1. Introduction
One of the most needed and challenging components in an ad-hoc wireless network is the development of practical localization algorithms for the automatic discovery of sensor position. Due to the low power, lower cost, and simple configuration requirements of wireless sensor networks, GPS devices and the installation of a base station may be precluded. Hence, robust and distributed internal algorithms are required for sensor positioning problems.
It has been shown that cluster architecture guarantees basic performance achievement in ad-hoc networks, since this effective topology control technique conserves limited energy resources, improves energy efficiency, and further provides scalability and robustness for the network. Accordingly, we propose a distributed localization algorithm for cluster-based wireless sensor networks. This paper assumes that a number of sensors are scattered about the landscape. Initially, all of the sensor positions are unknown and must deduce their positions based on the limited information they receive. The basic strategy is to allow groups of nearby sensors to deduce their positions relative to each other in the cluster formation. These clusters are defined by their shared “local” coordinate systems. To this end, the Cooperative Hierarchical Positioning Algorithm (CHPA) performs location estimation in four phases: (I) Initial Local Position Estimation; (II) Position Refinement, (III) Relative Global Coordinate System, and (IV) Cooperative Estimation Fusion.
In Phase I, at the local level, sensors exploit the “particle filter” methodology [
1,
2] to carry out the needed calculations. Besides the advantages of a Bayesian approach, the particles allow a robust method of location identification, which can be tailored to communicate (virtually) any amount of information between sensors. By quantifying the inherent trade-offs (cost of communication vs. improvement with increased communication), it is likely to lead to an adaptable strategy applicable in a variety of situations.
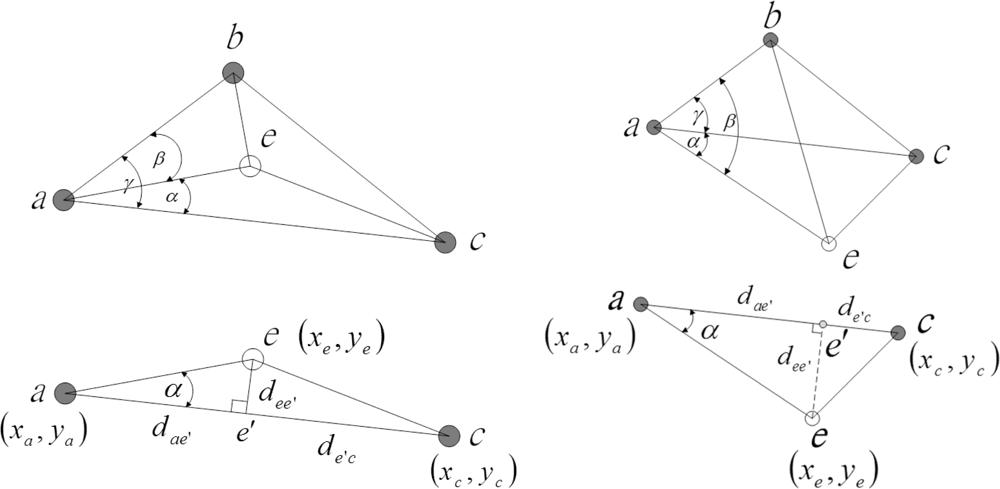
In Phase II, once a sensor has obtained the initial position estimate, due to the errors occurring in the distance estimation, the sensor needs to implement a refinement mechanism to determine its position. Assume that the mth sensor is located at position
, and the sensor’s best estimate of its current position at time k is
. The goal of the positioning refinement is to reduce the difference between the estimated locations and the real locations. This paper describes a distributed refinement scheme, which applies the Markov chain Monte Carlo (MCMC) method on each estimated sensor right after the location estimation such that estimation error and propagation error can be reduced in a distributed way.
In Phase III, a communication protocol allows nearby clusters (these which share “border sensors”) to merge into larger clusters until eventually the complete network is referred to the same coordinate system. The calculations are done in a decentralized manner since the cost of communication (in terms of power consumption) is high.
In Phase IV, based on the refined position estimates and the relative coordinate system, when the measurement does not meet the required estimation accuracy, the target sensor may broadcast a fusion message to its neighbors, group nearby two sensors into a measurement system, and trigger the cooperative sensor fusion to resolve conflicts or disagreements, and to complement the observations of the environment. This work introduces the centralized scheme, the progressive scheme, and the distributed scheme for cooperative position estimation. A centralized estimation approach is a process structure that all the neighboring sensors transmit their observations directly to the estimated sensor (the central unit) where the estimation is performed. The progressive estimation method is a processing structure in which the estimation groups sequentially update the estimation result based on each group’s local observation and partial decision from its previous groups in the sequence without sending data from all sensors to a central processing unit. For the distributed scheme, the target sensor fuses its local estimate and the estimates received from the neighborhood.
One of the unique features of our algorithm is the “sharing” of distributional data by the various sensors. This has the obvious intuitive effect of helping to make all the estimates consistent. But it may also have the effect of spreading misinformation if (for instance) a sensor malfunctions. It should be possible to include reliability measures that would effectively discard “bad” information. Hence we explore adding this feature into the basic algorithm to provide extra tolerance to sensor faults, which can be viewed as an attempt to reduce or remove error propagation.
The organization of this paper is as follows: Section 2 reviews the current literature on the sensor localization approaches. Section 3 formulates the position estimation problem and derives a hierarchical solution that relies on a cooperative self-localization protocol [
3]. Then, Section 4 investigates the impact of the measurement errors and the uncertainty associated with the system model on estimation accuracy. Section 5 summarizes the performance of the proposed localization methodology. Finally, Section 6 draws conclusions and shows future research directions.
2. Related Work
Recent approaches to location discovery often require the availability of GPS on some reference sensors [
4,
5], or assume some sensors with prior position information [
6,
7]. In [
8], the authors describe a centralized method using connectivity constraints and convex optimization when some number of beacon nodes are initialized with known positions. For a wireless ad-hoc network, these assumptions may not be reasonable because the information may not be available or because of the communication requirements. In [
9,
10], distributed systems for GPS-free positioning in ad-hoc networks are proposed to establish a relative global coordinate system. However, the computational burden of these procedures is heavy and their communications overhead is large.
[
11] presents a case study of applying particle filters to location estimation for ubiquitous computing. The performance results shows that it is practical to run particle filters on devices ranging from high-end servers to handholds. [
12] provides a theoretical foundation for the problem of network localization in which some nodes know their locations and other nodes determine their locations by measuring the distances to their neighbors. Grounded graphs and graph rigidity theory are applied to construct network localization. In [
13], the Cramer-Rao lower bound (CRLB) is derived for network localization. The authors argue that besides considering measurement errors, algorithmic errors should be explored in assessing localization accuracy. In [
14,
15], acoustic sensor networks for a relative localization system are analyzed by reporting the accuracy achieved in the position estimation. The proposed systems are designed for those applications where objects are not restricted to a particular environment and thus one cannot depend on any external infrastructure to compute their positions. The proposed mechanisms efficiently handle multiple acoustic sources by removing false-positive errors that arise from the different propagation ranges of radio and sound.
In [
9,
16,
17], clusters consisting of clusterheads and their cluster members are first localized in order to build local coordinate systems. Registration is then used to compute the transformations between neighboring coordinate systems such that the related global coordinate system can be established. The authors in [
18] propose a cluster-based localization approach to provide efficient and scalable localization in a large and high-density network. [
19] proposes to use cluster-based network topology for determining the position information of the sensor nodes. [
20] describes a distributed algorithm for localizing a cluster-based sensor network in the presence of range measurement noise and avoiding flip ambiguities. However, neither algorithm provides theoretical analysis for the problem of network localization.
In [
21], multidimensional scaling (MDS) is applied to perform distributed optimization for network localization. Priyantha
et al. [
22] use communication hops to estimate the network’s global layout without location information of known reference nodes. [
23] uses multilateration to organize a global coordinate system from local information. Patwari
et al. [
24] use one-hop multilateration from reference nodes using both received signal strength (RSS) and time of arrival (ToA). In [
25], with considering a motion model in the optimization, a maximum likelihood estimator is proposed to localize a small team of robots effectively.
In order to improve position estimates, several refinement schemes are proposed in the literature [
7,
26–
30] by using known sensor locations and distance measurements to neighboring sensors. [
7] presents an approach called AHLoS (Ad-Hoc Localization System) that enables sensor nodes to discover their locations using a set distributed iterative algorithms. [
26] presents the collaborative multilateration to enable ad-hoc deployed sensor nodes to accurately estimate their locations by using known beacon locations that are several hops away and distance measurements to neighboring nodes. To prevent error accumulation in the network, node locations are computed by setting up and solving a global non-linear optimization problem. [
28] proposes a heuristic refinement approach to improve position estimates. [
29] proposes an iterative quality-based localization (IQL) algorithm for location discovery. The IQL algorithm first determines an initial position estimate, after which the Weighted Least-Squares (WLS) algorithm is used iteratively to refine the position. In the WLS algorithm the Gaussian distribution is used to determine the reliability of measurements. [
30] attempts to find locations for the sensors which best fit the set of all range measurements made in the network in a least-mean-squares sense. [
27] demonstrates the utility of nonparametric belief propagation (NBP) for self-localization in sensor networks. However, the computational complexity and communication costs inherent in a distributed implementation of NBP are high. Comprehensive surveys of design challenges and positioning algorithms for wireless networks can be found in [
31–
36].
In this paper, we consider the possibility of flip ambiguity (detailed in Section 3.3.) and provide relative global localizations with measurement noise. One of the main characteristics of the proposed approach is that each sensor carries along a complete distribution of estimates of its position. It helps to solve the local minimum issues that often plague such nonlinear estimation problems by allowing the data to drive the collapse of the distribution—thus, as the data increases to the point where the position is more sure, then the distribution collapses to a point. Moreover, the distribution is inherently a measure of the accuracy of the estimation; hence if a given task requires a certain accuracy, it is possible to determine if that level of accuracy is currently available. Most importantly, the network localization is complete without absolute position information of reference nodes, which may be useful for commercial and scientific applications of wireless ad-hoc sensor networks.
Though much research has studied cooperative localization with the emphasis on algorithms [
9,
16,
32,
37] very few works focus on the fundamental performance limits and GPS-free positioning in the presence of range measurement inaccuracy. This paper outlines the technical foundations of the localization techniques and presents the tradeoffs in algorithm design. A scalable distributed algorithm for sensor localization problem is proposed and an estimation-theoretic analysis of the proposed measurement mechanism is presented to assess the achievable estimation accuracy and to explore the fundamental performance of the algorithm. Specifically, a statistical model is derived to describe the localization performance considering unreliable measurements, which may provide a valuable way to show the limits of performance.
3. Cooperative Hierarchical Positioning Algorithm (CHPA)
This section describes a distributed algorithm that forms a relative global coordinate system efficiently. The localization operation is performed in four phases: “initial local position estimation”, “position refinement”, “relative global coordinate system”, and “cooperative estimation fusion.” The main assumptions on the network are that (a) the sensors are in fixed but unknown locations, (b) all links between sensors are bidirectional, and (c) all sensors have the same transmitting range. Observe that there is no base station or centralized control to coordinate or supervise activities among sensors.
3.1. Phase I: Initial Local Position Estimation
When sensors of a network are first deployed, they may apply the Clustering Algorithm via Waiting Timer (CAWT) from [
38] to partition the sensors into clusters using the waiting timer
where
is the waiting time of sensor
i at time step 0 <
γ < 1 is inversely proportional to the number of neighbors. If the random waiting timer expires and none of the neighboring sensors are in a cluster, then sensor
i declares itself a clusterhead. It then broadcasts a message notifying its neighbors that they are assigned to join the new cluster with ID
i. After applying the CAWT, there are three different kinds of sensors: (1) the clusterheads (2) sensors with an assigned cluster ID (3) sensors without an assigned cluster ID, which will join any nearby cluster later and become 2-hop sensors. Thus, the topology of the ad-hoc network is now represented by a hierarchical collection of clusters.
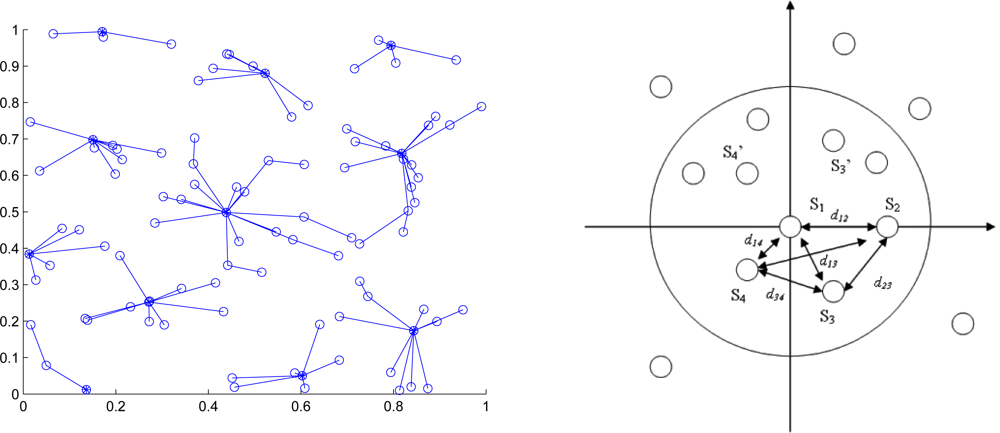
Figure 1 (left) shows an example of the cluster formation in a random network of 100 sensors with
R/ℓ = 0.175, where
R is the transmission range and ℓ is the side length of the square.
When the estimation procedure starts in a cluster-based network topology, a clusterhead called sensor 1 locates itself at the origin(0, 0) and selects the left-hand or the right-hand coordinate system as the local coordinate assignment. Then sensor 1 detects its neighbors and deploys one of the neighboring sensors, sensor 2, to the
x-axis at (
d12, 0) based on the distance information
d12. A third sensor is selected to be sensor 3 which has connectivity to both sensors 1 and sensor 2. Given the known positions of sensors 1 and 2 and distance information,
d13 and
d23, sensor 3 can estimate its own location to the responding coordinate system. Therefore, sensors 1, 2 and 3 considered as a group form a basis for this local coordinate system. The solvability of the network localization problem is detailed in [
39], which suggests that if the three known sensors are no-three-in-line, the network localization problem is solvable and the unknown position can be determined in the two-dimensional space. Accordingly, all other sensors which are within communication range of these sensors can then estimate their positions with respect to this local coordinate system. Similarly, as the cluster of known sensors grows, the location of each of the unknown sensors can be determined from three neighboring known sensors. Thus, the sensor locations can be obtained by building a local coordinate system from the clusterhead and applying multilateration to enable ad-hoc deployed sensor nodes to accurately estimate their locations by using known sensor locations and neighboring distance measurements.
Figure 1 (right) shows the estimation procedures of ad-hoc wireless sensor networks in the two-dimensional space with sufficient connectivity.
Suppose that a sensor does not know its position but is able to receive information from other sensors which are assumed to have relative local position estimates. There are many ways to “solve” this sensor location problem. This section details the Bayesian particle filter method which may be preferred because it is robust to noisy measurements, it allows for flexible information transmission, and it can be robust to lost or lossy data.
Assume the
mth sensor obtains a new measurement from (at least) three sensors and estimates its own position using the particle filter. The sensor position is given by the discrete-time state equation
where
is the position of the sensor and
wk is an uncorrelated Gaussian diffusion term describing the uncertainty. Note that this system equation is suitable for many different systems and the only changes will be the matrixes Φ and Γ, which depend on the system model. For instance, the differences of the methodology between a moving sensor and a fixed sensor are the choices of Φ and Γ, and the rest of the methodology is the same. Hence, the same basic procedure can be used in other tasks such as target tracking. Here we assume the sensors do not move between observations, Φ is the two-dimensional identity matrix, and Γ is a zero matrix. The measurement term for the
mth sensor is
where the sum is over the nearby sensors
,
Im is the index set of estimated known sensors, ||·|| denotes the ℓ
1-norm ranging measurement,
dmℓ represents the measured distance between the sensors and may be approximated in application by the inverse of the signal strength or by calculated from the time delay between transmission and reception [
40], and the measurement noise
vk is another uncorrelated zero mean Gaussian white noise process.
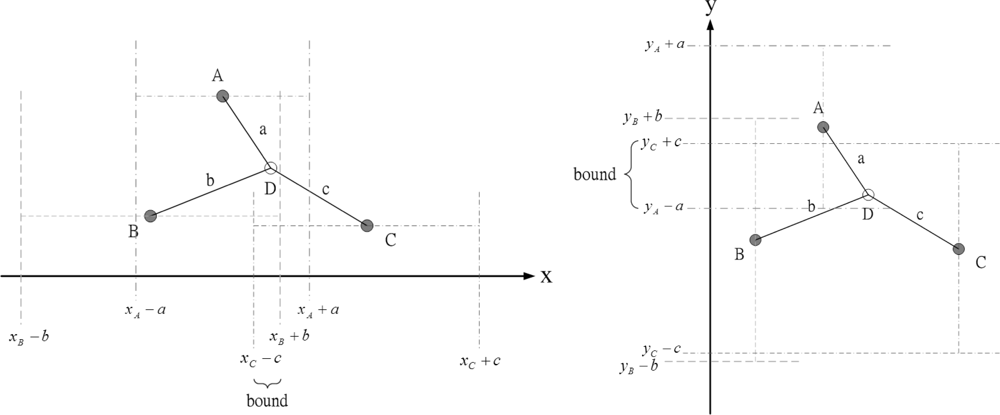
Before measurements are taken at
k = 1, the initial state vector is obtained by applying the distance measurements as constraints on the
x and
y coordinates of the unknown sensor. The idea in [
7], using known sensor positions and the bounding-box algorithm to extrapolate unknown sensor positions, inspires us to choose a proper prior density for generating initial samples.
Figure 2 shows how the distance information can be use to obtain the
x and
y coordinate bounds of the unknown sensor. Therefore, the unknown sensor combines its bounds on the coordinates to form a bounding box, which provides a good set of initial samples for the particle filtering. The particle filter method is shown in
Table 1.
3.2. Phase II: Position Refinement
Due to the error caused by the location estimation algorithm (the estimation error) and the error intrinsic to the problem (noisy distance measurements), location adjustment algorithms are needed in order to improve the estimation accuracy and limit the propagation errors. After the sensor is located near to its true position, a refinement technique is applied to elevate the estimates immediately. This subsection details the operation of a distributed model for refining the location estimates based on the initial position information from Phase I.
Because the particle filter loses diversity in the samples for static models, the Metropolis-Hastings (M-H) algorithm [
41] may be used to generate new samples and provide improved estimation accuracy. The basic idea of the M-H algorithm is to simulate an ergodic Markov chain whose samples are asymptotically distributed according to the target probability distribution π(·) and use a candidate proposal distribution
q(
xk(
i)
, ·) to select the candidate of the current state independently with the acceptance probability
Therefore, instead of using a centralized accumulator host to adjust sensor locations, applying the Markov chain Monte Carlo (MCMC) method on each estimated sensor right after the location estimation allows estimation error and propagation error to be reduced in a distributed way. Here we summarize the M-H algorithm with the initial value
x0(
i) in
Table 2. The performance evaluation and the discussion of the proposed location adjustment algorithms are depicted in Section 5.
3.3. Phase III: Relative Global Localization
This section shows how the geometrical and communication requirements change when merging two coordinate systems to a single one. At some point, as the position estimation proceeds, the coverage of two coordinate systems begin to overlap, at which time they may be merged together into a single coordinate system. Eventually, all sensors have been gathered into one coordinate system and the sensor location problem is solved. If there is GPS (or other absolute measures) available, then this coordinate system can be referenced to standard measurements. If there are no GPS available, then the coordinate system is relative.
3.3.2. Relative Global Coordinate System
Now we consider two neighboring clusters generated from clusterheads
A and
B. Denote the sensor which can communicate with more than one cluster as a border sensor. If there are two border sensors between cluster
A and
B, and if those two sensors can communicate with each other, the two clusters can be merged. This kind of network topology may be formed by applying the topology management algorithm proposed in [
42].
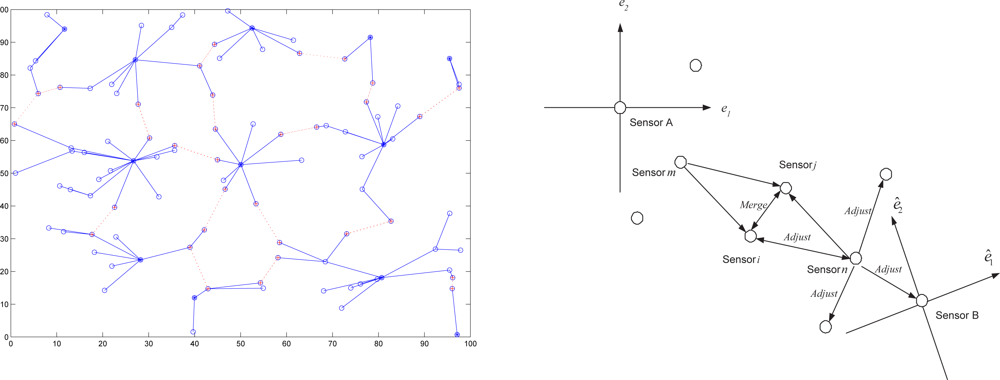
Figure 3 (left) shows an example of the cluster formation with distributed border sensors.
The process of merging the two clusters consists of a calculation of the adjustment information and a communication protocol whereby the results of that calculation can be transmitted throughout the cluster.
Figure 3 (right) illustrates the process of merging clusters by applying the communication protocol and the adjustment information in a two-dimensional space. This process of finding these adjustment quantities,
and
Rmerge, is called coordinate system registration [
43,
44]. The aim of coordinate registration is to transform a point
p in the right-hand or left-hand coordinate system to the corresponding point
p′ in the right-hand one applying the adjustment information:
.
Suppose cluster A and cluster B are adjacent and sensors i and j are two border sensors. Given that cluster A is in the reference right-hand coordinate system, here two cases are considered: (1) Cluster B is in the right-hand coordinate system; (2) Cluster B is in the left-hand coordinate system.
For case 1, based on the preliminary information, the border sensors have
Thus, the rotation angle
is
Then the orthogonal matrix
is obtained to encapsulate the rotation operation. With the adjustment information, the transformed positions of sensors
i and
j yield
Accordingly, the transformation errors are given by
For case 2, the positions of sensors
i and
j in the coordinate system of cluster B need to be mirrored around one of their axes. That is,
Thus, the rotation angle
is described as in (7) with
and the reoriented positions are
As a result, the transformation errors are
Given the transformation errors (10), (11), (17), and (18), the border sensors may use a criterion with local preliminary information such as neighboring connectivity to determine the relationship between the coordinate systems of two clusters. Considering the observations under the two hypotheses
and
, the decision rule for the registration process becomes: 1 : z1 < z2; 2 : z1 > z2. Based on the decision rule, the border sensors are able to compute the transformation errors for each case and to find the desired adjustment information for reorienting the coordinate system.
Once those calculations have been performed, sensor
i follows the communication protocol and transmits an
Adjust message to the sensors in the reoriented cluster in order to update their coordinates so that two local coordinate systems convert to a single one. This operation is applied repeatedly until the global coordinate system is established.
Figure 4 depicts the process of coordinate registration and how the coordinate transformation is performed. To establish an absolute coordinate system, the process can proceed identically to the merging and adjusting of two clusters and follow the same communication strategy with a minimum of three GPS sensors. An example of merging two clusters is illustrated in Section 5.5.
3.4. Phase IV: Cooperative Estimation Fusion
Based on the refined position estimates in Phase II and the relative coordinate system in Phase III, when the measurement does not meet the required estimation accuracy (e.g., the measurement variance is larger than the accuracy threshold), the estimated sensor, say sensor
m, may broadcast a fusion message to its neighbors and trigger the cooperative sensor fusion to resolve conflicts or disagreements, and to complement the observations of the environment. The cooperative estimation system can be organized by sensor
m with collecting the neighboring observations or grouping nearby two sensors into a measurement system with group IDs based on the neighboring geometric information. This subsection introduces the centralized scheme, the progressive scheme, and the distributed scheme for cooperative position estimation (
Figure 5).
3.4.1. The Centralized Scheme
A centralized position estimation scheme is a process structure that all the neighboring sensors transmit their observations directly to the estimated sensor (the central unit) where the estimation is performed. By means of the given measurements and (3), the approximated probability density function characterizing the cooperative estimation is obtained with the approaches in Phases I and II. The drawback is that if some sensors are faulty or the observations are corrupted, the fusion among all the neighboring sensors may deteriorate the estimation accuracy.
3.4.2. The Progressive Scheme
The progressive position estimation scheme is a processing structure that the estimation groups sequentially update the estimation result based on each group’s local observation and partial decision from its previous groups in the sequence without sending data from all sensors to a central processing unit [
45,
46]. Hence, only partial estimation results are transmitted through the network. In this work, the progressive scheme (
Table 4) is developed based on the particle-based approaches in Phases I and II, which are used for tracking filtering and predictive distributions in the position estimation process. Each cooperative group propagates only the mean and variance of the posterior density to its next estimation group. Therefore, as shown in
Figure 5, group
j +1 may approximate the posterior density of group
j as a Gaussian with the received mean and variance and use this Gaussian approximation [
47] for the initialization of the particle filtering.
Note that this particle-based technique allows a robust method of location identification and leads to a flexible strategy for the sensing task since any amount of information can be adaptively communicated between sensors.
3.4.3. The Distributed Scheme
The distributed scheme is executed in two steps: (1) Group Estimation: The position estimation is conducted within each cooperative group. Each group member sends its observation to the central unit of the cooperative group (e.g., the sensor with a higher sensor ID) where the local decision is performed. (2) Estimation Fusion: a fusion rule is applied to combine the posterior density of the estimation from each cooperative group in the estimated sensor.
Here we introduce two Bayesian fusion schemes for a distributed localization system. During the fusion process, sensor
m fuses its local estimate and the estimates received from the neighborhood. One possible way to combine the probabilistic information obtaining from different Bayesian measurement systems is to fuse the estimates linearly [
48],
i.e.,
where
Nc is the number of the neighboring Bayesian measurement systems in the fusion process, which is
Nc =
Nm/2
; Nm is the number of neighboring sensors of sensor
m; ω
mℓ is a weight such that, 0 ≤ ω
mℓ ≤ 1 and
;
ϕm0 is the local estimate of sensor
m;
ϕmℓ is the estimate received from the neighborhood;
ϕ̂m is the fused estimate of sensor
m.
Referring to (19), the weight reflects the significance attached to the estimate, which can be used to model the reliability of an information. As a result, the next issue is to determine ω
mℓ for each estimate and try to weight out faulty estimates. There are many strategies to choose ω
mℓ. One scheme is to use the utility measure. Since the utility of a sensor measurement is a function of the geometric location of the sensors, here we consider the Mahalanobis measure [
49]. Hence, with respect to a neighboring system estimate characterized by the mean
μmℓ and covariance Σ, the utility function for sensor
m is defined as the geometric measure
where
μm0 is the local estimated position of sensor
m and ℓ = 1, 2, . . . ,
Nc. That is, the utility measure is based on the Mahalanobis measure of the local estimate to a neighboring system estimate. In order to arrive at a consensus, the utility measure
mℓ can be shown to be
mℓ ≤ 1 [
50].
Given the utility measure, two estimates can be allowed to be compared in a common framework and measure how much they differ
|μm0 – μmℓ|. For a larger
mℓ, the neighboring system estimate may be weighted smaller, which means the weight of the estimate may be described by the inverse proportion of the utility measure. Therefore, when a neighboring system estimate succeeds the utility measure, it may cooperate with the local estimate with
where
Us is the index set of the neighboring estimates that pass the utility test. Otherwise,ω
ml is set to be zero. However, when the local estimate and the group estimates are non-coherent (
i.e.,
ml > 1,∀ ℓ), another possible approach for sensor
m is to choose the estimate with more confidence (less variance), or to exclude its local estimate and fuse the group estimates using the Covariance Intersection (CI) method [
51]. The CI method takes a convex combination of mean and covariance estimates that are represented in information space. Since these estimates are independent, the general form is
where
,
n ≥ 2,
ai is the estimate of the mean from available information,
Paiai is the estimate of the variance from available information,
c is the new estimate of the mean, and
Pcc is the new estimate of the variance. The distributed estimation approach is summarized in
Table 5.
5. Experiments and Discussion
In order to assess the performance of the proposed methodology, the feasibility of the proposed schemes is examined via simulation and numerical results. In the following experiments, the particle filtering methodology is applied with the number of samples N = 500.
5.1. Initial Position Estimation
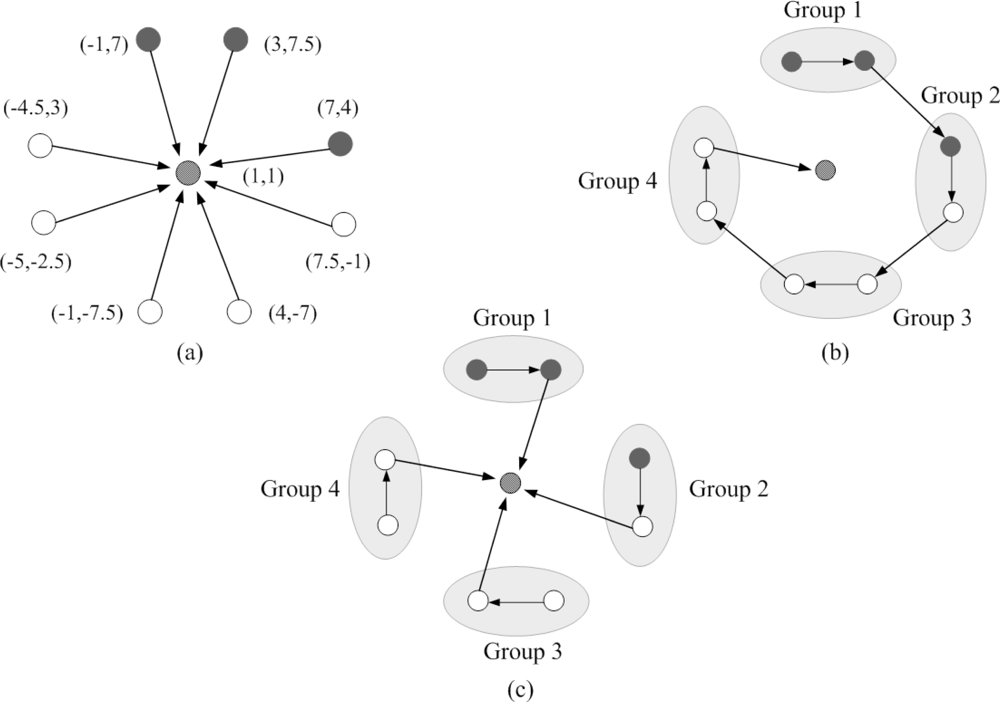
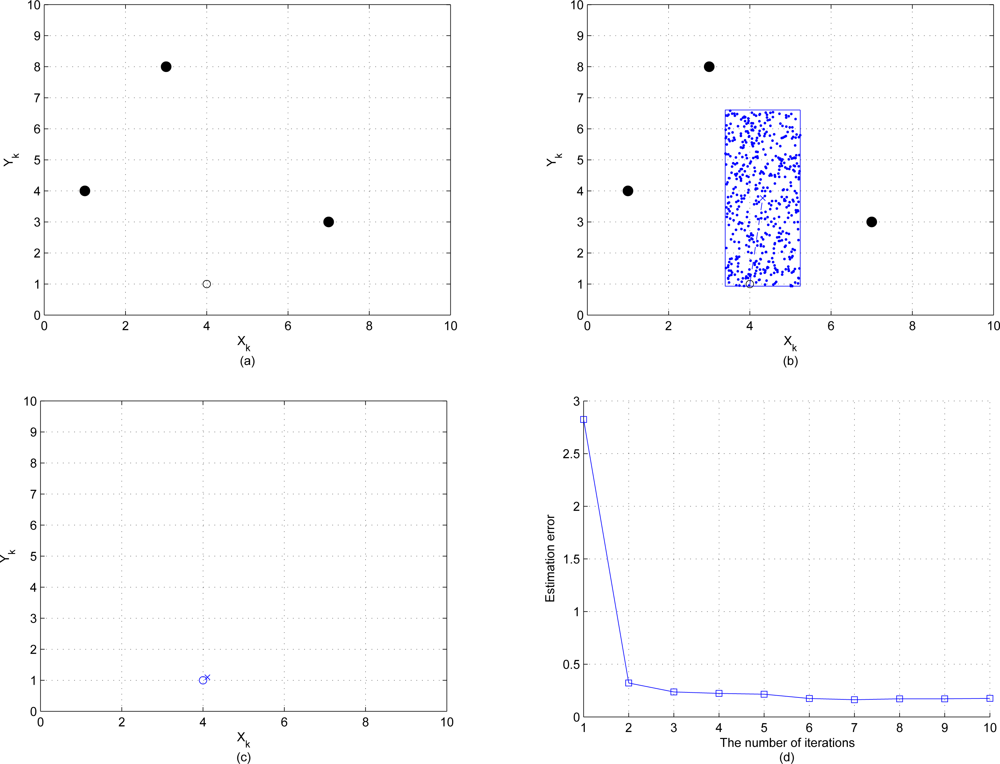
In this section we present the result of initial local position estimation by placing three reference nodes and one unknown node over the sensing field 10 × 10 units in size and assuming that this unknown node connects with all reference nodes. The positions of the three reference nodes are (7,3), (3,8), (1,4) and the true position of this unknown node is (4,1).
Figures 7 (a)–(c) show the procedures of initial position estimate by using particle filter method with the bounding box algorithm. “•” represents the reference node, “○” represents the unknown node, “·” represents the particle and “×” represents the initial estimated sensor location. The estimation error of the initial position estimate is shown in
Figure 7 (d), which depicts that the estimation error converges to 0.5 quickly after a few iterations.
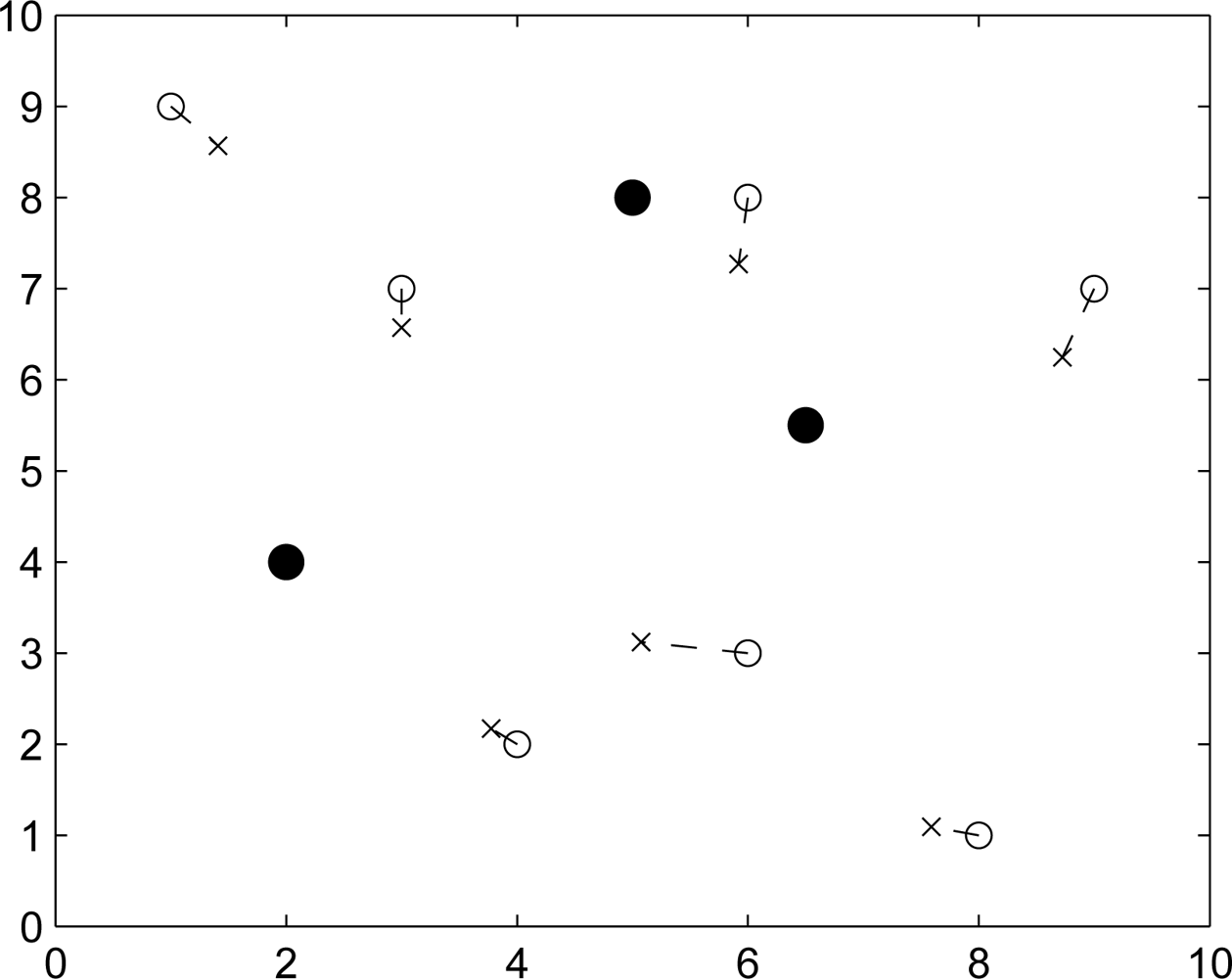
Figure 8 shows the resulting initial position estimation for a network of 25 nodes with 3 reference nodes, which suggests that the particle filter method with bounding box algorithm provides an acceptable performance of initial position estimation.
5.5. An Example of Merging Two Clusters
Figure 14 (left) shows the structure of two clusters generated from the initialized sensors
A and
B. There are two shared border sensors, sensor 1 and sensor 2, in the overlapping area.
Figure 14 (right) shows the position estimations of local coordinate systems. Note that applying the estimation procedures, these two clusters are generated from the initialized sensors
A and
B, which are located at the origin in their local coordinate systems.
Once the border sensors have the information of local coordinate systems from two clusters, they transmit
Merge signals. The effect will be to reorient the cluster centered on sensor
B. Therefore, sensor 1 uses its own information and the merge signal received from sensor 2 to calculate the adjustment information. Then sensor 1 transmits an
Adjust message to the sensors in the reoriented cluster to update their positions.
Figure 15 (left) depicts the movement of the reoriented cluster using the vector
and
Figure 15 (right) shows that the positions of the sensors in the reoriented cluster match the corresponding positions in the coordinate system of sensor
A using the rotation matrix
Rmerge.
5.6. Cooperative Estimation Fusion
In this set of experiments, two cases of the measurement deviation of the known positions are considered:
and
. The initial settings and group topology are illustrated in
Figure 5. Without loss of generality, suppose that the prior information for each cooperative scheme is the bounding box (detailed in Section 3.1.) of the estimated sensor using three neighboring sensors (e.g., the three black nodes shown in
Figure 5). For the centralized approach, the estimated sensor receives the distance and position information sent from each cooperative member and includes these information into measurement term (3). For the progressive approach, each cooperative group generates
N1 = 250 samples from the bounding box and
N2 = 250 samples from the Gaussian approximation from previous estimation group, which is described is
Table 4. For the distributed scheme, each cooperative group generates
N = 500 samples from the prior distribution (i.e., the bounding box) for particle filtering. Given the distance and position information of the neighboring known sensors, the best possible position measurement of the estimated sensor is obtained by combining 300 typical runs for each cooperative approach.
Observe that in the case of good distance observations and a moderate position deviation,
Figure 16 depicts that the estimated sensor may still obtain acceptable position estimate without cooperation. On the other hand, with poor distance observations, the cooperative techniques may be good approaches to improve the estimation accuracy.
The analysis of energy consumption (derived in Section 4.3.) shows that the total energy consumption of these estimation schemes are close when the data of all the sensors are applied. Given an accuracy threshold, the progressive process may terminate and return results without having all the sensors being visited such that computation time and network bandwidth can be reserved. Therefore, the strength of the progressive estimation scheme is the reduction of the amount of communication and the conservation of energy. However, compared with the centralized and distributed schemes, the progressive approach may produce a larger processing delay since it may spend more time on information processing when using the data from all the sensors. Among these three cooperative estimation methods, the distributed scheme may provide an efficient way to weight out the faulty sensors and corrupted observations to suppress the estimation error. This is because if some sensors are faulty or the observations are corrupted, the fusion among all the neighboring sensors (
i.e., the centralized scheme) may degrade the estimation performance as shown in
Figure 16.
5.7. Comparison
This subsection compares the localization algorithms from two perspectives: the algorithm perspective and the network topology perspective. Hence, the probabilistic approximation method (i.e., the particle filter) and the deterministic methods are investigated from the algorithm perspective. Moreover, the proposed hierarchical approach and other cluster-based approaches are discussed from the network topology perspective.
5.7.1. Algorithm Perspective
Several deterministic methods are proposed for sensor localization [
7,
9,
60,
61]. For instance, the Min-max method [
7], where the main idea is to construct a bounding box for each reference node using its position and distance measurement, and then to determine the intersection of these boxes. Notice that the above methods solve the localization problem with a single estimate; the point algorithm (SPA), where the location estimate is placed at the same position [
9]; the centroid algorithm, where the geometric centroid of the positions of the sensors that generates measurements presents the location estimate; the smooth weighted centroid algorithm, where the centroid position computation is weighted by the sensor likelihood models (e.g., the characteristics of the sensors and the measurements) [
61]. In contrast, the proposed CHPA method carries along a complete distribution of position estimation.
The following experiments are conducted in order to depict the weakness and the strength of each method.
Figure 17 depicts the initial position estimation using Min-max [
7] and particle filtering. Note that “•” represents the reference node, “○” represents the unknown node, and “×” represents the estimated sensor location. Min-max method has the advantage of being computationally cheap, but it requires a good placement for anchors. In Phase I, we use particle filter method with bounding box algorithm to carry out the initial position estimation. Compared with Min-max (
Figure 17 (left)), particle filter method
Figure 17 (right)) can give more precise location estimation in initial phase. In addition, the distribution of the initial position estimate can be used to do refinement.
Given the errors of distance measurements,
Figures 18 and
19 depict the position errors of the proposed CHPA and the SPA [
9] schemes. In the absence of measurement noise, the distance between the unknown sensor and the reference nodes defines a circle corresponding to possible sensor locations. Hence, the intersection of at least three circles gives the exact sensor location. However, due to the noisy measurements, these circles do not intersect at the same point. For the SPA scheme, two noisy measurements are applied to obtain two possible locations. Then the estimate of the unknown sensor location is determined by the third distance measurement.
Observe that in
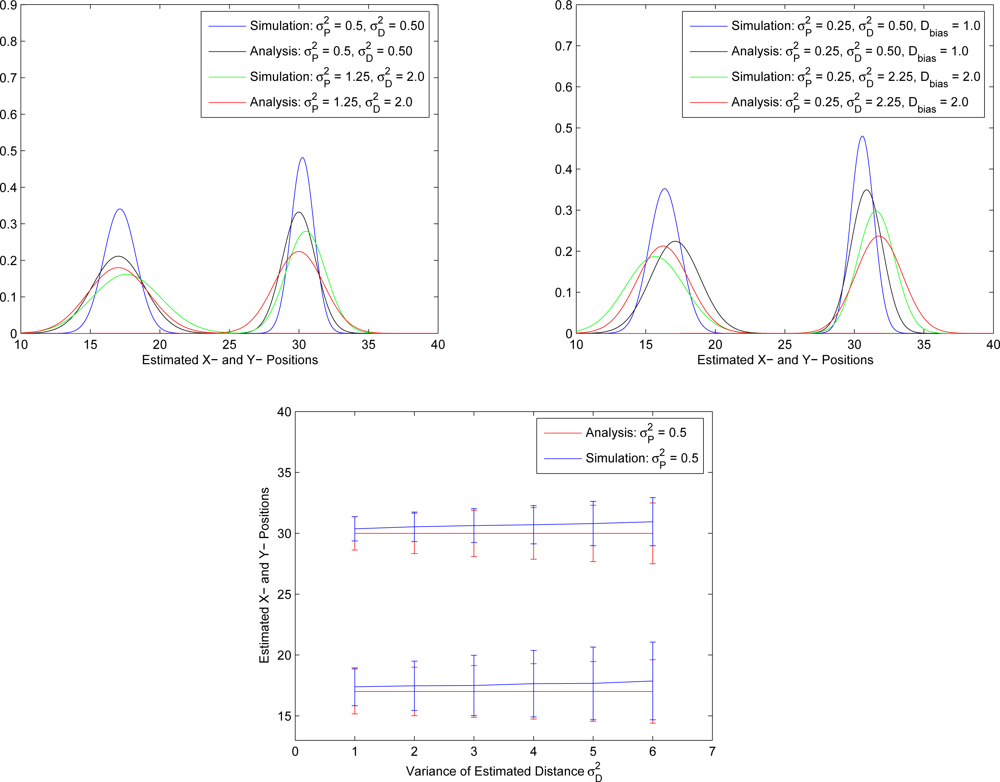
Figure 18 with a small distance measurement noise (
), the average estimated positions using the proposed CHPA and the single estimate using the SPA scheme are close. The average position errors of these two schemes nearly fall within 3% of the side length of the square
l = 10, which suggests that the deterministic localization method (SPA) may be applied to roughly determine the possible sensor location since the influence of the measurement variation on the localization performance is small in this scenario. On the other hand, in
Figure 19 with a larger distance measurement noise (
), although the average position errors of these two schemes nearly fall within 10% of the side length of the square, the SPA scheme may not explicitly describe the estimation behavior using a single estimate. In contrast, the proposed CHPA scheme may provide the statistical information of the estimation behavior with a distribution of the estimated location.
As expected, the proposed CHPA algorithm with particle filtering do require more computation time and memory than simpler deterministic position estimation algorithms. However, as shown in [
11], the particle filter method is proved to be feasible for location estimation on real devices used in ubiquitous computing. Therefore, the proposed sensor positioning system may be practical to share data from different sensor types and to provide distributional estimates to higher-level services and applications.
5.7.2. Network Topology Perspective
The cluster-based localization approaches are proposed because of the need for scalability and efficiency. Compared with the registration processes in [
9] and [
44], the computational complexity of the proposed method (detailed in Section 4.3.) is much lower since the calculations are not easy to implement for wireless sensor networks. [
18] applies a complex multidimensional scaling (MDS) algorithm [
62] to estimate the position of cluster heads. Thus, the cluster members can use clusterheads as reference nodes. Although this approach achieve reasonable accuracy, computational and communication overheads are high. In [
19], anchor nodes are deployed for deriving the position of adjacent clusterheads such that this set of nodes with known positions may form a basis for other clusterheads to localize themselves. The problem with manual entry of position information may limit the size and scalability of a sensor network. Therefore, the proposed CHPA approach may provide an efficient way to build up a coordinate system for wireless sensor networks.
6. Conclusions
We propose a distributed algorithm for the sensor positioning problem in hierarchical wireless sensor networks. By performing the proposed estimation procedures, a single global coordinate system can be established without GPS sensors using only distance information. In order to elevate the estimation accuracy, the Markov chain Monte Carlo (MCMC) steps may be applied to reduce the estimation error such that the propagation error can be suppressed. In the case of poor observations, cooperative estimation fusion schemes are proposed to complement the measurements of the environment and improve the estimation accuracy. Furthermore, the same basic approach can also solve the tracking problem in which the decentralized sensors combine their information to produce improved estimates of the target location. Therefore, one of the strengths of the approach is that (essentially) the same algorithm can be used to track targets with unknown positions.
There are many other algorithmic questions that would be worthwhile exploring. For example, the resampling method we have used is basic. More advanced techniques may be appropriate, depending on how typical distributions evolve, how many particles should be used, and how does this depend on the number of sensors, their density (in space), etc. Furthermore, we believe there are many ways to improve the performance of the algorithm: (a) by quantifying the trade-offs between amount of communication, speed of computation, and accuracy of the final estimates. (b) by examining alternate ways to “fuse” the received data. For example, once distributional estimates are “shared” between nearby sensors, what are the best ways of incorporating the data? (c) by using a notion of the reliability of the received data. For example, if the “distance” measured between two sensors varies, then this variation suggests an unreliability in the data and hence it should be discounted compared to measurements which are always consistent.
For the proposed measurement solution, trade-offs are found between model complexity, energy consumption, estimation accuracy, and sensible model description in real systems. Future plans will involve generalizing the methods to perform actual measurements to evaluate the performance of the proposed positioning system in ubiquitous computing environments.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}