A oneM2M-Based Query Engine for Internet of Things (IoT) Data Streams



Abstract
:1. Introduction
- We propose a oneM2M-based query engine for efficiently searching and retrieving IoT data streams.
- We define a JSON-based query language which enables users to specify data source search metadata properties and execution operators.
- The architecture of OMQ facilitates on-demand multiple ad-hoc queries and the efficient execution of hybrid infrastructure-edge query processing algorithms.
2. Related Works
2.1. oneM2M Middleware
2.2. IoT Data Processing
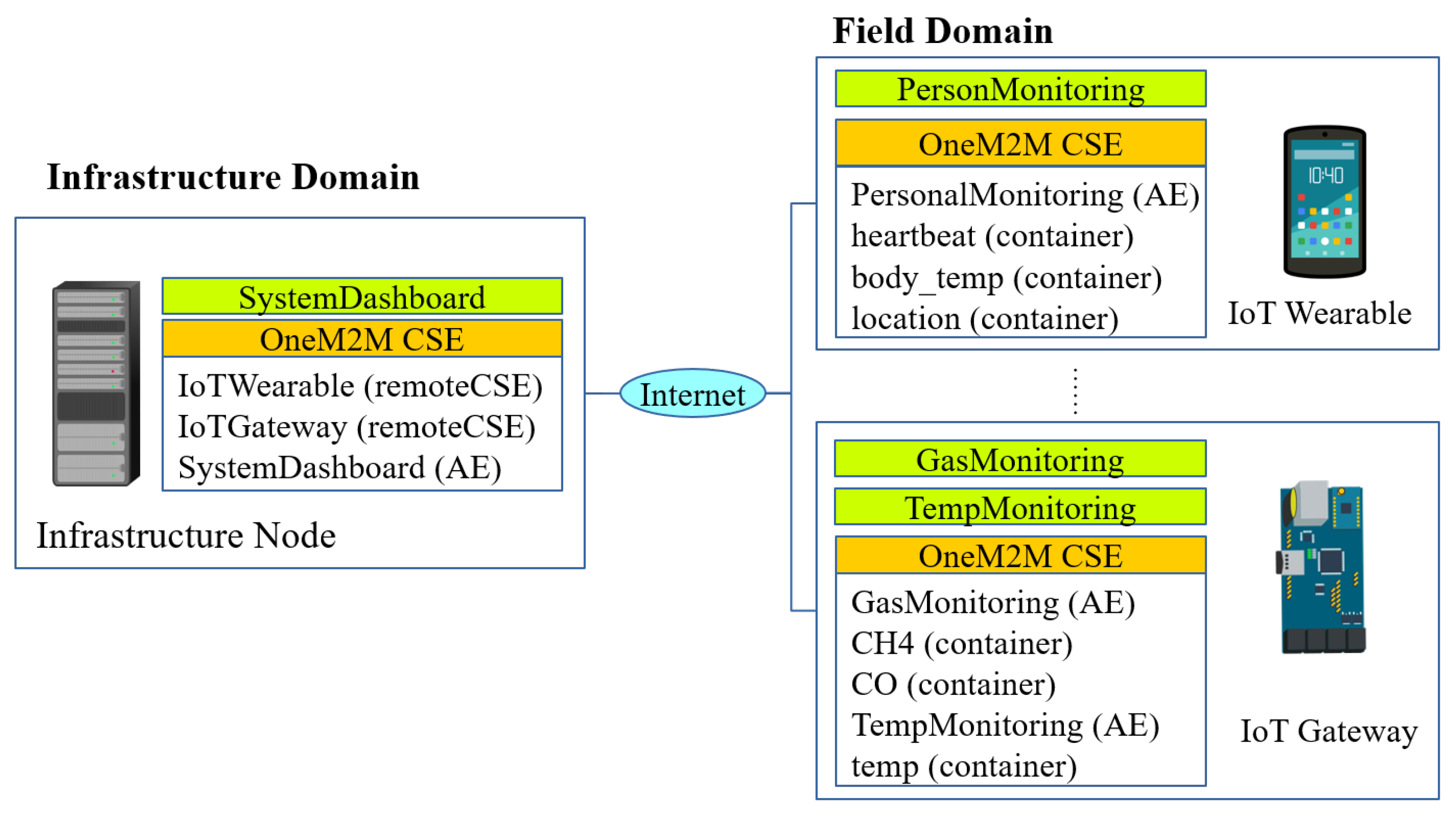
3. Introduction to oneM2M Standard
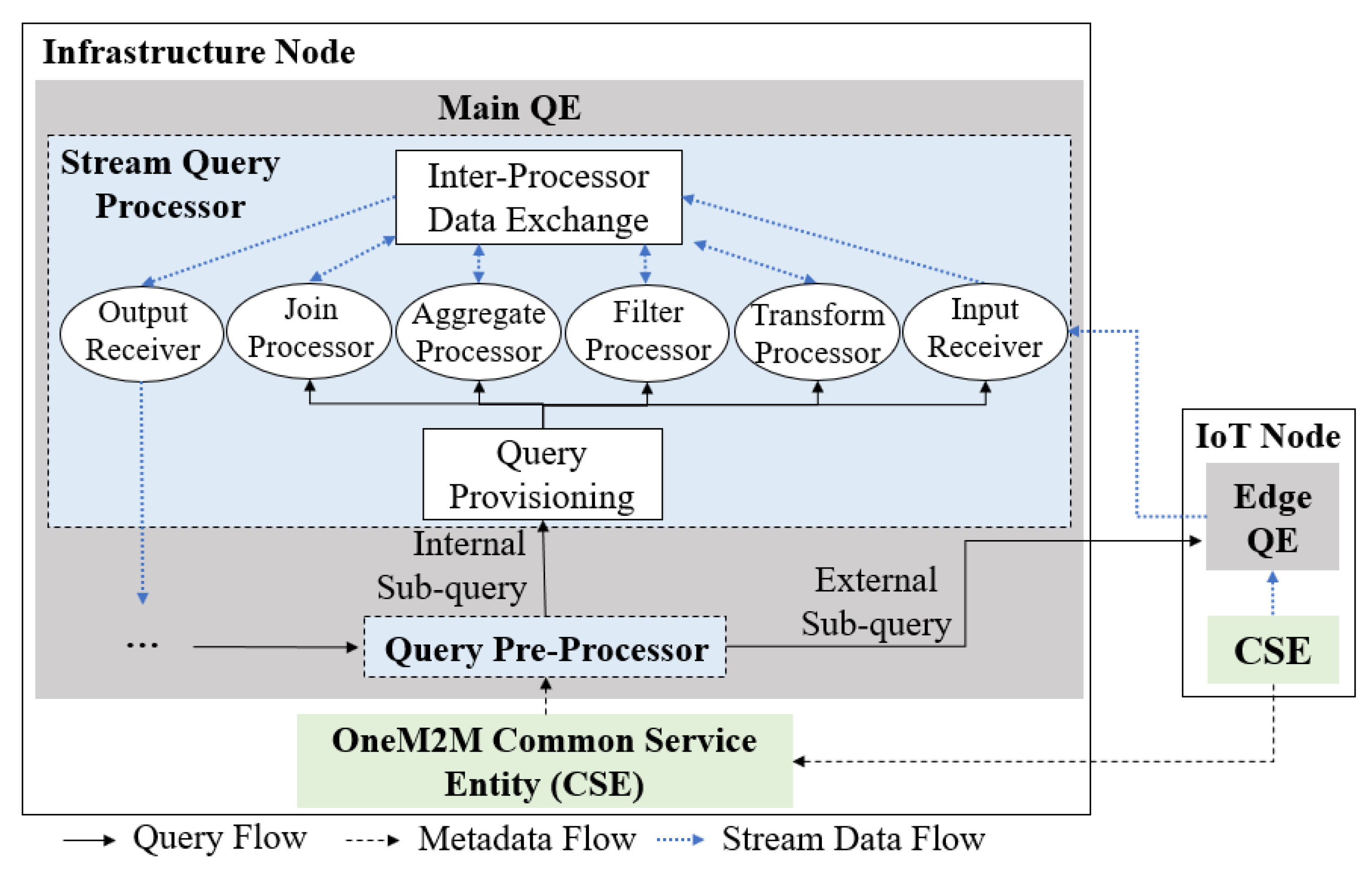
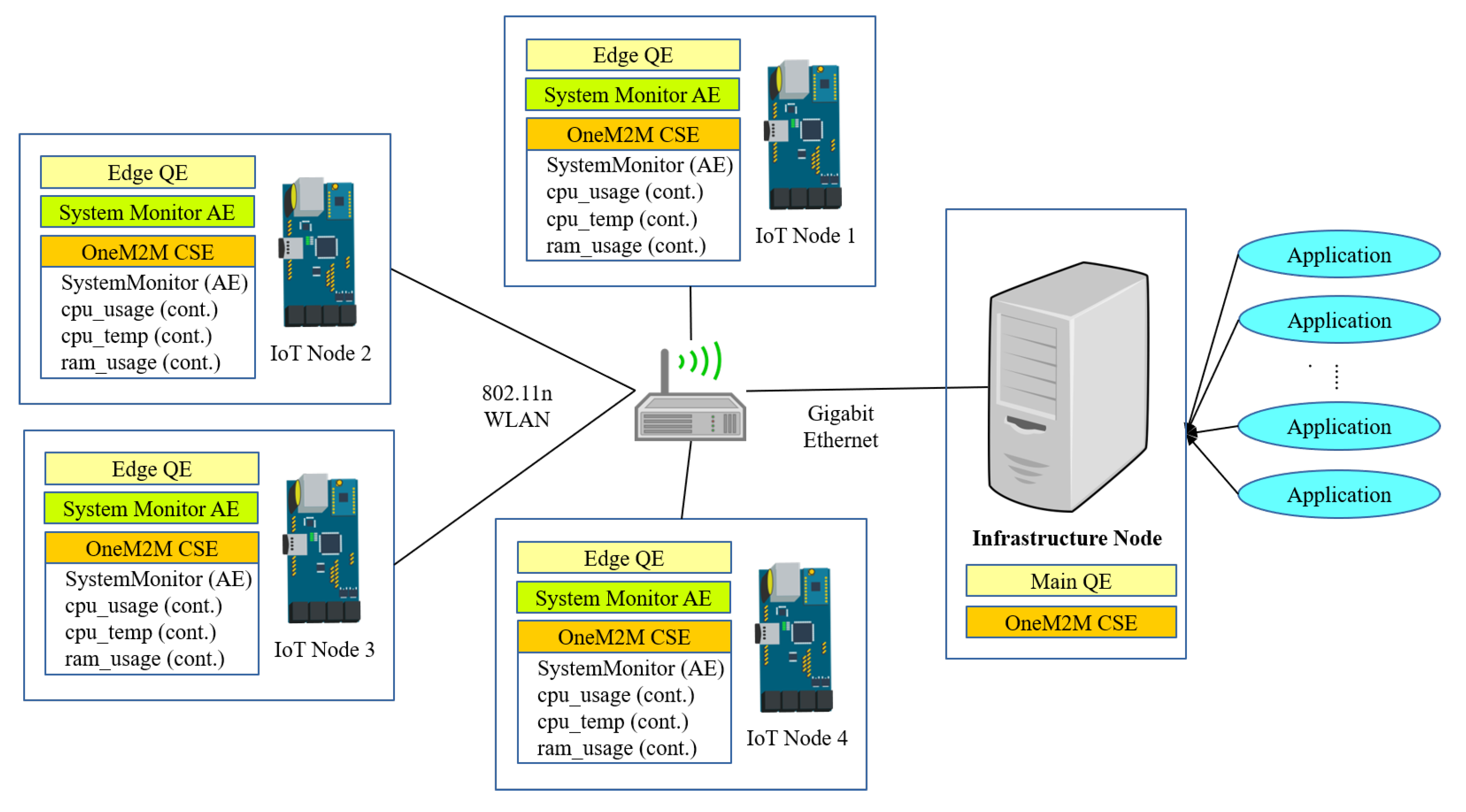
4. Proposed System Architecture
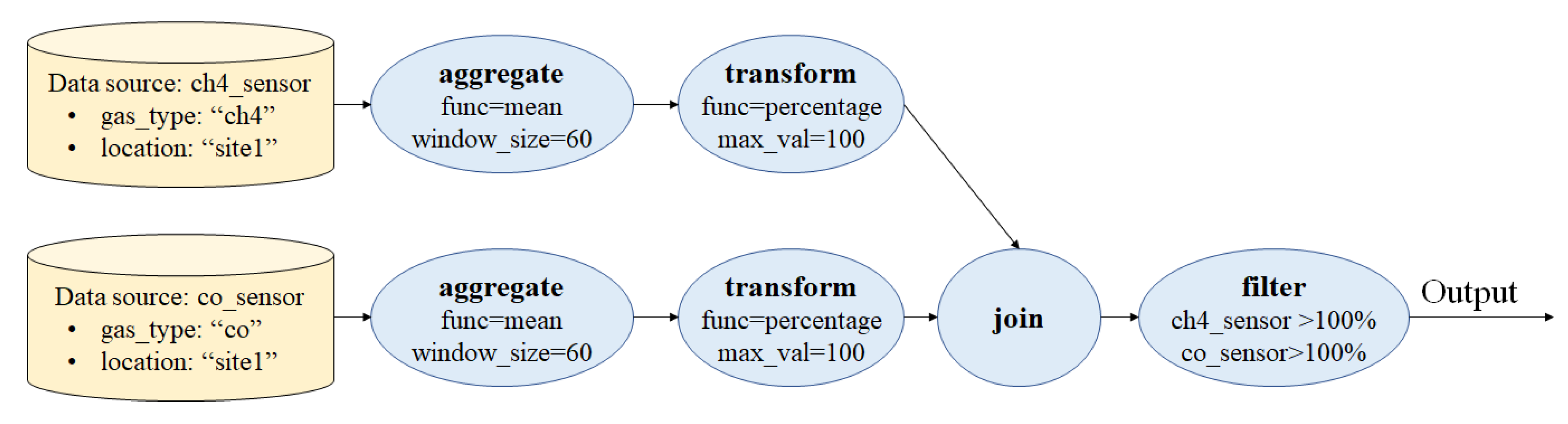
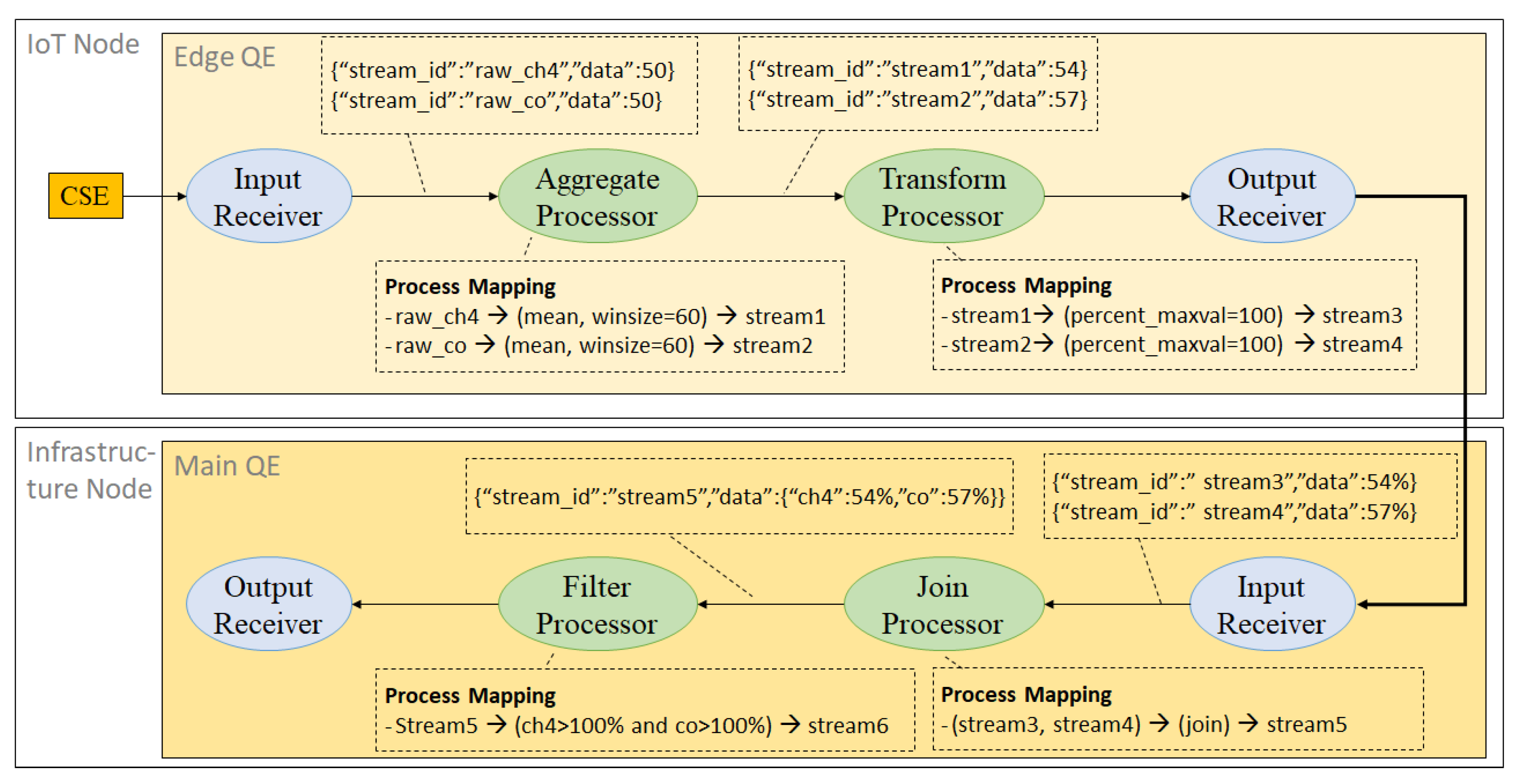
4.1. Query Language Definition
- Pre-join operators, where defines a set of chaining query processing operators that will be applied for each corresponding data source as pre-processing steps before joining the data into a single tuple.
- A join operator defines a join function that joins the inputs from several data sources into one tuple.
- Post-join operators defines a set of chaining operators applied to the data after being joined into a single tuple.
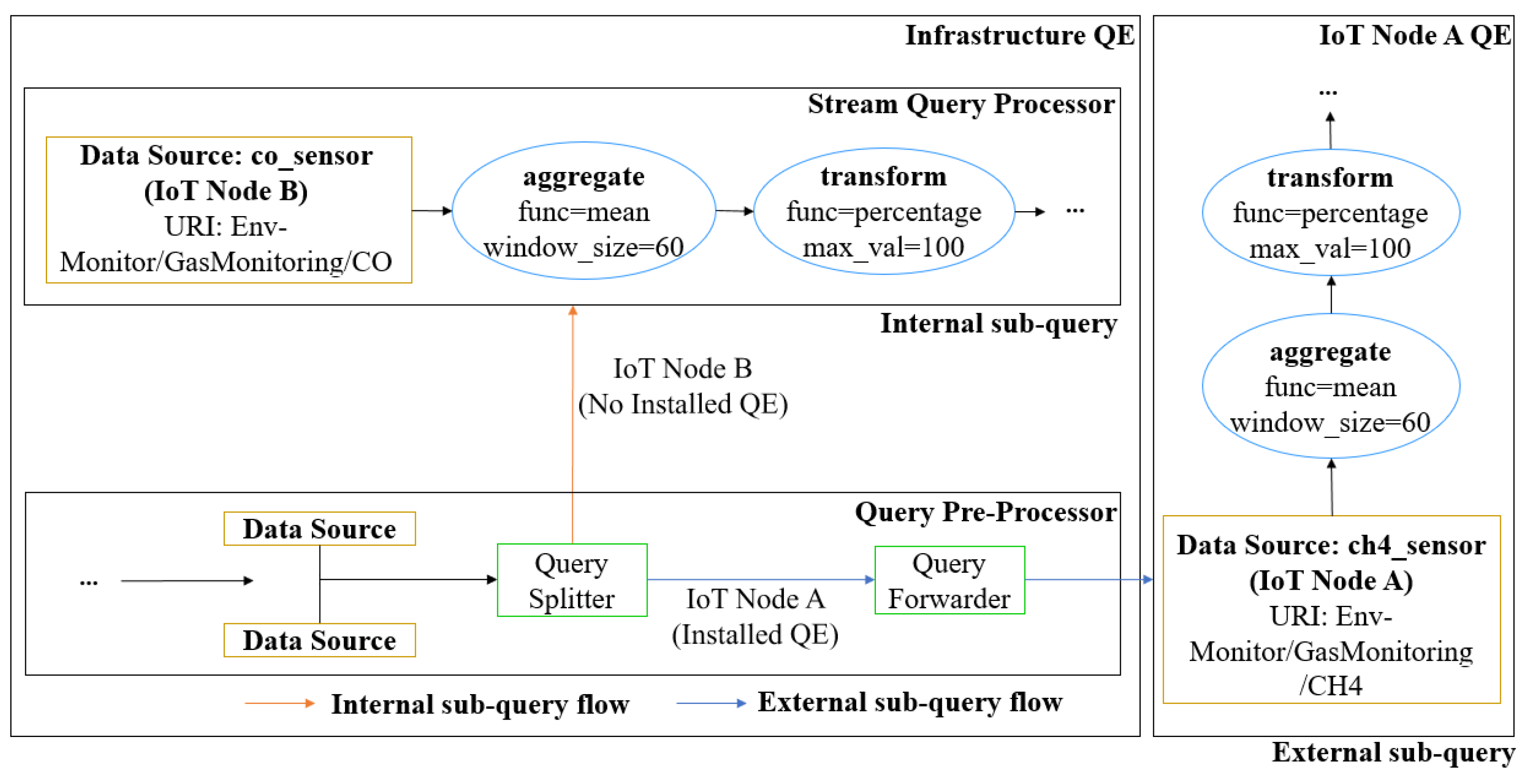
4.2. Query Engine Architecture
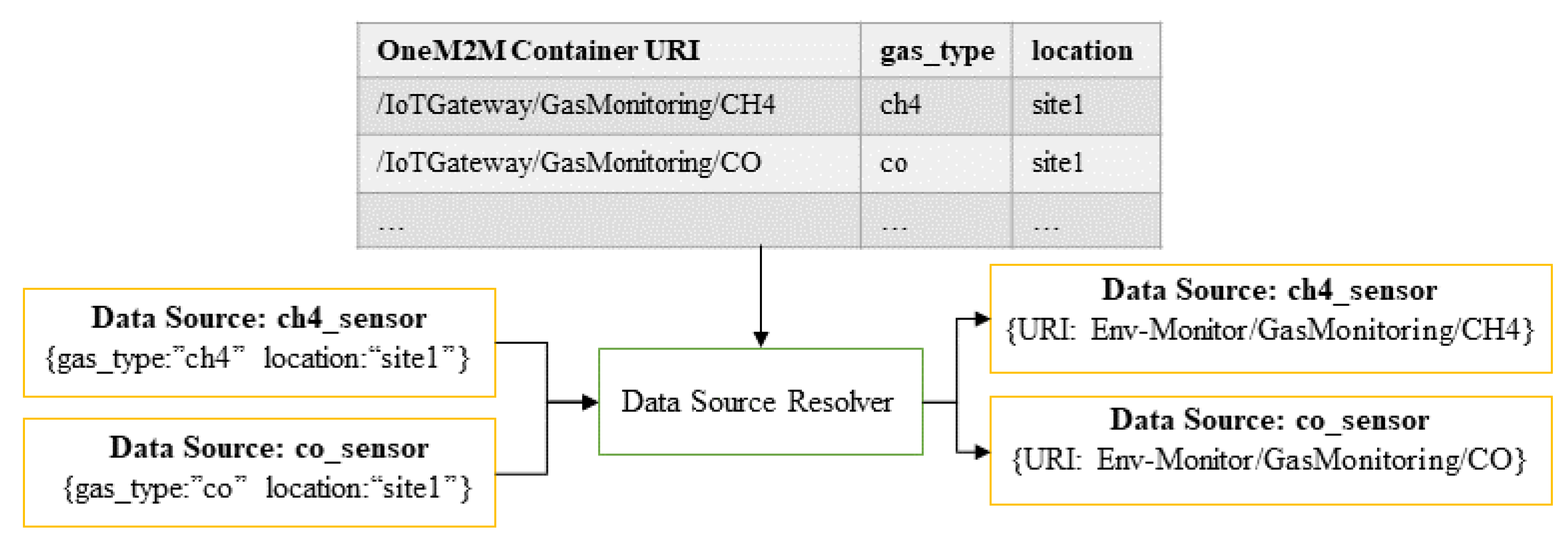
4.2.1. Query Pre-Processor
| Algorithm 1: Building metadata mapping for data source resolver |
| Input: : physical IP address of node, starting from IN Output: M  |
| Algorithm 2: Query Splitting Algorithm |
| Input: q: a query input Output: internal sub-query, external-subquery  |
4.2.2. Stream Query Processor
| Algorithm 3: Data processing inside an operator’s processor |
| Input: : Input stream data // This procedure is called whenever an operator’s processor get a new input data stream  |
| Algorithm 4: Inter-operator data exchange |
| Input: : Input stream identifier // This procedure is called whenever the inter-operator data exchange receives processed data from an operator’s processor  |
| Algorithm 5: Query provisioning |
| Input: : sub-query // This procedure is called whenever a new query need to be provisioned inside a QE  |
| Algorithm 6: Add process mapping to an operator processor |
| Input: : Input stream identifier Input: : Operator parameters Output: : Output stream identifier // This function is called when the query provisioner try to add an entry into one of operator processor’s process mapping table  |
5. Evaluation
5.1. Software Implementation
5.2. Experiments
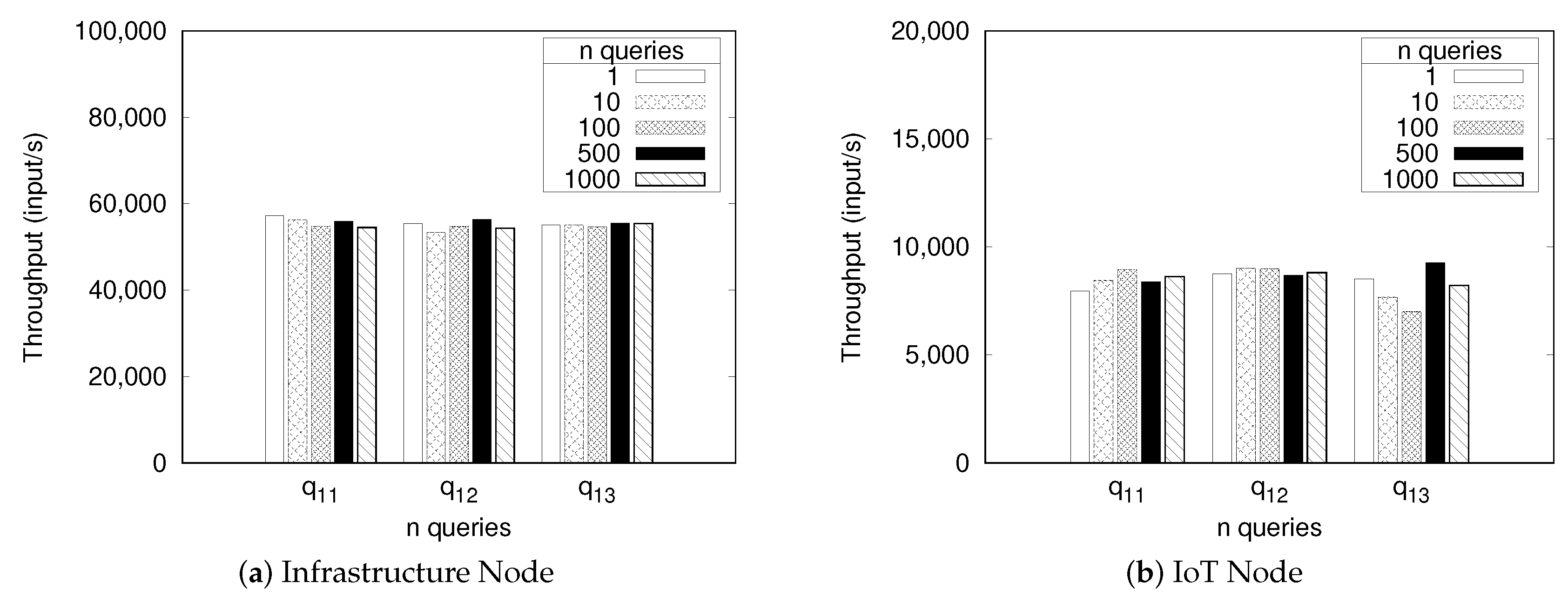
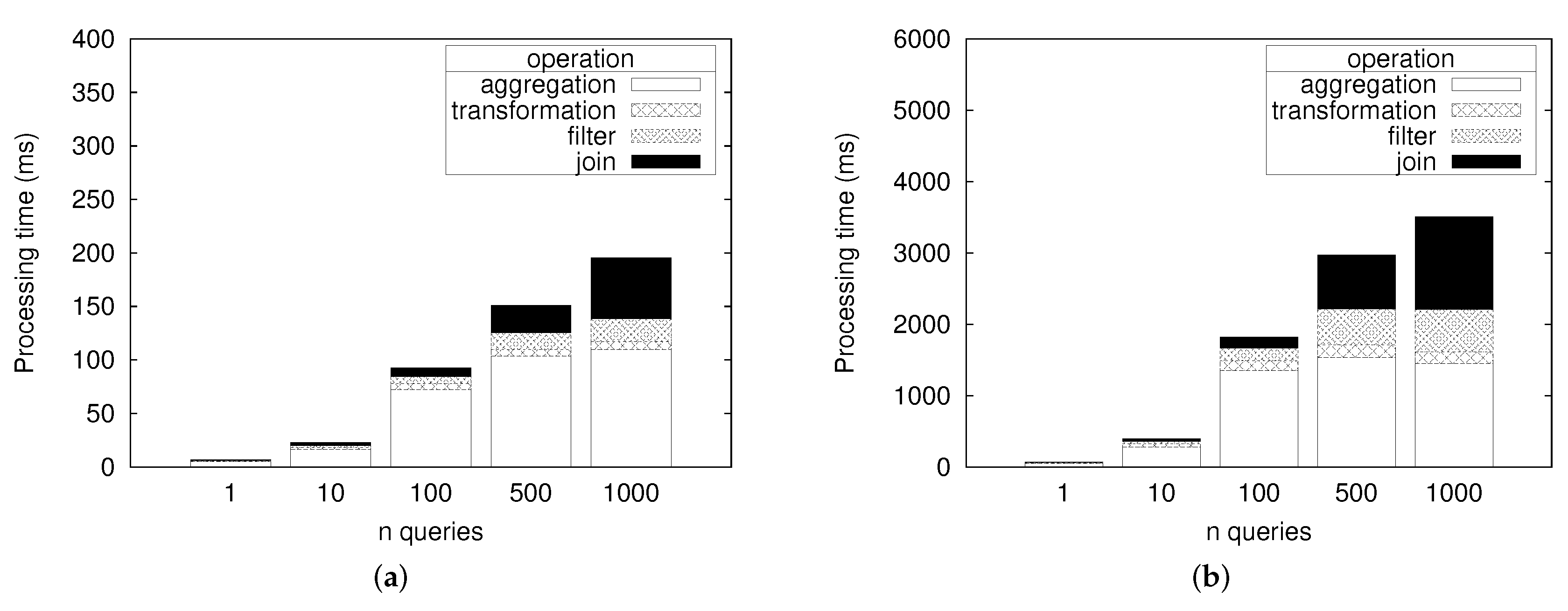
5.2.1. Stream Query Processor Benchmark
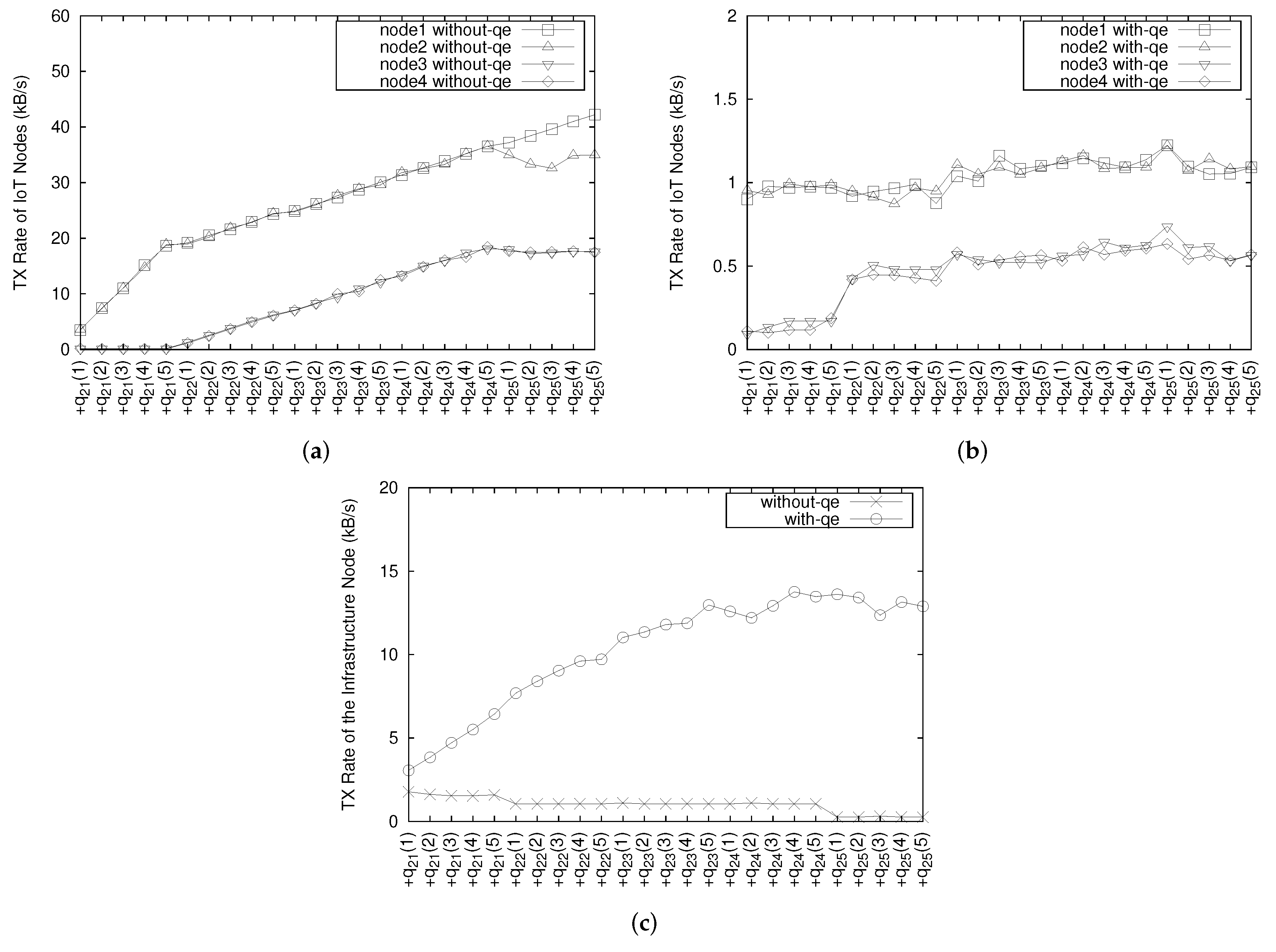
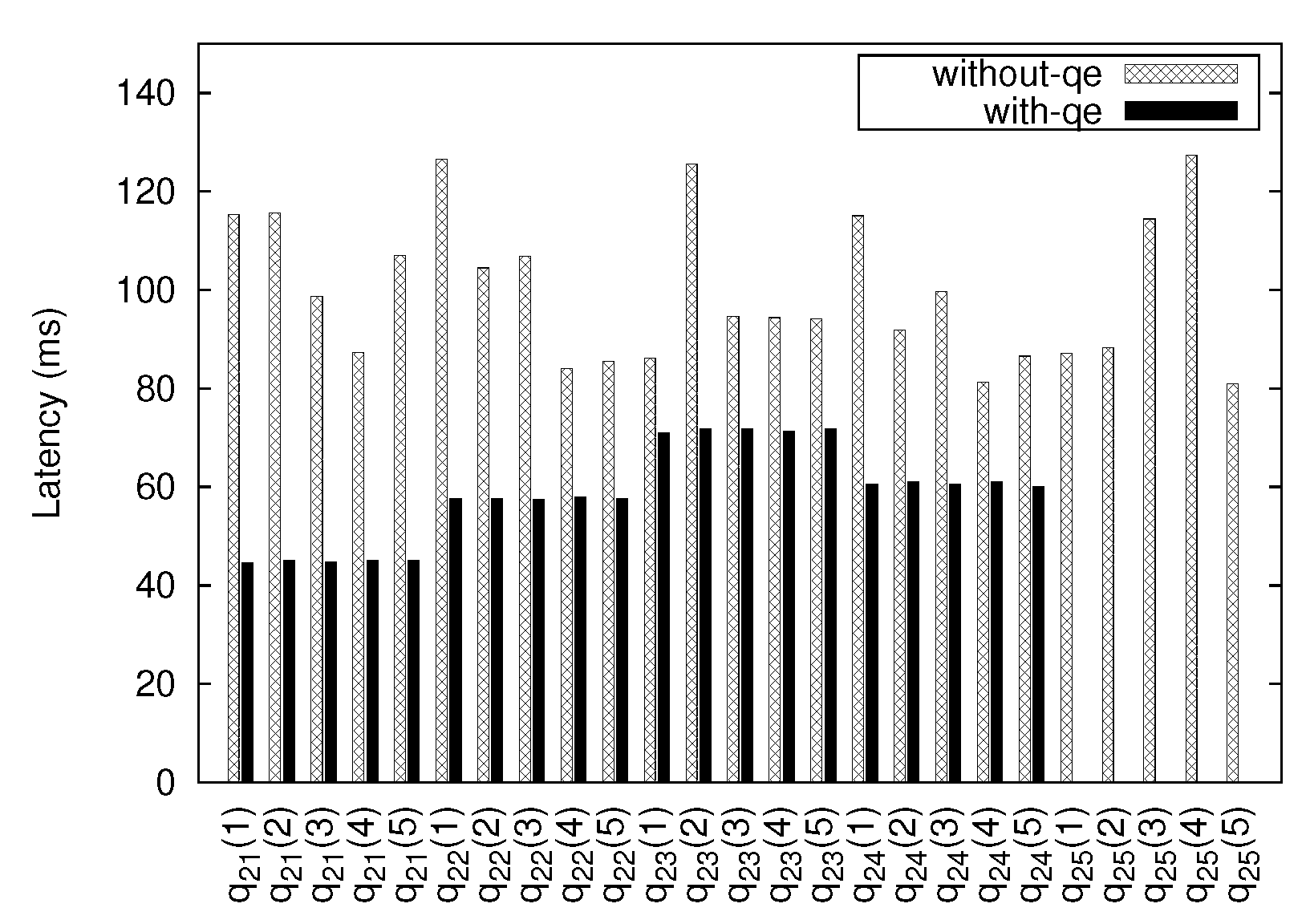
5.2.2. IoT Nodes System Monitoring
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Ray, P.P. A survey on Internet of Things architectures. J. King Saud Univ. Comput. Inform. Sci. 2018, 30, 291–319. [Google Scholar]
- Thakur, A.; Malekian, R.; Bogatinoska, D.C. Internet of Things Based Solutions for Road Safety and Traffic Management in Intelligent Transportation Systems. In International Conference on ICT Innovations; Springer: Cham, Switzerland, 2017; pp. 47–56. [Google Scholar]
- Singh, D.; Das, S.K.; Bagde, S.; MASIH, B.; Sharma, A.; GUPTA, P. Internet of Things Based Smart Hospital System Using Arduino Mega. i-Manag. J. Comput. Sci. 2017, 5, 1. [Google Scholar]
- Jo, B.; Baloch, Z. Internet of things-based arduino intelligent monitoring and cluster analysis of seasonal variation in physicochemical parameters of Jungnangcheon, an urban stream. Water 2017, 9, 220. [Google Scholar] [CrossRef]
- Sowe, S.K.; Kimata, T.; Dong, M.; Zettsu, K. Managing heterogeneous sensor data on a big data platform: IoT services for data-intensive science. In Proceedings of the 2014 IEEE 38th International Computer Software and Applications Conference Workshops (COMPSACW), Vasteras, Sweden, 21–25 July 2014; pp. 295–300. [Google Scholar]
- Abu-Elkheir, M.; Hayajneh, M.; Ali, N.A. Data Management for the Internet of Things: Design Primitives and Solution. Sensors 2013, 13, 15582–15612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Razzaque, M.A.; Milojevic-Jevric, M.; Palade, A.; Clarke, S. Middleware for Internet of Things: A Survey. Internet Things J. 2016, 3, 70–95. [Google Scholar] [CrossRef]
- Ngu, A.H.; Gutierrez, M.; Metsis, V.; Nepal, S.; Sheng, Q.Z. IoT middleware: A survey on issues and enabling technologies. Internet Things J. 2017, 4, 1–20. [Google Scholar] [CrossRef]
- Bröring, A.; Schmid, S.; Schindhelm, C.K.; Khelil, A.; Käbisch, S.; Kramer, D.; Phuoc, D.L.; Anicic, J.M.D.; Teniente, E. Enabling IoT ecosystems through platform interoperability. Software 2017, 34, 54–61. [Google Scholar] [CrossRef]
- Swetina, J.; Lu, G.; Jacobs, P.; Ennesser, F.; Song, J. Toward a standardized common M2M service layer platform: Introduction to oneM2M. Wirel. Commun. 2014, 21, 20–26. [Google Scholar] [CrossRef]
- Alaya, M.B.; Banouar, Y.; Monteil, T.; Chassot, C.; Drira, K. OM2M: Extensible ETSI-compliant M2M service platform with self-configuration capability. Procedia Comput. Sci. 2014, 32, 1079–1086. [Google Scholar] [CrossRef]
- Kim, J.; Choi, S.C.; Ahn, I.Y.; Sung, N.M.; Yun, J. From WSN towards WoT: Open API Scheme Based on oneM2M Platforms. Sensors 2016, 16, 1645. [Google Scholar] [CrossRef] [PubMed]
- Sicari, S.; Rizzardi, A.; Coen-Porisini, A.; Grieco, L.A.; Monteil, T. Secure OM2M service platform. In Proceedings of the 2015 IEEE International Conference on Autonomic Computing (ICAC), Grenoble, France, 7–10 July 2015; pp. 313–318. [Google Scholar]
- Lee, J.U.; Kim, Y.U.; Seo, J.B. HANDYPIA Platform and Service Technology for Semantic IoT Service. Smart Media 2014, 3, 36–42. [Google Scholar]
- Glaab, M.; Fuhrmann, W.; Wietzke, J.; Ghita, B. Toward enhanced data exchange capabilities for the oneM2M service platform. Commun. Mag. 2015, 53, 42–50. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Shanahan, J.G.; Dai, L. Large scale distributed data science using Apache Spark. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (SIGKDD), Sydney, Australia, 10–13 August 2015; pp. 2323–2324. [Google Scholar]
- Toshniwal, A.; Taneja, S.; Shukla, A.; Ramasamy, K.; Patel, J.M.; Kulkarni, S.; Jackson, J.; Gade, K.; Maosong, F.; Donham, J.; et al. Storm@ twitter. In Proceedings of the International conference on Management of data (SIGMOD), Snowbird, UT, USA, 22–27 June 2014; pp. 147–156. [Google Scholar]
- Chowdhery, A.; Levorato, M.; Burago, I.; Baidya, S. Urban IoT Edge Analytics. In Fog Computing in the Internet of Things; Springer: Cham, Switzerland, 2018; pp. 101–120. [Google Scholar]
- Mo, S.; Chen, H.; Zhang, X.; Li, C. TinyQP: A query processing system in wireless sensor networks. In Proceedings of the International Conference on Web-Age Information Management, Beidaihe, China, 14–16 June; Springer: Berlin/Heidelberg, Germany, 2013; pp. 788–791. [Google Scholar] [CrossRef]
- Al-Hoqani, N.; Yang, S.H.; Fiadzeawu, D.P.; Mcquillan, R.J. In-Network On-Demand Query-Based Sensing System for Wireless Sensor Networks. In Proceedings of the Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Diallo, O.; Rodrigues, J.; Sene, M. Real-time data management on wireless sensor networks: A survey. J. Netw. Comput. Appl. 2012, 35, 1013–1021. [Google Scholar] [CrossRef]
- Rahmani, A.M.; Gia, T.N.; Negash, B.; Anzanpour, A.; Azimi, I.; Jiang, M.; Liljeberg, P. Exploiting smart e-health gateways at the edge of healthcare internet-of-things: A fog computing approach. Future Gener. Comput. Syst. 2017, 78, 641–658. [Google Scholar] [CrossRef]
- Aberer, K.; Hauswirth, M.; Salehi, A. Infrastructure for Data Processing in Large-Scale Interconnected Sensor Networks. In Proceedings of the International Conference on Mobile Data Management, Mannheim, Germany, 1 May 2007; IEEE: Washington, DC, USA, 2007; pp. 198–205. [Google Scholar]
- Mueller, R.; Rellermeyer, J.S.; Duller, M.; Alonso, G. A generic platform for sensor network applications. In Proceedings of the International Conference on Mobile Adhoc and Sensor Systems (MAAS), Pisa, Italy, 8–11 October 2007; pp. 1–3. [Google Scholar]
- Cao, H.; Wachowicz, M.; Cha, S. Developing an edge analytics platform for analyzing real-time transit data streams. arXiv 2017, arXiv:1705.08449. [Google Scholar]
- Hu, L.; Sun, R.; Wang, F.; Fei, X.; Zhao, K. A Stream processing system for multisource heterogeneous sensor data. J. Sens. 2016, 2016, 4287834. [Google Scholar] [CrossRef]
- Govindarajan, N.; Simmhan, Y.; Jamadagni, N.; Misra, P. Event processing across edge and the cloud for internet of things applications. In Proceedings of the International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 101–104. [Google Scholar]
- Ghosh, R.; Simmhan, Y. Distributed Scheduling of Event Analytics across Edge and Cloud. arXiv 2016, arXiv:1608.01537. [Google Scholar] [CrossRef]
- Ravindra, P.; Khochare, A.; Reddy, S.P.; Sharma, S.; Varshney, P.; Simmhan, Y. ECHO: An Adaptive Orchestration Platform for Hybrid Dataflows across Cloud and Edge. arXiv 2017, arXiv:1707.00889. [Google Scholar]
- oneM2M Partners Type 1. Functional Architecture (TS-0001-V1.6.1). oneM2M Partners Type 1. 2015. Available online: http://www.onem2m.org/images/files/deliverables/TS-0001-Functional_Architecture-V1_6_1.pdf (accessed on 27 August 2018).
- oneM2M Partners Type 1. Service Layer Core Protocol Specification (TS-0001-V1.6.1). oneM2M Partners Type 1. 2015. Available online: https://www.onem2m.org/images/files/deliverables/UpdateRelease1/TS-0004-Service_Layer_Core_Protocol-V1_6_0.zip (accessed on 27 August 2018).
- Widya, P.W.; Yustiawan, Y.; Kwon, J. OMQ: An oneM2M-Based Query Engine System. Available online: https://github.com/yogagm/OMQ-onem2m-queryengine (accessed on 10 September 2018).
- Puiu, D.; Barnaghi, P.; Toenjes, R.; Kümper, D.; Ali, M.I.; Mileo, A.; Parreira, J.X.; Fischer, M.; Kolozali, S.; Farajidavar, N.; et al. Citypulse: Large scale data analytics framework for smart cities. IEEE Access 2016, 4, 1086–1108. [Google Scholar] [CrossRef]
- Jurgelionis, A.; Laulajainen, J.; Hirvonen, M.; Wang, A.I. An Empirical Study of NetEm Network Emulation Functionalities. In Proceedings of the 20th International Conference on Computer Communications and Networks, ICCCN 2011, Maui, HI, USA, 4 August–31 July 2011; pp. 1–6. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operator | Parameters | Description | Illustration |
|---|---|---|---|
| Aggregate () |
| Aggregate several data samples (within a range of window size) with an aggregate function such as mean, count, min, or max. Output rate determines how often the aggregation samples will be outputted regardless of the input data rate. |  |
| Transform () |
| Transform data from a given input into another form using a transformation function |  |
| Filter () |
| Filter a data input based on the given criteria |  |
| Join () |
| Join several data stream inputs into one combined tuple. By default, the join will be performed to combine all the latest data from several inputs. |  |
| Query | Data Sources | Operators |
|---|---|---|
|
| |
|
| |
|
|
| Query | Goal | Data Sources | Operators |
|---|---|---|---|
| Get status of node 1 and node 2 |
|
| |
| Get total memory usage of all nodes |
|
| |
| Get mean of CPU usage for every node during 2 s |
|
| |
| Get mean CPU usage of all node every 5 s |
|
| |
| Notify if node 3 CPU temperature is beyond 60 degree |
|
|
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Widya, P.W.; Yustiawan, Y.; Kwon, J. A oneM2M-Based Query Engine for Internet of Things (IoT) Data Streams. Sensors 2018, 18, 3253. https://doi.org/10.3390/s18103253
Widya PW, Yustiawan Y, Kwon J. A oneM2M-Based Query Engine for Internet of Things (IoT) Data Streams. Sensors. 2018; 18(10):3253. https://doi.org/10.3390/s18103253
Chicago/Turabian StyleWidya, Putu Wiramaswara, Yoga Yustiawan, and Joonho Kwon. 2018. "A oneM2M-Based Query Engine for Internet of Things (IoT) Data Streams" Sensors 18, no. 10: 3253. https://doi.org/10.3390/s18103253