1. Introduction
In very high resolution (VHR) remote sensing images, vehicle detection is an indispensable technology in both civilian and military surveillance, e.g., traffic management, urban planning, etc. Therefore, vehicle detection from aerial images has attracted significant attention worldwide [
1,
2,
3,
4,
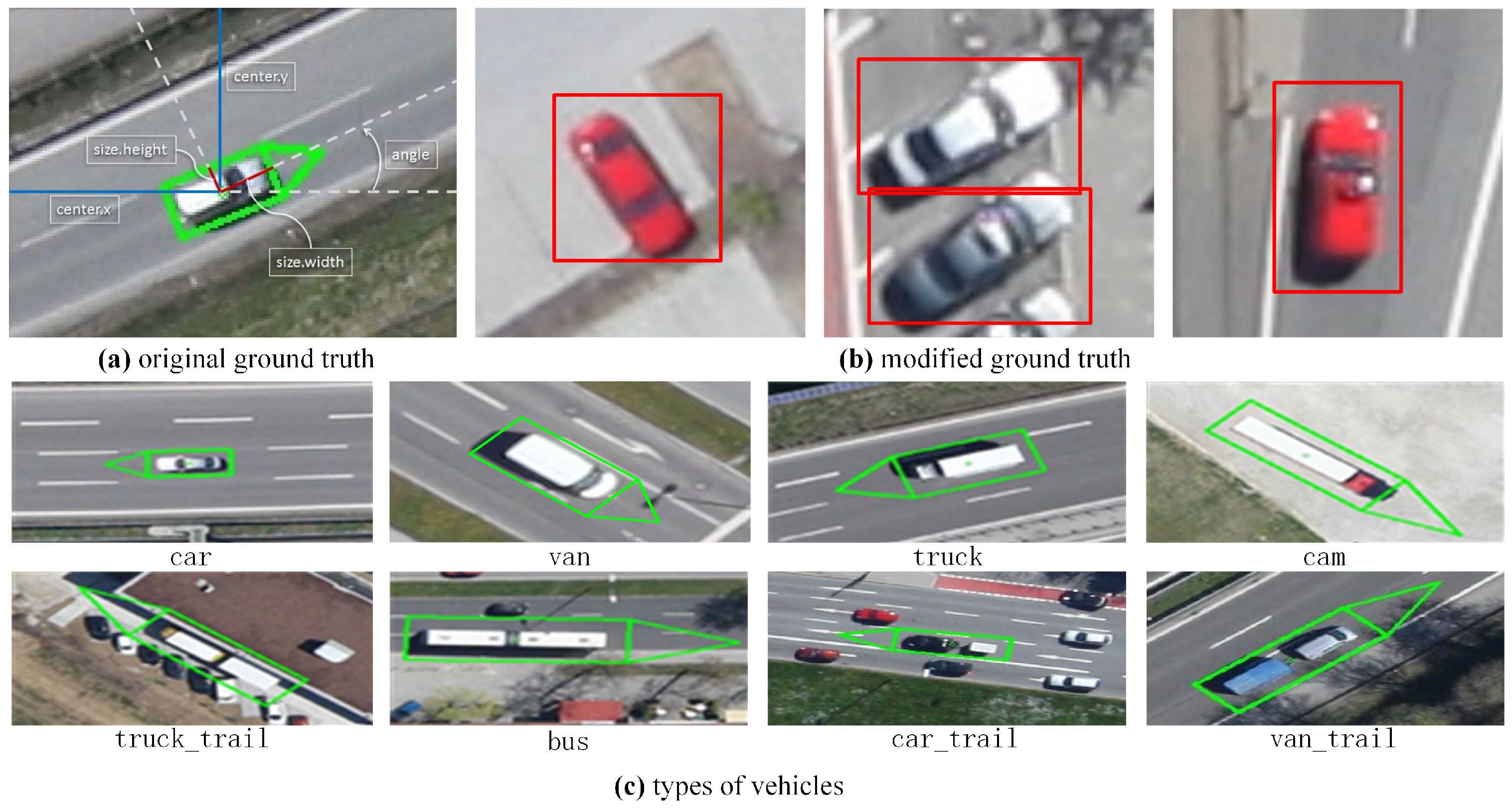
5]. However, automatic vehicle detection in aerial images still has a lot of challenges due to the relatively small size and variable orientation of vehicles (
Figure 1a). In addition, real-time detection in such large-scale aerial images with intricate backgrounds (
Figure 1b) also increases the difficulties.
In previous studies, the existing vehicle detection methods in aerial images are mostly based on sliding window search and manual features or shallow-learning-based features [
6,
7,
8,
9,
10,
11]. The work of [
2] is worth mentioning here, as the authors presented an approach that could detect vehicles with type and orientation attributes on large-scale aerial images without any geo-reference information available. This method employed a fast binary detector using integral channel features (ICFs) and an AdaBoost classifier in a soft-cascade structure to detect the location of the vehicles. Then, a histogram of oriented gradient (HOG) features was used to further classify the orientations and type of the vehicle, resulting in both rapid and effective detection performance. However, this method has some drawbacks. Firstly, hand-crafted features or shallow-learning based features influence the representational power, as well as the effectiveness of vehicle detection. Secondly, the sliding window technique leads to heavy computational costs.
In the field of computer vision, region convolutional neural network (R-CNN) based detection methods have achieved great success in nature scene images [
12], especially Faster R-CNN [
13]. Faster R-CNN employs a fully convolutional region proposal network (RPN) to generate object-like regions, and a classifier after RPN to further infer the candidate regions. Considering the powerful feature representation and fast speed, Faster R-CNN performs much better than the traditional sliding window based methods. However, directly utilizing it for vehicle detection in such large aerial imagery has many challenges, due to the big differences between aerial images and nature scene images. The differences and challenges are as follows: (1) vehicles (only
pixels) in aerial images (with the size of
pixels) are relatively smaller than those in nature scene images, thus increasing the difficulty of localization; (2) due to the large size and wide view of the aerial images, their backgrounds are more intricate than the nature scene images. Accurate vehicle detection in such aerial images is hard; (3) the aerial images are much larger than the nature scene images (approximately with the size of
pixels), increasing difficulties for rapid detection. In addition, the training data for vehicle detection in aerial images is much less, causing an over-fitting problem for region CNN-based methods. Considering all the challenges mentioned above, we argue that two reasons lead to Faster R-CNN’s poor performance. Firstly, region proposal network (RPN) in Faster R-CNN is not good enough to accurately detect small-sized vehicles, due to the relatively coarse feature maps. Secondly, the classifier after RPN cannot distinguish vehicles and complex backgrounds well, due to the lack of hard negative example (similar to vehicles, see
Figure 1) mining process.
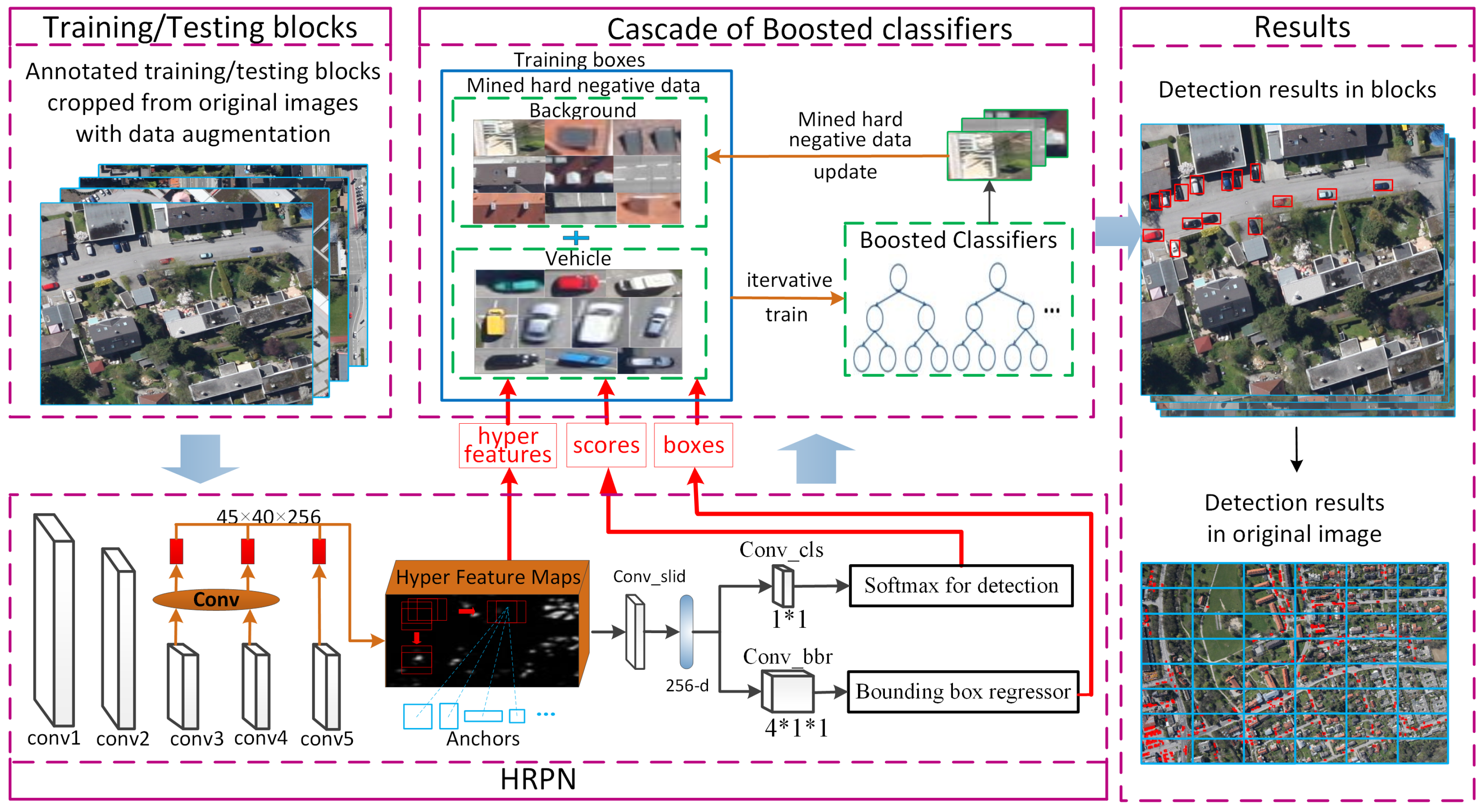
To address these problems, in this paper, we propose an accurate and robustness vehicle detection framework (see
Figure 2). Our method contains two parts: a hyper region proposal network (HRPN), aiming at predicting all of the possible bounding-boxes of vehicle-like objects with high recall rate, and a cascade of boosted classifiers to further verify the detection results from HRPN with high precision. Specifically, our HRPN is based on RPN. However, HRPN combines rich-detail feature maps of shallow layers with coarse-detail feature maps of deep layers, which is more suitable for small object detection than RPN. In addition, we replace the classifier after RPN by a cascade of boosted classifiers, which can reduce false detection by mining hard negative examples.
Moreover, limited annotated training data causes an over-fitting problem, and large-scale aerial images increase the difficulty of rapid detection. To overcome the two problems above, we crop the original large-scale training aerial images into image blocks, and augment the number of them by rotation. In addition, the testing aerial images are also cropped into blocks. The vehicles’ locations can be acquired when the blocks with testing results are stitched back together. Compared with [
2], our method is more accurate and more robust without setting the size of the detection window in advance. Compared with Faster R-CNN [
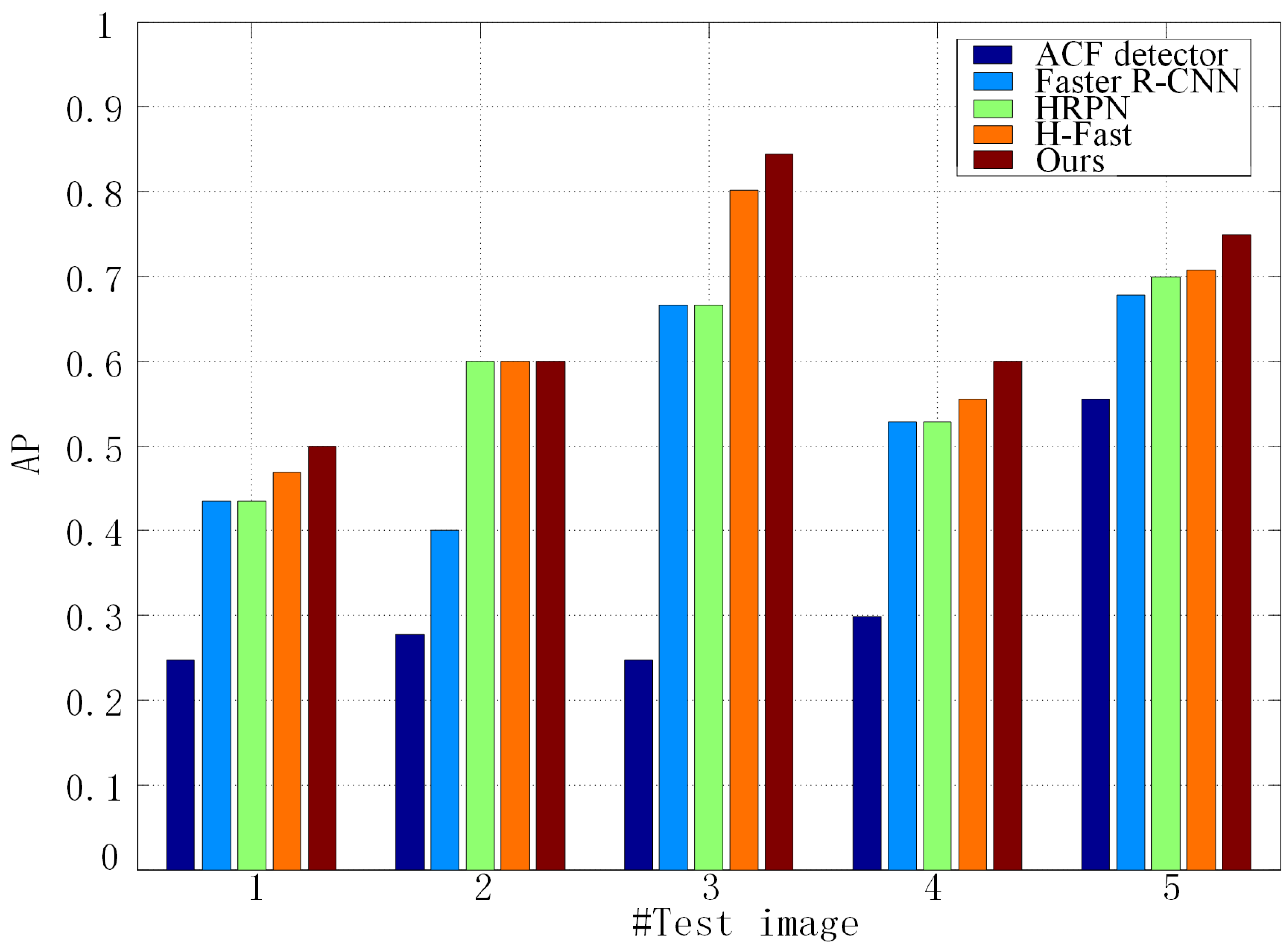
13], our method has better location accuracy and less false detection. Moreover, we successfully test our method on unmanned aerial vehicle (UAV) images and pansharpened color infrared (CIR) images, proving the robustness of our method. The main contributions of our work is: we combine a cascade of boosted classifiers with HRPN, which improves the classification accuracy by hard negative example mining.
This paper is organized as follows:
Section 2 discusses related works. The proposed method is detailed in
Section 3.
Section 4 reports the experimental results. Finally,
Section 5 concludes the paper.
2. Related Work
According to the existed object detection methods, the detection task can be divided into three main parts: generation of candidate regions, feature extraction and classification.
For generation of candidate regions, most of the existing vehicle detection methods employ a sliding-window search algorithm [
2,
3,
7,
8]. These methods need to set different sizes of windows to traverse the entire image, or use a fixed-size window to traverse the zoom images. Therefore, these sliding-window search based methods have a high complexity of time and generate a large number of redundant windows. Compared with the sliding-window based methods, region-proposal based methods reduce the computational costs. Traditional methods generate region proposals by merging segments that are likely be included in objects, e.g., super-pixels [
14], saliency [
15], selective search [
16], etc. Nevertheless, the human-designed generator for region proposals is still time-consuming. Recently, CNN based methods have been widely used in region proposals, such as Deepbox [
17] and RPN [
13]. These methods can generate candidate regions with deep learning features, resulting in promising performance and speed.
For feature extraction, hand-crafted features are widely used in vehicle detection. Shao et al. [
7] used Haar-like features and local binary patterns (LBP) for vehicle detection. Moranduzzo et al. [
3] made use of scale-invariant feature transform descriptors (SIFTs). Kluckner et al. [
8] and Tuermer et al. [
18] adopted a histogram of oriented gradient (HOG) features, while Liu [
2] employed a fast binary detector using ICFs. However, these hand-crafted features are not good enough at separating cars from the background in complex environments. Recently, region CNN-based detection methods have achieved great success in nature scene images, owing to their powerful feature representation. The most popular is region-based convolutional neural networks (R-CNN) [
19] and their improved methods Fast R-CNN [
20] and Faster R-CNN [
13]. All of them achieve state-of-the-art performance.
For classification, Shao et al. [
7] and Moranduzzo et al. [
3] used hand-crafted features with a support vector machine (SVM) for candidate region classification. However, AdaBoost gradually replaced SVM due to its good performance. Kluckner et al. [
8], Tuermer et al. [
18] and Liu et al. [
2] employed an AdaBoost classifier to verify candidate regions. This research demonstrates that the bootstrapping strategy, which mines hard negative examples and reweights examples for iterative training, improves the classifier considerably by reducing the number of false classification.
Considering all three parts of the detection, the region CNN-based detection methods have the best performance. R-CNN uses a selective search algorithm to generate object-like regions, and then extracts deep features for classification by SVM. In order to increase the speed and accuracy of detection further, Fast R-CNN employs a multi-task network for classification and bounding box regression, combining feature extraction and classification into one process. Nevertheless, their human-designed region proposal generator is still time-consuming. Thus, Faster R-CNN employs RPN to generate object-like regions and a CNN-based classifier to further infer the candidate regions. Faster R-CNN is an end-to-end method, achieving near real-time detection with state-of-the-art performance. However, it still has some drawbacks when applied to vehicle detection in aerial images. RPN is not suitable for small objects, owing to the coarse feature maps it uses. Meanwhile, the classifier is not good enough to distinguish objects from complex backgrounds, due to the lack of hard negative examples mining process.
We take the advantages of Faster R-CNN and hard negative example mining to propose our method, achieving state-of-the-art performance.
3. Proposed Method
The framework of our vehicle detection method is illustrated in
Figure 2. For training, we crop original large-scale images into blocks and augment the number of image blocks by rotation with four angles (i.e.,
,
,
, and
). Then, HRPN takes all the training image blocks as input for training and produces candidate region boxes, scores and corresponding hyper features. Finally, the outputs of HRPN are used to train a cascade of boosted classifiers, and the final classifier is obtained.
For testing, a large-scale testing image is cropped into image blocks. Then, HRPN takes these image blocks as input and generates candidate region boxes as well as hyper feature maps. The final classifier verifies these boxes using hyper features. Finally, all the detection results of blocks are stitched together to recombine the original image.
3.1. Hyper Region Proposal Network
There are two kinds of RPN structures: one is based on the Zeiler and Fergus model (ZF) [
21], and the other is based on the VGG model [
22]. Owing to the limited training data and video memory, we choose the relatively few parameter ZF-based RPN as the building block of our HRPN. Different from RPN, we combine the output feature maps of the last three convolutional layers to achieve a concatenated feature map. The reasons for our improvement are as follows: Ghodrati [
23] indicates that the deeper convolutional layers can get high recall but poor localization in detection, and the lower convolutional layers can get more accurate localization but low recall. In addition, the Fully Convolution Network (FCN) achieves great performance in segmentation [
24], in which the authors combine a high layer with a low layer for segmentation. Therefore, these imply that the combination of shallow features and deep features will result in better detection results.
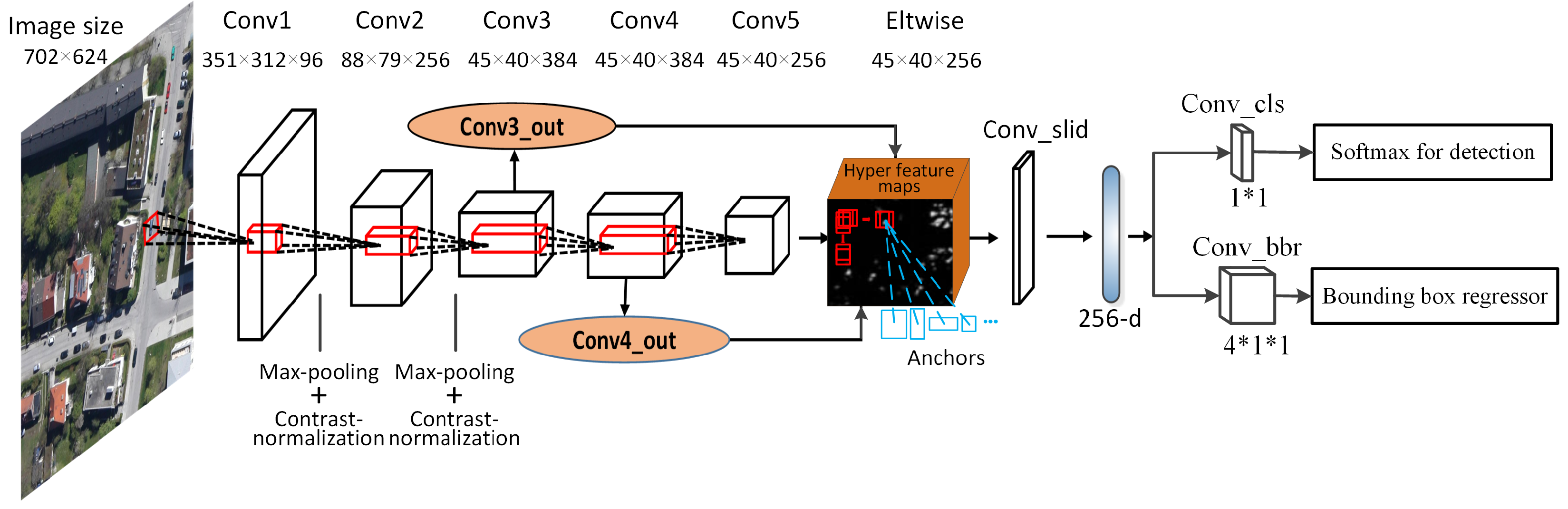
Figure 3 shows the architecture of HRPN.
3.1.1. Architecture
HRPN is a full convolutional network to generate candidate regions. The first convolutional layer (Conv1) takes the training images as input and has 96 kernels of size with a stride of two pixels. The second convolutional layer (Conv2) takes the output of the previous convolutional layer as input and filters it with a stride of two pixels by 256 kernels of size . The contrast normalization and max pooling layers are only configured after the first two convolutional layers. The third (Conv3), fourth (Conv4), and fifth (Conv5) convolutional layers are directly connected to each other, having 384 kernels of size , 384 kernels of size , and 256 kernels of size , respectively. We compute hyper feature maps from three convolutional layers (namely Conv3, Conv4 and Conv5), which have the same size but different levels of detail information. In addition, two convolutional layers (Conv3_out and Conv4_out) with kernel size of are added on the top of Conv3 and Conv4 feature maps, respectively, to compress them into the same number as conv5. Finally, we synthesize these three feature maps and get one single output cube, which we call hyper feature maps. The “Eltwise” layer is used to complete the operation, which simply adds the three feature maps together.
In order to generate candidate regions, we use the sliding window operation on hyper feature maps. This operation is implemented by a
convolutional layer, namely “Conv_slid”. The parameters of weight are initialized by “gaussian”, and the parameters of bias are initialized by “constant”. At each sliding window location, we simultaneously predict multiple region proposals associated with different scales and aspect ratios (namely anchors, see blue boxes in
Figure 3). As the size of vehicle is approximately
, we adopt anchors of three scales of
,
, and
pixels, and three aspect ratios of 1:1, 1:2, and 2:1. For 256 feature maps in total, we can extract a 256-d feature vector for each region proposal. Afterwards, these region proposals and their corresponding features are fed into two sibling
convolutional layers for box-classification and box-regression, respectively (namely conv_cls and conv_bbr). The first sibling layer outputs a vehicle-like score
, and the second sibling layer outputs the coordinates vector
of each predicted region after bounding box regression.
x and
y represent the top-left coordinates of the predicted region, whereas,
w and
h denote the width and height of the predicted region.
3.1.2. Training HRPN
To facilitate training by limited size of the training set, we use a pre-trained ZF model [
13,
25] based on ImageNet [
26] to initialize the parameters of five convolutional layers, and then domain-specifically fine-tuned with a smaller learning rate. Throughout the training process for HRPN, we have 70k iterations. During each iteration, we process a batch of the labeled image blocks into the network, and obtain region proposals for each image block. For each batch, the number of image blocks and predicted regions are
and
, respectively. If a predicted region has the Intersection-over-Union (IoU) bigger than 0.7 with the ground truth box, we assign a positive label to it (
). However, if the IoU ratio of a predicted regions is lower than 0.1 for all ground-truth boxes, we assign a negative label to it (
). Then, the remaining regions are discarded. The IoU ratio is defined as follows:
where
represents the intersection of the vehicle proposal box and ground truth box, and
denotes their union.
All of the positive and negative region proposals and their corresponding labels are fed into the loss function. In addition, a multi-task loss function is used to update the parameters of the network, aiming at minimizing the error of classification and localization. We use
as the softmax loss fuction for the classification of vehicles and backgrounds, and
as the box-regression loss. Just like [
13], the loss function is defined as
Equation (
2):
where
i is the index of a batch.
is the vehicle-like score for each predicted region, and
is the ground-truth label.
λ is the balance parameter. During each iteration, the number of positive and negative region proposals are the same. Therefore, we set
to weight both
and
terms equally.
denotes a smooth
loss [
13], which is the same as those in Faster R-CNN. It is defined as Equation (
3):
where
is the coordinates vector of the predicted region, and
is the coordinates vector of target ground-truth bounding-box. When the training of the HRPN is finished, we generate approximately 300 highly overlapped candidate region boxes of each test block. To reduce redundancy, non-maximum suppression (NMS) is adopted in the proposed regions based on the vehicle confidence score
. Finally, the remaining vehicle-like regions and their scores are used as the initial data for the boosted classifiers that follow.
3.2. Cascade of Boosted Classifiers
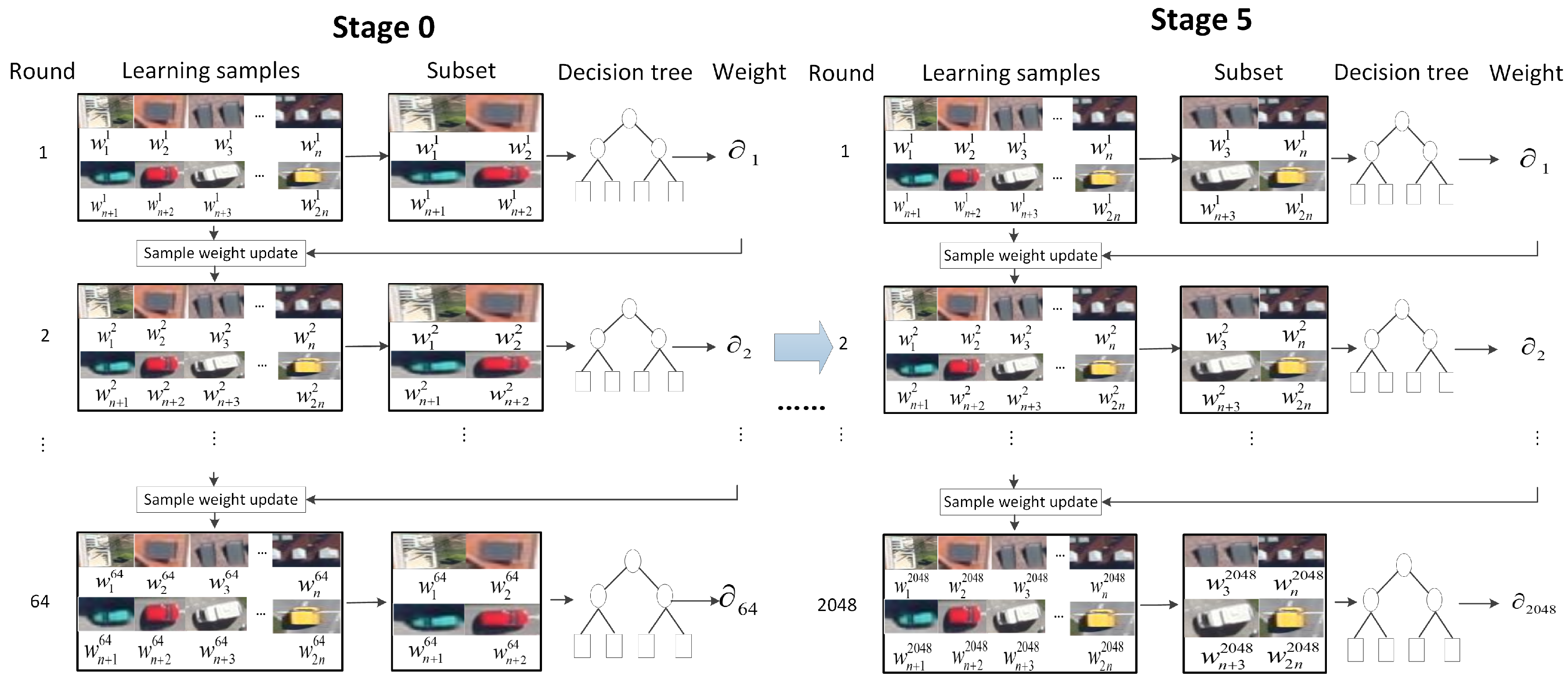
The HRPN has proposed candidate regions, scores and corresponding hyper features, which are used as training data for cascade of boosted classifiers. In this section, a candidate region is considered as a positive sample if it has an Intersection-over-Union (IoU) ratio bigger than 0.8 with the ground truth box, and the negative lower than 0.3. Initially, all the positive samples and the same number of randomly chosen negative samples from candidate regions are used as the training data. The training process of the cascade of boosted classifiers is illustrated in
Figure 4.
We set six stages for training. For stage 0, we use 10k positive examples and 10k negative examples to train the 64 weak classifiers. Then, all the training data of stage 0 plus 1k new negative examples are used to train the classifiers of stage 1. Each stage uses the reweighted examples from previous stage and the newly added negative examples for training.
Moreover, we use {64, 128, 256, 512, 1024, 2048} weak classifiers in each stage. A shallow decision tree is taken as a weak classifier. Then, the RealBoost algorithm [
27] is used to constitute strong classifiers from weak classifiers—namely, boosted classifiers. In stage 0, we set the weak classifier
following the form of RealBoost:
where
is the score of candidate region from HRPN. Following [
27], the weak classifier in each round of other stage is defined as Equation (
5):
where, in stage
i round
,
is the error rate of the decision tree, and
is the number of tree. In each round, we choose a subset of the training samples to train the classifier and the samples are reweighted according to the classification results. Specifically, the weights of the correctly categorized samples are reduced and the weights of the incorrectly categorized samples are increased. Thus, hard negative examples are mined and added into the training set.
After
times iterative training, the weights of training data are updated and
weak classifiers are obtained. The final detector
of stage
i is defined in Equation (
6):
where
is the weight of the decision tree.
After being trained by all stages, a classifier consisting of 2048 weak classifiers is obtained and used to classify candidate regions. Our implementation is based on [
28].
3.3. Implementation Details
In this paper, the structures and layers of HRPN are based on the existing ZF model, and the kernel sizes are the same as the ZF model. In HRPN, an input image will be resized to pixels before training and testing ( for image blocks with the size of pixels in the Munich Vehicle data set). Therefore, in order to achieve better results, we need to set different for a new dataset with different sizes of images. In addition, each batch consists of one image and 120 randomly selected anchors for training.
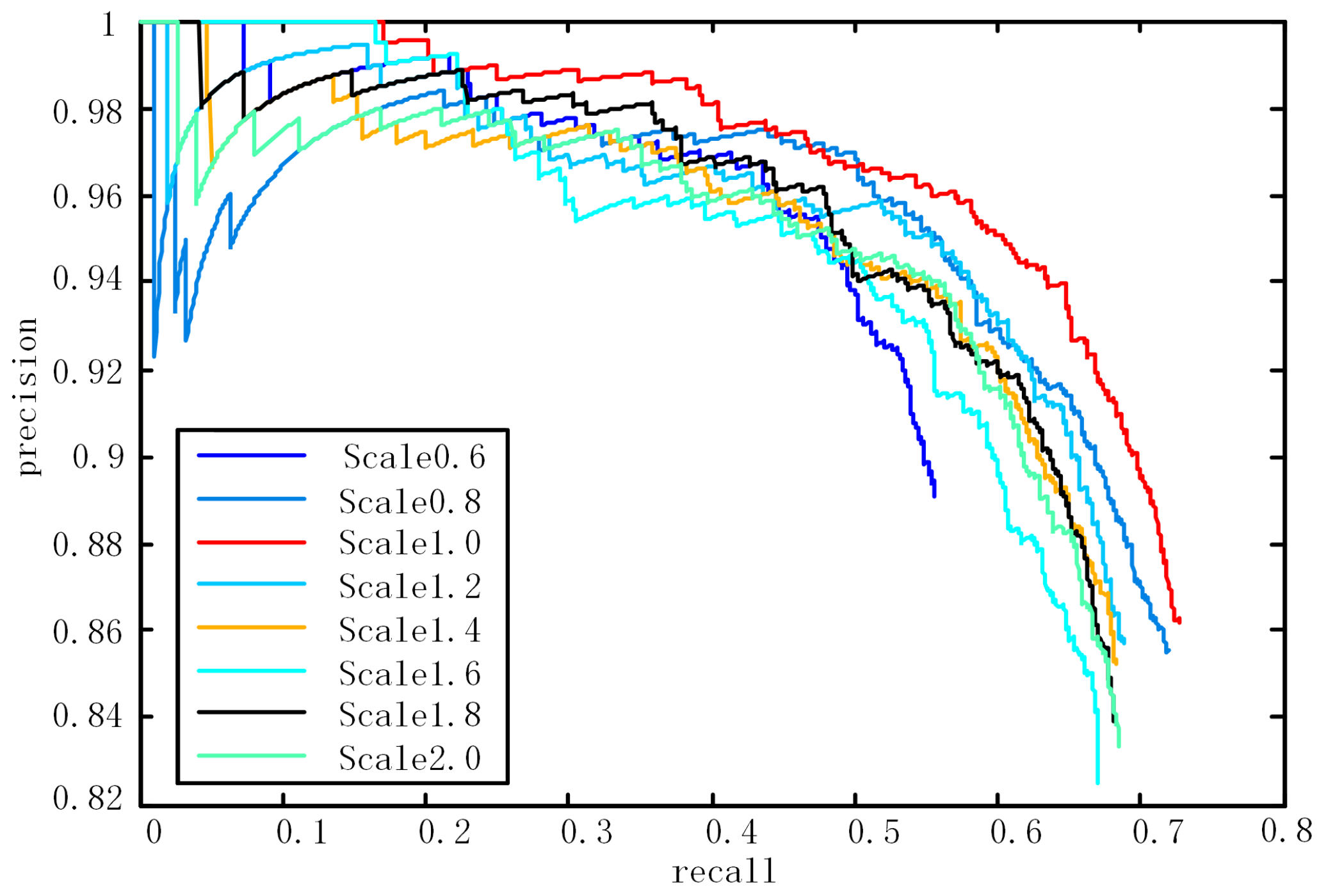
To determine the parameters of the anchor, a comparison experiment is done. We evaluate the mean average precision (mAP) under different scales and aspect ratios of anchors. The results are shown in
Table 1. As can be seen from the table, the results of one scale and three different ratios are better than that with one scale and one ratio. The results of three scales and three ratios are similar to those with one scale and three ratios. Taking all the results into account, we select the parameter of anchors with three scales and three ratios.
Other parameters of HRPN are the same as in Faster R-CNN [
13].
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}