Clustered Multi-Task Learning for Automatic Radar Target Recognition

Abstract
:1. Introduction
- (1)
- The theory of clustered multi-task learning is applied to radar target recognition.
- (2)
- The potentially useful multi-task relationships in the projection space are taken into consideration, which helps to discriminate the radar targets with similar patterns.
- (3)
- The proposed method can autonomously learn the multi-task relationships, cluster information and be easily extended to nonlinear domains.
- (4)
- APG method is used for solving the non-linear extension of multi-task learning, which guarantees the convergence and can be implemented in parallel computing.
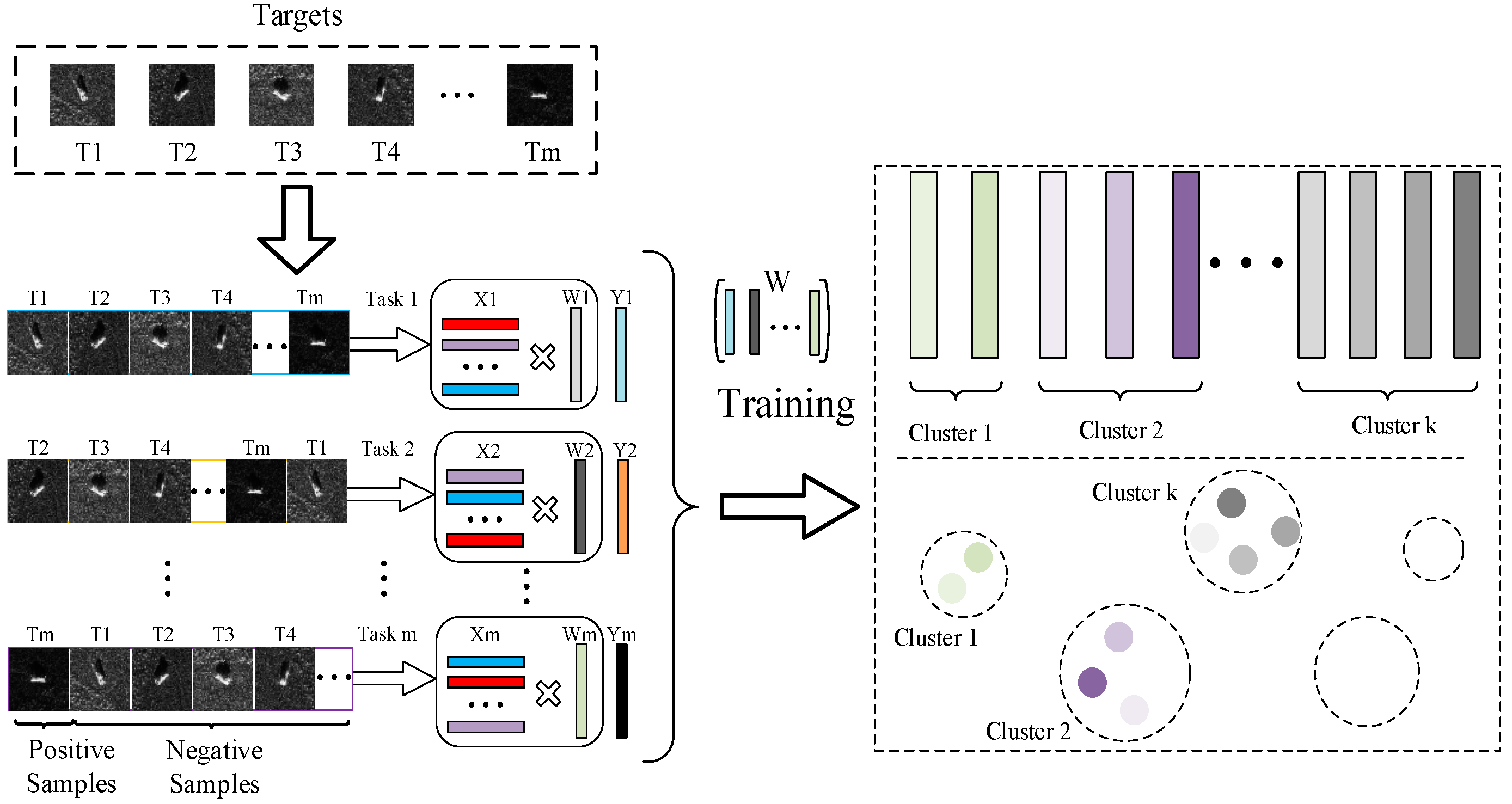
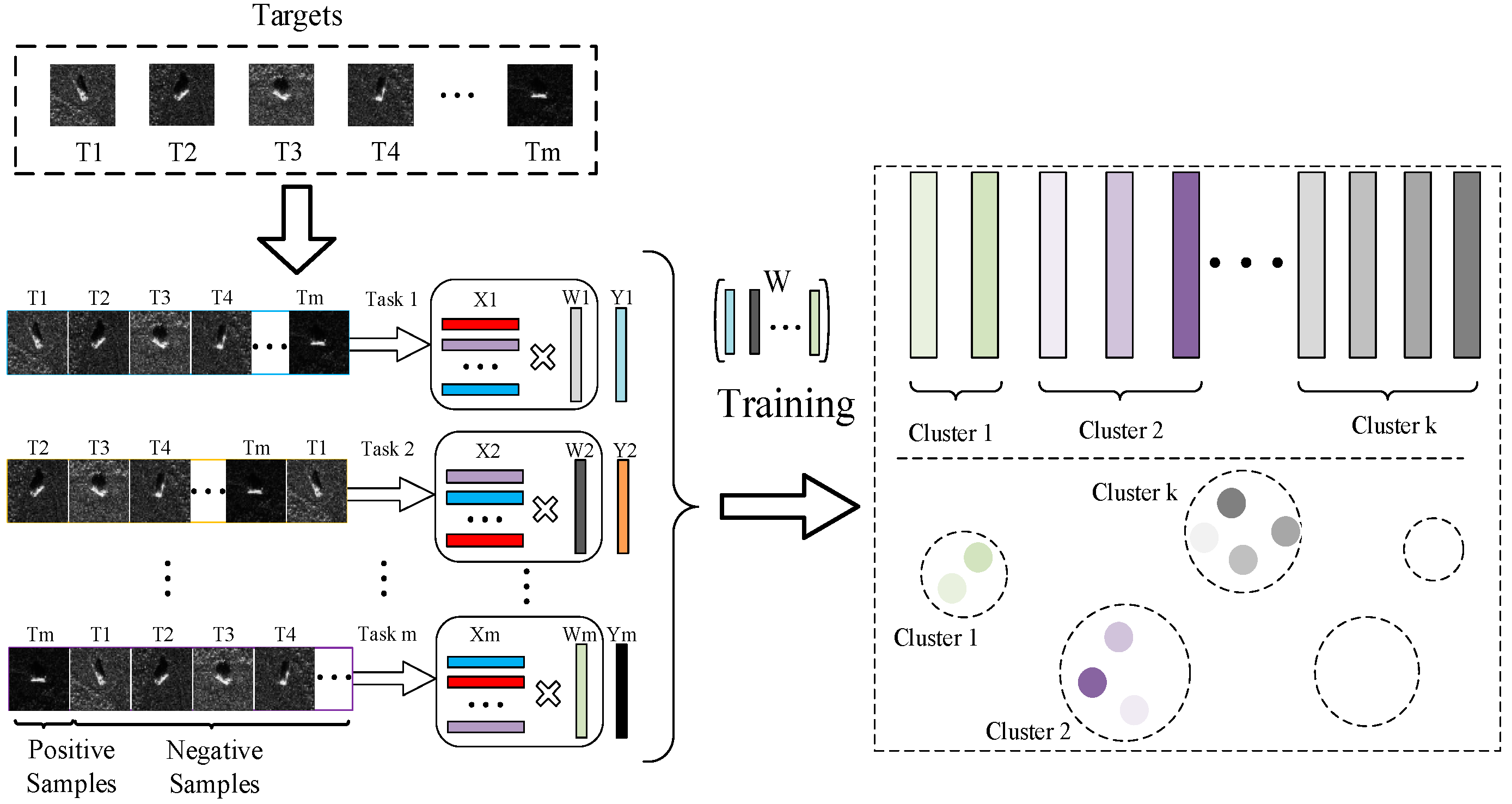
2. Clustered Multi-Task Learning
2.1. Preliminaries
2.2. Proposed Clustered Multi-Task Learning
2.3. Proposed Optimization Method
3. Experimental Results and Analysis
| Algorithm 1. Pseudo Code for Solving Problem (8) |
| 1: Input , , , , ; 2: Initialize , and ; 3: while not converged 4: Update and 5: Reformulate the optimize problem (9) into a dual form (12) 6: Update by Equation (14) 7: Solving problem (15) by using the APG method 8: Update by using Equation (21) 9: end while 10: Output , and . |
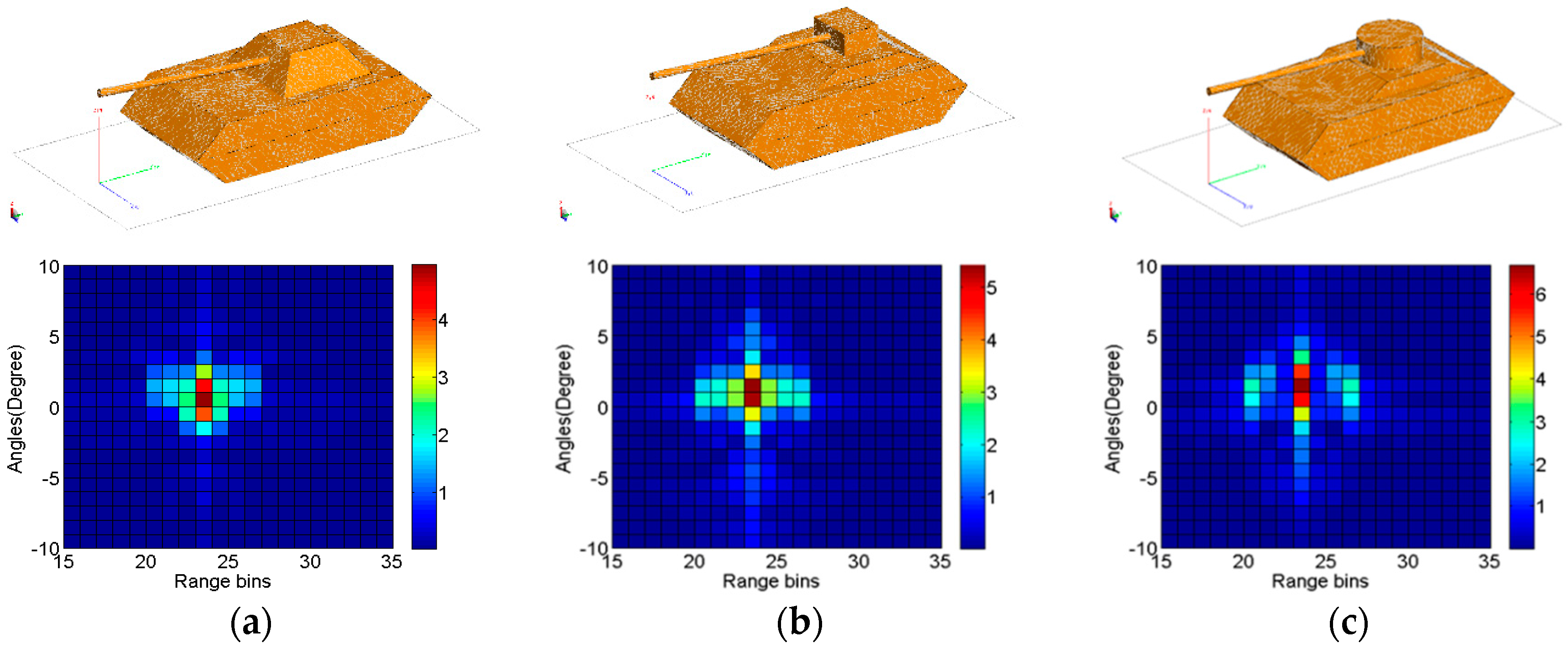
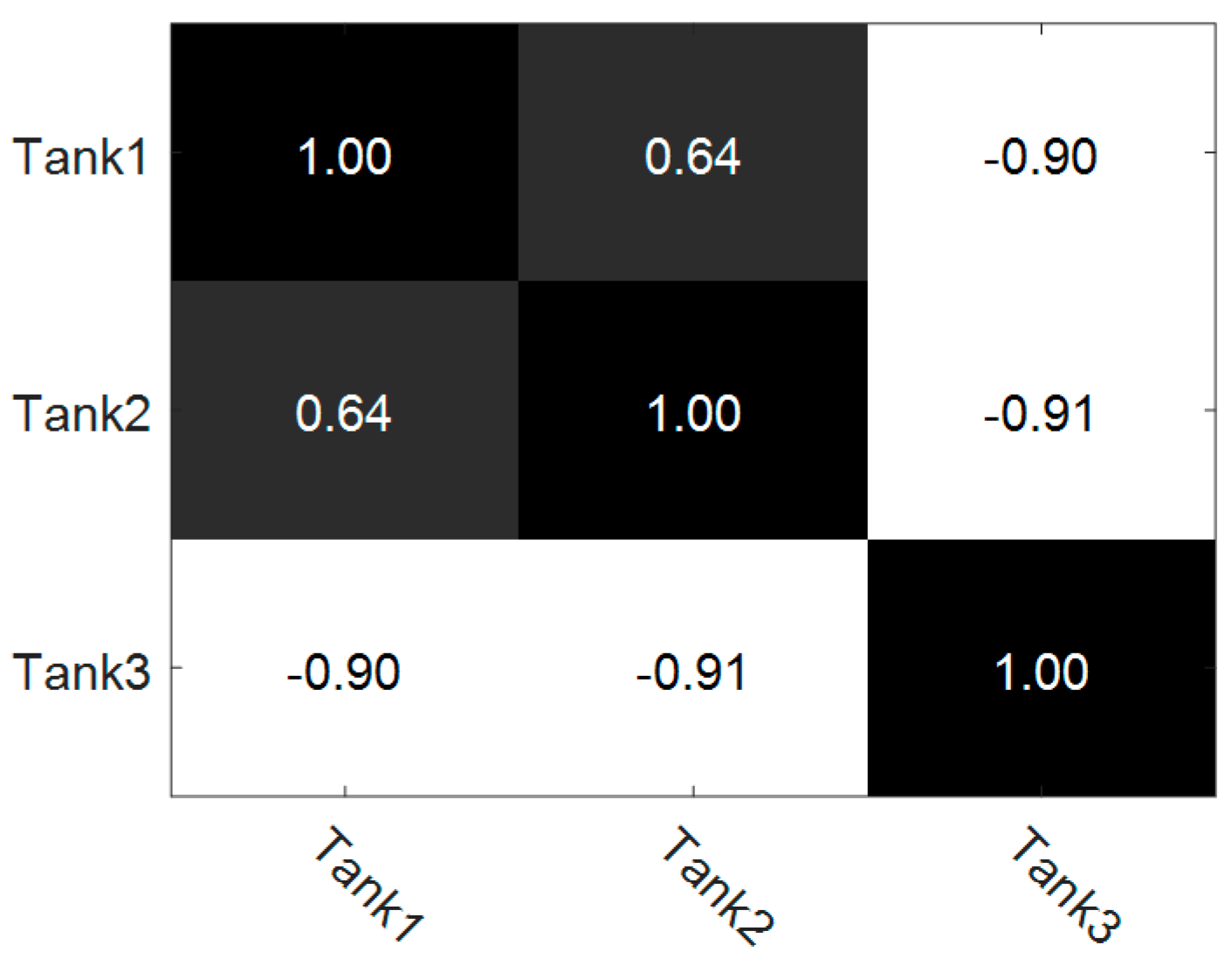
3.1. Investigations Based on a Simulated Database
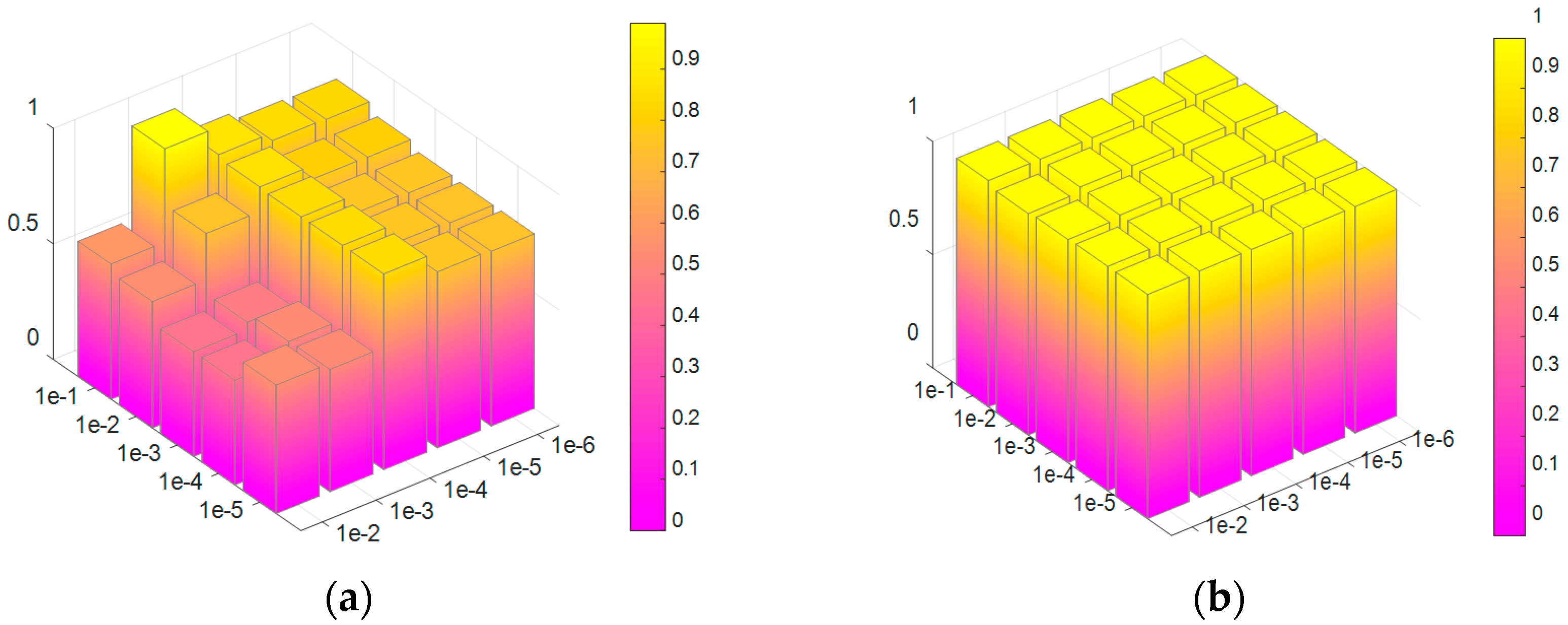
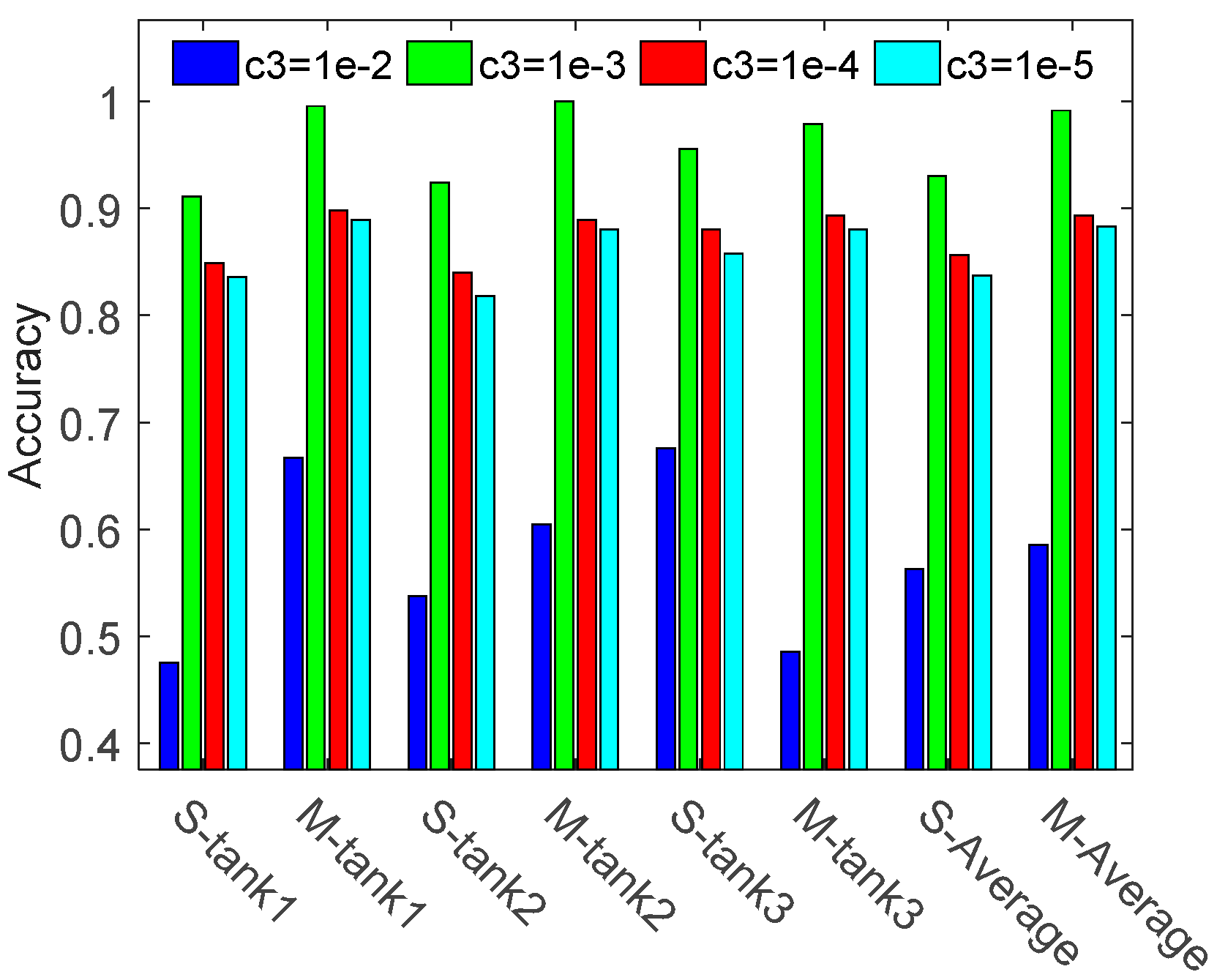
3.1.1. Influence of Model Parameters
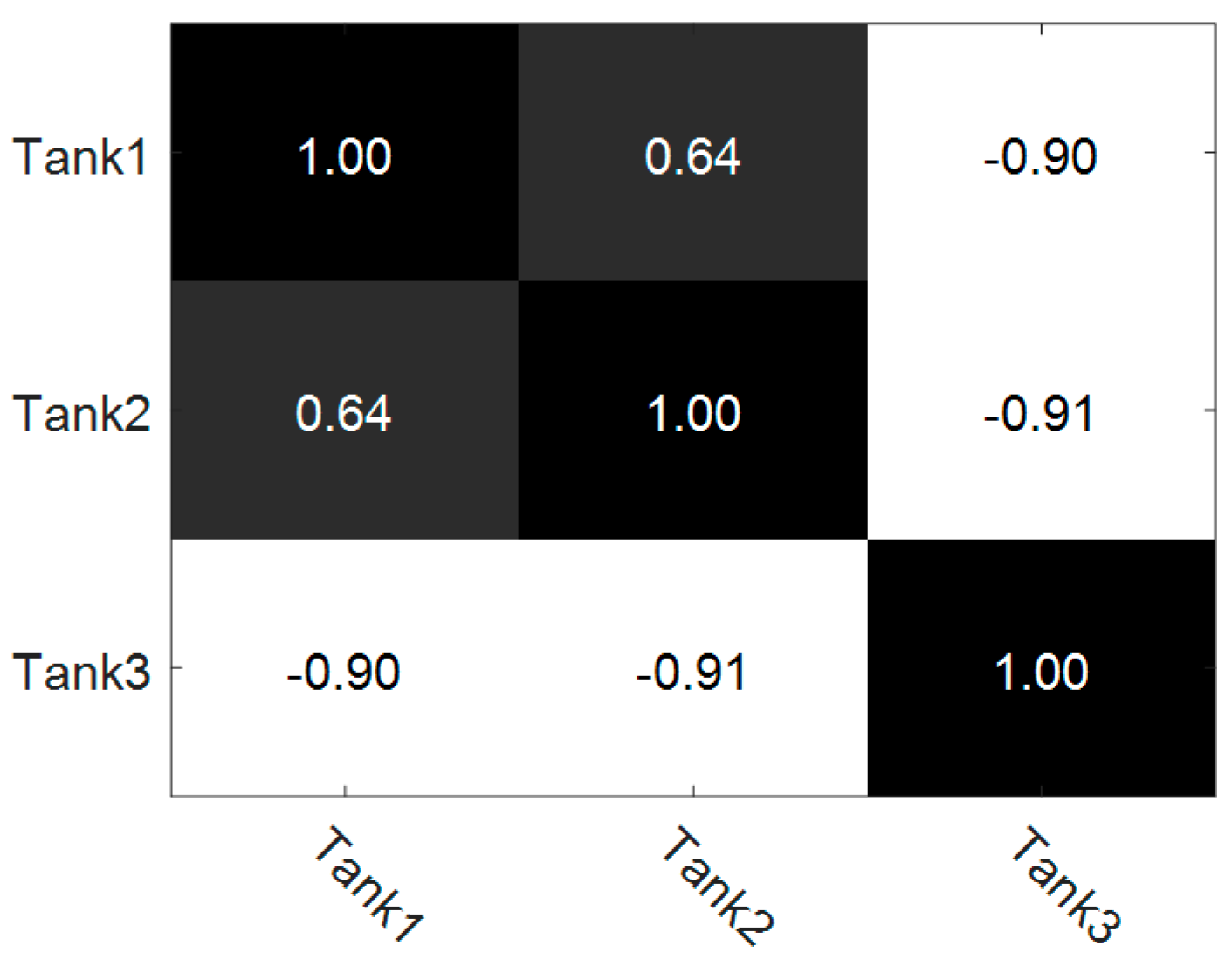
3.1.2. Comparison of Single Task and Multiple Task
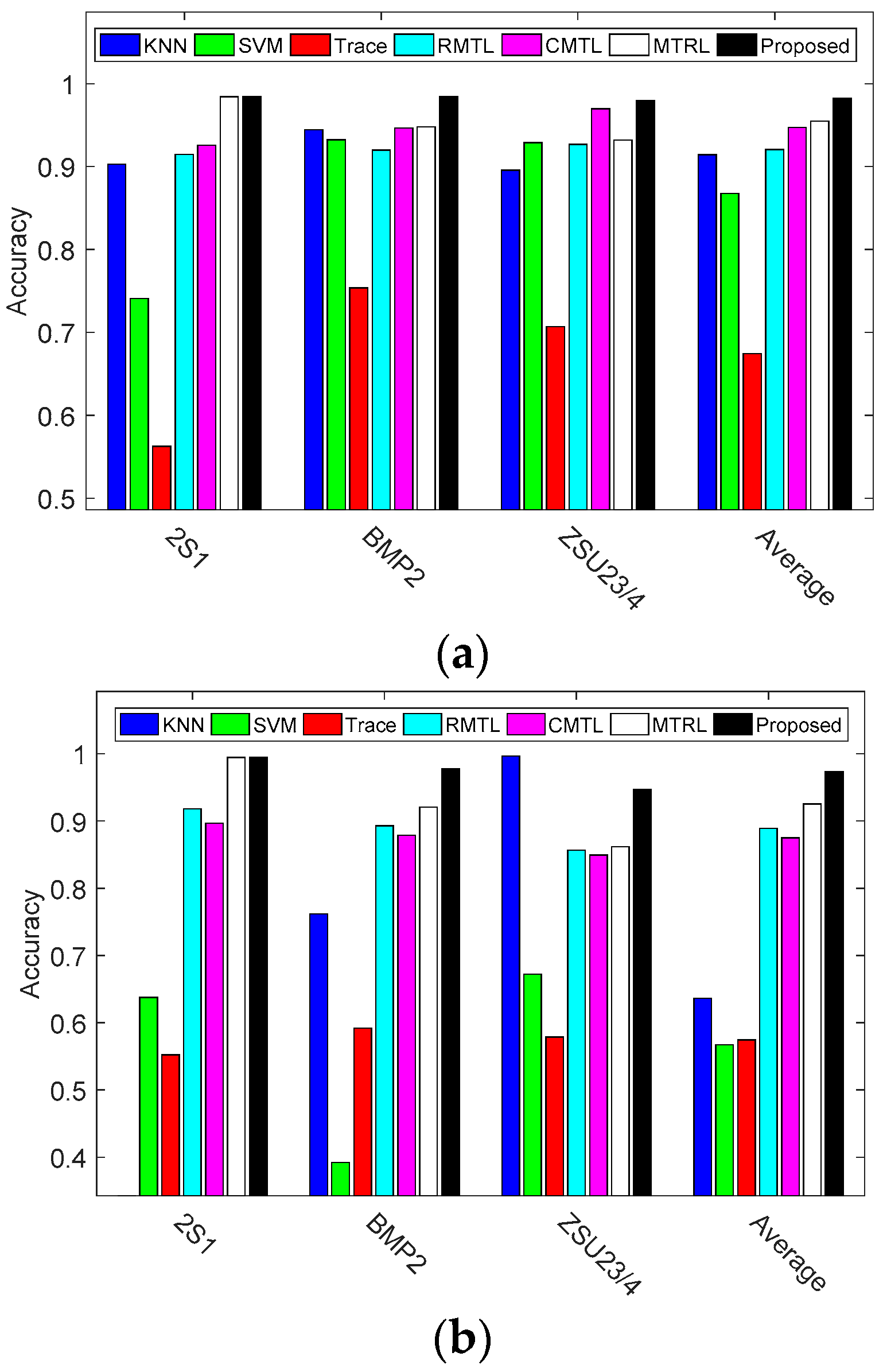
3.1.3. Comparison against the State of the Art
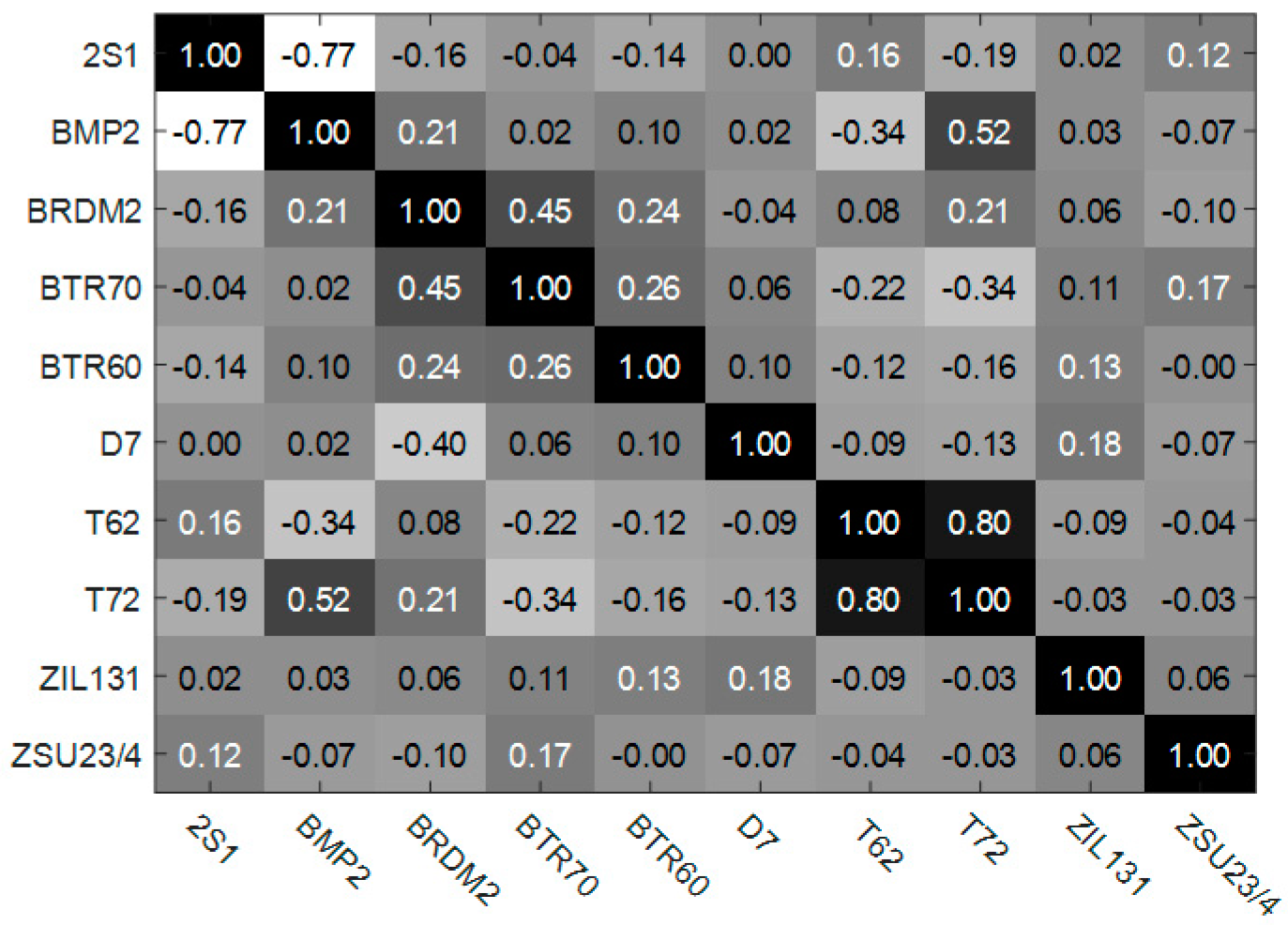
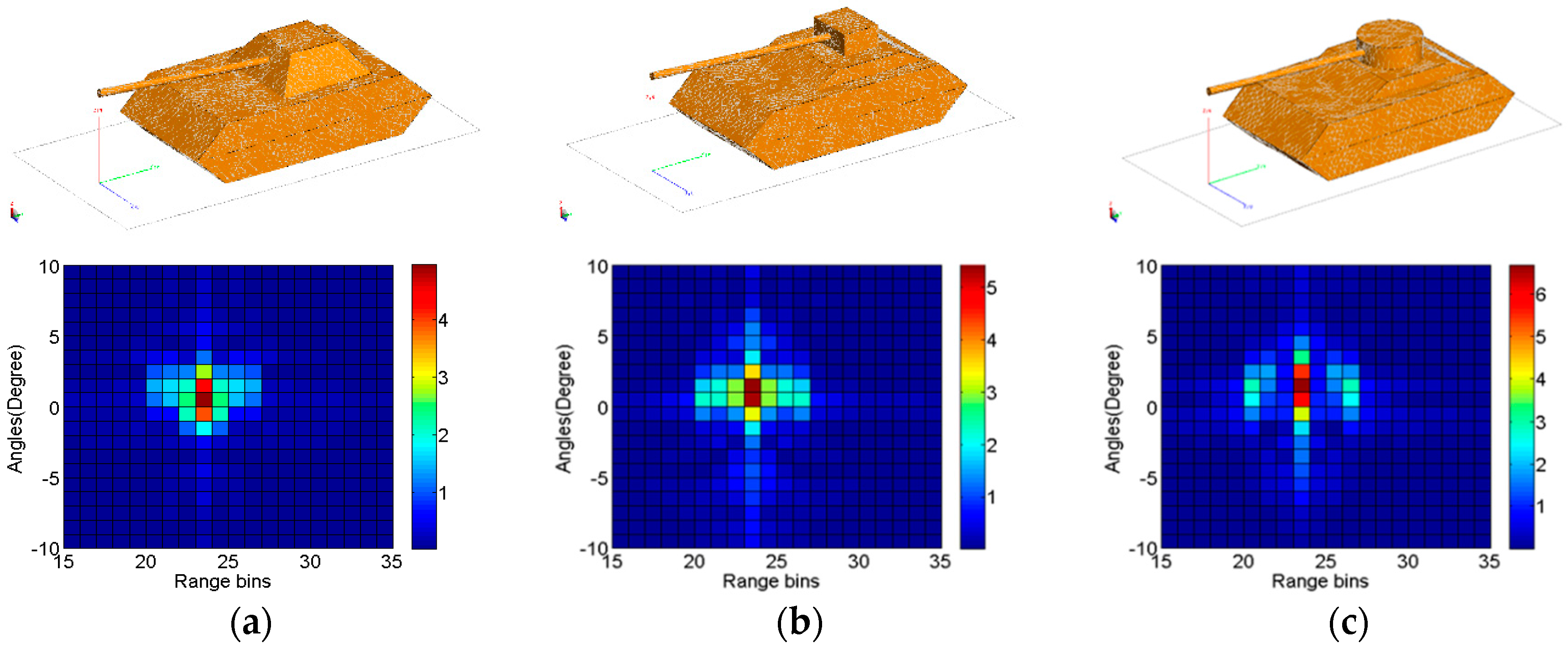
3.2. Investigations Based on MSTAR Database
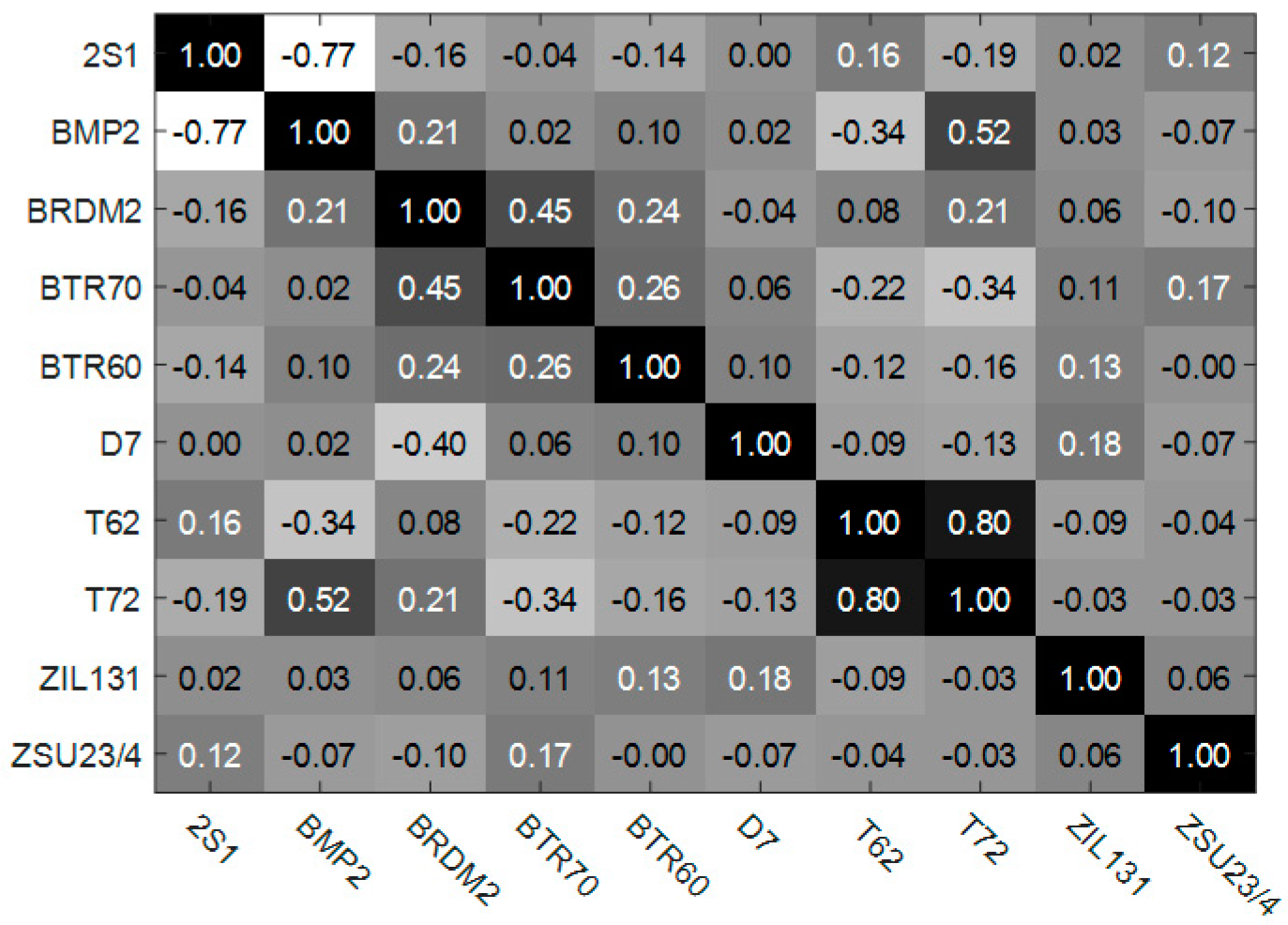
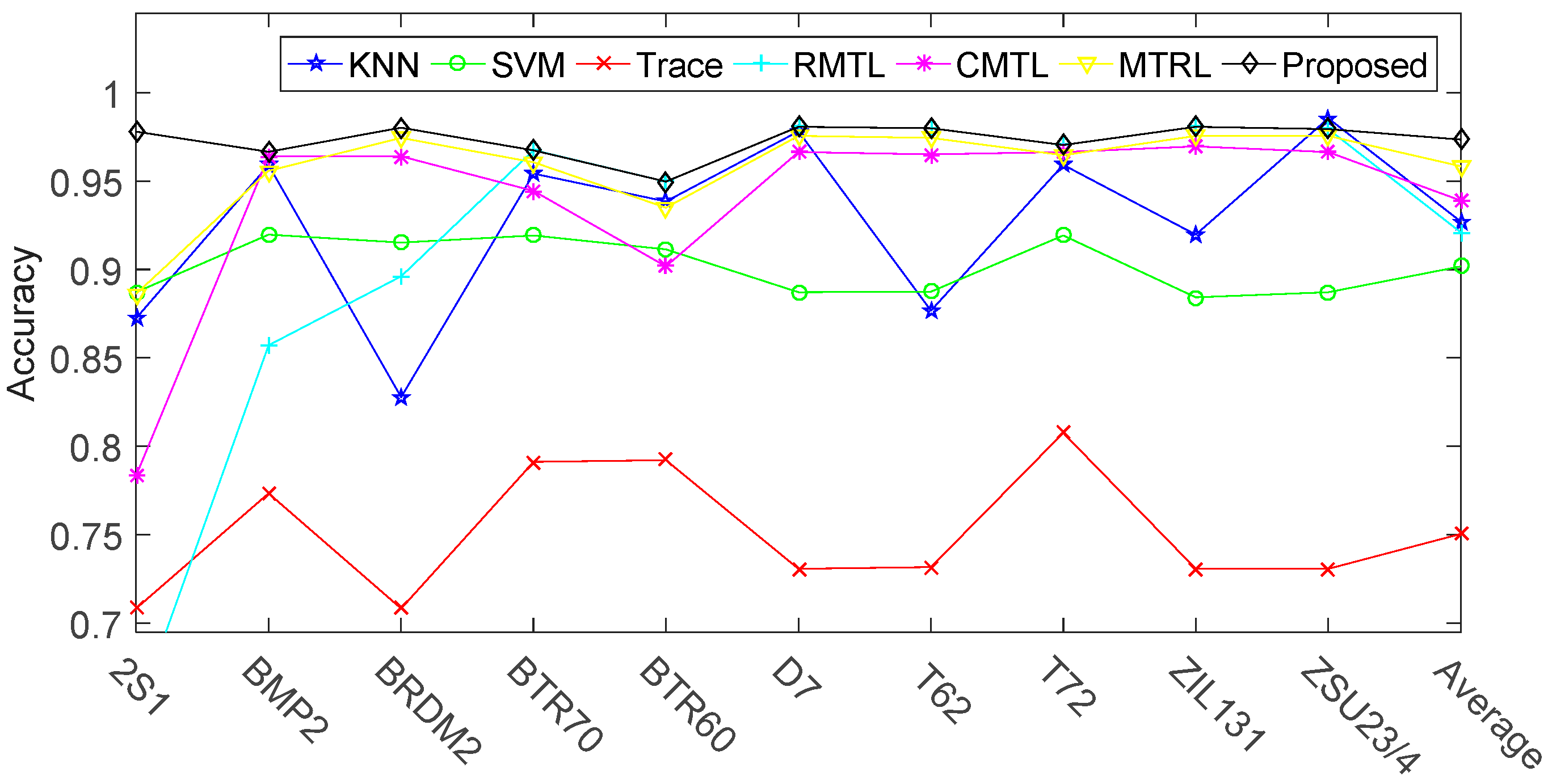
3.2.1. Target Recognition under Standard Operating Conditions (SOC)
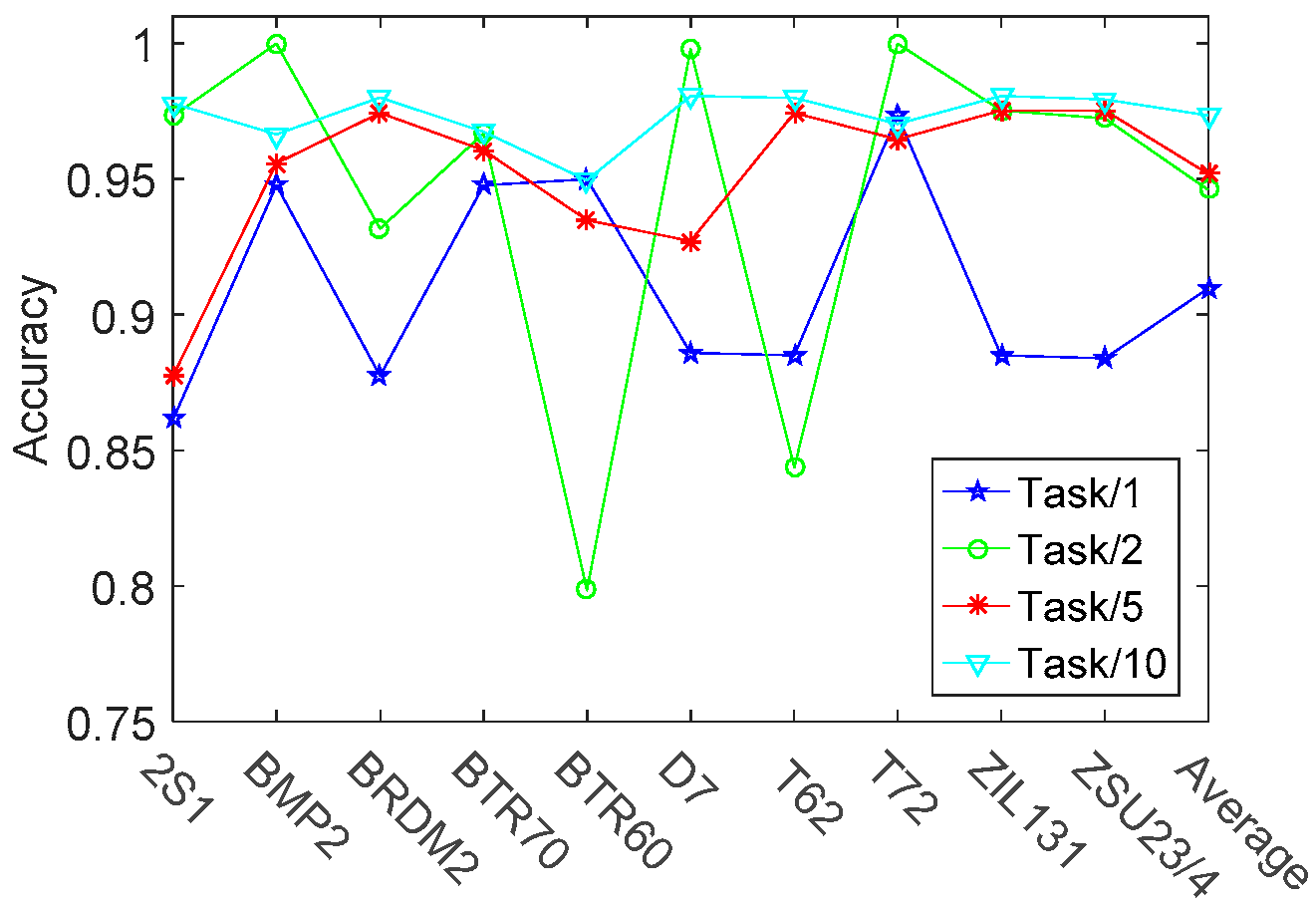
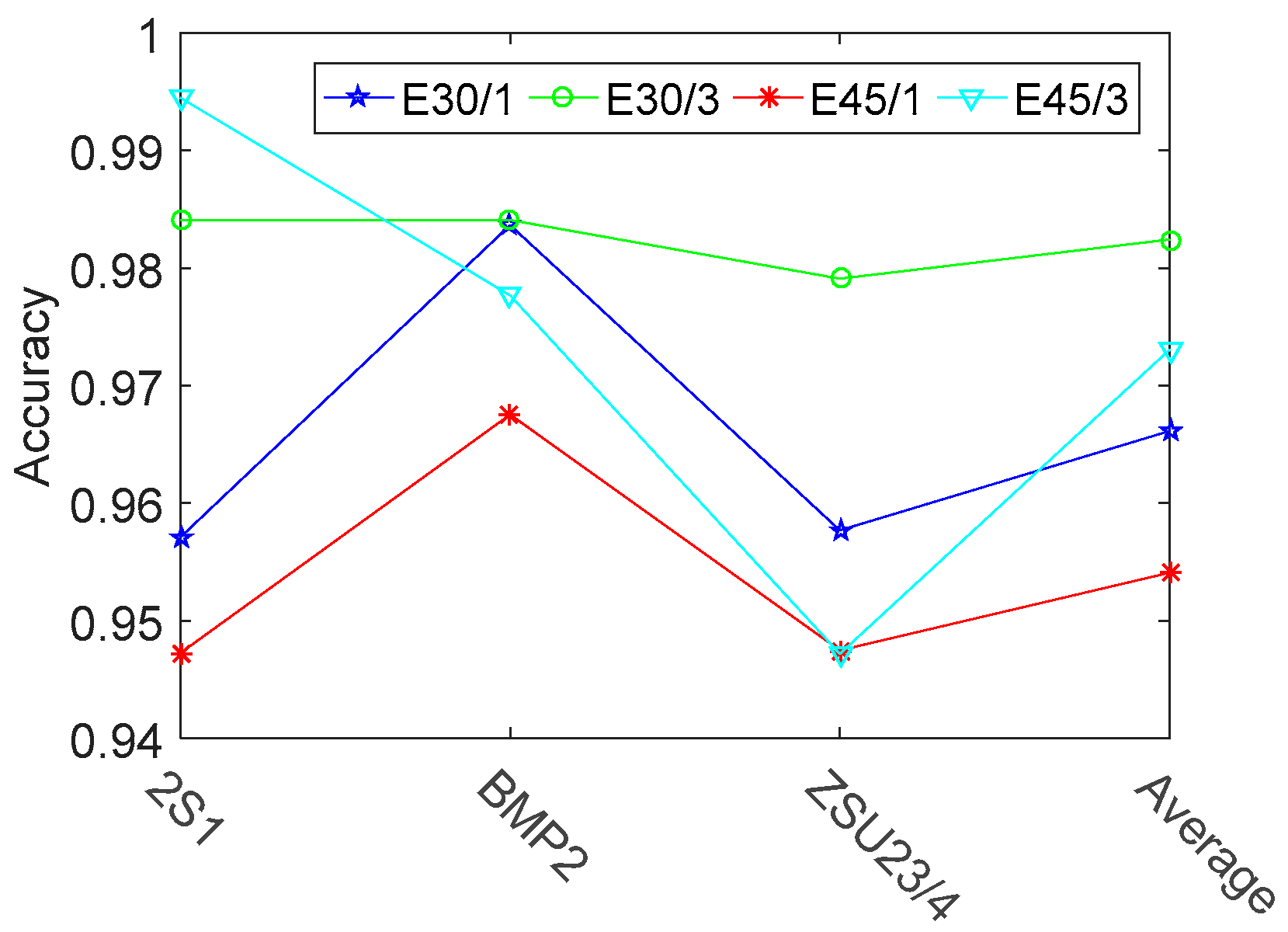
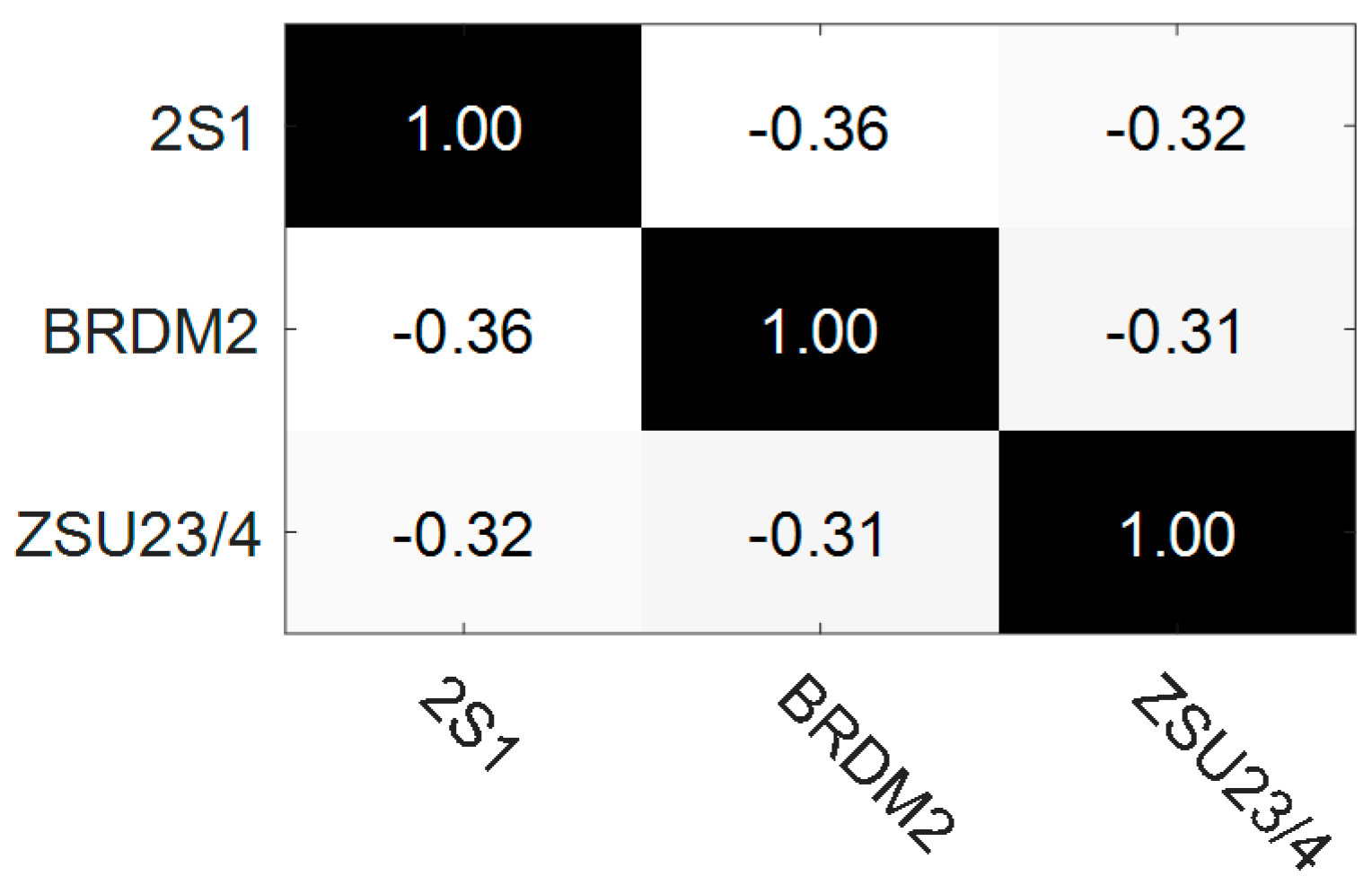
3.2.2. Target Recognition under Extended Operating Conditions (EOC)
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pan, M.; Jiang, J.; Li, Z.; Cao, J.; Zhou, T. Radar HRRP recognition based on discriminant deep autoencoders with small training data size. Electron. Lett. 2016, 52, 1725–1727. [Google Scholar]
- Zhou, D.Y. Radar target HRRP recognition based on reconstructive and discriminative dictionary learning. Signal Process. 2016, 126, 52–64. [Google Scholar] [CrossRef]
- Sun, Y.G.; Du, L.; Wang, Y.; Wang, Y.H.; Hu, J. SAR automatic target recognition based on dictionary learning and joint dynamic sparse representation. IEEE Geosci. Remote Sens. Lett. 2016, 99, 1777–1781. [Google Scholar] [CrossRef]
- Wang, S.N.; Jiao, L.C.; Yang, S.Y.; Liu, H.Y. SAR image target recognition via complementary spatial pyramid coding. Neurocomputing 2016, 196, 125–132. [Google Scholar] [CrossRef]
- Huang, X.Y.; Qiao, H.; Zhang, B. SAR target configuration recognition using tensor global and local discriminant embedding. IEEE Geosci. Remote Sens. Lett. 2016, 13, 222–226. [Google Scholar] [CrossRef]
- Song, S.L.; Xu, B.; Yang, J. SAR target recognition via supervised discriminative dictionary learning and sparse representation of the SAR-HOG feature. Remote Sens. 2016, 8, 683. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Xing, X.; Zou, H. Synthetic aperture radar target recognition with feature fusion based on a stacked autoencoder. Sensors 2017, 17, 192. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Principe, J.C. Support vector machines for SAR automatic target recognition. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 643–654. [Google Scholar] [CrossRef]
- Sun, Y.J.; Liu, Z.P.; Todorovic, S.; Li, J. Adaptive boosting for SAR automatic target recognition. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 112–125. [Google Scholar] [CrossRef]
- Dong, G.G.; Kuang, G.Y.; Wang, N.; Zhao, L.J.; Lu, J. SAR target recognition via joint sparse representation of monogenic signal. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3316–3328. [Google Scholar] [CrossRef]
- Zheng, H.; Geng, X.; Tao, D.C.; Jin, Z. A multi-task model for simultaneous face identification and facial expression recognition. Neurocomputing 2016, 171, 515–523. [Google Scholar] [CrossRef]
- Liu, A.; Lu, Y.; Nie, W.Z.; Su, Y.T.; Yang, Z.X. HEp-2 cells classification via clustered multi-task learning. Neurocomputing 2016, 195, 195–201. [Google Scholar] [CrossRef]
- Zhang, M.X.; Yang, Y.; Zhang, H.W.; Shen, F.M.; Zhang, D.X. L2, p-norm and sample constraint based feature selection and classification for AD diagnosis. Neurocomputing 2016, 195, 104–111. [Google Scholar] [CrossRef]
- Zhang, Y.; Yeung, D.Y. A regularization approach to learning task relationships in multitask learning. ACM Trans. Knowl. Discov. Data 2014, 8, 1–31. [Google Scholar] [CrossRef]
- Platt, J.C. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; MSR-TR-98-14; Microsoft: Redmond, WA, USA, 1998. [Google Scholar]
- Chen, X.; Pan, W.K.; Kwok, J.T.; Carbonell, J.G. Accelerated gradient method for multi-task sparse learning problem. In Proceedings of the Ninth IEEE International Conference on Data Mining, Miami, FL, USA, 6–9 December 2009; pp. 746–751. [Google Scholar]
- Evgeniou, T.; Pontil, M. Regularized multi-task learning. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 109–117. [Google Scholar]
- Zhou, J.Y.; Chen, J.H.; Ye, J.P. Clustered multi-task learning via alternating structure optimization. Adv. Neural Inf. Process. Syst. 2011, 2011, 702–710. [Google Scholar]
- Zhou, Q.; Zhao, Q. Flexible clustered multi-task learning by learning representative tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 266–278. [Google Scholar] [CrossRef] [PubMed]
- Guillaume, O.; Ben, T.; Michael, I.J. Joint covariate selection and joint subspace selection for multiple classification problems. Stat. Comput. 2010, 20, 231–252. [Google Scholar]
- Song, H.; Ji, K.; Zhang, Y.; Xing, X.; Zou, H. Sparse representation-based SAR image target classification on the 10-class MSTAR data set. Appl. Sci. 2016, 6, 26. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Description |
|---|---|
| KNN | K-nearest neighbor classifier. |
| SVM [8] | Support vector machine learning. |
| Trace-norm Regularized multi-task learning (Trace) [20] | Trace method assumes that all models share a common low dimensional subspace. |
| Regularized multi-task learning (RMTL) [17] | RMTL method assumes that all tasks are similar, and the parameter vector of each task is similar to the average parameter vector. |
| Clustered Multi-Task Learning (CMTL) [18] | CMTL assumes that multiple tasks follow a clustered structure and that such a clustered structure is prior. In the experiments, we perform multiple single task learning to get the trained mode parameters, and based on which to obtain the clustered structure. |
| Multi-task relationship learning (MTRL) [14] | MTRL can autonomously learn the positive and negative task correlation. |
| Waveform | Center Frequency | Band-Width | Number of Frequency Samples | Meshing Size | Depression Angles | Azimuth Angles |
|---|---|---|---|---|---|---|
| Chirp Signal | 1.5 GHz | 1 GHz | 1000 | 15° | 0–180° with 1° steps |
| Method | KNN | SVM | Trace | RMTL | CMTL | MTRL | Proposed |
|---|---|---|---|---|---|---|---|
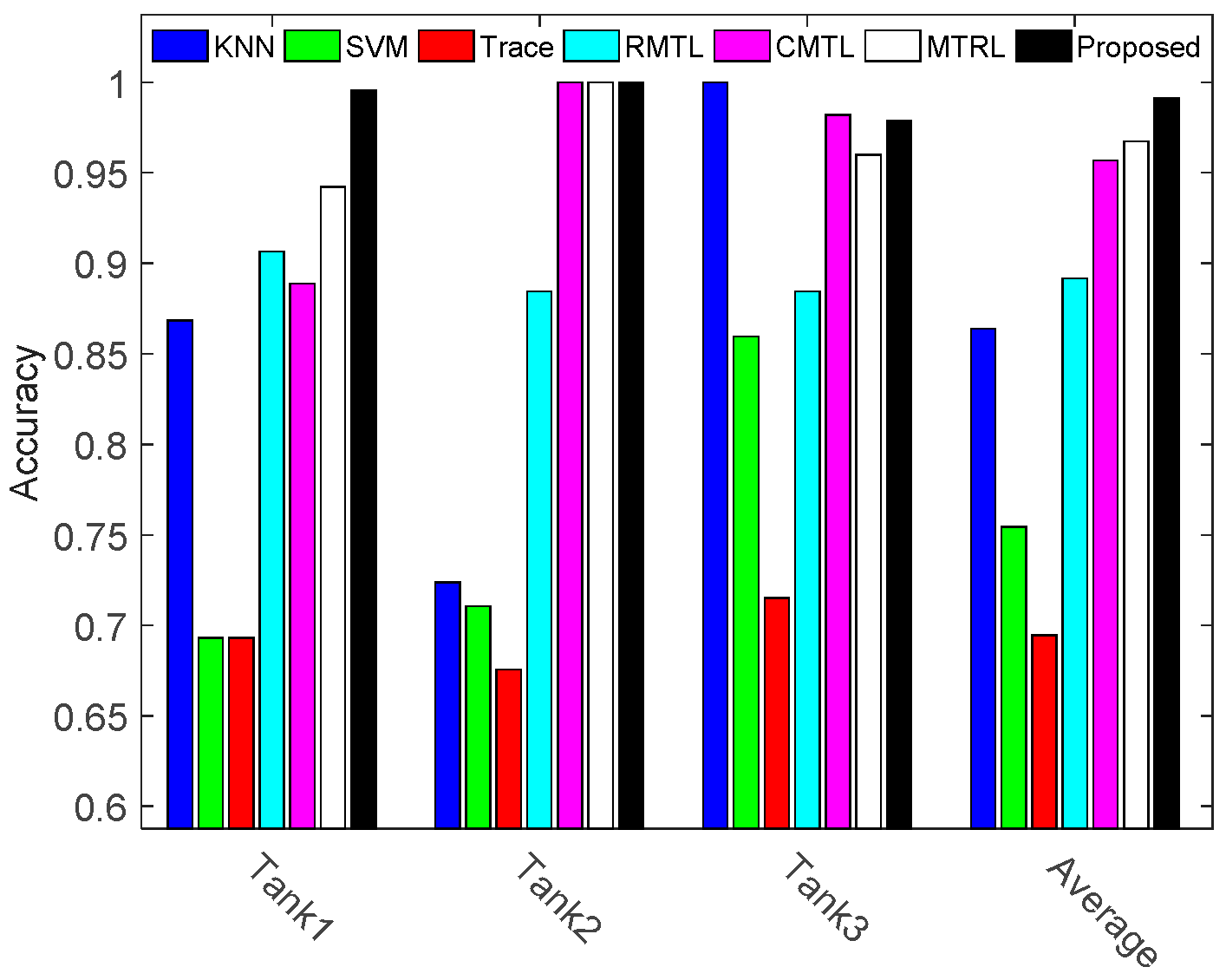
| Tank 1 | 0.8684 | 0.6929 | 0.6929 | 0.9066 | 0.9822 | 0.9600 | 0.9956 |
| Tank 2 | 0.7237 | 0.7105 | 0.6754 | 0.8844 | 1.0000 | 1.0000 | 1.0000 |
| Tank 3 | 1.0000 | 0.8596 | 0.7149 | 0.8844 | 0.8889 | 0.9522 | 0.9789 |
| Average | 0.8640 | 0.7543 | 0.6944 | 0.8918 | 0.9570 | 0.9674 | 0.9915 |
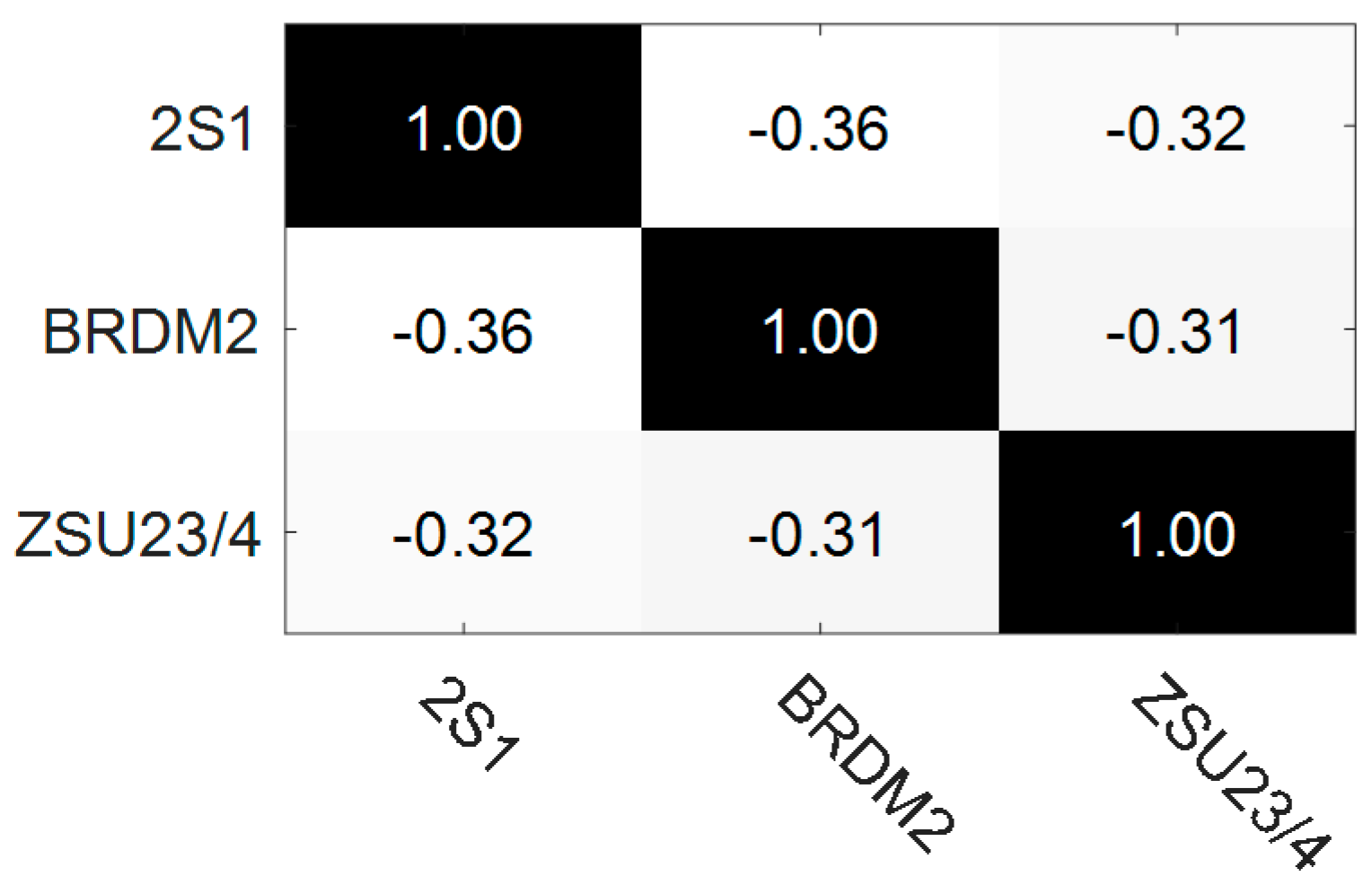
| Target | 2S1 | BRDM2 | BTR60 | D7 | T62 | ZIL131 | ZSU23/4 | BRT70 | T72 | BMP |
|---|---|---|---|---|---|---|---|---|---|---|
| Training (17°) | 299 | 298 | 256 | 299 | 299 | 299 | 299 | 233 | 232(SN_132) 231(SN_812) 228(SN_s7) | 233(SN_9563) 232(SN_9566) 233(SN_c21) |
| Testing (15°) | 274 | 274 | 195 | 274 | 273 | 274 | 274 | 196 | 196(SN_132) 195(SN_812) 191(SN_s7) | 195(SN_9563) 196(SN_9566) 196(SN_c21) |
| Methods | KNN | SVM | Trace | RMTL | CMTL | MTRL | Proposed |
|---|---|---|---|---|---|---|---|
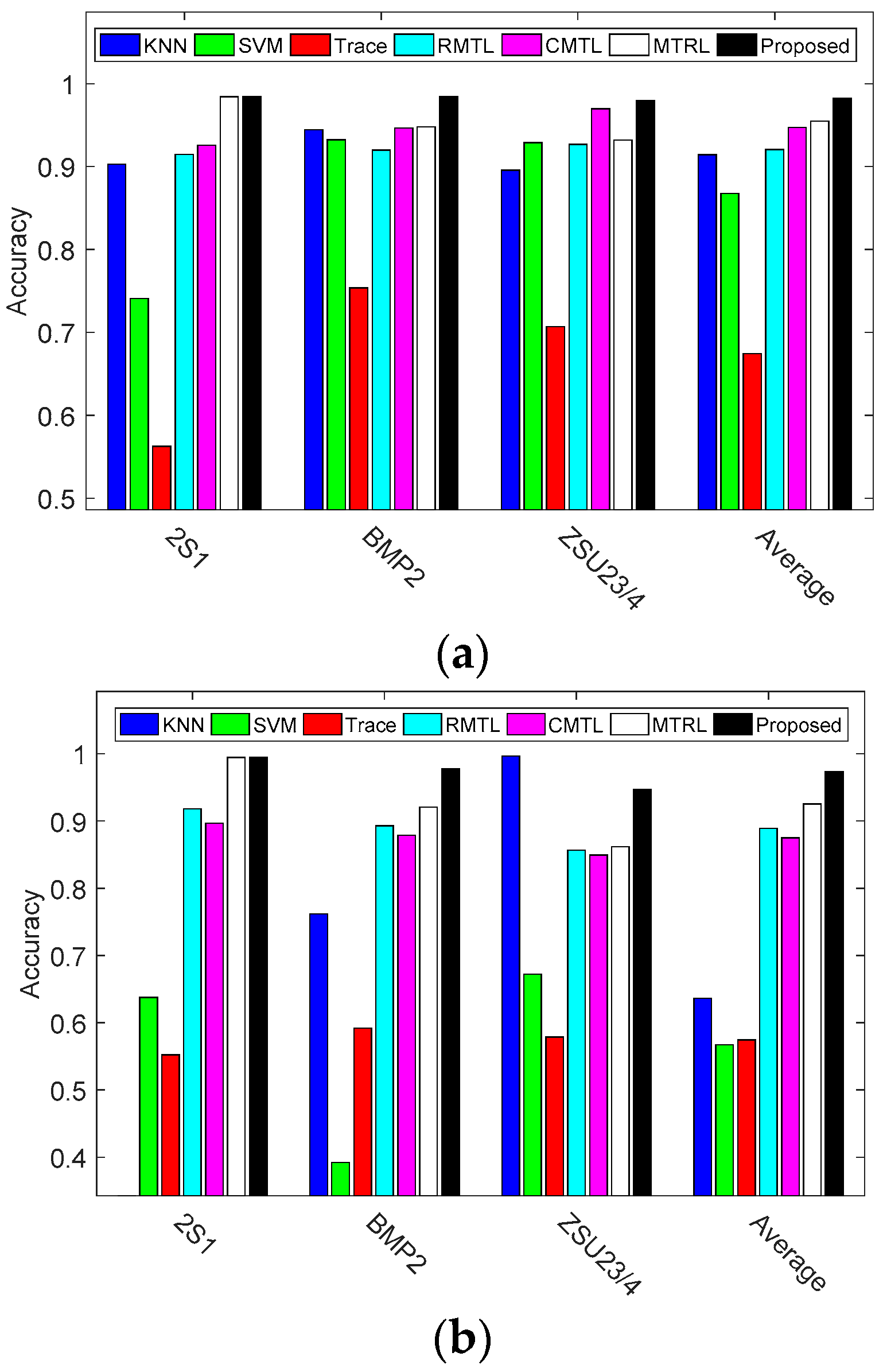
| 2S1 | 0.8723 | 0.8870 | 0.7082 | 0.6480 | 0.7833 | 0.8860 | 0.9780 |
| BMP2 | 0.9590 | 0.9196 | 0.7733 | 0.8571 | 0.9641 | 0.9558 | 0.9665 |
| BRDM2 | 0.8277 | 0.9151 | 0.7082 | 0.8960 | 0.9637 | 0.9757 | 0.9802 |
| BRT70 | 0.9541 | 0.9192 | 0.7910 | 0.9674 | 0.9444 | 0.9606 | 0.9674 |
| BTR60 | 0.9385 | 0.9113 | 0.7921 | 0.9497 | 0.9016 | 0.9350 | 0.9497 |
| D7 | 0.9781 | 0.8870 | 0.7306 | 0.9806 | 0.9664 | 0.9754 | 0.9806 |
| T62 | 0.8767 | 0.8874 | 0.7316 | 0.9799 | 0.9650 | 0.9731 | 0.9799 |
| T72 | 0.9592 | 0.9192 | 0.8075 | 0.9703 | 0.9670 | 0.9646 | 0.9703 |
| ZIL131 | 0.9197 | 0.8841 | 0.7412 | 0.9806 | 0.9696 | 0.9788 | 0.9806 |
| ZSU23/4 | 0.9854 | 0.8870 | 0.7200 | 0.9794 | 0.9658 | 0.9720 | 0.9794 |
| Average | 0.9271 | 0.9017 | 0.7504 | 0.9209 | 0.9391 | 0.9584 | 0.9734 |
| Target | 2S1 | BRDM2 | ZSU23/4 |
|---|---|---|---|
| Training (17°) | 299 | 298 | 299 |
| Testing (30°) | 288 | 287 | 288 |
| Testing (45°) | 303 | 303 | 303 |
| Methods | Training (17°)–Testing (30°) | Training (17°)–Testing (45°) | ||||||
|---|---|---|---|---|---|---|---|---|
| 2S1 | BMP2 | ZSU23/4 | Average | 2S1 | BMP2 | ZSU23/4 | Average | |
| KNN | 0.9028 | 0.9444 | 0.8955 | 0.9142 | 0.1505 | 0.7617 | 0.9967 | 0.6363 |
| SVM | 0.7409 | 0.9322 | 0.9288 | 0.8673 | 0.6373 | 0.3917 | 0.6719 | 0.5670 |
| Trace | 0.5625 | 0.7534 | 0.7067 | 0.6742 | 0.5518 | 0.5918 | 0.5787 | 0.5741 |
| RMTL | 0.9144 | 0.9199 | 0.9265 | 0.9203 | 0.9149 | 0.9195 | 0.8830 | 0.9058 |
| CMTL | 0.9254 | 0.9464 | 0.9697 | 0.9472 | 0.9166 | 0.8987 | 0.8692 | 0.8948 |
| MTRL | 0.9841 | 0.9477 | 0.9319 | 0.9546 | 0.9945 | 0.9481 | 0.9082 | 0.9502 |
| Proposed | 0.9841 | 0.9841 | 0.9791 | 0.9824 | 0.9945 | 0.9777 | 0.9472 | 0.9731 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Bao, W.; Xu, L.; Zhang, H. Clustered Multi-Task Learning for Automatic Radar Target Recognition. Sensors 2017, 17, 2218. https://doi.org/10.3390/s17102218
Li C, Bao W, Xu L, Zhang H. Clustered Multi-Task Learning for Automatic Radar Target Recognition. Sensors. 2017; 17(10):2218. https://doi.org/10.3390/s17102218
Chicago/Turabian StyleLi, Cong, Weimin Bao, Luping Xu, and Hua Zhang. 2017. "Clustered Multi-Task Learning for Automatic Radar Target Recognition" Sensors 17, no. 10: 2218. https://doi.org/10.3390/s17102218
APA StyleLi, C., Bao, W., Xu, L., & Zhang, H. (2017). Clustered Multi-Task Learning for Automatic Radar Target Recognition. Sensors, 17(10), 2218. https://doi.org/10.3390/s17102218