4. Experiments, Results, and Discussion
We now determine the most suitable value of
p based on the graph of MSE plotted against each lag
p and by the analysis of percentage decrease in MSE as
p increases.
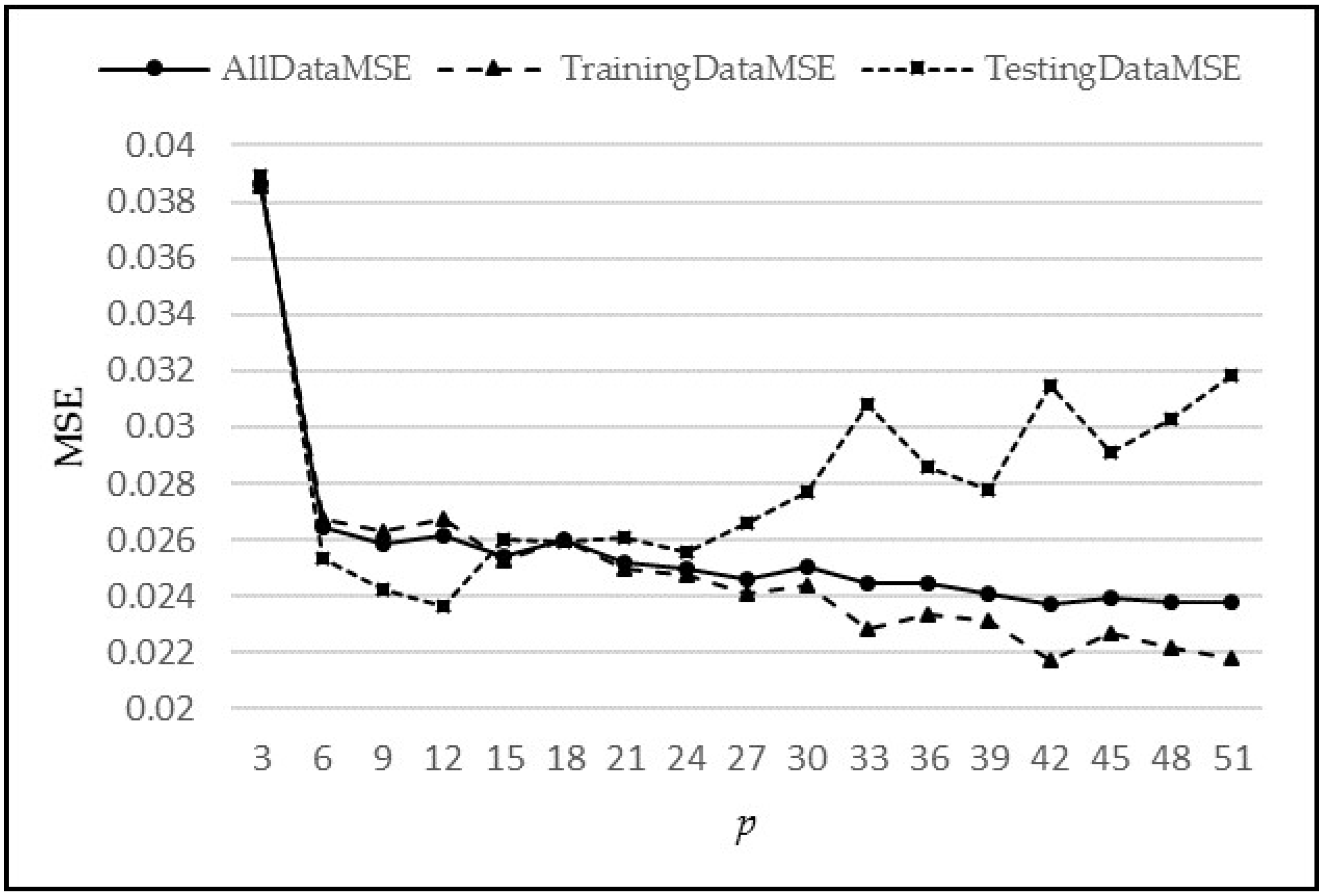
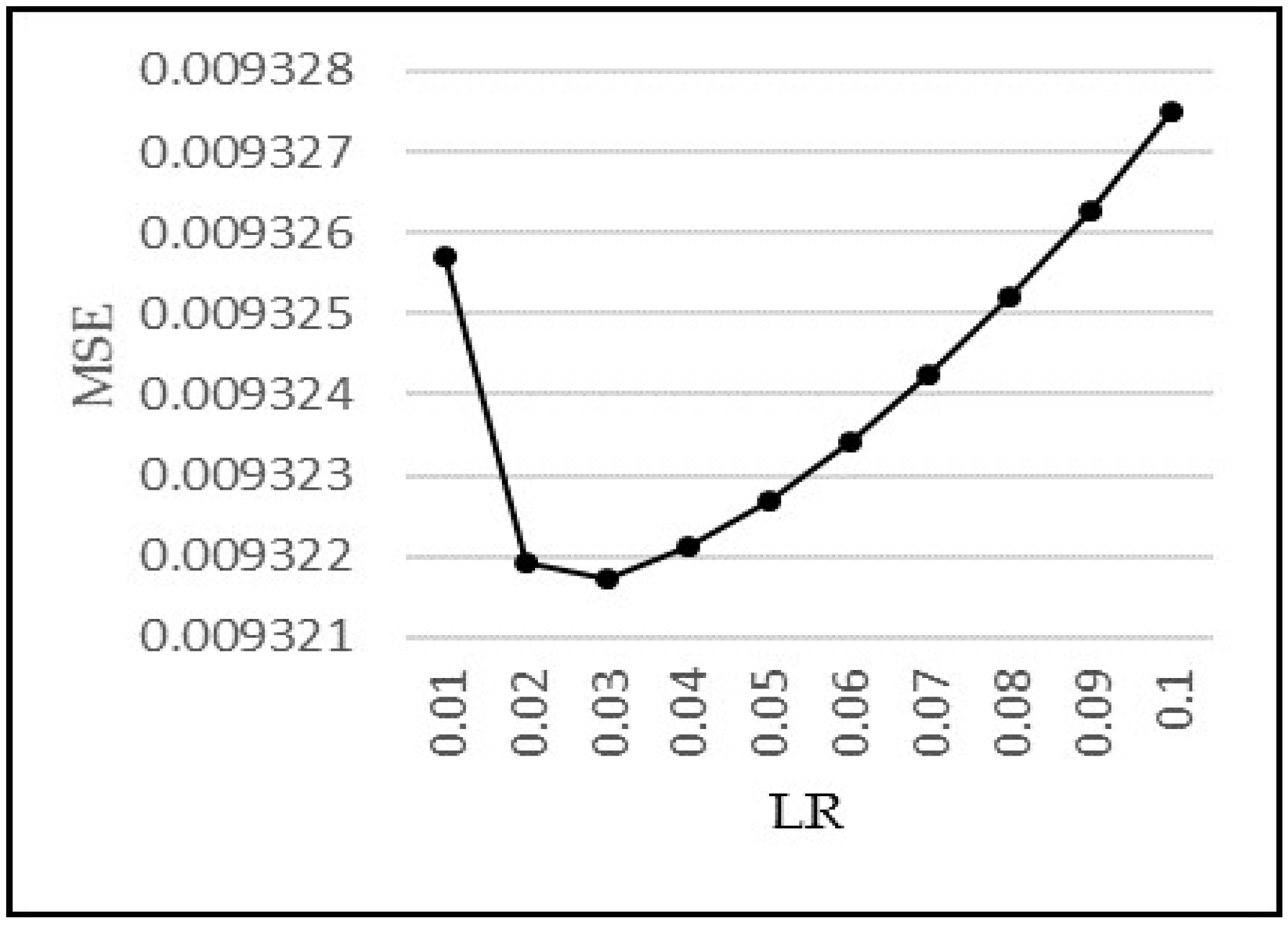
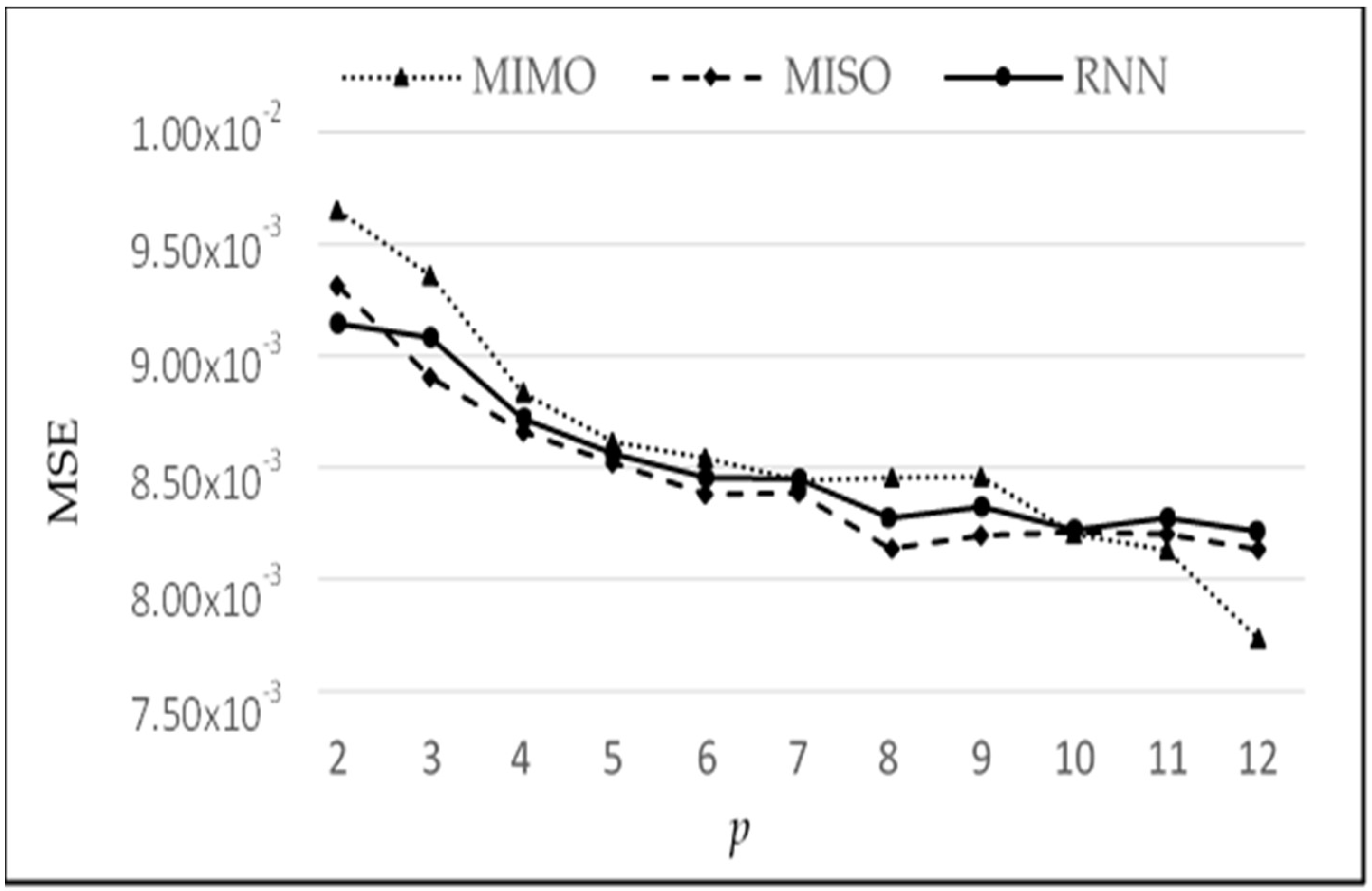
Figure 13 shows the graph of MSE vs.
p. A suitable choice of
p (
p*) value is based on a trade-off between reducing MSE vs. increasing the complexity of the network. As, we increase
p, the MSE decreases; however, the complexity also increases. A larger value of
p requires larger numbers of neurons at the input layer, which in turn requires a larger number of weights in the neural network. The weights are learned in an iterative manner, so the larger the number of weights needed, the more time and space is required for convergence, hence, increasing the time and resource complexity of the system.
Table 3 shows the relative reduction in MSE as
p is increased on a step by step basis. It may be noted that as
p is increased, the percentage decrease in MSE at each stage keeps on reducing. Since each increase in p also increases the complexity of the system, we heuristically chose
p = 5, where the reduction in error is 1.98%, while the subsequent increase in
p will only decrease the percentage error by 1.2%, as shown in the last column of
Table 3.
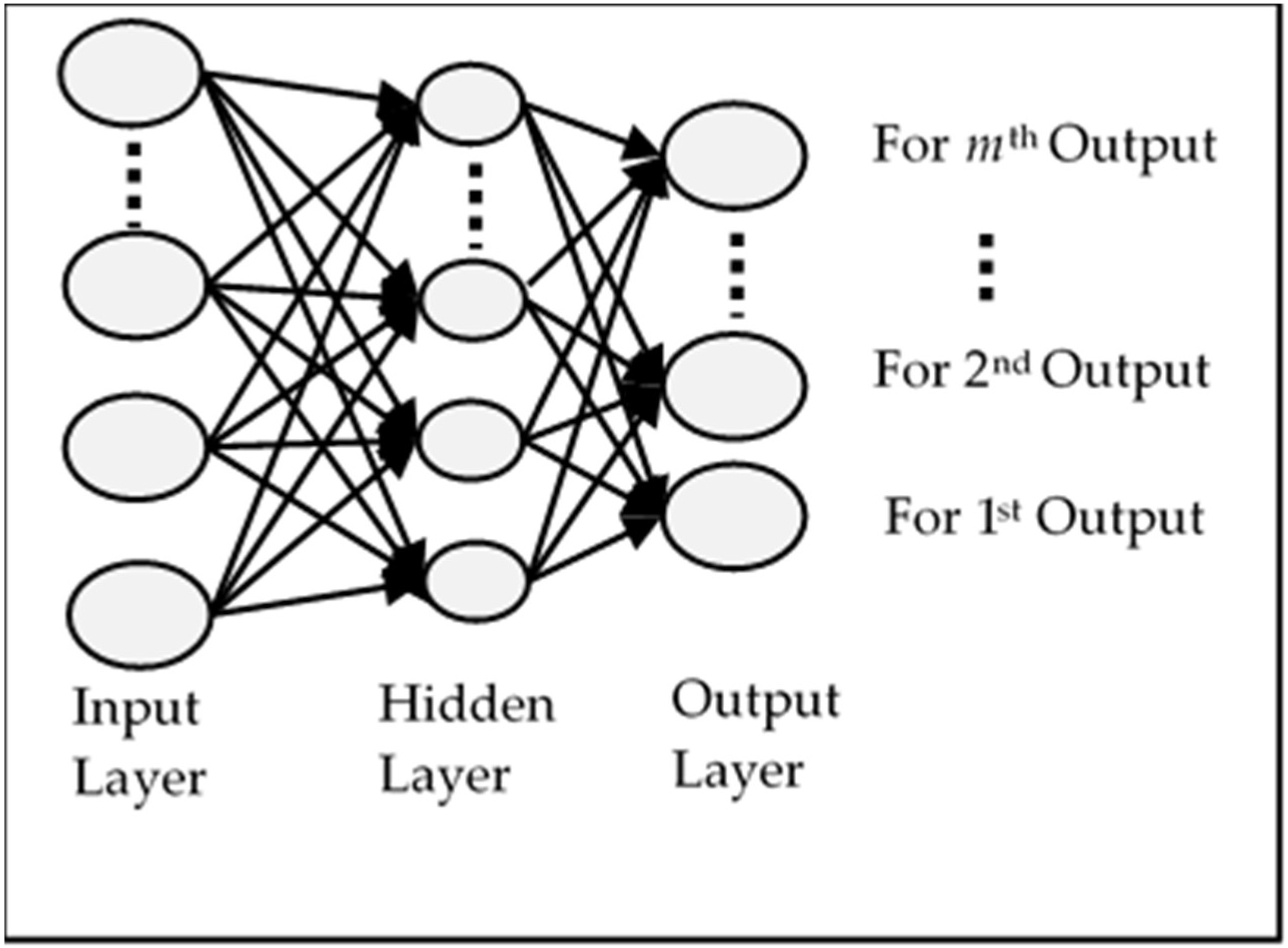
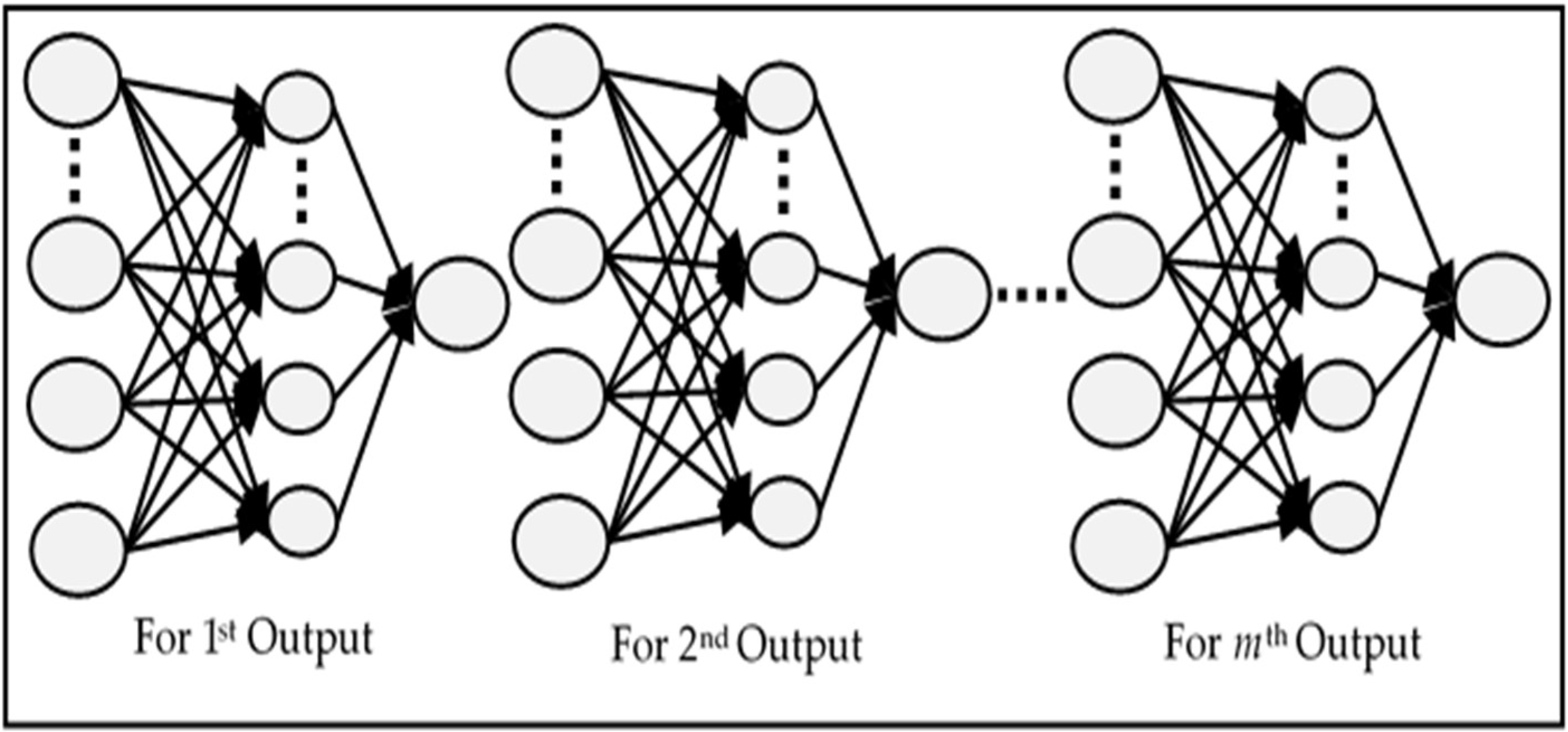
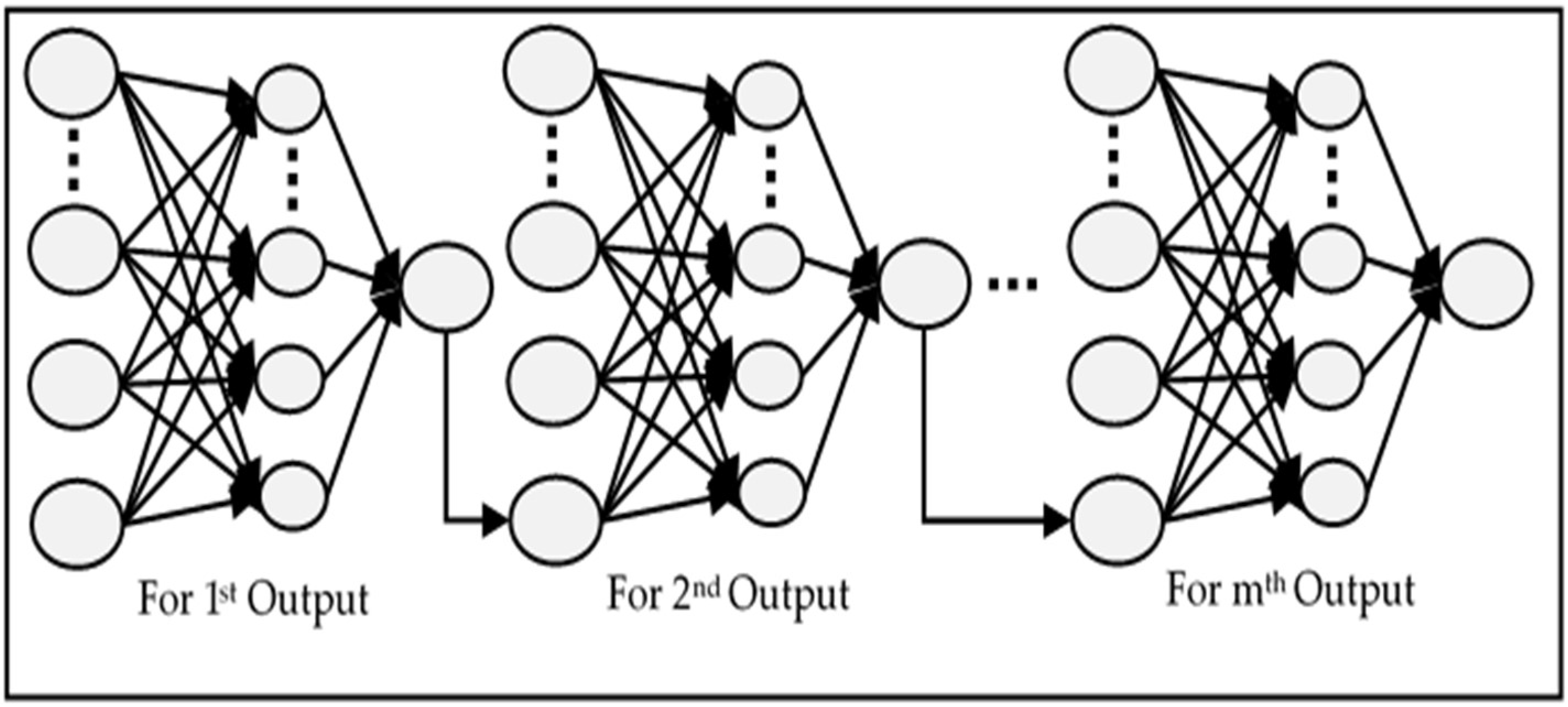
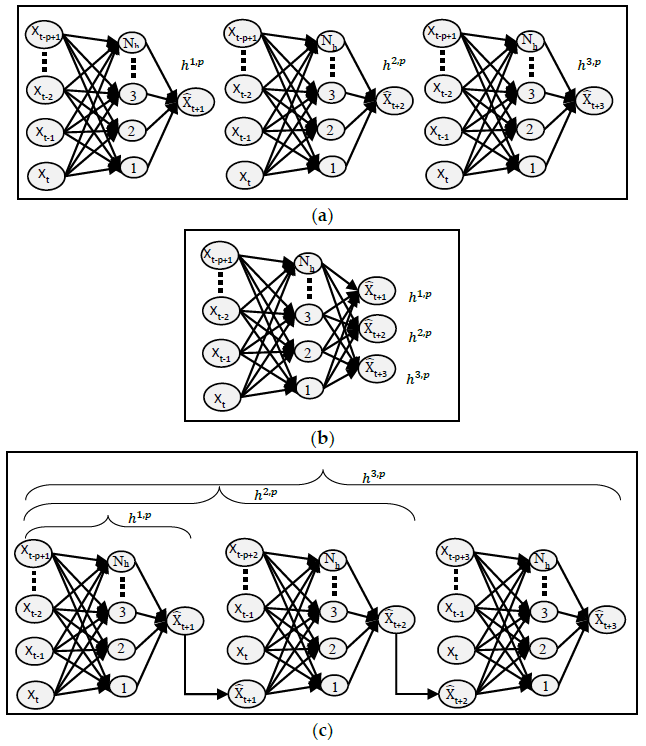
The comparative analysis of models MIMO, MISO, and RNN can also be seen in
Figure 13. MIMO generally performed the worst as it has the largest MSE for each value of
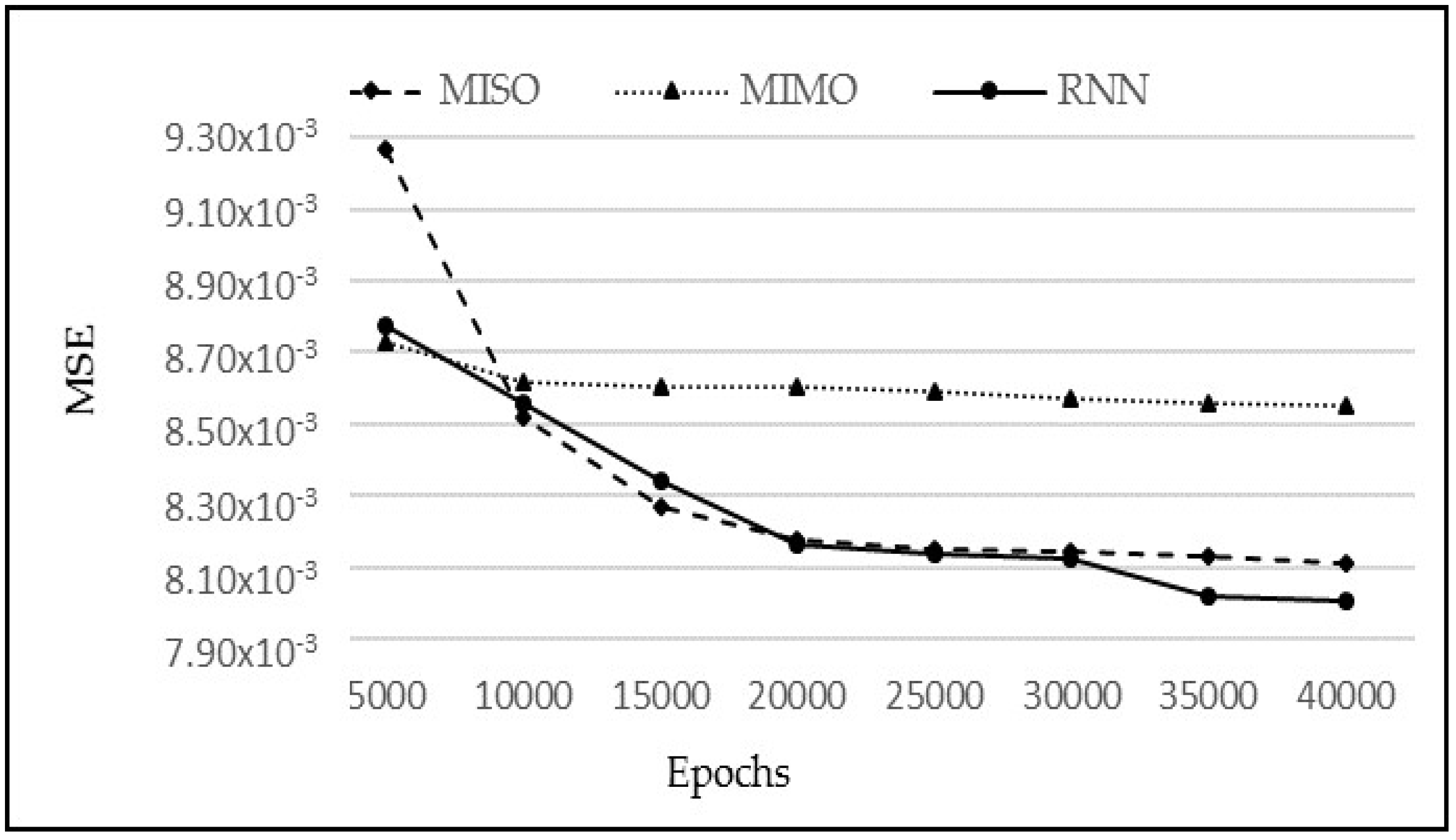
p; however, it is not very different from the other two models. Similarly, MISO and RNN have very close results, but MISO generally outperformed RNN. To analyse the performance of these models more closely and deeply, these experiments have been run again with varying learning iterations. Initially, 10,000 epochs were used to train the model. The models were then tested between 5000 to 40,000 epochs to see the effect of a longer training time on every model. The other parameters were kept the same while
p = 5 was used for the input layer. The results are shown in
Figure 14.
From
Figure 14, it is clear that there is almost a constant performance by MIMO after 10,000 epochs; showing no change in the MSE as the training time progresses. As far as the MISO and RNN are concerned, both show a very similar performance between 10,000 and 30,000 epochs. However, after 30,000 epochs, there is a slight drop in MSE for RNN, giving the notion that if the algorithms are trained for a longer period of time, then RNN may slightly outperform the other models for this dataset. However, the difference above may not be statistically significant and all three techniques continue to be subsequently analysed in the remaining experiments. Next, their respective observations and predictions for one-step–ahead, two-step-ahead, and three-step-ahead are analysed in
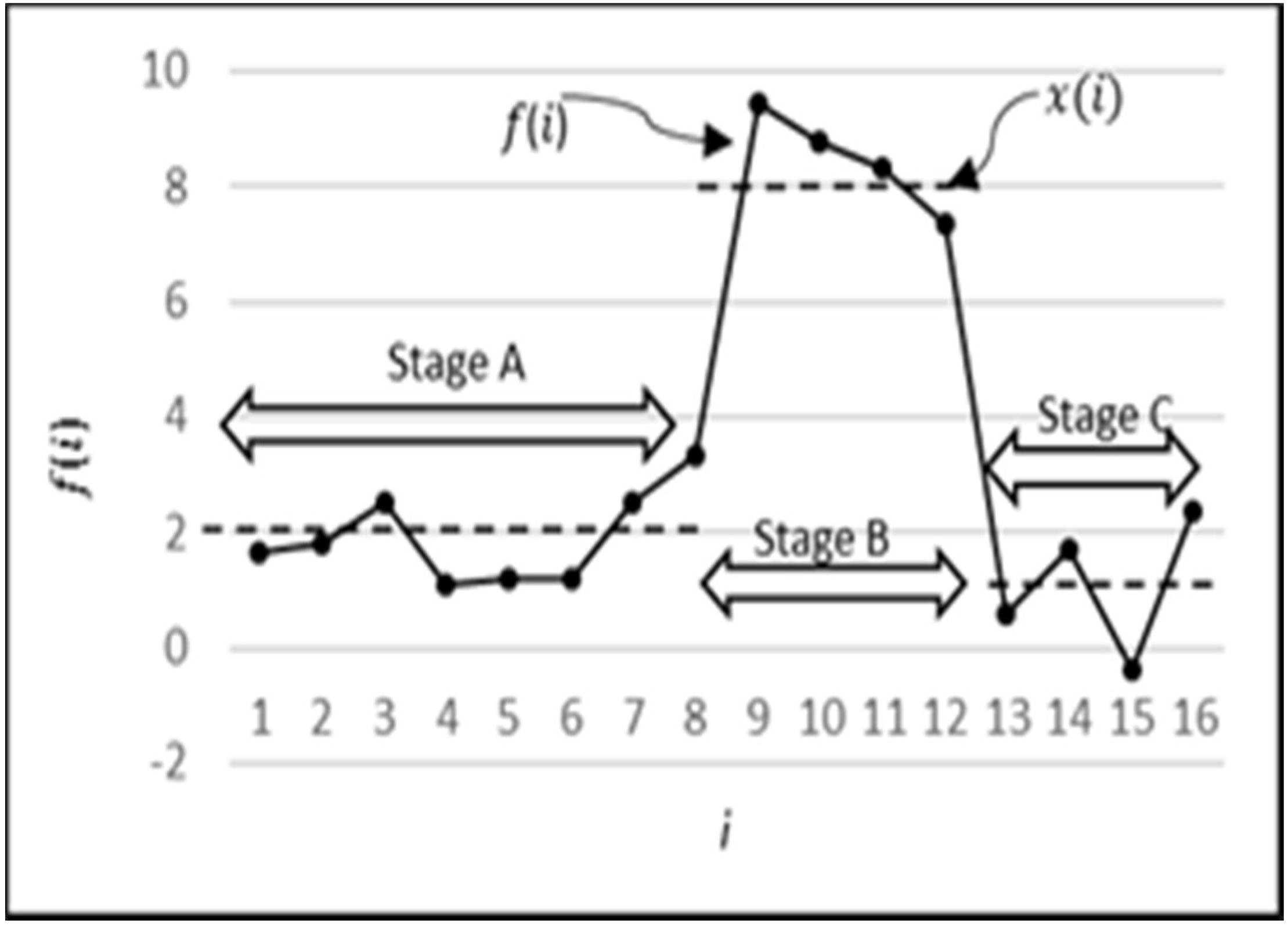
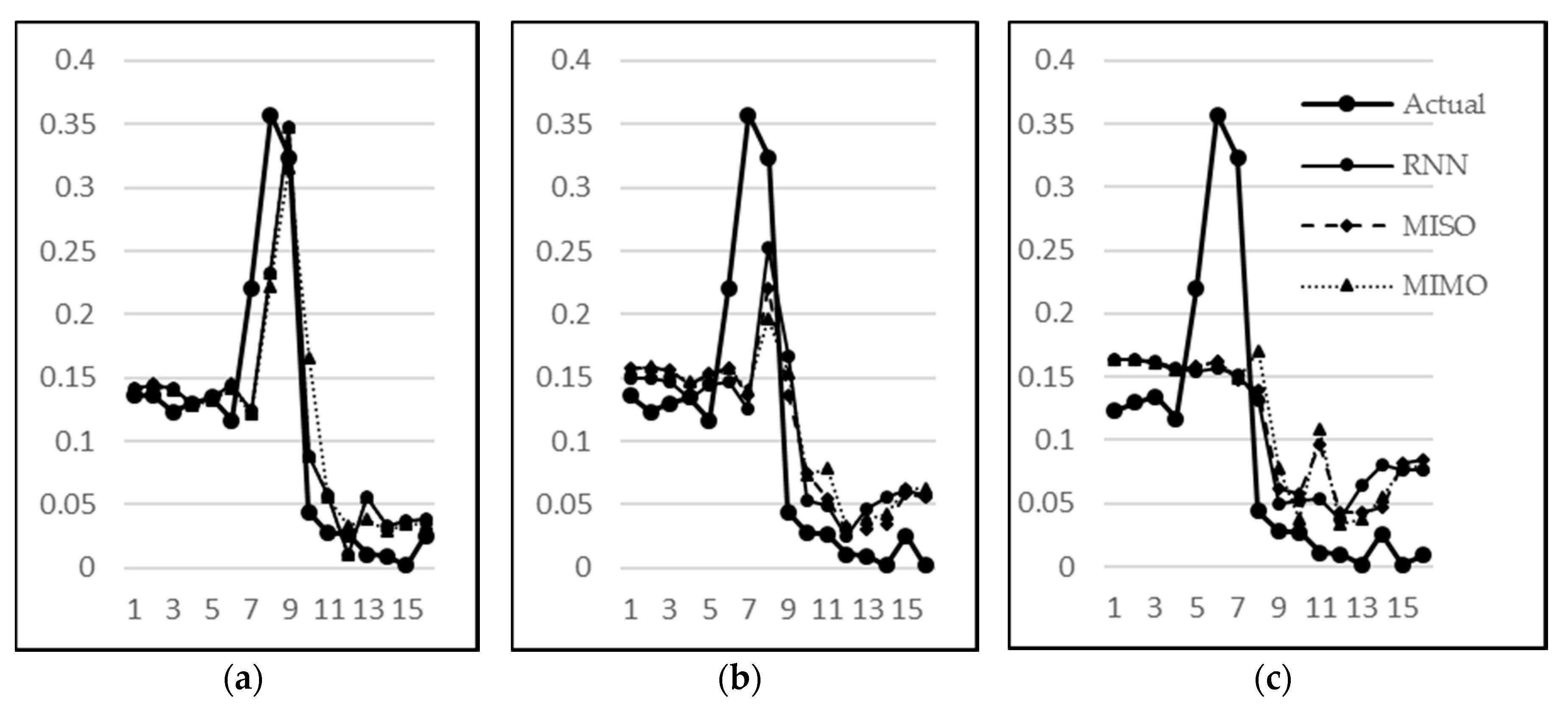
Figure 15a–c, respectively. The sudden rise (stage B) in water level is less and less predictable in one, two, and three step-ahead predictions, respectively. However, the subsequent behaviour (stage C) is predictable with a reasonable accuracy even in three-step-ahead predictions. It can also be seen that MISO and RNN have almost similar predictions for one-step-ahead predictions, which is intuitively correct since there is no difference in both models for this category. Their performance, however, differs for two-step-ahead and three-step-ahead predictions since RNN utilizes the previous predictions for the next prediction. Hence, overall RNN has performed better than MISO and MIMO when considering the collective performance of all three outputs.
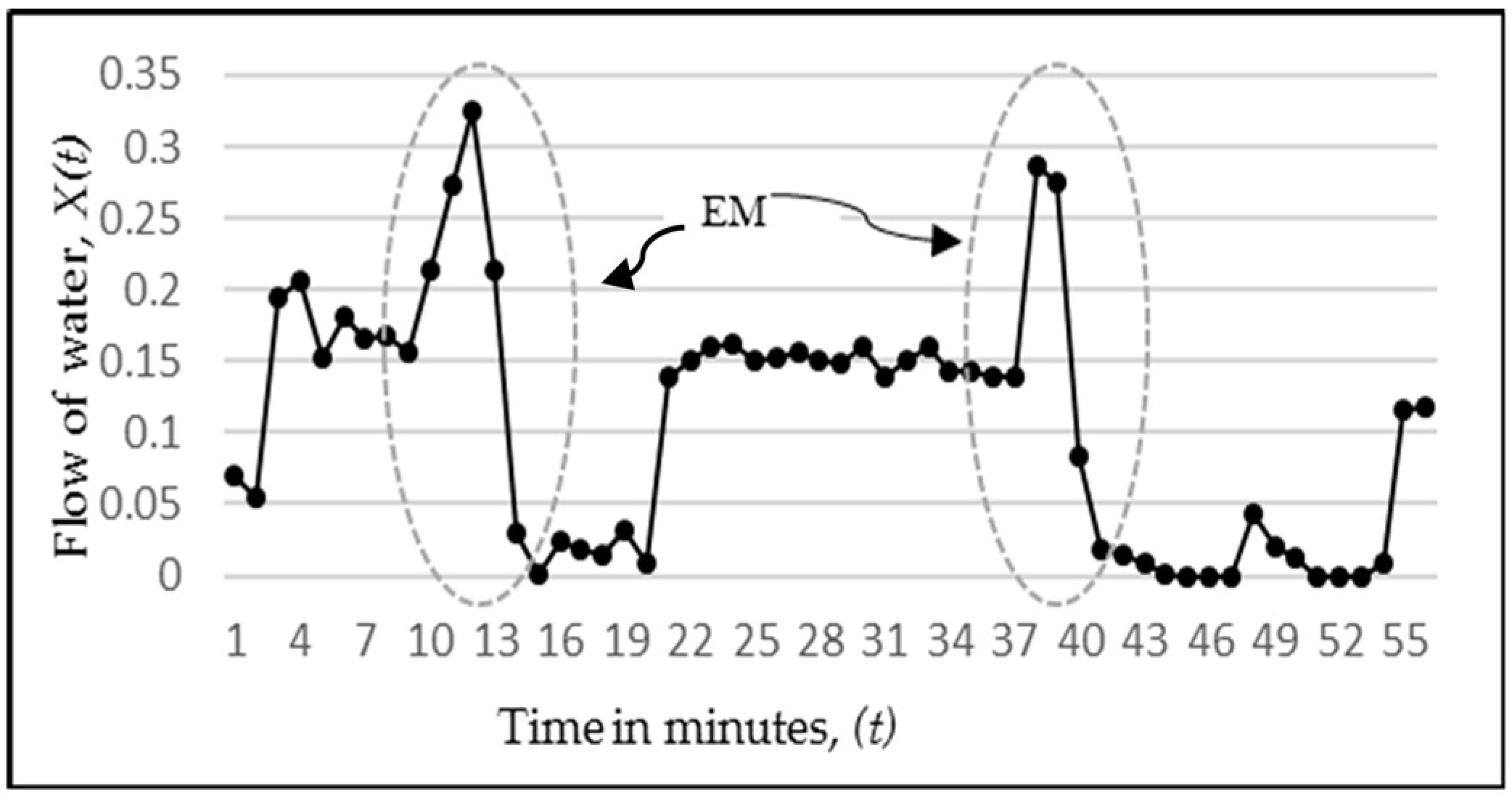
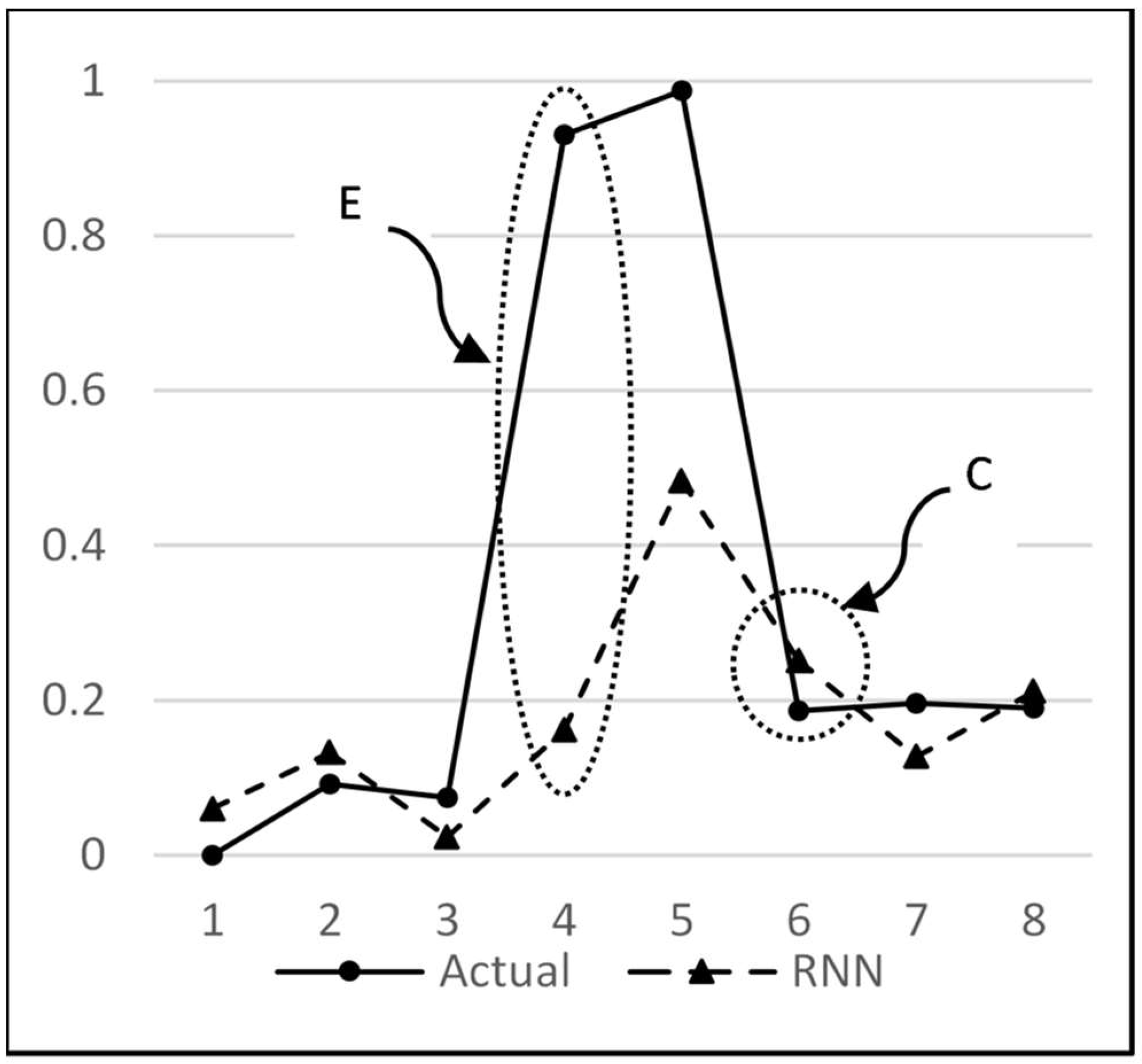
An analysis of the predictions by RNN and MISO for all possible combinations reveals that both of these models have a similar performance. Ideally, a large difference in performance was expected with RNN because of the advantage that it uses the previous outputs to make the next predictions. But a close analysis has revealed that the same advantage is the reason for not displaying a remarkable difference when compared to MISO. This can be explained by the graph in
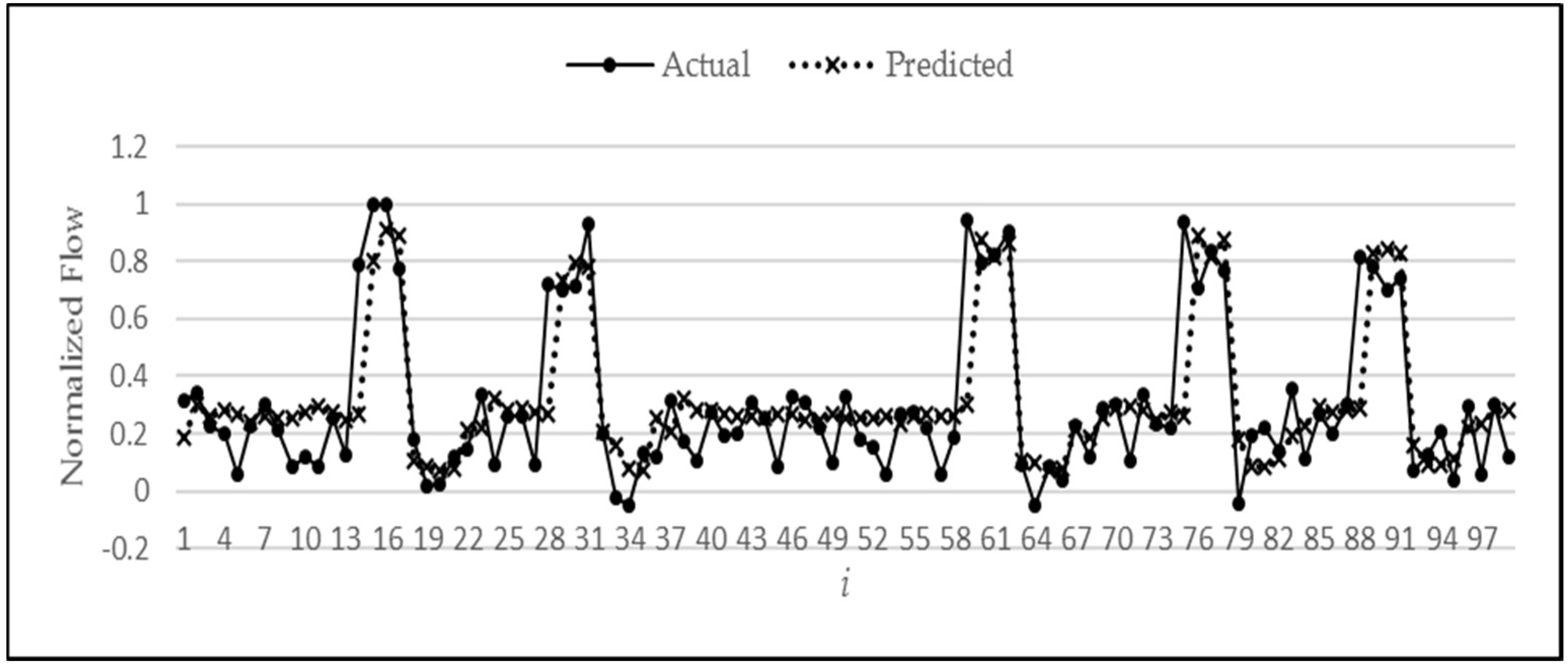
Figure 16. Here, the magnitude indicated by circle E is the error amount in predicting the sudden rise in water flow, which in turn is propagated back to the network as an input to determine the next output. This accumulation of error in multi-step-ahead predictions lowers the anticipated performance of the model. This sudden rise in water flow is an unpredictable behaviour since its occurrence is random and can happen at any point in time. What is predictable, however, is that after going through a sudden rise, the water stays there for one or two readings, and then it goes down to zero. Hence, this explains why even though RNN is the overall best performer, it does not outperform MISO to the extent expected. It may be noted that the above behaviour has been partly subsequently predicted by the RNN model, as marked by the circle C in
Figure 16. At point
t = 5, the actual flow is 0.96, and at point
t = 6, it is 0.2. The prediction by ANN at point 5 is 0.5, but at point 6, it predicted that the flow would not continue to stay high and would fall to zero, regardless of the fact that it is high in the most recent readings. Hence, it was correct in learning the pattern and making a prediction close to the actual value of 0.2.
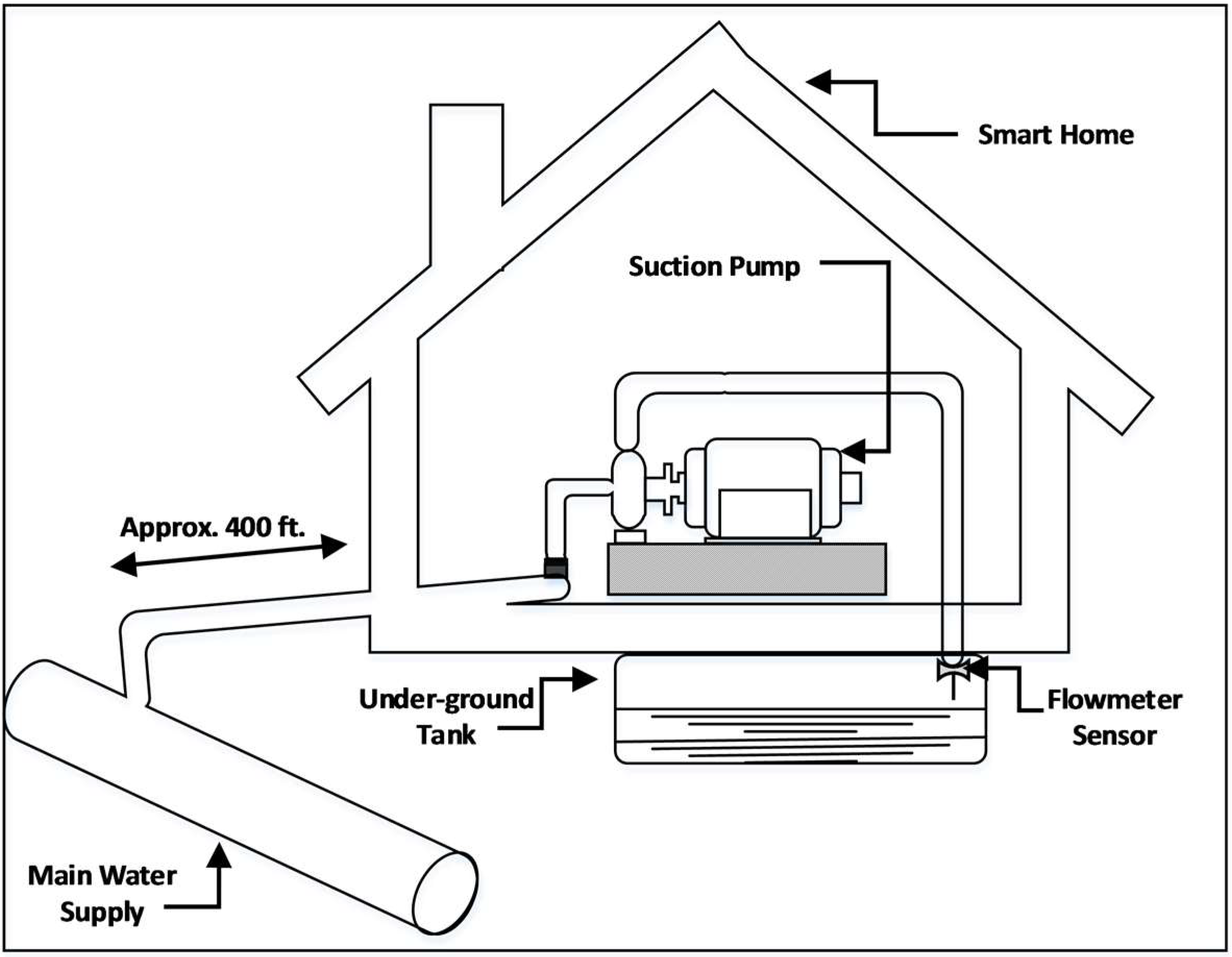
Once the models are learned, they can potentially be used as a decision support system to decide the state of the suction pump. The system would take
p = 5 five most recent readings of the flowmeter sensor, apply RNN to it, predict
m = 3 future outputs, and suggest a state of the pump. If all three predicted outputs are below the threshold (
Tf) value, then the pump would be turned OFF; otherwise, it would be kept ON until the next reading. The same procedure will be repeated for every reading until the pump is turned OFF by the system or by an external source. To evaluate the performance of this system, 100 cases from the flowmeter data series are extracted. The series exhibit four distinct types of behaviours, labelled as categories, which are listed in
Table 4. The count of each case is also shown. Please note that the count of each category does not necessarily reflect the frequency of occurrence of each category and this factor is not relevant to the result.
All the three models, along with their ensemble (a combination of MIMO, MISO, and RNN), were tested to find the model which gives the best accuracy along with other performance measures. The ensemble model is a committee model which uses the voting mechanism for prediction [
25,
26,
27]. If the majority votes for the ON state, it predicts ON and if the majority votes for the OFF state, it predicts OFF. As explained earlier, the values predicted by these models are compared against a threshold value
Tf which needs to be determined. The most appropriate value of (
Tf) was based on a combination of two factors: (i) a judgment of what is an appropriate level of flow; and (ii) determination of the accuracy of the decision support system for which several values were tested, including 0.01, 0.025, 0.05, 0.075, and 0.1. For each value of
Tf, the corresponding accuracies are given in
Table 5. After an analysis of these two factors, it was found that the most appropriate value of
Tf was 0.075, which further can be confirmed by
Table 5, as it gives the maximum accuracy. Next, the performances of all the models using
Tf = 0.075 are given in
Table 6.
Finally, the models were evaluated using the usual performance measures such as accuracy, precision, recall, and F-measure. Their equations are given below, where TP = true positive, TN = true negative, FP = false positive, and FN = false negative.
We have used the ON state of the pump as the positive class, while the OFF state is the negative class. In this study, FP is more critical than the FN measure because it represents those situations where the decision was taken to keep the pump ON whereas it should have been turned OFF. Similarly, TN is more critical than TP as it represents those situations where the pump should have been turned OFF and the same is suggested by the model. As shown in
Table 6, RNN has outperformed all other models including the ensemble model in all of the performance measures. It gives 86% accuracy, 91% precision, 74% recall, and 82% F-measure values. A case representative of each, TP, TN, FP, and FN, is shown in
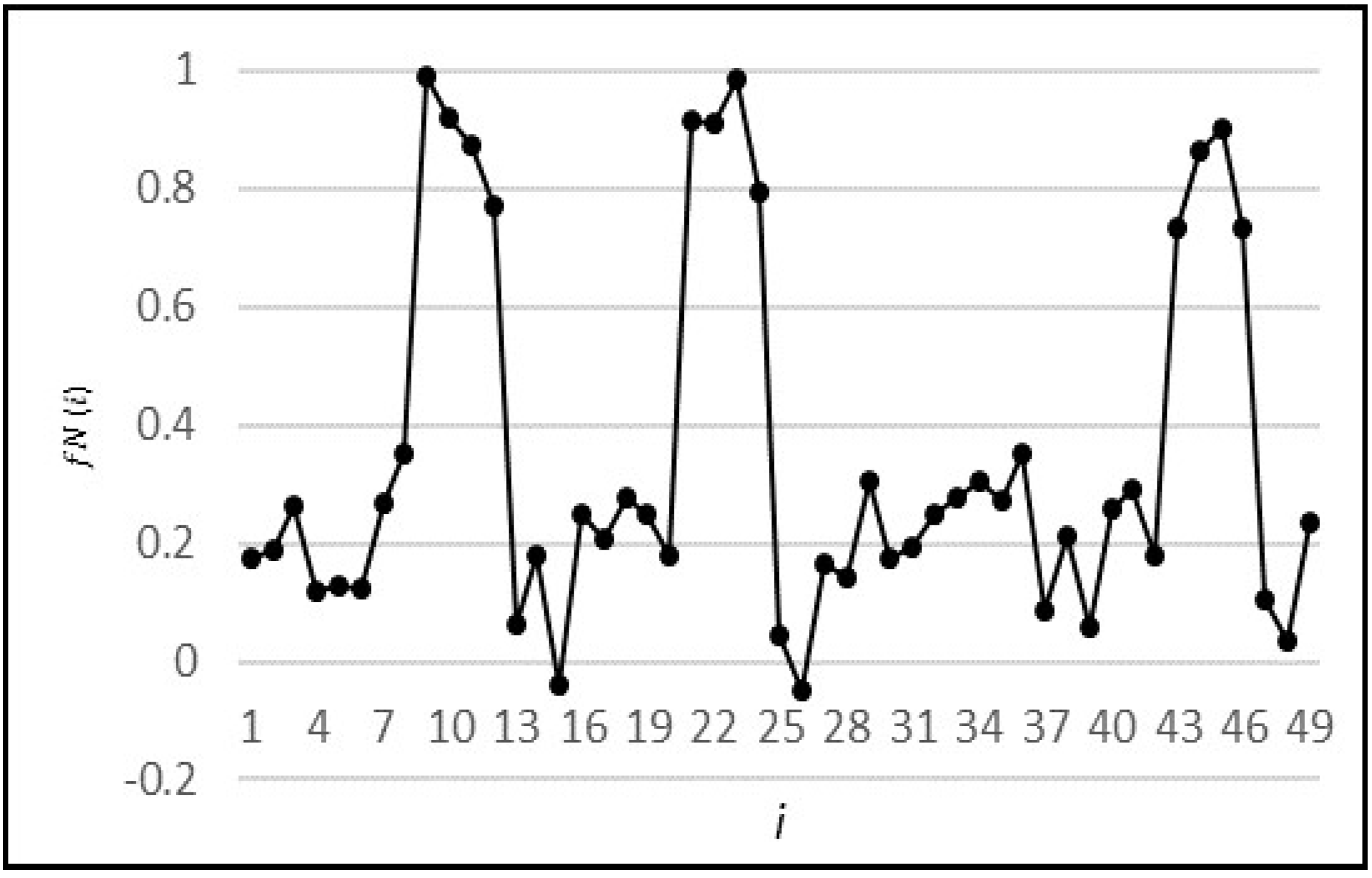
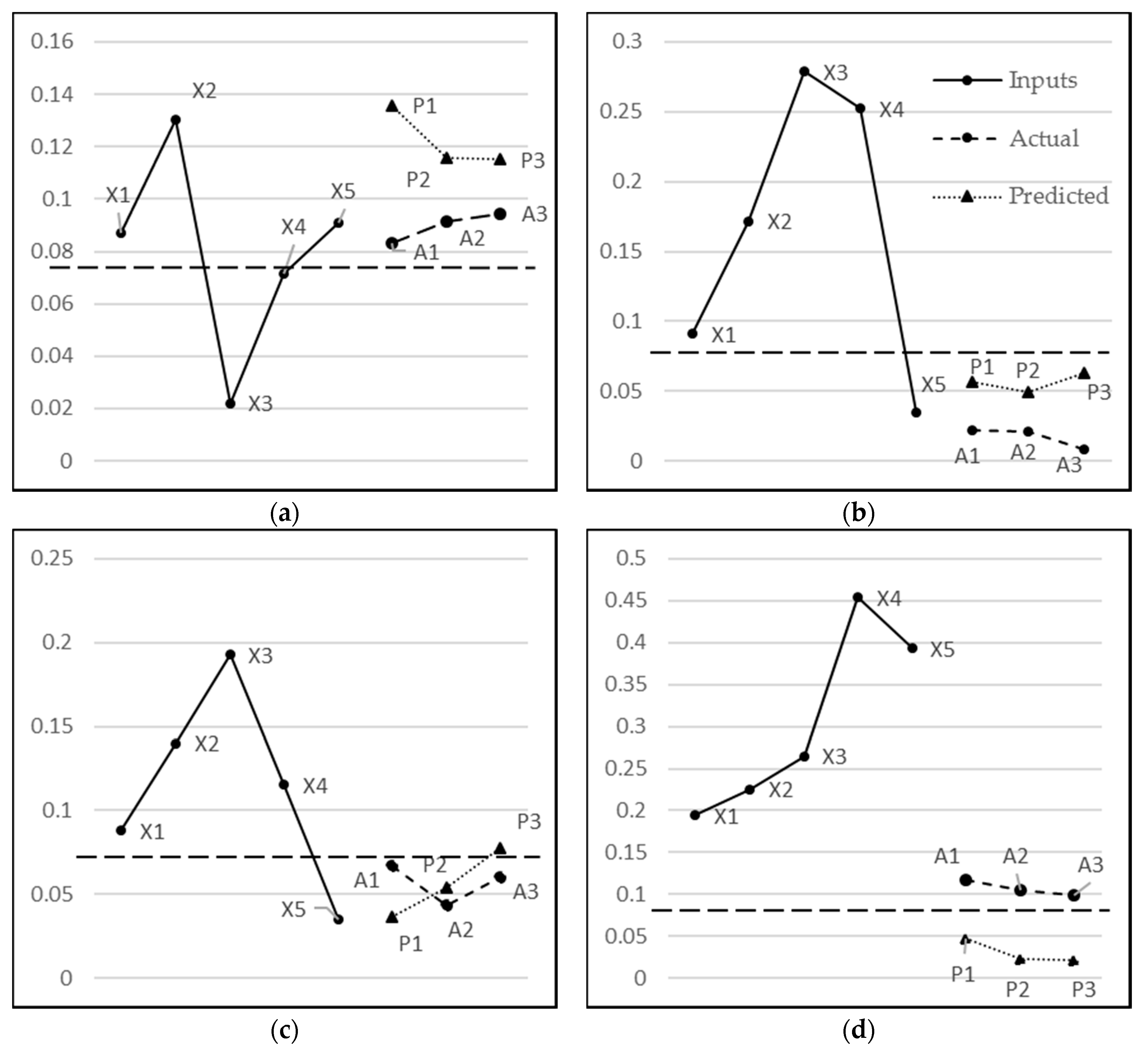
Figure 17. For example,
Figure 17b shows the TN scenario where both the actual and predicted values fall below the threshold and hence, the prediction is accurate. On the other hand,
Figure 17d depicts the scenario where predicted values fall below the threshold and the actual values, while being quite low, are above the threshold. Hence, this falls under the case of FN predictions.
We now summarize the performance of RNN for each category in
Table 7. Category 1 contains the cases having the peculiar behaviour which were referred to as EM. The model was applied to 49 such cases where the model has achieved more than 97% accuracy, indicating that the model is able to locate the correct time to switch off the pump in 97% of the cases. Similarly, the model has a good accuracy for Categories 3 and 4, exhibiting 95.65% and 70% accuracy, respectively. However, it has a low accuracy of 55.56% for Category 2 cases, where the pattern is observed but the water flow does not stop. However, the low accuracy in this category is not of significance since the frequency of occurrence of category 2 cases is quite rare (as described earlier for
Table 4). In such cases, the ideal decision should have been to keep the pump ON, which our model misses more than 40% of the time. This is also understandable, since the sample that we extracted from the flowmeter data to train the model is mainly comprised of Category 1 cases. This was due to the reason that we were primarily interested in predicting the best time to shut off the pump. Hence, based on the above analysis, it can be seen that the RNN model has exhibited a good performance by multiple performance metrics to show its power of capturing the EM and making a successful automatic system based on its prediction.
In retrospect, it may be noted that there could be a simpler technique to shut-off the hydraulic suction pump using a fixed threshold time value, which shuts off the pump if there is no water flow below a threshold value for a certain period of time. However, using such a simple technique would clearly not be optimal and would result in an excessive ON time for the pump, thus wasting energy and degrading the performance of the system.
5. Conclusions
IoT enhances the quality of life by connecting the digital world to the real world via utilizing various sensors in everyday objects. These sensors sense streams of data, which in turn may contain behaviors of special interest (i.e., the EM behavior in this study). It may be noted that no assumption has been made in our model that requires previous knowledge of the pattern to train our proposed model using the Artificial Neural Network (ANN). The raw data from the sensors after necessary pre-processing was fed into our model. We have not explicitly used any parameters pertaining to the EM pattern in learning the parameters of our network. Thus, our model was capable of learning the patterns and predicting the future with specific prior knowledge of a specific pattern. However, the occurrence of a pattern which was learnable by our system allowed the system to have a better accuracy in predicting the future. This, in turn, helped in making an autonomous system to manage resources in a smart home/building.
While the specific parameters that have been used in the system have to a certain extent been both data-driven and heuristically determined, we believe that these parameters will continue to provide accurate predictions for the life of the system. The basis of our belief is drawn from the fact that the period from which the data has been selected covers a very wide period of about twelve months. However, the general applicability of this model to be used as an autonomous system is intended to be further explored in the future by expanding the dataset to cover subsequent independent epochs. This is expected to further confirm the model’s general applicability. It is suggested that these explorations to better incorporate the changes in the behavior of the system are updated in the model after a certain period (e.g., annually) to update the learning process. This process, if introduced, will require fine-tuning of the model on an occasional basis by incorporating any changes in the behavior of the data over a longer period of time.
This research found the Artificial Neural Network (ANN) to be useful in recognizing such behavior in real-time data. Three models of ANN, namely MIMO, MISO, and RNN, were applied for three-step-ahead predictions of a flowmeter’s data series. Among these models, RNN was found to have the best performance. It was then used to make an automated decision support system to decide upon the appropriate state of the suction pump. The model was evaluated using 100 cases of different categories, where it was found to provide 86% accuracy, suggesting that a decision based on such a model can make the correct decisions 86% of the time.
In the future, this work may be extended to extract rules from neural networks as these rules can give further insight into the behavior.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}