Three different mean functions have been used to fit the model: the zero mean function, the constant mean function and the linear mean function. These mean functions were combined with basis kernels (SE, Mat , RQ). The independent noise kernel (IN), which we combined additively with the basis kernels, resulted consequently in a poor model fit (larger residual and BIC), when compared to the model without this kernel, and was therefore excluded from the results. Since the hyperparameter optimization did sometimes not succeed when using an additive kernel with order higher than one, we also withhold these data. Further kernel functions, such as periodic ones, were not examined, because we expect only local structures due to the log-distance path loss model and due to the lower and upper bounds of RSSs.
5.2.1. Test Error and Bayesian Information Criterion
The following tables show the test error and the BIC of the predictions obtained from Gaussian process regression with priors formed by the combinations of mean and covariance functions as shown in the tables. A better fitting model is indicated by the smallest test error and the lowest BIC.
The model measures for the Indoor training data can be found in
Table 2.
Consider the test error with respect to the mean functions. One can observe that the constant mean function outperforms the zero mean and the linear mean function consistently; the zero mean function yields always lower test errors than the linear mean function. The BIC shows contrasting results. The linear mean function presents most times a lower BIC than the constant mean function; anyhow, they are very close. The BIC for the models with zero mean function is the largest at all times when compared to the other mean functions.
With regard to the different kernel functions, the test error does not point to a candidate. The model with the additive SE kernel yielded the lowest test error; the SE and Matérn kernel show a similar result. The SE kernel works better when combined with the zero mean function and the Matérn kernel better with the constant mean function. The BIC reveals more clearly the more appropriate models: the Matérn kernel fits the data best followed by the Matérn and then followed by the squared exponential kernel. As expected, the more complex models (the last three) have larger BICs than the models with fewer parameters. Note that the model derived with a zero mean and squared exponential covariance function is also a model with few parameters, but yielding a relatively high BIC.
Table 2.
Test error and BIC of a Gaussian process regression for different Gaussian process models trained with Indoor data. Model measures are averages over several access points and 10-fold cross-validation. The lowest values are highlighted.
Table 2.
Test error and BIC of a Gaussian process regression for different Gaussian process models trained with Indoor data. Model measures are averages over several access points and 10-fold cross-validation. The lowest values are highlighted.
| Mean Function/Kernel | Test Error/dBm | BIC |
|---|
| Zero | Const | Lin | Zero | Const | Lin |
|---|
| SE | 9.856 | 9.714 | 9.864 | 703.093 | 682.127 | 682.051 |
| Mat | 9.727 | 9.686 | 9.890 | 691.012 | 684.433 | 684.421 |
| Mat | 9.829 | 9.715 | 9.916 | 693.923 | 682.010 | 681.903 |
| Mat | 9.847 | 9.741 | 9.915 | 697.181 | 681.882 | 681.730 |
| RQ | 9.796 | 9.727 | 9.900 | 691.367 | 684.291 | 684.075 |
| sum of SE and SE | 9.860 | 9.709 | 9.922 | 707.760 | 686.931 | 687.104 |
| prodof SE and SE | 9.900 | 9.723 | 9.854 | 707.089 | 686.870 | 686.856 |
| addof SE | 9.765 | 9.684 | 9.762 | 704.530 | 693.851 | 694.259 |
Table 3.
Test error and BIC for different Gaussian process models trained with the outdoor data. The values are averages over several access points and 10-fold cross-validation. The lowest test error and BIC are highlighted.
Table 3.
Test error and BIC for different Gaussian process models trained with the outdoor data. The values are averages over several access points and 10-fold cross-validation. The lowest test error and BIC are highlighted.
| | Mean Function/Kernel | Test Error/dBm | BIC |
|---|
| Zero | Const | Lin | Zero | Const | Lin |
|---|
| Outdoor-1 | SE | 8.982 | 9.025 | 9.085 | 1015.224 | 994.559 | 994.662 |
| Mat | 9.075 | 9.041 | 9.090 | 999.759 | 993.034 | 992.891 |
| Mat | 9.087 | 9.054 | 9.101 | 1004.740 | 991.610 | 991.580 |
| Mat | 9.065 | 9.051 | 9.097 | 1009.041 | 992.243 | 992.330 |
| RQ | 9.064 | 9.055 | 9.107 | 1002.027 | 995.405 | 995.051 |
| sum of SE and SE | 8.984 | 9.034 | 9.068 | 1020.611 | 999.941 | 1000.402 |
| prod of SE and SE | 9.008 | 9.026 | 9.082 | 1020.691 | 1000.822 | 1000.060 |
| add of SE | 8.971 | 8.964 | 9.017 | 1032.788 | 1021.243 | 1020.440 |
| Outdoor-2 | SE | 7.315 | 7.348 | 7.401 | 372.575 | 356.170 | 357.956 |
| Mat | 7.326 | 7.289 | 7.333 | 366.333 | 357.939 | 360.296 |
| Mat | 7.338 | 7.322 | 7.382 | 368.586 | 356.720 | 358.833 |
| Mat | 7.345 | 7.335 | 7.393 | 370.125 | 356.221 | 358.537 |
| RQ | 7.354 | 7.361 | 7.418 | 367.016 | 357.939 | 359.611 |
| sum of SE and SE | 7.317 | 7.337 | 7.401 | 376.122 | 359.774 | 361.995 |
| prod of SE and SE | 7.296 | 7.339 | 7.386 | 376.388 | 359.774 | 362.188 |
| add of SE | 7.225 | 7.207 | 7.283 | 375.852 | 366.793 | 367.726 |
Based on the test error and BIC and contemplating both model measures, we consider a Gaussian prior with constant mean function and Matérn covariance function as the best candidate for this dataset.
In
Table 3, the test error and the BIC from the outdoor data sets can be observed.
Give consideration to the mean functions first. For both outdoor datasets, mostly the constant mean function provides the lowest test errors, but also models trained with the zero mean function yielded low test errors: in 38% of the models trained with the Outdoor-1 radio map and in 50% of the models fitted to the Outdoor-2 data. Regarding the BIC for the Outdoor-1 radio map, on average, the constant and the linear mean function perform equally well, even though the linear mean function achieved the lowest BIC. For the Outdoor-2 data, the constant mean function provides throughout the lowest BIC. The zero mean function on the contrary produced models that attained always the largest BIC.
Choosing a kernel based solely on the smallest test error would result again in the additive SE kernel function, followed by the SE and the kernels derived as the sum or product of the SE kernel. However, taking the BIC into account shows that exactly these kernels fit the data worst, particularly when combined with the zero mean functions. For both outdoor radio maps, the lowest BICs resulted from models with the Matérn class or squared exponential functions.
We believe a model based on the constant mean function and the Matérn kernel with or balances well between the obtained test errors and BICs for the outdoor data. Comparing this to the outcomes from the Indoor data also implies that the Gaussian process models incorporating a Gaussian prior distribution with constant mean and Matérn covariance function fit indoor and outdoor radio maps equally well.
The results from the data joining the three radio maps (see
Table 4) confirm the already obtained findings.
Table 4.
Test error and BIC for different Gaussian process models trained with the Test-bed data. Model measures are averages over several access points and 10-fold cross-validation. The lowest values of each category are typeset in bold.
Table 4.
Test error and BIC for different Gaussian process models trained with the Test-bed data. Model measures are averages over several access points and 10-fold cross-validation. The lowest values of each category are typeset in bold.
| Mean Function/Kernel | Test Error / dBm | BIC |
|---|
| Zero | Const | Lin | Zero | Const | Lin |
|---|
| SE | 9.277 | 9.286 | 9.403 | 1498.148 | 1458.365 | 1460.108 |
| Mat | 9.351 | 9.318 | 9.422 | 1459.503 | 1451.745 | 1452.113 |
| Mat | 9.346 | 9.308 | 9.435 | 1472.590 | 1452.499 | 1453.363 |
| Mat | 9.347 | 9.305 | 9.433 | 1481.816 | 1454.384 | 1455.309 |
| RQ | 9.334 | 9.325 | 9.428 | 1462.458 | 1455.182 | 1456.116 |
| sum of SE and SE | 9.278 | 9.290 | 9.388 | 1504.146 | 1464.460 | 1466.045 |
| prod of SE and SE | 9.274 | 9.287 | 9.400 | 1504.203 | 1464.387 | 1466.445 |
| add of SE | 9.059 | 9.051 | 9.141 | 1544.440 | 1531.548 | 1531.577 |
With respect to the test error, models using the constant mean function or zero mean function outperform models relying on the linear mean functions. The best test error was obtained with priors based on the additive SE kernel, but the corresponding BIC is also one of the largest. Furthermore, the test error of the model trained with the zero mean and SE covariance function is quite low, but the BICs, which were obtained with the zero mean function, are throughout the largest. Once again, the zero mean and linear mean function perform contrary to the low model measures; the zero mean function has the low test errors, but large BICs and, vice versa, the linear mean function. On the contrary the constant mean function yielded consistently low model measures.
Consider the model measure for the different kernels: again, only the combination of constant mean function and Matérn kernels attained low test errors and low BICs. The SE kernel yielded again low test errors, but relatively high BICs, as well, which is not expected for a kernel with few hyperparameters (having the same number of hyperparameters as, for instance, the Matérn kernel). This dataset also reconfirms that models with the additive kernel attain very low test errors.
The evaluation of the test error and BIC for the presented data already provides some insights, which we summarize:
In all datasets, it can be seen that the lowest BIC was achieved when the constant mean function was combined with the Matérn kernels with the roughness parameter: for the indoor data, and for the two outdoor datasets and for the joined radio map. The same models yielded low test errors, as well.
Models employing the zero mean function produced the largest BICs no matter the dataset. As the SE function only result in low test errors when the zero mean function was used, we sort out the squared exponential kernel as an immediate choice.
For all datasets, the lowest test error was obtained by models with a constant mean function and an additive SE kernel of order one; however, the BIC obtained by these models is much larger than, for instance, the BIC of the models with Matérn functions, indicating a poor fit.
The test error and BIC obtained from models trained with either indoor or outdoor data are not distinguishable. In other words, for the available data, the choice of the Gaussian process prior distribution does not affect the final model notably.
For the Matérn class functions, we choose as a tradeoff between general applicability (roughness versus smoothness) and model fit (BIC and the test error are in all cases very close to the lowest model measures)
Up to this point, we only narrowed down the search for the most suitable prior distribution to a combination of the constant mean function with a kernel from the Matérn class or with the additive squared exponential function; all of following results are obtained by Gaussian process models based on a prior with a constant mean function.
The two leftover prior candidates, constant mean function with either Matérn
or additive SE
, are examined as follows.
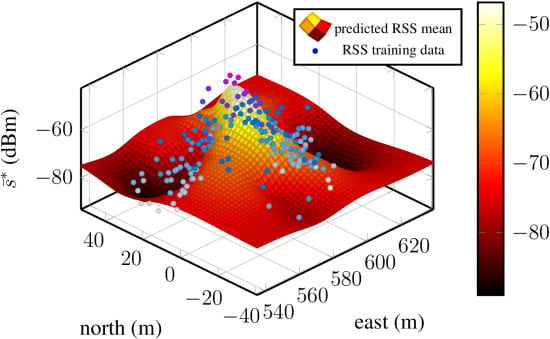
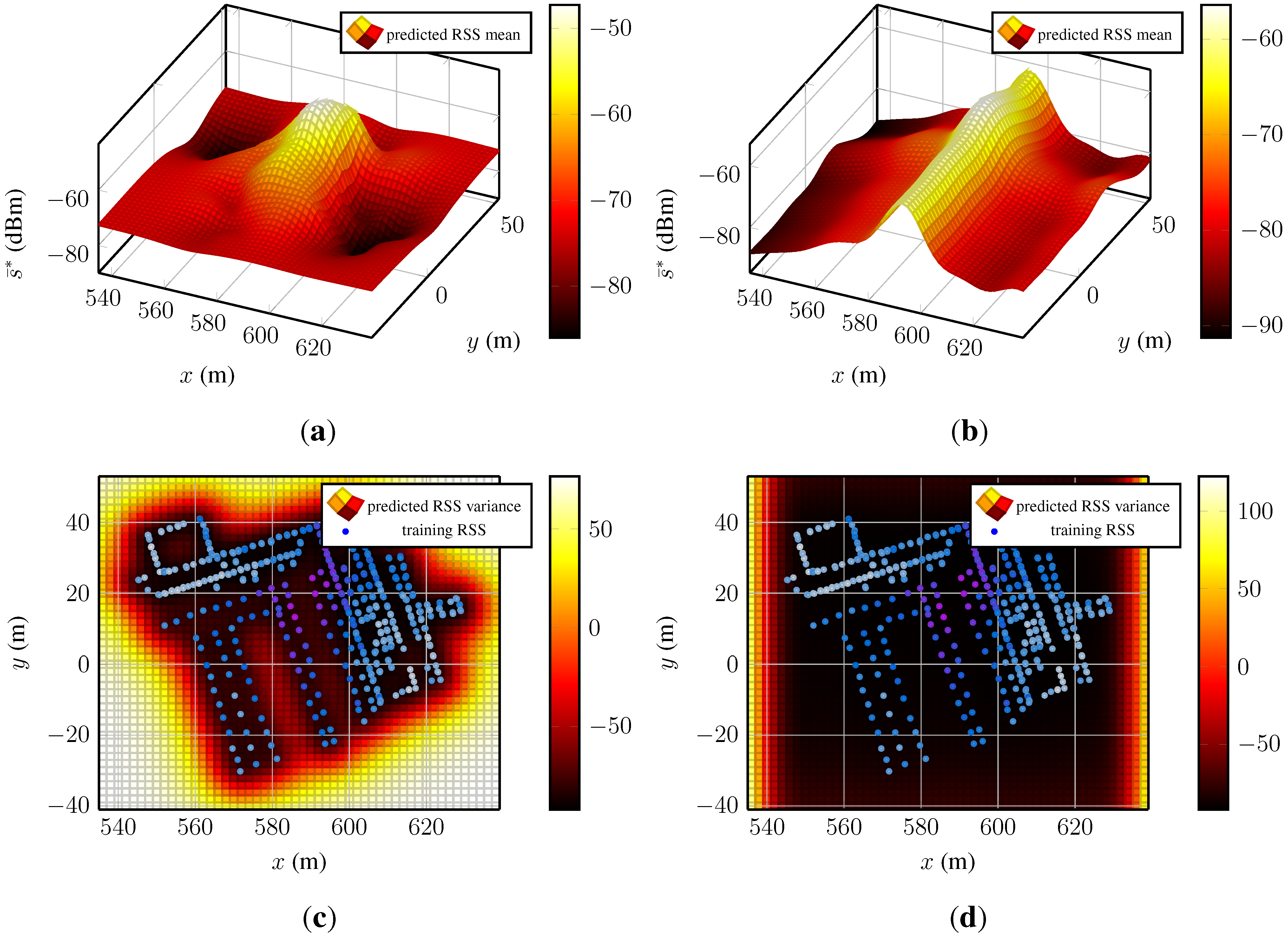
Figure 4 presents the predictive mean functions for the test bed dataset, the model based on the Matérn
function on the left and the model based on the additive SE kernel on the right.
Figure 4a shows a spatial RSS distribution with a decaying function with a global maximum and local minima and maxima. The corresponding variance function (
Figure 4c) is low where information from training data is available and grows towards regions where no information about the underlying process is available. In contrast, the results in
Figure 4b,d are not comprehensible. The predicted mean function in
Figure 4b shows an almost constant structure along the y-axis, around 590 m. The covariance function in
Figure 4d is flat over a large area and rises towards the edges of the test area. The flat region does not reflect the uncertainty that is expected considering the training points. Such a spatial distribution of signal strengths is nonphysical and unexplainable by the existing environment and/or the models of wave propagation.
Figure 4.
Predicted RSS mean and covariance functions of two Gaussian processes of one access point. The two models were obtained by a Gaussian process regression model with prior distributions chosen according the lowest residuals and BIC: constant mean function in combination with Matérn and additive SE kernel. (a) Predicted RSS mean function of a Gaussian process using a prior with Matérn kernel; (b) predicted RSS mean function of a Gaussian process using a prior with additive SE kernel of order one; (c) predicted RSS mean function of a Gaussian process using a prior with Matérn kernel and the corresponding training data; (d) predicted RSS mean function of a Gaussian process a prior with additive SE kernel of order one and the corresponding training data. The two processes where trained with the same data. The magnitudes of the mean and covariance function are indicated with the color bars. The panels depicting the covariance functions present the training data, as well. Large training data are colored purple–dark blue and low RSS light blue–white.
Figure 4.
Predicted RSS mean and covariance functions of two Gaussian processes of one access point. The two models were obtained by a Gaussian process regression model with prior distributions chosen according the lowest residuals and BIC: constant mean function in combination with Matérn and additive SE kernel. (a) Predicted RSS mean function of a Gaussian process using a prior with Matérn kernel; (b) predicted RSS mean function of a Gaussian process using a prior with additive SE kernel of order one; (c) predicted RSS mean function of a Gaussian process using a prior with Matérn kernel and the corresponding training data; (d) predicted RSS mean function of a Gaussian process a prior with additive SE kernel of order one and the corresponding training data. The two processes where trained with the same data. The magnitudes of the mean and covariance function are indicated with the color bars. The panels depicting the covariance functions present the training data, as well. Large training data are colored purple–dark blue and low RSS light blue–white.
![Sensors 15 22587 g004]()
The mean and covariance functions have shown that a Gaussian process regression with a prior based on the additive SE kernel fails to fit the data and that the small test error is misleading. As a result, we establish the Matérn kernel-based covariance function for the RSS Gaussian process model as the kernel of choice.
We also like to address a point made in [
12]: that a model with a prior distribution based on the SE kernel fits RSSs better when the training data are scarcely distributed than a model with a prior using the Matérn kernel. Therefore, we looked also into the model fit obtained from undersampled training data of a single access point from the Test-bed data; only every forth point of the radio map was used to train the model. We compare models using the constant mean plus squared exponential or Matérn covariance function trained with either the complete or undersampled fingerprints. The data in
Table 5 confirm the statement of [
12], but only if the training data are very scarce.
Table 5.
Test error and BIC obtained from eight Gaussian process model fits with constant mean function. For each of the two kernels, the model was fitted either using the complete training data (full) or using only a subset of the training data (undersampled) for both access points. The lowest BIC is typeset in bold.
Table 5.
Test error and BIC obtained from eight Gaussian process model fits with constant mean function. For each of the two kernels, the model was fitted either using the complete training data (full) or using only a subset of the training data (undersampled) for both access points. The lowest BIC is typeset in bold.
| Training Data/Kernel | BIC-APD | BIC-APS |
|---|
| Full | Undersampled | Full | Undersampled |
|---|
| SE | 3559.841 | 939.622 | 1077.977 | 288.091 |
| Mat | 3542.781 | 936.257 | 1073.987 | 288.178 |
The table presents the BICs of eight models, four of these are fitted with data from an access point with a dense fingerprint distribution (AP
D; see
Figure 4c), and four models are trained with data from an access point with a scarce fingerprint distribution (AP
S, see
Figure 5a). If the data from AP
D are used to fit the models, the Matérn kernel based model fits the data better than the model with the SE kernel, even if only the forth part of the fingerprints is used. This changes when we use data from AP
S to train the models. When using the full set of fingerprints, the Mat
function-based model outperforms the SE kernel-based model, but if the number of fingerprints is further reduced, the model employing the SE kernel fits the data better.
The reason lies in the greater adaptability of the Matérn function. The Matérn function is more flexible than the smoother squared exponential function; hence, it is able to model spatially very close RSSs, which may vary a lot, better. However, at the same time, it might overfit the data in cases where the structure of the training data is actually smooth.
Nonetheless, the decision when the number of training data is low enough to use the squared exponential function is difficult. Besides the radio map generation process, the principle factors affecting the “visibility” of access points at a certain position are the distance to the access points, objects of the environment and the variance of RSSs. In reality, without additional provisions, the spatial density of RSSs of an access point is hard to control and to predict. The general trend, however, is that the spatial density of fingerprints of an access point is lower in regions far from that access point. Since the Matérn function is the more flexible and wider applicable kernel and no indicator of fingerprint density is known, we do not suggest using the squared exponential function.
We conclude this section illustrating the main advantage of using Gaussian process models in fingerprinting techniques compared to basic fingerprinting.
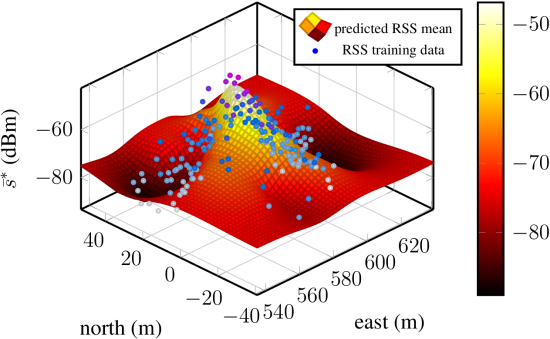
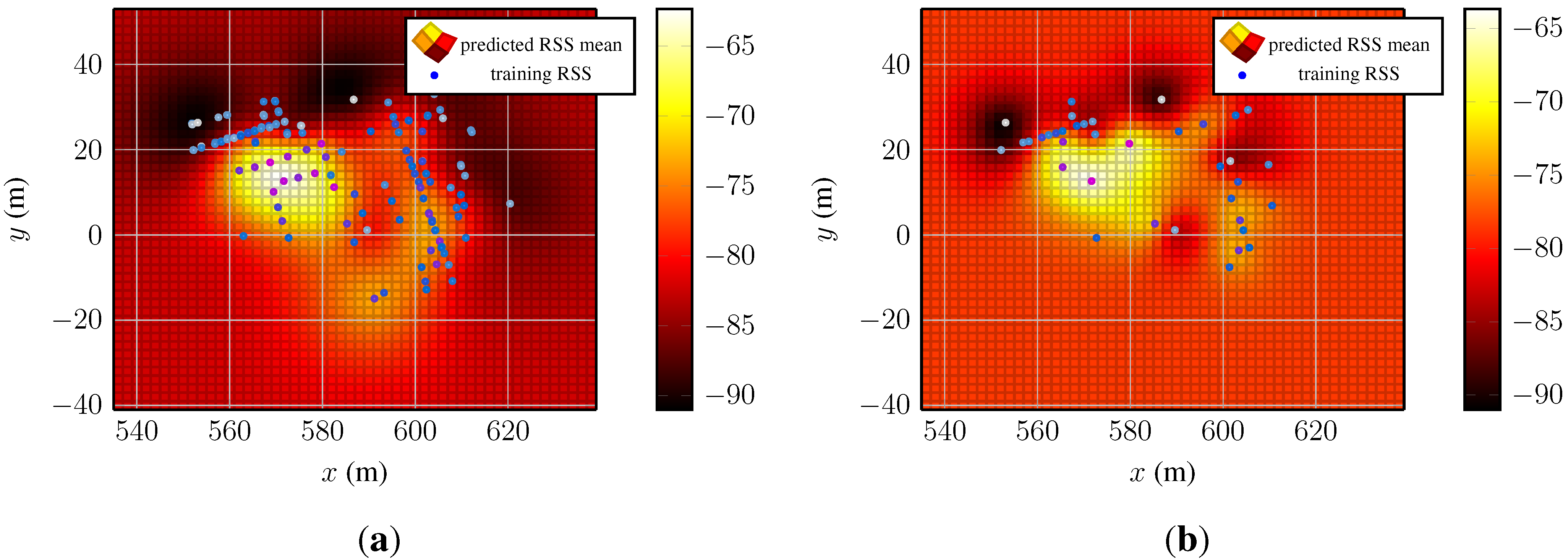
Figure 5 depicts the mean and covariance function of the access point and the corresponding training data.
Figure 5.
Predictions from two Gaussian process regression models for a single access point. The used Gaussian process prior has constant mean and Matérn function. (a) Predicted RSS mean of a model that was trained with the full set of its fingerprints; (b) predicted RSS mean of a model trained with the fourth part of its fingerprints. The two models were trained with a different number of training data. The magnitude of the mean function is indicated with the color bars. Large training data are colored purple–dark blue and low RSS light blue–white.
Figure 5.
Predictions from two Gaussian process regression models for a single access point. The used Gaussian process prior has constant mean and Matérn function. (a) Predicted RSS mean of a model that was trained with the full set of its fingerprints; (b) predicted RSS mean of a model trained with the fourth part of its fingerprints. The two models were trained with a different number of training data. The magnitude of the mean function is indicated with the color bars. Large training data are colored purple–dark blue and low RSS light blue–white.
The Gaussian process on the left-hand side (
Figure 5a) was optimized with the complete training data and the one on the right-hand side (
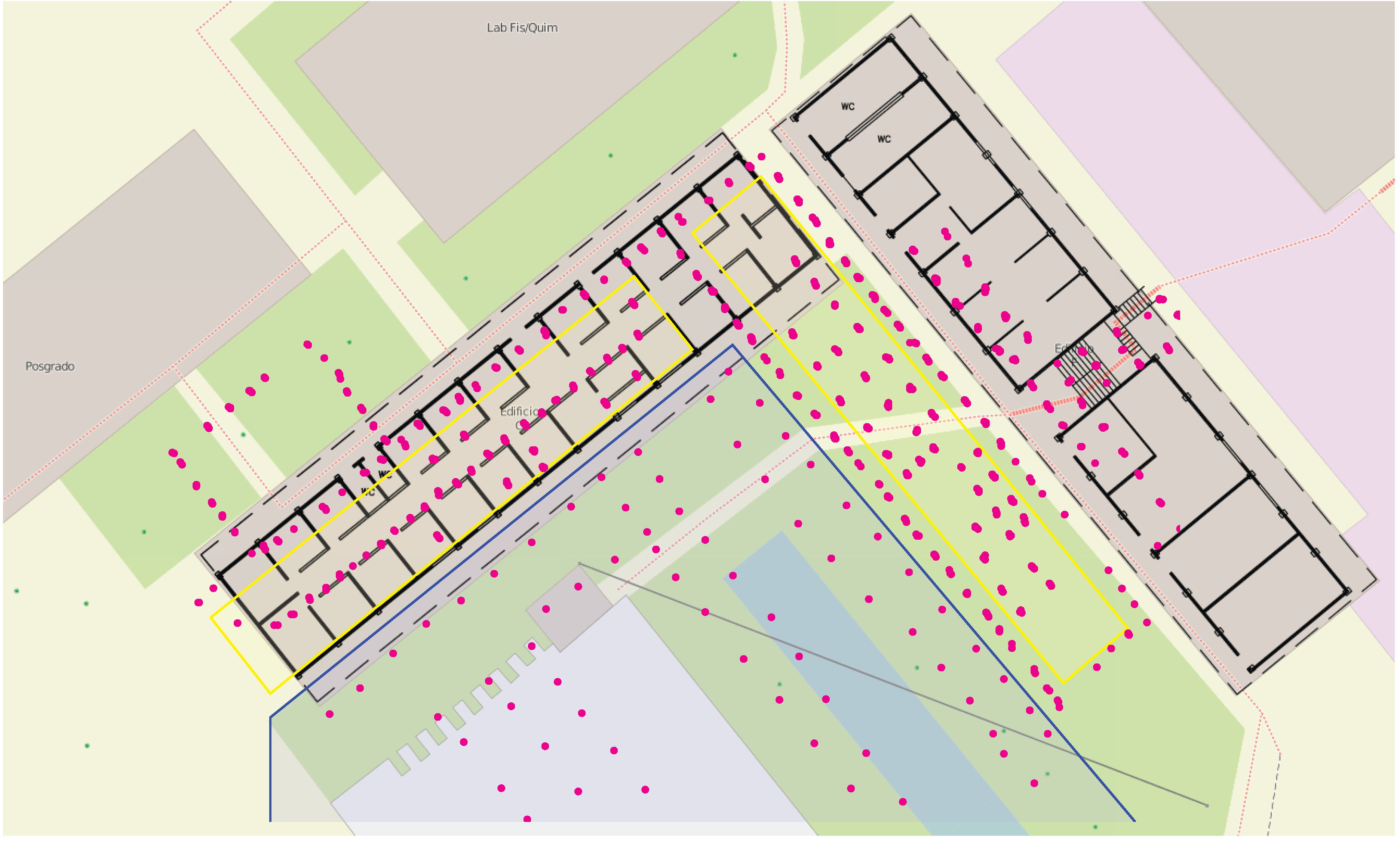
Figure 5b) with the undersampled training data. Even though only the forth part of the fingerprints was used to fit the model, the main features of the mean function are present: the valleys behind the left building (compare
Figure 1) and the peak in [560, 580]×[0, 20]. Only the lack of training samples in [580, 600]×[0, −20] and about (620, 7) in
Figure 5a causes the local maximum visible about (592, −14) and parts of the valley behind the right building in
Figure 5a to be smoothed over.
5.2.2. Residuals
To see if the chosen Gaussian process is completely able to model the underlying structure of the data, the residuals of the Test-bed data are assessed. We present the residuals obtained from Gaussian process models with constant mean function and Matérn
kernel, fitted to the RSSs of two access points exemplifying the findings, namely the same access points as in the previous section: AP
D and AP
S; their corresponding fingerprints can be found in
Figure 4c and
Figure 5a. To illustrate and discuss the residual’s properties, we have chosen scatter plots of the residuals over space, the predictions
versus training data, and the histogram and the norm probability plot of the residuals. In the following, all panels on the left-hand side correspond to access point AP
D and the panels on the right-hand side to the access point AP
S, respectively.
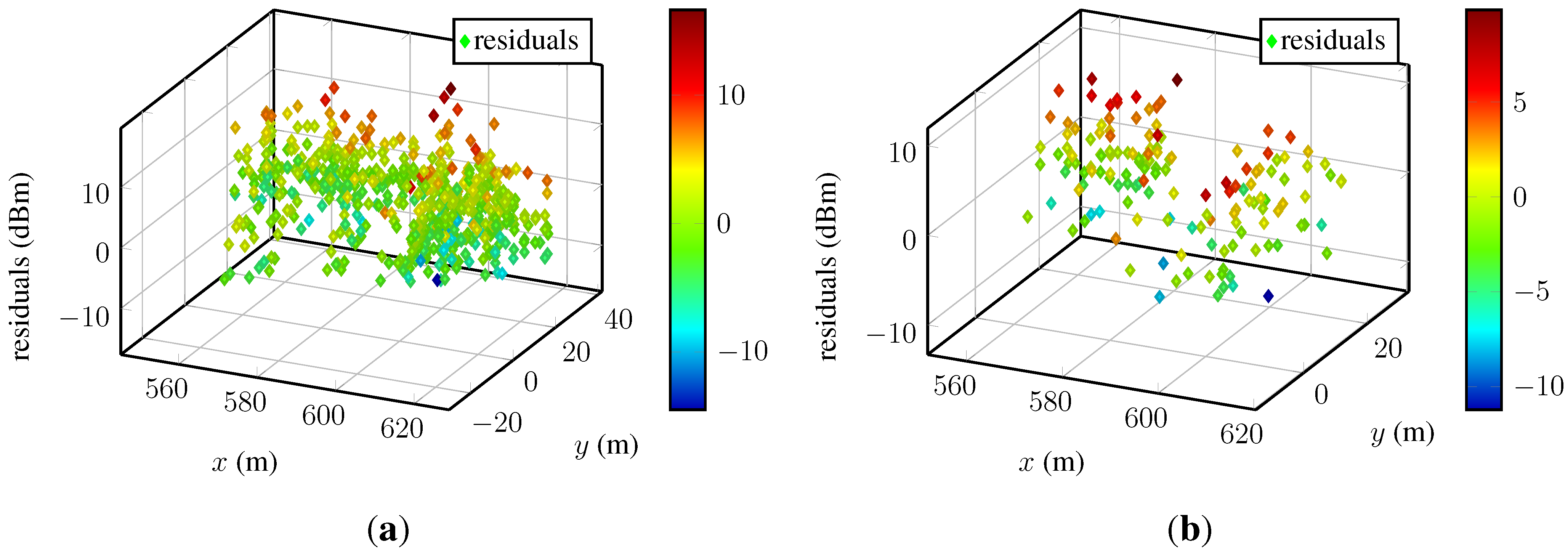
To examine the residuals dependent on the fingerprint positions, we refer the reader to
Figure 6.
Figure 6.
Residuals plotted against space for two different access points: (a) An access point with many fingerprints; (b) an access point with few fingerprints. The magnitude of the residuals are indicated by the color bars.
Figure 6.
Residuals plotted against space for two different access points: (a) An access point with many fingerprints; (b) an access point with few fingerprints. The magnitude of the residuals are indicated by the color bars.
The spatial dependency of the residuals for two-dimensional input data is difficult to assess in these static figures. No perspective allows a proper view, and the evaluation of many different cross-sections would be required to assess the spatial dependency rigorously. Moreover, the unknown positions of access points, possibly affecting the spatial distribution of the residuals, make this even harder. Besides the two examples, we visually examined the residuals of many access points from different datasets. This inspection did not reveal any spatial dependency or systematic pattern of the residuals.
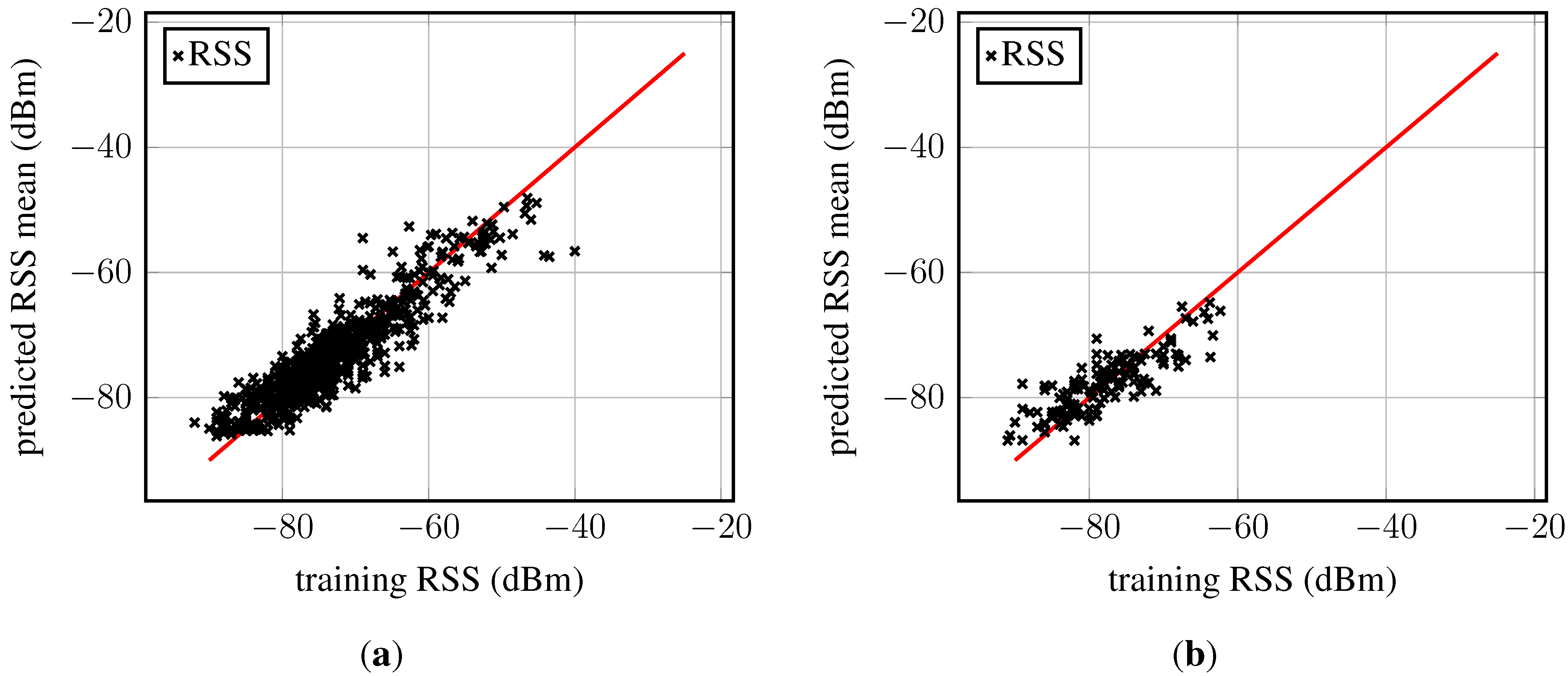
Figure 7 depicts the predicted RSS
versus the training data. For perfect predictions, all points would lie on the red line; here, the points are basically randomly distributed around that line, indicating an appropriate model fit. However, in both panels (
Figure 7a,b), outliers within large training RSS region can be observed, meaning that the largest training samples could not be “reached” by the model’s mean function. This observation suggests that the chosen model underestimates the RSS observations at these peaks (these RSSs are the largest and probably measured very close to the access point). It is noteworthy that not all access points present these outliers. On the lower RSS bound, points concentrate a bit on the upper half in both figures, again suggesting an underestimation. This effect was only observed for a few access points.
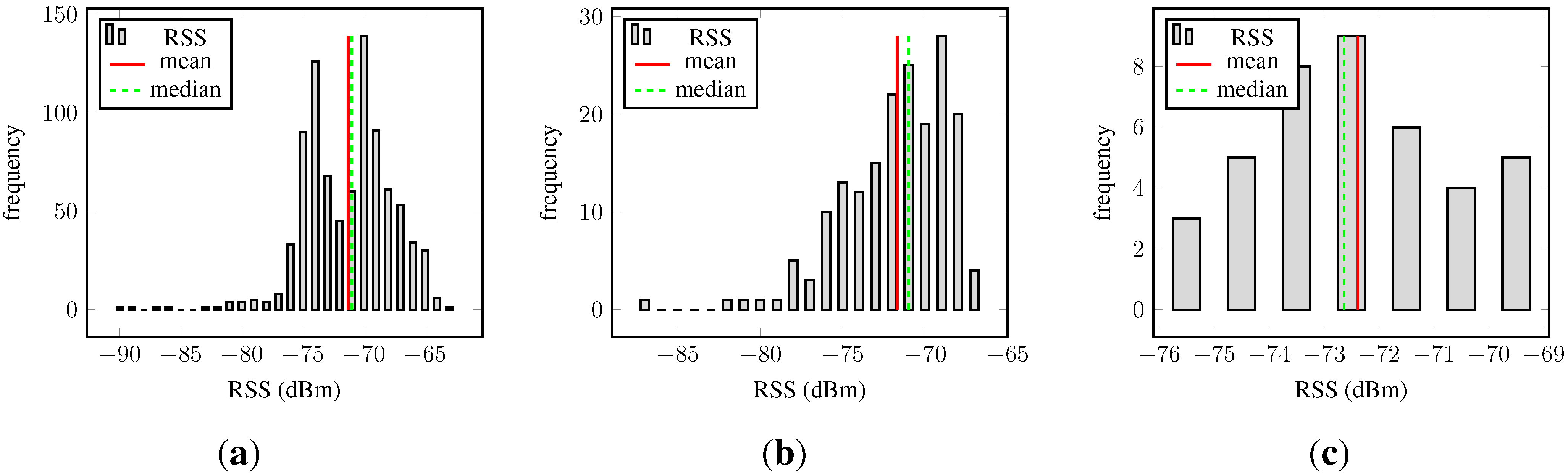
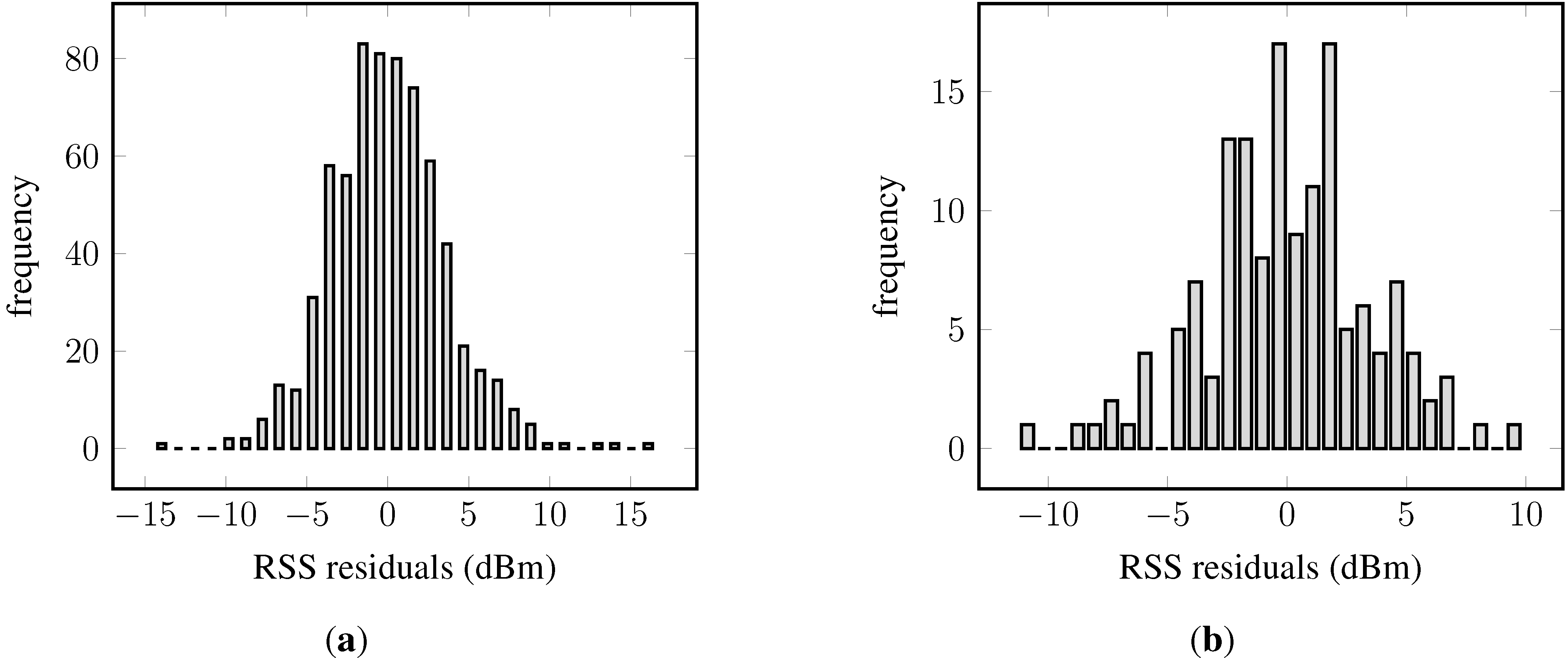
Recall Equation (1); Gaussian process regression expects a Gaussian process prior distribution. Given that a Gaussian distributions was chosen as the likelihood function, the residuals are expected to be about normally distributed and centered around zero. The histograms of the residuals are shown in
Figure 8. Most importantly, in both cases, the residuals are symmetrically distributed around zero, though the residuals are not normally distributed. The left-hand side panel shows outliers at the upper and lower bound of the residuals. The histogram obtained from data of AP
S (
Figure 8b) presents multiple modes, and also, the tails are too large for a normal distribution; however, the small sample size might contribute to these observations.
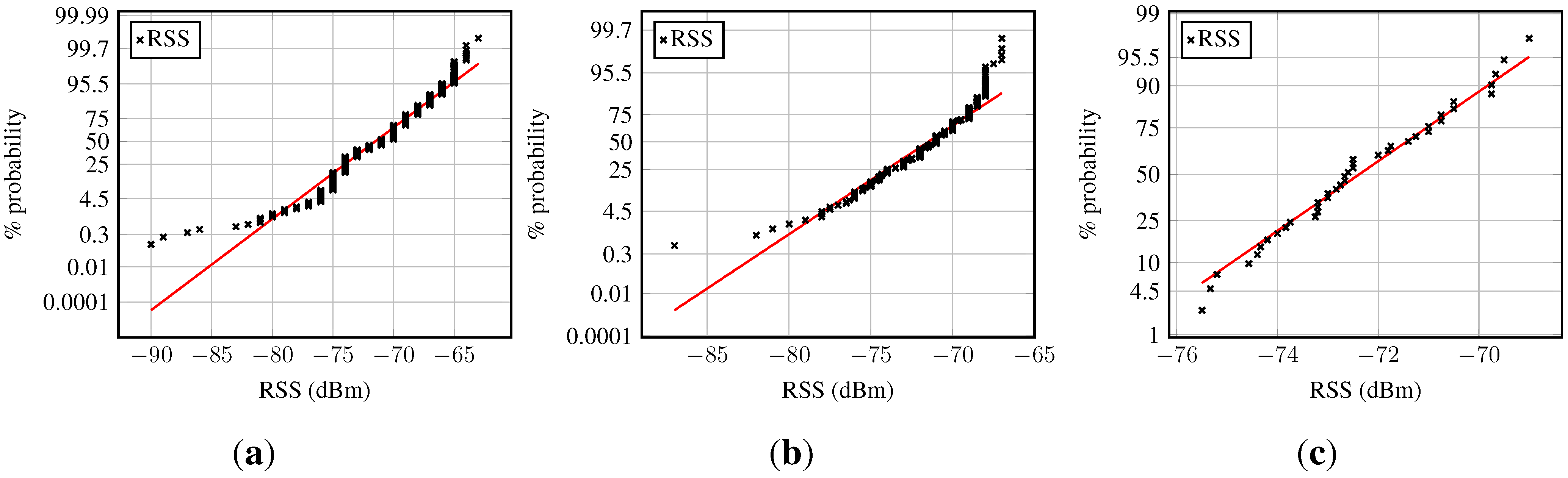
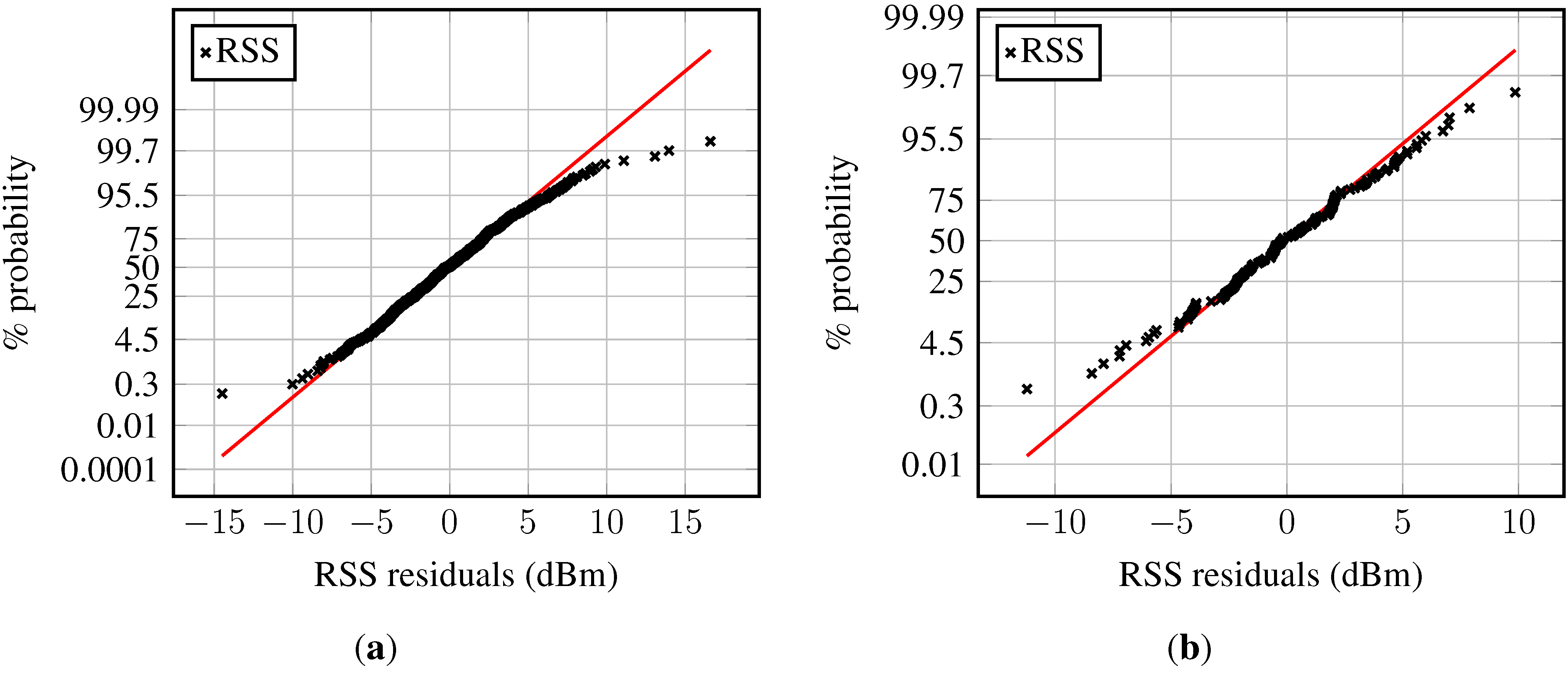
For further details, the norm probability plot is examined; see
Figure 9 (samples from a normal distribution would ideally lie on the red line). The majority of the residuals in
Figure 9a follow a normal distribution. However, heavy tails can be observed, and also, the number of outliers is fairly small: about 1.5% of the sample. The residuals in the second example are approximately Gaussian distributed, as can be seen in
Figure 9b. Their distribution also has slightly larger tails than normally-distributed samples would have. The few atypical residuals that exist are not that large, as in
Figure 9a.
Figure 7.
Predicted RSS versus training RSS for two access points: (a) An access point with many fingerprints; (b) an access point with few fingerprints. The red line indicates under- and over-fitting of the training data.
Figure 7.
Predicted RSS versus training RSS for two access points: (a) An access point with many fingerprints; (b) an access point with few fingerprints. The red line indicates under- and over-fitting of the training data.
Figure 8.
Histogram of residuals of two Gaussian process regression models, each for a different access point: (a) An access point with many fingerprints; (b) an access point with few fingerprints.
Figure 8.
Histogram of residuals of two Gaussian process regression models, each for a different access point: (a) An access point with many fingerprints; (b) an access point with few fingerprints.
Figure 9.
Norm probability plot of the model residuals from Gaussian process regression models of two different access points: (a) An access point with many fingerprints; (b) an access point with few fingerprints.
Figure 9.
Norm probability plot of the model residuals from Gaussian process regression models of two different access points: (a) An access point with many fingerprints; (b) an access point with few fingerprints.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






