Locating Sensors for Detecting Source-to-Target Patterns of Special Nuclear Material Smuggling: A Spatial Information Theoretic Approach

Abstract
:
1. Introduction
1.1. Literature Review
1.1.1. Network Interdiction Models
1.1.2. Proposed Approach/Perspective
1.1.3. Sensor Location Modeling
1.2. Proposed Spatial Information Theoretic Approach
2. Problem Statement
2.1. Notation and Brief Definitions
- m = number of observations, or equivalent to the number of sensors if temporal factors are omitted,
- n = number of ST pairs |I| × |J|,
- D = ST flow vector, consisting of n elements d(i,j), where d(i,j) = ST volume with destination in zone j, originating their trips from zone i,
- D− = a priori estimate of the mean values in the ST flow vector, consisting of n elements,
- D+ = a posteriori estimate of the mean values in the ST flow vector,
- P− = a priori error covariance matrix of ST flow estimate, consisting of (n × n) elements,
- P+ = a posteriori error covariance matrix, i.e., conditional covariance matrix of estimation errors after including measurements,
- H = sensor matrix that maps unknown ST flows D to measurements C, consisting of (m×n) elements,
- p(l)(i,j) = SNM link flow proportions, i.e., proportion of smuggling ST flows from origin i to destination j, contributing to the passing flow on link l,
- K = updating gain matrix, consisting of (n × m) elements,
- C = SNM volume counts,
- R = variance covariance matrix for combined errors, including measurement and modeling errors,
- ε = combined error term, ε ∼ N (0, R).
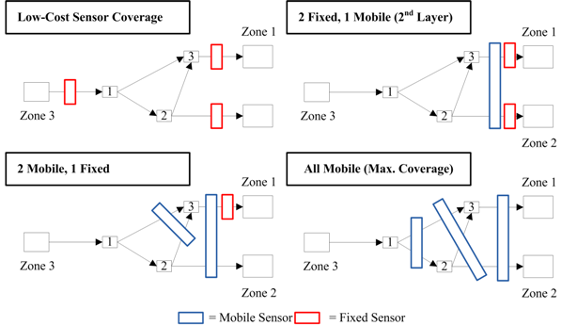
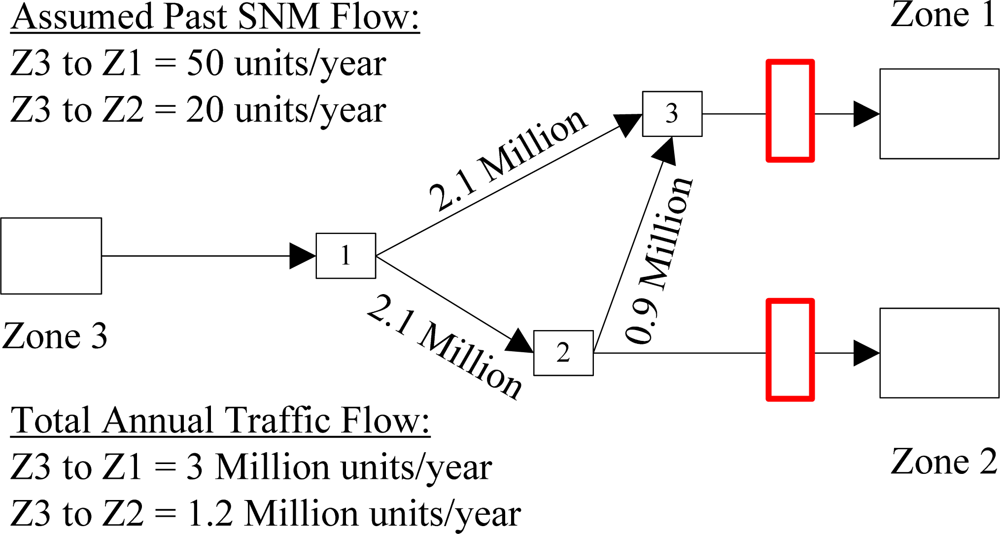
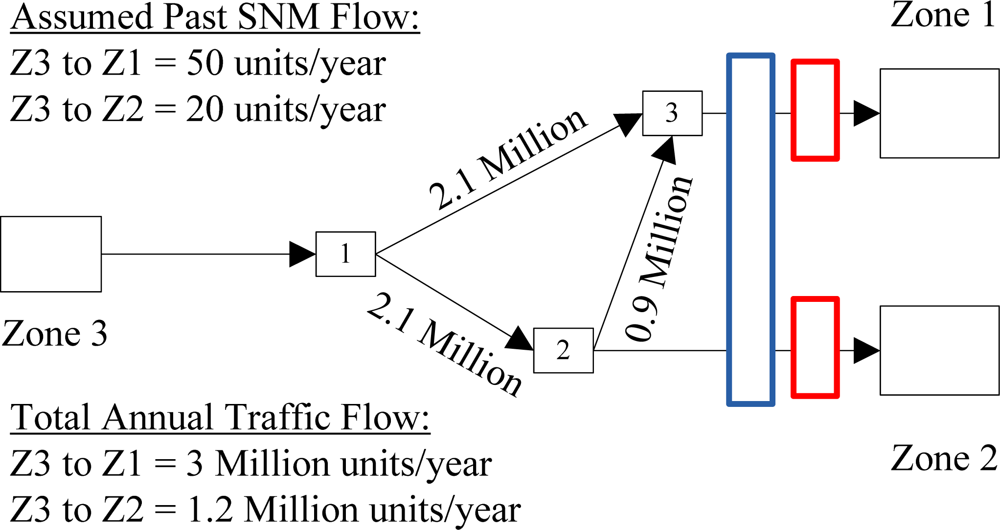
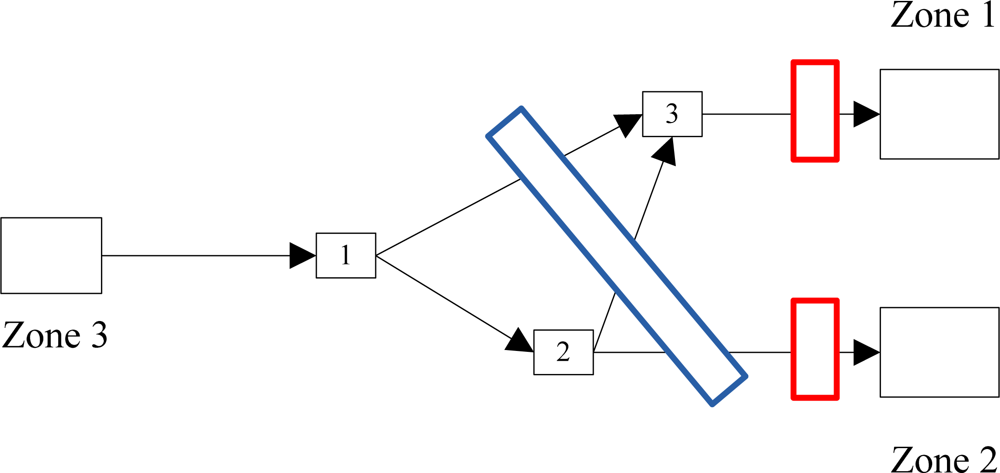
2.2. Sensor Coverage Types
2.3. Objectives
- Fixed and mobile sensors with similar technologies might have correlated measurement errors. If the same sensor technology is placed throughout the network, then the correlation of the errors associated with the same technology will be high. A goal of this research is to understand the correlation between sensor technologies and locating and integrating correlated and uncorrelated, as well as fixed and mobile, sensors over an entire multi-modal transportation network to minimize the total detection errors and best interdict SNM smuggling flow.
- The tradeoff between reliability and cost is fundamental to any technology-driven product. Simply purchasing the most costly and reliable sensors and placing them in a network does not necessarily produce the best results. A goal of this research is to understand the tradeoffs between equipment costs and detection accuracy and selecting the best combination of sensors and their locations to improve the system-wide reliability.
3. Kalman Filtering-Based Information Updating Process
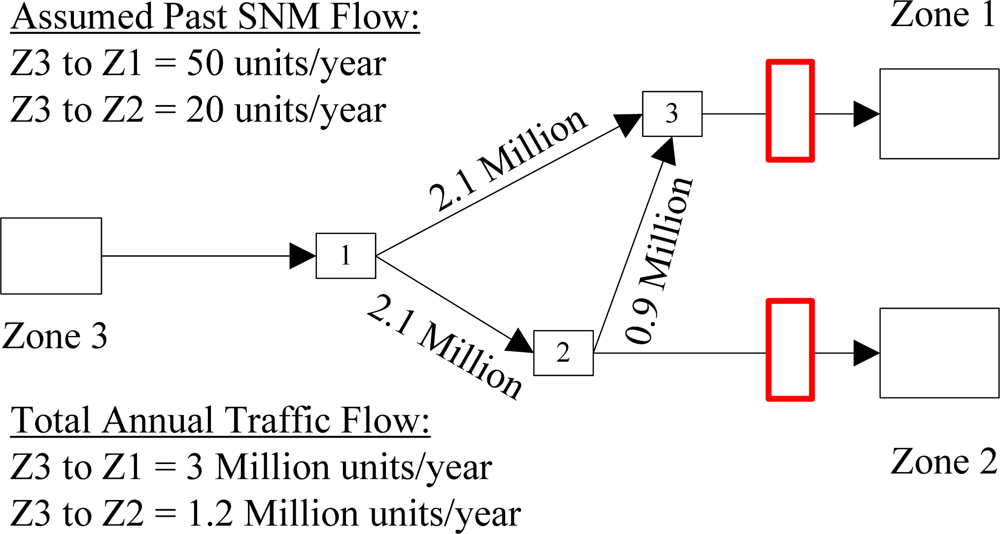
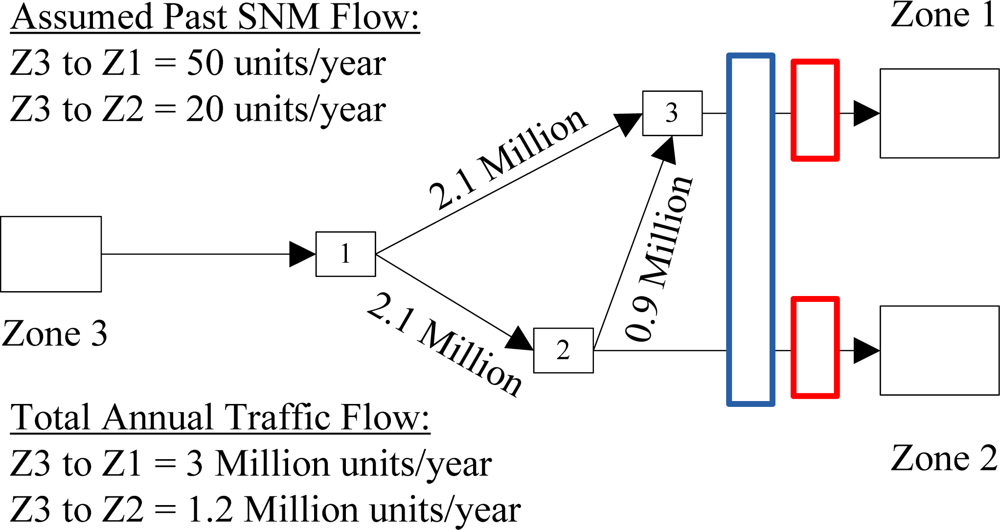
3.1. Step-by-Step Example
3.2. A Priori Estimates
3.3. Updating Phase
4. Measures of Information
4.1. Trace
4.2. Entropy
4.3. Total Flow Variance
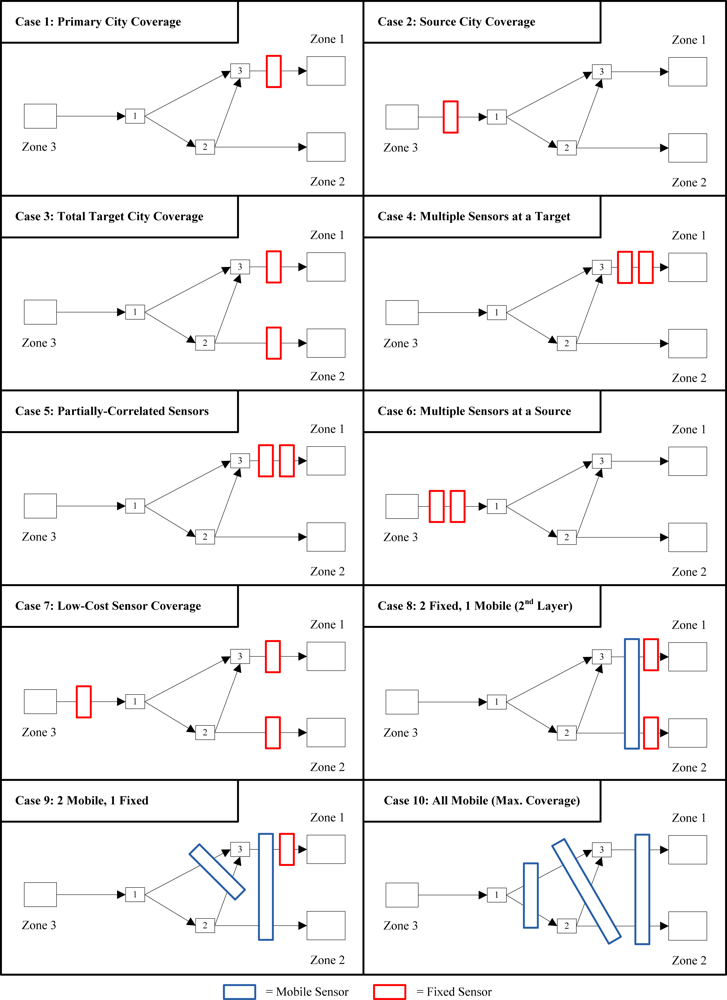
5. Discussion of Results
- Correlated or uncorrelated measurement errors for networked detectors;
- Probabilistic coverage of mobile or re-locatable sensors;
- Different economic and risk impacts of miss rate and false alarm rate; and
- Impact of spatial source-to-target SNM smuggling flow distribution on sensor network design.
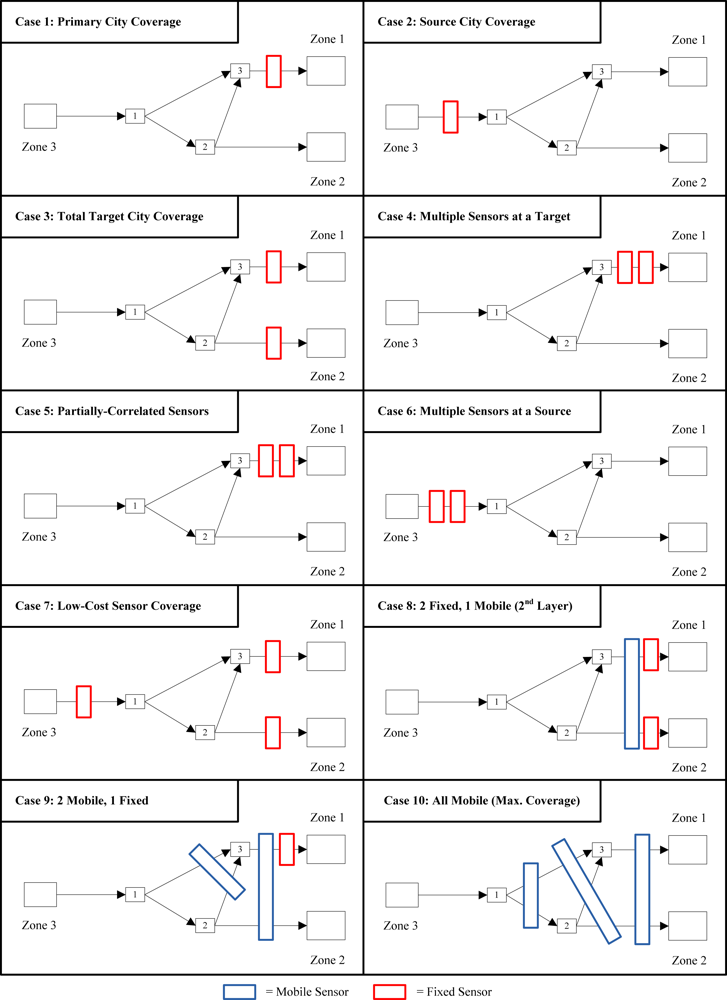
5.1. Fixed Sensor Cases
5.2. Mobile Sensor Cases
6. Sensor Network Design for a Large-scale Network
- Construct a transportation network representation with nodes and links. For example, the U.S. railroad network has 10,560 nodes and 25,882 links.
- Setup an analysis zonal structure: Entry ports represent origins, hub and classification yards represent potential sensor locations, and large metropolitan areas represent potential destinations.
- With inputs from DHS or other agencies, setup a prior source-to-target destination matrix, and estimate the uncertainty range of each source-to-target pair to construct P−.
- Perform traffic assignment process and assign commodity flow to different paths according to the existing routing plans of railroad companies.
- Since SNM flow is an extremely small fraction of total commodity flow, we need to also estimate the screening coverage associated with different detection technologies and policies.
- Finally, generate the H matrix based on the above four factors: (1) underlying network, (2) OD pattern for column, (3) source-to-target pair-link incidence matrix (each link is a row), and (4) percentage to be scanned.
- Obtain R matrix using estimates of sensor error.
7. Conclusions
Acknowledgments
References
- The World Bank. Container Port Traffic (TEU: 20 Foot Equivalent Units). Available online: http://data.worldbank.org/indicator/IS.SHP.GOOD.TU (accessed on August 3, 2010).
- Wood, R. Deterministic network interdiction. Math. Comput. Model 1993, 17, 1–18. [Google Scholar]
- Israeli, E; Wood, R. Shortest-path network interdiction. Networks 2002, 40, 97–111. [Google Scholar]
- Dimitrov, N; Gonzalez, MA; Michalopoulos, DP; Morton, DP; Nehme, MV; Popova, E; Schneider, EA; Thoreson, GG. Interdiction Modeling for Smuggled Nuclear Material. Proceedings of the 49th Annual Meeting of the Institute of Nuclear Materials Management, Nashville, TN, USA, July 2008.
- Lam, WHK; Lo, HP. Accuracy of O-D estimates from traffic counting stations. Traffic Eng. Contr 1990, 31, 358–367. [Google Scholar]
- Yang, H; Iida, Y; Sasaki, T. An analysis of the reliability of an origin-destination trip matrix estimated from traffic counts. Transp. Res. Part B Methodol 1991, 25, 351–363. [Google Scholar]
- Zhou, X; List, GF. An information-theoretic sensor location model for traffic origin-destination demand estimation applications. Transp. Sci 2010, 44, 254–273. [Google Scholar]
- Shannon, CE. A Mathematical Theory of Communication. Bell Syst. Tech. J 1948, 27, 379–423. [Google Scholar]
- Hintz, K; McVey, E; Center, U; Dahlgren, V. Multi-process constrained estimation. IEEE Trans. Syst. Man Cybern 1991, 21, 237–244. [Google Scholar]
- Lee, J. Constrained maximum-entropy sampling. Oper. Res 1998, 46, 655–664. [Google Scholar]
- Zhao, F; Shin, J; Reich, J. Information-driven dynamic sensor collaboration. IEEE Signal Process. Mag 2002, 19, 61–72. [Google Scholar]
- Denzler, J; Brown, CM. Information theoretic sensor data selection for active object recognition and state estimation. IEEE Trans. Pattern Anal. Mach. Intell 2002, 24, 145–157. [Google Scholar]
- Akyildiz, IF; Su, W; Sankarasubramaniam, Y; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag 2002, 40, 102–114. [Google Scholar]
- Huang, CF; Tseng, YC. The Coverage Problem in a Wireless Sensor Network. Proceedings of the 2nd ACM International Conference on Wireless Sensor Networks and Applications, San Diego, CA, USA, September 2003; pp. 115–121.
- Meguerdichian, S; Koushanfar, F; Potkonjak, M; Srivastava, MB. Coverage Problems in Wireless Ad-Hoc Sensor Networks. Proceedings of Twentieth Annual Joint Conference of the IEEE Computer and Communications Societies, IEEE INFOCOM 2001, Anchorage, AK, USA, April 2001; pp. 1380–1387.
- Neidhardt, A; Luss, H; Krishnan, KR. Data Fusion and Optimal Placement of Fixed and Mobile Sensors. Proceedings of Sensors Applications Symposium, Atlanta, GA, USA, February 2008; pp. 128–133.
- Cheng, J; Xie, M; Chen, R; Roberts, F. A Mobile Sensor Network for the Surveillance of Nuclear Materials in Metropolitan Areas; DIMACS 2009-19; Rutgers University: New Brunswick, NJ, USA, 2009. [Google Scholar]
- Kalman, R. A new approach to linear filtering and prediction problems. J. Basic Eng. [Online]. 1960, 82, 35–45. Available online: http://www.elo.utfsm.cl/~ipd481/Papersvarios/kalman1960./pdf (accessed on March 3, 2008). [Google Scholar]
- Gelb, A; Kasper, JF, Jr; Nash, RA, Jr; Price, CF; Sutherland, AA, Jr. Applied Optimal Estimation; Gelb, A, Ed.; M.I.T. Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Wikipedia. Variance. Available online: http://en.wikipedia.org/wiki/Variance (accessed on June 15, 2010).
- Magnanti, TL; Wong, RT. Network design and transportation planning: models and algorithms. Transp. Sci 1984, 18, 1–55. [Google Scholar]
- Alfeeli, B; Pickrell, G; Garland, MA; Wang, A. Behavior of random hole optical fibers under gamma ray irradiation and its potential use in radiation sensing applications. Sensors 2007, 7, 676–688. [Google Scholar]
- Mayer, K; Wallenius, M; Ray, I. Nuclear forensics: A methodology providing clues on the origin of illicitly trafficked nuclear materials. Analyst 2005, 130, 433–441. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transportation (Passenger and Freight) Flow | Nuclear Material Smuggling Flow | |
|---|---|---|
| Origin | Home/office/warehouse | Source city |
| Destination | Warehouse/office/home | Target city |
| Detectors | In-pavement loop detectors, road-side vehicle counting stations, vehicle identification readers | Fixed and handheld detectors, Radio Frequency Identification (RFID) detector |
| Flow Volume | High | Extremely low |
| Objective | Improve system observability to maximize system mobility | Improve system observability to maximize SNM flow to be interdicted |
| Case | Description | Inputs/Outputs | Trace | Det. | Entropy | Total Flow Var. |
|---|---|---|---|---|---|---|
| 1 | One fixed sensor covers Zone 1 | 1.800 | 0.800 | −0.223 | 1.800 | |
| 2 | One fixed sensor covers Zone 3 | 2.167 | 0.667 | −0.405 | 0.833 | |
| 3 | Total coverage for Zones 1 & 2 (one fixed sensor each) | 1.300 | 0.400 | −0.916 | 1.300 | |
| 4 | Two fixed sensors cover Zone 1 | 1.444 | 0.444 | −0.811 | 1.444 | |
| 5 | Two partially-correlated fixed sensors cover Zone 1 | 1.541 | 0.541 | −0.615 | 1.541 | |
| 6 | Two fixed sensors cover Zone 3 | 1.909 | 0.364 | −1.012 | 0.455 | |
| 7 | Three low-cost fixed sensors cover Zones 1, 2, and 3. | 1.205 | 0.308 | −1.179 | 0.795 | |
| 8 | Two fixed sensors: #1 covers Zone 1, #2 covers Zone 2. One mobile sensor covers half flow to both Zone 1 and Zone 2. | 1.178 | 0.329 | −1.112 | 1.068 | |
| 9 | Two mobile sensors: #1 covers both paths to Zone 1, #2 covers both Zone 1 and Zone 2. One fixed sensor covers Zone 1. | 1.511 | 0.550 | −0.599 | 1.328 | |
| 10 | Three mobile sensors: #1 covers each available path equally, #2 covers Zone 1& Zone 2, and #3 covers both paths to Zone 1. | 2.720 | 1.317 | 0.275 | 1.646 |
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Przybyla, J.; Taylor, J.; Zhou, X. Locating Sensors for Detecting Source-to-Target Patterns of Special Nuclear Material Smuggling: A Spatial Information Theoretic Approach. Sensors 2010, 10, 8070-8091. https://doi.org/10.3390/s100908070
Przybyla J, Taylor J, Zhou X. Locating Sensors for Detecting Source-to-Target Patterns of Special Nuclear Material Smuggling: A Spatial Information Theoretic Approach. Sensors. 2010; 10(9):8070-8091. https://doi.org/10.3390/s100908070
Chicago/Turabian StylePrzybyla, Jay, Jeffrey Taylor, and Xuesong Zhou. 2010. "Locating Sensors for Detecting Source-to-Target Patterns of Special Nuclear Material Smuggling: A Spatial Information Theoretic Approach" Sensors 10, no. 9: 8070-8091. https://doi.org/10.3390/s100908070
APA StylePrzybyla, J., Taylor, J., & Zhou, X. (2010). Locating Sensors for Detecting Source-to-Target Patterns of Special Nuclear Material Smuggling: A Spatial Information Theoretic Approach. Sensors, 10(9), 8070-8091. https://doi.org/10.3390/s100908070