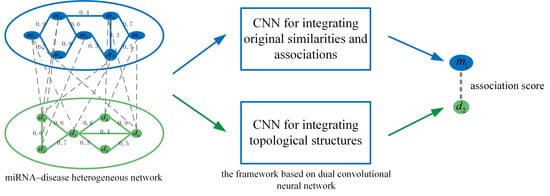
We construct a prediction model based on dual CNN, which is composed of left and right parts. The left part learns from the original feature information of miRNAs and diseases. The complex, implicit and nonlinear miRNA–disease feature information is captured by the CNN layer. The right part combines miRNA and disease network topology information and represents it deeply by the CNN layer. Finally, we integrate the results of the left and right to obtain final prediction scores for disease-associated miRNAs.
3.3.1. Embedding Layer
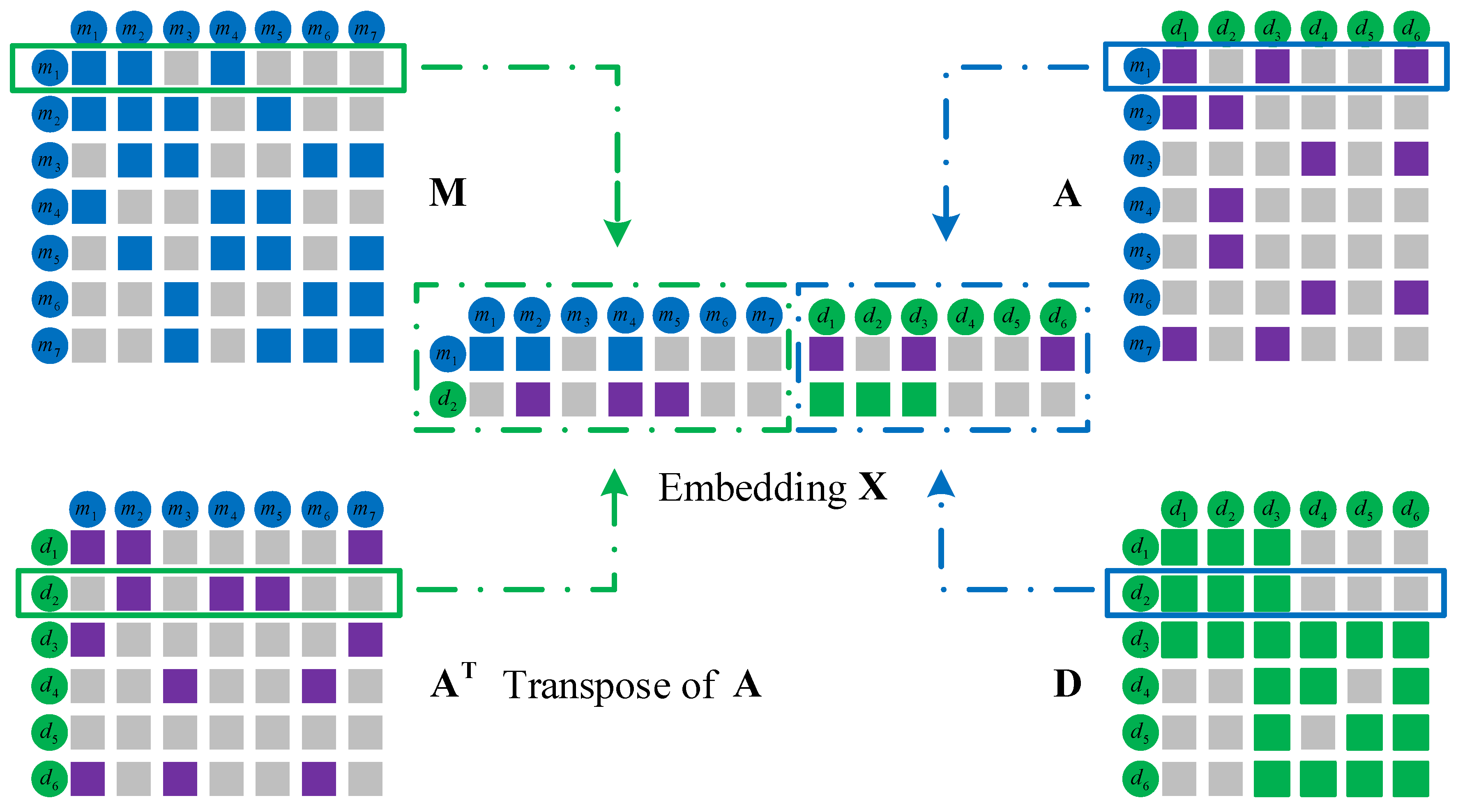
Embedding in the left part by integrating miRNA and disease original feature information. Functionally similar miRNAs are usually involved in similar diseases and vice versa. Therefore, we integrate miRNA and disease similarities and miRNA–disease associations to construct the embedding in the left part. We take the miRNA and disease in Figure 5 as an example to elaborate the integration process. The first row of represents the similarities between and all the miRNAs, and the second row of represents the associations between and all the miRNAs. The miRNA is similar to and , and the disease has a known association with , and . Thus, miRNA and disease are likely to be associated. Similarly, we integrate the first row of with the second row of . Among them, miRNA is associated with , and , and disease is similar to and , so miRNA and disease are likely to be associated. The final integration result is represented by the feature matrix .
Embedding in the right part by integrating the networks topology. We firstly obtain network topology information by random walking in the miRNA and disease networks, respectively. The basic principle of a random walk with restart is that the walker starts from a node in the network at 0th time and walks randomly in the miRNA (or disease) network. When the current node of the walker is more similar to a neighbor node, the probability that the walker turns to it is greater. Therefore, after the walking process converges, the probability that the walker reaches a certain node is greater, indicating that the node is more similar to the starting node. We define the convergent vector as , which represents the similarities between the starting node and all the nodes.
We take the miRNA network as an example to illustrate its computational process in detail. Firstly, we need to row-normalize the original miRNA similarities matrix M to obtain the probabilistic transfer matrix W. Then, based on the following random walk with restart iteration formula,
the network topology-based miRNA similarities are obtained. Taking miRNA as an example, the current random walk from node , the first element of is then set to 1 and the other elements are 0. The parameter represents the probability that the walker returns to the starting node for re-walking. is the transposed matrix of , represents the probability that the walker arrives at each miRNA node at time , and represents the arrival probability at time . After the walking process is converged, the vector is obtained and regarded as a part of the embedding in the right part. When norm between and is less than , the convergence condition is satisfied. Similarly, in the disease network, we randomly walk from the disease node, and finally get the vector as a part of the right embedding.
We integrate the similarity and association information of miRNA and disease based on network topology to form the embedding in Figure 6. The final integration result is represented by the feature matrix .
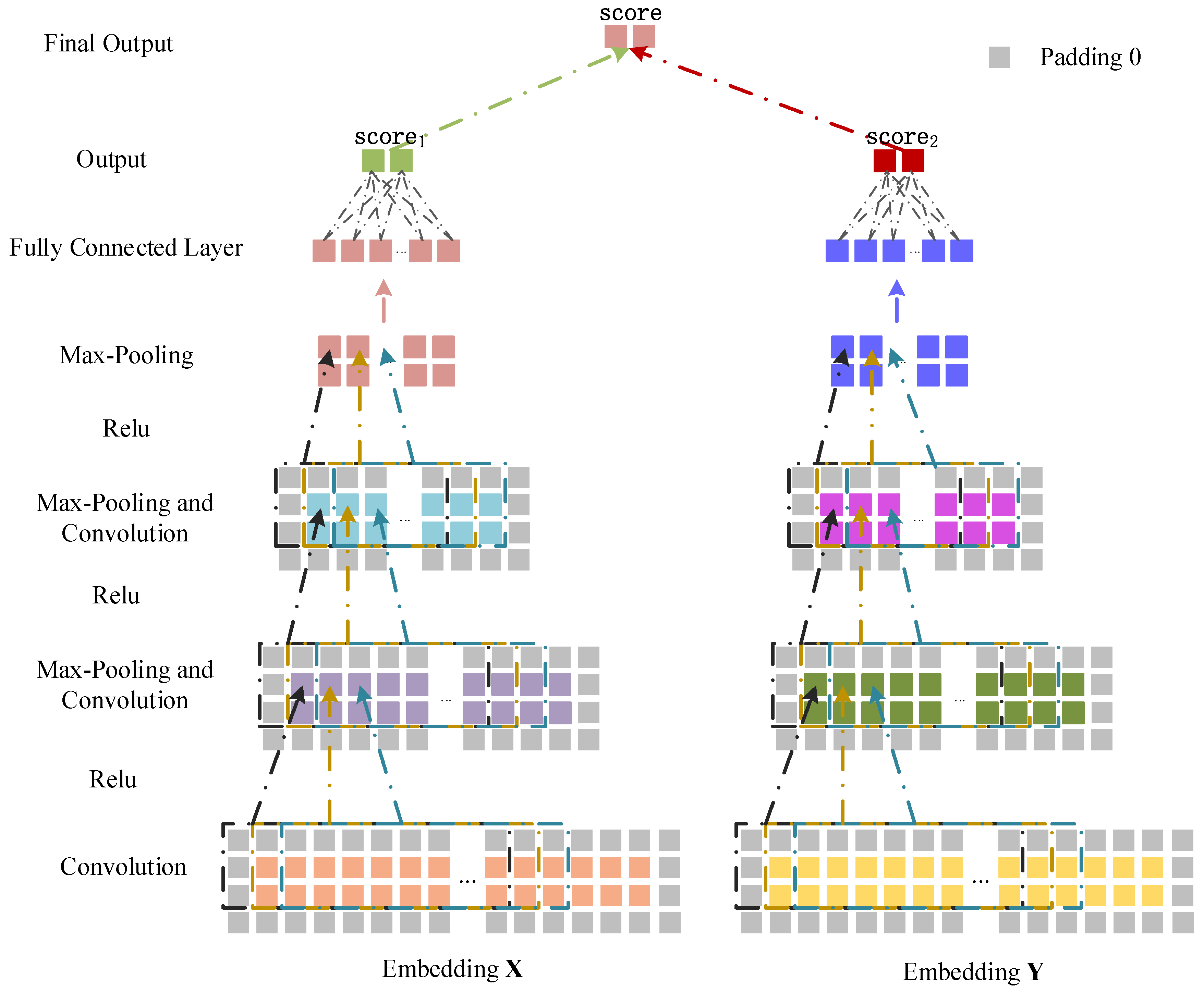
3.3.2. Convolutional Module on the Left
We treat the embedding as the input data of the CNN module to learn the original feature representation (Figure 7). For the convolutional layer, we set the length and width of a convolution filter to and , and the convolution filters can be represented as . We apply to to get the feature output ,
where is the convolution result when the jth convolution filter slides to the ith position of , and is a nonlinear activation function (relu). is a bias vector, and is the first column vector in the sliding window when the filter moves to the ith position of . In the pooling layer, the max-pooling operation is performed on to get ,
where is the pooling value of the pth position of the jth convolution filter and is the sliding window length of the pooling operation. We use as the input of the second convolutional layer, and obtain the output of the second pooling layer . Similarly, as the input of the third convolutional layer can obtain . Finally, we flatten to a column vector and obtain the association prediction score of and through the fully connected layer. The score is defined as ,
where is a weight matrix between the fully connected layer and the output layer.
3.3.3. Convolutional Module on the Right
The embedding in the right part is input to learn the feature representation of the network topology (Figure 7). The convolution and pooling processes of the right part are similar to that in the left part. The convolutional operation and the max-pooling operation are defined as follows,
where is the feature output of the convolution operation and is the first column vector in the sliding window when the filter moves to the ith position of . is obtained by performing the max-pooling operation on . We use as the input of the second convolutional layer, and obtain the output of the second pooling layer . Similarly, as the input of the third convolutional layer can obtain . Finally, we flatten to the column vector and get the association score between and by the fully connected layer. The score is defined as ,
where is the weight matrix between the fully connected layer and the output layer.
3.3.4. Combined Strategy
The association scores and are obtained from different perspectives of miRNA–disease information. To take complete advantage of the prediction results from the left and right parts, we integrate the two scores as the final association score between a miRNA and a disease. It is defined as follows,
where the parameter is used to adjust the importance of and . The loss functions of the left and right CNNs are defined as and
where indicates the actual association between a miRNA and a disease. is 1 when the miRNA is associated with the disease, otherwise is 0. and represent the scores of miRNA–disease associations that are classified as the negative sample and the positive one, respectively. and indicate the corresponding probabilities obtained by the softmax function. represents the number of training samples.
4. Conclusions
A novel method based on a dual convolutional neural network, CNNDMP, is developed for prioritizing potential disease miRNAs. CNNDMP’s embedding layer is constructed from the biological perspective by combining the biological premise about miRNA–disease associations. At the same time, the embedding layer captures the original similarities and associations of miRNAs and diseases, as well as the topology structure of the miRNA and disease networks. The new framework based on a dual convolutional neural network is constructed for learning the deep features of the original similarities and associations of miRNAs and diseases, and the new miRNA and disease similarities. The results of cross-validation on 15 common diseases confirms CNNDMP’s superior performance. The case studies on three diseases further show that CNNDMP has a strong ability to discover candidate disease miRNAs.
Supplementary Materials
The following are available online at https://www.mdpi.com/1422-0067/19/12/3732/s1.
Author Contributions
P.X. and T.Z. conceived the prediction method, and P.X. wrote the paper. Y.D. and Y.L. developed the computer programs. Y.G. and T.Z. analyzed the results and revised the paper.
Funding
The work was supported by the Natural Science Foundation of Heilongjiang Province (F2015013, F2017024), the Fundamental Research Foundation of Universities in Heilongjiang Province for Technology Innovation (KJCX201805), the Fundamental Research Foundation of Universities in Heilongjiang Province for Youth Innovation Team (RCYJTD201805), the Postdoctoral Science Foundation of Heilongjiang Province, and the Young Innovative Talent Research Foundation of Harbin Science and Technology Bureau (2017RAQXJ094, 2015RAQXJ004, 2016RQQXJ135).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Meister, G.; Tuschl, T. Mechanisms of gene silencing by double-stranded RNA. Nature 2004, 431, 343. [Google Scholar] [CrossRef] [PubMed]
- Bartel, D.P. MicroRNAs: Genomics, biogenesis, mechanism, and function. Cell 2004, 116, 281–297. [Google Scholar] [CrossRef]
- Ambros, V. microRNAs: Tiny regulators with great potential. Cell 2001, 107, 823–826. [Google Scholar] [CrossRef]
- Ambros, V. The functions of animal microRNAs. Nature 2004, 431, 350. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Guo, M.; Liu, X.; Wang, C.; Liu, Y.; Liu, G. Identify bilayer modules via pseudo-3D clustering: Applications to miRNA-gene bilayer networks. Nucleic Acids Res. 2016, 44, e152. [Google Scholar] [CrossRef] [PubMed]
- Calin, G.A.; Croce, C.M. MicroRNA-cancer connection: The beginning of a new tale. Cancer Res. 2006, 66, 7390–7394. [Google Scholar] [CrossRef] [PubMed]
- Meola, N.; Gennarino, V.A.; Banfi, S. MicroRNAs and genetic diseases. Pathogenetics 2009, 2, 7. [Google Scholar] [CrossRef] [PubMed]
- Sayed, D.; Abdellatif, M. MicroRNAs in development and disease. Physiol. Rev. 2011, 91, 827–887. [Google Scholar] [CrossRef] [PubMed]
- Pasquinelli, A.E. MicroRNAs and their targets: Recognition, regulation and an emerging reciprocal relationship. Nat. Rev. Genet. 2012, 13, 271. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Q.; Hao, Y.; Wang, G.; Juan, L.; Zhang, T.; Teng, M.; Liu, Y.; Wang, Y. Prioritization of disease microRNAs through a human phenome-microRNAome network. BMC Syst. Boil. 2010, 4, S2. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, Q.; Zheng, Y.; Lv, S.; Ning, S.; Sun, J.; Huang, T.; Zheng, Q.; Ren, H.; Xu, J.; et al. Prioritizing human cancer microRNAs based on genes’ functional consistency between microRNA and cancer. Nucleic Acids Res. 2011, 39, e153. [Google Scholar] [CrossRef] [PubMed]
- Lewis, B.P.; Shih, I.H.; Jones-Rhoades, M.W.; Bartel, D.P.; Burge, C.B. Prediction of mammalian microRNA targets. Cell 2003, 115, 787–798. [Google Scholar] [CrossRef]
- John, B.; Enright, A.J.; Aravin, A.; Tuschl, T.; Sander, C.; Marks, D.S. Human microRNA targets. PLoS Biol. 2004, 2, e363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kertesz, M.; Iovino, N.; Unnerstall, U.; Gaul, U.; Segal, E. The role of site accessibility in microRNA target recognition. Nat. Genet. 2007, 39, 1278. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Yan, C.C.; Zhang, X.; You, Z.H.; Deng, L.; Liu, Y.; Zhang, Y.; Dai, Q. WBSMDA: Within and between score for miRNA-disease association prediction. Sci. Rep. 2016, 6, 21106. [Google Scholar] [CrossRef] [PubMed]
- Pasquier, C.; Gardès, J. Prediction of miRNA-disease associations with a vector space model. Sci. Rep. 2016, 6, 27036. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.Q.; Rong, Z.H.; Chen, X.; Yan, G.Y.; You, Z.H. MCMDA: Matrix completion for miRNA-disease association prediction. Oncotarget 2017, 8, 21187. [Google Scholar] [CrossRef] [PubMed]
- Lan, W.; Wang, J.; Li, M.; Liu, J.; Wu, F.X.; Pan, Y. Predicting microRNA-disease associations based on improved microRNA and disease similarities. IEEE/ACM Trans. Comput. Boil. Bioinform. 2016. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Xuan, P.; Wang, X.; Zhang, T.; Li, J.; Liu, Y.; Zhang, W. A non-negative matrix factorization based method for predicting disease-associated miRNAs in miRNA-disease bilayer network. Bioinformatics 2017, 34, 267–277. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Q.; Luo, J.; Liang, C.; Cai, J.; Ding, P. A graph regularized non-negative matrix factorization method for identifying microRNA-disease associations. Bioinformatics 2017, 34, 239–248. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zeng, X.; He, Z.; Zou, Q. Inferring microRNA-disease associations by random walk on a heterogeneous network with multiple data sources. IEEE/ACM Trans. Comput. Boil. Bioinform. 2017, 14, 905–915. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Liao, B.; Li, Z. Global Similarity Method Based on a Two-tier Random Walk for the Prediction of microRNA–Disease Association. Sci. Rep. 2018, 8, 6481. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Liu, L.; Lü, L.; Zou, Q.; Valencia, A. Prediction of potential disease-associated microRNAs using structural perturbation method. Bioinformatics 2018, 1, 8. [Google Scholar] [CrossRef] [PubMed]
- You, Z.H.; Huang, Z.A.; Zhu, Z.; Yan, G.Y.; Li, Z.W.; Wen, Z.; Chen, X. PBMDA: A novel and effective path-based computational model for miRNA-disease association prediction. PLoS Comput. Boil. 2017, 13, e1005455. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zou, Q.; Rodriguez-Paton, A. Meta-path methods for prioritizing candidate disease miRNAs. IEEE/ACM Trans. Comput. Boil. Bioinform. 2017. [Google Scholar] [CrossRef]
- Ding, L.; Wang, M.; Sun, D.; Li, A. A novel method for identifying potential disease-related miRNAs via a disease–miRNA–target heterogeneous network. Mol. BioSyst. 2017, 13, 2328–2337. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Zhang, X.; Zou, Q. Integrative approaches for predicting microRNA function and prioritizing disease-related microRNA using biological interaction networks. Brief. Bioinform. 2015, 17, 193–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, Q.; Li, J.; Song, L.; Zeng, X.; Wang, G. Similarity computation strategies in the microRNA-disease network: A survey. Brief. Funct. Genom. 2015, 15, 55–64. [Google Scholar] [CrossRef] [PubMed]
- Zou, Q.; Chen, L.; Huang, T.; Zhang, Z.; Xu, Y. Machine learning and graph analytics in computational biomedicine. Artif. Intell. Med. 2017, 83, 1. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wang, Y.; Luo, J.; Zhao, W.; Zhou, X. Deep learning of the splicing (epi)genetic code reveals a novel candidate mechanism linking histone modifications to ESC fate decision. Nucleic Acids Res. 2017, 45, 12100–12112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Z.; Ren, F.; Liu, C.; He, S.; Sun, G.; Gao, Q.; Yao, L.; Zhang, Y.; Miao, R.; Cao, Y.; et al. dbDEMC: A database of differentially expressed miRNAs in human cancers. BMC Genom. 2010, 11, S5. [Google Scholar] [CrossRef] [PubMed]
- Xie, B.; Ding, Q.; Han, H.; Wu, D. miRCancer: A microRNA–cancer association database constructed by text mining on literature. Bioinformatics 2013, 29, 638–644. [Google Scholar] [CrossRef] [PubMed]
- Ruepp, A.; Kowarsch, A.; Schmidl, D.; Buggenthin, F.; Brauner, B.; Dunger, I. PhenomiR: A knowledgebase for microRNA expression in diseases and biological processes. Genome Boil. 2010, 11, R6. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Jiang, D.R.; Xu, C.C.; Zhu, G.L.; Wu, Z.S.; Wu, Q. Differential expression profile analysis of miRNAs with HER-2 overexpression and intervention in breast cancer cells. Int. J. Clin. Exp. Pathol. 2017, 10, 5039–5062. [Google Scholar]
- Maltseva, D.V.; Galatenko, V.V.; Samatov, T.R.; Zhikrivetskaya, S.O.; Khaustova, N.A.; Nechaev, I.N.; Shkurnikov, M.U.; Lebedev, A.E.; Mityakina, I.A.; Kaprin, A.D.; et al. miRNome of inflammatory breast cancer. BMC Res. Notes 2014, 7, 871. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.Y.; Yi, W.; Zhang, M.Y.; Xu, R.; Zeng, L.S.; Long, X.R.; Zhou, X.; Zheng, X.; Kang, Y.; Wang, H.Y. MicroRNA-711 is a prognostic factor for poor overall survival and has an oncogenic role in breast cancer. Oncol. Lett. 2016, 11, 2155–2163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, J.; Zhou, X.; Wong, C.W. Genome-wide identification of estrogen receptor alpha regulated miRNAs using transcription factor binding data. Bioinform.-Trends Methodol. 2011. [Google Scholar] [CrossRef]
- Sun, Y.; Su, B.; Zhang, P.; Xie, H.; Zheng, H.; Xu, Y.; Du, Q.; Zeng, H.; Zhou, X.; Chen, C.; et al. Expression of miR-150 and miR-3940-5p is reduced in non-small cell lung carcinoma and correlates with clinicopathological features. Oncol. Rep. 2013, 29, 704–712. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Qiu, C.; Tu, J.; Geng, B.; Yang, J.; Jiang, T.; Cui, Q. HMDD v2.0: A database for experimentally supported human microRNA and disease associations. Nucleic Acids Res. 2013, 42, D1070. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Wang, J.; Lu, M.; Song, F.; Cui, Q. Inferring the human microRNA functional similarity and functional network based on microRNA-associated diseases. Bioinformatics 2010, 26, 1644–1650. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xuan, P.; Han, K.; Guo, Y.; Li, J.; Li, X.; Zhong, Y.; Zhang, Z.; Ding, J. Prediction of potential disease-associated microRNAs based on random walk. Bioinformatics 2015, 31, 1805–1815. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Receiver operating feature curve (ROC) curve of CNNDMP and the other four methods. AUC = area under the curve.
Figure 1.
Receiver operating feature curve (ROC) curve of CNNDMP and the other four methods. AUC = area under the curve.

Figure 2.
Precision–recall (PR) curve of CNNDMP and the other four methods.

Figure 3.
Recall values of top k candidates of CNNDMP and the other four methods.

Figure 4.
Construction of a miRNA–disease heterogeneous network and matrix representation. (a) The miRNA similarities network is constructed based on two miRNAs whose similarity are greater than 0 and the matrix representation . We represent miRNA network topology information and the similarity values between miRNAs by a weighted network. Each node represents a miRNA entity, and the weight on edge represents miRNA similarity values in the weighted network. (b) The disease similarities network and its matrix representation . (c) The miRNA–disease associations network is constructed based on the known associations between miRNAs and diseases, and its corresponding matrix representation . When a disease is associated with a miRNA, they are connected by a dotted line. (d) miRNA–disease heterogeneous network. It effectively integrates miRNA similarities, disease similarities and miRNA–disease association information.
Figure 4.
Construction of a miRNA–disease heterogeneous network and matrix representation. (a) The miRNA similarities network is constructed based on two miRNAs whose similarity are greater than 0 and the matrix representation . We represent miRNA network topology information and the similarity values between miRNAs by a weighted network. Each node represents a miRNA entity, and the weight on edge represents miRNA similarity values in the weighted network. (b) The disease similarities network and its matrix representation . (c) The miRNA–disease associations network is constructed based on the known associations between miRNAs and diseases, and its corresponding matrix representation . When a disease is associated with a miRNA, they are connected by a dotted line. (d) miRNA–disease heterogeneous network. It effectively integrates miRNA similarities, disease similarities and miRNA–disease association information.

Figure 5.
Integration of miRNA and disease original features to construct the embedding in the left part.
Figure 5.
Integration of miRNA and disease original features to construct the embedding in the left part.

Figure 6.
Integration of miRNA and disease network topological features to construct the embedding in the right part.
Figure 6.
Integration of miRNA and disease network topological features to construct the embedding in the right part.

Figure 7.
miRNA–disease association prediction framework based on dual CNN.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
ROC-AUCs and PR-AUCs at different values of .
| 0.1 | 0.2 | 0.3 | 0.4 | 0.4 | 0.5 | 0.7 | 0.8 | 0.9 | |
|---|---|---|---|---|---|---|---|---|---|
| ROC-AUC | 0.890 | 0.918 | 0.934 | 0.939 | 0.946 | 0.950 | 0.952 | 0.954 | 0.956 |
| PR-AUC | 0.340 | 0.401 | 0.442 | 0.462 | 0.491 | 0.503 | 0.513 | 0.521 | 0.538 |
Table 2.
Prediction results of CNNDMP and the other four methods for 15 diseases in terms of ROC-AUCs.
Table 2.
Prediction results of CNNDMP and the other four methods for 15 diseases in terms of ROC-AUCs.
| Disease Name | ROC-AUC CNNDMP | GSTRW | DMPred | PBMDA | Liu’s Method |
|---|---|---|---|---|---|
| Breast neoplasm | 0.987 | 0.822 | 0.938 | 0.852 | 0.863 |
| Hepatocellular carcinoma | 0.986 | 0.779 | 0.900 | 0.803 | 0.845 |
| Renal cell carcinoma | 0.950 | 0.816 | 0.903 | 0.813 | 0.832 |
| Squamous cell carcinoma | 0.936 | 0.817 | 0.908 | 0.881 | 0.890 |
| Colorectal neoplasm | 0.910 | 0.737 | 0.842 | 0.826 | 0.857 |
| Glioblastoma | 0.926 | 0.814 | 0.904 | 0.803 | 0.842 |
| Heart failure | 0.972 | 0.817 | 0.987 | 0.791 | 0.828 |
| Acute myeloid leukemia | 0.961 | 0.788 | 0.890 | 0.844 | 0.874 |
| Lung neoplasm | 0.962 | 0.791 | 0.948 | 0.905 | 0.920 |
| Melanoma | 0.978 | 0.789 | 0.913 | 0.836 | 0.860 |
| Ovarian neoplasm | 0.958 | 0.830 | 0.929 | 0.889 | 0.897 |
| Pancreatic neoplasm | 0.945 | 0.838 | 0.916 | 0.891 | 0.904 |
| Prostatic neoplasm | 0.964 | 0.822 | 0.951 | 0.843 | 0.855 |
| Stomach neoplasm | 0.954 | 0.762 | 0.908 | 0.821 | 0.836 |
| Urinary bladder neoplasm | 0.956 | 0.816 | 0.919 | 0.854 | 0.865 |
| Average AUC | 0.956 | 0.802 | 0.917 | 0.844 | 0.865 |
Table 3.
Prediction results of CNNDMP and the other four methods for 15 diseases in terms of PR-AUCs.
Table 3.
Prediction results of CNNDMP and the other four methods for 15 diseases in terms of PR-AUCs.
| Diseases Name | PR-AUC CNNDMP | GSTRW | DMPred | PBMDA | Liu’s Method |
|---|---|---|---|---|---|
| Breast neoplasm | 0.894 | 0.322 | 0.699 | 0.574 | 0.573 |
| Hepatocellular carcinoma | 0.893 | 0.279 | 0.501 | 0.454 | 0.498 |
| Renal cell carcinoma | 0.365 | 0.150 | 0.293 | 0.181 | 0.186 |
| Squamous cell carcinoma | 0.287 | 0.109 | 0.213 | 0.211 | 0.208 |
| Colorectal neoplasm | 0.367 | 0.141 | 0.186 | 0.367 | 0.371 |
| Glioblastoma | 0.330 | 0.151 | 0.219 | 0.217 | 0.243 |
| Heart failure | 0.602 | 0.191 | 0.700 | 0.168 | 0.189 |
| Acute myeloid leukemia | 0.368 | 0.140 | 0.211 | 0.191 | 0.236 |
| Lung neoplasms | 0.636 | 0.147 | 0.511 | 0.537 | 0.503 |
| Melanoma | 0.657 | 0.171 | 0.389 | 0.363 | 0.397 |
| Ovarian neoplasm | 0.490 | 0.169 | 0.404 | 0.361 | 0.361 |
| Pancreatic neoplasm | 0.555 | 0.137 | 0.329 | 0.364 | 0.354 |
| Prostatic neoplasm | 0.568 | 0.166 | 0.463 | 0.282 | 0.264 |
| Stomach neoplasm | 0.608 | 0.220 | 0.446 | 0.344 | 0.346 |
| Urinary bladder neoplasm | 0.470 | 0.163 | 0.315 | 0.252 | 0.280 |
| Average AUC | 0.538 | 0.177 | 0.392 | 0.324 | 0.334 |
Table 4.
Comparison of different methods based on AUCs with a paired t-test.
| p-Value | DMPred | GSTRW | PBMDA | Liu’s Method |
|---|---|---|---|---|
| p-value of ROC-AUC between CNNDMP and other methods | 6.44998 × 10−4 | 9.60973 × 10−16 | 2.65553 × 10−10 | 1.25344 × 10−10 |
| p-value of PR-AUC between CNNDMP and other methods | 0.02972 | 1.75747 × 10−6 | 0.00111 | 0.00151 |
Table 5.
The top 50 breast cancer-related candidates.
| Rank | miRNA Name | Evidence | Rank | miRNA Name | Evidence |
|---|---|---|---|---|---|
| 1 | hsa-mir-1266 | dbDEMC | 26 | hsa-mir-663 | dbDEMC |
| 2 | hsa-mir-942 | dbDEMC | 27 | hsa-mir-545 | dbDEMC |
| 3 | hsa-mir-384 | dbDEMC | 28 | hsa-mir-525 | dbDEMC |
| 4 | hsa-mir-374b | dbDEMC | 29 | hsa-mir-520f | dbDEMC |
| 5 | hsa-mir-1293 | dbDEMC | 30 | hsa-mir-520g | dbDEMC |
| 6 | hsa-mir-3148 | Literature [34] | 31 | hsa-mir-659 | dbDEMC |
| 7 | hsa-mir-569 | Literature [35] | 32 | hsa-mir-150 | miRCancer, PhenomiR |
| 8 | hsa-mir-431 | dbDEMC | 33 | hsa-mir-592 | dbDEMC |
| 9 | hsa-mir-711 | Literature [36] | 34 | hsa-mir-1254 | dbDEMC |
| 10 | hsa-mir-325 | dbDEMC | 35 | hsa-mir-548c | dbDEMC |
| 11 | hsa-mir-1302 | Literature [37] | 36 | hsa-mir-675 | miRCancer |
| 12 | hsa-mir-33a | dbDEMC | 37 | hsa-mir-3940 | Literature [38] |
| 13 | hsa-mir-1246 | dbDEMC | 38 | hsa-mir-1299 | dbDEMC |
| 14 | hsa-mir-376b | dbDEMC | 39 | hsa-mir-377 | dbDEMC |
| 15 | hsa-mir-487a | dbDEMC | 40 | hsa-mir-519a | dbDEMC |
| 16 | hsa-mir-1236 | dbDEMC | 41 | hsa-mir-1180 | dbDEMC |
| 17 | hsa-mir-548a | dbDEMC | 42 | hsa-mir-1184 | dbDEMC |
| 18 | hsa-mir-624 | dbDEMC | 43 | hsa-mir-3151 | dbDEMC |
| 19 | hsa-mir-633 | dbDEMC | 44 | hsa-mir-627 | dbDEMC |
| 20 | hsa-mir-1181 | dbDEMC | 45 | hsa-mir-1273a | dbDEMC |
| 21 | hsa-mir-382 | dbDEMC | 46 | hsa-mir-1972 | dbDEMC |
| 22 | hsa-mir-448 | dbDEMC | 47 | hsa-mir-208a | dbDEMC, PhenomiR |
| 23 | hsa-mir-583 | dbDEMC | 48 | hsa-mir-668 | dbDEMC |
| 24 | hsa-mir-518a | dbDEMC | 49 | hsa-mir-635 | dbDEMC |
| 25 | hsa-mir-433 | dbDEMC | 50 | hsa-mir-619 | dbDEMC |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xuan, P.; Dong, Y.; Guo, Y.; Zhang, T.; Liu, Y. Dual Convolutional Neural Network Based Method for Predicting Disease-Related miRNAs. Int. J. Mol. Sci. 2018, 19, 3732. https://doi.org/10.3390/ijms19123732
AMA Style
Xuan P, Dong Y, Guo Y, Zhang T, Liu Y. Dual Convolutional Neural Network Based Method for Predicting Disease-Related miRNAs. International Journal of Molecular Sciences. 2018; 19(12):3732. https://doi.org/10.3390/ijms19123732
Chicago/Turabian StyleXuan, Ping, Yihua Dong, Yahong Guo, Tiangang Zhang, and Yong Liu. 2018. "Dual Convolutional Neural Network Based Method for Predicting Disease-Related miRNAs" International Journal of Molecular Sciences 19, no. 12: 3732. https://doi.org/10.3390/ijms19123732
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.