A Sensor Network Data Compression Algorithm Based on Suboptimal Clustering and Virtual Landmark Routing Within Clusters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Suboptimal Clustering and Virtual Landmark Routing within Cluster
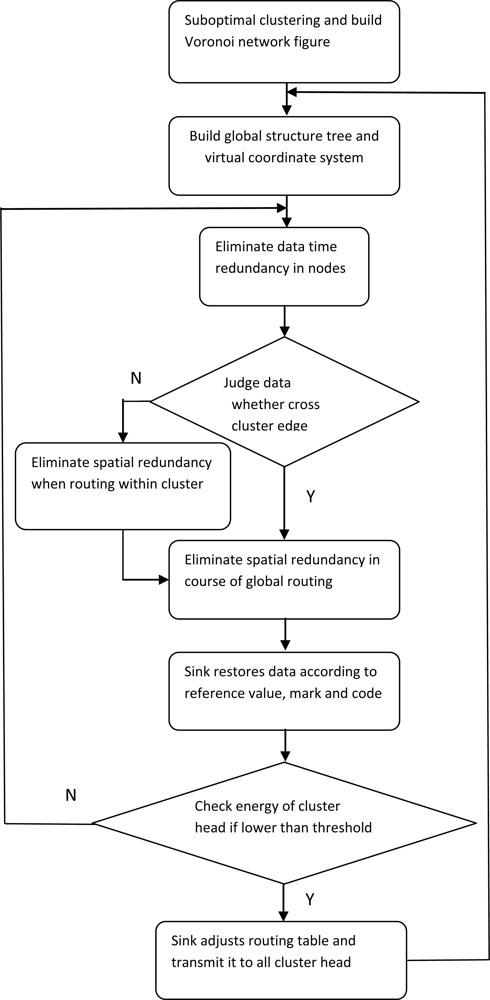
3. Algorithm Description and Flow Chart
- Sensor networks are divided into some clusters based on suboptimal clustering theory, and cluster heads are randomly appointed by the sink at first. A Voronoi network is established and then edge region nodes will be formed.
- A structure tree rooted from the sink and including all cluster heads will be established. Meanwhile, a virtual coordinate system is built within clusters on the condition that the cluster is appointed as reference node. Cluster head and nodes within the cluster are imparted a global mark and a local mark, respectively.
- Time redundancy will be eliminated through coding the difference between the present instant monitor value and values stored in some pre-instance (the amount of data stored depends on the actual application and the memory of the node). This way a group of raw monitoring values can be replaced by reference values and compression code.
- Routing in clusters can be realized through a greedy algorithm based on a virtual coordinate system. Spatial redundancy can be eliminated in a similar way by eliminating time redundancy in the course of routing within clusters. The difference is that the next hop node is set as reference node. The reference node local mark will be included and only time redundancy need be compressed around monitoring values obtained by the cluster head.
- If the cluster heads have gathered all compressed data within a cluster, then compressed data will be transmitted from the cluster head to a sink along the route in the global table. In the course of transmitting data, if data have reached edge region nodes, edge region routing discussed above will be executed, or non-edge region routing will be executed. Spatial redundancy existing in adjacent clusters will be eliminated when data cross the edge region. As a reference, clusters which are nearby the sink won’t execute the spatial redundancy compression. As a supplement in case that routing within cluster is trapped into a local loop, flooding routing will be executed.
- According to reference values, compression code and the global marks transmitted from cluster heads, nodes where spatial compression code is produced can be ascertained. The sink first decodes the spatial compression code according to the mapping relationship between code and difference, and then decodes the time compression code. In combination with reference values, raw data can be recovered in the sink.
- The sink will check the energy of cluster heads periodically. If the remaining energy is lower than a threshold, the node with most energy in the cluster will be elected to replace the raw cluster head, and the global routing table will be regulated by the sink and broadcast to all cluster heads, and then step (2) or step (3) will be executed.
- The sensor networks are divided into k*k (the value of k depends on the practical application) parts evenly based on a virtual grid. Every part will be divided into k*k parts recursively until the smallest virtual grid only includes one node. Since the deployment of nodes is random, the smallest virtual grid may include zero, one or more nodes. If more than one node is included in the same smallest virtual grid, average value will be regarded as the monitoring value of the smallest virtual grid. If there is no node included, an interpolated value from an adjacent grid will be regarded as the grid value.
- The smallest virtual grid is in the lowest layer, and cluster head will be elected among the k*k adjacent smallest virtual grids. Recursively, different cluster heads in different layers will be elected. The layer structure tree is established in the whole network.
- If the interval is set as T and the value obtained in the moment p needs to be transmitted to cluster heads in a higher layer, then values obtained at moments p + n*Ṭn = 1,2,3…) will need to be transmitted to cluster heads in higher layer. Values obtained between the moments p and p + T will be compared with the value obtained at moment p; if the difference is smaller than a threshold, values will be considered the same as historic values in the higher layer and there is no need to transmit data to the higher layer, or if different they will be transmitted to the higher layer.
- Since the memory of nodes is limited, historic values are stored by reverse-exponential means, namely, values obtained at moments t-1, t-2, t-4, t-8 and t-16 will be stored if the present moment is t. That is to say, the nearer values obtained are from the present moment, the higher the possibility the value will be stored in nodes.
- To eliminate spatial redundancy, starting from the lowest layer, k*k adjacent virtual grids will be mapped into a k*k matrix, which will be processed with a discrete cosine transform.
- According to a preset compression ratio r, there are r*k*k values in the transformed matrix that will be sent to a higher layer and others will be replaced by zeros. The discrete cosine transform will be executed from the lowest layer to the highest layer recursively. When all compression values are obtained, the sink can recover all raw data through an inverse discrete cosine transform.
4. Simulation Results and Analysis
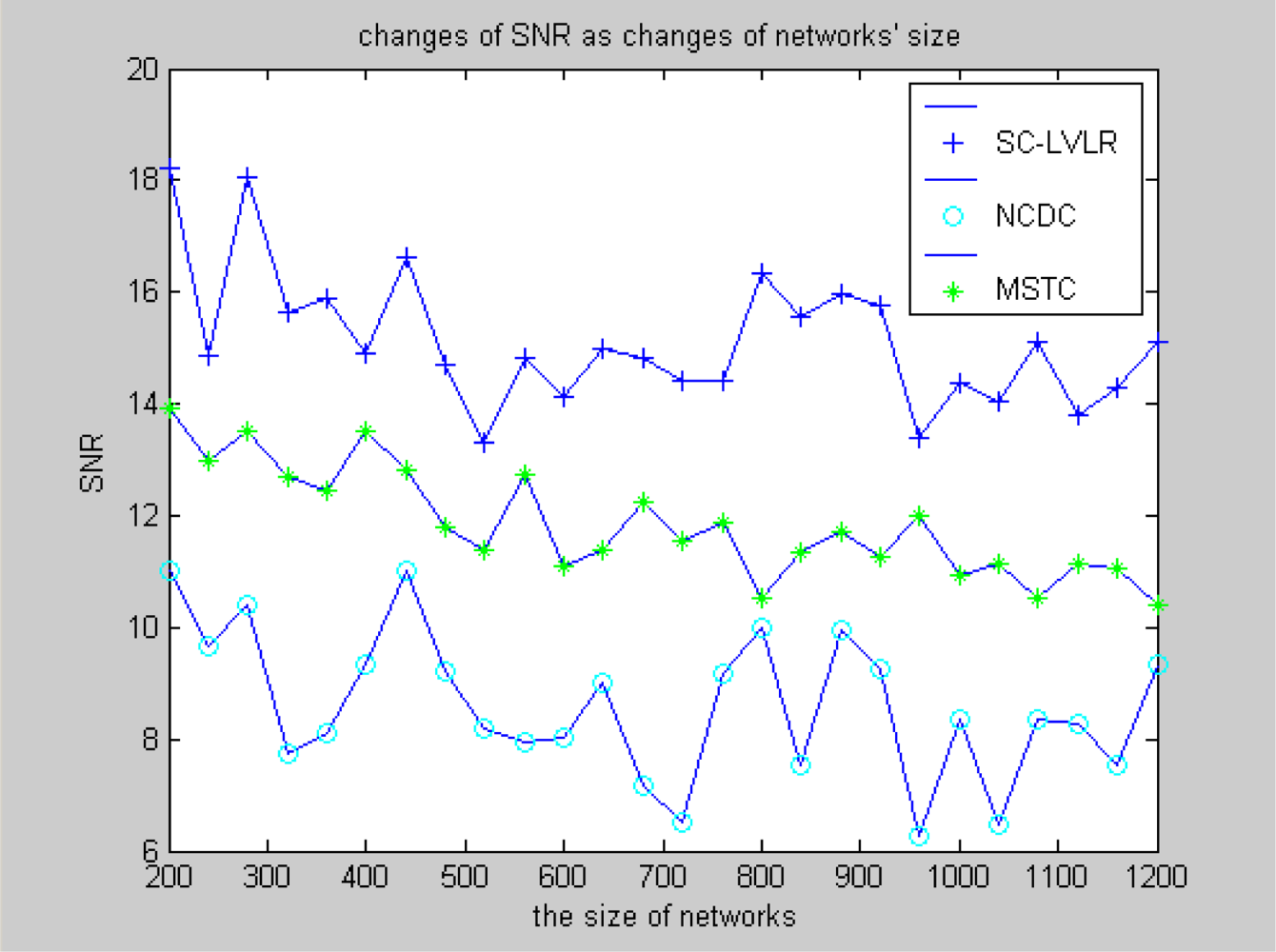
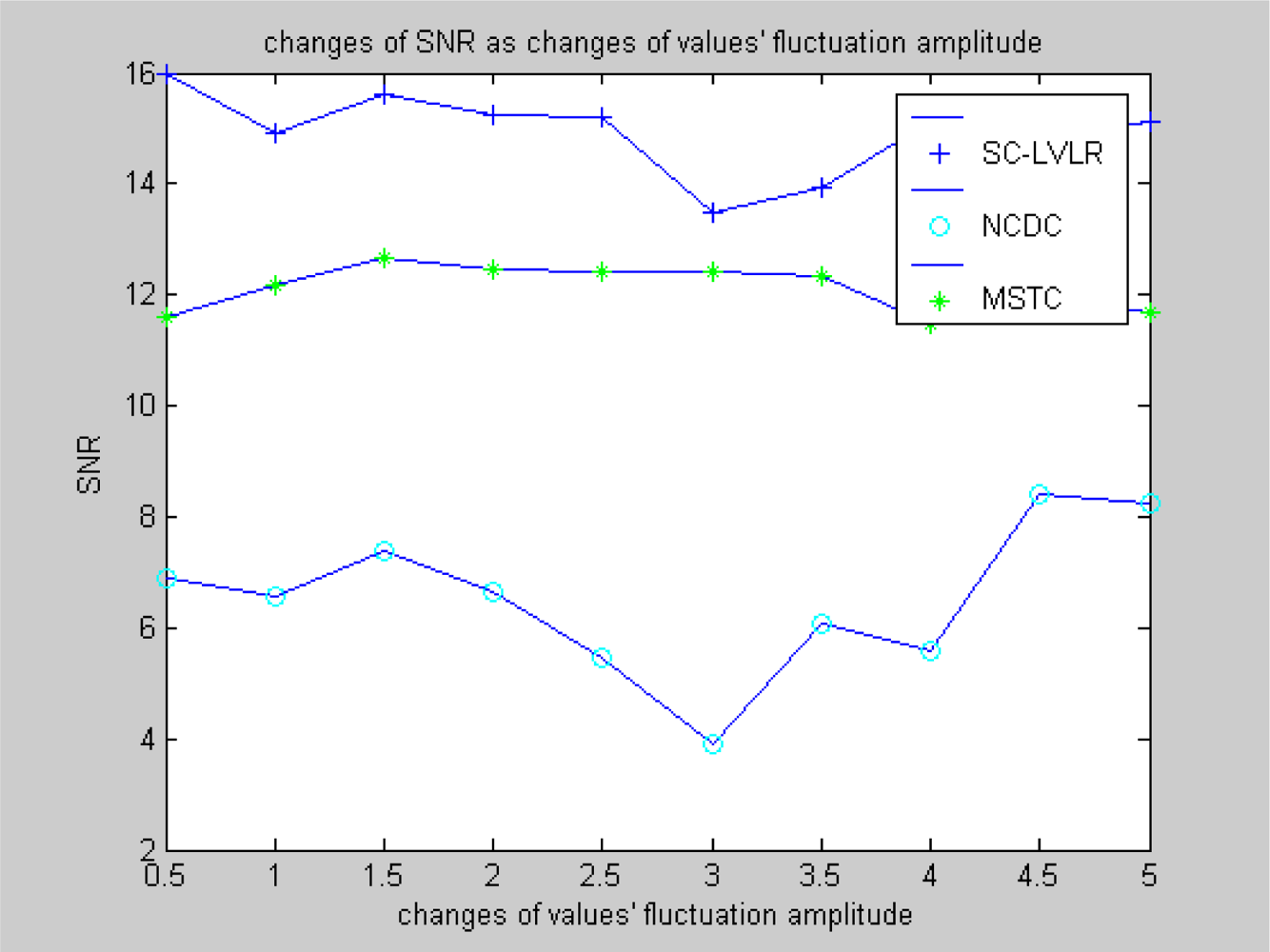
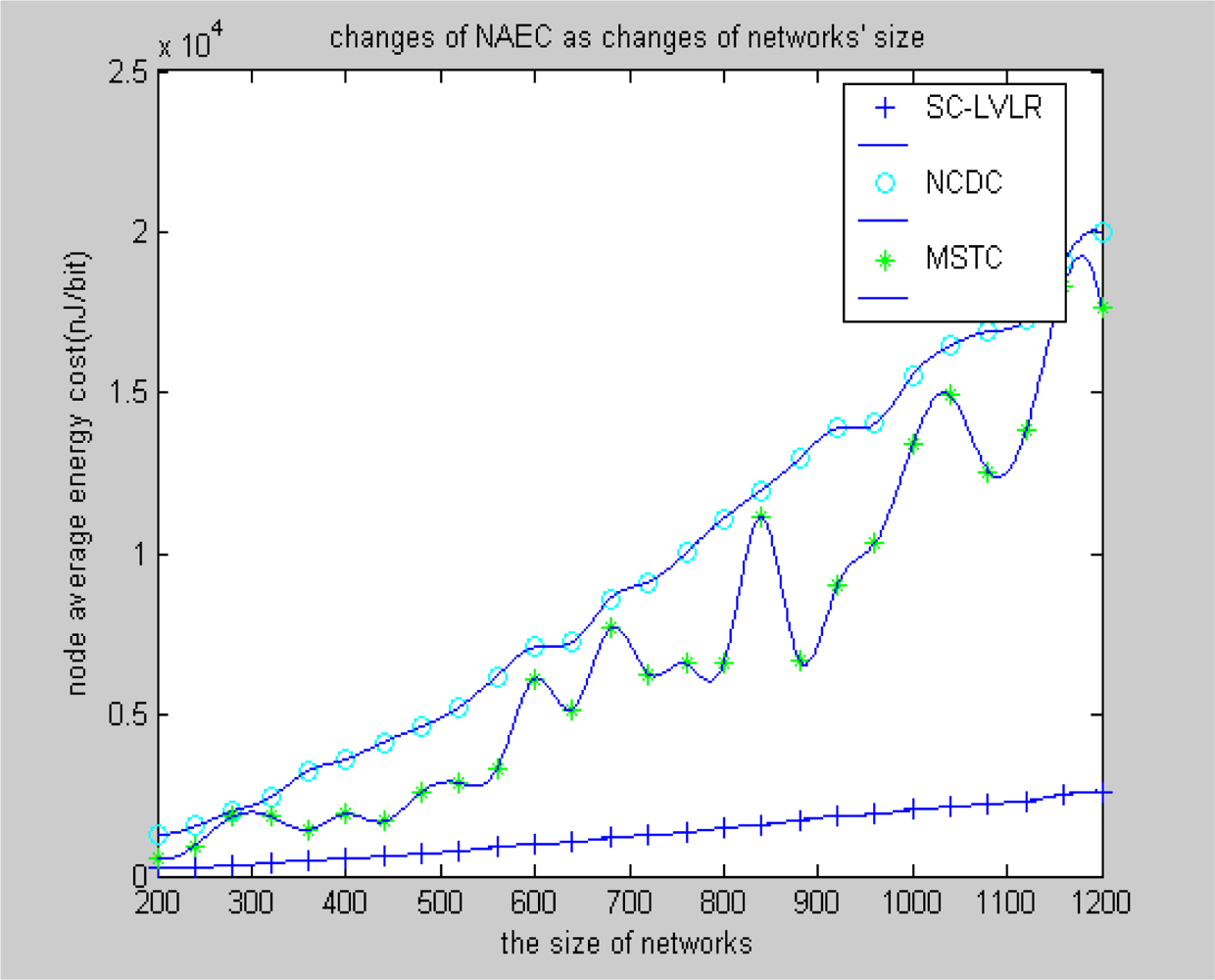
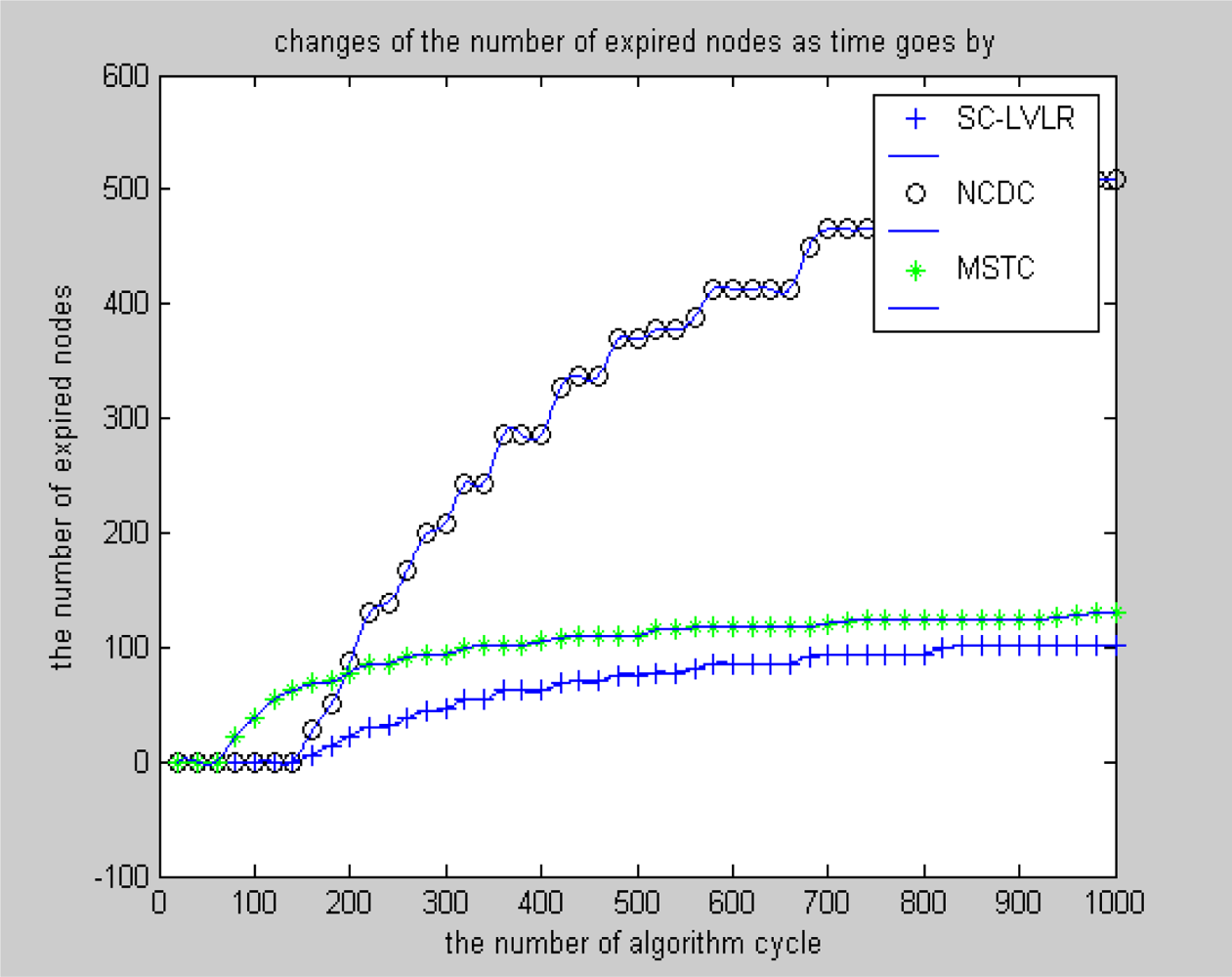
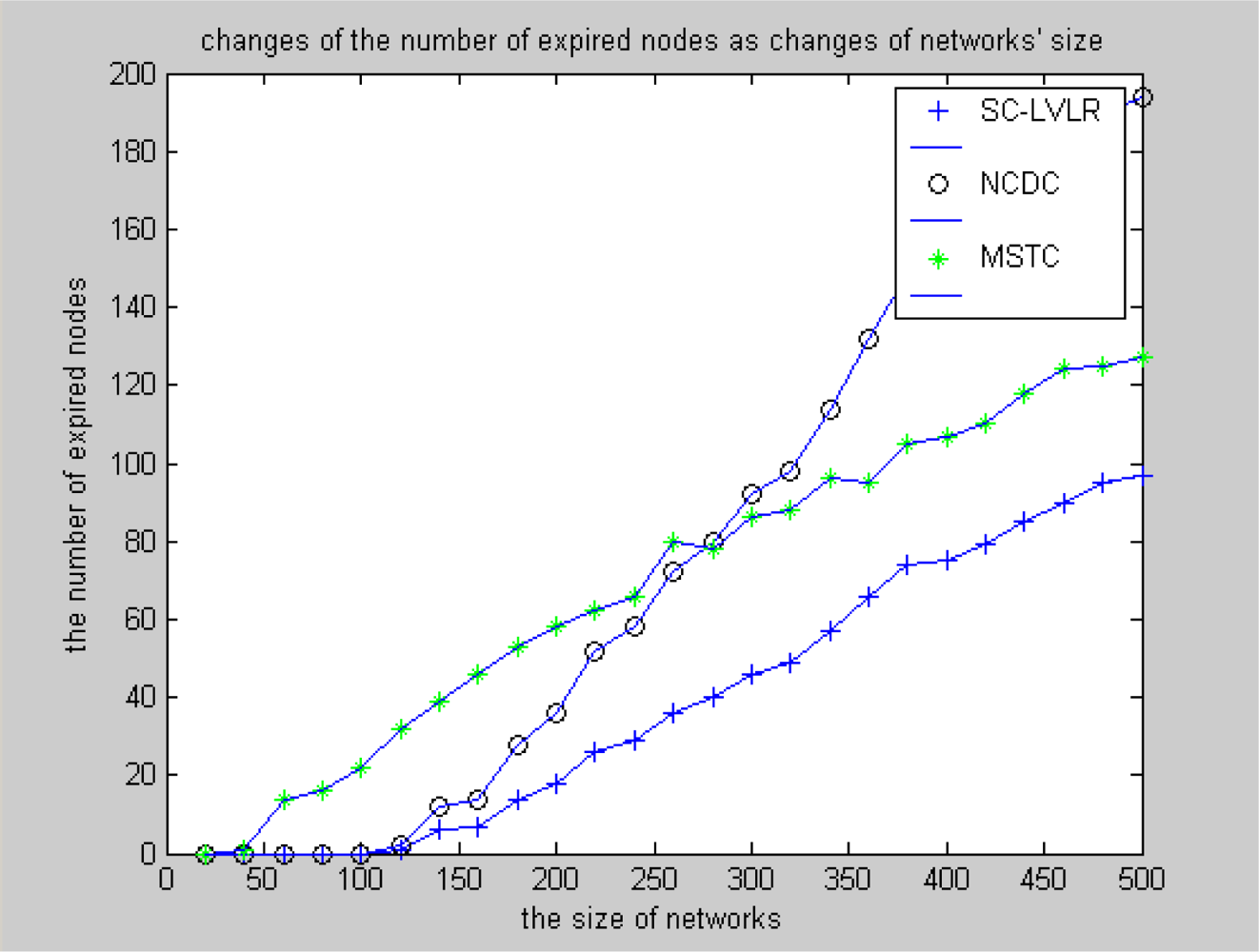
- Suboptimal clustering can gather a suitable amount of nodes which have spatial correlativity as a cluster, which is beneficial for eliminating spatial data redundancy, balancing the energy cost of networks and extending the longevity of the whole network. MSTC forms clusters evenly based on a virtual grid, which leads to some clusters including more nodes and the cluster heads expiring frequently and even some local holes may appear quickly.
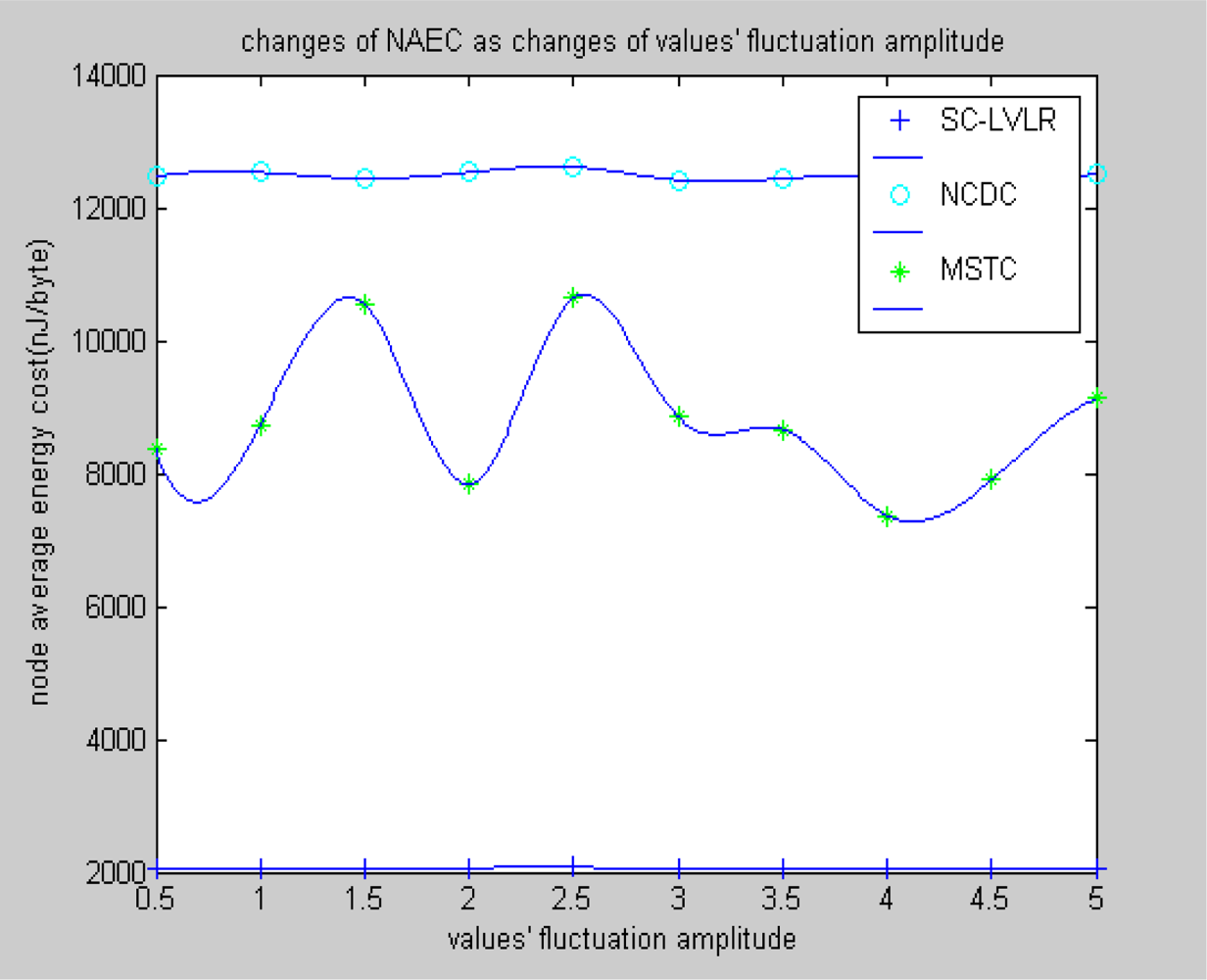
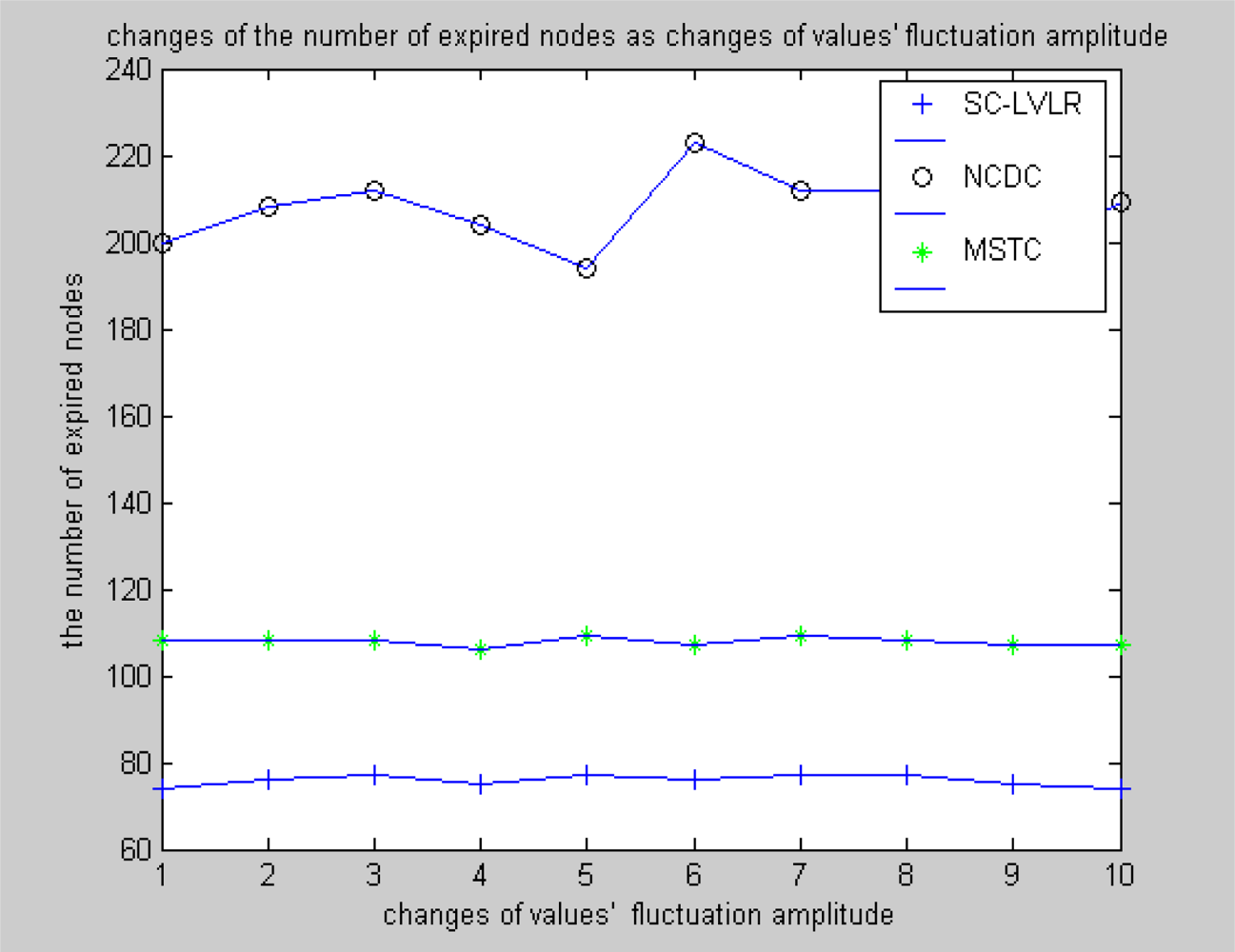
- The same compression dictionary is used to code the difference, both in eliminating spatial redundancy and time redundancy. The accuracy of recovered data can be regulated by changing the size of the coding dictionary. However, MSTC eliminates time redundancy by comparing differences with a threshold. If the threshold is too large, the accuracy of recovered data will be obviously affected, or time redundancy can’t be eliminated effectively.
- Data spatial redundancy in the course of routing is eliminated based on a local virtual coordinate system, which is not only beneficial for reducing network congestion and improving the real-time ability of networks, but also beneficial for reducing the average energy cost of nodes, so the compressive performance of the whole network will obviously be improved. In MSTC, data from different adjacent nodes are mapped into a matrix, which is executed by discrete cosine transformation. For eliminating data spatial redundancy, a compression ratio is set and the transform coefficients are reduced correspondingly. However, when reducing transform coefficients directly according to a fixed compression ratio, this is not able to reflect any dynamic changes of the monitored data. If the ratio is too high, the accuracy of the recovered data will be greatly reduced, or the data spatial redundancy can’t be eliminated efficiently.
4.1. Algorithm performance evaluation model
4.2. Simulation experiment
5. Conclusions
Acknowledgments
References and Notes
- Potdar, V; Sharif, A; Chang, E. Wireless sensor networks: A Survey. Proceedings of the 2009 International Conference on Advanced Information Networking and Applications Workshops, Bradford, UK, 26–29 May 2009; pp. 636–641.
- Jia, L; Noubir, G; Rajaraman, R; Ravi, S. GIST: Group independent spanning tree for data aggregation in dense sensor networks. Proceedings of Distributed Computing in Sensor Systems—Second IEEE International Conference, San Francisco, CA, USA, 18–20 June 2006; pp. 282–304.
- Deligiannakis, A; Kotidis, Y; Vassalos, V; Stoumpos, V; Delis, A. Another outlier bites the dust: Computing meaningful aggregates in sensor networks. Proceedings of the 2009 IEEE International Conference on Data Engineering, Washington, DC, USA, 29 March–2 April 2009; pp. 988–999.
- Lin, S; Kalogeraki, V; Gunopulos, D; Lonardi, S. Online information compression in sensor networks. Proceedings of the 2006 IEEE International Conference on Communications, Istanbul, Turkey, 11–15 July 2006; pp. 3371–3376.
- Chou, J; Petrovic, D; Ramachandran, K. A distributed and adaptive signal processing approach to exploiting correlation in sensor networks. Ad. Hoc. Netw 2004, 2, 387–403. [Google Scholar]
- Chedy, R; Marc, P. Mining multidimensional sequential patterns over data streams. Proceedings of Data Warehousing and Knowledge Discovery—10th International Conference, Turin, Italy, 2–5 September 2008; pp. 263–272.
- Zhou, S; Lin, Y; Zhang, J; Ouyang, J; Lu, X. A wavelet data compression algorithm using ring topology for wireless sensor networks. J. Software 2007, 18, 669–680. [Google Scholar]
- Sundeep, P; Bhaskar, K; Ramesh, G. The impact of spatial correlation on routing with compression in wireless sensor networks. ACM Trans. Sens. Netw 2008, 4, 28–35. [Google Scholar]
- Wang, Y-C; Hsieh, Y-Y; Tseng, Y-C. Multiresolution spatial and temporal coding in a wireless sensor network for long-term monitoring applications. IEEE Trans. Comput 2009, 6, 827–838. [Google Scholar]
- Pattem, S; Krishnamachari, B; Govindan, R. The impact of spatial correlation on routing with compression in wireless sensor networks. Proceedings of the Third International Symposium on Information Processing in Sensor Networks, Berkeley, CA, USA, 26–27 April 2004; pp. 28–35.
- Fang, Q; Gao, J; Guibas, LJ; de Silva, V; Zhang, L. GLIDER: Gradient landmark-based distributed routing for sensor networks. Proceedings of the 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, March 2005; pp. 339–350.
- Wang, A; Chandraksan, A. Energy-efficient dsps for wireless sensor networks. IEEE Sig. Process. Mag 2002, 7, 68–78. [Google Scholar]









© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Jiang, P.; Li, S. A Sensor Network Data Compression Algorithm Based on Suboptimal Clustering and Virtual Landmark Routing Within Clusters. Sensors 2010, 10, 9084-9101. https://doi.org/10.3390/s101009084
Jiang P, Li S. A Sensor Network Data Compression Algorithm Based on Suboptimal Clustering and Virtual Landmark Routing Within Clusters. Sensors. 2010; 10(10):9084-9101. https://doi.org/10.3390/s101009084
Chicago/Turabian StyleJiang, Peng, and Shengqiang Li. 2010. "A Sensor Network Data Compression Algorithm Based on Suboptimal Clustering and Virtual Landmark Routing Within Clusters" Sensors 10, no. 10: 9084-9101. https://doi.org/10.3390/s101009084
APA StyleJiang, P., & Li, S. (2010). A Sensor Network Data Compression Algorithm Based on Suboptimal Clustering and Virtual Landmark Routing Within Clusters. Sensors, 10(10), 9084-9101. https://doi.org/10.3390/s101009084