A Multi-Fault Diagnosis Method for Sensor Systems Based on Principle Component Analysis



Abstract
:1. Introduction
2. CMAC Algorithms
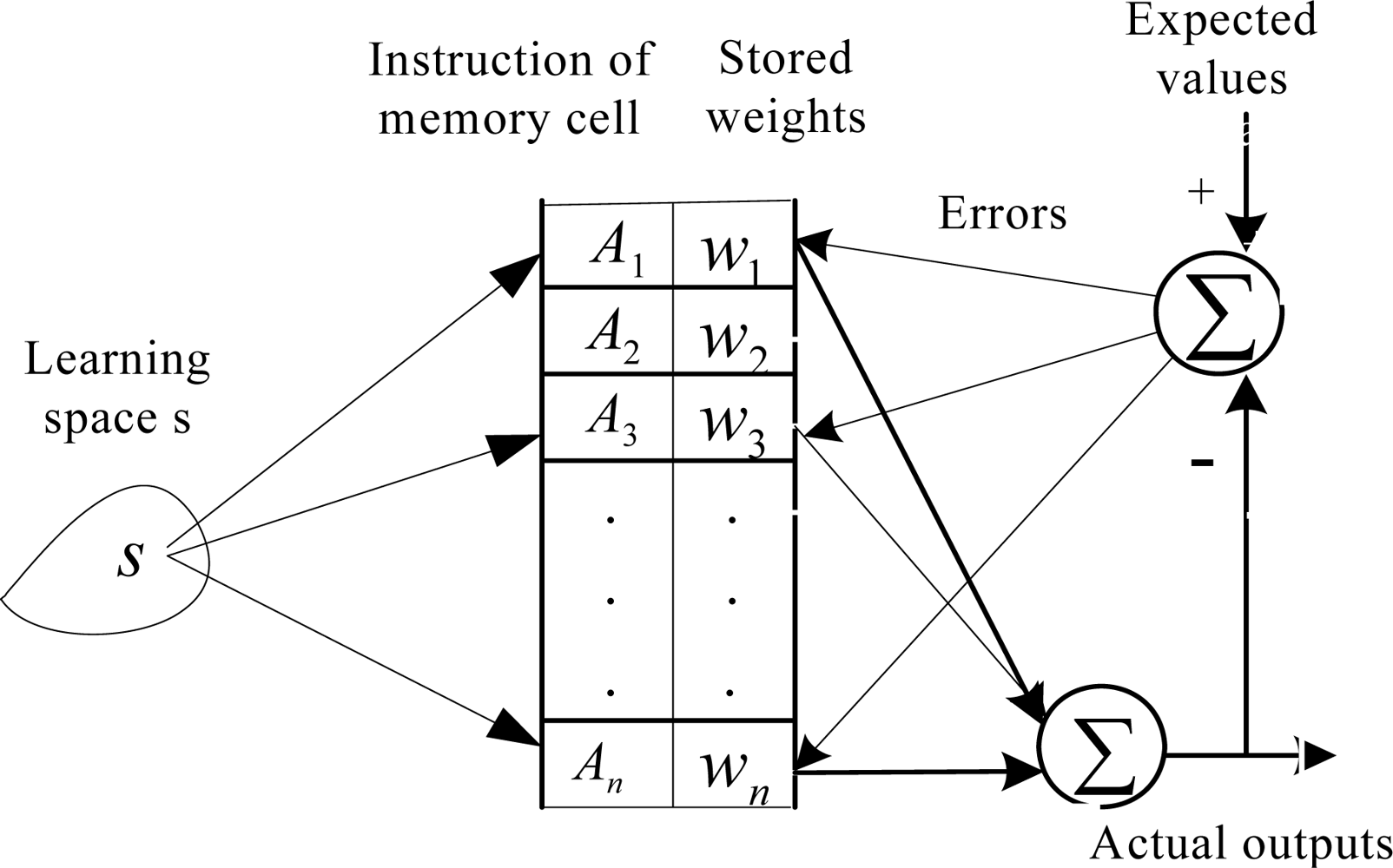
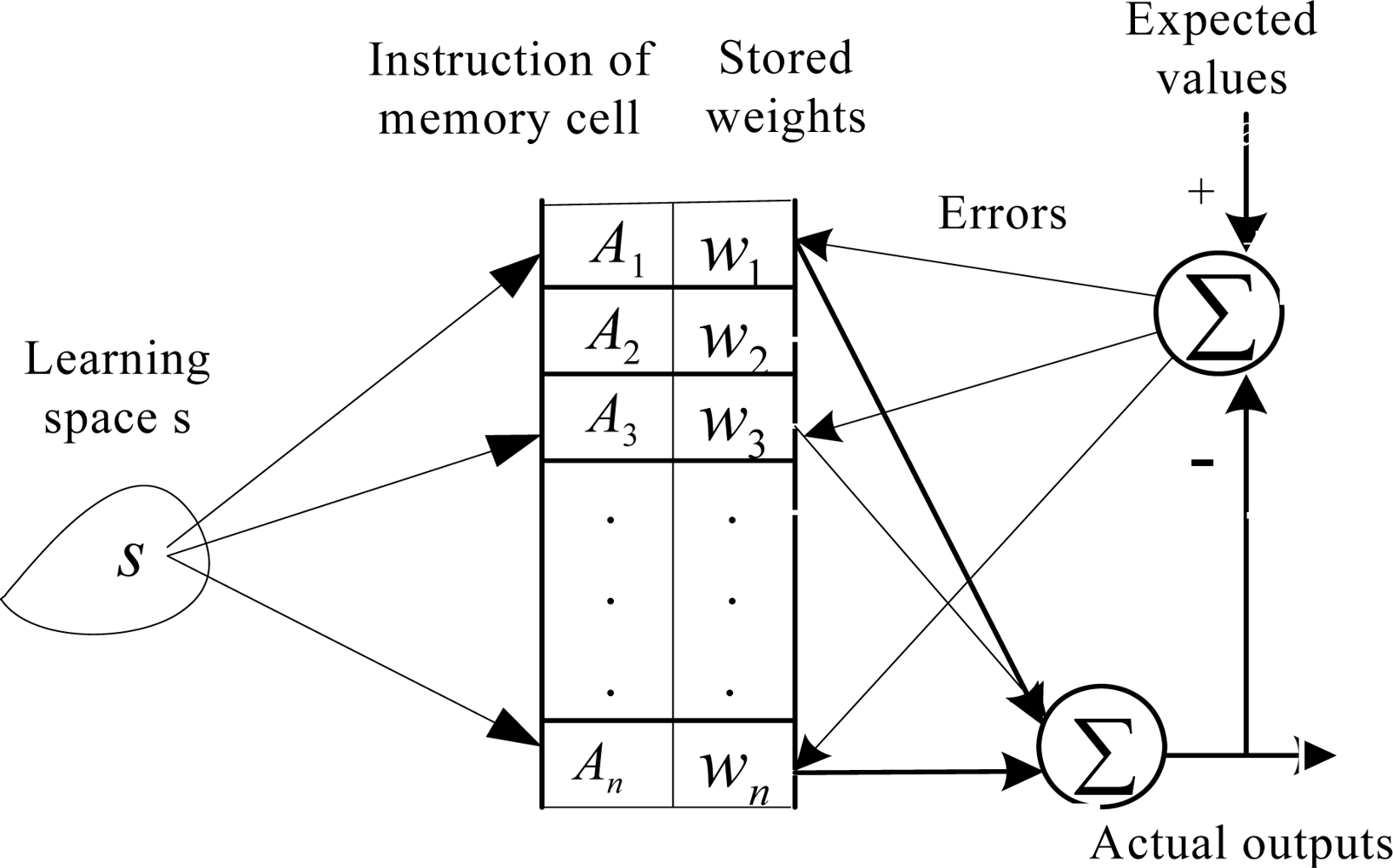
2.1. Conventional CMAC Algorithm
2.2. CA-CMAC Algorithm
3. The Proposed Multi-Fault Sensor System Diagnosis Model Based on PCA
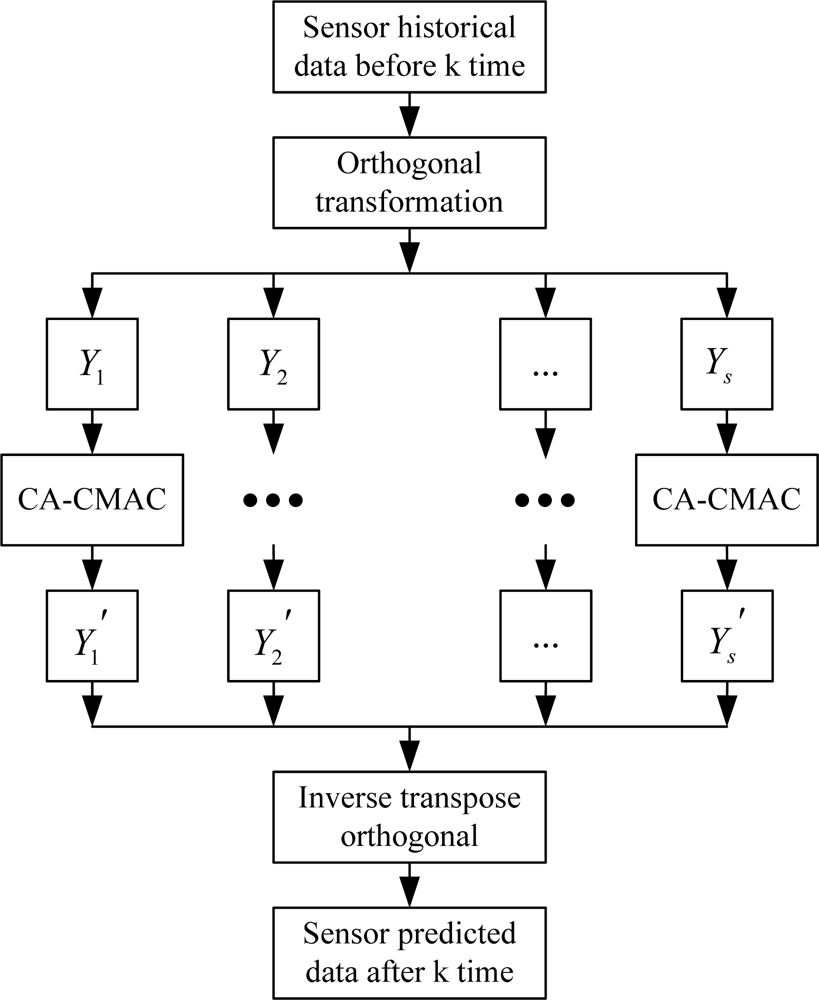
3.1. Principle of PCA and Signal Forecasting Model
3.2. Detection and Isolation of a Multi-fault Sensor System Based on PCA
(1) Detection of Faulty Sensors
(2) Sensor Fault Isolation Algorithm in Multi-fault Cases
① Reconstruction and Isolation of Sensor Signals
② Reconstruction and Isolation of Multi-Sensor Signals
4. Simulation Study
4.1. Sensors Model
4.2. Multi-fault Sensor Diagnosis Based on PCA
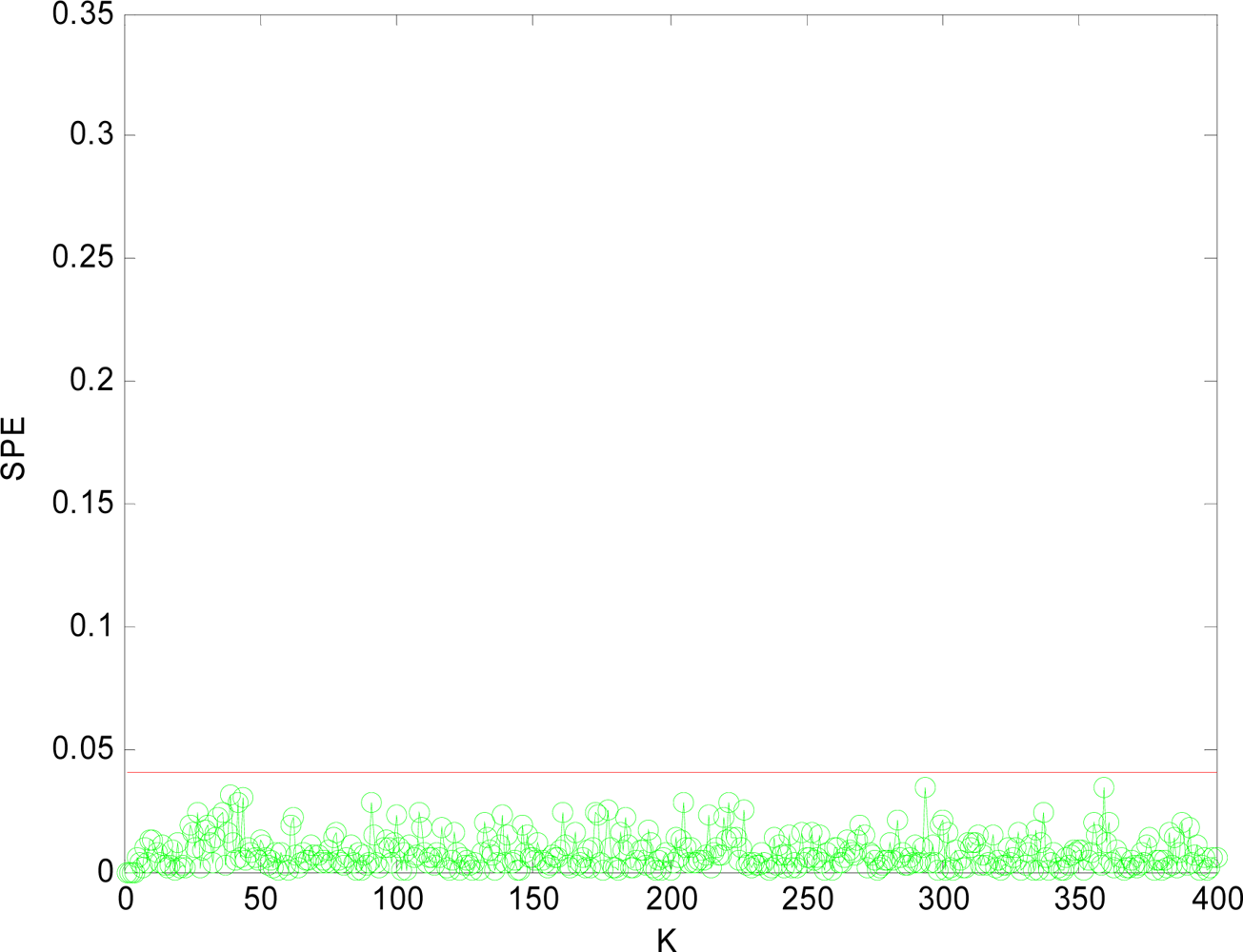
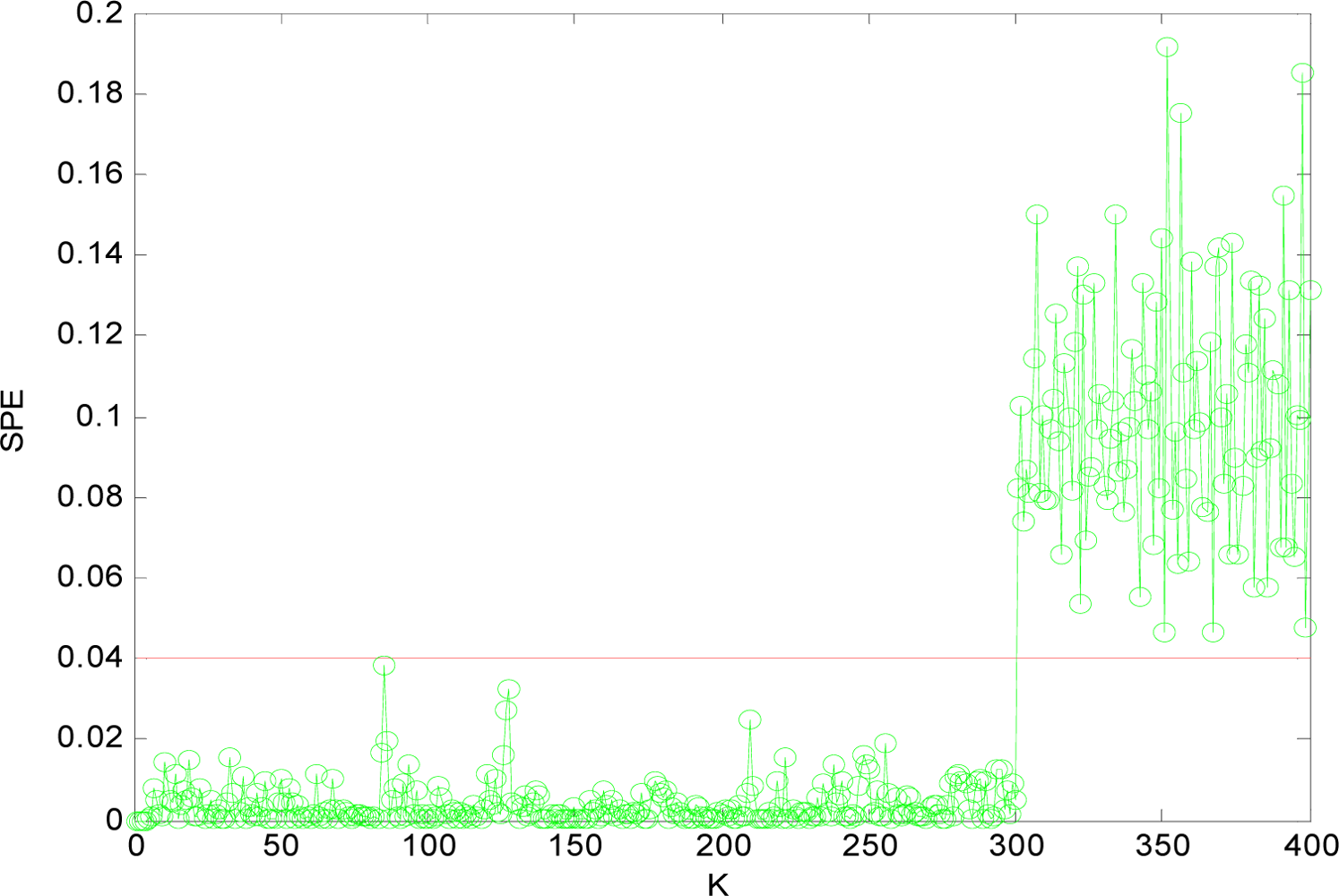
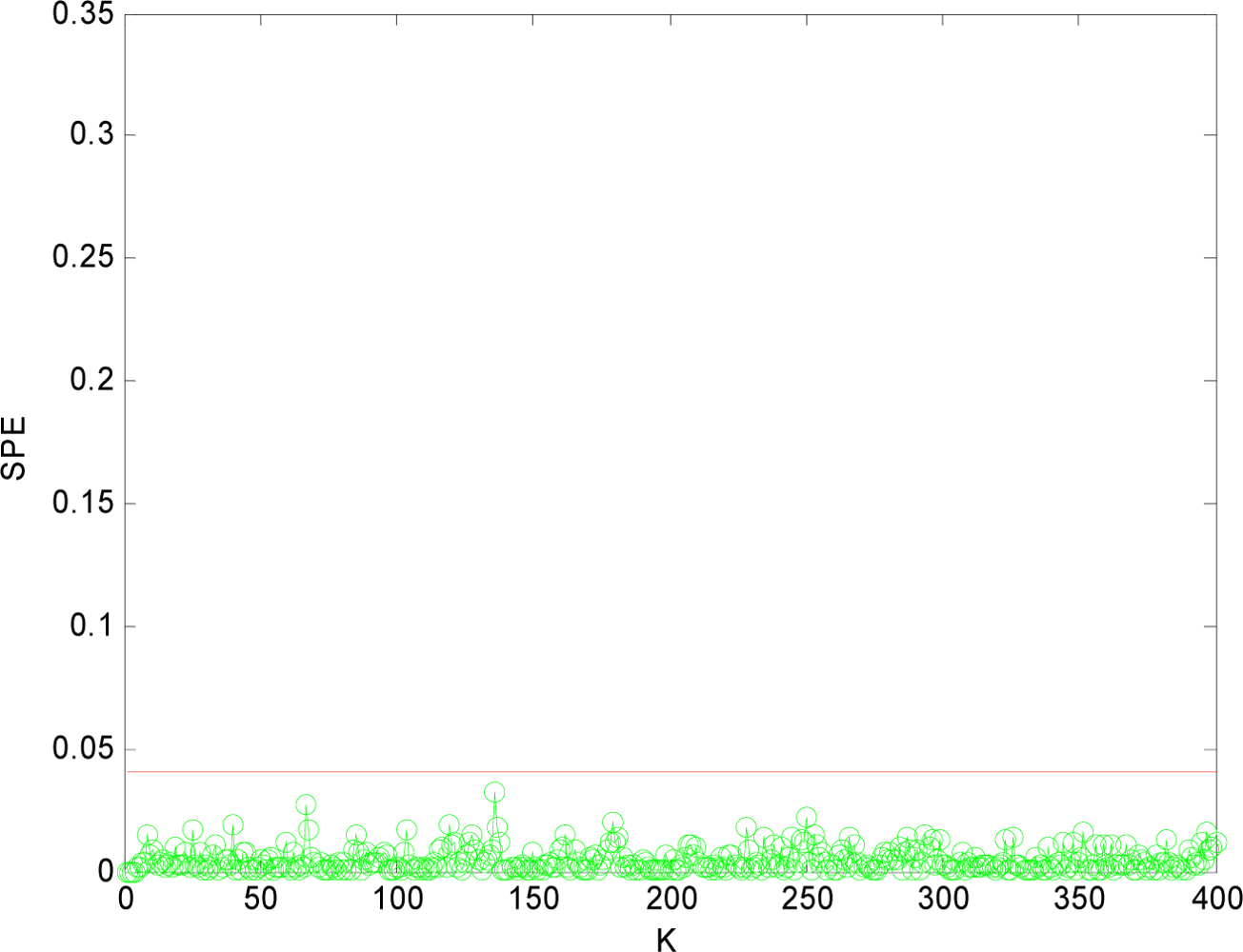
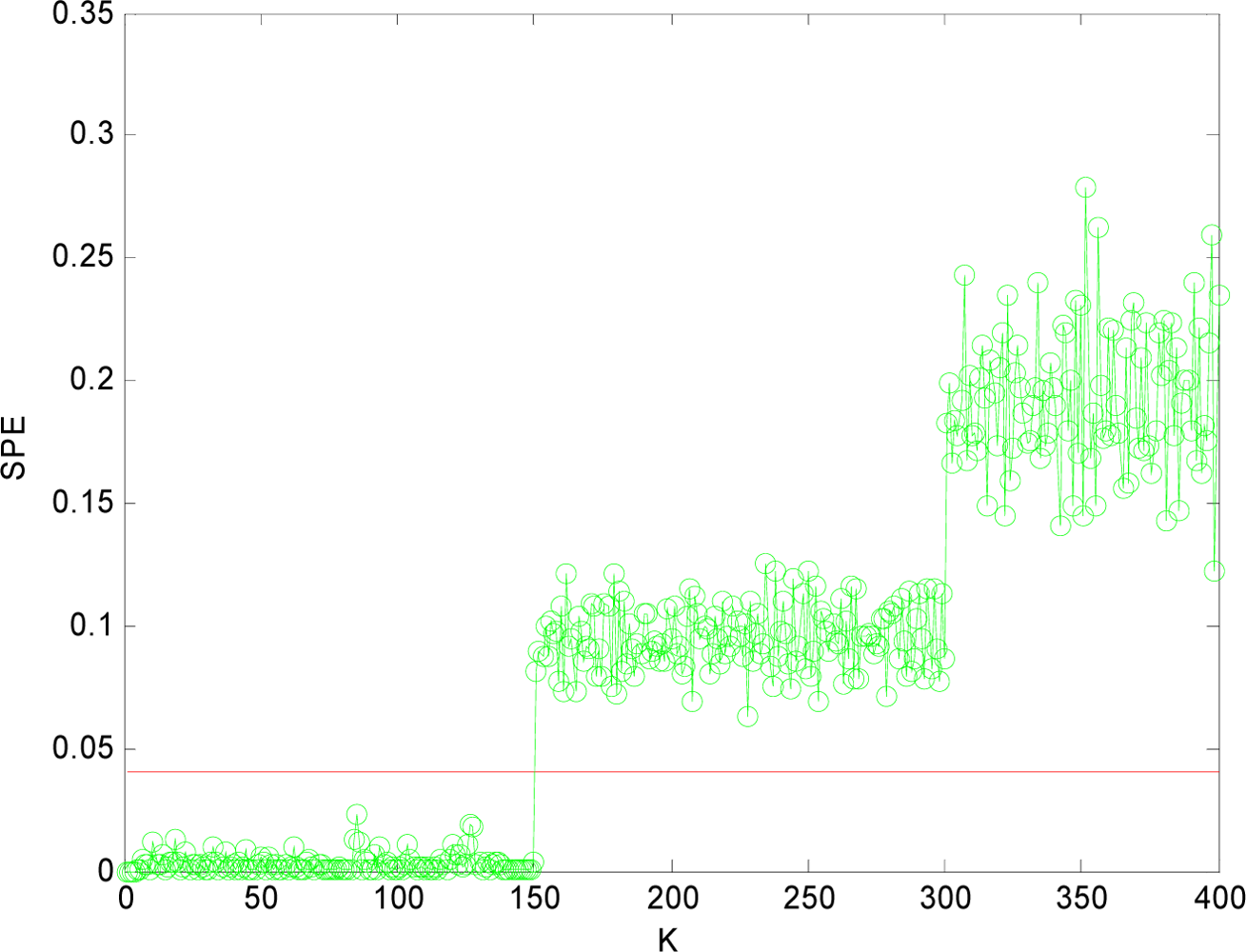
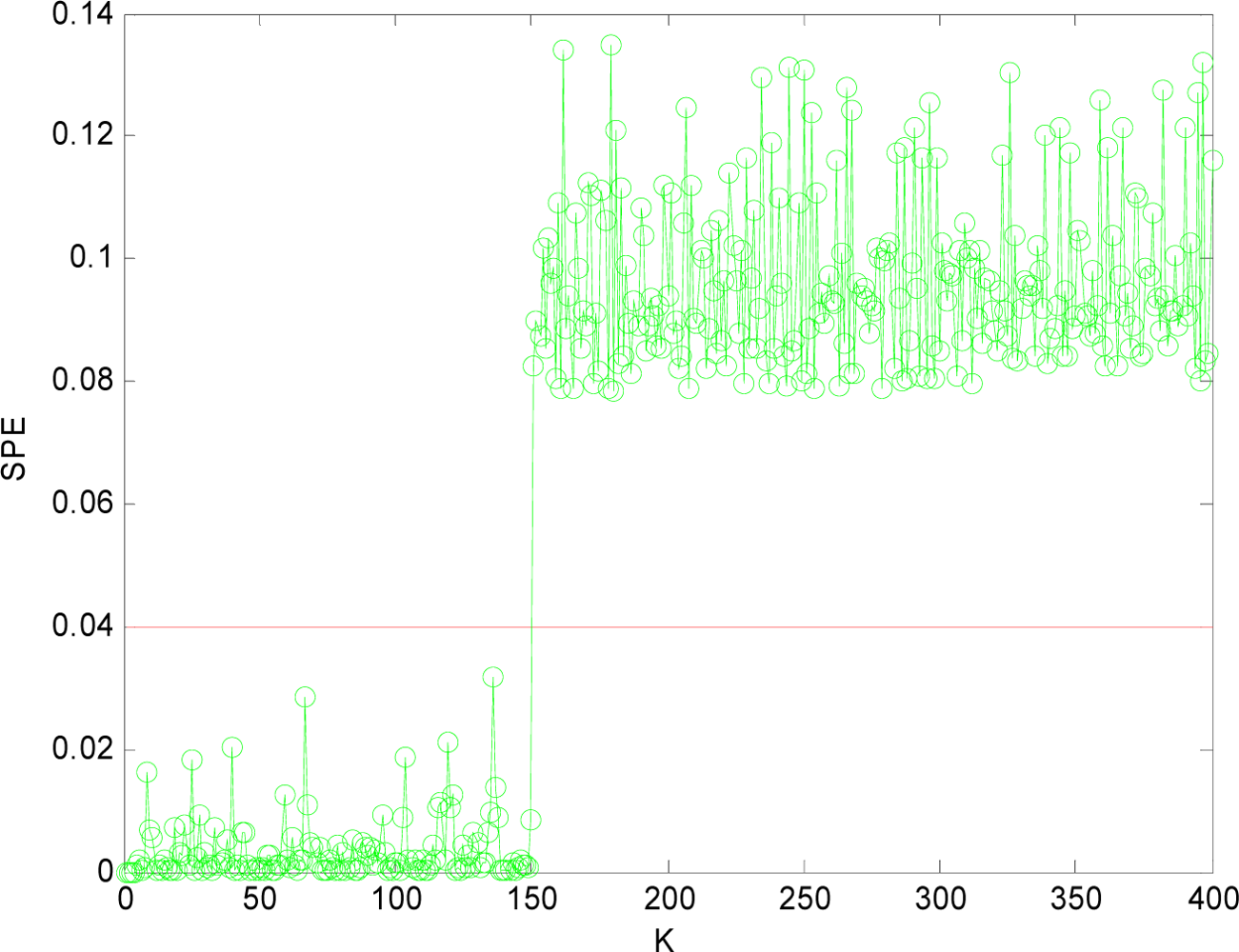
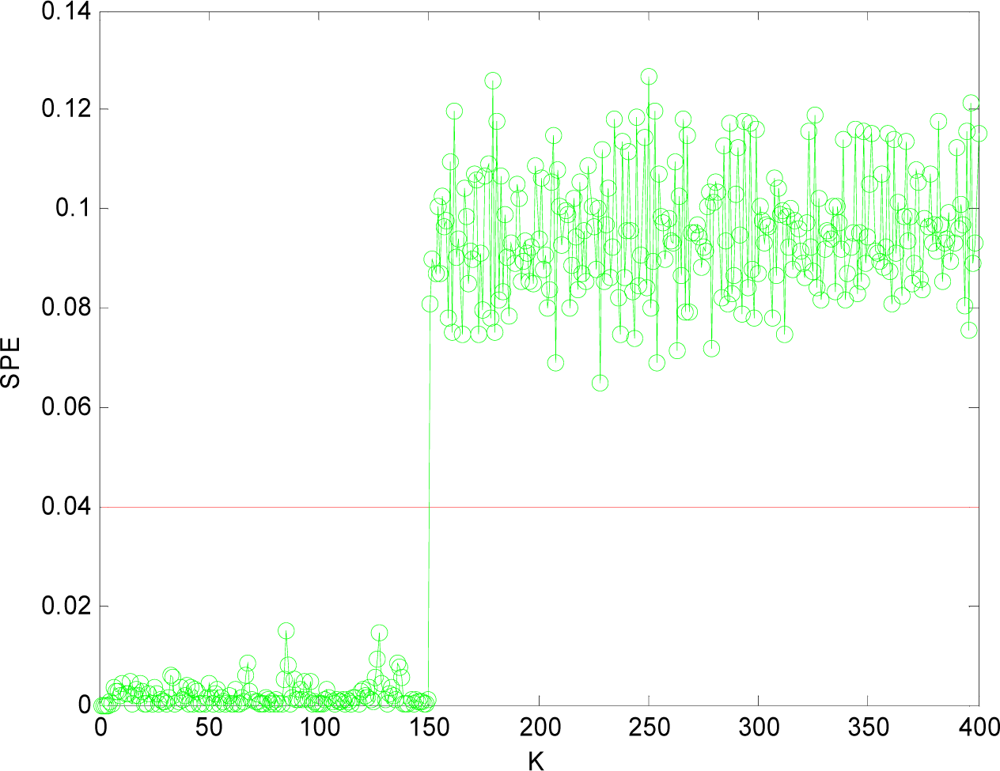
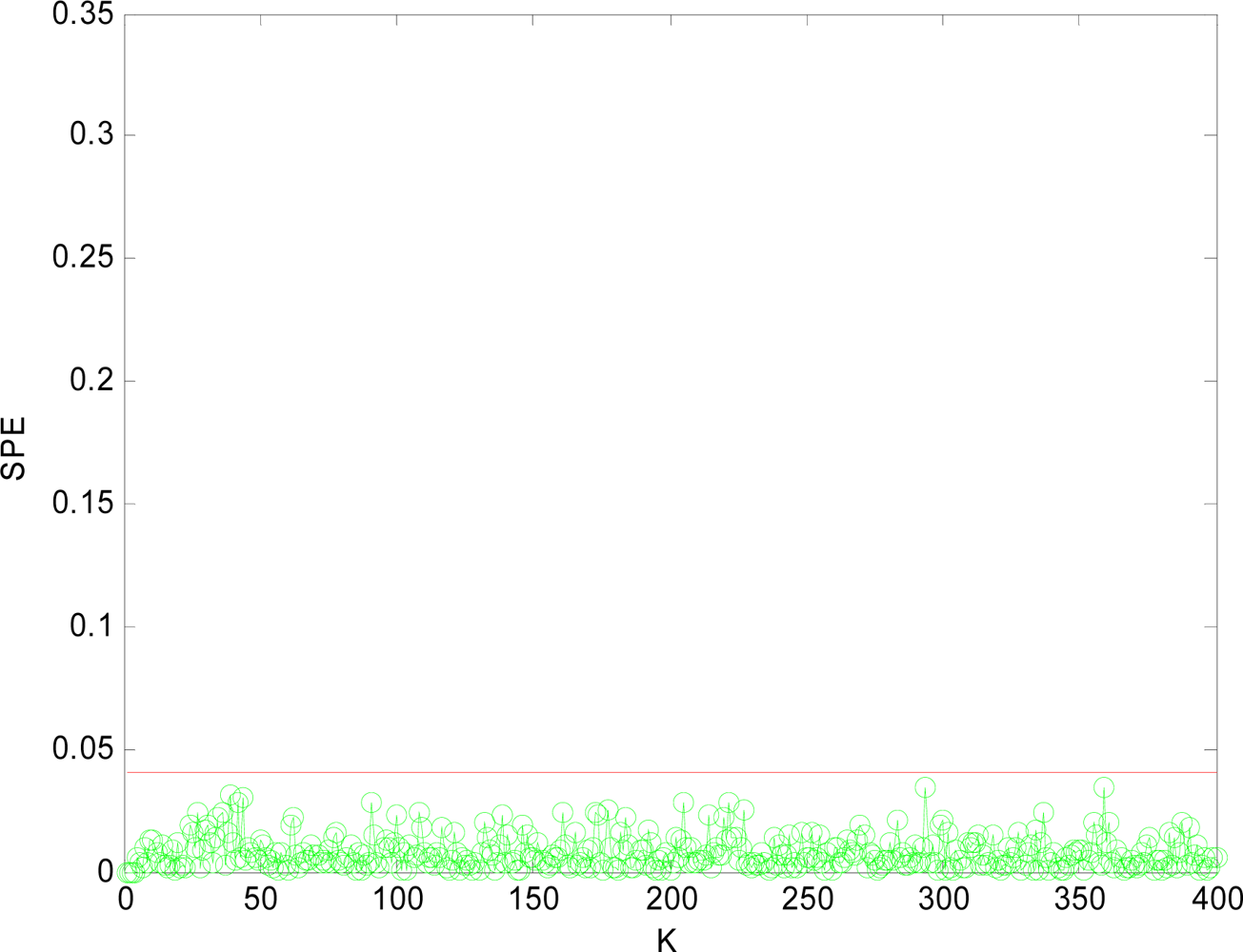
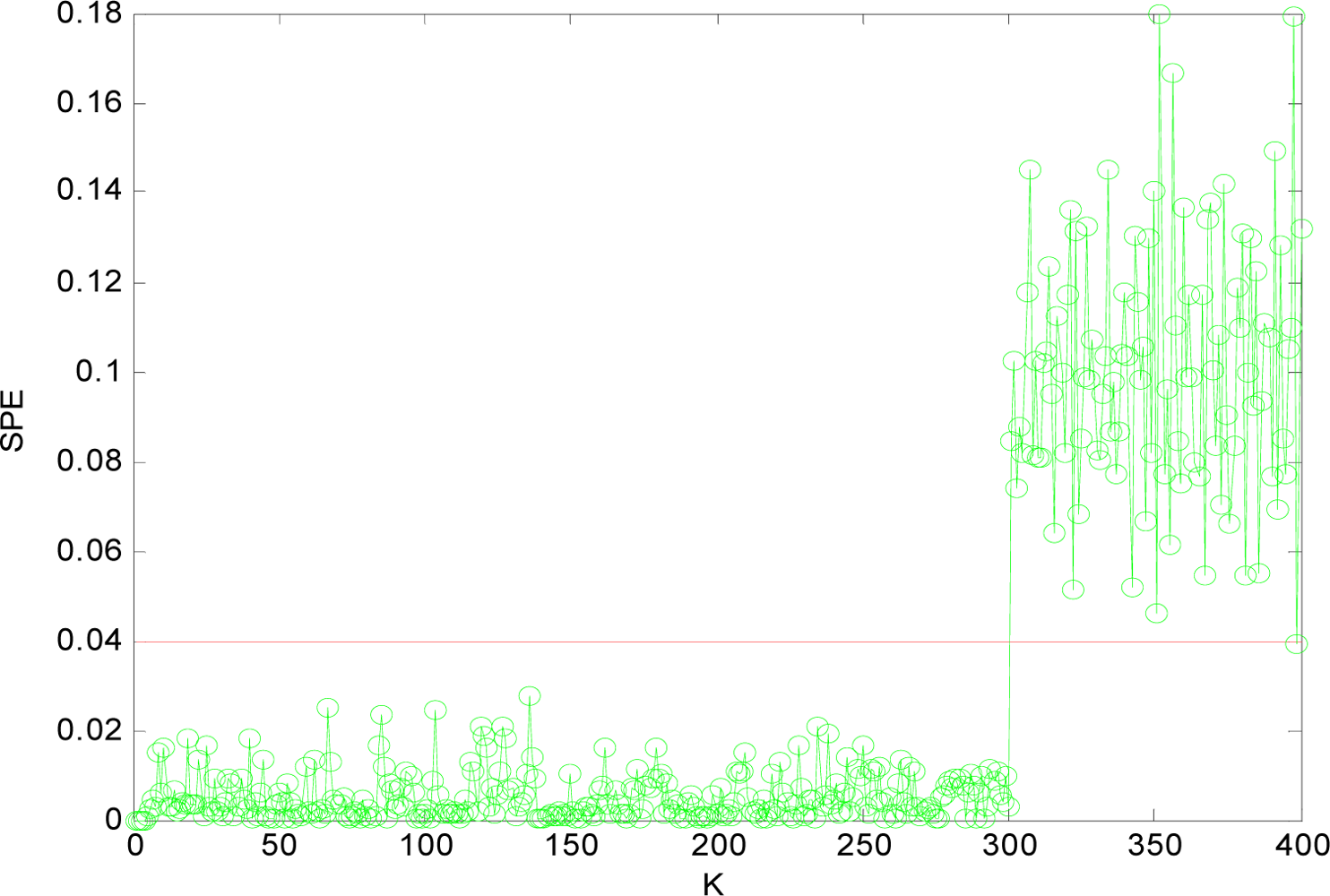
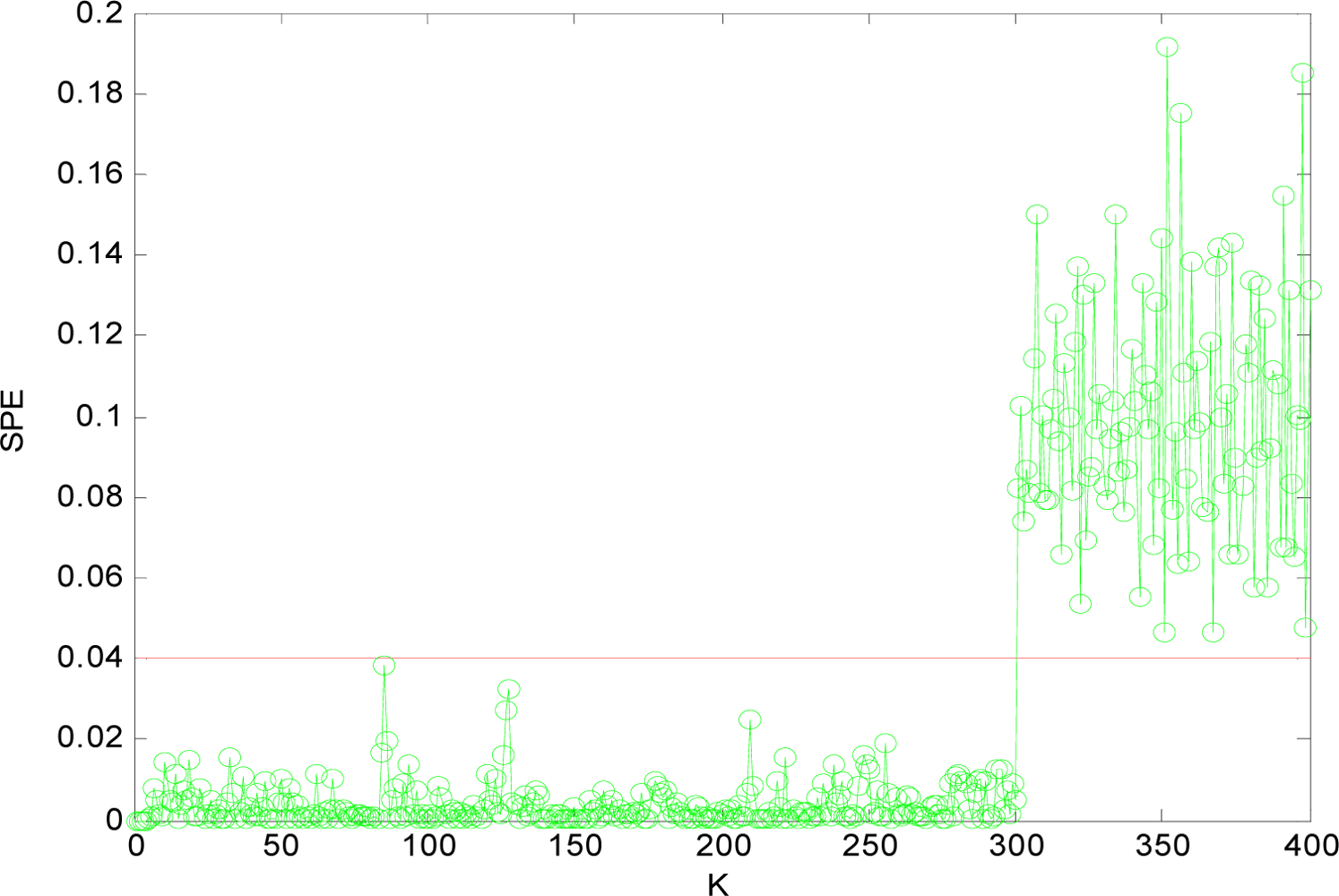
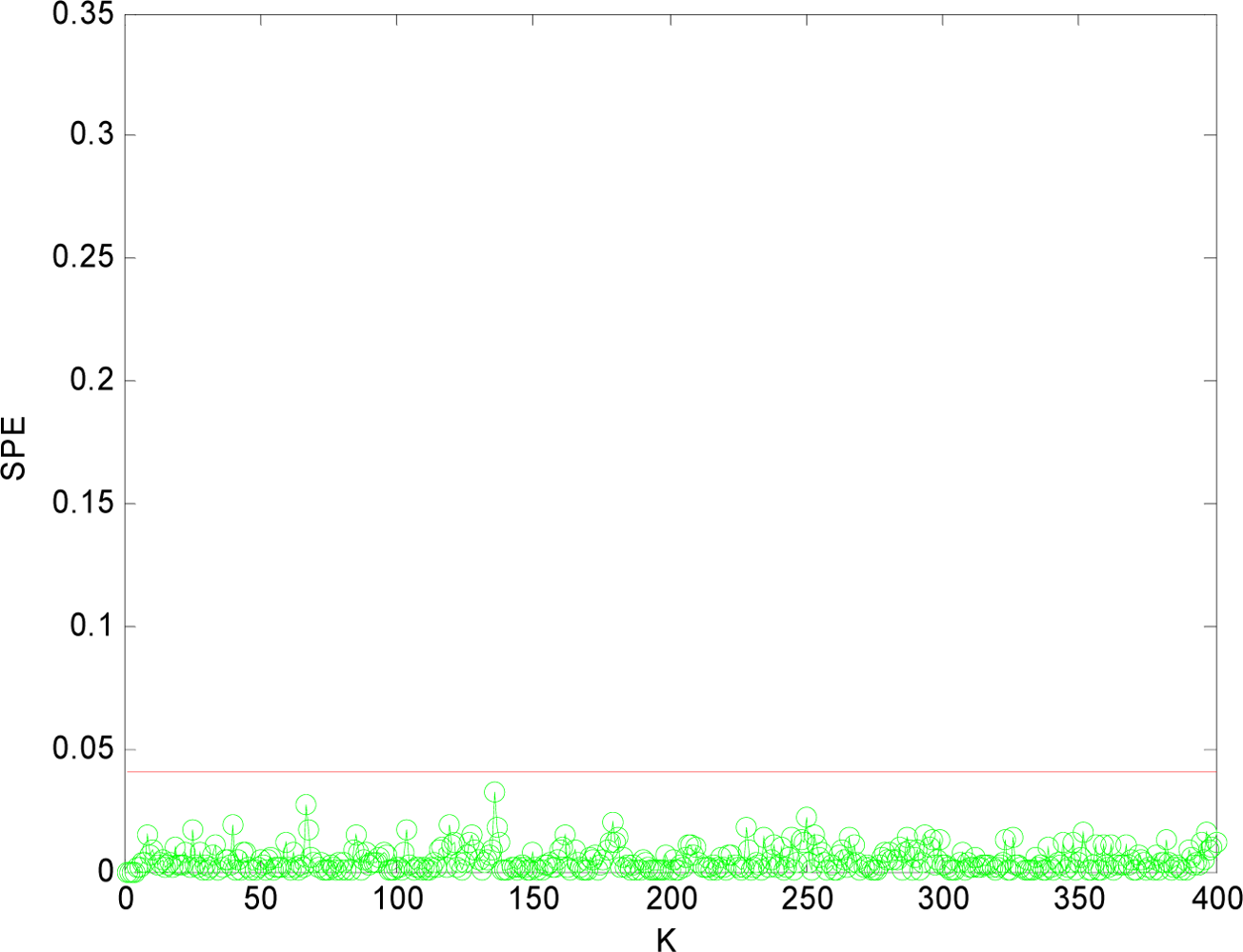
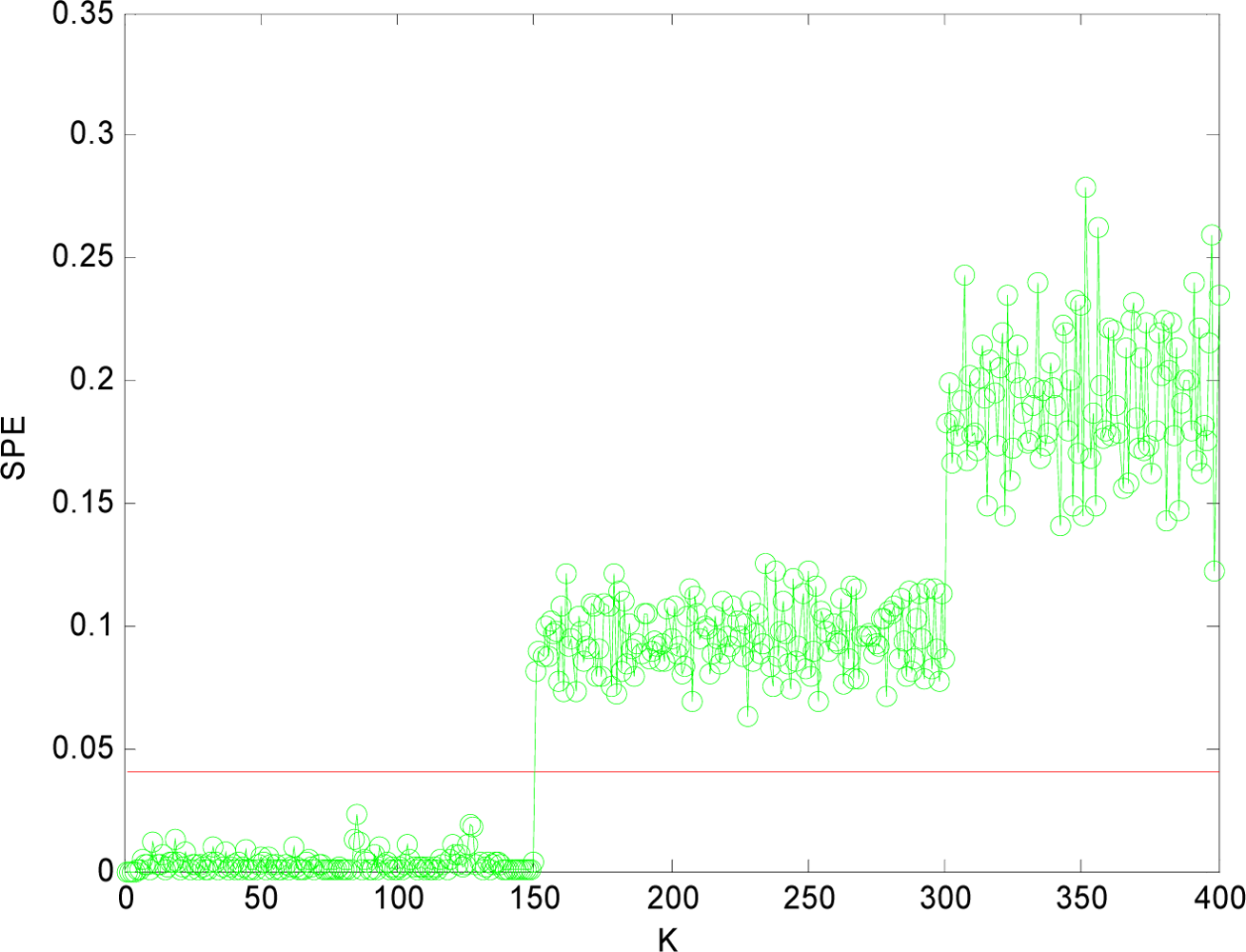
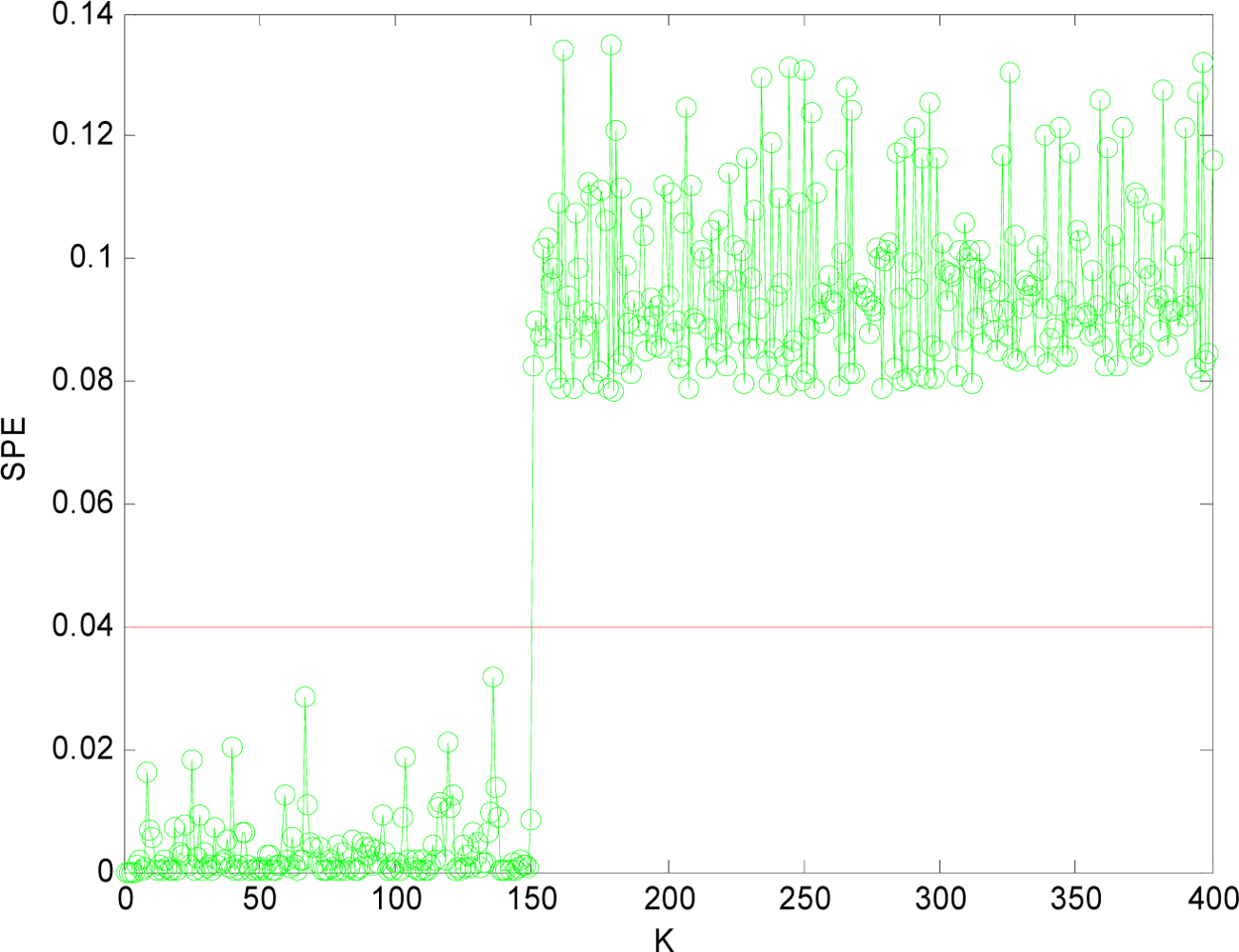
(1) Sensor Fault Detection
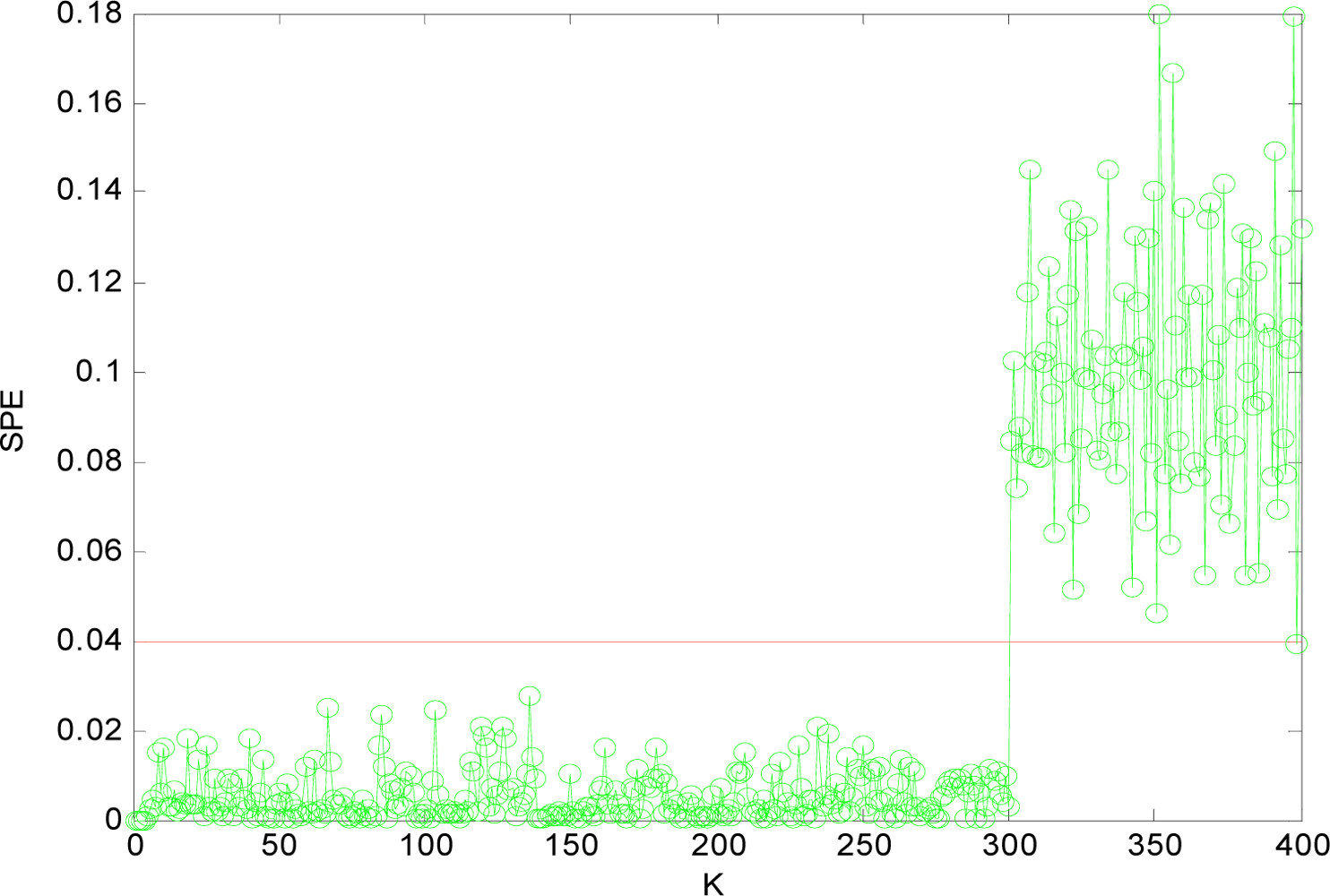
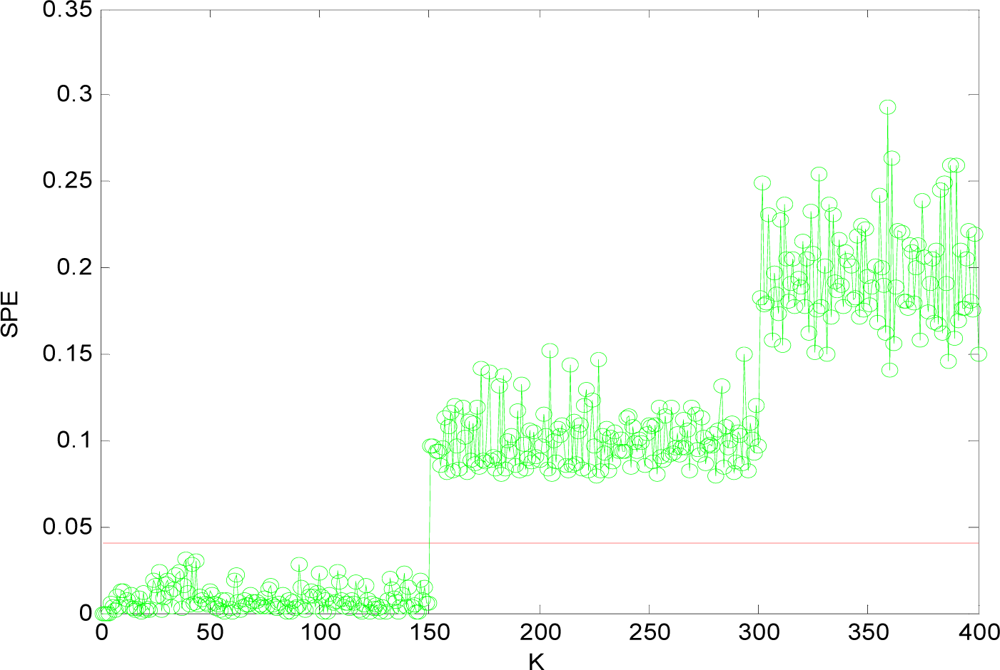
(2) Multi-Sensor Fault Isolation
5. Comparison among Ca-Cmac, Conventional Cmac and Bp Network
6. Conclusions
Acknowledgments
References
- Puyati, W.Y.; Walairacht, A. Efficiency Improvement for Unconstrained Face Recognition by Weight Probability Values of Modular PCA and Wavelet PCA. Proceedings of 10th International Conference on Advanced Communication Technology, Gangwon-Do, Korea, 2008; pp. 1449–1453.
- Peng, D.Z.; Zhang, Y. Dynamics of Generalized PCA and MCA Learning Algorithms. IEEE Trans. Neural Netw 2007, 18, 1777–1784. [Google Scholar]
- Zhao, K.; Upadhyaya, B.R. Model Based Approach for Fault Detection and Isolation of Helical Coil Steam Generator Systems Using Principal Component Analysis. IEEE Trans. Nucl. Sci 2006, 53, 2343–2352. [Google Scholar]
- Dunia, R.; Qin, S.J.; Edgar, T.F.; McAvoy, T.J. Identification of Faulty Sensors Using Principal Component Analysis. AIChE J 1996, 42, 2797–2812. [Google Scholar]
- Ricardo, D.; Qin, S.J.; Thomas, F.E.; McAvoy, T.J. Use of Principal Component Analysis for Sensor Fault Identification. Comput. Chem. Eng 1996, 20, 713–718. [Google Scholar]
- Hui, D.; Liu, J.H. Drift Reduction of Gas Sensor by Wavelet and Principal Component Analysis. Sens. Actuat 2003, 96, 354–361. [Google Scholar]
- Li, R.Y.; Rong, G. Fault Isolation by Partial Dynamic Principal Component Analysis in Dynamic Process. Chinese J. Chem. Eng 2006, 14, 486–493. [Google Scholar]
- Hsieh, W.W. Nonlinear Principal Component Analysis by Neural Networks. Tellus Ser. A 2001, 53, 599–615. [Google Scholar]
- Harkat, M.F.; Mourot, G.; Ragot, J. Nonlinear Pca Combining Principal Curves and Rbf-Networks for Process Monitoring. Proceedings 42th IEEE Conference on Decision and Control, Maui, HI, USA, 2003; pp. 1956–1961.
- Harkat, M.F.; Mourot, G. Variable Reconstruction Using RBF-NLPCA for Process Monitoring. IFAC Symposium on Fault Detection, Supervision and Safety for Technical Process, Washington, DC, USA, 2003; pp. 55–63.
- Kramer, M.A. Nonlinear Principal Component Analysis Using Auto-Associative Neural Networks. AIChE J 1991, 37, 233–243. [Google Scholar]
- Albus, J.S. A New Approach to Manipulator Control: The Cerebellar Model Articulation Controller (CMAC). Dyn. Syst. Measur. Control 1975, 97, 220–227. [Google Scholar]
- Albus, J.S. Data Storage in Cerebeller Model Articulation Controller (CMAC). ASME J. Dynam. Syst. Meas. Control 1975, 97, 228–233. [Google Scholar]
- Zhu, D.Q.; Kong, M. Adaptive Fault-Tolerant Control of Non-Linear Systems: An Improved Cmac-Based Fault Learning Approach. Int. J. Control 2007, 80, 1576–1594. [Google Scholar]
- Feng, S.S.; Ted, T.; Hung, T.H. Credit Assigned Cmac and Its Application to Online Learning Robust Controllers. IEEE Trans. Syst. Man Cybern 2003, 33, 202–213. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neural Network | Training Cycle
| |||||
| 0 | 1 | 2 | 3 | 4 | 5 | |
| BP | 2.77223 | 2.67898 | 0.52841 | 0.21499 | 0.03188 | 0.02098 |
| CMAC | 2.90312 | 0.29E-02 | 0.54E-02 | 0.51E-02 | 0.30E-02 | 0.12E-02 |
| CA-CMAC | 2.90312 | 0.31E-04 | 0.51E-04 | 0.31E-04 | 0.10E-04 | 0.21E-05 |
| Neural Network | Training Cycle
| |||||
| 6 | 7 | 8 | 9 | 10 | 11 | |
| BP | 0.01487 | 0.01156 | 0.00580 | 0.00391 | 0.00316 | 0.00282 |
| CMAC | 0.34E-03 | 0.66E-04 | 0.55E-05 | 0.23E-06 | 0.25E-05 | 0.29E-05 |
| CA-CMAC | 0.29E-06 | 0.24E-07 | 0.79E-09 | 0.30E-09 | 0.74E-09 | 0.64E-09 |
©2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/)
Share and Cite
Zhu, D.; Bai, J.; Yang, S.X. A Multi-Fault Diagnosis Method for Sensor Systems Based on Principle Component Analysis. Sensors 2010, 10, 241-253. https://doi.org/10.3390/s100100241
Zhu D, Bai J, Yang SX. A Multi-Fault Diagnosis Method for Sensor Systems Based on Principle Component Analysis. Sensors. 2010; 10(1):241-253. https://doi.org/10.3390/s100100241
Chicago/Turabian StyleZhu, Daqi, Jie Bai, and Simon X. Yang. 2010. "A Multi-Fault Diagnosis Method for Sensor Systems Based on Principle Component Analysis" Sensors 10, no. 1: 241-253. https://doi.org/10.3390/s100100241
APA StyleZhu, D., Bai, J., & Yang, S. X. (2010). A Multi-Fault Diagnosis Method for Sensor Systems Based on Principle Component Analysis. Sensors, 10(1), 241-253. https://doi.org/10.3390/s100100241