The Light and Dark Sides of Virtual Screening: What Is There to Know?

 ,
,  ,
,  and
and
Abstract
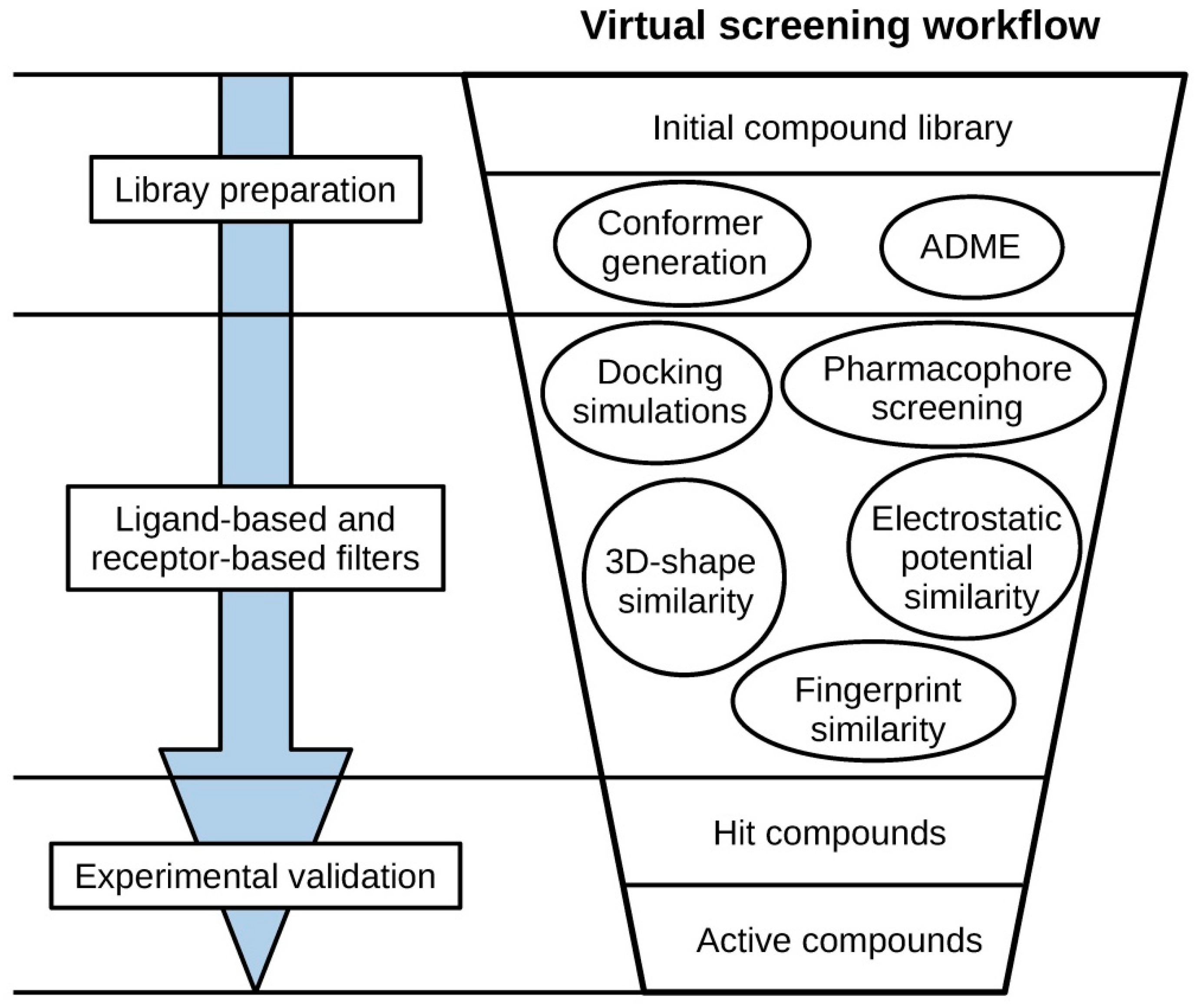
:1. Virtual Screening
2. First Steps
- Bibliographic research. First, bibliographic research on the receptor is recommended, considering aspects such as its biological function, natural ligands, and catalytic mechanism, as well as its involvement in pathological processes. This information can be found in databases such as UniProt [12] or Brenda [13]. It is also important to review previous attempts to develop compounds that modulate the activity of the receptor of interest and their mechanisms of action, as well as the current challenges that these compounds face and their limitations. In this regard, the analysis of structure–activity relationship (SAR) studies can provide useful insights into how to design inhibitors for a given target. Structure–activity relationship studies are experiments in which a compound is modified by adding a series of different substituents in one or several parts of the molecule and evaluating the experimental activity of the resulting compounds towards the target of interest. This provides information on the compound substituents that are preferred by the target in each part of the molecule, and therefore, reveals which modifications could be applied to a compound to further increase its activity towards the target and which ones should not be applied, as they would result in activity losses. Although in some cases, molecular visualization software could aid us in rationalizing the causes of the activity changes observed in SAR studies by analyzing them within the protein environment with the naked eye, there are methods that help us to better understand the nature of the interactions between the ligand and the protein. For example Flare [14] can be used to represent and compare the electrostatic potentials and hydrophobicity of both the ligand and the protein to determine whether the introduction of a particular functional group is favorable for activity or not. While this type of information may be important for establishing an appropriate VS strategy, it can also be crucial in the final steps of the VS to: (a) select hits for bioactivity testing that show features which have previously been reported to be important for activity; and (b) avoid selecting compounds that would perform unfavorable interactions with the target that may have been overlooked by earlier steps of the VS workflow.
- Activity and structural data collection. On the one hand, activity data of previously reported inhibitors as well as their structure should be retrieved from databases such as ChEMBL [15], Reaxys [16], BindingDB [17] or PubChem [18], as a large amount of structure variability of compounds will improve the performance of the developed ligand-based models and give a more representative computational validation of the VS methods used [1]. On the other hand, it is important to determine whether the 3D structure of the receptor has been elucidated, and if that is the case, the available quantity and quality of crystallographic structures. A careful inspection of these structures will allow us to assess the flexibility of the receptor and evaluate whether receptor-based approaches can be implemented in the VS. Crystallographic models of protein and protein–ligand complexes can be obtained from the Protein Data Bank (PDB) [19,20] database, but it should be kept in mind that the atoms in these models correspond to how the crystallographers have interpreted the data of the electron density maps. Therefore, it is recommended to validate the reliability of such coordinates (especially for those corresponding to the binding site and to the co-crystallized ligand) with specialized visualization software such as VHELIBS [21] before using the PDB files in VS.
- Library preparation. The collection of compounds to which the VS workflow will be applied is referred to as the VS library. Apart from retrieving the structures and activities of compounds with known activity for VS development and validation purposes, the structures of compounds to which the VS should be applied also need to be obtained, generating the so-called virtual screening library. This library of compounds can come from an in-house collection of compounds of interest, it can be obtained from different databases, such as ZINC [22] or Reaxys [16], or directly from a commercial compound supplier. In many cases, the structures of these compounds are collected in 2D format, but many VS methods require the 3D conformation of compounds (i.e., the arrangement of atoms of a molecule in space). Thus, the 3D conformations that molecules adopt usually need to be predicted in a process known as conformational sampling, in which conformers are first generated by determining bond lengths, bond angles, and torsion angles, and then ranked to prioritize the low-energy conformations that are accessible with a reasonable probability at room temperature [23]. The software commonly used to perform these tasks are shown in Table 1. In a recent benchmarking of conformer generator ensembles [24], commercial ensemble generators like OMEGA [25] and ConfGen [26] showed high performance, closely followed by the freely available implementation of the distance geometry [27] algorithm by RDKit [28], which also showed high robustness. In conformer generators, molecules are first fragmented by their rotatable bonds. These fragments are then re-joined while sampling their spatial distributions based on different criteria to obtain conformers. OMEGA [25] and ConfGen [26] are systematic approaches that sample each rotatable bond in the molecule systematically in discrete intervals. The distance geometry [27] algorithm implementation by RDKit [28], on the other hand, is a stochastic method in which the conformational space of a molecule is sampled randomly, but considering a small amount of empirical information [29]. Generating a sufficiently broad set of conformations for each compound is crucial to cover the compound’s conformational space and to achieve optimal results in many VS methodologies that depend on the 3D conformation of compounds (e.g., 3D fingerprints, 3D-shape comparison, electrostatic potential comparison, pharmacophore screening). Otherwise, it is a limitation for subsequent methods if the bioactive conformation of interest is not included among the conformers generated for a given compound [1]. On the other hand, the generation of high-energy conformations that have a low probability of being accessed by the molecule at room temperature should be avoided, as they may be misleading and cause false positive results [1]. In addition to the spatial distribution of atoms, other aspects need to be considered when molecules are prepared for VS purposes. Many VS methodologies are dependent on the charge of molecules (e.g., electrostatic potential comparison, protein–ligand docking, pharmacophore screening), so it is important to ensure that the charges of compounds are properly defined as they may not be present, or they may not be assigned correctly. The different possible protonation states at the pH of interest also need to be generated for each molecule, as well as its tautomeric states [1]. In addition, other aspects such as stereochemistry and the presence of salt and solvent fragments also need to be considered during molecule preparation. Software such as Standardizer [30] or LigPrep [31] and tools such as MolVS [32] can be used for this purpose.
3. Ligand-Based Virtual Screening
3.1. Fingerprint-Based Methods
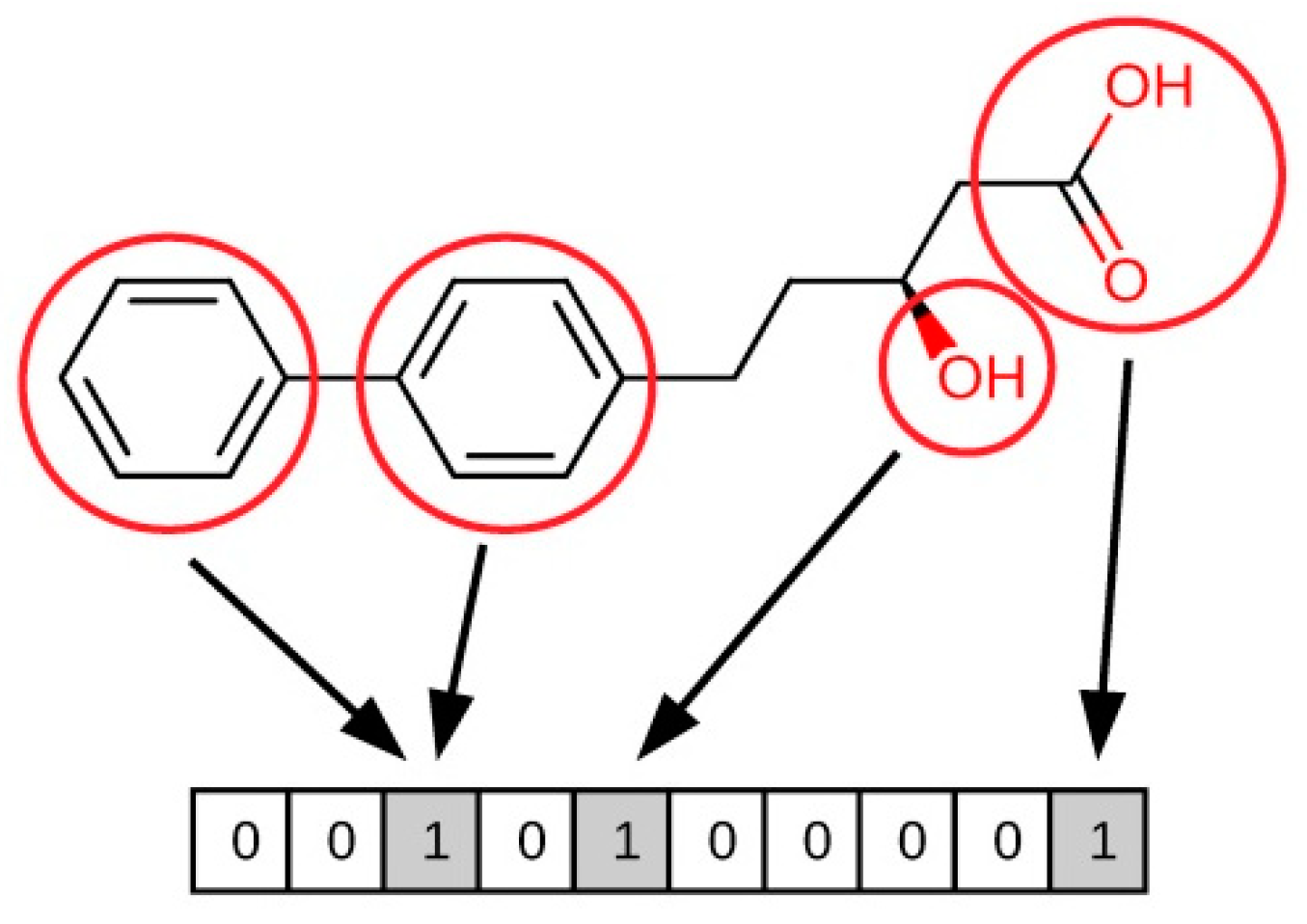
- Sub-structure keys-based fingerprints. In this type of fingerprint, the bit string corresponds to a series of predefined structural keys, and each bit relates to the presence or absence of a given feature in the molecule. Therefore, these fingerprints are effective when the structural keys used by the fingerprint are present in the molecules to be compared, but they are not that meaningful otherwise. Examples of this type of fingerprint include MACCS [50,51], PubChem fingerprints [18], and BCI fingerprints [52].
- Topological or path-based fingerprints. In this type of fingerprint, bits are defined from fragments of the molecules themselves. For every atom in a molecule, fragments are obtained by progressively increasing the length up to a determined number of bonds, usually following a linear path. Then, these fragments are hashed to generate the fingerprint. As fingerprints are generated from the molecules themselves, every molecule produces a meaningful fingerprint, and its length can be adjusted. However, in topological fingerprints with a reduced number of bits, bit collisions may occur as a result of assigning more than one different feature to a given bit. Examples of this type of fingerprint include the Daylight fingerprints [53] and OpenEye’s Tree fingerprints [54].
- Circular fingerprints. In this type of fingerprint, bits are also defined from molecule fragments, but these fragments are obtained from the environment of each atom up to a determined radius instead of a path. Examples of this type of fingerprint include Molprint2D [54,55], extended-connectivity fingerprints (ECFPs), and functional-class fingerprints (FCFPs) [56].
- Pharmacophore fingerprints. A pharmacophore is the spatial arrangement of features that allow the ligands to interact with the binding site of a target protein (see Section 3.4 for more details). Pharmacophore fingerprints incorporate these molecule features and the distances between them into the fingerprint [57].
- A high similarity coefficient value does not always imply that two compounds will have the same activity. Some minor structural changes could greatly modulate the activity of a compound depending on how they affected the interactions with the protein. These great changes in activity due to small changes in compound structure are commonly known as activity cliffs (see Section 4), and they constitute the main reason why activity values cannot always be inferred from similarity measures. Thus, the comparison of similarity coefficients should be seen as an attempt at simplification that bypasses medicinal chemistry in order to establish an automated approximation of the activity of compounds [49,63].
- There is no universal cutoff value for determining that compounds with a certain range of similarity to reference compounds will have similar activity values. As fingerprints are designed in different ways, if we compare the similarities between two compounds with a given similarity coefficient using two different types of fingerprints, the similarity values obtained will most likely differ. A similar situation will occur when two compounds are compared using the same fingerprint but a different similarity metric [49,63]. Therefore, as the similarity value between two compounds is affected by both the type of fingerprint and the similarity coefficient used, the optimal cutoff will also be dependent on these two factors and will have to be evaluated case by case using the appropriate statistical measures (see Section 5). Moreover, different types of fingerprints perform differently in different situations [1], so the fingerprint results obtained should be validated computationally in order to choose the appropriate fingerprint (see Section 5).
- Similarity coefficients assign equal importance to all fingerprint bits. This is a limitation in the following two situations: (a) inactive compounds that do not possess the critical features for activity that are present in the active compounds used as a reference but still accomplish good similarity values by matching most of the fingerprint bits will be wrongly predicted to be active; and (b) active compounds that only match the critical features for activity with the active compounds used as a reference and are structurally different from them will be wrongly predicted to be inactive [1,49,63].
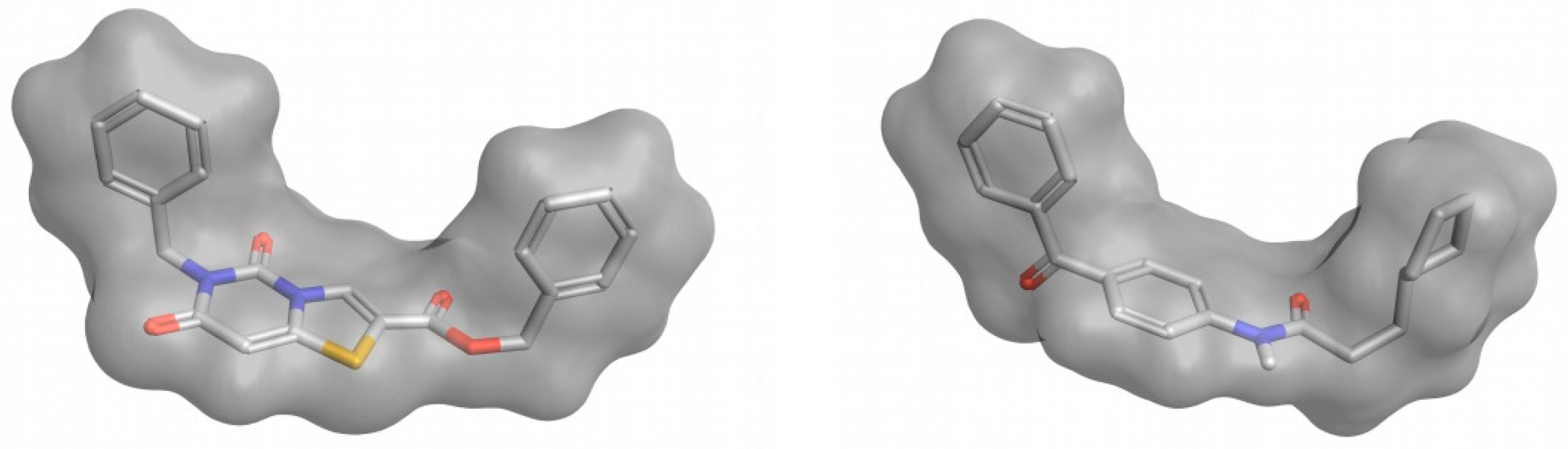
3.2. 3D-Shape Similarity
- Alignment-free or non-superposition methods. As these methods are independent of the position and orientations of molecules, they are much faster and could be used to screen large compound databases
- Alignment or superposition-based methods. These methods require a superposition between the reference compounds and the compounds in the database. Although they are highly effective, they are computationally expensive and a sub-optimal alignment may lead to errors in comparing the molecules. These methods make it possible to visualize the alignment together with the similarity values, which can aid in the design of new molecules and be a guide for their further optimization. As an alignment is performed, these methods can also include comparisons of surface properties such as hydrophobicity and polarity.
- Atomic Distance-Based Shape Similarity Methods. As the shape of a molecule can be described by the relative positions of its atoms, these methods rely on the computation and comparison of inter-atomic distance descriptors to determine shape similarity. These methods do not require the molecules involved to be aligned, and therefore, are faster than alignment-based methods.
- Volume-Based Shape Similarity Methods. Two molecules will have a similar shape if they have a similar volume. Therefore, shape similarity can be described in terms of volume occupancy. The most widely adopted models to describe shape similarity in terms of volume are the hard-sphere model [74,75] and the Gaussian-sphere model [75,76]. The hard-sphere model treats each atom in the molecule as a sphere, and the volume of each molecule is calculated based on the unions and intersections of their volumes. The Gaussian-sphere model represents a molecule as a set of overlapping Gaussian spheres. The inclusion–exclusion principle is applied to obtain the volume of the molecule by calculating the volume of all Gaussians and their intersections.
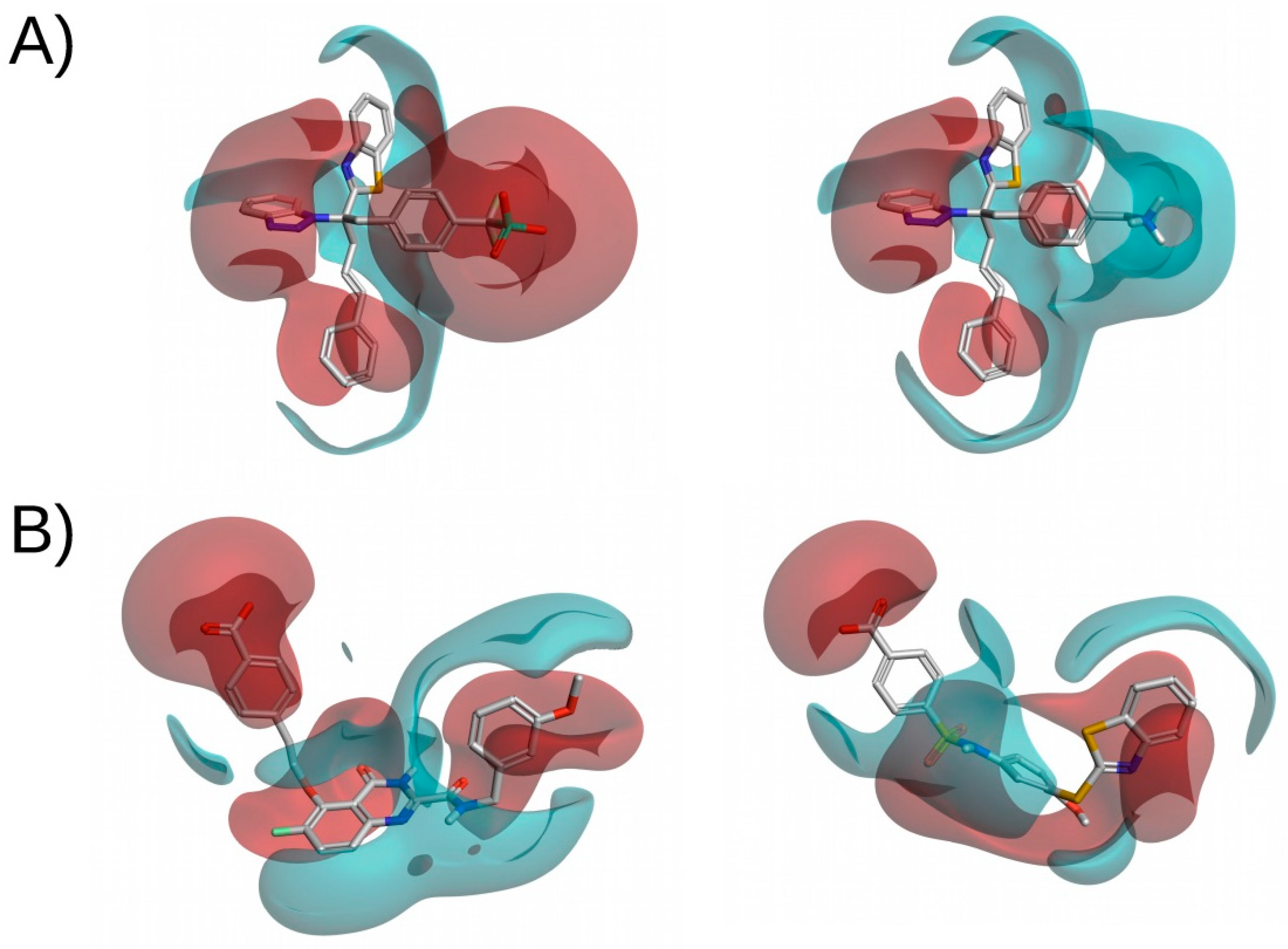
3.3. Electrostatic Potential Similarity
3.4. Ligand-Based Pharmacophores
- Select a set of active ligands to generate the pharmacophore. First a set of active ligands is obtained, from which the pharmacophore features will be generated, usually based on the common features of the ligands. Ligands that are not active for the target of interest may also be used to discard pharmacophore hypotheses.
- Generate 3D conformations of the ligands. A determined number of low-energy conformations is generated for each bioactive compound so that the conformation in which the ligand binds to the receptor is likely to be included.
- Identify ligand features. The substructures and functional groups of the ligand are transformed to pharmacophoric features. These features often include: (a) hydrogen-bond donor feature, (b) hydrogen-bond acceptor feature, (c) negative-charge feature, (d) positive-charge feature, (e) hydrophobic feature, and (f) aromatic-ring feature. The distances between the features of the ligand are computed and the combination of features and distances is used as an abstract representation of the ligand.
- Superimpose ligands. Ligand representations are superimposed so that a maximum number of features occupy the same regions of space.
- Generate pharmacophore. Features that occupy the same region and are present in the majority of ligands are included in the pharmacophore.
- Validation. The pharmacophore needs to be validated to ensure that it is able to discriminate active compounds from inactive compounds. This is usually done by screening a set of actives and a set of decoys, which are compounds similar to actives that do not present bioactivity for the target of interest (see Section 5).
4. Receptor-Based Virtual Screening
4.1. Protein–Ligand Docking
- Protein preparation. As experimental structures, X-ray crystallographic protein structures present problems such as missing hydrogen atoms, missing residues, incomplete side-chains, undefined protonation states or the presence of crystallization products that are not found in vivo. These aspects need to be corrected before the crystallographic structure can be used to perform protein–ligand docking.
- Binding site definition. The limits of the cavity of the protein in which compounds should be docked can be defined to restrict the space occupied by docked poses. In this step it is possible to define constraints to require that the ligands perform certain interactions with the protein or occupy a certain space within the binding site.
- Conformational sampling. A search algorithm is responsible for identifying the possible conformations (docked poses) in which each compound may fit in the binding site. Constraints can be defined during docking to require the resulting docked poses to bind to a certain region of the binding site or to perform a certain interaction with the receptor.
- Scoring. Finally, the affinity of each docked pose for the target is approximated with a scoring function that predicts the strength of the interaction, generating a score for each docked pose. Then, the docked poses are ranked according to the score provided by the docking function to obtain the docked pose that is most likely to represent the real binding mode of the compound.
- Although the search algorithm provides potential orientations of the compound in the binding site, this does not imply that the compound can actually bind to the protein. Moreover, even if the compound is an actual ligand of target, this does not imply that the real binding mode of the compound is among the docking poses, as the search algorithm can fail to predict it. Thus, docking should be seen as a means of generating hypotheses on how the compound may bind in the binding site of the target (i.e., docked poses), but not as definite proof that the compound binds in a determined fashion [1,84].
- Docking software are often wrongly used to predict the activity of compounds based on the score provided by docking functions. Although this may be possible in some cases for structurally similar compounds, scoring functions are not accurate enough to predict the binding affinity of compounds that have different structures and different predicted binding modes. The low success rate of scoring functions at predicting the binding affinity of compounds should be taken into account when a docking simulation is performed [1,84,85]. Instead of aiming at predicting compound activity, protein–ligand docking should be used to enrich the initial library in active compounds by discarding compounds that are not able to fit in the binding site of the protein and by keeping the compounds that are more likely to show a good binding affinity as predicted by the scoring function. The latter can be achieved, for instance, by establishing a docking score threshold.
- The flexibility of the protein can be accounted for in docking procedures in an approach known as induced-fit docking [86]. This is often not the case in virtual screening, as this methodology implies an added computational cost. Instead, usually only the flexibility of the ligand is considered, and the receptor atoms are not allowed to change their spatial location. However, in proteins with a flexible binding site able to accommodate very diverse ligands, this may not be the right approach and allowing the movement of some protein residues could be considered [1]. A possible workaround to account for the flexibility of the protein without resorting to induced-fit docking may be to use all the available conformations observed for the receptor to perform protein–ligand docking.
4.2. Structure-Based Pharmacophores
- (a)
- Using conformations of ligands that are co-crystallized with the receptor. In this case, the pharmacophore features are also obtained from active compounds, but as they are co-crystallized with the receptor, their bioactive conformations are already known and there is no need to generate conformations.
- (b)
- Using the residues in the binding site to determine pharmacophore features. In this case, the pharmacophore features are not obtained from the ligands, but rather from the receptor. This method makes it possible to compare pharmacophores obtained from different crystallographic structures of the same target.
- (c)
- Docking fragments into the binding site of the receptor. In this case, a fragment library is docked, the docked fragments are clustered, and pharmacophore features are generated from these clusters. The nature of the interaction of the cluster of fragments determines the type of feature, and the docking scores of the fragments in the cluster determine the relevance of the feature. This method makes it possible to probe the binding site and identify interactions not considered in the design of previous inhibitors that could potentially be important for activity. An interesting utility for evaluating the potential activity contribution of each pharmacophoric feature in a fragment-based pharmacophore is the E-pharmacophores [87] utility from Schrödinger, which assigns an energetic contribution to each pharmacophore feature based on the docking scores of the fragments.
5. Computational Validation
- Actives. Active compounds (or simply actives) are compounds which have been reported to have a high activity towards the target of interest. Compounds used as a reference to build the different filters that form the virtual screening workflow fall into this category. The exact activity threshold over which a compound is considered to be active is arbitrary, but compounds are often considered as actives if they have IC50, Ki or EC50 activity values around the micromolar and nanomolar range. The higher the threshold selected, the more restrictive the virtual screening. It should be taken into account that even if a compound has been reported to have a certain activity for the target of interest, the action mechanism may differ from the action mechanism that the VS is seeking (e.g., the compound may exert its action by binding to an allosteric site of the protein instead of the catalytic site). The VS should not be able to identify these compounds as actives as their binding mode is different and this would decrease the performance of the VS. Therefore, active compounds with unreported protein-binding modes represent intrinsic limitations of the VS validation [1].
- Inactives. Inactive compounds (or simply inactives) are compounds which have been reported to have a low activity (or no activity) towards the target of interest. Hit compounds that are similar to inactives are considered to have a higher chance of being inactive, and therefore, should be avoided. Analogously to actives, an arbitrary activity threshold under which compounds are believed to be inactive should be predefined. The higher the threshold, the more demanding will the virtual screening be, as it will be necessary to discern between active and inactive compounds with higher accuracy due to the smaller difference in activity between the two groups. PubChem [18] and ChEMBL [15] are databases of chemical compounds that include inactive compounds.
- Decoys. Decoy compounds (or simply decoys) are compounds that resemble active compounds but for which the activity towards the target of interest has not been reported, and since they are likely to be inactive, they are presumed to be so [35]. Decoys are generally obtained by searching for compounds that have similar physical descriptors (e.g., molecular weight, number of rotational bonds, total hydrogen bond donors, total hydrogen bond acceptors, and octanol–water partition coefficient) to active compounds, but that are chemically different from them (which can be determined by fingerprint similarity) [35]. In validation protocols, decoys are usually used instead of inactives due to the low amount of null results reported in the literature and the consequent lack of data on inactive compounds. Similarly to what occurs with active compounds that act through different action modes than the one assessed by the VS, as decoys are putative inactive compounds but their activity for the target of interest has not been determined, a small portion of them may actually be active, and therefore, this also constitutes an intrinsic limitation for assessing VS performance [1]. Decoys can be obtained either directly from databases, such as DUD-E [88], or through the use of tools, such as DecoyFinder [35], which makes it possible to obtain sets of decoys that match the provided sets of active compounds.
- True positives. Active compounds that are predicted to be active.
- True negatives. Inactive compounds that are predicted to be inactive.
- False positives. Inactive compounds that are predicted to be active.
- False negatives. Active compounds that are predicted to be inactive.
- Sensitivity. Also referred to as recall, hit rate or true positive rate (TPR), this measures the proportion of actual positives that are correctly identified as such:
- Specificity. Also referred to as selectivity or true negative rate (TNR), this measures the proportion of actual negatives that are correctly identified as such:
- Precision. Also referred to as positive predictive value (PPV), this measures the proportion of positive results that correspond to actual positives:
- Negative predictive value (NPV). This measures the proportion of negative results that correspond to actual negatives:
- False negative rate (FNR). Also referred to as miss rate, this measures the proportion of actual positives incorrectly classified as such (it complements sensitivity):
- Fall-out. Also referred to as false positive rate (FPR), this measures the proportion of actual negatives that are incorrectly classified as such (it complements specificity):
- Accuracy. This measures the proportion of correctly predicted results among the total number of cases examined:
- F1 score. This is a measure obtained from the harmonic mean of the sensitivity and the precision statistical measures. It considers both measures in order to determine the performance of the classifier:
- Matthews correlation coefficient (MCC). This is a correlation coefficient between the observed and predicted binary classifications that returns a value between −1 and +1. A coefficient of +1 represents a perfect prediction, a coefficient of 0 indicates that the prediction is no better than a random prediction, and a coefficient of −1 indicates total disagreement between prediction and observation. The MCC is generally regarded as a balanced measure that can be used even if the classes are of very different sizes. It is calculated using the following formula:
- Enrichment factor (EF). The EF is a measure of how much the sample is enriched with actives after a determined filter or a series of filters is applied. It is calculated as the ratio between the proportion of actives after and before the VS step.in which:
- a1 = actives before the VS step
- a2 = actives after the VS step
- d1 = decoys before the VS step
- d2 = decoys after the VS step
6. Hit Selection
7. Experimental Validation
- Fluorescent or highly colored compounds. These compounds may give false readouts in fluorimetric and colorimetric assays, giving a positive signal even when no protein is present.
- Compounds that trap the toxic or reactive metals used to synthesize molecules in a screening library or which are used as reagents in assays. These metals give rise to signals that have nothing to do with the compound’s interaction with the protein.
- Compounds that sequester reactive metal ions necessary for the reaction.
- Compounds that coat the protein, altering it chemically and affecting its function in an unspecific way without fitting into its binding site.
- Identify potential PAINS based on structure. Most PAINS fall into 16 different categories according to their chemotypes. Therefore, hits that are candidates of being PAINS can be identified by checking whether they have one of these chemotypes [90]. While this is more effectively done by eye, several in silico tools that implement chemical similarity and substructure searches have also been developed for this purpose [38,91,92,93]. Nevertheless, this does not ensure that all PAINS are discarded and experimental testing will ultimately be needed to identify whether hit compounds giving positive experimental results are acting as PAINS or not.
- Perform more than one assay. To have more certainty that a hit compound which gives a positive experimental result is not a PAIN compound, it is advisable to conduct at least one more assay that detects activity with a different readout in order to check whether the compound is interfering with the assay or not. It is also advisable to check the activity of hits against unrelated targets and if the inhibition of the target of interest is competitive to determine whether the binding of the hit compound is specific or not.
- Inhibition by colloidal aggregates can be significantly attenuated by small amounts of a non-ionic detergent such as Triton-X or Tween-20 [96].
- Inhibition by colloidal aggregates can also be attenuated by increasing enzyme concentration, whereas this should not affect the inhibition by well-behaved inhibitors if the receptor concentration to Ki ratio is high [96].
8. ADME
- A maximum of 5 hydrogen bond donors.
- A maximum of 10 hydrogen bond acceptors.
- A molecular weight of less than 500 daltons.
- An octanol–water partition coefficient not greater than 5.
9. Conclusions and Future Perspectives
Funding
Acknowledgments
Conflicts of Interest
References
- Scior, T.; Bender, A.; Tresadern, G.; Medina-Franco, J.L.; Martínez-Mayorga, K.; Langer, T.; Cuanalo-Contreras, K.; Agrafiotis, D.K. Recognizing pitfalls in virtual screening: A critical review. J. Chem. Inf. Model. 2012, 52, 867–881. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Zhang, K.Y.J. Hierarchical virtual screening approaches in small molecule drug discovery. Methods 2015, 71, 26–37. [Google Scholar] [CrossRef] [PubMed]
- Lavecchia, A.; Di Giovanni, C. Virtual screening strategies in drug discovery: A critical review. Curr. Med. Chem. 2013, 20, 2839–2860. [Google Scholar] [CrossRef] [PubMed]
- Kar, S.; Roy, K. How far can virtual screening take us in drug discovery? Expert Opin. Drug Discov. 2013, 8, 245–261. [Google Scholar] [CrossRef] [Green Version]
- Lionta, E.; Spyrou, G.; Vassilatis, D.K.; Cournia, Z. Structure-based virtual screening for drug discovery: Principles, applications and recent advances. Curr. Top. Med. Chem. 2014, 14, 1923–1938. [Google Scholar] [CrossRef] [PubMed]
- Braga, R.C.; Alves, V.M.; Silva, A.C.; Nascimento, M.N.; Silva, F.C.; Liao, L.M.; Andrade, C.H. Virtual screening strategies in medicinal chemistry: The state of the art and current challenges. Curr. Top. Med. Chem. 2014, 14, 1899–1912. [Google Scholar] [CrossRef]
- Macalino, S.J.Y.; Gosu, V.; Hong, S.; Choi, S. Role of computer-aided drug design in modern drug discovery. Arch. Pharm. Res. 2015, 38, 1686–1701. [Google Scholar] [CrossRef]
- Cerqueira, N.M.F.S.A.; Gesto, D.; Oliveira, E.F.; Santos-Martins, D.; Brás, N.F.; Sousa, S.F.; Fernandes, P.A.; Ramos, M.J. Receptor-based virtual screening protocol for drug discovery. Arch. Biochem. Biophys. 2015, 582, 56–67. [Google Scholar] [CrossRef]
- Haga, J.; Ichikawa, K.; Date, S. Virtual Screening Techniques and Current Computational Infrastructures. Curr. Pharm. Des. 2016, 22, 3576–3584. [Google Scholar] [CrossRef]
- Cruz-Monteagudo, M.; Schürer, S.; Tejera, E.; Pérez-Castillo, Y.; Medina-Franco, J.L.; Sánchez-Rodríguez, A.; Borges, F. Systemic QSAR and phenotypic virtual screening: Chasing butterflies in drug discovery. Drug Discov. Today 2017, 22, 994–1007. [Google Scholar] [CrossRef]
- Fradera, X.; Babaoglu, K. Overview of Methods and Strategies for Conducting Virtual Small Molecule Screening. Curr. Protoc. Chem. Biol. 2017, 9, 196–212. [Google Scholar] [CrossRef] [PubMed]
- Bateman, A.; Martin, M.J.; O’Donovan, C.; Magrane, M.; Alpi, E.; Antunes, R.; Bely, B.; Bingley, M.; Bonilla, C.; Britto, R.; et al. UniProt: The universal protein knowledgebase. Nucleic Acids Res. 2017, 45, D158–D169. [Google Scholar]
- Placzek, S.; Schomburg, I.; Chang, A.; Jeske, L.; Ulbrich, M.; Tillack, J.; Schomburg, D. BRENDA in 2017: New perspectives and new tools in BRENDA. Nucleic Acids Res. 2017, 45, D380–D388. [Google Scholar] [CrossRef] [PubMed]
- Cheeseright, T.; Mackey, M.; Rose, S.; Vinter, A. Molecular Field Extrema as Descriptors of Biological Activity: Definition and Validation. J. Chem. Inf. Model. 2006, 46, 665–676. [Google Scholar] [CrossRef] [PubMed]
- Gaulton, A.; Hersey, A.; Nowotka, M.; Bento, A.P.; Chambers, J.; Mendez, D.; Mutowo, P.; Atkinson, F.; Bellis, L.J.; Cibrián-Uhalte, E.; et al. The ChEMBL database in 2017. Nucleic Acids Res. 2017, 45, D945–D954. [Google Scholar] [CrossRef] [PubMed]
- Reaxys. Available online: https://www.reaxys.com/ (accessed on 18 March 2019).
- Gilson, M.K.; Liu, T.; Baitaluk, M.; Nicola, G.; Hwang, L.; Chong, J. BindingDB in 2015: A public database for medicinal chemistry, computational chemistry and systems pharmacology. Nucleic Acids Res. 2016, 44, D1045–D1053. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Thiessen, P.A.; Bolton, E.E.; Chen, J.; Fu, G.; Gindulyte, A.; Han, L.; He, J.; He, S.; Shoemaker, B.A.; et al. PubChem Substance and Compound databases. Nucleic Acids Res. 2016, 44, D1202–D1213. [Google Scholar] [CrossRef]
- RCSB PDB. Available online: http://www.rcsb.org (accessed on 18 March 2019).
- Berman, H.M. The Protein Data Bank. Nucleic Acids Res. 2000, 28, 235–242. [Google Scholar] [CrossRef] [Green Version]
- Cereto-Massagué, A.; Ojeda, M.J.; Joosten, R.P.; Valls, C.; Mulero, M.; Salvado, M.J.; Arola-Arnal, A.; Arola, L.; Garcia-Vallvé, S.; Pujadas, G. The good, the bad and the dubious: VHELIBS, a validation helper for ligands and binding sites. J. Cheminform. 2013, 5, 36. [Google Scholar] [CrossRef]
- Sterling, T.; Irwin, J.J. ZINC 15—Ligand Discovery for Everyone. J. Chem. Inf. Model. 2015, 55, 2324–2337. [Google Scholar] [CrossRef]
- Hawkins, P.C.D. Conformation Generation: The State of the Art. J. Chem. Inf. Model. 2017, 57, 1747–1756. [Google Scholar] [CrossRef]
- Friedrich, N.-O.; de Bruyn Kops, C.; Flachsenberg, F.; Sommer, K.; Rarey, M.; Kirchmair, J. Benchmarking Commercial Conformer Ensemble Generators. J. Chem. Inf. Model. 2017, 57, 2719–2728. [Google Scholar] [CrossRef]
- Hawkins, P.C.D.; Skillman, A.G.; Warren, G.L.; Ellingson, B.A.; Stahl, M.T. Conformer Generation with OMEGA: Algorithm and Validation Using High Quality Structures from the Protein Databank and Cambridge Structural Database. J. Chem. Inf. Model. 2010, 50, 572–584. [Google Scholar] [CrossRef]
- Watts, K.S.; Dalal, P.; Murphy, R.B.; Sherman, W.; Friesner, R.A.; Shelley, J.C. ConfGen: A Conformational Search Method for Efficient Generation of Bioactive Conformers. J. Chem. Inf. Model. 2010, 50, 534–546. [Google Scholar] [CrossRef]
- Blaney, J.M.; Dixon, J.S. Distance Geometry in Molecular Modeling; Wiley-Blackwell: Hoboken, NJ, USA, 2007; pp. 299–335. [Google Scholar]
- RDKit: Open-Source Cheminformatics. Available online: http://www.rdkit.org (accessed on 18 March 2019).
- Riniker, S.; Landrum, G.A. Better Informed Distance Geometry: Using What We Know to Improve Conformation Generation. J. Chem. Inf. Model. 2015, 55, 2562–2574. [Google Scholar] [CrossRef]
- Standardizer 16.10.10.0. ChemAxon, 2016. Available online: http://www.chemaxon.com (accessed on 18 March 2019).
- Schrödinger, LLC. Schrödinger Release 2018-3: LigPrep; Schrödinger, LLC: New York, NY, USA, 2018. [Google Scholar]
- MolVS: Molecule Validation and Standardization. Available online: https://molvs.readthedocs.io/en/latest/ (accessed on 18 March 2019).
- Schrödinger, LLC. Schrödinger Release 2018-1: Maestro; Schrödinger, LLC: New York, NY, USA, 2018. [Google Scholar]
- VIDA 4.4.0: OpenEye Scientific Software, Santa Fe, NM. Available online: http://www.eyesopen.com (accessed on 18 March 2019).
- Cereto-Massagué, A.; Guasch, L.; Valls, C.; Mulero, M.; Pujadas, G.; Garcia-Vallvé, S. DecoyFinder: An easy-to-use python GUI application for building target-specific decoy sets. Bioinformatics 2012, 28, 1661–1662. [Google Scholar] [CrossRef]
- Schrödinger, LLC. Schrödinger Release 2018-3: QikProp; Schrödinger, LLC: New York, NY, USA, 2018. [Google Scholar]
- Daina, A.; Michielin, O.; Zoete, V. SwissADME: A free web tool to evaluate pharmacokinetics, drug-likeness and medicinal chemistry friendliness of small molecules. Sci. Rep. 2017, 7, 42717. [Google Scholar] [CrossRef]
- FAFDrugs4. Available online: http://fafdrugs4.mti.univ-paris-diderot.fr/ (accessed on 18 March 2019).
- Hawkins, P.C.D.; Skillman, A.G.; Nicholls, A. Comparison of Shape-Matching and Docking as Virtual Screening Tools. J. Med. Chem. 2007, 50, 74–82. [Google Scholar] [CrossRef] [Green Version]
- Sastry, G.M.; Dixon, S.L.; Sherman, W. Rapid Shape-Based Ligand Alignment and Virtual Screening Method Based on Atom/Feature-Pair Similarities and Volume Overlap Scoring. J. Chem. Inf. Model. 2011, 51, 2455–2466. [Google Scholar] [CrossRef]
- EON 2.2.0.5: OpenEye Scientific Software, Santa Fe, NM. Available online: http://www.eyesopen.com (accessed on 18 March 2019).
- Dixon, S.L.; Smondyrev, A.M.; Knoll, E.H.; Rao, S.N.; Shaw, D.E.; Friesner, R.A. PHASE: A new engine for pharmacophore perception, 3D QSAR model development, and 3D database screening: 1. Methodology and preliminary results. J. Comput. Aided. Mol. Des. 2006, 20, 647–671. [Google Scholar] [CrossRef]
- Wolber, G.; Langer, T. LigandScout: 3-D Pharmacophores Derived from Protein-Bound Ligands and Their Use as Virtual Screening Filters. J. Chem. Inf. Model. 2004, 45, 160–169. [Google Scholar] [CrossRef]
- Friesner, R.A.; Banks, J.L.; Murphy, R.B.; Halgren, T.A.; Klicic, J.J.; Mainz, D.T.; Repasky, M.P.; Knoll, E.H.; Shelley, M.; Perry, J.K.; et al. Glide: A new approach for rapid, accurate docking and scoring. 1. Method and assessment of docking accuracy. J. Med. Chem. 2004, 47, 1739–1749. [Google Scholar] [CrossRef]
- Jones, G.; Willett, P.; Glen, R.C.; Leach, A.R.; Taylor, R. Development and validation of a genetic algorithm for flexible docking. J. Mol. Biol. 1997, 267, 727–748. [Google Scholar] [CrossRef] [Green Version]
- Allen, W.J.; Balius, T.E.; Mukherjee, S.; Brozell, S.R.; Moustakas, D.T.; Lang, P.T.; Case, D.A.; Kuntz, I.D.; Rizzo, R.C. DOCK 6: Impact of new features and current docking performance. J. Comput. Chem. 2015, 36, 1132–1156. [Google Scholar] [CrossRef]
- Morris, G.M.; Huey, R.; Lindstrom, W.; Sanner, M.F.; Belew, R.K.; Goodsell, D.S.; Olson, A.J. AutoDock4 and AutoDockTools4: Automated docking with selective receptor flexibility. J. Comput. Chem. 2009, 30, 2785–2791. [Google Scholar] [CrossRef]
- Johnson, M.A.; Maggiora, G.M. Concepts and Applications of Molecular Similarity; John Wiley & Sons: New York, NY, USA, 1990. [Google Scholar]
- Cereto-Massagué, A.; Ojeda, M.J.; Valls, C.; Mulero, M.; Garcia-Vallvé, S.; Pujadas, G. Molecular fingerprint similarity search in virtual screening. Methods 2014, 71, 6–11. [Google Scholar] [CrossRef]
- Accelrys, MACCS Structural Keys. Available online: http://www.3dsbiovia.com (accessed on 18 March 2019).
- Durant, J.L.; Leland, B.A.; Henry, D.R.; Nourse, J.G. Reoptimization of MDL Keys for Use in Drug Discovery. J. Chem. Inf. Comput. Sci. 2002, 42, 1273–1280. [Google Scholar] [CrossRef]
- Gianti, E.; Sartori, L. Identification and Selection of “Privileged Fragments” Suitable for Primary Screening. J. Chem. Inf. Model. 2008, 48, 2129–2139. [Google Scholar] [CrossRef]
- Daylight Chemical Information Systems, Daylight. Available online: http://www.daylight.com (accessed on 18 March 2019).
- Bender, A.; Mussa, H.Y.; Glen, R.C.; Reiling, S. Molecular Similarity Searching Using Atom Environments, Information-Based Feature Selection, and a Naïve Bayesian Classifier. J. Chem. Inf. Comput. Sci. 2003, 44, 170–178. [Google Scholar] [CrossRef]
- Bender, A.; Mussa, H.Y.; Glen, R.C.; Reiling, S. Similarity Searching of Chemical Databases Using Atom Environment Descriptors (MOLPRINT 2D): Evaluation of Performance. J. Chem. Inf. Comput. Sci. 2004, 44, 1708–1718. [Google Scholar] [CrossRef]
- Rogers, D.; Hahn, M. Extended-Connectivity Fingerprints. J. Chem. Inf. Model. 2010, 50, 742–754. [Google Scholar] [CrossRef]
- McGregor, M.J.; Muskal, S.M. Pharmacophore fingerprinting. 2. Application to primary library design. J. Chem. Inf. Comput. Sci. 2000, 40, 117–125. [Google Scholar] [CrossRef]
- Schwartz, J.; Awale, M.; Reymond, J.-L. SMIfp (SMILES fingerprint) Chemical Space for Virtual Screening and Visualization of Large Databases of Organic Molecules. J. Chem. Inf. Model. 2013, 53, 1979–1989. [Google Scholar] [CrossRef]
- Chemical Computing Group Inc. Molecular Operating Environment (MOE); Chemical Computing Group Inc.: Montréal, QC, Canada, 2013. [Google Scholar]
- Deng, Z.; Chuaqui, C.; Singh, J. Structural Interaction Fingerprint (SIFt): A Novel Method for Analyzing Three-Dimensional Protein−Ligand Binding Interactions. J. Med. Chem. 2003, 47, 337–344. [Google Scholar] [CrossRef]
- Xue, L.; Godden, J.W.; Stahura, F.L.; Bajorath, J. Design and Evaluation of a Molecular Fingerprint Involving the Transformation of Property Descriptor Values into a Binary Classification Scheme. J. Chem. Inf. Comput. Sci. 2003, 43, 1151–1157. [Google Scholar] [CrossRef]
- Bajusz, D.; Rácz, A.; Héberger, K. Why is Tanimoto index an appropriate choice for fingerprint-based similarity calculations? J. Cheminform. 2015, 7, 20. [Google Scholar] [CrossRef]
- Maggiora, G.; Vogt, M.; Stumpfe, D.; Bajorath, J. Molecular Similarity in Medicinal Chemistry. J. Med. Chem. 2014, 57, 3186–3204. [Google Scholar] [CrossRef]
- Ho, T.K. Random Decision Forest. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Cherkassky, V. The Nature of Statistical Learning Theory. IEEE Trans. Neural Netw. 1997, 8, 1564. [Google Scholar] [CrossRef]
- Labute, P. Binary QSAR: A new method for the determination of quantitative structure activity relationships. Pac. Symp. Biocomput. 1999, 444–455. [Google Scholar]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [Green Version]
- Zupan, J.; Gasteiger, J. Neural Networks in Chemistry and Drug Design: An Introduction, 2nd ed.; Wiley-VCH: Weinheim, Germany, 1999. [Google Scholar]
- Lavecchia, A. Machine-learning approaches in drug discovery: Methods and applications. Drug Discov. Today 2015, 20, 318–331. [Google Scholar] [CrossRef]
- Melville, J.L.; Burke, E.K.; Hirst, J.D. Machine learning in virtual screening. Comb. Chem. High Throughput Screen. 2009, 12, 332–343. [Google Scholar] [CrossRef]
- Lima, A.N.; Philot, E.A.; Trossini, G.H.G.; Scott, L.P.B.; Maltarollo, V.G.; Honorio, K.M. Use of machine learning approaches for novel drug discovery. Expert Opin. Drug Discov. 2016, 11, 225–239. [Google Scholar] [CrossRef]
- Maltarollo, V.G.; Gertrudes, J.C.; Oliveira, P.R.; Honorio, K.M. Applying machine learning techniques for ADME-Tox prediction: A review. Expert Opin. Drug Metab. Toxicol. 2015, 11, 259–271. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Zhang, K.Y.J. Advances in the Development of Shape Similarity Methods and Their Application in Drug Discovery. Front. Chem. 2018, 6, 1–21. [Google Scholar] [CrossRef]
- Connolly, M.L. Computation of molecular volume. J. Am. Chem. Soc. 1985, 107, 1118–1124. [Google Scholar] [CrossRef]
- Grant, J.A.; Pickup, B.T. A Gaussian Description of Molecular Shape. J. Phys. Chem. 1995, 99, 3503–3510. [Google Scholar] [CrossRef]
- Grant, J.A.; Gallardo, M.A.; Pickup, B.T. A fast method of molecular shape comparison: A simple application of a Gaussian description of molecular shape. J. Comput. Chem. 1996, 17, 1653–1666. [Google Scholar] [CrossRef]
- Mezey, P.G. Molecular Surfaces; John Wiley & Sons, Ltd.: New York, NY, USA, 2007; pp. 265–294. [Google Scholar]
- Lee, B.; Richards, F.M. The interpretation of protein structures: Estimation of static accessibility. J. Mol. Biol. 1971, 55, 379-IN4. [Google Scholar] [CrossRef]
- Connolly, M.L. Solvent-accessible surfaces of proteins and nucleic acids. Science 1983, 221, 709–713. [Google Scholar] [CrossRef]
- Sala, E.; Guasch, L.; Iwaszkiewicz, J.; Mulero, M.; Salvadó, M.-J.; Pinent, M.; Zoete, V.; Grosdidier, A.; Garcia-Vallvé, S.; Michielin, O.; et al. Identification of human IKK-2 inhibitors of natural origin (part I): Modeling of the IKK-2 kinase domain, virtual screening and activity assays. PLoS ONE 2011, 6, e16903. [Google Scholar] [CrossRef]
- Guasch, L.; Sala, E.; Castell-Auví, A.; Cedó, L.; Liedl, K.R.; Wolber, G.; Muehlbacher, M.; Mulero, M.; Pinent, M.; Ardévol, A.; et al. Identification of PPARgamma Partial Agonists of Natural Origin (I): Development of a Virtual Screening Procedure and In Vitro Validation. PLoS ONE 2012, 7, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Wermuth, C.G.; Ganellin, C.R.; Lindberg, P.; Mitscher, L.A. Glossary of terms used in medicinal chemistry (IUPAC Recommendations 1998). Pure Appl. Chem. 1998, 70, 1129–1143. [Google Scholar] [CrossRef]
- Ripphausen, P.; Nisius, B.; Peltason, L.; Bajorath, J. Quo Vadis, Virtual Screening? A Comprehensive Survey of Prospective Applications. J. Med. Chem. 2010, 53, 8461–8467. [Google Scholar] [CrossRef] [PubMed]
- Kolb, P.; Irwin, J. Docking Screens: Right for the Right Reasons? Curr. Top. Med. Chem. 2009, 9, 755–770. [Google Scholar] [CrossRef]
- Irwin, J.J.; Shoichet, B.K. Docking Screens for Novel Ligands Conferring New Biology. J. Med. Chem. 2016, 59, 4103–4120. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Lill, M.A. Induced fit docking, and the use of QM/MM methods in docking. Drug Discov. Today Technol. 2013, 10, e411–e418. [Google Scholar] [CrossRef] [Green Version]
- Salam, N.K.; Nuti, R.; Sherman, W. Novel Method for Generating Structure-Based Pharmacophores Using Energetic Analysis. J. Chem. Inf. Model. 2009, 49, 2356–2368. [Google Scholar] [CrossRef]
- Mysinger, M.M.; Carchia, M.; Irwin, J.J.; Shoichet, B.K. Directory of useful decoys, enhanced (DUD-E): Better ligands and decoys for better benchmarking. J. Med. Chem. 2012, 55, 6582–6594. [Google Scholar] [CrossRef]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-Based Clustering Based on Hierarchical Density Estimates; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–172. [Google Scholar]
- Baell, J.; Walters, M.A. Chemistry: Chemical con artists foil drug discovery. Nature 2014, 513, 481–483. [Google Scholar] [CrossRef] [Green Version]
- Panaceas, I.M. The Ecstasy and Agony of Assay Interference Compounds. Biochemistry 2017, 56, 1316–1366. [Google Scholar]
- About PAINS-Remover. Available online: http://www.cbligand.org/PAINS/ (accessed on 18 March 2019).
- Patterns. Available online: http://zinc15.docking.org/patterns/home (accessed on 18 March 2019).
- Aggergator Advisor. Available online: http://advisor.docking.org (accessed on 18 March 2019).
- McGovern, S.L.; Caselli, E.; Grigorieff, N.; Shoichet, B.K. A common mechanism underlying promiscuous inhibitors from virtual and high-throughput screening. J. Med. Chem. 2002, 45, 1712–1722. [Google Scholar] [CrossRef] [PubMed]
- Feng, B.Y.; Shoichet, B.K. A detergent-based assay for the detection of promiscuous inhibitors. Nat. Protoc. 2006, 1, 550–553. [Google Scholar] [CrossRef] [PubMed]
- Lipinski, C.A.; Lombardo, F.; Dominy, B.W.; Feeney, P.J. Experimental and computational approaches to estimate solubility and permeability in drug discovery and development settings. Adv. Drug Deliv. Rev. 1997, 23, 3–25. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Software | Developer |
|---|---|---|
| Graphical user interface | Flare [14] | Cresset |
| Maestro [33] | Schrödinger, LLC | |
| VIDA [34] | OpenEye Scientific Software Inc. | |
| Decoy set preparation | DecoyFinder [35] | Cheminformatics and Nutrition Research Group (Universitat Rovira I Virgili) |
| Crystal structure validation | VHELIBS [21] | Cheminformatics and Nutrition Research Group (Universitat Rovira I Virgili) |
| Molecule standardization | Standardizer [30] | ChemAxon |
| LigPrep [31] | Schrödinger, LLC | |
| MolVS [32] | RDKit | |
| Conformer generation | OMEGA [25] | OpenEye Scientific Software Inc. |
| ConfGen [26] | Schrödinger, LLC | |
| Distance Geometry (DG) [27] | RDKit | |
| ETKDG [29] | RDKit | |
| ADME property prediction | QikProp [36] | Schrödinger, LLC |
| SwissADME [37] | Swiss Institute of Bioinformatics | |
| FAFDrugs4 [38] | UMRS Paris Diderot-Inserm 973 | |
| Shape similarity | ROCS [39] | OpenEye Scientific Software Inc. |
| Shape screening [40] | Schrödinger, LLC | |
| Electrostatic potential similarity | EON [41] | OpenEye Scientific Software Inc. |
| Pharmacophore | Phase [42] | Schrödinger, LLC |
| Ligandscout [43] | Inte:Ligand GmbH | |
| Docking | Glide [44] | Schrödinger, LLC |
| GOLD [45] | The Cambridge Crystallographic Data Centre | |
| DOCK [46] | University of California San Francisco | |
| Autodock [47] | The Scripps Research Institute |
| Predicted Condition | True Condition | |
|---|---|---|
| Positive | Negative | |
| Positive | True positives (TP) | False positives (FP) |
| Negative | False negatives (FN) | True negatives (TN) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gimeno, A.; Ojeda-Montes, M.J.; Tomás-Hernández, S.; Cereto-Massagué, A.; Beltrán-Debón, R.; Mulero, M.; Pujadas, G.; Garcia-Vallvé, S. The Light and Dark Sides of Virtual Screening: What Is There to Know? Int. J. Mol. Sci. 2019, 20, 1375. https://doi.org/10.3390/ijms20061375
Gimeno A, Ojeda-Montes MJ, Tomás-Hernández S, Cereto-Massagué A, Beltrán-Debón R, Mulero M, Pujadas G, Garcia-Vallvé S. The Light and Dark Sides of Virtual Screening: What Is There to Know? International Journal of Molecular Sciences. 2019; 20(6):1375. https://doi.org/10.3390/ijms20061375
Chicago/Turabian StyleGimeno, Aleix, María José Ojeda-Montes, Sarah Tomás-Hernández, Adrià Cereto-Massagué, Raúl Beltrán-Debón, Miquel Mulero, Gerard Pujadas, and Santiago Garcia-Vallvé. 2019. "The Light and Dark Sides of Virtual Screening: What Is There to Know?" International Journal of Molecular Sciences 20, no. 6: 1375. https://doi.org/10.3390/ijms20061375