Intelligent Control of a Sensor-Actuator System via Kernelized Least-Squares Policy Iteration

Abstract
: In this paper a new framework, called Compressive Kernelized Reinforcement Learning (CKRL), for computing near-optimal policies in sequential decision making with uncertainty is proposed via incorporating the non-adaptive data-independent Random Projections and nonparametric Kernelized Least-squares Policy Iteration (KLSPI). Random Projections are a fast, non-adaptive dimensionality reduction framework in which high-dimensionality data is projected onto a random lower-dimension subspace via spherically random rotation and coordination sampling. KLSPI introduce kernel trick into the LSPI framework for Reinforcement Learning, often achieving faster convergence and providing automatic feature selection via various kernel sparsification approaches. In this approach, policies are computed in a low-dimensional subspace generated by projecting the high-dimensional features onto a set of random basis. We first show how Random Projections constitute an efficient sparsification technique and how our method often converges faster than regular LSPI, while at lower computational costs. Theoretical foundation underlying this approach is a fast approximation of Singular Value Decomposition (SVD). Finally, simulation results are exhibited on benchmark MDP domains, which confirm gains both in computation time and in performance in large feature spaces.1. Introduction
This paper explores a technique called compressive reinforcement learning, analogous to recent work on compressed sensing, wherein approximation spaces are constructed by measurements representing random correlations with value functions. A Random Projections is a simple but elegant technique that has both a strong theoretical foundation and a wide range of applications including signal processing, medical image reconstruction, machine learning and data mining. Its theoretical foundation rests on the Johnson–Lindenstrauss lemma [1]: given a set of samples S in a high-dimensional feature space Rn, if we construct an orthogonal projection of those sample points onto a random d-dimensional subspace, then if , the projection is Lipschitz; in other words, pairwise distances are preserved with high probability (P > 1/2) up to a small distortion factor of 1 ± ɛ. Intuitively, this process can be thought of as applying a random rotation to a high-dimensional manifold and then reading off the first d coordinates. Compared with other linear dimension reduction methods, like Principal Component Analysis (PCA), Factor Analysis (FA), etc., Random Projections are data-independent, which significantly reduces the computational cost. In [2], Least-square temporal difference algorithm (LSTD) [3] is analyzed with approximation error analysis in finite-sample scenario. In [4], Random Projections are integrated with reinforcement learning algorithms that solve Markov Decision Processes (MDPs) in the context of least-squares temporal difference learning setting.
Kernelized reinforcement learning, as it is named, aims at bring the benefits of non-parametric kernel approaches to reinforcement learning algorithms family. A kernelized least-squares policy iteration (KLSPI) is proposed in [5] by replacing inner product via kernel in LSTD architecture. [6] follows similar style by introducing kernel approach into LSPE [7] framework. Other approaches, such as [8–10], seems to be more inspired from the Gaussian processes, where the covariance function is displaced with kernel function. Meanwhile, L2 regularization is also intensively studied in these Gaussian process driving approaches and also in [11]. In KLSPI, kernels are used as basis for efficient policy evaluation. A sparsification procedure based on approximate linear dependency (ALD) is performed for sparsification, which is an online, fast approximate version of PCA [12]. KLSPI reaches two progresses: One is better convergence both in reduced convergence time and in better convergence precision than regular LSPI, the other is automatic feature selection via ALD-based kernel sparsification. Therefore, the KLSPI algorithm provides a general RL method with generalization performance and convergence guarantee for large-scale MDP problems.
In this paper, a new framework, called Compressive Kernelized Reinforcement Learning (CKRL), for computing near-optimal policies in sequential decision making with uncertainty is proposed via incorporating the non-adaptive data-independent Random Projections and nonparametric Kernelized Least-squares Policy Iteration (KLSPI). One of the central ideas is that Random Projections are able to constitute an efficient sparsification technique and this brings about both faster convergence rate and lower computational costs than regular LSPI. Theoretical foundation underlying this approach is a fast approximation of Singular Value Decomposition (SVD). Experimental results also demonstrate that this approach enjoys the benefit of nonparametric approaches as well as alleviating the computation cost induced by non-adaptive random projections.
Here is a brief roadmap to the rest of the paper. In Section 2, background knowledge of the three major perspectives comprising this paper is introduced on compressed sensing and random projections, kernel regression and sparsification and approximate Markov Decision Processes algorithms. In Section 3, unified framework and overview of state-of-art kernelized reinforcement learning algorithm is given, with extensive analysis on both kernel sparsification and error decomposition analysis. In Sections 4 and 5, the algorithms of Compressive Kernelized Reinforcement Learning algorithm are proposed with intensive theoretical analysis in Section 5. Finally, experimental results are conducted in the context of various experimental settings on different benchmark domains to validate the effectiveness of the proposed approach in Section 6.
2. Background
2.1. Compressed Sensing and Random Projections
Let us first have a brief review of some important concepts and theorems that will be used in this paper.
Lemma 1: (Restricted Isometry Property) A m × n compression matrix C ∈ Rm×n satisfies the Restricted Isometry Property (RIP), (k, ε)-RIP, if it acts as a near-isometry with distortion factor ε over all k-sparse vectors, that is, for any k-sparse vector x ∈ Rn, the following near-isometry property holds
2.2. Kernel Regression, Regularization and Sparsification
Now we give a brief introduction of kernel, kernel matrix, kernel trick and kernel regression. A kernel is a symmetric function representing the similarity between two samples,
Kernel regression [14], also called the Nadaraya–Watson model, is a kernelized form of linear least-square regression [15]. Given the linear model t = Φw + ε, the sum-of-squares error function without L2 regularization term is given by . Introduce the representation of w = ΦT a, and Gram matrix K = ΦΦT, we have . So the kernel regression for the linear model is
We now give proof that the compressed kernel matrix CKCT is nonsingular whenever rank(K) ≥ d.
Theorem 1: If the kernel matrix K satisfies rank(K) ≥ d, the compressed kernel CKCT will be nonsingular, i.e., rank(CKCT) = d, where C is the randomly generated compression matrix.
Proof:
If rank(K) ≥ d, there exists a sequence {ir1, ir2, ⋯, ird} and {ic1, ic2, ⋯, icd} such that the sub-matrix Ksub which are drawn from K with rows of index {ir1, ir2, ⋯, ird}, and columns of index {ic1, ic2, ⋯, icd} such that rank (Ksub) = d Next draw arbitrary d rows and columns from C, which form square matrix Csub such that
2.3. Approximate Solutions of Markov Decision Processes in Large Feature Space
A Markov Decision Process (MDP) [17] is defined by the tuple (S, A, , R, γ), comprised of a set of states S, a set of (possibly state-dependent) actions A (As), a dynamical system model comprised of the transition probabilities specifying the probability of transition to state s′ from state s under action a, and a reward model R. A policy π: S → A is a deterministic mapping from states to actions. Associated with each policy π is a value function υπ, which is a fixed point of the Bellman equation:
In Reinforcement Learning, it is indeed a huge computational challenge for LSPI to work with large amount of features. Besides heavy computation costs, another concern is learning performance, since a lot of training data is needed for large feature spaces. The third concern is data efficiency. Often the key to data-efficiency is sample reusage, i.e., samples are not used only once (as in Q-learning), but for multiple times instead. Since samples would be scarce in the large feature space, data reusage is of critical importance.
Corresponding to the methods mentioned above, introducing L1 based method into LSPI, which is called LARS-TD [19], provides an effective way for L1 regularization and feature selection. Another way is to do feature compression with Random Projections as an alternative of feature selection, as proposed in [2], which is the application of CLRS in reinforcement learning. The third way is to implement the kernel trick in LSPI, e.g., kernel-based LSPI (KLSPI). Generally, the complexity of kernelized methods scales well with the feature dimension, but the bad news is that the complexity now depends on the number of data instead. Kernel sparsification, therefore, plays a critical role in the performance of KLSPI here. In [5], a kernel sparsification method called ALD originated from [12] on kernelized recursive Least-squares regression is implemented.
3. Kernelized Least-Squares Policy Iteration with Regularization
3.1. Kernelized Least-squares Policy Iteration
Nonparametric approximators have been combined with a number of algorithms for approximate policy evaluation. For instance, kernel-based approximators are combined with LSTD and LSTD-Q by [5,11], and with LSPE-Q by [6]. Document [10] used the related framework of Gaussian processes to approximate value functions in policy evaluation. Document [15] showed that, in fact, the algorithms in [8,10,12], are identically the same on condition that the same samples and the same kernel function are used. A kernel-based approximator can be seen as linearly parameterized if all the samples are known in advance. In certain cases, this property can be exploited to extend the theoretical guarantees about approximate policy evaluation from the parametric case to the nonparametric case [5]. Document [11] provided performance guarantees for their kernel-based LSTD-Q variant for the case when only a finite number of samples is available.
An important concern in the nonparametric case is controlling the complexity of the approximator. Computational burden, which is often the curse of nonparametric approximators in real applications of kernel-based methods and Gaussian processes, grows with the number of samples considered. Many of the approaches mentioned above employ various kernel sparsification techniques to limit sample complexity, i.e., the number of samples that contribute to the solution ([5,12]).
Kernel-based LSPI introduces the kernel trick into least-square temporal difference learning to derive a kernelized version of LSTD. In KLSPI, kernels are used as basis in LSPI framework for efficient policy evaluation. A generalized kernelized model-based LSTD framework is presented in [15], where kernelized least-squares policy iteration is reduced to a more general framework of kernel regression in Reinforcement Learning. Kernel regression of the reward model and transition model can be depicted as follows, respectively.
Let us define K′ = PK, where
3.2. Regularization on Kernelized Reinforcement Learning Algorithms
How to successfully implement kernelized reinforcement learning algorithm involves various sparsification and regularization method. There are two main questions concerning the regularization. The first question is “How to regularize?”. To answer this question, there are several frameworks of L2-regularized kernelized LSTD, which can be roughly divided into three categories to the best of our knowledge. The first is adding regularization term to the kernel regression model of (12) and (13), respectively, i.e.,
Another category of regularized kernelized LSTD is in [11], in which a kernel matrix of size 2n is constructed, where n is the number of samples, which uses kernel values between pairs of next state. The authors have shown that the algorithm can be used efficiently when the value function approximation lie in a reproducing kernel Hilbert space (RKHS). They also developed finite sample error bound for the regularized algorithm.
Lemma 2 [15]: The KLSPI value function is equivalent to the unregularized model-based value function given the same trajectories.
Proof: We give a sketch proof here which extends mainly three steps. In a same trajectory, s′i = si+1, so we have K′ = GK. Secondly using K′ = GK we can have
The third sparsification technique is aiming at reducing sample complexity in streaming data, which renders it applicable in real applications. A sparsification procedure based on approximate linear dependency (ALD) can be performed, which is an online, fast approximate version of PCA [12]. ALD reaches two progresses. The first is better convergence both in reduced convergence time and in better convergence precision than regular LSPI. The other advantage is automatic feature selection using ALD-based kernel sparsification. Therefore, KLSPI provides a general RL method with generalization performance and convergence guarantee for large-scale MDPs.
Except the first question on how to implement to regularization, another question, both palpable and profound, is when to implement regularization. Generally there are two possible sparsification schemes which differ in when to practise sparsification: preprocessing and postprocessing. Preprocessing is to directly compress the feature space by feature selection. It then learns a basis of the sample (si, ai) from the compressed feature space, and then use it in LSPI. In this case, it is equivalent to compressing the feature set in advance, and the same feature vector is used at every iteration for a new sample. The ALD sparsification is a typical method of this approach. In this method, each sample in the compressed dictionary spans a feature, and ALD is aiming at compressing this dictionary so that the number of elements in the dictionary is much smaller compared with the number of the whole sample set. In the ALD approach, a subset of samples x̃1, ..., x̃d is constructed in order to avoid redundant information. The dictionary is used such that ϕ(x̃1), ..., ϕ(x̃d) spans approximately ϕ(x1), ..., ϕ(xn), while being of minimal size. So the sparsification is actually in the feature space and can be counted as doing feature selection via abandoning redundant samples in forming the dictionary. KLSPI is an adaptation of this idea into LSTD framework. In [12], ALD is a kind of feature selection method, and can be considered as an online approximate algorithm of PCA, while at much reduced computational cost.
The postprocessing scheme is to indirectly adapt sparsification to LSTD, which is to learn a high-dimensional basis k̃ (si) of the sample (si, ai, ri, s′i, π (s′i)) first, then use some technique for sparsification, and use the sparsified basis k (si) in policy iteration to generate the new policy. In this case, one needs to recompute a basis at each iteration of LSPI since different feature vectors are used at each iteration, as π (s′) depends on the current policy. The A, b matrix is computed as follows:
3.3. Error Decomposition Analysis
Let us move to introduce the Bellman error of the kernelized value function, which is the one-step temporal difference error,
4. Algorithm Design
The General Framework of KLSPI with sparsification is described in Algorithm 1.
5. Theoretical Analysis
We use subtitle C to stand for compressed version, K for kernelized version, CK for kernelized LSTD-RP, and KC for compressed KLSTD. In the following, n stands for the number of samples, D stands for the dimension of full dimensional space, and d stands for the dimension of compressed dimensional space. In kernel regression, we have D = n.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: |
| • A sample data set (si, ai, ri, s′i) |
| • A kernel function k (·, ·) |
| Output: |
| • policy π(t) |
| Pre-processing Sparsification to generate compact Dic |
| REPEAT: |
| Policy Evaluation: |
| Compute k̃ (si) based on Dic. |
| Post-processing Sparsification of k̃ (si) to generate k (si) |
| Compute A, b |
| Compute solution w = A−1b, V̂ (si) = k (si)T w |
| Policy Improvement: |
| Compute Policy π(t) |
| ENDLOOP |
Here is using ALD as an optional pre-processing sparsification step and LSTD-RP as a post-processing sparsification step.
| Input: |
| • A sample data set (si, ai, ri, s′i) |
| • A kernel function k (·, ·) |
| • A compression dimension d |
| Output: |
| • policy π(t) |
| Use ALD to generate compact Dic (optional) |
| REPEAT: |
| Policy Evaluation: |
| Compute k̃ (si) based on Dic. |
| Construct compression matrix C. |
| k (si) = Ck̃ (si) |
| Compute A, b |
| Compute solution w = A−1 b, V̂ (si) = k (si)T w |
| Policy Improvement: |
| Compute Policy π(t) |
| ENDLOOP |
5.1. Random Projections is Approximate SVD
We have to be careful to extend any conclusion of linear projection to Random Projections since there is no guarantee that the Random Projections matrix is a projection operator, because C is generally not orthogonal (note that Random Projections is spherically random rotation plus coordinate sampling). A linear mapping can cause significant distortions in the data set if C is not orthogonal. Orthogonalizing C is, however, usually very computationally expensive and thus does not justify its cost. Instead, we can rely on a result in [21], that is, in a high-dimensional space, there exists a much larger number of almost orthogonal than orthogonal directions. Thus vectors having random directions might be sufficiently close to orthogonal, and equivalently CT C ≈ I, where I is the identity matrix, and according to experimental experience [21], the mean squared difference between CT C and an identity matrix was about per element. A lemma in [22] can be used to prove this.
Theorem 2 Suppose that A is a real m × n matrix. Select a target rank k ≥ 2 and an oversampling parameter p ≥ 2, where k + p ≤ min {m, n}. Execute the proto-algorithm with a standard Gaussian test matrix to obtain an m × (k + p) matrix Q with orthonormal columns. Then the expectation of approximation error is bounded
Proposition 1: For compression matrix C, the following holds:
Each column of C is approximately orthogonal.
CTC formulates an approximately identity matrix, i.e., CT C ≈ I.
Low rank matrix approximation is important in a wide variety of scientific applications including statistics, signal processing, machine learning, etc. Principal Component Analysis, as a unsupervised dimensionality reduction method, is the optimal solution when the target cost function is the sum of the mean square reconstruction error. The general idea of PCA, kernel PCA and ALD is to project the entire ambient feature space onto a lower dimensional manifold spanned by the topmost eigenvectors of the sample covariance matrix in feature space corresponding to the leading eigenvalues.
The problem formulation is trying to find a low rank matrix X to minimize the approximation error of ||A − X||. If we limit the minimizer to the form of X = CCT A, the problem formulation of this family would be divided into fixed-precision approximation problem and fixed-rank approximation problem [22].
For the fixed-precision approximation problem, suppose we are given a m × n matrix A and a positive error tolerance ε. The task is to find a compression d × m matrix C with minimal d = d (ε) orthonormal column such that
For fixed-rank approximation problem, given a matrix A, a predefined compression rank d, the problem is to find matrix C with orthonormal columns such that the approximation error ε = ε (d) is minimized.
5.2. LSTD with Random Projections
First let us have a brief review of LSTD-RP. In LSPI-RP, there is
5.3. Kernelized LSTD with Random Projections
Next we will prove the equivalence of the compressed Kernel-based LSTD with kernelized LSTD-RP, i.e., if we perform Compressed Linear Regression to the sample set, and practise Kernel-based LSTD based on the compressed kernel matrix, this would be identical to the performance of the kernelized version of LSTD-RP for feature compression.
Theorem 3: The solution of the kernelized LSTD-RP is the approximate solution of the compressed kernel-based least-square temporal difference learning algorithm, namely,
Proof:
(1): For kernelized LSTD-RP, we just replace the basis set Φn,D with Kn,n in Equations (24) and (26), where n = D. Thus we get
(2):Next we develop the compressed version of kernelized value function approximation. As in [15], the kernelized value function V̂K can be represented as
(3): Based on the above analysis, we have
Note that if we insert instead of in the second equation, we would have
6. Experiment Result
6.1. Experimental Setting
We now present several comparison studies to show the effectiveness of our method. It is noteworthy to mention that the benefit of introducing Random Projections for feature compression lies mainly in reduction of computational cost. The overall performance, however, highly depends on the quality of the randomly generated compression matrix C; it is thus reasonable that the variance will be higher than in the ALD-based methods. Also we restrict the problems with finite sample set and large amount of features.
Unlike L1 regularization, LSPI-RP does not assume that the representation w.r.t the original basis is sparse. To implement L1-regularized method, we need the target function to be sparse in the selected representation. Mathematically, the sparsity appears in the bound instead of the dimension. So, if the signal is not sparse, its sparsity will be equal to the dimension, and thus, the large dimension appears in the bound. In LSPI-RP, however, instead of the requirement on sparsity of the original basis, a requirement is imposed on the features such that they are supposed to be of specific form in order to perform better than LSPI in high-dimensional space. So in LSPI-RP it would be of critical importance of the basis [2]. The second point, as mentioned above, the necessity of using LSPI-RP is as mentioned above on the scenarios where there is scarce amount of samples compared with the cardinality of features F, which would often lead to overfitting for regular LSPI. The setting is preferable for LSPI-RP where the number of samples is smaller than or at the same order of the number of features.
6.2. Experimental Analysis
First we define parameters used in the experiment:
d: the compression dimension
n: the number of samples, which is also the full dimension in kernelized LSPI
θ: the compression ratio of d/D.
ɛ: the threshold parameter for ALD dictionary.
Pendulum
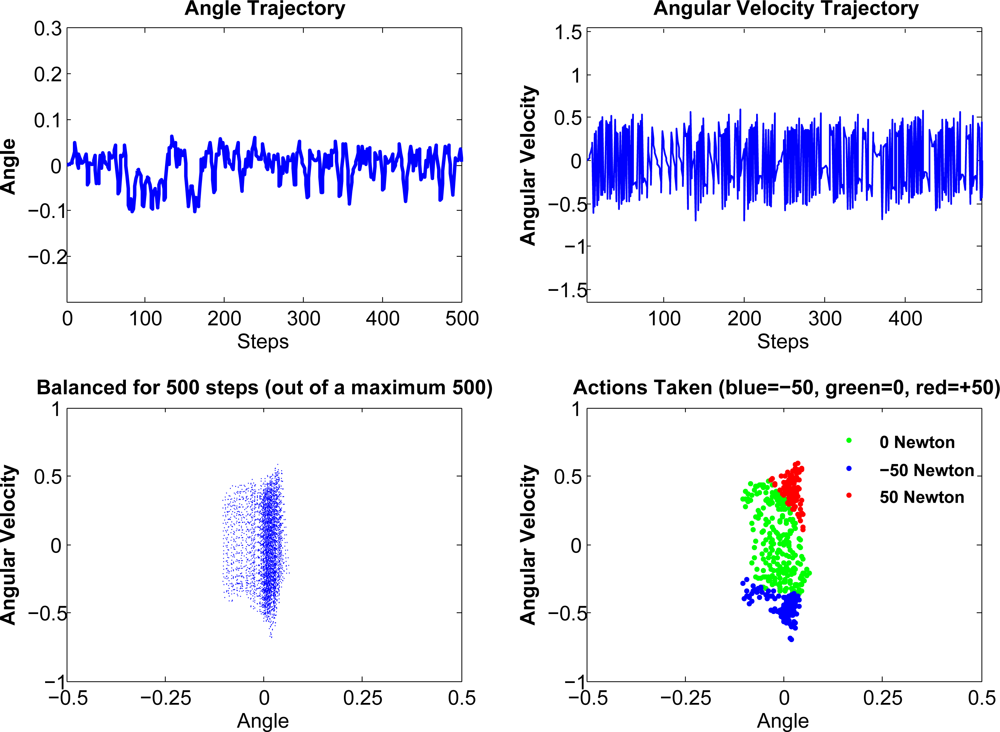
The pendulum domain is a typical under-actuated system which is highly unstable. Here we give some illustrative example of compressed kernelized LSPI in pendulum domain. Here we collect 2, 000 samples, and the compression ratio is 0.2. Here we take 20 runs on average, and the average runs to converge of compressed KLSPI, ALD-based KLSPI and regular LSPI are 7.4, 7.8, 8.6 runs. From here we can see that compressed KLSPI has the advantage of faster convergence. This merit will be more explicit as we will show in Figures 2 and 5.
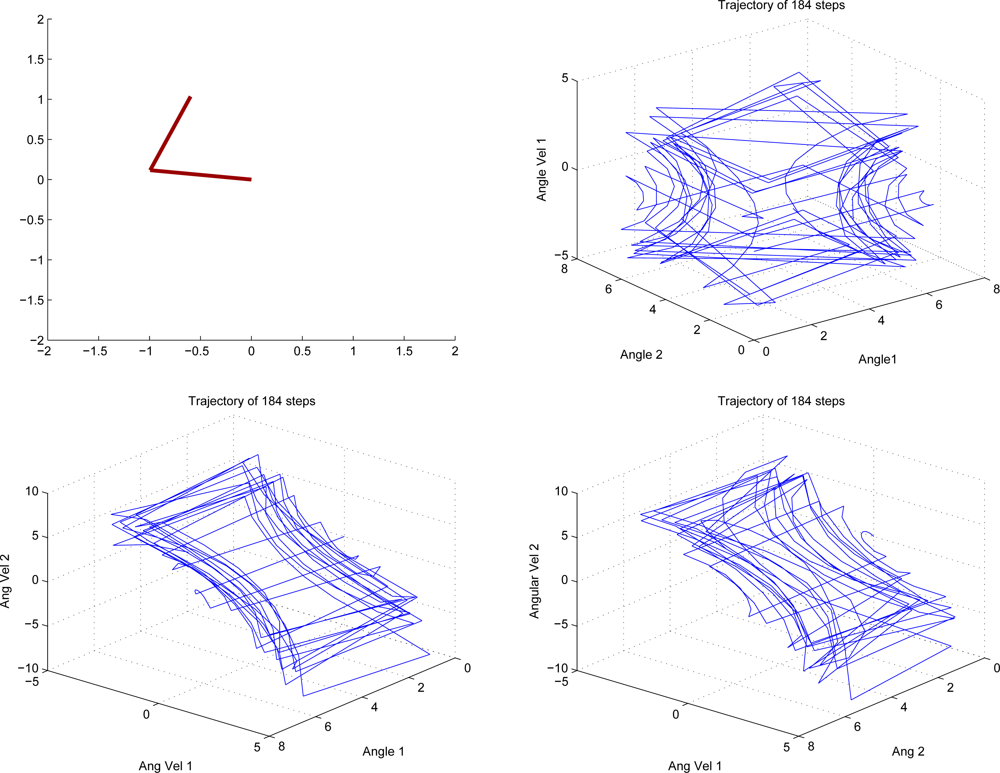
Acrobot
The Acrobot is an under-actuated double pendulum which is a typical working benchmark for its nonlinear dynamics. It consists of two arms where torque can only be applied at the second joint. The system is described by four continuous variables: the two joint angles, θ1 and θ2, and the angular velocities, θ̇1 and θ̇2. There are three actions corresponding to positive (a = 1), negative (a = −1), and zero (a = 0) torque. The time step was set to 0.05 and actions were selected after every fourth update to the state variables according to the equations of motion. The goal for this domain is to raise the tip of the second link above a certain height in minimum time (we used a height of 1, where both links have a length of 1). The reward function is therefore −1 for each time step until the goal is achieved and the discount factor is γ = 0.99. Episodes begin with the all state variables at value 0 which corresponds to the two links hanging straight down and motionless. Figure 3 is an illustration figure of Acrobot. Figure 4 shows a snapshot of a successful run.
(1): Comparison of Compression Ratio
In this experiment, we shall seek the optimal compressing dimension d with different number of samples. Up to our best knowledge, there is no tighter bound on how to choose d in compressed LSPI yet. In [2], a covering number bound of d is given with an empirical extension to a rule of thumb that . One can see that from the experimental results in Table 1, rule of thumb experience that still applies.
(2): Comparison of Kernel Sparsification: ALD vs. Compressed Sensing
In this experiment, several comparison studies are carried out to compare the two kernel sparsification technique: ALD and Compressed Sensing. Briefly, both two methods are highly adaptable and only depends on one parameter. The ALD method depends mainly on one parameter: the dictionary threshold ε. Likewise, the compressed sensing technique also depends on one parameter: the compressed ratio θ = d/D. To be fair, we will give identical compression dimension d, which means that the compressed dimension is equal to the size of the ALD dictionary. The problem setting in Experiment 2 is like this: given large amounts of data, the ALD dictionary is still considerably large. How to compress this dictionary further is an interesting topic worth attention. One heuristic idea, of course, is to make the accuracy threshold of ALD dictionary υ larger so that the accuracy tolerance becomes larger, and correspondingly the dictionary size becomes smaller. However, based on the compressive reinforcement learning framework, here is another attractive method, first we build the ALD dictionary with a very strict accuracy threshold υ and build an ALD dictionary with large size. Then we use the Random Projections to compress the basis generated by this “large” dictionary. Comparison studies are carried out and experimental results in Table 2 show that our method is better than the combo of these two methods, which in turn is better than purely using only one.
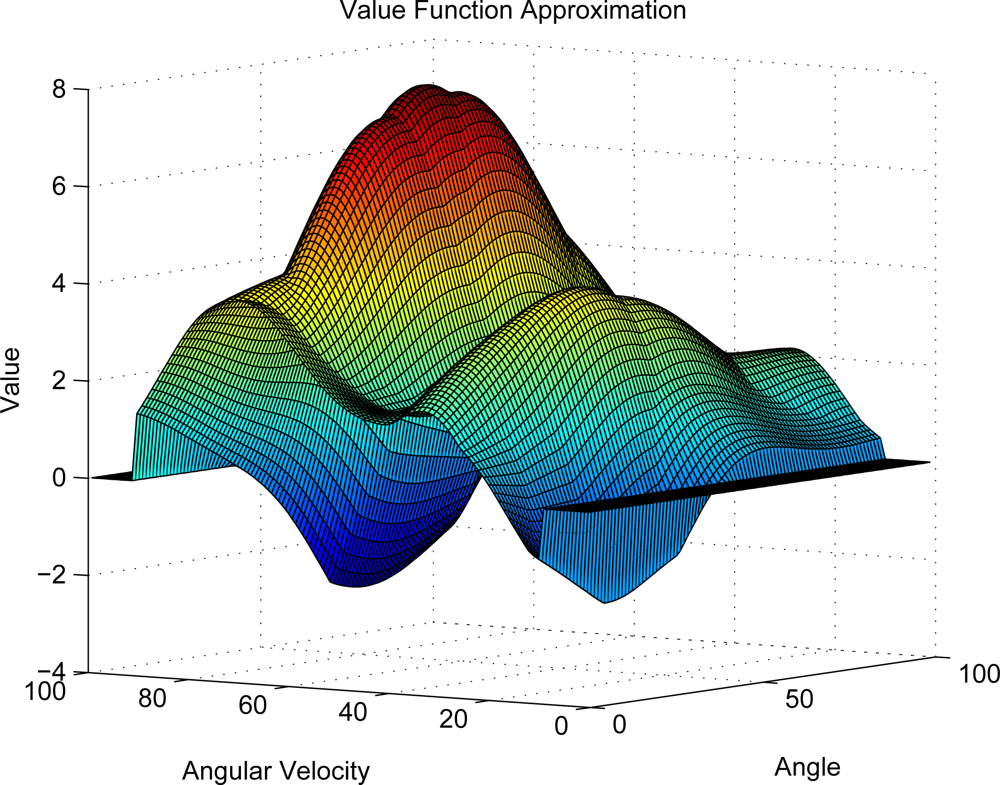
6.3. Compressed KLSPI in Value Function Approximation
In this experiment, we will show the approximated value function of Compressed Kernelized LSPI on pendulum domain. From Figure 5, we can see that although there are some dissimilarity, the approximated value function can produce good policy and is satisfactory enough to capture the main topology of the true value function.
6.4. Compare RBF Kernel and GGK Kernel
In here we give a new kernel function, namely, Geodesic Gaussian Kernel (GGK). Compared with RBF kernel, GGK can capture the topology on the manifold where the samples lies on instead of the Euclidean distance used in RBF kernel. Moreover, since GGKs are local by nature, the ill effects of local noise are constrained locally.
Geodesic Gaussian Kernels on Graphs:
A natural definition of the distance would be the shortest path. So we define Gaussian kernels on graphs based on the shortest path:
7. Conclusions
In this paper a new nonparametric reinforcement learning framework called Compressive Kernelized Reinforcement Learning (CKRL) is proposed based on Gaussian process, compressed Sensing and random projections. We compare compressed kernelized LSPI, kernelized LSPI, and regular LSPI along with different kernels based on Euclidean distance and Graph-based Geodesic distance, respectively. Preliminary theoretical proof and experimental results are also given. There are various interesting future directions along this research venue. For instance, how to integrate L1 regularization into this framework is a promising topic to explore. Another promising future direction is to introduce this compressive reinforcement learning framework to policy gradient approaches with regular MDP [24] and POMDP [25].
8. Acknowledgement
The authors would like to acknowledge the support by Guangdong Science Foundation of China under Grant S2011010006116, the National Natural Science Foundation of China under Grant No. 61172165, and Science and Technology Planning Project of Shenzhen city (JC200903180648A).
References
- Tsaig, Y.; Donoho, D.L. Compressed sensing. IEEE Trans. Inform. Theory 2006, 52, 1289–1306. [Google Scholar]
- Maillard, O.A.; Ghavamzadeh, M.; Lazaric, A.; Munos, R. LSTD with random projections. Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010.
- Bradtke, S.; Barto, A. Linear least-squares algorithms for temporal difference learning. Mach. Learn 1996, 22, 33–57. [Google Scholar]
- Liu, B.; Mahadevan, S. Compressed reinforcement learning with random projections. Proceedings of 25th Conference on Artificial Intelligence, Vancouver, BC, Canada, 6–9 December 2011.
- Xu, X.; Hu, D.; Lu, X. Kernel-based least squares policy iteration for reinforcement learning. IEEE Trans. Neural Netw 2007, 18, 973–992. [Google Scholar]
- Jung, T.; Polani, D. Kernelizing LSPE (λ). IEEE International Symposium on Approximate Dynamic Programming and Reinforcement Learning (ADPRL 2007), Honolulu, HI, USA, 1–5 April 2007; pp. 338–345.
- Nedic, A.; Bertsekas, D. Least-squares policy evaluation algorithms with linear function approximation. Discrete Event Syst. J 2003, 13, 79–110. [Google Scholar]
- Engel, Y; Mannor, S; Meir, R. Reinforcement learning with Gaussian processes. Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 201–208.
- Li, S.; Meng, M.; Chen, W. SP-NN: A novel neural network approach for path planning. IEEE International Conference on Robotics and Biomimetics, Sanya, China, 15–18 December 2007; pp. 1355–1360.
- Rasmussen, C. E.; Kuss, M. Gaussian processes in reinforcement learning. In Advances in Neural Information Processing Systems; Vancouver, BC, Canada; 13–18; December; 2004; pp. 751–759. [Google Scholar]
- Farahmand, A.M.; Szepesvi, C.; Ghavamzadeh, M.; Mannor, S. Regularized policy iteration. Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008.
- Engel, Y.; Mannor, S.; Meir, R. The kernel recursive least squares algorithm. IEEE Trans. Sign. Process 2003, 52, 2275–2285. [Google Scholar]
- Blum, A. Random projection, margins, kernels, and feature-selection. LNCS 2006, 3940, 52–68. [Google Scholar]
- Nadaraya, E. A. On estimating regression. Theory Probab. Appl 1964, 9, 141–142. [Google Scholar]
- Taylor, G.; Parr, R. Kernelized value function approximation for reinforcement learning. Proceedings of 27th International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1017–1024.
- Zhou, S.; Lafferty, J.; Wasserman, L. Compressed and privacy-sensitive sparse regression. IEEE Trans. Inform. Theory 2009, 55, 846–866. [Google Scholar]
- Puterman, M. L. Markov Decision Processes; Wiley Interscience: New York, NY, USA; p. 1994.
- Maillard, O.A.; Munos, R. Compressed least-squares regression. Proceedings of Advances in Neural Information Processing Systems 22, Vancouver, BC, Canada, 12–15 December 2009; pp. 1213–1221.
- Kolter, J. Z.; Ng, A. Y. Regularization and feature selection in least-squares temporal difference learning. Proceedings of 27th International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009.
- Mahadevan, S.; Liu, B. Basis construction from power series expansions of value functions. In Advances in Neural Information Processing Systems 23; Vancouver, BC, Canada; 6–9; December; 2010; pp. 1540–1548. [Google Scholar]
- Bingham, E.; Mannila, H. Random projection in dimensionality reduction: Applications to image and text data. In Knowledge Discovery and Data Mining; ACM Press: San Francisco, CA, USA, 2001; pp. 245–250. [Google Scholar]
- Martinsson, P. G.; Halko, N.; Tropp, J. A. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. arXiv 2010. arXiv:0909.4061v2.. [Google Scholar]
- Lagoudakis, M.G.; Parr, R. Least-squares policy iteration. J. Mach. Learn. Rese 2003, 4, 1107–1149. [Google Scholar]
- Liu, B.; Li, S.; Lou, Y.; Chen, S.; Liang, Y. A Hierarchical learning architecture with multiple-goal representations and multiple time-scale based on approximate dynamic programming. Neural Comput. Appl 2012. in press.. [Google Scholar]
- Liu, B.; He, H.; Daniel, W. R. Two-time-scale online actor-critic paradigm driven by POMDP. Proceedings of International Conference on Networking, Sensing and Control (ICNSC), Chicago, IL, USA, 10–12 April 2010; pp. 243–248.






| Compression Ratio | Balancing Steps | With Failure? |
|---|---|---|
| 100 | 412 | Y |
| 150 | 380 | Y |
| 300 | 312 | N |
| 400 | 227 | N |
| ALD Threshold | Size of ALD Dic | Compression Ratio | Avg Blancing Steps |
|---|---|---|---|
| 0.1 | 184 | * | 178 |
| 0.3 | 117 | * | 270 |
| 0.1 | 117 | 117/184 | 194 |
| * | * | 117/3, 000 | 403(with failure) |
| * | * | 184/3, 000 | 341(with failure) |
© 2012 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Liu, B.; Chen, S.; Li, S.; Liang, Y. Intelligent Control of a Sensor-Actuator System via Kernelized Least-Squares Policy Iteration. Sensors 2012, 12, 2632-2653. https://doi.org/10.3390/s120302632
Liu B, Chen S, Li S, Liang Y. Intelligent Control of a Sensor-Actuator System via Kernelized Least-Squares Policy Iteration. Sensors. 2012; 12(3):2632-2653. https://doi.org/10.3390/s120302632
Chicago/Turabian StyleLiu, Bo, Sanfeng Chen, Shuai Li, and Yongsheng Liang. 2012. "Intelligent Control of a Sensor-Actuator System via Kernelized Least-Squares Policy Iteration" Sensors 12, no. 3: 2632-2653. https://doi.org/10.3390/s120302632