Stacked Sparse Auto-Encoders (SSAE) Based Electronic Nose for Chinese Liquors Classification


School of Electrical and Information Engineering, Tianjin University, Tianjin 300072, China
*
Authors to whom correspondence should be addressed.
Sensors 2017, 17(12), 2855; https://doi.org/10.3390/s17122855
Submission received: 15 October 2017
/
Revised: 1 December 2017
/
Accepted: 2 December 2017
/
Published: 8 December 2017
(This article belongs to the Special Issue Electronic Tongues and Electronic Noses)
Abstract
:This paper presents a stacked sparse auto-encoder (SSAE) based deep learning method for an electronic nose (e-nose) system to classify different brands of Chinese liquors. It is well known that preprocessing; feature extraction (generation and reduction) are necessary steps in traditional data-processing methods for e-noses. However, these steps are complicated and empirical because there is no uniform rule for choosing appropriate methods from many different options. The main advantage of SSAE is that it can automatically learn features from the original sensor data without the steps of preprocessing and feature extraction; which can greatly simplify data processing procedures for e-noses. To identify different brands of Chinese liquors; an SSAE based multi-layer back propagation neural network (BPNN) is constructed. Seven kinds of strong-flavor Chinese liquors were selected for a self-designed e-nose to test the performance of the proposed method. Experimental results show that the proposed method outperforms the traditional methods.
1. Introduction
In recent years, with the improvement of people’s living standard, people pay more and more attention to food safety. Chinese liquors industry is a unique traditional light industry in China. However, counterfeit and fake liquor problems have been plaguing the industry and consumers. How to identify Chinese liquors quickly and accurately is an urgent problem to be solved. Traditional testing instruments, such as chromatograph and spectrometer, are expensive, bulky and inconvenient to carry, and difficult to realize rapid detection [1].
Electronic nose (e-nose) is a portable and rapid instrument inspired by olfactory systems of mammals, which has been widely used in food safety, environmental monitoring and disease diagnosis [2,3,4]. Data processing procedure of a traditional e-nose mainly consists of several steps: pre-processing, feature extraction (generation and reduction) and classification. Each step has plenty of optional methods or algorithms, and different choices may lead to different identification results. For example, Jing et al. [5] presented a new combination method for Chinese liquor classification. In the step of feature generation, ten features were selected based on information theory. In the procedure of feature reduction, they have tested performance of two methods: kernel entropy component analysis (KECA) and kernel principle component analysis (KPCA). Finally, they presented a multi-linear classifier and used the back propagation neural network (BPNN) as well as the linear discrimination analysis (LDA) for comparison. More recently, Jia et al. [6] proposed a new hybrid algorithm for Chinese liquors classification, in which man-made features were reduced using a combined KECA-LDA technique and the extreme learning machine (ELM) was applied as a classifier. Before they found this optimal KECA-LDA-ELM combination algorithm, they have tried some other combination algorithms, such as KECA-BPNN, KECA-ELM, and KECA-LDA-BPNN. Obviously, in the traditional design of an e-nose, obtaining optimal combination method is complex and time consuming.
The motivation of our work is to simplify the traditional data-processing steps for e-noses using deep learning (DL) techniques. The concept of deep learning (DL) was first presented by Hinton and Bengio in 2006 [7,8], to solve the optimization problems of deep network structure. The stacked sparse auto-encoder (SSAE) was a kind of DL model, which was presented by Hinton and Ranzato et al. [9,10]. In the past few years, DL has been successfully applied to image recognition [11], speech recognition [12], and target recognition [13]. DL techniques break the limitation of layer numbers and overcome the gradient dilution and the local minimum problems in traditional neural networks [14,15]. To our knowledge, DL methods have not been widely used for data processing of e-noses. Längkvist and Loutfi [16] applied deep belief networks (DBN) and conditional restricted Boltzmann machine (CRBM) for an e-nose to identify the special bacteria in blood and agar. Längkvist et al. [17] used two unsupervised feature learning methods: stacked restricted Boltzmann machines and stacked auto-encoders, for fast classification of meat spoilage markers. More recently, Liu et al. [18] implemented the DL technique to tackle the sensor drift problem and then to improve the classification performance of the machine olfaction system.
As far as we know, there is no report on DL based e-noses for Chinese liquors recognition. In this paper, we present a stacked sparse auto-encoder (SSAE) [19] based DL approach for Chinese liquors classification. We use the SSAE to learn inherent features automatically from the response curves of gas sensors in unsupervised manner. After that, the learned features are used for training a BPNN to classify different brands of liquors. The proposed method does not need the steps of preprocessing and feature extraction. In the experimental procedure, seven brands of strong-flavor Chinese liquors were selected to test the effectiveness of our proposed method. The results of the SSAE based method were compared with those of stacked auto-encoders (SAE) [20] based BPNN [21] and SSAE based support vector machine (SVM) [22] as well as two kinds of traditional methods.
The remainder of this paper is organized as follows: Section 2 presents the method description, including spare auto-encoder, SSAE based BPNN method and traditional methods applied to the data processing of the e-nose we designed. Section 3 describes the experiments and results. Finally, conclusions are given in Section 4.
2. Method Description
2.1. Sparse Auto-Encoder
As an unsupervised learning algorithm, an auto-encoder network consists of three layers: input layer, hidden layer and output layer [23]. It makes the output layer equal to the input layer, which minimizes the reconstruction error to extract a best expression of the hidden layer. The auto-encoder network based data processing for e-noses consists of two steps (as shown in Figure 1): Firstly, the original e-nose data is encoded from the input layer to the hidden layer (encoding):
where denotes the feature expression of the hidden layer; m and n are the total number of the nodes in the input and hidden layers, respectively. W is the weight matrix and b represents the bias vector. is the sigmoid function, which is expressed as . Secondly, the feature expression y is decoded from the hidden layer to the output layer (decoding):
The feature expression y is decoded to obtain the reconstructed vector , where b′ stands for the bias vector.
The sparse auto-encoder [24] is an extension of the auto-encoder, which introduces sparse restrictions to the hidden nodes, in order to control the number of activated neurons. The system complexity and parameters can be reduced due to less number of activated neurons, so that the sparse auto-encoder can learn better features [25]. The cost function of the sparse auto-encoder under the entire data set is expressed as:
The first term is the square root error indicating the difference between the input and the output. The second term is the weight decay term used to solve the over-fitting problem, where is the weight attenuation coefficient and is the weight corresponding to the input node i and the hidden node j. The last term is the sparse penalty term, where stands for the sparse target value, is the weight of the sparse penalty item, and is the average activation quantity of the hidden unit j. The back-propagation algorithm is adopted to obtain the parameters W and b by minimizing the cost function J [21], where the stochastic gradient descent approach is used for training. The parameters W and b in each iteration process can be updated as:
where is the learning rate. A forward propagation algorithm is used to compute the average activation quantity to get the error, and then the back-propagation algorithm is applied to update the parameters W and b.
2.2. SSAE Based BPNN (SSAE-BPNN)
An SSAE is usually built with multiple sparse auto-encoders. Figure 2 shows an SSAE composed by two sparse auto-encoders, where the hidden layer of the first sparse auto-encoder is treated as the input layer of the second sparse auto-encoder. A greedy layer-wise unsupervised algorithm [18] is used to train each sparse auto-encoder independently. After the SSAE is trained to learn the features, the multi-layer BPNN is used for classification. Instead of direct utilization of learned features of SSAE, the parameters of SSAE are used to initialize the BPNN to get the features for classification. The steps of training the SSAE based BPNN are described as follows:
- (1)
- Pre-training: The two sparse auto-encoders are trained in succession, and the SSAE parameters (W and b, cf. Equations (1) and (2)) are obtained after the pre-training step;
- (2)
- Constructing BPNN: The encoder layers of SSAE is taken as the first three layers of the multi-layer BPNN, and the third layer (the second hidden layer of BPNN) is connected with the output layer which corresponds to the types of Chinese liquors in our study through Softmax regression (see Figure 3);
- (3)
- Initialization: The network parameters of the first three layers are initialized with the pre-training parameters;
- (4)
- Fine-tuning: The forward propagation algorithm is used to train the BPNN network, and then the parameters are fine-tuned using the back-propagation algorithm with the labels.
2.3. Data Processing Procedures Based on SSAE-BPNN and Traditional Methods
Two traditional methods are used to compare with the SSAE-BPNN method. The response curves of ten gas sensors are sampled at a frequency of 100 Hz.
The first traditional method is presented by Jing et al. [5]. The data processing procedure is described as follows: Firstly, the original response curves are preprocessed by wavelet denoising filters and conductivity normalization. Secondly, ten features for each response curve are chosen, they are (1) the time reaching the response maximum value; (2) root mean square; (3) arithmetic mean; (4) geometric mean; (5) harmonic mean; (6) the maximum value of the first-order derivative; (7) the time when the maximum value of the first-order derivative is reached; (8) the average differential; (9) the integration of the response curve when it reaches the maximum value and (10) the mean curvature. After feature generation, the dimension of the original feature space for ten response curves is 100, and then the dimension is reduced to 20 using KECA. Finally, the classification of Chinese liquors is implemented using BPNN and SVM.
The procedure of the second traditional method can be illustrated by the upper part of Figure 4. Firstly, the original response curves of ten gas sensor are preprocessed using the Savitzky-Golay wave filter [26]. Secondly, we select five features for each response curve, including (1) the maximum value, (2) the maximum value of the first-order derivative, (3) the response value corresponding to the maximum of first-order derivative, (4) the minimum value of the first-order derivative and (5) the maximum value of the second-order derivative. The dimension of the original feature space for ten response curves is 50. Then, the number of features is reduced to 19 using the PCA method [27]. The extracted features are applied to classify the Chinese liquors using BPNN and SVM.
The features selection for traditional methods is usually manual, which is time-consuming and hard to be appropriate. Due to this reason, we presented a deep learning method to learn the features automatically instead of manual choice. Compared with the relatively complicated procedures of traditional method (see the upper part of Figure 4), the structure of the proposed SSAE-BPNN method (see the lower part of Figure 4) is quite concise. Firstly, we directly use the SSAE method to learn the features from the down-sampled response curves. Then the SSAE based BPNN method is applied to classify the Chinese liquors.
3. Experiments and Results
3.1. Experimental Materials
Seven kinds of strong-flavor Chinese liquors were used in the experiments, including Bianfenghu (BFH), Bainianwanjiu (BNWJ), Hongjinjiu (HJJ), Lanjinjiu (LJJ), Luzhoulaojiao (LZLJ), Mianzhudaqu (MZDQ), Niulanshan (NLS). Table 1 provides the detailed information for the seven kinds of Chinese liquors.
3.2. Electronic Nose
The self-designed e-nose system [28] for Chinese liquors identification consists of three parts: liquor dynamic evaporation and sampling device, sensor chamber reaction device, control and data acquisition system (shown in Figure 5). A physical picture of the e-nose experimental platform is shown in Figure 6. Through the hardware and software design, the e-nose system can realize automated sampling scheme with a friendly user interface. After setting up the experimental condition parameters and dropping the liquor sample, the sampling process is implemented automatically. The sensor array consists of ten types of metal oxide semiconductor (MOS) sensors, which are TGS series (TGS2602, TGS2611, TGS2620, TGS880) from Figaro Engineering Inc. (Osaka, Japan), MiCS series (MiCS-5121, MiCS-5521, MiCS-5524, MiCS-5526) from SGX Sensortech Inc. (High Wycombe, Britain), and MP502 as well as WSP2110 from Winsensor Ltd. (Zhenzhou, China). MOS sensors have a shortcoming of slow recovery, especially for the online monitoring applications. To solve this problem, a reservoir computing approach could be used to overcome the slow temporal dynamics of MOS sensor arrays, allowing identification and quantification of chemicals of interest continuously and reducing measurement delays [29].
The experimental procedure is like this: 5 μL for each kind of Chinese liquors was dripped into the inlet of the evaporator chamber using a pipette gun. Then the evaporator chamber was heated to a constant temperature of 65 °C. After the liquid liquors were evaporated into gas, the sample was inhaled to the reaction chamber with an air pump, and the gas was contacted with the sensor array. Finally, the response curves were saved. After each experiment, the evaporator chamber and the reaction chamber were cleaned for 3 min and 1 min, respectively. The experimental process was repeated 30 times for each kind of Chinese liquors and totally 210 groups of data were obtained.
3.3. Parameters Setting for SSAE-BPNN
DeepLearn Toolbox [30] is an open source software library that includes popular machine learning and artificial intelligence techniques, such as Artificial Neural Networks (ANN), Convolutional Neural Networks (CNN), Stacked Auto-encoders (SAE) and Deep Belief Networks (DBN), etc. We utilized ANN and SAE algorithms in DeepLearn Toolbox to realize the SSAE-BPNN and added SVM algorithm to SAE in DeepLearn Toolbox to realize the SSAE-SVM.
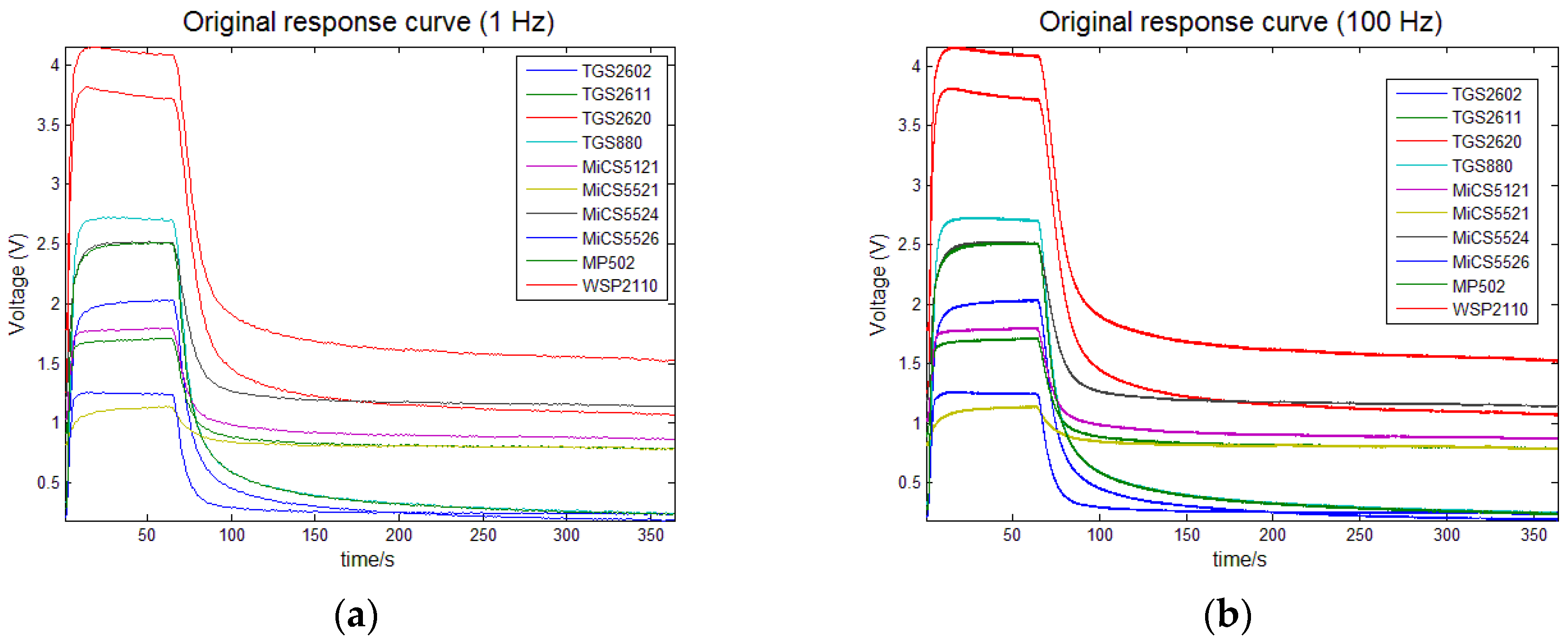
Figure 7 presents the recorded response curves of ten gas sensors with a sampling frequency of 100 Hz. The recorded time for each gas sensor was 364 s and the initial dimension of 100 Hz data (364,000) was too large as the input of the proposed method. So, the analyzed data were collected with an interval of 1 s, i.e., the recorded response data were down-sampled from 100 Hz to 1 Hz for the SSAE method to learn from. As shown in Figure 7, when the sampling rate was down-sampled to 1 Hz, the overall trend of response curves was not changed, which almost made no effect on the feature learning. Therefore, the total number of the analyzed data for each experiment was 3640 and then we chose 3640 nodes in the input layer of the constructed SSAE-BPNN.
To alleviate the possible over-fitting problems caused by small samples, we want to use a simple network structure to implement deep learning [30]. To achieve better classification results, we have carried out tests with different number of hidden layers and hidden-layer nodes for the SSAE. During the tests, the number of nodes in each hidden layer was set to 200, and the iteration times for both the pre-training and fine-tuning procedures were set to 10. Other parameters' settings were listed in Table 2. The test results showed that the classification rate cannot be effectively increased with an increase in the number of hidden layers. As shown in Figure 8, when the hidden-layer numbers are set 3 and 4, the classification accuracy are 91.71% and 91.28%, respectively, which are lower than 93.04% obtained with two hidden layers. Therefore, the number of the hidden layers for the SSAE was set to 2 in our subsequent study.
Figure 9 illustrates the influence of the number of hidden-layer nodes on classification accuracy, where the horizontal ordinate is the number of the 1st hidden-layer nodes and the legend represents the number of the 2nd hidden-layer. When the numbers of two hidden-layer nodes were changed, the classification accuracy of different choice was given. The optimal settings for the number of nodes in the 1st and the 2nd hidden-layers were 200 and 100, respectively. Considering that there are seven kinds of Chinese liquors tested in the experiment, the number of nodes in output layer was set as 7.
Figure 10 shows the influences of the sparse target value and the sparse weight on the classification accuracy, from which the optimal settings for the both values were set to 0.01 and 0.1, respectively. Using the similar choice method, we set the learning rates for SSAE () and BPNN () to 0.1 and 1, respectively. All the parameter settings for the SSAE-BPNN are listed in Table 2.
3.4. Experimental Results and Discussion
3.4.1. SSAE-BPNN
Considering that the samples number is small, we adopted the way of cross-validation to evaluate the performance of the proposed SSAE-BPNN and the traditional methods, where the cross-validation could also eliminate the over-fitting problems [31]. The 210 groups of data were randomly divided into ten groups, i.e., a ten-fold cross validation was used. When any one group was used as the testing set, the other nine groups were used as the training sets. The average of ten classification accuracy was taken as the final result. In this work, we adopted the 10-fold cross-validation rather than the leave-one-out cross-validation because the latter cost more time and had the same performance with the 10-fold validation.
The training process was divided into two steps. The first step is an unsupervised pre-training process, and the second step is a supervised fine-tuning process. Figure 11 presents the relationship between the iteration times and the classification accuracy, from which we can see that when the iteration times is 10, the classification accuracy exceeds 90%. With an increase in the iteration times, the accuracy increases slowly. When the iteration times reaches 90, the highest classification accuracy of 96.67% can be obtained.
Figure 12 shows the relationship between the mean squared errors (MSE) and the iteration times during the fine-tuning process. When the iteration times reaches 90, MSE converges to 0.
3.4.2. SSAE-BPNN VS SAE-BPNN and SSAE-SVM
In order to demonstrate the function of sparsity in the feature learning process, the performance of SAE and SSAE has been compared. As shown in Figure 13 and Table 3, at the same iteration times, the classification accuracy of SAE-BPNN is lower than that of SSAE-BPNN. In addition, the performance of BPNN and SVM was also compared.
An SSAE-SVM was also constructed for comparison. The SSAE-SVM used the features learned by the SSAE (the second hidden-layer output of the SSAE) as the input of the SVM classifier. For a fair comparison, here the SSAE was kept the same as the one used in the SSAE-BPNN, but the features learned by the SSAE was not fine-tuned during training for the SVM. The test results show that SSAE-BPNN is superior to SSAE-SVM, see Figure 14 and Table 4. From Table 3 and Table 4, we can find that the cross-validation interval of confidence for SSAE-BPNN is lower than both the SAE-BPNN and SSAE-SVM, which indicates that the SSAE-BPNN has a better classification precision.
3.4.3. SSAE-BPNN VS Traditional Methods
The classification results are shown in Table 3. The first traditional method (the KECA based, cf. [5]) has been applied to process the first-generation e-nose data (see Figure 15), and obtained good classification results. However, when it was utilized to the second-generation e-nose data (see Figure 7), the results were not satisfactory. Thus, the second traditional method (the PCA based) was used for comparison. To get information about the data distribution, the projected three-dimensional PCA score plot using the second traditional method is shown in Figure 16. The recognition results based on the two traditional methods and the SSAE based method are presented in Table 5. The second PCA based traditional method is superior to the KECA-based method, but it is still inferior to our proposed SSAE-BPNN method. The employed time of each method is also listed in Table 5. It could be seen that the traditional methods cost more time due to the man-made feature extraction process. Although the SSAE-BPNN costs more time than the SSAE-SVM, it is worth to obtain better results.
4. Conclusions
A novel deep learning (DL) based data-processing method has been proposed for electronic noses (e-noses) to classify different brands of Chinese liquors. The proposed method utilizes a stacked sparse auto-encoder (SSAE) to directly learn the features from the gas sensors’ response data, and the learned result is then used to construct a new BPNN, i.e., SSAE-BPNN. By combining the SSAE with a support vector machine (SVM), an SSAE-SVM is also constructed. The SSAE based methods do not need the tedious and complicated steps used in traditional methods for e-noses, such as preprocessing and feature extraction (generation and reduction).
To verify and compare the classification performance of the proposed method as well as the traditional methods, seven kinds of strong-flavor Chinese liquors have been used as experimental materials using the self-designed e-nose. The results show that the SSAE-BPNN method achieves the highest 96.67% classification accuracy, which is superior to the results of SSAE-SVM and two kinds of traditional methods.
It is important to emphasize that traditional methods can obtain good classification results by optimizing the data-processing procedure, e.g., combinatorial feature extraction methods and classifiers. However, due to many choices in combination, the optimization process is normally empirical and complicated. The proposed SSAE based DL method can not only simplify the data processing process, but also can obtain good classification results.
In the future work, to realize rapid and on-line liquors recognition based on e-noses systems, we will try other deep neural network approach, like deep reservoir computing algorithm, to solve the problems of the slow temporal dynamics of sensor arrays.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (No. 61573253, 61271321) and Tianjin Natural Science Foundation (No. 16JCYBJC16400).
Author Contributions
Wei Zhao, Qing-Hao Meng and Pei-Feng Qi proposed the DL based data processing method, and designed the experiments; Wei Zhao and Pei-Feng Qi implemented the experiments; Wei Zhao, Pei-Feng Qi and Ming Zeng analyzed the data; Wei Zhao, Ming Zeng and Pei-Feng Qi wrote the manuscript; Qing-Hao Meng revised the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, J.J.; Song, C.X.; Hou, C.J.; Huo, D.Q.; Shen, C.H.; Luo, X.G.; Yang, M.; Fa, H.B. Development of a colorimetric sensor array for the discrimination of Chinese liquors based on selected volatile markers determined by GC-MS. J. Agric. Food Chem. 2014, 62, 10422–10430. [Google Scholar] [CrossRef] [PubMed]
- Baietto, M.; Wilson, A.D. Electronic-Nose Applications for Fruit Identification, Ripeness and Quality Grading. Sensors 2015, 15, 899–931. [Google Scholar] [CrossRef] [PubMed]
- Lidia, E.; Laura, C.; Selena, S. Electronic Nose Testing Procedure for the Definition of Minimum Performance Requirements for Environmental Odor Monitoring. Sensors 2016, 16, 1548. [Google Scholar] [CrossRef]
- Zhou, H.; Luo, D.; Gholamhosseini, H.; Li, Z.; He, J. Identification of Chinese Herbal Medicines with Electronic Nose Technology: Applications and Challenges. Sensors 2017, 17, 1073. [Google Scholar] [CrossRef] [PubMed]
- Jing, Y.Q.; Meng, Q.H.; Qi, P.F.; Zeng, M.; Li, W.; Ma, S.G. Electronic nose with a new feature reduction method and a multi-linear classifier for Chinese liquor classification. Rev. Sci. Instrum. 2014, 85, 055004. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.M.; Meng, Q.H.; Jing, Y.Q.; Qi, P.F.; Zeng, M.; Ma, S.G. A New Method Combining KECA-LDA with ELM for Classification of Chinese Liquors Using Electronic Nose. IEEE Sens. J. 2016, 16, 8010–8017. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 153–160. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Ranzato, M.; Poultney, C.; Chopra, S.; Lecun, Y. Efficient Learning of Sparse Representations with an Energy-Based Model. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 1137–1144. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; Lecun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. 3D object recognition with Deep Belief Nets. In Proceedings of the NIPS’09—22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1339–1347. [Google Scholar]
- Poon, H.; Domingos, P. Sum-Product Networks: A New Deep Architecture. In Proceedings of the UAI’11—Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, Barcelona, Spain, 14–17 July 2011; pp. 337–346. [Google Scholar]
- Zinkevich, M.; Weimer, M.; Smola, A.J.; Li, L. Parallelized Stochastic Gradient Descent. In Proceedings of the NIPS’10—23nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 2595–2603. [Google Scholar]
- Längkvist, M.; Loutfi, A. Unsupervised feature learning for electronic nose data applied to Bacteria Identification in Blood. In Proceedings of the NIPS workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 3 December 2011. [Google Scholar]
- Längkvist, M.; Coradeschi, S.; Loutfi, A.; Rayappan, J.B. Fast classification of meat spoilage markers using nanostructured ZnO thin films and unsupervised feature learning. Sensors 2013, 13, 1578–1592. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.H.; Hu, X.N.; Ye, M.; Cheng, X.Q.; Li, F. Gas Recognition under Sensor Drift by Using Deep Learning. Int. J. Intell. Syst. 2015, 30, 907–922. [Google Scholar] [CrossRef]
- Lyons, J.; Dehzangi, A.; Heffernan, R.; Sharma, A.; Paliwal, K.; Sattar, A.; Zhou, Y.; Yang, Y. Predicting backbone Cα angles and dihedrals from protein sequences by stacked sparse auto-encoder deep neural network. J. Comput. Chem. 2014, 35, 2040–2046. [Google Scholar] [CrossRef] [PubMed]
- Gehring, J.; Miao, Y.J.; Metze, F.; Waibel, A. Extracting deep bottleneck features using stacked auto-encoders. In Proceedings of the 2013 IEEE Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3377–3381. [Google Scholar]
- Zhang, L.; Tian, F.C.; Liu, S.Q.; Guo, J.L.; Hu, B.; Ye, Q.; Dang, L.; Peng, X.; Kadri, C.; Feng, J. Chaos based neural network optimization for concentration estimation of indoor air contaminants by an electronic nose. Sens. Actuators A 2013, 189, 161–167. [Google Scholar] [CrossRef]
- Güney, S.; Atasoy, A. Multiclass classification of n-butanol concentrations with k-nearest neighbor algorithm and support vector machine in an electronic nose. Sens. Actuators B 2012, 166–167, 721–725. [Google Scholar] [CrossRef]
- Shin, H.C.; Orton, M.R.; Collins, D.J.; Doran, S.J.; Leach, M.O. Stacked Autoencoders for Unsupervised Feature Learning and Multiple Organ Detection in a Pilot Study Using 4D Patient Data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1930–1943. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Zhang, Z.; Marchi, E.; Schuller, B. Sparse Autoencoder-Based Feature Transfer Learning for Speech Emotion Recognition. In Proceedings of the 5th Biannu Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 511–516. [Google Scholar]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Chen, J.; Jönsson, P.; Tamura, M.; Gu, Z.H.; Matsushita, B.; Eklundh, L. A simple method for reconstructing a high-quality NDVI time-series data set based on the Savitzky–Golay filter. Remote. Sens. Environ. 2004, 91, 332–344. [Google Scholar] [CrossRef]
- Yang, S.; Xie, S.; Xu, M.; Zhang, C.; Wu, N.; Yang, J.; Zhang, L.; Zhang, D.; Jiang, Y.; Wu, C. A novel method for rapid discrimination of bulbus of Fritillaria by using electronic nose and electronic tongue technology. Anal. Methods 2017, 7, 943–952. [Google Scholar] [CrossRef]
- Qi, P.F.; Meng, Q.H.; Zhou, Y.; Jing, Y.Q.; Zeng, M. A portable E-nose system for classification of Chinese liquor. In Proceedings of the IEEE SENSORS, Busan, Korea, 1–4 November 2016. [Google Scholar]
- Fonollosa, J.; Sheik, S.; Huerta, R.; Marco, S. Reservoir computing compensates slow response of chemosensor arrays exposed to fast varying gas concentrations in continuous monitoring. Sens. Actuators B 2015, 215, 618–629. [Google Scholar] [CrossRef]
- Arel, I.; Rose, D.C.; Karnowski, T.P. Deep machine learning—A new frontier in artificial intelligence research. IEEE Comput. Intell Mag. 2010, 5, 13–18. [Google Scholar] [CrossRef]
- Raudys, S.J.; Jain, A.K. Small Sample Size Effects in Statistical Pattern Recognition: Recommendations for Practitioners. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 252–264. [Google Scholar] [CrossRef]
Figure 1.
Structure of an auto-encoder neural network (“+1” represents the bias vector).

Figure 2.
A stacked sparse auto encoder (SSAE) network composed of two sparse auto-encoders.

Figure 3.
SSAE based multi-layer back propagation neural network (BPNN).

Figure 4.
SSAE-BPNN vs. Traditional methods.

Figure 5.
Structure of the designed e-nose system for Chinese liquors recognition.

Figure 6.
E-nose experiment platform.

Figure 7.
Response curves of the sensor array, (a) represents the original response curve (1 Hz); (b) represents the original response curve (100 Hz).
Figure 7.
Response curves of the sensor array, (a) represents the original response curve (1 Hz); (b) represents the original response curve (100 Hz).

Figure 8.
Influence of the number of hidden layers on classification accuracy.

Figure 9.
Influence of the number of hidden-layer nodes on classification accuracy.

Figure 10.
Influence of the SSAE parameters on classification accuracy, (a) shows the influence of the sparse target value on classification accuracy; (b) shows the influence of the sparse weight on classification accuracy.
Figure 10.
Influence of the SSAE parameters on classification accuracy, (a) shows the influence of the sparse target value on classification accuracy; (b) shows the influence of the sparse weight on classification accuracy.

Figure 11.
Influence of iteration times on classification accuracy.

Figure 12.
Relationship between the fine-tuning mean squared error (MSE) and iteration times.

Figure 13.
Comparison of SSAE-BPNN and SAE-BPNN.

Figure 14.
Comparison of SSAE-BPNN and SSAE-SVM.

Figure 15.
Response curves of the first generation e-nose platform.

Figure 16.
Three-dimensional principal component analysis (PCA) score plot.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Sample information of experimental liquors.
| Name | Alcohol (Vol) | Raw Materials | Origin Place (China) |
|---|---|---|---|
| BFH | 40% Vol | Sorghum, wheat, barley, pea | Tianjin |
| BNWJ | 38% Vol | Sorghum, wheat, barley, pea | Anhui |
| MZDQ | 38% Vol | Sorghum, rice, wheat, corn | Sichuan |
| LJJ | 48% Vol | Sorghum, wheat, barley, pea | Tianjin |
| HJJ | 38% Vol | Sorghum, wheat, barley, pea | Tianjin |
| NLS | 42% Vol | Sorghum, wheat, rice | Beijing |
| LZLJ | 38% Vol | Sorghum, rice, wheat | Sichuan |
Table 2.
Parameters setting up of SSAE-BPNN.
| SSAE | Value | Definition | BPNN | Value | Definition |
|---|---|---|---|---|---|
| 3640 | No. of input-layer nodes | 3640 | No. of input-layer nodes | ||
| 200 | No. of 1st hidden-layer nodes | 200 | No. of 1st hidden-layer nodes | ||
| 100 | No. of 2nd hidden-layer nodes | 100 | No. of 2nd hidden-layer nodes | ||
| 0.01 | Sparse target value | 7 | No. of output-layer nodes | ||
| 0.1 | Sparse weight | 1 | Learning rate | ||
| 0.1 | Learning rate |
Table 3.
Accuracy and interval of confidence of SSAE-BPNN & SAE-BPNN.
| Iteration Times | SSAE-BPNN | SAE-BPNN | ||
|---|---|---|---|---|
| Accuracy | Interval of Confidence | Accuracy | Interval of Confidence | |
| 8 | 0.915079 | 0.007976 | 0.906122 | 0.008116 |
| 15 | 0.926531 | 0.007706 | 0.921088 | 0.007706 |
| 20 | 0.934014 | 0.007493 | 0.92517 | 0.010546 |
| 30 | 0.948299 | 0.005786 | 0.936735 | 0.006572 |
| 40 | 0.952381 | 0.008248 | 0.948299 | 0.008878 |
| 50 | 0.955102 | 0.004647 | 0.95034 | 0.005399 |
| 60 | 0.953061 | 0.003286 | 0.945578 | 0.007199 |
| 70 | 0.956463 | 0.006406 | 0.95102 | 0.011571 |
| 80 | 0.961224 | 0.005786 | 0.956463 | 0.006406 |
| 90 | 0.966667 | 0.003888 | 0.944898 | 0.008632 |
Table 4.
Accuracy and interval of confidence of SSAE-BPNN & SSAE-SVM.
| Iteration Times | SSAE-BPNN | SSAE-SVM | ||
|---|---|---|---|---|
| Accuracy | Interval of Confidence | Accuracy | Interval of Confidence | |
| 10 | 0.923810 | 0.006148 | 0.914286 | 0.009524 |
| 20 | 0.934014 | 0.007493 | 0.923129 | 0.01853 |
| 30 | 0.948299 | 0.005786 | 0.934014 | 0.010075 |
| 40 | 0.952381 | 0.008248 | 0.936735 | 0.011571 |
| 50 | 0.955102 | 0.004647 | 0.940136 | 0.014511 |
| 60 | 0.953061 | 0.003286 | 0.948299 | 0.011143 |
| 70 | 0.956463 | 0.006406 | 0.95034 | 0.009858 |
| 80 | 0.961224 | 0.005786 | 0.953061 | 0.018934 |
| 90 | 0.966667 | 0.003888 | 0.954422 | 0.011939 |
Table 5.
Recognition results and employed time based on traditional methods and DL methods.
| Algorithm | Traditional Method 1 | Traditional Method 2 | DL Methods | |||
|---|---|---|---|---|---|---|
| KECA-BPNN | KECA-SVM | PCA-BPNN | PCA-SVM | SSAE-BPNN | SSAE-SVM | |
| Accuracy (%) | 70.47 | 72.86 | 90.47 | 91.90 | 96.67 | 95.44 |
| Time (s) | 892 | 872 | 587 | 567 | 59 | 39 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhao, W.; Meng, Q.-H.; Zeng, M.; Qi, P.-F. Stacked Sparse Auto-Encoders (SSAE) Based Electronic Nose for Chinese Liquors Classification. Sensors 2017, 17, 2855. https://doi.org/10.3390/s17122855
AMA Style
Zhao W, Meng Q-H, Zeng M, Qi P-F. Stacked Sparse Auto-Encoders (SSAE) Based Electronic Nose for Chinese Liquors Classification. Sensors. 2017; 17(12):2855. https://doi.org/10.3390/s17122855
Chicago/Turabian StyleZhao, Wei, Qing-Hao Meng, Ming Zeng, and Pei-Feng Qi. 2017. "Stacked Sparse Auto-Encoders (SSAE) Based Electronic Nose for Chinese Liquors Classification" Sensors 17, no. 12: 2855. https://doi.org/10.3390/s17122855
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.