1. Introduction
The current state-of-the-art of the technology for increasing traffic safety fades the boundary between on-board and infrastructure safety systems. On-board -primary or secondary- safety systems focus on providing assistance to the driver or deploy all actions oriented to protect the occupants when an accident occurs. However, whereas primary safety systems try to avoid accidents, secondary safety systems aim to lessen the consequences for occupants. On the other hand, infrastructure safety systems are normally used to provide drivers with information concerning the environment which may change mainly due to weather conditions (rain, fog, snow, etc.), traffic conditions, state of the road, etc.
Additionally, the emergence of the Internet of Things (IoT) opens a new world of possibilities for the smart cities and traffic safety because new devices can take advantage of it to improve their functionality. The creation of a network composed by different objects connected each other is a cutting-edge concept. This is a new opportunity to enhance the city’s urban infrastructure since sensors can share information about their environment for handling different devices. This kind of information would be very useful to manage the traffic in a city and, at the same time, to increase the safety.
Object identification is a very useful technique since it allows to distinguish different object types in order to act accordingly depending on the application requirements (e.g., object tracking to deal with the traffic density or object recognition to distinguish between vehicles and people for managing road light signals or to differentiate the vehicle type to handle toll.). However the detection of those objects is required before the identification. There are several sensors able to detect presence or motions; therefore there are multiple alternatives to carry this proposal out. Vehicle detection is not so complicated since vehicles have many metallic parts which may cause some variation of a magnetic field produced by some buried coils [
1]. However, it is not suitable solution for people detection. Optical methods, like videocameras- based systems [
2], can solve this problem since they are able to detect and to identify all kind of objects; but they are very computationally intensive and require expensive devices. On the other hand, ultrasonic sensors provide a short range, and hence they are not an extended solution. Nevertheless, despite the fact that radar technology is very similar to the previous one its range is larger since it uses an electromagnetic wave instead of an ultrasonic one. For all these issues, among all of the above mentioned alternatives, the radar technology is the one selected for this work.
Radar sensors provide a signal when some motion occurs in theirs area of detection; therefore the object detection is not a complex task. However, object identification requires to analyze deeply the radar echo. For example, Fang
et al. [
3] utilized time-frequency analysis, multi-threshold detection, and Hough transform as main signal processing methods to extract speed and shape information of vehicles whereas Alaee and Amindavar [
4] applied Chirplet transform to radar signal in order to make the target classification using the nearest neighbor clustering technique. Moreover, a two-stage support vector machine (SVM) classification method using Mel-Frequency Cepstrum coefficients is developed and proposed in [
5]. Another alternative is proposed by Gharaibeh and Yaqot [
6]. They presented a methodology based on Particle Swarm Optimization (PSO) that improved the computational speed for the nearest neighbor clustering technique. Other objects are analyzed in [
7] where Briones
et al. developed a radar system that operates in land and air and classifies different targets using an artificial neural network trained with the Levenberg-Marquardt algorithm. Our proposal implies to obtain information from the radar echo, in both time and frequency domains, in order to distinguish vehicles and pedestrian from other kind of objects. An expert system based on a classification tree [
8] is developed to meet those requirements. Moreover, sensor cooperation is a support not only to guarantee high reliability but also to estimate the movement tracking of the detected object considering the devices which can detect that object. However, it is important to mention that the echo signal received from the same object type may be different whether some change in the environment is produced. For instance, if a branch of a tree interferes with the radar echo it may cause that a radar device, which was identifying pedestrian correctly, fails and therefore provides wrong identifications. Therefore, the system has also to be able to adapt to those changes using some machine learning techniques.
The objective of this work is not only to identify different objects but also to adapt the system to changing environments combining system cooperation and machine learning techniques. Consequently, a generic proof of concept is presented which could be employed for different applications such as automatic traffic management or effective control for shadow tolls.
In many situations, traffic jams may be avoided by implementing a suitable traffic lights operation management in a city. For instance, nowadays, a simple solution is provided in some crossings to deal with the traffic light control. It consists of pushing a button when a pedestrian has the intention to cross a road. However, this is not an automatic solution and also it is not useful for all people (e.g., blind people) because it requires pressing the button to turn on green the pedestrian signal. Using the proposed radar-based system would be possible to automate this process, especially at night or low pedestrian density streets. When a radar-based device identifies a pedestrian, it can communicate to other devices that there is a person on the street which causes an effective network between this radar-based device and the other ones located closely. The network goal is not only to pass information about the presence of a pedestrian in order to locate him/her, but also to verify that the identification of that radar device is correct (hit). This verification can be done through cooperation since the network gives the opportunity make a joint decision using multiple hypotheses about the object type. If a radar device provides ongoing misses (wrong identifications), it should modify its own identification algorithm in order to adapt its behavior to this new situation.
On the other hand, as mentioned before, this system can also be useful for shadow tolls since it may distinguish several vehicles types such as cars, trucks or motorcycles in order to pay the tax accordingly. It could minimize the contractual payment made by a government per driver to a private company since different fares should be applied depending on the type of the vehicle.
Moreover, the proposed system is very versatile since it can be supported by the city infrastructure, as previous examples demonstrate, but also it can be applied as a part of a vehicle in order to improve vehicle-to-vehicle communication. It means that each vehicle can be dealt as a device inside the cooperative network and it can share information about the presences in the environment to others vehicles at real time. Therefore, the autonomous driving could be enhanced since each vehicle can share environment information while it is moving around.
All these issues make the proposed system extremely useful for short-term outlooks on road safety applications. However, one of the most important requirements of this work is to implement all of these functionalities in an embedded system. In this way, an external computer is not required since a compact hardware platform can be integrated in multiples system to provide it with these functionalities.
The rest of the article is organized as following.
Section 2 specifies the system implementation and the general proposed scheme. In
Section 3 some issues about theoretical concepts of decision tree and clustering are given, but alsoand the cooperative network and some cooperative strategies are presented.
Section 4 shows the real and simulated results. And finally, in
Section 5, some conclusions and future works are provided.
2. Overall System
In order to develop the proposed system, a low-cost hardware platform was implemented [
8]. This is based on a DSP (Digital Signal Processor) which is in charge of analyzing the radar signal and implementing the expert system that deals with the radar information to identify the detected object. A low-cost and low-power radar device has been selected which works in the 10 GHz band (ISM band) so no authorization is required for its use.
The expert system is based on a decision tree therefore it has to be trained before the commissioning. A decision tree is a flowchart-like probabilistic method for classifying different entities analyzing some of their intrinsic parameters. They are supervised methods within the machine learning field so they require a train stage which implies to create the structure of the tree according to some real examples. In this work a decision tree is used to classify different kind of objects such as pedestrians, vehicles or other types of road-environment objects and, in our case under study, the previous training consists of collecting several echoes of the radar device provided by different kind of detected objects. After that, these signals are used to extract the main characteristics of each object category so every new taken signal will correspond to a specific category. Consequently, the proposed device –or node- is composed by the radar, a conditioned stage for adapting the radar signal, a DSP for signal processing and some communication interfaces.
In spite of the fact that this radar-based device can detect and identify different objects, which are previously defined, our new proposal for this work tries to go further. Adaptation to changing environment and also reliability improvements are sought; therefore some modifications of the early device are required. The new proposal implies to modify the structure of the decision tree in order to allow internal changes and also it can include some cooperative skills using a network support.
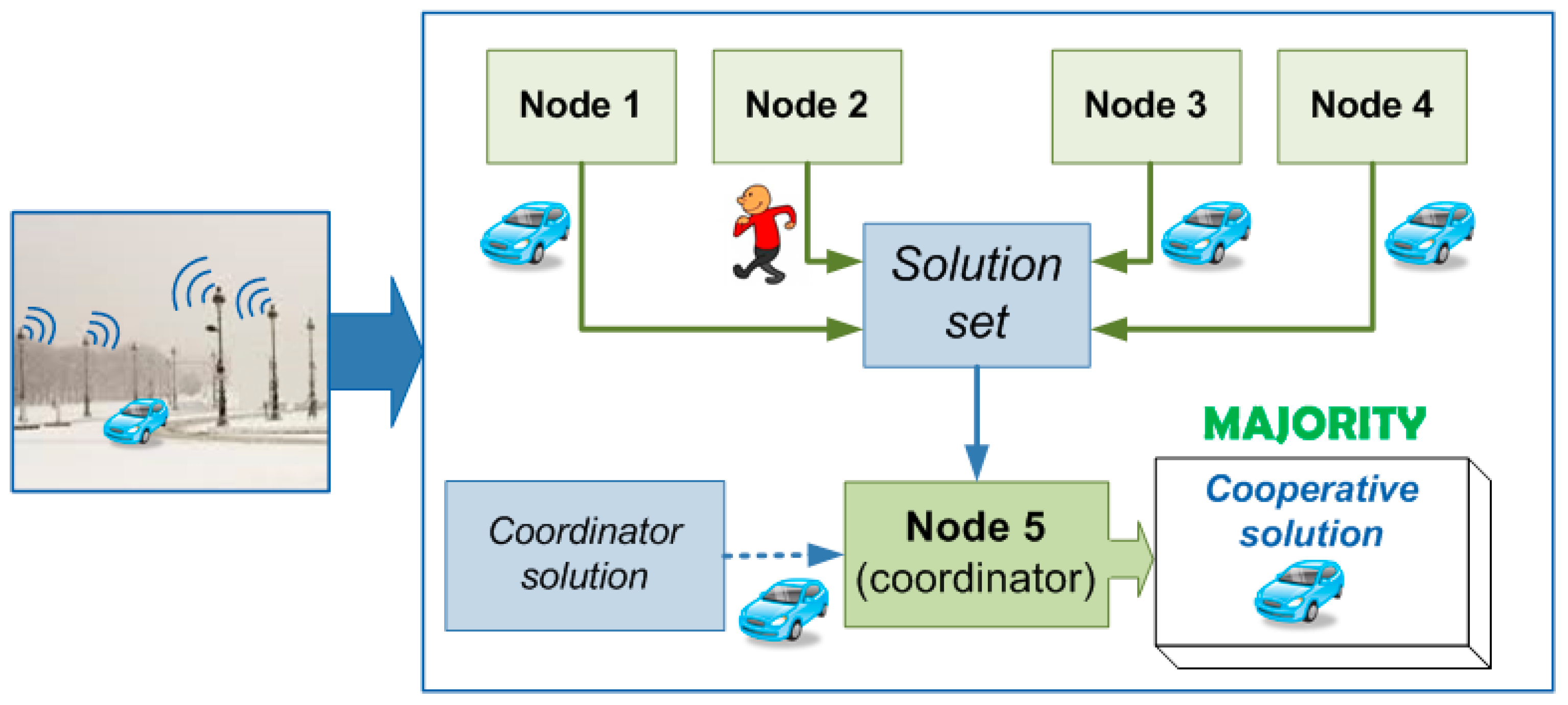
On the one hand, cooperation will provide more reliability since it allows make a joint decision taking into account different hypothesis over the same object. Moreover, on the other hand, a dynamic classification tree is proposed in order to adapt the system behavior to some environment changes using also the cooperative network and some clustering techniques. The whole scheme of the proposed system is shown in
Figure 1 where two different stages are defined.
The classification stage provides a category which corresponds to the kind of the detected object. The main functionality of this stage is supported by the classification tree- or decision tree- since it has to provide the identification of the new detected object according to its previous training. However, the decision tree has been modified for including an “unknown” category. This category collects the objects which cannot be classified with a high level of reliability. Furthermore, although the decision tree provides a valid category, the final decision is not only given by this classification tree but also the cooperation among the others has to be taken into account. Therefore, a communication network is required to provide the support for sharing information among different devices placed at different locations but belonging to the same network. Once a classification tree provides an identification result, this has to be shared among the rest of the nodes that belong to the same cooperative network in order to obtain a cooperative identification result. Using this procedure, the system is able to assure a more reliable identification since different nodes participate in the final decision.
Figure 1.
Whole scheme of the proposed system.
Figure 1.
Whole scheme of the proposed system.
The adaptation to changing environments is achieved in the learning stage. In this process the system uses those objects that have been classified as “unknown objects” for creating a new label to define them correctly. In order to assign the label, cooperative contributions have to be taken into account so the cooperative network is also in charge of defining this new label.
Figure 2 specifies the contribution of the cooperation and machine learning methods to the whole system functionality.
Figure 2.
Identification process combining different machine learning methods and cooperation.
Figure 2.
Identification process combining different machine learning methods and cooperation.
4. Results
In this section several results from different points of view are presented. First of all, the coverage analysis shows how far the devices can be placed to guarantee communication among them avoiding isolated devices. Moreover, some simulated results related to machine learning algorithms are also presented. However, in order to achieve an interpretable view of those results, graphs presented in this section show only a representation in two or three dimensions, hence in some graphs the less significant features of the training set are not observed. Finally, the system performance is analyzed to demonstrate if the proposed solution is suitable for embedded systems.
Nevertheless, the system cannot be tested completely since the cooperation has not been included yet. Therefore, the whole system does not label the “unknown” objects until now. However, the presented results are enough to evaluate in general terms whether or not the proposed architecture could be appropriated.
4.1. Coverage Analysis
The parameters that have been considered for the coverage analysis are shown in
Table 1. It is important to mention that the obstacle losses have been estimated for a multiobject space according to the recommendations given by the ITU (International Telecommunication Union).
Table 1.
Parameters for the coverage analysis.
Table 1.
Parameters for the coverage analysis.
| Parameter | Value | Value (Natural Units) |
|---|
| Frecuency (f) | - | 2.4 GHz |
| Wave length (λ) | - | 0.125 m |
| Transmitted power (PT) | 3 dBm = −27 dB | 1.995 mW |
| Antenna gain (GT y GR) | 32.39 dBm = 2.3880 dB | 1.7330 |
| Obstacle losses (LOBS) | 0 dBm = −30 dB | 0.001 |
| Cable losses (LT y LR) | 29.77 dBm = −0.2325 dB | 0.9479 |
| Sensitivity | −97 dBm = −127 dB | 0.1995 pW |
The coverage analysis has been studied for different cases.
Figure 11 and
Figure 12 show the theoretical results obtained when the Friis Equation (4) is used and the parameters of the
Table 1 are applied.
These results demonstrate that the cable losses are almost irrelevant since cases 3 and 4 are very similar. Furthermore, simulations show that the maximum distance among devices could be more than 50 m since the receiver sensitivity is −97 dBm. However, it is advisable to give a security margin and no to go so closely to the sensitivity value. Therefore, our real measures verify that 35 m is an appropriated distance to assure nodes coverage.
Figure 11.
Estimation of maximum distances using Friis formula.
Figure 11.
Estimation of maximum distances using Friis formula.
Figure 12.
Zoom of maximum distances estimations.
Figure 12.
Zoom of maximum distances estimations.
4.2. Decision Tree Pruning and Clustering Results
Results shown in this section do not consider the cooperative model implementation. It means that the modification of the decision tree is made using only the information generates in the own device without using external information provided by the cooperative network. The inclusion of the cooperative information for modifying the decision tree is one of the future works proposed in this article. Therefore, in this section the influence of both pruning and clustering thresholds are evaluated.
In order to analyze the influence of the pruning in the decision tree algorithm, different pruning thresholds have been simulated. Results are shown in a graph that represents the training set and the unknown area created during the pruning process. In the case of a pruning threshold of 0.05, the created “Unknown Area” is small compared to the total area available to accommodate new objects. In contrast, a pruning threshold of 0.15 generates the “Unknown Area” to be too large causing some classes to disappear.
Figure 13 shows the evolution of the “Unknown Area” with the increasing of the pruning threshold.
Figure 13.
Evolution of “Unknown Area”.
Figure 13.
Evolution of “Unknown Area”.
Identically to the decision tree algorithm results, the influence of the clustering threshold has also been analyzed. Therefore, different situations have been simulated using different clustering thresholds. When a clustering threshold of 0.1 is applied, the number of clusters generated is high and the problem is that most of the clusters are unitary, as the clusters are not a combination of several instances. In contrast, a clustering threshold of 0.5 creates heterogeneous clusters where the instances are too different among them.
Figure 14 and
Table 2 show the evolution of the clusters for different threshold values.
Figure 14.
Evolution of clusters.
Figure 14.
Evolution of clusters.
Table 2.
Clustering threshold.
Table 2.
Clustering threshold.
| | Clustering Threshold |
|---|
| 0.1 | 0.2 | 0.5 |
|---|
| Number of Groups | 22 | 13 | 6 |
| Unitary Groups | 17 (77.27%) | 9 (69.23%) | 1 (16.67%) |
The validation of the dynamic decision tree learning architecture was developed in two different stages. During the first stage, a simulation of 10 new classifications was carried out. The result of the learned instances corresponds to 2 different objects. In
Figure 15 the obtained results are presented.
Figure 15.
Training set including new classifications.
Figure 15.
Training set including new classifications.
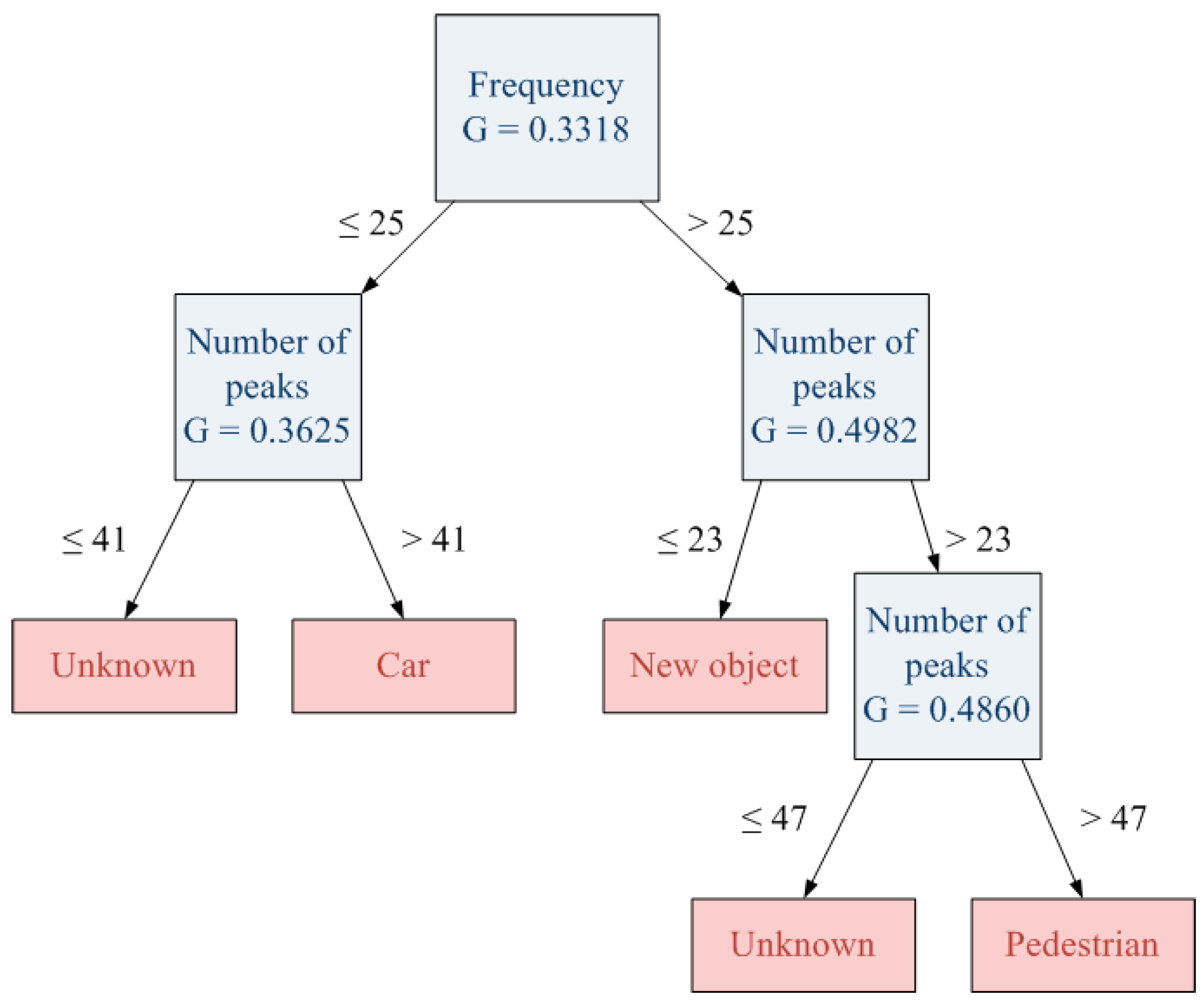
In spited of the fact that new object has been identified, the new decision tree generated after the completion of the clustering process does not include any of these new learned objects. This effect is produced since the decision tree does not have enough information to include new objects in the decision tree.
Figure 16 shows this new decision tree which does not include any “unknown” category.
Figure 16.
New decision tree generated.
Figure 16.
New decision tree generated.
In order to avoid the effect of the previous stage, the second one includes 10 instances of the same object in the training set, so there are more examples for a specific “unknown” object. However, results of this stage are very conditioned by the applied pruning threshold value. For instance, if the applied pruning threshold is the same like the one used in the previous decision tree, the new generated tree is able to classify the new object (
Figure 17) including a “new object” category. However, it will create a wide area of unknown objects that collects those that were correctly classified in the previous decision tree (e.g., pedestrian). This implies that some early hits become new misses since pedestrian zone turns into “unknown” zone.
Figure 18 shows the result with a pruning threshold of 0.1.
Figure 17.
Decision tree with the same pruning threshold (0.1).
Figure 17.
Decision tree with the same pruning threshold (0.1).
Figure 18.
Unknown areas with the same pruning threshold (0.1).
Figure 18.
Unknown areas with the same pruning threshold (0.1).
In contrast, if the pruning threshold is reduced, the generated decision tree is able to classify both new and previously learned objects (
Figure 19) and the area of the unknown objects will be more appropriate.
Figure 20 shows the result for a half pruning threshold comparing with the original one (0.05). In this case, pedestrians are correctly classified and also new objects are detected.
Figure 19.
Decision tree with less pruning threshold (0.05).
Figure 19.
Decision tree with less pruning threshold (0.05).
Figure 20.
Unknown areas with the less prunning threshold (0.05).
Figure 20.
Unknown areas with the less prunning threshold (0.05).
4.3. System Performance and Memory Requirements
One of the main goals of this work is the implementation of the machine learning algorithms inside an embedded system; therefore the performance of this kind of platforms is very important. Therefore, both computing time and memory requirements are important factors to take into account for an embedded system.
4.3.1. Computing Time Analysis
In this section the computing time spent in the creation of a decision tree using the modified C4.5 algorithm proposed in this work is analyzed.
The computing time depends on both the number of instances of the training set and the number of nodes created in the decision tree (
Table 3).
Figure 21 shows the computing time against the number of instances of the training set. In general, the greater number of instances present in the training set, the longer computation time is required. However, in some cases the system deviates from the premise. As shown in
Figure 21, in spite of increasing the number of instances from 20 to 25, the execution time is reduced. This is due to the fact that the number of nodes is also reduced in this case. Therefore, the decision tree is less complex and takes less time to create itself.
Table 3.
Computing time.
| Computing Time |
|---|
| Number of Instances | Execution Time (s) | Nodes of the Decision Tree |
|---|
| 10 | 13.98 | 7 |
| 15 | 21.15 | 7 |
| 20 | 30.10 | 11 |
| 25 | 21.58 | 6 |
| 30 | 28.79 | 7 |
| 34 | 38.58 | 9 |
Figure 21.
Computing time of the decision tree algorithm.
Figure 21.
Computing time of the decision tree algorithm.
4.3.2. Memory Requirements
As mentioned above, the system is implemented using a DSP (dsPIC33FJ64MC802) therefore a very limited memory size is available. The C4.5 algorithm makes use of recursion which causes that the dynamic memory used by the system becomes fragmented. This fragmentation leads to an inefficient memory use. Therefore, a good way to overcome this drawback is to use the memory management capabilities of an Operating System (OS). However, a complete OS has a strong footprint over the DSP program memory and for this reason, only the memory management layer of an OS is implemented.
Table 4 and
Figure 22 show the dynamic memory used by the system using or not the memory management layer of freeRTOS.
Table 4.
Use of dynamic memory.
Table 4.
Use of dynamic memory.
| | Use of Dynamic Memory |
|---|
| Without Using OS | Using Free RTOS |
|---|
| Free Memory | 71.43% | 74.05% |
| Memory Occupied | 25.95% | 25.95% |
| Fragmented Memory | 2.62% | 0.00% |
Figure 22.
Dynamic memory using an OS.
Figure 22.
Dynamic memory using an OS.
As it is shown in
Table 4, using the memory management capabilities of the OS, the free dynamic memory increases by 2.62% with a footprint of just 780 Bytes over the data memory and 264 Bytes over the program memory. The required amount of dynamic memory for the learning architecture follows a geometric progression with the number of instances of the training set as shown
Figure 23. For instance, it means that using the memory management capabilities of the OS and for a number of instances around 70, the saved memory will be 1310 Bytes.
Figure 23.
Evolution of the dynamic memory with the number of instances.
Figure 23.
Evolution of the dynamic memory with the number of instances.
5. Conclusions and Future Work
Taking into account the current simulation results, several conclusions are obtained considering different parts of the proposed scheme. On the one hand, for the decision tree algorithm, it is necessary to select the pruning threshold properly in order to optimize the “unknown” area. A low pruning threshold wastes a lot of space in the features space whereas a high pruning threshold degenerates the learning which causes the extinction of some classes (
Figure 13). The optimization of the pruning threshold is mandatory due to the fact that learning capabilities increase when the “unknown” area is optimized.
Something similar occurs with clustering threshold. The selection of an adequate threshold affects largely the number and the definition of new objects that the system is able to detect. A low clustering threshold implies the detection of too many objects that in fact belong to the same category. In contrast, a high clustering threshold produces the detection of objects which are poorly defined (
Figure 14). Therefore, an appropriate selection of the clustering threshold may help the learning process since the system could learn homogenous objects that are properly defined.
The presented results also demonstrate that the system, using the complete learning architecture, is able to learn new objects. However, it is unable to classify them as long as a high number of instances are learned. This effect is due to the fact that the number of learned instances for one object has to be comparable to the number of instances of the rest of the trained objects. Otherwise, the decision tree algorithm will assume that the object is a strange object and it will be classified as “Unknown”. Furthermore, in order to allow the system to evolve and to learn correctly, it is mandatory to adjust the pruning threshold. This adjustment could be automatic taking into account the number of instances of the training set and the number of different objects to classify.
On the other hand, the proposed learning architecture, with the modified machine learning algorithms, is suitable for embedded systems in which memory and computational complexity are resources to be optimized. However, the required memory to execute the decision tree algorithm increases exponentially with the number of instances of the decision tree (
Figure 23), which means that the size of the training set has to be bounded unless an external memory is included in the embedded system.
Summing up, early results demonstrate that the implementation of an adaptive-dynamic classification tree is possible. However, memory requirements have to be considered especially for embedded system developments. Moreover, it is important to mention that the system is not complete yet, since cooperative algorithms are not included although several cooperative algorithms have been studied independently [
15,
16]. For this reason the current system is able to learn new kind of objects but it is not able to label them. Therefore, future works are focused on improving the system including some cooperative algorithms for network implementation. In this way, the system behavior will be more adaptive and also more reliable since it could take advantage of the cooperation benefits.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












