
A Novel Method for Speech Acquisition and Enhancement by 94 GHz Millimeter-Wave Sensor

 , ,
, ,
Abstract
:1. Introduction
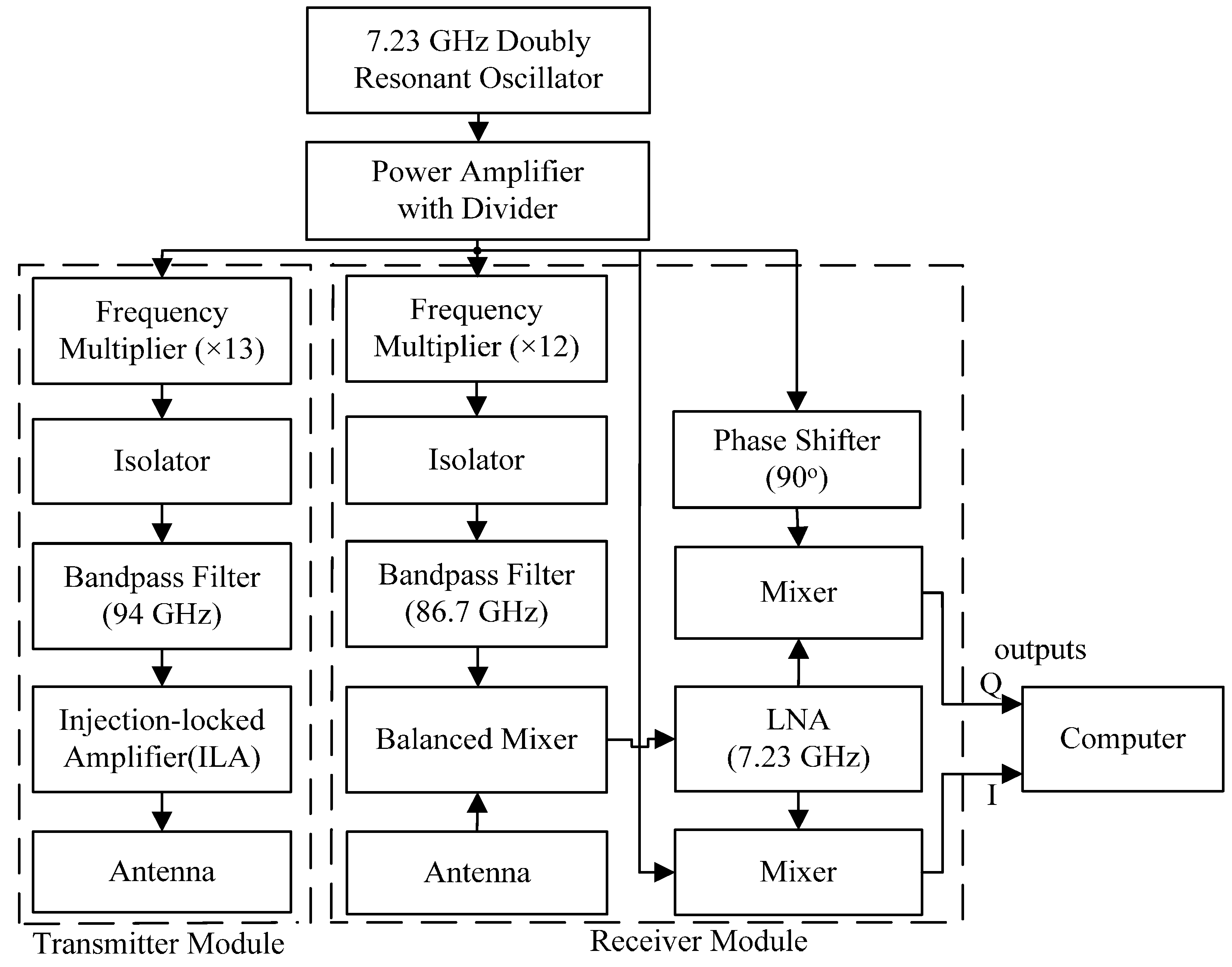
2. The 94 GHz MMW Radar Sensor
2.1. Quadrature Doppler Radar Theory
2.2. The 94 GHz MMW Radar System

2.3. Safety
3. Experimental Section
3.1. Subjects and the Experiment
3.2. Evaluations
4. Methods
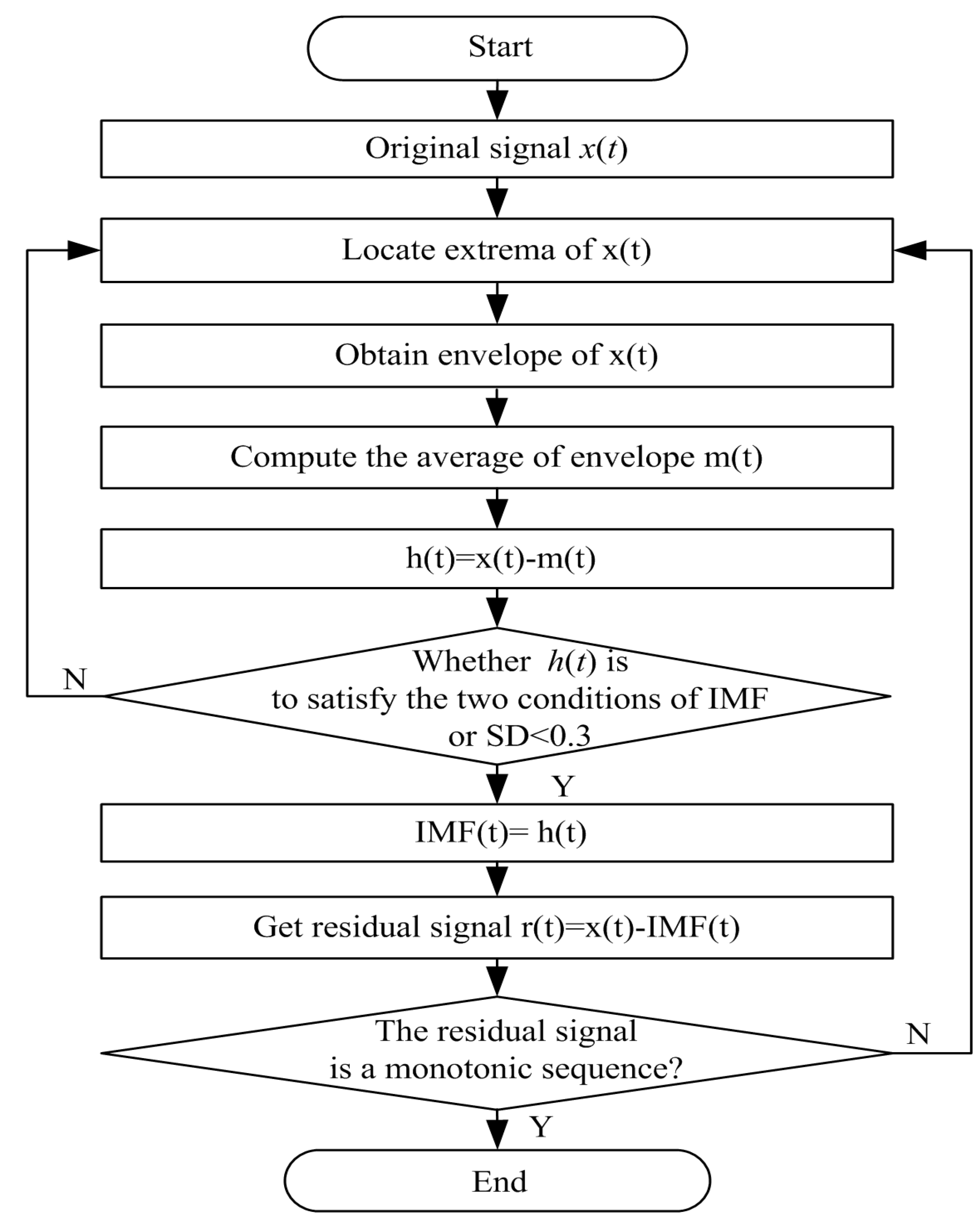
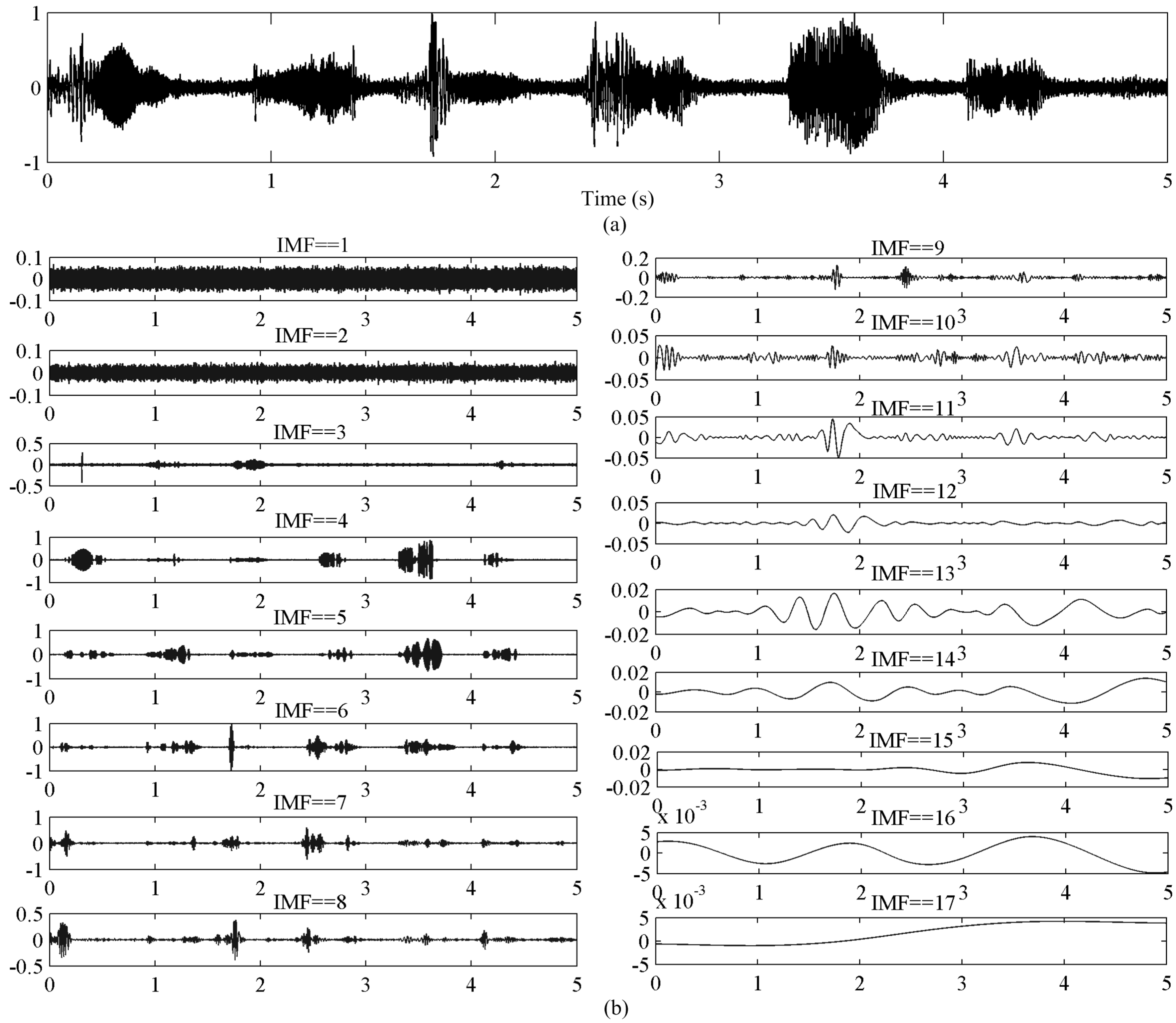
4.1. Empirical Mode Decomposition
- Locate all the extrema (maxima/minima) of x(t).
- Interpolate the maxima and minima points by cubic splines to obtain an upper envelope eu(t) and a lower envelope ed(t), respectively.
- Compute the average m1(t) of the upper and lower envelopes, subtracted from the original signal x(t) to obtain h1(t) = x(t) − m1(t).
- Judging whether h1(t) is to satisfies the following two conditions of IMF:
- (a)
- In the whole data item, the number of extrema should be equal to the number of zero crossings, or one difference at the most.
- (b)
- At any point, the mean of the maxima envelope and the minima envelope should be zero. That is to say, signal is symmetric about the time axis.
If h1(t) satisfies the conditions to be an IMF, it is regarded as the first IMF1(t), IMF1(t) = h1(t). - If h1(t) does not satisfy the two conditions, the h1(t) is regarded as a new signal, steps 1–4 are repeated on h1(t) to generate the following h2(t). If h2(t) does not satisfy the two conditions, there is a standard deviation (SD) to terminate the sifting process. The stopping criterion is given by:Usually, the value range of SD is between 0.2 and 0.3 [19]. If h2(t) satisfies the SD, then the IMF1(t) = h2(t). If h2(t) does not meet the stopping criterion, and the h2(t) is regarded as a new signal, steps 1–5 are repeated on h2(t) to generate the following hi(t), until the hi(t) satisfies the two conditions of IMF or SD. Then, the IMF1(t) = hi(t).
- Once the IMF1(t) is generated and subtracted the original signal to get a residual r1(t): r1(t) = x(t) − IMF1(t). The residual signal is treated as the original signal, and steps 1–5 are repeated to get the next residual signal. Therefore, the residual signal can be expressed as rn(t) = rn−1(t) − MFn(t). At this point, the rn(t) is a monotonic sequence. After the sifting process, the original signal can be decomposed into several IMF components IMF1(t), IMF2(t), … IMFn(t) and a residual sequence rn(t). Therefore, the original signal can be expressed as:

4.2. Mutual Information Entropy
4.3. Selecting the Reconstruction Components

4.4. The Proposed Algorithm for Radar Speech Enhancement
- Decompose the given signal x(t) into IMFs using the sifting process.
- Compute the energy entropy of each IMFs using Equations (14) and (15).
- Compute the MIE of the adjacent IMF components using Equation (13).
- Determine the cutoff point of high frequency and middle frequency modes using Equation (16).
- Determine the cutoff point of the middle frequency and low frequency modes using the FT of IMF.
- Denoise the high frequency and middle frequency modes using Equations (17)–(19).
- Reconstruct the speech with the processed signal and remaining low frequency modes using Equation (20).
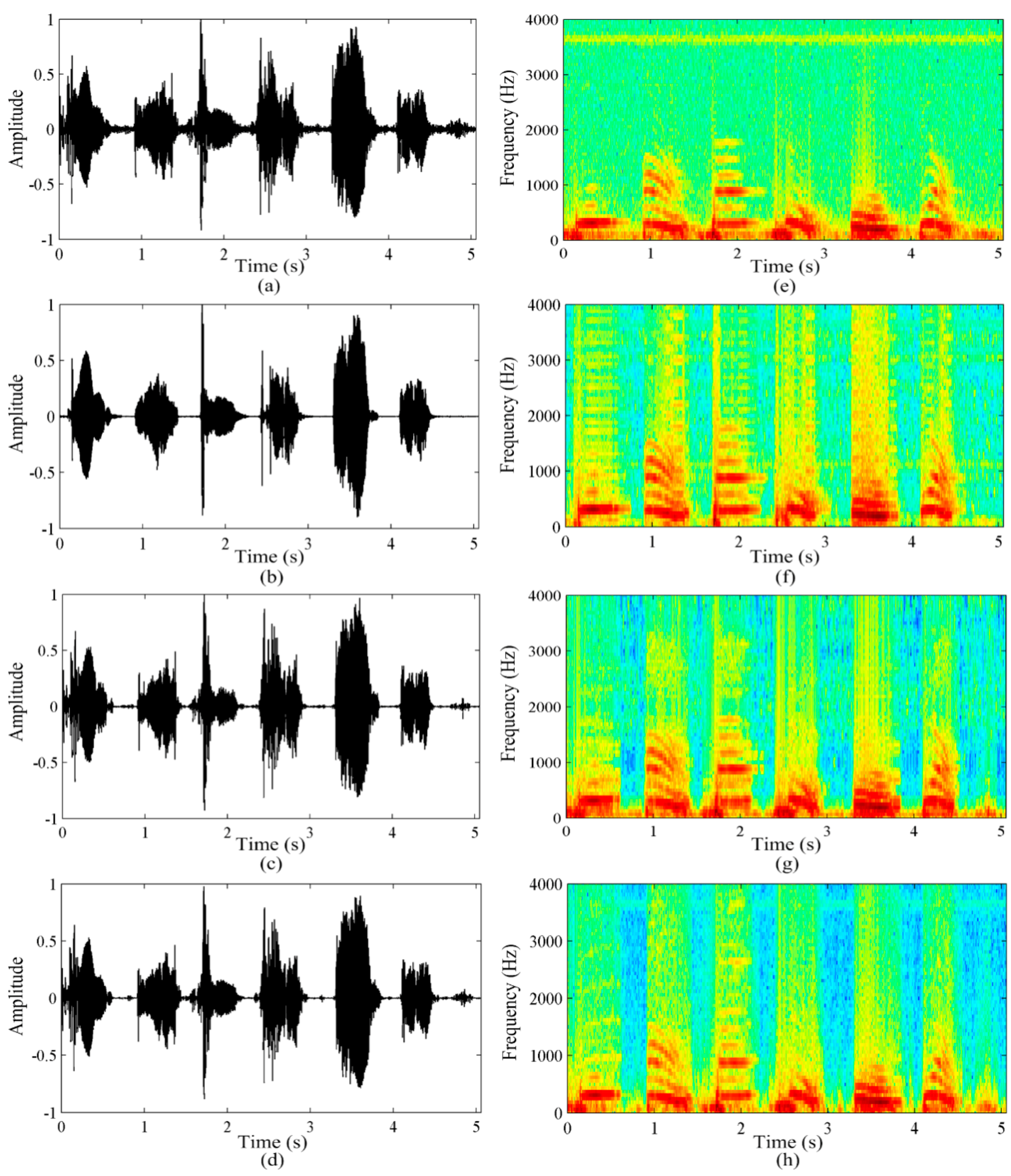
5. Results and Discussion


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Enhancement Algorithms | White | Pink | Babble |
|---|---|---|---|
| Spectral subtraction | 2.78 (0.30) | 2.98 (0.38) | 2.64 (0.35) |
| Wavelet shrinkage | 3.25 (0.46) | 3.37 (0.32) | 3.21 (0.27) |
| Proposed method | 3.59 (0.37) | 3.71 (0.35) | 3.56 (0.42) |
| Enhancement Algorithms | White | Pink | Babble | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| −5 | 0 | 5 | 10 | −5 | 0 | 5 | 10 | −5 | 0 | 5 | 10 | |
| Spectral subtraction | 4.1 | 7.1 | 8.9 | 9.7 | 3.7 | 6.8 | 7.4 | 9.2 | 2.3 | 3.7 | 7.1 | 8.7 |
| Wavelet shrinkage | 4.6 | 7.6 | 10.2 | 12.3 | 4.1 | 7.2 | 8.6 | 12.1 | 2.7 | 5.6 | 7.3 | 11.9 |
| Proposed method | 5.2 | 7.5 | 10.9 | 14.9 | 4.8 | 7.3 | 10.2 | 13.7 | 3.9 | 6.7 | 10.1 | 12.3 |
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Avargel, Y.; Cohen, I. Speech measurements using a laser Doppler vibrometer sensor: Application to speech enhancement. In Proceedings of the Hands-Free Speech Communication and Microphone Arrays (HSCMA), Edinburgh, Scotland, 30 May–1 June 2011; pp. 109–114.
- Holzrichter, J.F.; Burnett, G.C.; Ng, L.C.; Lea, W.A. Speech articulator measurements using low power EM-wave sensors. J. Acoust. Soc. Am. 1998, 103, 622–625. [Google Scholar] [CrossRef] [PubMed]
- Eid, A.M.; Wallace, J.W. Ultrawideband Speech Sensing. IEEE Antennas Wireless Propag. Lett. 2009, 8, 1414–1417. [Google Scholar] [CrossRef]
- Lin, C.S.; Chang, S.F.; Chang, C.C.; Lin, C.C. Microwave Human Vocal Vibration Signal Detection Based on Doppler Radar Technology. IEEE Trans. Microw. Theory Tech. 2010, 58, 2299–2306. [Google Scholar] [CrossRef]
- Li, Z.W. Millimeter wave radar for detecting the speech signal applications. Int. J. Infrared Mill. Wave. 1996, 17, 2175–2183. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, C.; Lu, G.; Jing, X. A new method for identifying the life parameters via radar. EURASIP J. Adv. Signal Process. 2007, 101, 8–16. [Google Scholar]
- Wang, J.Q.; Zheng, C.X.; Jin, X.J.; Lu, G.H.; Wang, H.B.; Ni, A.S. Study on a non-contact life parameter detection system using millimeter wave. Hangtian Yixue yu Yixue Gongcheng/Space Med. Med. Eng. 2004, 17, 157–161. [Google Scholar]
- Li, S.; Wang, J.Q.; Niu, M.; Liu, T.; Jing, X.J. Millimeter wave conduct speech enhancement based on auditory masking properties. Microw. Opt. Technol. Lett. 2008, 50, 2109–2114. [Google Scholar] [CrossRef]
- Li, S.; Wang, J.; Niu, M.; Liu, T.; Jing, X. The enhancement of millimeter wave conduct speech based on perceptual weighting. Prog. Electromagn. Res. B 2008, 9, 199–214. [Google Scholar] [CrossRef]
- Tian, Y.; Li, S.; Lv, H.; Wang, J.; Jing, X. Smart radar sensor for speech detection and enhancement. Sens. Actuator A Phys. 2013, 191, 99–104. [Google Scholar] [CrossRef]
- Jiao, M.; Lu, G.; Jing, X.; Li, S.; Li, Y.; Wang, J. A novel radar sensor for the non-contact detection of speech signals. Sensors 2010, 10, 4622–4633. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Tian, Y.; Lu, G.; Zhang, Y.; Lv, H.; Yu, X.; Xue, H.; Zhang, H.; Wang, J.; Jing, X. A 94-GHz millimeter-wave sensor for speech signal acquisition. Sensors 2013, 13, 14248–14260. [Google Scholar] [CrossRef] [PubMed]
- Mikhelson, I.V.; Bakhtiari, S.; Elmer, T.W., II; Sahakian, A.V. Remote sensing of heart rate and patterns of respiration on a stationary subject using 94-GHz millimeter-wave interferometry. IEEE Trans. Biomed. Eng. 2011, 58, 1671–1677. [Google Scholar] [CrossRef] [PubMed]
- Bakhtiari, S.; Elmer, T.W., II; Cox, N.M.; Gopalsami, N.; Raptis, A.C.; Liao, S.; Mikhelson, I.; Sahakian, A.V. Compact millimeter-wave sensor for remote monitoring of vital signs. IEEE Trans. Instrum. Meas. 2012, 61, 830–841. [Google Scholar] [CrossRef]
- Boll, S.F. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acous. Speech. Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Proakis, J.G.; Manolakis, D.G. Digital Signal Processing: Principles, Algorithms and Applications; Prentice Hall: Upper Saddle River, NJ, USA, 1992. [Google Scholar]
- Donoho, D.L.; Johnstone, I.M. Ideal spatial adaptation by wavelet shrinkage. Biometrika 1994, 81, 425–455. [Google Scholar] [CrossRef]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inform. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. A 1998. [Google Scholar] [CrossRef]
- Flandrin, P.; Goncalves, P.; Rilling, G. Detrending and denoising with empirical mode decompositions. In Proceedings of the XII EUSIPCO, Vienna, Austria, 6–10 September 2004; pp. 1581–1584.
- Kopsinis, Y.; McLaughlin, S. Development of EMD-Based Denoising Methods Inspired by Wavelet Thresholding. IEEE Trans. Signal Process. 2009, 57, 1351–1362. [Google Scholar] [CrossRef]
- Khaldi, K.; Boudraa, A.O.; Bouchikhi, A.; Alouane, M.T.-H. Speech enhancement via EMD. EURASIP J. Adv. Signal Process. 2008, 2008, 1–8. [Google Scholar] [CrossRef]
- Boudraa, A.O.; Cexus, J.C.; Saidi, Z. EMD-Based Signal Noise Reduction. Int. J. Signal Process. 2004, 1, 33–127. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kazemi, S.; Ghorbani, A.; Amindavar, H.; Li, C. Cyclostationary approach to Doppler radar heart and respiration rates monitoring with body motion cancelation using Radar Doppler System. Biomed. Signal Process. Control 2014, 13, 79–88. [Google Scholar] [CrossRef]
- Li, C.; Chen, F.; Jin, J.; Lv, H.; Li, S.; Lu, G.; Wang, J. A Method for Remotely Sensing Vital Signs of Human Subjects Outdoors. Sensors 2015, 15, 14830–14844. [Google Scholar] [CrossRef] [PubMed]
- Bakhtiari, S.; Liao, S.; Elmer, T.; Gopalsami, N.S.; Raptis, A.C. A Real-time Heart Rate Analysis for a Remote Millimeter Wave I-Q Sensor. IEEE Trans. Biomed. Eng. 2011, 58, 1839–1845. [Google Scholar] [CrossRef] [PubMed]
- Sivannarayana, N.; Rao, K.V. I-Q imbalance correction in time and frequency domains with application to pulse doppler radar. Sadhana 1998, 23, 93–102. [Google Scholar] [CrossRef]
- Chioukh, L.; Boutayeb, H.; Deslandes, D.; Wu, K. Noise and Sensitivity of Harmonic Radar Architecture for Remote Sensing and Detection of Vital Signs. IEEE Trans. Microw. Theory Tech. 2014, 62, 1847–1854. [Google Scholar] [CrossRef]
- Lin, J.C. A new IEEE standard for safety levels with respect to human exposure to radio-frequency radiation. IEEE Ant. Propag. Mag. 2006, 48, 157–159. [Google Scholar] [CrossRef]
- World Medical Association. World Medical Association Declaration of Helsinki: Ethical principles for medical research involving human subjects. JAMA 2013, 310, 2191–2194. [Google Scholar]
- Boudraa, A.O.; Cexus, J.C. EMD-based signal filtering. IEEE Trans. Instrum. Meas. 2007, 56, 2196–2202. [Google Scholar] [CrossRef]
- Omitaomu, O.A.; Protopopescu, V.A.; Ganguly, A.R. Empirical Mode Decomposition Technique with Conditional Mutual Information for Denoising Operational Sensor Data. IEEE Sens. J. 2011, 11, 2565–2575. [Google Scholar] [CrossRef]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural. Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed]
- Sugiyama, M. Machine learning with squared-loss mutual information. Entropy 2012, 15, 80–112. [Google Scholar] [CrossRef]
- Fleuret, F. Fast binary feature selection with conditional mutual information. J. Mach. Learn. Res. 2004, 5, 1531–1555. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, F.; Li, S.; Li, C.; Liu, M.; Li, Z.; Xue, H.; Jing, X.; Wang, J. A Novel Method for Speech Acquisition and Enhancement by 94 GHz Millimeter-Wave Sensor. Sensors 2016, 16, 50. https://doi.org/10.3390/s16010050
Chen F, Li S, Li C, Liu M, Li Z, Xue H, Jing X, Wang J. A Novel Method for Speech Acquisition and Enhancement by 94 GHz Millimeter-Wave Sensor. Sensors. 2016; 16(1):50. https://doi.org/10.3390/s16010050
Chicago/Turabian StyleChen, Fuming, Sheng Li, Chuantao Li, Miao Liu, Zhao Li, Huijun Xue, Xijing Jing, and Jianqi Wang. 2016. "A Novel Method for Speech Acquisition and Enhancement by 94 GHz Millimeter-Wave Sensor" Sensors 16, no. 1: 50. https://doi.org/10.3390/s16010050
APA StyleChen, F., Li, S., Li, C., Liu, M., Li, Z., Xue, H., Jing, X., & Wang, J. (2016). A Novel Method for Speech Acquisition and Enhancement by 94 GHz Millimeter-Wave Sensor. Sensors, 16(1), 50. https://doi.org/10.3390/s16010050