1. Introduction
Increasing our work efficiency while being able to perform tasks accurately is a problem people have been trying to solve for years. The physical nature of our body limits us from being consistently efficient in performing long, repetitive tasks. To overcome this problem, scientists and engineers started developing assistive technologies which would recognize and imitate human gestures to perform tasks that we consider difficult or strenuous. As a result, developing systems that can capture human motion and recognize different gestures simultaneously is important.
Gestures are physical movements of different parts of the body that are expressive and meaningful to human beings. We perform gestures to convey information or to interact with the environment. Gesture recognition has a wide variety of applications that include, but is not restricted to, developing aids for the hearing impaired, recognizing sign language, navigating in virtual environments, and automation of manufacturing tasks,
etc. [
1]. There are various techniques that can be used to recognize gestures, ranging from using mathematical models based on the Hidden Markov Model [
2] and Markov Chains [
1] to applying computer vision-based approaches [
1,
3], by using data gloves [
4] and accelerometers [
5,
6], or using a combination of any of the above [
1]. Gestures can be hand and arm gestures, head and face gestures or full body movements. It is important to note that a gesture is a small movement and tasks or activities can be considered as a series of gestures performed in sequence.
The work presented in this paper is a continuation of work that used wearable IMU (Inertial Measurement Unit) sensors to implement a full body motion capture system in virtual reality [
7]. This work suggests that motion capture and gesture recognition can be combined into a single system that allows for fully body gesture capture and recognition and will facilitate grammar-based activity recognition, all possible at interactive rates. Finally, this work also demonstrates two key novel elements: one, that the gesture recognition system does not require a kinematic model to achieve good results and; two, the human being does not have to be overly instrumented to achieve reasonable results.
2. Related Works
A lot of work on gesture recognition can be found in the current literature which incorporates the use of different types of sensors and models for several real life and virtual applications. They cover both IMU sensor-based applications as well as vision-based recognition systems. Gesture recognition using virtual reality interfaces became more prominent with the invention of systems like Microsoft’s Kinect [
8], the Nintendo Wii, Oculus Rift,
etc. In [
9], a hidden Markov model-based training and recognition algorithm was used on data collected from a Wii controller to develop a gesture recognition system.
Vision-based gesture recognition has been on the rise since we started developing better cameras, image and video compression technologies, in consort with faster processors and GPUs (Graphics Processing Units). These systems cover several application areas such as surveillance, detection, control and other analyses of captured motion data. Using a multiple sensor based approach, Lementec
et al. [
10] presented a gesture recognition algorithm using Euler angles. Their work is part of a control system for an Unmanned Aerial Vehicle (UAV). A wide array of vision-based approaches exist and the reader may explore [
3,
11] for details. The problems with vision-based systems are their high computational expense as they incorporate the use of GPUs, the limited range of use created by the camera viewing volume, and a large number of cameras required to cover large spaces.
Many gesture recognition systems exist which use a specific part or parts of the body to recognize gestures using a limited number of sensors. This has become more apparent in recent work as a result of the increasing popularity of wearable fitness devices. uWave is a gesture recognition system that uses gesture-based interactions from a single three-axis accelerometer [
12]. It requires a single training sample for each pattern and allows users to define their own personal gestures. An automatic hand gesture recognition system has also been developed for use in Augmented Reality [
13]. It is able to differentiate between static and dynamic gestures.
Zhu
et al. [
14] created a smart assisted living (SAIL) system that can aid the elderly and the disabled using a human-robot interaction (HRI) technology. They studied hand gesture recognition and daily activity recognition using artificial neural networks. For daily activity recognition, they developed a multi-sensor fusion system.
The examination in [
15] uses only an eight-sensor system
versus our ten, and in that configuration, it cannot do effective motion capture. The inverse kinematic elements will not work if major bones are missed during motion capture. Moreover, their recognition rates fall around the 80% mark. The work in [
16] is an old project that was intended to assist developers in developing applications without having to know much about machine learning systems. The recognition rates for this project allow any system which is built with it, to recognize only the simplest of gestures (for example, left
versus right-hand gestures using an accelerometer). In the study performed in [
17], the sensor is on the device that the person is interacting with, and not being worn on the body. Furthermore, the gestures or activities selected could be classified with an accelerometer alone given the simple nature of the gestures. The work in [
18], while interesting, also takes on the simplest of activities (Tai Chi). Because of the slow motion, much can be done by orientation sensors rather than pure body pose. The authors do not mention anything about runtime. With the work being about Dynamic Time Warping as well, it seems like they were also working on pre-segmented data. Overall, much work has been done evaluating different methods of gesture recognition with IMU sensors for various subsets of the body including the arm [
10,
19,
20], the leg [
21], the torso [
22] and the head [
23,
24]. In these cases, a smaller number of IMU sensors were used due to the localized focus on a specific body part. In all of these cases, the subset of sensors to recognize gestures on a single limb eliminates the opportunity for full body motion capture.
Some full-body capture, recognition or interaction systems can be found in the current literature, such as ALIVE [
25]. A couple of view-invariant full-body gesture recognition systems are described in [
26,
27], but these are vision-based systems. On the other hand, references [
28,
29,
30] describe Microsoft Kinect-based full-body recognition. These systems offer little mobility as the Kinect sensor needs to be kept in place to capture data, and the Kinect cannot be used outdoors. A gesture recognition system to interact with a robot has been introduced in [
17], but the sensors are in the robot, not on the body of a human being.
The system that most closely resembles our work is the OPPORTUNITY project [
31], a full-body complex activity recognition system. However, the authors used 72 sensors of 10 different modalities (including IMU sensors) to capture data from twelve subjects. It should be noted that with so many sensors in the system, it is impossible to determine the generalization capabilities until a test dataset grows immensely large. The OPPORTUNITY project not only instruments the human very highly, it also instruments the environment and objects that are interacted with. Thus, any activity that uses the instrumented fork, for example, is clearly separable from the rest of the activities to be detected. This allows for a simple hierarchical classification system, such as a decision tree, as a first step. The authors use standard pattern classifiers such as k-NN, NCC, LDA and QDA in [
32,
33] to evaluate and benchmark the activity dataset. They use only mean and/or variance as features, which is understandable because the data from 72 sensors are already quite descriptive for classification purposes. The overlap in IMU sensors between this work and our own consists only of five IMU sensors, four located on the upper and lower arms. The fifth IMU sensor used is on the back, whereas ours is placed on the abdomen, which aside from the obvious orientation issues, should be similar. Our sensors are a subset of the IMU sensors used in the OPPORTUNITY project, and ours use only gyro and accelerometer data processed through a built-in sensor fusion algorithm that produces a quaternion value. Moreover, we don’t assume a kinematic model or sensor hierarchy in the gesture recognition portion of this work.
There are not many wearable gesture recognition datasets available publicly, making direct comparisons of methods difficult. As seen from [
34], most of the full-body datasets are Kinect-based apart from a few, such as the OPPORTUNITY dataset mentioned above. Although we are doing an upper-body gesture recognition, the outcome from our study will be the foundation for modeling a wearable sensor-based full-body gesture recognition system. However, the recent survey by LaViola Jr. [
35] examines the results of many different 3D gesture recognitions systems and ours is comparably accurate.
Our contributions to the current state-of-the-art include:
Extracting five feature descriptors including velocity and angular velocity from quaternions which are very good at representing rotations as compared to Euler angle or matrix representations [
36] and eliminating gimbal lock.
Using a limited number of sensors to preserve as much generalization in the data as possible but cover as many of the major movements of the upper body.
Presenting an interactive recognition rate that will allow for more complex activity recognition at interactive rates.
Presenting results that generalize to the population, i.e., where the test users dataset is not included in training.
This work also suggests that to achieve reasonable recognition for smaller gestures that can allow non-traditional interaction with systems, the human does not need to be so highly instrumented, nor does the environment need to be instrumented.
This work exhibits the effect of velocity on recognition rates and suggests that velocity and acceleration features should only be included when speed of the gesture is an important performance consideration. E.g. training applications.
5. Gesture Recognition Using Multiple Sensors
With the technical setup in place for a wearable motion capture system, we designed a comprehensive gesture recognition system. The model was built to classify among six different gestures performed by humans. We followed standard experimental methodologies to run the experiment and analyze the results using SVMs and ANNs.
5.1. Features
We calculated variance, range, velocity, angular velocity and covariance from the dataset. As the data was collected from a set of five sensors, every feature label contains the serial number of the sensor that is relevant to the feature. A feature labeled as “var_15_qx” refers to variances calculated using the vector from Sensor 15. We call these types of features “Single Sensor-based Features” because each of these features are calculated by using data from one sensor at a time. On the other hand, a feature labelled as “cov_15_16_qx” refers to the covariance of Sensor 15 and Sensor 16’s output for the quaternion element. Variance, Range, Velocity and Angular Velocity are the four single sensor-based features used in this study whereas Covariance is the only multiple sensor-based feature that has been used here. The entire feature set has 115 features. Variance, range and, covariance are simple statistical measurements of the data whereas velocity and angular velocity are physical properties extracted from the dataset.
Velocity, by definition, is the distance traveled over time towards a specific direction,
i.e., the speed of an object towards the direction it is traveling. We considered this as an important feature because every gesture is unique and, therefore, should show varying degrees of velocity. Moreover, it is expected that different participants will perform gestures at different speeds. We calculated distance summing over the Euclidean distances of each consecutive data points in every sample. Thus, velocity was calculated in the following manner:
To calculate time, we used the following equation:
In Equations (13) and (14), is the value of data point at the i-th index of the sample, n is the number of data points in the sample and sensor frequency is 110 Hz.
Angular velocity is the rate of change of angular displacement of an object about its axis of rotation [
55]. In other words, it is the rate of change of angular positions of a rotating body. This feature gives us positional information of the active limbs in 3-D space. The rationale behind using this as one of the features is similar to that of using velocity. It is calculated in two steps—the first step is to convert the quaternions to Euler angles and the next step is to calculate the angular velocities from these angles. From the different parameterizations that are possible to convert quaternions to Euler angles [
56], we chose to use:
where
;
;
;
constitute a unit quaternion
.
We can calculate the angular velocity vectors Precession, Nutation, and Spin from Equations (15)–(17) as follows:
The parameter ‘time’ in Equations (21)–(23) is calculated in a similar manner as in Equation (14). Here, sensor frequency is 82.5 Hz, which is calculated after the conversion to Euler angles. We have 15 of these features.
5.2. Data Collection and Partitioning
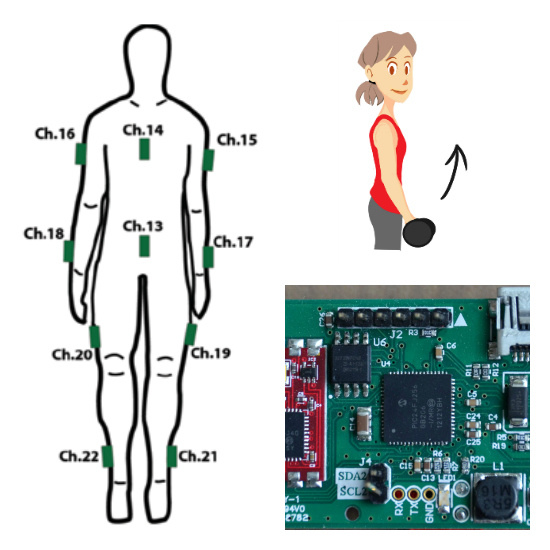
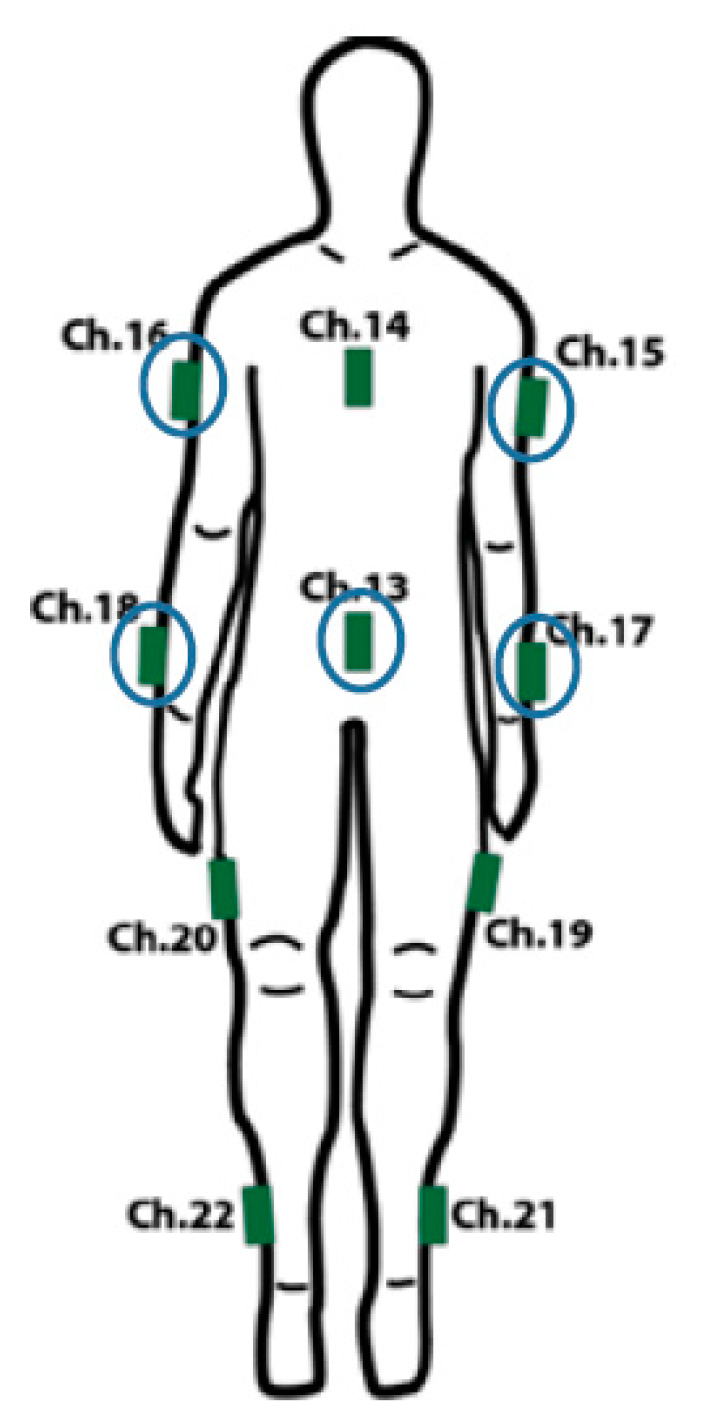
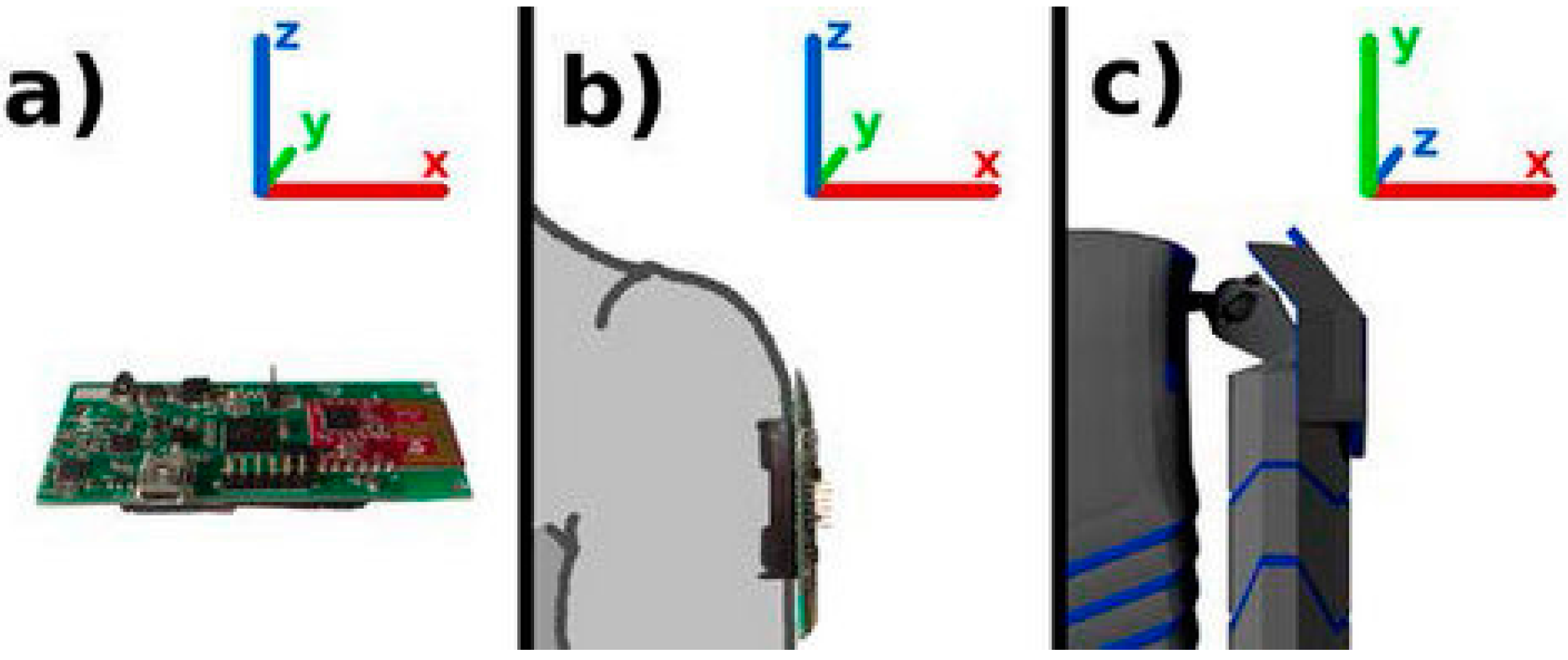
Data was gathered using a subset of sensors from the wearable motion capture system described previously. Two sensors were placed on both the arms and one on the upper abdomen (positions Ch. 13, 15, 16, 17 and 18 in
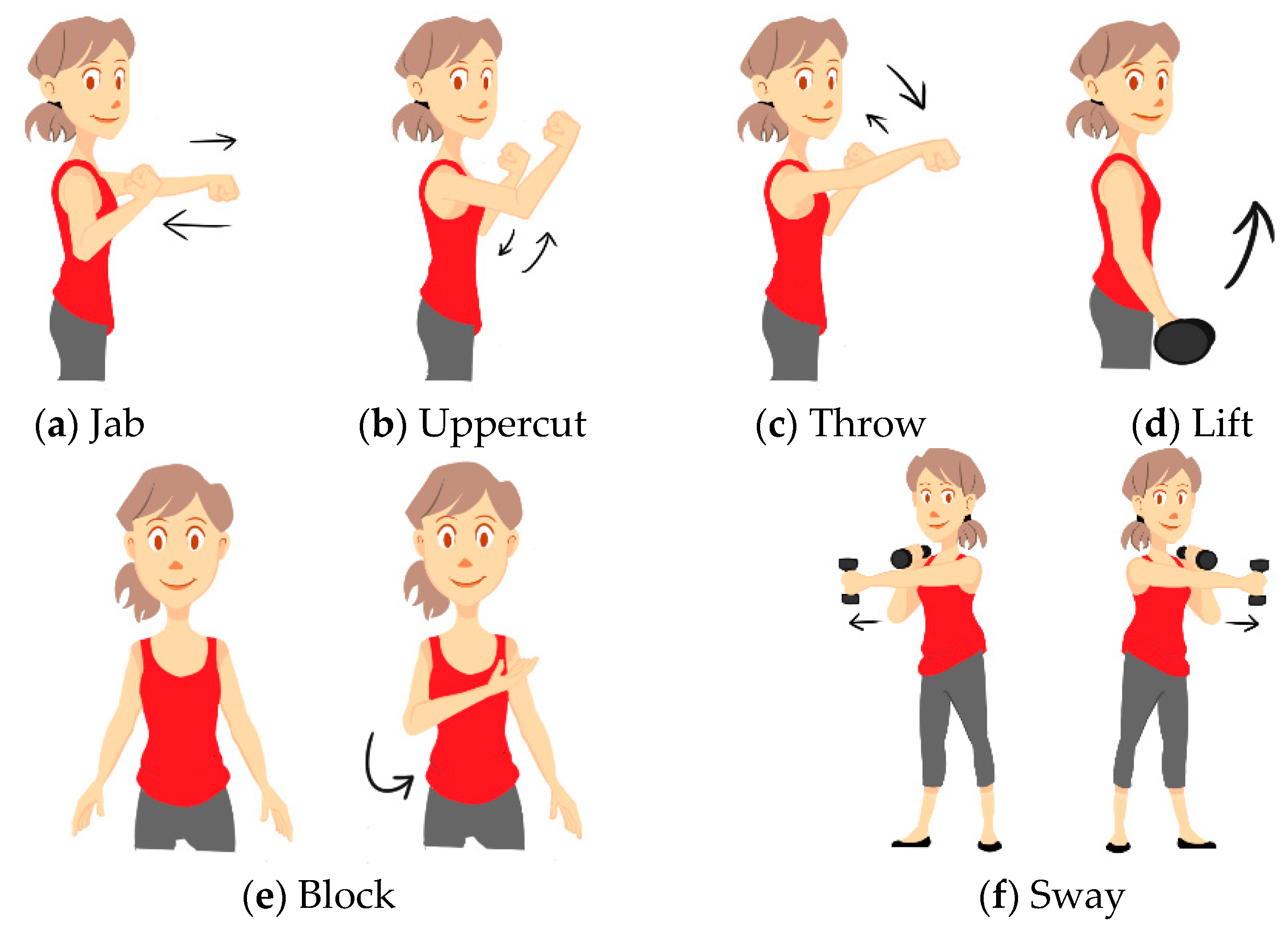
Figure 3). We used six gestures in our study: Jab, Uppercut, Throw, Lift, Block and Sway (
Figure 7). Jab, Uppercut, and Block are combat gestures. Throw, Lift and Sway can be related to other aspects of our daily lives in different ways.
We collected anonymous data from 11 participants, four females and seven males. Our raw dataset has around 20 samples per gesture from each participant. For each sample, participants were asked to perform the respective gesture for about five seconds using one of their hands while keeping the other hand still. They used their left and right hands alternatively for each sample which yielded in 50% data from the left hands (LH) and 50% from the right hands (RH) (not applicable for Sway). On average, they performed five instances of a gesture continuously within the timeframe. Thus, each of the five sensors in our setup collected about 100 instances (20 samples × 5 instances/sample) of every gesture per participant. This yielded in a total of about 600 instances per participant from each sensor.
While these numbers reflect the ideal scenario, problems like missing values and participants getting fatigued contributed to the discrepancy in the actual number of samples. From the raw dataset, we derived a Euler angle dataset. Both of these datasets were used to extract various features which are explained later in
Section 5.4. The raw dataset consists of 1080 samples which contain a total of 2,959,765 coordinates.
Table 1 shows the gesture-wise distribution of samples.
Using the raw and the Euler angle datasets, we have extracted 124,200 features points, in the form of 115 identical features for every sample in the dataset. To deal with missing values (due to sensor data loss, for example), we interpolate the value from the prior and post data values that were available.
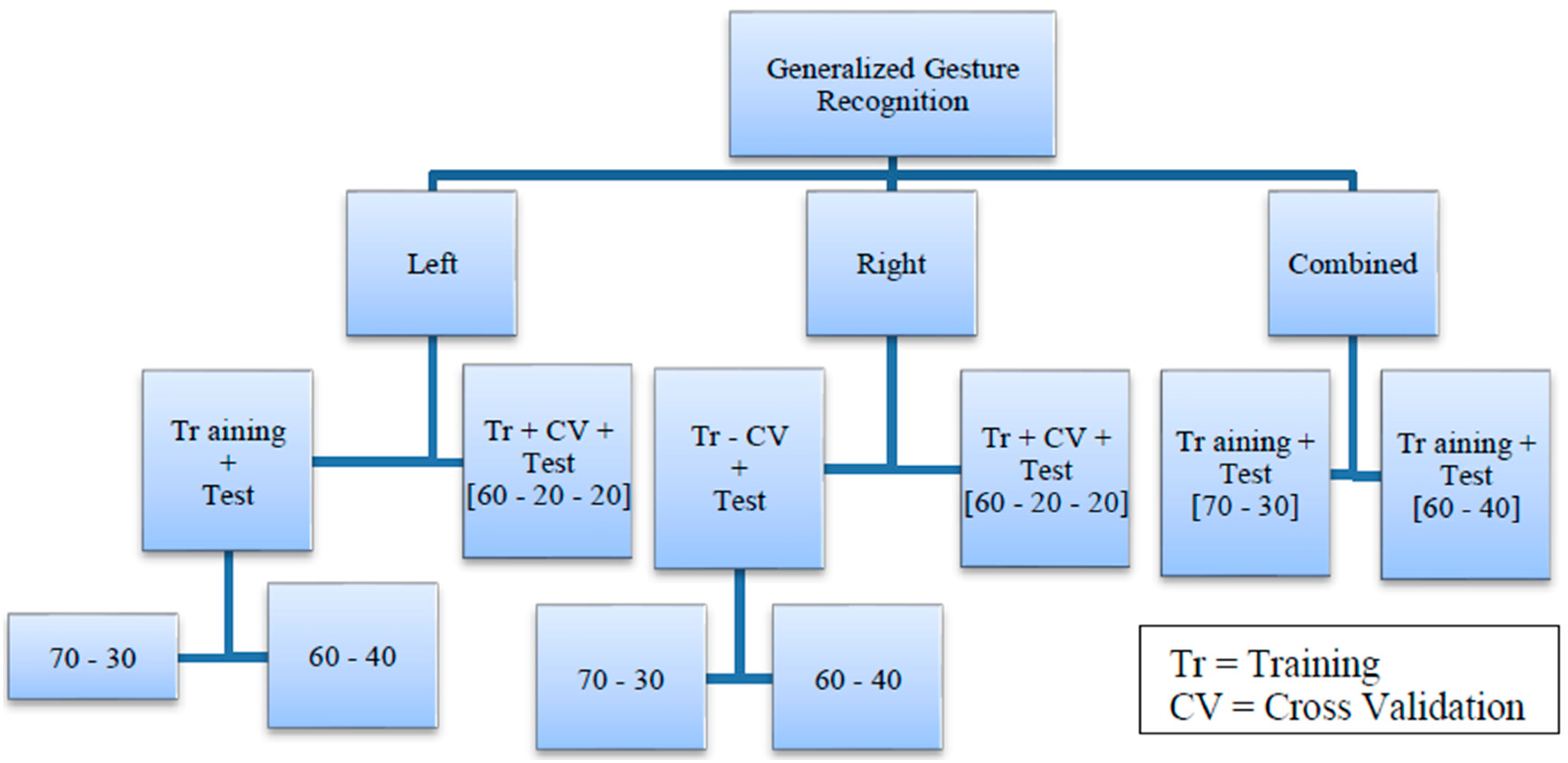
We organized the data into two categories: Generalized Gesture Recognition and User Specific Gesture Recognition. The generalized dataset includes training and test set data from any participant without repetition. Here, we are not interested in the individual from whom the data is coming but only interested in the gestures. This rule applies to any of the training, cross-validation or test set under this category. The splits for this dataset is shown in
Figure 8.
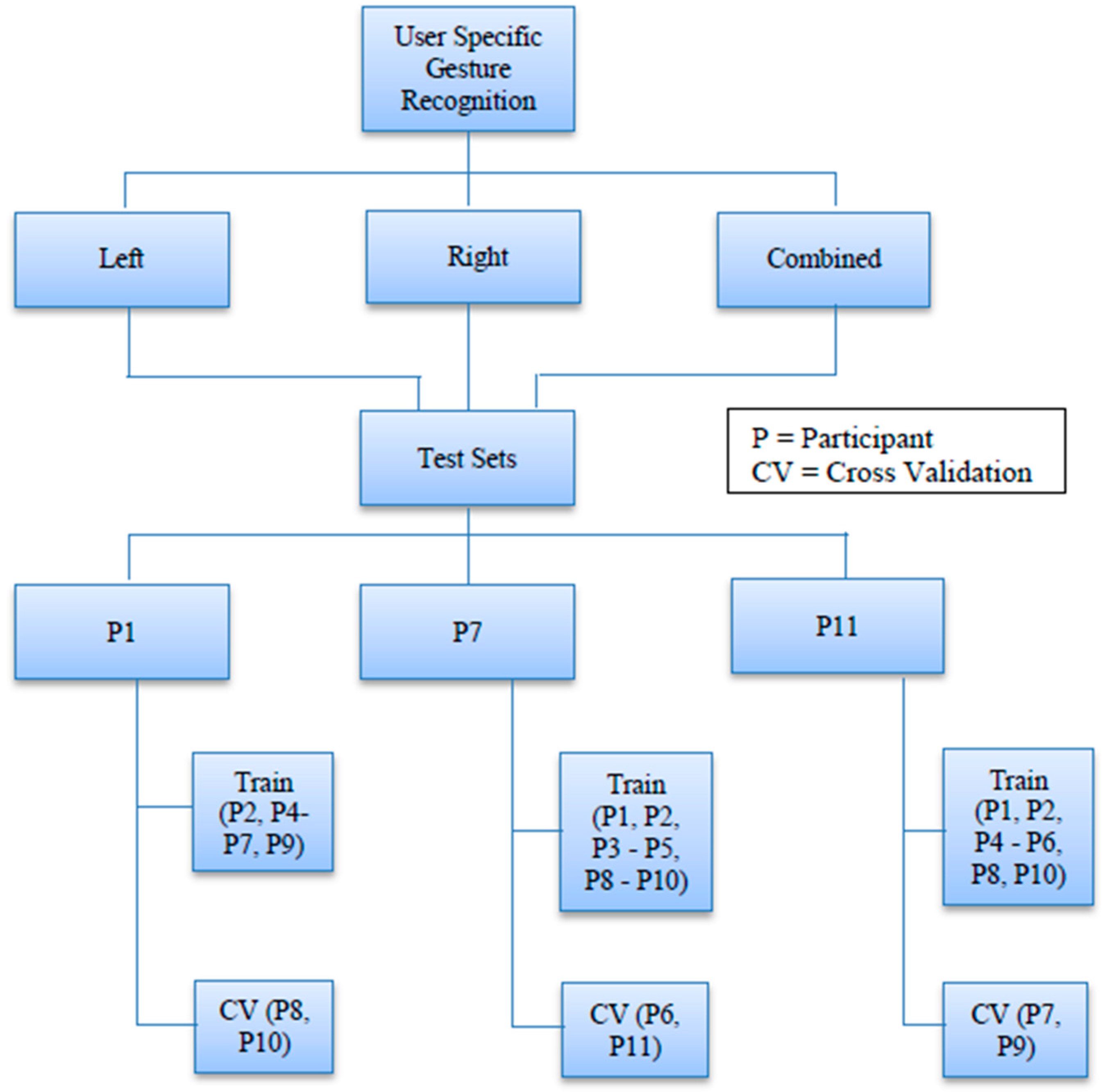
Every user specific dataset comprises a test set that contains data from a specific individual within the participants. As a result, the corresponding training set does not contain any data from this individual.
Figure 9 shows the data splits for this case.
We made three different test cases and none of them contains any common sample. For example, case P1 (
Figure 9) has a test set that contains data from only participant 1 but case P7 has a test set that includes data from participant 7 only. This method tests whether our model is capable of recognizing a particular person’s gestures as opposed to recognizing any gesture in general, which is a probable reflection of a real life gesture recognition scenario where a user does not need to train in order to use the system. During the selection process of our test sets, we tried to maintain fairness by randomizing the sequence of the participant datasets before selecting the three mentioned above.
Both the categories have separate datasets corresponding to left-hand gestures, right-hand gestures and a combined dataset that includes data from both of these sets. Each dataset is divided into three parts: Training, Cross Validation and Test sets with proportions of 60% for training, 20% for cross-validation and 20% for testing. For the combined case, two different partitions were made with the proportions being 70%–30% and 60%–40% respectively for training and testing.
5.3. Data Preprocessing
After creating the partitions, we standardized the datasets so that they have zero mean and unit variance. Standardization (also called scaling) was done in batches such that the cross-validation and test sets have same standardized outputs as their corresponding training sets. It is very useful for classifiers like SVM and Neural Network. Scaling the data to fit into a smaller numeric range such as [0,1] or [−1, +1] lets all features contribute equally to the classification process. It can also make training faster because of the uniform, smaller range of the dataset [
57]. This is very beneficial in training Artificial Neural Networks as it reduces its chances of getting stuck in local optima [
58].
5.4. Classifier Setup and Initial Experiment
With the data prepared for the training phase, we performed a quick experiment to understand how the two classifiers, SVM and ANN would perform after being trained with scaled data. We also used the results from this step to tune the parameters of the classifiers. We ran this experiment for both the generalized and user specific case.
5.4.1. SVM
Cost was set to 1.0 to 3.0 with increments of 0.5, kernel was set to linear. Varying the cost parameter over 1.0 did not yield any difference in the results. Therefore, we decided to use 1.0 later in our experiment as well. We used “linear kernel” because we have a large number of features. Non-linear kernels map data onto a higher dimensional space, which we do not require for our feature set.
5.4.2. ANN
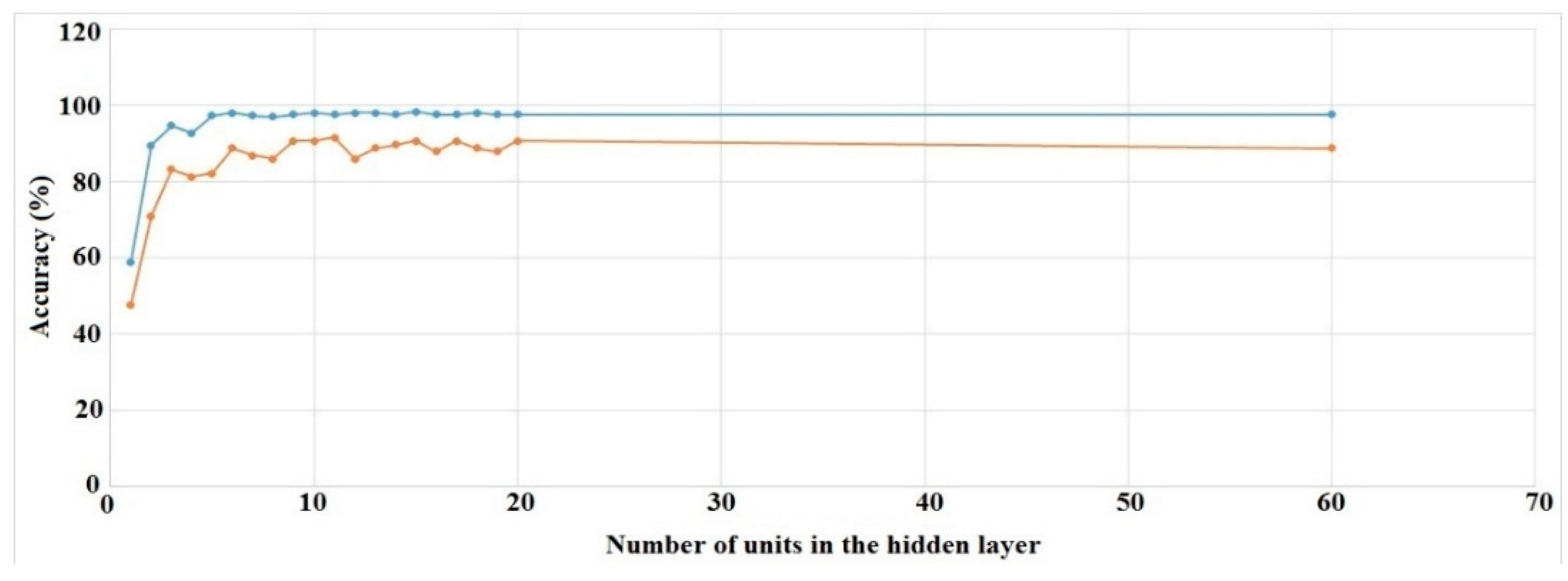
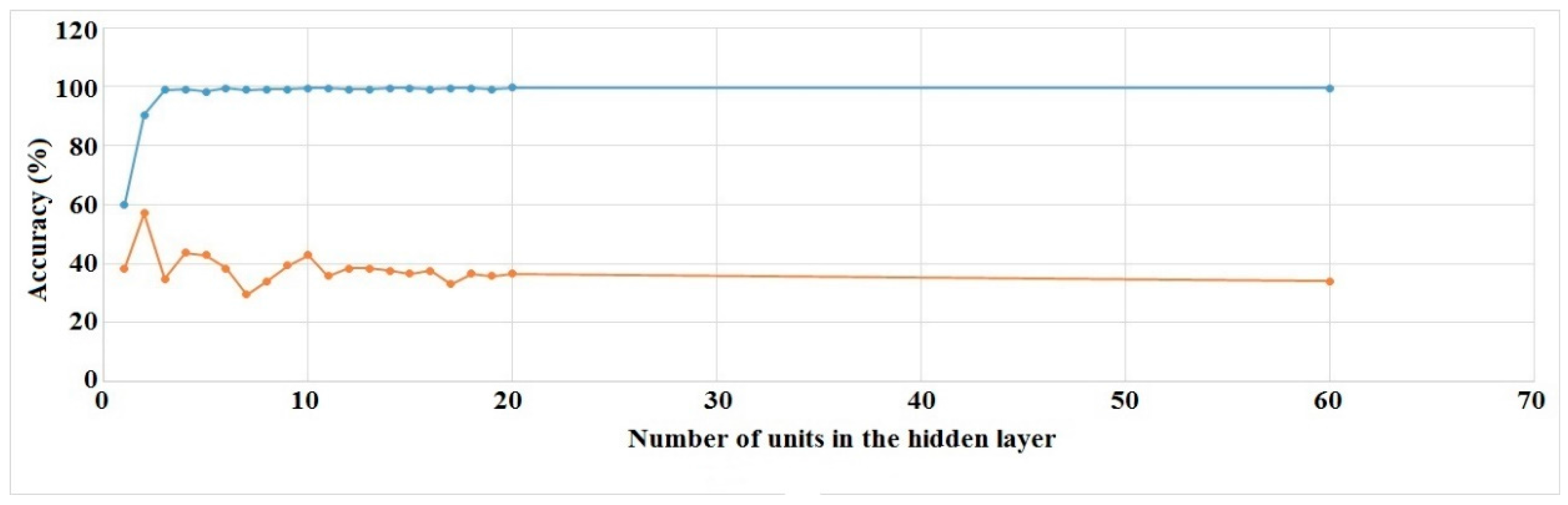
1 through 20 and “a” numbers of units in the hidden layer were tested where , learning rate, was set to 0.1, momentum, m was set to 0.2, epoch was set to 500, validation set size was set to 20% and validation threshold was set to 20.
We ran the experiments for all of the hidden layer settings (16 runs) mentioned above. Training and validation set accuracies for Right Hand Generalized and Left Hand User Specific cases are shown in
Figure 10 and
Figure 11.
The other two cases show similar results. The figures show that validation set accuracies start to settle at around 15 units in the hidden layer. As a result, we chose to use this value for every subsequent experiment.
Table 2 shows training and validation set accuracies for the Generalized Gesture Recognition case. Confusion matrix for the Right Hand Generalized case with SVM for the 60-20-20 partition (
Figure 8) is given in
Table 3 to show which gestures are basically getting misclassified. Misclassified gesture pairs are marked in bold.
Looking at the confusion matrix, we can see that the classifier is mostly confusing Jab with Throw, Uppercut with Throw and Lift, Block with Lift. Confusion matrices for the left hand and for the right hand with ANN show similar results. This is normal at this stage of the experiment because these gestures have a lot of similarities in the way they were performed.
We used the test case “P7” (
Figure 9) to examine our parameter selection and classifier accuracy for User Specific Gesture Recognition.
Table 4 shows training and validation set accuracies for different datasets along with classifier training time.
From
Table 5 we see that the gesture mix-ups are Throw with Jab, Block with Lift and Sway with Throw. Two of the gestures, Jab and Uppercut, were not recognized at all by the classifiers.
The gestures that are similar have not been classified properly in most of the cases. There can be two reasons behind this—one is that the current classifier parameters are not suitable for this type of datasets. The other one would be the dataset itself. Since the classifiers showed acceptable performance for the generalized cases (above 90% validation set accuracy), we are inclined to believe that the latter one is the reason behind such a poor performance. In particular, we believe that if we reduce the dimension of the dataset and keep only the data that contribute to most of the variations, we should be able to achieve better accuracy with current settings.
5.5. Dimensionality Reduction
As mentioned in
Section 5.1, we calculated 115 features from the raw data. However, all of these features do not contribute well to every gesture in terms of variation in data. For example, most of the features calculated from sensors 15 and 16 would not be too useful to classify left-hand gestures because these two sensors were subject to very limited to no movement during the performance of those gestures. On the other hand, data from sensor 19 might be very useful to distinguish Sway because other gestures had very limited use of this sensor during the study. Therefore, we need to apply a proper dimensionality reduction technique to get the most out of our feature set. Principal Component Analysis (PCA) was our choice because its operating principles match with our requirements.
We applied PCA by using Weka’s [
59] attribute selection tool which ranks the PCs in terms of their Eigenvalues and keeps only those that fall within the specified variation. Initially, we applied PCA on the entire feature dataset, ranked the principal component using Weka and kept those components which cumulatively attributed to 95% of the variation in the dataset. We followed this procedure for both the generalized and the user specific cases.
8. Conclusions
From the results of our experiments, we can deduce that human gesture recognition is not a problem that can be solved using any out of the box classification system. Different scenarios demand different configurations of the experiment and different approach strategies for accurate classification.
We built a complete human gesture recognition system based on Support Vector Machine and Artificial Neural Network for six different gestures by collecting data from 11 participants. We explored two scenarios by organizing the same dataset in two different ways: Generalized Gesture Recognition, where we included data from every individual in our test sets to test our system’s performance on recognizing the gestures, regardless of who performed the gestures, and User Specific Gesture Recognition where we tested if our system can perform well when it is given a test dataset from a specific individual to mimic a real life use of the system.
Our experiments revealed that if we have a good set of features, it is easier to recognize random human gestures in general as compared to recognizing a set of gestures from an individual alone. While achieving very good accuracy for the former requires applying basic data preprocessing techniques and common dimensionality reduction methods that are most commonly used in the literature, achieving the same results in the latter scenario is trickier. It requires a good understanding of the dataset and proper feature selection methods. We achieved near perfect gesture recognition in the generalized case by following standard experimental methodologies such as feature extraction, standardization, cross-validation and dimensionality reduction using PCA. However, the same methodology performed poorly on the user specific case. To overcome this problem, we decided to exclude all velocity-based features from our feature set and then follow the same gesture recognition procedure as mentioned above. Eventually, we were able to achieve near perfect overall recognition rates on all of our datasets for this case.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}