1. Introduction
Aperture synthesis using interferometric technique has long been used for synthesizing very large apertures for radio telescopes like Very Large Array (VLA), Atacama Large Millimeter/sub-millimeter Array (ALMA) and Allen Telescope Array (ATA). It has successfully been used for remote sensing mission with all-weather capabilities, Soil moisture and Ocean Salinity (SMOS) being the first satellite carrying such payload while Geostationary Synthetic Thinned Aperture Radiometer (GeoSTAR) and Geostationary Atmospheric Sounder (GAS) are also being developed using the similar imaging technique. In recent past, Synthetic Aperture Interferometric Radiometry (SAIR) has been found useful for a few other applications, being one of them is passive millimeter wave imaging for detection of concealed dangerous/prohibited items [
1].
SAIR based passive MMW security screening systems present a very effective option for maintaining security and controlling illegal trafficking as they are sensitive to not only metallic objects but to non-metallic items as well and can provide video rate imaging with large field of view. Passive imaging technique make them safer as the persons or articles being scanned are not subjected to any radiations. These imagers calculate cross-correlation between all the possible pairs of baseband signals after quadrature demodulation, to form a visibility function sample [
2]. Since the signal to noise ratio (SNR) of passive imagers is very low, usually the cross-correlation results need to be integrated over a long period of time [
3]. As given in basic radiometer equation (1), the SNR is proportional to the square root of the product of bandwidth and integration time [
4]. Thus, we can also improve the SNR by increasing bandwidth despite a relatively short time available for a security scanner equipment to observe a moving person/object.
where,
= Signal to Noise Ratio
= Constant greater than or equal to 1
= Antenna Temperature
= System Temperature
= Bandwidth
= Signal Averaging Time
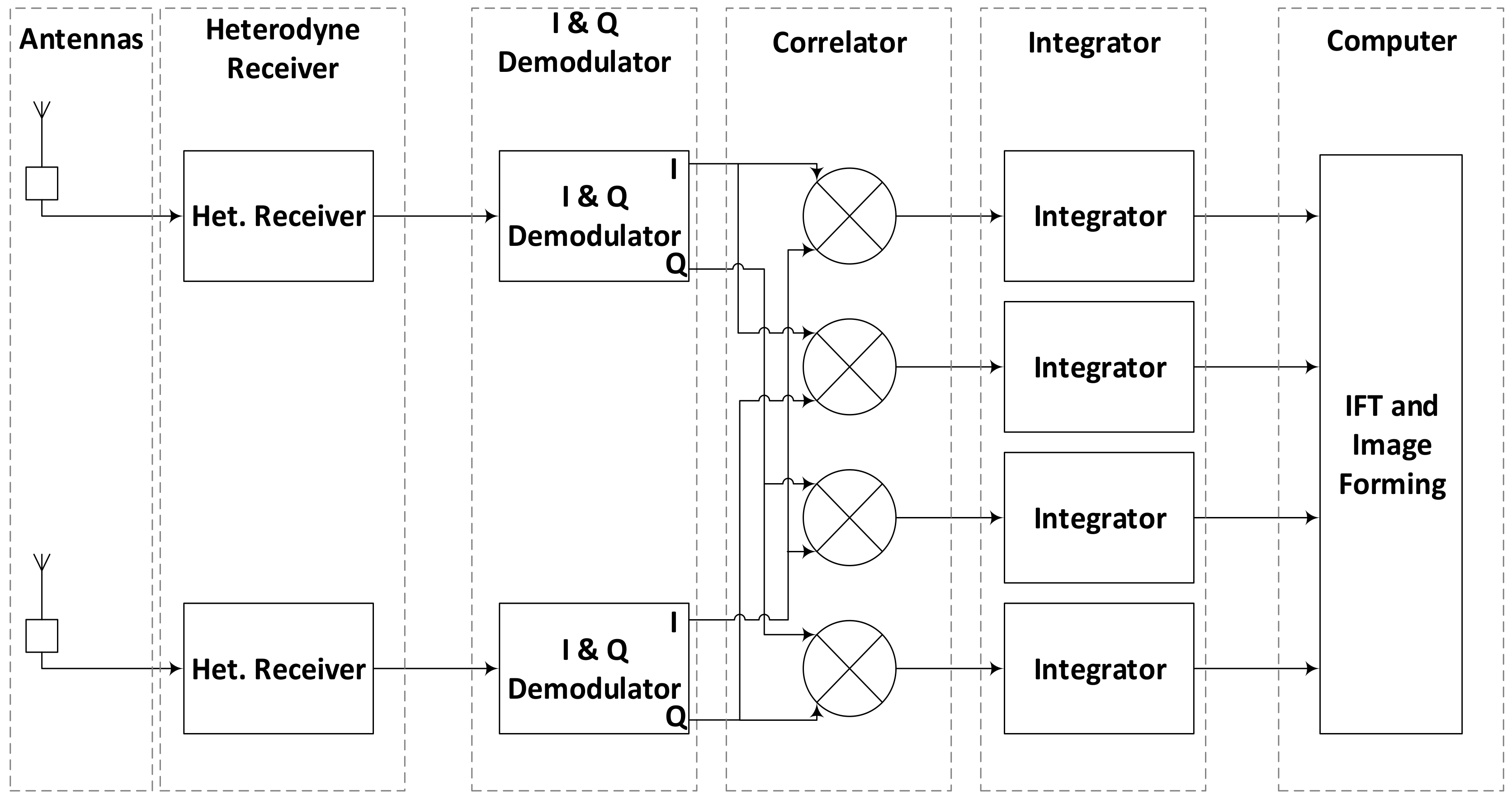
The data sampling rate is, therefore, important for such passive imaging systems to improve SNR and imaging rate. The brightness temperature image is finally formed by applying inverse Fourier transform to the time integrated visibility function samples as per Van-Cittert-Zernike theorem. A complete flow of operations in SAIR imaging system is shown in
Figure 1 while theory of the radiometric imaging is discussed in detail in [
3,
4,
5,
6,
7,
8,
9].
Two versions of Passive Millimeter Wave Imagers for security screening application i.e., BHU-2D [
5] and BHU-2D-U [
3] have already been developed and tested by Beihang University. BHU-2D have 24 receiving elements with 160 MHz bandwidth and BHU-2D-U have 48 receiving elements with 200 MHz bandwidth [
3]. The work being presented in this article is a part of further enhancements in this system targeted to improve sensitivity and increase resolution in video rate imaging. The new imaging system will use an increased number of antennas to achieve these objectives i.e., approximately 1024, with bandwidth greater than 1 GHz in W band, just like suggested in [
10] for their TRL6 prototype. Considering the required amount of processing for a 2-D aperture synthesis imager in the context of current state of the art digital technology, it is challenging to find a feasible solution. We are, therefore, proceeding with two-pronged strategy; 1st is 2-D aperture synthesis with thinned array having high imaging rate similarly as presented in [
11] & 2nd is the combination of aperture synthesis with analog phased-array (aperture synthesis in one dimension and analog phased-array in the other) with full filled array which is expected to have relatively low imaging rate for the similar level of sensitivity and resolution.
2. Digital Signal Processing Requirements
For the digitization of an analog signal, there exist many possibilities ranging from 1 to several bits quantization. It has been reported in [
23] that 2-level digitization is quite noisy and least efficient, whereas much of this loss in efficiency can be recovered by 3-level A/D conversion. Going beyond that i.e., 4-level or more, however, results in minor improvements only. 2B/3L digitization, therefore, is efficient (ɳ
Q = 0.8) and appears to be the best trade-off [
23], at least on paper in ideal case. On the other hand, when taking into consideration the practical issues of higher communication bandwidth, system complexity and hardware utilization, 1B/2L digitization scheme proves to be a better option, especially when the number of input channels is large and bandwidth is high. 1B/2L scheme has the potential to provide an optimum solution in all aspects at the cost of minimal loss of efficiency [
24]. This approach is already proving good in many practical situations, for example systems referred in [
7,
8]. Therefore, we have adopted 1B/2L A/D conversion for our system [
25].
The instruments designed for continuum observation are required to measure an average correlation over the entire bandwidth of the signal [
4,
19], whereas those for spectral lines analysis may require to analyze different frequency components across multiple sub-bands of the entire bandwidth by calculating correlations between several lags of each input. Since an imaging system like proposed in this work falls in the category of continuum observation instruments, we rely only on zero offset signals and implement our correlator in XF configuration for being more intuitive and its simplistic development.
The bottle neck in implementation of a SAIR system lies in the movement of the data from several channels and processing it in parallel in the order of hundreds of MHz or even in GHz. Correlation and integration operations are the most compute intensive parts as compared to the other operations in a SAIR imager shown in
Figure 1. The number of operations is given as
where,
Thus, if we go for a 2-D aperture synthesis system, it will increase the throughput and processing requirements of digital backend system, enormously i.e., in the order of 1015 operations per second, for a 1024 antennas system having bandwidth equal to 1 GHz.
Obviously, performing this amount of processing in real time can result in a very complex and costly system which would not be suitable for security application. Therefore, as mentioned above, we have adopted a two-pronged strategy and it has been decided to find an efficient architecture for correlator to process the outputs from 32 antennas at first step and then build upon this design to achieve the capability of processing 1024 antennas, at the next level of hierarchy. For 2-D aperture synthesis approach, the future course of action is largely dependent upon how many channels of correlator can be accommodated in a single device. While for the second approach, this design is planned to be used “as it is” for the first prototype. For a 32-antenna correlator, if (32I + 32Q) 64 signals are sampled at 2 GHz, our basic correlator module will require around 4 trillion correlation and accumulation operations per second. At the time of this writing, such performance is only reported by a few dedicated correlator ASICs whereas the goal of work being presented here is to achieve this performance in an FPGA chip with enough room left for A/D interface and control logic. It would result in a single chip digital correlation solution for 32 antennas and help build more complex imaging system using multiple FPGA chips by reducing the complexity in next level of hierarchy.
3. Correlation System Design
In this section we describe our design and the design logic from all aspects.
3.1. Implementation Platform
Generally, most of the recent high-performance, real-time digital processing systems are developed using FPGA, GPU or ASIC depending upon the performance requirements and nature of application. GPUs are very powerful data processing devices that can process a lot of data in parallel and are very effective for DSP operations on multiple parallel data streams even in real time. However, they have their own fixed architecture, data flow and programming requirements with limited I/O capabilities. GPUs cannot directly perform real-time data acquisition, requiring another device to interface with A/D chips. They are most often used for implementing complex DSP algorithms with integer or floating-point operands. Using such devices for simply correlating and integrating a few bit operands might not utilize their strength optimally. There are a few examples of using GPUs in large radio telescope systems such as Murchison Widefield Array (MWA) [
14], but even in this system data acquisition and correlation is performed by FPGA devices and GPUs are only used for carrying out some complex processing tasks after correlation. ASIC, on the other hand, provides the most efficient and customizable solution as it can also be observed that two of the most recent relevant projects i.e., GAS [
19] and GeoSTAR [
22] chose to go for ASIC as the best possible solution. However, considering its high Non-Recurring Engineering (NRE) cost limits this option for our project at this stage when we are still trying different techniques for obtaining the best results. In this situation, FPGAs are the optimum solution providing a lot of customization opportunities within an affordable budget. Hence we chose Xilinx Kintex UltraScale device (XCKU115) for our system being moderate to high cost device offering plenty of resources that can accommodate quite a handsome amount of functionality.
3.2. Design Partition
In order to achieve high throughput and enable efficient routing, we have partitioned our design into high-speed and low-speed parts; low-speed clock being 6 times slower than the high-speed clock. Both, the high-speed and the low-speed clocks are derived from the same clock so as to avoid the problems emerging from asynchronous clock domain crossing. The integration is divided into two stages just like [
7,
19]. The high-speed circuit is localized only within correlator and first stage integration module. The difference from [
7,
19] is that they implemented the first stage as a pre-scaler which is not a part of readout values, while we have implemented it as two stage accumulation. The idea of design partition in low-speed and high speed clock domains arisen from our baseline implementation [
26] where all the correlation and accumulation operations are carried out on the same, high-speed clock. It was observed that all the critical paths existed between the first stage integrator and the second stage, where signals from 256 first stage integrators were being accumulated by a pair of an adder and a DPRAM. This is quite obvious with our system’s architecture that divides the three operational steps into two stages or sub-cycles where each channel has dedicated hardware resources for first stage while the hardware for second stage is shared between 256 channels. As a result, the hardware for first stage can be implemented in a confined place with shorter data paths while the hardware for second stage has 256 multi-bit data paths that must be implemented relatively at distant places in a device. Two options were considered to address this problem; first was to introduce a pipeline stage between both the stages and the second was partitioning the design into high-speed and low-speed clock domains. Both the options involved adding some hardware but adding pipeline stage for multi-bit data lines is more expensive than adding just a few flip-flops for control signals. Thus, the second option was preferred, in addition, it also had the potential to decrease the power consumption. Gains and costs of this technique can be seen in results section.
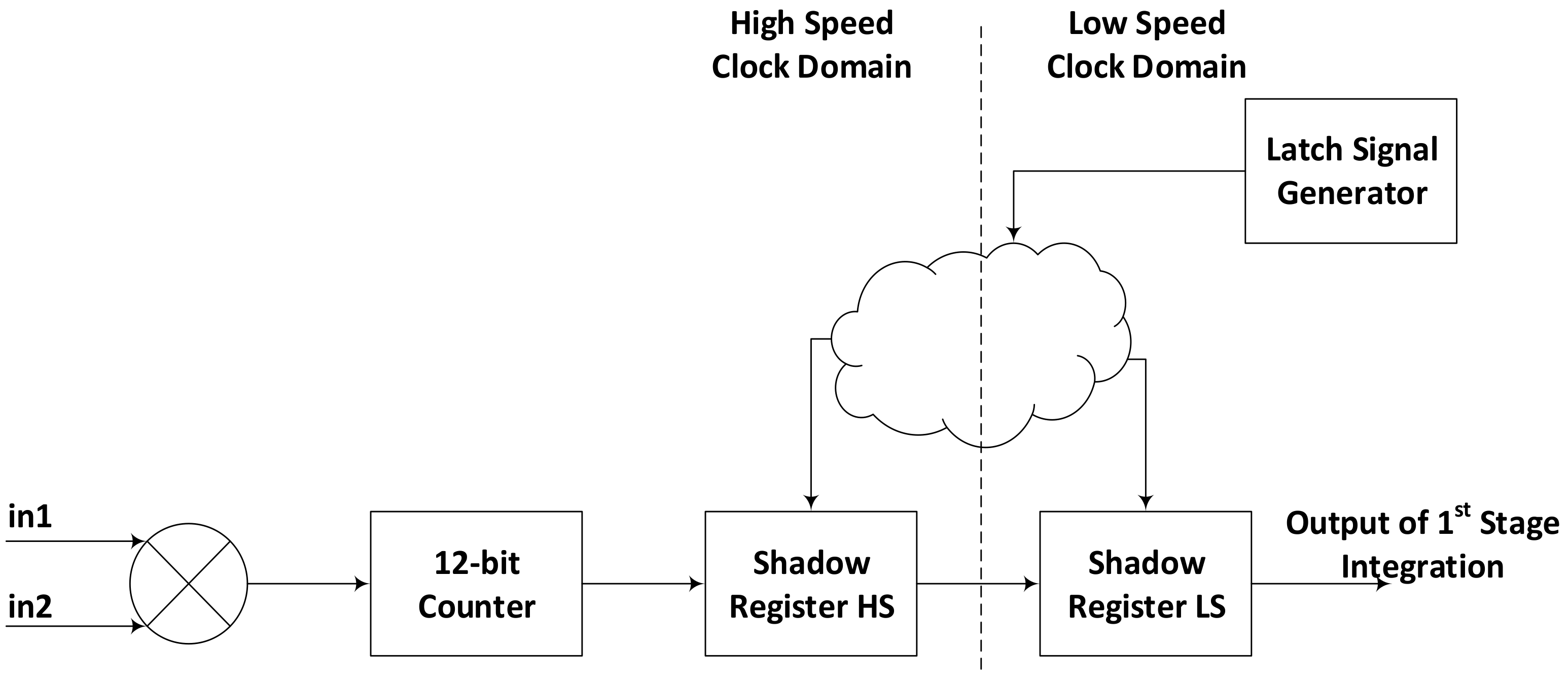
The control signals entering the correlator and first stage integrator, for latching the results of first stage integration are referenced with slower clock whereas the inputs are obviously referenced with high-speed clock. Control signals are then shifted to high-speed clock domain where all the correlation and first stage integration is performed. As the control signal for data latching is asserted, the results of first stage integration are latched in high-speed clock domain. The latched values are then shifted to slower clock domain for further processing in the second stage. In this way all the signals and values that might have to travel long paths between the modules implemented at some distances get more time for register-to-register movement while signals confined within a small area i.e., within correlator and first stage integrator are referenced with high speed clock. This partition in indicated in
Figure 2.
3.3. First Stage Integration
Complete correlation and integration is divided into three steps. In first step, the correlation between two 1-bit inputs is calculated with XNOR operation. In the second step, each correlation result controls the operation of an up-counter, used as first stage integrator. The counter value is stored in a dual latch each time the latch signal is asserted. The dual latch consists of two consecutive shadow registers; first one is clocked with high-speed clock while second register is driven by slower clock.
Figure 2 shows the complete picture of hardware for correlation and first stage integration. Since, for 64 channel correlator, there are 2016 possible input combinations and hence the number of correlation and first stage integration units, we opted to design this part in FPGA fabric using logic resources instead of dedicated DSP48 slices. Although in XCKU115 device, we can afford to use DSP slices but that would have made our design too much device dependent as this many DSP slices are available only in the top devices of any FPGA family. Secondly, these DSP slices are distributed over the device, using them would have caused unnecessarily long routes as well. Thirdly, if we would have to expand this design for more than 64 channels, the number of possible input combinations would go beyond the available DSP slices in any FPGA device. After first stage integration, second stage integration is started.
3.4. Second Stage Integration
While first stage integration is implemented using dedicated hardware for each pair of correlation, the second stage uses a multiplexed approach by integrating results from 256 first stage integrators in one second stage integrator, thus requiring 8 such modules for 2016 pairs. There is a 10-bit counter operating at slower clock, which marks the start of second stage integration cycle with each overflow. It is shown in
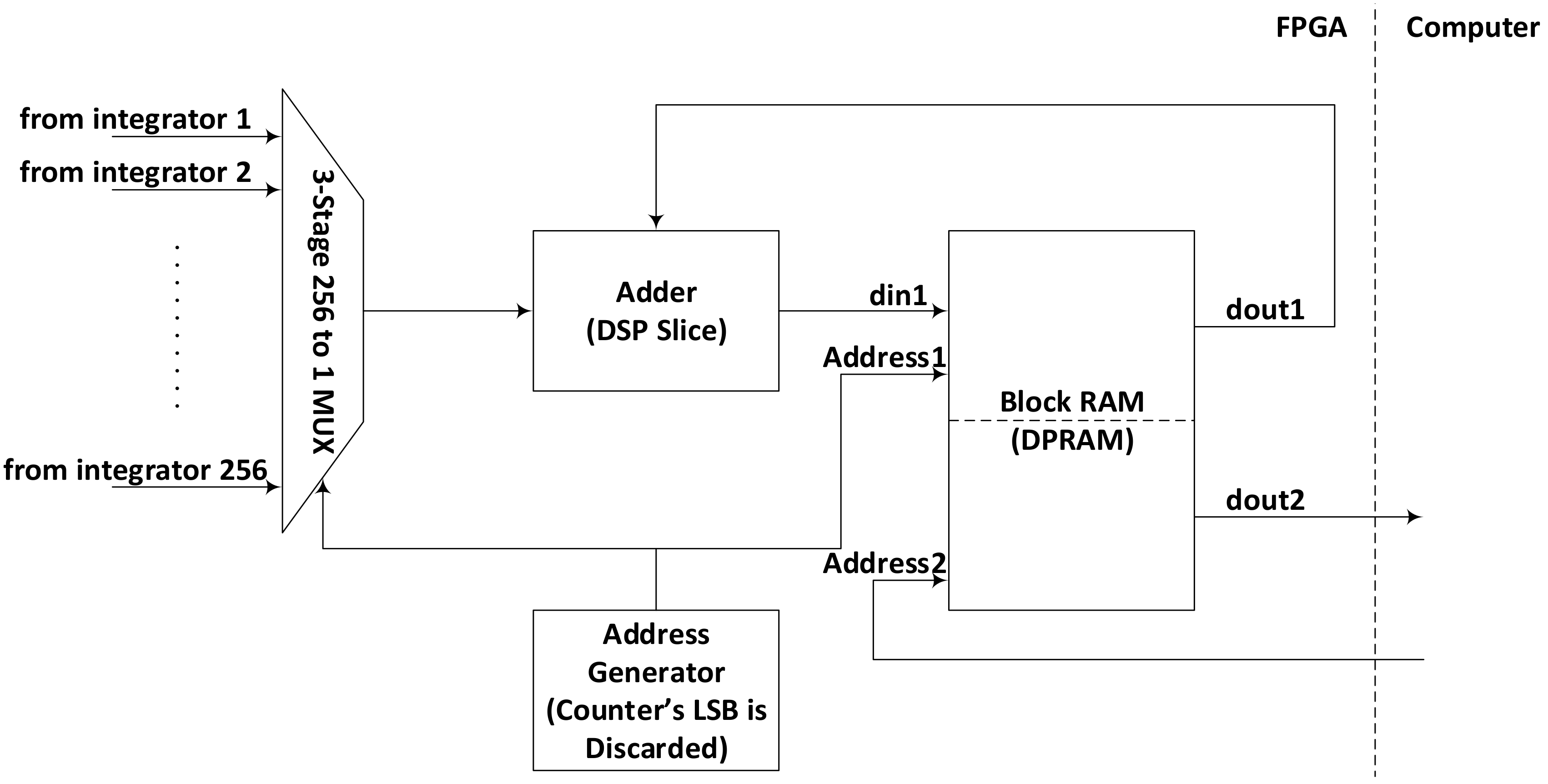
Figure 2 as latch signal generator. As soon as the start of second stage integration is indicated by latch signal generator, the output of first stage integration is latched into a register and moved subsequently to another register referenced with the slower clock. The second stage integration is performed by the combination of a DPRAM and a DSP slice, configuration of which is explained in
Figure 3. Out of possible configurations of internal RAM available in FPGA, 512 × 36 is found to be the most suitable for this system, although there are other configurations offering different combinations of width and depth. Reducing width cannot provide us the required integration and increasing width simply exceeds the integration requirements. Similarly increasing the length of the DPRAM can increase the number of sequentially performed integration operations, causing more cycles to finish the second integration cycle while reducing the length can results in inefficient use of RAM blocks that can cause increased power consumption.
This 512 × 36 DPRAM is used in ping-pong configuration, with only 256 locations being used at a time while sparing the other 256 for computer read operation. Whenever, the master computer asserts that a read operation is going to begin, the second stage integration switches to the other half of the DPRAM for further operation. This way, the system keeps integrating and computer keeps reading the values, at the same time and without interfering each other. It helps maintaining coherence of the data read by the computer by presenting a picture where all the results belong to the same instance of time.
Another counter clocked by the slower clock is used as address generator for the second stage integrator. The second stage integration involves reading a particular location in DPRAM, adding a corresponding first stage integration value with it using a DSP slice and finally writing it back to the same location. The DPRAM requires one clock cycles to present the data at its output after read is enabled with a valid address at its input and at least one clock cycle time is required for add operation in DSP slice. The whole accumulation/integration process requires two clock cycles for its safe operation. We, therefore, dedicate two clock cycles for each integration operation by discarding the lowest significant bit of the address generator and using only upper 8 bits for addressing. This way it takes 512 clock cycles to complete second stage integration cycle.
3.5. Readout
As the master computer asserts signal for start of read cycle, that particular half of the DPRAM being used at that instance of time for second stage integration is spared for computer readout and the alternate half is dedicated for the next cycle of second stage integration. However, if an integration process is already in progress, then this switching is delayed to let the cycle complete. Since the read operation is supported by maximum at slower clock speed and we use the RAM in dual port configuration, computer can safely read while second stage integration process is writing at some other location in the same half.
3.6. Parallel Operation
We assume that the correlator receives the input data digitized at a maximum speed of 2 GHz, but the FPGA technology, due to its flexibility and configurable nature cannot support such high-speed operations. This fact limits the bandwidth achievable on FPGA devices [
21]. Since we are using the largest available device in Kintex UltraScale family offering abundant on-chip resources, we introduced some parallel processing in our design.
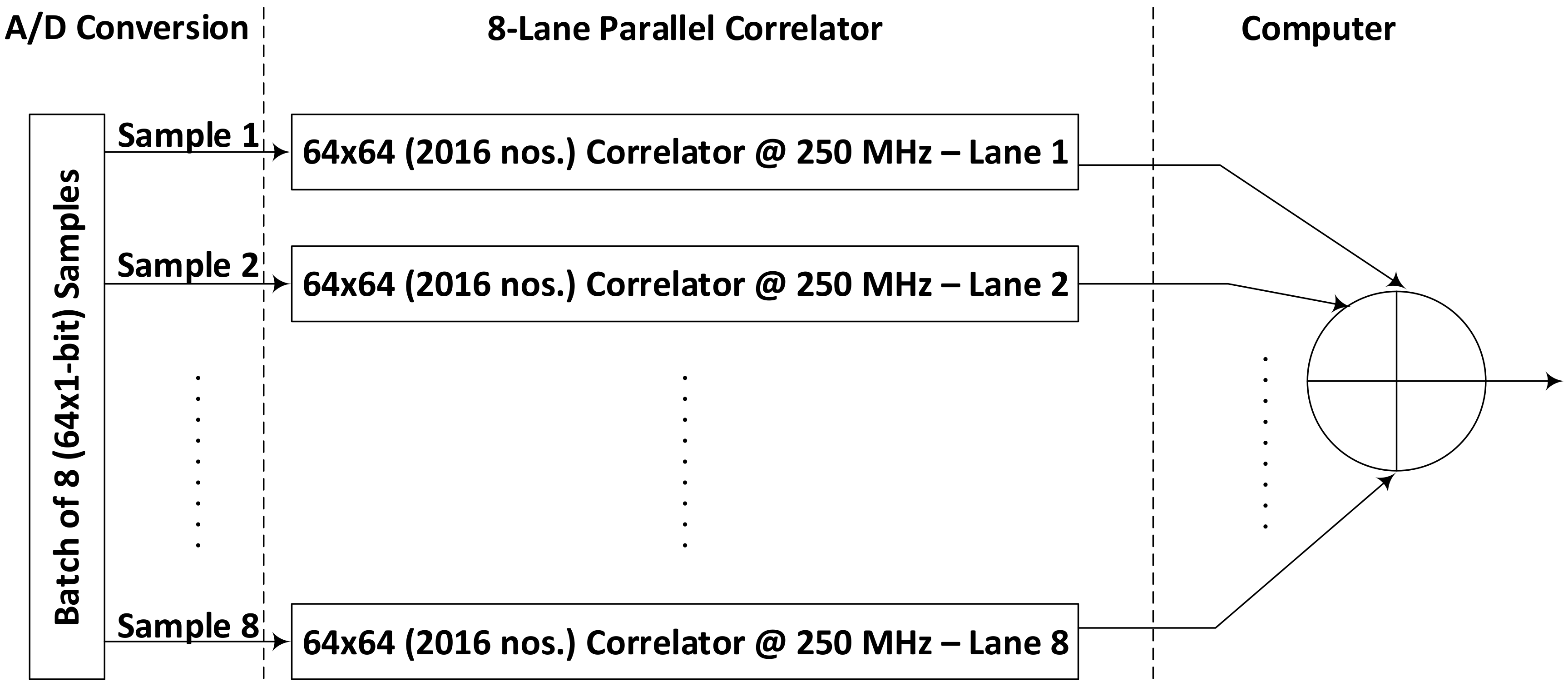
Figure 4 shows how eight parallel processing correlators are used to enable the processing of 8 samples at a time as suggested by [
27] (Here, 64 1-bit samples from I & Q channels of 32 antennas sampled at an instance of time is referred to as one sample).
It is kind of a batch processing idea. The input data streams from all the channels are accumulated for 8 cycles and then this batch of data is forwarded to 8 correlator channels. In this way, each correlator correlates and integrates the incoming data samples with a gap of 7 samples. Correlator 1, for example, correlates the data samples 1, 9, 17 and so on while correlator 2 process the data samples 2, 10, 18 and so on. The master computer reads the results from these 8 parallel operating correlators and can add their results for each channel to make a full integration result. Using these parallel datapaths, we managed to process the data sampled at 2 GHz by running this 8-lane parallel processing correlator unit at 250 MHz.
4. Design Verification and Results
The design is verified for its functional correctness in simulation using Vivado Simulator. A set of pseudo-random data consisting 65 K samples for each of 64 channels, was generated in MATLAB. It served as the digitized input stream for correlator. A code in MATLAB was developed to calculate the correlation of this data set and integrate it for the whole length, just like it is expected of our FPGA correlator. Then the same data set was fed to the design under test and results after second stage integration were saved in a file. Again using MATLAB, the results from MATLAB and RTL functional simulation were compared to evaluate the correctness of our design.
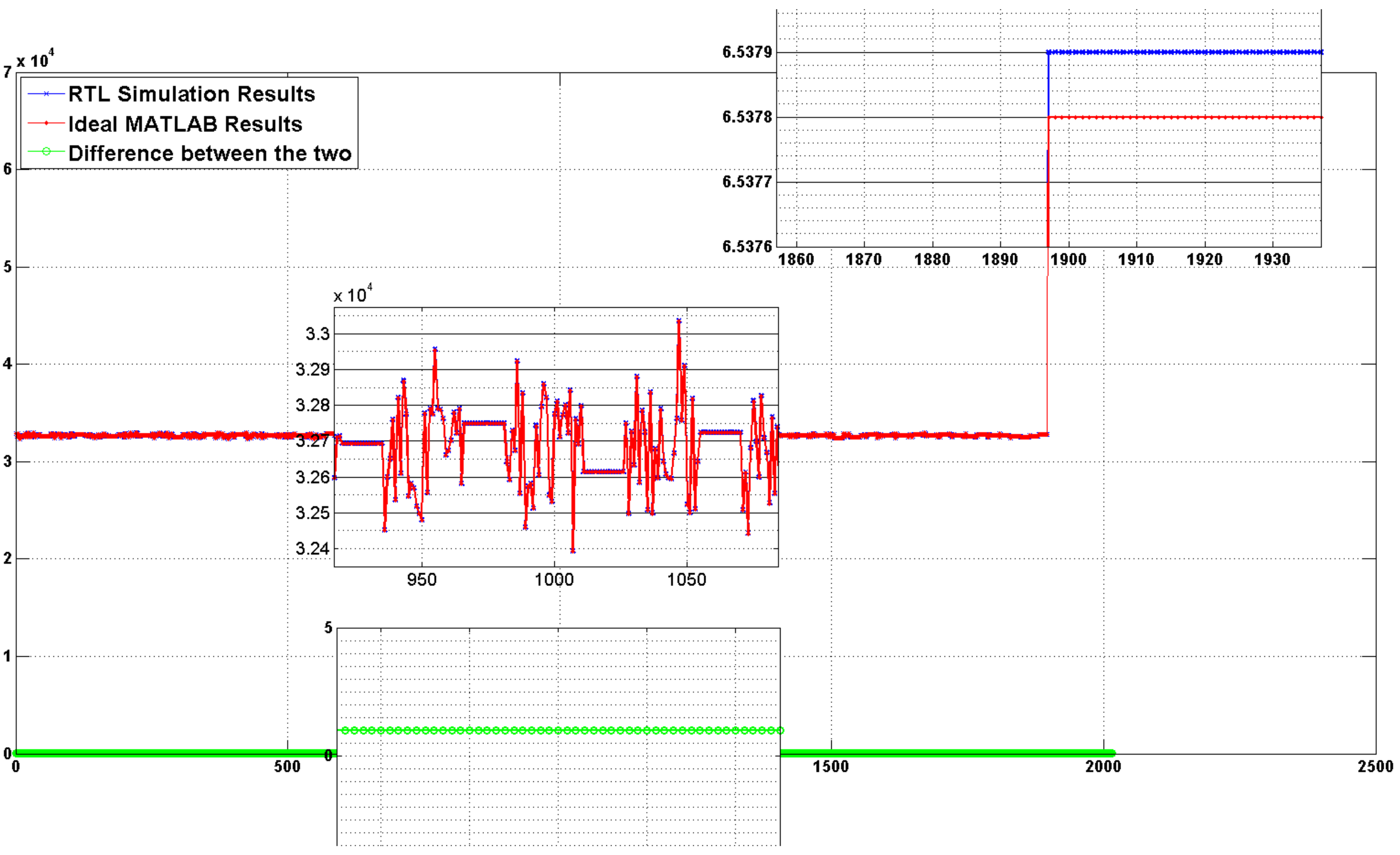
Results from Vivado RTL simulation exactly followed the results from MATLAB verifying the functionality of our design. The plot of difference between both the results is a straight line showing a constant bias of 1 in RTL design, as shown in
Figure 5. Even this difference of one is because of first pipeline stage, as it takes one clock cycle after power-on reset for data to reach the input of correlator. At power-on reset all the registers, including first pipeline stage registers that latch the inputs, are at the same level so for correlator the first sample is all one or all zeroes adding one false correlation to overall result. Other than this difference, both the plots exactly follow each other throughout, as obvious from zoomed in parts of
Figure 5.
The design was synthesized and implemented in Vivado platform with some timing constraints. The high-speed clock was constrained to run at 3.8 ns (~263 MHz) and the slow-speed clock to be exactly 6 time slower i.e., 22.8 ns (~43 MHz). Implementation results show that these constraints were successfully met for all paths in the design. It can safely be assumed that this correlator can perform well at 250 MHz resulting in a collective capacity of 2 GHz from all 8 lanes. This is where our proposed design partition technique for correlator implementation proved fruitful, as our first design without this partition could only run at 200 MHz giving a total of 1.6 GHz throughput as described in [
26]. Device view shows that the correlation and first stage integration modules, running at higher frequency, were implemented using resources with minimum physical separation while the modules containing second stage of integration were implemented using device resources scattered over comparatively large area owing to the fixed location of BRAM and DSP slices. However, the second stage integration could easily meet timing requirements as it was clocked by the slower signal.
Device utilization is reflected in the
Table 1. It is quite obvious that approximately 50% of the device is utilized. It would enable the digitization circuit interface and master processor interface to be implemented on the same device. In this way, all the digital correlation system for 64-channel, except A/D front-end circuit would be implemented on a single chip reducing inter-chip communication overhead and component count in the system. Device utilization is where we have paid the price of achieving higher throughput by consuming considerably more hardware resources on-chip. It can be observed in
Table 1 that while only 2% more device look-up tables are utilized, the utilization of registers is almost 50% more than our baseline implementation, approaching to 51% of total available registers in the device. However, that still leaves quite a lot of resources for interface and control circuitry to be implemented on the same device.
Power consumption estimate in
Table 2, as provided by the Vivado, reflects a total of 7.457 W for the operation of this design at 263 MHz. This is equivalent to 1.76 mW/correlator/GHz, 9–14 times higher than the ASIC but 4–8 times less than the FPGA implementation as reported by [
19]. This is partly because of newer device used for our implementation and partly because of keeping high speed processing localized and performing all other possible operations at lower speed. Although FPGA is not a very suitable platform for measuring power efficiency because of its configurable nature and circuit implementation methodology, our results shows some power saving as compared to baseline implementation as per expectations. Our design partitioning has paid off on this front as well by consuming lower power due to localization of high frequency circuit and letting a considerable part of the circuit to run at lower frequency.
5. Conclusions
Design of a digital correlator for Passive Millimeter Wave Imager is presented in detail with a focus on improving throughput using frequency based design partitioning. This correlator is designed for a system using SAIR technique, therefore, the presented design can also find its application in other remote sensing applications based on this imaging method. Total throughput achievable by this design on Xilinx Kintex UltraScale XCKU115 device approaches to 4 Trillion 1B/2L correlation and accumulation operations per second as a result of running 8 lanes of 64-channel correlators in parallel at 250 MHz. The results obtained in simulation exactly follow the expected results as calculated in MATLAB, verifying the functional correctness. Synthesis and implementation results from Vivado platform proves the throughput claims and feasibility of implementation on the mentioned device. Comparison of results with our baseline implementation shows (
Table 1 and
Table 2) the gains and cost (in terms of hardware utilization) of using frequency based design partitioning at logic level for a digital cross correlator.
Overall, this correlator design fits well in imaging system, meeting all functional and practical requirements. However, we currently focus on reducing device utilization that has increased substantially as a result of applying design partitioning technique. Reducing hardware requirements can allow using smaller devices for imaging system based on the combination of aperture synthesis and analog phased array techniques and save a handsome amount of financial resources effectively reducing the system cost. On the other hand, reduction in device utilization can increase the maximum number of correlation channels in a single device which is the key factor deciding the maximum achievable scale for our 2D aperture synthesis system.
Acknowledgments
This work is supported by the Chinese Ministry of Science and Technology Contract No. 2016YFC0800401.
Author Contributions
Muhammad Asif completed the baseline design, conceived this idea to improve the throughput, modified the design, suggested the testing methodology and wrote the paper; Xiangzhou Guo suggested relevant study material, defined the system level parameters including input/output specifications and required performance parameters; Jing Zhang performed the testing to validate the design; Jungang Miao provided guidance and financial support throughout the research work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shi, X.; Yang, M.H. Development of passive millimeter wave imaging for concealed weapon detection indoors. Microw. Opt. Technol. Lett. 2014, 56, 1701–1706. [Google Scholar] [CrossRef]
- Yao, X.; Zheng, C.; Yang, B.; Zhang, J.; Miao, J. Implementation of the Digital Correlation Unit for Synthetic Aperture Interferometric Radiometer. In Proceedings of the Green Computing and Communications (GreenCom), 2013 IEEE and Internet of Things (iThings/CPSCom), IEEE International Conference on and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013; pp. 1608–1611. [Google Scholar]
- Zheng, C.; Yao, X.; Hu, A.; Miao, J. Initial Results of a Passive Millimeter-Wave Imager Used for Concealed Weapon Detection Bhu-2d-U. Prog. Electromagn. Res. C 2013, 43, 151–163. [Google Scholar] [CrossRef]
- Thompson, A.R.; Moran, J.M.; Swenson, G.W. Interferometry and Synthesis in Radio Astronomy, 3rd ed.; Astronomy and Astrophysics Library; Springer International Publishing: Cham, Switzerland, 2017; ISBN 978-3-319-44429-1. [Google Scholar]
- Zheng, C.; Yao, X.; Hu, A.; Miao, J. A Passive Millimeter-Wave Imager Used for Concealed Weapon Detection. Prog. Electromagn. Res. B 2013, 46, 379–397. [Google Scholar] [CrossRef]
- Salmon, N.A.; Wilkinson, P.; Taylor, C. Interferometric aperture synthesis for next generation passive millimetre wave imagers. Proc. SPIE 2012, 8544, 854405. [Google Scholar]
- Rautiainen, K.; Kainulainen, J.; Auer, T.; Pihlflyckt, J.; Kettunen, J.; Hallikainen, M.T. Helsinki University of Technology L-Band Airborne Synthetic Aperture Radiometer. IEEE Trans. Geosci. Remote Sens. 2008, 46, 717–726. [Google Scholar] [CrossRef]
- Lambrigtsen, B.H.; Wilson, W.J.; Tanner, A.B.; Kangaslahti, P. GeoSTAR: A synthetic aperture microwave sounder for geostationary missions. Proc. SPIE 2005, 5659, 185. [Google Scholar]
- Camps Carmona, A.J. Aplication of Interferometric Radiometry to Earth Observation; Universitat Politècnica de Catalunya: Barcelona, Spain, 1996. [Google Scholar]
- Salmon, N.A.; Wilkinson, P.N.; Taylor, C.T.; Benyezzar, M. Minimising the costs of next generation aperture synthesis passive millimetre wave imagers. Proc. SPIE 2011, 8188, 818808. [Google Scholar]
- Salmon, N.A.; Beale, J.; Parkinson, J.; Hayward, S.; Hall, P.; Macpherson, R.; Lewis, R.; Harvey, A. Passive millimetre wave digital beam-forming security imaging. Proc. SPIE 2007, 6739, 67390S. [Google Scholar]
- Weinreb, S. A Digital Spectral Analysis Technique and its Application to Radio Astronomy; Massachusetts Institute of Technology: Cambridge, MA, USA, 1963. [Google Scholar]
- Rauch, K.P.; Hawkins, D.; Lane, L.; Pine, B. CARMA Correlator: Reconfiguration and Signal Processing. In Astronomical Data Analysis Software and Systems XV ASP Conference Series; Gabriel, C., Arviset, C., Ponz, D., Solano, E., Eds.; ASP: San Francisco, CA, USA, 2006; Volume 351, pp. 157–160. [Google Scholar]
- Edgar, R.G.; Clark, M.A.; Dale, K.; Mitchell, D.A.; Ord, S.M.; Wayth, R.B.; Pfister, H.; Greenhill, L.J. Enabling a high throughput real time data pipeline for a large radio telescope array with GPUs. Comput. Phys. Commun. 2010, 181, 1707–1714. [Google Scholar] [CrossRef] [Green Version]
- Escoffier, R.P.; Comoretto, G.; Webber, J.C.; Baudry, A.; Broadwell, C.M.; Greenberg, J.H.; Treacy, R.R.; Cais, P.; Quertier, B.; Camino, P.; et al. The ALMA correlator. Astron. Astrophys. 2007, 462, 801–810. [Google Scholar] [CrossRef]
- Okumura, S.K.; Momose, M.; Kawaguchi, N.; Kanzawa, T.; Tsutsumi, T.; Tanaka, A.; Ichikawa, T.; Suzuki, T.; Ozeki, K.; Natori, K.; et al. 1-GHz Bandwidth Digital Spectro-Correlator System for the Nobeyama Millimeter Array. Publ. Astron. Soc. Jpn. 2000, 52, 393–400. [Google Scholar] [CrossRef]
- Perley, R.A.; Napier, P.J.; Jackson, J.; Butler, B.J.; Carlson, B.; Fort, D.; Dewdney, P.E.; Clark, B.; Hayward, R.; Durand, S.; et al. The Expanded Very Large Array. Proc. IEEE 2009, 97, 1448–1462. [Google Scholar] [CrossRef]
- Ryman, E.; Emrich, A.; Andersson, S.; Riesbeck, J.; Svensson, L.; Larsson-Edefors, P. 3.6-GHz 0.2-mW/ch/GHz 65-nm cross-correlator for synthetic aperture radiometry. In Proceedings of the 2011 IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 19–21 September 2011; pp. 1–4. [Google Scholar]
- Ryman, E.; Emrich, A.; Andersson, S.B.; Svensson, L.; Larsson-Edefors, P. 1.6 GHz Low-Power Cross-Correlator System Enabling Geostationary Earth Orbit Aperture Synthesis. IEEE J. Solid-State Circuits 2014, 49, 2720–2729. [Google Scholar] [CrossRef]
- Tanner, A.B.; Brown, S.T.; Dinardo, S.J.; Gaier, T.M.; Kangaslahti, P.P.; Lambrigtsen, B.H.; Wilson, W.J.; Piepmeier, J.R.; Ruf, C.S.; Gross, S.M.; et al. Initial results of the GeoSTAR Prototype (Geosynchronous Synthetic Thinned Array Radiometer). In Proceedings of the 2006 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2006; pp. 1–10. [Google Scholar]
- Gaier, T.; Lambrigtsen, B.; Kangaslahti, P.; Lim, B.; Tanner, A.; Harding, D.; Owen, H.; Soria, M.; O’Dwyer, I.; Ruf, C.; et al. GeoSTAR-II: A prototype water vapor imager/sounder for the PATH mission. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 3626–3628. [Google Scholar]
- Gaier, T.; Kangaslahti, P.; Lambrigtsen, B.; Ramos-Perez, I.; Tanner, A.; McKague, D.; Ruf, C.; Flynn, M.; Zhang, Z.; Backhus, R.; et al. A 180 GHz prototype for a geostationary microwave imager/sounder-GeoSTAR-III. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2021–2023. [Google Scholar]
- Ruf, C.S. Digital correlators for synthetic aperture interferometric radiometry. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1222–1229. [Google Scholar] [CrossRef]
- Batz, O.; Kraft, U.; Lindemer, W.; Reichel, H. Design and implementation of the MIRAS digital correlator. In Proceedings of the 1996 International Geoscience and Remote Sensing Symposium, Lincoln, NE, USA, 27–31 May 1996; Volume 2, pp. 872–874. [Google Scholar]
- Zheng, C.; Yao, X.; Hu, A.; Miao, J. Closed form calibration of 1bit/2level correlator used for synthetic aperture interferometric radiometer. Prog. Electromagn. Res. M 2013, 29, 193–205. [Google Scholar] [CrossRef]
- Asif, M.; Guo, X.; Zhang, J.; Miao, J. An FPGA based 1.6 GHz cross-correlator for synthetic aperture interferometric radiometer. In Proceedings of the 2017 Progress in Electromagnetics Research Symposium-Fall (PIERS-FALL), Singapore, 19–22 November 2017; pp. 1078–1085. [Google Scholar]
- Meller, M. Some aspects of designing real-time digital correlators for noise radars. In Proceedings of the 2010 IEEE Radar Conference, Washington, DC, USA, 10–14 May 2010; pp. 821–825. [Google Scholar]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}