
Node Detection and Internode Length Estimation of Tomato Seedlings Based on Image Analysis and Machine Learning


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Crop Materials and Image Acquisition
2.2. Node Detection
2.2.1. Stem Area Extraction
2.2.2. Candidate Node Detection
2.2.3. False Positive Elimination Based on Main Stem Detection
2.2.4. False Positive Elimination Based on Bag of Visual Words
2.3. Node Order Estimation
2.4. Internode Length Estimation
2.5. Performance Evaluation
2.6. Implementation
3. Results
4. Discussion and Conclusion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Markovic, V.; Djurovka, M.; Ilin, Z. The effect of seedling quality on tomato yield, plant and fruit characteristics. In Proceedings of the I Balkan Symposium on Vegetables and Potatoes, Belgrade, Yugoslavia, 4–7 July 1996; pp. 163–170.
- Kim, E.Y.; Park, S.A.; Park, B.J.; Lee, Y.; Oh, M.M. Growth and antioxidant phenolic compounds in cherry tomato seedlings grown under monochromatic light-emitting diodes. Hortic. Environ. Biotechnol. 2014, 55, 506–513. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, X.; Wang, W.; Wu, X. Review on the proceeding of automatic seedlings classification by computer vision. J. Forest. Res. 2002, 13, 245–249. [Google Scholar]
- Li, L.; Zhang, Q.; Huang, D. A Review of Imaging Techniques for Plant Phenotyping. Sensors 2014, 14, 20078–20111. [Google Scholar] [CrossRef] [PubMed]
- Behmann, J.; Mahlein, A.K.; Rumpf, T.; Römer, C.; Plümer, L. A review of advanced machine learning methods for the detection of biotic stress in precision crop protection. Precis. Agric. 2014, 16, 239–260. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Mutka, A.; Bart, R. Image-based phenotyping of plant disease symptoms. Front. Plant Sci. 2015, 5. [Google Scholar] [CrossRef] [PubMed]
- Rousseau, D.; Chéné, Y.; Belin, E.; Semaan, G.; Trigui, G.; Boudehri, K.; Franconi, F.; Chapeau-Blondeau, F. Multiscale imaging of plants: Current approaches and challenges. Plant Methods 2015, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, R.; Damerow, L.; Sun, Y.; Blanke, M.M. Using colour features of cv. ’Gala’ apple fruits in an orchard in image processing to predict yield. Precis. Agric. 2012, 13, 568–580. [Google Scholar] [CrossRef]
- Payne, A.; Walsh, K.; Subedi, P.; Jarvis, D. Estimation of mango crop yield using image analysis—Segmentation method. Comput. Electron. Agric. 2013, 91, 57–64. [Google Scholar] [CrossRef]
- Stajnko, D.; Rakun, J.; Blanke, M. Modelling Apple Fruit Yield Using Image Analysis for Fruit Colour, Shape and Texture. Eur. J. Hortic. Sci. 2009, 74, 260–267. [Google Scholar]
- Font, D.; Tresanchez, M.; Martínez, D.; Moreno, J.; Clotet, E.; Palacín, J. Vineyard yield estimation based on the analysis of high resolution images obtained with artificial illumination at night. Sensors 2015, 15, 8284–8301. [Google Scholar] [CrossRef] [PubMed]
- Payne, A.; Walsh, K.; Subedi, P.; Jarvis, D. Estimating mango crop yield using image analysis using fruit at ’stone hardening’ stage and night time imaging. Comput. Electron. Agric. 2014, 100, 160–167. [Google Scholar] [CrossRef]
- Wang, Q.; Nuske, S.; Bergerman, M.; Singh, S. Automated Crop Yield Estimation for Apple Orchards. In Experimental Robotics; Springer International Publishing: New York, USA, 2013; pp. 745–758. [Google Scholar]
- Linker, R.; Cohen, O.; Naor, A. Determination of the number of green apples in RGB images recorded in orchards. Comput. Electron. Agric. 2012, 81, 45–57. [Google Scholar] [CrossRef]
- Kurtulmus, F.; Lee, W.S.; Vardar, A. Immature peach detection in colour images acquired in natural illumination conditions using statistical classifiers and neural network. Precis. Agric. 2013, 15, 57–79. [Google Scholar] [CrossRef]
- Guo, W.; Rage, U.K.; Ninomiya, S. Illumination invariant segmentation of vegetation for time series wheat images based on decision tree model. Comput. Electron. Agric. 2013, 96, 58–66. [Google Scholar] [CrossRef]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On Plant Detection of Intact Tomato Fruits Using Image Analysis and Machine Learning Methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Fukatsu, T.; Ninomiya, S. Automated characterization of flowering dynamics in rice using field-acquired time-series RGB images. Plant Methods 2015, 11, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Sibomana, I.C.; Aguyoh, J.N.; Opiyo, A.M. Water stress affects growth and yield of container grown tomato (Lycopersicon esculentum Mill) plants. Glob. J. Bio-Sci. BioTechnol. 2013, 2, 461–466. [Google Scholar]
- McCall, D.; Atherton, J.G. Interactions between diurnal temperature fluctuations and salinity on expansion growth and water status of young tomato plants. Ann. Appl. Biol. 1995, 127, 191–200. [Google Scholar] [CrossRef]
- Grimstad, S.O. The effect of a daily low temperature pulse on growth and development of greenhouse cucumber and tomato plants during propagation. Sci. Hortic. 1993, 53, 53–62. [Google Scholar] [CrossRef]
- Turhan, A.; Ozmen, N.; Serbeci, M.S.; Seniz, V. Effects of grafting on different rootstocks on tomato fruit yield and quality. Hortic. Sci. 2011, 38, 142–149. [Google Scholar]
- Davis, P.F. Orientation-independent recognition of chrysanthemum nodes by an artificial neural network. Comput. Electron. Agric. 1991, 5, 305–314. [Google Scholar] [CrossRef]
- Mohammed Amean, Z.; Low, T.; McCarthy, C.; Hancock, N. Automatic plant branch segmentation and classification using vesselness measure. In Proceedings of the 2013 Australasian Conference on Robotics and Automation (ACRA 2013), Sydney, Australia, 2–4 December 2013.
- McCarthy, C.L.; Hancock, N.H.; Raine, S.R. Automated internode length measurement of cotton plants under field conditions. Trans. ASABE 2009, 52, 2093–2103. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth & Brooks/Cole Advanced Books & Software: Monterey, CA, USA, 1984; Volume 5, pp. 95–96. [Google Scholar]
- Zhang, T.Y.; Suen, C.Y. A Fast Parallel Algorithm for Thinning Digital Patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Sarfraz, M. Segmentation Algorithm. In Computer-Aided Intelligent Recognition Techniques and Applications, 1st ed.; John Wiley and Sons: New York, NY, USA, 2005; p. 56. [Google Scholar]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the ECCV International Workshop on Statistical Learning in Computer Vision, Florence, Italy, 7–13 October 2004; pp. 59–74.
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Procedings of the Alvey Vision Conference 1988, Manchester, UK, 31 August–2 September 1988; pp. 147–151.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Itseez. OpenCV 2014. Available online: https://github.com/itseez/opencv (accessed on 5 July 2016).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2015. [Google Scholar]
- Kurtulmus, F.; Lee, W.S.; Vardar, A. Green citrus detection using ’eigenfruit’, color and circular Gabor texture features under natural outdoor conditions. Comput. Electron. Agric. 2011, 78, 140–149. [Google Scholar] [CrossRef]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window size impact in human activity recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [PubMed]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311.
- Zhou, X.; Yu, K.; Zhang, T.; Huang, T.S. Image classification using super-vector coding of local image descriptors. In Computer Vision–ECCV 2010; Springer: Berlin, Germany, 2010; pp. 141–154. [Google Scholar]
- Picard, D.; Gosselin, P.H. Improving image similarity with vectors of locally aggregated tensors. Int. Conf. Image Process. 2011, 669–672. [Google Scholar] [CrossRef]
- Perronnin, F.; Liu, Y.; Sánchez, J.; Poirier, H. Large-scale image retrieval with compressed Fisher vectors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3384–3391.
- Chatfield, K.; Lempitsky, V.; Vedaldi, A.; Zisserman, A. The devil is in the details: an evaluation of recent feature encoding methods. In BMVC; Hoey, J., McKenna, S., Trucco, E., Eds.; BMVA Press: Dundee, Scotland, 2011; p. 8. [Google Scholar]
- Wang, H. Feature Fusion for Image Classification Based on Affinity Propagation. Int. J. Digit. Content Technol. Appl. 2013, 7, 480–487. [Google Scholar]
- Long, Y. Blind image quality assessment using compact visual codebooks. In Proceedings of the 18th World Congress of CIGR, Beijing, China, 16–19 September 2014.
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar]
- Chen, C.; Liaw, A.; Breiman, L. Using Random Forest to Learn Imbalanced Data; Technical Report; Department of Statistics, University of California: Berkeley, CA, USA, 2004. [Google Scholar]
- Bertram, L.; Karlsen, P. Patterns in stem elongation rate in chrysanthemum and tomato plants in relation to irradiance and day/night temperature. Sci. Hortic. 1994, 58, 139–150. [Google Scholar] [CrossRef]
- Shimizu, H.; Heins, R.D. Photoperiod and the Difference between Day and Night Temperature Influence Stem Elongation Kinetics in Verbena bonariensis. J. Am. Soc. Hortic. Sci. 2000, 125, 576–580. [Google Scholar]
- Koyano, Y.; Chun, C.; Kozai, T. Controlling the Lengths of Hypocotyl and Individual Internodes of Tomato Seedlings by Changing DIF with Time. Shokubutsu Kankyo Kogaku 2005, 17, 68–74. (In Japanese) [Google Scholar] [CrossRef]
- Fukatsu, T. Possibility of Mobile Robot Field Server. In Proceedings of the 33rd Asia-Pacific Advanced Network, Chiang Mai, Tailand, 13–17 February 2012.








{kind=link}
{kind=link}
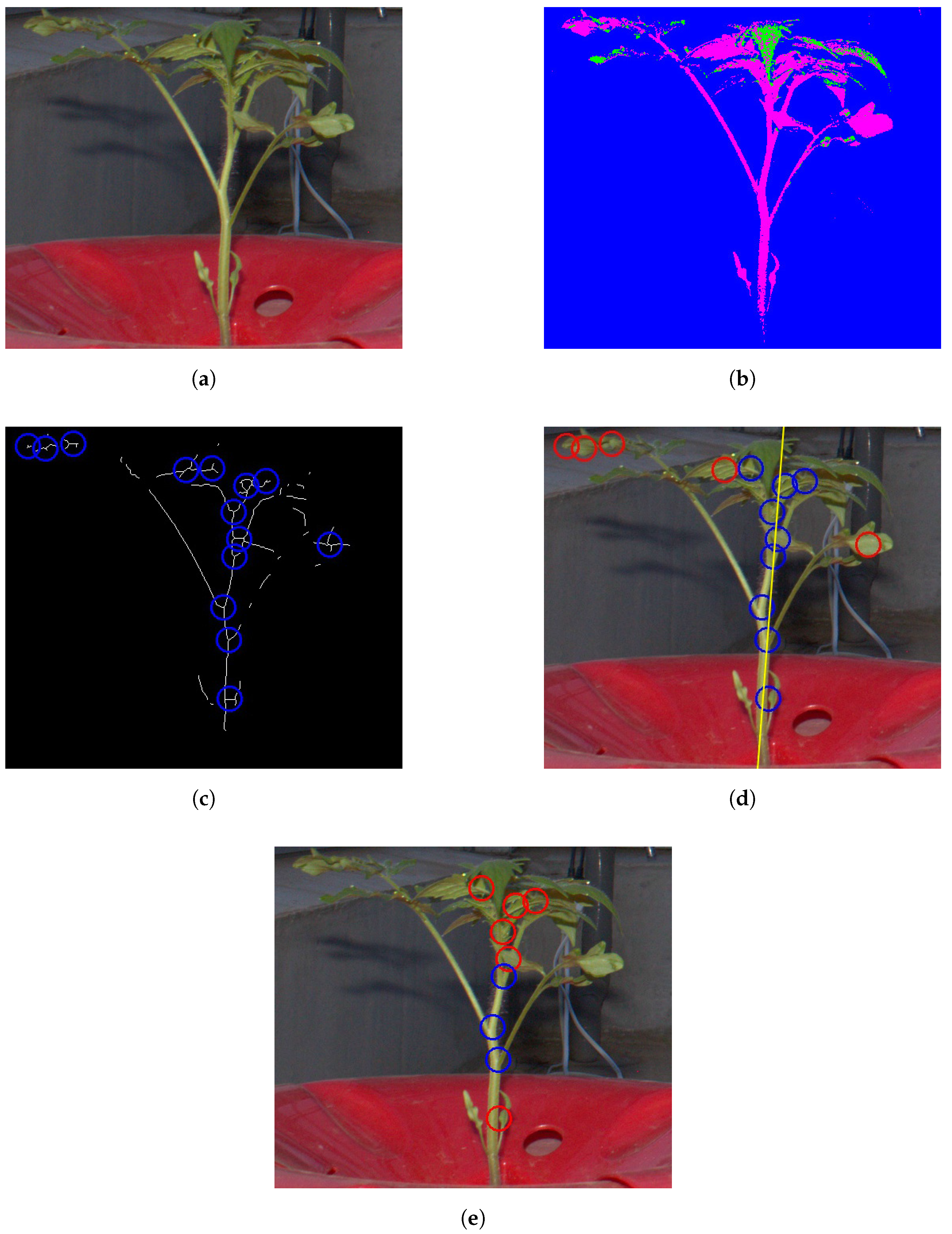{kind=link}
{kind=link}
{kind=link}
{kind=link}
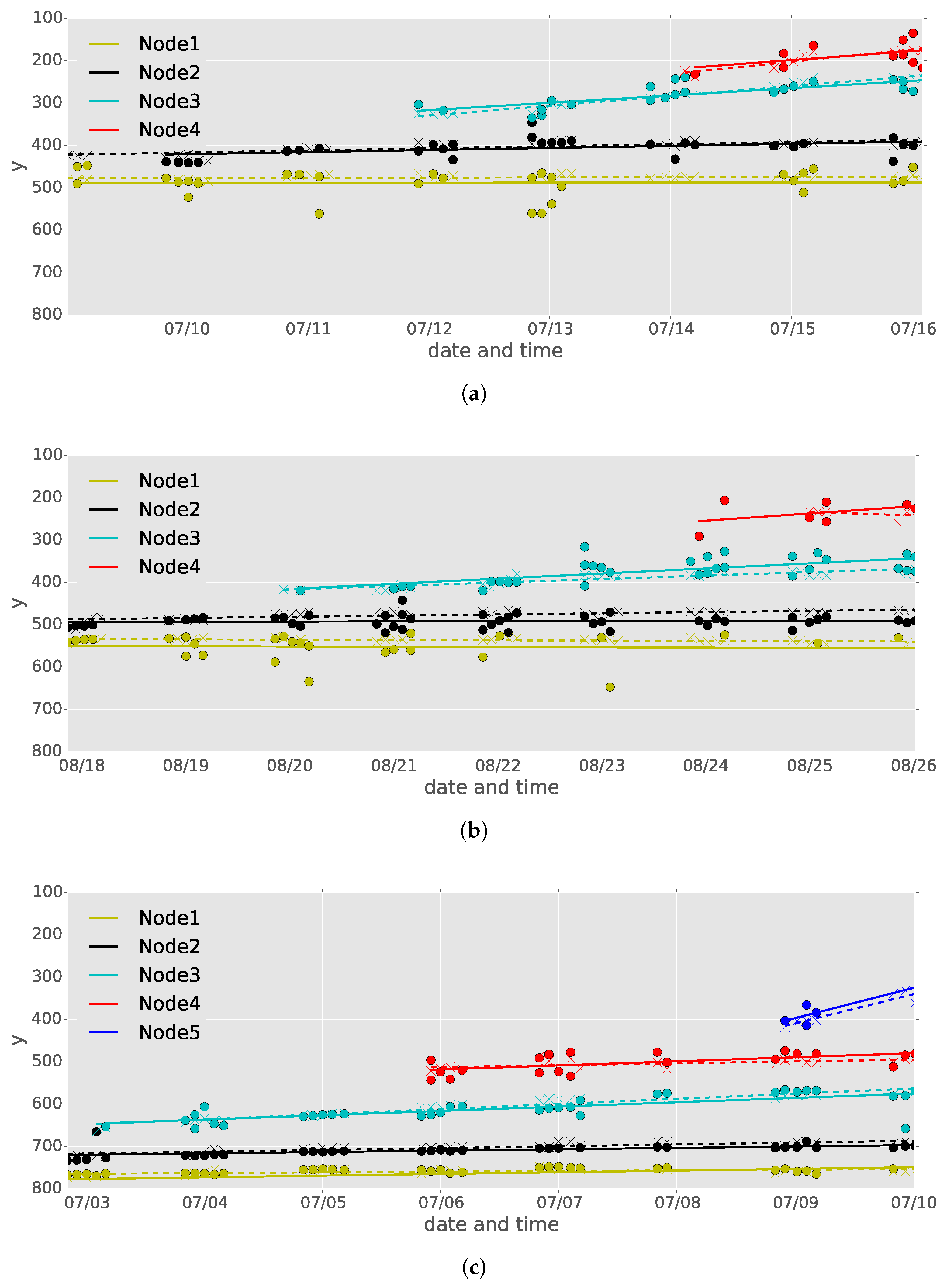{kind=link}
{kind=link}
| Seedling | Sowing Date | Experimental Period | Number of Images |
|---|---|---|---|
| A | 19 June 2014 | 9–16 July 2014 | 36 |
| B | 23 July 2014 | 18–26 August 2014 | 43 |
| C | 19 June 2014 | 2–10 July 2014 | 35 |
| Seedling A | Seedling B | Seedling C | |
|---|---|---|---|
| Node region | 212 | 191 | 211 |
| Non-node region | 242 | 286 | 255 |
| Seedling | Node Order | Original | MS | MS + BoVWs | Total Node Number | |||
|---|---|---|---|---|---|---|---|---|
| Recall | Precision | Recall | Precision | Recall | Precision | |||
| A | 1 | 0.72 | - | 0.72 | - | 0.61 | - | 36 |
| 2 | 0.89 | - | 0.89 | - | 0.69 | - | 36 | |
| 3 | 0.83 | - | 0.83 | - | 0.74 | - | 23 | |
| 4 | 0.64 | - | 0.73 | - | 0.45 | - | 11 | |
| All | 0.79 | 0.21 | 0.80 | 0.42 | 0.64 | 0.79 | 106 | |
| B | 1 | 0.67 | - | 0.65 | - | 0.58 | - | 43 |
| 2 | 0.67 | - | 0.65 | - | 0.63 | - | 43 | |
| 3 | 0.41 | - | 0.41 | - | 0.59 | - | 32 | |
| 4 | 0.67 | - | 0.50 | - | 0.50 | - | 6 | |
| All | 0.63 | 0.24 | 0.61 | 0.35 | 0.61 | 0.66 | 124 | |
| C | 1 | 0.94 | - | 0.94 | - | 0.94 | - | 35 |
| 2 | 1.00 | - | 1.00 | - | 0.94 | - | 35 | |
| 3 | 0.94 | - | 0.97 | - | 0.97 | - | 32 | |
| 4 | 0.68 | - | 0.68 | - | 0.79 | - | 19 | |
| 5 | 0.71 | - | 0.57 | - | 0.43 | - | 7 | |
| All | 0.92 | 0.17 | 0.92 | 0.40 | 0.91 | 0.91 | 128 | |
| All | All | 0.77 | 0.17 | 0.76 | 0.37 | 0.72 | 0.78 | 358 |
| Seedling | Internode | Mean of Internode Length | Relative Error (%) | |
|---|---|---|---|---|
| Observed (mm) | Estimated (mm) | |||
| A | 1–2 | 29.6 | 33.1 | 11.5 |
| 2–3 | 47.2 | 49.2 | 4.3 | |
| 3–4 | 24.3 | 27.7 | 13.9 | |
| All | 34.6 | 37.5 | 8.5 | |
| B | 1–2 | 25.0 | 25.1 | 0.4 |
| 2–3 | 33.2 | 46.0 | 38.6 | |
| 3–4 | 55.3 | 49.8 | 10.0 | |
| All | 30.5 | 35.2 | 15.4 | |
| C | 1–2 | 23.2 | 22.7 | 2.3 |
| 2–3 | 39.6 | 40.1 | 1.4 | |
| 3–4 | 35.0 | 40.0 | 14.2 | |
| 4–5 | 48.5 | 49.1 | 1.2 | |
| All | 33.1 | 34.2 | 3.2 | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamamoto, K.; Guo, W.; Ninomiya, S. Node Detection and Internode Length Estimation of Tomato Seedlings Based on Image Analysis and Machine Learning. Sensors 2016, 16, 1044. https://doi.org/10.3390/s16071044
Yamamoto K, Guo W, Ninomiya S. Node Detection and Internode Length Estimation of Tomato Seedlings Based on Image Analysis and Machine Learning. Sensors. 2016; 16(7):1044. https://doi.org/10.3390/s16071044
Chicago/Turabian StyleYamamoto, Kyosuke, Wei Guo, and Seishi Ninomiya. 2016. "Node Detection and Internode Length Estimation of Tomato Seedlings Based on Image Analysis and Machine Learning" Sensors 16, no. 7: 1044. https://doi.org/10.3390/s16071044